【ESP32|音频】一文读懂WAV音频文件格式【详解】
简介
最近在学习I2S音频相关内容,无可避免会涉及到关于音频格式的内容,所以刚开始接触的时候有点一头雾水,后面了解了下WAV相关内容,大致能够看懂wav音频格式是怎么样的了。本文主要为后面ESP32 I2S音频系列文章做铺垫,所以本篇将介绍WAV音频文件格式,并通过C代码生成一段1S的正弦波WAV音频写入到SD卡里面。
WAV(Waveform Audio File Format) 是一种音频文件格式,用于存储音频数据。它是由 微软 和 IBM 开发的,通常用于存储高质量的原始音频数据。
如果一段单声道音频的采样率为 44100 Hz,一分钟的音频数据大约有 5.04MB。这个值是可以大致计算的,后面我们会提到。WAV 文件一般未经过压缩,因此能够提供音频的 高保真度,但相比其他音频格式,相同时间内的文件会显得较大。所以一开始我打算用SPIFFS存储WAV音频的时候发现好像不太现实,毕竟ESP32 SPIFFS空间太小了,而 WAV文件几秒的音频动不动就好几M了,这样子的话只能播放短时间的音频就不符合我的要求了。
WAV文件基于RIFF格式,这是一种用于存储多媒体数据的通用格式。
也就是说WAV是基于RIFF格式的一种具体应用,RIFF格式还被用于许多其他文件类型。
什么是RIFF格式
RIFF(Resource Interchange File Format,资源交换文件格式)是一种通用的文件格式标准,由微软和IBM于1991年联合开发,用于存储和交换多媒体数据,如音频、视频、图像等。RIFF格式以其灵活性和可扩展性著称,能够容纳各种类型的数据,并被广泛应用于多种文件类型,例如:
- WAV(音频)
- AVI(视频)
- ANI(动画光标)
可以简单理解为它是一种通用的文件容器格式,它通过一个个块的形式(称之为chunk)存储多媒体数据。
以下是基于RIFF格式的不同文件类型及其用途的表格:
| 文件类型 | 扩展名 | 用途 |
|---|---|---|
| WAV | .wav | 存储音频数据 |
| AVI | .avi | 存储音频和视频数据 |
| RMI | .rmi | 存储MIDI音乐数据 |
| ANI | .ani | 存储动画光标 |
| WEBP | .webp | 存储图像数据(主要用于Web) |
可以看到除了WAV是基于RIFF格式的,还有其他文件类型也是基于RIFF的,这里我们也可以看到很多文件格式会用特定的标识符,比如WAV, AVI,这里就涉及到FOURCC标识符。RIFF 文件的结构通常以标识符 “RIFF” 开头,紧接着是文件大小(4 字节),再后面跟着的就是一个四字符代码(FOURCC),用于指明文件的数据类型。
FOURCC标识符
FOURCC(Four-Character Code,四字符代码)是由 4 个字节组成的标识符,通常使用可打印的 ASCII 字符,它在 RIFF 文件中用来标识数据的具体格式。比如:
WAV 文件:以 “RIFF” 开头,FOURCC 为 “WAVE”,表示这是一个音频文件。
AVI 文件:以 “RIFF” 开头,FOURCC 为 "AVI “”(注意末尾有空格),表示这是一个视频文件。
FOURCC 的设计要求正好 4 个字符,如果不足则用空格填充,且对大小写敏感。这种标识方式不仅用于文件类型的最顶层定义,还用于文件内部的各个数据块,每个数据块称作一个chunk,比如 WAV 文件中包含 "fmt "(格式信息)和 “data”(音频数据)这两个chunk。
字节序
WAV文件的字节数据还涉及到字节序的问题。字节序(Byte Order)是指多字节数据(如整数、浮点数等)在计算机内存中存储的顺序。不同的计算机体系结构可能采用不同的字节序方式,这可能会导致在不同平台之间传输数据时出现问题。字节序问题主要体现在多字节数据的存储顺序上,尤其是在跨平台的数据交换和存储中需要特别注意。根据字节存储时从低位开始还是从高位开始分为两种:大端序和小端序。
大端序(Big-Endian)
大端字节序是一种字节顺序,其中数据的高字节存储在内存的低地址处,低字节存储在高地址处。
例如,对于一个4字节的整数 0x12345678,它的字节序会按以下顺序存储:
| 地址 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 数据 | 0x12 | 0x34 | 0x56 | 0x78 |
这种存储方式类似于我们阅读数字的顺序,从左到右。
小端序(Little-Endian)
小端字节序是一种字节顺序,其中数据的低字节存储在内存的低地址处,高字节存储在高地址处。
对于同样的4字节整数 0x12345678,它的字节序会按以下顺序存储:
| 地址 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 数据 | 0x78 | 0x56 | 0x34 | 0x12 |
这种存储方式将数字的低位放在前面,更符合计算机内部的处理逻辑。
WAV文件结构
WAV文件基于RIFF格式。RIFF格式的结构是一个个块构成的,一个块称为一个chunk,每个chunk都有一个4字节的ID(FOURCC),紧随其后的是4字节的块大小(chunk size),然后是块数据 (data) 。 最外层的是RIFF chunk,里面在套着"fmt" chunk和"data" chunk。

我们来看一下WAV文件的结构:

