高并发多级缓存架构实现思路
目录
1.整体架构
3.安装环境
1.1 使用docket安装redis
1.2 配置redis缓存链接:
1.3 使用redisTemplate实现
1.4 缓存注解优化
1.4.1 常用缓存注解简绍
1.4.2 @EnableCaching注解的使用
1.4.3使用@Cacheable
1.4.4@CachePut注解的使用
1.4.5 优化
2.安装Nginx
2.1 安装OpenRest使用Nginx
2.2 Nginx实现动静分离站点架构
2.2.1Nginx实现缓存
2.2.2 Cache_Purge代理缓存清理
3. 缓存一致性
3.1实现原理讲解
3.1 Canal安装
1.整体架构
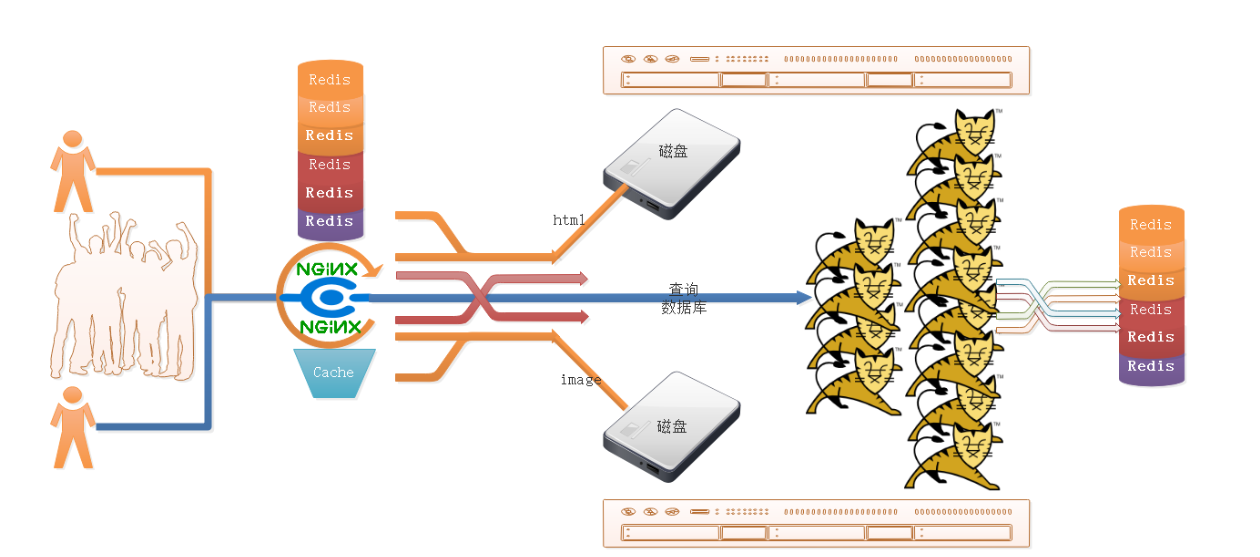
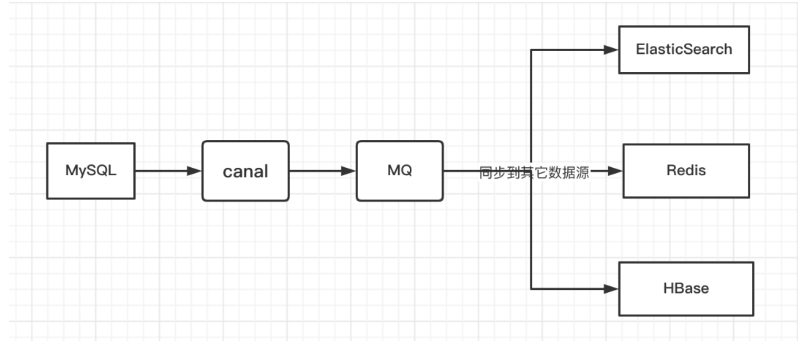
三级缓存框架图(redis,nginx,mysql)
在大并发场景下,通过引入缓存机制,减轻后端Tomcat服务的压力,避免因请求过多导致Tomcat宕机,同时提高系统的整体响应速度和性能。优化流程如下:
-
请求到达Nginx Nginx作为代理层,具有极强的抗压能力,能够承载大量的并发请求。
-
缓存策略实施
-
第一道缓存:Redis缓存
-
请求到达Nginx后,首先查询Redis缓存。
-
如果Redis中存在缓存数据,则直接返回缓存数据给用户,无需再进行后续处理。
-
-
第二道缓存:Nginx缓存
-
如果Redis中没有缓存数据,则查询Nginx自身的缓存。
-
如果Nginx缓存中有数据,也直接返回给用户。
-
-
请求路由到Tomcat
-
如果Redis和Nginx缓存中都没有数据,则将请求路由到后端的Tomcat服务。
-
-
-
Tomcat处理与缓存更新
-
Tomcat接收到请求后,从数据库中加载数据。
-
加载完成后,将数据存入Redis缓存(以便后续请求可以直接从Redis获取)。
-
同时,响应数据给用户。
-
-
后续请求处理
-
当用户再次发起相同查询请求时,会优先查询Redis缓存。
-
如果Redis缓存中存在数据,直接返回,避免再次访问Tomcat。
-
如果Redis缓存失效或不存在,再按照上述流程查询Nginx缓存或路由到Tomcat。
-
-
最终效果
-
通过Redis和Nginx的双重缓存机制,大幅减少了后端Tomcat服务被调用的次数,降低了Tomcat的负载。
-
提高了系统的整体性能和响应速度,增强了系统的稳定性和可靠性。
-
关键点
-
缓存优先级:优先使用Redis缓存,因为Redis的性能更高,适合存储热点数据。Nginx缓存作为补充,用于进一步减轻后端压力。
-
缓存更新:Tomcat加载数据后及时更新Redis缓存,确保缓存数据的时效性和准确性。
-
缓存失效策略:需要合理设置Redis和Nginx缓存的失效时间,以平衡缓存命中率和数据新鲜度。
上面这套缓存架构被多个大厂应用,除了可以有效提高加载速度、降低后端服务负载之外,还可以防止缓存雪崩,为服务稳定健康打下了坚实的基础,这也就是鼎鼎有名的多级缓存架构体系。
现在来思考以下问题:
1.如何实现多级缓存?
2.如何优化redis缓存?
3.nginx如何读取缓存的数据?
4.redis如何和数据库保持同步?
3.安装环境
1.1 使用docket安装redis
docker直接拉取rides
[root@localhost ~]# docker pull redis:7.0.5
配置容器以及说明
docker run -p 6379:6379 --name redis --restart=always \-v /usr/local/redis/redis.conf:/etc/redis/redis.conf \-v /usr/local/redis/data:/data \-d redis:7.0.5 redis-server /etc/redis/redis.conf \--appendonly yes --requirepass 123456参数说明:-restart=always 总是开机启动-p 宿主机端口和容器端口映射-v 挂载数据卷-d 后台启动redis- -appendonly yes 开启持久化--requirepass 123456 设置密码查看是否启动成功
[root@localhost ~]# docker ps

