【技术派后端篇】ElasticSearch 实战指南:环境搭建、API 操作与集成实践
1 ES介绍及基本概念
ElasticSearch是一个基于Lucene 的分布式、高扩展、高实时的基于RESTful 风格API的搜索与数据分析引擎。
RESTful 风格API的特点:
- 接受HTTP协议的请求,返回HTTP响应;
- 请求的参数是JSON,返回响应的内容也是JSON格式;
- 请求的类型(GET、POST、PUT、DELETE)就代表对资源的操作类型。
1.1 基本概念
在Elasticsearch(ES)的体系中,各核心概念清晰且独特,支撑着其强大的搜索与数据分析能力:
- 字段(Field):字段代表一种属性,类似于关系型数据库表中的列。在数据库里,每一行数据由多个属性值构成,比如员工表中,“姓名”“年龄”“职位”这些列就是字段,对应具体员工的数据,如“张三”“30”“工程师”就是字段值。在ES中,一个字段同样承载特定的属性信息,像一篇博客文章,“标题”“发布时间”“内容”等都可作为字段。
- 文档(Document):ES的数据存储方式与传统关系型数据库截然不同,所有数据均以JSON格式的document形式存在。document作为ES索引与搜索的最小数据单元,类比于数据库中的一行数据。以电商平台为例,一条商品信息记录就是一个document,它由“商品名称”“价格”“库存”“描述”等多个字段值组成,可能像这样:
{"商品名称": "智能手表","价格": 1299,"库存": 50,"描述": "具备多种健康监测功能的智能手表"
}
- 映射(Mapping):Mapping用于定义document中每个字段的类型、字段所采用的分词器等细节,其作用等同于关系型数据库中的表结构,为数据的存储与处理提供规范。例如,在一个新闻资讯索引中,“标题”字段可定义为字符串类型,并使用标准分词器,以便对标题进行合理切分用于搜索;“发布时间”字段定义为日期类型,方便按时间范围检索新闻。通过这样的映射定义,ES能更高效地管理和利用数据。
- 索引(Index):Index是Elasticsearch存储数据的载体,可理解为关系型数据库中的数据库概念,用于存放一类相同或相似的document。假设运营一个在线图书馆系统,可能会有“小说类书籍索引”“学术文献索引”等。“小说类书籍索引”中存放的就是所有小说书籍相关的document,每个document包含书籍的名称、作者、出版社、内容简介等信息。
- 类型(Type):Type属于逻辑层面的数据分类方式,一种Type类似于一张表,像常见的用户表、订单表等。在Elasticsearch 6.X版本中,默认Type为_doc ;而到了ES 7.x版本,Type这一概念已被移除 。在早期的论坛系统ES应用中,可能会设置“用户类型”和“帖子类型”,“用户类型”的document存储用户的账号、密码、注册时间等信息;“帖子类型”的document存放帖子的标题、内容、发布者、发布时间等数据。但在7.x及之后版本,不再使用这种多类型区分方式,而是更强调数据的统一索引管理 。
1.2 ES原理与倒排索引
1.2.1 ES整体原理概述
ES 是一个分布式的搜索与数据分析引擎,基于 Lucene 构建。它将数据存储在分布式的节点上,以实现高可用性、高扩展性和高性能。其核心工作流程围绕索引和搜索两个关键环节。在索引阶段,数据被处理并构建索引结构;搜索阶段则依据构建好的索引快速检索出符合条件的数据。
1.2.2 倒排索引的概念
传统数据库使用的是正向索引,即从文档 ID 到文档内容及单词位置的映射。而倒排索引恰恰相反,是从单词到包含该单词的文档 ID 列表的映射。简单来说,倒排索引就是将文档中的每个单词提取出来,记录每个单词在哪些文档中出现过以及出现的位置等信息。
例如,有以下两篇技术博客文章:
文章 1(ID=1):“Elasticsearch 是强大的搜索工具,适用于大数据场景。”
文章 2(ID=2):“学习技术博客写作,掌握搜索技巧很重要,比如使用 Elasticsearch。”
倒排索引构建过程如下:
| 单词 | 包含该单词的文档ID列表 |
|---|---|
| Elasticsearch | 1, 2 |
| 是 | 1 |
| 强大的 | 1 |
| 搜索 | 1, 2 |
| 工具 | 1 |
| 适用于 | 1 |
| 大数据 | 1 |
| 场景 | 1 |
| 学习 | 2 |
| 技术博客 | 2 |
| 写作 | 2 |
| 掌握 | 2 |
| 技巧 | 2 |
| 很重要 | 2 |
| 比如 | 2 |
| 使用 | 2 |
这样在搜索时,根据输入的关键词能快速定位到包含该关键词的文档,大大提高搜索效率。
1.2.3 以技术博客网站文章检索为例
假设一个技术博客网站有大量文章,存储在ES中。当用户在搜索框输入关键词“Elasticsearch”进行检索时,ES的工作流程如下:
- 用户输入:用户在博客网站搜索框输入“Elasticsearch”。
- 请求发送:网站将搜索请求发送给ES服务器。
- 倒排索引查询:ES在倒排索引中查找“Elasticsearch”这个单词,找到对应的文档ID列表,即[1, 2]。
- 文档获取:根据文档ID,从存储文档的地方获取对应的两篇文章内容。
- 结果返回:将这两篇文章的相关信息(如标题、摘要等)返回给用户展示。
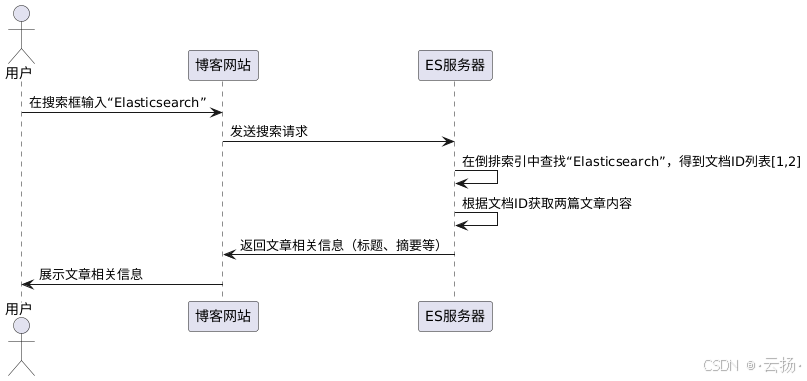
通过这种基于倒排索引的机制,ES能够快速准确地从海量的技术博客文章中找到用户需要的内容,为用户提供高效的搜索体验 。
2 ES环境搭建
2.1 Windows版安装步骤
2.1.1 ElasticSearch安装
- 安装Java环境:下载并安装JDK(Java Development Kit),并配置好Java环境变量。具体可参考相关Java安装教程。
- 下载安装包:从ElasticSearch官网下载适合Windows系统的zip安装包。
注意:不要下载最新版本,最好根据IK分词器的版本来下载,不然可能会没有对应的分词器版本
-
解压文件:将下载后的zip文件解压到指定目录,例如
D:\elasticsearch。 -
启动服务:进入解压目录下的
bin目录,双击elasticsearch.bat文件启动ElasticSearch服务。启动后,在浏览器地址栏输入http://localhost:9200/,若能看到ElasticSearch相关信息,说明启动成功。

