从单模态到多模态:五大模型架构演进与技术介绍
前言
- 1. ResNet — 残差神经网络
- 背景
- 核心问题与解决方案
- 原理
- 模型架构
- ResNet 系列变体
- 技术创新与影响
- 2. ViT — Vision Transformer
- 背景
- 核心思想
- 发展历程
- Transformer的起源:
- ViT的出现:
- ViT的进一步发展:
- 模型架构
- 技术创新与影响
- 3. Swin Transformer
- 背景
- 核心思想
- 模型架构
- 技术创新与影响
- CLIP — Contrastive Language-Image Pre-training
- 背景
- CLIP 核心思想
- 模型架构
- 训练方法
- 零样本推理(Zero-Shot Prediction)
- 关键实验结果
- 技术创新与影响
- 5. ViLT — Vision-and-Language Transformer
- 背景
- . ViLT 的核心特点
- 模型架构
- 技术创新与影响

人工智能领域的模型架构经历了从单模态(专注于单一数据类型)到多模态(融合多种数据类型)的跨越式发展。这一过程中,残差学习、注意力机制、对比学习等技术的突破推动了模型的性能提升和应用场景扩展。本文将深入解析五个里程碑模型——ResNet、ViT、Swin Transformer、CLIP、ViLT,探讨其核心架构与技术创新,并梳理从单模态到多模态的技术演进路径。
1. ResNet — 残差神经网络
背景
2015年,何恺明团队提出的深度残差网络(ResNet)解决了深度卷积神经网络训练中的梯度消失/爆炸问题,使得构建和训练超深网络成为可能。ResNet在ImageNet竞赛中取得当时最先进的性能,并获得了2015年CVPR最佳论文奖。
核心问题与解决方案
传统CNN模型在层数增加时会遇到退化问题(degradation problem):随着网络深度增加,准确率开始饱和,然后迅速下降。ResNet通过引入残差学习框架解决了这一问题。
原理
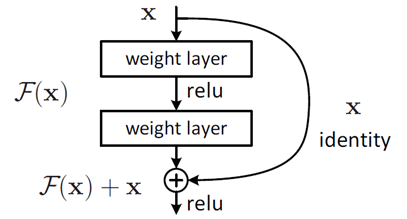
残差学习(Residual Learning):随着网络深度的增加,传统的深层网络面临着梯度消失或梯度爆炸的问题,使得网络难以训练。ResNet通过引入“残差块”(Residual Block),让网络可以轻松地学习恒等映射(Identity Mapping)。这意味着,在深层次网络中,如果某一层没有对特征提取有帮助,则该层可以学为零,从而不会对最终结果造成负面影响。
模型架构
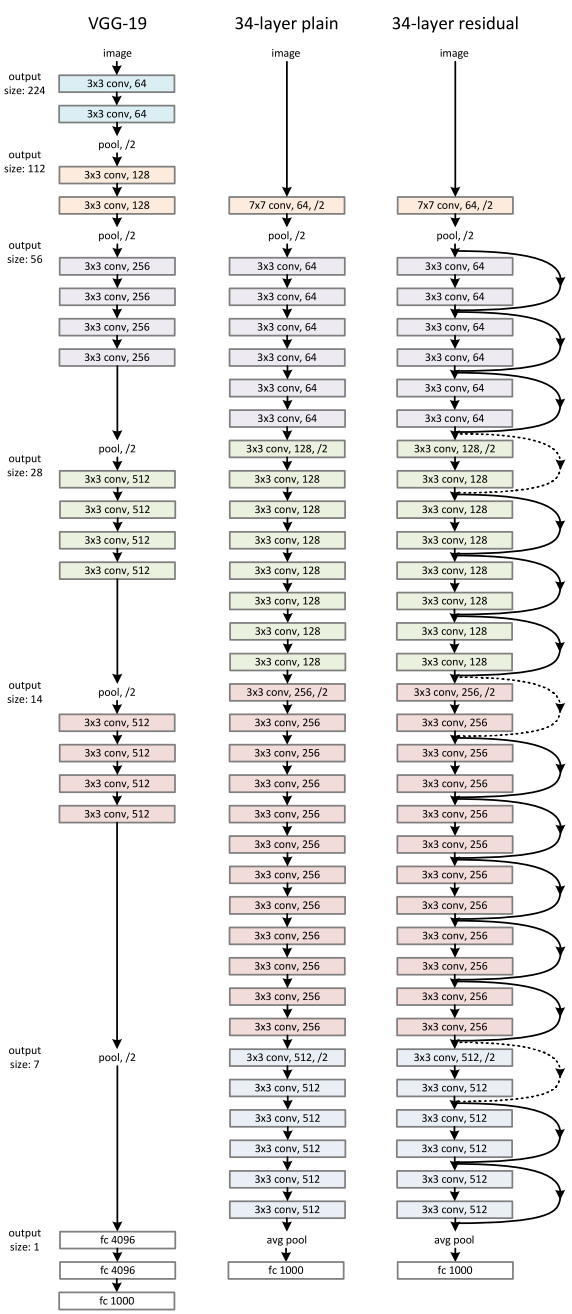
ResNet的架构 : ResNet34 使用的受 VGG-19 启发的 34 层普通网络架构,随后添加了快捷连接。随后通过这些快捷连接将该架构转变为残差网络,如下图所示:
ResNet的核心是残差块(Residual Block),其结构如下:
- 残差连接(Skip Connection):将输入信号直接添加到层的输出
- 残差学习:网络不直接学习原始映射H(x),而是学习残差
F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x
一个基本的残差块可以表示为:
y = F ( x , W i ) + x y = F(x, {Wi}) + x y=F(x,Wi)+x
其中F(x, {Wi})表示残差映射,可以是多层堆叠的卷积操作。
ResNet的完整架构包括:
- 初始卷积层(7×7卷积,步长2)
- 最大池化层(3×3,步长2)
- 4组残差块堆叠(每组有不同数量的残差块)
- 全局平均池化
- 全连接层+Softmax
ResNet有多种变体,包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,数字表示网络深度。
ResNet 系列变体
| 模型 | 层数 | 参数量 | 结构说明 |
|---|---|---|---|
| ResNet-18 | 18 | 11M | 基础残差块 |
