机器学习 Day11 决策树
1.决策树简介
- 原理:思想源于程序设计的 if - else 条件分支结构 ,是一种树形结构。内部节点表示属性判断,分支是判断结果输出,叶节点是分类结果 。
- 案例:以母亲给女儿介绍男朋友为例。女儿依次询问年龄(≤30 )、长相(帅或中等 )、收入(中等 )、是否为公务员(是 ),通过一系列判断决定去见男方。
-
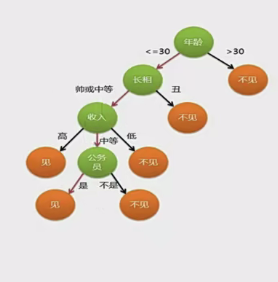
由什么来决定年龄放在最上面呢?
熵
- 概念:物理学中是 “混乱” 程度度量。系统越有序越集中,熵值越低;越混乱分散,熵值越高 。1948 年香农提出信息熵概念。从信息完整性看,数据越集中熵值越小;从信息有序性看,系统越有序熵值越低 ,纯度越高。

信息熵案例

2.分类原理
2.1信息增益(ID3算法)
2.1.1理论

其实Ent(D)就是我们上边讲的熵的计算公式,类别就是标签值,Ent(D,a)的分数部分就是在总样本中被该属性分类的样本占比,后面那个Ent(D^v)就是在对应的分类中,每个标签值的概率求信息熵。
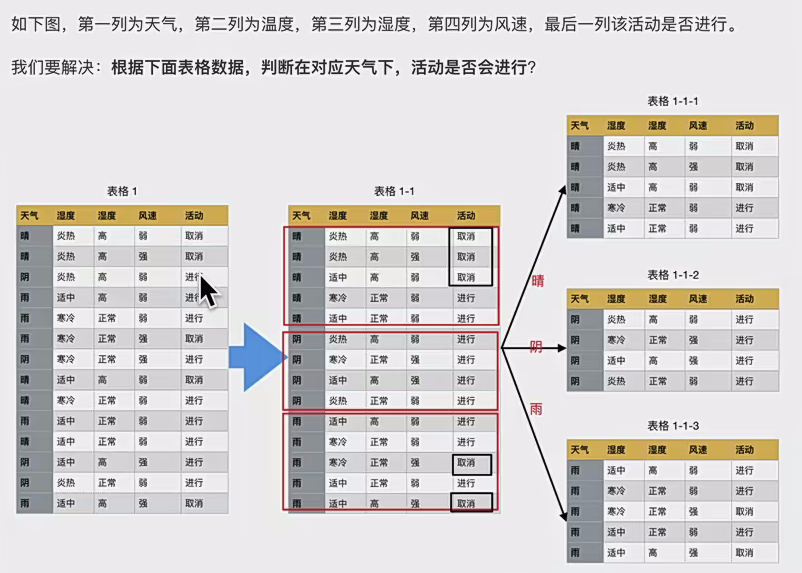
2.2.2案例:

你看那个ent(D^1/2)里边就是分母就是这个类别的总数,分子就是标签值对应的数。。,可以看到决策树对分类数据很友好。对于数值类数据如何做,之后有例子。
2.2信息增益率(C4.5算法)
2.2.1概念
概念
- 信息增益的局限性:信息增益准则对可取值数目较多的属性有偏好。如将 “编号” 作为候选划分属性时,按信息增益公式计算其信息增益很大,但这样划分出的结果不具泛化效果,无法有效预测新样本。因此需要引入增益率。
- 信息增益率定义:为减少上述偏好带来的不利影响,C4.5 决策树算法使用信息增益率选择最优划分属性 。

- 分母就是上一节的信息增益,分子就是总体被属性分成多少份中的每一份占比,套用熵的公式,只不过是属性分类树,而不是熵中标签值数了。。。
2.2.2案例
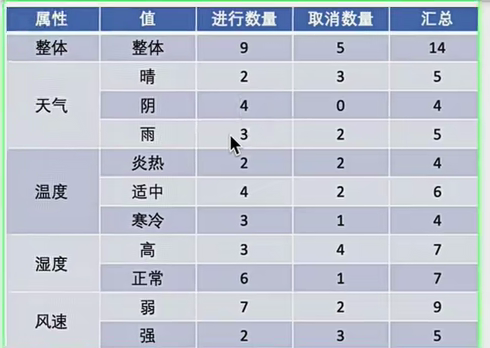
a.计算总信息熵
 以上计算就是2.1中的计算
以上计算就是2.1中的计算
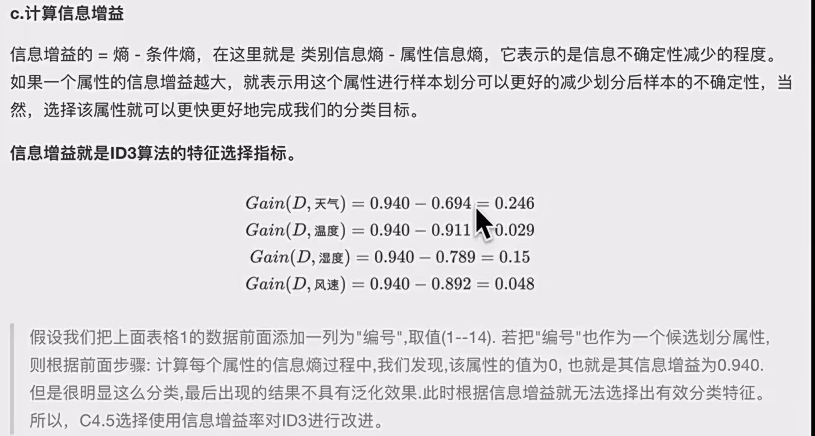
d.分裂继续执行
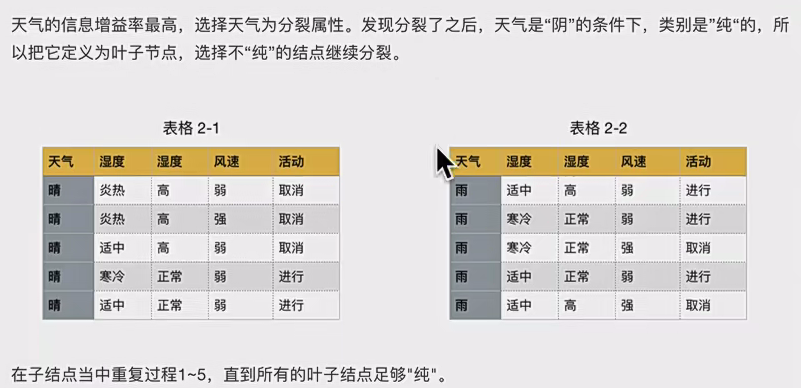
但是事实上经常做不到分完是纯的 ,而且id3和c4.5得到的数不一定是二叉树。