这张图的最左边是字节序,然后是偏移量,每个数据字段区域的名称及对应区域的字节大小。
字节序:
前面我们提到WAV的字节序问题,那在WAV中每个chunk里面的字节数据是以什么方式存储的呢?在RIFF格式中,所有多字节的 数值数据(如块大小、音频采样率等)都以小端序存储。而ID,即FOURCC标识符,是4个ASCII字符的组合,按照ASCII字符的顺序直接存储, 所以它的字节序是大端序。
偏移量:
偏移量是指当前数据字段相对于文件开始位置的字节数。比如ChunkID的偏移量是0,表示它是文件的开始部分;ChunkSize的偏移量是4,表示它从文件的第4个字节开始,
WAVE音频文件结构主要分为三个部分:
1. RIFF Chunk Descriptor (偏移量0-12)
这是文件的头部,提供文件的身份和基本信息:
- ChunkID (偏移量0,4字节) 标识文件为RIFF类型,通常为字符串 "RIFF"。 每个字符在ASCII表中都对应一个十六进制数。比如,R的ASCII码是0x52,I是0x49,F是0x46,第二个F也是0x46,那连起来的话, "RIFF"这四个字母对应的ASCII码就是0x52 0x49 0x46 0x46。
- ChunkSize (偏移量4,4字节) 表示整个文件的大小(不包括前8字节,即 ChunkID 和 ChunkSize)。
- 整个文件大小(不包含前8字节)=
36 + SubChunk2Size或4 + (8 + SubChunk1Size) + (8 + SubChunk2Size)或文件总大小-8 - Format (偏移量8,4字节) 指定文件格式为 "WAVE"。对应57 41 56 45。
2. fmt Sub-chunk (偏移量12-36)
这部分描述音频的格式信息,是播放或处理音频时必须了解的关键数据:
- Subchunk1ID (偏移量12,4字节) 标识这是 "fmt " 子块。和上面的"RIFF"一样,使用ASCII字符标识,不足四个字符,末尾用空格补齐。对应66 6D 74 20
- Subchunk1Size (偏移量16,4字节) 表示此子块的大小(对于PCM通常为16字节)。
- AudioFormat (偏移量20,2字节) 指定音频格式,例如PCM(未压缩音频,值为1)。
- NumChannels (偏移量22,2字节) 声道数,例如1(单声道)或2(立体声)。
- SampleRate (偏移量24,4字节) 采样率,例如44100 Hz(CD音质)。
- ByteRate (偏移量28,4字节) 每秒字节数,计算公式为:
SampleRate * NumChannels * BitsPerSample / 8 - BlockAlign (偏移量32,2字节) 每个采样块的字节数,计算公式为:
NumChannels * BitsPerSample / 8 - BitsPerSample (偏移量34,2字节) 每个样本采样的位数,例如8位或16位。
3. data Sub-chunk (偏移量36起)
这部分存储实际的音频数据:
- Subchunk2ID (偏移量36,4字节) 标识这是 "data" 子块。对应64 61 74 61。
- Subchunk2Size (偏移量40,4字节) 表示音频数据的大小。 datasize =
NumSamples × NumChannels × BitsPerSample / 8,其中NumSamples 是总样本数 - data (偏移量44起,可变大小) 包含原始的音频采样数据。
WAV文件头
WAV文件的前44字节称为 WAV的文件头 ,剩下的data为WAV文件实际的音频数据。所以整个WAV文件的大小应等于
文件头44字节 + data字节大小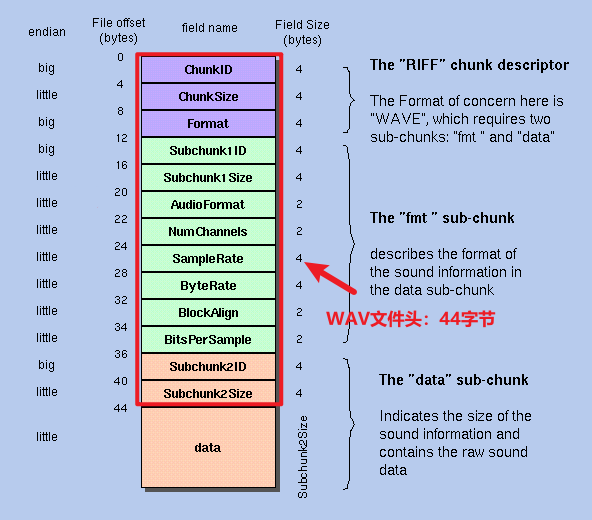
这个文件头主要注意ChunkSize ,Subchunk2Size,ByteRate ,BlockAlign 这几个参数,我们重点介绍一下。
ChunkSize
ChunkSize字段里面存储着 “它之后的数据总大小” 的这个数据 (对于当前chunk的剩余部分)。所以 ChunkSize 指 对于ChunkSize字段后面的数据大小,不包括前8字节,即 4字节的ChunkID 和4字节的ChunkSize,所以ChunkSize大小是
文件总大小-8。 (从ChunkID到data是一个WAV文件,ChunkSize实际就是从下个地址08开始到WAV文件结尾的总字节数)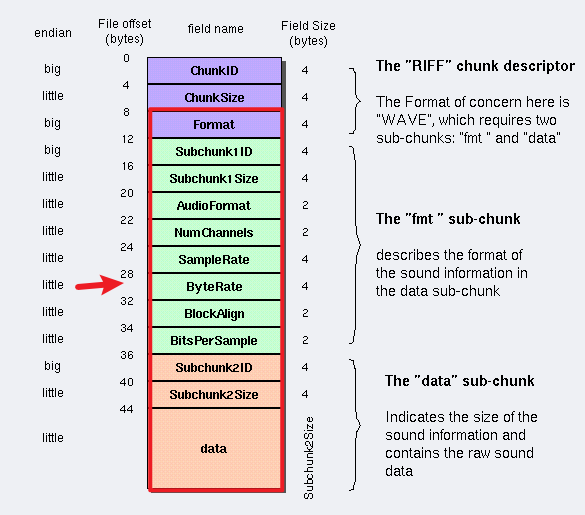
ChunkSize大小还等于
36 + SubChunk2Size。(下图红色框+蓝色框)。因为同理Subchunk2Size 指 对于Subchunk2Size字段后面的数据大小,而这个数据刚好就是WAV真正的音频数据,即 datasize,
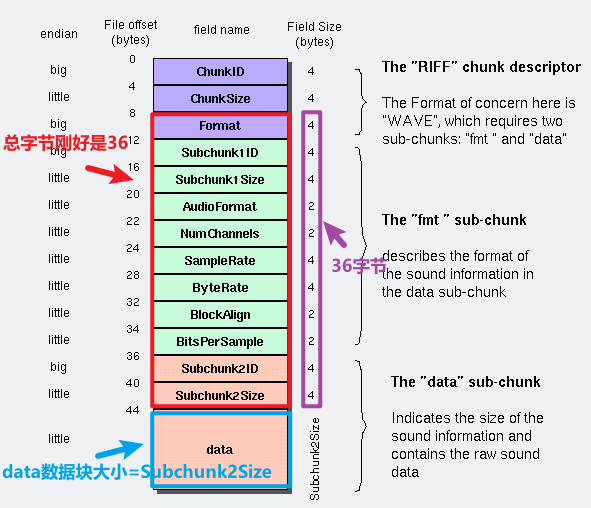
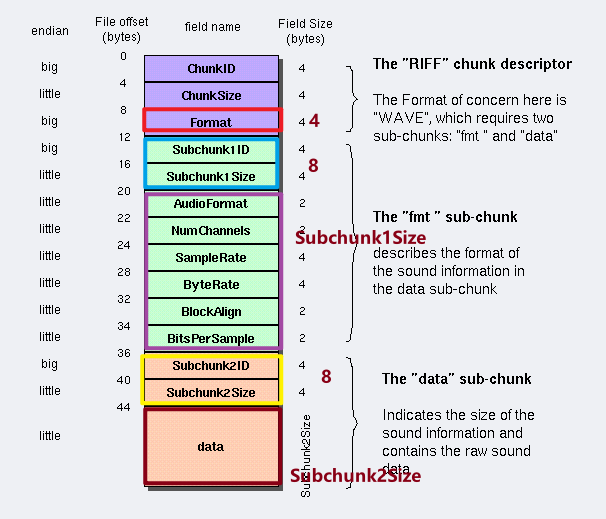
ChunkSize还等于
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size),这个式子比较长,主要是分的比较细,如下图:
ByteRate
ByteRate表示每秒传输的字节数,比如一段采样率8000hz,采样深度16bit的音频,单声道,则一秒采样8000个样本,每个样本16位,每秒采样样本字节大小为
8000 * 16 / 8 * 1声道 = 16000字节,除以8是为了转换为字节,所以ByteRate = SampleRate * NumChannels * BitsPerSample / 8BlockAlign
BlockAlign指每个采样块的字节数,或者说一帧的样本,如果是单声道音频,一帧样本就包含一个声道数据;如果是双声道音频,一帧样本包含左声道数据和右声道数据。比如一段采样深度16bit的音频,单声道,一帧就是
16 / 8 * 1声道 = 2字节。所以BlockAlign = NumChannels * BitsPerSample / 8。讲到采样帧这里顺便提一下之前学习遇到的困惑,之前学习I2S了解到在对音频样本采样时,如果是双声道音频,左声道和右声道是一帧样本,在同一时刻采样,那为什么WS又区分WS=0和WS=1呢? 在之前学过I2S的通信格式的那个图里一般左边是左声道,右边是右声道,这样子看起来并不是在同一个时刻。这里其实是我混淆了采样和传输的过程,采样确实是同时采样的,但是传输是先传输左声道,再传输右声道。这里参考了别人画的图,很形象借用一下。
假设一个 buffer 包含 4 个周期、而一个周包含 1024 帧、一帧包含两个样本(左、右两个声道),每个样本长度为2bytes。

