【C++11】列表初始化、右值引用、完美转发、lambda表达式
📚 博主的专栏
🐧 Linux | 🖥️ C++ | 📊 数据结构 | 💡C++ 算法 | 🌐 C 语言
上篇文章:unordered_map、unordered_set底层编写
下篇文章:C++11:新的类功能、模板的可变参数、包装器
本篇文章主要讲解C++11的这些内容:
1. C++11简介
2. 列表初始化
3. 变量类型推导
4. 范围for循环
5. 新增加容器---静态数组array、forward_list以及unordered系列6. 右值引用
7. 完美转发
8. lambda表达式
目录
C++11简介
统一的列表初始化(不是初始化列表)
std::initializer_list:
std::initializer_list使用场景:
C++11增加的声明
auto
decltype(推导对象类型,再用此类型定义对象)
编辑nullptr
范围for循环
智能指针
STL中一些变化
右值引用
左值引用和右值引用
什么是左值?什么是左值引用?
什么是右值?什么是右值引用?
左值引用不能给右值区别名:(const加引用左值可以 )
右值引用不能给左值区别名:(可以给move以后的左值取别名)
右值引用意义
移动构造和移动赋值能够提高传值返回的效率
结合场景讲解:
场景一(定义对象并赋值):
场景二(定义对象后再赋值):
右值引用本身就是一个左值
push_back等方法也有左、右值引用,提高键值效率(写匿名对象好)
上面所讲的效率提升,指的是自定义类型的深拷贝的类,因为深拷贝的类才有转移资源的说法,对于内置类型和浅拷贝自定义类型,没有移动系列方法
完美转发
为什么用完美转发
作用:
要知道完美转发在函数模版里面是用来干嘛的
lambda表达式
C++98中的一个例子
lambda表达式语法
举例:
lambda类型到底是什么?
捕捉a、b对象给lambda:
修改外面的a、b
捕捉列表是否能够传地址?不能直接传
捕捉列表的其他使用:
lambda适合用的场景:
C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言, C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个重点去学习。C++11增加的语法特性非常篇幅非常多,我们这里没办法一 一讲解,所以本节课程主要讲解实际中比较实用的语法。
C++官网:
C++11 - cppreference.com小故事:
1998年是C++标准委员会成立的第一年,本来计划以后每5年视实际需要更新一次标准,C++国际标准委员会在研究C++ 03的下一个版本的时候,一开始计划是2007年发布,所以最初这个标准叫C++ 07。但是到06年的时候,官方觉得2007年肯定完不成C++ 07,而且官方觉得2008年可能也完不成。最后干脆叫C++ 0x。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的时候也没完成,最后在2011年终于完成了C++标准。所以最终定名为C++11。
统一的列表初始化(不是初始化列表)
一切皆可以用列表初始化
{}初始化
在C++98中,标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
{int _x;int _y;
};int main()
{int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };Point p = { 1, 2 };Point p2 = 1; //单参数构造函数的隐式类型转化return 0;
}
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。,多参数隐式类型转换,构造+拷贝构造编译器优化成直接构造
struct Point
{int _x;int _y;
};
int main()
{int x1 = 1;int x2{ 2 };int array1[]{ 1, 2, 3, 4, 5 };int array2[5]{ 0 };Point p1 = { 1, 2 };//多参数构造函数的隐式类型转换Point p2 = { 1 }; //单参数也可以用列表初始化Point p3{ 1, 2 };// C++11中列表初始化也可以适用于new表达式中int* pa = new int[4] { 0 };return 0;
}创建对象时也可以使用列表初始化方式调用构造函数初始化
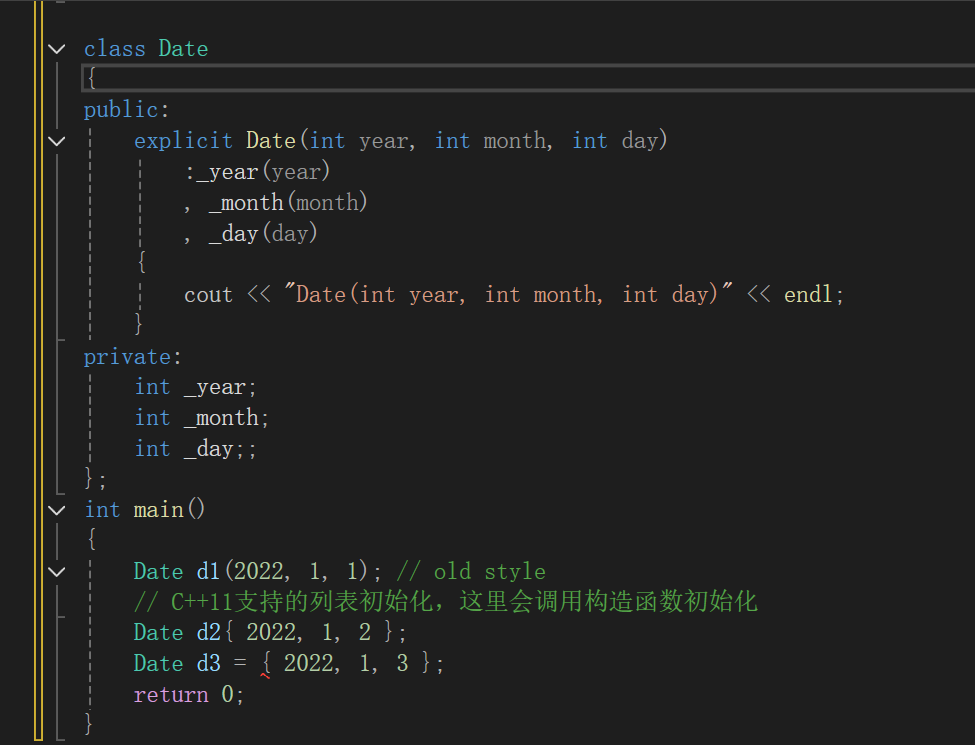
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;;
};
int main()
{Date d1(2022, 1, 1); // old style// C++11支持的列表初始化,这里会调用构造函数初始化Date d2{ 2022, 1, 2 };Date d3 = { 2022, 1, 3 };return 0;
}如果不想让隐式类型转换发生可以在构造函数前添加explicit:
std::initializer_list:
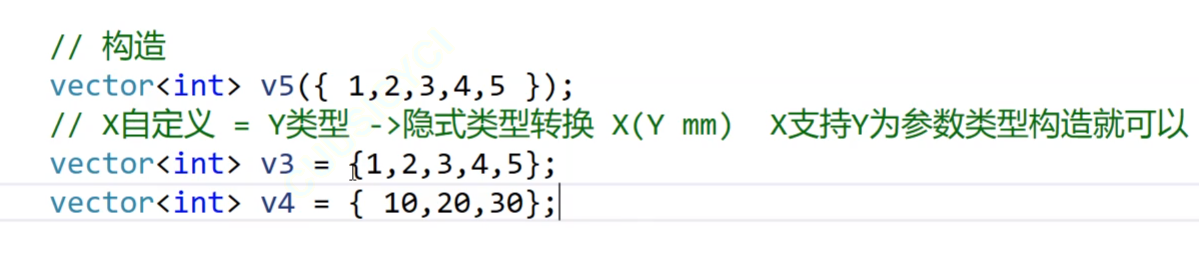
按理来说当我们想要这样初始化容器对象的时候:
int main()
{vector<int> v1;vector<int> v2(10, 1);vector<int> v3 = { 1, 2, 3, 4, 5 };vector<int> v4 = { 10, 20, 30, 40, 50 };return 0;
}构造函数应该写成这样:

std::initializer_list的介绍文档:
std::initializer_list使用场景:
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值
cplusplus.com/reference/list/list/list/
cplusplus.com/reference/vector/vector/vector/
cplusplus.com/reference/map/map/map/
cplusplus.com/reference/vector/vector/operator=/
initializer_list就是一个常量数组,语法就直接支持将一个数组直接给initializer_list,在32为机器下是8字节,他是两个指针,一个指针指向常量数组的开始,一个指针指向常量数组的结束

注意这两种写法的区别:当Y类型要赋值给x类型的时候,这时候就叫做隐式类型转换,x得支持Y类型为参数的构造就可以
模拟实现vector也支持{}初始化和赋值vector的简单使用和模拟实现这篇文章有怎么使用initializer_list来支持,查看目录

int main()
{vector<int> v = { 1,2,3,4 };list<int> lt = { 1,2 };// 这里{"sort", "排序"}会先初始化构造一个pair对象map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };// 使用大括号对容器赋值v = { 10, 20, 30 };return 0;
}从前的pair写法,与最方便的写法:在map和set讲过使用方法


C++11增加的声明
auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将其用于实现自动类型推断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
注意:auto的小特性:
int main() {int i = 0;auto x = i;//x++会不会影响i,不会,x就是i的拷贝x++;//k++会不会影响i,会,k就是i的别名auto& k = i;k++;return 0; }//j是i的引用,别名int& j = i;//此时的y是j的什么?拷贝auto y = j;y的地址和j、i的地址不相同

decltype(推导对象类型,再用此类型定义对象)
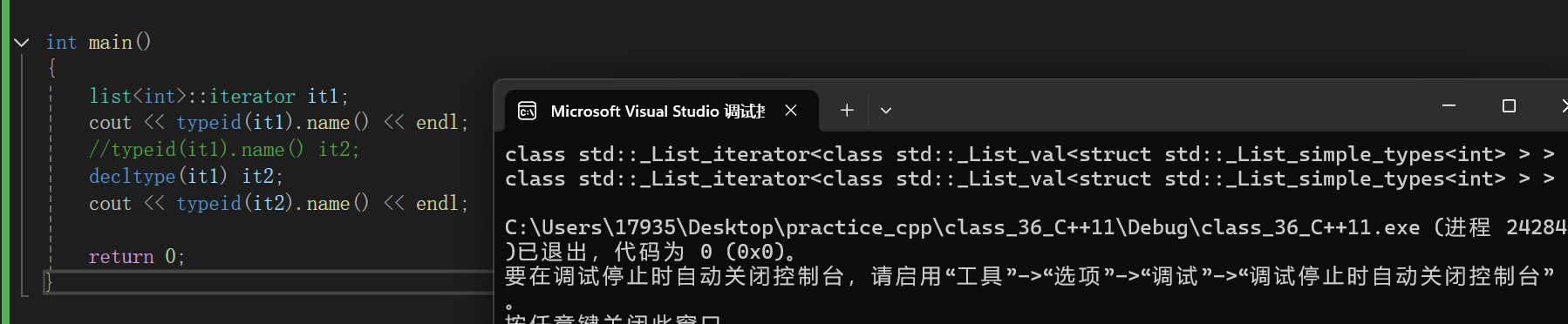
关键字decltype将变量的类型声明为表达式指定的类型。和typeid有点像(typeid是拿到真实的类型输出字符串)decltype用来推导类型,并且可以使用推导出的类型给来定义一个新对象。
相比于auto的优势在于:在这种情况下,如何拿到ret3的类型,来构造一个模版参数是ret3类型的B对象?使用typeid无法解决。
template<class T> class B { public:T* New(int n){return new T[n];} };auto func1() {list<int> lt;auto ret = lt.begin();return ret; }int main() {auto ret3 = func1();B<>return 0; }decltype能帮我们进行模版传参:
但是同auto一样,虽然在编写代码的时候轻松了一些,但是代码的可读性降低:

 nullptr
nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
范围for循环
C++17支持:模块化处理,x,y相当于pair里的first和second
但是在写范围for的时候想写这种写法,尽量加上const 和&,否则这个地方会有深拷贝的问题。
在这里x相当于pair的first是不能被修改的,y相当于second可以被修改,被修改不会影响x(是一个拷贝,因为拷贝的代价还挺大的,因此最好加上const和& ,不需要改变的值就加const)



