Transformer-PyTorch实战项目——文本分类
Transformer-PyTorch实战项目——文本分类
————————————————————————————————————————————
【前言】
这篇文章将带领大家使用Hugging Face里的模型进行微调,并运用在我们自己的新项目——文本分类中。需要大家提前下载好Trasformers库,并配置好环境。
【数据集来源】link
————————————————————————————————————————————
目录
- Transformer-PyTorch实战项目——文本分类
- 【前言】
- Step1 导入相关包
- Step2 加载数据
- Step3 创建Dataset
- Step4 划分数据集
- Step5 创建Dataloader
- Step6 创建模型及优化器
- Step7 训练与验证
- Step8 模型训练
- Step9 模型预测
————————————————————————————————————————————
Step1 导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification
————————————————————————————————————————————
Step2 加载数据
import pandas as pddata = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data
运行结果:

我们可以看到这是一个关于酒店评论的数据集,内容为“review”,标签为“label”
【注意】这里我们需要提醒一下:数据集中有可能会存在空项。这时我们需要将数据集中的空项去除,将数据集规整。
我们可以用下面代码进行处理:
data = data.dropna()
data
运行结果:

我们可以看到这张图片的维度是 {7765 × 2},而上一张图片的维度是 {7766 × 2},也就是说在这个数据集中有一条空项。
当数据量很大时我们无法通过常规检索方式检查数据集中是否有空项,那么我们可以在每一次加载数据集的时候运行这段代码,以确保一处数据集中的空项
————————————————————————————————————————————
Step3 创建Dataset
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self) -> None:super().__init__()self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")self.data = self.data.dropna()def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def __len__(self):return len(self.data)
1.初始化时,MyDataset会调用pandas中的read_csv()函数从地址中读取解析数据集
2.getitem()定义通过索引访问类的实例中的数据
3.len()用于返回对象的长度,它用于告诉 DataLoader 数据集的大小,从而正确地分批加载数据。
dataset = MyDataset()
for i in range(5):print(dataset[i])
运行和结果:

————————————————————————————————————————————
Step4 划分数据集
from torch.utils.data import random_splittrainset, validset = random_split(dataset, lengths=[0.9, 0.1])
len(trainset), len(validset)
这一步主要用于将数据集划分为训练集和测试集。
lengths=[0.9,0.1]
将数据集按照【训练集 :测试集】=【0.9 :0.1】的比例来划分
除了这种方式,一下这种方式也可以划分数据集
# 手动划分数据集
train_data = data[:90]
train_labels = labels[:90]
valid_data = data[90:]
valid_labels = labels[90:]
运行结果:

训练集有6989个样例,测试集有776个样例
————————————————————————————————————————————
Step5 创建Dataloader
import torchtokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")def collate_func(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])#将输入统一规整到一定的长度inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
这段代码定义了一个 collate_func 函数,用于在使用 PyTorch 的 DataLoader 时对数据进行批处理。这个函数的作用是将一个批次的数据(batch)转换为模型可以直接输入的格式。
1.AutoTokenizer.from_pretrained(“hfl/rbt3”):
①使用 Hugging Face 的 transformers 库加载预训练的分词器(hfl/rbt3 是一个预训练的中文模型)。
②分词器的作用是将文本转换为模型可以理解的输入格式(如 token IDs 和注意力掩码)。
2.batch:
①batch 是一个列表,每个元素是一个元组 (text, label),表示一个样本及其对应的标签。
②这个列表是由 DataLoader 提供的,DataLoader 会将数据集中的样本按批次加载。
3.texts 和 labels:
①texts 是一个列表,存储所有样本的文本内容。
②labels 是一个列表,存储所有样本的标签。
3.tokenizer(texts, …):
①使用分词器对文本进行处理,将文本转换为模型可以理解的格式。
②max_length=128:将所有文本的长度统一为 128。
③padding=“max_length”:如果文本长度不足 128,用填充符([PAD])填充到 128。
④truncation=True:如果文本长度超过 128,截断为 128。
⑤return_tensors=“pt”:返回 PyTorch 张量。
⑥inputs[“labels”]:将标签列表转换为 PyTorch 张量,并存储在 inputs 字典中,键为 “labels”。
4.返回值:
inputs 是一个字典,包含处理后的输入数据和标签,可以直接传递给模型进行训练或推理。
from torch.utils.data import DataLoadertrainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
这段代码展示了如何使用 PyTorch 的 DataLoader 类来创建训练集和验证集的数据加载器(DataLoader)。DataLoader 是 PyTorch 中用于加载数据的工具,它支持批量加载、打乱数据、多线程数据加载等功能。
1.trainset 和 validset:
①trainset 和 validset 是数据集对象,通常是继承自 torch.utils.data.Dataset 的自定义类的实例。
②这些数据集对象需要实现 len 和 getitem 方法,以便 DataLoader 可以正确地加载数据。
2.batch_size:
①batch_size 参数指定每个批次加载的数据样本数量。
②在训练时,通常使用较小的批次大小(如 32),以便更好地利用 GPU 的计算能力。
③在验证时,可以使用较大的批次大小(如 64),以加快验证速度。
.3.shuffle:
①shuffle 参数控制是否在每个 epoch 开始时打乱数据。
②在训练时,通常设置为 True,以避免模型对数据的顺序产生依赖。
③在验证时,通常设置为 False,以保持数据的顺序一致。
4.collate_fn:
①collate_fn 是一个函数,用于将多个样本组合成一个批次。
②默认情况下,DataLoader 会将多个样本组合成一个列表。如果需要对数据进行特殊处理(如填充、截断等),可以自定义 collate_fn。
③在上述代码中,collate_func 是一个自定义的函数,用于处理文本数据并将其转换为模型可以接受的格式。
5.collate_func 的作用
collate_func 是一个自定义函数,用于将一个批次的数据(batch)转换为模型可以直接输入的格式。具体来说,它完成以下任务:
①提取每个样本的文本和标签。
②使用分词器对文本进行处理,将文本转换为 token IDs 和注意力掩码。
③将标签列表转换为 PyTorch 张量。
④返回一个字典,包含处理后的输入数据和标签。
next(enumerate(trainloader))[1]
运行结果:
查看输入的矩阵
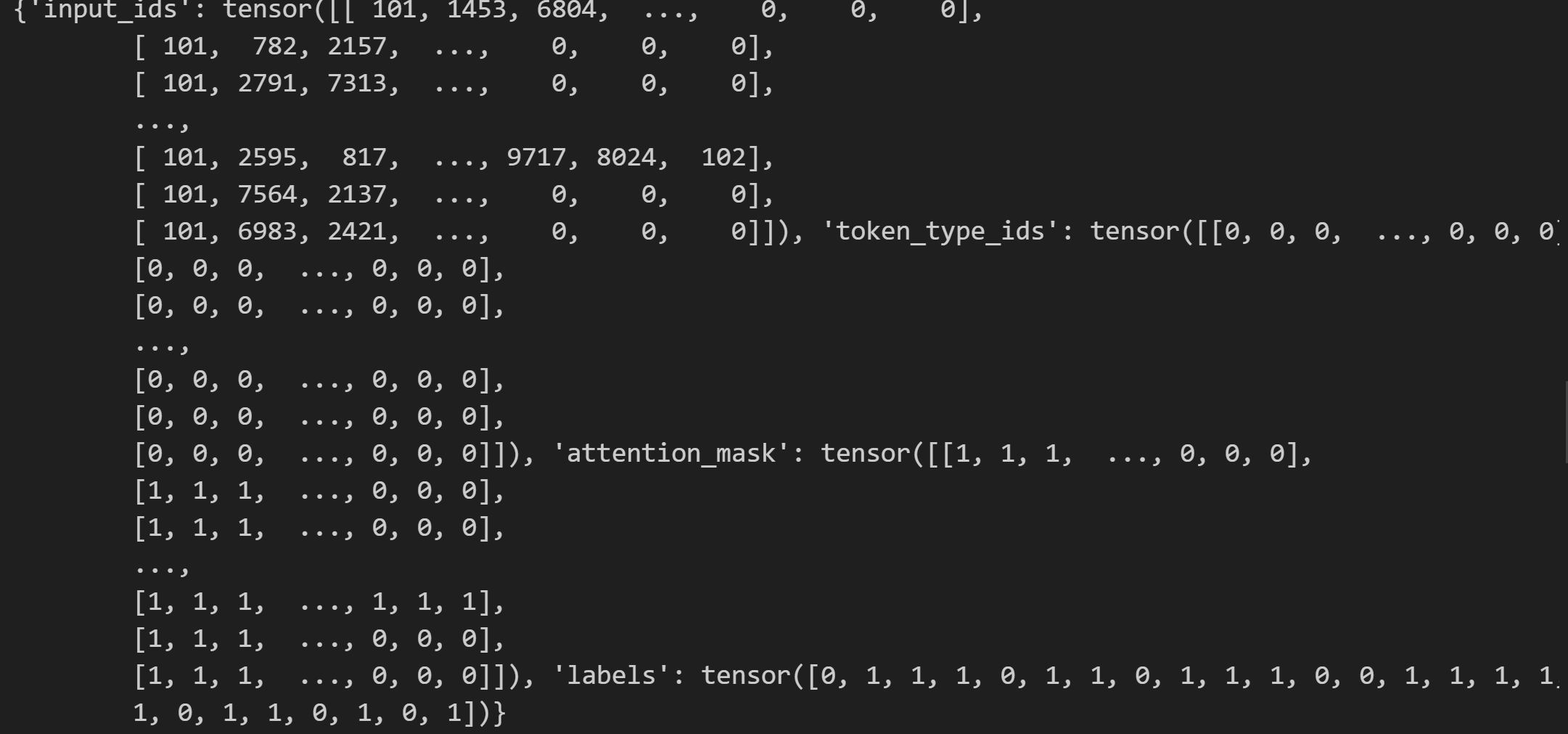
————————————————————————————————————————————
Step6 创建模型及优化器
from torch.optim import Adammodel = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3")if torch.cuda.is_available():model = model.cuda()
1.AutoModelForSequenceClassification.from_pretrained(“hfl/rbt3”):
①使用 Hugging Face 的 transformers 库加载预训练的模型。
②hfl/rbt3 是一个预训练的中文模型,适用于序列分类任务(如情感分析、文本分类等)。
③AutoModelForSequenceClassification 是一个通用类,可以根据预训练模型的类型自动加载相应的模型。
2.torch.cuda.is_available():
①检查是否有可用的 GPU。
②如果有可用的 GPU,torch.cuda.is_available() 返回 True,否则返回 False。
3.model.cuda():
①将模型移动到 GPU 上。
②cuda() 方法会将模型的所有参数和缓冲区移动到 GPU 上,从而加速模型的训练和推理。
