深入浅出 NVIDIA CUDA 架构与并行计算技术

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、CUDA为何重要:并行计算的时代
2、NVIDIA在GPU计算领域的角色
二、CUDA简介
1、什么是CUDA
2、CUDA的历史与发展
三、CUDA架构解析
1、GPU vs CPU:架构对比
2、CUDA核心组件
四、CUDA编程模型
1、CUDA程序的基本结构
2、Kernel函数与线程层级
3、内存管理与数据传输(Host ↔ Device)
一、引言
1、CUDA为何重要:并行计算的时代
🧠 单核时代的终结
曾几何时,我们对计算性能的追求是这样的:
“CPU 主频越高越好,单核越强越牛!” 🐎
但摩尔定律渐趋放缓,散热瓶颈越来越明显,频率提升也越来越难……
于是,计算行业悄悄转向了一条新路:并行计算。
🔀 串行 vs 并行:一次做一件事 vs 同时做很多事
| 场景 | 串行(CPU) | 并行(GPU) |
|---|---|---|
| 洗100个苹果 | 一人洗100个 🍎 | 100个人各洗一个 🍎 |
| 图像渲染 | 一像素一像素地算 🐢 | 一次处理上万像素 🚀 |
| 视频编解码 | 一帧帧慢慢处理 🎞️ | 多线程同时压缩处理 📽️ |
🎮 CUDA 的登场:让 GPU 不只是打游戏!
NVIDIA 发现:
“嘿,我们家显卡这么猛,为什么不拿来干点科研的活呢?”
于是他们发布了 CUDA(Compute Unified Device Architecture)

2、NVIDIA在GPU计算领域的角色
💬 “为啥大家一提 GPU 计算就想到 NVIDIA?”
🏆 NVIDIA 在 GPU 计算领域的角色
💡 从显卡厂商到计算王者的转型
在很多人眼中,NVIDIA 一开始只是“做显卡的公司”:
🎮 给游戏加速
🎬 给影视渲染
🎨 给设计师画图更丝滑
BUT!
NVIDIA 真正的雄心,从来不止于此 —— 它要让 GPU 成为 通用计算平台,改变整个计算产业的未来。
📊 市场格局:几乎垄断的存在
| 领域 | NVIDIA 份额(粗略估计) | 代表产品 |
|---|---|---|
| 深度学习训练硬件 | 90%+ | A100、H100、DGX |
| 高性能计算(HPC) | 80%+ | Tesla 系列、NVLink |
| AI 推理 & 云计算加速器 | 快速增长中 | L40、T4、Grace Hopper |

二、CUDA简介
1、什么是CUDA
你有没有想过,电脑里的 显卡(GPU) 除了打游戏、看电影,其实还可以帮我们做科学计算、跑 AI 模型、挖矿(没错,就是你听说过的那个)🤯
这背后,有一项“黑科技”功不可没——CUDA!
🧠 简单来说,CUDA 是什么?
CUDA,全称是 Compute Unified Device Architecture,由 NVIDIA 开发。
通俗点说,它是让显卡“听懂”程序员指令的工具,让 GPU 不只是画画图,还能做“正经数学题”。🎨 ➡️ 📐📊
🎮 CPU vs GPU:一场角色扮演大比拼
| 属性 | CPU(中央处理器)🧑💻 | GPU(图形处理器)🕹️ |
|---|---|---|
| 核心数量 | 少(通常 4~16) | 多(上千个) |
| 单核能力 | 强(能干大事) | 弱(擅长干重复的活) |
| 擅长任务 | 串行处理(一步步来) | 并行处理(群体作战) |
| 应用场景 | 系统操作、逻辑控制等 | 图形渲染、AI计算等 |
举个栗子 🌰:
想象一下,CPU 是“全能型学霸”,擅长一心一用,解决复杂逻辑题;
而 GPU 是“搬砖小能手”,擅长一口气搬 100 块砖,非常适合干重复又密集的活儿,比如矩阵运算、图像处理、深度学习。
👷 CUDA:让程序员调动显卡的“千军万马”
以前 GPU 只能画画图,程序员很难直接让它干别的活。
CUDA 的出现就像给程序员发了一把钥匙🔑,可以“呼叫”GPU,让它帮忙处理计算任务!
✅ 支持 C/C++/Python 编程语言
✅ 你写的代码可以运行在 GPU 上,而不是 CPU
✅ 支持大规模并行运算,速度飞快!
🎯 举个实际例子
假如你要给 1 亿个数字都加上 1。
-
用 CPU:你排队慢慢加,每次处理一个(像银行窗口🙃)
-
用 CUDA + GPU:你开 10,000 个窗口一起加(像春运高速收费站🏁)
速度那叫一个快!
🤖 CUDA 用在哪里?
💡 深度学习模型训练(比如 ChatGPT 的训练就靠它)
🧬 生物医学模拟
🎞️ 视频转码、图像处理
🌍 天气预测、地震模拟、金融风险分析……

2、CUDA的历史与发展
🎬 1. 起点:GPU 只是“画面小工”
🔙 时间回到 2000 年前后——那时的 GPU(比如 GeForce2)基本只是负责“画图”的:
-
把游戏渲染得更炫酷
-
把视频播放得更顺滑
完全是为显示服务的「图形小助手」🎨,离“通用计算”还差十万八千里。
💡 2. 萌芽:聪明人发现“GPU 运算能力好猛!”
在科研圈,有人开始偷偷用 GPU 来做“非图形计算”。他们发现:
✨“这玩意居然跑矩阵比 CPU 快多了?”
那时的 GPU 没有专门支持“通用计算”的编程接口,只能用很复杂的 OpenGL/DirectX Shader 技巧“曲线救国”,开发难度堪比修仙⚒️
🚀 3. 决定性转折:2006 年 CUDA 横空出世
NVIDIA 看到机会来了,果断出手!
🗓️ 2006 年:CUDA 1.0 正式发布!
它是全球第一个面向 GPU 的通用计算平台,程序员终于可以用 C 语言控制 GPU 干活了🔥
从此,GPU 不再是“图形工具人”,而成为了“并行计算的加速王”。
📈 4. 快速进化:从 Fermi 到 Hopper,一代更比一代猛
CUDA 平台与 NVIDIA GPU 架构是配套演进的:
| 年份 | 架构代号 | 特点亮点 |
|---|---|---|
| 2008 | Tesla | 第一代 GPGPU,支持双精度浮点 |
| 2010 | Fermi | 引入 L1/L2 缓存,提升通用计算性能 |
| 2012 | Kepler | 提升能效,支持动态并行 |
| 2016 | Pascal | 加入 Tensor 核心前奏,HPC 友好 |
| 2017 | Volta | 初代 Tensor Cores,AI 训练神器 |
| 2020 | Ampere | 强化 AI 计算,支持多精度并行 |
| 2022 | Hopper | 全面 AI 化身,专为 Transformer 打造 |
| 2024 | Blackwell | 最新旗舰,推理性能暴涨 |
每一代 CUDA Toolkit 也在同步升级,支持更强的编译器、更高级的优化、更丰富的库。
🧠 5. 与 AI 深度绑定:CUDA 成为 AI 的发动机
-
2012:AlexNet 横空出世,用 NVIDIA GTX 580 训练,AI 炸裂出圈💥
-
之后:PyTorch、TensorFlow 等深度学习框架,几乎都离不开 CUDA 后端
-
现在:从 ChatGPT 到 Stable Diffusion,背后 GPU 加速都是靠 CUDA ✊
🧩 6. 今日 CUDA:不仅仅是一个库,更是一整个宇宙
CUDA 不再只是“让 GPU 干活”,它成了一个完整的开发生态:
-
📦 各种库:cuDNN、cuBLAS、TensorRT、NCCL…
-
🧰 工具链:Nsight、Visual Profiler、CUDA Graph…
-
🌍 平台支持:从嵌入式 Jetson 到数据中心 DGX 全都能用