-
安装为Windows服务(可选) :
- 设置环境变量:右键点击“此电脑”,选择“属性”,点击“高级系统设置”,在弹出窗口中点击“环境变量”。在系统变量中新建变量,变量名可设为
ELASTICSEARCH_HOME,变量值为ElasticSearch的安装目录(如D:\elasticsearch);然后在Path变量中添加%ELASTICSEARCH_HOME%\bin。 - 安装服务:以管理员身份运行命令提示符,进入ElasticSearch的
bin目录,执行elasticsearch-service.bat install命令安装服务。可使用elasticsearch-service.bat start启动服务、elasticsearch-service.bat stop停止服务、elasticsearch-service.bat remove移除服务。
- 设置环境变量:右键点击“此电脑”,选择“属性”,点击“高级系统设置”,在弹出窗口中点击“环境变量”。在系统变量中新建变量,变量名可设为
-
修改 Elasticsearch 配置为 HTTP(不推荐用于生产环境):如果发现启动ES后无法访问,打开 Elasticsearch 安装目录下的 config 文件夹,找到
elasticsearch.yml文件,修改配置之后再重启ElasticSearch,即可正常访问。
2.1.2 Kibana安装
- 下载安装包:从Kibana官网下载与ElasticSearch版本匹配的Windows版
.zip安装包。 - 解压文件:在D盘新建
kibana目录,将下载的.zip文件解压到该目录下,解压后得到kibana-版本号-windows-x86_64文件夹(即$KIBANA_HOME)。 - 配置文件:打开
$KIBANA_HOME\config\kibana.yml配置文件,设置elasticsearch.url为指向ElasticSearch实例地址,默认http://localhost:9200一般无需修改。如果ElasticSearch服务地址有变化,需相应调整。 - 启动服务:进入
$KIBANA_HOME\bin目录,双击kibana.bat启动Kibana。启动后可在浏览器输入http://localhost:5601访问Kibana界面。
2.1.3 IK分词器安装
- 下载:根据ElasticSearch版本,从https://github.com/medcl/elasticsearch-analysis-ik/releases下载对应的IK分词器压缩包。例如,若ElasticSearch是7.10.1版本,则下载
ik-710.1.zip。 - 解压与放置:解压下载的文件,将解压后的文件夹复制到ElasticSearch安装目录下的
plugins文件夹内,并将文件夹重命名为analysis-ik。比如ElasticSearch安装在D:\elasticsearch,则将文件夹复制到D:\elasticsearch\plugins\analysis-ik。 - 重启ElasticSearch:以管理员身份运行
bin目录下的elasticsearch.bat重启ElasticSearch,即可加载IK分词器。可通过发送请求测试分词效果,如使用Postman等工具。
2.2 Ubuntu版(Linux版)安装步骤
2.2.1 ElasticSearch安装
- 下载和解压:
- 从ElasticSearch官网(https://www.elastic.co/cn/downloads/elasticsearch )选择合适版本下载,然后上传到Ubuntu服务器。也可在命令行执行
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-版本号-linux-x86_64.tar.gz下载(下载速度可能较慢)。 - 执行解压缩命令
tar -zxvf elasticsearch-版本号-linux-x86_64.tar.gz -C /usr/local。
- 从ElasticSearch官网(https://www.elastic.co/cn/downloads/elasticsearch )选择合适版本下载,然后上传到Ubuntu服务器。也可在命令行执行
- 配置JDK(若有冲突):新版本ElasticSearch压缩包自带JDK,若Ubuntu已安装JDK且版本不符,启动时会报错。可切换到解压目录的
bin目录,执行export JAVA_HOME=/usr/local/elasticsearch-版本号/jdk指定使用自带JDK 。 - 创建专用用户:
root用户不能直接启动ElasticSearch,需创建专用用户,如user-es。使用命令useradd user-es创建用户,passwd user-es设置密码 。 - 修改配置文件:进入
config文件夹,编辑elasticsearch.yml文件。可修改http.port等参数,如http.port: 19200。还可根据需求配置集群相关参数等。 - 解决内存权限问题:若启动报错
max virtual memory areas vm.max_map_count (65530) is too low, increase to at least (262144),切换到root用户(sudo su),编辑/etc/sysctl.conf文件,在文件末尾添加vm.max_map_count=262144,保存退出后执行sysctl -p刷新配置 。 - 启动服务:切换到专用用户(
su user-es),进入ElasticSearch的bin目录,执行./elasticsearch启动服务。启动成功后可通过http://服务器IP:端口号(如http://127.0.0.1:19200)访问,出现相关信息则安装成功。