2.2.3 C4.5的优点
 2.3基尼指数(CART算法)
2.3基尼指数(CART算法)
2.3.1原理

基尼指数和那个信息增益很相识,只不过把ent(D^v)该为了gini(D^v)
注意,这个算法划分后一定是二叉树,它只有不是(或者大于)这个属性的某个值或者是(或者小于)这个属性的某个值,可以看这个案例:
2.3.2案例
这是数据
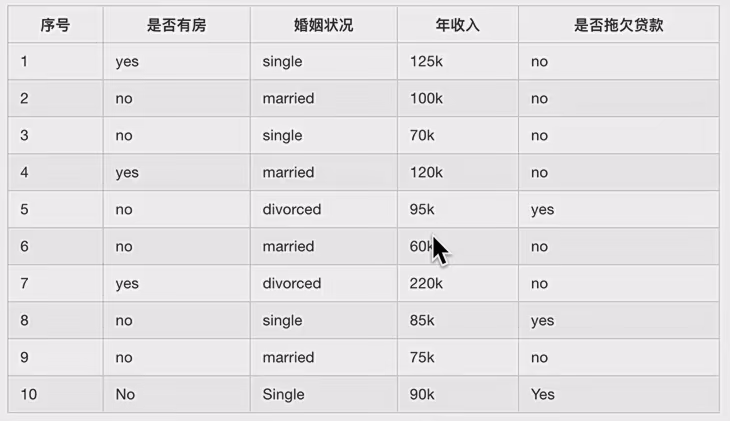


你看这里就是体现了是一个二叉树,因为当一个属性有大于两个值时,你要一个一个算,每次把一个当做左子树,其他作为右子树,这样每个都算完后,选一个最小的分类值作为要分类节点,左子树是属于这个,右子树是其他的。(可以发现分类数据可以做这个处理,如果是数值类型数据该如何处理??)
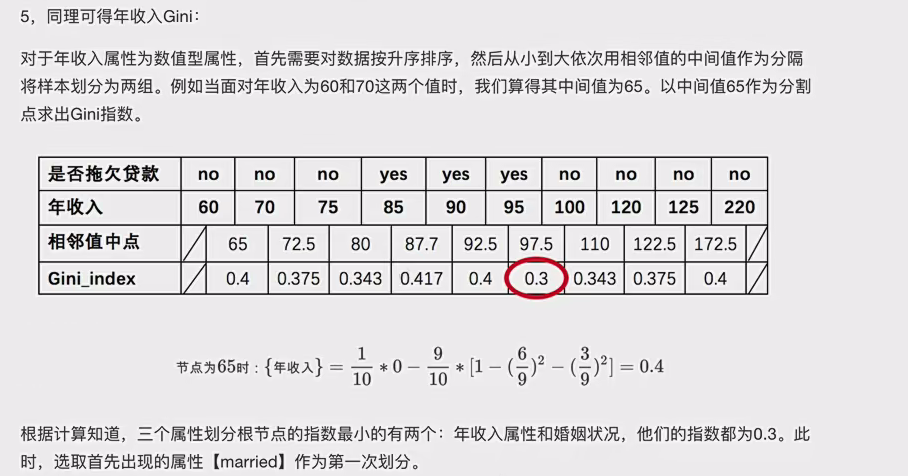
:说一下怎么来的,其实和信息增益一样,十分之1和9就是如果按照65来划分会将10个样本划分为小于65的一份和大于65的9份。。然后它们乘的就是每份里的基尼指数,比如第一份里边标签值都是no说以就是(1-(1/1)^2-(0/1)^2)=0 第二个同样,9份里边6个no,3个yes于是就是图里那样,看见没其实计算方法和信息增益是一样的。只不过前者是乘上ent(D^v)
这个数值类型你要一个一个算,然后看那个最小来选择最小的,假设上面选择了以65为中间值的。
选好第一次节点以及属性值后,分割数据,循环到结束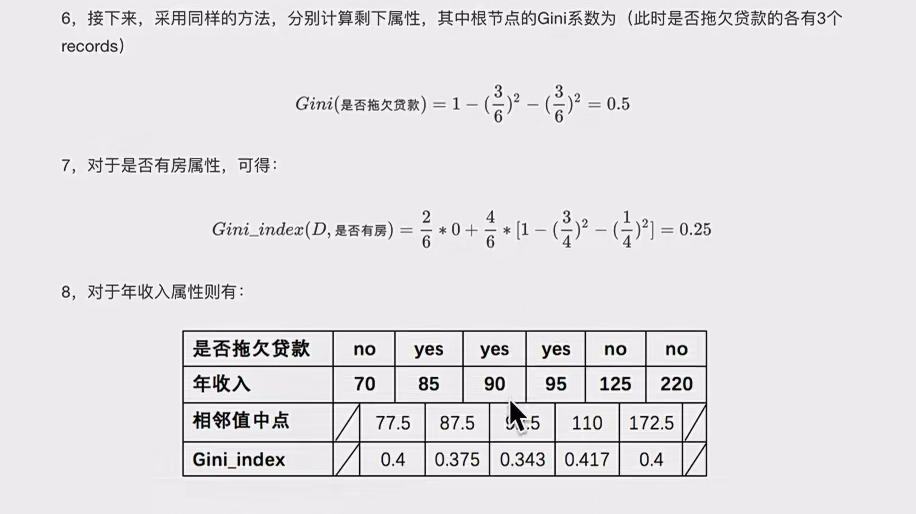 最后有如下决策树:
最后有如下决策树: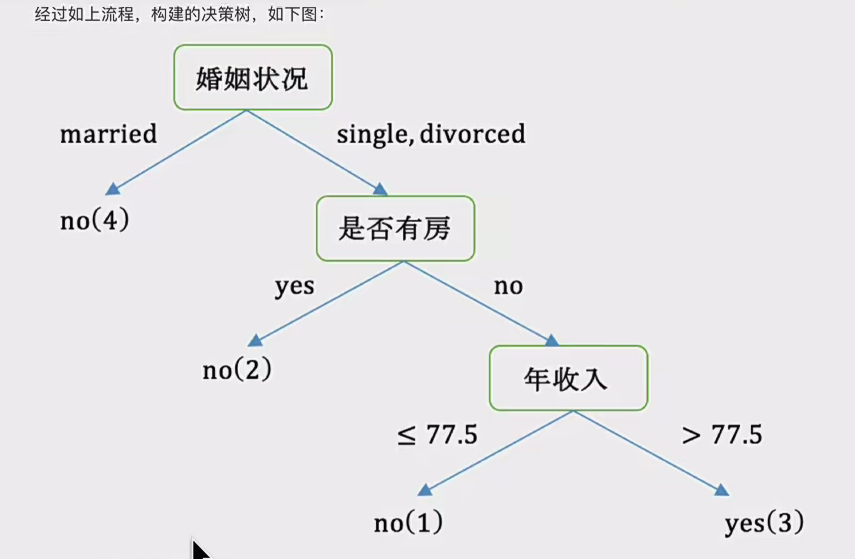
总而言之,算法流程就是:

