【4.1.-4.20学习周报】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 一、方法介绍
- 1.1HippoRAG
- 1.2HippoRAG2
- 二、实验
- 2.1实验概况
- 2.2实验代码
- 2.3实验结果
- 总结
摘要
本博客介绍了论文《From RAG to Memory: Non-Parametric Continual Learning for
Large Language Models》提出HippoRAG 2框架,以解决现有检索增强生成(RAG)系统在模拟人类长期记忆方面的局限。首先分析了持续学习LLMs的挑战及RAG方法的不足,如无法捕捉长期记忆的意义构建和关联性。接着介绍HippoRAG 2的离线索引和在线检索流程,通过密集 - 稀疏集成、深度上下文关联和识别记忆等改进,增强了与人类记忆机制的契合度。实验表明,HippoRAG 2在事实、意义构建和关联记忆任务上全面超越标准RAG方法,为LLMs的非参数持续学习开辟了新途径。
之前的周报我也有提到HippoRAG,HippoRAG 2是对HippoRAG进行升级和改进
Abstract
This blog presents the paper From RAG to Memory: Non-Parametric Continual Learning for Large Language Models proposes the HippoRAG 2 framework to address the limitations of existing Retrieval Enhancement Generation (RAG) systems in simulating human long-term memory. Firstly, the challenges of continuous learning LLMs and the shortcomings of RAG methods, such as the inability to capture the meaning-making and correlation of long-term memory, were analyzed. Next, the offline indexing and online retrieval process of HippoRAG 2 is introduced, which enhances the fit with human memory mechanisms through improvements such as dense-sparse integration, deep context association, and recognition memory. Experiments show that HippoRAG 2 surpasses the standard RAG method in fact, meaning construction and associative memory tasks, opening up a new way for nonparametric continuous learning of LLMs
一、方法介绍
最近提出了几个RAG框架,这些框架使用LLM来显式地构建其检索语料库,以解决这些限制。为了增强意义构建,这种结构增强RAG方法允许LLM生成摘要或知识图(KG)结构连接不同但相关的段落组,从而提高RAG系统理解更长的更复杂的话语的能力。
为了解决联想性差距,HippoRAG使用了个性化PageRank算法和LLM自动构建KG并赋予检索过程多跳推理能力的能力。
尽管这些方法在这两种更具挑战性的记忆任务中表现出了强大的性能,但要使RAG真正接近人类的长期记忆,还需要在更简单的记忆任务中进行非业务操作。为了了解这些系统是否能够实现这样的业务,研究者进行了全面的实验,不仅通过多跳QA大规模语篇理解同时评估它们的联想性和意义构建能力,还通过简单的QA任务测试它们的事实记忆能力。
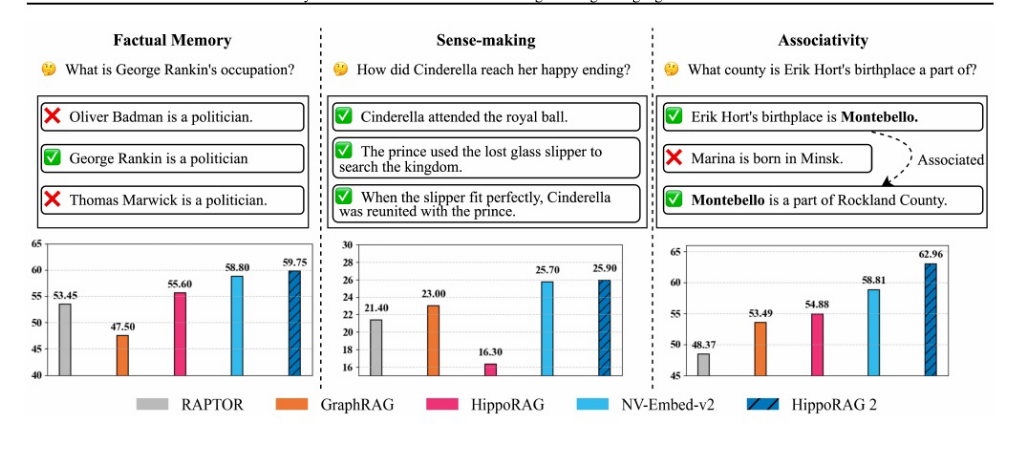
如上图所示,,在所有三种基准类型上,与最强的基于嵌入的RAG方法相比,所有先前的结构增强方法都表现不佳。
研究者提出的方法,HippoRAG 2,利用HippoRAG的OpenIE和个性化PageRank (PPR)方法的优势,同时通过将段落整合到PPR图搜索过程中,解决了基于查询的上下文化限制。在KG三元组的选择中更深入地涉及查询,并在在线检索过程中使用LLM来识别检索到的三元组何时不相关。
1.1HippoRAG
