基于CNN+ViT的蔬果图像分类实验
本文只是做一个简单融合的实验,没有任何新颖,大家看看就行了。
1.数据集
本文所采用的数据集为Fruit-360 果蔬图像数据集,该数据集由 Horea Mureșan 等人整理并发布于 GitHub(项目地址:Horea94/Fruit-Images-Dataset),广泛应用于图像分类和目标识别等计算机视觉任务。该数据集共包含141 类水果和蔬菜图像,总计 94,110 张图像,每张图像的尺寸统一为 100×100 像素,且背景已统一处理为白色背景,以减少背景噪声对模型训练的影响。
数据集中涵盖了大量常见和不常见的果蔬品类,主要包括:
- 苹果(多个品种:如深雪、金苹果、金红、青奶奶、粉红女士、红苹果、红美味等)
- 香蕉(黄色、红色、淑女手指等)
- 葡萄(蓝色、粉红色、白色多个品种)
- 柑橘类(橙子、柠檬、酸橙、葡萄柚、柑橘等)
- 热带水果(芒果、木瓜、红毛丹、百香果、番石榴、荔枝、菠萝、火龙果等)
- 浆果类(蓝莓、覆盆子、草莓、黑加仑、红醋栗、桑葚等)
- 核果类与坚果类(桃子、李子、杏、椰子、榛子、核桃、栗子、山核桃等)
- 蔬菜类(黄瓜、茄子、胡椒、番茄、洋葱、花椰菜、甜菜根、玉米、土豆等)
- 其他类如:仙人掌果实、杨布拉、姜根、格兰纳迪拉、Physalis(灯笼果)、油桃、佩皮诺、罗望子、大头菜等。
在数据划分方面,本研究按照如下比例进行数据集划分:
(1)训练集:70,491 张图像
其中按照 8:2 的比例划分出验证集,得到最终:
训练子集:56,432 张
验证集:14,059 张
(2)测试集:23,619 张图像