CUDA 的成长 = 从一把螺丝刀 🪛 ➡️ 到一整套核武库 💣
它改变了 GPU 的命运,也重新定义了“计算”的方式。
今天,如果你说你搞 AI、做科学计算、研究机器学习,却没听说过 CUDA——那就像学魔法不知道哈利波特🧙♂️。
三、CUDA架构解析
1、GPU vs CPU:架构对比
在 CUDA 的世界里,最常听到的问题之一就是:
“既然我有 CPU,为什么还要用 GPU 来计算呢?”
这个问题就像问:
“我有一辆小轿车,为什么还需要火车?”🚗 vs 🚄
它们各有专长!CPU 和 GPU 不是谁更好,而是适合干不同的活。
🏗️ 架构对比:一个是多面手,一个是并行狂魔
| 特性 | 🧑💻 CPU(中央处理器) | 🕹️ GPU(图形处理器) |
|---|---|---|
| 核心数量 | 少(4~16个高性能核心) | 多(数百到上万个) |
| 每个核心的能力 | 强,能处理复杂指令 | 弱,专注简单重复计算 |
| 控制单元 | 多,负责调度和决策 | 少,更依赖外部控制 |
| 缓存系统 | 大,层次复杂(L1/L2/L3) | 小而专注 |
| 适合的任务类型 | 串行任务、多任务处理 | 数据并行、大规模计算 |
| 延迟 vs 吞吐量 | 低延迟、决策快 | 高吞吐、批量处理猛 |
| 编程难度 | 简单,工具成熟 | 相对复杂(CUDA等) |
| 举个例子 | 跑操作系统、打开网页 | 训练 AI、视频渲染 |
🧩 用生活举个例子!
-
CPU 像一位博士👨🎓:一个人能力特别强,但只能一心一用,适合解决逻辑复杂、步骤多的问题。
-
GPU 像一群工人👷♂️👷♀️:单个能力可能不高,但可以分工协作,把重复性的任务快速干完,效率爆表!
💡 实际场景谁上场?
| 场景 | 谁更合适 |
|---|---|
| 打开浏览器、运行操作系统 | ✅ CPU |
| 视频渲染、图形处理 | ✅ GPU |
| 训练深度神经网络(AI) | ✅ GPU |
| 数据库查询、事务处理 | ✅ CPU |
| 模拟气候、科学建模、并行计算 | ✅ GPU |
| 编译代码、跑脚本 | ✅ CPU |
| 游戏里的实时光影渲染 | ✅ GPU |
🚦 并行模型上的区别
| 特性 | CPU | GPU |
|---|---|---|
| 并行粒度 | 粗粒度(每核处理独立任务) | 细粒度(线程块内高度同步) |
| 指令模型 | MIMD(多指令多数据) | SIMT(单指令多线程) |
| 控制逻辑 | 多样化、复杂 | 简化、统一控制 |
📘 名词解释:
-
MIMD:每个核心都可以执行不同的指令
-
SIMT:多个线程执行相同的指令,但处理不同的数据
🧠 小结一句话!
CPU 负责“聪明的决策”,GPU 擅长“傻快的计算”
它们不是敌人,而是互补搭档,现代计算中通常是搭配使用的!
2、CUDA核心组件
🔧 CUDA 核心组件:构建 GPU 编程的四大金刚
你可以把 CUDA 想象成一个“GPU 软件开发的操作系统”,它不是一个单一的程序,而是由一整套核心组件组成的“超级工具箱”。
下面我们来看看构成 CUDA 的四大金刚 🔥
1️⃣ CUDA Runtime API(运行时 API)
💬 它是开发者最常打交道的接口,是你用 C/C++ 写 CUDA 程序的“入口”。
📌 功能包括:
-
GPU 内存分配和释放(
cudaMalloc/cudaFree) -
设备信息查询(
cudaGetDeviceProperties) -
启动 kernel(
<<< >>>语法就是它支持的)
🧠 类比一下:
就像你用 Python 写脚本,Python 帮你处理内存、线程这些底层细节,CUDA Runtime API 就是帮你“简单调用 GPU”。
2️⃣ CUDA Driver API(驱动层 API)
🛠️ 更底层、更灵活、更复杂。适用于需要细粒度控制 GPU 资源的场景。
📌 功能包括:
-
设备初始化与上下文管理(更手动)
-
加载 PTX、模块化内核编程
-
编译时更灵活地控制 GPU 行为
🎯 谁在用?
-
深度学习框架开发者(例如 PyTorch 底层封装)
-
系统级别的 GPU 控制和调优
🧠 类比一下:
Runtime API 是自动挡 🚗,Driver API 是手动挡赛车 🏎️,能玩得更极限,但也更难操作。
3️⃣ CUDA 核函数(Kernel Function)
🚀 这是你写的代码真正运行在 GPU 上的“主力部队”。
📌 特点:
-
用
__global__关键字声明 -
用
<<<grid, block>>>语法来启动(指定并行粒度) -
每个线程独立执行一份 kernel 的代码
🧠 类比一下:
Kernel 像是“工厂车间的流水线工人”👷,你一次下达指令,成百上千个“工人”在不同岗位同步干活。
__global__ void add(int *a, int *b, int *c) {int i = threadIdx.x;c[i] = a[i] + b[i];
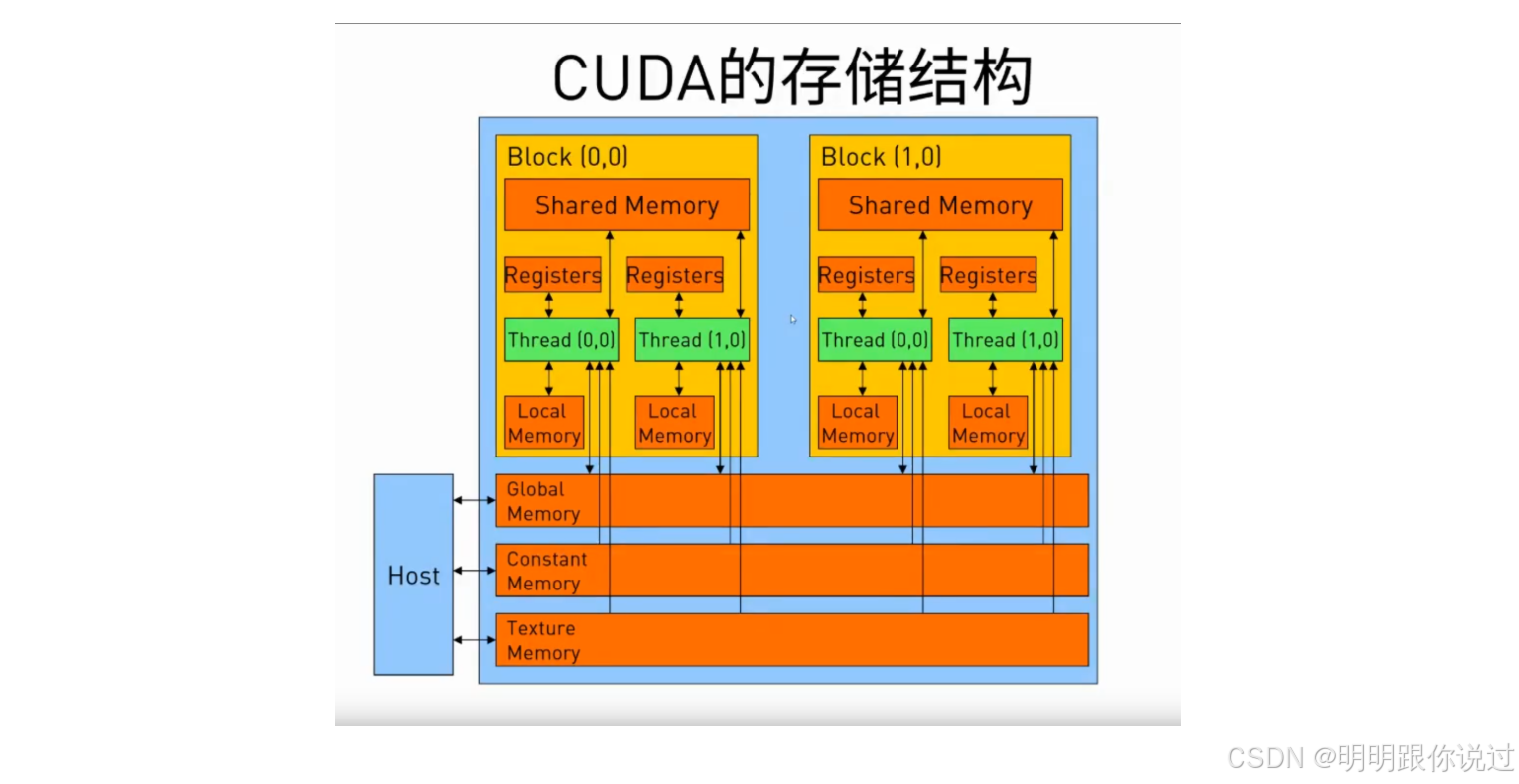
}4️⃣ CUDA 内存模型(Memory Model)
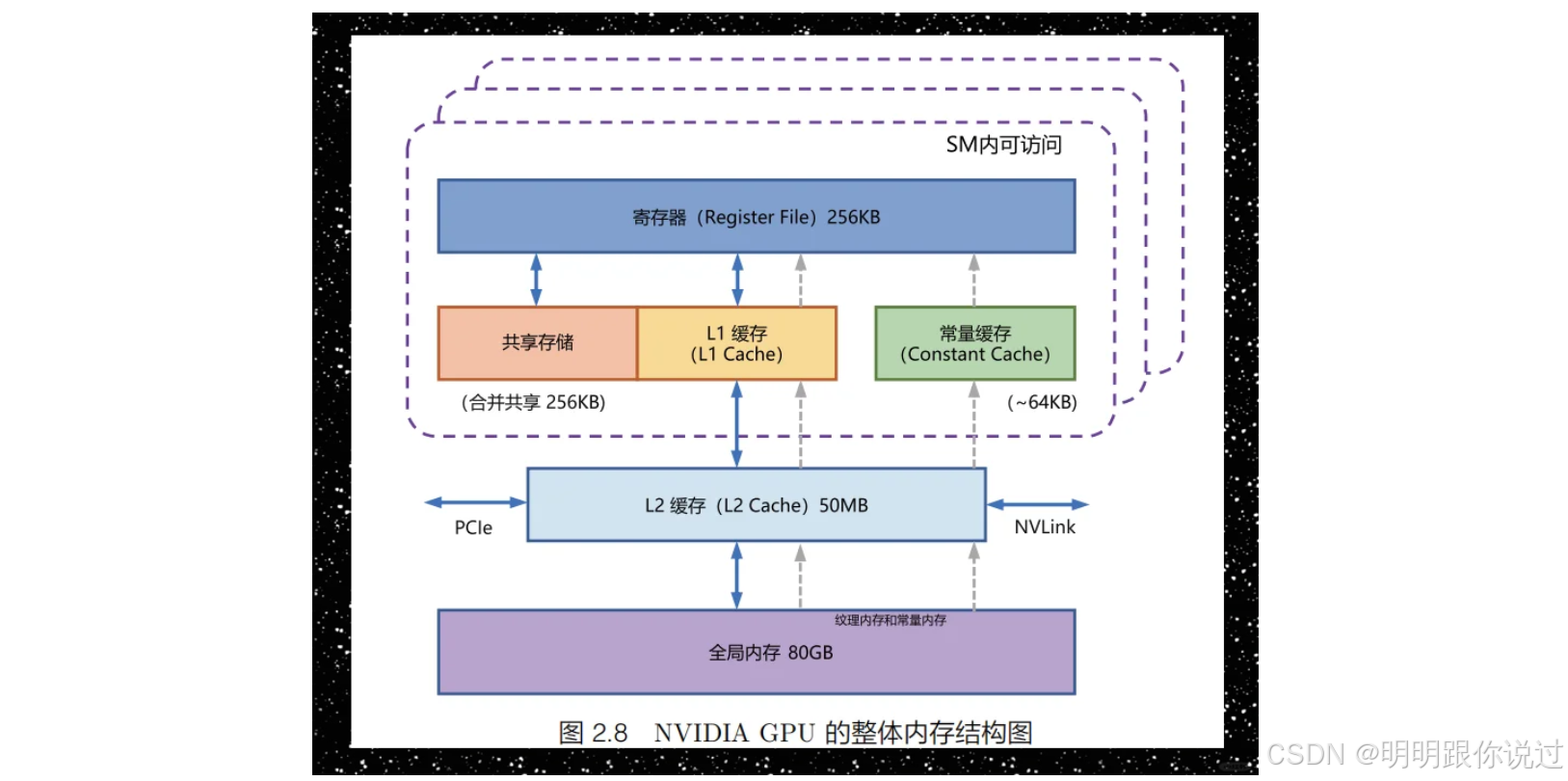
💾 GPU 的内存系统是多层次的,用得好 = 性能飞起🚀
| 类型 | 特性 | 示例 |
|---|---|---|