1.2 配置redis缓存链接:
修改bootstrap.yml,增加配置Redis缓存链接,如下:
# Redis配置redis:host: 192.168.31.135 #换成自己虚拟机的ipport: 6379password:1234561.3 使用redisTemplate实现
引入 RedisTemplate 来进行缓存的读取和写入操作,将确保在查询数据库之前先尝试从 Redis 中获取数据,并在获取到数据库结果后将其存储到 Redis 中。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;@Service
public class SkuService {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Autowiredprivate AdItemsMapper adItemsMapper;@Autowiredprivate SkuMapper skuMapper;private static final String CACHE_NAME = "ad-items-skus";// 方法参数类型应与缓存键的类型一致,这里假设id是String类型的,如果不是,请调整public List<Sku> typeSkuItems(String id) {// 尝试从Redis中获取缓存数据List<Sku> skus = (List<Sku>) redisTemplate.opsForValue().get(CACHE_NAME + ":" + id);if (skus == null) {System.out.println("查询数据库!!!");// 如果Redis中没有缓存的数据,则查询数据库QueryWrapper<AdItems> adItemsQueryWrapper = new QueryWrapper<AdItems>();adItemsQueryWrapper.eq("type", Integer.parseInt(id));List<AdItems> adItems = this.adItemsMapper.selectList(adItemsQueryWrapper);// 获取所有SkuIdList<String> skuIds = adItems.stream().map(adItem -> adItem.getSkuId()).collect(Collectors.toList());// 批量查询Skuskus = skuMapper.selectBatchIds(skuIds);// 将查询结果存入Redis,并设置过期时间(例如1小时)//redisTemplate.opsForValue().set(CACHE_NAME + ":" + id, skus, 1, TimeUnit.HOURS);// 设置永不过期redisTemplate.opsForValue().set(CACHE_NAME + ":" + id, skus);}return skus;}
}思考:
redisTemplate虽然可以实现,但是代码耦合性高,如何简化并实现相同效果??
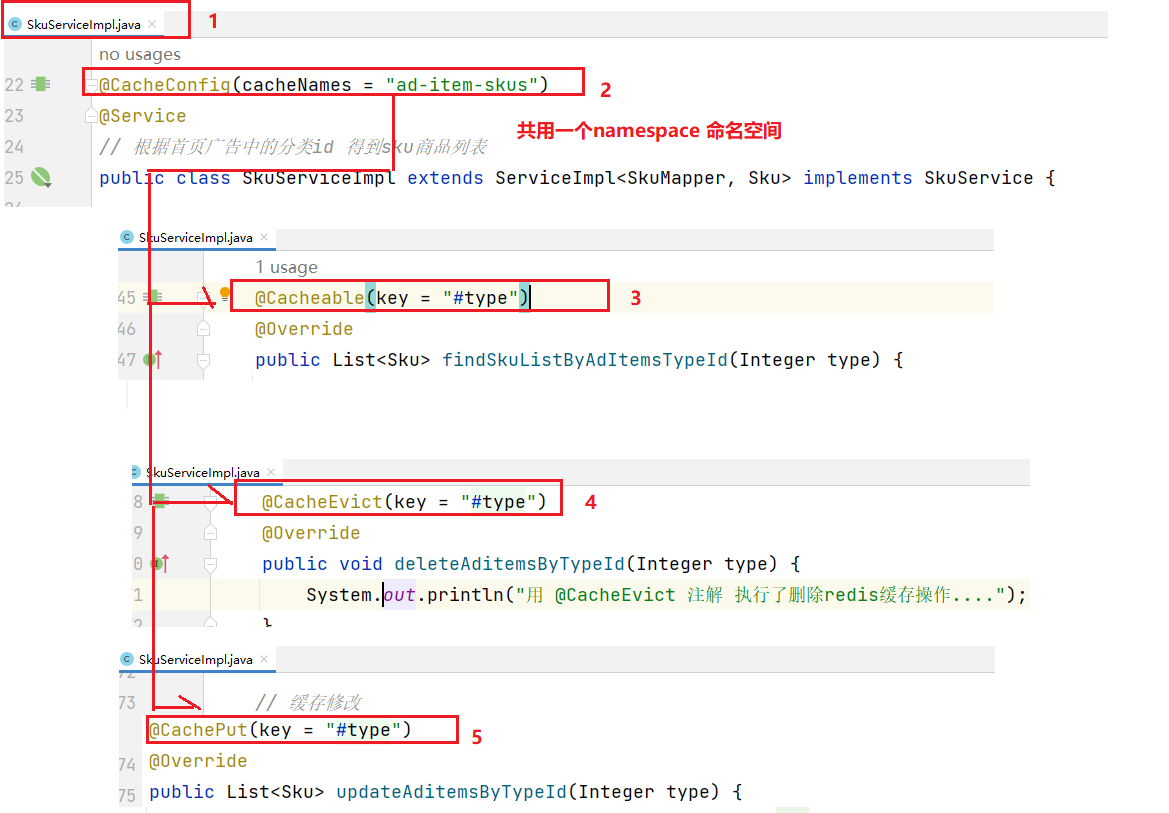
1.4 缓存注解优化
1.4.1 常用缓存注解简绍
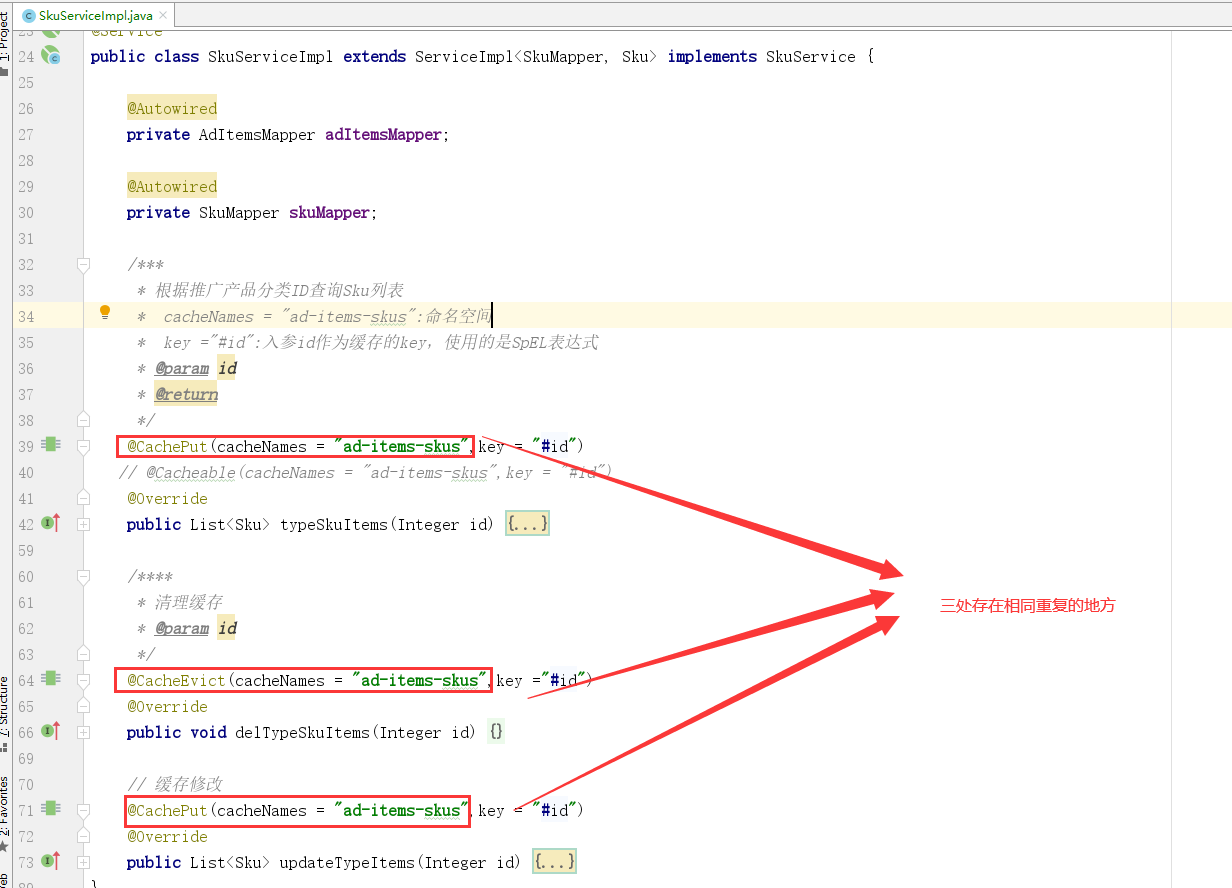
@EnableCaching: 开关性注解,在项目启动类或某个配置类上使用此注解后,则表示允许使用注解的方式进行缓存操作。
@Cacheable: 会判断缓存是否存在,可用于类或方法上;在目标方法执行前,会根据key先去缓存中查询看是否有数据,有就直接返回缓存中的key对应的value值。不再执行目标方法;无则执行目标方法,并将方法的返回值作为value,并以键值对的形式存入缓存。
@CacheEvict: 删除缓存,可用于类或方法上;在执行完目标方法后,清除缓存中对应key的数据(如果缓存中有对应key的数据缓存的话)。
@CachePut: 不会判断缓存是否存在,可用于类或方法上;在执行完目标方法后,并将方法的返回值作为value,并以键值对的形式存入缓存中。
@Caching: 三合一,此注解即可作为@Cacheable、@CacheEvict、@CachePut三种注解中的的任何一种或几种来使用。
@CacheConfig: 可以用于配置@Cacheable、@CacheEvict、@CachePut这三个注解的一些公共属性,例如cacheNames、keyGenerator。
1.4.2 @EnableCaching注解的使用
1.4.3使用@Cacheable
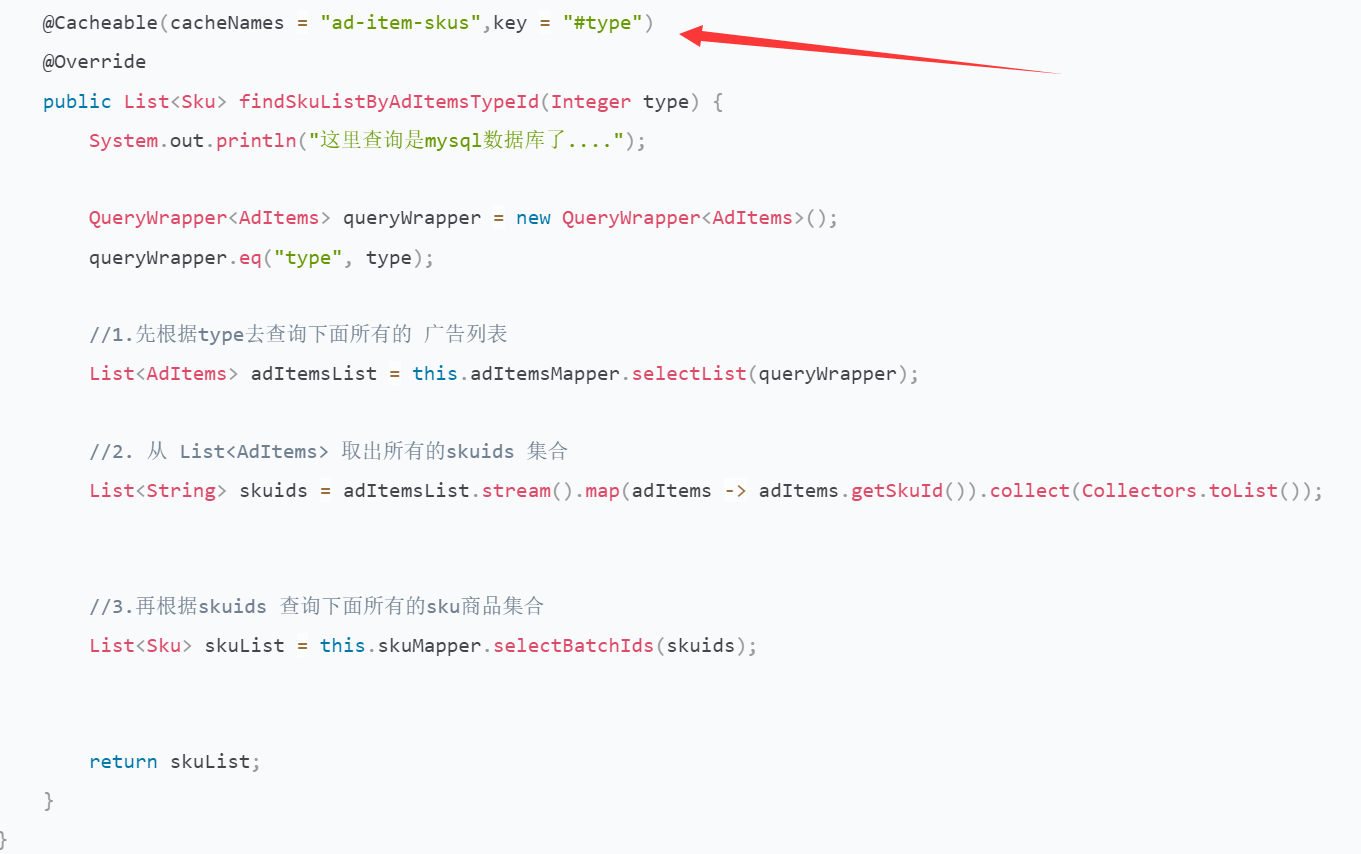
测试
第一次查询:

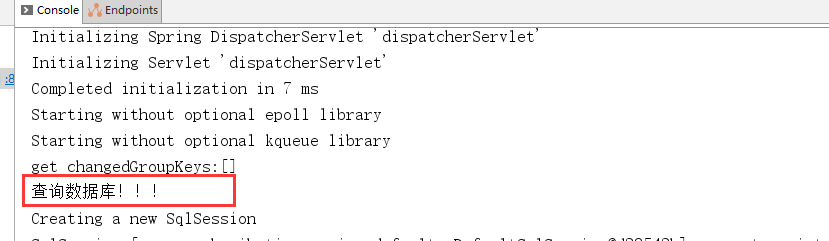
第二次测试:

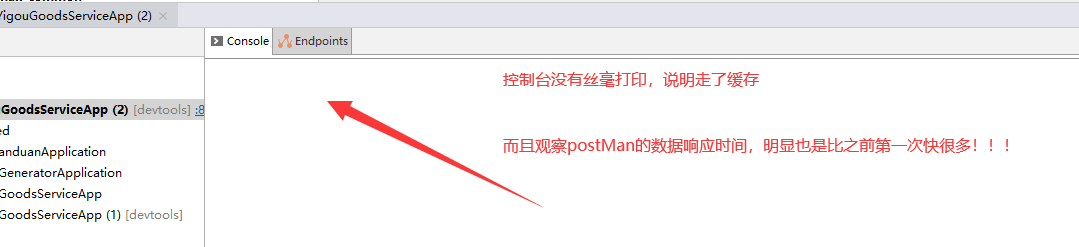
使用缓存注解存储数据到redis缓存中,key的过期时间是多久呢?
答案是:-1 永不过期!
注意:
对应的实体类要进行序列化 implements Serializeable,否则会报错!
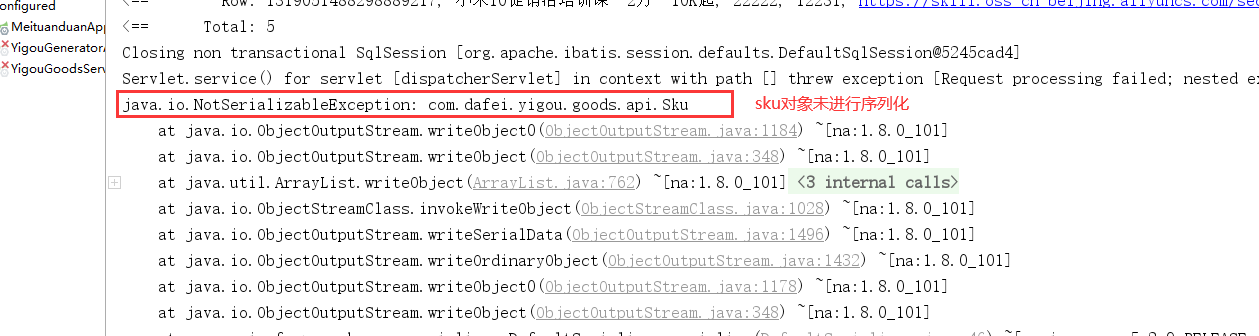
实体类序列化:
1.4.4@CachePut注解的使用

