深度学习 从入门到精通 day_01
Pytorch安装
torch安装
python版本3.9.0
在官方文档里面找到适合你设备的PyTorch版本及对应的安装指令执行即可:https://pytorch.org/get-started/previous-versions/
针对我的网络及设备情况,我复制了如下指令完成了Torch的安装:
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118 离线安装:浏览器打开链接:https://download.pytorch.org/whl/cu118,找到torch,点击进入下载页面,找到适合自己cuda版本的安装包,下载即可(使用迅雷下载比较快)。
下载完成后,在Anaconda prompt界面切换到自己的虚拟环境(windows系统中转换目录命令为:cd C:Users/....),并将目录切换到torch安装包所在的文件夹,输入命令:
pip install torch-2.0.1+cu118-cp39-cp39-win_amd64.whl 其他第三方库安装:
1. numpy库
pip install numpy==1.26.0 -i https://mirrors.huaweicloud.com/repository/pypi/simple2. matplotlib库
pip install matplotlib -i https://mirrors.huaweicloud.com/repository/pypi/simple3. pandas库
pip install pandas -i https://mirrors.huaweicloud.com/repository/pypi/simple4. sklean库
pip install scikit-learn -i https://mirrors.huaweicloud.com/repository/pypi/simple5. opencv库
pip install opencv-python -i https://mirrors.huaweicloud.com/repository/pypi/simple6. torchsummary库
pip install torchsummary -i https://mirrors.huaweicloud.com/repository/pypi/simple1. 认识人工智能
1.1 人工智能是什么
AI : Artificial Intelligence,旨在研究、开发能够模拟、延伸和扩展人类智能的理论、方法、技术及应用系统,是一种拥有自主学习和推理能力的技术。它模仿人类大脑某些功能,包括感知、学习、理解、决策和问题解决。
AI本质
-
本质是数学计算
-
数学是理论关键
-
计算机是实现关键:算力
-
新的有效算法,需要更大的算力
NLP(说话,听)、CV(眼睛)、自动驾驶、机器人(肢体动作)、大模型。
1.2 人工智能实现过程
三要素:数据、网络、算力
① 神经网络:找到合适的数学公式;
② 训练:用已有数据训练网络,目标是求最优解;
③ 推理:用模型预测新样本;
1.3 术语关系图
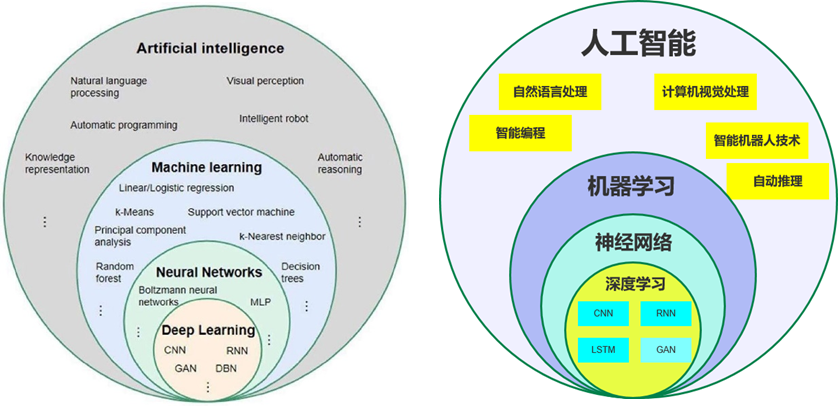
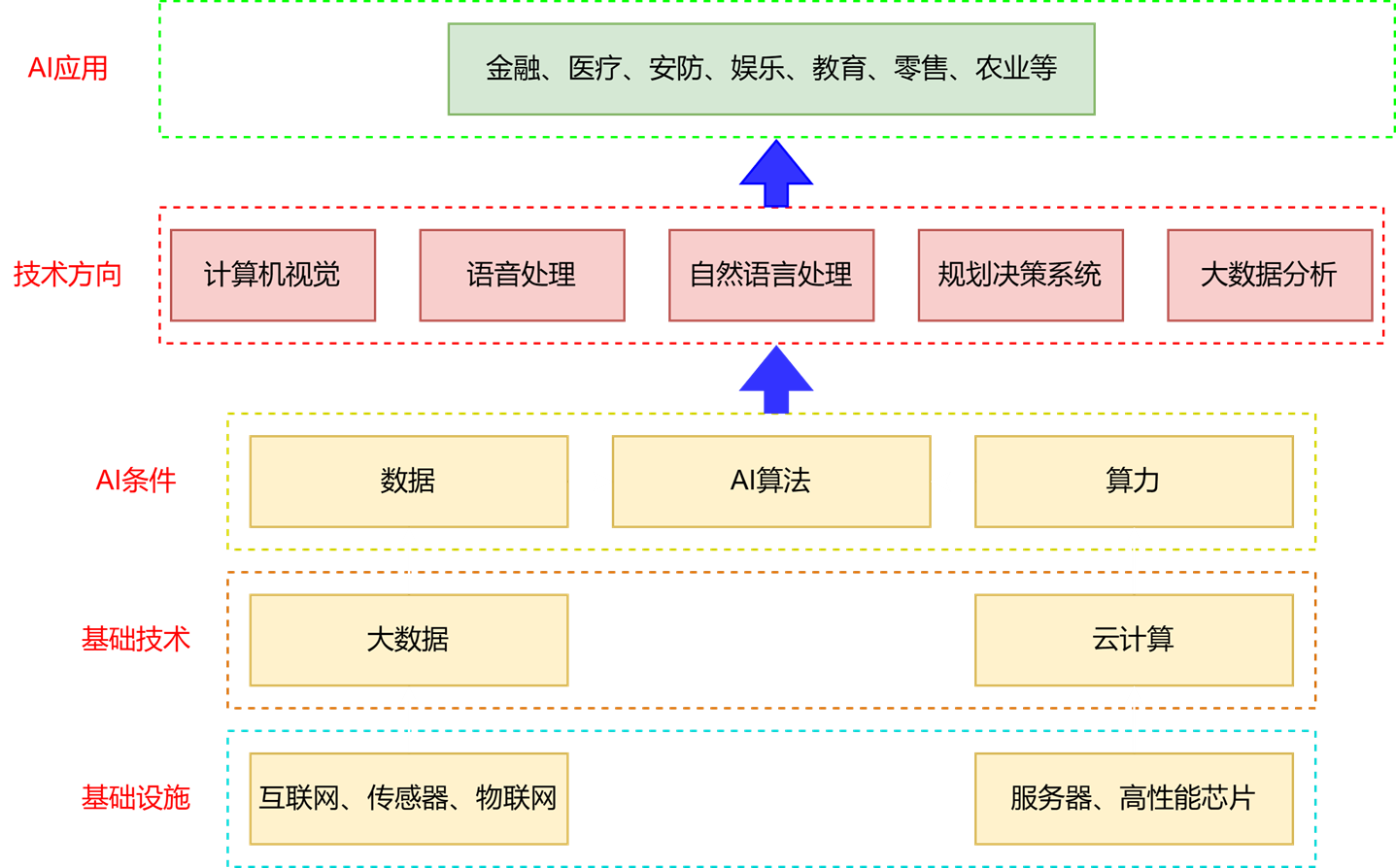
1.4 AI产业大生态
2. 初识Torch
2.1 pytorch简介
PyTorch是一个基于Python的深度学习框架,它提供了一种灵活、高效、易于学习的方式来实现深度学习模型。PyTorch最初由Facebook开发,被广泛应用于计算机视觉、自然语言处理、语音识别等领域。
PyTorch使用张量(tensor)来表示数据,可以轻松地处理大规模数据集,且可以在GPU上加速。
PyTorch提供了许多高级功能,如**自动微分(automatic differentiation)、自动求导(automatic gradients)**等,这些功能可以帮助我们更好地理解模型的训练过程,并提高模型训练效率。
2.2 多彩的江湖
除了PyTorch,还有很多其它常见的深度学习框架:
1. TensorFlow: Google开发,广泛应用于学术界和工业界。TensorFlow提供了灵活的构建、训练和部署功能,并支持分布式计算。
2. Keras: Keras是一个高级神经网络API,已整合到TensorFlow中。
3. PaddlePaddle: PaddlePaddle(飞桨)是百度推出的开源深度学习平台,旨在为开发者提供一个易用、高效的深度学习开发框架。
4. MXNet:由亚马逊开发,具有高效的分布式训练支持和灵活的混合编程模型。
5. Caffe:具有速度快、易用性高的特点,主要用于图像分类和卷积神经网络的相关任务。
6. CNTK:由微软开发的深度学习框架,提供了高效的训练和推理性能。CNTK支持多种语言的接口,包括Python、C++和C#等。
7. Chainer:由Preferred Networks开发的开源深度学习框架,采用动态计算图的方式。
3. Tensor概述
PyTorch会将数据封装成张量(Tensor)进行计算,所谓张量就是元素为相同类型的多维矩阵。张量可以在 GPU 上加速运行。
3.1 概念
张量是一个多维数组,通俗来说可以看作是扩展了标量、向量、矩阵的更高维度的数组。张量的维度决定了它的形状(Shape),例如:
-
标量 是 0 维张量,如
a = torch.tensor(5) -
向量 是 1 维张量,如
b = torch.tensor([1, 2, 3]) -
矩阵 是 2 维张量,如
c = torch.tensor([[1, 2], [3, 4]]) -
更高维度的张量,如3维、4维等,通常用于表示图像、视频数据等复杂结构。
3.2 特点
动态计算图:PyTorch 支持动态计算图,这意味着在每一次前向传播时,计算图是即时创建的。
GPU 支持:PyTorch 张量可以通过 .to('cuda') 移动到 GPU 上进行加速计算。
自动微分:通过 autograd 模块,PyTorch 可以自动计算张量运算的梯度,这对深度学习中的反向传播算法非常重要。
3.3 数据类型
PyTorch中有3种数据类型:浮点数、整数、布尔。其中,浮点数和整数又分为8位、16位、32位、64位,加起来共9种。
为什么要分为8位、16位、32位、64位呢?
场景不同,对数据的精度和速度要求不同。通常,移动或嵌入式设备追求速度,对精度要求相对低一些。精度越高,往往效果也越好,自然硬件开销就比较高。
4. Tensor的创建
在Torch中张量以 "类" 的形式封装起来,对张量的一些运算、处理的方法被封装在类中,官方文档:https://pytorch.org/docs/stable/torch.html#tensors
4.1 基本创建方式
以下讲的创建tensor的函数中有两个有默认值的参数dtype和device, 分别代表数据类型和计算设备,可以通过属性dtype和device获取。
4.1.1 torch.tensor
注意这里的tensor是小写,该API是根据指定的数据创建张量。
示例:
import torch
import numpy as npdef test001():# 1. 用标量创建张量tensor = torch.tensor(5)print(tensor.shape)# 2. 使用numpy随机一个数组创建张量tensor = torch.tensor(np.random.randn(3, 5))print(tensor)print(tensor.shape)# 3. 根据list创建tensortensor = torch.tensor([[1, 2, 3], [4, 5, 6]])print(tensor)print(tensor.shape)print(tensor.dtype)if __name__ == '__main__':test001()注:如果出现如下错误:
UserWarning: Failed to initialize NumPy: _ARRAY_API not found 一般是因为numpy和pytorch版本不兼容,可以降低numpy版本,步骤如下:
1. anaconda prompt中切换虚拟环境:
conda activate 虚拟环境名称2. 卸载numpy:
pip uninstall numpy3. 安装低版本的numpy:
pip install numpy==1.26.04.1.2 torch.Tensor
注意这里的Tensor是大写,该API根据形状创建张量,其也可用来创建指定数据的张量。
示例:
import torch
import numpy as npdef test002():# 1. 根据形状创建张量tensor1 = torch.Tensor(2, 3)print(tensor1)# 2. 也可以是具体的值tensor2 = torch.Tensor([[1, 2, 3], [4, 5, 6]])print(tensor2, tensor2.shape, tensor2.dtype)tensor3 = torch.Tensor([10])print(tensor3, tensor3.shape, tensor3.dtype)# 指定tensor数据类型tensor1 = torch.Tensor([1,2,3]).short()print(tensor1)tensor1 = torch.Tensor([1,2,3]).int()print(tensor1)tensor1 = torch.Tensor([1,2,3]).float()print(tensor1)tensor1 = torch.Tensor([1,2,3]).double()print(tensor1)if __name__ == "__main__":test002()torch.Tensor与torch.tensor区别:
| 特性 | torch.Tensor() | torch.tensor() |
|---|---|---|
| 数据类型推断 | 强制转为 torch.float32 | 根据输入数据自动推断(如整数→int64) |
显式指定 dtype | 不支持 | 支持(如 dtype=torch.float64) |
| 设备指定 | 不支持 | 支持(如 device='cuda') |
| 输入为张量时的行为 | 创建新副本(不继承原属性) | 默认共享数据(除非 copy=True) |
