(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇
本篇参考bilibili如何在本地微调DeepSeek-R1-8b模型_哔哩哔哩_bilibili
上篇:(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇
初始变量
max_seq_length = 2048
dtype = None
load_in_4bit = True
- 单批次最大处理模型大小
- dype 参数的数据精度,包括各种矩阵中的数据的精例如 float32(高精度)、float16(半精度),选择None则是自动选择精度
- 4bit量化,可以将模型部署在消费级的显卡上,而不损失大量的精度
model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,token = hf_token,
)
- 解包操作,对于该方法复制给两个变量
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"## 模型输入
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
- input_ids这里是将字符转换为token
- max_new_tokens 生成的最大长度
- use_cache 缓存开启,也就是保存之前的键值对(这里还不太懂)
- attention_mask 指的是 Padding Mask 指的是忽略输入文本长度,针对样本不同的token填充例如[PAD],在矩阵中赋值为0
model = FastLanguageModel.get_peft_model(model,r=16,target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",],lora_alpha=16,lora_dropout=0,bias="none",use_gradient_checkpointing="unsloth", # True or "unsloth" for very long contextrandom_state=3407,use_rslora=False,loftq_config=None,
)
-
Lora的基本概念,通过分解detw的值ΔW=A⋅B
-
r 分解矩阵的秩的大小:d×r+r×k
-
lora_alpha, LoRA缩放因子(ΔW = α * A*B)通常为r的倍数
-
lora_dropout 丢弃率,防止过拟合
-
bias 偏置项,减少训练量 wx+b的b