2.2.2 Kibana安装
- 下载和解压:从Kibana官网(https://www.elastic.co/cn/downloads/kibana )下载与ElasticSearch版本匹配的安装包,例如
kibana-版本号-linux-x86_64.tar.gz。使用命令wget https://artifacts.elastic.co/downloads/kibana/kibana-版本号-linux-x86_64.tar.gz下载后,执行tar -zxvf kibana-版本号-linux-x86_64.tar.gz解压 。 - 修改配置文件:进入解压后的目录,编辑
config/kibana.yml文件,配置内容如下:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://服务器IP:9200"
kibana.index: ".kibana"
将服务器IP替换为实际ElasticSearch服务器的IP地址。
3. 启动服务:切换到解压目录的bin目录,执行./kibana &(&表示在后台运行)启动Kibana。启动过程中若ElasticSearch未启动会有警告,连接成功后可通过浏览器访问http://服务器IP:5601 。
2.2.3 IK分词器安装
- 下载:根据ElasticSearch版本,从https://github.com/medcl/elasticsearch-analysis-ik/releases下载对应的IK分词器压缩包。
- 解压与放置:解压下载的文件,将解压后的文件夹(需命名为
analysis-ik)复制到ElasticSearch安装目录下的plugins文件夹内。比如ElasticSearch安装在/usr/local/elasticsearch-版本号,则将文件夹复制到/usr/local/elasticsearch-版本号/plugins/analysis-ik。 - 重启ElasticSearch:切换到启动ElasticSearch的专用用户,进入ElasticSearch的
bin目录,执行./elasticsearch重启服务,即可加载IK分词器。
3 RESTful API操作ES
3.1 操作索引
- 添加索引
PUT user
向Elasticsearch集群添加名为user的索引。若索引已存在,会返回相应错误提示。
- 查询单个索引
GET /teacher
获取名为teacher的索引的相关信息,如索引的基本设置、映射等。若索引不存在,会返回404错误。
- 查询多个索引
GET /user,student
同时获取user和student两个索引的相关信息。可一次性查看多个索引的状态,方便对比和管理。
- 查询所有索引
GET /_all
返回Elasticsearch集群中的所有索引的相关信息。在管理多个索引,需要快速了解整体索引情况时使用。
- 删除索引
DELETE /student
从Elasticsearch集群中删除名为student的索引及其包含的所有文档数据。删除操作不可逆,谨慎使用。
- 打开索引
POST /student/_open
将处于关闭状态的student索引打开,使其可进行数据的读写和查询操作。索引关闭时,对其进行的任何数据操作都会失败。
- 关闭索引
POST /student/_close
关闭student索引,关闭后索引不可读写,但索引数据仍存储在磁盘上。可用于在维护索引或减少资源占用时临时关闭索引。
3.2 数据类型
3.2.1 简单数据类型
我们先来看一个简单的映射定义:
PUT teacher/_mapping
{"properties": {"id": {"type": "integer" },"name": {"type": "text"},"isMale": {"type": "boolean"}}
}
在定义映射的时候,类比于定义数据库中的表结构,我们需要指明每一个字段的名称,数据类型等等信息,所以我们先得了解映射中包含的数据类型。
-
字符串
- text:会分词,不支持聚合
- keyword:不会分词,将全部内容作为一个词条,支持聚合
-
数值:long, integer, short, byte, double, float, half_float, scaled_float
-
布尔:boolean
-
二进制:binary
-
范围类型:integer_range,float_range, long_range, double_range, date_range
-
日期:date
3.2.2 复杂数据类型
- 数组:[ ] 没有专门的数组类型,ES会自动处理数组类型数据
比如说 给某一个字段 定义为 integer类型,那么这个字段是可以存储 integer数组的,ES会自动处理
- 对象:{ } Object: object(for single JSON objects 单个JSON对象)
3.3 操作映射
- 给已存在索引添加映射
PUT /user/_mapping
{"properties":{"id": {"type":"integer"},"name":{"type":"keyword"},"age":{"type":"long"}}
}
为已存在的user索引添加字段映射,定义id为整数类型、name为关键词类型、age为长整型。添加映射时,字段类型一旦确定,后续修改会受限制。
- 创建索引并指定映射
PUT teacher
{"mappings": {"properties": {"tid":{"type": "integer"},"tname":{"type": "text"}}}
}
创建名为teacher的索引,并同时指定其映射,定义tid为整数类型、tname为文本类型。在创建索引时规划好映射,能确保数据存储和查询的准确性。
- 查询映射
GET /teacher/_mapping
获取teacher索引的映射信息,包括字段类型、分词器设置等。方便查看索引的结构定义,排查查询问题。
- 修改映射(只能添加字段)
PUT /teacher/_mapping
{"properties":{"height":{"type":"float"},"weight":{"type":"double"}}
}
向teacher索引的映射中添加height和weight字段,分别为浮点型和双精度型。Elasticsearch不支持直接修改已存在字段的类型,只能添加新字段。
3.4 操作文档
- 添加文档 - 指定文档id
POST /user/_doc/1
{"id": 1001,"name":"贾宝玉","age":15
}
向user索引中添加一个文档,并指定文档的id为1。若指定id的文档已存在,会覆盖原有文档。
- 添加文档 - 不指定文档id
POST /user/_doc
{"id":1002,"name":"贾迎春","age":13
}
向user索引添加文档,Elasticsearch会自动生成一个唯一的文档id。适用于对文档id无特定要求的场景。
- 查询文档 - 根据文档id查询
GET /user/_doc/1
GET /user/_doc/NsORPo0BJehhapNsslSw
根据文档id获取user索引中的文档。若文档不存在,会返回404错误。
- 查询文档 - 查询所有文档
GET /user/_search
获取user索引中的所有文档。在数据量较大时,可能需要结合分页参数使用,避免一次性返回过多数据。
- 修改文档 - 直接覆盖
POST /user/_doc/1
{"id": 2001,"name":"刘姥姥","age":80
}
用新的文档数据覆盖user索引中id为1的文档。会完全替换原有文档内容,包括所有字段。
- 修改指定字段
POST /user/_update/1
{"doc": {"name":"贾琏","age": 30}
}
仅修改user索引中id为1的文档的name和age字段,其他字段保持不变。比直接覆盖更灵活,可减少数据传输量。
- 删除文档(指定文档id)
DELETE /user/_doc/1
删除user索引中id为1的文档。删除操作不可逆,操作前需确认数据是否不再需要。
3.5 IK分词器测试
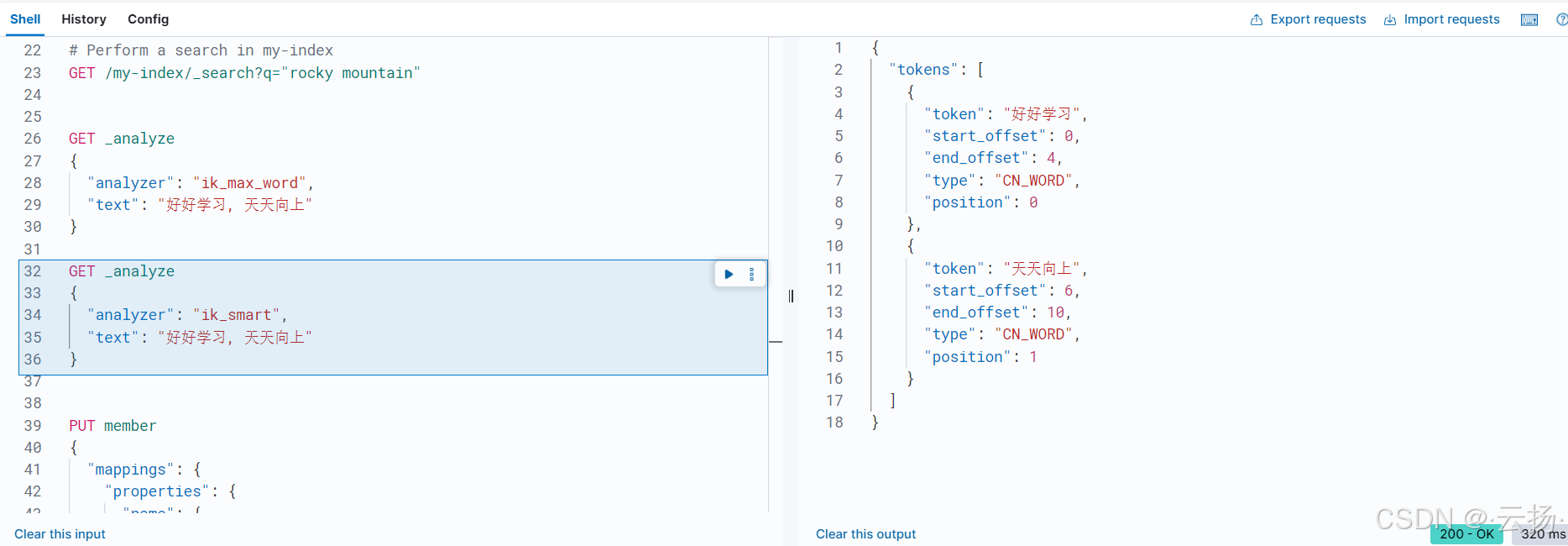
- ik_max_word分词模式
GET /_analyze
{"text": "湖南是全国唯一一个叫湖南的省份","analyzer": "ik_max_word"
}
使用ik_max_word分词器对文本进行分词,它会尽可能细粒度地切分文本,如上述文本会被切分成“湖南”“是”“全国”“唯一”“一个”“叫”“湖南”“的”“省份”等多个词条。
- ik_smart分词模式
GET /_analyze
{"text": "湖南是全国唯一一个叫湖南的省份","analyzer": "ik_smart"
}
ik_smart分词器的粒度更粗,会对文本进行更合理的合并切分,上述文本可能被切分成“湖南”“是”“全国”“唯一一个”“叫”“湖南的省份”等词条。
- 使用ES自带的分词器
GET /_analyze
{"text": "stone is best man, ciggar is handsome man","analyzer": "standard"
}
使用ES自带的standard分词器对英文文本进行分词,它会按空格和标点符号进行切分,并将单词转换为小写形式,如上述文本会被切分成“stone”“is”“best”“man”“ciggar”“is”“handsome”“man”等词条。
3.6 ES批量操作
- 创建索引并设置映射
DELETE /teacher
PUT /teacher
{"mappings": {"properties": {"id":{"type": "integer"},"name":{"type": "text","analyzer": "ik_max_word"},"age":{"type": "integer"}}}
}
先删除可能存在的teacher索引,再创建新的teacher索引,并设置其映射。其中name字段使用ik_max_word分词器进行分词。
- 查询索引中的所有文档
GET /teacher/_search
获取teacher索引中的所有文档,用于查看当前索引中的数据内容。
- 批量操作
POST /_bulk
{"create":{"_index":"teacher","_id":"1"}}
{"id":1,"name":"金角大王","age":30}
{"create":{"_index":"teacher","_id":"2"}}
{"id":2,"name":"银角大王","age":20}
{"create":{"_index":"teacher","_id":"3"}}
{"id":3,"name":"小钻风","age":10}
{"delete":{"_index":"teacher","_id":"1"}}
{"update":{"_index":"teacher","_id":"2"}}
{"doc":{"name":"狮驼岭","age":1000}}
在一次请求中对teacher索引执行多个操作,包括创建文档(create)、删除文档(delete)和更新文档(update)。批量操作可减少网络请求次数,提高数据处理效率。
- 创建另一个索引并设置映射