Subchunk2Size
Subchunk2Size表示音频数据的大小(字节),一般可以预估计算,有了ByteRate ,一般乘以时间,就可以得到音频总大小。 或者知道样本数也可以估算出来,比如一段采样率44100,采样深度16bit的音频,单声道,时间一分钟60s,字节速率
ByteRate=44100 * 16 / 8 = 88200,即每秒传输字节数88200字节,再乘以时间,88200 * 60 = 5292000字节 ≈ 5.04 MB。Subchunk2Size大小因为表示的是WAV音频实际数据大小,所以也叫datasize,后面编写程序时我们将使用datasize这个字段名称。 使用时间去估计音频数据大小可能会有误差,但是这个误差一般不会很大。我们还可以通过样本数去估计音频数据大小,即NumSamples × NumChannels × BitsPerSample / 8,其中NumSamples是总样本数,NumChannels × BitsPerSample / 8 就是每个采样样本的字节数(即BlockAlign), 乘以总样本数,就可以得到总样本字节大小。以上我们讲了ChunkSize ,Subchunk2Size,ByteRate ,BlockAlign 这几个比较主要的参数,还有一些其他参数在WAV文件中是默认的。为了方便查看,将以上内容整理为表格:
偏移 大小 字段名 内容/说明 0 4 ChunkID "RIFF"(52 49 46 46)4 4 ChunkSize 文件大小 - 8
或
36 + SubChunk2Size
或
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size)8 4 Format "WAVE"(57 41 56 45)12 4 Subchunk1ID "fmt "(66 6D 74 20)16 4 Subchunk1Size 16(表示 PCM 格式时) 20 2 AudioFormat 1 表示 PCM;其他为压缩格式 22 2 NumChannels 声道数(1=单声道,2=立体声) 24 4 SampleRate 采样率(如 44100) 28 4 ByteRate 每秒传输的字节数 = SampleRate * NumChannels * BitsPerSample / 832 2 BlockAlign 每个采样块的字节数 = NumChannels × BitsPerSample / 834 2 BitsPerSample 每个样本的位数(如 16) 36 4 Subchunk2ID "data"(64 61 74 61)40 4 Subchunk2Size 音频数据的大小(字节) = NumSamples × NumChannels × BitsPerSample / 8WAV音频文件格式示例
了解了RIFF格式,字节序和WAV文件结构等相关参数后,我们先举一个WAV音频文件格式示例,再来看看实际的音频文件格式是什么样子的。
假设有一段WAV音频文件如下(十六进制显示)52 49 46 46 24 08 00 00 57 41 56 45 66 6d 74 20 10 00 00 00 01 00 02 00
22 56 00 00 88 58 01 00 04 00 10 00 64 61 74 61 00 08 00 00 00 00 00 00
24 17 1e f3 3c 13 3c 14 16 f9 18 f9 34 e7 23 a6 3c f2 24 f2 11 ce 1a 0d对音频数据按照上面WAV文件结构进行划分:

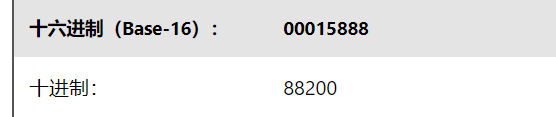
我们可以得到RIFF chunk, ChunkSize, Subchunk1Size,AudioFormat等相关参数,这里要注意除了ASCII字符,其他数据都是以小端序存储的。 比如ByteRate为 88 58 01 00,小端序应为:0x00015888,对应的十进制为88200。
再比如BlockAlign=4, 根据我们前面举的例子计算(双倍),它是一段双声道音频。那对于一段实际音频,我们如何查看它的十六进制格式呢?我们可以通过 Hex Editor这个软件,
HxD Hex Editor 是一款功能强大的十六进制编辑器和磁盘编辑器,它可以让你直接查看和编辑二进制文件的内容。你可以使用HxD Hex
Editor来分析、修改和处理各种数据格式,包括程序文件、磁盘映像、内存转储以及其他二进制文件。这里我自己生成了一段30S的WAV音频。我们用HxD软件打开它看看。