-
andom_state,用来确保实验可以复现(保存初始化元素)
-
use_rslora lora变体
-
use_gradient_checkpointing 梯度检查点
Forward: [Layer1-5 → 检查点 → Layer6-10 → 检查点 → …] 仅存储检查点激活
Backward:-
从最后一个检查点重计算 Layer6-10
-
计算 Grad10-6
-
从中间检查点重计算 Layer1-5
-
计算 Grad5-1
具体来说,就是删除其中一些向量a,我们在反向传播的时候要用到的a通过再次前向传输进行计算输出
用空间换时间
-
trainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=2,gradient_accumulation_steps=4,# Use num_train_epochs = 1, warmup_ratio for full training runs!warmup_steps=5,max_steps=60,learning_rate=2e-4,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),logging_steps=10,optim="adamw_8bit",weight_decay=0.01,lr_scheduler_type="linear",seed=3407,output_dir="outputs",),
)-
SFTTrainer是trl库中专门用于对语言模型进行监督式微调(Supervised Fine-Tuning)的训练器,通常用于指令微调(Instruction Tuning)。 -
dataset_num_proc=2
作用: 指定在预处理数据集(例如,进行分词)时使用的 CPU 进程数量。
-
per_device_train_batch_size=2 Batch Size 是指在单次模型权重更新前,模型处理的样本数量。
-
gradient_accumulation_steps=4 小批次反向传播
-
warmup_steps 在训练开始的前
warmup_steps步(这里是 5 步),学习率会从一个很小的值(通常是 0)逐渐线性增加到设定的learning_rate。这有助于在训练初期稳定模型,避免因初始梯度过大导致训练发散。- max_steps=60 训练将在执行了 60 次权重更新后停止,无论处理了多少数据或完成了多少轮(Epoch)。如果同时设置了