在这里对之前看过的HippoRAG做一个简单的复习。HippoRAG是是一个受神经生物学启发的llm长期记忆框架,每个组件都旨在模拟人类记忆的各个方面。该框架由三个主要部分组成:人工新皮层(LLM),海马旁区(PHR编码器)和人工海马(开放KG)。这些组成部分协作复制了人类长期记忆中观察到的相互作用。
对于HippoRAG离线索引,LLM将pass -sages处理成KG三元组,然后将其合并到工海马索引中。同时,PHR负责检测同义词以实现信息互连。对于HippoRAG在线检索,LLM新皮层从查询中提取命名实体,而PHR编码器将这些实体链接到海马体索引。然后,在KG上进行个性化PageRank (personal - personalisedPageRank, PPR)算法,进行基于上下文的检索。尽管HippoRAG试图从非参数RAG构建记忆,但其有效性受到一个关键缺陷的阻碍:以实体为中心的方法会导致索引和推理过程中的上下文丢失,以及语义匹配困难。
1.2HippoRAG2
基于HippoRAG中提出的神经生物学启发的长期记忆框架,HippoRAG 2的结构遵循类似的两阶段过程:离线索引和在线检索.
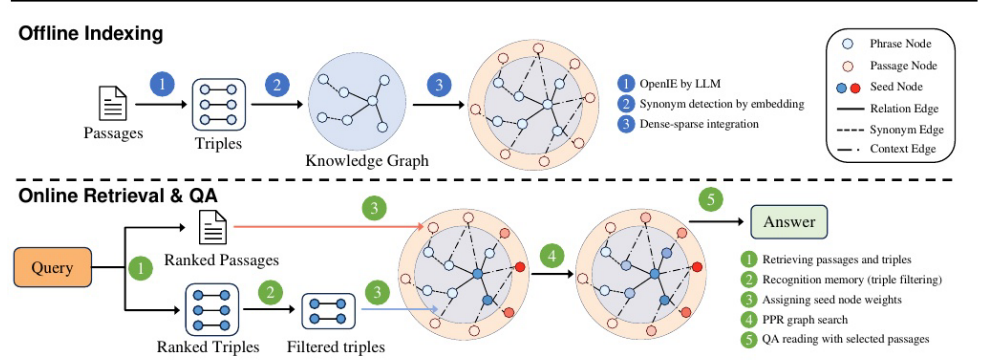 HippoRAG 2方法。对于离线索引,使用LLM从段落中提取开放的KG三元组,并将同义词检测应用于短语节点。这些短语和段落一起构成了开放式的KG。对于在线检索,嵌入模型对段落和三元组进行评分,以识别个性化PageRank (PPR)算法的两种类型的种子节点。识别记忆使用LLM过滤最上面的三元组。然后,PPR算法在KG上执行基于上下文的检索,为最终的QA任务提供最相关的段落。上面KG节点的不同颜色反映了它们的概率质量;深色表示PPR过程引起的可能性较高。
HippoRAG 2方法。对于离线索引,使用LLM从段落中提取开放的KG三元组,并将同义词检测应用于短语节点。这些短语和段落一起构成了开放式的KG。对于在线检索,嵌入模型对段落和三元组进行评分,以识别个性化PageRank (PPR)算法的两种类型的种子节点。识别记忆使用LLM过滤最上面的三元组。然后,PPR算法在KG上执行基于上下文的检索,为最终的QA任务提供最相关的段落。上面KG节点的不同颜色反映了它们的概率质量;深色表示PPR过程引起的可能性较高。
HippoRAG2在原有的基础上通过引入以下几个层面来增强与人类长期记忆的关联,:1)它在开放的KG中无缝地集成了概念和上下文信息,增强了构建索引的全面性和原子性。2)通过利用KG结构超越孤立的KG节点,它促进了更多的上下文感知检索。3)它结合了识别记忆,以改进图搜索的种子节点选择。
受人脑中观察到的密集-稀疏整合的启发,研究者将短语节点作为提取概念的稀疏编码形式,同时将密集编码纳入我们的KG中,以表示这些概念产生的上下文。首先,采用了一种编码方法——类似于短语的编码方式,使用嵌入模型。然后在KG中以特定的方式集成这两种类型的编码。与HippoRAG中的文档集成(简单地从图搜索嵌入匹配中聚合分数)不同,通过引入通道节点来增强KG,实现上下文信息的更无缝集成。这种方法保留了与HippoRAG相同的离线索引过程,同时在构建过程中使用与通道相关的附加节点和边来丰富图结构。具体来说,语料库中的每个段落都被视为一个段落节点,上下文边缘标记为“contains”,将该段落与从该段落衍生出来的所有短语连接起来。
Recognition Memory:回忆和识别是人类记忆检索中的两个互补过程。回忆涉及在没有外部线索的情况下主动检索信息,而识别则依赖于在外部刺激的帮助下识别信息。受此启发,我们将查询到三重检索建模为一个两步过程。1) Query to Triple:使用嵌入模型检索图的top-k个三元组T。2)三重过滤:使用llm来过滤检索到的T并生成三元组T′⊆T。
二、实验
2.1实验概况
研究者选择了三种比较方法作为基线:1)经典寻回犬BM25 (、和GTR (Ni et al., 2022)。2)在BEIR排行榜上表现良好的大型嵌入模型、,包括阿里巴巴- nlp /GTE-Qwen2-7B-Instruct 、、GritLM/GritLM- 7b 、和nvidia/NV-Embed-v2 、。3)结构增强RAG方法,包括RAPTOR 、GraphRAG 、LightRAG ()和Hip-poRAG 。
数据集:为了评估RAG系统在增强联想性和意义构建的同时保留
事实记忆的能力,选择了对应于三种关键挑战类型的数据集:1)简单QA主要评估准确回忆和检索事实知识的能力。2)多跳QA(Multi-hop QA)通过要求模型连接多
个信息来得出答案来衡量关联性。3)话语理解(discourseunderstanding)通过测试的方法来评估意义构建对冗长、复杂的叙述进行解释和推理的能力。