| Global Memory | 所有线程可访问,容量大,访问慢 | cudaMalloc 分配的内存 |
| Shared Memory | 每个线程块共享,访问速度快 | 用 __shared__ 声明 |
| Local Memory | 每线程独享,实为全局空间 | 局部变量(寄存器不足时) |
| Registers | 每线程专属,最快 | 编译器自动分配 |
| Constant Memory | 只读缓存,供所有线程共享,适合常量传递 | __constant__ |
| Texture/Surface | 专用于图像处理,带缓存优化 | 适合做图像/矩阵采样等 |
🧠 类比一下:
内存就像厨房里的原料分区,寄存器是你手边的调料台,Global memory 是仓库,Shared memory 是工位中间的调料包。
四、CUDA编程模型
1、CUDA程序的基本结构
🧱 CUDA 程序的基本结构:从 CPU 到 GPU 的“打工外包流程”
要写一个 CUDA 程序,其实核心流程就一句话:
🗣️ 主程序在 CPU 上运行,但把计算“打包”交给 GPU 干
下面我们一步步拆解这个“GPU 打工队”的工作流程 👷♂️
🧭 基本结构总览(5 个步骤)
一个典型 CUDA 程序结构可分为以下 5 步:
1️⃣ 准备数据(在 CPU 上)
2️⃣ 分配 GPU 内存并复制数据(Host ➡ Device)
3️⃣ 编写并调用 CUDA 核函数(Kernel)
4️⃣ 把计算结果从 GPU 拷回 CPU(Device ➡ Host)
5️⃣ 释放内存资源,程序结束
🧪 示例:两个数组相加(Vector Add)
我们用一个经典的例子来演示 CUDA 程序的完整结构:向量加法
📌 功能:
c[i] = a[i] + b[i];🧾 完整代码框架:
#include <stdio.h>
#include <cuda_runtime.h>// CUDA 核函数:每个线程负责加一个元素
__global__ void vectorAdd(int *a, int *b, int *c, int n) {int i = threadIdx.x;if (i < n)c[i] = a[i] + b[i];
}int main() {const int N = 10;int a[N], b[N], c[N]; // 在 CPU(host)上的数组int *d_a, *d_b, *d_c; // GPU(device)上的指针// 初始化数据for (int i = 0; i < N; i++) {a[i] = i;b[i] = i * 2;}// 1. 分配 GPU 内存cudaMalloc((void**)&d_a, N * sizeof(int));cudaMalloc((void**)&d_b, N * sizeof(int));cudaMalloc((void**)&d_c, N * sizeof(int));// 2. 拷贝数据到 GPUcudaMemcpy(d_a, a, N * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, b, N * sizeof(int), cudaMemcpyHostToDevice);// 3. 启动 Kernel(让 GPU 干活!)vectorAdd<<<1, N>>>(d_a, d_b, d_c, N);// 4. 把结果拷回 CPUcudaMemcpy(c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);// 5. 打印结果printf("Result:\n");for (int i = 0; i < N; i++)printf("%d + %d = %d\n", a[i], b[i], c[i]);// 6. 释放 GPU 内存cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);return 0;
}🧠 每步拆解说明:
| 步骤 | 内容 | 说明 📝 |
|---|---|---|
| 1 | cudaMalloc | 在 GPU 上申请内存 |
| 2 | cudaMemcpy(Host ➡ Device) | 把 CPU 数据传给 GPU |
| 3 | <<<blocks, threads>>> 启动 kernel | 设置并行维度、执行函数 |
| 4 | cudaMemcpy(Device ➡ Host) | 把结果从 GPU 拷回 CPU |
| 5 | cudaFree | 清理资源,避免内存泄露 |
🔍 补充:线程模型简要说明
-
<<<1, N>>>:意思是启动 1 个 block,每个 block 有 N 个线程 -
threadIdx.x:获取当前线程在 block 中的编号(0 ~ N-1)
🧠 可以把每个线程想成一个“工人”,threadIdx.x 就是工号,它负责数组中第几个元素的加法。
📦 小贴士:想学得更好,可以试试…
-
把
N改大点,看 GPU 性能 -
改成 2D/3D grid/block,理解多维并行
-
加个计时器看看 GPU 比 CPU 快多少(
cudaEvent)
✅ 小结一句话!
CUDA 程序结构 = 在 CPU 上安排好任务,然后启动成千上万个线程去 GPU 上“并行开工”💪