| 推荐使用场景 | 需要快速创建浮点张量 | 需要精确控制数据类型或设备 |
4.1.3 torch.IntTensor
用于创建指定类型的张量,还有诸如Torch.FloatTensor、 torch.DoubleTensor、 torch.LongTensor......等。
如果数据类型不匹配,那么在创建的过程中会进行类型转换,要尽可能避免,防止数据丢失。
示例:
import torchdef test003():# 1. 创建指定形状的张量tt1 = torch.IntTensor(2, 3)print(tt1)tt2 = torch.FloatTensor(3, 3)print(tt2, tt2.dtype)tt3 = torch.DoubleTensor(3, 3)print(tt3, tt3.dtype)tt4 = torch.LongTensor(3, 3)print(tt4, tt4.dtype)tt5 = torch.ShortTensor(3, 3)print(tt5, tt5.dtype)if __name__ == "__main__":test003()4.2 创建线性和随机张量
在 PyTorch 中,可以轻松创建线性张量和随机张量。
4.2.1 创建线性张量
使用torch.arange 和 torch.linspace 创建线性张量:
import torch
import numpy as np# 不用科学计数法打印
torch.set_printoptions(sci_mode=False)def test004():# 1. 创建线性张量r1 = torch.arange(0, 10, 2)print(r1)# 2. 在指定空间按照元素个数生成张量:等差r2 = torch.linspace(3, 10, 10)print(r2)r2 = torch.linspace(3, 10000000, 10)print(r2)if __name__ == "__main__":test004()4.2.2 随机张量
使用torch.randn 创建随机张量。
1. 随机数种子:随机数种子(Random Seed)是一个用于初始化随机数生成器的数值。随机数生成器是一种算法,用于生成一个看似随机的数列,但如果使用相同的种子进行初始化,生成器将产生相同的数列。
示例:随机数种子的设置和获取
import torchdef test001():# 设置随机数种子torch.manual_seed(123)# 获取随机数种子print(torch.initial_seed())if __name__ == "__main__":test001() 2. 随机张量:在 PyTorch 中,种子影响所有与随机性相关的操作,包括张量的随机初始化、数据的随机打乱、模型的参数初始化等。通过设置随机数种子,可以做到模型训练和实验结果在不同的运行中进行复现。
示例:
import torchdef test001():# 1. 设置随机数种子torch.manual_seed(123)# 2. 获取随机数种子,需要查看种子时调用print(torch.initial_seed())# 3. 生成随机张量,均匀分布(范围 [0, 1))# 创建2个样本,每个样本3个特征print(torch.rand(2, 3))# 4. 生成随机张量:标准正态分布(均值 0,标准差 1)print(torch.randn(2, 3))# 5. 原生服从正态分布:均值为2, 方差为3,形状为1*4的正态分布print(torch.normal(mean=2, std=3, size=(1, 4)))if __name__ == "__main__":test001()注:不设置随机种子时,每次打印的结果不一样。
4.3 创建0、1张量
在 PyTorch 中,你可以通过几种不同的方法创建一个只包含 0 和 1 的张量。
4.3.1 创建全0张量
torch.zeros() 和 torch.zeros_like() 创建全0张量。
示例:
import torch
import numpy as npdef test001():# 创建全0张量data = torch.zeros(2, 3)print(data, data.dtype)mask = np.random.randn(3, 4)print(mask)data = torch.zeros_like(torch.tensor(mask))print(data)if __name__ == "__main__":test001()4.3.2 创建全1张量
torch.ones() 和 torch.ones_like() 创建全1张量。
示例:
import torch
import numpy as npdef test001():# 创建全1张量data = torch.ones(2, 3)print(data, data.dtype)mask = np.zeros((3, 4))print(mask)data = torch.ones_like(torch.tensor(mask))print(data)if __name__ == "__main__":test001()4.4 创建指定值张量
torch.full() 和 torch.full_like() 创建全为指定值张量。
示例:
import torch
import numpy as npdef test001():# 创建指定值的张量data = torch.full((2, 3), 666.0)print(data, data.dtype)mask = np.zeros((3, 4))data = torch.full_like(torch.tensor(mask), 999)print(data)if __name__ == "__main__":test001()4.5 创建单位矩张量
创建主对角线上为1的单位张量....
示例:
import torch
import numpy as npdef test002():data = torch.eye(4)print(data)if __name__ == "__main__":test002()5. Tensor常见属性
张量有device、dtype、shape等常见属性,知道这些属性对我们认识Tensor很有帮助。
5.1 获取属性
示例:
import torchdef test001():data = torch.tensor([1, 2, 3])print(data.dtype, data.device, data.shape)if __name__ == "__main__":test001()5.2 切换设备
默认在cpu上运行,可以显式的切换到GPU:不同设备上的数据是不能相互运算的。
示例:
import torchdef test001():data = torch.tensor([1, 2, 3])print(data.dtype, data.device, data.shape)# 把数据切换到GPU进行运算device = "cuda" if torch.cuda.is_available() else "cpu"data = data.to(device)print(data.device)if __name__ == "__main__":test001() 或者使用cuda进行切换:data = data.cuda()
当然也可以直接创建在GPU上:
# 直接在GPU上创建张量
data = torch.tensor([1, 2, 3], device='cuda')
print(data.device)5.3 类型转换
在训练模型或推理时,类型转换也是张量的基本操作,是需要掌握的。
示例:
import torchdef test001():data = torch.tensor([1, 2, 3])print(data.dtype) # torch.int64# 1. 使用type进行类型转换data = data.type(torch.float32)print(data.dtype) # float32data = data.type(torch.float16)print(data.dtype) # float16# 2. 使用类型方法data = data.float()print(data.dtype) # float32# 16 位浮点数,torch.float16,即半精度data = data.half()print(data.dtype) # float16data = data.double()print(data.dtype) # float64data = data.long()print(data.dtype) # int64data = data.int()print(data.dtype) # int32# 使用dtype属性data = torch.tensor([1, 2, 3], dtype=torch.half)print(data.dtype)if __name__ == "__main__":test001()6. Tensor数据转换
6.1 Tensor与Numpy
Tensor 与 Numpy 都是常见数据格式。
6.1.1 张量转Numpy
1. 浅拷贝:调用numpy()方法可以把Tensor转换为Numpy,此时内存是共享的。
示例:
import torchdef test003():# 1. 张量转numpydata_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])data_numpy = data_tensor.numpy()print(type(data_tensor), type(data_numpy))# 2. 他们内存是共享的data_numpy[0, 0] = 100print(data_tensor, data_numpy)if __name__ == "__main__":test003() 2. 深拷贝:使用copy()方法可以避免内存共享。
示例:
import torchdef test003():# 1. 张量转numpydata_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 2. 使用copy()避免内存共享data_numpy = data_tensor.numpy().copy()print(type(data_tensor), type(data_numpy))# 3. 此时他们内存是不共享的data_numpy[0, 0] = 100print(data_tensor, data_numpy)if __name__ == "__main__":test003()6.1.2 Numpy转张量