2.2实验代码
完整项目代码:实验代码
以下展示HippoRAG2的关键实现代码:
import torch
from transformers import AutoModel, AutoTokenizer, pipeline
import networkx as nx
import numpy as np# Load models
llm_model_name = "meta-llama/Llama-3.3-70B-Instruct"
encoder_model_name = "nvidia/NV-Embed-v2"
llm_tokenizer = AutoTokenizer.from_pretrained(llm_model_name)
llm_model = AutoModel.from_pretrained(llm_model_name)
encoder_tokenizer = AutoTokenizer.from_pretrained(encoder_model_name)
encoder_model = AutoModel.from_pretrained(encoder_model_name)# Offline Indexing
def offline_indexing(corpus):"""Build the knowledge graph from the corpus during offline indexing.Args:corpus (list): List of text passages.Returns:kg (nx.DiGraph): Knowledge graph with phrase and passage nodes.phrase_to_passage (dict): Mapping of phrases to passage IDs."""kg = nx.DiGraph()phrase_to_passage = {}for passage_id, passage in enumerate(corpus):# Extract triples using LLMtriples = extract_triples(passage)for triple in triples:subject, relation, object_ = triplekg.add_edge(subject, object_, relation=relation)phrase_to_passage[subject] = passage_idphrase_to_passage[object_] = passage_id# Add passage node and connect to phrasespassage_node = f"passage_{passage_id}"kg.add_node(passage_node, type="passage", content=passage)for triple in triples:kg.add_edge(passage_node, triple[0], relation="contains")kg.add_edge(passage_node, triple[2], relation="contains")# Synonym detectionphrases = [node for node in kg.nodes if not node.startswith("passage_")]if phrases:phrase_embeddings = get_embeddings(phrases)for i in range(len(phrases)):for j in range(i + 1, len(phrases)):similarity = cosine_similarity(phrase_embeddings[i], phrase_embeddings[j])if similarity > 0.8: # Synonym thresholdkg.add_edge(phrases[i], phrases[j], relation="synonym")kg.add_edge(phrases[j], phrases[i], relation="synonym")return kg, phrase_to_passagedef extract_triples(passage):"""Extract triples from a passage using an LLM (simplified placeholder).Args:passage (str): Text passage.Returns:list: List of (subject, relation, object) triples."""# Placeholder: In practice, use OpenIE with LLMreturn [("example_subject", "example_relation", "example_object")]def get_embeddings(texts):"""Generate embeddings for a list of texts using the encoder.Args:texts (list): List of text strings.Returns:torch.Tensor: Embeddings tensor."""inputs = encoder_tokenizer(texts, return_tensors="pt", padding=True, truncation=True)with torch.no_grad():embeddings = encoder_model(**inputs).last_hidden_state.mean(dim=1)return embeddingsdef cosine_similarity(a, b):"""Compute cosine similarity between two vectors.Args:a (np.ndarray): First vector.b (np.ndarray): Second vector.Returns:float: Cosine similarity score."""return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))# Online Retrieval
def online_retrieval(query, kg, phrase_to_passage, corpus):"""Perform online retrieval for a given query.Args:query (str): User query.kg (nx.DiGraph): Knowledge graph.phrase_to_passage (dict): Mapping of phrases to passage IDs.corpus (list): List of text passages.Returns:str: Generated answer."""