2.模型简述
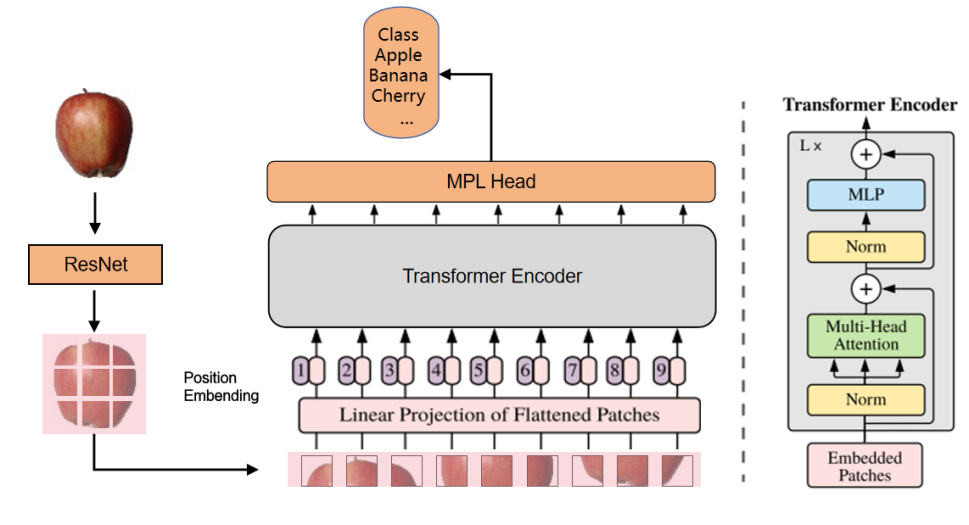
在图像分类任务中,深度学习方法已经取得了显著的进展,如残差神经网络(ResNet),Vision Transformer展现了较强的性能。ResNet作为CNN下的网络架构,在局部特征提取方面具有优势,能够有效地捕捉图像中的空间结构信息。而Vision Transformer作为Transformer的变种,在捕捉全局依赖关系和建模长程依赖性方面的具有更好的优势。
由于CNN的卷积操作本质上能够生成具有空间局部关联性的特征图,实际上可以视为一种变相的patch操作。因此,在将CNN与Transformer相结合时,可以避免传统ViT中对输入图像进行切分patch的操作,只需对图像进行位置编码,从而使得Transformer能够有效处理这些具有空间结构的特征图。这种设计不仅减少了计算开销,还使得整个模型在处理图像时更具效率与准确性。
同时,与原始ViT框架中描述的技术不同,原始框架通常会将一个可学习的位置嵌入向量预先添加到编码后的patch序列中,作为图像的位置信息进行表示。然而,为了简化模型的实现并提高计算效率,本文在架构设计上有所调整,省略了额外的位置编码步骤。具体来说,本文的模型通过直接输入编码后的patch序列到Transformer块中,跳过了对每个patch进行独立位置编码的操作。
基于这一思路,结合了残差神经网络(ResNet)和Vision Transformer(ViT)两种网络架构,将它们以串行连接的方式进行融合。具体模型架构图如下图所示
3.实验
模型代码(基于tensorflow2.X)
import glob
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers,models
import warnings
warnings.filterwarnings('ignore')
import osTrain = r"D:\archive (1)\fruits-360_dataset_100x100\fruits-360\Training"
Test = r"D:\archive (1)\fruits-360_dataset_100x100\fruits-360\Test"IMAGE_SIZE = 100
NUM_CLASSES = 141
BATCH_SIZE = 32imagegenerator = ImageDataGenerator(rescale=1.0 / 255.0, validation_split=0.2, rotation_range=10, horizontal_flip=True)# Training and validation data generators
Train_Data = imagegenerator.flow_from_directory(Train,target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=BATCH_SIZE,class_mode='categorical',subset='training'
)
Validation_Data = imagegenerator.flow_from_directory(Train,target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=BATCH_SIZE,class_mode='categorical',subset='validation'
)# Test data generator (no augmentation)
test_imagegenerator = ImageDataGenerator(rescale=1.0 / 255.0)
Test_Data = test_imagegenerator.flow_from_directory(Test,target_size=(IMAGE_SIZE,IMAGE_SIZE),batch_size=BATCH_SIZE,class_mode='categorical',# subset='test'
)
class ResidualBlock(layers.Layer):def __init__(self, filters, kernel_size=(3, 3), strides=1):super(ResidualBlock, self).__init__()self.conv1 = layers.Conv2D(filters, kernel_size, strides=strides, padding="same", activation='relu')self.conv2 = layers.Conv2D(filters, kernel_size, strides=1, padding='same', activation='relu')self.shortcut = layers.Conv2D(filters, (1, 1), strides=strides, padding='same', activation='relu')self.bn1 = layers.BatchNormalization()self.bn2 = layers.BatchNormalization()self.relu = layers.ReLU()def call(self, inputs):x = self.conv1(inputs)x = self.bn1(x)x = self.relu(x)x = self.conv2(x)x = self.bn2(x)shortcut = self.shortcut(inputs)x = layers.add([x, shortcut])x = self.relu(x)return x# ResNet Model definition
