Python爬虫第15节-2025今日头条街拍美图抓取实战
目录
一、项目背景与概述
二、环境准备与工具配置
2.1 开发环境要求
2.2 辅助工具配置
三、详细抓取流程解析
3.1 页面加载机制分析
3.2 关键请求识别技巧
3.3 参数规律深度分析
四、爬虫代码实现
五、实现关键
六、法律与道德规范
一、项目概述
在当今互联网时代,数据采集与分析已成为重要的技术能力。本教程将以今日头条街拍美图为例,详细介绍如何通过Python实现Ajax数据抓取的完整流程。
今日头条作为国内领先的内容平台,其图片内容资源丰富,特别是街拍类图片深受用户喜爱。通过分析其Ajax接口,我们可以学习到现代Web应用的数据加载方式,掌握处理动态内容的爬虫开发技巧。
二、环境准备与工具配置
2.1 开发环境要求
1. Python环境:建议使用Python 3.6及以上版本
- 可通过官网下载安装:https://www.python.org/downloads/
- 安装后验证:`python --version`
2. 必需库安装:
pip install requests urllib3 hashlib multiprocessing3. 推荐开发工具:
- IDE:PyCharm、VS Code
- 浏览器:Chrome(用于开发者工具分析)
- 调试工具:Postman(用于接口测试)
2.2 辅助工具配置
1. Chrome开发者工具:
- 快捷键F12或右键"检查"打开
- 重点使用Network面板和Elements面板
- 建议开启"Preserve log"选项保留请求记录
2. 代理设置(可选):
略
三、详细抓取流程解析
3.1 页面加载机制分析
现代Web应用普遍采用前后端分离架构,理解其数据加载原理至关重要:
1. 传统网页:服务端渲染,HTML包含所有内容
2. 现代SPA:初始HTML为空壳,通过Ajax动态加载数据
下面以今日头条为例分析:
首次加载基础框架