智能指针
在之后单独写一篇文章来讲
STL中一些变化
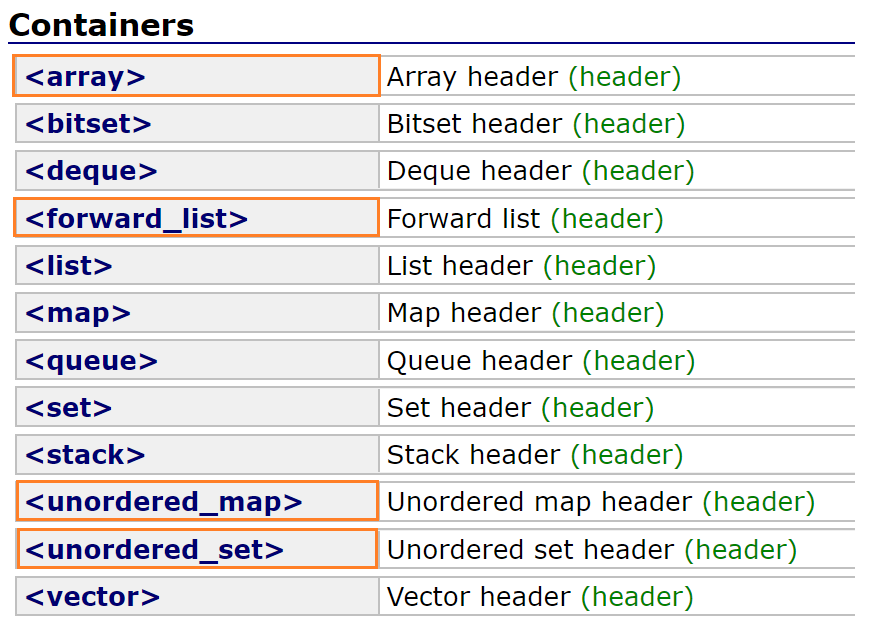
新容器
用橘色圈起来是C++11中的一些几个新容器,但是实际最有用的是unordered_map和unordered_set。这两个我们前面已经进行了非常详细的讲解,其他的大家了解一下即可。
其中array是一个静态的数组 ,为了替代C语言的静态数组,好处在于对于越界的检查更严格
实践当中并没有那么的有用。因为不如vector,也可以检查越界,也可以动态开辟空间
forward_list向前的链表,单向链表,省一个指针,但在实际场景当中也不常用。
容器中的一些新方法
如果我们再细细去看会发现基本每个容器中都增加了一些C++11的方法,但是其实很多都是用得比较少的,用处不大,按理不需要更新。有些部分,很需要,但是迟迟不出,比如网络库。
比较有意义的(vector,list,map等等几个都有):移动构造(右值引用),以及initializer_list
比如提供了cbegin和cend方法返回const迭代器等等,但是实际意义不大,因为begin和end也是可以返回const迭代器的,这些都是属于锦上添花的操作。
实际上C++11更新后,容器中增加的新方法最后用的插入接口函数的右值引用版本:
http://www.cplusplus.com/reference/vector/vector/emplace_back/
emplace_back对标的就是push_back
http://www.cplusplus.com/reference/vector/vector/push_back/
-----------------------------------------------------------------------------------------
http://www.cplusplus.com/reference/map/map/emplace/
emplace对标的就是insert
http://www.cplusplus.com/reference/map/map/insert/
但是这些接口到底意义在哪?网上都说他们能提高效率,他们是如何提高效率的?
请看下面的右值引用和移动语义章节的讲解。另外emplace还涉及模板的可变参数,也需要再继续深入学习后面章节的知识。
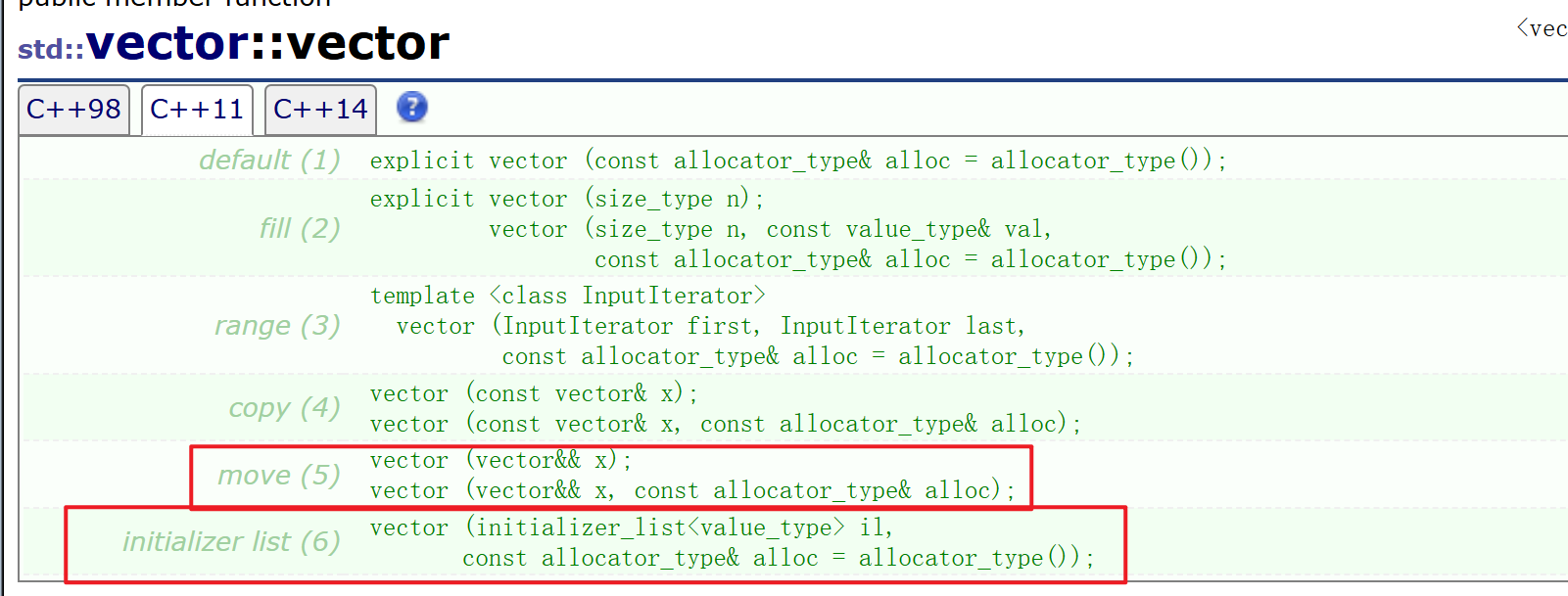


右值引用
左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可获取它的地址+可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
//a是左值,10是右值
int a = 10;
//b是左值
int b = a;
//c是左值
const int c = 10;
//*p是左值
int* p = &a;
vector<int> v(10, 1);
//v[1]是左值,是一个表达式
v[1];cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &(*p) << endl;
cout << &(v[1]) << endl;
左值和右值的区分就在于:能否取地址,简单来说左值可以被取地址,不能被取地址的就是右值
什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
像是临时对象和匿名对象等都是属于右值
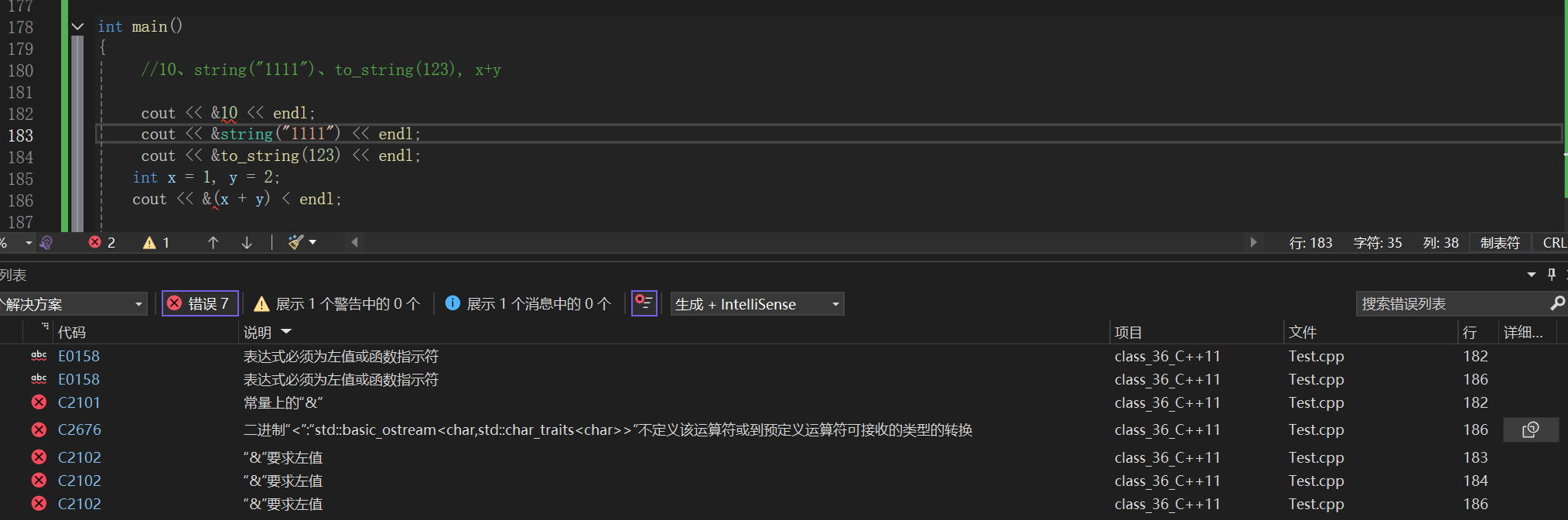
左值右值的意思就是他是一个表达式,它本身就是一个值或者是函数会返回值