测试:
第一次
观察控制台,会发现它是查了数据库

redis中也存了缓存

第二次
观察控制台,会发现它仍然是查了数据库

redis中也存了缓存

第三次
观察控制台,会发现它还是走数据库查询

redis中也存了缓存

经过连续测试三次,会发现 CachePut 注解,就是将数据放进redis缓存中,并不存在判断缓存操作!!!
1.4.5 优化
2.安装Nginx
多级缓存架构图思路:
首先用户请求先进入到Nginx ,Nginx拦截后,先找redis是否有缓存,如果redis 有数据,就直接响应给用户。如果redis缓存无数据,就会去查询nginx缓存数据。
2.1 安装OpenRest使用Nginx
OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。OpenResty® 通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。OpenResty® 的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
Nginx并发能力强 、稳定、消耗资源小
Lua:所有脚本语言中最强的
安装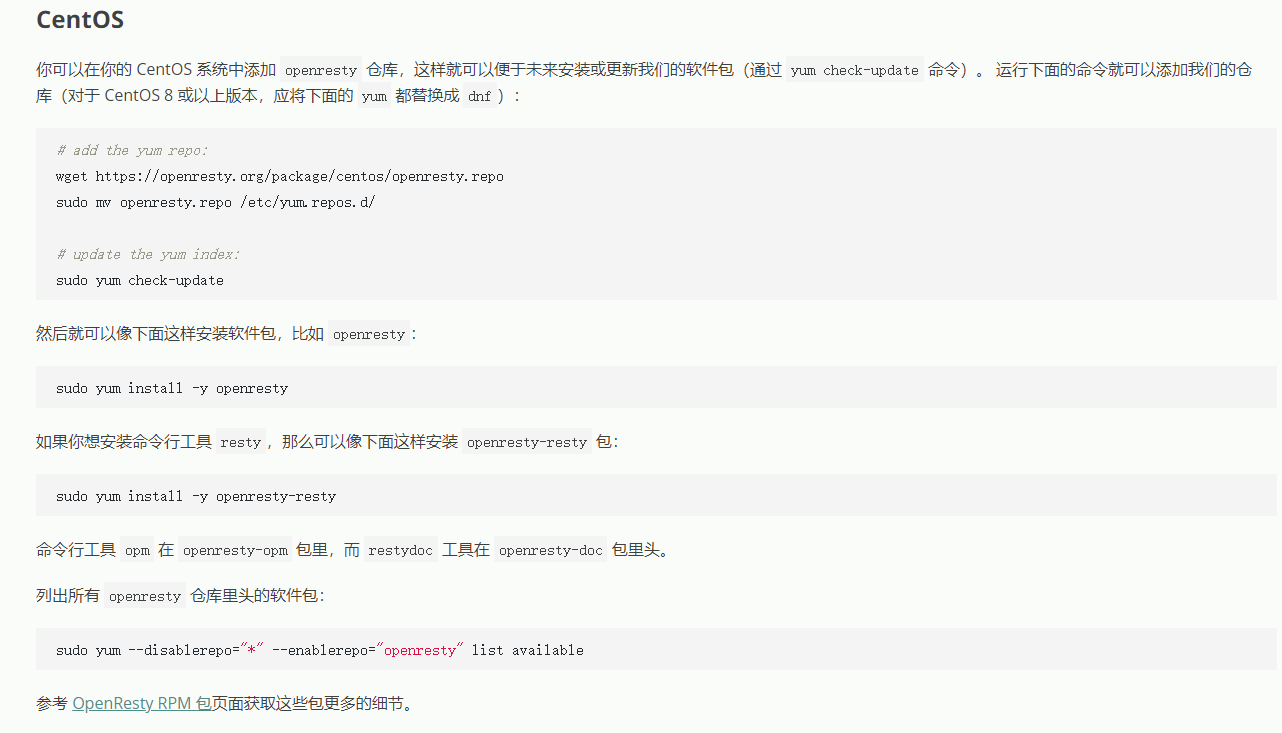
进行安装包:
#进入安装包
cd openresty-1.11.2.5#安装
[root@localhost openresty-1.11.2.5]# ./configure --prefix=/usr/local/openresty --with-luajit --without-http_redis2_module --with-http_stub_status_module --with-http_v2_module --with-http_gzip_static_module --with-http_sub_module --add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/
参数说明:
--prefix=/usr/local/openresty:安装路径
--with-luajit:安装luajit相关库,luajit是lua的一个高效版,LuaJIT的运行速度比标准Lua快数十倍。
--without-http_redis2_module:现在使用的Redis都是3.x以上版本,这里不推荐使用Redis2,表示不安装redis2支持的lua库
--with-http_stub_status_module:Http对应状态的库
--with-http_v2_module:对Http2的支持
--with-http_gzip_static_module:gzip服务端压缩支持
--with-http_sub_module:过滤器,可以通过将一个指定的字符串替换为另一个字符串来修改响应
--add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/:Nginx代理缓存清理工具会报错:
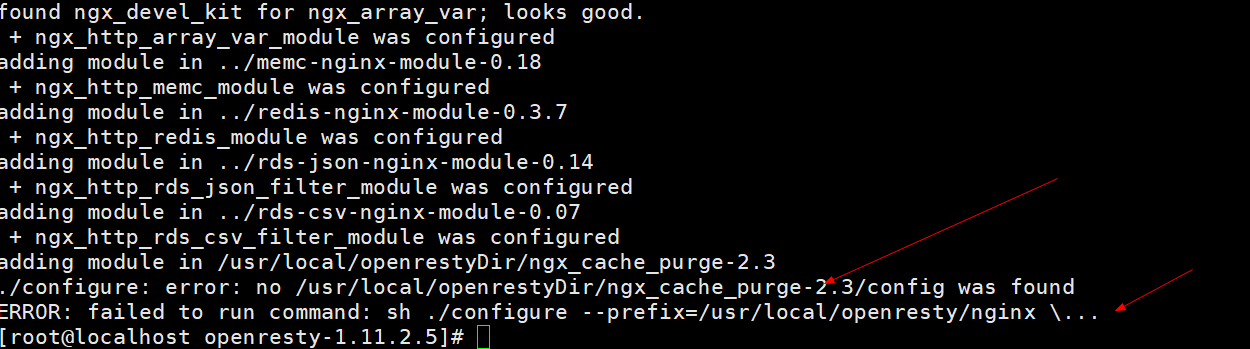
解决方案,安装Nginx代理缓存工具:
mkdir -p /usr/local/openrestyDir cd /usr/local/openrestyDir wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gztar -xvf ngx_cache_purge-2.3.tar.gz再次安装:
[root@localhost openresty-1.11.2.5]# ./configure --prefix=/usr/local/openresty --with-luajit --without-http_redis2_module --with-http_stub_status_module --with-http_v2_module --with-http_gzip_static_module --with-http_sub_module --add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/报错解决:
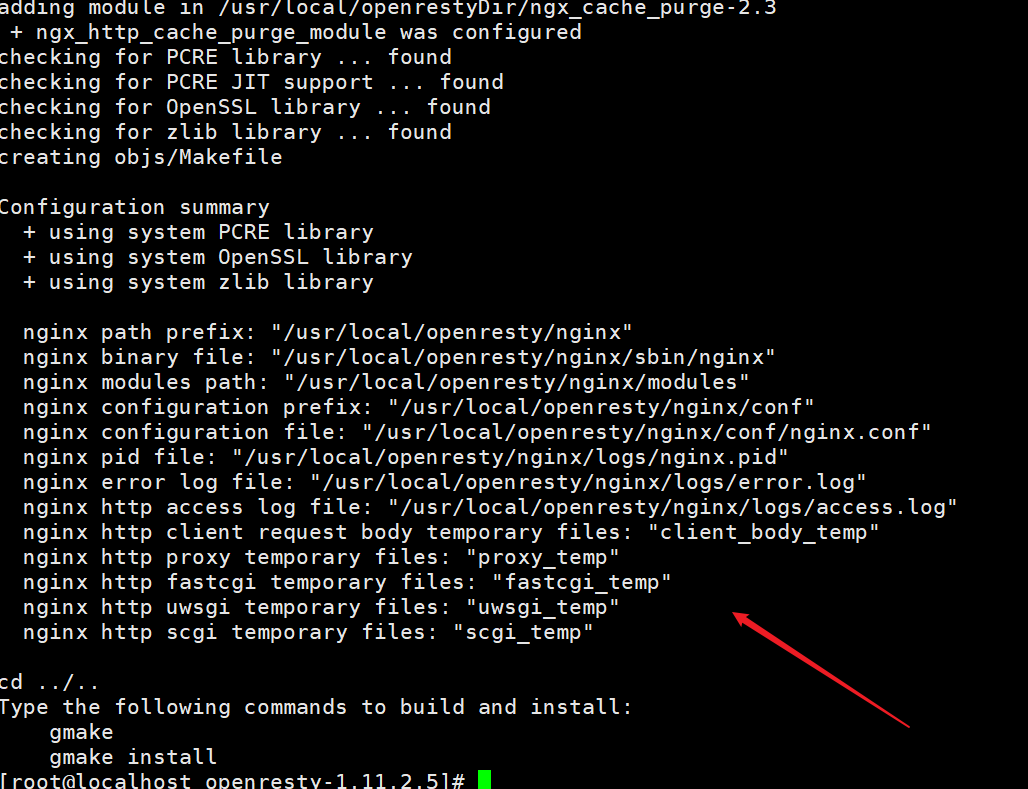
测试访问:
[root@localhost openresty-1.11.2.5]# cd /usr/local/openresty
[root@localhost openresty]# ll
总用量 240
drwxr-xr-x. 2 root root 123 8月 7 19:32 bin
-rw-r--r--. 1 root root 22924 8月 7 19:32 COPYRIGHT
drwxr-xr-x. 6 root root 56 8月 7 19:32 luajit
drwxr-xr-x. 6 root root 70 8月 7 19:32 lualib
drwxr-xr-x. 6 root root 54 8月 7 19:32 nginx
drwxr-xr-x. 43 root root 4096 8月 7 19:32 pod
-rw-r--r--. 1 root root 216208 8月 7 19:32 resty.index
drwxr-xr-x. 5 root root 47 8月 7 19:32 site
浏览器地址栏访问: http://192.168.31.134:80
注意: 检查自己linux服务器的 80 端口是否被放开?
或者 直接关闭了防火墙 也可以 !
2.2 Nginx实现动静分离站点架构
我们打开京东商城,搜索手机,查看网络可以发现响应页面后,页面又会发起很多请求,还没有查看多少信息就已经有393个请求发出了,而多数都是图片,一个人请求如此,人多了对后端造成的压力是非比寻常的,该如何降低静态资源对服务器的压力呢?
项目完成后,项目上线如果所有请求都经过Tomcat,并发量很大的时候,对项目而言将是灭顶之灾,电商项目中一个请求返回的页面往往会再次发起很多请求,而绝大多数都是图片或者是css样式、js等静态资源,如果这些静态资源都去查询Tomcat,Tomcat的压力会增加数十倍甚至更高。
这时候我们需要采用动静分离的策略:
1、所有静态资源,经过Nginx,Nginx直接从指定磁盘中获取文件,然后IO输出给用户
2、如果是需要查询数据库数据的请求,就路由到Tomcat集群中,让Tomcat处理,并将结果响应给用户例如我的门户代码放到front上,将front上传到/usr/local/shangpinmall/web/static目录下,再修改/usr/local/openresty/nginx/conf/nginx.conf,配置如下:
#门户发布
server {listen 80;server_name www.shangpinyungou.com;location / {root /usr/local/shangpinmall/web/static/frant;}
}配置结束后一定要进行刷新:nginx -s reload
访问 www.shangpinyungou.com 效果如下:
2.2.1Nginx实现缓存
1)开启Proxy_Cache缓存:
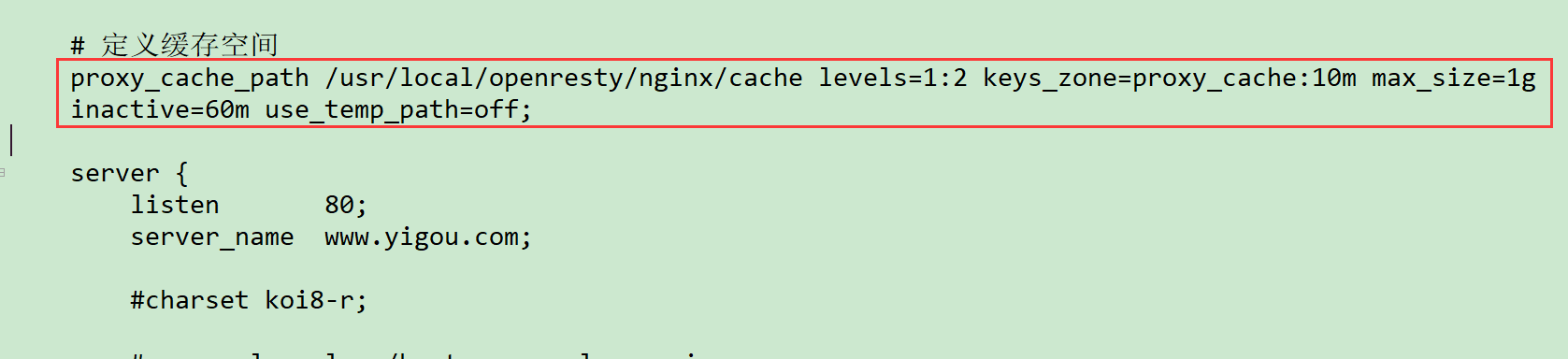
我们需要在nginx.conf中配置才能开启缓存:
proxy_cache_path /usr/local/openresty/nginx/cache levels=1:2 keys_zone=proxy_cache:10m max_size=1g inactive=60m use_temp_path=off;
参数说明:
【proxy_cache_path】指定缓存存储的路径,缓存存储在/usr/local/openresty/nginx/cache目录 【levels=1:2】设置一个两级目录层次结构存储缓存,在单个目录中包含大量文件会降低文件访问速度,因此我们建议对大多数部署使用两级目录层次结构。 如果 levels 未包含该参数,Nginx 会将所有文件放在同一目录中。 keys_zone 缓存空间的名字 叫做: proxy_cache key是 10M 【keys_zone=proxy_cache:10m】设置共享内存区域,用于存储缓存键和元数据,例如使用计时器。拥有内存中的密钥副本,Nginx 可以快速确定请求是否是一个 HIT 或 MISS 不必转到磁盘,从而大大加快了检查速度。1 MB 区域可以存储大约 8,000 个密钥的数据,因此示例中配置的 10 MB 区域可以存储大约 80,000 个密钥的数据。 max_size 缓存数据的大小 【max_size=1g】设置缓存大小的上限。它是可选的; 不指定值允许缓存增长以使用所有可用磁盘空间。当缓存大小达到限制时,一个称为缓存管理器的进程将删除最近最少使用的缓存,将大小恢复到限制之下的文件。 // 表达一个缓存多久没去使用后,就会过期 【inactive=60m】指定项目在未被访问的情况下可以保留在缓存中的时间长度。在此示例中,缓存管理器进程会自动从缓存中删除 60 分钟未请求的文件,无论其是否已过期。默认值为 10 分钟(10m)。非活动内容与过期内容不同。Nginx 不会自动删除缓存 header 定义为已过期内容(例如 Cache-Control:max-age=120)。过期(陈旧)内容仅在指定时间内未被访问时被删除。访问过期内容时,Nginx 会从原始服务器刷新它并重置 inactive 计时器。 // 不使用临时目录 【use_temp_path=off】表示NGINX会将临时文件保存在缓存数据的同一目录中。这是为了避免在更新缓存时,磁盘之间互相复制响应数据,我们一般关闭该功能。
2)Proxy_Cache属性:
proxy_cache:设置是否开启对后端响应的缓存,如果开启的话,参数值就是zone的名称,比如:proxy_cache。proxy_cache_valid:针对不同的response code设定不同的缓存时间,如果不设置code,默认为200,301,302,也可以用any指定所有code。proxy_cache_min_uses:指定在多少次请求之后才缓存响应内容,这里表示将缓存内容写入到磁盘。proxy_cache_lock:默认不开启,开启的话则每次只能有一个请求更新相同的缓存,其他请求要么等待缓存有数据要么限时等待锁释放;nginx 1.1.12才开始有。
配套着proxy_cache_lock_timeout一起使用。proxy_cache_key:缓存文件的唯一key,可以根据它实现对缓存文件的清理操作。Nginx代理缓存热点数据应用
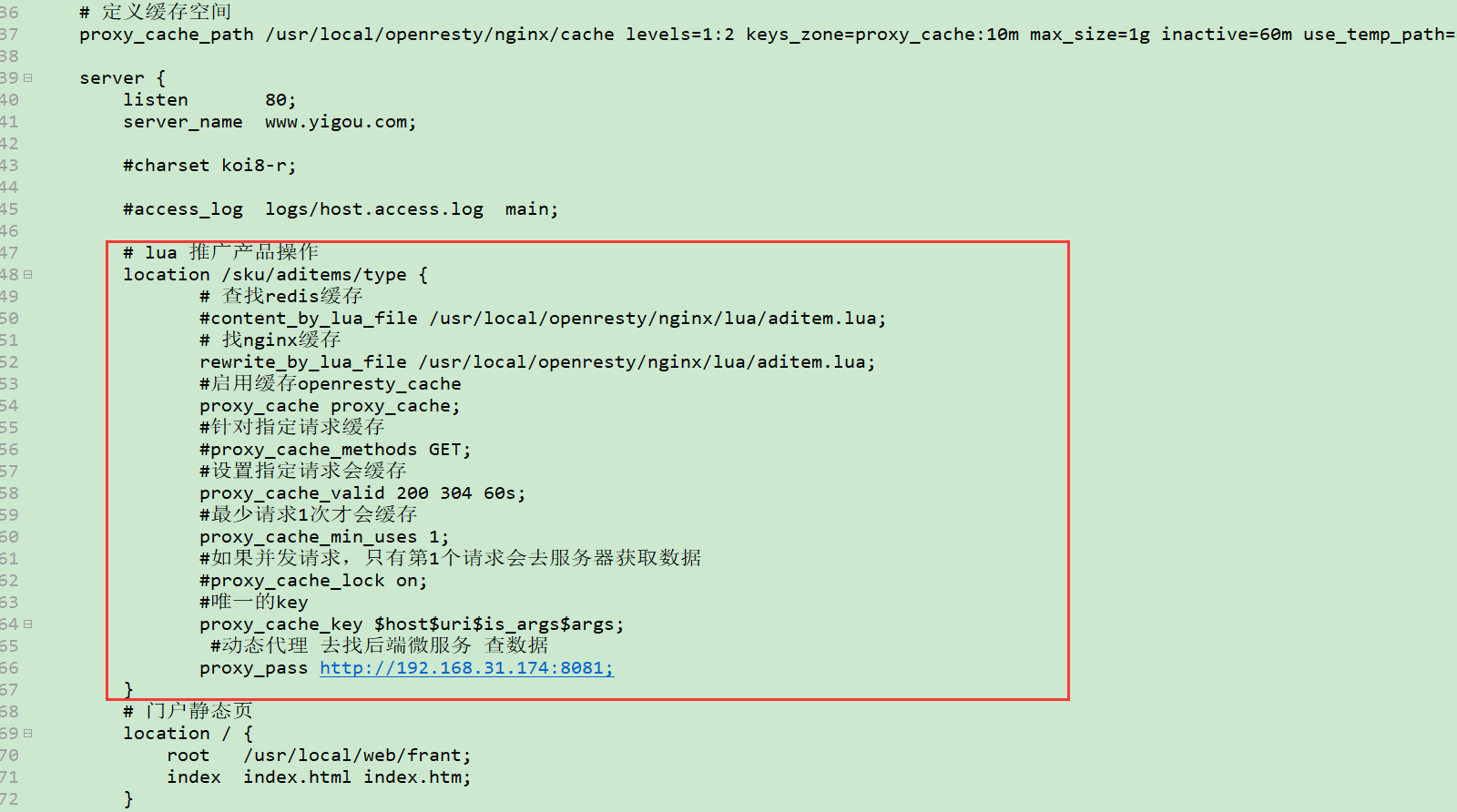
1)开启代理缓存
修改nginx.conf,添加如下配置:
proxy_cache_path /usr/local/openresty/nginx/cache levels=1:2 keys_zone=proxy_cache:10m max_size=1g inactive=60m use_temp_path=off;
修改nginx.conf,添加如下配置:
# lua 推广产品操作location /sku/aditems/type {# 查找redis缓存#content_by_lua_file /usr/local/openresty/nginx/lua/aditem.lua;# 找nginx缓存rewrite_by_lua_file /usr/local/openresty/nginx/lua/aditem.lua;#启用缓存openresty_cacheproxy_cache proxy_cache;#针对指定请求缓存#proxy_cache_methods GET;#设置指定请求会缓存proxy_cache_valid 200 304 60s;#最少请求1次才会缓存proxy_cache_min_uses 1;#如果并发请求,只有第1个请求会去服务器获取数据#proxy_cache_lock on;#唯一的keyproxy_cache_key $host$uri$is_args$args;#动态代理 去找后端微服务 查数据 这里的地址是填写你当前windows的ip地址服务器 (我们去看我们nacos中服务注册的ip就可以了)proxy_pass http://192.168.18.1:8081;}# 门户静态页location / {root /usr/local/web/frant;index index.html index.htm;}重启nginx或者重新加载配置文件nginx -s reload,再次测试
进行测试,关闭运行的代码,只要不关闭虚拟机再次刷新我们发现数据仍然显示出来,说明缓存起到作用
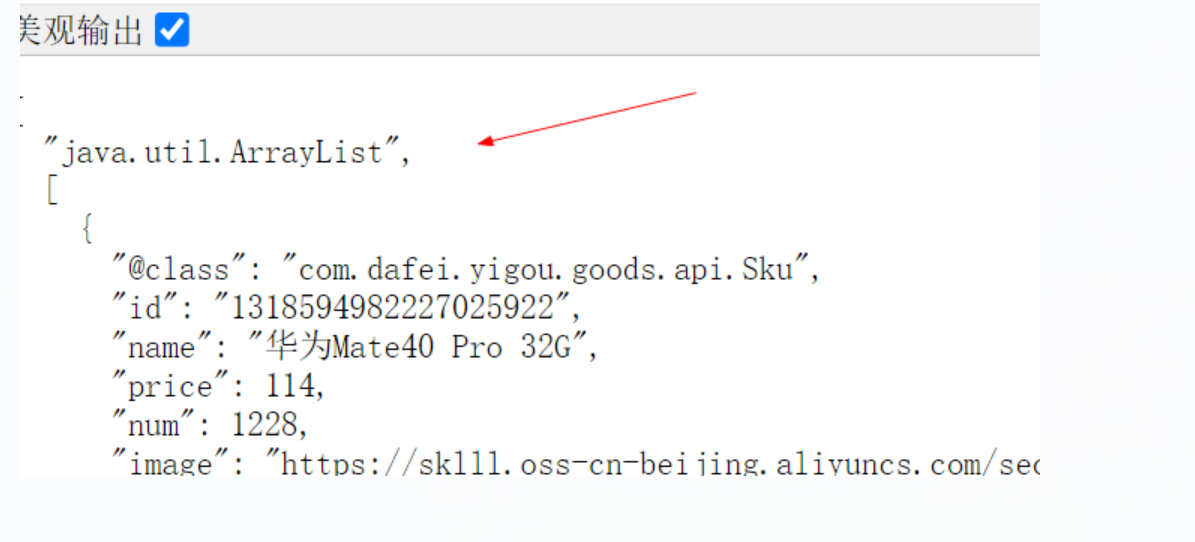
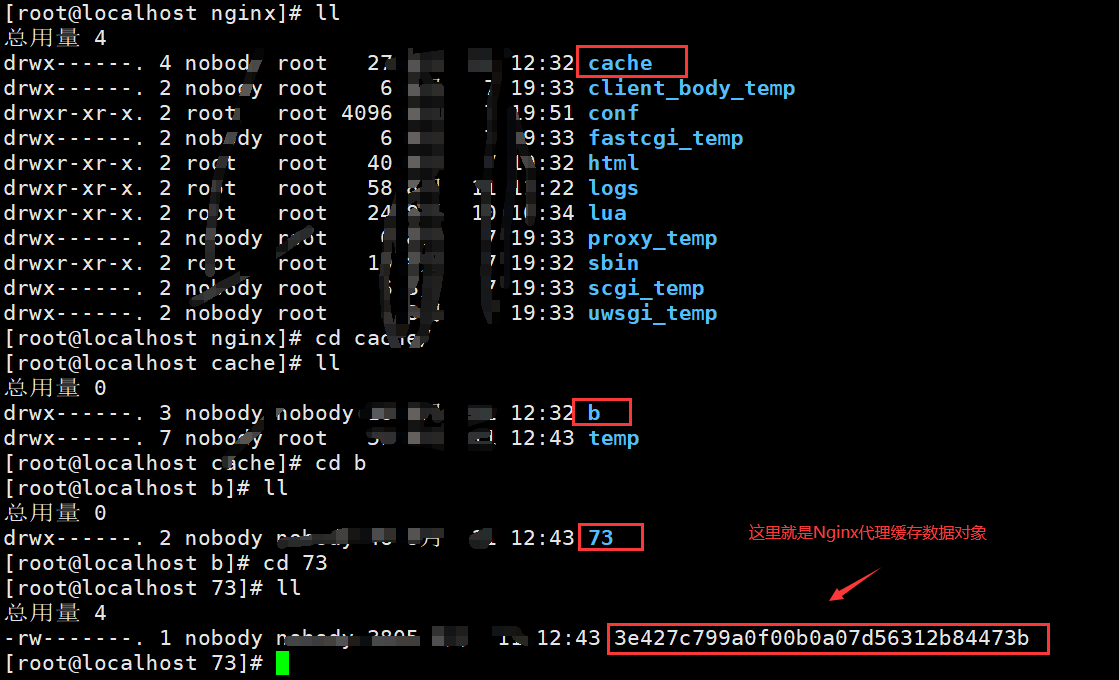
我们可以找一下nginx代理缓存的存储位置
可以发现cache目录下多了目录和一个文件,这就是Nginx缓存:
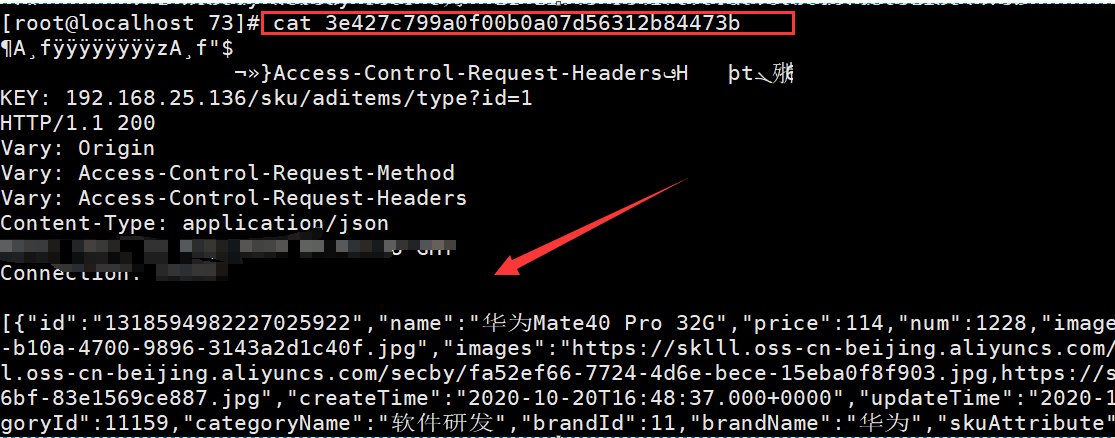
可以发现下面个规律:
1:先查找Redis缓存
2:Redis缓存没数据,直接找Nginx缓存
3:Nginx缓存没数据,则找真实服务器
2.2.2 Cache_Purge代理缓存清理
很多时候我们如果不想等待缓存的过期,想要主动清除缓存,可以采用第三方的缓存清除模块清除缓存 nginx_ngx_cache_purge。
安装nginx的时候,需要添加purge模块,purge模块我们已经下载了,在 /usr/local/openrestyDir 目录下,添加该模块 --add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/,这一个步骤我们在安装OpenRestry的时候已经实现了。
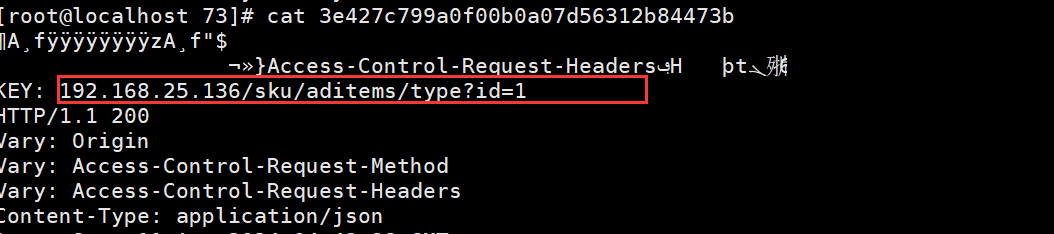
在实际部署中,你需要确保Nginx已经安装并启用了Purge模块。你可以通过运行nginx -V来检查是否已经启用了--with-http_purge_module
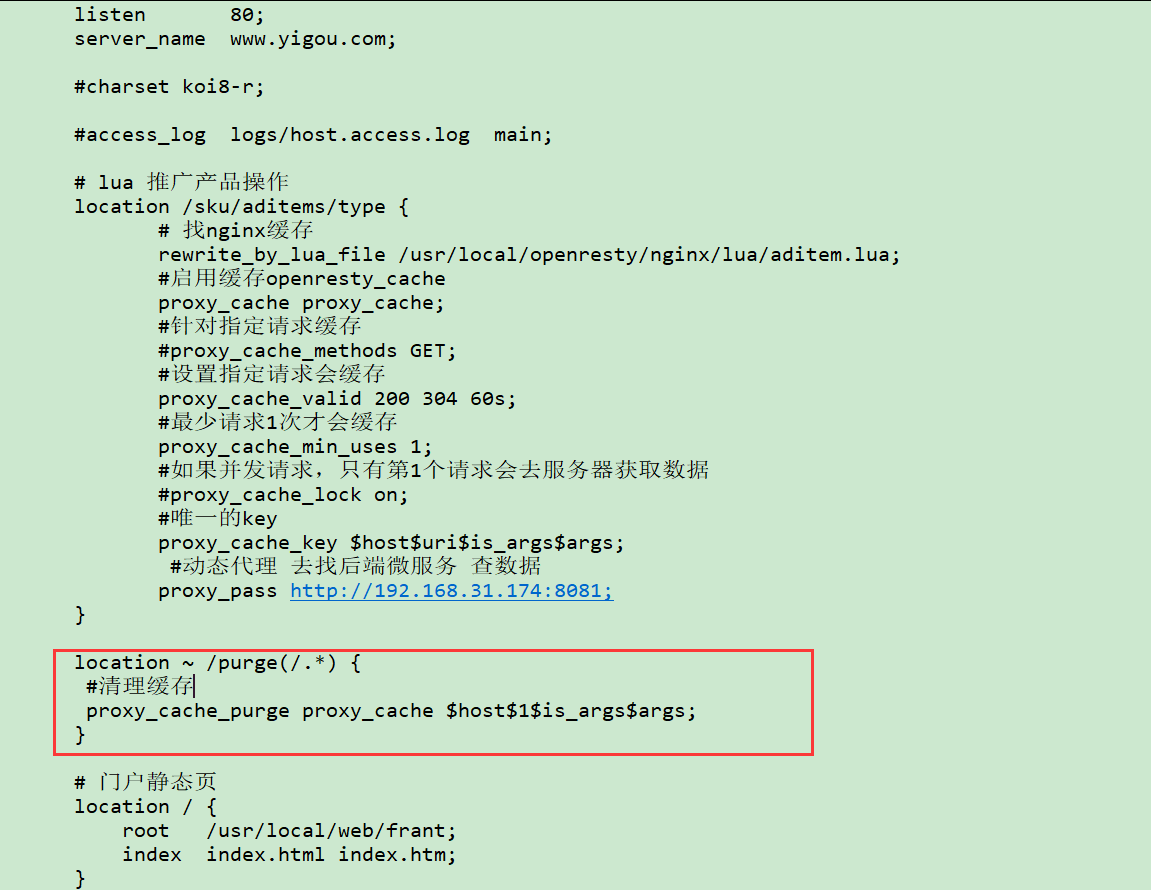
#清理缓存
location ~ /purge(/.*) {#清理缓存 匹配 http://192.168.31.136/sku/aditems/type?id=1proxy_cache_purge proxy_cache $host$1$is_args$args;
}1$ 表示第一个路径 /purge 后面的路径匹配 (/sku/aditems/type,不包含/purge自己) http://192.168.25.136/sku/aditems/type?id=1此时访问 http://192.168.31.136/purge/sku/aditems/type?id=1,表示清除缓存,如果出现如下效果表示清理成功:
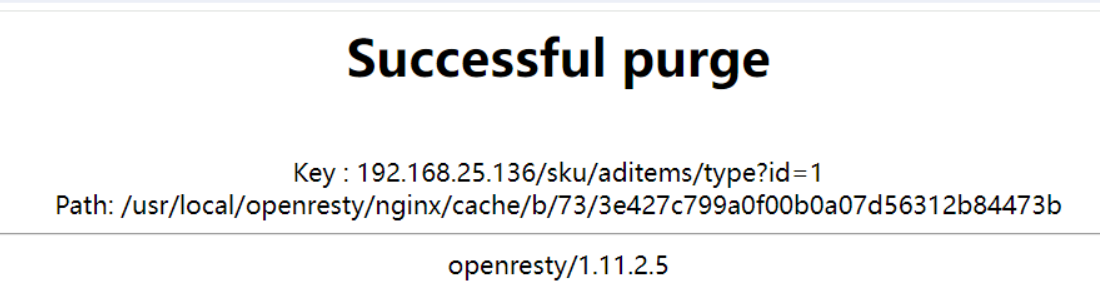
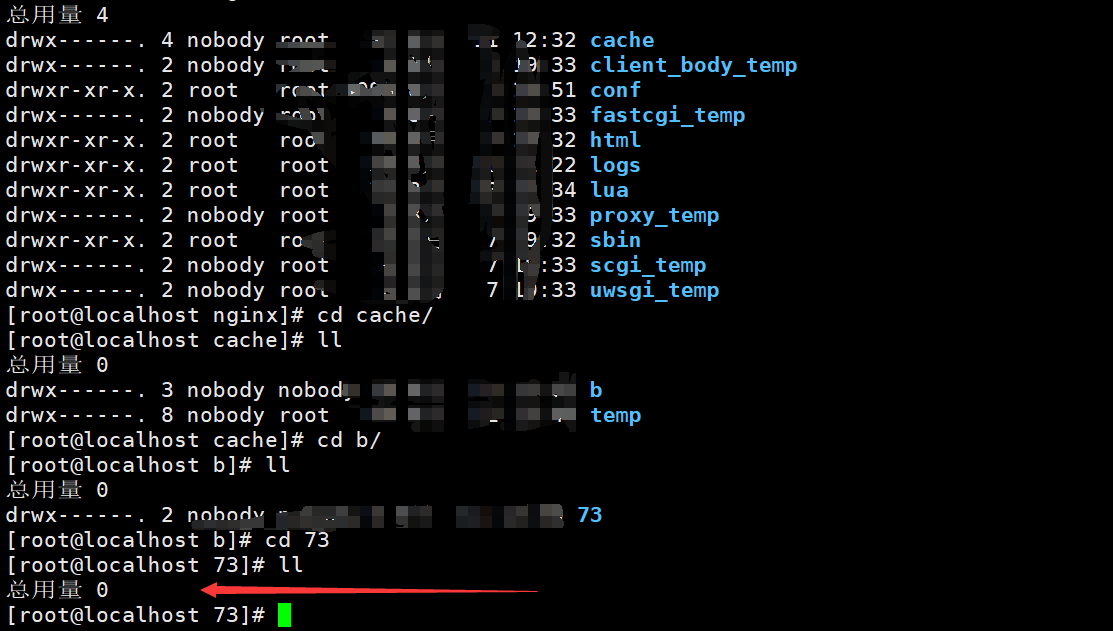
怎么确定,nginx代理缓存被清除了呢?
我们可以再次去看nginx代理数据对象数据,还是否存在
3. 缓存一致性
3.1实现原理讲解
上面我们虽然实现了多级缓存架构但是问题也出现了,如果数据库中数据发生变更,如何更新Redis缓存呢?如何更新Nginx缓存呢?我们可以使用阿里巴巴的技术解决方案Canal来实现,通过Canal监听数据库变更,并实时消费变更数据,并更新缓存。
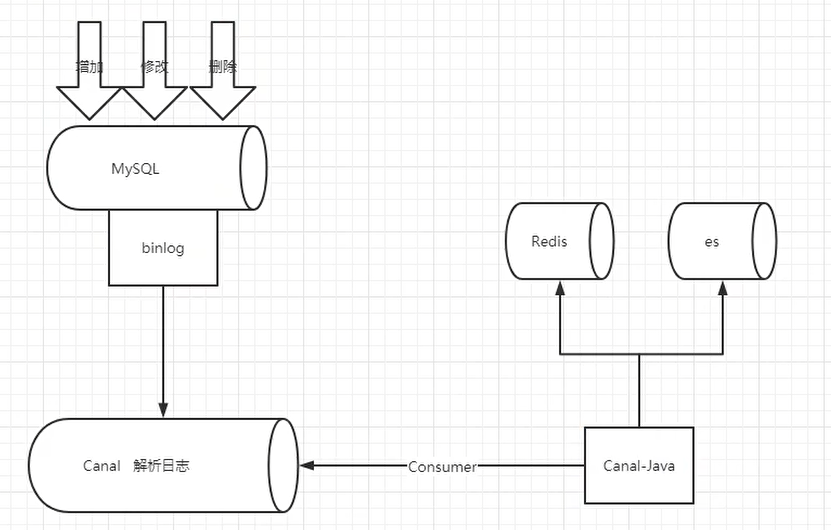
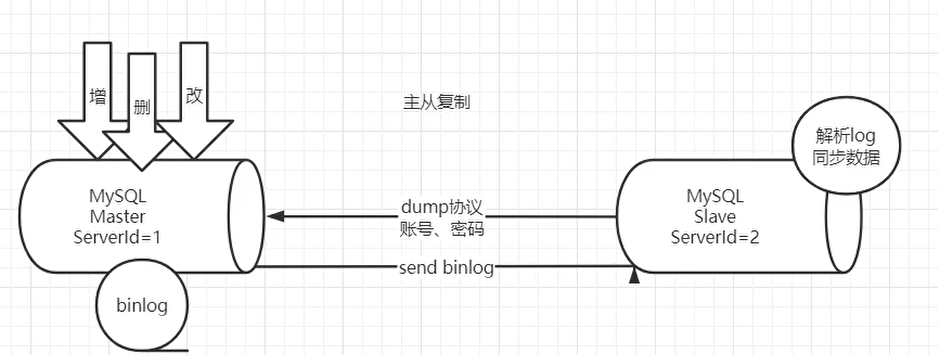
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
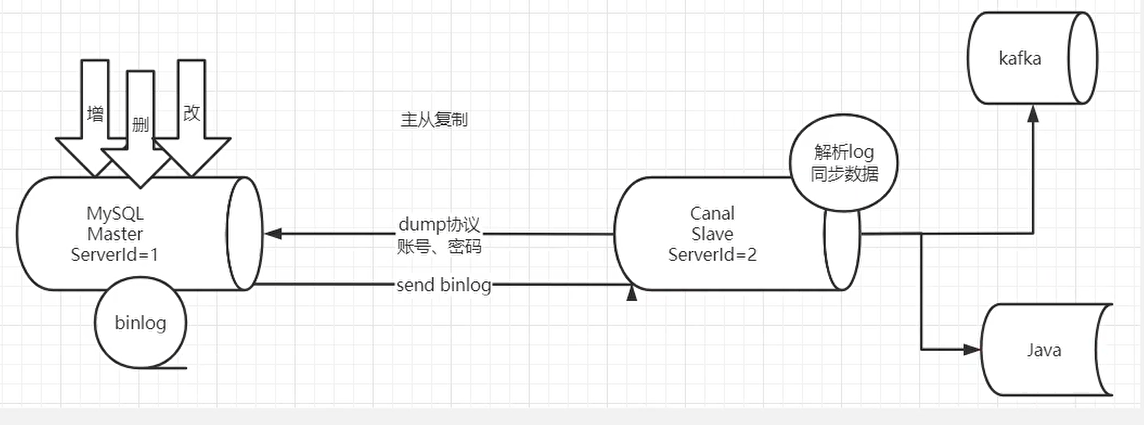
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
- 再发送到存储目的地,比如MySQL,Kafka,ElasticSearch等等。
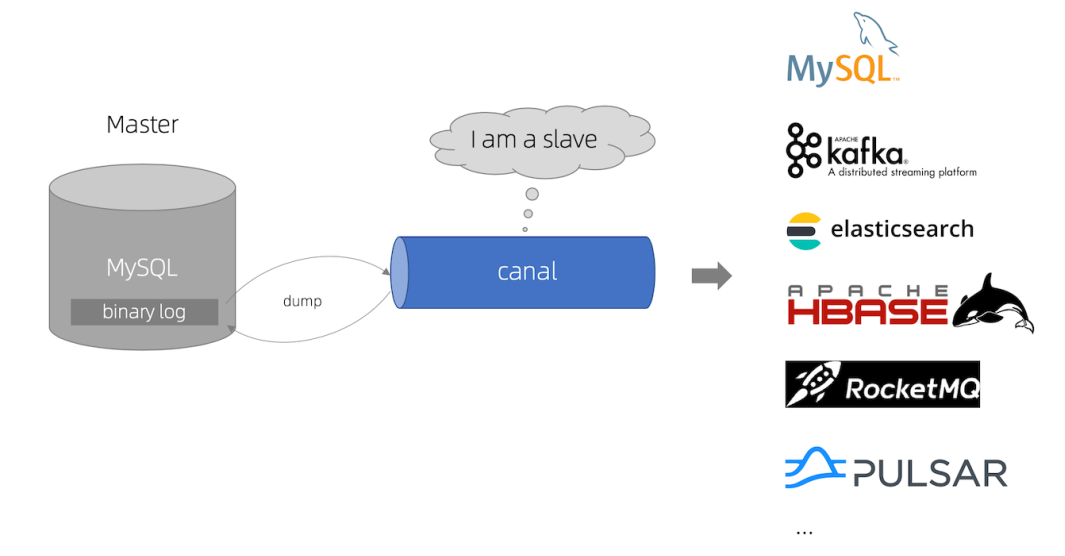
canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。而且能做到同步数据的实时性,是一种比较好的数据同步方案。
以上只是canal的原理和入门,实际项目并不是这样玩的,在实际项目中我们是配置MQ模式,配合RabbitMQ或者Kafka,canal会把数据发送到MQ中的topic,然后通过消息队列的消费者进行处理。
3.1 Canal安装
MySQL开启binlog
对于MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下:
docker exec -it mysql /bin/bash
cd /etc/mysql/
vim mysqld.cnf
[mysqld]
# 修改容器中的MySQL时间不同步的问题
default_time_zone='+8:00'
# 修改容器中的MySQL分组only_full_group_by问题
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#修改表名不区分大小写问题
lower_case_table_names=1
# 设置服务器的排序规则为 utf8_general _ci
collation-server=utf8_general_ci
#设置服务器的默认字符集为 utf8
character-set-server=utf8# 开启 binlog
log-bin=mysql-bin
# 选择 ROW 模式
binlog-format=ROW
# 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
server_id=1 [client]
# 设置客户端的默认字符集为 utf8
default-character-set=utf8注:docker默认没有vim工具,可以在数据卷下进行操作,也可以安装工具
授权canal
权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
先进入到 docker 中mysql 容器内部
docker exec -it mysql mysql -uroot -p
CREATE USER canal IDENTIFIED BY 'canal';GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;重新启动MySQL即可
Canal安装
linux硬盘空间不够的排查与清理
linux硬盘空间不够的排查与清理_linux清理磁盘空间-CSDN博客
我们采用docker安装方式:
[root@localhost ~]# docker pull canal/canal-server:v1.1.7
docker安装canal: docker环境下Canal的安装使用_docker 安装canal-CSDN博客
# 提前创建 /usr/local/docker/canal/conf 目录,接着来执行拷贝配置文件命令
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /usr/local/docker/canal/conf
docker cp canal:/home/admin/canal-server/conf/canal.properties /usr/local/docker/canal/conf# 删除原先的canal服务
docker rm -f canaldocker run --name canal \
-p 11111:11111 \
--restart=always \
-v /usr/local/docker/canal/conf/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-v /usr/local/docker/canal/conf/canal.properties:/home/admin/canal-server/conf/canal.properties \
-d canal/canal-server:v1.1.7[root@localhost ~]# docker exec -it canal /bin/bash[root@6adf5de6d4df admin]# lsapp.sh bin canal-server health.sh node_exporter node_exporter-1.6.1.linux-amd64[root@6adf5de6d4df admin]# cd canal-server/
[root@6adf5de6d4df canal-server]# ls
bin conf lib logs plugin[root@6adf5de6d4df canal-server]# cd conf/
[root@6adf5de6d4df conf]# ls
canal.properties canal_local.properties example logback.xml metrics spring进入 example
[root@6adf5de6d4df conf]# cd example/
[root@6adf5de6d4df example]# ls
h2.mv.db instance.properties入容器,修改核心配置canal.properties 和instance.properties,canal.properties 是canal自身的配置,instance.properties是需要同步数据的数据库连接配置。
[root@localhost conf]# ls
canal.properties instance.properties
[root@localhost conf]#
[root@localhost conf]# vim canal.properties