在今日头条首页( https://www.toutiao.com/),直接输入街拍搜索,然后如下点击图片选项,就会出现大把的美女图片。
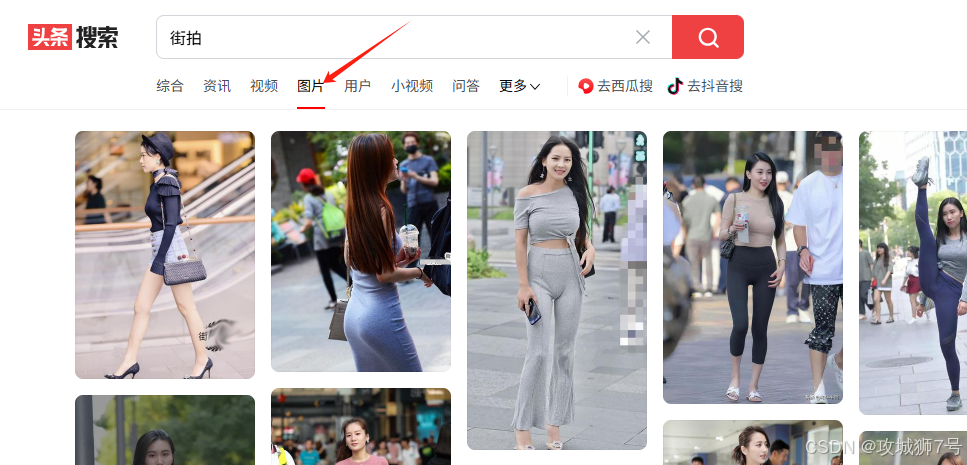
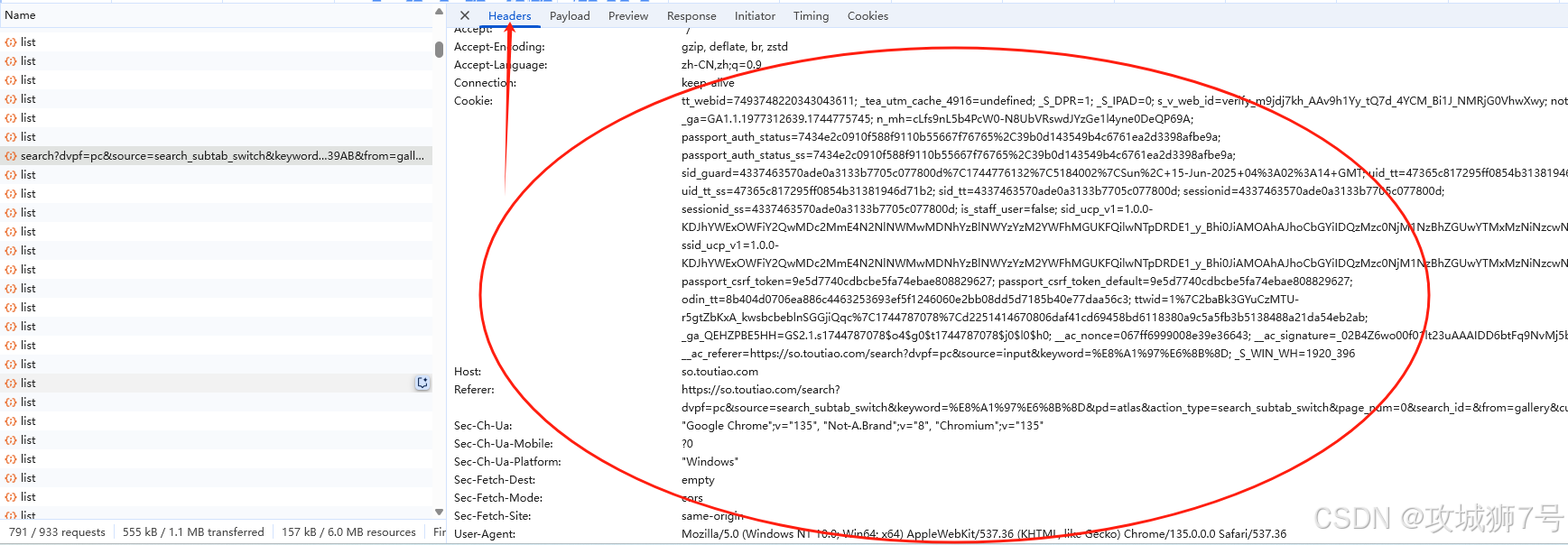
这时按ctrl+s即可保存所有已加载的网页内容,保存下来的网页可以直接搜到jpeg的图片链接。但是我们现在要查看接口请求,我们按F12打开开发者工具,重新加载页面,查看所有的网络请求。
首先,查看发起第一个网络请求,请求的URL是 ( https://so.toutiao.com/search?dvpf=pc&source=search_subtab_switch&keyword=%E8%A1%97%E6%8B%8D&pd=atlas&action_type=search_subtab_switch&page_num=0&search_id=&from=gallery&cur_tab_title=gallery )。然后打开Preview选项卡,查看响应体内容。要是页面上的内容是依据第一个请求的结果渲染出来的 。
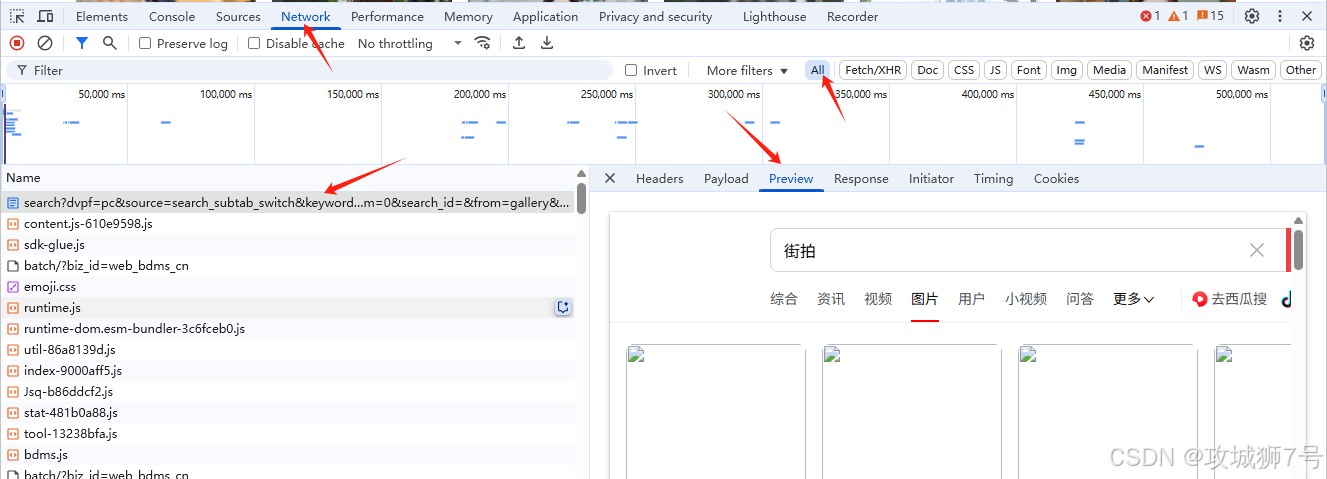
由于查看他的请求头内容Headers没有明确的 X-Requested-With 请求头,看不出是ajax请求。
通过XHR请求获取实际内容
然而我点击Fetch/XHR进行过滤ajax请求,并快速向下滚动页面就会发现下面某接口:
https://so.toutiao.com/search?dvpf=pc&source=search_subtab_switch&keyword=%E8%A1%97%E6%8B%8D&pd=atlas&action_type=search_subtab_switch&page_num=1&search_id=20250416152239B787556EC505238FF4F8&from=gallery&cur_tab_title=gallery&rawJSON=1
其中请求头内容的sec-fetch-mode: cors 和其他请求头(如 accept: */*)以及请求的行为模式(如通过查询参数发送数据),这些都是AJAX 请求特征。
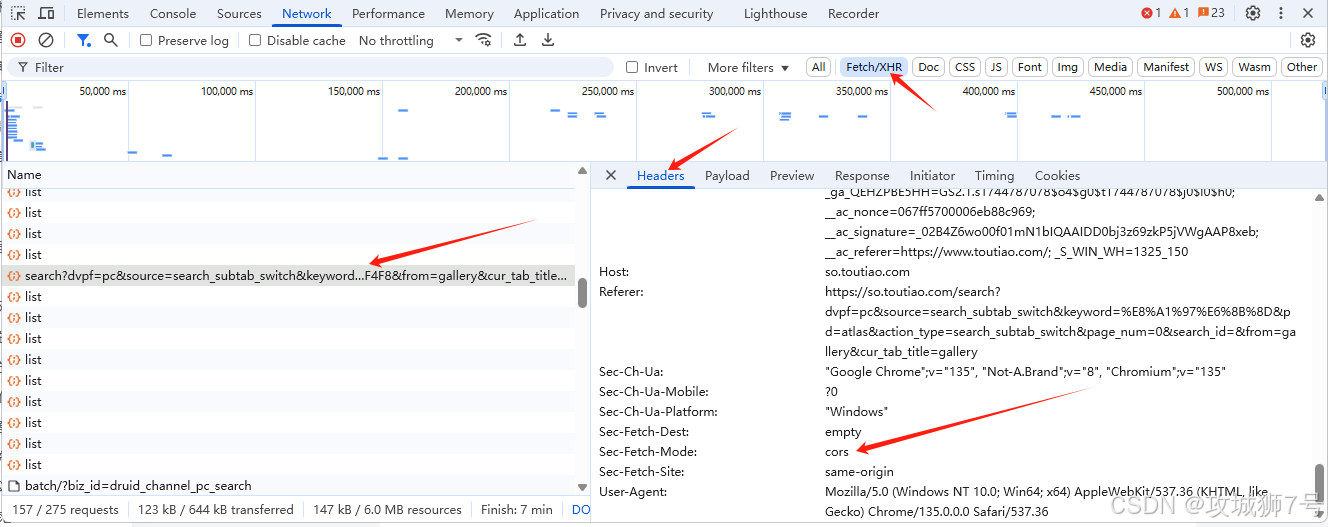
然后点击Preview查看响应数据的数据结构
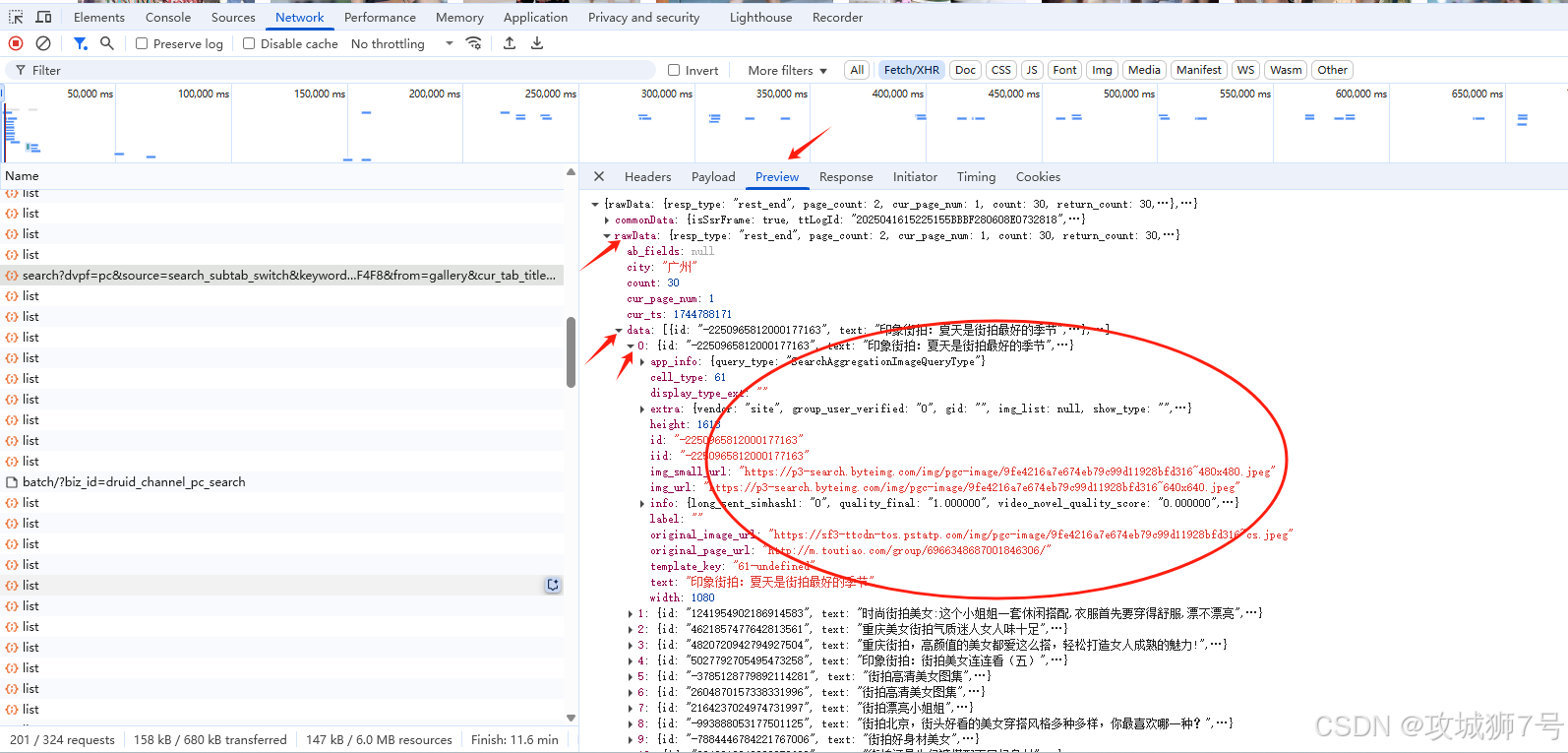
看得出为了防止连续被爬取图片,参数page_num和search_id是有限制关系的,即使page_num有规律,但是search_id却另外计算获取。
3.2 关键请求识别技巧
在开发者工具的Network面板中:
1. 过滤XHR请求:快速定位Ajax调用
2. Preview功能:直观查看JSON数据结构
3. Headers分析:
- Request URL:接口地址
- Request Method:GET/POST
- Query Parameters:请求参数
4. 时序分析:通过Waterfall了解加载顺序
3.3 参数规律深度分析
从提供的 URL,我们可以解析出一系列的查询参数(query parameters),每个参数都有其特定的作用:
1. `dvpf=pc`: 这个参数可能指示请求是从个人计算机(PC)发出的,可能用于区分不同设备类型的请求,如移动端或平板电脑。
2. `source=search_subtab_switch`: 这个参数可能表示请求的来源,这里是“search_subtab_switch”,可能是指用户在搜索结果的子标签页之间进行切换时触发的请求。
3. `keyword=%E8%A1%97%E6%8B%8D`: 这是经过URL编码的搜索关键词,解码后是“街拍”。这是用户在搜索框中输入的关键词。
4. `pd=atlas`: 这个参数的具体含义不是很清晰,它可能指的是请求的特定部分或页面(Page Division)。
5. `action_type=search_subtab_switch`: 类似于 `source` 参数,这个参数可能指明了用户执行的动作类型,这里是在搜索子标签页之间切换。
6. `page_num=1`: 这个参数指示请求的是搜索结果的第几页,这里是第2页,从0开始算。
7. `search_id=20250416152239B787556EC505238FF4F8`: 这是一个唯一的搜索会话标识符,用于追踪用户的搜索会话。
8. `from=gallery`: 这个参数可能指示用户是从图库部分发起搜索的。
9. `cur_tab_title=gallery`: 这个参数可能表示当前活动的标签页标题是图库。
10. `rawJSON=1`: 这个参数指示服务器返回的数据格式应该是原始的 JSON 格式,而不是经过任何服务器端处理的数据。
每个参数都是键值对的形式,通过 `&` 符号连接。服务器会解析这些参数,以便根据用户的请求提供定制化的内容。例如,服务器可以根据 `keyword` 参数提供搜索关键词的相关结果,`page_num` 参数用来分页显示结果,而 `search_id` 用来保持搜索会话的连续性。
四、爬虫代码实现
模拟请求的时候需要设置必要的请求头参数,包括cookie等,不然请求拿不到数据。因为search_id暂时还没找到解决办法,只能获取某一页数据。由于search_id会变,所以下面拿了最新的模拟请求:
import requests
import re
import os
from hashlib import md5
import json
from urllib.parse import urlencode
import time
import gzip