PUT /member
{"mappings": {"properties": {"id":{"type": "integer"},"name":{"type": "keyword"},"addr":{"type": "text","analyzer": "ik_max_word"},"gender":{"type": "keyword"},"money":{"type": "integer"}}}
}
创建名为member的索引,并设置其映射。addr字段使用ik_max_word分词器,方便对地址进行分词查询。
- 查询索引信息
GET /member/_search
GET /member/_mapping
分别查询member索引中的所有文档和获取member索引的映射信息,用于了解索引的数据和结构。
3.7 ES高级查询
- match_all查询
GET /member/_search
{"query": {"match_all": {}},"from": 0,"size": 3
}
查询member索引中的所有文档,并指定从第0条开始,返回3条数据。常用于获取索引的部分数据样本,或在不关心具体查询条件时获取全部数据。
- term查询
GET /member/_search
{"query": {"term": {"addr": {"value": "山区"}}}
}
在member索引中查询addr字段值为“山区”的文档。term查询不会对搜索关键字进行分词,直接与目标字段进行精确匹配。
- 全文查询 - match
GET /member/_search
{"query": {"match": {"addr": "湖北武汉"}}
}
对member索引的addr字段进行全文查询,会对搜索关键字“湖北武汉”进行分词,然后与addr字段的分词结果进行匹配。默认取并集,即只要匹配到其中一个分词结果的文档就会被返回。
- 模糊查询 - 通配符查询
GET /member/_search
{"query": {"wildcard": {"addr": {"value": "武?"}}}
}
在member索引中查询addr字段值以“武”开头且后面跟任意一个字符的文档。?表示占位,*表示通配任意多个字符。
- 正则查询
GET /member/_search
{"query": {"regexp": {"addr": "[A-Z a-z 0-9_]+(.)*"}}
}
使用正则表达式对member索引的addr字段进行查询,匹配由字母、数字、下划线组成且后面可跟任意字符的地址。
- 前缀查询
GET /member/_search
{"query": {"prefix": {"addr": {"value": "青"}}}
}
在member索引中查询addr字段值以“青”开头的文档。前缀查询不太适用于text类型字段,因为text类型字段会被分词,可能导致查询结果不准确。
- queryString多条件查询
GET /member/_search
{"query": {"query_string": {"fields": ["addr","gender"], "query": "武汉 AND 男"}}
}
在member索引中查询addr字段包含“武汉”且gender字段为“男”的文档。注意AND和OR要大写,且不要使用simple_query_string,它不会识别AND或OR关键字。
- 排序查询
GET /member/_search
{"query": {"match_all": {}},"sort": [{"money": {"order": "asc"}}]
}
查询member索引中的所有文档,并按money字段的值进行升序排序。可根据需求指定其他字段进行排序,以及选择升序(asc)或降序(desc)。
- 范围查询
GET /member/_search
{"query": {"range": {"money": {"gte": 300,"lte": 600}}},"sort": [{"money": {"order": "desc"}}],"from": 0,"size": 3
}
在member索引中查询money字段值在300到600之间的文档,并按money字段的降序排序,返回前3条数据。
3.8 bool查询
- must条件
GET /member/_search
{"query": {"bool": {"must": [{"term": {"addr": {"value": "武汉"}}},{"term": {"gender": {"value": "女"}}}]}}
}
查询member索引中addr字段为“武汉”且gender字段为“女”的文档,会计算文档的近似度得分。must条件下的所有子条件都必须满足才能匹配到文档。
- filter条件
GET /member/_search
{"query": {"bool": {"filter": [{"match": {"addr": "湖北武汉"}},{"range": {"money": {"gte": 200,"lte": 500}}}]}}
}
查询member索引中addr字段包含“湖北武汉”且money字段值在200到500之间的文档,filter不会计算近似度得分,查询效率更高,适用于不需要计算得分的精确过滤场景。
- must_not条件
GET /member/_search
{"query": {"bool": {"must_not": [{"match": {"addr": "武汉"}},{"term": {"gender": {"value": "女"}}}]}}
}
查询member索引中addr字段不包含“武汉”且gender字段不为“女”的文档,同样不会计算近似度得分。
- should条件
GET /member/_search
{"query": {"bool": {"should": [{"term": {"addr": {"value": "武汉"}}},{"term": {"gender": {"value": "女"}}}]}}
}
查询member索引中addr字段为“武汉”或者gender字段为“女”的文档,会计算近似度得分。只要满足should中的一个子条件,文档就可能被返回。
- 综合练习
GET /member/_search
{"query": {"bool": {"filter": [{"range": {"money": {"gte": 200,"lte": 600}}},{"term": {"gender": "男"}}],"must": [{"match": {"addr": "湖北武汉"}}]}}
}
查询member索引中money字段值在200到600之间、gender为“男”且addr包含“湖北武汉”的文档。
4 技术派整合ES
4.1 构造 RestHighLevelClient 客户端
- 引入依赖:在
paicoding-service模块的 pom 文件中,我们需要引入 es 和 es-client 相关的依赖。具体的依赖配置如下:
<!--引入es-high-level-client相关依赖 start-->
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>6.8.2</version>
</dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>6.8.2</version>
</dependency>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>6.8.2</version>
</dependency>
- 配置 yml 文件:在
paicoding-web模块的src->main->resource-env->dev->application-dal.yml中,配置 ES 的相关信息。具体配置如下:
# elasticsearch配置
elasticsearch:# 是否开启ES?本地启动如果没有安装ES,可以设置为false关闭ESopen: false# es集群名称clusterName: elasticsearchhosts: 127.0.0.1:9200userName: elasticpassword: elastic# es 请求方式scheme: http# es 连接超时时间connectTimeOut: 1000# es socket 连接超时时间socketTimeOut: 30000# es 请求超时时间connectionRequestTimeOut: 500# es 最大连接数maxConnectNum: 100# es 每个路由的最大连接数maxConnectNumPerRoute: 100
在配置 yml 文件时,一定要注意格式的正确性,避免因格式错误导致配置失效。
- 编写 config 配置类
RestHighLevelClient:配置类的作用是将 RestHighLevelClient 客户端的创建交由 Spring 管理。具体的配置类代码如下:
/*** es配置类** @author ygl* @since 2023-05-25**/
@Slf4j
@Data
@Configuration
// 下面这个表示只有 elasticsearch.open = true 时,采进行es的配置初始化;当不使用es时,则不会实例 RestHighLevelClient
@ConditionalOnProperty(prefix = "elasticsearch", name = "open")
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticsearchConfig {// 是否开启ESprivate Boolean open;// es host ip 地址(集群)private String hosts;// es用户名private String userName;// es密码private String password;// es 请求方式private String scheme;// es集群名称private String clusterName;// es 连接超时时间private int connectTimeOut;// es socket 连接超时时间private int socketTimeOut;// es 请求超时时间private int connectionRequestTimeOut;// es 最大连接数private int maxConnectNum;// es 每个路由的最大连接数private int maxConnectNumPerRoute;/*** 如果@Bean没有指定bean的名称,那么这个bean的名称就是方法名*/@Bean(name = "restHighLevelClient")public RestHighLevelClient restHighLevelClient() {// 此处为单节点esString host = hosts.split(":")[0];String port = hosts.split(":")[1];HttpHost httpHost = new HttpHost(host, Integer.parseInt(port));// 