[root@6adf5de6d4df example]# vim instance.properties
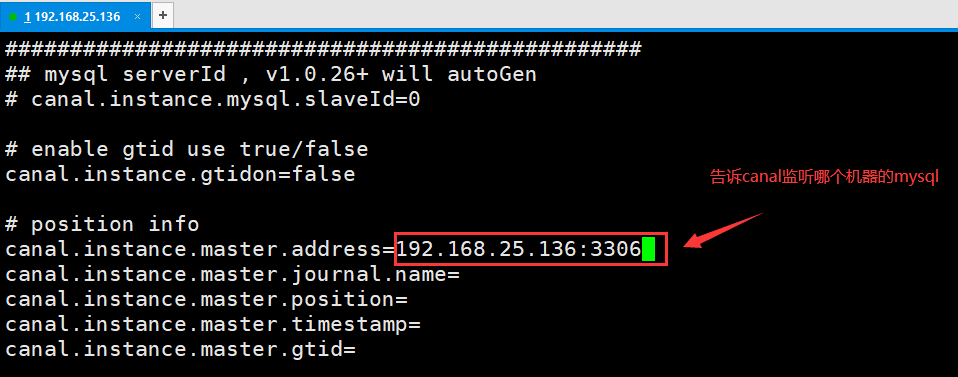
修改配置如下:
# position info canal.instance.master.address=192.168.25.136:3306
另一处配置:
找到 canal.instance.filter.regex 这里 进行修改