2.4总结


记住,id3只能用于分类变量,c4.5可以用连续性变量,它们用于分类。cart均可以而且也可以用来回归。多变量决策树采用特征的线性组合。

3.剪枝(防止过拟合)
3.1引入
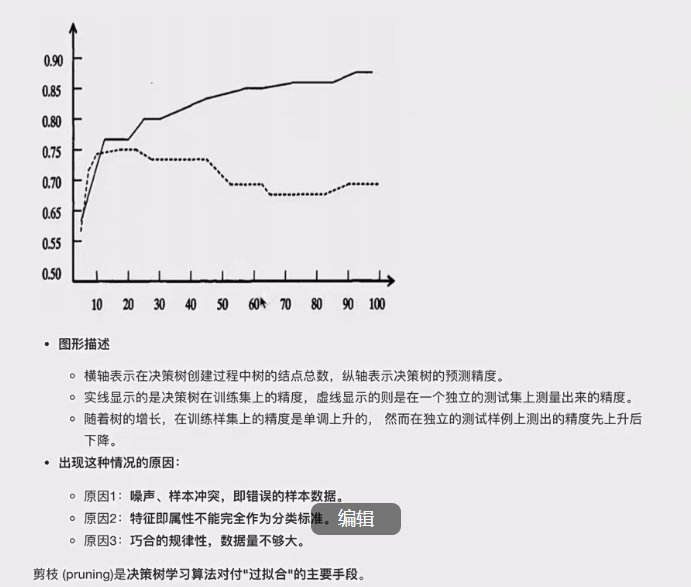

这个就叫做剪枝.
3.2剪枝类型

3.2.1预剪枝
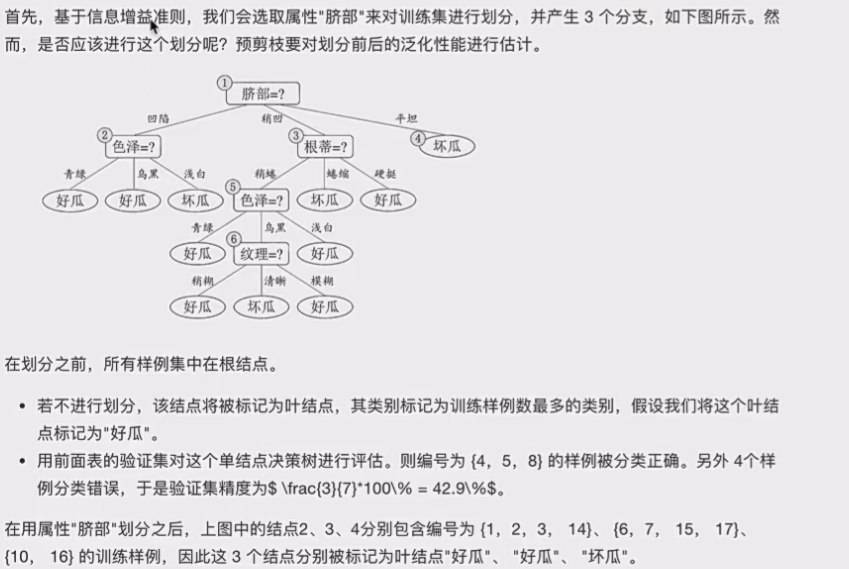
注意,要用验证集去进行准确率测量,因为要避免过拟合,提高泛化型
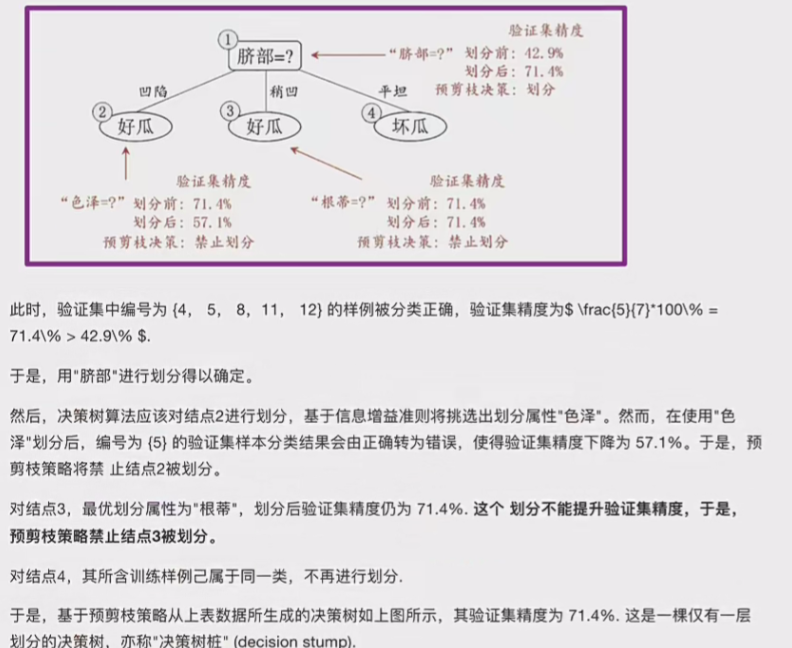
这就是预剪枝的过程。
3.2.2后剪枝
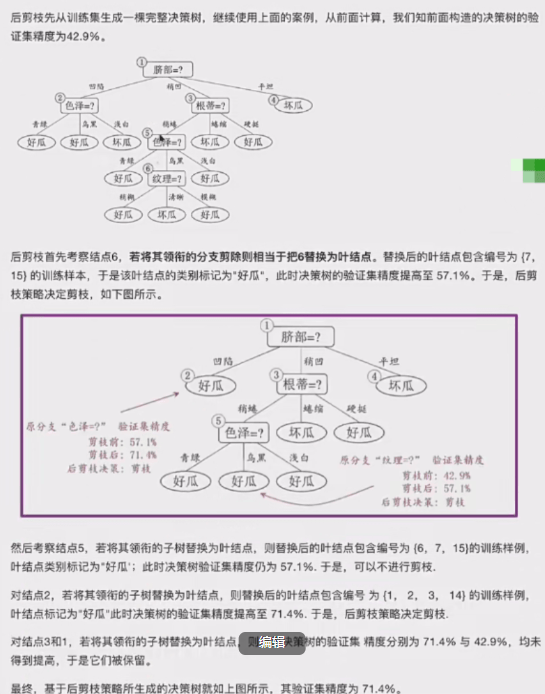
3.2.3两种方法对比
1. 核心差异对比
| 对比维度 | 预剪枝 | 后剪枝 |
|---|---|---|
| 剪枝时机 | 树生成过程中 | 树完全生成后 |
| 剪枝方向 | 自上而下 | 自底向上 |
| 分支保留情况 | 较少分支 | 较多分支 |
| 时间复杂度 | O(n) - 较低 | O(n²) - 较高 |
| 空间复杂度 | 较低 | 需要存储完整树,较高 |
| 实现难度 | 较简单 | 较复杂 |
2. 性能
-
后剪枝优势明显:
-
保留了更多可能有效的分支路径
-
通过"事后验证"能更准确判断哪些分支应该保留
-
典型情况下泛化精度比预剪枝高10-15%
-
-
预剪枝局限性:
-
早期停止可能导致丢失有潜力的分支
-
"目光短浅"问题:无法预见后续可能出现的有效划分
-
3. 时间开销详解
3.1 预剪枝时间构成
-
结点划分评估:每次划分前计算验证集精度
-
比较决策:单次比较即可决定是否划分
-
总时间 ≈ 树深度 × 结点评估时间
3.2 后剪枝时间构成
-
完整树构建时间
-
后处理时间:
-
需要考察每个非叶结点
-
每个结点的剪枝评估需要重新计算验证集精度
-
最坏情况下需评估O(n²)次(n为结点数)
-
3.3 实测数据参考
在UCI标准数据集上的实验结果:
-
预剪枝耗时:完整树构建时间的30-50%
-
后剪枝耗时:完整树构建时间的200-300%
4. 实际应用建议
4.1 推荐使用后剪枝的场景
-
数据量中等(万级以下样本)
-
对模型精度要求极高
-
计算资源充足
-
特征维度较高时
4.2 推荐使用预剪枝的场景
-
超大规模数据集(百万级以上)
-
实时性要求高
-
资源受限环境
-
特征维度较低时
4.3 混合策略建议
对于关键业务场景可考虑:
-
先使用预剪枝快速生成初步模型
-
在重要分支区域使用后剪枝精细调整
-
通过交叉验证确定最佳剪枝强度
4.特征工程----------特征提取
4.1. 特征提取概述
特征提取是将原始数据(如文本、图像、字典等)转换为机器学习算法可以理解的数值特征的过程。这是机器学习预处理的关键步骤。
主要分类:
-
字典特征提取(特征离散化)
-
文本特征提取
-
图像特征提取(之后讲)
4.2. 字典特征提取代码
4.2.1 DictVectorizer使用
Scikit-learn提供了DictVectorizer类来实现字典特征提取:先实例化,再使用fit_transform(数据)转化。