# Query to triplesquery_embedding = get_embeddings([query])[0]triples = [(s, o, d['relation']) for s, o, d in kg.edges(data=True) if d['relation'] != "contains" and d['relation'] != "synonym"]if triples:triple_texts = [f"{s} {r} {o}" for s, r, o in triples]triple_embeddings = get_embeddings(triple_texts)similarities = [cosine_similarity(query_embedding, emb) for emb in triple_embeddings]top_k_indices = np.argsort(similarities)[-5:][::-1] # Top-5 triplestop_k_triples = [triples[i] for i in top_k_indices]else:top_k_triples = []# Recognition memory filteringfiltered_triples = filter_triples(query, top_k_triples)# Personalized PageRankif filtered_triples:seed_phrases = set()for triple in filtered_triples:seed_phrases.add(triple[0])seed_phrases.add(triple[2])seed_passages = [node for node in kg.nodes if node.startswith("passage_")]seed_nodes = list(seed_phrases) + seed_passages# Assign reset probabilitiesreset_probabilities = {}phrase_total = len(seed_phrases)passage_total = len(seed_passages)for node in seed_phrases:reset_probabilities[node] = 0.95 / phrase_total if phrase_total > 0 else 0for node in seed_passages:reset_probabilities[node] = 0.05 / passage_total if passage_total > 0 else 0ppr_scores = nx.pagerank(kg, personalization=reset_probabilities, alpha=0.5)ranked_passages = sorted([(node, score) for node, score in ppr_scores.items() if node.startswith("passage_")],key=lambda x: x[1],reverse=True)top_passage_ids = [int(node.split("_")[1]) for node, _ in ranked_passages[:5]]else:# Fallback to embedding-based retrievalpassage_embeddings = get_embeddings(corpus)similarities = [cosine_similarity(query_embedding, emb) for emb in passage_embeddings]top_passage_ids = np.argsort(similarities)[-5:][::-1]# Generate answercontext = " ".join([corpus[i] for i in top_passage_ids])answer = generate_answer(query, context)return answerdef filter_triples(query, triples):"""Filter triples based on relevance to the query using LLM (simplified placeholder).Args:query (str): User query.triples (list): List of (subject, relation, object) triples.Returns:list: Filtered list of triples."""# Placeholder: In practice, use LLM with prompts as in Appendix Areturn triples # Simplified: return all triplesdef generate_answer(query, context):"""Generate an answer using the LLM based on query and context (simplified placeholder).Args:query (str): User query.context (str): Retrieved context.Returns:str: Generated answer."""# Placeholder: In practice, use LLM for QAreturn "Generated answer based on context"# Example usage
if __name__ == "__main__":corpus = ["Example passage 1 about some topic.","Example passage 2 with related information.",# Add more passages as needed]kg, phrase_to_passage = offline_indexing(corpus)query = "What is the topic discussed in the passages?"answer = online_retrieval(query, kg, phrase_to_passage, corpus)print(f"Query: {query}")print(f"Answer: {answer}")
2.3实验结果
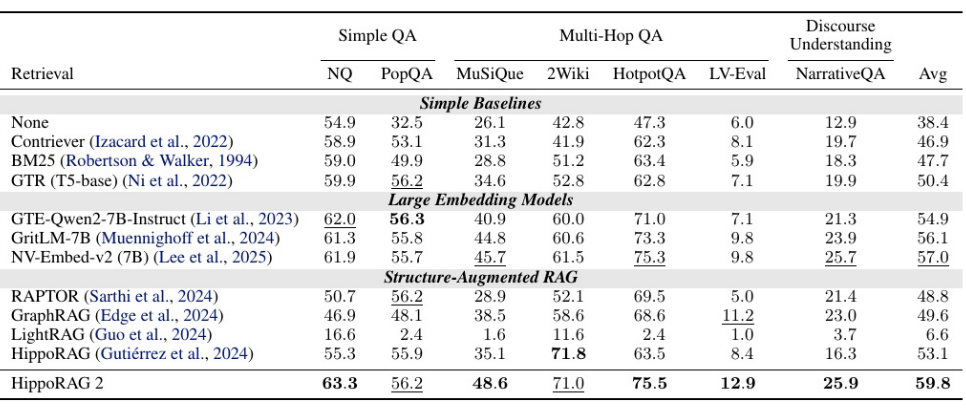
可以从上图看到,hippoRAG2在所有QA数据集上的表现均超过了基线模型以及之前的hippoRAG。
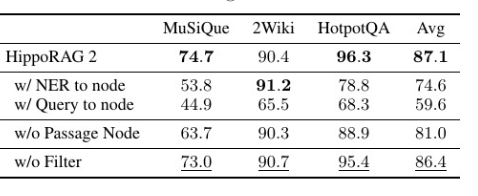
研究者针对所提出的连接方法、图构建方法和三重滤波方法设计了烧蚀实验,结果如上图所示。每个引入的机制都促进了HippoRAG 2。首先,具有更深上下文化的
链接方法带来了显著的性能提升。值得注意的是,没有对ner_to -node或查询to-node方法应用过滤过程;然而,无论是否应用过滤,查询到三重方法的性能始
终优于其他两种链接策略。与ner_to -node相比,查询-to-triple平均提高Recall12.5%。此外,查询到节点并不比ner_to -node具有优势,因为查询和KG节点在不
同的粒度级别上操作,而NER结果和KG节点都对应于短语级表示。
总结
基于HippoRAG,引入深度段落整合、上下文感知检索和识别记忆机制,使知识图谱更好融合概念与上下文信息。
在多类记忆任务上超越现有方法,尤其在联想记忆任务上比先进嵌入模型提升7%。
识别记忆中三元组过滤的精度有提升空间,部分样本过滤后无匹配短语或无三元组,需依赖密集检索结果。
个性化PageRank图搜索组件在部分样本中表现不佳,虽识别关键短语,但难以返回理想结果。
相关文章:

【4.1.-4.20学习周报】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract一、方法介绍1.1HippoRAG 1.2HippoRAG2二、实验2.1实验概况2.2实验代码2.3实验结果 总结 摘要 本博客介绍了论文《From RAG to Memory: Non-Parametri…...

vim笔记
vim三种模式切换 命令常用 复制粘贴...

【JAVA】基础知识“抽象类”详解,从入门到理解~
目录 1. 抽象类 1.1 什么是抽象类❓ 1.2 为什么需要抽象类❓ 1.3 抽象类语法 1.4 抽象类特征 ① 抽象类是被abstract修饰的 ② 被abstract修饰的方法称为抽象方法,这个方法可以没有具体的实现 ③ 当一个类中含有抽象方法的时候,该类必须使用abst…...

docker 启动mysql9认证失败
docker compose 启动mysql9认证失败 随着mysql更新到了9版本,在docker中相较于8减少了一些体积,很吸引人尝试, 但是在使用原本的配置文件拉起mysql,连接时却提示权限认证失败 1045 - Access denied for user root172.18.0.1 (…...

【Axure绘制原型】图片切割、交互动效、热区、动态面板、元件显示隐藏、表单元件、表格、内联框架
切割 功能:将图片切成多部分。 通过移动鼠标可以调整两条虚线的位置,点击。虚线相当于切割刀,被虚线分离的部分将变成单独的图 切割后的图片: 交互 交互动效的构成: 目标:谁触发交互(元…...
:筛选特定空间范围内的POI数据)
DeepSeek智能时空数据分析(一):筛选特定空间范围内的POI数据
时空数据分析很有用,但是GIS/时空数据库技术门槛太高 时空数据分析在优化业务运营中至关重要,尤其在数据驱动决策的当下,其价值正随大模型时代的到来进一步凸显。然而,三大挑战仍制约其发展:技术门槛高,需…...

使用mybatisPlus自带的分页方法+xml实现数据分页
:因为需要实现多表关联分页,原本想的是直接使用selectpagehelper,但是pagehelper只对xml文件生效;后面发现可以直接使用mybatisplus自带的分页,不依靠pagehelper实现多表关联分页; 实现类:关键…...

第六节:React Hooks进阶篇-自定义Hook设计
实战题:实现一个useWindowSize或useFetch 自定义 Hook 设计实战:useWindowSize 与 useFetch 实现详解 一、useWindowSize:实时监听窗口尺寸 1. 基础实现(TypeScript 版) import { useState, useEffect } from react…...

Mybatis--XML映射文件配置和动态SQL
XML文件配置 MyBatis中文网 动态SQL...

【Java学习笔记】位运算
位运算 一、原码,反码,补码 (1) 二进制的最高位是符号位:0 表示正数,1 表示负数(怎么记? 1旋转一下变成-) (2) 正数的原码、反码、补码都一样(三码合一) (3) 负数的反码…...