左值引用不能给右值区别名:(const加引用左值可以 )
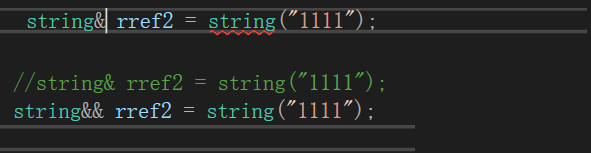
但是const左值加引用可以
// 左值引用能否给右值取别名 -- 不可以,但是const左值引用可以const string& ref1 = string("1111");const int& ref2 = 10;右值引用不能给左值区别名:(可以给move以后的左值取别名)
右值引用能否给左值取别名 -- 不可以,但是可以给move以后的左值取别名
string s1("1111");
string&& rref5 = move(s1);右值引用意义
移动构造和移动赋值能够提高传值返回的效率
引用的意义:减少拷贝,提高效率
左值引用解决了:引用传值传参传引用返回(不用拷贝)
没有彻底解决的问题:引用返回值的问题没有彻底解决,如果返回值是一个func2中的局部对象,不能用引用返回,出了作用域就被销毁
// 左值引用的场景 void func1(const string& s); string& func2();
结合场景讲解:
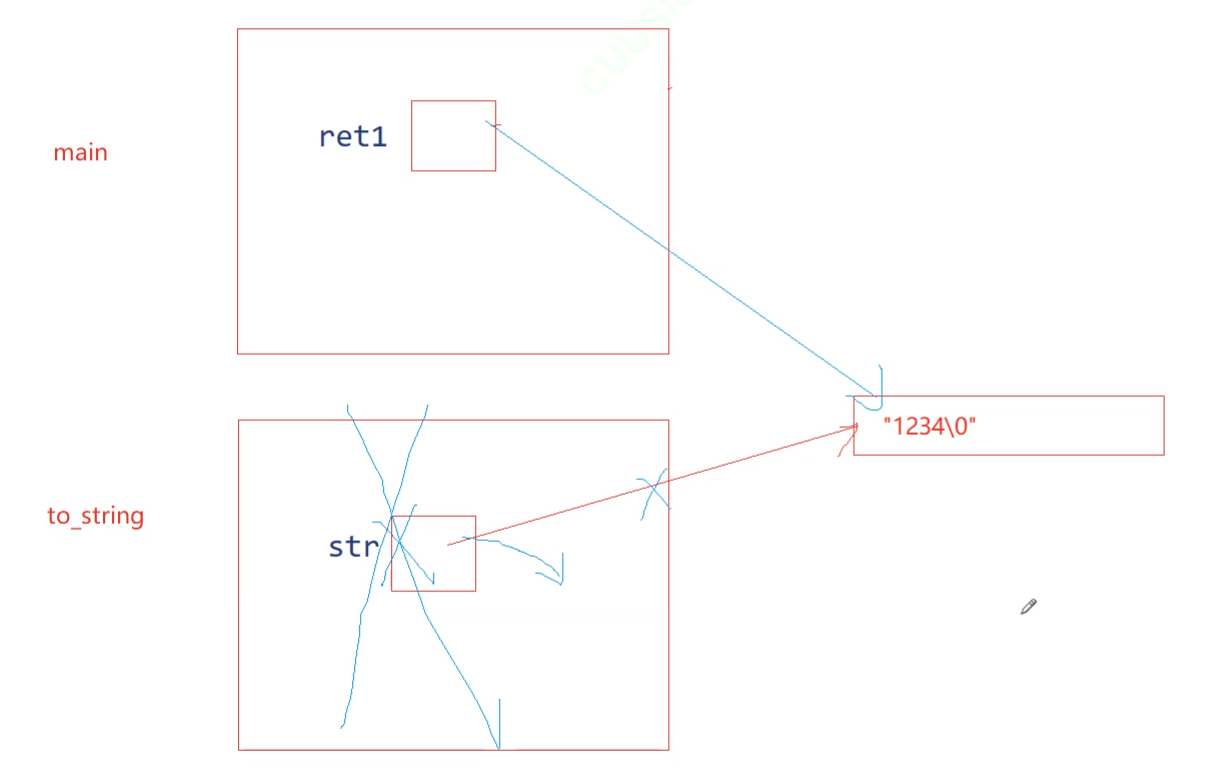
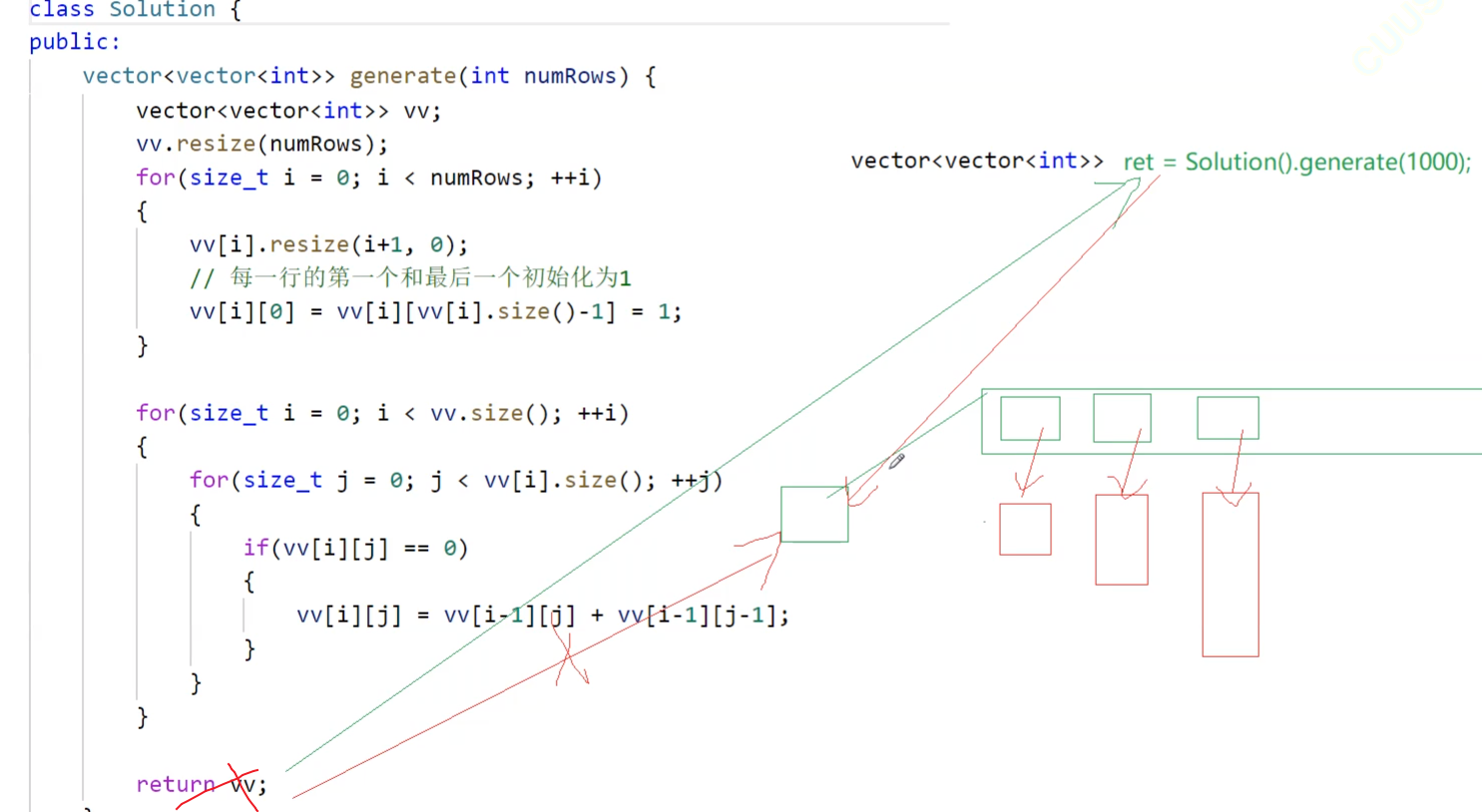
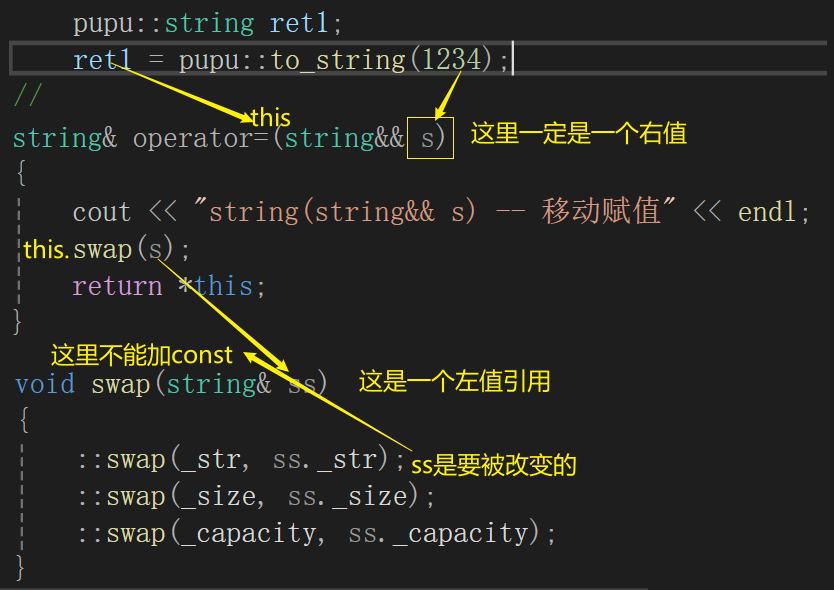
比如说这里的to_string,把整形转成字符串,转成字符串就存到了一个局部对象str,这里就不能用左值引用返回,不能返回他的别名,因为他的别名的生命周期就在这函数作用域里面,能否使用右值引用返回?也不能。
pupu::string& to_string(int value)
{bool flag = true;if (value < 0){flag = false;value = 0 - value;}pupu::string str;while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return str;
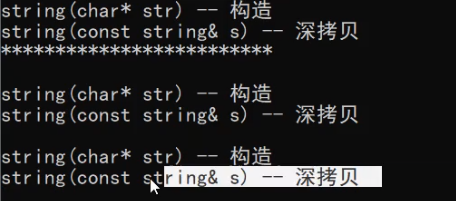
}我们使用一个之前写过的String:来看看这里一共调用了多少次拷贝构造
namespace pupu
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str) -- 构造" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造// 左值string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};pupu::string to_string(int value){bool flag = true;if (value < 0){flag = false;value = 0 - value;}pupu::string str;while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return str;}
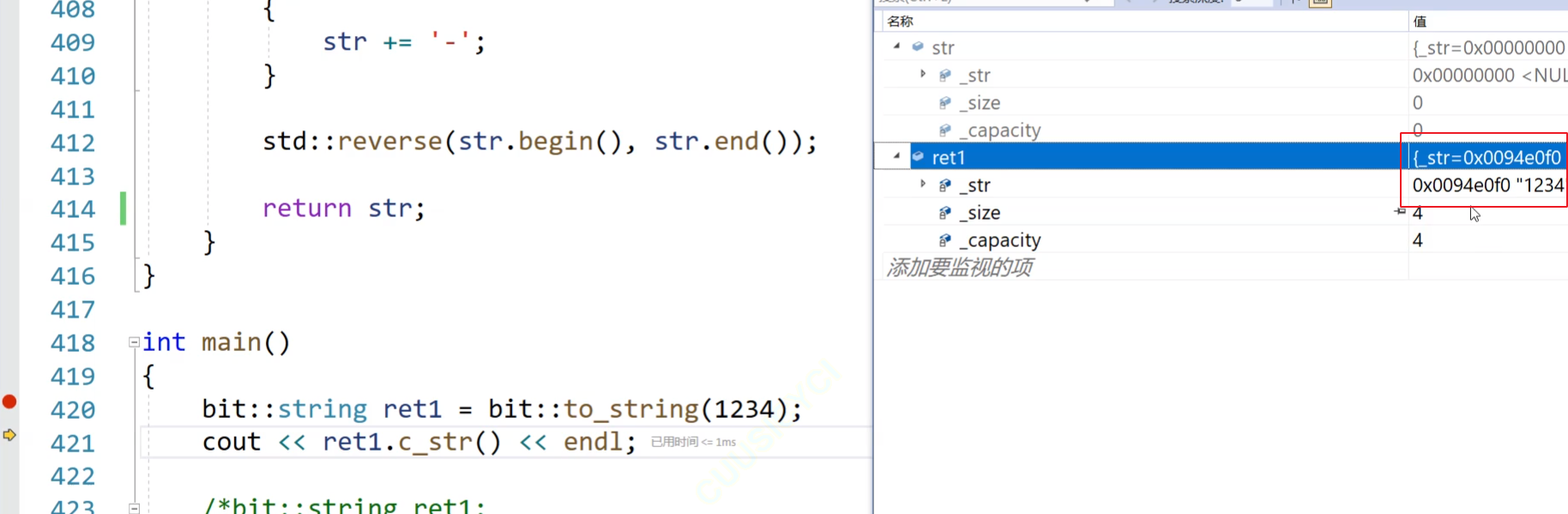
}int main()
{pupu::string ret1 = pupu::to_string(1234);cout << ret1.c_str() << endl;return 0;
}
场景一(定义对象并赋值):
vs2019及以下可以看到的结果:这里的赋值过程是一个构造加一个深拷贝
改进方法:
添加左值引用:
在这里使用左值引用:会导致程序崩溃
右值引用:
也不能使用右值引用,move(str),会导致程序崩溃
str已经销毁了,不管是左值引用还是右值引用,引用的值都被销毁了,引用也不存在了

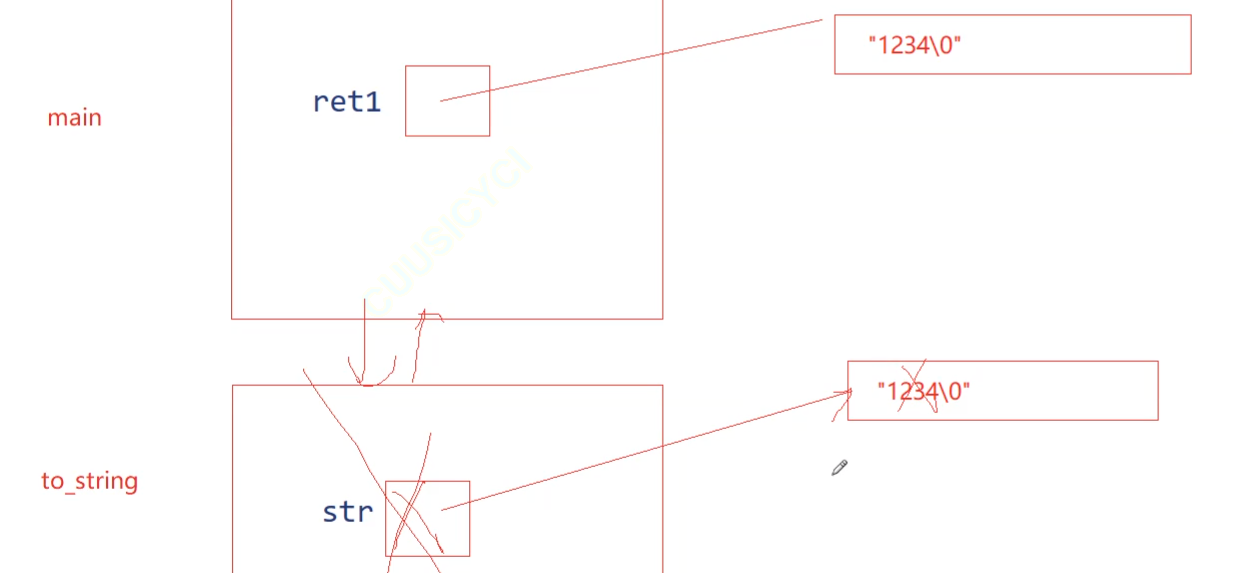
解决办法:
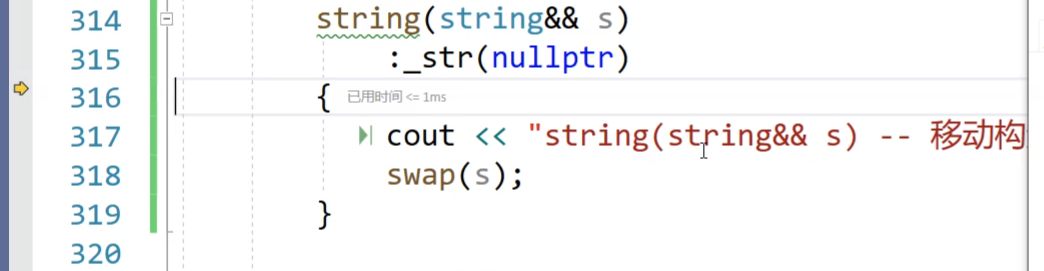
加移动构造:和左值的拷贝构造构成重载,编译器自己去匹配
// 移动构造string(string&& s):_str(nullptr){cout << "string(string&& s) -- 移动构造" << endl;}而这个值已经是要被销毁的,也就是将亡值,因此我们加上一个交换swap(s),使得将亡值给到ret
移动构造右值(将亡值)string(string&& s):_str(nullptr){cout << "string(string&& s) -- 移动构造" << endl;swap(s);}测试:
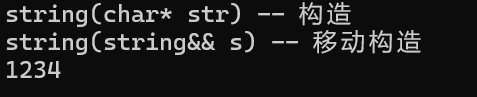
int main() {pupu::string ret1 = pupu::to_string(1234);cout << ret1.c_str() << endl;return 0; }
这个值虽然是左值,但是可以强行move成右值,编译器识别到两次移动构造,直接给优化成一次了。
左值的资源是不能被掠夺的,而右值的资源可以被掠夺
对比一下拷贝构造:拷贝你的资源,你再被销毁,有了移动构造,被强行识别成了右值,因此就能掠夺资源,无需拷贝,直接拿走这个空间的值