也可以分为内存共享和不共享
1. 浅拷贝:from_numpy方法转Tensor默认是内存共享的。
示例:
import numpy as np
import torchdef test006():# 1. numpy转张量data_numpy = np.array([[1, 2, 3], [4, 5, 6]])data_tensor = torch.from_numpy(data_numpy)print(type(data_tensor), type(data_numpy))# 2. 他们内存是共享的data_tensor[0, 0] = 100print(data_tensor, data_numpy)if __name__ == "__main__":test006() 2. 深拷贝:使用传统的torch.tensor()则内存是不共享的。
示例:
import numpy as np
import torchdef test006():# 1. numpy转张量data_numpy = np.array([[1, 2, 3], [4, 5, 6]])data_tensor = torch.tensor(data_numpy)print(type(data_tensor), type(data_numpy))# 2. 内存是不共享的data_tensor[0, 0] = 100print(data_tensor, data_numpy)if __name__ == "__main__":test006()6.2 Tensor与图像
图像是我们视觉处理中最常见的数据,而 Pillow 是一个强大的图像处理库,提供了丰富的图像操作功能,例如打开、保存、裁剪、旋转、调整大小等。如果你没有安装 Pillow,可以通过以下命令安装:
pip install pillowtorchvision 是 PyTorch 的一个官方库,专门用于计算机视觉任务。它简化了计算机视觉任务的开发流程,提供了数据集、预处理、模型和工具函数等一站式解决方案。安装命令:
pip install torchvision6.2.1 图片转Tensor
示例:
import torch
from PIL import Image
from torchvision import transforms
import osdef test001():dir_path = os.path.dirname(__file__)file_path = os.path.join(dir_path,'img', '1.jpg')file_path = os.path.relpath(file_path)print(file_path)# 1. 读取图片img = Image.open(file_path)# transforms.ToTensor()用于将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并自动进行数值归一化和维度调整# 将像素值从 [0, 255] 缩放到 [0.0, 1.0](浮点数)# 自动将图像格式从 (H, W, C)(高度、宽度、通道)转换为 PyTorch 标准的 (C, H, W)transform = transforms.ToTensor()img_tensor = transform(img)print(img_tensor)if __name__ == "__main__":test001()6.2.2 图片转Tensor
示例:
import torch
from PIL import Image
from torchvision import transforms
import osdef test001():dir_path = os.path.dirname(__file__)file_path = os.path.join(dir_path,'img', '1.jpg')file_path = os.path.relpath(file_path)print(file_path)# 1. 读取图片img = Image.open(file_path)# transforms.ToTensor()用于将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并自动进行数值归一化和维度调整# 将像素值从 [0, 255] 缩放到 [0.0, 1.0](浮点数)# 自动将图像格式从 (H, W, C)(高度、宽度、通道)转换为 PyTorch 标准的 (C, H, W)transform = transforms.ToTensor()img_tensor = transform(img)print(img_tensor)if __name__ == "__main__":test001()6.3 PyTorch图像处理
通过一个Demo加深对Torch的API理解和使用:
import torch
from PIL import Image
from torchvision import transforms
import osdef test003():# 获取文件的相对路径dir_path = os.path.dirname(__file__)file_path = os.path.relpath(os.path.join(dir_path, 'dog.jpg'))# 加载图片img = Image.open(file_path)# 转换图片为tensortransform = transforms.ToTensor()t_img = transform(img)print(t_img.shape)# 获取GPU资源,将图片处理移交给CUDAdevice = 'cuda' if torch.cuda.is_available() else 'cpu't_img = t_img.to(device)t_img += 0.3# 将图片移交给CPU进行图片保存处理,一般IO操作是基于CPU的t_img = t_img.cpu()transform = transforms.ToPILImage()img = transform(t_img)img.show()if __name__ == "__main__":test003()7. Tensor常见操作
在深度学习中,Tensor是一种多维数组,用于存储和操作数据,我们需要掌握张量各种运算。
7.1 获取元素值
我们可以把单个元素tensor转换为Python数值,这是非常常用的操作。
import torchdef test002():data = torch.tensor([18])print(data.item())passif __name__ == "__main__":test002()注意:1. 和Tensor的维度没有关系,都可以取出来!;2. 如果有多个元素则报错;3. 仅适用于CPU张量,如果张量在GPU上,需先移动到CPU。
gpu_tensor = torch.tensor([1.0], device='cuda')
value = gpu_tensor.cpu().item() # 先转CPU再提取7.2 元素值运算
常见的加减乘除次方取反开方等各种操作,带有_的方法则会替换原始值。
import torchdef test001():# 生成范围 [0, 10) 的 2x3 随机整数张量data = torch.randint(0, 10, (2, 3))print(data)# 元素级别的加减乘除:不修改原始值print(data.add(1))print(data.sub(1))print(data.mul(2))print(data.div(3))print(data.pow(2))# 元素级别的加减乘除:修改原始值data = data.float()data.add_(1)data.sub_(1)data.mul_(2)data.div_(3.0)data.pow_(2)print(data)if __name__ == "__main__":test001()7.3 阿达玛积
阿达玛积是指两个形状相同的矩阵或张量对应位置的元素相乘。它与矩阵乘法不同,矩阵乘法是线性代数中的标准乘法,而阿达玛积是逐元素操作。假设有两个形状相同的矩阵 A和 B,它们的阿达玛积 C=A∘B定义为:
其中:Cij 是结果矩阵 C的第 i行第 j列的元素;Aij和 Bij分别是矩阵 A和 B的第 i行第 j 列的元素。
在 PyTorch 中,可以使用mul函数或者*来实现。
import torchdef test001():data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])print(data1 * data2)def test002():data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])print(data1.mul(data2))if __name__ == "__main__":test001()test002()7.4 Tensor相乘
矩阵乘法是线性代数中的一种基本运算,用于将两个矩阵相乘,生成一个新的矩阵。
假设有两个矩阵:
1. 矩阵 A的形状为 m×n(m行 n列)。
2. 矩阵 B的形状为 n×p(n行 p列)。
矩阵 A和 B的乘积 C=A×B是一个形状为 m×p的矩阵,其中 C的每个元素 Cij,计算 A的第 i行与 B的第 j列的点积。计算公式为:![]()
矩阵乘法运算要求如果第一个矩阵的shape是 (N, M),那么第二个矩阵 shape必须是 (M, P),最后两个矩阵点积运算的shape为 (N, P)。
在 PyTorch 中,使用@或者matmul完成Tensor的乘法。
import torchdef test006():data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])data2 = torch.tensor([[3, 2], [2, 3], [5, 3]])print(data1 @ data2)print(data1.matmul(data2))if __name__ == "__main__":test006()7.5 张量拼接