循环队列的实现
循环队列 实现一个循环队列:C语言代码解析与设计思路1. 循环队列的基本概念2. 数据结构设计3. 初始化队列4. 入队操作5. 出队操作6. 获取队列头部和尾部元素7. 判断队列是否为空或满8. 释放队列资源9. 总结 实现一个循环队列:C语言代码解析与设计思路 在…...

案例驱动的 IT 团队管理:创新与突破之路:第五章 创新管理:从机制设计到文化养成-5.2 技术决策民主化-5.2.1案例:架构设计评审的“七人决策制“
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 案例驱动的 IT 团队管理:创新与突破之路 - 第五章 创新管理:从机制设计到文化养成5.2 技术决策民主化5.2.1 案例:架构设计评审的“七人决…...

数据库—MySQL游标详解笔记
一、游标是什么? 游标(Cursor) 是数据库中用于逐行遍历查询结果集的数据库对象。它允许开发者像操作指针一样逐行读取数据,适用于需要对查询结果逐行处理的复杂业务逻辑。 核心特点: 逐行操作:类似编程中…...

Genspark:重新定义AI搜索与代理的全能型工具
在当今快速发展的AI技术领域,搜索工具正在经历前所未有的变革。Genspark,这家由前百度高管景鲲和朱凯华创立的AI公司,为我们带来了全新的AI代理引擎体验。作为一位专注于AI工具分享的博主,今天我将为大家详细介绍这款强大的工具&a…...

深入理解设计模式之模板方法模式 1d87ab8b42e98069b6c2c5a3d2710f9a
深入理解设计模式之模板方法模式 深入理解设计模式之模板方法模式 在软件开发的漫长征程中,我们常常会遇到各种复杂的业务逻辑,其中部分逻辑具有相似的流程框架,但在具体细节上又有所不同。这种情况下,模板方法模式就如同一位得…...

Cursor + MCP,实现自然语言操作 GitLab 仓库
本分分享如何使用 cursor mcp 来操作极狐GitLab 仓库,体验用自然语言在不接触极狐GitLab 的情况下来完成一些仓库操作。 极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitL…...
)
界面开发框架DevExpress XAF实践:如何在Blazor项目中集成.NET Aspire?(一)
DevExpress XAF是一款强大的现代应用程序框架,允许同时开发ASP.NET和WinForms。DevExpress XAF采用模块化设计,开发人员可以选择内建模块,也可以自行创建,从而以更快的速度和比开发人员当前更强有力的方式创建应用程序。 .NET As…...

【C++】特化妙技与分文件编写 “雷区”
目录 目录非类型模板参数非类型模板参数vs宏代换 模板的特化函数模板的特化函数模板特化的坑 类模板特化全特化偏特化 模板分离编译原理解决方案 end 目录 非类型模板参数 模板参数可分为类型形参和非类型形参。 类型形参: 出现在模板参数列表中,跟在…...

qt+mingw64+cmake+libqrencode项目编译和搭建成功记录
最近要使用高拍仪拍照获取照片,然后识别照片中的二维码数据、使用QZxing只能识别出一个条码、另外一个条码准备测试用其他的开源项目(如libqrencode-4.1.1)来进行测试,故进行本文的项目环境搭建测试,最后成功。 本机开…...

观察者设计模式详解:解耦通知机制的利器
在面向对象设计中,设计模式为我们提供了通用的解决方案,以应对常见的开发问题。观察者设计模式是其中非常经典且实用的一种模式,广泛应用于GUI系统、事件处理、消息推送等场景。今天,我们就深入探讨观察者模式的概念、结构和特点&…...

Vim使用完全指南:从基础到高效编辑
Vim使用完全指南:从基础到高效编辑 一、Vim简介与基本概念 Vim(Vi IMproved)是从vi发展出来的一个功能强大的文本编辑器,以其高效性和灵活性著称,特别适合程序开发和系统管理任务。与常规文本编辑器不同,…...

C语言——数组
在C语言中,数组是一组相同类型元素的集合,并且每个数据都有自己对应的一个序号,我们称之为数组下标或者索引。接下来我们就来看看数组是如何定义的吧! 目录 1.一维数组 1.1 定义与初始化 1.2 一维数组的使用 1.3 一维数组在内…...
)
电商|基于java+vue的农业电商系统(源码+数据库+文档)
农业电商系统 目录 基于java的农业电商系统 一、前言 二、系统设计 三、系统功能设计 系统功能实现 前台: 后台: 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️…...