2、Kernel函数与线程层级
🧩 Kernel 函数与线程层级:并行计算的发动机 🚀
在 CUDA 编程中,我们不会一个个处理数据,而是:
把任务切片,丢给成千上万个线程同时运行!
这些线程由 GPU 上的 Kernel 函数统一调度执行。那么:
-
什么是 Kernel 函数?
-
怎么安排线程分工?
-
什么是 Block、Grid、Thread?
接下来逐一拆解!
🔧 什么是 Kernel 函数?
Kernel 是 CUDA 程序中由 GPU 执行的函数,它是并行计算的核心。
__global__ void myKernel(...) {// 每个线程执行这段代码
}🔹 __global__ 关键字告诉编译器:
这个函数运行在 GPU 上,但可以被 CPU 调用。
🔹 启动方式:
myKernel<<<gridSize, blockSize>>>(...);这不是语法糖,而是在告诉 CUDA:
“我要启动多少线程来跑这个函数。”
🧱 线程的三层层级结构
CUDA 中线程的组织就像军队建制,非常有层级感:
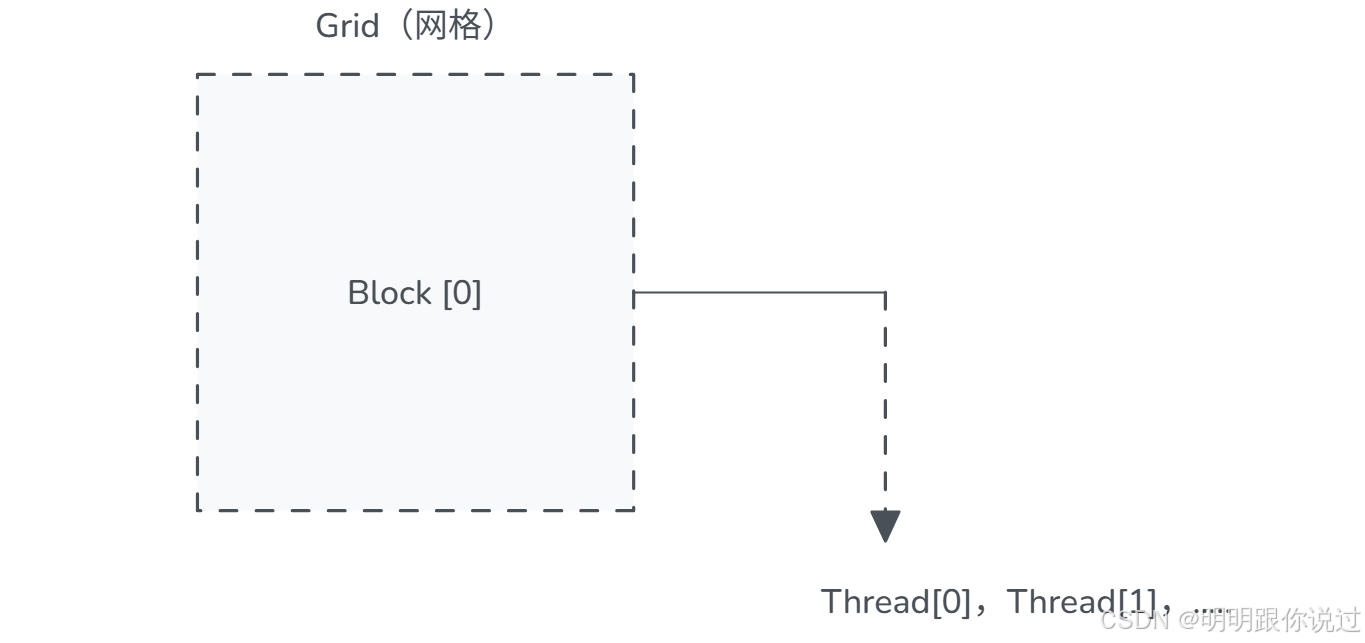
| 层级 | 作用说明 | 举例(1D) |
|---|---|---|
| Grid | 由多个 Block 组成(可以是1D/2D/3D) | 一个网格网(任务总量) |
| Block | 一个线程块,包含若干线程 | 一组线程在同一块中 |
| Thread | 最小执行单位 | 每个处理一小段任务 |
🧠 类比一下:
-
Grid:公司里的整个部门 🏢
-
Block:每个小组 👥
-
Thread:组员 👤
🧮 每个线程怎么知道“我是谁”?
CUDA 提供了 3 个内置变量,线程启动时自动可用:
| 变量 | 说明 | 类型 |
|---|---|---|
threadIdx | 当前线程在 Block 中的索引 | uint3 |
blockIdx | 当前 Block 在 Grid 中的索引 | uint3 |
blockDim | 每个 Block 有多少线程 | dim3 |
gridDim | Grid 中有多少个 Block | dim3 |
🧠 小结一句话!
Kernel 是执行体,Grid 是组织方式,Thread 是计算单位
你写一次 Kernel,CUDA 帮你复制成千上万份“工人”去同时执行💥