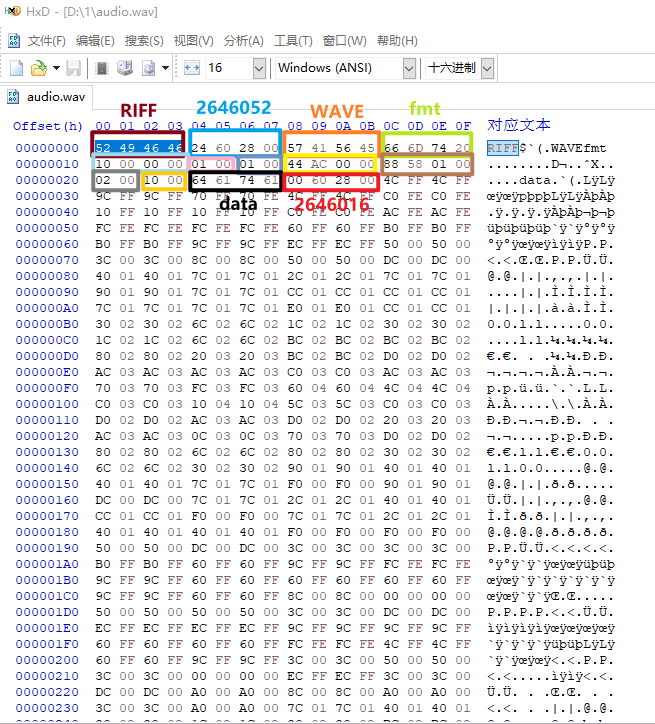
当我们框选头四个字节时,可以看到右边也有显示它的对应文本为:RIFF,表示这是一个基于RIFF格式的文件。我们将每个数据按照上面的结构进行划分,可以看到这个数据格式和我们介绍的WAV格式相符。除了框选的部位,后面都是真正的WAV音频数据即data。 框选的所有部分我们称之为 文件头,以四个字节为一组,数一下可以发现刚好有11组,11 * 4= 44字节,刚好是WAV文件头的字节数。 而WAV数据大小就是上面图片最后红色框的2646016字节,则整个WAV文件字节数应为
2646016 + 44 = 2646060字节。右键查看这个音频的文件属性:
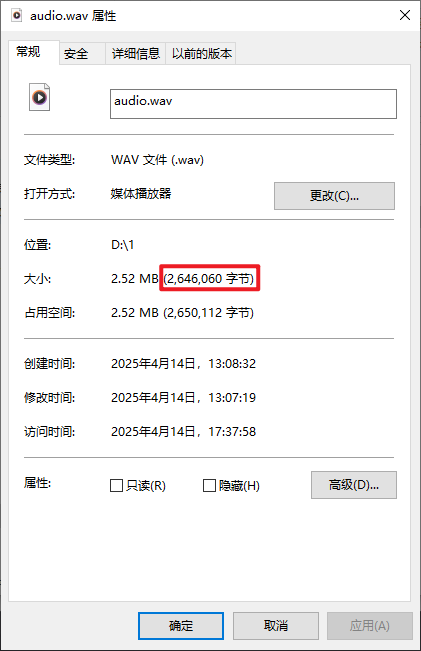
这和我们的计算结果一致。关于这个WAV文件头的详细信息如下:
52 49 46 46 RIFF标识
24 60 28 00 ChunkSize = 2646052(除去前8个字节文件大小)
57 41 56 45 WAV标识
66 6D 74 20 fmt标识
10 00 00 00 , Subchunk1Size =16(表示 PCM 格式时固定为16)
01 00 AudioFormat=1 ,音频格式:PCM(未压缩)(表示 PCM 格式时固定为1)
01 00 声道数:1(单声道)
44 ac 00 00 采样率:44100 Hz
88 58 01 00 字节率:88200 字节/秒
02 00 块对齐:2字节(每个采样点的字节数)
10 00 位深度:16位(每个采样点2字节)
64 61 74 61 data标识
00 60 28 00 Subchunk2Size = 2646016 (音频数据大小)WAV文件大小:2646060 字节
现在我们是通过WAV文件信息得到这些参数,比如音频数据大小 2646016 。前面我们说过WAV文件大小可以预估,那我们来计算一下看看有什么差异。以上面我生成的audio.wav文件为例, 假设我们已经知道一些基本参数,一段采样率44100, 采样深度16bit, 单声道WAV音频,如果我们通过字节速率ByteRate去计算再乘以时间,则
估计总音频文件大小应为44100 * 16 / 8 * 30 = 2646000字节,但实际大小为2646016字节,我们估计出来的音频大小比实际小。这是因为采样音频时长并不是精确的30 秒, 如果是精确30秒,采样点数量应该是44100 × 30 = 1323000个,我们通过 Subchunk2Size (实际音频大小),计算实际样本数却为2646016 / 2 = 1323008,比 1323000 多 8 个采样点,而每个采样点占 2 字节,所以实际整体多了16字节。 反过来我们可以计算实际采样时间为1323008 / 44100 ≈ 30.0001814058956秒, 多出8个采样点的时间刚好为1 / 44100 * 8 = 0.0001814058956秒。所以我们通过时间去预估WAV音频数据大小的话和实际相比是有差异的,但是我们一般会先预估大小,然后再更新WAV文件头。使用ESP32将WAV文件写入SD卡
以上我们介绍了WAV相关内容后,我们将介绍一个例子,将WAV音频文件写入SD卡,生成的WAV音频为一段1S的正弦波音频。
上面我们知道通过一段WAV文件头信息,可以得到它的一些参数;反过来我们也可以写入一些参数到WAV文件头里,生成WAV文件,所以WAV头部的定义是不可避免的。【定义WAV文件头】
假设我们要生成的WAV音频参数,采样率8000,采样深度16bit, 单声道,那么我们可以预估ChunkSize,Subchunk2Size(即datasize)大小,因为采样率是8000Hz,我们要生成1秒的音频,则1秒有8000个样本,每个样本大小为2字节(采样深度16bit),则 datasize = 16000, 根据公式直接计算的话就是
NumSamples × NumChannels × BitsPerSample / 8 = 8000 x 1 x 16 /8 = 16000字节。ChunkSize = 36 + datasize = 16036字节。其他参数可以参考上面的表格,这里就不赘述了。将其转化为16进制,小端序,定义WAV文件头:
const uint8_t wavHeader[44] = {0x52, 0x49, 0x46, 0x46, // "RIFF"0xA4, 0x3E, 0x00, 0x00, // chunksize: 160360x57, 0x41, 0x56, 0x45, // "WAVE"0x66, 0x6D, 0x74, 0x20, // "fmt "0x10, 0x00, 0x00, 0x00, // fmt块大小 (16)0x01, 0x00, // 音频格式 (1 = PCM)0x01, 0x00, // 声道数 (1)0x40, 0x1F, 0x00, 0x00, // 采样率 (8000 Hz)0x80, 0x3E, 0x00, 0x00, // 字节率 (16000)0x02, 0x00, // 块对齐 (2)0x10, 0x00, // 每样本位数 (16)0x64, 0x61, 0x74, 0x61, // "data"0x80, 0x3E, 0x00, 0x00 // datasize: 16000 };【创建并打开文件】
为了写入SD卡,我们还要初始化SD卡。创建一个文件取名为test.wav并打开它:
#define SD_CS_PIN 5// 初始化SD卡 if (!SD.begin(SD_CS_PIN)) { Serial.println("SD卡初始化失败!"); return; } Serial.println("SD卡初始化成功。");//创建并打开文件 File wavFile = SD.open("/test.wav", FILE_WRITE); if (!wavFile) { Serial.println("无法创建文件!"); return; }【写入WAV头部】
File 类是Arduino SD库的一部分,这里我们创建了一个 File 类对象取名为wavFile,wavFile.write用于向 SD 卡上的文件写入数据。使用
size_t write(const uint8_t *buf, size_t size)将文件头写入前面创建的文件中,这里要注意第一个参数类型是uint8_t *类型的,如果写入的buffer不是uint8_t *类型,需要进行强制类型转换。wavFile.write(wavHeader, 44);【 生成440Hz正弦波音频】
正弦波公式为:
y = A * sin(ωt+φ)其中,
A:振幅,那么y的取值范围就是
[-A, A];
ω:角频率,ω = 2 * π * f,其中f为频率,周期T = 1 / f;
φ:初相位;以下是生成一段1秒440Hz正弦波音频的示例:
// 生成并写入440Hz正弦波音频数据 const int sampleRate = 8000; // 采样率 const int frequency = 440; // 正弦波频率 const int numSamples = sampleRate * 1; // 1秒的样本数 for (int i = 0; i < numSamples; i++) { float time = (float)i / sampleRate; int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time)); }【写入WAV音频文件并关闭文件】
使用
size_t write(const uint8_t *buf, size_t size)将前面生成的正弦波音频数据写入前面创建的文件中并进行强制类型转换。wavFile.write((uint8_t*)&sample, 2); // 写入16位样本 wavFile.close(); Serial.println("WAV文件写入完成。");整合后的代码如下:
#include <SD.h> #include <SPI.h>// SD卡片选引脚 #define SD_CS_PIN 5// WAV文件头部(44字节) const uint8_t wavHeader[44] = {0x52, 0x49, 0x46, 0x46, // "RIFF"0xA4, 0x3E, 0x00, 0x00, // chunksize: 160360x57, 0x41, 0x56, 0x45, // "WAVE"0x66, 0x6D, 0x74, 0x20, // "fmt "0x10, 0x00, 0x00, 0x00, // fmt块大小 (16)0x01, 0x00, // 音频格式 (1 = PCM)0x01, 0x00, // 声道数 (1)0x40, 0x1F, 0x00, 0x00, // 采样率 (8000 Hz)0x80, 0x3E, 0x00, 0x00, // 字节率 (16000)0x02, 0x00, // 块对齐 (2)0x10, 0x00, // 每样本位数 (16)0x64, 0x61, 0x74, 0x61, // "data"0x80, 0x3E, 0x00, 0x00 // datasize: 16000 };void setup() { Serial.begin(115200);// 初始化SD卡 if (!SD.begin(SD_CS_PIN)) { Serial.println("SD卡初始化失败!"); return; } Serial.println("SD卡初始化成功。");// 创建并打开文件 File wavFile = SD.open("/test.wav", FILE_WRITE); if (!wavFile) { Serial.println("无法创建文件!"); return; }// 写入WAV头部 wavFile.write(wavHeader, 44);// 生成并写入440Hz正弦波音频数据 const int sampleRate = 8000; // 采样率 const int frequency = 440; // 正弦波频率 const int numSamples = sampleRate * 1; // 1秒的样本数 for (int i = 0; i < numSamples; i++) { float time = (float)i / sampleRate; int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time)); wavFile.write((uint8_t*)&sample, 2); // 写入16位样本 }// 关闭文件 wavFile.close(); Serial.println("WAV文件写入完成。"); }void loop() { }这里我们观察到如果使用数组定义WAV文件头的话需要计算它的十六进制比较麻烦,我们可以定义一个WAV头部结构体,写入ASCII字符和公式,这样可以更方便地计算 WAV 文件头的信息,而不用手动去处理十六进制数据。
使用结构体定义WAV文件头:
// 定义 WAV 头部结构体 struct WavHeader {char riff[4] = {'R', 'I', 'F', 'F'}; // "RIFF"uint32_t chunkSize; // 文件大小 - 8char wave[4] = {'W', 'A', 'V', 'E'}; // "WAVE"char fmt[4] = {'f', 'm', 't', ' '}; // "fmt "uint32_t fmtChunkSize = 16; // fmt 块大小 (16 for PCM)uint16_t audioFormat = 1; // 音频格式 (1 = PCM)uint16_t numChannels = 1; // 声道数 (1 = 单声道)uint32_t sampleRate = SAMPLE_RATE; // 采样率 (8000 Hz)uint32_t byteRate = SAMPLE_RATE * 2; // 字节率 (sampleRate * numChannels * bitsPerSample / 8)uint16_t blockAlign = 2; // 块对齐 (numChannels * bitsPerSample / 8)uint16_t bitsPerSample = 16; // 每样本位数 (16 bits)char data[4] = {'d', 'a', 't', 'a'}; // "data"uint32_t dataSize; // 数据块大小 };使用结构体定义WAV文件头的话我们只是定义了一个类型,所以我们需要定义一个结构体变量,因为我们没有直接给出 chunkSize 和 datasize ,所以我们需要计算音频数据大小,创建并初始化WAV文件头。这里由于样本比较简单,所以我们直接可以确定样本数去计算音频数据大小,后面就不需要再更新WAV文件头了。
// 计算音频数据大小const int numSamples = SAMPLE_RATE * 1; // 1 秒的样本数const int bytesPerSample = 2; // 16 位,每个样本 2 字节uint32_t dataSize = numSamples * bytesPerSample; // 数据大小:16000 字节uint32_t chunkSize = 36 + dataSize; // 文件总大小 - 8:16036 字节// 创建并初始化 WAV 头部WavHeader header;header.chunkSize = chunkSize; // 设置 chunkSizeheader.dataSize = dataSize; // 设置 dataSize完整代码
修改后的完整代码如下:
#include <SD.h> #include <SPI.h>// 定义常量 #define SD_CS_PIN 5 // SD卡片选引脚 #define SAMPLE_RATE 8000 // 采样率(8000 Hz) #define PI 3.1415926535 // π 值// 定义 WAV 头部结构体 struct WavHeader {char riff[4] = {'R', 'I', 'F', 'F'}; // "RIFF"uint32_t chunkSize; // 文件大小 - 8char wave[4] = {'W', 'A', 'V', 'E'}; // "WAVE"char fmt[4] = {'f', 'm', 't', ' '}; // "fmt "uint32_t fmtChunkSize = 16; // fmt 块大小 (16 for PCM)uint16_t audioFormat = 1; // 音频格式 (1 = PCM)uint16_t numChannels = 1; // 声道数 (1 = 单声道)uint32_t sampleRate = SAMPLE_RATE; // 采样率 (8000 Hz)uint32_t byteRate = SAMPLE_RATE * 2; // 字节率 (sampleRate * numChannels * bitsPerSample / 8)uint16_t blockAlign = 2; // 块对齐 (numChannels * bitsPerSample / 8)uint16_t bitsPerSample = 16; // 每样本位数 (16 bits)char data[4] = {'d', 'a', 't', 'a'}; // "data"uint32_t dataSize; // 数据块大小 };void setup() {Serial.begin(115200);// 初始化 SD 卡if (!SD.begin(SD_CS_PIN)) {Serial.println("SD卡初始化失败!");return;}Serial.println("SD卡初始化成功。");// 创建并打开文件File wavFile = SD.open("/test.wav", FILE_WRITE);if (!wavFile) {Serial.println("无法创建文件!");return;}// 计算音频数据大小const int numSamples = SAMPLE_RATE * 1; // 1 秒的样本数const int bytesPerSample = 2; // 16 位,每个样本 2 字节uint32_t dataSize = numSamples * bytesPerSample; // 数据大小:16000 字节uint32_t chunkSize = 36 + dataSize; // 文件总大小 - 8:16036 字节// 创建并初始化 WAV 头部WavHeader header;header.chunkSize = chunkSize; // 设置 chunkSizeheader.dataSize = dataSize; // 设置 dataSize// 写入 WAV 头部wavFile.write((uint8_t*)&header, sizeof(header));// 生成并写入音频数据(440 Hz 正弦波)const int frequency = 440;for (int i = 0; i < numSamples; i++) {float time = (float)i / SAMPLE_RATE;int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time));wavFile.write((uint8_t*)&sample, 2);}// 关闭文件wavFile.close();Serial.println("WAV文件写入完成。"); }void loop() { }以上通过ESP32生成的一段1S的正弦波音频写入SD卡模块,硬件上只需ESP32和SD模块。下面我们介绍如何将ESP32和SD模块进行接线。
ESP32