在 PyTorch 中,cat 和 stack 是两个用于拼接张量的常用操作,但它们的使用方式和结果略有不同:
-
cat:在现有维度上拼接,不会增加新维度。
-
stack:在新维度上堆叠,会增加一个维度。
7.5.1 torch.cat
元素级别的 torch.cat(concatenate 的缩写)用于沿现有维度拼接张量。换句话说,它在现有的维度上将多个张量连接在一起。这些张量在非拼接维度上的形状必须相同。
import torchdef test001():tensor1 = torch.tensor([[1, 2, 3], [4, 5, 6]])tensor2 = torch.tensor([[7, 8, 9], [10, 11, 12]])# 1. 在指定的维度上进行拼接:0,按垂直方向,张量列数要一致print(torch.cat([tensor1, tensor2], dim=0))# 输出:# tensor([[ 1, 2, 3],# [ 4, 5, 6],# [ 7, 8, 9],# [10, 11, 12]])# 2. 在指定的维度上进行拼接:1,按水平方向,张量行数要一致print(torch.cat([tensor1, tensor2], dim=1))# 输出:# tensor([[ 1, 2, 3, 7, 8, 9],# [ 4, 5, 6, 10, 11, 12]])if __name__ == "__main__":test001()7.5.2 torch.stack
torch.stack 用于在新维度上拼接张量。换句话说,它会创建一个新的维度,然后沿该维度堆叠张量。
功能:将多个张量沿着新维度堆叠(注意是新建维度,不是拼接)
关键特性:
-
所有输入张量的形状必须完全相同。
-
输出张量的维度比输入张量多一维(新增的维度位置由
dim指定)。
import torchdef test002():tensor1 = torch.tensor([[1, 2, 3], [4, 5, 6]])tensor2 = torch.tensor([[7, 8, 9], [10, 11, 12]])# 1. 沿新创建的第0维度堆叠,将tensor1和tensor2直接拼到一起,可以理解为按行堆叠print(torch.stack([tensor1, tensor2], dim=0))# 输出:# [# [[1, 2, 3], [4, 5, 6]], # t1# [[7, 8, 9], [10, 11, 12]] # t2# ]# 2. 沿新创建的第1维度堆叠,一行一行的拼接,可以理解为每行按列堆叠print(torch.stack([tensor1, tensor2], dim=1))# 输出:# [# [[1, 2, 3], [7, 8, 9]], # t1的第1行和t2的第1行# [[4, 5, 6], [10, 11, 12]] # t1的第2行和t2的第2行# ]# 3. 一列一列的拼接,可以理解为按元素堆叠print(torch.stack([tensor1, tensor2], dim=-1))# [# [[1, 7], [2, 8], [3, 9]], # t1和t2第1行的元素配对# [[4, 10], [5, 11], [6, 12]] # t1和t2第2行的元素配对# ]if __name__ == "__main__":test002()注意:要堆叠的张量必须具有相同的形状。
7.5.3 cat和stack方法特点
相同点:张量的形状必须完全相同,并且不会自动广播扩展形状。
不同点:
| 特性 | torch.cat | torch.stack |
|---|---|---|
| 输出维度 | 不新增维度,仅在指定维度上扩展 | 新增一个维度 |
| 用途 | 拼接已有维度的数据 | 堆叠数据以创建新维度 |
7.6 形状操作
在 PyTorch 中,张量的形状操作是非常重要的,因为它允许你灵活地调整张量的维度和结构,以适应不同的计算需求。
7.6.1 reshape
可以用于将张量转换为不同的形状,但要确保转换后的形状与原始形状具有相同的元素数量。
import torchdef test001():data = torch.randint(0, 10, (4, 3))print(data)# 1. 使用reshape改变形状data = data.reshape(2, 2, 3)print(data)# 2. 使用-1表示自动计算data = data.reshape(2, -1)print(data)if __name__ == "__main__":test001()7.6.2 view
view进行形状变换的特征:
1. 张量在内存中是连续的;
2. 返回的是原始张量视图,不重新分配内存,效率更高;
3. 如果张量在内存中不连续,view 将无法执行,并抛出错误。
1. 内存连续性:张量的内存布局决定了其元素在内存中的存储顺序。对于多维张量,内存布局通常按照最后一个维度优先的顺序存储,即先存列,后存行。例如,对于一个二维张量 A,其形状为 (m, n),其内存布局是先存储第 0 行的所有列元素,然后是第 1 行的所有列元素,依此类推。
如果张量的内存布局与形状完全匹配,并且没有被某些操作(如转置、索引等)打乱,那么这个张量就是连续的。
PyTorch 的大多数操作都是基于 C 顺序的,我们在进行变形或转置操作时,很容易造成内存的不连续性。
import torchdef test001():tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])print("正常情况下的张量:", tensor.is_contiguous())# 对张量进行转置操作tensor = tensor.t()print("转置操作的张量:", tensor.is_contiguous())print(tensor)# 此时使用view进行变形操作tensor = tensor.view(2, -1)print(tensor)if __name__ == "__main__":test001()2. 和reshape比较:view:高效,但需要张量在内存中是连续的;reshape:更灵活,但涉及内存复制。
3. view变形操作:
import torchdef test002():tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 将 2x3 的张量转换为 3x2reshaped_tensor = tensor.view(3, 2)print(reshaped_tensor)# 自动推断一个维度reshaped_tensor = tensor.view(-1, 2)print(reshaped_tensor)if __name__ == "__main__":test002()7.6.3 transpose
transpose 用于交换张量的两个维度,注意,是2个维度,它返回的是原张量的视图。
torch.transpose(input, dim0, dim1)参数:input:输入的张量;dim0:要交换的第一个维度;dim1:要交换的第二个维度。
import torchdef test003():data = torch.randint(0, 10, (3, 4, 5))print(data, data.shape)# 使用transpose进行形状变换transpose_data = torch.transpose(data,0,1)# transpose_data = data.transpose(0, 1)print(transpose_data, transpose_data.shape)if __name__ == "__main__":test003()transpose 返回新张量,原张量不变,转置后的张量可能是非连续的(is_contiguous() 返回 False),如果需要连续内存(如某些操作要求),可调用 .contiguous():
y = x.transpose(0, 1).contiguous()7.6.4 permute
它通过重新排列张量的维度来返回一个新的张量,**不改变张量的数据**,只改变维度的顺序。
torch.permute(input, dims)参数:input: 输入的张量;dims: 一个整数元组,表示新的维度顺序。
import torchdef test004():data = torch.randint(0, 10, (3, 4, 5))print(data, data.shape)# 使用permute进行多维度形状变换permute_data = data.permute(1, 2, 0)print(permute_data, permute_data.shape)if __name__ == "__main__":test004()和 transpose 一样,permute 返回新张量,原张量不变,重排后的张量可能是非连续的(is_contiguous() 返回 False),必要时需调用 .contiguous():
y = x.permute(2, 1, 0).contiguous() 维度顺序必须合法:dims 中的维度顺序必须包含所有原始维度,且不能重复或遗漏。例如,对于一个形状为 (2, 3, 4) 的张量,dims=(2, 0, 1) 是合法的,但 dims=(0, 1) 或 dims=(0, 1, 2, 3) 是非法的。
与 transpose() 的对比:
| 特性 | permute() | transpose() |
|---|---|---|
| 功能 | 可以同时调整多个维度的顺序 | 只能交换两个维度的顺序 |
| 灵活性 | 更灵活 | 较简单 |
| 使用场景 | 适用于多维张量 | 适用于简单的维度交换 |
7.6.5 flatten
flatten 用于将张量展平为一维向量。
tensor.flatten(start_dim=0, end_dim=-1) 参数:
start_dim:从哪个维度开始展平。
end_dim:在哪个维度结束展平。默认值为 '-1',表示展平到最后一个维度。
start_dim 和 end_dim 是闭区间,即包含起始和结束维度。
import torchdef test005():data = torch.randint(0, 10, (3, 4, 5))# 展平flatten_data = data.flatten(1, -1)print(flatten_data)if __name__ == "__main__":test005()7.6.6 升维和降维