num_train_epochs,max_steps会覆盖它。这里设置为 60,表明这是一个非常短的训练过程,可能用于快速验证代码或流程是否正常。注释提示完整训练应使用num_train_epochs。
- max_steps=60 训练将在执行了 60 次权重更新后停止,无论处理了多少数据或完成了多少轮(Epoch)。如果同时设置了
-
num_train_epochs = 1 删除
max_steps=60,设置num_train_epochs = 1作为 -
fp16=not is_bfloat16_supported(), 数据精度问题
bf16=is_bfloat16_supported(), -
logging_steps=10 设置记录训练指标(如损失、学习率等)的频率
-
optim=“adamw_8bit” adam优化器
-
-
weight_decay=0.01 权重衰减是一种正则化技术,通过在损失函数中添加一个与权重平方和成正比的惩罚项,来防止模型权重变得过大,有助于减少过拟合。区别(L2)
-
lr_scheduler_type=“linear” 学习率调度器负责在训练过程中动态调整学习率,这里是线性增加
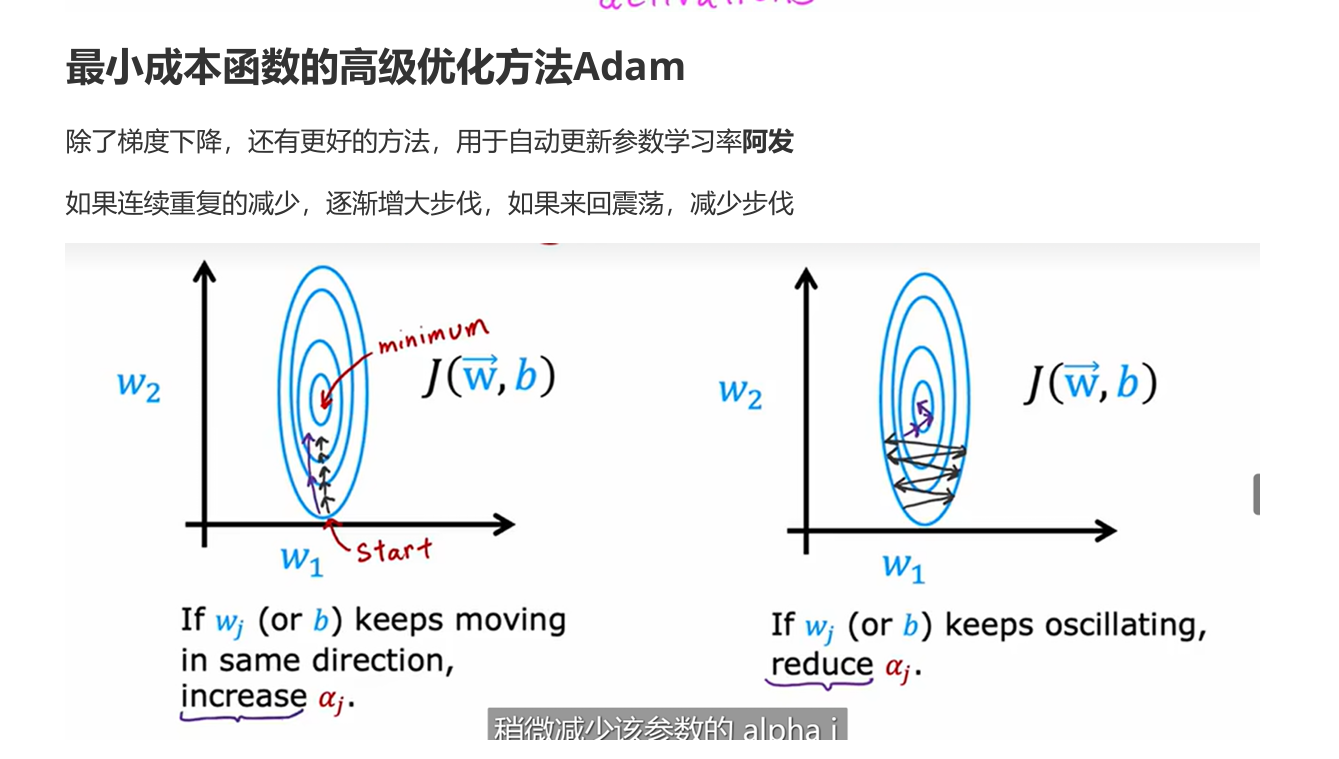
这里的学习处理的一些参数设置关系
训练开始 (Step 0 -> Step 5):
- Warmup 控制:
warmup_steps=5生效。 - Scheduler (Linear) 配合: 学习率从 0 开始线性增加。
- Optimizer (AdamW_8bit) 执行: 在每一步使用这个逐渐增大的学习率和计算出的梯度来更新模型权重。
预热结束 (Step 5):
- 学习率达到峰值
learning_rate=2e-4。
训练继续 (Step 6 -> Step 60):
- Scheduler (Linear) 控制:
lr_scheduler_type="linear"生效。学习率从2e-4开始线性下降,目标是在第 60 步时降到 0。 - Optimizer (AdamW_8bit) 执行: 在每一步使用这个逐渐减小的学习率和计算出的梯度来更新模型权重。
训练结束 (Step 60):
- 学习率理论上降到 0,训练停止。
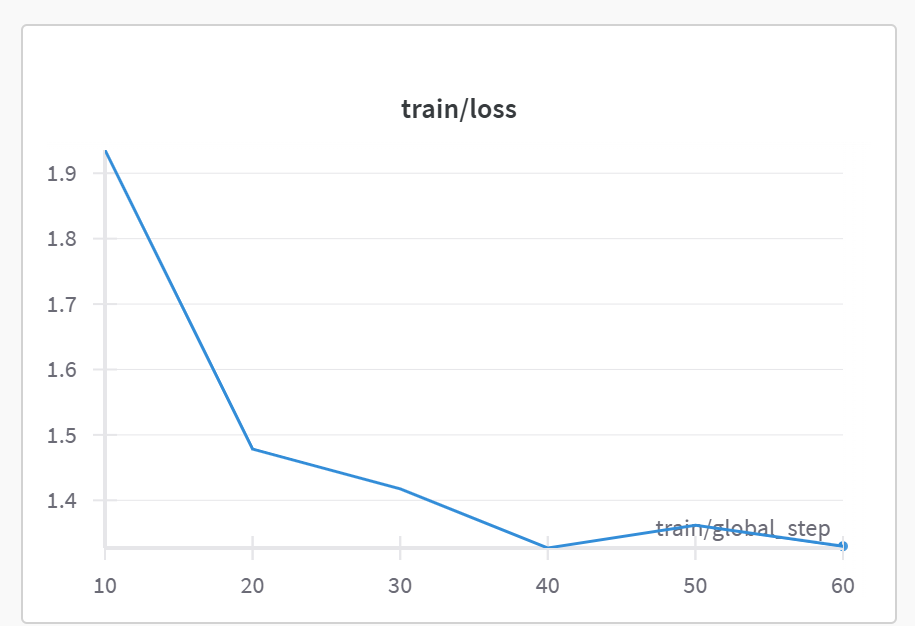
wandb图标观察
train/loss(训练损失)
-
X 轴:
train/global_step- 训练进行的全局步数(优化器更新次数),从 10 到 60。 -
Y 轴: Loss (损失值) - 模型在训练数据上计算出的损失函数值。这个值越低通常表示模型拟合训练数据越好。
-