import iodef get_page(page_num):base_url = 'https://so.toutiao.com/search?'params = {'dvpf': 'pc','source': 'search_subtab_switch','keyword': '街拍','pd': 'atlas','action_type': 'search_subtab_switch','page_num': page_num,'search_id': '202504161626333A15E72F0B54BF7C39AB','from': 'gallery','cur_tab_title': 'gallery','rawJSON': '1'}headers = {'Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Cookie': 'tt_webid=7493748220343043611; _tea_utm_cache_4916=undefined; _S_DPR=1; _S_IPAD=0; s_v_web_id=verify_m9jdj7kh_AAv9h1Yy_tQ7d_4YCM_Bi1J_NMRjG0VhwXwy; notRedShot=1; _ga=GA1.1.1977312639.1744775745; n_mh=cLfs9nL5b4PcW0-N8UbVRswdJYzGe1l4yne0DeQP69A; passport_auth_status=7434e2c0910f588f9110b55667f76765%2C39b0d143549b4c6761ea2d3398afbe9a; passport_auth_status_ss=7434e2c0910f588f9110b55667f76765%2C39b0d143549b4c6761ea2d3398afbe9a; sid_guard=4337463570ade0a3133b7705c077800d%7C1744776132%7C5184002%7CSun%2C+15-Jun-2025+04%3A02%3A14+GMT; uid_tt=47365c817295ff0854b31381946d71b2; uid_tt_ss=47365c817295ff0854b31381946d71b2; sid_tt=4337463570ade0a3133b7705c077800d; sessionid=4337463570ade0a3133b7705c077800d; sessionid_ss=4337463570ade0a3133b7705c077800d; _S_WIN_WH=1920_396; __ac_nonce=067ff6999008e39e36643; __ac_signature=_02B4Z6wo00f01lt23uAAAIDD6btFq9NvMj5bVtpAAPEx9d; __ac_referer=https://so.toutiao.com/search?dvpf=pc&source=input&keyword=%E8%A1%97%E6%8B%8D','Host': 'so.toutiao.com','Referer': 'https://so.toutiao.com/search?dvpf=pc&source=search_subtab_switch&keyword=%E8%A1%97%E6%8B%8D&pd=atlas&action_type=search_subtab_switch&page_num=0&search_id=&from=gallery&cur_tab_title=gallery','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"'}url = base_url + urlencode(params)try:# 直接请求数据response = requests.get(url, headers=headers, stream=True)if response.status_code == 200:try:# 尝试直接解析响应内容content = response.texttry:json_data = json.loads(content)return json_dataexcept json.JSONDecodeError:print(f"Failed to decode JSON. Response content: {content[:200]}...")# 如果解析失败,尝试解码原始内容raw_content = response.content.decode('utf-8', errors='ignore')print(f"Raw content: {raw_content[:200]}...")return Noneexcept Exception as e:print(f"Error processing response: {str(e)}")print(f"Response headers: {response.headers}")return Noneelse:print(f"Request failed with status code: {response.status_code}")return Noneexcept requests.ConnectionError as e:print('Error occurred while fetching the page:', e)return Nonedef parse_images(json_data):if not json_data or 'rawData' not in json_data:return# 解析返回的JSON数据data = json_data['rawData'].get('data', [])for item in data:if item.get('text') and (item.get('img_url') or item.get('original_image_url')):title = item.get('text', '')# 优先使用img_urlimage_url = item.get('img_url', '')if not image_url:image_url = item.get('original_image_url', '')yield {'title': title,'image': image_url,'width': item.get('width', 0),'height': item.get('height', 0)}def save_image(item):if not item.get('title') or not item.get('image'):return# 清理文件名中的非法字符title = re.sub(r'[\\/:*?"<>|]', '_', item.get('title'))img_path = 'img' + os.path.sep + titleif not os.path.exists(img_path):os.makedirs(img_path)max_retries = 3retry_count = 0original_url = item.get('image')# 构建可能的URL列表image_urls = []if 'pstatp.com' in original_url or 'ttcdn-tos' in original_url:# 移除协议头以便替换域名url_without_protocol = original_url.split('://')[-1]# 替换域名domains = ['p3-search.byteimg.com','p1-search.byteimg.com','p6-search.byteimg.com','p3-tt.byteimg.com','p1-tt.byteimg.com','p6-tt.byteimg.com']# 替换图片格式和尺寸formats = ['~640x640.jpeg','~480x480.jpeg','~noop.image','~tplv-tt-cs0.jpeg']base_url = url_without_protocol.split('~')[0]for domain in domains:for fmt in formats:url = f'https://{domain}/{base_url.split("/", 1)[1]}{fmt}'if url not in image_urls:image_urls.append(url)# 始终添加原始URL作为最后的选项if original_url not in image_urls:image_urls.append(original_url)# 请求头img_headers = {'Accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Referer': 'https://so.toutiao.com/','Origin': 'https://so.toutiao.com','Sec-Fetch-Dest': 'image','Sec-Fetch-Mode': 'no-cors','Sec-Fetch-Site': 'cross-site','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36','Cookie': 'tt_webid=7493748220343043611; _tea_utm_cache_4916=undefined; _S_DPR=1; _S_IPAD=0; s_v_web_id=verify_m9jdj7kh_AAv9h1Yy_tQ7d_4YCM_Bi1J_NMRjG0VhwXwy'}success = Falsefor image_url in image_urls:if retry_count >= max_retries:breaktry:# 使用stream=True来分块下载response = requests.get(image_url, headers=img_headers, stream=True, timeout=10)if response.status_code == 200:try:# 使用响应内容的前8192字节来计算MD5first_chunk = next(response.iter_content(chunk_size=8192))file_name = md5(first_chunk).hexdigest()file_path = img_path + os.path.sep + f'{file_name}.jpg'if not os.path.exists(file_path):# 分块写入文件,先写入第一块with open(file_path, 'wb') as f:f.write(first_chunk)# 继续写入剩余的块for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)print('Downloaded image path is %s' % file_path)print(f'Image size: {item.get("width")}x{item.get("height")}')else:print('Already Downloaded', file_path)success = Truebreakexcept Exception as e:print(f'Error processing image data: {str(e)}')continueelse:print(f"Failed to download