class ResNetModel(layers.Layer):def __init__(self):super(ResNetModel, self).__init__()self.conv1 = layers.Conv2D(32, (5, 5), activation='relu', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),padding='same')self.maxpool1 = layers.MaxPooling2D((2, 2))# Residual Blocksself.resblock1 = ResidualBlock(32,strides=1)self.resblock2 = ResidualBlock(64,strides=2)self.resblock3 = ResidualBlock(128,strides=2)self.resblock4 = ResidualBlock(256, strides=2)# self.global_avg_pool = layers.GlobalAveragePooling2D()def call(self, inputs):print(inputs.shape)x = self.conv1(inputs)print(x.shape)x = self.maxpool1(x)print(x.shape)# Apply Residual Blocksx = self.resblock1(x)print(x.shape)x = self.resblock2(x)print(x.shape)# x = self.resblock3(x)# print(x.shape)# x = self.resblock4(x)# x = self.global_avg_pool(x)# print(x.shape)return x
class TransformerEncoder(layers.Layer):def __init__(self, num_heads=8, key_dim=64, ff_dim=256, dropout_rate=0.1):super(TransformerEncoder, self).__init__()self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=key_dim)self.dropout1 = layers.Dropout(dropout_rate)self.norm1 = layers.LayerNormalization()self.ff = layers.Dense(ff_dim, activation='relu')self.ff_output = layers.Dense(key_dim*num_heads)self.dropout2 = layers.Dropout(dropout_rate)self.norm2 = layers.LayerNormalization()def call(self, x):# Multi-head self-attentionattention_output = self.attention(x, x)attention_output = self.dropout1(attention_output)x = self.norm1(attention_output + x) # Residual connection# Feed Forward Networkff_output = self.ff(x)ff_output = self.ff_output(ff_output)ff_output = self.dropout2(ff_output)x = self.norm2(ff_output + x) # Residual connectionreturn x# Vision Transformer (ViT) 模型
class VisionTransformer(models.Model):def __init__(self, input_shape=(100, 100, 3), num_classes=141, num_encoders=3, patch_size=8, num_heads=16,key_dim=4, ff_dim=256, dropout_rate=0.2):super(VisionTransformer, self).__init__()self.patch_size = patch_size#Resnetself.resnet=ResNetModel()# Patch Embeddingself.conv = layers.Conv2D(64, (patch_size, patch_size), strides=(patch_size, patch_size), padding='valid')self.reshape = layers.Reshape((-1, 64))self.norm = layers.LayerNormalization()# 位置编码层self.position_encoding = self.add_weight("position_encoding", shape=(1, 625, 64))# Stack multiple Transformer Encoder layersself.encoders = [TransformerEncoder(num_heads=num_heads, key_dim=key_dim, ff_dim=ff_dim, dropout_rate=dropout_rate) for _ inrange(num_encoders)]# Global Average Poolingself.global_avg_pooling = layers.GlobalAveragePooling1D()# Fully connected layerself.fc1 = layers.Dense(256, activation='relu')self.dropout = layers.Dropout(0.2)self.fc2 = layers.Dense(num_classes, activation='softmax')def call(self, inputs):#resnetx = self.resnet(inputs)# print("===========================")# print(x.shape)# Patch Embeddingx = self.reshape(x)# 添加位置编码x = x + self.position_encoding # 将位置编码加到Patch嵌入向量中# print(x.shape)# x = self.norm(x)# Apply multiple Transformer encodersfor encoder in self.encoders:x = encoder(x)# Global Average Poolingx = self.global_avg_pooling(x)# Fully connected layersx = self.fc1(x)x = self.dropout(x)x = self.fc2(x)return x
# 构建 Vision Transformer 模型vit_model = VisionTransformer(input_shape=(100, 100, 3), num_classes=141, num_encoders=3)
vit_model.build(input_shape=(None, IMAGE_SIZE, IMAGE_SIZE, 3)) # 手动构建模型