————————————————————————————————————————————
Step7 训练与验证
def evaluate():model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}output = model(**batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validset)
1. model.eval():
将模型设置为评估模式,关闭 Dropout 和 BatchNorm 等训练时的特定行为。
2.torch.inference_mode():
使用 torch.inference_mode() 上下文管理器,禁用梯度计算,提高推理速度并减少内存占用。
3.batch:
①batch 是一个字典,包含输入数据和标签。
②如果 GPU 可用,将数据移动到 GPU 上。
4.output.logits:
①模型的输出是一个包含 logits 的对象。
②使用 torch.argmax 获取预测的类别。
5.acc_num:
①统计预测正确的样本数量。
②使用 (pred.long() == batch[“labels”].long()).float().sum() 计算每个批次中预测正确的样本数量。
6.返回值:
返回准确率,即预测正确的样本数量除以验证集的总样本数量。
def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()for batch in trainloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}optimizer.zero_grad()output = model(**batch)output.loss.backward()optimizer.step()if global_step % log_step == 0:print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")global_step += 1acc = evaluate()print(f"ep: {ep}, acc: {acc}")
train() 函数
train() 函数用于训练模型,并在每个 epoch 结束时调用 evaluate() 函数评估模型的准确率。
1.model.train():
将模型设置为训练模式,启用 Dropout 和 BatchNorm 等训练时的特定行为。
2.global_step:
用于记录全局步数,即整个训练过程中处理的批次总数。
3.optimizer.zero_grad():
清空之前的梯度,避免梯度累积。
4.output.loss.backward():
计算损失的梯度,并通过反向传播更新模型参数。
5.optimizer.step():
更新模型参数。
6.日志记录:
每隔 log_step 个步骤打印一次训练损失。
7.调用 evaluate():
在每个 epoch 结束时调用 evaluate() 函数,评估模型在验证集上的准确率。
————————————————————————————————————————————
Step8 模型训练
train()
运行结果:
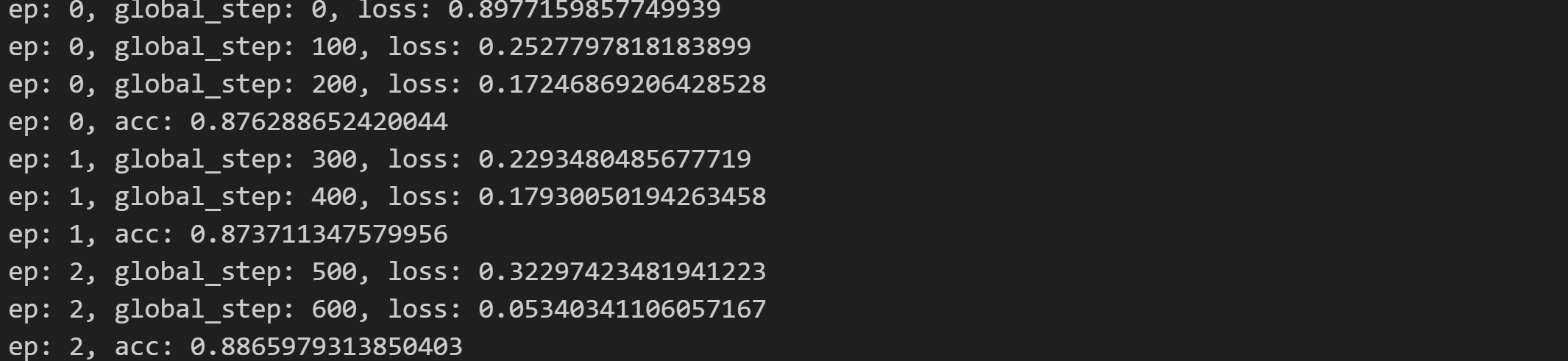
————————————————————————————————————————————
Step9 模型预测
sen = "我觉得这家酒店不错,饭很好吃!"
id2_label = {0: "差评!", 1: "好评!"}
model.eval()
with torch.inference_mode():inputs = tokenizer(sen, return_tensors="pt")#inputs = {k: v.cuda() for k, v in inputs.items()}logits = model(**inputs).logitspred = torch.argmax(logits, dim=-1)print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
1. sen:
输入的文本句子,表示对酒店的评价。
2.id2_label:
一个字典,将模型的预测结果(类别索引)映射为人类可读的标签。0 表示差评,1 表示好评。
3.model.eval():
将模型设置为评估模式,关闭 Dropout 和 BatchNorm 等训练时的特定行为。
4.torch.inference_mode():
使用 torch.inference_mode() 上下文管理器,禁用梯度计算,提高推理速度并减少内存占用。
5.tokenizer(sen, return_tensors=“pt”):
使用分词器对输入文本进行处理,生成模型可以理解的输入格式(如 token IDs 和注意力掩码)。
return_tensors=“pt” 表示返回 PyTorch 张量。
6.inputs = {k: v.cuda() for k, v in inputs.items()}:
如果 GPU 可用,将输入数据移动到 GPU 上。这一步在代码中被注释掉了,可以根据需要启用。
**7.model(**inputs).logits:
将处理后的输入传递给模型,获取模型的输出(logits)。
8.torch.argmax(logits, dim=-1):
使用 torch.argmax 获取 logits 的最大值所在的索引,即预测的类别。
9.id2_label.get(pred.item()):
将预测的类别索引通过 id2_label 映射为人类可读的标签。
10.输出结果:
打印输入句子和模型的预测结果。
相关文章:
Transformer-PyTorch实战项目——文本分类
Transformer-PyTorch实战项目——文本分类 ———————————————————————————————————————————— 【前言】 这篇文章将带领大家使用Hugging Face里的模型进行微调,并运用在我们自己的新项目——文本分类中。需要大家提前下…...