构建连接对象RestClientBuilder builder = RestClient.builder(httpHost);// 设置用户名、密码CredentialsProvider credentialsProvider = new BasicCredentialsProvider();credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));// 连接延时配置builder.setRequestConfigCallback(requestConfigBuilder -> {requestConfigBuilder.setConnectTimeout(connectTimeOut);requestConfigBuilder.setSocketTimeout(socketTimeOut);requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeOut);return requestConfigBuilder;});// 连接数配置builder.setHttpClientConfigCallback(httpClientBuilder -> {httpClientBuilder.setMaxConnTotal(maxConnectNum);httpClientBuilder.setMaxConnPerRoute(maxConnectNumPerRoute);httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);return httpClientBuilder;});return new RestHighLevelClient(builder);}
}
需要注意的是,在 yml 中的 elasticsearch.hosts 配置中,不要添加 https 前缀,只需填写 127.0.0.1:9200 即可,否则在配置类中创建 HttpHost 时会出错。
4.2 技术派首页全局查询走 ES 数据库
在进行 ES 查询整合之前,我们先来了解一下大致的逻辑:
- 根据查询条件在 ES 中查询数据。
- 从查询结果中提取出 id,并将这些 id 添加到 ids 集合中。
- 使用 ids 集合去 MySQL 数据库中查询相应的数据。
通过这种方式,可以大大提高查询的效率,相比直接在 MySQL 中进行 like% 值 % 的查询,性能有显著提升。
在 paicoding-service 模块的 ArticleReadServiceImpl 类中,我们需要注入 RestHighLevelClient 客户端,然后编写实现代码。具体代码如下:
public List<SimpleArticleDTO> querySimpleArticleBySearchKey(String key) {// TODO 当KEY为空时,返回热门推荐if (StringUtils.isBlank(key)) {return Collections.emptyList();}key = key.trim();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(key,ESFieldConstant.ES_FIELD_TITLE,ESFieldConstant.ES_FIELD_SHORT_TITLE);searchSourceBuilder.query(multiMatchQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{ESIndexConstant.ES_INDEX_ARTICLE}, searchSourceBuilder);SearchResponse searchResponse = null;try {searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}SearchHits hits = searchResponse.getHits();SearchHit[] hitList = hits.getHits();List<Integer> ids = new ArrayList<>();for (SearchHit documentFields : hitList) {ids.add(Integer.parseInt(documentFields.getId()));}if (ObjectUtils.isEmpty(ids)) {return null;}List<ArticleDO> records = articleDAO.selectByIds(ids);return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle())).collect(Collectors.toList());
}
4.3 兼容未安装 ES 继续走 MySQL 查询
考虑到有些小伙伴可能没有安装 ES 和 Canal,为了保证代码在这种情况下也能正常运行,我们进行了兼容性处理,使得在未安装 ES 时,首页查询依然可以走 MySQL 数据库。
首先,在 yml 中增加了是否开启 ES 的配置项:
# elasticsearch配置
elasticsearch:# 是否开启ES?本地启动如果没有安装ES,可以设置为false关闭ESopen: true# es集群名称clusterName: elasticsearchhosts: 127.0.0.1:9200userName: elasticpassword: elastic# es 请求方式scheme: http# es 连接超时时间connectTimeOut: 1000# es socket 连接超时时间socketTimeOut: 30000# es 请求超时时间connectionRequestTimeOut: 500# es 最大连接数maxConnectNum: 100# es 每个路由的最大连接数maxConnectNumPerRoute: 100
然后,在 Service 层将 open 值注入:
@Value("${elasticsearch.open}")
private Boolean openEs;
最后,在业务层的代码中实现兼容逻辑:
@Override
public List<SimpleArticleDTO> querySimpleArticleBySearchKey(String key) {// TODO 当KEY为空时,返回热门推荐if (StringUtils.isBlank(key)) {return Collections.emptyList();}// 如果没有开启ES,那么继续从MYSQL中获取数据if (!openEs) {List<ArticleDO> records = articleDAO.listSimpleArticlesBySearchKey(key);return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle())).collect(Collectors.toList());}// ES整合逻辑key = key.trim();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(key,ESFieldConstant.ES_FIELD_TITLE,ESFieldConstant.ES_FIELD_SHORT_TITLE);searchSourceBuilder.query(multiMatchQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{ESIndexConstant.ES_INDEX_ARTICLE}, searchSourceBuilder);SearchResponse searchResponse = null;try {searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}SearchHits hits = searchResponse.getHits();SearchHit[] hitList = hits.getHits();List<Integer> ids = new ArrayList<>();for (SearchHit documentFields : hitList) {ids.add(Integer.parseInt(documentFields.getId()));}if (ObjectUtils.isEmpty(ids)) {return null;}List<ArticleDO> records = articleDAO.selectByIds(ids);return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle())).collect(Collectors.toList());
}
5 ES集群相关知识
5.1 ES集群基础概念
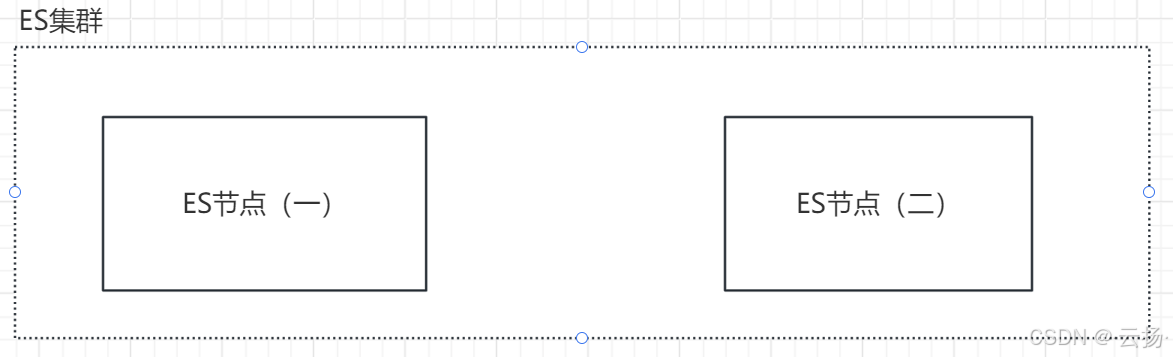
- 定义与组成:Elasticsearch(ES)集群是由多个ES节点组成的集合 ,节点间协同工作,实现数据存储、搜索及分析功能。
- 优势
- 效率提升:多节点并行处理搜索请求,相比单节点搜索效率更高。
- 存储扩容:突破单节点磁盘空间限制,利用多个节点存储资源,扩大数据存储容量。
- 高可用性:部分节点故障时,集群仍能对外提供服务,保障整体可用性。
5.2 ES集群节点
- 节点类型
- 主节点(Master Node):负责管理集群元数据,如索引创建、删除,分片分配,监控节点状态等。为防止脑裂,一般设置奇数个主节点。脑裂是指在集群中,多个节点都认为自己是主节点,导致集群出现多个“大脑”,从而使集群状态混乱、数据不一致等问题。设置奇数个主节点,是因为在选举主节点时,奇数个节点能避免出现平局情况,降低脑裂风险 。
- 数据节点(Data Node):用于存储数据,执行数据的增、删、改、查及聚合操作,需根据数据量和查询需求合理配置资源。
- 协调节点(Coordinate Node):不承担主节点和数据节点功能,专门负责接收请求、转发请求至其他节点、汇总返回数据。大规模集群并发查询量大时,可添加独立协调节点。
- Ingest节点:对文档数据进行预处理,如通过管道实现数据转换与丰富,可按需水平扩展。一个节点可兼具多种角色,小规模集群可不严格区分。
- 节点协作:数据节点向主节点发送心跳数据包汇报状态,主节点依此监控集群状态。
5.3 ES集群分片
- 主分片(Primary Shard)
- 定义:将索引文档数据分散存储的单元,所有主分片数据合起来构成完整索引数据,主分片数量至少为1 。
- 作用:承载索引的原始数据存储,是数据写入和读取的基础单元。
- 副本分片(Replica Shard)
- 定义:主分片的备份,数量大于等于0 。
- 作用:提高数据可用性和查询性能,主分片故障时可顶替提供服务,还可分担查询负载。
- 分片规则
- 主分片和副本分片不能存储在同一节点上。
- 单节点ES可有多主分片,但无副本分片。
- 创建索引时可指定主、副本分片数量,索引创建后,主分片数量不可更改,仅副本分片数量可调整。