SD卡模块

ESP32和SD模块接线
ESP32 SD模块 D5 CS D18 SCK D23 MOSI D19 MISO 5V VCC GND GND 按照以上步骤,编译上传代码后,应能在SD卡找到生成的名为test.wav的音频文件,播放会听到1秒的正弦波声音。
同样我们用HxD软件打开我们生成的test.wav文件
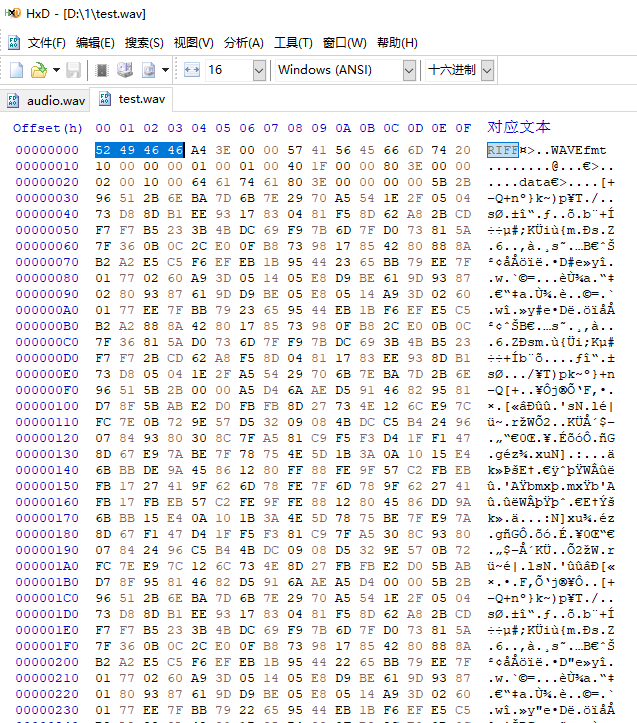
对比我们代码里的WAV文件头数据,可以发现数据是一样的,这说明WAV文件头确实是按照我们的要求写入了WAV文件了,而且使用数组或者结构体表示 WAV 头部这两种方法都可以实现,建议采用第二个代码的方式,使用结构体和动态计算 chunkSize等数据,确保 WAV 文件头部的正确性、灵活性和兼容性。
总结
以上我们介绍了什么是WAV音频文件,还有一些音频格式的相关概念、参数,并实际观察了WAV文件的数据内容,对WAV文件结构有了更深入的了解,然后我们通过ESP32生成了一段1S的正弦波音频,并将其写入SD模块,方法是通过将音频参数写入WAV文件头,并通过SD和文件系统相关函数将文件头写入我们创建的文件里,这样我们就可以在SD卡里通过读卡器读取里面的正弦波音频数据了。
关于WAV文件头的每个参数是如何计算和填写的,在我们介绍WAV文件头的时候,已经举例并且说明了,我们也可以直接参考一开始总结的表格,里面有详细说明和相关公式,这些公式并不需要死记硬背,理解了每个参数的含义还是比较容易理解的。在介绍WAV文件头的时候,还有一些参数没有详细说明,比如AudioFormat, 1表示PCM,至于其他值表示的压缩格式应该是什么样子这里没有提到,还有LIST 块相关本文也没有提到,因为我们主要针对WAV文件进行介绍,所以这里不作提及,感兴趣的小伙伴可以自行去了解下~
本文是为后面ESP I2S音频学习内容作为铺垫,因为WAV文件格式的内容还是比较多的,所以单独写一篇介绍。后面大家关于WAV文件有疑惑的地方,可以参考这篇文章。因为本人也是初学,以上是个人理解加上搜索资料学习到的,如果有什么问题,可以提出交流讨论,欢迎指正!需要HxD软件和想听一下源代码工程生成的WAV音频文件是什么声音的可以评论区留言!已经整理好所有文件 ~ 创作不易,多多点赞收藏哦! ~
相关文章:

【ESP32|音频】一文读懂WAV音频文件格式【详解】
简介 最近在学习I2S音频相关内容,无可避免会涉及到关于音频格式的内容,所以刚开始接触的时候有点一头雾水,后面了解了下WAV相关内容,大致能够看懂wav音频格式是怎么样的了。本文主要为后面ESP32 I2S音频系列文章做铺垫࿰…...

数据通信学习笔记之OSPF路由汇总
区域间路由汇总 路由汇总又被称为路由聚合,即是将一组前缀相同的路由汇聚成一条路由,从而达到减小路由表规模以及优化设备资源利用率的目的,我们把汇聚之前的这组路由称为精细路由或明细路由,把汇聚之后的这条路由称为汇总路由或…...

【C++】priority_queue的底层封装和实现
目录 前言基本结构如何设置默认大小堆底层实现仿函数的使用向上调整算法向下调整算法其他接口 end 前言 priority_queue的介绍 优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中的元素构造成堆的结构,因此priorit…...

2023年全国青少年信息素养大赛 Python编程挑战赛 小学全年级组 初赛真题答案详细解析
2023信息素养大赛 Python编程挑战赛 选择题(共15题,每题5分,共75分) 1、关于列表的索引,下列说法正确的是 A、列表的索引从0开始 B、列表的索引从1开始 C、列表中可能存在两个元素的索引一致 D、列表中索引的最大…...

十三种通信接口芯片——《器件手册--通信接口芯片》
目录 通信接口芯片 简述 基本功能 常见类型 应用场景 详尽阐述 1 RS485/RS422芯片 1. RS485和RS422标准 2. 芯片功能 3. 典型芯片及特点 4. 应用场景 5. 设计注意事项 6. 选型建议 2 RS232芯片 1. RS232标准 2. 芯片功能 3. 典型芯片及特点 4. 应用场景 5. 设计注意事项 6…...
——神经网络与模型训练过程详解)
PyTorch生成式人工智能实战(1)——神经网络与模型训练过程详解
PyTorch生成式人工智能实战(1)——神经网络与模型训练过程详解 0. 前言1. 传统机器学习与人工智能2. 人工神经网络基础2.1 人工神经网络组成2.2 神经网络的训练 3. 前向传播3.1 计算隐藏层值3.2 执行非线性激活3.3 计算输出层值3.4 计算损失值3.5 实现前…...

【软件系统架构】事件驱动架构
一、引言 在当今的软件开发和系统架构领域,事件驱动架构(Event - Driven Architecture,EDA)正逐渐成为构建复杂、分布式和可扩展系统的热门选择。随着信息技术的不断发展,传统的架构模式在应对高并发、实时性要求高、数…...

Doris FE 常见问题与处理指南
在数据仓库领域,Apache Doris 凭借其卓越性能与便捷性被广泛应用。其中,FE(Frontend)作为核心组件,承担着接收查询请求、管理元数据等关键任务。然而,在实际使用中,FE 难免会遭遇各类问题&#…...