注意X的规定几乎是字典,实际中要提取,需要写为字典,或者可以用以前学过的one-hot编码。,即pd.get_dummies()函数
from sklearn.feature_extraction import DictVectorizerdata = [{'city': '北京', 'temperature': 100},{'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}]# 实例化转换器,sparse=False表示返回密集矩阵
transfer = DictVectorizer(sparse=False)# 转换数据
data_new = transfer.fit_transform(data)print("转换结果:\n", data_new)
print("特征名称:\n", transfer.get_feature_names())4.2.2 输出结果解析

这是一个sparse矩阵,,它只储存了不为0的位置,前面的坐标就是那个位置,在一个二维矩阵里那些位置不为0的坐标,加上True结果是这个:(其实sparse矩阵就是下面这个矩阵的非零位置)
转换结果:
[[ 0. 1. 0. 100.][ 1. 0. 0. 60.][ 0. 0. 1. 30.]]其实这个就是我们之前讲过的One-Hot编码,让我们再复习一遍
4.2.3. One-Hot编码原理
4.2.3.1 什么是One-Hot编码
One-Hot编码是将分类变量转换为机器学习算法更易理解的形式的过程。它为每个类别创建一个新的二进制特征(0或1)。
4.2.3.2 编码示例
原始数据:
Sample Category
1 Human
2 Human
3 Penguin
4 Octopus
5 Alien
6 Octopus
7 AlienOne-Hot编码后:
| Sample | Human | Penguin | Octopus | Alien |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 |
| 5 | 0 | 0 | 0 | 1 |
| 6 | 0 | 0 | 1 | 0 |
| 7 | 0 | 0 | 0 | 1 |
4.2.3.3 One-Hot编码特点
-
避免数值偏见:防止算法误认为类别之间有数值关系(如认为Alien>Penguin)
-
维度增加:类别变量有N个不同值,将生成N个新特征
-
稀疏性:每个样本在新特征中只有一个1,其余都是0
4.2.4. 应用场景与注意事项
4.2.4.1 适用场景
-
分类特征没有内在顺序关系时
-
类别数量不太大时(避免维度灾难)
-
基于树的模型通常不需要One-Hot编码(参考决策树)
4.2.4.2 注意事项
-
维度控制:当类别过多时,考虑:
-
合并低频类别
-
使用其他编码方式(如目标编码)
-
-
数值特征:像temperature这样的连续数值特征不需要One-Hot编码
-
内存考虑:大数据集使用稀疏矩阵表示更节省内存
4.3文本特征提取(其实就是对词的一个统计)
使用CountVectorizer这个实例化可以进行特征提取

注意X是文本或者包含文本的可迭代对象,stop_words=[]列表里放的是我们不需要统计的词
4.3.1只含有英文的文本
比如有以下数据(注意是纯英文的)

from sklearn.feature_extraction.text import CountVectorizerdef text_count_demo():"""对文本进行特征抽取,countvectorizer:return: None"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata = transfer.fit_transform(data)print("文本特征抽取的结果: \n", data.toarray())print("返回特征名字: \n", transfer.get_feature_names())return Noneif __name__ == "__main__":text_count_demo()
注意data本来返回的还是sparse矩阵,由于这里不能使用sparse=Flase转化为可以识别的格式,,,我们需要用toarray()给它转化为可以理解的数组 。
 上面那个矩阵就是下面的词在每句话里的出现的次数 ,注意不统计标点和单个字符
上面那个矩阵就是下面的词在每句话里的出现的次数 ,注意不统计标点和单个字符
4.3.2含有中文的文本
之所以能对含有英文的文本进行处理是因为英文单词之间有自然的空格,而中文没有,那怎么办呢?其实分词后就和上别一样了
4.3.2.1分词
使用jieba分词处理:注意返回的是一个生成器,要进行转化。

案例:
from sklearn.feature_extraction.text import CountVectorizer
import jiebadef cut_word(text):"""对中文进行分词"我爱北京天安门"——>"我 爱 北京 天安门":param text: 输入的中文文本:return: 分词后的文本(以空格连接词语的字符串形式)"""# 用结巴对中文字符串进行分词text = " ".join(list(jieba.cut(text)))#"a".join(可迭代对象)就是把可迭代对象的每个元素用a连接起来#返回字符串return textdef text_chinese_count_demo2():"""对中文进行特征抽取:return: None"""data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所"]# 将原始数据转换成分好词的形式text_list = []for sent in data:text_list.append(cut_word(sent))print(text_list)# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata = transfer.fit_transform(text_list)print("文本特征抽取的结果: \n", data.toarray())print("返回特征名字: \n", transfer.get_feature_names())return Noneif __name__ == "__main__":text_chinese_count_demo2()
4.4高频词处理:
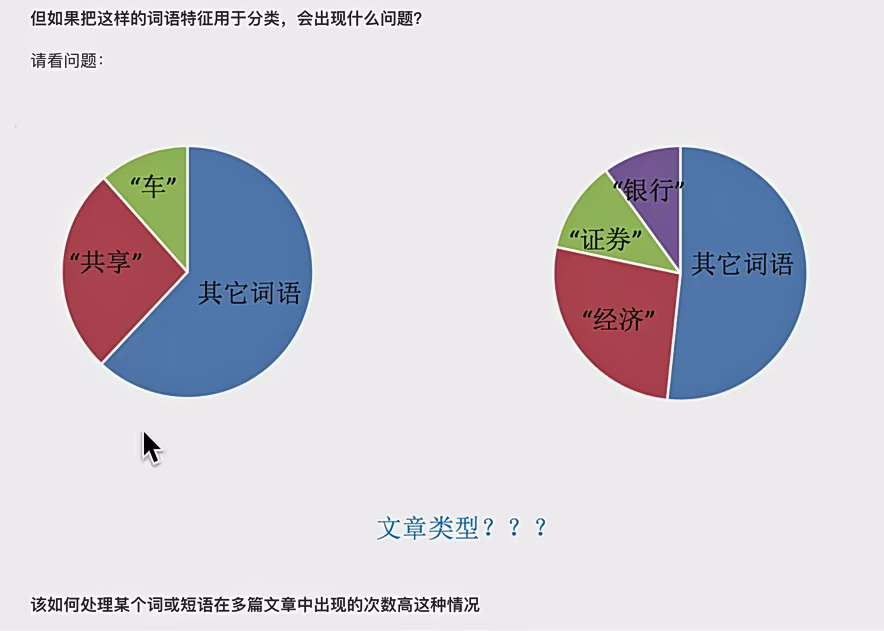 TF - idf 文本特征提取
TF - idf 文本特征提取
- 主要思想:如果某个词语在一篇文章中出现的概率高,并且在其他文章中很少出现,就认为此词语具有很好的类别区分能力,适合用来对文本进行分类。例如在体育类文章中频繁出现的 “足球”“比赛” 等词,在科技类文章中很少出现,这些词对于区分体育类文本就很有价值。
- 作用:用于评估一个字词对于一个文件集或一个语料库中的某一份文件的重要程度。比如在学术论文集中,专业术语在相关主题论文中重要程度高,通过 TF - idf 可以衡量出其重要性。
3.5.1 公式
- 词频(term frequency, tf):指的是某一个给定的词语在该文件中出现的频率。计算方法是词语在文件中出现的次数除以文件的总词语数 。例如,若一篇文章总词语数是 100 个,词语 “非常” 出现了 5 次,那么 “非常” 一词在该文件中的词频就是 5÷100 = 0.05 。
- 逆向文档频率(inverse document frequency, idf):是一个词语普遍重要性的度量。计算方式为总文件数目除以包含该词语之文件的数目,再将得到的商取以 10 为底的对数 。比如 “非常” 一词在 1,000 份文件出现过,而文件总数是 10,000,000 份,其逆向文件频率就是 lg (10,000,000÷1,000) = 3 。
- tf - idf 公式:
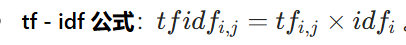 。其中tfij是词语i在文档j中的词频,idfi是词语i的逆向文档频率。最终得出的tfidf结果可以理解为词语i在文档j中的重要程度 。如上述例子中,“非常” 对于这篇文档的 tf - idf 的分数为 0.05×3 = 0.15 。
。其中tfij是词语i在文档j中的词频,idfi是词语i的逆向文档频率。最终得出的tfidf结果可以理解为词语i在文档j中的重要程度 。如上述例子中,“非常” 对于这篇文档的 tf - idf 的分数为 0.05×3 = 0.15 。
通过 TF - idf 方法,可以量化文本中词语的重要性,在文本分类、信息检索等自然语言处理任务中广泛应用,帮助筛选出对文本内容有重要表征作用的词语。
5.决策树算法的API,还是先实例化在调用