# 打印模型摘要
vit_model.summary()
# 编译模型
vit_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),loss='categorical_crossentropy',metrics=['accuracy']
)
checkpoint_path = "training_checkpoints_1/vit_model_checkpoint_epoch_{epoch:02d}.h5"# 创建ModelCheckpoint回调
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,monitor='val_accuracy', # 你可以选择监控验证集的损失或准确度save_best_only=True, # 只保存验证集损失最小的模型save_weights_only=True, # 只保存权重(而不是整个模型)verbose=1 # 打印日志
)
# 检查是否有保存的模型权重文件
checkpoint_dir = "training_checkpoints_1/"
# 查找所有的 .h5 文件
checkpoint_files = glob.glob(os.path.join(checkpoint_dir, "vit_model_checkpoint_epoch_*.h5"))
# print(latest_checkpoint)
if checkpoint_files:# 使用 os.path.getctime() 获取文件创建时间(或者使用 getmtime() 获取修改时间)latest_checkpoint = max(checkpoint_files, key=os.path.getctime)print(f"Loading model from checkpoint: {latest_checkpoint}")# 加载模型权重vit_model.load_weights(latest_checkpoint)
else:print("No checkpoint found, starting from scratch.")# 训练模型
history = vit_model.fit(Train_Data,epochs=20,validation_data=Validation_Data,shuffle=True,callbacks=[checkpoint_callback]
)# 评估模型
test_loss, test_acc = vit_model.evaluate(Test_Data)
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_acc}")
# 训练和验证的准确率和损失历史记录
def plot_training_history(history):# 创建子图plt.figure(figsize=(14, 6))# 准备训练准确率和验证准确率的图plt.subplot(1, 2, 1)plt.title('Accuracy History')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.plot(history.history['accuracy'], label='Training Accuracy', marker='o')plt.plot(history.history['val_accuracy'], label='Validation Accuracy', color='green', marker='o')plt.legend()# 准备训练损失和验证损失的图plt.subplot(1, 2, 2)plt.title('Loss History')plt.xlabel('Epochs')plt.ylabel('Loss')plt.plot(history.history['loss'], label='Training Loss', marker='o')plt.plot(history.history['val_loss'], label='Validation Loss', color='green', marker='o')plt.legend()# 显示图形plt.tight_layout()plt.show()# 绘制训练过程
plot_training_history(history)
for i in range(16):# 获取测试数据的下一个批次img_batch, labels_batch = Test_Data.next()img = img_batch[0] # 获取当前批次的第一张图像true_label_idx = np.argmax(labels_batch[0]) # 获取真实标签的索引# 获取真实标签的名称true_label = [key for key, value in Train_Data.class_indices.items() if value == true_label_idx]# 扩展维度以匹配模型输入EachImage = np.expand_dims(img, axis=0)# 进行预测prediction = vit_model.predict(EachImage)# 获取预测标签predicted_label = [key for key, value in Train_Data.class_indices.items() ifvalue == np.argmax(prediction, axis=1)[0]]# 获取预测的概率predicted_prob = np.max(prediction, axis=1)[0]# 绘制图像plt.subplot(4, 4, i + 1)plt.imshow(img)plt.title(f"True: {true_label[0]} \nPred: {predicted_label[0]} \nProb: {predicted_prob:.2f}")plt.axis('off')plt.tight_layout()
plt.show()做了如下参数实验
| ResNet层数 | Encoder层数 | num_heads | test_accuracy |
| 2(32,64) | 3 | 4 | 92.14% |
| 3(32,64,128) | 3 | 4 | 94.53% |
| 2(32,64) | 3 | 8 | 96.19% |
| 3(32,64,128) | 3 | 8 | 97.46% |
| 2(32,64) | 3 | 16 | 93.32% |
| 3(32,64,128) | 3 | 16 | 93.17% |
分类效果图