5.4 文档在ES集群中的操作
-
存储流程
- 用户将存储请求发送到集群中任意一个节点。
- 接收请求的节点通过文档路由,把数据发送给对应的主分片。
- 主分片将数据同步给它的所有副本分片。

-
搜索流程
- 用户向集群中任意一个节点发起搜索请求。
- 接收请求的节点(协调节点)把每个主分片和它的副本分片看作“同一组”分片,从中选择一组有完整数据的分片(默认轮训选择),然后分发请求。
- 被选中的分片进行查询,之后返回结果。
- 协调节点把收到的结果聚合,返回给用户。

5.5 ES 集群相关问题及解决
- 脑裂问题:因网络问题,集群被分成两个,出现两个 “大脑”(主节点) ,导致数据不一致 。解决方法包括设置
- 最小主节点数量,计算公式为
discovery.zen.minimum_master_nodes: (有master资格节点数/2) + 1; - 设置专门奇数个主节点;
- 采用单播发现机制(关闭多播发现机制
discovery.zen.ping.multicast.enabled: false,配置单播发现主节点 ip 地址discovery.zen.ping.unicast.hosts : ("master1", "master2", "master3") ); - 配置选举发现数,延长 ping master 等待时长(如
discovery.zen.ping_timeout: 30 ,discovery.zen.minimum_master_nodes: 2) 。
- 最小主节点数量,计算公式为
- 分片数量配置:索引分片数指定后一般不可更改,除非重做索引 。ElasticSearch 推荐最大 JVM 堆空间 30 - 32G ,可据此估算分片数量,如预计数据量 200GB ,最多分配 7 - 8 个分片 。初始阶段,可按节点数量的 1.5 - 3 倍创建分片,如 3 个节点,分片数最多不超 9 个 。对于基于日期、搜索少、数据量小(如每个索引 1GB 甚至更小 )的索引需求,如日志管理,建议分配 1 个分片 。

6 总结
本文全面讲解 ElasticSearch(ES)相关知识。ES 是基于 Lucene 的分布式搜索与分析引擎,有分布式、高扩展、高实时特性,采用 RESTful 风格 API 。介绍了字段、文档等基本概念,基于倒排索引的原理。详述 Windows 和 Ubuntu 版搭建步骤,RESTful API 操作及 ES 集成。还提及 ES 集群中的脑裂问题,主节点在管理集群元数据中起关键作用,为防止脑裂,通常设置奇数个主节点,避免选举时出现平局,降低集群状态混乱、数据不一致等风险。
7 参考链接
- 技术派实现ES查询
- 项目仓库(GitHub)
- 项目仓库(码云)
相关文章:

【技术派后端篇】ElasticSearch 实战指南:环境搭建、API 操作与集成实践
1 ES介绍及基本概念 ElasticSearch是一个基于Lucene 的分布式、高扩展、高实时的基于RESTful 风格API的搜索与数据分析引擎。 RESTful 风格API的特点: 接受HTTP协议的请求,返回HTTP响应;请求的参数是JSON,返回响应的内容也是JSON…...

Spring Boot 应用程序中配置使用consul
配置是 Spring Boot 应用程序中的一部分,主要用于配置服务端口、应用名称、Consul 服务发现以及健康检查等功能。以下是对每个部分的详细解释: 1. server.port server:port: 8080作用:指定 Spring Boot 应用程序运行的端口号。解释…...

【设计模式——策略模式】
为什么要使用策略模式? 策略模式是一种行为设计模式,它允许在运行时选择算法或行为。通过将算法封装在独立的类中,客户端可以在运行时动态地选择和切换算法,而无需修改原有代码。这种模式特别适合需要灵活切换行为的场景。 形象…...

helm账号密码加密
1、安装工具 sudo apt update sudo apt install gnupg -y wget https://github.com/getsops/sops/releases/download/v3.10.2/sops-v3.10.2.linux.amd64 mv sops-v3.10.2.linux.amd64 /usr/local/bin/sops chmod x /usr/local/bin/sops2、生成加密文件 gpg --full-generate-…...
 / 数组变换(位运算) / 装箱问题(01背包))
【今日三题】添加字符(暴力枚举) / 数组变换(位运算) / 装箱问题(01背包)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 添加字符(暴力枚举)数组变换(位运算)装箱问题(01背包) 添加字符(暴力枚举) 添加字符 当在A的开头或结尾添加字符直到和B长度…...

数据处理与GUI开发场景下Python常见类型错误解析与应对策略
数据处理与GUI开发场景下Python常见类型错误解析与应对策略 前言 Python 作为一种广泛应用于数据处理和 GUI 开发的高级编程语言,其动态类型特性为开发者带来了极大的灵活性,但同时也容易引发各种类型错误。在数据处理中,从数据采集、清洗到…...

【论文阅读笔记】模型的相似性
文章目录 The Platonic Representation Hypothesis概述表征收敛的依据表征收敛的原因实验依据未来发展的局限性 Similarity of Neural Network Representations Revisited概述问题背景相似性度量s的性质可逆线性变换不变性正交变换不变性各向同性缩放不变性典型度量满足的性质 …...