6.案例
6.1案例背景
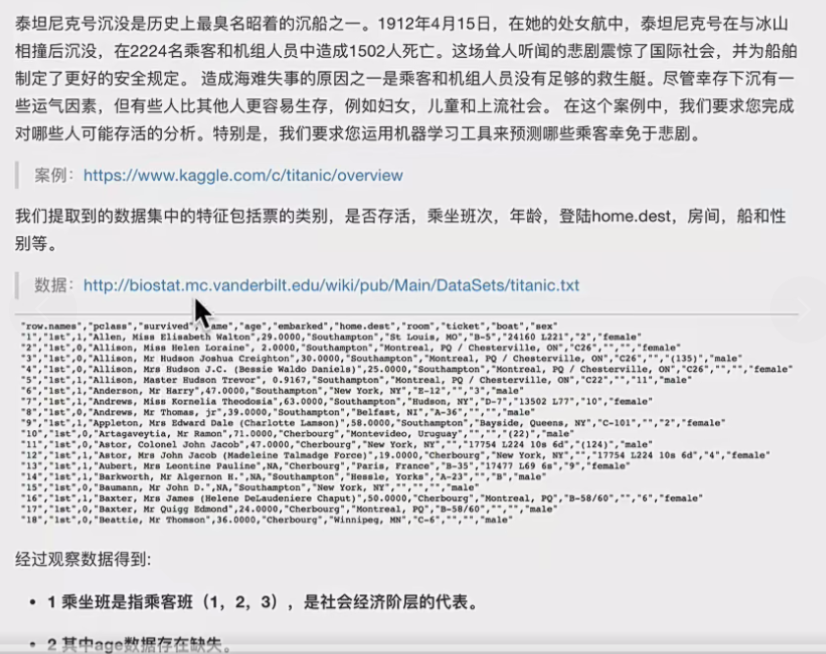
6.2步骤分析

6.3代码
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz# 1. 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")# 2. 数据基本处理
# 2.1 确定特征值、目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
# 2.2 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 3. 特征工程(字典特征抽取)
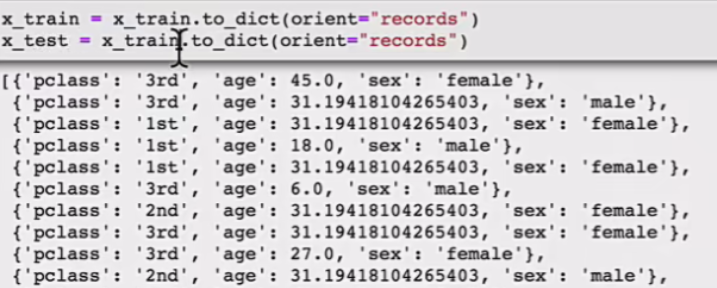
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))# 4. 决策树模型训练和模型评估
# 4. 机器学习(决策树)
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
estimator.fit(x_train, y_train)# 5. 模型评估
score = estimator.score(x_test, y_test)
print("模型得分:", score)
y_predict = estimator.predict(x_test)
print("预测结果:", y_predict)注意里边的字典转化:
参数意义:


7.决策树可视化

8.回归决策树
8.1算法描述

意思就是我们的回归决策树也是循环所有的特征所有的取值,看哪一个让损失函数最小 ,而分类决策树是让信息差最大。其次回归决策树采取的是这一分类的平均值进行输出。

可以看到那个优化的公式,我们还是和基尼指数一样,给他划分为一个二叉树。
8.2案例
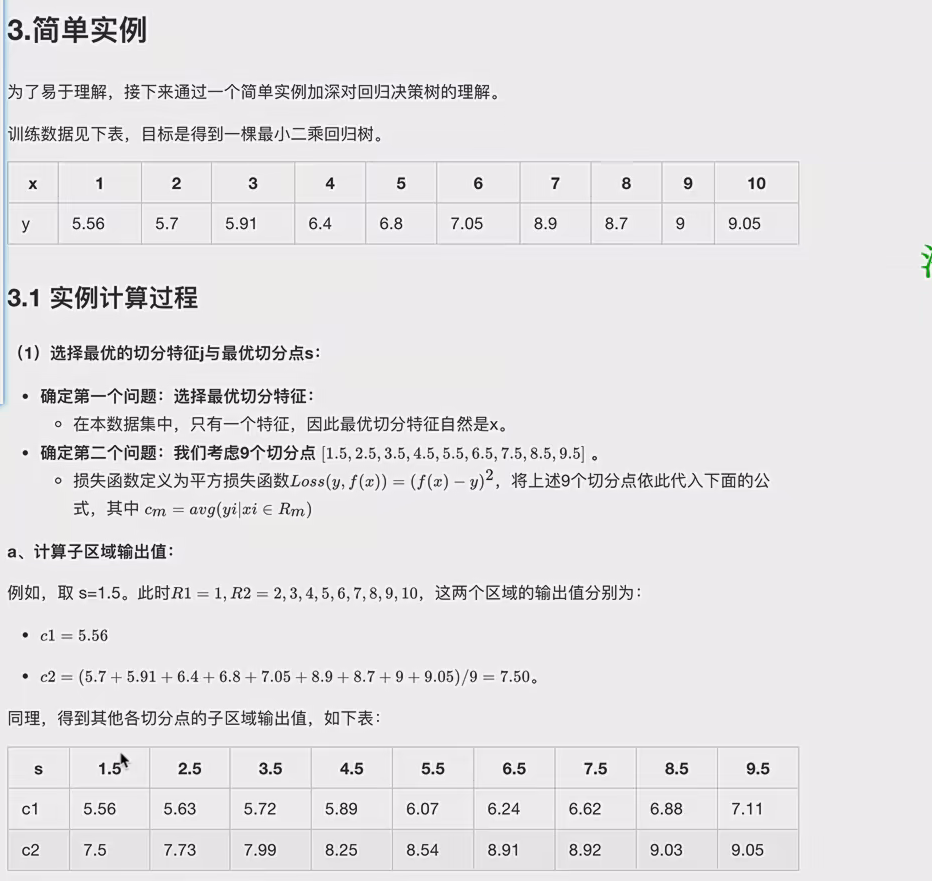