Linux-服务器负载评估方法
在 Linux 服务器中,top 命令显示的 load average(平均负载)反映了系统在特定时间段内的负载情况。它通常显示为三个数值,分别代表过去 1 分钟、5 分钟和 15 分钟的平均负载。 1. 什么是 Load Average? Load average …...
Transformer编程题目,结合RTX 3060显卡性能和市场主流技术
以下是10道针对4年经验开发者的Transformer编程题目,结合RTX 3060显卡性能和市场主流技术,每题包含模型选择和实现逻辑描述: 题目1:医疗报告结构化提取 模型选择:BioBERT-base 要求: 开发从PDF医疗报告中提…...
)
Web三漏洞学习(其二:sql注入)
靶场:NSSCTF 、云曦历年考核题 二、sql注入 NSSCTF 【SWPUCTF 2021 新生赛】easy_sql 这题虽然之前做过,但为了学习sql,整理一下就再写一次 打开以后是杰哥的界面 注意到html网页标题的名称是 “参数是wllm” 那就传参数值试一试 首先判…...

VLAN的知识
1.什么是VLAN? VLAN是虚拟局域网,逻辑隔离广播域和网络区域 是一种通过将局域网内的设备逻辑地划分为一个个网络的技术 2.对比逻辑网络分割和物理网络分割? 逻辑网络分割是VLAN,隔离广播域和网络区域 物理网络分割是路由&…...