3、内存管理与数据传输(Host ↔ Device)
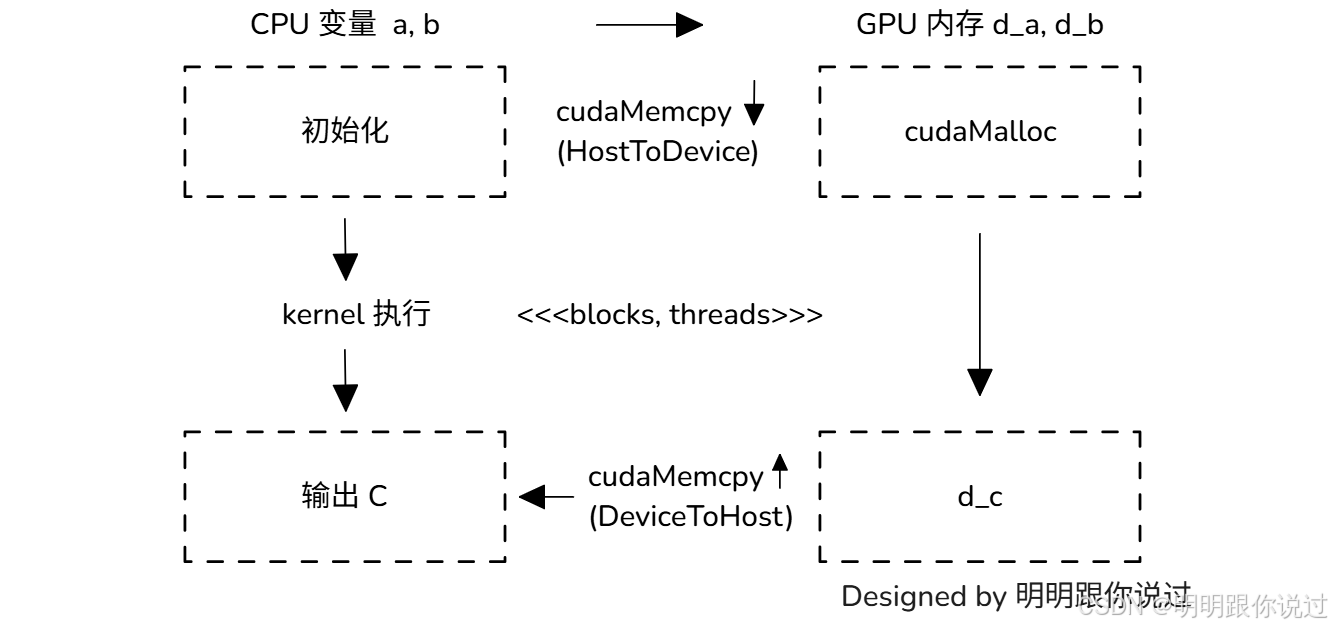
💾 内存管理与数据传输(Host ↔ Device)
在 CUDA 编程中,CPU(Host) 和 GPU(Device) 是两套完全独立的世界,它们各自有自己的内存空间:
🧠 CPU 内存 = 主内存(RAM)
🎮 GPU 内存 = 显存(VRAM)
CUDA 编程最重要的一步就是:
想办法把数据在 Host 和 Device 之间“搬来搬去” 🚚
🧭 你必须搞懂的三件事:
| 内容 | 作用 | 类比(搬砖打工) |
|---|---|---|
cudaMalloc() | 在 GPU 上分配显存 | 给 GPU 准备砖堆 🧱 |
cudaMemcpy() | Host ↔ Device 数据传输 | 搬砖车来回运材料 🚛 |
cudaFree() | 释放 GPU 分配的内存资源 | 工地收工,清理现场 🧹 |
🧪 示例代码:准备一批数据送去 GPU 加工
const int N = 100;
int a[N], b[N], c[N];
int *d_a, *d_b, *d_c;// 1. 在 GPU 上分配内存
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));// 2. 把 CPU 上的原材料送到 GPU
cudaMemcpy(d_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, N * sizeof(int), cudaMemcpyHostToDevice);// 3. 执行 Kernel 计算(略)// 4. 把结果从 GPU 拷回 CPU
cudaMemcpy(c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);// 5. 清理资源
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);🚥 cudaMemcpy 的四种传输方向
| 常量名 | 从哪传 → 传到哪 | 场景 |
|---|---|---|
cudaMemcpyHostToDevice | 🧠 CPU → 🎮 GPU | 把数据送去计算 |
cudaMemcpyDeviceToHost | 🎮 GPU → 🧠 CPU | 拿结果回来用 |
cudaMemcpyDeviceToDevice | 🎮 GPU → 🎮 GPU | GPU 内部数据拷贝 |
cudaMemcpyHostToHost | 🧠 CPU → 🧠 CPU | 和普通 memcpy 类似 |
📦 内存管理流程图(逻辑图)
✅ 小结一句话
CUDA 内存管理 = 分配 + 拷贝 + 回收,像操作 GPU 的物流仓库一样💼
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
相关文章:

深入浅出 NVIDIA CUDA 架构与并行计算技术
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、CUDA为何重要:并行计算的时代 2、NVIDIA在…...

网安融合:打造网络+安全一体化的超预期体验
近日,2025锐捷网络EBG(中国)核心伙伴大会在苏州圆满落幕。来自全国2000合作伙伴齐聚苏州,共同见证这场盛会的举办。会上,锐捷网络发布了七大战略产品解决方案。其中网络安全产品事业部产品市场总监沈世海发布了“打造网络安全一体化的超预期体验”的主题报告。报告围绕让“让渠…...

通义灵码 Rules 库合集来了,覆盖Java、TypeScript、Python、Go、JavaScript 等
通义灵码新上的外挂 Project Rules 获得了开发者的一致好评:最小成本适配我的开发风格、相当把团队经验沉淀下来,是个很好功能…… 那么有哪些现成的 Rules 可以抄作业呢,今天我们官方输出了 Java、TypeScript、Python、Go、JavaScript 等语…...

3D人脸扫描技术如何让真人“进入“虚拟,虚拟数字人反向“激活“现实?
随着虚拟人技术的飞速发展,超写实数字人已经成为数字娱乐、广告营销和虚拟互动领域的核心趋势。无论是企业家、知名主持人还是明星,数字分身正在以高度还原的形象替代真人参与各类活动,甚至成为品牌代言、直播互动的新宠。 3D人脸扫描&#…...

12孔AG调陶笛音域全解析:从E4到C6的演奏艺术
一、音域范围的精准界定 12孔AG调陶笛的音域范围为E4(低音Mi)至C6(高音Do),横跨13个自然音级(即E4-F4-G4-A4-B4-C5-D5-E5-F5-G5-A5-B5-C6)。若以半音计算,实际覆盖15个半音…...

IDEA编译错误Refer to the generated Javadoc files in xxx apidocs dir
文章目录 一、IDEA编译报错 Refer to the generated Javadoc1.1、报错内容1.2、解决办法 一、IDEA编译报错 Refer to the generated Javadoc 1.1、报错内容 Command line was: /opt/jdk1.8.0_181/jre/../bin/javadoc options packagesRefer to the generated Javadoc files i…...

高效培训,借助课程编辑器塑造卓越团队
(一)打造沉浸式培训体验 在企业人才培养体系里,培训是提升员工能力素质的重要手段,课程编辑器中的 VR 技术为企业培训带来新体验。以机械制造企业为例,以往员工培训靠书面资料、平面图片或简单视频讲解复杂机械设备结…...

Pikachu靶场-CSRF
CSRF (跨站请求伪造) 详细介绍与技术分析 一、什么是 CSRF? CSRF(Cross-Site Request Forgery,跨站请求伪造),是一种利用已认证用户的身份,诱使该用户执行恶意操作的攻击手段。攻击者通过伪造一个用户请求,…...
: 在Linux系统上部署项目)
Flask(3): 在Linux系统上部署项目
1 前言 说实话,我并不想接触linux系统,要记住太多的命令。我更习惯windows系统,鼠标点点,只要记住少量的命令就可以了。 但是我选择了python,就注定无法逃避linux系统。虽然python也能在windows上很好的运行࿰…...

React JSX 语法深度解析与最佳实践
本文系统梳理 JSX 语法的完整知识体系。通过原理剖析、代码示例和开发警示,帮助开发者建立严谨的 JSX 使用认知。 一、JSX 本质解析 1.1 编译机制 JSX 通过 Babel 转换为 React.createElement 调用,以下为转换对照: // 原始 JSX <MyCo…...

岚图L3智能架构发布,9大首发新技术引领电动车变革
4月16日,岚图汽车在北京举办了L3级智能架构技术发布会,发布岚图天元智架。 据「TMT星球」了解,天元智架首发青云L3级智能安全行驶平台与鲲鹏L3级智能安全驾驶系统两大核心智能化技术集群,融合多项先进技术与黑科技,推…...
)
Nginx | Apache 配置 WebSocket 多层代理基本知识(附疑难杂症)
目录 前言1. 问题所示2. 基本知识3. 原理分析3.1 返回2003.2 返回4003.3 返回5004. 彩蛋前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 1. 问题所示 本地测试可以,上了域名的测试就不行了! WebSocket con…...
之对话自动生成标题设为用户第一次对话发的文字)
山东大学软件学院创新项目实训开发日志(18)之对话自动生成标题设为用户第一次对话发的文字
本次功能的实现主要集中在后端,前端代码不用改变: 前端界面效果展示:...