| ResNet-34 | 34 | 21M | 基础残差块 |
| ResNet-50 | 50 | 25M | Bottleneck 残差块 |
| ResNet-101 | 101 | 44M | Bottleneck 残差块 |
| ResNet-152 | 152 | 60M | Bottleneck 残差块 |
技术创新与影响
- 解决深度网络训练问题:残差连接使得信息可以直接从浅层传递到深层
- 梯度流动改善:短路连接有助于梯度在反向传播中更好地流动
- 表示能力增强:更深的网络具有更强的特征提取能力
- 训练稳定性:残差学习框架使训练更加稳定
2. ViT — Vision Transformer
背景
2020年10月,谷歌研究团队发布了论文"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",首次将自然语言处理领域的Transformer架构直接应用于计算机视觉任务,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
核心思想
ViT的核心思想是将图像视为"单词序列",摒弃了CNN中的归纳偏置(如平移不变性、局部连接等),完全依赖自注意力机制处理视觉信息。
发展历程
Transformer的起源:
- 2017年,Google提出了Transformer模型,这是一种基于Seq2Seq结构的语言模型,它首次引入了Self-Attention机制,取代了基于RNN的模型结构。
- Transformer的架构包括Encoder和Decoder两部分,通过Self-Attention机制实现了对全局信息的建模,从而能够解决RNN中的长距离依赖问题。
ViT的出现:
- ViT采用了Transformer模型中的自注意力机制来建模图像的特征,这与CNN通过卷积层和池化层来提取图像的局部特征的方式有所不同。
- ViT模型主体的Block结构基于Transformer的Encoder结构,包含Multi-head Attention结构。
ViT的进一步发展:
- 随着研究的深入,ViT的架构和训练策略得到了进一步的优化和改进,使其在多个计算机视觉任务中都取得了与CNN相当甚至更好的性能。
- 目前,ViT已经成为计算机视觉领域的一个重要研究方向,并有望在未来进一步替代CNN成为主流方法。
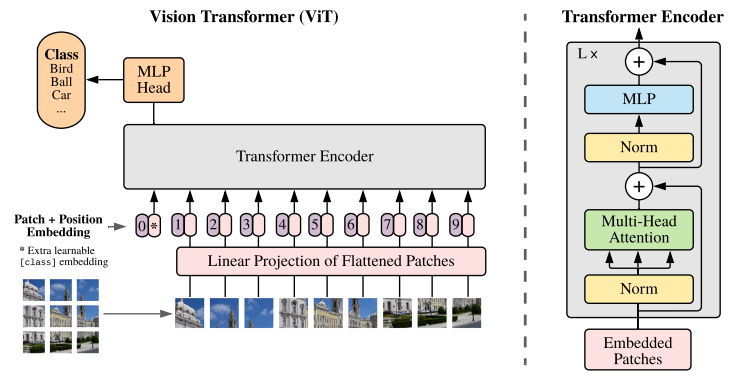
模型架构
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测
ViT的处理流程如下:
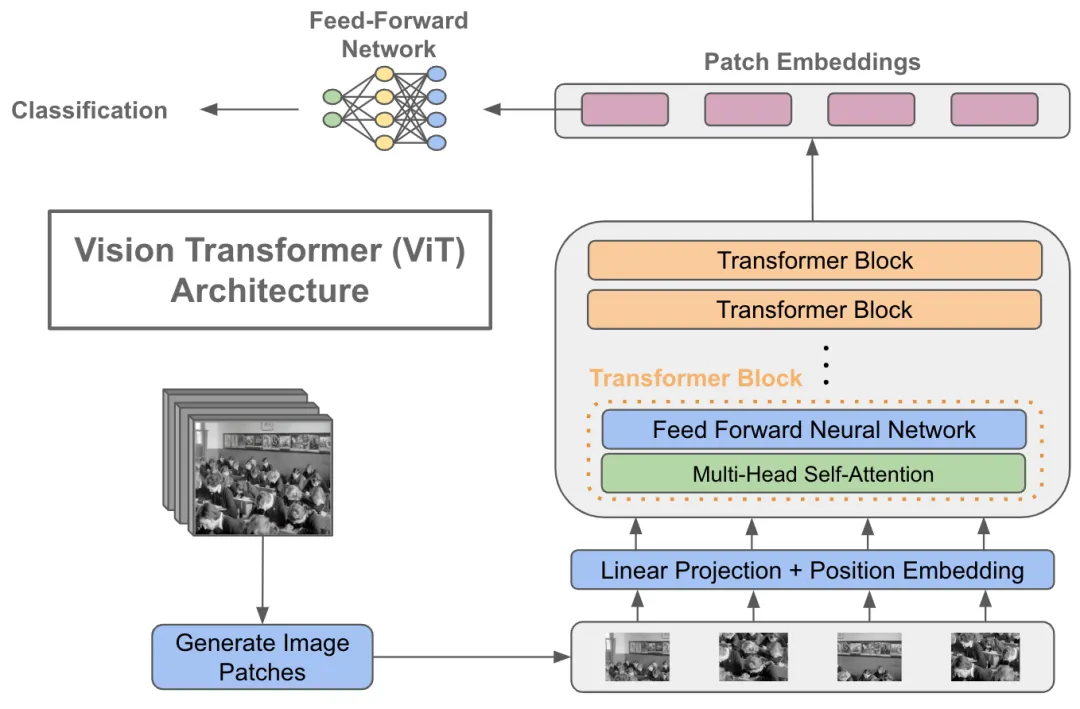
-
图像分块与线性投影
- 将输入图像划分为固定尺寸的方形区域(如16×16像素),生成二维网格序列。每个图像块经全连接层进行线性投影,转化为768维特征向量。此时视觉数据完成形态转换,形成类序列结构。
-
类别标记注入
- 在序列首部插入可学习的分类标识向量,该特殊标记贯穿整个网络运算,最终作为图像表征的聚合载体。此操作使序列长度由N增至N+1,同时保持特征维度一致性。
-
位置编码融合
- 通过可训练的位置嵌入表为每个序列元素注入空间信息。采用向量相加方式而非拼接,在保留原始特征维度的前提下,使模型感知元素的相对位置关系。
-
Transformer编码架构
-
由多层相同结构模块堆叠组成,每个模块包含:
-
层归一化处理的多头注意力机制:将特征拆分为多个子空间(如12个64维头部),并行捕获异构关联模式,输出重聚合后维持768维
-
多层感知机扩展层:先进行4倍维度扩展(768→3072)增强表征能力,再投影回原维度保证结构统一性
-
-
特征演化与输出
- 所有编码模块保持输入输出同维度(197×768),实现深度堆叠。最终提取首位的类别标记向量作为全局图像描述符,或采用全序列均值池化策略,接入分类器完成视觉任务。这种架构通过序列化处理实现了视觉与语言模型的范式统一。
ViT的公式表示:
z 0 = [ x c l a s s ; x 1 E ; x 2 E ; . . . ; x N E ] + E p o s z_0 = [x_class; x_1^E; x_2^E; ...; x_N^E] + E_pos z0=[xclass;x1E;x2E;...;xNE]+Epos
z l = M S A ( L N ( z l − 1 ) ) + z l − 1 z_l = MSA(LN(z_{l-1})) + z_{l-1} zl=MSA(LN(zl−1))+zl−1
z l = M L P ( L N ( z l ) ) + z l z_l = MLP(LN(z_l)) + z_l zl=MLP(LN(zl))+zl
y = L N ( z L 0 ) y = LN(z_L^0) y=LN(zL0)
技术创新与影响
- 打破CNN垄断:ViT证明了纯Transformer架构在视觉任务上的可行性
- 缩小模态差距:为视觉和语言任务提供了统一的架构基础
- 全局感受野:自注意力机制天然具有全局视野,不同于CNN的局部感受野
- 数据效率权衡:需要大量数据预训练才能超越CNN模型
ViT的出现标志着计算机视觉领域的范式转变,开启了"Transformer时代",大大推动了视觉-语言多模态模型的发展。
3. Swin Transformer
背景
微软研究院于2021年3月发表Swin Transformer,试图解决ViT在计算效率和细粒度特征提取方面的局限性,尤其是针对密集预测任务(如目标检测、分割)。
核心思想
Swin Transformer的核心思想在于利用窗口内的自注意力机制,同时通过层级结构实现跨窗口的信息交互,从而实现了高效的视觉特征提取和表达。具体来说:
- 窗口化自注意力(Window-based Self-Attention, W-MSA):将图像划分为不重叠的窗口,仅在每个窗口内进行自注意力计算。
- 移位窗口(Shifted Windows, SW-MSA):通过在相邻层之间移动窗口位置,实现窗口间的交互,弥补W-MSA缺乏跨窗口连接的不足。
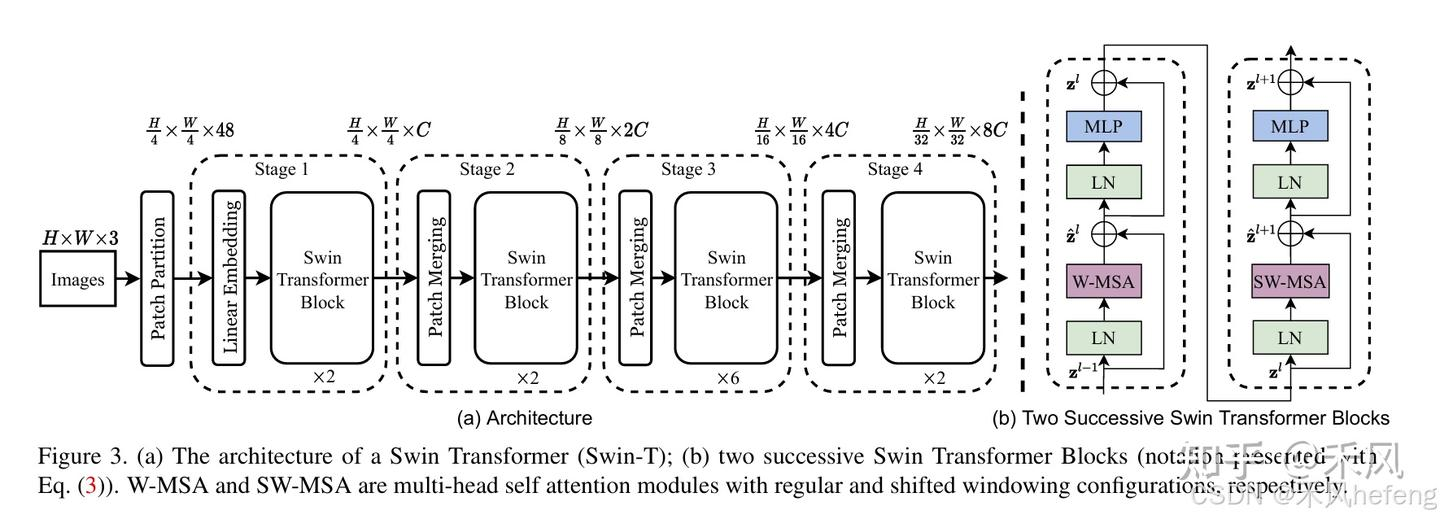
- 层次化结构:借鉴CNN的多尺度设计,Swin Transformer通过逐步合并patch降低分辨率,扩大感受野,形成类似金字塔的特征提取过程
模型架构
Swin Transformer的关键设计包括:
- 层级结构:类似CNN的层级特征图,分辨率逐层下降
- 窗口自注意力:将自注意力计算限制在局部窗口内(如7×7大小)
- 窗口移位操作:在连续层之间交替使用常规窗口和移位窗口,使得不同窗口之间可以交换信息
- 相对位置编码:在窗口内使用相对位置偏置而非绝对位置编码
Swin Transformer包含4个阶段:
Swin Transformer的整体架构包括Patch Embedding、多个Swin Transformer Block以及分类头。下面逐步介绍其主要组成部分:
- Patch Partition:这是模型对输入图像进行预处理的一种重要操作。该操作的主要目的是将原始的连续像素图像分割成一系列固定大小的图像块(patches),以便进一步转化为Transformer可以处理的序列数据 2。
- Swin Transformer Block:是模型的核心单元,每个block包含以下步骤:
- Layer Normalization
- W-MSA或SW-MSA
- 残差连接
- 再次Layer Normalization
- 前馈网络(FFN)
- 残差连接
- Patch Merging:为了实现层次化特征提取,Swin Transformer在每个stage结束后通过Patch Merging合并相邻patch。这一步骤类似于卷积神经网络中的池化操作,但采用的是线性变换而不是简单的最大值或平均值操作 5。
- 输出模块:包括一个LayerNorm层、一个AdaptiveAvgPool1d层和一个全连接层,用于最终的分类或其他任务 4
技术创新与影响
- 线性计算复杂度:窗口注意力使得计算复杂度与图像大小成线性关系,而非ViT的二次关系
- 层级表示:生成多尺度特征,适合各种视觉任务
- 跨窗口连接:移位窗口机制允许信息在不同窗口间流动