看看底层:
在这个程序结束之前,会先去调用移动构造
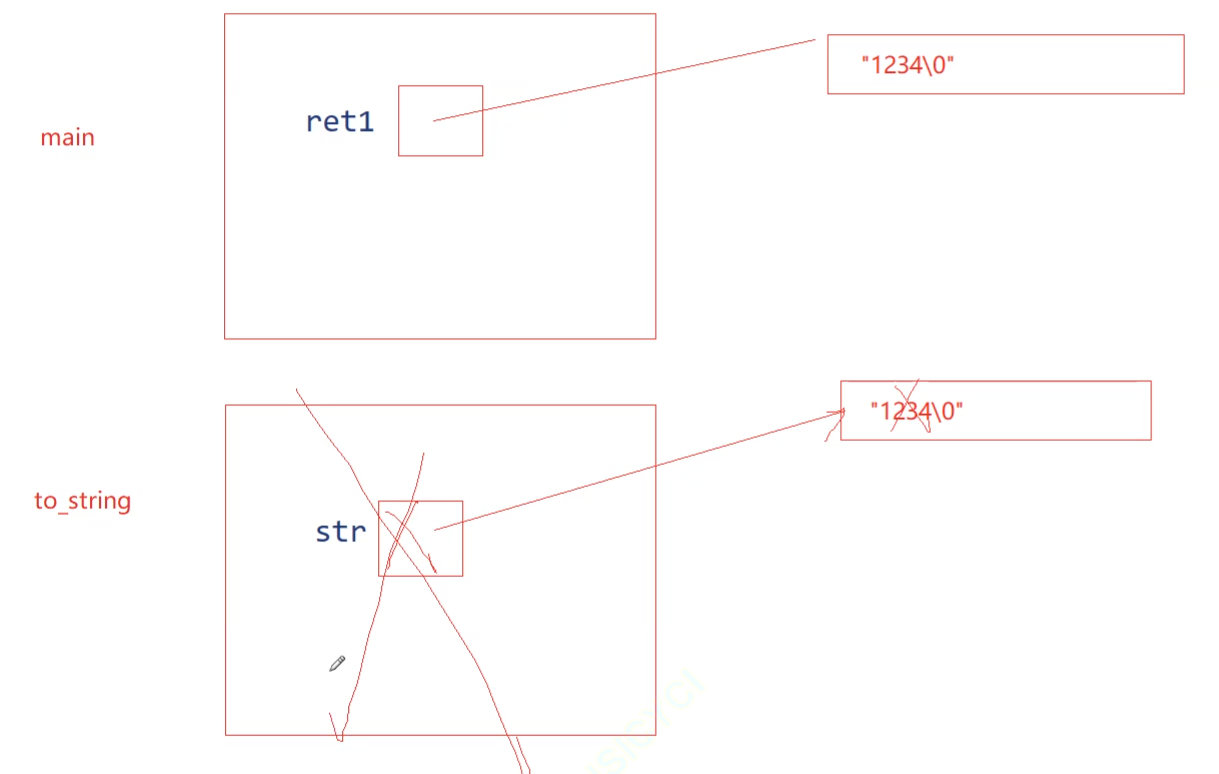
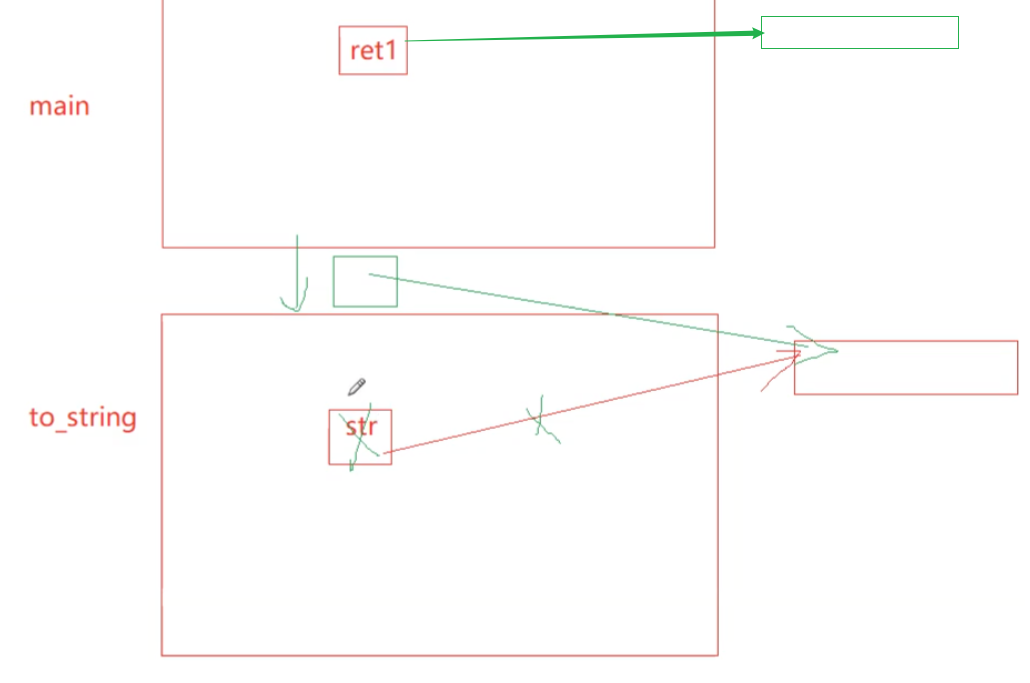
回到return str这里:str已经被销毁了,资源已经被换给了ret
ret有了同样的虚拟地址资源、数据:

严格的来说不是右值延长了 将亡变量 的生命周期,而是延长了将亡值,资源的生命周期,使得资源换给了接受变量,这个str还是在出作用域就被销毁。
如果你是一个左值我只能对你进行深拷贝,如果你是一个右值,我就可以转移你的资源。
场景二(定义对象后再赋值):
看这个测试:(vs2022加上move好看效果,不然会被编译器优化)
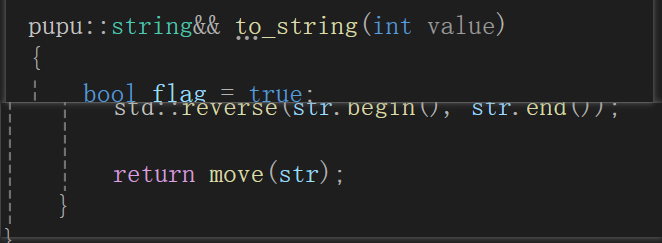
并缩减to_string代码:
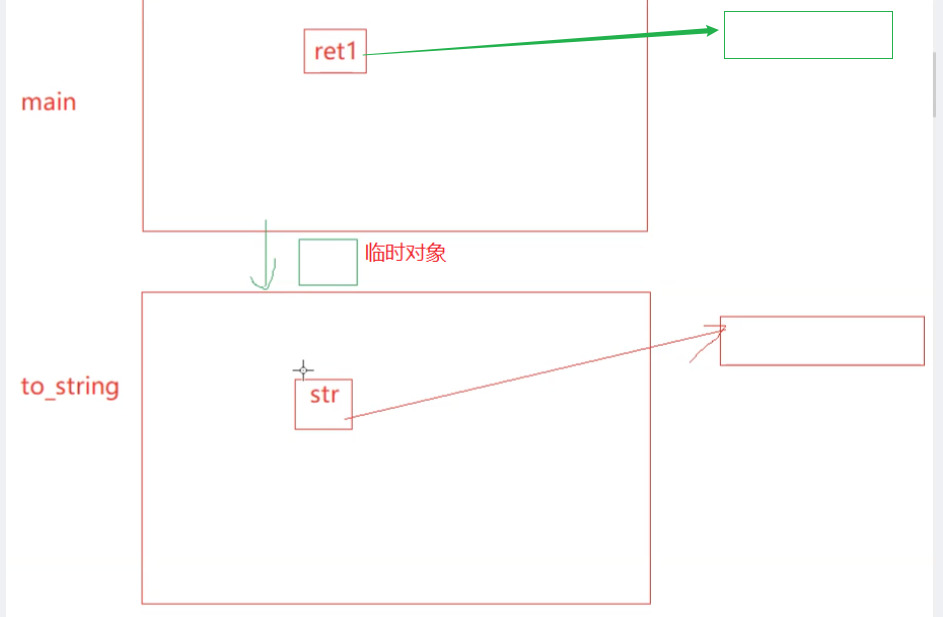
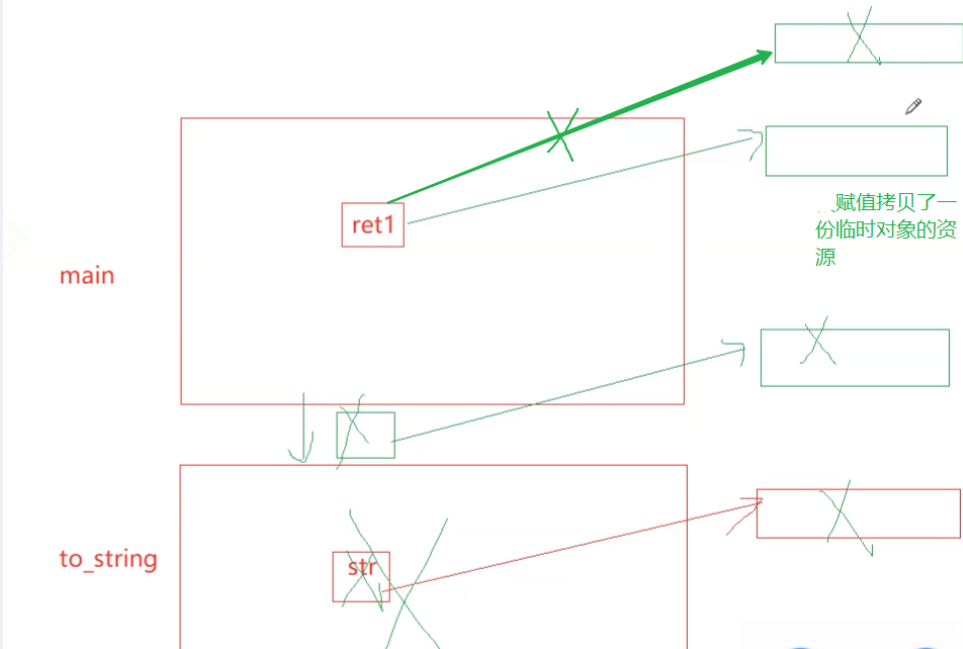
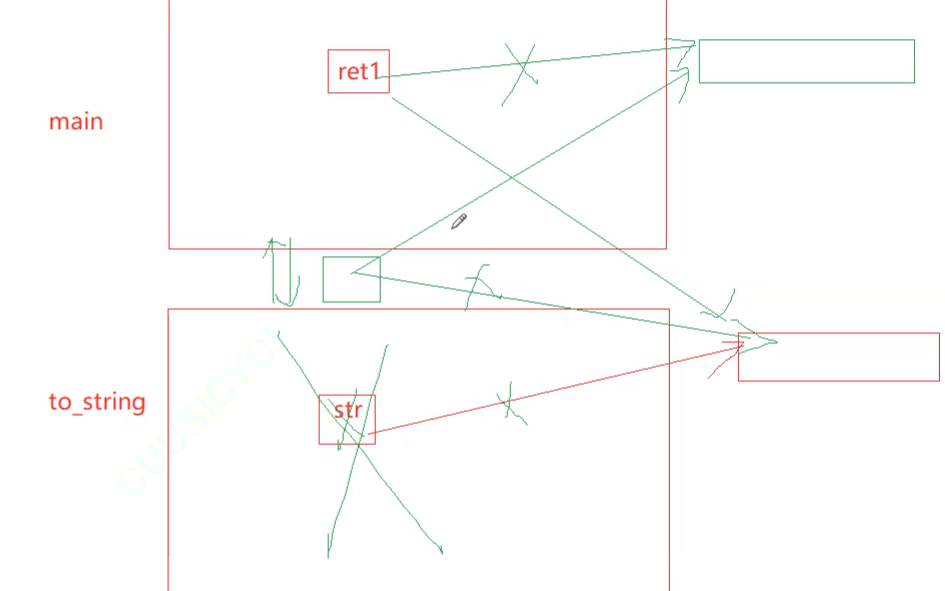
pupu::string to_string(int value) {pupu::string str;//...std::reverse(str.begin(), str.end());return move(str);//return的时候中间会产生临时对象,他默认是一个左值,会走拷贝构造 }int main() {pupu::string ret1;ret1 = pupu::to_string(1234);return 0; }屏蔽掉移动构造:释放了三次资源,拷贝了两次资源
return 的时候会产生临时变量,如果返回的对象比较小,就像现在,是存在寄存器中的,存不下的时候,就放在ret和str的栈帧之间(ret在被定义的时候,本身就是有资源的))
然后,str所存的值拷贝给临时对象,str被销毁:
然后这个临时对象给ret1:
再去做深拷贝,临时对象被销毁:这里一共释放了三次资源,拷贝了两次资源
所以C++11就做了右值引用出来:
有了移动构造和移动赋值
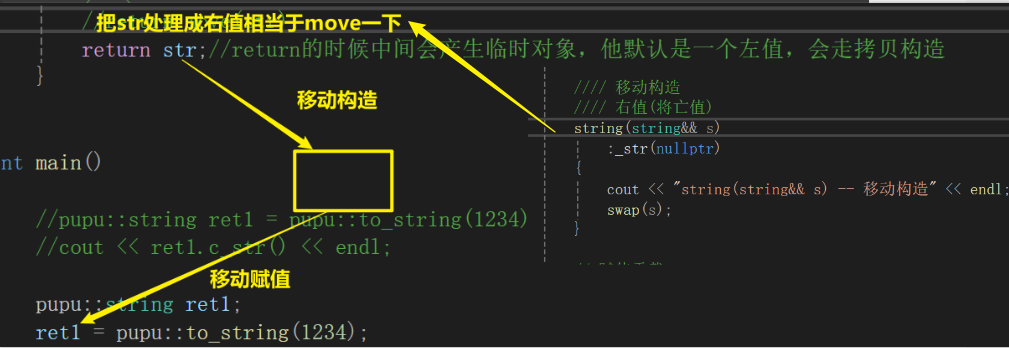
首先将str识别成右值,不识别成右值,那么第一次就会是拷贝构造,第二次才是移动构造
移动构造和移动赋值的特点:如果你是右值,就直接转移你的资源,如下图,将str的资源转给ret1
对于vs2022写成move(str)更好观察:这是还未添加移动构造的时候
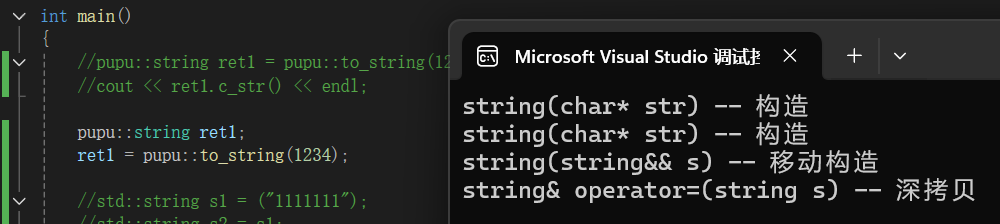
添加移动赋值:
//移动赋值// s3 = 将亡值对象,不拷贝你,直接拿你的资源string& operator=(string&& s){cout << "string(string&& s) -- 移动赋值" << endl;swap(s);return *this;}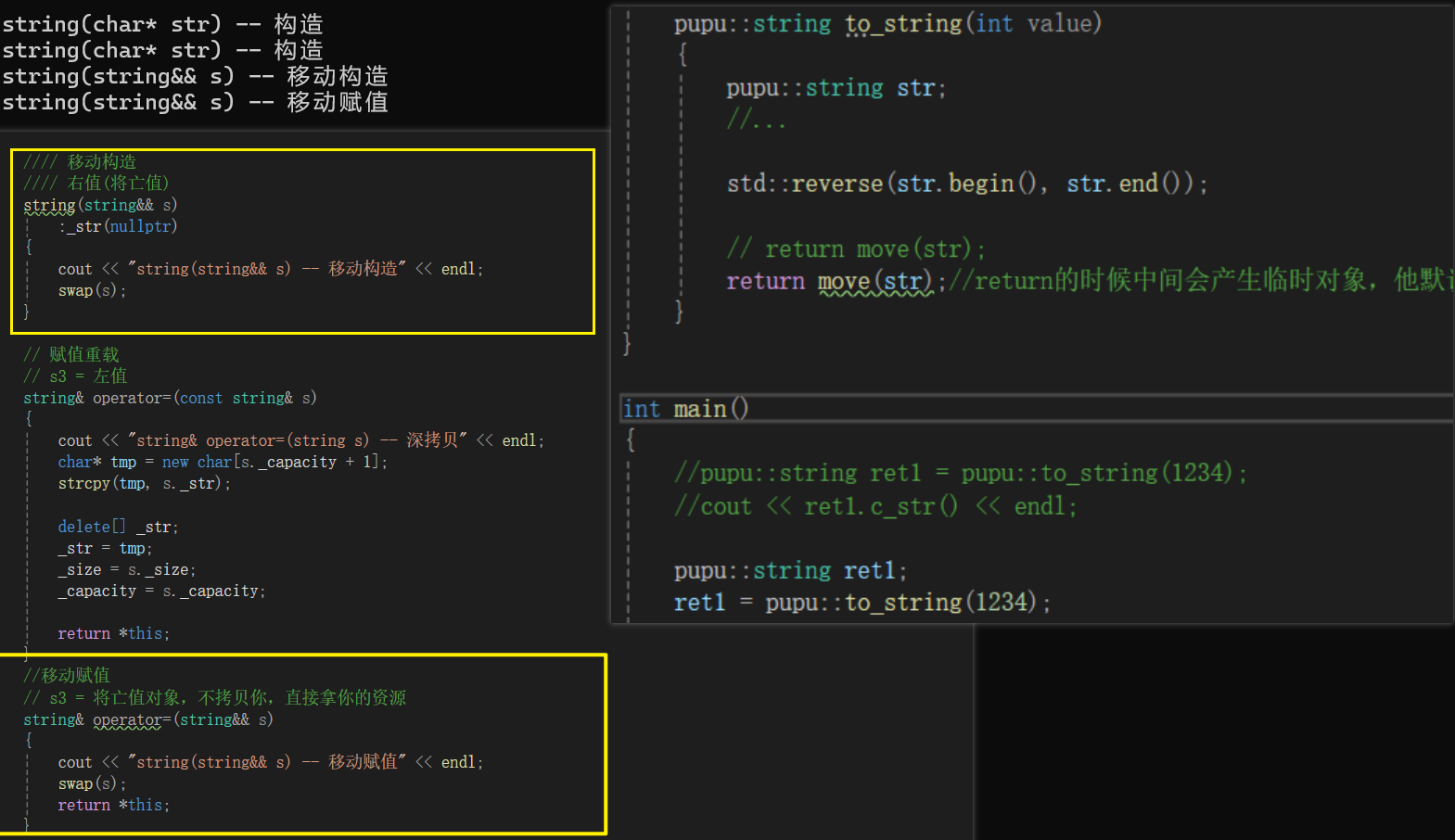
移动构造和移动赋值的过程:只释放一次资源,没有拷贝资源
临时对象不再去拷贝,而是直接转移走str的资源,str被销毁
ret1原来自己是有一个资源的,在次和临时对象进行了一次交换,互相指向对方的资源:
临时对象是一个将亡值,被销毁的时候顺带将ret1原有的资源也一起带走销毁。