image, status code: {response.status_code}")print(f"Image URL: {image_url}")except Exception as e:print('Error downloading image:', str(e))print(f"Image URL: {image_url}")retry_count += 1if not success and retry_count < max_retries:print(f"Retrying... ({retry_count}/{max_retries})")time.sleep(2)if not success:print(f"Failed to download image after trying all URL variations")def main(page):json_data = get_page(page)if json_data:for item in parse_images(json_data):save_image(item)else:print(f"Failed to get data for page {page}")if __name__ == '__main__':# 爬取第1页print('Starting page 1...')main(1)print('Page 1 completed')
爬取结果:
五、实现关键
1. 请求头模拟
headers = {'Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Referer': 'https://so.toutiao.com/','Origin': 'https://so.toutiao.com','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24"...','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"'
}- 模拟真实浏览器的请求头
- 添加 Referer 和 Origin 防盗链
- 设置正确的 Sec-Fetch-* 系列头
- 使用最新的 Chrome User-Agent
2. Cookie 处理
'Cookie': 'tt_webid=7493748220343043611; _tea_utm_cache_4916=undefined; s_v_web_id=verify_m9jdj7kh_AAv9h1Yy_tQ7d_4YCM_Bi1J_NMRjG0VhwXwy; ...'- 使用有效的会话 Cookie
- 包含必要的认证信息
- 保持登录状态
3. 多域名策略
domains = ['p3-search.byteimg.com','p1-search.byteimg.com','p6-search.byteimg.com','p3-tt.byteimg.com','p1-tt.byteimg.com','p6-tt.byteimg.com'
]- 尝试多个 CDN 域名
- 在域名被封禁时自动切换
- 使用不同的图片服务器
4. URL 格式变换
formats = ['~640x640.jpeg','~480x480.jpeg','~noop.image','~tplv-tt-cs0.jpeg'
]- 尝试不同的图片格式和尺寸
- 使用多种图片后缀
- 适应不同的图片处理参数
5. 请求延时和重试
time.sleep(2) # 增加等待时间
max_retries = 3 # 最大重试次数- 添加请求间隔,避免频率过高
- 实现重试机制
- 错误时优雅退出
6. 分块下载
response = requests.get(url, headers=headers, stream=True)
for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)- 使用流式下载
- 分块处理大文件
- 避免内存占用过大
7. 错误处理
try:# 下载尝试
except Exception as e:print('Error downloading image:', str(e))print(f"Image URL: {image_url}")- 详细的错误信息记录
- 异常捕获和处理
- 失败时的优雅降级
8. URL 优先级策略
# 优先使用img_url
image_url = item.get('img_url', '')
if not image_url:image_url = item.get('original_image_url', '')- 优先使用缩略图 URL
- 备选原始图片 URL
- 多重 URL 备份
9. 请求超时设置
response = requests.get(image_url, headers=img_headers, stream=True, timeout=10)- 设置合理的超时时间
- 避免请求挂起
- 提高程序稳定性
10. 文件处理优化
file_name = md5(first_chunk).hexdigest()
if not os.path.exists(file_path):# 写入文件- 使用 MD5 避免重复下载
- 检查文件是否存在
- 文件名清理和规范化
由于反爬虫的限制,上面的关键步骤提高了爬虫的成功率和稳定性,同时也避免了对目标服务器造成过大压力。
后续优化:后续可以尝试分页爬取
六、法律与道德规范
1. robots.txt检查:
- 访问 `http://www.toutiao.com/robots.txt`
- 遵守爬虫协议规定
2. 合理使用原则:
- 控制请求频率
- 不进行商业性使用
- 尊重版权信息
3. 数据使用建议:
- 仅用于学习研究
- 不存储敏感信息
- 及时删除原始数据
相关文章:

Python爬虫第15节-2025今日头条街拍美图抓取实战
目录 一、项目背景与概述 二、环境准备与工具配置 2.1 开发环境要求 2.2 辅助工具配置 三、详细抓取流程解析 3.1 页面加载机制分析 3.2 关键请求识别技巧 3.3 参数规律深度分析 四、爬虫代码实现 五、实现关键 六、法律与道德规范 一、项目概述 在当今互联网时代&a…...

std::map gdb调试ok ,直接运行会crash
在使用 std::map 并且在调试模式下没有问题,但在直接运行时出现崩溃(crash)的情况,通常是由于以下几个原因引起的: 未初始化的变量使用:在调试模式下,某些变量可能因为调试工具(如 G…...

【2025年泰迪杯数据挖掘挑战赛】A题 数据分析+问题建模与求解+Python代码直接分享
目录 2025年泰迪杯数据挖掘挑战赛A题完整论文:建模与求解Python代码1问题一的思路与求解1.1 问题一的思路1.1.1对统计数据进行必要说明:1.1.2统计流程:1.1.3特殊情况的考虑: 1.2 问题一的求解1.2.1代码实现1.2.2 问题一结果代码分…...

git在分支上会退到某个指定的commit
1、在idea上先备份好分支(基于现有分支new branch) 2、在gitlab管理端删除现有分支 3、在idea中大卡terminal,执行 git log 查看commit log ,找到要会退到的commit唯一码,然后执行git reset 唯一码 4、查看本地代码状态 git st…...

Cursor入门教程-JetBrains过度向
Cursor使用笔记 **前置:**之前博主使用的是JetBrains的IDE,VSCode使用比较少,所以会尽量朝着JetBrains的使用习惯及样式去调整。 一、设置语言为中文 如果刚上手Cursor,那么肯定对Cursor中的众多选项配置项不熟悉,这…...

MySQL之text字段详细分类说明
在 MySQL 中,TEXT 是用来存储大量文本数据的数据类型。TEXT 类型可以存储非常长的字符串,比 VARCHAR 类型更适合存储大块的文本数据。TEXT 数据类型分为以下几个子类型,每个子类型用于存储不同大小范围的文本数据: TINYTEXT: 可以…...
为什么 Transformer 要使用多头注意力机制?
简而言之,多头注意力机制可以让模型从不同的在空间中并行地捕捉到不同的特征关系,从而更全面,更灵活地理解序列中的信息。 举个例子,如果要看一幅画,就不能简单地只关注例如颜色,还要关注到结构࿰…...

Python项目--基于Python的自然语言处理文本摘要系统
1. 项目概述 自然语言处理(NLP)是人工智能领域中一个重要的研究方向,而文本摘要作为NLP的一个重要应用,在信息爆炸的时代具有重要意义。本项目旨在开发一个基于Python的文本摘要系统,能够自动从长文本中提取关键信息,生成简洁而全…...
)
【Web APIs】JavaScript 操作多个元素 ③ ( 鼠标经过高亮显示 | onmouseover 事件设置 | onmouseout 事件设置 )
文章目录 一、核心要点解析 - 鼠标经过高亮显示1、案例需求2、获取高亮显示的 列表行3、鼠标经过 onmouseover 事件设置4、鼠标离开 onmouseout 事件设置5、设置高亮方式 二、完整代码示例1、完整代码示例2、执行结果 一、核心要点解析 - 鼠标经过高亮显示 1、案例需求 案例需求…...

金融的未来
1. DeFi的爆发式增长与核心使命 DeFi(去中心化金融)的使命是重构传统金融基础设施,通过区块链技术实现更高的透明度、可访问性、效率、便利性和互操作性。其增长数据印证了这一趋势: TVL(总锁定价值)爆炸…...
)
[ElasticSearch]Suggest查询建议(自动补全纠错)
概述 搜索一般都会要求具有“搜索推荐”或者叫“搜索补全”的功能,即在用户输入搜索的过程中,进行自动补全或者纠错。以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest。 四种Suggester 1 Term Suggester…...

GPT-4.1 提示词使用指南
GPT-4.1 提示词使用指南 参考:https://cookbook.openai.com/examples/gpt4-1_prompting_guide 为什么要关注 GPT-4.1 提示词使用指南? GPT-4.1 比其前代模型 GPT-4o 更倾向于严格跟随指令,而不是像 GPT-4o 那样更自由地推断用户和系统提示…...
╭)
es6面试常见问题╮(╯▽╰)╭
ES6(ECMAScript 2015)的一些常见面试问题,涵盖了变量声明、箭头函数、模板字符串、解构赋值、模块化、类、Promise、生成器等关键特性。有些面试就是问问,对老程序员面试其实不问这么多╮(╯▽╰)╭ 文章目录 **1. 变量声明****1.1 `let` 和 `const` 与 `var` 的区别是什么…...

Xenomai 如何实现 <10μs 级抖动控制
1. 抖动(Jitter)的定义与重要性 1.1 什么是抖动? 在实时控制系统中,抖动(Jitter)指任务实际执行时间与预期周期时间的偏差。例如: • 设定一个任务每 100μs 运行一次,但实际运行时间…...

前端基础常见的算法
你整理的这些前端常见算法知识点挺实用的,适合复习或面试准备。下面我帮你稍微整理美化一下格式,并补充一点细节,让内容更清晰易读: 1. 排序算法 冒泡排序(Bubble Sort) 原理:通过重复比较相邻元…...

RPA机器人技术原理初探
RPA(Robotic Process Automation,机器人流程自动化)通过模拟人类操作界面元素来实现自动化任务,其技术原理可分为以下核心模块: 一、基础技术架构 界面元素识别技术 选择器(Selector)引擎&#…...

AWS CloudFront加速S3配置跨域
1、点击分配 源我们就选择S3–>选择我们要加速的S3存储桶 2、创建OAC访问方式 在我们的来源访问处–>来源访问控制设置(推荐)–>选择创建新的OAC(Create new OAC)–>自定义名字按默认选项保存–>选择刚刚新创建的OAC 3、选择查看器的配置 根据具体情况&#x…...