【web考试系统的设计】
文章目录 一、实验背景与目的二、实验设计与实现思路1. 功能架构2. 核心代码实现 总结 一、实验背景与目的 本次实验旨在深入理解Request、response对象的作用,Request对象的作用是与客户端交互,收集客户端的Form、Cookies、超链接,或者收集…...

【MySQL】库的操作
🏠个人主页:Yui_ 🍑操作环境:Centos7 🚀所属专栏:MySQL 文章目录 1. 创建一个数据库1.1 创建一个数据库(演示 2. 字符集和校验规则2.1 字符集2.2 校验规则2.3 知识补充:)…...

Face Swap 1.3.8| 解锁专业版,无限制换脸,视频换脸,释放您的创造力
Face Swap Pro - AI Photo Editor 「换脸 - AI 照片编辑器」释放您的创造力!通过换脸 - AI 照片编辑器,将您的想象变为现实,这是在照片和视频中交换人脸的终极应用程序。无论您是想探索不同的造型,穿越到另一个时代,还…...

AUTOSAR图解==>AUTOSAR_SWS_DefaultErrorTracer
AUTOSAR 默认错误追踪器(Default Error Tracer)详细分析 基于AUTOSAR 4.4.0规范的深入解析 目录 概述 DET模块的作用DET模块的定位 架构设计 模块架构接口设计 状态与行为 状态转换错误报告流程 API与数据结构 API概览数据类型定义 配置与扩展 模块配置回调机制 总结 1. 概述 …...
)
【hadoop】master一键启动hadoop集群(高可用)
之前写了一篇【hadoop】master一键启动zkServer-CSDN博客 现在是最好的安排: 1. cd ~ vim hadoop-all.sh #!/bin/bash# 检查参数是否为 start 或 stop if [ "$1" "start" ]; then# 启动服务sh ~/zk-all.sh startstart-dfs.shstart-yarn.s…...

细说STM32单片机FreeRTOS任务管理API函数及多任务编程的实现方法
目录 一、FreeRTOS任务管理API函数 1、任务管理API函数 2、获取任务的句柄 (1)函数xTaskGetCurrentTaskHandle() (2)函数xTaskGetIdleTaskHandle() (3)函数xTaskGetHandle() 3、单个任务的操作 &a…...

从0开始掌握动态规划
动态规划的核心思想 -- 以空间换时间 复杂点说通过分解问题为子问题并存储子问题解来优化复杂计算的算法策略。 简单看个问题。 一,初始:求最长连续递增子序列 nums [10,9,2,5,3,7,101,18] 求上面数组中的最长连续递增子序列,输出其长度 …...

解锁向量数据库:实现高效过滤与管理的实用方法
1. 带过滤的相似性搜索 大多数向量数据库不仅可以存储向量数据,还支持存储相关元数据。这些元数据可以包括文本原文、扩展信息、页码、文档 ID、作者、创建时间等自定义信息,通常用于实现数据检索。 向量数据库记录 向量(vector)元数据(metadata)id遗…...

数码管LED显示屏矩阵驱动技术详解
1. 矩阵驱动原理 矩阵驱动是LED显示屏常用的一种高效驱动方式,利用COM(Common,公共端)和SEG(Segment,段选)线的交叉点控制单个LED的亮灭。相比直接驱动,矩阵驱动可以显著减少所需I/…...

C++模板初阶
1.函数模板 模板是C中一个非常重要的东西,也是下一步学stl的最后一块拼图。那看看最后一块拼图是什么呢?C祖师爷在写C语言时遇到了有个非常难受的地方: 遇到有很多类型变量交换的时候就要写不同的交换函数,再新增类型的交换还要…...

第六章:6.3求一个3*3的整型矩阵对角线元素之和
//求一个3*3的整型矩阵对角线元素之和 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> int main() {int i 0, j 0;int arr[3][3] { 0 };printf("请输入一个3*3的矩阵:\n");for (i 0; i < 3; i){for (j 0; j < 3; j){scanf("%d", …...
)
Oracle 19c部署之初始化实例(三)
上一篇文章中,我们已经完成了数据库软件安装,接下来我们需要进行实例初始化工作。 一、初始化实例的两种方式 1.1 图形化初始化实例 描述:图形化初始化实例是通过Oracle的Database Configuration Assistant (DBCA)工具完成的。用户通过一系…...

RAGFlowwindows本地pycharm运行
Python环境准备 1. 安装pipx。如已经安装,可跳过本步骤: python -m pip install --user pipxpython -m pipx ensurepath## 验证安装pipx --version2. 安装 uv。如已经安装,可跳过本步骤: pipx install uv ## 设置为阿里云 PyPI…...

阿里云RAM账号免密登录Java最佳实践
参考官方文章地址:如何使用免登访问流程_阿里云集成转售解决方案-阿里云帮助中心 参考代码地址:如何使用安全访问服务Python及Java示例代码_阿里云集成转售解决方案-阿里云帮助中心 1. RAM的含义 阿里云的访问控制RAM(Resource Access Manag…...
)
基于LightRAG进行本地RAG部署(包括单卡多卡本地模型部署、调用阿里云或DeepSeekAPI的部署方法、RAG使用方法)
1.简介 RAG(Retrieval-Augmented Generation)是一种结合了检索(Retrieval)和生成(Generation)的自然语言处理模型架构。它旨在解决传统生成模型在面对复杂任务时可能出现的生成内容缺乏准确性和多样性的不…...

GPIO输出模式
这个 typedef enum 是 STM32 中 GPIO 模式的定义,每一个模式都代表着 GPIO 引脚的不同工作方式。不同的模式会影响引脚的输入或输出状态,以及是否具有其他功能(如外设功能)。接下来,我将详细解释每个模式的作用和如何使…...

Linux,redis数据库安装使用
Redis 非关系型数据库 介绍 安装 主从模式 哨兵模式 集群模式 redis 数据类型/增删改查 redis 持久化 redis 雪崩 击穿 穿透 LAMPredis 数据迁移 git redis 安装部署 1,下载或者上传redis 6.2.14 wget http://download.redis.io/releases/redis-6.2.14.tar.gz …...