MVC协同工作流程
1. 视图层(View)代码作用 核心代码示例(以JSP为例): <!-- register.jsp --> <form action"registerServlet" method"post">用户名: <input type"text" na…...

OpenGL shader开发实战学习笔记:第十章 法线贴图
1. 10 法线贴图 1.1. 什么是法线贴图 我们如果想要在盾牌上实现凹凸感,应该如何做?一种方法是添加更多的顶点来建模更多的细节,但是网格的顶点越多,渲染网格所需的顶点着色器计算就越多,网格占用的内存就越多。大多数…...

神经光子渲染:物理级真实感图像生成——从麦克斯韦方程到深度学习
一、技术背景与核心突破 2025年,神经光子渲染(Photonic Neural Rendering, PNR)技术通过物理光学方程与神经辐射场的深度融合,在AIGC检测工具(如GPTDetector 5.0)的识别准确率从98%降至12%。该技术突破性地…...

MCP 协议知识分享
MCP 协议知识分享 一、MCP 协议概述1.1 定义与背景1.2 核心价值1.3 与传统 API 的对比 二、技术架构与工作原理2.1 核心组件2.2 通信机制2.3 典型工作流程 三、关键技术与应用场景3.1 核心技术3.2 典型应用场景 四、与微软技术的集成4.1 Azure OpenAI 服务4.2 Playwright MCP 服…...

spring boot 文件下载
1.添加文件下载工具依赖 Commons IO is a library of utilities to assist with developing IO functionality. <dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version> </depe…...

Redis --- 基本数据类型
Redis --- 基本数据类型 Redis Intro5种基础数据类型 Redis Intro Redis(Remote Dictionary Server)是一款开源的高性能键值存储系统,常用于缓存、消息中间件和实时数据处理场景。以下是其核心特点、数据类型及典型使用场景: 核心…...

随机IP的重要性:解锁网络世界的无限可能
IP地址不仅是连接互联网的“身份证”,更是企业、开发者和个人用户实现高效运营与安全防护的核心工具。然而,固定IP的局限性日益凸显——从隐私泄露到访问受限,从爬虫封禁到商业竞争壁垒,这些问题如何破解?答案就是随机…...

C#: 用Libreoffice实现Word文件转PDF
现实场景中要实现Word格式转PDF格式还是比较常见的。 如果要用开源的组件,只有用Libreoffice了。 一、下载安装Libreoffice 先进入如下链接,找到最新版本和匹配的操作系统来安装。 官网试过,下载是能下载,但安装了用不了&…...

客户验收标准模糊,如何明确
客户验收标准模糊往往会导致项目延迟、质量不符合期望或客户不满意,明确验收标准的关键在于与客户的充分沟通、制定清晰的文档、并确保双方对目标一致性达成共识。在项目的执行过程中,如果客户未能明确表达他们的验收标准,或者项目团队未能确…...

Halcon应用:九点标定-手眼标定
提示:若没有查找的算子,可以评论区留言,会尽快更新 Halcon应用:九点标定-手眼标定 前言一、Halcon应用?二、应用实战1、图形理解[eye-to-hand]:1.1、开始应用2 图形理解[eye-in-hand] 前言 本篇博文主要用…...

springboot3 cloud gateway 配置websocket代理转发教程
前言 最近微服务的项目,需要集成websocket的功能,我在其中的一个微服务模块中集成websocket代码实现,通过模块的端口测试正常,但是通过springboot cloud gateway的端口访问,连接失败!我通过各种百度、和AI…...

详解与FTP服务器相关操作
目录 什么是FTP服务器 搭建FTP服务器相关 编辑 Unity中与FTP相关的类 上传文件到FTP服务器 使用FTP服务器上传文件的关键点 开始上传 从FTP服务器下载文件到客户端 使用FTP下载文件的关键点 开始下载 关于FTP服务器的其他操作 将文件的上传,下载&…...

制作一款打飞机游戏教程8:抖动
我们讨论了爆炸效果,这是非常重要的内容。我们制作了一个可以改变大小的小圆点,并展示了一些微调,比如绘制的圆圈数量和颜色调整等。但我们也提到将要做一些重大改变,这些改变将涉及到颜色的使用方式。 颜色使用方式的改变 目前…...
)
Linux搭建环境:从零开始掌握基础操作(四)
您好,我是程序员小羊! 前言 软件测试第一步就是搭建测试环境,如何搭建好测试环境,需要具备两项的基础知识: 1、Linux 命令: 软件测试第一个任务, 一般都需要进行环境搭建, 一部分,环境搭建内容是在服…...

第2.4节:学会像AWK一样思考
1 第2.4节:学会像AWK一样思考 AWK的工作方式类似于工厂的流水线。文本数据就像流水线上的产品,AWK逐行读取这些文本,对每行文本进行分割处理,然后通过一系列的模式匹配和动作执行来完成特定的任务。下面我们详细介绍AWK的工作流程…...

内网穿透原理解析、使用网络场景、及如何实现公网访问步骤教程
不多废话,一文了解内网穿透原理解析、使用网络场景、及如何实现公网访问步骤教程。 一,内网穿透原理解析 内网穿透的核心原理是通过中间服务器端口数据转发或点到点技术建立端对端的直连通信通道,使外网设备能够访问内网设备和服务。 1&…...
,侧重点会有所不同。看看Deepseek的建议)
购买电脑时,主要需要关注以下核心配置,它们直接影响性能、使用体验和价格。根据需求(办公、游戏、设计、编程等),侧重点会有所不同。看看Deepseek的建议
1. 处理器(CPU) 作用:电脑的“大脑”,影响整体运算速度和多任务处理能力。关键参数: 品牌与型号:Intel(酷睿i3/i5/i7/i9)或 AMD(锐龙R3/R5/R7/R9)。核心/线程…...

数据结构与算法[零基础]---4.树和二叉树
四、树和二叉树 (一)树 1.相关定义 树是由一个或多个结点组成的有限集T,它满足以下两个条件:第一个是有一个特定的结点,作为根结点;第二个其余的结点分成m(m>0)个互不相交的有限集T0,T1,.…...

Sklearn入门之数据预处理preprocessing
、 Sklearn全称:Scipy-toolkit Learn是 一个基于scipy实现的的开源机器学习库。它提供了大量的算法和工具,用于数据挖掘和数据分析,包括分类、回归、聚类等多种任务。本文我将带你了解并入门Sklearn下的preprocessing在机器学习中的基本用法。 获取方式…...

4.16学习总结 IO流综合练习
爬虫获取网站内的数据,获得完整姓名 网站一:姓氏 网站二:男生名字 网站三:女生名字 进行拼接,获取完整的男生女生姓名。 //导包 import org.apache.commons.io.FileUtils; import java.io.*; import java.io.IOEx…...

大模型全景解析:从技术突破到行业变革
目录 一、引言:人工智能的新纪元 二、大模型发展历史与技术演进 1. 早期探索期(2015-2017):从"人工智障"到初具规模 RNN/LSTM架构时代(2013-2017) Transformer革命(2017…...
)
充电宝项目中的MQTT(轻量高效的物联网通信协议)
文章目录 补充:HTTP协议MQTT协议MQTT的核心特性MQTT vs HTTP:关键对比 EMQX项目集成EMQX集成配置客户端和回调方法具体接口和方法处理处理类 补充:HTTP协议 HTTP是一种应用层协议,使用TCP作为传输层协议,默认端口是80…...