8.3代码对比
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn import linear_model# 生成数据
x = np.array(list(range(1, 11))).reshape(-1, 1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])# 训练模型
model1 = DecisionTreeRegressor(max_depth=1)#决策树回归
model2 = DecisionTreeRegressor(max_depth=3)#决策树回归
model3 = linear_model.LinearRegression()#简单的线性回归model1.fit(x, y)
model2.fit(x, y)
model3.fit(x, y)# 模型预测
X_test = np.arange(0.0, 10.0, 0.01).reshape(-1, 1) # 生成1000个数,用于训练模型
y_1 = model1.predict(X_test)
y_2 = model2.predict(X_test)
y_3 = model3.predict(X_test)# 结果可视化
plt.figure(figsize=(10, 6), dpi=100)
plt.scatter(x, y, label="data")
plt.plot(X_test, y_1, label="max_depth=1")
plt.plot(X_test, y_2, label="max_depth=3")
plt.plot(X_test, y_3, label='liner regression')plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()plt.show()注意我们生成数据因为要预测,我们必须转化为二维的,仅仅是np.array(list(range(1,11)))是一个一维数组,所以通过形状转变变为二维。
x = np.array(list(range(1, 11))).reshape(-1, 1)
图如下:
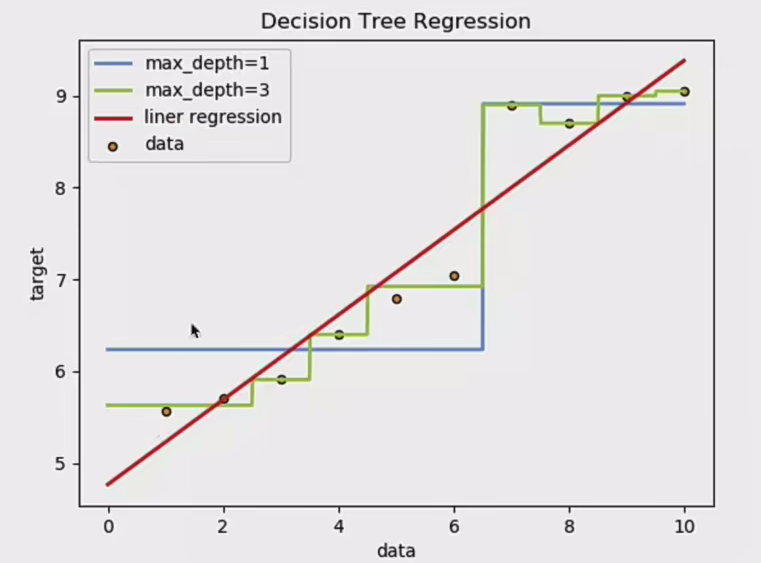 很正常,我们看决策树回归的算法就是选取某一段的平均值,你看所以这幅图绿和蓝线都是阶梯形状的。
很正常,我们看决策树回归的算法就是选取某一段的平均值,你看所以这幅图绿和蓝线都是阶梯形状的。
8.4优缺点

相关文章:

机器学习 Day11 决策树
1.决策树简介 原理:思想源于程序设计的 if - else 条件分支结构 ,是一种树形结构。内部节点表示属性判断,分支是判断结果输出,叶节点是分类结果 。案例:以母亲给女儿介绍男朋友为例。女儿依次询问年龄(≤3…...

【HFP】深入解析蓝牙 HFP 协议中呼叫转移、呼叫建立及保持呼叫状态的机制
目录 一、核心指令概述 1.1 ATCMER:呼叫状态更新的 “总开关” 1.2 ATBIA:指示器的 “精准控制器” 1.3 指令对比 1.4 指令关系图示 二、CIEV 结果码:状态传递的 “信使” 2.1 工作机制 2.2 三类核心指示器 三、状态转移流程详解 3…...
)
音频识别优化(FFT)
整合多频段检测、动态阈值调整和持续时长验证的完整代码实现,包含详细注释: #include "esp_dsp.h" #include "driver/i2s.h" #include "esp_log.h" #include "math.h" static const char* TAG "ADV_FRE…...
)
【Redis】Redis基本命令(1)
KEYS 返回所有满足样式(pattern)的key。 KEY * 返回所有key,不简易使用 性能问题:当 Redis 存储百万级键时,会消耗大量 CPU 和内存资源,Redis 是单线程模型,KEYS * 执行期间会阻塞其他所有命令…...

IDEA2024 pom.xml依赖文件包报红解决
异常: 原因: 本地的Maven Repository库中不存在对应版本的dependency依赖,所以导致报红。 解决: 方法1:找到对应项目,右键Sync Project 就可以了 方法2:修改setting中maven的自动更新…...

Qt 信号与槽复习
Qt 信号与槽复习 Qt 信号与槽(Signals and Slots)机制是 Qt 框架的核心特性之一,用于实现对象之间的通信。它提供了一种松耦合的方式,使得组件可以独立开发和复用,广泛应用于 GUI 编程、事件处理和跨模块交互。本文将…...

RestControllerAdvice 和 ControllerAdvice 两个注解的区别与联系
它们都用于实现全局的通用处理逻辑,主要应用在以下三个方面: 全局异常处理: 使用 ExceptionHandler 注解的方法。全局数据绑定: 使用 InitBinder 注解的方法。全局数据预处理: 使用 ModelAttribute 注解的方法。 联系: 核心功能相同: 两者都提供了上述…...

最快打包WPF 应用程序
在 Visual Studio 中右键项目选择“发布”,目标选“文件夹”,模式选“自包含”,生成含 .exe 的文件夹,压缩后可直接发给别人或解压运行,无需安装任何东西。 最简单直接的新手做法: 用 Visual Studio 的“…...
与 Go 协程的运行原理不同 为何Go 能在低配机器上承接10万 Websocket 协议连接)
Java NIO Java 虚拟线程(微线程)与 Go 协程的运行原理不同 为何Go 能在低配机器上承接10万 Websocket 协议连接
什么是Java NIO? Java NIO(New Input/Output) 是Java 1.4(2002年)引入的一种非阻塞、面向缓冲区的输入输出框架,旨在提升Java在高性能和高并发场景下的I/O处理能力。它相比传统的 Java IO(java…...