Manus AI “算法-数据-工程“三位一体的创新
Manus AI在多语言手写识别领域的技术突破,通过算法创新、数据工程与场景适配的协同作用,解决了传统手写识别的核心痛点。以下是其关键技术路径与创新点的系统性分析: 一、深度学习模型与算法优化 混合神经网络架构Manus AI采用"CNN与LST…...

Flutter Expanded 与 Flexible 详解
目录 1. 引言 2. Expanded 的基本用法 3. Flexible 的基本用法 4. Expanded vs Flexible 的区别 4.1 基础定义 4.2 关键差异 5. Expanded 深度解析 5.1 按比例分配 5.2 强制填充特性 6. Flexible 深度解析 6.1 基础用法:动态收缩 6.2 结合 fit 参数控制…...

乘用车制动系统设计:保障行车安全的核心技术
摘要 随着汽车工业的快速发展,乘用车制动系统的设计至关重要。本文详细阐述了乘用车制动系统的工作原理、组成部分、常见类型,深入分析了制动系统设计过程中的关键要点,包括制动力分配、制动管路设计、制动助力系统选型等。同时,…...

电力行业在保障用电安全方面正积极采用先进的物联网技术
电力行业在保障用电安全方面正积极采用先进的物联网技术 电力行业的物联网安全用电监管装置正发挥着至关重要的作用。 ASCO 电不着安全用电装置凭借其卓越的性能,成为了解决用电安全问题的得力助手。 当电漏电这种危险情况悄然发生时,物联网 ASCO 电不着…...
)
TDengine 语言连接器(PHP)
简介 PHP 语言广泛用于 Web 开发的开源脚本语言。它语法简单,容易学习,既支持面向过程,也支持面向对象编程。具有跨平台性,能与多种数据库交互,可与 HTML 等前端技术配合,动态生成网页内容。常用于开发各类…...

使用docker该怎么做:从公有仓库拉取镜像并上传到私有仓库
在容器化部署中,将公有镜像仓库(如Docker Hub)的镜像迁移到私有仓库(如Harbor、Nexus)是常见需求。 一、为什么需要将镜像从公有仓库传到私有仓库? 网络连通性:公有仓库依赖公网访问ÿ…...

list的使用
1:list文档 list文档 在之前我们对于链表有过最初始的模拟实现,现在进入C之后,我们可以在STL库中发现到链表这个容器的使用,list的底层也是我们最初实现的双向链表。 2:list的使用 list的接口有很多,我们…...

Redis遇到Hash冲突怎么办
在 Redis 中,哈希冲突通常是指当多个键的哈希值相同或位于相同的哈希槽中时发生冲突。Redis 通过底层的哈希表和一些冲突解决机制(如开放地址法、链表法等)来处理哈希冲突问题。这些通常是透明的,作为开发者,我们无需直…...
颜色空间转换-----将 BGR图像转换为 I420(YUV 4:2:0)格式函数BGR2I420())
OpenCV 图形API(42)颜色空间转换-----将 BGR图像转换为 I420(YUV 4:2:0)格式函数BGR2I420()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从BGR色彩空间转换为I420色彩空间。 该函数将输入图像从BGR色彩空间转换为I420。R、G和B通道值的传统范围是0到255。 输出图像必须是8位无…...

简述Apache RocketMQ
整体架构分析 基本流程 模块特性 发送消息流程原理分析 同步发送 sync 异步发送 async 直接发送 one-way 主从同步(HA)机制分析 消息投递 持久化机制 RocketMQ的RPC通信 RocketMQ中Remoting通信模块的具体实现 消息的协议涉及与编码解码 消…...

AI融合SEO关键词实战指南
内容概要 随着人工智能技术的迭代升级,SEO关键词策略正经历从人工经验驱动向数据智能驱动的范式转变。本指南聚焦AI技术在搜索引擎优化中的系统性应用,通过构建多层技术框架实现关键词全生命周期管理。核心方法论涵盖语义分析引擎的构建原理、基于NLP的…...

RK3588 实现音视频对讲
RK3588 实现音视频对讲方案 RK3588是瑞芯微推出的一款高性能处理器,非常适合用于音视频对讲系统的开发。以下是基于RK3588实现音视频对讲的方案概述: 硬件架构 核心处理器:RK3588 (4xCortex-A76 4xCortex-A55)视频处理: 内置8…...

OSPF区域间路由计算
ABR:区域边界路由器,连接两个不同区域的设备就称为ABR(不同厂商不同,定义很模糊) ASBR:自治系统边界路由器,引入了外部路由,将不是自治系统外部的不是OSPF路由的条目变成OSPF路由条目…...

NAT、代理服务、内网穿透
NAT、代理服务、内网穿透 1、NAT1.1、NAT过程1.2、NAPT2、内网穿透3、内网打洞3、代理服务器3.1、正向代理3.2、反向代理1、NAT 1.1、NAT过程 之前我们讨论了IPv4协议中IP地址数量不充足的问题。NAT技术是当前解决IP地址不够用的主要手段,是路由器的一个重要功能。 NAT能够将…...

阿尔特拉 EP1C12F324I7N AlteraFPGA Cyclone
EP1C12F324I7N 属于 Altera Cyclone I 系列 FPGA 中的中低密度型号,面向成本敏感、功耗受限的嵌入式与数据通路应用。该器件采用 0.13 μm 全层铜 SRAM 工艺,集成约 12 060 个逻辑单元(LE)、239 616 位片上 RAM、249 路可编…...
加密与 SQL Server 建立安全连接“问题)
解决“驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接“问题
参考链接: https://blog.csdn.net/yyj12138/article/details/123073146...

QtApplets-实现应用程序单例模式,防止重复运行
QtApplets-实现应用程序单例模式,防止重复运行 文章目录 QtApplets-实现应用程序单例模式,防止重复运行摘要引言实现原理核心代码实现头文件定义实现文件 使用方法技术要点解析1. 文件锁机制2. 进程 ID 管理3. Windows 互斥量4. 跨平台兼容 注意事项…...

nodejs使用pkg打包文件
pkg配置 "pkg": {"assets": ["*.html","*.css","*.js"],"mirror": "https://npmmirror.com/mirrors/node-v8-compile-cache/"},"bin": "server.js",嵌入到exe中的资源使用assets打…...

学习笔记十六——Rust Monad从头学
🧠 零基础也能懂的 Rust Monad:逐步拆解 三大定律通俗讲解 实战技巧 📣 第一部分:Monad 是什么? Monad 是一种“包值 链操作 保持结构”的代码模式,用来处理带上下文的值,并方便连续处理。 …...

Idea连接远程云服务器上的MySQL,开放云服务器端口
1.开放云服务器的3306端口 (1)进入到云服务器的控制台 (2)点击使用的云服务器 (3)点击 配置安全组规则 (4)添加规则 (5)开放端口 2.创建可以远程访问…...