由此可以看到有了移动构造和移动赋值彻底拯救了传值返回的场景,提高了效率
再看示例:
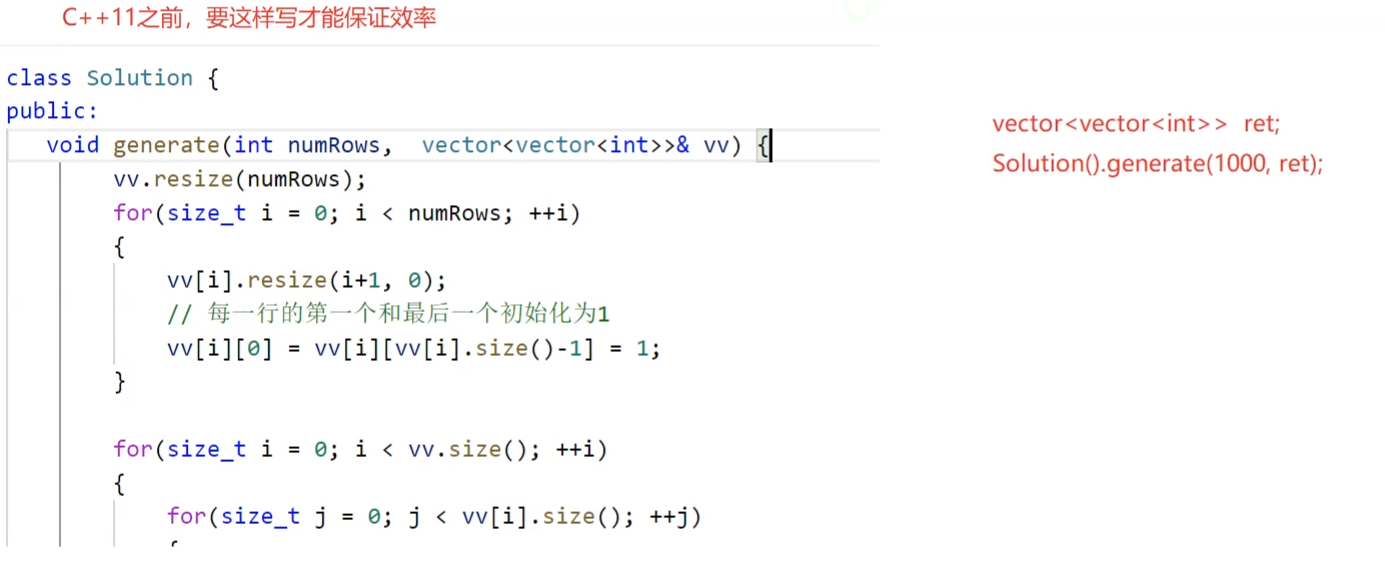
杨辉三角,在C++11之前要这样写,才能保证效率:这个时候就没有拷贝了,vv是ret的引用。
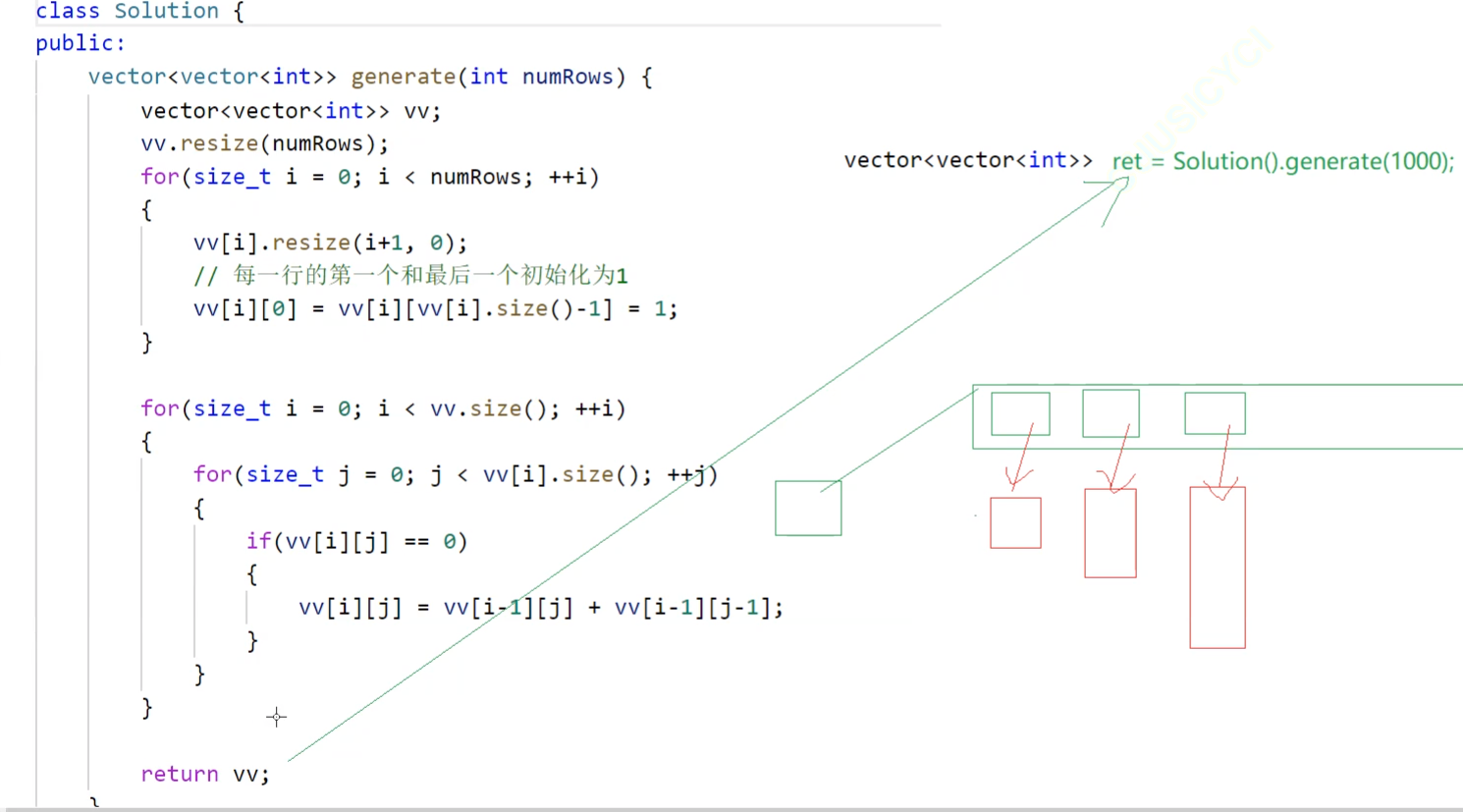
在C++11出来后:直接资源转移
vv对象是指向这个vector的,移动构造就是直接让,ret指向vv的资源,vv出作用域被销毁
移动构造和移动赋值是什么,是本身传给他们的就是一个右值, 然后在函数中利用右值的别名,只需要交换资源,没有什么代价,而现代写法没有什么优化,虽然他们都是交换,但交换的不是一个东西,现代写法是利用自己构造的对象来进行一个值交换,还是进行了深拷贝,移动赋值的交换是交换将亡值的资源。
以上我们讲到了移动构造和移动赋值能够提高传值返回的效率
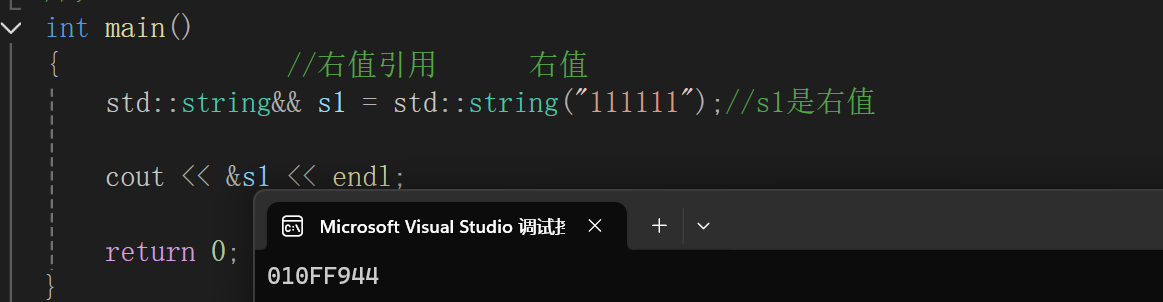
右值引用本身就是一个左值
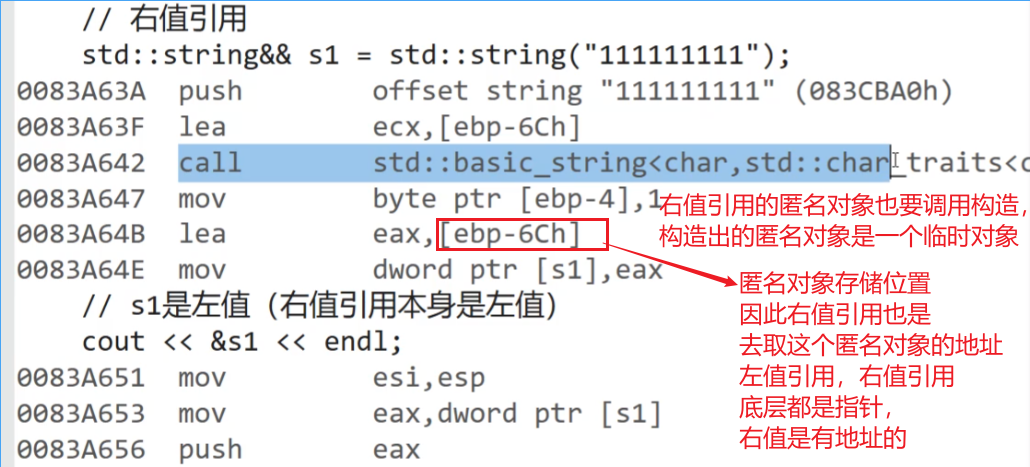
此时的s1右值还是左值???
//右值引用 右值std::string&& s1 = std::string("111111");//s1是右值cout << &s1 << endl;通过是否能取地址来确认:
已经确定了 std::string("111111"),是右值。
实际上是右值引用s1的属性就是一个左值
解释:前面有讲到过普通左值引用不能引用右值,const左值引用才能引用右值
因为,只有右值引用本身处理成左值,才能实现移动构造和移动赋值
如何做到的:
右值也是有地址的,只是不让取
底层右值引用也是存了右值的地址,才好转移资源(重点不是可以取地址)。
是左值的真正意义在于:语法的逻辑自洽,能够保证移动构造移动赋值,转移资源的语法逻辑是自洽的。右值是不想被改变的,因此不能加左值引用,因为加了左值引用就能被改变,因此想加左值引用就要加const,保证右值不会被改变
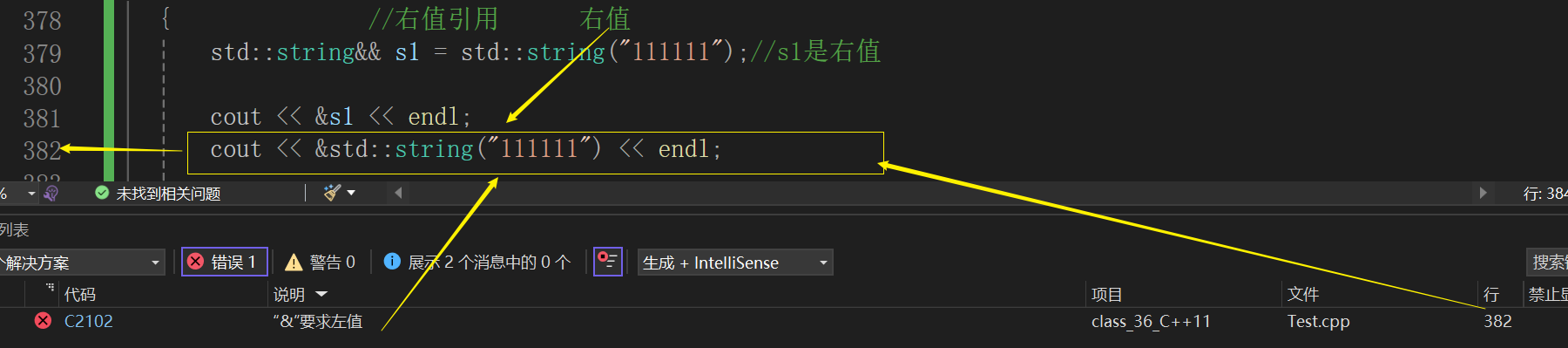
那右值还有什么办法能够在不加const的情况下用左值引用???强转:
std::string& s2 = (std::string&)std::string("111");
因为右值是有空间存储的,所以就可以改他。
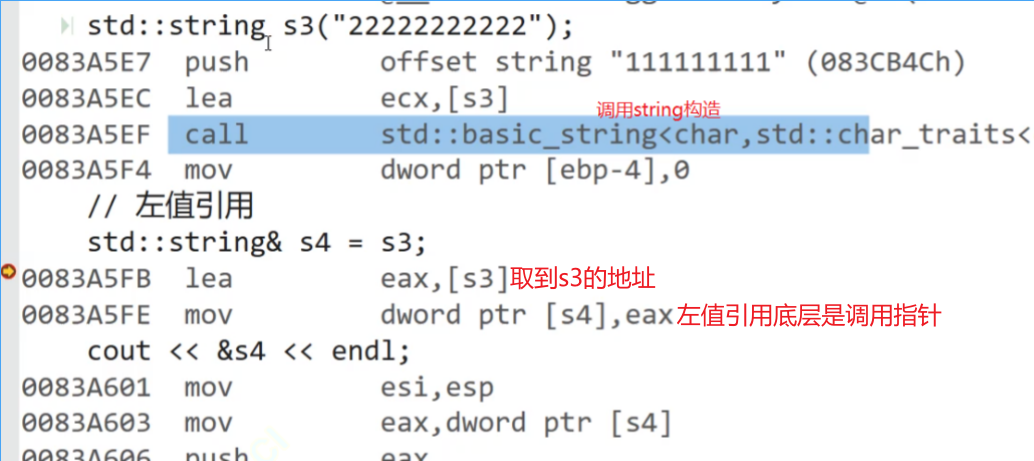
还可以先得到一个右值引用,再左值引用他的右值引用
std::string&& s3 = std::string("111111111");std::string& s4 = s3;push_back等方法也有左、右值引用,提高键值效率(写匿名对象好)
区别在于,如果是左值就匹配左值引用,右值就匹配右值引用
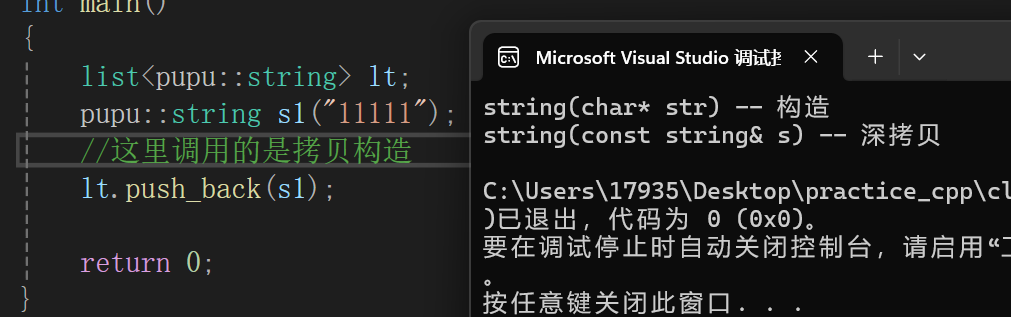
用于:push_back当中这里对于s1是调用了一个拷贝构造
链表里面要插入一个值的时候就还要去构造一个节点 ,这个节点里面得有一个string,这个链表存的是string,因此这里所做的是一个深拷贝,s1是一个左值,不能被转移资源,只能做深拷贝。
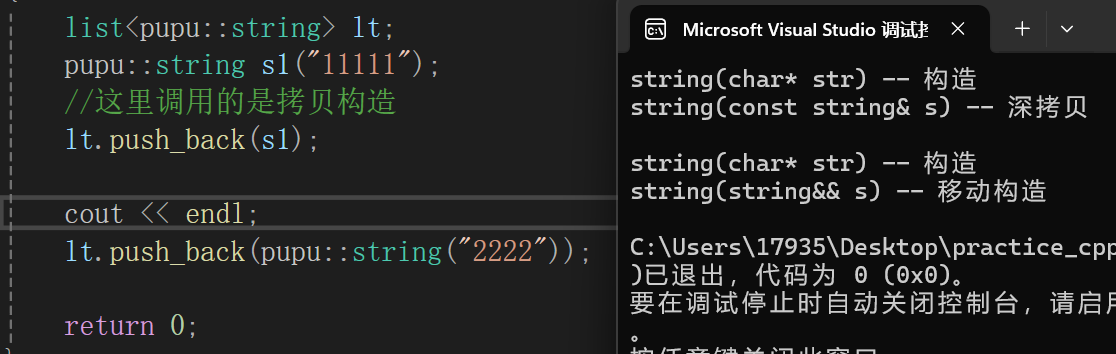
而这里就是调用的移动构造,因为里面是一个右值是一个将亡值,可以被掠夺资源,被掠夺资源之后,就让你置空
lt.push_back(pupu::string("2222"));
也能这样写:
看看底层:调用了之前自己所写的list,给之前写的list加上右值版本:无论是左值还是右值都掉用push_back,左值引用调用左值的,右值调用右值引用的
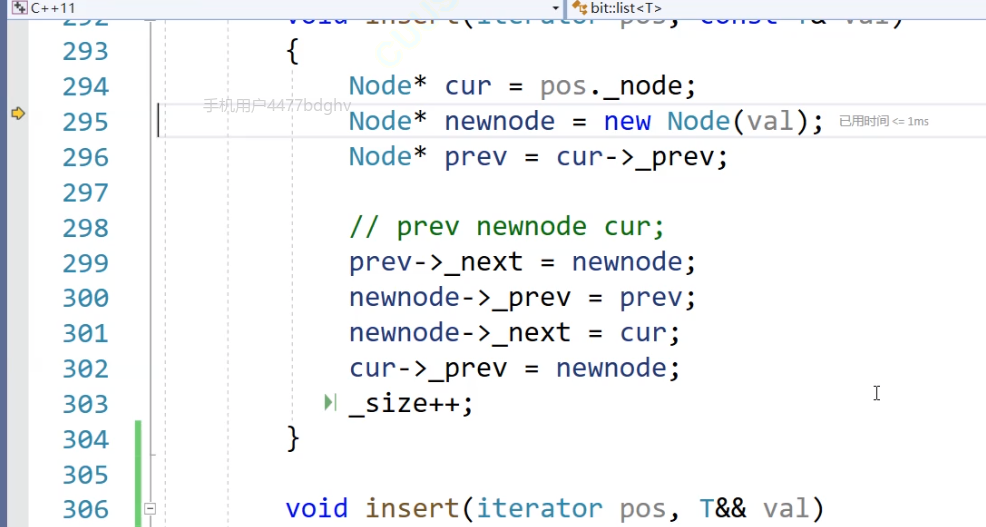
//右值版本void push_back(T&& x){insert(end(), forward<T>(x));}但是:push_back是复用的insert,insert这里是左值引用的const
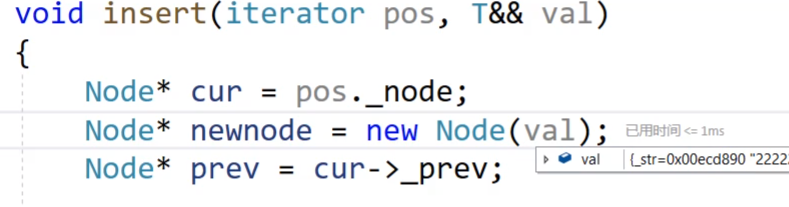
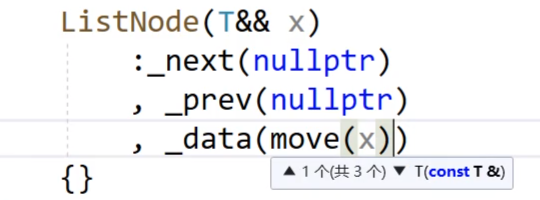
void insert(iterator pos, const T& val){Node* cur = pos._node;Node* newnode = new Node(val);Node* prev = cur->_prev;// prev newnode cur;prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;_size++;}但是实际上,insert也有右值引用版本:
因此我们再添加一个右值引用版本的insert
void insert(iterator pos, T&& val){Node* cur = pos._node;Node* newnode = new Node(forward<T>(val));Node* prev = cur->_prev;// prev newnode cur;prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;_size++;}还是未达到目的
调试代码发现没有去调用右值引用:
push_back调用的是右值引用的:
但是insert却没有调用右值引用的:
这是因为,前面的右值引用要能够去交换,它本身的属性是左值,为了移动构造,因此想要就想到使用右值引用,就在传参给insert的时候,传右值move(x);
void push_back(const T& x){insert(end(), move(x));}但是还有一点:在insert中,要构造的时候,会传给这个val,这个val也应该是string右值引用,会调用构造
因此又进入了链表的构造,这里是左值引用,也需要加右值引用版本的List构造,
每一层都需要有右值引用版本
到了new Node(val)时,这里又传左值,因此,需要转成move
这样才能用到移动构造
注意:move就是把左值属性转成右值。