ServletContextAttributeListener 的用法笔记250417
ServletContextAttributeListener 的用法笔记250417 以下是关于 ServletContextAttributeListener 的用法详解,涵盖核心方法、实现场景、注意事项及最佳实践,帮助您有效监听应用级别属性(ServletContext)的变化: 1. 核…...

iptables 防火墙
目录 熟悉Linux防火墙的表,链结构 理解数据包匹配的基本流程 学会编写iptables规则 前言 在当今信息化时代,网络安全已成为企业和个人不可忽视的重要议题。随着网络攻击手段的不断升级,构建一个坚固的网络安全防线显得尤为迫切。在Linux系统中,iptables作为一款…...

【厦门大学】DeepSeek大模型及其企业应用实践
DeepSeek大模型及其企业应用实践 前言1. 大模型:人工智能的前沿1.1 大模型的概念1.2 大模型的发展历程1.3 人工智能与大模型的关系1.4 大模型的分类 2. 大模型产品2.1 国外的大模型产品2.2 国内的大模型产品2.3 主流大模型“幻觉”评测 3. 大模型的行业应用3.1 自然…...

解锁智能制造:PLC远程下载如何让设备运维效率提升10倍?
一、2025年远程运维的三大变革驱动力 政策强制: 欧盟CE新规要求:2025年起工业设备必须具备远程审计接口 中国等保2.0:工业控制系统远程访问需达到三级防护 技术成熟: 5G专网边缘计算实现ms级响应 算法自动诊断PLC程序异常&#x…...
)
卷积神经网络CNN(李宏毅)
目录 怎么把一张影响当成一个模型输入? 同样的 pattern出现在图片不同的位置。 第三个问题:Pooling: 阿尔法Go是怎么下围棋的: CNN不能处理的问题 CNN专门用在影像辨识方面 怎么把一张影响当成一个模型输入? 一张…...

URL / GET请求 中文UTF-8编码JS转化
以长颈鹿为例 decodeURIComponent 将编码转为中文 encodeURIComponent 会对整个参数字符串转义(包括 :// 等符号)。 encodeURI 仅转义非合法 URL 字符(不转义 :/?& 等保留字符)。 decodeURIComponent("%E9%95%BF%E9…...

Flink 内部通信底层原理
Flink 集群内部节点之间的通信是用 Akka 实现,比如 JobManager 和 TaskManager 之间的通信。而 operator 之间的数据传输是用 Netty 实现。 RPC 框架是 Flink 任务运行的基础,Flink 整个 RPC 框架基于 Akka 实现。 一、相关概念 RPC(Remote Procedure Call) 概念 定义:…...

async-profiler火焰图找出耗CPU方法
事情起于开发应用对依赖的三方包(apache等等)进行了升级后(主要是升级spring),CPU的使用率较原来大幅提升,几个应用提升50%-100%。 查找半天,对比每次版本的cpu火焰图,看不出有什么…...

深入理解Qt状态机的应用
深入理解Qt状态机的应用 Chapter1 深入理解Qt状态机的应用(一)什么是有限状态机?状态机的组成应用示例交通信号控制灯系统简单在线购物流程系统 Qt状态机框架Qt状态机框架组成常用接口说明 应用示例源码 Chapter2 深入理解Qt状态机的应用&…...

Python入门安装和语法基础
1.Python简介 Python是解释型语言, ython就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写&am…...
)
Windows 图形显示驱动开发-WDDM 1.2功能—Windows 8 中的 DirectX 功能改进(四)
一、无覆盖和放弃 在基于磁贴的延迟呈现 (TBDR) 体系结构上呈现内容: Direct3D 11.1 中的呈现目标现在可以使用一组新的资源 API 来支持放弃行为。 开发人员必须了解此功能,并调用额外的 Discard () 方法,以在 TBDR 体系结构 (更高效地运行…...

如何分析服务器日志以追踪黑客攻击行为
分析服务器日志是追踪黑客攻击行为的关键手段。通过系统性地检查日志文件,可以发现异常访问模式、入侵痕迹和后门活动。以下是详细的日志分析方法: 一、重点日志文件定位 Web服务器日志 Nginx: /var/log/nginx/access.log(访问日志࿰…...

React 对state进行保留和重置
对 state 进行保留和重置 各个组件的 state 是各自独立的。根据组件在 UI 树中的位置,React 可以跟踪哪些 state 属于哪个组件。你可以控制在重新渲染过程中何时对 state 进行保留和重置。 开发环境:Reacttsantd 学习内容 React 何时选择保留或重置状态…...