- 通用视觉骨干网:成为视觉领域的通用主干网络,用于分类、检测和分割等多种任务
Swin Transformer成功地将Transformer的优势与CNN的层级结构相结合,为后续多模态模型提供了更高效的视觉特征提取器。
CLIP — Contrastive Language-Image Pre-training
背景
CLIP(Contrastive Language-Image Pretraining)是 OpenAI 在 2021 年提出的 多模态预训练模型,通过对比学习将图像和文本映射到同一语义空间,实现 零样本(Zero-Shot)分类、跨模态检索等任务。它彻底改变了传统视觉模型的训练方式,成为多模态领域的里程碑工作。
CLIP 核心思想
(1) 核心目标
-
学习图像和文本的联合表示,使匹配的图文对在特征空间中靠近,不匹配的远离。
-
无需人工标注的类别标签,直接利用自然语言描述(如“一只猫在沙发上”)作为监督信号。
(2) 关键创新
-
对比学习(Contrastive Learning):通过大规模图文对训练,拉近正样本对(匹配图文),推开负样本对(不匹配图文)。
-
自然语言作为监督信号:摆脱固定类别标签的限制,支持开放词汇(Open-Vocabulary)任务。
-
零样本迁移能力:预训练后可直接用于下游任务(如分类、检索),无需微调。
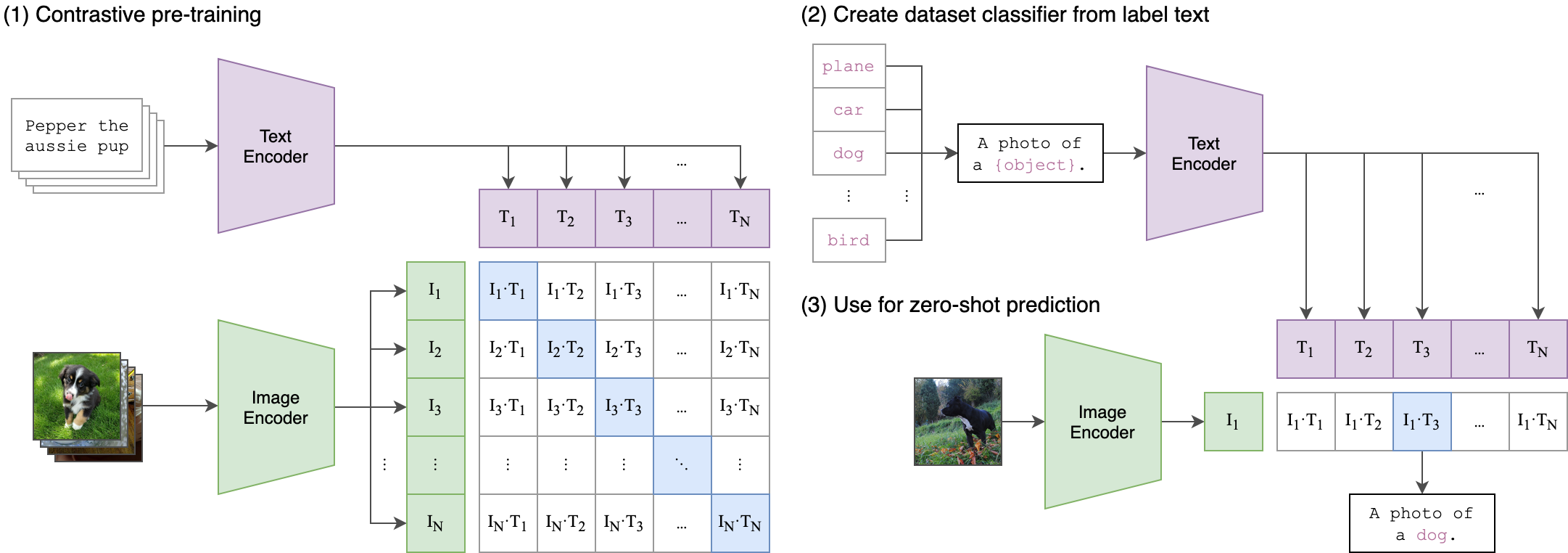
模型架构
CLIP 包含两个独立的编码器:
-
图像编码器(Image Encoder):
-
可选架构:ViT(Vision Transformer) 或 ResNet(如 ResNet-50)。
-
输入:图像 → 输出:图像特征向量(如 512 维)。
-
-
文本编码器(Text Encoder):
-
基于 Transformer(类似 GPT-2)。
-
输入:文本描述 → 输出:文本特征向量(与图像特征同维度)。
-
训练方法
1. 对比损失(Contrastive Loss)
- 对一个 batch 中的 N 个图文对:
- 计算图像特征 Ii 和文本特征 Tj的余弦相似度矩阵
S i , j = I i ⋅ T j S i , j = I i ⋅ T j Si,j=Ii⋅TjS i,j =I i ⋅T j Si,j=Ii⋅TjSi,j=Ii⋅Tj
损失函数(对称交叉熵损失):
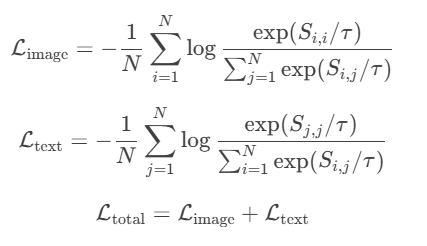
其中τ 是温度系数(可学习参数)。
(2) 训练数据
-
数据集:4 亿个互联网公开图文对(WebImageText)。
-
数据增强:随机裁剪、颜色抖动等。
零样本推理(Zero-Shot Prediction)
(1) 分类任务流程
-
构建文本模板:
- 将类别名称(如“dog”)填入提示模板(Prompt Template),例如:
“a photo of a {dog}”
- 生成所有类别的文本描述,并编码为文本特征 T1,T2,…,T K 。
- 将类别名称(如“dog”)填入提示模板(Prompt Template),例如:
- 编码待分类图像:得到图像特征 I
- 计算相似度:
-
图像特征与所有文本特征计算余弦相似度。
-
选择相似度最高的文本对应的类别作为预测结果。
-
(2) 优势
-
无需微调:直接利用预训练模型。
-
支持开放词汇:新增类别只需修改文本描述,无需重新训练。
关键实验结果
(1) 零样本分类性能
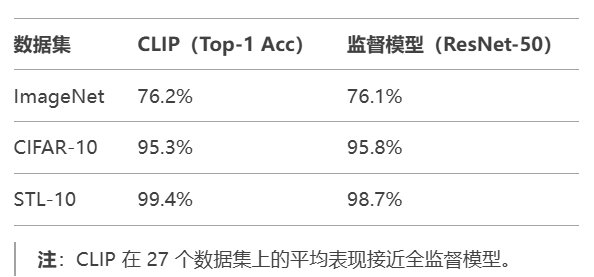
技术创新与影响
- 零样本迁移学习:无需针对特定任务微调即可应用于新类别
- 大规模预训练:在4亿图像-文本对上训练
- 多模态理解:构建图像和文本的联合表示空间
- 灵活性:可用于图像分类、图像检索、文本检索等多种任务
- 减少标注依赖:利用互联网上自然存在的图像-文本对训练
CLIP开创了视觉-语言预训练的新范式,证明了通过自然语言监督可以学习到强大且通用的视觉表示,奠定了多模态AI系统的基础。
5. ViLT — Vision-and-Language Transformer
背景