注:
# table regex #canal.instance.filter.regex=.*\\..* 任意数据库的任意表 #监听配置 canal.instance.filter.regex=shop_goods.ad_items
配置完毕重启即可!
bootstrap.yml:
server:port: 8083
spring:application:name: mall-canal-servicecloud:nacos:config:file-extension: yaml# nacos 配置中心地址server-addr: 192.168.254.131:8848discovery:#Nacos的注册地址server-addr: 192.168.254.131:8848
#Canal配置
canal:server: 192.168.254.131:11111 # canal的服务器ipdestination: example # canal 中配置的实例目录
#日志配置
logging:pattern:console: "%msg%n"level:root: error以上就是本期的分享啦,希望能够帮到你

相关文章:

高并发多级缓存架构实现思路
目录 1.整体架构 3.安装环境 1.1 使用docket安装redis 1.2 配置redis缓存链接: 1.3 使用redisTemplate实现 1.4 缓存注解优化 1.4.1 常用缓存注解简绍 1.4.2 EnableCaching注解的使用 1.4.3使用Cacheable 1.4.4CachePut注解的使用 1.4.5 优化 2.安装Ngin…...

Qt 的 事件队列
Qt 的 事件队列 是其核心事件处理机制之一,用于管理和分发系统与用户生成的事件(如鼠标点击、键盘输入、定时器、信号槽中的队列连接等)。理解 Qt 的事件队列对多线程、界面响应以及异步处理尤为关键。 一、Qt 的事件处理模型概览 Qt 是基于…...

html-css样式
1. 所有类型为文本的 元素的样式 指定所有类型为文本的 元素的样式 /* 文本框的样式 */ input[type"text"] { font-size: 25px;width: 80px; /* 文本框的宽度 */ padding: 25px; } font-size:字体大小 width:文本框宽度 padding&#…...
:STM32F103加入Flash控制器)
Qemu-STM32(十五):STM32F103加入Flash控制器
概述 本文主要描述了在Qemu平台中,如何添加STM32F103的Flash控制器模拟代码。 参考资料 STM32F1XX TRM手册,手册编号:RM0008 添加步骤 1、在hw/arm/Kconfig文件中添加STM32F1XX_FLASH,如下所示: 号部分为新增加内容 diff -…...
)
设计模式(责任链模式)
责任链模式 模板模式、策略模式和责任链模式,这三种模式具有相同的作用:复用和扩展,在实际的项目开发中比较常用,特别是框架开发中,我们可以利用它们来提供框架的扩展点,能够让框架的使用者在不修改框架源…...
以及张量转换错误)
【Mac-ML-DL】深度学习使用MPS出现内存泄露(leaked semaphore)以及张量转换错误
MPS加速修改总结 先说设备:MacBook Pro M4 24GB 事情的起因是我在进行深度学习的时候想尝试用苹果自带的MPS进行训练加速,修改设备后准备开始训练,但是出现如下报错: UserWarning: resource_tracker: There appear to be 1 leak…...

Hadoop集群部署教程-P5
Hadoop集群部署教程-P5 Hadoop集群部署教程(续) 第十七章:安全增强配置 17.1 认证与授权 Kerberos认证集成: # 生成keytab文件 kadmin -q "addprinc -randkey hdfs/masterEXAMPLE.COM" kadmin -q "xst -k hdfs.…...
)
Github 2FA(Two-Factor Authentication/两因素认证)
Github 2FA认证 多因素用户认证(Multi-Factor Authentication),基本上各个大互联网平台,尤其是云平台厂商(如:阿里云的MFA、华为云、腾讯云/QQ安全中心等)都有启用了,Github算是搞得比较晚些了。 双因素身…...
)
Spark大数据分析与实战笔记(第四章 Spark SQL结构化数据文件处理-05)
文章目录 每日一句正能量第4章 Spark SQL结构化数据文件处理章节概要4.5 Spark SQL操作数据源4.5.1 Spark SQL操作MySQL4.5.2 操作Hive数据集 每日一句正能量 努力学习,勤奋工作,让青春更加光彩。 第4章 Spark SQL结构化数据文件处理 章节概要 在很多情…...

使用 Azure AKS 保护 Kubernetes 部署的综合指南
企业不断寻求增强其软件开发和部署流程的方法。DevOps 一直是这一转型的基石,弥合了开发与运营之间的差距。然而,随着安全威胁日益复杂,将安全性集成到 DevOps 流水线(通常称为 DevSecOps)已变得势在必行。本指南深入探…...

遵守 Vue3 的单向数据流原则:父组件传递对象 + 子组件修改对象属性,安全地实现父子组件之间复杂对象的双向绑定示例代码及讲解
以下是针对 父组件传递对象 子组件修改对象属性 的完整示例代码,同时遵守 Vue3 的单向数据流原则: 1. 父组件代码 (ParentComponent.vue) vue <template><!-- 通过 v-model 传递整个对象 --><ChildComponent v-model"formData&qu…...

Unchained 内容全面上链,携手 Walrus 迈入去中心化媒体新时代
加密新闻媒体 Unchained — — 业内最受信赖的声音之一 — — 现已选择 Walrus 作为其去中心化存储解决方案,正式将其所有媒体内容(文章、播客和视频)上链存储。Walrus 将替代 Unchained 现有的中心化存储架构,接管其全部历史内容…...

20.3 使用技巧2
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 20.3.3 修改表头单元格 设置列表头单元格的内容: 一是可以通过 DataGridView.Columns[列号].HeaderCell来获得对应列的单…...

【Axure绘制原型】小图标使用技巧
获取小图标的网站:https://www.iconfont.cn/ 搜索相关图标 点击下载-复制SVG代码 回到Axure软件中粘贴,此时会显示出图片 在Axure软件中右键-变换图片-转换为形状 即可...

音视频之H.265/HEVC预测编码
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 预测编码是视频编码中的核心技术之一。对于视频信号来说,一幅图像内邻近像素之间有着较强的空间相关性,相邻图像之…...

无人机遥感与传统卫星遥感:谁更适合你的需求?
在对地观测领域,无人机遥感和卫星遥感是两种重要的技术手段,各自具有独特的技术原理、性能特点和应用优势。本文将从技术原理、性能特点和应用场景三个方面,对无人机遥感和卫星遥感进行系统对比,帮助读者全面了解两种技术的差异与…...

学习笔记—C++—模板初阶
目录 模板初阶 泛型编程 函数模板 模版概念 函数模版格式 模版的原理 函数模板的实例化 模版参数的匹配规则 类模板 模板初阶 泛型编程 使用函数重载虽然可以实现,但是有一下几个不好的地方: 1. 重载的函数仅仅是类型不同,代码复…...

【Python进阶】字典:高效键值存储的十大核心应用
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:基础操作案例2:字典推导式…...