在后续的网络学习中,升维和降维是常用操作,需要掌握。
unsqueeze:用于在指定位置插入一个大小为 1 的新维度。
squeeze:用于移除所有大小为 1 的维度,或者移除指定维度的大小为 1 的维度。
1. squeeze降维
torch.squeeze(input, dim=None)参数:
-
input: 输入的张量。
-
dim (可选): 指定要移除的维度。如果指定了 dim,则只移除该维度(前提是该维度大小为 1);如果不指定,则移除所有大小为 1 的维度。
import torchdef test006():data = torch.randint(0, 10, (1, 4, 5, 1))print(data, data.shape)# 进行降维操作data1 = data.squeeze(0).squeeze(-1)print(data.shape)# 移除所有大小为 1 的维度data2 = torch.squeeze(data)# 尝试移除第 1 维(大小为 3,不为 1,不会报错,张量保持不变。)data3 = torch.squeeze(data, dim=1)print("尝试移除第 1 维后的形状:", data3.shape)if __name__ == "__main__":test006()2. unsqueeze升维
torch.unsqueeze(input, dim)参数:
-
input: 输入的张量。
-
dim: 指定要增加维度的位置(从 0 开始索引)。
import torchdef test007():data = torch.randint(0, 10, (32, 32, 3))print(data.shape)# 升维操作data = data.unsqueeze(0)print(data.shape)if __name__ == "__main__":test007()7.7 张量分割
7.7.1 chunk
用于将张量沿着指定维度分割成多个块。每个块的大小相同(如果可能),或者最后一个块可能较小。
torch.chunk(input, chunks, dim=0)参数:
-
input: 输入的张量。
-
chunks: 需要分割的块数。
-
dim: 指定沿着哪个维度进行分割(默认为 0)。
返回一个包含分割后张量的列表。列表的长度等于 chunks。
import torchdef test001():# 创建一个张量x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15]])# 沿第 0 维分割成3块# 5 行无法被 3 整除,所以前两块各有 2 行,最后一块有 1 行print(torch.chunk(x, 3))# 沿第 1 维分割成 3 块print(torch.chunk(x, chunks=3, dim=1))# 如果 chunks 超过该维的长度,会返回该维度大小的块数(不会报错)print(torch.chunk(x, chunks=10, dim=1))if __name__ == "__main__":test001()7.7.2 split
用于将张量沿着指定维度分割成多个子张量。与 chunk 不同,split 可以指定每个子张量的大小,而不是简单地均分。
torch.split(tensor, split_size_or_sections, dim=0)参数
-
tensor: 输入的张量。
-
split_size_or_sections:
-
如果是一个整数,表示每个子张量的大小(沿指定维度)。
-
如果是一个列表,表示每个子张量的具体长度。
-
-
dim: 指定沿着哪个维度进行分割(默认为 0)。
返回一个包含分割后子张量的元组。
import torch# 创建一个形状为 [6, 3] 的张量
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]])
print("原始张量:\n", x)
print("原始形状:", x.shape)# 沿第 0 维按大小 2 分割
splits = torch.split(x, split_size_or_sections=2, dim=0)
# enumerate 是 Python 内置函数,用于在遍历可迭代对象(如列表、元组、字符串等)时,同时获取元素及其对应的索引。它返回一个枚举对象(iterator),生成 (index, value) 元组。
for i, split in enumerate(splits):print(f"第 {i} 部分:\n", split)print(f"第 {i} 部分的形状:", split.shape)# 沿第 0 维按大小 [2, 1, 3] 分割
splits = torch.split(x, split_size_or_sections=[2, 1, 3], dim=0)
for i, split in enumerate(splits):print(f"第 {i} 部分:\n", split)print(f"第 {i} 部分的形状:", split.shape)# 分段大小之和必须等于该维度长度(这里是 2+1+3=6),否则会报错
splits = torch.split(x, split_size_or_sections=[2, 1, 4], dim=0)
print(splits)8. 数学运算
8.1 基本操作
1. floor: 向下取整;2. ceil:向上取整;3. round:四舍五入;4. trunc:裁剪,只保留整数部分;5. frac:只保留小数部分;6. fix:向零方向舍入;7. %:取余。
示例:
import torchdef test001():data = torch.tensor([[1, 2, 3], # 1[4, 5, 6], # 2[10.5, 18.6, 19.6], # 3[11.05, 19.3, 20.6], # 4])print(torch.floor(data))print(torch.ceil(data))print(torch.round(data))print(torch.trunc(data))print(torch.fix(data))print(torch.frac(data))if __name__ == "__main__":test001()8.2 三角函数
1. torch.cos(input,out=None);2. torch.cosh(input,out=None) # 双曲余弦函数;3. torch.sin(input,out=None);4. torch.sinh(input,out=None) # 双曲正弦函;5. torch.tan(input,out=None);6. torch.tanh(input,out=None) # 双曲正切函数。
示例:
import torch# 关闭科学计数法打印
torch.set_printoptions(sci_mode=False)def test002():data = torch.tensor([torch.pi, torch.pi / 2])print(torch.sin(data))print(torch.cos(data))if __name__ == "__main__":test002()8.3 统计学函数
1. torch.mean(): 计算张量的平均值;2. torch.sum(): 计算张量的元素之和;3. torch.std(): 计算张量的标准差;4. torch.var(): 计算张量的方差。默认为样本方差;5. torch.median(): 计算张量的中位数;6. torch.max(): 计算张量的最大值7. torch.min(): 计算张量的最小值;8. torch.sort(): 对张量进行排序;9. torch.topk(): 返回张量中的前 k 个最大值或最小值;10. torch.histc(): 计算张量的直方图;11. torch.unique(): 返回张量中的唯一值;12. torch.bincount(): 计算张量中每个元素的出现次数。
9. 保存和加载
张量数据可以保存下来并再次加载使用,示例:
import torchdef save_tensor():# 1. 定义一个张量x = torch.tensor([[1, 2, 3], [4, 5, 6]])# 2. 保存到文件中torch.save(x, "x.pt")def load_tensor():# 1. 加载张量x = torch.load("x.pt")# 2. 打印张量print(x, x.device)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 3. 加载到指定设备x = torch.load("x.pt", map_location=device)print(x, x.device)if __name__ == "__main__":load_tensor()10. 并行化
在 PyTorch 中,你可以查看和设置用于 CPU 运算的线程数。PyTorch 使用多线程来加速 CPU 运算,但有时你可能需要调整线程数来优化性能。
10.1 查看线程数
使用 torch.get_num_threads() 来查看当前 PyTorch 使用的线程数:
import torchdef get_threads():# 获取pytorch运行的线程数print(torch.get_num_threads())passif __name__ == "__main__":get_threads()10.2 设置线程数
使用 torch.set_num_threads() 设置 PyTorch 使用的线程数:
import torchdef set_get_threads():# 设置pytorch运行的线程数torch.set_num_threads(4)print(torch.get_num_threads())if __name__ == "__main__":set_get_threads()设置线程数时,确保考虑到你的 CPU 核心数和其他进程的资源需求,以获得最佳性能。
10.3 注意事项
1. 线程数设置过高可能会导致线程竞争,反而降低性能;
2. 线程数设置过低可能会导致计算资源未得到充分利用;
3. 当使用 GPU 进行计算时,线程数设置对性能影响较小,因为 GPU 计算并不依赖于 CPU 线程数。
相关文章:

深度学习 从入门到精通 day_01
Pytorch安装 torch安装 python版本3.9.0 在官方文档里面找到适合你设备的PyTorch版本及对应的安装指令执行即可:https://pytorch.org/get-started/previous-versions/ 针对我的网络及设备情况,我复制了如下指令完成了Torch的安装: …...

AutoToM:让AI像人类一样“读心”的突破性方法
引言:AI如何理解人类的“内心世界”? 如何让AI像人类一样理解他人的意图、情感和动机?这一问题的核心是心智理论(Theory of Mind, ToM),即通过观察行为推断心理状态的能力。近日,约翰霍普金斯大…...

Java实现Redis
String类型 代码 package com.whop.changyuan2.redisTest;import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.cor…...

DAY09:【pytorch】nn网络层
1、卷积层 1.1 Convolution 1.1.1 卷积操作 卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加卷积核:又称为滤波器、过滤器,可认为是某种模式、某种特征 1.1.2 卷积维度 一般情况下…...

河南普瑞维升企业案例:日事清SOP流程与目标模块实现客户自主简报功能落地
公司简介: 河南普瑞维升企业管理咨询有限公司成立于2017年,目前公司主营业务是为加油站提供全方面咨询管理服务,目前公司成功运营打造河南成品油,运营站点15座,会员数量已达几十万,在加油站周边辐射区域内…...
)
LeetCode面试热题150中19-22题学习笔记(用Java语言描述)
Day 04 19、最后一个单词的长度 需求:给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 代码表示 public class Q19_1 {p…...