RFID 赋能部队智能物联网仓储建设:打造信息化高效解决方案
在当今军事现代化进程的宏大背景下,部队后勤保障工作无疑占据着举足轻重的地位,而仓储管理作为其中的核心环节,更是至关重要。传统的仓储管理模式在面对当下物资种类繁杂、数量庞大的现状时,已显得力不从心,效率低下、…...

结构型屏蔽在高频电子设备中的应用与优化
在当今高度电子化的时代,随着电子产品工作频率不断提高,设备内部温度上升,电磁环境日趋复杂,电磁兼容(EMC)问题成为设计和制造过程中必须重点解决的问题。EMC不仅关系到设备自身的稳定运行,更涉…...

【教程】Ubuntu修改ulimit -l为unlimited
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 问题描述 解决方法一 解决方法二 解决方法三 (终极) 问题描述 查系统资源限制 ulimit -l如果返回的是 64 或其他较小值,那么RDM…...

【HDFS】BlockPlacementPolicyRackFaultTolerant#getMaxNode方法的功能及具体实例
方法参数说明: numOfChosen:已经选择的节点数numOfReplicas:还需要选择的副本数方法的返回值是一个长度为2的数组:[调整后的要选出多少个节点(不包括已经选择的), 每个机架最大能选择的节点数] @Overrideprotected int[] getMaxNodesPerRack(int numOfChosen, int numOfR…...
)
水污染治理(生物膜+机器学习)
文章目录 **1. 水质监测与污染预测****2. 植物-微生物群落优化****3. 系统设计与运行调控****4. 维护与风险预警****5. 社区参与与政策模拟****挑战与解决思路****未来趋势** 前言: 将机器学习(ML)等人工智能技术融入植树生物膜系统ÿ…...

数模小白变大神的日记2025.4.15日
分工 1.论文:mathtype (Latex) 2.建模;相应的建模知识与撰写方法,写摘要 3.编程:matlab、SPSs、(Python) 评价模型 1. 层次分析法 ①层次分析法是一种多目标、多准则的决策问题 ②层次分析法是一种主观加权法 ③层次分析法通过以下步骤实现: 1.构…...

STM32提高篇: 以太网通讯
STM32提高篇: 以太网通讯 一.以太网通讯介绍二.W5500芯片介绍1.W5500芯片特点2.W5500应用目标3.接入框图 三.驱动移植四.tcp通讯五.udp通讯六.http_server 一.以太网通讯介绍 以太网(Ethernet)是一种计算机局域网技术。IEEE组织的IEEE 802.3标准制定了以…...
)
4-15记录(冒泡排序,快速选择排序)
算法稳定 简单选择排序的实质就是最后一个和第一个比较,小,就换位置,然后继续用最后一个数字和第二个比较,以此类推。 但是算法不稳定,本来下划线的2在后面,但是经过算法后去了前面 快速排序 实现过程&am…...