充电宝项目中集成地图地址解析功能梳理
文章目录 MongoDB数据库引入pom依赖配置yaml配置文件参考POJOXLocationRepositoryservice服务方法 腾讯地图接口申请api key配置api key启动类配置RestTemplate控制层服务层 MongoDB数据库 MongoDB对应经纬度的查询具体很好的支持. 引入pom依赖 <dependency><group…...
)
算法基础(以acwing讲述顺序为主,结合自己理解,持续更新中...)
文章目录 算法的定义一、基础算法排序二分高精度前缀和与差分双指针算法位运算离散化区间合并 算法的定义 这是我从百度上面搜的定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系…...

栈实现队列
栈实现队列 用栈实现队列:C 语言代码解析栈的基本实现栈的初始化栈的销毁入栈操作检查栈是否为空出栈操作获取栈顶元素获取栈中元素个数 用栈实现队列队列的创建入队操作出队操作获取队首元素检查队列是否为空队列的销毁 总结 用栈实现队列:C 语言代码解…...

Redis原理与Windows环境部署实战指南:助力测试工程师优化Celery调试
引言 在分布式系统测试中,Celery作为异步任务队列常被用于模拟高并发场景。而Redis作为其核心消息代理,其性能和稳定性直接影响测试结果。本文将深入解析Redis的核心原理,主要讲解Windows环境部署redis,为测试工程师提供一套完整…...

HWDeviceDRM的三个子类,HWPeripheralDRM HWTVDRM HWVirtualDRM
在很多采用 DRM 架构的 Android 平台(尤其是 QTI 平台,比如 sdm / display-hal 模块中),HWDeviceDRM 是一个基类,抽象了所有类型的 Display 输出设备的共通 DRM 行为,而它有三个常见的子类,对应…...

金融 IC 卡 CCRC 认证:从合规到业务安全的升级路径
在金融科技飞速发展的当下,金融 IC 卡作为现代金融交易的重要载体,广泛应用于各类支付场景,从日常的购物消费到线上金融理财,其安全性直接关系到用户的资金安全和金融机构的稳定运营。CCRC(中国网络安全审查技术与认证…...

微硕WSP6949 MOS管在强排热水器中的应用与市场分析
微硕WSP6949 MOS管在强排热水器中的应用与市场分析 一、引言 强排热水器作为一种常见的家用电器,其核心部件之一是驱动电路,而MOS管作为驱动电路中的关键元件,其性能直接影响到热水器的运行效率和稳定性。微硕半导体推出的WSP6949 MOS管&am…...
)
文件操作(二进制文件)
C中对文件操作需要包含头文件 #include<fstream> 文件类型分为两类: 1. 文本文件:文件以文本对应的 ASCII 码形式存储在计算机中 2. 二进制文件:文件以文本的二进制形式存储在计算机中,用户一 般不能直接读懂 文件…...
)
ESP-ADF外设子系统深度解析:esp_peripherals组件架构与核心设计(输入类外设之按键Button)
ESP-ADF外设子系统深度解析:esp_peripherals组件架构与核心设计(输入类外设之按键Button) 版本信息: ESP-ADF v2.7-65-gcf908721 简介 本文档详细分析ESP-ADF中的输入类外设实现机制,包括按键(button)、触摸(touch)和ADC按键(a…...

HOW - 企业团队自建 npm 仓库
文章目录 一、明确需求二、选型:常用方案三、Verdaccio 搭建步骤1. 安装 Node.js 环境2. 全局安装 verdaccio3. 启动服务4. 配置(可选)5. 用户登录与发布四、团队使用方式1. 使用 `.npmrc` 文件统一配置2. 发布范围包(Scoped packages)五、权限控制六、进阶集成七、测试和…...

键值对和Map的区别
数组里存储键值对和使用Map(在不同语言里也被叫做字典、哈希表等)存在多方面的区别,下面从多个维度进行分析,同时给出C#和C的代码示例。 区别分析 1. 查找效率 数组存储键值对:查找特定键的值时,通常需要…...

CS61A:STRING REPRESENTATION
Python 规定所有对象都应该产生两种不同的字符串表示形式:一种是人类可解释的文本,另一种是 Python 可解释的表达式。字符串的构造函数 str 返回一个人类可读的字符串。在可能的情况下,repr 函数会返回一个计算结果相等的 Python 表达式。rep…...

AI编程新纪元:GitHub Copilot、CodeGeeX与VS2022的联合开发实践
引言:AI编程时代的到来 在软件开发领域,我们正站在一个历史性的转折点上。GitHub Copilot、CodeGeeX等AI编程助手的出现,结合Visual Studio 2022的强大功能,正在重塑代码编写的本质。这不仅是工具层面的革新,更是开发范式的根本转变。能够有效利用这些AI工具的开发者将跨…...

iOS崩溃堆栈分析
文章目录 一、背景二、获取崩溃日志三、使用 dSYM 文件符号化堆栈信息1. 准备 dSYM 文件2. 符号化方法使用 Xcode使用 atos 命令 一、背景 在 iOS 开发中,分析崩溃日志和堆栈信息是调试的重要环节。上线APP往往只能获取到堆栈信息无法获取到具体的崩溃日志…...

kafka服务端和springboot中使用
kafka服务端和springboot中使用 一、kafka-sever安装使用 下载kafka-server https://kafka.apache.org/downloads.html 启动zookeeper zookeeper-server-start.bat config\zookeeper.properties 启动kafka-server kafka-server-start.bat config\server.properties创建主…...

05-DevOps-Jenkins自动拉取构建代码
新建Gitlab仓库 先在Gitab上创建一个代码仓库,选择创建空白项目 安装说明进行填写,然后点击创建项目 创建好的仓库是空的,什么都没有 新建一个springboot项目,用于代码上传使用。 只是为了测试代码上传功能,所以代码…...

win7/win10/macos如何切换DNS,提升网络稳定性
本篇教程教您如何在Windows10、Windows8.1、Windows7、MacOS操作系统切换DNS,以提升系统的稳定性,获得更好的操作体验。 Windows10及Windows8.1 1、右键单击“此计算机”,然后选择“属性”。进入Windows系统界面后,选择左侧的“…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——A35M33异核通信测试
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 第四章 ATK-DLMP257B功能测试——A35&M33…...

maven如何解决jar包依赖冲突
maven如何解决jar包依赖冲突 1.背景2.报错信息3.解决思路3.1.查找jsqlparser冲突3.2.发现冲突3.2.解决冲突 4.Dromara Warm-Flow 1.背景 在ruoyi-vue项目集成Warm-Flow过程中,需要把mybatis升级为mybatis-plus,按照Warm-Flow常见问题中升级过程…...

过往记录系列 篇六:国家队护盘历史规律梳理
文章目录 系列文章护盘触发条件与时间规律护盘信号识别特征市场反应规律退出策略历史演变系列文章 过往记录系列 篇一:牛市板块轮动顺序梳理 过往记录系列 篇二:新年1月份(至春节前)行情历史梳理 过往记录系列 篇三:春节行情历史梳理 过往记录系列 篇四:年报月行情历史梳…...
)
string的模拟实现 (6)
目录 1.string.h 2.string.cpp 3.test.cpp 4.一些注意点 本篇博客就学习下如何模拟实现简易版的string类,学好string类后面学习其他容器也会更轻松些。 代码实现如下: 1.string.h #define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include <…...

多模态思维链AI医疗编程:从计算可持续性到开放域推理的系统性解决方案
多模态思维链AI医疗编程:从计算可持续性到开放域推理的系统性解决方案 医疗AI领域的多模态思维链技术正在重塑临床决策支持、医学影像分析和医疗流程优化的范式。本指南从计算可持续性、错误传播控制、伦理安全防护和通用性扩展四大维度,系统解析医疗大模型落地落地的关键要…...

BTS7960 直流电机控制程序
/*************正转逻辑*****************/ LEN1 REN1 while() { LPWN0 DELAY LPWM1 DELAY } /************反转逻辑******************/ LEN1 REN1 while() { RPWN0 DELAY RPWM1 DELAY } /******************************/ /***2025 测试直流电机正反转past…...

vue3 uniapp vite 配置之定义指令
动态引入指令 // src/directives/index.js import trim from ./trim;const directives {trim, };export default {install(app) {console.log([✔] 自定义指令插件 install 触发了!);Object.entries(directives).forEach(([key, directive]) > {app.directive(…...

Mysql-JDBC
JDBCUtils public class JDBCUtils {/*** 工具类的构造方法一般写成私有*/private JDBCUtils(){}//静态代码块再类加载的时候执行,且执行一次static{try {Class.forName("com.mysql.cj.jdbc.Driver");} catch (ClassNotFoundException e) {e.printStackT…...

如何在爬虫中合理使用海外代理?在爬虫中合理使用海外ip
我们都知道,爬虫工作就是在各类网页中游走,快速而高效地采集数据。然而如果目标网站分布在多个国家或者存在区域性限制,那靠普通的网络访问可能会带来诸多阻碍。而这时,“海外代理”俨然成了爬虫工程师们的得力帮手! …...

安卓环境搭建开发工具下载Gradle下载
1.安装jdk(使用java语言开发安卓app) 核心库 java.lang java.util java.sq; java.io 2.安装开发工具(IDE)android studio https://r3---sn-2x3elnel.gvt1-cn.com/edgedl/android/studio/install/2023.3.1.18/android-studio-2023.3.1.18-windows.exe下载完成后一步一步安装即…...
)
k8s+helm部署tongweb7云容器版(by lqw)
安装准备 1.联系销售获取安装包和授权(例如:tongweb-cloud-7.0.C.6_P3.tar.gz)。 2.已安装docker和k8s集群,参考: k8s集群搭建 3.有对应的docker私库,没有的可以参考: harbor搭建 4.docker已经…...

关于DApp、DeFi、IDO私募及去中心化应用开发的综合解析
一、DApp(去中心化应用)技术开发 1. 技术架构与开发流程 分层架构 : 前端层 :使用React/Vue.js构建用户界面,通过Web3.js或Ethers.js与区块链交互。 智能合约层 :以太坊系常用Solidity,Solana…...

招贤纳士|Walrus 亚太地区招聘高级开发者关系工程师
职位介绍: 开发者关系团队(Developer Relations)通过线上线下方式与开发者社区互动,提供专业支持和指导,帮助他们在 Sui 和 Walrus 上构建下一代 Web3 应用。团队通过与社区对话,了解开发者的痛点…...
)
Qt实现文件传输客户端(图文详解+代码详细注释)
Qt实现文件传输客户端 1、 客户端UI界面设计2、客户端2.1 添加网络模块和头文件2.2 创建Tcp对象2.3 连接按钮2.3.1 连接按钮连接信号与槽2.3.2 连接按钮实现 2.4 读取文件2.4.1 连接读取文件的信号与槽2.4.2 读取文件槽函数实现2.5 进度条2.5.1 设置进度条初始值2.5.2 初始化进…...

STL详解 - list的模拟实现
目录 1. list 的基本结构 1.1 构造函数 2. 迭代器的实现 2.1 构造函数 2.2 自增和自减操作符 2.3 比较操作符 2.4 解引用和箭头操作符 3. list 容器的实现 3.1 构造函数 3.2 拷贝构造 3.3 赋值运算符重载 3.4 析构函数 3.5 迭代器相关函数 3.6 插入和删除函数 3.…...