曲线解读: 图表显示损失值从训练开始(第 10 步之后)的较高值(约 1.9)迅速下降,然后在后续步骤中(20 到 60 步)下降速度减缓,最终达到约 1.35 左右。
-
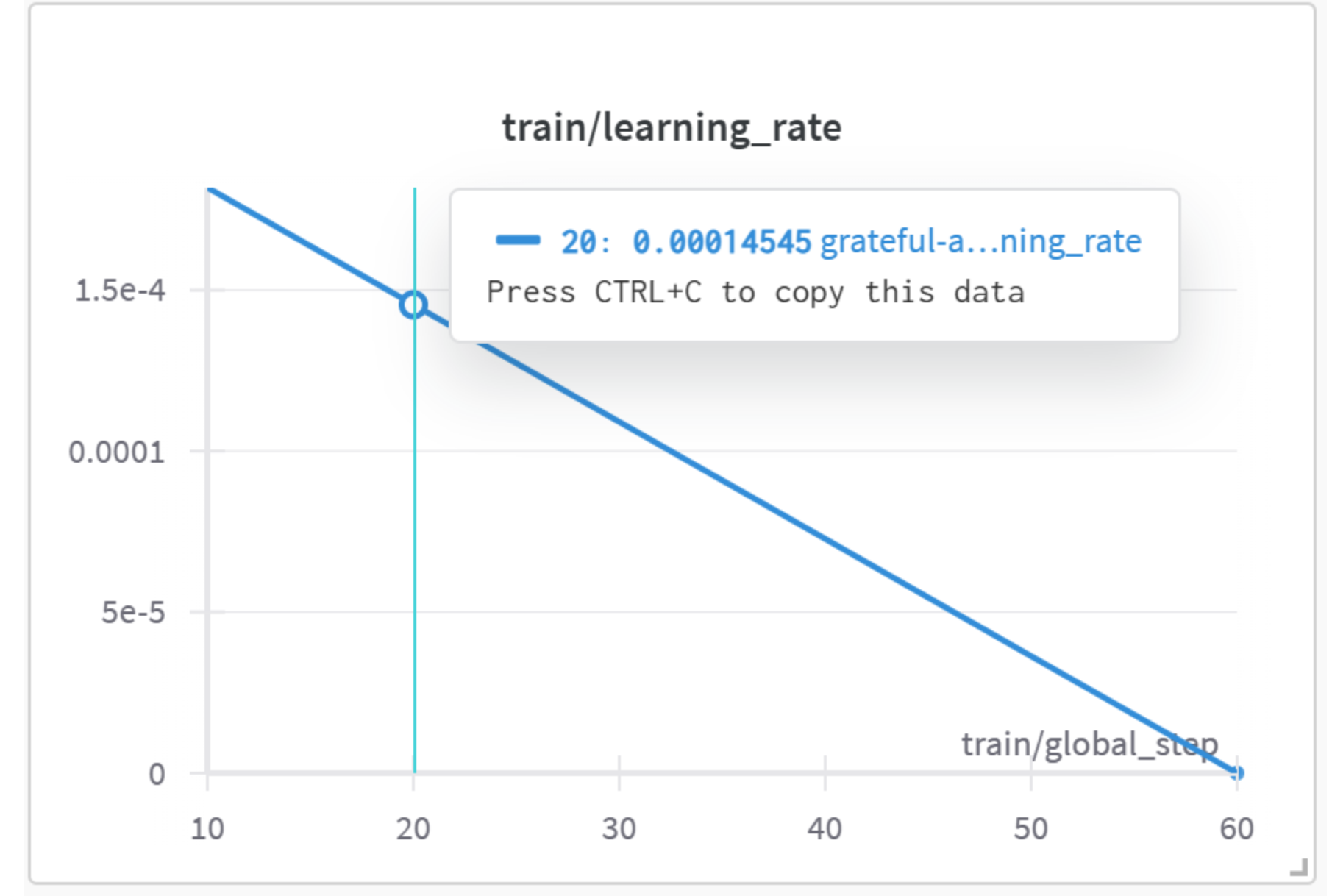
train/learning_rate(训练学习率)
- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Learning Rate (学习率) - 优化器在每一步实际使用的学习率。
- 曲线解读: 学习率从第 10 步时的一个较高值(接近你设置的峰值
2e-4,这里显示约 1.6e-4 可能是因为记录点和实际峰值点略有偏差或 warmup 刚结束)开始,随着步数增加线性下降,在第 60 步接近 0。 - 意义: 这个图完美地验证了你的学习率调度设置:
warmup_steps=5(前 5 步预热,图中未完全显示,因为 x 轴从 10 开始) 和lr_scheduler_type="linear"以及max_steps=60。学习率在预热后达到峰值,然后线性衰减至训练结束。
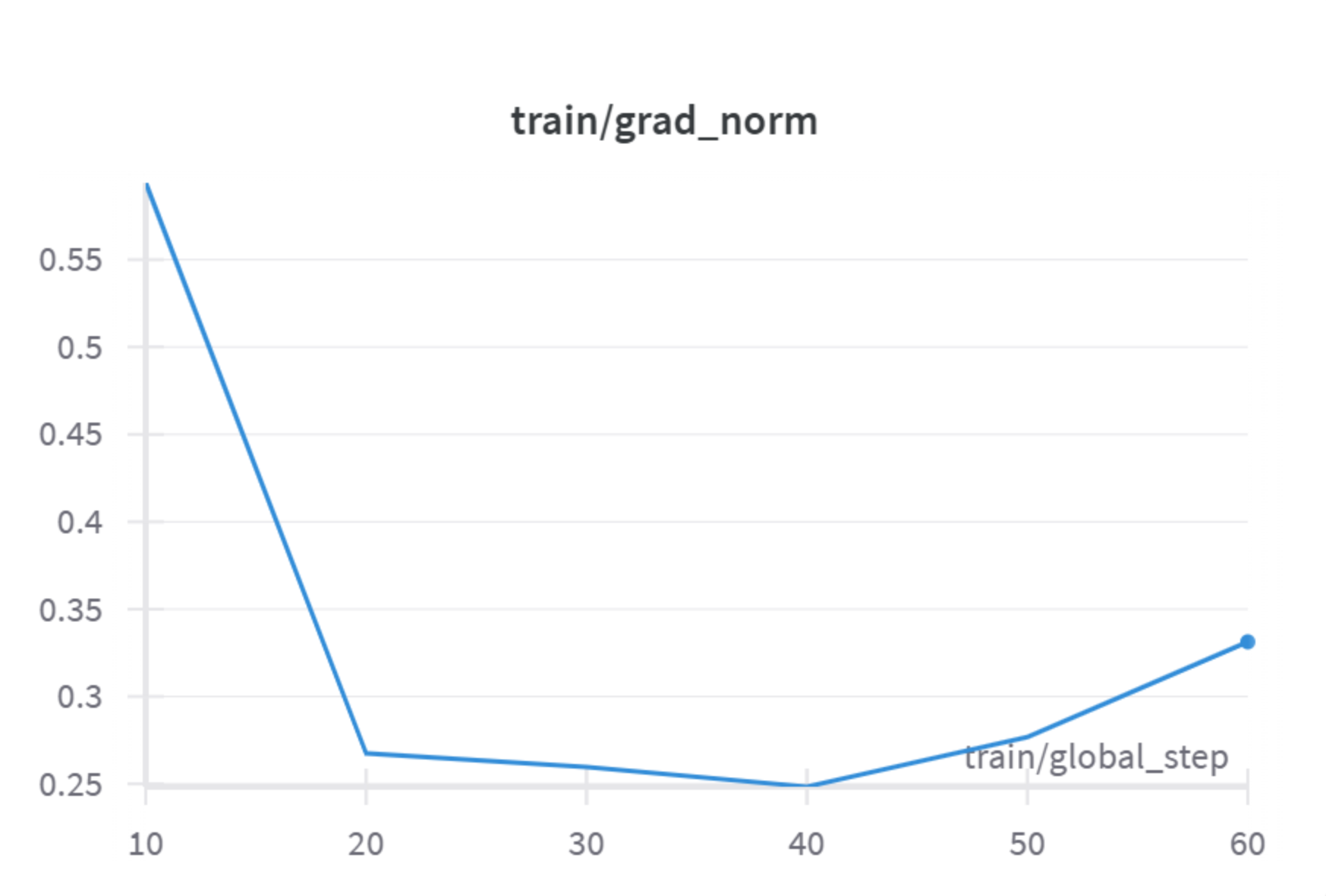
train/grad_norm(训练梯度范数)- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Grad Norm (梯度范数) - 模型所有参数梯度组成的向量的长度(范数)。它衡量了梯度的大小。
- 曲线解读: 梯度范数在训练早期(第 10 步)相对较高(约 0.58),然后迅速下降到 0.3 左右(第 20 步),之后趋于稳定,最后略有回升到 0.35 左右。
- 意义: 梯度范数可以帮助诊断训练稳定性。初始值较高表明模型离最优解较远,需要较大调整。迅速下降表明模型快速进入损失较低的区域。后续稳定或轻微波动是正常的。需要警惕的是梯度范数爆炸(变得非常大)或消失(变得非常接近 0),这两种情况都可能阻碍训练。你图中的值看起来在合理范围内。
- X 轴:
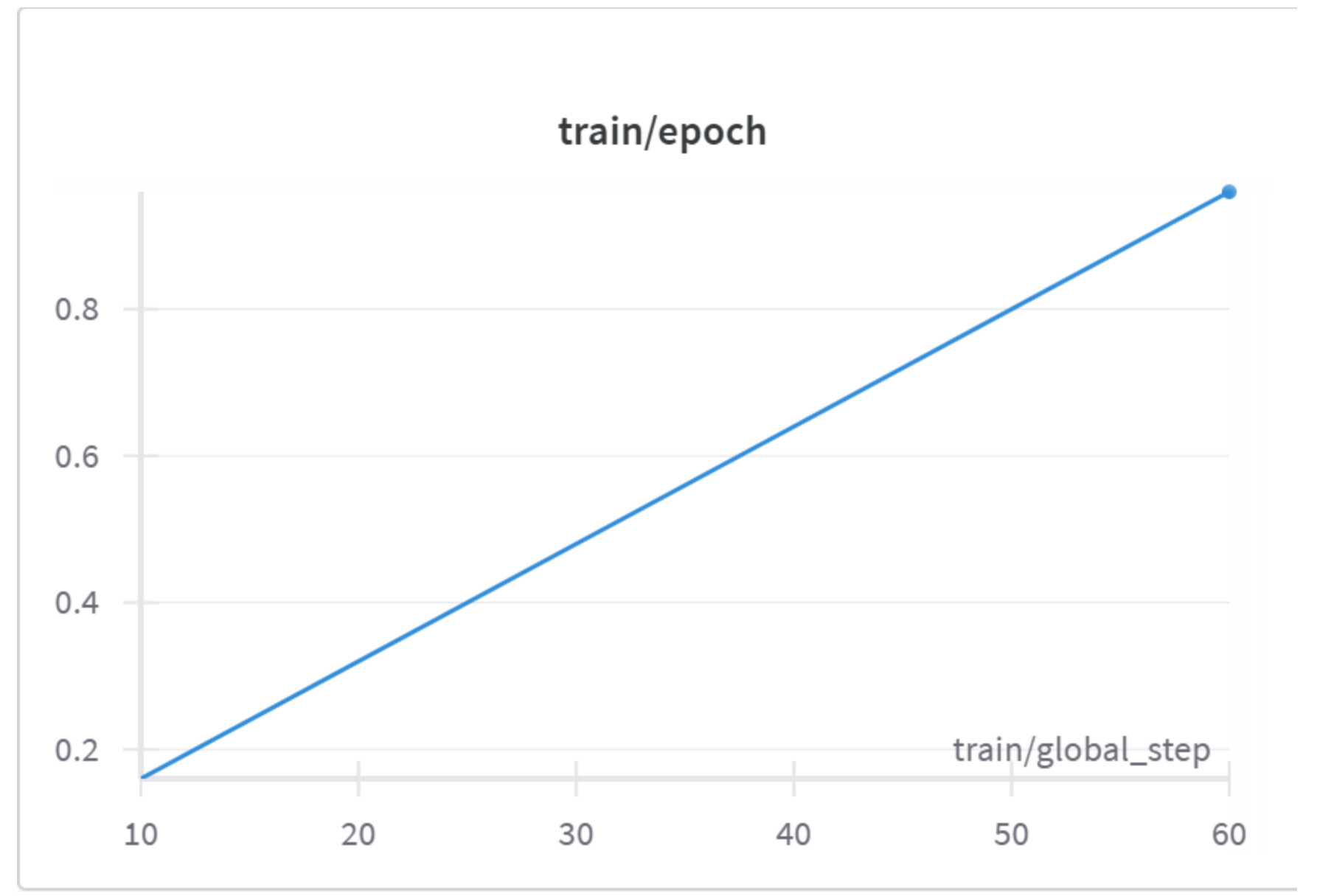
train/epoch(训练轮数)- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Epoch - 当前训练进度相当于遍历了整个训练数据集的多少比例。
- 曲线解读: Epoch 值随着全局步数的增加而线性增加,从第 10 步的约 0.15 增加到第 60 步的约 0.9。
- X 轴:
完整代码
pip install unsloth # 安装unsloth库