云服务器CVM标准型S5实例性能测评——2025腾讯云
腾讯云服务器CVM标准型S5实例具有稳定的计算性能,CPU采用采用 Intel Xeon Cascade Lake 或者 Intel Xeon Cooper Lake 处理器,主频2.5GHz,睿频3.1GHz,CPU内存配置2核2G、2核4G、4核8G、8核16G等配置,公网带宽可选1M、3…...
方法详解)
【Pytorch之一】--torch.stack()方法详解
torch.stack方法详解 pytorch官网注释 Parameters tensors:张量序列,也就是要进行stack操作的对象们,可以有很多个张量。 dim:按照dim的方式对这些张量进行stack操作,也就是你要按照哪种堆叠方式对张量进行堆叠。dim的…...

监控+日志=DevOps 运维的“千里眼”与“顺风耳”
监控+日志=DevOps 运维的“千里眼”与“顺风耳” 在 DevOps 体系中,监控和日志管理是不可或缺的运维基石。有人说,开发只管把代码写好,运维才是真正的“操盘手”,让系统稳定运行、不宕机、不崩溃。而要做到这一点,精准的监控与日志管理 是关键。 试想一下:如果没有监控…...

实战|使用环信Flutter SDK构建鸿蒙HarmonyOS应用及推送配置
本文为大家介绍如何在 Flutter 环境创建 Harmony 项目并集成环信即时通讯IM以及环信 Flutter Harmony 推送配置。 已经基于环信的 Flutter 项目也可以参考本文适配鸿蒙端。 一、开发环境要求 前置条件 1.安装DevEco-Studio 2.安装模拟器 DevEco-Studio 下载与操作指导&…...

构建知识体系
我认为,仅仅建立知识点之间的连接还不足够,还要建立自己的知识体系。 那么什么是知识体系呢? 知识体系,可以理解为立体的知识系统。 立体的知识系统,代表着跨越了多个领域、行业、学科的知识,是多个层面…...

Android Mainline简介
关键要点 Android Mainline 是通过模块化更新 Android 核心组件的框架,可能提高安全性。允许通过 Google Play 系统更新分发模块,无需完整固件更新。能简化厂商工作并减少碎片化,但覆盖范围有限。 什么是 Android Mainline? And…...
)
2026《数据结构》考研复习笔记二(C++面向对象)
C面向对象 一、类二、继承三、重载运算符和重载函数四、多态代码示例 一、类 1.1类&对象 class classname//class是关键词,classname是类名 { Access specifiers://访问修饰符:private/public/protected Date members/variables;//变量 Member fun…...

【C++】12.list接口介绍
在C标准库中,std::list 是一个基于双向链表实现的顺序容器,它支持高效的插入和删除操作,但无法直接通过下标进行随机访问。以下是关于 std::list 的简单介绍: 核心特性 底层结构 双向链表实现,每个节点包含数据、前驱指…...

决策卫生问题:考公考编考研能补救高考选取职业的错误吗
对于决策者来说,“认识你自己”是一个永恒的主题;警惕认知中的缺陷,比什么都重要。在判断与决策问题上,管理者和专业人士往往都非常自信。人类远远不如我们想象的那么理性,人类的判断也远远不如我们想象的那么完美。在…...

考研系列-计算机网络-第一章、计算机网络体系结构
一、计算机网络概述 1.知识点总结 性能指标: 注意这个指标: 2.习题总结 (一)选择题 广域网点对点,局域网广播技术 (二)简答题 (1)概念性题目: (2)计算型题目 这个题目主要是注意两种交换方式: 电路交换:…...

状态模式:有限状态机在电商订单系统中的设计与实现
状态模式:有限状态机在电商订单系统中的设计与实现 一、模式核心:用状态切换驱动行为变化 在电商订单系统中,订单状态会随着用户操作动态变化:「已创建」的订单支付后变为「已支付」,发货后变为「已发货」࿰…...

nohup命令使用说明
文章目录 如何在后台运行程序呢?如何正常运行代码重定向呢?nohup: ignoring input 如何在后台运行程序呢? 使用nohup命令即可, nohup python dataset/ReferESpatialDataset.py >>dataset_20250417.log 2>&1 &n…...

使用原生button封装一个通用按钮组件
效果图 代码 <script lang"ts" setup> import { computed, ref, watch } from "vue";/*** 按钮属性接口*/ interface ButtonProps {/** 按钮类型:default(默认)/dark/plain/link */type?: "default" | "dark" | &q…...

osu ai 论文笔记 DQN
e https://theses.liacs.nl/pdf/2019-2020-SteeJvander.pdf Creating an AI for the Rhytm Game osu! 20年的论文 用监督学习训练移动模型100首歌能达到95准确率 点击模型用DQN两千首歌65准确率 V抖用的居然不是强化学习? 5,6星打96准确度还是有的东西的 这是5.…...

perf 的使用方法
perf的架构 1.perf event event are pure kernel counters, in this case they are called software events. Examples include: context-switches, minor-faults.events is the processor itself and its Performance Monitoring Unit (PMU). It provides a list of events …...
)
【MCP教程】Claude Desktop 如何连接部署在远程的remote mcp server服务器(remote host)
前言 最近MCP特别火热,笔者自己也根据官方文档尝试了下。 官方文档给的Demo是在本地部署一个weather.py,然后用本地的Claude Desktop去访问该mcp服务器,从而完成工具的调用: 但是,问题来了,Claude Deskto…...

使用python帮助艺术家完成角色动画和服装模型等任务
使用python帮助艺术家完成角色动画和服装模型等任务 声明:克隆项目第 1 步:准备 Python 环境第 2 步:安装依赖✅ 第 3 步:运行项目主入口报错:报错:**降级 Python 到 3.10 或 3.11**推荐版本: 创…...

Python爬虫实战:基于 Python Scrapy 框架的百度指数数据爬取研究
一、引言 1.1 研究背景 在当今信息时代,市场调研和趋势分析对于企业和研究机构至关重要。百度指数能够精准反映关键词在百度搜索引擎上的热度变化情况,为市场需求洞察、消费者兴趣分析等提供了极具价值的数据支持。通过对百度指数数据的爬取和分析,企业可以及时调整营销策略…...

【Python】python系列之函数闭包概念
目录 一、函数 二、闭包 2.1 概念 2.2闭包的应用场景 2.3代码实例 实例 1:简单计数器闭包 实例 2:带参数的闭包 实例 3:闭包用于数据封装和隐藏 一、函数 函数是实现特定功能的代码段的封装,在需要时可以多次调用函数来实…...

【React】什么是 Hook
useStateuseEffectuseRef 什么是hook?16.8版本出现的新特性。可以在不编写class组件的情况下使用state以及其它的React特性 为什么有hook?class组件很难提取公共的重用的代码,然后反复使用;不编写类组件也可以使用类组件的状态st…...

香港科技大学广州|智能交通学域博士招生宣讲会—北京理工大学专场
香港科技大学广州|智能交通学域博士招生宣讲会—北京理工大学专场 🕙时间:4月23日(星期三)16:00 🏠地点:北京理工大学中关村校区唯实报告厅 🔗报名链接:https://www.wj…...

食品计算—Coarse-to-fine nutrition prediction
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...