ViLT(Vision-and-Language Transformer)是 2021 年提出的一种 纯 Transformer 架构的视觉-语言多模态模型,其核心思想是 用统一的 Transformer 同时处理图像和文本,无需卷积网络(CNN)或区域特征提取(如 Faster R-CNN),极大简化了多模态模型的复杂度。
. ViLT 的核心特点
(1) 极简架构设计
- 完全基于 Transformer:
-
传统多模态模型(如 LXMERT、UNITER)依赖 CNN 提取图像特征 或 Faster R-CNN 提取区域特征,计算成本高。
-
ViLT 直接对原始图像像素进行 Patch Embedding(类似 ViT),文本则通过 Token Embedding 输入,两者共享同一 Transformer 编码器。
-
(2) 模态交互方式
-
单流架构(Single-Stream):
-
图像和文本的嵌入向量拼接后输入同一 Transformer,通过自注意力机制直接交互。
-
对比双流架构(如 CLIP),计算更高效,模态融合更彻底。
-
(3) 轻量高效
-
参数量仅为传统模型的 1/10:
-
ViLT-Base 参数量约 110M,而类似功能的 UNITER 需 1B+ 参数。
-
训练速度提升 2-10 倍,适合低资源场景。
-
模型架构
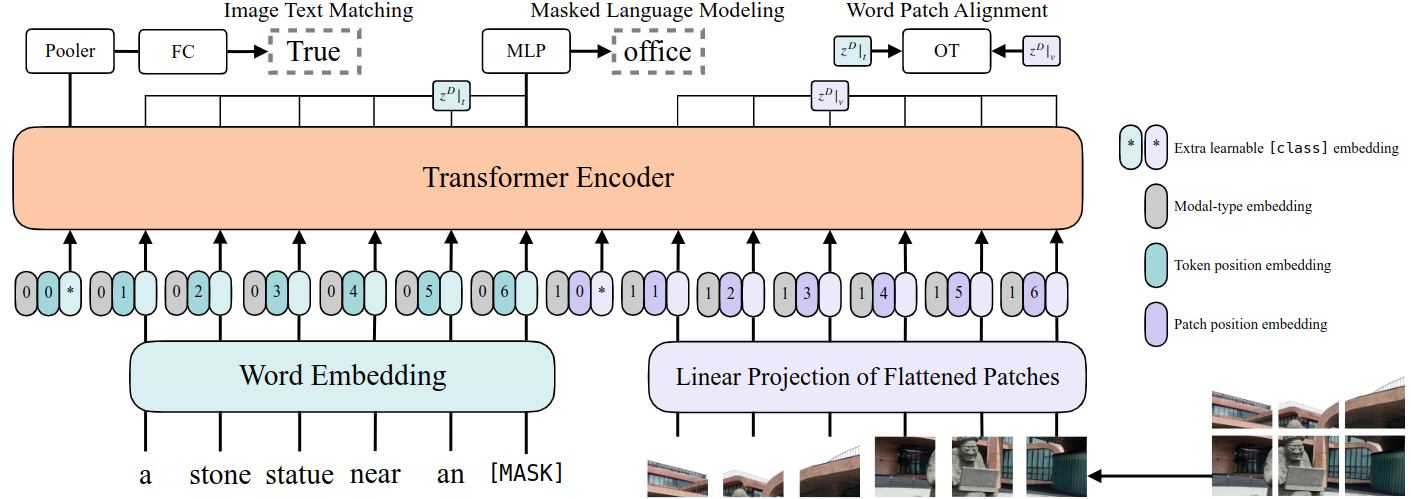
- 文本经过pre-trained BERT tokenizer得到word embedding(前面有CLS token,图中*表示)
- 图片经过ViT patch projection层得到patch embedding(也是用*表示CLS token);
- 文本特征+文本位置编码+模态嵌入得到最终的text embedding,图像这边也是类似的操作得到image embedding;二者concat拼接之后,一起输入transformer layer,然后做MSA交互(多头自注意力)
(1) 输入表示
-
图像输入:
-
将图像分割为 N×N 的 Patches(如 32×32)。
-
线性投影为 Patch Embeddings,并添加位置编码(Position Embedding)。
-
-
文本输入:
-
使用 WordPiece 分词,生成 Token Embeddings。
-
添加位置编码和模态类型编码(Modality-Type Embedding)。
-
(2) 共享 Transformer 编码器
- 图像和文本的 Embeddings 拼接后输入 Transformer:
I n p u t = [ I m a g e E m b ; T e x t E m b ] + P o s i t i o n E m b + M o d a l i t y E m b Input=[Image_Emb;Text_Emb]+Position_Emb+Modality_Emb Input=[ImageEmb;TextEmb]+PositionEmb+ModalityEmb
-
通过多层 Transformer Blocks 进行跨模态交互:
-
自注意力机制:图像 Patch 和文本 Token 互相计算注意力权重。
-
模态无关性:不预设图像/文本的优先级,完全依赖数据驱动学习。
-
(3) 预训练任务
-
图像-文本匹配(ITM):
- 二分类任务,判断图像和文本是否匹配。
-
掩码语言建模(MLM):
- 随机掩盖文本 Token,预测被掩盖的词(类似 BERT)。
-
掩码图像建模(MIM):
- 随机掩盖图像 Patches,预测被掩盖的像素(类似 MAE)。
技术创新与影响
- 简化流程:移除了预提取的视觉特征,大大简化了处理流程
- 计算效率:比之前的视觉-语言模型快10-100倍
- 端到端训练:整个模型可以从头到尾联合优化
- 性能与效率平衡:虽然性能可能略低于最先进模型,但效率大幅提升
资源友好:降低了计算和存储需求,使多模态模型更易于部署
ViLT代表了多模态模型架构简化的重要趋势,表明有效的模态融合不一定需要复杂的特征提取步骤,为后续更高效的多模态系统铺平了道路。
相关文章:

从单模态到多模态:五大模型架构演进与技术介绍
前言 1. ResNet — 残差神经网络背景核心问题与解决方案原理模型架构ResNet 系列变体技术创新与影响 2. ViT — Vision Transformer背景核心思想发展历程Transformer的起源:ViT的出现:ViT的进一步发展: 模型架构技术创新与影响 3. Swin Trans…...

基于 Java 的淘宝 API 调用实践:商品详情页 JSON 数据结构解析与重构
一、引言 在电商领域,淘宝拥有海量的商品数据。通过调用淘宝 API 可以获取商品详情页的 JSON 数据,这对于商家进行市场分析、竞品调研等具有重要意义。本文将详细介绍如何使用 Java 调用淘宝 API,获取商品详情页的 JSON 数据,并对…...

Sentinel源码—3.ProcessorSlot的执行过程二
大纲 1.NodeSelectorSlot构建资源调用树 2.LogSlot和StatisticSlot采集资源的数据 3.Sentinel监听器模式的规则对象与规则管理 4.AuthoritySlot控制黑白名单权限 5.SystemSlot根据系统保护规则进行流控 3.Sentinel监听器模式的规则对象与规则管理 (1)Sentinel的规则对象 …...

【C++11】列表初始化、右值引用、完美转发、lambda表达式
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🌐 C 语言 上篇文章:unordered_map、unordered_set底层编写 下篇文章:C11:新的类功能、模板的可…...
)
Spring中IOC的重点理解(笔记)
Spring: 出现在2002左右.解决企业级开发的难度.减轻对项目模块 类与类之间的管理帮助开发人员创建对象,管理对象之间的关系. 补充:什么是OCP原则?(面试) (1)是软件七大开发当中最基本的一个原则ÿ…...

数据库系统概论|第三章:关系数据库标准语言SQL—课程笔记4
前言 前面详细介绍了关于SELECT语句的相关使用方法,继续上文的介绍,本文将继续介绍数据查询的其他相关操作,主要包括排序(ORDER BY)子句、分组(GROUP BY)子句。与此同时,介绍完单表…...

【1】CICD持续集成-docker本地搭建gitlab代码仓库社区版
一、gitlab社区版概述 GitLab社区版(Community Edition, CE)是一个开源的版本控制系统,适用于个人开发者、中小团队及大型企业。 GitLab社区版采用MIT许可证,用户可以免费使用和修改源代码。其主要功能包括代码托管、版本控制…...
)
Verdi工具使用心得知识笔记(一)
Verdi工具使用知识点提炼 本文来源于移知,具体文档请咨询厚台 一、基础概念 波形依赖 Verdi本身无法生成波形,需配合VCS等仿真工具生成.fsdb文件。核心功能模块 • nTrace:代码调试与追踪 • nSchema:原理图分析 • nState&…...
数据编码)
【25软考网工笔记】第二章 数据通信基础(4)数据编码
目录 一、曼彻斯特编码 1. 以太网 2. 题型(考试过的选择题) 1)题目解析 二、差分曼彻斯特编码 三、两种曼彻斯特编码特点 编辑 1. 双相码 2. 将时钟和数据包含在信号数据流中 3. 编码效率低 4. 数据速率是码元速率的一半 5. 应用案例 编辑 1&…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——USB OTG测试
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 第四章 ATK-DLMP257B功能测试——USB OTG测试…...

现代c++获取linux系统磁盘大小
现代c获取linux系统磁盘大小 前言一、命令获取系统磁盘大小二、使用c获取系统磁盘大小三、总结 前言 本文介绍一种使用c获取linux系统磁盘大小的方法 一、命令获取系统磁盘大小 在linux系统中可以使用lsblk命令显示当前系统磁盘大小,如下图所示 lsblk二、使用c获…...

tcp和udp的数据传输过程以及区别
tcp和udp的数据传输过程以及区别 目录 一、数据传输过程 1.1 UDP 数据报服务图 1.2 TCP 字节流服务图 1.3 tcp和udp的区别 1.3.1 连接特性 1.3.2 可靠性 1.3.3 数据传输形式 1.3.4 传输效率与开销 应用场景 一、数据传输过程 1.1 UDP 数据报服务图 这张图展示了 UDP 数据报服务…...

C++项目-衡码云判项目演示
衡码云判项目是什么呢?简单来说就是这是一个类似于牛客、力扣等在线OJ系统,用户在网页编写代码,点击提交后传递给后端云服务器,云服务器将用户的代码和测试用例进行合并编译,返回结果到网页。 项目最大的两个亮点&…...