车载刷写架构 --- 刷写流程中重复擦除同一地址的问题分析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

一个测试GPU可用的测试实例
一个测试GPU可用的测试实例: import torch import torch.nn as nn import torch.optim as optim import time import gc import numpy as np from torch.cuda.amp import autocast, GradScalerclass LargeNN(nn.Module):def __init__(self, use_attentionTrue):sup…...

chili3d调试笔记2+添加web ui按钮
onclick 查找 打个断点看看 挺可疑的,打个断点看看 挺可疑的,打个断点看看 打到事件监听上了 加ui了 加入成功 新建弹窗-------------------------------------- 可以模仿这个文件,写弹窗 然后在这里注册一下,外部就能调用了 对了…...

Go-zero:JWT鉴权方式
1.简述 用于记录在go-zero的后端项目中如何添加jwt中间件鉴权 2.流程 配置api.yaml Auth:AccessSecret: "secret_key"AccessExpire: 604800config中添加Auth结构体 Auth struct {AccessSecret stringAccessExpire int64 }types定义jwt token的自定义数据结构&#…...

MySQL的MVCC机制详解
1. 什么是MVCC? MVCC(Multi-Version Concurrency Control,多版本并发控制)是数据库系统中用于实现并发控制的一种技术。它通过保存数据在某个时间点的快照来实现,使得在同一个数据行上可以同时存在多个版本࿰…...

Postman做自动化测试
Postman也可以实现接口自动化 1.在Scripts写断言,图中红框处。不会写可以偷懒使用蓝框处会自动填写 2.单个运行调试,结果显示在TestResults 3.多个接口都写好断言并调通后,在包揽这些接口的文件夹下运行,图示以两个接口为例&…...

Meltdown原理介绍:用户空间读取内核内存
摘要 计算机系统的安全性从根本上依赖内存隔离,如,内核地址范围被标记为不可访问并受到保护,以防用户非法访问。本文介绍了Meltdown。 利用现代处理器上乱序执行,来读取内核任意的内存位置,包括个人数据和密码。乱序执行是必不可少的用来提升性能的手段,并在现代处理器中…...
--树)
数据结构和算法(七)--树
一、树 树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物,例如家谱、单位的组织架构、等等。 树是由n(n>1)个有限结点组成一个具有层次关系的集合。把它叫做"树"是因为它看起来像一…...

UDP猜数字游戏与TCP文件传输案例解析
目录 案例一:UDP协议实现的猜数字游戏 游戏概述 服务器端代码 客户端代码 (udp_client.py) 游戏特点 案例二:TCP协议实现的文件传输工具 工具概述 服务器端代码 客户端代码 工具特点 总结对比 案例一:UDP协议实现的猜数字游戏 游…...

WPF View 与ViewModel注入对象
View 和ViewModel中使用同一个类型的类,注入的对象在主机中通过在服务中添加 AddTransient 获取的不是同一个对象,在 View 绑定了在ViewModel 中是取不到的,应该在View 中注入ViewModel 对象,使用View中的ViewModel对象里面的参数…...

如何下载免费地图数据?
按照以下步骤下载免费地图数据。 1、安装GIS地图下载器 从GeoSaaS(.COM)官网下载“GIS地图下载器”软件:,安装完成后桌面上出现”GIS地图下载器“图标。 双击桌面图标打开”GIS地图下载器“ 2、下载地图数据 点击主界面底部的“…...

B端可视化方案,如何助力企业精准决策,抢占市场先机
在当今竞争激烈的商业环境中,企业需要快速、准确地做出决策以抢占市场先机。B端可视化方案通过将复杂的企业数据转化为直观的图表和仪表盘,帮助企业管理层和业务人员快速理解数据背后的业务逻辑,从而做出精准决策。本文将深入探讨B端可视化方…...

IAR打包生成的hex和.a文件的区别
IAR打包生成的hex和.a文件的区别 在使用IAR Embedded Workbench进行嵌入式开发时,项目生成的文件中常见的两种文件类型是HEX文件和.a文件。它们在项目开发和部署过程中扮演着不同的角色。 HEX文件 定义与用途 HEX文件是一种十六进制表示的二进制文件格式…...

黑马点评:Redis消息队列【学习笔记】
目录 当前业务存在的问题 认识消息队列 List PubSub (publish subscribe) Stream 单消费模式 消费者组模式 对比 异步秒杀优化 当前业务存在的问题 JVM内存限制:当前使用的是JDK提供的阻塞队列,使用的是JVM的内存,如果不加以限制&…...

thinkphp:部署完整项目到本地phpstudy
一、准备工作 首先准备一个thinkphp的项目文件;准备mysql数据库 二、小皮初步搭建 1、建立网站 在小皮界面,网站->创建网站->输入域名,选择PHP版本等 注:确保端口未被占用 2、将项目文件放入根目录 网站->管理->…...

关于链接库
在 C# 中,链接库主要分为两种类型:托管链接库和非托管链接库,以下为你详细介绍它们的特点和导入方式: 托管链接库 特点 托管链接库通常是用 .NET 兼容的语言(如 C#、VB.NET 等)编写的,运行在…...

小程序返回按钮,兼容所有机型的高度办法
现象 在使用返回按钮的时候在不同机型上返回按钮小图标位置总是不一样,一会高一会低。 原因 因为手机的状态栏一般是不一样的,导致设置固定高度的时候就随时在改变。 解决办法 直接获取胶囊按钮的top值和height值将返回按钮的top值设置为一样的&…...

Docker镜像迁移指南:从Windows构建到Ubuntu运行
Docker镜像迁移指南:从Windows构建到Ubuntu运行 本文档详细介绍如何在Windows系统中构建SVM分类服务的Docker镜像,并将其迁移到Ubuntu系统中运行。 项目概述 本项目是一个使用FastAPI构建的SVM图像分类服务,可以将上传的图像分类为五种不同…...

XR技术赋能艺术展演|我的宇宙推动东方美学体验化
本次广州展览现场引入我的宇宙XR体验模块,通过空间计算与动作捕捉技术,让观众在潮玩艺术氛围中体验虚拟互动,打造“看得懂也玩得动”的展演新场景。 作为科技与文化融合的推动者,我的宇宙正在以“体验科技”为媒介,为潮…...

半导体制造如何数字化转型
半导体制造的数字化转型正通过技术融合与流程重构,推动着这个精密产业的全面革新。全球芯片短缺与工艺复杂度指数级增长的双重压力下,头部企业已构建起四大转型支柱: 1. 数据中枢重构产线生态 台积电的「智慧工厂4.0」部署着30万物联网传感器…...

windows虚拟机隐藏“弹出虚拟驱动”
PVE8 上安装的windows虚拟机,SCSI控制器使用了VitrlIO,安装virtio驱动后,右下角有弹出选项,virtio驱动的网卡、Balloon、串口等设备都是标准的PCI设备,支持热插拔,因此Windows系统会在界面上显示设备可以弹…...

AI工具箱源码+成品网站源码+springboot+vue
大家好,今天给大家分享一个靠AI广告赚钱的项目:AI工具箱成品网站源码,源码支持二开,但不允许转售!! 本人专门为小型企业和个人提供的解决方案。 不懂技术的也可以直接部署工具箱网站,成为站长&…...