如果我们现在list的模版参数是int、日期类,不再是string,push_back(),左右值引用的区别:没区别,是左值还是右值,int没有拷贝构造和移动构造,浅拷贝的类不存在转移资源的说法。
上面所讲的效率提升,指的是自定义类型的深拷贝的类,因为深拷贝的类才有转移资源的说法,对于内置类型和浅拷贝自定义类型,没有移动系列方法
完美转发
模板中的&& 万能引用
上面所添加的move的方式,的优化方式就是完美转发:
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值,
我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面学习的完美转发
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值。
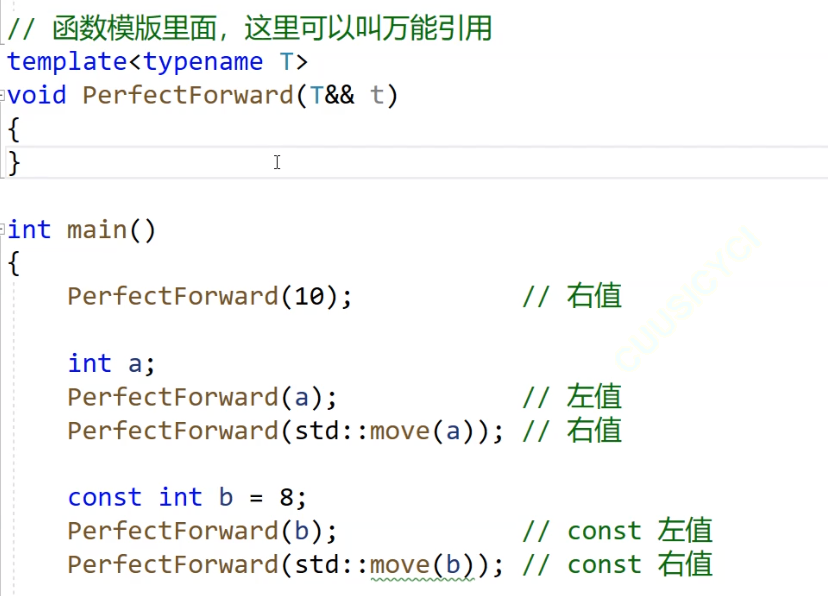
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }// 右值引用,引用后,右值引用本身属性变成左值
// std::forward<T>(t)在传参的过程中保持了t的原生类型属性。// 函数模版里面,这里可以叫万能引用
// 实参传左值,就推成左值引用
// 实参传右值,就推成右值引用
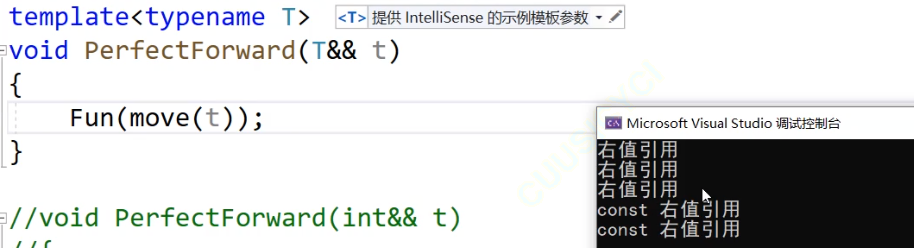
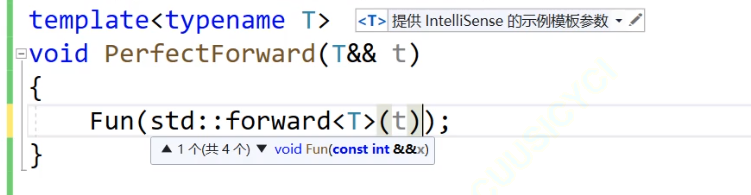
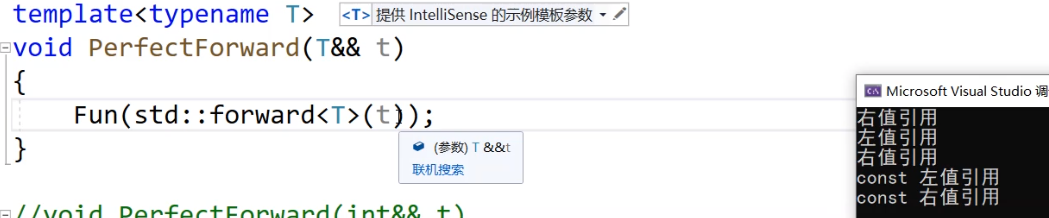
template<typename T>
void PerfectForward(T&& t)
{//Fun((T&&)t);Fun(forward<T>(t));
}
//以下等等都是函数模版要推导出来的函数
void PerfectForward(int&& t)
{Fun((int&&)t);
}void PerfectForward(int& t)
{Fun((int&)t);
}void PerfectForward(const int&& t)
{Fun((const int&&)t);
}void PerfectForward(const int& t)
{Fun((const int&)t);
}int main()
{PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0;
}注意一下:右值也有const的概念
为什么用完美转发
函数模版里面,这里可以叫万能引用,引用折叠,看起来我是右值引用,但是我是一个模版,因此是万能引用,有了模版,灵活推导,但是要注意的是右值被右值引用,我的属性会退化成左值引用
通过我们传什么值,推出什么引用的函数
这里不能用move来解决:使用了move就全变成右值引用了
解决办法:不写模版了,在需要传右值的地方move
优化的解决办法:完美转发,move和完美转发的本质都是类型转化