相关文章:

基于CNN+ViT的蔬果图像分类实验
本文只是做一个简单融合的实验,没有任何新颖,大家看看就行了。 1.数据集 本文所采用的数据集为Fruit-360 果蔬图像数据集,该数据集由 Horea Mureșan 等人整理并发布于 GitHub(项目地址:Horea94/Fruit-Images-Datase…...
)
MySQL SQL 执行顺序(理论顺序)
示例 SQL: SELECT name, COUNT(*) FROM users WHERE age > 18 GROUP BY name HAVING COUNT(*) > 1 ORDER BY name ASC LIMIT 10;虽然语句是从 SELECT 写起的,但执行顺序其实是这样的: 执行顺序SQL 子句作用说明①FROM确定查询的…...

用Allan Deviation的方式估计长时间频率偏差
在电路设计中,若需要评估OSC长时间的偏差(秒级别),观测的时间越多,低频噪声1/f上载的越厉害,如何通过PhaseNoise去有效估计长时间的偏差呢?...

无人机避障与目标识别技术分析!
一、无人机避障技术 1. 技术实现方式 传感器融合: 视觉传感(RGB/双目/红外相机):基于SLAM(同步定位与地图构建)实现环境建模,但依赖光照条件。 激光雷达(LiDAR)&…...
)
2025年渗透测试面试题总结-拷打题库01(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 2025年渗透测试面试题总结-拷打题库01 1. PHP爆绝对路径方法? 2. 渗透工具及最常用工具 3…...

大厂面试:六大排序
前言 本篇博客集中了冒泡,选择,二分插入,快排,归并,堆排,六大排序算法 如果觉得对你有帮助,可以点点关注,点点赞,谢谢你! 1.冒泡排序 //冒泡排序ÿ…...

Python爬虫第15节-2025今日头条街拍美图抓取实战
目录 一、项目背景与概述 二、环境准备与工具配置 2.1 开发环境要求 2.2 辅助工具配置 三、详细抓取流程解析 3.1 页面加载机制分析 3.2 关键请求识别技巧 3.3 参数规律深度分析 四、爬虫代码实现 五、实现关键 六、法律与道德规范 一、项目概述 在当今互联网时代&a…...

std::map gdb调试ok ,直接运行会crash
在使用 std::map 并且在调试模式下没有问题,但在直接运行时出现崩溃(crash)的情况,通常是由于以下几个原因引起的: 未初始化的变量使用:在调试模式下,某些变量可能因为调试工具(如 G…...

【2025年泰迪杯数据挖掘挑战赛】A题 数据分析+问题建模与求解+Python代码直接分享
目录 2025年泰迪杯数据挖掘挑战赛A题完整论文:建模与求解Python代码1问题一的思路与求解1.1 问题一的思路1.1.1对统计数据进行必要说明:1.1.2统计流程:1.1.3特殊情况的考虑: 1.2 问题一的求解1.2.1代码实现1.2.2 问题一结果代码分…...

git在分支上会退到某个指定的commit
1、在idea上先备份好分支(基于现有分支new branch) 2、在gitlab管理端删除现有分支 3、在idea中大卡terminal,执行 git log 查看commit log ,找到要会退到的commit唯一码,然后执行git reset 唯一码 4、查看本地代码状态 git st…...

Cursor入门教程-JetBrains过度向
Cursor使用笔记 **前置:**之前博主使用的是JetBrains的IDE,VSCode使用比较少,所以会尽量朝着JetBrains的使用习惯及样式去调整。 一、设置语言为中文 如果刚上手Cursor,那么肯定对Cursor中的众多选项配置项不熟悉,这…...

MySQL之text字段详细分类说明
在 MySQL 中,TEXT 是用来存储大量文本数据的数据类型。TEXT 类型可以存储非常长的字符串,比 VARCHAR 类型更适合存储大块的文本数据。TEXT 数据类型分为以下几个子类型,每个子类型用于存储不同大小范围的文本数据: TINYTEXT: 可以…...
为什么 Transformer 要使用多头注意力机制?
简而言之,多头注意力机制可以让模型从不同的在空间中并行地捕捉到不同的特征关系,从而更全面,更灵活地理解序列中的信息。 举个例子,如果要看一幅画,就不能简单地只关注例如颜色,还要关注到结构࿰…...

Python项目--基于Python的自然语言处理文本摘要系统
1. 项目概述 自然语言处理(NLP)是人工智能领域中一个重要的研究方向,而文本摘要作为NLP的一个重要应用,在信息爆炸的时代具有重要意义。本项目旨在开发一个基于Python的文本摘要系统,能够自动从长文本中提取关键信息,生成简洁而全…...
)
【Web APIs】JavaScript 操作多个元素 ③ ( 鼠标经过高亮显示 | onmouseover 事件设置 | onmouseout 事件设置 )
文章目录 一、核心要点解析 - 鼠标经过高亮显示1、案例需求2、获取高亮显示的 列表行3、鼠标经过 onmouseover 事件设置4、鼠标离开 onmouseout 事件设置5、设置高亮方式 二、完整代码示例1、完整代码示例2、执行结果 一、核心要点解析 - 鼠标经过高亮显示 1、案例需求 案例需求…...