《MySQL基础:了解MySQL周边概念》
1.登录选项的认识 -h:指明登录部署了mysql服务的主机,默认为127.0.0.1-P:指明要访问的端口号,默认为3306-u:指明登录用户-p:指明登录密码 2.什么是数据库 2.1认识数据库 第一点理解。 mysql是数据库的客户…...
:DataFrame 数据排序与排名 - 快速定位关键数据)
零基础上手Python数据分析 (15):DataFrame 数据排序与排名 - 快速定位关键数据
写在前面 在上一篇文章中,我们学习了如何使用 Pandas 对 DataFrame 进行分组(groupby())和聚合(agg(), apply(), transform()),这使我们能够从不同维度对数据进行汇总和分析。然而,仅仅得到聚合结果往往不够,我们经常需要知道 “谁是第一?”,“哪些数据排在前面/后面…...

案例驱动的 IT 团队管理:创新与突破之路:第五章 创新管理:从机制设计到文化养成-5.1 创新激励体系-5.1.2 OKR 与创新项目的结合
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 OKR 与创新项目的结合:驱动 IT 团队突破性创新的机制设计1. 背景与挑战:创新管理的核心痛点1.1 传统绩效管理体系的失效1.2 OKR 的适应性优势 2. 机制…...
)
数据库10(代码相关语句)
while循环 declare avgprice numeric(10,2) set avgprice(select avg(price)from titles) //自定义参数 while avgprice<10 //循环条件 begin update titles set priceprice*1.1 end //循环语句操作,当avgprice<10,所有price都加0.1 case语句 查询authors表…...

【Pandas】pandas DataFrame tail
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

淘宝 API 与爬虫混合开发:突破官方接口限制的商品数据采集进阶方案
一、引言 在电商数据挖掘领域,获取淘宝商品数据是一项重要任务。淘宝提供了 API 接口,但其存在调用频率、数据范围等限制。为了更全面、高效地采集商品数据,我们可以采用淘宝 API 与爬虫混合开发的方案,结合两者的优势࿰…...

MAC-基于 Spring 框架的高并发批量任务处理方案
基于 Spring 框架的高并发批量任务处理方案 以下结合 Spring 的特性(如 @Async、线程池管理、事务控制)实现高并发批量任务处理,涵盖 任 务分片、异步执行、资源隔离、熔断降级 等核心能力。 一、线程池配置(资源隔离) 通过 ThreadPoolTaskExecut…...

文件包含漏洞 不同语言危险函数导致的漏洞详解
目录 1. 什么是文件包含漏洞? 2. 文件包含漏洞如何利用?实际案例解析 案例 1:PHP 本地文件包含(LFI) 案例 2:PHP 远程文件包含(RFI) 案例 3:Java 目录遍历与文件包含…...

Android ViewPager使用预加载机制导致出现页面穿透问题
缘由 在应用中使用ViewPager,并且设置预加载页面。结果出现了一些异常的现象。 我们有4个页面,分别是4个Fragment,暂且称为FragmentA、FragmentB、FragmentC、FragmentD,ViewPager在MainActivity中,切换时&#x…...
css 中float属性及clear的释疑
float属性可以让元素脱离文档流,父元素中的子元素设置为float,则会导致父元素的高度塌陷。 <style type"text/css"> .father{ /*没有给父元素定义高度*/background:#ccc; border:1px dashed #999; } .box01,.box02,.box0…...

SpringBoot异常处理之自定义统一的错误处理页面
总体来讲,springboot里处理异常有五种方式,先看第一种: 利用springboot的默认配置,我们自定义统一的错误处理页面 前面说了SpringBoot只是帮助我们做了整合的工作,做配一堆的默认配置工作,异常处理的配置…...

事务管理:确保数据一致性与业务完整性
摘要:本文围绕事务管理展开,先回顾事务基本概念与操作,后深入探讨Spring事务管理。通过具体案例剖析事务管理在实际应用中的问题及解决方案,详细介绍Transactional注解及其属性rollbackFor和propagation的使用。 关键词ÿ…...
)
回收镀锡废水的必要性(笔记)
镀锡废水若直接排放,将对环境、经济和社会造成多重危害,其回收处理具有迫切性和深远意义。以下从环境、资源、法规、技术与实践、可持续发展五大维度展开分析: 一、环境危害的紧迫性:重金属与污染物的致命威胁 成分复杂…...

java 洛谷题单【算法2-1】前缀和、差分与离散化
P8218 【深进1.例1】求区间和 解题思路 前缀和数组: prefixSum[i] 表示数组 a 的前 (i) 项的和。通过 prefixSum[r] - prefixSum[l - 1] 可以快速计算区间 ([l, r]) 的和。 时间复杂度: 构建前缀和数组的时间复杂度是 (O(n))。每次查询的时间复杂度是 …...

FoundationPose 4090部署 真实场景迁移
参考链接: github代码 4090部署镜像拉取 前期准备 搜狗输入法安装 4090双屏不ok:最后发现是hdmi线坏了。。。。 demo 复现 环境部署(docker本地化部署) 拉取镜像 docker pull shingarey/foundationpose_custom_cuda121:late…...

[dp14_回文串] 分割回文串 II | 最长回文子序列 | 让字符串成为回文串的最少插入次数
目录 1.分割回文串 II 题解 2.最长回文子序列 题解 3.让字符串成为回文串的最少插入次数 题解 回文串,想通过s[i] s[j] 来实现状态变化,由二维数组 右下角 开始扩散 1.分割回文串 II 链接: 132. 分割回文串 II 给你一个字符串 s&…...

美团一面总结
八股的问题里Spring存在不足,无法将八股的知识和项目串联起来。 记录几个值得研究的问题: 端口80到8080是怎么到的 又是怎么一步一步到controller? [用户请求80端口] ↓ [Nginx监听80端口并转发 → 8080] ↓ [Tomcat监听8080端口,…...

Selenium2+Python自动化:利用JS解决click失效问题
文章目录 前言一、遇到的问题二、点击父元素问题分析解决办法实现思路 三、使用JS直接点击四、参考代码 前言 在使用Selenium2和Python进行自动化测试时,我们有时会遇到这样的情况:元素明明已经被成功定位,代码运行也没有报错,但…...

PyTorch的benchmark模块
PyTorch的benchmark模块主要用于性能测试和优化,包含核心工具库和预置测试项目两大部分。以下是其核心功能与使用方法的详细介绍: 1. 核心工具:torch.utils.benchmark 这是PyTorch内置的性能测量工具,主要用于代码片段的执行时间…...

基于MLKit的Android人脸识别应用开发实践
基于MLKit的Android人脸识别应用开发实践 https://gitee.com/wenhua512/face-recognition 1. 项目概述 1.1 功能特点 实时人脸检测与跟踪人脸特征提取与识别自动/手动采集模式人脸数据管理相机参数优化 1.2 技术选型 MLKit人脸检测MediaPipe人脸网格CameraX相机框架Room数…...

【技术派后端篇】ElasticSearch 实战指南:环境搭建、API 操作与集成实践
1 ES介绍及基本概念 ElasticSearch是一个基于Lucene 的分布式、高扩展、高实时的基于RESTful 风格API的搜索与数据分析引擎。 RESTful 风格API的特点: 接受HTTP协议的请求,返回HTTP响应;请求的参数是JSON,返回响应的内容也是JSON…...

Spring Boot 应用程序中配置使用consul
配置是 Spring Boot 应用程序中的一部分,主要用于配置服务端口、应用名称、Consul 服务发现以及健康检查等功能。以下是对每个部分的详细解释: 1. server.port server:port: 8080作用:指定 Spring Boot 应用程序运行的端口号。解释…...