EmbeddingBag介绍与案例
我们可以用一个具体的例子来说明 EmbeddingBagCollection 的核心作用和它如何处理用户特征。假设我们的用户特征包括 “item_id” 和 “cate_id” 两个字段,每个字段都有各自的离散取值,也就是一些整数 ID。为了让模型能处理这些离散数据,我们…...

css button 点击效果
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><title>button点击效果</title><style>#container {display: flex;align-items: center;justify-content: center;}.pushable {position: relat…...

Missashe考研日记-day22
Missashe考研日记-day22 1 专业课408 学习时间:3h学习内容: 先把昨天关于进程调度的课后习题做了,然后花了挺长时间预习OS的最最最最重要的一部分——同步与互斥问题,这部分大二上课的时候就懵懵懂懂的,得认真再领悟…...

二十、FTP云盘
1、服务端 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <sys/types.h> #include <unistd.h> #include <sys/types.h> /* See NOTES */ #include <sys/socket.h> #include <netinet/in.h>…...

SVM-RF回归预测matlab代码
数据为Excel股票预测数据。 数据集划分为训练集、验证集、测试集,比例为8:1:1 模块化结构: 代码将整个流程模块化,使得代码更易于理解和维护。不同功能的代码块被组织成函数或者独立的模块,使得代码逻辑清晰,结构化程…...

Lombok @Builder 注解的进阶玩法:自定义 Getter/Setter 方法全攻略
大家好呀!👋 今天我们来聊聊 Java 开发中超级实用的 Lombok 库,特别是它的 Builder 注解。很多小伙伴都用过 Builder 来简化对象的创建,但你们知道吗?当我们需要自定义 getter/setter 方法时,Builder 也能玩…...
)
C++每日训练 Day 16:构建 GUI 响应式信号机制(面向初学者)
📘 本篇我们将结合之前的 SignalHub 与 Dispatcher 机制,构建一个适合 GUI 场景的响应式信号系统。以按钮点击为例,构建一个跨线程安全的事件响应系统,配合协程挂起/恢复,让 UI 编程也能更优雅易读。本篇以通俗方式讲解…...
(2))
HCIP(OSPF )(2)
OSPF 公共报文头部 版本(8bit):目前常用版本为 2,用于标识 OSPF 协议版本。不同版本在功能特性和报文格式上可能存在差异,高版本通常会修复旧版本的漏洞、扩展功能,如支持更多类型的网络拓扑、增强安全性等…...

zynq7020 ubuntu_base 跟文件系统
整体流程 制作 ubuntu_base 镜像运行 petalinux 构建的 ramdisk 系统用 ramdisk 系统把 ubuntu_base 镜像烧录到 emmc从 emmc 跟文件系统 启动内核 制作 ubuntu_base 镜像 制作 ubuntu_base 镜像 sudo apt-get install qemu-user-static # 安装 q…...
 Spring Boot 与 NoSQL)
51、Spring Boot 详细讲义(八) Spring Boot 与 NoSQL
3、 Elasticsearch 集成 3.1 Elasticsearch 概述 3.1.1 Elasticsearch 的核心概念 Elasticsearch 是一个开源的分布式搜索引擎,主要用于实时数据检索和分析。它的核心功能包括全文检索、结构化查询和分析大规模数据。 分布式搜索引擎: Elasticsearch 将数据分布存储在多个…...

什么是分库分表?
分库分表是一种数据库的分布式架构设计策略,以下是详细介绍: 概念 • 随着互联网的发展,数据量呈爆炸式增长,单个数据库服务器可能难以应对海量数据的存储和访问压力。分库分表就是将原本庞大的数据库拆分成多个小的数据库&#…...

如何让别人访问到自己本地项目?使用内网穿透工具简单操作下实现公网连接!
本地搭建服务器的系统项目网络地址,在没有公网IP使用的情况下,如何让局域网外别人访问到自己本地网站和应用呢?这里介绍一种通用的内网发布公网访问,且简便操作的内网穿透实现方法。 一、什么是内网穿透? 1. 先了解内…...

第一篇:linux之虚拟环境与centos安装
第一篇:linux之虚拟环境与centos安装 文章目录 第一篇:linux之虚拟环境与centos安装一、vmware安装二、centos安装1、centos虚拟环境安装2、centos操作系统配置3、常见问题解决 一、vmware安装 我们想要运行linux,需要先安装一个虚拟软件&am…...

Redis List 的详细介绍
Redis List 的详细介绍 以下是 Redis List 的详细介绍,从基础命令、内部编码和使用场景三个维度展开: 一、基础命令 Redis List 支持双向操作(头尾插入/删除),适用于队列、栈等场景,以下是核心命令分类&a…...