pip install bitsandbytes unsloth_zoo # 安装工具库import torch # 加载torch库
from unsloth import FastLanguageModel # ############## 加载模型和分词器#####################
# 超参数设置
max_seq_length = 2048 #模型的上下文长度,可以任意选择,内部提供了RoPE Scaling 技术支持
dtype = None # 通常设置为None,使用Tesla T4, V100等GPU时可用Float16,使用Ampere+时用Bfloat16
load_in_4bit = True # 以4位量化进行微调# 基于unsloth加载deepseek的蒸馏模型
model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,token = hf_token,
)# ################# 提示模板 #######################
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""# ##################### 微调前推理示例 #######################
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])# ###################### 更新提示模板 #######################
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""# ####################### 处理函数 #########################
EOS_TOKEN = tokenizer.eos_token # 末尾必须加上 EOS_TOKENdef formatting_prompts_func(examples):inputs = examples["Question"]cots = examples["Complex_CoT"]outputs = examples["Response"]texts = []for input, cot, output in zip(inputs, cots, outputs):text = train_prompt_style.format(input, cot, output) + EOS_TOKENtexts.append(text)return {"text": texts,}# ################### 加载数据集 ##########################
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train[0:500]", trust_remote_code=True)
print(dataset.column_names)dataset = dataset.map(formatting_prompts_func, batched = True)
print(dataset["text"][0])# ################## 微调参数设置 #####################
model = FastLanguageModel.get_peft_model(model,r=16, # 选择任何数字 > 0 !建议 8、16、32、64、128微调过程的等级。#数字越大,占用的内存越多,速度越慢,但可以提高更困难任务的准确性。太大也会过拟合target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",], # 选择所有模块进行微调lora_alpha=16, # 微调的缩放因子,建议将其等于等级 r,或将其加倍。lora_dropout=0, # 将其保留为 0 以加快训练速度!可以减少过度拟合,但不会那么多。bias="none", # 将其保留为 0 以加快训练速度并减少过度拟合!use_gradient_checkpointing="unsloth", # True or "unsloth" for very long contextrandom_state=3407, # 随机种子数use_rslora=False, # 支持等级稳定的 LoRA,高级功能可自动设置 lora_alpha = 16loftq_config=None, # 高级功能可将 LoRA 矩阵初始化为权重的前 r 个奇异向量。#可以在一定程度上提高准确性,但一开始会使内存使用量激增。
)# ################# 训练参数设置 #######################
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supportedtrainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=2,gradient_accumulation_steps=4,# Use num_train_epochs = 1, warmup_ratio for