Ubuntu系统18.04更新驱动解决方法
原始是:ubuntu18.04里面的驱动是470,对应cuda11.4 现在需要更新为525,对应cuda为12.0 实现: 1、打开终端 Ctrl Alt T2、使用 lspci 命令(快速查看显卡型号) lspci | grep -i vga3、终端输入 ubuntu-d…...

Rocky Linux 9.x 基于 kubeadm部署k8s
搭建集群使用docker下载K8s,使用一主两从模式 主机名IP地址k8s- master192.168.1.141k8s- node-1192.168.1.142k8s- node-2192.168.1.143 一:准备工作 VMware Workstation Pro新建三台虚拟机Rocky Linux 9(系统推荐最小化安装) …...

MATLAB程序实现了一个物流配送优化系统,主要功能是通过遗传算法结合四种不同的配送策略,优化快递订单的配送方案
%% 主函数部分 % function main()clear; clc; close all;% 生成或加载算例 filename = D:\快递优化\LogisticsInstance.mat; if ~exist(filename, file)instance = generate_instance();save(filename, -struct, instance); elseinstance = load(filename); end% 遗传算法参数配…...

利用宝塔面板搭建RustDesk服务
一、介绍 1.1官网 https://rustdesk.com/ 1.2github仓库 https://github.com/rustdesk/rustdesk 1.3特点 RustDesk 支持多种操作系统,包括 Windows、macOS、Linux、Android 和 iOS。它甚至提供网页版客户端,可以在浏览器中直接使用。 用户可以通过…...

前端与Java后端交互出现跨域问题的14种解决方案
跨域问题是前端与后端分离开发中的常见挑战,以下是14种完整的解决方案: 1 前端解决方案( 开发环境代理) 1.1 Webpack开发服务器代理 // vue.config.js 或 webpack.config.js module.exports {devServer: {proxy: {/api: {target: http://localhost:8…...
)
PBKDF2全面指南(SpringBoot实现版)
文章目录 第一部分:PBKDF2基础概念1. 什么是PBKDF2?2. 为什么需要PBKDF2?3. PBKDF2的工作原理4. PBKDF2与其他密码散列函数的比较第二部分:在Java和SpringBoot中使用PBKDF21. Java内置的PBKDF2支持2. SpringBoot中集成PBKDF22.1 添加依赖2.2 配置PBKDF2密码编码器2.3 自定义…...

基于RV1126开发板的rknn-toolkit-lite使用方法
1. rknn-toolkit-lite介绍 rknn-toolkit-lite是用于python算法的推理的组件,当前已经在EASY-EAI-Nano完成适配,用户可以用它进行深度学习算法的纯python开发。而且同时支持已经进行了预编译的模型,短短几行代码即可完成算法的推理,…...

一款轻量级的PHP地址发布页面源码
源码介绍 一款轻量级的PHP链接发布页面源码,适合快速搭建个性化的链接导航网站,支持动态链接管理和多种风格模板切换 1:后台登录地址为/admin/login.php,提供便捷的配置入口。 2:默认用户名是admin,密码为…...

分布式计算领域的前沿工具:Ray、Kubeflow与Spark的对比与协同
在当今机器学习和大数据领域,分布式计算已成为解决大规模计算问题的关键技术。本文将深入探讨三种主流分布式计算框架——Ray、Kubeflow和Spark,分析它们各自的特点、应用场景以及如何结合它们的优势创建更强大的计算平台。 Spark批量清洗快,…...
)
【专题刷题】双指针(一)
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:1,本人解法 本人屎山代码;2,优质解法 优质代码;3,精益求精,…...

火山引擎旗下防御有哪些
首先,我需要确认用户是不是打错了,比如把“引擎”当成了“云”,或者他们真的想了解火山引擎的防御机制。火山引擎是字节跳动旗下的云服务平台,类似于阿里云或腾讯云,所以用户可能想了解的是其安全防护措施。 接下来&am…...

python程序打包——nuitka使用
目前python打包成exe的工具主要有:PyInstaller Briefcase py2exe py2app Nuitka CX_Freeze等。 不同于C代码,可以直接编译成可执行的exe文件,或者js代码在浏览器中就能执行,python代码必须通过python解释器来运行,…...