58.最后一个单词的长度
目录 一、问题描述 二、解题思路 三、代码 四、复杂度分析 一、问题描述 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 二、解题思…...

leetcode_344.反转字符串_java
344. 反转字符串 1、题目 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 示例 1: 输入:…...

Android --- FrameWork 入门:极速上手AOSP
文章目录 一、硬件要求二、虚拟机安装三、开发环境搭建四、下载编译源码 一、硬件要求 CPU不低于6核心,建议8核及以上 内存不低于32G,建议64G 存储空间不低于500G,建议 1TB SSD 二、虚拟机安装 1.下载ubuntu,官网网址如下: releases.ubuntu.com/focal…...

“大湾区珠宝艺境花园”璀璨绽放第五届消博会
2025年4月13日,第五届中国国际消费品博览会(以下简称"消博会")重要主题活动——《大湾区珠宝艺境花园》启动仪式在海南国际会展中心2号馆隆重举行。由广东省金银珠宝玉器业厂商会组织带领粤港澳大湾区优秀珠宝品牌,以“…...

Spring Boot系列之使用Arthas Tunnel Server 进行远程调试实践
Spring Boot系列之使用Arthas Tunnel Server 进行远程调试实践 前言 在开发和运维 Java 应用的过程中,远程诊断和调试是一个不可或缺的需求。尤其是当生产环境出现问题时,能够快速定位并解决这些问题至关重要。Arthas 是阿里巴巴开源的一款强大的 Java…...

ILGPU的核心功能使用详解
什么是ILGPU? ILGPU 是一种用于高性能 GPU 程序的新型 JIT(即时)编译器 (也称为 kernels)编写的 .基于 Net 的语言。ILGPU 完全 用 C# 编写,没有任何原生依赖项,允许您编写 GPU 真正可移植的程序。…...
 工具)
Ubuntu服务器日志满audit:backlog limit exceeded了会报错解决方案-Linux 审计系统 (auditd) 工具
auditd 是 Linux 系统中的审计守护进程,负责收集、记录和监控系统安全相关事件。以下是相关工具及其功能: 核心组件 auditd - 审计守护进程 系统的审计服务主程序 收集系统调用信息并写入日志文件 通常存储在 /var/log/audit/audit.log auditctl - 审计控…...

数据加载与保存
通用方式 SparkSQL提供了通用的数据加载方式,使用spark.read.loa方法,并可通过format指定数据类型(如csv、jdbc、json、orc、parquet、textFile)。 load方法后需传入数据路径(针对csv、jdbc、json、orc、parquet、…...

TODO!! IM项目2
感觉似乎部署好了 真不容易 mysql、redis、 rocketmq(nameserver、broker)、nginx 看代码里是mybatisplus、netty->protobuf协议 现在还发不出去消息 每个密码都要改对 现在可以发消息了但不能at 房间成员也没有 broker内存不够? 从…...

Android ImageView 使用详解
文章目录 一、基本使用1. XML 中声明 ImageView2. Java/Kotlin 中设置图片 二、图片缩放类型 (scaleType)三、加载网络图片1. 使用 Glide (推荐)2. 使用 Picasso 四、高级功能1. 圆形图片2. 圆角图片3. 图片点击缩放动画 五、性能优化六、常见问题解决 ImageView 是 Android 中…...

工资管理系统的主要功能有哪些
工资管理系统通过自动化薪资计算、税务处理、员工数据管理、报表生成等功能,极大地提升了薪资发放的效率和准确性。在传统的人工薪资管理中,HR人员需要手动计算每位员工的薪资,并确保符合税务要求,极易出错且耗时。而现代工资管理…...

WordPiece 详解与示例
WordPiece详解 1. 定义与背景 WordPiece 是一种子词分词算法,由谷歌于2012年提出,最初用于语音搜索系统,后广泛应用于机器翻译和BERT等预训练模型。其核心思想是将单词拆分为更小的子词单元(如词根、前缀/后缀),从而解决传统分词方法面临的词汇表过大和未知词(OOV)处…...

【LeetCode基础算法】滑动窗口与双指针
定长滑动窗口 总结:入-更新-出。 入:下标为 i 的元素进入窗口,更新相关统计量。如果 i<k−1 则重复第一步。 更新:更新答案。一般是更新最大值/最小值。 出:下标为 i−k1 的元素离开窗口,更新相关统计量…...

日本Shopify 3月数据:家居品类销售额激增120%!
2024年第一季度末,电商平台运营商Shopify发布了3月份的最新销售数据,引发业界高度关注。据最新数据显示,日本市场家居品类销售在3月份实现了惊人的增长,同比激增120%,成为该区域增速最快的类目。这一变化不仅映射出日本…...

C语言多进程素数计算
题目描述: 以下代码实现了一个多进程素数计算程序,通过fork()函数创建子进程来并行计算指定范围内的素数。请仔细阅读代码并回答以下问题。 #include "stdio.h" #include "unistd.h" #include <sys/types.h> #include "…...

链表知识回顾
类型:单链表,双链表、循环链表 存储:在内存中不是连续存储 删除操作:即让c的指针指向e即可,无需释放d,因为java中又内存回收机制 添加节点: 链表的构造函数 public class ListNode {// 结点…...

数据库勒索病毒威胁升级:企业数据安全防线如何用安当RDM组件重构
摘要:2025年Q1全球数据库勒索攻击量同比激增101.8%,Cl0p、Akira等团伙通过边缘设备漏洞渗透企业核心系统,制造业、金融业等关键领域面临数据加密与业务停摆双重危机。本文深度解析勒索病毒对数据库的五大毁灭性影响,结合安当RDM防…...