金融的未来
1. DeFi的爆发式增长与核心使命 DeFi(去中心化金融)的使命是重构传统金融基础设施,通过区块链技术实现更高的透明度、可访问性、效率、便利性和互操作性。其增长数据印证了这一趋势: TVL(总锁定价值)爆炸…...
)
[ElasticSearch]Suggest查询建议(自动补全纠错)
概述 搜索一般都会要求具有“搜索推荐”或者叫“搜索补全”的功能,即在用户输入搜索的过程中,进行自动补全或者纠错。以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest。 四种Suggester 1 Term Suggester…...

GPT-4.1 提示词使用指南
GPT-4.1 提示词使用指南 参考:https://cookbook.openai.com/examples/gpt4-1_prompting_guide 为什么要关注 GPT-4.1 提示词使用指南? GPT-4.1 比其前代模型 GPT-4o 更倾向于严格跟随指令,而不是像 GPT-4o 那样更自由地推断用户和系统提示…...
╭)
es6面试常见问题╮(╯▽╰)╭
ES6(ECMAScript 2015)的一些常见面试问题,涵盖了变量声明、箭头函数、模板字符串、解构赋值、模块化、类、Promise、生成器等关键特性。有些面试就是问问,对老程序员面试其实不问这么多╮(╯▽╰)╭ 文章目录 **1. 变量声明****1.1 `let` 和 `const` 与 `var` 的区别是什么…...

Xenomai 如何实现 <10μs 级抖动控制
1. 抖动(Jitter)的定义与重要性 1.1 什么是抖动? 在实时控制系统中,抖动(Jitter)指任务实际执行时间与预期周期时间的偏差。例如: • 设定一个任务每 100μs 运行一次,但实际运行时间…...

前端基础常见的算法
你整理的这些前端常见算法知识点挺实用的,适合复习或面试准备。下面我帮你稍微整理美化一下格式,并补充一点细节,让内容更清晰易读: 1. 排序算法 冒泡排序(Bubble Sort) 原理:通过重复比较相邻元…...

RPA机器人技术原理初探
RPA(Robotic Process Automation,机器人流程自动化)通过模拟人类操作界面元素来实现自动化任务,其技术原理可分为以下核心模块: 一、基础技术架构 界面元素识别技术 选择器(Selector)引擎&#…...

AWS CloudFront加速S3配置跨域
1、点击分配 源我们就选择S3–>选择我们要加速的S3存储桶 2、创建OAC访问方式 在我们的来源访问处–>来源访问控制设置(推荐)–>选择创建新的OAC(Create new OAC)–>自定义名字按默认选项保存–>选择刚刚新创建的OAC 3、选择查看器的配置 根据具体情况&#x…...

58.最后一个单词的长度
目录 一、问题描述 二、解题思路 三、代码 四、复杂度分析 一、问题描述 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 二、解题思…...

leetcode_344.反转字符串_java
344. 反转字符串 1、题目 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 示例 1: 输入:…...

Android --- FrameWork 入门:极速上手AOSP
文章目录 一、硬件要求二、虚拟机安装三、开发环境搭建四、下载编译源码 一、硬件要求 CPU不低于6核心,建议8核及以上 内存不低于32G,建议64G 存储空间不低于500G,建议 1TB SSD 二、虚拟机安装 1.下载ubuntu,官网网址如下: releases.ubuntu.com/focal…...

“大湾区珠宝艺境花园”璀璨绽放第五届消博会
2025年4月13日,第五届中国国际消费品博览会(以下简称"消博会")重要主题活动——《大湾区珠宝艺境花园》启动仪式在海南国际会展中心2号馆隆重举行。由广东省金银珠宝玉器业厂商会组织带领粤港澳大湾区优秀珠宝品牌,以“…...

Spring Boot系列之使用Arthas Tunnel Server 进行远程调试实践
Spring Boot系列之使用Arthas Tunnel Server 进行远程调试实践 前言 在开发和运维 Java 应用的过程中,远程诊断和调试是一个不可或缺的需求。尤其是当生产环境出现问题时,能够快速定位并解决这些问题至关重要。Arthas 是阿里巴巴开源的一款强大的 Java…...