full training runs!warmup_steps=5,max_steps=60,learning_rate=2e-4,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),logging_steps=10,optim="adamw_8bit",weight_decay=0.01,lr_scheduler_type="linear",seed=3407,output_dir="outputs",),
)# ################### 模型训练 #################
trainer_stats = trainer.train()# ################### 模型保存 ##################
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local) # 本地模型保存
tokenizer.save_pretrained(new_model_local) # 分词器保存# 将模型和分词器以合并的方式保存到指定的本地目录
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",) # model.push_to_hub("your_name/lora_model", token = "...") # Online saving
# tokenizer.push_to_hub("your_name/lora_model", token = "...") # Online saving
相关文章:
 微调deepseek-8b模型参数详解以及全流程——训练篇)
(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇
本篇参考bilibili如何在本地微调DeepSeek-R1-8b模型_哔哩哔哩_bilibili 上篇:(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇 初始变量 max_seq_length 2048 dtype None load_in_4bit True单批次最大处理模型大小dy…...

基于 PyGetWindow 获取窗口信息和控制窗口
PyGetWindow 是基于Python的一款简单、跨平台的模块,用来获取窗口信息和控制窗口。可以实现的功能有: 获取当前系统中所有打开窗口的列表。 根据窗口标题、窗口句柄等属性获取特定的窗口对象。 激活、最小化、最大化和关闭窗口。 获取和设置窗口的位置、…...