作用:
你是什么值,我就保持你的什么属性(比如如果是左值就直接返回,如果是右值就相当于加了move):
就像是也可以直接:在传的时候强转。

因此前面list时也可以将接收左右值的地方加上完美转发
要知道完美转发在函数模版里面是用来干嘛的
防止右值引用,向下传值的时候丢失属性,属性为左值,但我们又想他属性保持右值。
lambda表达式
C++98中的一个例子
在C++98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort方法
#include <algorithm>
#include <functional>
int main()
{int array[] = { 4,1,8,5,3,7,0,9,2,6 };// 默认按照小于比较,排出来结果是升序std::sort(array, array + sizeof(array) / sizeof(array[0]));// 如果需要降序,需要改变元素的比较规则std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());return 0;
}如果待排序元素为自定义类型,需要用户自定义排序时的比较规则:
struct Goods
{string _name; // 名字double _price; // 价格int _evaluate; // 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}
};
struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};
struct ComparePriceGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._price > gr._price;}
};
int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };sort(v.begin(), v.end(), ComparePriceLess());sort(v.begin(), v.end(), ComparePriceGreater());
}随着C++语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法,都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式。
lambda表达式语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
1. lambda表达式各部分说明
- [capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
- (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
- mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
- ->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
- {statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
- 注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。
举例:
1.捕捉列表不能省略 2.参数列表(如果不需要参数传递,就能全省略)3.mutable,可以省略,表示默认const 4.返回值类型 + 一个函数体(返回值类型通常可以省略,只要返回值是明确的情况下,因为会自动推导)
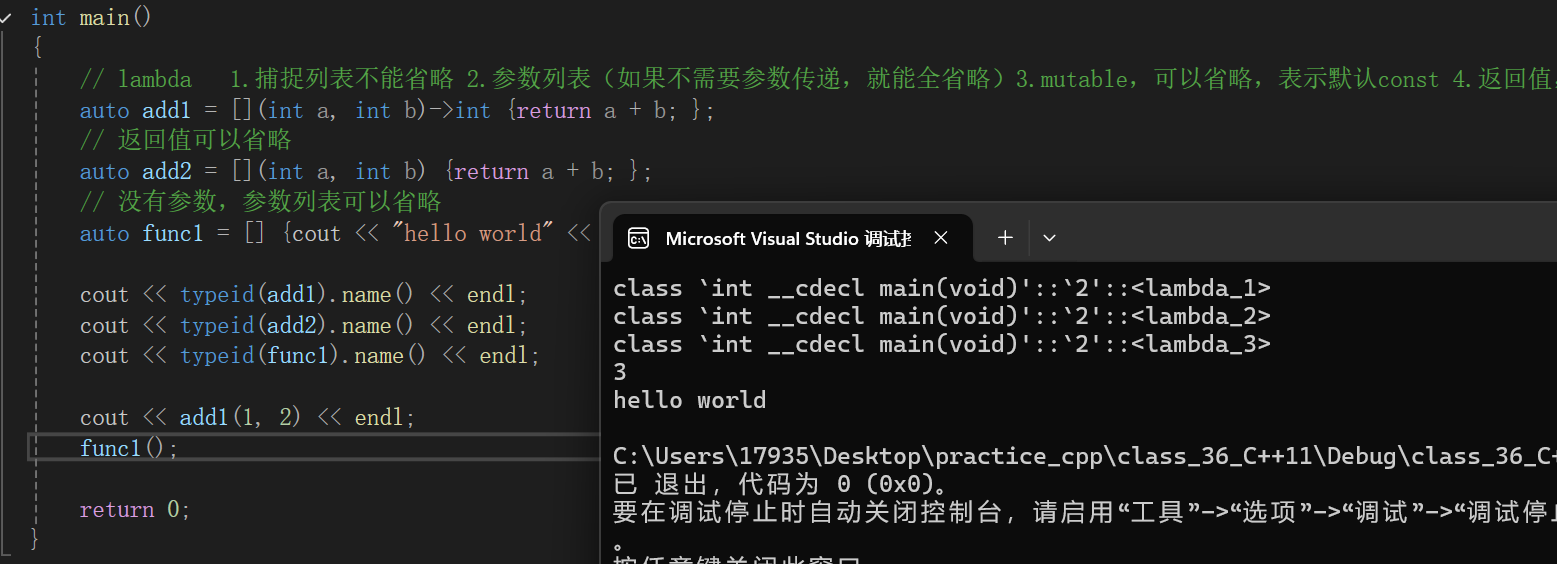
int main() {// lambda 1.捕捉列表不能省略 2.参数列表(如果不需要参数传递,就能全省略)3.mutable,可以省略,表示默认const 4.返回值,一个函数体auto add1 = [](int a, int b)->int {return a + b; };// 返回值可以省略auto add2 = [](int a, int b) {return a + b; };// 没有参数,参数列表可以省略auto func1 = [] {cout << "hello world" << endl; };cout << typeid(add1).name() << endl;cout << typeid(add2).name() << endl;cout << typeid(func1).name() << endl;cout << add1(1, 2) << endl;func1();return 0; }lambda函数是一个局部的匿名函数,如何调用这个函数
1.使用auto来推导,像仿函数或者,使用函数名调用一样的,或者用包装器
auto add1 = [](int a, int b)->int {return a + b; };// 返回值可以省略auto add2 = [](int a, int b) {return a + b; };cout << typeid(add1).name() << endl;cout << add1(1, 2) << endl;
因此像前面的自定义类型,需要用户自定义排序时的比较规则:我们也可以使用lambda来写一个价格的升序的函数:
auto priceless = [](const Goods& g1, const Goods& g2)
{return g1._price < g2._price;
};
sort(v.begin(), v.end(), priceless);
在实践当中还能写的更为简洁:
我们可以直接将lambda表达式(是有类型的)看作是一个和priceless一样的对象:
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) { return g1._price < g2._price; });
直接将这个lambda表达式传给了sort的compare模版。lambda的类型到底是什么编译器知道
这样写无疑更加的便捷:
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){return g1._evaluate < g2._evaluate;});sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){return g1._evaluate > g2._evaluate;});
lambda类型到底是什么?
vs2022
vs2019
lambda的本质就是仿函数,lambda原理类似于范围for,lambda编译时,编译器会生成对应的仿函数。对我们而言lambda的类型是未知的,编译器知道。
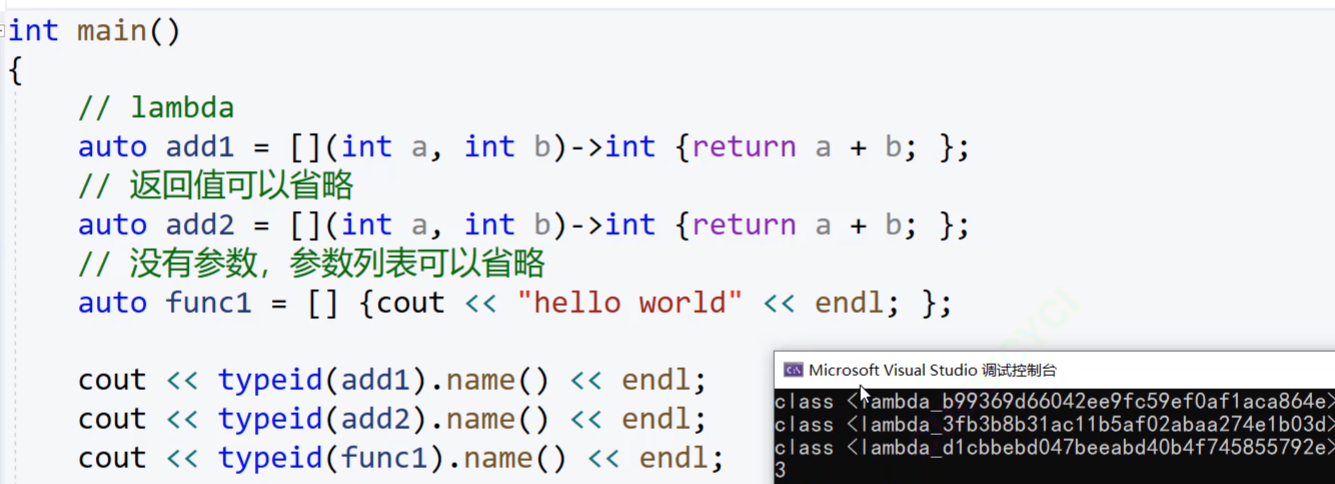
我们现在想实现两个数交换的lambda表达式,这里体现了auto的价值:
int main() {int a = 1, int b = 2;auto swap1 = [](int& x, int& y){int tmp = x;x = y;y = tmp;};swap1(a, b);return 0; }捕捉a、b对象给lambda:
捕捉a,b给lambda用,默认捕捉过来的是const并且是传值捕捉,上面的a,b和这里的a,b不是同一个a,b(可以认为是一个拷贝,并且加了const)
auto swap2 = [a, b](){int tmp = a;a = b;b = tmp;};swap2();因此需要取消const也就是加mutable
auto swap2 = [a, b]() mutable{int tmp = a;a = b;b = tmp;};swap2();lambda里的a,b是拷贝过来的,虽然被修改,也不会影响原来的a,b
修改外面的a、b
//引用int& REF = a;//一般引用是这样的//引用的捕捉,不是取地址,不要混淆了auto swap3 = [&a, &b]() //容易混淆取地址和引用{int tmp = a;a = b;b = tmp;};swap3();捕捉列表是否能够传地址?不能直接传
间接传:
int* pa = &a, * pb = &b;
auto swap3 = [pa, pb]() //容易混淆取地址和引用{int tmp = *pa;*pa = *pb;*pb = tmp;};捕捉列表的其他使用:

int main()
{int a = 1, b = 2, c = 3, d = 4, e = 5;// 传值捕捉所有对象auto func1 = [=](){return a + b + c * d;};cout << func1() << endl;// 传引用捕捉所有对象auto func2 = [&](){a++;b++;c++;d++;e++;};func2();cout << a << b << c << d << e << endl;// 混合捕捉,传引用捕捉所有对象,但是d和e传值捕捉auto func3 = [&, d, e](){a++;b++;c++;//d++;//e++;};func3();cout << a << b << c << d << e << endl;// a b传引用捕捉,d和e传值捕捉auto func4 = [&a, &b, d, e]() mutable{a++;b++;d++;e++;};func4();cout << a << b << c << d << e << endl;return 0;
}
lambda适合用的场景:
想定义一个直接可以使用的小函数,就可以使用
结语:
随着这篇关于题目解析的博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容,让我们在知识的道路上共同前行。
相关文章:

【C++11】列表初始化、右值引用、完美转发、lambda表达式
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🌐 C 语言 上篇文章:unordered_map、unordered_set底层编写 下篇文章:C11:新的类功能、模板的可…...
)
Spring中IOC的重点理解(笔记)
Spring: 出现在2002左右.解决企业级开发的难度.减轻对项目模块 类与类之间的管理帮助开发人员创建对象,管理对象之间的关系. 补充:什么是OCP原则?(面试) (1)是软件七大开发当中最基本的一个原则ÿ…...

数据库系统概论|第三章:关系数据库标准语言SQL—课程笔记4
前言 前面详细介绍了关于SELECT语句的相关使用方法,继续上文的介绍,本文将继续介绍数据查询的其他相关操作,主要包括排序(ORDER BY)子句、分组(GROUP BY)子句。与此同时,介绍完单表…...

【1】CICD持续集成-docker本地搭建gitlab代码仓库社区版
一、gitlab社区版概述 GitLab社区版(Community Edition, CE)是一个开源的版本控制系统,适用于个人开发者、中小团队及大型企业。 GitLab社区版采用MIT许可证,用户可以免费使用和修改源代码。其主要功能包括代码托管、版本控制…...
)
Verdi工具使用心得知识笔记(一)
Verdi工具使用知识点提炼 本文来源于移知,具体文档请咨询厚台 一、基础概念 波形依赖 Verdi本身无法生成波形,需配合VCS等仿真工具生成.fsdb文件。核心功能模块 • nTrace:代码调试与追踪 • nSchema:原理图分析 • nState&…...
数据编码)
【25软考网工笔记】第二章 数据通信基础(4)数据编码
目录 一、曼彻斯特编码 1. 以太网 2. 题型(考试过的选择题) 1)题目解析 二、差分曼彻斯特编码 三、两种曼彻斯特编码特点 编辑 1. 双相码 2. 将时钟和数据包含在信号数据流中 3. 编码效率低 4. 数据速率是码元速率的一半 5. 应用案例 编辑 1&…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——USB OTG测试
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 第四章 ATK-DLMP257B功能测试——USB OTG测试…...