编写了一个专门供强化学习玩的贪吃蛇小游戏,可以作为后续学习的playgraound
文章目录 **试玩效果****项目背景****核心设计思路****代码亮点解析****与强化学习算法的对接示例****扩展方向****总结****完整代码**把训练一个会玩小游戏的智能体,作为学习强化学习的一个目标,真的是很有乐趣的一件事。我已经不知为此花费了多少日夜了。如今已是着魔了一般…...

chain_type=“stuff 是什么 ? 其他方式有什么?
chain_type="stuff 是什么 ? 其他方式有什么? 目录 chain_type="stuff 是什么 ? 其他方式有什么?1. `chain_type="stuff"`2. `chain_type="map_reduce"`3. `chain_type="refine"`4. `chain_type="map_rerank"`在 LangCh…...
)
在IDEA里面建立maven项目(便于java web使用)
具体步骤: 第一次有的电脑你再创建项目的时候右下角会提醒你弹窗:让你下载没有的东西 一定要下载!!可能会很慢 运行结果: 因为他是默认的8080端口所以在运行的时候输入的url如下图: 新建了一个controller代…...

MyBatis 详解
1. 什么是 MyBatis? MyBatis 是一款优秀的 持久层框架,它通过 XML 或注解配置,将 Java 对象(POJO)与数据库操作(SQL)进行灵活映射,简化了 JDBC 的复杂操作。 核心思想:S…...

郑州工程技术学院党委书记甘勇一行莅临埃文科技调研交流
为深化产教融合、推动人工智能领域人才培养与产业需求精准对接,2025年4月9日下午,郑州工程技术学院党委书记甘勇、河南省人工智能产业创新发展联盟执行秘书长孟松涛等一行莅临埃文科技调研交流。 一、聚焦技术前沿 共话AI产业变革 座谈会上,…...

AI应用开发之扣子第一课-夸夸机器人
首先,进入官网:点击跳转至扣子。 1.创建智能体 登录进网站后,点击左上角+图标,创建智能体,输入智能体名称、功能介绍 2.输入智能体提示词 在“人设与回复逻辑”输入以下内容: # 角色 你是一…...

Node.js 数据库 CRUD 项目示例
希望使用Nodejs操作数据库做CRUD,用deepseek实战搜索“使用Nodejs对数据库表做CRUD的项目例子”,找到了解决方案,如下图所示: 项目结构 nodejs-crud-example/ ├── config/ │ └── db.js # 数据库连接配置 ├──…...
的使用介绍)
ESP8266/32作为AVR编程器(ISP programmer)的使用介绍
ESP8266作为AVR编程器( ISP programmer)的使用介绍 🌿ESP8266自带库例程:https://github.com/esp8266/Arduino/tree/master/libraries/ESP8266AVRISP📍支持ESP8266/32的ESP_AVRISP其它开源工程(个人没有再去验证)&…...

union all几个常见问题及其解决方案
UNION ALL 是 SQL 中用于合并两个或多个 SELECT 语句结果集的操作符。与 UNION 不同,UNION ALL 不会去除重复的记录,它简单地将一个查询的结果附加到另一个查询的结果之后。尽管 UNION ALL 相对来说更高效(因为它不需要检查重复项)…...

21.C++11
1.列表初始化 1.1C11中的{} •C11以后想统⼀初始化⽅式,试图实现⼀切对象皆可⽤{}初始化,{}初始化也叫做列表初始化。 • 内置类型⽀持,⾃定义类型也⽀持,⾃定义类型本质是类型转换,中间会产⽣临时对象,最…...

【交叉编译】目标机编译安装对应依赖库总结
1、解压目标机交叉编译工具链 # 创建工具链存放目录(可选) sudo mkdir -p /opt/toolchain# 解压到目标路径(示例路径:/opt/toolchain) sudo tar -xzvf 目标主机编译工具链.tar.gz -C /opt/toolchain# 查看解压后的目录…...

Docker华为云创建私人镜像仓库
Docker华为云创建私人镜像仓库 在华为云官网的 产品 中搜索 容器镜像服务 : 或者在其他页面的搜索栏中搜索 容器镜像服务 : 进入到页面后,点击 创建组织 (华为云的镜像仓库称为组织): 设置组织名字后&…...