C# 对列表中的元素的多个属性进行排序
目录 前言一、OrderBy、OrderByDescending、ThenBy、ThenByDescending二、Sort 前言 在开发过程中,我们经常需要 根据列表中的元素的某个属性进行排序,下面我们将简单介绍常用的排序函数。 例如此处有一个类,拥有的元素为编号和值 public …...

OpenCV颜色变换cvtColor
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 颜色变换是imgproc模块中一个常用的功能。我们生活中看到的大多数彩色图片都是RGB类型的,但是在进行图像处理时需要用到灰度图、二值图、HSV(六角锥体模型,这个模型中颜色的…...

java IO/NIO/AIO
(✪▽✪)曼波~~~~!让曼波用最可爱的赛马娘方式给你讲解吧!(⁄ ⁄•⁄ω⁄•⁄ ⁄) 🎠曼波思维导图大冲刺(先看框架再看细节哦): 📚 解释 Java 中 IO、NIO、AIO 的区别和适用场景: …...

如何深入理解引用监视器,安全标识以及访问控制模型与资产安全之间的关系
一、核心概念总结 安全标识(策略决策的 “信息载体) 是主体(如用户、进程)和客体(如文件、数据库、设备)的安全属性,用于标记其安全等级、权限、访问能力或受保护级别,即用于标识其安全等级、权限范围或约束…...

宜搭与金蝶互通——连接器建立
一、 进入连接器工厂 图1 连接器入口 二、 新建连接器 图2 新建连接器第一步 1、 连接器显示名,如图2中①所示; 2、 图2中②域名,是金蝶系统API接口里面的“完整服务地址”com之前的信息,不含“https”,如图3中①所示; 3、 Base Url通常为“/”,如图2…...

中间件--ClickHouse-7--冷热数据分离,解决Mysql海量数据瓶颈
在web应用中,当数据量非常大时,即使MySQL的存储能够满足,但性能一般也会比较差。此时,可以考虑使用ClickHouse存储历史数据,在Mysql存储最近热点数据的方式,来优化和提升查询性能。ClickHouse的设计初衷就是…...

1.1 设置电脑开机自动用户登录exe开机自动启动
本文介绍两个事情: 1.Windows如何开机自动登录系统(不用输密码) 2. 应用程序(.exe)如何开机自动启动 详细解释如下: 一、Windows如何开机自动登录系统(不用输密码) 设备上的工控机,如果开机后都需要操作人员输入密码&…...

vscode stm32 variable uint32_t is not a type name 问题修复
问题 在使用vscodekeil开发stm32程序时,发现有时候vscode的自动补全功能失效,且problem窗口一直在报错。variable “uint32_t” is not a type name uint32_t 定义位置 uint32_t 实际是在D:/Keil_v5/ARM/ARMCC/include/stdint.h中定义的。将D:/Keil_v5…...

动态规划与记忆化搜索的区别与联系
记忆化搜索(Memoization)和动态规划(Dynamic Programming, DP)都是解决重叠子问题的高效算法技术,但它们有着不同的实现方式和特点。 1. 基本概念 记忆化搜索(自顶向下) 本质:带有…...

html+js+clickhouse环境搭建
实验背景: 我目前有一台服务器A,和一台主机B,两台设备属于同一局域网,相互之间可以通讯。服务器A中部署着clickhouse,我在主机B中想直接通过javascript代码访问服务器中的clickhouse数据库并获取数据。 ClickHouse 服务…...

生命护航行动再启航!
温州好人陈飞携防溺水课堂,为乡村少年宫筑起安全防线 图文作者:华夏之音/李望 随着夏日热浪的滚滚而来,楠溪江畔的安全警钟再次响起。在这片如诗如画的土地上,一场旨在保护青少年生命安全的防溺水课堂活动拉开了…...

Android Compose Activity 页面跳转动画详解
下面我将全面详细地介绍在 Compose 中实现 Activity 跳转动画的各种方法,包括基础实现、高级技巧和最佳实践。 一、基础 Activity 过渡动画 1. overridePendingTransition 传统方式 这是最基础且兼容性最好的方法,适用于所有 Android 版本。 实现步骤…...

Android启动初始化init.rc详解
1. Android启动与init.rc简介 1.1 Android启动过程 一张图简单阐述一下 (网络图片,侵删) 1.2 init.rc 简介 Linux的重要特征之一就是一切都是以文件的形式存在的,例如,一个设备通常与一个或多个设备文件对应。这些…...

Linux驱动开发-①regmap②IIO子系统
Linux驱动开发-IIO驱动 一,regmap二,IIO子系统2.1初始化相关工作2.2 通道2.3 读实现 over 一,regmap 对于spi和i2c,读写寄存器的框架不同,但设备本质一样,因此就有了regmap模型来对其进行简化,提供统一的接…...

HTML5好看的水果蔬菜在线商城网站源码系列模板5
文章目录 1.设计来源1.1 主界面1.2 关于我们1.3 商品服务1.4 果蔬展示1.5 联系我们1.6 商品具体信息1.7 登录注册 2.效果和源码2.1 动态效果2.2 源代码 源码下载万套模板,程序开发,在线开发,在线沟通 作者:xcLeigh 文章地址&#…...

L2-033 简单计算器满分笔记
本题要求你为初学数据结构的小伙伴设计一款简单的利用堆栈执行的计算器。如上图所示,计算器由两个堆栈组成,一个堆栈 S1 存放数字,另一个堆栈 S2 存放运算符。计算器的最下方有一个等号键,每次按下这个键,计算器就…...

其他网页正常进入,但是CSDN进入之后排版混乱
显示不正常,排版混乱 解决方法: ①打开网络设置 ②更改适配器 ③所连接的网络 --右键 属性 然后就可以正常访问了。...

BFC详解
1.定义: FC的全称为Formatting Conttext,元素在标准流里面 块级元素的布局属于Block Formatting Context(BFC)——即block level box都是BFC中布局 行内级元素的布局属于Inline Formatting Context (IFC) 2.那么在哪些情况下会创建BFC? 根元素…...
vlan配置实验)
(H3C)vlan配置实验
1.实验拓扑 2.实验配置 [S1]dis cu #version 7.1.070, Alpha 7170 #sysname S1 # vlan 10 # vlan 20 # interface GigabitEthernet1/0/1port link-mode bridgeport link-type trunkport trunk permit vlan 1 10 20combo enable fiber # interface GigabitEthernet1/0/2port li…...

idea mvn执行打包命令后控制台乱码
首先在idea中查看maven的编码方式 执行mvn -v命令 查看编码语言是GBK C:\Users\13488>mvn -v Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) Maven home: D:\maven\apache-maven-3.6.3\bin\.. Java version: 1.8.0_202, vendor: Oracle Corporation, runt…...
) 与 lodash 的 cloneDeep:深度拷贝的比较与基础知识)
JSON.parse(JSON.stringify()) 与 lodash 的 cloneDeep:深度拷贝的比较与基础知识
JSON.parse(JSON.stringify()) 与 lodash 的 cloneDeep:深度拷贝的比较与基础知识 在 JavaScript 开发中,**深拷贝(Deep Copy)**是一个常见需求,尤其是在处理复杂对象和嵌套数据结构时。JSON.parse(JSON.stringify(o…...