C 语言中的 volatile 关键字
1、概念 volatile 是 C/C 语言中的一个类型修饰符,用于告知编译器:该变量的值可能会在程序控制流之外被意外修改(如硬件寄存器、多线程共享变量或信号处理函数等),因此编译器不应对其进行激进的优化(如缓存…...

mysql表类型查询
普通表 SELECT table_schema AS database_name,table_name FROM information_schema.tables WHERE table_schema NOT IN (information_schema, mysql, performance_schema, sys)AND table_type BASE TABLEAND table_name NOT IN (SELECT DISTINCT table_name FROM informatio…...

JavaScript事件循环
目录 JavaScript 执行机制与事件循环 一、同步与异步代码 1. 同步代码(Synchronous Code) 2. 异步代码(Asynchronous Code) 二、事件循环(Event Loop) 1. 核心组成 2. 事件循环基本流程 3. 运行机制…...

Linux》》bash 、sh 执行脚本
通常使用shell去运行脚本,两种方法 》bash xxx.sh 或 bash “xxx.sh” 、sh xxx.sh 或 sh “xxx.sh” 》bash -c “cmd string” 引号不能省略 我们知道 -c 的意思是 command,所以 bash -c 或 sh -c 后面应该跟一个 command。...
)
Git完全指南:从入门到精通版本控制 ------- Git 查看提交历史(8)
Git提交历史深度解析:从代码考古到精准回退 前言 在软件开发的生命周期中,提交历史是团队协作的时空胶囊。Git作为分布式版本控制系统,其强大的历史追溯能力可帮助开发者: 精准定位引入Bug的提交分析代码演进趋势恢复误删的重要…...
:解锁数据驱动的商业成功密码)
精益数据分析(2/126):解锁数据驱动的商业成功密码
精益数据分析(2/126):解锁数据驱动的商业成功密码 大家好!在如今这个数据爆炸的时代,数据就像一座蕴含无限宝藏的矿山,等待着我们去挖掘和利用。最近我在深入研读《精益数据分析》这本书,收获了…...

【ssti模板注入基础】
一、ssti模板注入简介 二、模板在开发中的应用 为什么要使用模板 为什么要用模板来提升效率: 不管我们输入什么,有一部分内容都是不会变的 除了内容之外其他都不会变,如果我们有成千上万的页面,如果不用模板,就算复…...

如何在 Kali 上解决使用 evil-winrm 时 Ruby Reline 的 quoting_detection_proc 警告
在使用 Kali Linux 运行 Ruby 工具(例如 evil-winrm)时,你可能会遇到以下警告: Warning: Remote path completions is disabled due to ruby limitation: undefined method quoting_detection_proc for module Reline这个警告会导…...
)
从零开始搭建PyTorch环境(支持CUDA)
从零开始搭建PyTorch环境(支持CUDA) 本文将详细介绍如何在Windows系统上为RTX 3050显卡配置支持CUDA的PyTorch环境。 环境准备 本教程基于以下环境: 显卡:NVIDIA RTX 3050操作系统:WindowsPython版本:3.1…...

【扩散模型连载 · 第 2 期】逆向扩散建模与神经网络的角色
上期回顾 我们在第 1 期中介绍了 正向扩散过程(Forward Process),并用 CIFAR-10 图像演示了加噪过程: 正向过程是固定的,无需训练,但我们感兴趣的是:如何从纯噪声一步步“还原”出真实图像&…...

Mysql约束
约束其实就是创建表的时候给表的某些列加上限制条件。 主键约束和自增长约束比较重要 一、Mysql约束-主键约束 简介 指定的主键不能重复也不可以出现空值 1.添加单列主键 语法1:create table 表名(字段名 数据类型 primary key); 点开…...
)
力扣热题100—滑动窗口(c++)
3.无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 unordered_set<char> charSet; // 用于保存当前窗口的字符int left 0; // 窗口左指针int maxLength 0; // 最长子串的长度for (int right 0; right < s.siz…...

Linux网络编程第一课:深入浅出TCP/IP协议簇与网络寻址系统
知识点1【网络发展简史】 **网络节点:**路由器和交换机组成 交换机的作用:拓展网络接口 路由:网络通信路径 1、分组交换 分组的目的: 数据量大,不能一次型传输,只能分批次传输,这里的每一批…...

论文阅读笔记:Generative Modeling by Estimating Gradients of the Data Distribution
1、参考来源 论文《Generative Modeling by Estimating Gradients of the Data Distribution》 来源:NeurIPS 2019 论文链接:https://arxiv.org/abs/1907.05600 参考链接: 【AI知识分享】真正搞懂扩散模型Score Matching一定要理解的三大核心…...

C++零基础实践教程 函数 数组、字符串与 Vector
模块四:函数 (代码复用与模块化) 随着程序变得越来越复杂,把所有代码都堆在 main 函数里会变得难以管理和阅读。函数 (Function) 允许你将代码分解成逻辑上独立、可重用的块。这就像把一个大任务分解成几个小任务,每个小任务交给一个专门的“…...

照片处理工具:基于HTML与JavaScript实现详解
在当今数字时代,处理照片已成为日常需求。 本文将详细介绍一个基于HTML和JavaScript的照片处理工具的实现原理,这个工具可以调整图片尺寸、格式,并精确控制输出文件大小。 实现如下,不需要任何编辑器,txt文本、浏览器就行!! 工具功能概述 这个照片处理工具提供以下核心…...

MyBatis-OGNL表达式
介绍 OGNL(Object-Graph Navigation Language)是一种强大的表达式语言,用于获取和设置Java对象图中的属性。在MyBatis中,OGNL常用于动态SQL构建,如条件判断、循环等。以下是关于OGNL表达式的整合信息,包括…...

Web Worker在uniapp鸿蒙APP中的深度应用
文章目录 一、Web Worker核心概念解析1.1 什么是Web Worker?1.2 为什么在鸿蒙APP中使用Web Worker?1.3 性能对比实测 二、uniapp中的Web Worker完整实现2.1 基础配置步骤2.1.1 项目结构准备2.1.2 鸿蒙平台特殊配置 2.2 Worker脚本编写规范2.3 主线程通信…...