AgentOps - 帮助开发者构建、评估和监控 AI Agent
文章目录 一、关于 AgentOps二、关键集成 🔌三、快速开始 ⌨️2行代码中的Session replays 首类开发者体验 四、集成 🦾OpenAI Agents SDK 🖇️CrewAI 🛶AG2 🤖Camel AI 🐪Langchain 🦜…...

n8n 为技术团队打造的安全工作流自动化平台
AI MCP 系列 AgentGPT-01-入门介绍 Browser-use 是连接你的AI代理与浏览器的最简单方式 AI MCP(大模型上下文)-01-入门介绍 AI MCP(大模型上下文)-02-awesome-mcp-servers 精选的 MCP 服务器 AI MCP(大模型上下文)-03-open webui 介绍 是一个可扩展、功能丰富且用户友好的…...

MyBatis:SpringBoot结合MyBatis、MyBatis插件机制的原理分析与实战
🪁🍁 希望本文能给您带来帮助,如果有任何问题,欢迎批评指正!🐅🐾🍁🐥 文章目录 一、背景二、Spring Boot项目中结合MyBatis2.1 数据准备2.2 pom.xml依赖增加2.3 applicat…...

【数据结构】3.单链表专题
文章目录 单链表的实现0、准备工作1、链表的打印2、尾插3、头插4、尾删5、头删6、查找指定数据的位置7、在指定位置之前插入数据8、在指定位置之后插入数据9、删除指定位置的数据10、删除指定位置之后的数据11、单链表的销毁 单链表的实现 什么是单链表呢?单链表可…...
** 认证考试)
**Microsoft Certified Professional(MCP)** 认证考试
1. MCP 认证考试概述 MCP(Microsoft Certified Professional)是微软认证体系中的一项入门级认证,旨在验证考生在微软产品和技术(如 Windows Server、Azure、SQL Server、Microsoft 365)方面的技能。2020 年࿰…...

C++学习之游戏服务器开发git命令
目录 1.服务器需求分析 2.面向框架编程简介 3.ZINX框架初始 4.回显标准输入 5.VS结合GIT 6.完善readme范例 7.添加退出功能 8.添加命令处理类 9.添加日期前缀思路 10.添加日期前缀功能 1.服务器需求分析 zinx 描述 zinx 框架是一个处理多路 IO 的框架。在这个框架中提…...

Maven 多仓库与镜像配置全攻略:从原理到企业级实践
Maven 多仓库与镜像配置全攻略:从原理到企业级实践 一、核心概念:Repository 与 Mirror 的本质差异 在 Maven 依赖管理体系中,repository与mirror是构建可靠依赖解析链的两大核心组件,其核心区别如下: 1. Repositor…...

无锁队列--知识分享
目录 无锁队列 无锁队列是什么 为什么需要无锁队列 队列的类型 无锁队列的分类 ringbuffer(SPSC) ret_ring(MPMC) 无锁队列 无锁队列是什么 无锁队列通过原子操作来实现线程安全的队列,属于非阻塞队列 …...

Flask快速入门
1.安装 Flask 要使用 Flask,你需要先安装它。打开终端,运行以下命令: pip install flask 2.创建文件结构 3.app.py from flask import Flask:从 flask 库中导入 Flask 类。app Flask(__name__):创建一个 Flask 应…...

LeetCode -- Flora -- edit 2025-04-16
1.两数之和 1. 两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按…...
)
【Unity笔记】实现可视化配置的Unity按键输入管理器(按下/长按/松开事件 + UnityEvent绑定)
【Unity笔记】实现可视化配置的Unity按键输入管理器 适用于角色控制、技能触发的Unity按键输入系统,支持UnityEvent事件绑定、长按/松开监听与启用开关 一、引言 在 Unity 游戏开发中,处理键盘输入是最常见的交互方式之一。尤其是角色控制、技能释放、菜…...
(详细示例))
SpringMVC学习(请求与响应。常见参数类型接收与响应。@RequestParam、@RequestBody的使用)(详细示例)
目录 一、请求与响应。(RequestMapping) (1)使用注解RequestMapping对业务模块区分。 StudentController。 TeacherController。 (2)Apifox请求与响应。 "/student/login"。 "/teacher/login"。 二、常见参数…...

springboot 切面拦截自定义注解
使用切面来拦截被该注解标记的方法 依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency>1. 定义自定义注解 import java.lang.annotation.ElementType; imp…...
)
QT —— 信号和槽(自定义信号和槽函数)
QT —— 信号和槽(自定义信号和槽函数) 自定义信号和槽函数一、自定义信号函数规范1. 声明位置2. 返回值与实现3. 参数与重载 二、自定义槽函数规范1. 声明位置(不同版本差异)2. 返回值与实现3. 参数与重载 三、信号发射规范1. 基…...

朋克编码以潮玩语言讲述中国文化|益民艺术馆展演东方潮力
朋克编码于广州益民艺术馆推出“艺术家潮玩”系列主题展,将传统文化元素融入 潮玩设计,并通过数字科技与空间场景创新,讲述中国故事、传递东方美学。 展览作品结合太空猿等原创 IP 与“中式元素”视觉符号,引发观众情感共鸣。“我…...

TA学习之路——2.2 模型与材质基础
1.模型基础 1.1 图形渲染管线 1.2 模型实现的原理 点连成线,线构成面,面构成模型。 1.2 UV UV例如一个正方体的纸盒展开,平铺在一个二维的坐标系中。 模型的每一个顶点在三维空间和二维空间中都能一 一对应。在二维坐标系中的顶点对应的位置就是顶点的纹理坐标。 因此…...

helm的go模板语法学习
1、helm chart 1.0、什么是helm? 介绍:就是个包管理器。理解为java的maven、linux的yum就好。 安装方法也可参见官网: https://helm.sh/docs/intro/install 通过前面的演示我们知道,有了helm之后应用的安装、升级、查看、停止都…...
)
Windows 图形显示驱动开发-WDDM 1.2功能—Windows 8 中的 DirectX 功能改进(一)
Windows 8包括 Microsoft DirectX 功能改进,使开发人员、最终用户和系统制造商受益。 功能改进在以下几个方面: 像素格式 (5551、565、4444) :在低功耗硬件配置下,DirectX 应用程序的性能更高。双精度着色器功能:高级…...
)
软件测试|App测试面试相关问题(2)
一、App 稳定怎么做的?Monkey 怎么用(App 稳定测试)? 稳定性这块,我们当时用的是SDK 自动的一个Monkey 工具进行测试的,其实Monkey工具主要通过模拟用户发送伪随机时间去操作软件,通过执行Monkey 命令,它会自动出报告ÿ…...
)
模拟电路需要了解的一些基础知识(部分)
基本的单路元件 1. 电阻;特性:阻碍电流流动,消耗电能并转化为热能(遵循欧姆定律)。是无源元件,应用:限流、分压、发热等; 2. 电容;特性:存储电荷和电场能&am…...

[特殊字符] MySQL MCP 开发实战:打造智能数据库操作助手
💡 简介:本文详细介绍如何利用MCP(Model-Control-Panel)框架开发MySQL数据库操作工具,使AI助手能够直接执行数据库操作。 📚 目录 引言MCP框架简介项目架构设计开发环境搭建核心代码实现错误处理策略运行和…...