3DS 转 STL 全攻略:传统工具与迪威模型网在线转换深度解析
在 3D 建模与 3D 打印的技术领域中,常常会遇到需要将不同格式的文件进行转换的情况。其中,把 3DS 文件转换为 STL 格式是较为常见的操作。3DS 文件作为一种旧版 Autodesk 3D Studio 使用的 3D 图像格式,存储着丰富的信息,包括网格…...
CSRF攻防实战 - 从原理到防护的最佳实践)
最新Spring Security实战教程(十一)CSRF攻防实战 - 从原理到防护的最佳实践
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

远程医疗系统安全升级:构建抗CC攻击的全方位防护网
随着云计算、大数据和互联网技术的不断发展,远程医疗系统正在逐步走进大众视野,为患者提供便捷高效的医疗服务。然而,远程医疗系统在便利性的背后也面临着严峻的网络安全挑战,其中,CC攻击(Challenge Collap…...

【Java学习笔记】进制与进制转换
进制与进制转换 一、进制介绍 二进制:0、1,满 2 进 1,以 0b 或 0B 开头。 十进制:0-9,满 10 进 1。 八进制:0-7,满 8 进 1,以数字 0 开头表示。 十六进制:0-9 及 A(10…...

《SpringBoot中@Scheduled和Quartz的区别是什么?分布式定时任务框架选型实战》
🌟 大家好,我是摘星! 🌟 今天为大家带来的是Scheduled和Quartz对比分析: 新手常见困惑: 刚学SpringBoot时,我发现用Scheduled写定时任务特别简单。但当我看到同事在项目里用Quartz时&…...

RestSharp和Newtonsoft.Json结合发送和解析http
1.下载RestSharp和Newtonsoft.Json 2编写ApiRequest和ApiResponse和调用工具类HttpRestClient 请求模型 /// <summary>/// 请求模型/// </summary>public class ApiRequest{/// <summary>/// 请求地址/api路由地址/// </summary>public string Route {…...

[图论]Kruskal
Kruskal 本质:贪心,对边进行操作。存储结构:边集数组。适用对象:可为负权图,可求最大生成树。核心思想:最短的边一定在最小生成树(MST)上,对最短的边进行贪心。算法流程:对全体边集…...

腾讯云对象存储以及项目业务头像上传
腾讯云上传步骤: service-vod模块化中 ①、参考文档,引入依赖 ②、配置文件application.properties ③、创建工具类 初始化bean的时候读取配置文件 Component public class ConstantPropertiesUtil implements InitializingBean{Value("${t…...

Windows下导入文件中的环境变量
在Windows批处理脚本(.bat)中,通过文件获取并设置环境变量通常涉及逐行读取文件内容并动态赋值给变量。以下是具体实现方法及示例: 一、从文件读取变量并设置到环境变量 假设有一个配置文件(如env_config.txt…...

【音视频开发】第五章 FFmpeg基础
【音视频开发】第五章 FFmpeg基础 文章目录 【音视频开发】第五章 FFmpeg基础一、播放器框架1.媒体文件读取阶段2.音频处理流程3.视频处理流程 二、常用音视频概念1.常用音视频术语2.复用器3.编解码器 三、FFmpeg 库1.整体结构 四、FFmpeg 常用函数1.libavformat 封装/解封装2.…...

【ESP32|音频】一文读懂WAV音频文件格式【详解】
简介 最近在学习I2S音频相关内容,无可避免会涉及到关于音频格式的内容,所以刚开始接触的时候有点一头雾水,后面了解了下WAV相关内容,大致能够看懂wav音频格式是怎么样的了。本文主要为后面ESP32 I2S音频系列文章做铺垫࿰…...

数据通信学习笔记之OSPF路由汇总
区域间路由汇总 路由汇总又被称为路由聚合,即是将一组前缀相同的路由汇聚成一条路由,从而达到减小路由表规模以及优化设备资源利用率的目的,我们把汇聚之前的这组路由称为精细路由或明细路由,把汇聚之后的这条路由称为汇总路由或…...

【C++】priority_queue的底层封装和实现
目录 前言基本结构如何设置默认大小堆底层实现仿函数的使用向上调整算法向下调整算法其他接口 end 前言 priority_queue的介绍 优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中的元素构造成堆的结构,因此priorit…...

2023年全国青少年信息素养大赛 Python编程挑战赛 小学全年级组 初赛真题答案详细解析
2023信息素养大赛 Python编程挑战赛 选择题(共15题,每题5分,共75分) 1、关于列表的索引,下列说法正确的是 A、列表的索引从0开始 B、列表的索引从1开始 C、列表中可能存在两个元素的索引一致 D、列表中索引的最大…...

十三种通信接口芯片——《器件手册--通信接口芯片》
目录 通信接口芯片 简述 基本功能 常见类型 应用场景 详尽阐述 1 RS485/RS422芯片 1. RS485和RS422标准 2. 芯片功能 3. 典型芯片及特点 4. 应用场景 5. 设计注意事项 6. 选型建议 2 RS232芯片 1. RS232标准 2. 芯片功能 3. 典型芯片及特点 4. 应用场景 5. 设计注意事项 6…...
——神经网络与模型训练过程详解)
PyTorch生成式人工智能实战(1)——神经网络与模型训练过程详解
PyTorch生成式人工智能实战(1)——神经网络与模型训练过程详解 0. 前言1. 传统机器学习与人工智能2. 人工神经网络基础2.1 人工神经网络组成2.2 神经网络的训练 3. 前向传播3.1 计算隐藏层值3.2 执行非线性激活3.3 计算输出层值3.4 计算损失值3.5 实现前…...

【软件系统架构】事件驱动架构
一、引言 在当今的软件开发和系统架构领域,事件驱动架构(Event - Driven Architecture,EDA)正逐渐成为构建复杂、分布式和可扩展系统的热门选择。随着信息技术的不断发展,传统的架构模式在应对高并发、实时性要求高、数…...

Doris FE 常见问题与处理指南
在数据仓库领域,Apache Doris 凭借其卓越性能与便捷性被广泛应用。其中,FE(Frontend)作为核心组件,承担着接收查询请求、管理元数据等关键任务。然而,在实际使用中,FE 难免会遭遇各类问题&#…...

Manus AI “算法-数据-工程“三位一体的创新
Manus AI在多语言手写识别领域的技术突破,通过算法创新、数据工程与场景适配的协同作用,解决了传统手写识别的核心痛点。以下是其关键技术路径与创新点的系统性分析: 一、深度学习模型与算法优化 混合神经网络架构Manus AI采用"CNN与LST…...

Flutter Expanded 与 Flexible 详解
目录 1. 引言 2. Expanded 的基本用法 3. Flexible 的基本用法 4. Expanded vs Flexible 的区别 4.1 基础定义 4.2 关键差异 5. Expanded 深度解析 5.1 按比例分配 5.2 强制填充特性 6. Flexible 深度解析 6.1 基础用法:动态收缩 6.2 结合 fit 参数控制…...