【15】数据结构之基于树的查找算法篇章
目录标题 二叉排序树 Binary Sort Tree二叉排序树的插入二叉树排序树的删除二叉排序树的查找二叉排序树的调试与代码集合 平衡二叉树-AV树平衡二叉树的平衡化旋转平衡二叉树的代码调试与代码集合 B树B树的查找B树的插入B树和B*树 二叉排序树 Binary Sort Tree 二叉…...

自定义类型之结构体
1.结构体类型概述 结构体类型是一种用户自定义的数据类型,用于将不同类型的数据组合成一个整体。在C语言中,结构体使用struct关键字定义,由一系列具有相同类型或不同类型的数据构成的数据集合,也称为结构。结构体中的数据在逻辑上…...

SGFormer:卫星-地面融合 3D 语义场景补全
论文介绍 题目:SGFormer: Satellite-Ground Fusion for 3D Semantic Scene Completion 会议:IEEE / CVF Computer Vision and Pattern Recognition Conference 论文:https://www.arxiv.org/abs/2503.16825 代码:https://githu…...

应急响应篇钓鱼攻击邮件与文件EML还原蠕虫分析线索定性处置封锁
钓鱼邮件的eml中会有 邮件服务器地址域名(发信人)发送的本地IP和主机名发送的内容以及附件 邮件钓鱼: 攻击者目的:通过发信人,附件,取得突破 定性钓鱼邮件 威胁情报,人工分析来源,…...

利用纯JS开发浏览器小窗口移动广告小功能
效果展示 直接上代码 如果要用到vue项目里面,直接按照vue的写法改动就行,一般没有多大的问题,顶部的占位是我项目需求,你可以按照要求改动。 <!DOCTYPE html> <html> <head><meta charset"utf-8"…...

java Stream流
Stream流 双列集合无法直接使用stream流,可以通过keyset()或enteyset转换为单列集合,再进行操作 1.单列集合 package mystream;import java.util.ArrayList; import java.util.Collections;public class StreamDemo1 {public sta…...

【实战中提升自己】 防火墙篇之VPX部署–L2TP over IPSEC
1 VPx部署【L2TP Over ipsec】 说明:在VPX上面,我们希望与分部建立VPX,保证与分部的财务部正常通信,另外还提供L2TP Over ISPEC功能,方便远程接入访问内部服务器等。当然我们也可以做详细的控制ÿ…...
(java)整数替换)
贪心算法(20)(java)整数替换
给定一个正整数 n ,你可以做如下操作: 如果 n 是偶数,则用 n / 2替换 n 。如果 n 是奇数,则可以用 n 1或n - 1替换 n 。 返回 n 变为 1 所需的 最小替换次数 。 示例 1: 输入:n 8 输出:3 解…...

实验二.单按键控制LED
1.实验任务 如图4.1所示:在P0.0端口上接一个发光二极管L1,按键按一下灯亮,在按一下灯灭。 2.电路原理图 3.系统板上硬件连线 把“单片机系统”区域中的P0端口用导线连接到“八路发光二极管指示模块”区域中的L1端口上。 4.程序设计内容...

Ubuntu 常用命令行指令
1. 文件与目录操作 命令作用示例ls列出目录内容ls -l(详细列表)cd切换目录cd ~/Documentspwd显示当前目录路径pwdmkdir创建目录mkdir new_folderrm删除文件rm file.txtrm -r递归删除目录rm -r old_dircp复制文件cp file.txt backup/mv移动/重命名文件mv…...
)
Cribl 数据脱敏 -02 (附 测试数据)
先把实验的测试方向如下: Match Regex Replace Expression Example result <...

【项目管理】第16章 项目采购管理-- 知识点整理
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

根据关键字搜索日志内容,常用的Linux命令
在 Linux 中,根据关键字搜索日志内容是运维和开发的常见需求。以下是常用的命令及场景示例: 1. grep 基础搜索 (1) 简单关键字匹配 # 在文件中搜索包含 "error" 的行 grep "error" /var/log/nginx/error.log# 忽略大小写ÿ…...