搭建用友U9Cloud ERP及UAP IDE环境
应用环境 Microsoft Windows 10.0.19045.5487 x64 专业工作站版 22H2Internet Information Services - 10.0.19041.4522Microsoft SQL Server 2019 - 15.0.2130.3 (X64)Microsoft SQL Server Reporing Services 2019 - 15.0.9218.715SQL Server Management Studio -18.6 laster…...

Linux 系统新磁盘分区XFS挂载
以下是Linux系统中对新硬盘进行XFS文件系统格式化和挂载的完整操作指南: 一、确认硬盘识别 查看已识别硬盘 执行 lsblk 或 fdisk -l 命令,确认新硬盘设备标识(如 /dev/sdb)。 二、硬盘分区(可选) …...
)
Oracle测试题目及笔记(单选)
所有题目来自于互联网搜索 当 Oracle 服务器启动时,下列哪种文件不是必须的(D)。 A.数据文件 B.控制文件 C.日志文件 D.归档日志文件 数据文件、日志文件-在数据库的打开阶段使用 控制文件-在数…...

C语言链接数据库
目录 使用 yum 配置 mysqld 环境 查看 mysqld 服务的版本 创建 mysql 句柄 链接数据库 使用数据库 增加数据 修改数据 查询数据 获取查询结果的行数 获取查询结果的列数 获取查询结果的列名 获取查询结果所有数据 断开链接 C语言访问mysql数据库整体源码 通过…...

深入浅出 Redis:核心数据结构解析与应用场景Redis 数据结构
引言:Redis 为何如此之快?数据结构是关键 Redis (Remote Dictionary Server) 作为一款高性能的内存键值数据库,凭借其闪电般的速度和丰富的功能,在缓存、消息队列、排行榜等众多场景中得到了广泛应用。除了基于内存存储这一核心优…...

告别昂贵语音合成服务!用GPT-SoVITS生成你的个性化AI语音
文章目录 前言1.GPT-SoVITS V2下载2.本地运行GPT-SoVITS V23.简单使用演示4.安装内网穿透工具4.1 创建远程连接公网地址 5. 固定远程访问公网地址 前言 今天给大家介绍一款AI语音克隆工具——GPT-SoVITS。这款由花儿不哭大佬开发的工具是一款强大的训练声音模型与音频生成工具…...

前沿要塞:Vue组件安全工程的防御体系重构与技术突围
总章数字世界的钢铁长城 在某个凌晨3点的红蓝对抗演练中,某电商平台因组件级XSS漏洞导致千万级用户数据泄露。这不是虚构的灾难场景,而是2023年某A轮企业的真实遭遇。当传统安全方案在新型攻击面前节节败退时,我们需要为Vue组件铸造全新的数字…...
XGBoost简介|神经网络与决策树)
吴恩达深度学习复盘(19)XGBoost简介|神经网络与决策树
XGBoost 多年来,机器学习研究人员提出了许多构建决策树的方法,目前最常用的方法是对样本或决策树的实现收费。其中,XGBoost 是一种非常快速且易于使用的开源实现,已成功用于赢得许多机器学习竞赛和商业应用。 算法原理 基本思想…...

Docker部署禅道21.6开源版本
将数据库相关环境变量分开,增加注释或空格使得命令更易读。 如果你的 MySQL 主机、端口等配置没有变化,应该确保这些信息是安全的,并考虑使用 Docker secrets 或环境变量配置来避免直接暴露敏感信息。 docker run -d -it --privilegedtrue …...

《MySQL:MySQL表结构的基本操作》
创建表 CREATE TABLE table_name ( field1 datatype, field2 datatype, field3 datatype ) character set 字符集 collate 校验规则 engine 存储引擎; field 表示列名 datatype 表示列的类型 character set 字符集,如果没有指定字符集,则以所在数据…...

C++解析操作mat文件方法-基于vs2019
前言 工作中需要将C#脚本转为C++,所转脚本主要功能是进行mat数据文件的解析和矩阵运算。 1.C#版本 原C#脚本主要是基于 MathNet.Numerics.data.Matlab、MathNet.Numerics.LineAlgebra.Double、 MathNet.Numerics.LineAlgebra 中的MatlabReader、DenseMatrix、Matrix进行mat文…...

OpenCV 模板匹配方法详解
文章目录 1. 什么是模板匹配?2. 模板匹配的原理2.1数学表达 3. OpenCV 实现模板匹配3.1基本步骤 4. 模板匹配的局限性5. 总结 1. 什么是模板匹配? 模板匹配(Template Matching)是计算机视觉中的一种基础技术,用于在目…...

自已实现一个远程打印方案 解决小程序或APP在外面控制本地电脑打印实现
常规通过小程序或APP在外出时控制本地电脑实现打印功能,可以结合远程桌面技术、云打印服务或开发定制化的远程打印解决方案。 但这里我们采用自已的实现方案来解决 服务器端实现 搭建一个后端socket服务,监听来自手机的打印请求。监听到打印任务后向本…...

Oracle_00000
contents 基本使用 基本使用 Oracle安装后会自动创建sys和system这两个用户。 sys用户:具有最高权限。具有sysdba角色,有create database的权限。该用户默认密码是:manager system用户:管理员用户,具有sysoper角色。没…...

深入剖析 ORM:原理、优缺点、场景及多语言框架示例
ORM 即对象关系映射(Object Relational Mapping),它是一种编程技术,其作用是在面向对象编程语言里,把对象模型和关系型数据库的数据结构之间创建起映射,这样开发者就能够使用面向对象的方式来操作数据库&am…...

ARINC818协议-持续
一、帧头帧尾 SOF 和 EOF 分别代表视频帧传输的开始与结束,它们在封装过程有多种状态,SOF 分为 SOFi 和 SOFn,EOF 分为 EOFt 和 EOFn。传输系统中的视频信息包括像素数据信 息和辅助数据信息,分别存储在有效数据中的对象 0 和对象…...

【uniapp】uni.setClipboardData 方法失效 bug 解决方案
写了一个 copy 方法,但是怎么也没有弹窗复制成功 <text click"toCopy(myInfo.id)">复制 </text> 逐步打印发现 1 正常打印,2 没有打印,说明问题出现在 setClipboardData 方法执行中 toCopy(n) {// console.log(1,ty…...

智能sc一面
智能sc一面-2025/4/17 更多完善:真实面经 Java 的异常分类 异常分为两类,一类Error,一类Execption。这两个类都是Throwable的子类,只有继承Throwable 的类才可以被throw或者catch Error: 表示严重的系统问题,通常与代码无关&am…...

SAP HANA使用命令行快速导出导入
楔子 今天折腾了接近一下午,就为了使用SAP HANA自带的命令行工具来导出数据备份。 SAP HANA(后续简称Hana)是内存数据库,性能这一方面上还真没怕过谁。 由于SAP HANA提供了Hana Studio这个桌面工具来方便运维和DBA使用…...

Oracle DBMS_SCHEDULER 与 DBMS_JOB 的对比
Oracle DBMS_SCHEDULER 与 DBMS_JOB 的对比 一 基本概述对比 特性DBMS_JOB (旧版)DBMS_SCHEDULER (新版)引入版本Oracle 7 (1992年)Oracle 10g R1 (2003年)当前状态已过时但仍支持推荐使用的标准设计目的基础作业调度企业级作业调度系统 二 功能特性对比 2.1 作业定义能力 …...