无人机故障冗余设计技术要点与难点!
一、技术要点 1. 冗余架构设计 硬件冗余:关键部件(飞控、电机、电池、通信模块)采用双余度或三余度设计,例如: 双飞控系统:主飞控失效时,备用飞控无缝接管。 电机动力冗余:六轴无…...

MySQL数据库表查询
测试表company.employee5 mysql> create database company; #创建一个库; 创建一个测试表: mysql> CREATE TABLE company.employee5(id int primary key auto_increment not null,name varchar(30) not null,sex enum(male,female) default male not null,hi…...
)
ADB的安装及抓取日志(2)
三、ADB抓取日志 在使用ADB抓取日志前,首先要保证电脑已经安装并配置ADB,在上一节已经验证完成。连接设备:可通过USB或者WI-FI,将安卓设备与电脑连接,并启用USB调试模式,此处我选择的是通过电脑与安卓设备…...

【C++】 —— 笔试刷题day_17
一、小乐乐改数字 题目解析 这道题,它们给定一个数,我们要对它进行修改;如果某一位是奇数,就把它变成1,;如果是偶数,就把它变成0; 让我们输出最后得到的数。 算法思路 这道题,总体…...

traceId传递
1、应用内传递通过ThreadLocal,InheritableThreadLocal传递 2、跨进程的应用间传递,这种会涉及到远程rpc通信,mq通信,数据库通信等。 feign:拦截器中改变请求头 feign.RequestInterceptor, 这个机制能够实现修改请求对象的目的,…...

自然科技部分详解
光的反射 凸面镜与凹面镜 凸透镜和凹透镜 空气开关原理 短路是指电路中突然的电流过大,这会让线圈的磁性增大,来克服内设的弹簧导致断开 过载会让电流增大,两金属片受热膨胀触发断开 核电荷数是指原子核所带的电荷数。 在原子中…...

蓝桥杯 9. 九宫幻方
九宫幻方 原题目链接 题目描述 小明最近在教邻居家的小朋友小学奥数,而最近正好讲述到了三阶幻方这个部分。 三阶幻方是指将 1 ~ 9 不重复地填入一个 33 的矩阵中,使得每一行、每一列和每一条对角线的和都是相同的。 三阶幻方又被称作九宫格&#x…...

算法——希尔排序
目录 一、希尔排序定义 二、希尔排序原理 三、希尔排序特点 四、两种解法 五、代码实现 一、希尔排序定义 希尔排序是一种基于插入排序的排序算法,也被称为缩小增量排序。它通过将待排序的数组分割成若干个子序列,对子序列进行排序,然后…...

亚马逊热销变维权?5步搭建跨境产品的安全防火墙
“产品热卖,引来维权”——这已经悄然成为越来越多跨境卖家的“热销烦恼”。曾经拼品拼量,如今却要步步谨慎。商标侵权、专利投诉、图片盗用……这些问题一旦发生,轻则下架、账号被限,重则冻结资金甚至封店。 别让“热销”变“受…...

20250416-Python 中常见的填充 `pad` 方法
Python 中常见的填充 pad 方法 在 Python 中,pad 方法通常与字符串或数组操作相关,用于在数据的前后填充特定的值,以达到指定的长度或格式。以下是几种常见的与 pad 相关的用法: 1. 字符串的 pad 操作 虽然 Python 的字符串没有…...

JavaEE-0416
今天修复了一个查询数据时数据显示哈希码: 搜索检阅后得到显示该格式的原因: 重写 POJO 类的 toString 方法 在 Java 编程中,默认情况下,对象的 toString() 方法会返回类似于 com.cz.pojo.Score2a266d09 的字符串。这是由于默认…...

团体程序设计天梯赛L2-008 最长对称子串
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。 输入格式: 输入在一行中给出长度不超过1000的非空字符串。 输出格式&…...
)
命令模式 (Command Pattern)
命令模式(Command Pattern)是一种行为型设计模式,它将请求封装成一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持可撤销的操作。该模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。 一、基础 1.1 意图 将请求封…...
)
Elasticsearch 8.18 中提供了原生连接 (Native Joins)
作者:来自 Elastic Costin Leau 探索 LOOKUP JOIN,这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令。 很高兴宣布 LOOKUP JOIN —— 这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令,旨在执行左 joins 以进行…...
)
在线终端(一个基于 Spring Boot 的在线终端模拟器,实现了类 Linux 命令行操作功能)
Online Terminal 一个基于 Spring Boot 的在线终端模拟器,实现了类 Linux 命令行操作功能。 功能特点 模拟 Linux 文件系统操作支持基础的文件和目录管理命令提供文件内容查看和编辑功能支持文件压缩和解压缩操作 快速开始 环境要求 JDK 8Maven 3.6 运行项目 克隆项目到…...
)
vue+electron ipc+sql相关开发(三)
在 Electron 中使用 IPC(Inter-Process Communication)与 SQLite 数据库进行通信是一个常见的模式,特别是在需要将数据库操作从渲染进程(Vue.js)移到主进程(Electron)的情况下。这样可以更好地管理数据库连接和提高安全性。下一篇介绍结合axios写成通用接口形式,虽然没…...

C++静态变量多线程中的未定义行为
静态变量,是 C 程序员最早接触的语言特性之一。它有状态、生命周期长、初始化一次,用起来真是香。 但只要程序一旦进入多线程的世界,很多你原以为“稳定可靠”的写法,可能就突然开始“不对劲”了。静态变量首当其冲。 今天我们就…...
 Docker)
黑马商城项目(二) Docker
一、Docker快速入门 安装Docker - 飞书云文档 二、命令解读 常见命令: 数据卷: 案例1 数据卷挂载: 案例2 本地目录挂载: 挂载到指定目录能够保存数据(即使Mysql容器被删除) docker run -d \--name mysql …...

玩转Docker | 使用Docker部署Memos笔记工具
玩转Docker | 使用Docker部署Memos笔记工具 前言一、Memos介绍Memos简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署Memos服务下载镜像创建容器创建容器检查容器状态检查服务端口安全设置四、访问Memos服务访问Memos首页注册账号五、基本使用…...