现代c++获取linux系统磁盘大小
现代c获取linux系统磁盘大小 前言一、命令获取系统磁盘大小二、使用c获取系统磁盘大小三、总结 前言 本文介绍一种使用c获取linux系统磁盘大小的方法 一、命令获取系统磁盘大小 在linux系统中可以使用lsblk命令显示当前系统磁盘大小,如下图所示 lsblk二、使用c获…...

tcp和udp的数据传输过程以及区别
tcp和udp的数据传输过程以及区别 目录 一、数据传输过程 1.1 UDP 数据报服务图 1.2 TCP 字节流服务图 1.3 tcp和udp的区别 1.3.1 连接特性 1.3.2 可靠性 1.3.3 数据传输形式 1.3.4 传输效率与开销 应用场景 一、数据传输过程 1.1 UDP 数据报服务图 这张图展示了 UDP 数据报服务…...

C++项目-衡码云判项目演示
衡码云判项目是什么呢?简单来说就是这是一个类似于牛客、力扣等在线OJ系统,用户在网页编写代码,点击提交后传递给后端云服务器,云服务器将用户的代码和测试用例进行合并编译,返回结果到网页。 项目最大的两个亮点&…...

C 语言中的 volatile 关键字
1、概念 volatile 是 C/C 语言中的一个类型修饰符,用于告知编译器:该变量的值可能会在程序控制流之外被意外修改(如硬件寄存器、多线程共享变量或信号处理函数等),因此编译器不应对其进行激进的优化(如缓存…...

mysql表类型查询
普通表 SELECT table_schema AS database_name,table_name FROM information_schema.tables WHERE table_schema NOT IN (information_schema, mysql, performance_schema, sys)AND table_type BASE TABLEAND table_name NOT IN (SELECT DISTINCT table_name FROM informatio…...

JavaScript事件循环
目录 JavaScript 执行机制与事件循环 一、同步与异步代码 1. 同步代码(Synchronous Code) 2. 异步代码(Asynchronous Code) 二、事件循环(Event Loop) 1. 核心组成 2. 事件循环基本流程 3. 运行机制…...

Linux》》bash 、sh 执行脚本
通常使用shell去运行脚本,两种方法 》bash xxx.sh 或 bash “xxx.sh” 、sh xxx.sh 或 sh “xxx.sh” 》bash -c “cmd string” 引号不能省略 我们知道 -c 的意思是 command,所以 bash -c 或 sh -c 后面应该跟一个 command。...
)
Git完全指南:从入门到精通版本控制 ------- Git 查看提交历史(8)
Git提交历史深度解析:从代码考古到精准回退 前言 在软件开发的生命周期中,提交历史是团队协作的时空胶囊。Git作为分布式版本控制系统,其强大的历史追溯能力可帮助开发者: 精准定位引入Bug的提交分析代码演进趋势恢复误删的重要…...
:解锁数据驱动的商业成功密码)
精益数据分析(2/126):解锁数据驱动的商业成功密码
精益数据分析(2/126):解锁数据驱动的商业成功密码 大家好!在如今这个数据爆炸的时代,数据就像一座蕴含无限宝藏的矿山,等待着我们去挖掘和利用。最近我在深入研读《精益数据分析》这本书,收获了…...

【ssti模板注入基础】
一、ssti模板注入简介 二、模板在开发中的应用 为什么要使用模板 为什么要用模板来提升效率: 不管我们输入什么,有一部分内容都是不会变的 除了内容之外其他都不会变,如果我们有成千上万的页面,如果不用模板,就算复…...

如何在 Kali 上解决使用 evil-winrm 时 Ruby Reline 的 quoting_detection_proc 警告
在使用 Kali Linux 运行 Ruby 工具(例如 evil-winrm)时,你可能会遇到以下警告: Warning: Remote path completions is disabled due to ruby limitation: undefined method quoting_detection_proc for module Reline这个警告会导…...
)
从零开始搭建PyTorch环境(支持CUDA)
从零开始搭建PyTorch环境(支持CUDA) 本文将详细介绍如何在Windows系统上为RTX 3050显卡配置支持CUDA的PyTorch环境。 环境准备 本教程基于以下环境: 显卡:NVIDIA RTX 3050操作系统:WindowsPython版本:3.1…...

【扩散模型连载 · 第 2 期】逆向扩散建模与神经网络的角色
上期回顾 我们在第 1 期中介绍了 正向扩散过程(Forward Process),并用 CIFAR-10 图像演示了加噪过程: 正向过程是固定的,无需训练,但我们感兴趣的是:如何从纯噪声一步步“还原”出真实图像&…...

Mysql约束
约束其实就是创建表的时候给表的某些列加上限制条件。 主键约束和自增长约束比较重要 一、Mysql约束-主键约束 简介 指定的主键不能重复也不可以出现空值 1.添加单列主键 语法1:create table 表名(字段名 数据类型 primary key); 点开…...
)
力扣热题100—滑动窗口(c++)
3.无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 unordered_set<char> charSet; // 用于保存当前窗口的字符int left 0; // 窗口左指针int maxLength 0; // 最长子串的长度for (int right 0; right < s.siz…...

Linux网络编程第一课:深入浅出TCP/IP协议簇与网络寻址系统
知识点1【网络发展简史】 **网络节点:**路由器和交换机组成 交换机的作用:拓展网络接口 路由:网络通信路径 1、分组交换 分组的目的: 数据量大,不能一次型传输,只能分批次传输,这里的每一批…...

论文阅读笔记:Generative Modeling by Estimating Gradients of the Data Distribution
1、参考来源 论文《Generative Modeling by Estimating Gradients of the Data Distribution》 来源:NeurIPS 2019 论文链接:https://arxiv.org/abs/1907.05600 参考链接: 【AI知识分享】真正搞懂扩散模型Score Matching一定要理解的三大核心…...

C++零基础实践教程 函数 数组、字符串与 Vector
模块四:函数 (代码复用与模块化) 随着程序变得越来越复杂,把所有代码都堆在 main 函数里会变得难以管理和阅读。函数 (Function) 允许你将代码分解成逻辑上独立、可重用的块。这就像把一个大任务分解成几个小任务,每个小任务交给一个专门的“…...

照片处理工具:基于HTML与JavaScript实现详解
在当今数字时代,处理照片已成为日常需求。 本文将详细介绍一个基于HTML和JavaScript的照片处理工具的实现原理,这个工具可以调整图片尺寸、格式,并精确控制输出文件大小。 实现如下,不需要任何编辑器,txt文本、浏览器就行!! 工具功能概述 这个照片处理工具提供以下核心…...

MyBatis-OGNL表达式
介绍 OGNL(Object-Graph Navigation Language)是一种强大的表达式语言,用于获取和设置Java对象图中的属性。在MyBatis中,OGNL常用于动态SQL构建,如条件判断、循环等。以下是关于OGNL表达式的整合信息,包括…...

Web Worker在uniapp鸿蒙APP中的深度应用
文章目录 一、Web Worker核心概念解析1.1 什么是Web Worker?1.2 为什么在鸿蒙APP中使用Web Worker?1.3 性能对比实测 二、uniapp中的Web Worker完整实现2.1 基础配置步骤2.1.1 项目结构准备2.1.2 鸿蒙平台特殊配置 2.2 Worker脚本编写规范2.3 主线程通信…...

无人机故障冗余设计技术要点与难点!
一、技术要点 1. 冗余架构设计 硬件冗余:关键部件(飞控、电机、电池、通信模块)采用双余度或三余度设计,例如: 双飞控系统:主飞控失效时,备用飞控无缝接管。 电机动力冗余:六轴无…...

MySQL数据库表查询
测试表company.employee5 mysql> create database company; #创建一个库; 创建一个测试表: mysql> CREATE TABLE company.employee5(id int primary key auto_increment not null,name varchar(30) not null,sex enum(male,female) default male not null,hi…...
)
ADB的安装及抓取日志(2)
三、ADB抓取日志 在使用ADB抓取日志前,首先要保证电脑已经安装并配置ADB,在上一节已经验证完成。连接设备:可通过USB或者WI-FI,将安卓设备与电脑连接,并启用USB调试模式,此处我选择的是通过电脑与安卓设备…...

【C++】 —— 笔试刷题day_17
一、小乐乐改数字 题目解析 这道题,它们给定一个数,我们要对它进行修改;如果某一位是奇数,就把它变成1,;如果是偶数,就把它变成0; 让我们输出最后得到的数。 算法思路 这道题,总体…...

traceId传递
1、应用内传递通过ThreadLocal,InheritableThreadLocal传递 2、跨进程的应用间传递,这种会涉及到远程rpc通信,mq通信,数据库通信等。 feign:拦截器中改变请求头 feign.RequestInterceptor, 这个机制能够实现修改请求对象的目的,…...

自然科技部分详解
光的反射 凸面镜与凹面镜 凸透镜和凹透镜 空气开关原理 短路是指电路中突然的电流过大,这会让线圈的磁性增大,来克服内设的弹簧导致断开 过载会让电流增大,两金属片受热膨胀触发断开 核电荷数是指原子核所带的电荷数。 在原子中…...

蓝桥杯 9. 九宫幻方
九宫幻方 原题目链接 题目描述 小明最近在教邻居家的小朋友小学奥数,而最近正好讲述到了三阶幻方这个部分。 三阶幻方是指将 1 ~ 9 不重复地填入一个 33 的矩阵中,使得每一行、每一列和每一条对角线的和都是相同的。 三阶幻方又被称作九宫格&#x…...

算法——希尔排序
目录 一、希尔排序定义 二、希尔排序原理 三、希尔排序特点 四、两种解法 五、代码实现 一、希尔排序定义 希尔排序是一种基于插入排序的排序算法,也被称为缩小增量排序。它通过将待排序的数组分割成若干个子序列,对子序列进行排序,然后…...

亚马逊热销变维权?5步搭建跨境产品的安全防火墙
“产品热卖,引来维权”——这已经悄然成为越来越多跨境卖家的“热销烦恼”。曾经拼品拼量,如今却要步步谨慎。商标侵权、专利投诉、图片盗用……这些问题一旦发生,轻则下架、账号被限,重则冻结资金甚至封店。 别让“热销”变“受…...

20250416-Python 中常见的填充 `pad` 方法
Python 中常见的填充 pad 方法 在 Python 中,pad 方法通常与字符串或数组操作相关,用于在数据的前后填充特定的值,以达到指定的长度或格式。以下是几种常见的与 pad 相关的用法: 1. 字符串的 pad 操作 虽然 Python 的字符串没有…...

JavaEE-0416
今天修复了一个查询数据时数据显示哈希码: 搜索检阅后得到显示该格式的原因: 重写 POJO 类的 toString 方法 在 Java 编程中,默认情况下,对象的 toString() 方法会返回类似于 com.cz.pojo.Score2a266d09 的字符串。这是由于默认…...

团体程序设计天梯赛L2-008 最长对称子串
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。 输入格式: 输入在一行中给出长度不超过1000的非空字符串。 输出格式&…...
)
命令模式 (Command Pattern)
命令模式(Command Pattern)是一种行为型设计模式,它将请求封装成一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持可撤销的操作。该模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。 一、基础 1.1 意图 将请求封…...
)
Elasticsearch 8.18 中提供了原生连接 (Native Joins)
作者:来自 Elastic Costin Leau 探索 LOOKUP JOIN,这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令。 很高兴宣布 LOOKUP JOIN —— 这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令,旨在执行左 joins 以进行…...
)
在线终端(一个基于 Spring Boot 的在线终端模拟器,实现了类 Linux 命令行操作功能)
Online Terminal 一个基于 Spring Boot 的在线终端模拟器,实现了类 Linux 命令行操作功能。 功能特点 模拟 Linux 文件系统操作支持基础的文件和目录管理命令提供文件内容查看和编辑功能支持文件压缩和解压缩操作 快速开始 环境要求 JDK 8Maven 3.6 运行项目 克隆项目到…...
)
vue+electron ipc+sql相关开发(三)
在 Electron 中使用 IPC(Inter-Process Communication)与 SQLite 数据库进行通信是一个常见的模式,特别是在需要将数据库操作从渲染进程(Vue.js)移到主进程(Electron)的情况下。这样可以更好地管理数据库连接和提高安全性。下一篇介绍结合axios写成通用接口形式,虽然没…...

C++静态变量多线程中的未定义行为
静态变量,是 C 程序员最早接触的语言特性之一。它有状态、生命周期长、初始化一次,用起来真是香。 但只要程序一旦进入多线程的世界,很多你原以为“稳定可靠”的写法,可能就突然开始“不对劲”了。静态变量首当其冲。 今天我们就…...
 Docker)
黑马商城项目(二) Docker
一、Docker快速入门 安装Docker - 飞书云文档 二、命令解读 常见命令: 数据卷: 案例1 数据卷挂载: 案例2 本地目录挂载: 挂载到指定目录能够保存数据(即使Mysql容器被删除) docker run -d \--name mysql …...

玩转Docker | 使用Docker部署Memos笔记工具
玩转Docker | 使用Docker部署Memos笔记工具 前言一、Memos介绍Memos简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署Memos服务下载镜像创建容器创建容器检查容器状态检查服务端口安全设置四、访问Memos服务访问Memos首页注册账号五、基本使用…...

c#从ftp服务器下载文件读取csv
从 FTP 服务器下载文件的功能,并且支持根据文件名称的前缀或直接文件名进行查找和下载。以下是对代码的一些建议和修改,以确保它能够满足您的需求,尤其是如果您希望仅下载特定类型的文件(例如 .csv 文件) using Syste…...

电脑知识 | TCP通俗易懂详解 <三>tcp首部中ACK、SYN、FIN等信息填写案例_握手时
目录 一、👋🏻前言 二、🤝🏻握手时的快递单 1.👫第一次握手(发送方) 2.👫第二次握手(收件方) 3.👫第三次握手(发件方)…...
)
go学习记录(第二天)
Java里面的类对象可以对应go里面的结构体吗 表格对比 Java 类 (Class)Go 结构体 (Struct)封装数据和行为(字段方法)主要封装数据(字段),方法通过接收者关联支持继承(extends…...