ILGPU的核心功能使用详解
什么是ILGPU? ILGPU 是一种用于高性能 GPU 程序的新型 JIT(即时)编译器 (也称为 kernels)编写的 .基于 Net 的语言。ILGPU 完全 用 C# 编写,没有任何原生依赖项,允许您编写 GPU 真正可移植的程序。…...
 工具)
Ubuntu服务器日志满audit:backlog limit exceeded了会报错解决方案-Linux 审计系统 (auditd) 工具
auditd 是 Linux 系统中的审计守护进程,负责收集、记录和监控系统安全相关事件。以下是相关工具及其功能: 核心组件 auditd - 审计守护进程 系统的审计服务主程序 收集系统调用信息并写入日志文件 通常存储在 /var/log/audit/audit.log auditctl - 审计控…...

数据加载与保存
通用方式 SparkSQL提供了通用的数据加载方式,使用spark.read.loa方法,并可通过format指定数据类型(如csv、jdbc、json、orc、parquet、textFile)。 load方法后需传入数据路径(针对csv、jdbc、json、orc、parquet、…...

TODO!! IM项目2
感觉似乎部署好了 真不容易 mysql、redis、 rocketmq(nameserver、broker)、nginx 看代码里是mybatisplus、netty->protobuf协议 现在还发不出去消息 每个密码都要改对 现在可以发消息了但不能at 房间成员也没有 broker内存不够? 从…...

Android ImageView 使用详解
文章目录 一、基本使用1. XML 中声明 ImageView2. Java/Kotlin 中设置图片 二、图片缩放类型 (scaleType)三、加载网络图片1. 使用 Glide (推荐)2. 使用 Picasso 四、高级功能1. 圆形图片2. 圆角图片3. 图片点击缩放动画 五、性能优化六、常见问题解决 ImageView 是 Android 中…...

工资管理系统的主要功能有哪些
工资管理系统通过自动化薪资计算、税务处理、员工数据管理、报表生成等功能,极大地提升了薪资发放的效率和准确性。在传统的人工薪资管理中,HR人员需要手动计算每位员工的薪资,并确保符合税务要求,极易出错且耗时。而现代工资管理…...

WordPiece 详解与示例
WordPiece详解 1. 定义与背景 WordPiece 是一种子词分词算法,由谷歌于2012年提出,最初用于语音搜索系统,后广泛应用于机器翻译和BERT等预训练模型。其核心思想是将单词拆分为更小的子词单元(如词根、前缀/后缀),从而解决传统分词方法面临的词汇表过大和未知词(OOV)处…...

【LeetCode基础算法】滑动窗口与双指针
定长滑动窗口 总结:入-更新-出。 入:下标为 i 的元素进入窗口,更新相关统计量。如果 i<k−1 则重复第一步。 更新:更新答案。一般是更新最大值/最小值。 出:下标为 i−k1 的元素离开窗口,更新相关统计量…...

日本Shopify 3月数据:家居品类销售额激增120%!
2024年第一季度末,电商平台运营商Shopify发布了3月份的最新销售数据,引发业界高度关注。据最新数据显示,日本市场家居品类销售在3月份实现了惊人的增长,同比激增120%,成为该区域增速最快的类目。这一变化不仅映射出日本…...

C语言多进程素数计算
题目描述: 以下代码实现了一个多进程素数计算程序,通过fork()函数创建子进程来并行计算指定范围内的素数。请仔细阅读代码并回答以下问题。 #include "stdio.h" #include "unistd.h" #include <sys/types.h> #include "…...

链表知识回顾
类型:单链表,双链表、循环链表 存储:在内存中不是连续存储 删除操作:即让c的指针指向e即可,无需释放d,因为java中又内存回收机制 添加节点: 链表的构造函数 public class ListNode {// 结点…...