50%时效提升!中巴新航线如何重构ebay跨境电商物流成本?
50%时效提升!中巴新航线如何重构eBay跨境电商物流成本? 近年,拉美市场逐步升温,特别是巴西,已成为中国跨境卖家争相布局的新蓝海市场。而随着eBay大力拓展拉美板块,更多卖家开始将目光投向这个人口超2亿、…...

自建 eSIM RSP 服务指南
一、 自建 eSIM RSP 服务的必要性评估 在决定是否自建 RSP(远程 SIM 配置)服务时,企业需要全面了解其带来的利弊。以下是核心要点: 1. GSMA 安全认证 (SAS-SM) 的重要性 目的: 确保 RSP 服务符合全球移动网络运营商 (MNO) 对安…...

TensorRT模型部署剪枝
TensorRT模型部署剪枝 本文属于学习笔记,在重点章节或代码位置加入个人理解,欢迎批评指正! 参考: CUDA与TensorRT部署部署实战第四章 一. Pruning 学习目标 理解什么是模型剪枝模型剪枝的分类,以及各类剪枝的利弊都…...

Servlet 线程安全与并发编程深度解析
Servlet 线程安全与并发编程深度解析 一、Servlet 线程安全机制与风险场景 1.1 Servlet 容器工作原理 单实例多线程模型:每个Servlet在容器中只有一个实例,通过线程池处理并发请求请求处理流程: 接收HTTP请求创建HttpServletRequest和HttpS…...

C++学习:六个月从基础到就业——面向对象编程:封装、继承与多态
C学习:六个月从基础到就业——面向对象编程:封装、继承与多态 本文是我C学习之旅系列的第九篇技术文章,主要讨论C中面向对象编程的三大核心特性:封装、继承与多态。这些概念是理解和应用面向对象设计的关键。查看完整系列目录了解…...

光谱相机的成像方式
光谱相机的成像方式决定了其如何获取物体的空间与光谱信息,核心在于分光技术与扫描模式的结合。以下是主要成像方式的分类解析: 一、滤光片切换型 1. 滤光片轮(Filter Wheel) 原理:通过旋转装有多个窄带…...

Excel 中让表格内容自适应列宽和行高
Excel 中让表格内容自适应列宽和行高 目录 Excel 中让表格内容自适应列宽和行高自适应列宽自适应行高在Excel中让表格内容自适应列宽和行高,可参考以下操作: 自适应列宽 方法一:手动调整 选中需要调整列宽的列(如果是整个表格,可点击表格左上角行号和列号交叉处的三角形全…...

android rtsp 拉流h264 h265,解码nv12转码nv21耗时卡顿问题及ffmpeg优化
一、 背景介绍及问题概述 项目需求需要在rk3568开发板上面,通过rtsp协议拉流的形式获取摄像头预览,然后进行人脸识别 姿态识别等后续其它操作。由于rtsp协议一般使用h.264 h265视频编码格式(也叫 AVC 和 HEVC)是不能直接用于后续处…...
--网络编程)
Day(21)--网络编程
网络编程 在网络通信协议下,不同计算机上运行的程序,进行的数据传输 应用场景:即使通信、网友对战、金融证券等等,不管是什么场景,都是计算机和计算机之间通过网络进行的数据传输 java.net 常见的软件架构 C/S&am…...

Android主流播放器功能详解
Android主流播放器功能详解 前言 本文将深入介绍Android三大主流播放框架(ijkplayer、ExoPlayer和MediaPlayer)的功能特性和实战应用,帮助你选择合适的播放框架并掌握其使用方法。 三大播放框架概述 播放框架开发方特点适用场景MediaPlayerAndroid官方简单易用,系统内置…...

牟乃夏《ArcGIS Engine地理信息系统开发教程》学习笔记2
目录 一、ArcGIS Engine概述 1、 定义 2、 核心功能 3、 与ArcObjects(AO)的关系 二、开发环境搭建 1、 开发工具要求 2、 关键步骤 三、 ArcGIS Engine核心组件 1、 对象模型 2、 类库分类 四、 第一个AE应用程序(C#示例…...
从零搭建一个完整的TTS系统-第一节-效果演示)
语音合成(TTS)从零搭建一个完整的TTS系统-第一节-效果演示
一、概述 语音合成又叫文字转语音(TTS-text to speech ),本专题我们记录从零搭建一个完整的语音合成系统,包括文本前端、声学模型和声码器,从模型训练到系统的工程化实现,模型可以部署在手机等嵌入式设备上…...
)
文章记单词 | 第35篇(六级)
一,单词释义 across [əˈkrɒs] prep. 从一边到另一边;横过;在… 对面;遍及;在… 上;跨越;adv. 从一边到另一边;横过;宽;从… 的一边到另一边;在…...

MySQL Binlog 数据恢复总结
🌲 总入口:你想恢复什么? 恢复类型 ├── 表结构 表数据(整张表被 DROP) │ ├── Binlog 中包含 CREATE TABLE │ │ └── ✅ 直接用 mysqlbinlog 提取建表 数据语句,回放即可 │ └── B…...
)
【Linux】进程基础入门指南(下)
> 🍃 本系列为Linux的内容,如果感兴趣,欢迎订阅🚩 > 🎊个人主页:【小编的个人主页】 >小编将在这里分享学习Linux的心路历程✨和知识分享🔍 >如果本篇文章有不足,还请多多包涵&a…...

NoETL×大模型:Aloudata重构数据智能新范式,开启Chat BI新落地之道
在当今数据驱动的时代,企业对于高效、智能的数据处理与分析需求日益增长。随着大模型的兴起,如DeepSeek等,数据智能领域正经历着前所未有的变革。 Aloudata大应科技创始人&CEO周卫林表示,企业的核心竞争力包括人才壁垒、技术…...