数据库勒索病毒威胁升级:企业数据安全防线如何用安当RDM组件重构
摘要:2025年Q1全球数据库勒索攻击量同比激增101.8%,Cl0p、Akira等团伙通过边缘设备漏洞渗透企业核心系统,制造业、金融业等关键领域面临数据加密与业务停摆双重危机。本文深度解析勒索病毒对数据库的五大毁灭性影响,结合安当RDM防…...

50%时效提升!中巴新航线如何重构ebay跨境电商物流成本?
50%时效提升!中巴新航线如何重构eBay跨境电商物流成本? 近年,拉美市场逐步升温,特别是巴西,已成为中国跨境卖家争相布局的新蓝海市场。而随着eBay大力拓展拉美板块,更多卖家开始将目光投向这个人口超2亿、…...

自建 eSIM RSP 服务指南
一、 自建 eSIM RSP 服务的必要性评估 在决定是否自建 RSP(远程 SIM 配置)服务时,企业需要全面了解其带来的利弊。以下是核心要点: 1. GSMA 安全认证 (SAS-SM) 的重要性 目的: 确保 RSP 服务符合全球移动网络运营商 (MNO) 对安…...

TensorRT模型部署剪枝
TensorRT模型部署剪枝 本文属于学习笔记,在重点章节或代码位置加入个人理解,欢迎批评指正! 参考: CUDA与TensorRT部署部署实战第四章 一. Pruning 学习目标 理解什么是模型剪枝模型剪枝的分类,以及各类剪枝的利弊都…...

Servlet 线程安全与并发编程深度解析
Servlet 线程安全与并发编程深度解析 一、Servlet 线程安全机制与风险场景 1.1 Servlet 容器工作原理 单实例多线程模型:每个Servlet在容器中只有一个实例,通过线程池处理并发请求请求处理流程: 接收HTTP请求创建HttpServletRequest和HttpS…...

C++学习:六个月从基础到就业——面向对象编程:封装、继承与多态
C学习:六个月从基础到就业——面向对象编程:封装、继承与多态 本文是我C学习之旅系列的第九篇技术文章,主要讨论C中面向对象编程的三大核心特性:封装、继承与多态。这些概念是理解和应用面向对象设计的关键。查看完整系列目录了解…...

光谱相机的成像方式
光谱相机的成像方式决定了其如何获取物体的空间与光谱信息,核心在于分光技术与扫描模式的结合。以下是主要成像方式的分类解析: 一、滤光片切换型 1. 滤光片轮(Filter Wheel) 原理:通过旋转装有多个窄带…...

Excel 中让表格内容自适应列宽和行高
Excel 中让表格内容自适应列宽和行高 目录 Excel 中让表格内容自适应列宽和行高自适应列宽自适应行高在Excel中让表格内容自适应列宽和行高,可参考以下操作: 自适应列宽 方法一:手动调整 选中需要调整列宽的列(如果是整个表格,可点击表格左上角行号和列号交叉处的三角形全…...

android rtsp 拉流h264 h265,解码nv12转码nv21耗时卡顿问题及ffmpeg优化
一、 背景介绍及问题概述 项目需求需要在rk3568开发板上面,通过rtsp协议拉流的形式获取摄像头预览,然后进行人脸识别 姿态识别等后续其它操作。由于rtsp协议一般使用h.264 h265视频编码格式(也叫 AVC 和 HEVC)是不能直接用于后续处…...
--网络编程)
Day(21)--网络编程
网络编程 在网络通信协议下,不同计算机上运行的程序,进行的数据传输 应用场景:即使通信、网友对战、金融证券等等,不管是什么场景,都是计算机和计算机之间通过网络进行的数据传输 java.net 常见的软件架构 C/S&am…...

Android主流播放器功能详解
Android主流播放器功能详解 前言 本文将深入介绍Android三大主流播放框架(ijkplayer、ExoPlayer和MediaPlayer)的功能特性和实战应用,帮助你选择合适的播放框架并掌握其使用方法。 三大播放框架概述 播放框架开发方特点适用场景MediaPlayerAndroid官方简单易用,系统内置…...