)
解锁动态规划的奥秘:从零到精通的创新思维解析(8)
前言: 小编在前几日讲述了关于动态规划的习题,下面小编继续跟着上次的步伐,继续进入多状态dp问题的讲解(但是今天这个题目不需要多状态),今天由于小编的精力有限,所以我就仅仅先讲述一个题目&am…...

使用RUN pip install flask和RUN pip install -r requirements.txt
在编写dockerfile文件的时候,有时候会遇上使用RUN pip install -r requirements.txt的情况,而且requirements.txt文件里面就一个包名,例如flask,那么不禁要问为什么不直接写成RUN pip install flask呢?其实不是不行&am…...

512天,倔强生长:一位技术创作者的独白
亲爱的读者与同行者: 我是倔强的石头_,今天是我在CSDN成为创作者的第512天。当系统提示我写下这篇纪念日文章时,我恍惚间想起了2023年11月19日的那个夜晚——指尖敲下《开端——》的标题,忐忑又坚定地按下了“发布”键。那时的我…...

【Java SE】Collections类详解
参考笔记:java Collections类 详解-CSDN博客 目录 一、Collections类简介 二、Collection类常用方法 1. 排序 ① static void reverse(List list) ② static void shuffle(List list) ③ static void sort(List list) ④ static void sort(List list, Comparator …...
)
Android LiveData学习总结(源码级理解)
LiveData 工作原理 数据持有与观察者管理:LiveData 内部维护着一个数据对象和一个观察者列表。当调用 observe 方法注册观察者时,会将 LifecycleOwner 和 Observer 包装成 LifecycleBoundObserver 对象并添加到观察者列表中。生命周期感知:L…...

RabbitMQ 为什么引入 Exchange 的概念, 交换机有什么作用.
RabbitMQ 引入 Exchange 的概念是为了实现消息的灵活路由和解耦生产者与消费者,这是 AMQP(Advanced Message Queuing Protocol)协议的核心设计之一。以下是 Exchange 存在的主要原因: 1. 解耦生产者与队列 问题:如果生…...

rabbitmq引入C++详细步骤
1. 安装RabbitMQ服务器 在Windows上:先安装Erlang,再安装RabbitMQ服务器。安装完成后,可通过访问http://localhost:15672来检查RabbitMQ服务器是否正常运行,默认的用户名和密码是guest/guest。 在Linux上:可使用包管理…...

Android 9.0系统源码定制:实现开机启动特定App的全面指南
在Android 9.0系统中,若需要通过修改系统源码实现开机启动特定应用(如系统预装应用或第三方应用),通常涉及对系统框架层(Framework)的深度定制开发。以下是详细的实现步骤和关键代码位置整理: 1…...

如何在不同版本的 Elasticsearch 之间以及集群之间迁移数据
作者:来自 Elastic Kofi Bartlett 当你想要升级一个 Elasticsearch 集群时,有时候创建一个新的独立集群并将数据从旧集群迁移到新集群会更容易一些。这让用户能够在不冒任何停机或数据丢失风险的情况下,在新集群上使用所有应用程序测试其所有…...

MySQL数据库精研之旅第六期:玩转数据库约束
目录 一、数据库约束的概念 二、约束类型 三、NOT NULL 非空约束 四、DEFAULT 默认值约束 五、UNIQUE 唯一约束 六、PRIMARY KEY 主键约束 七、FOREIGN KEY 外键约束 八、Check 约束 一、数据库约束的概念 数据库约束是指对数据库表中的数据所施加的规则或条件…...

【Java】面向对象程序三板斧——如何优雅设计包、封装数据与优化代码块?
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:【Java】内容概括 【前言】 在Java编程中,类和对象是面向对象编程的核心概念。而包(Package&am…...

MCP、RAG与Agent:下一代智能系统的协同架构设计
一、智能系统架构的范式转移 1.1 传统架构的局限性 架构类型典型问题新架构需求单体架构扩展性差,维护成本高模块化解耦简单微服务缺乏智能决策能力认知能力嵌入纯LLM系统事实性错误,知识固化动态知识增强 1.2 三大核心组件的定位 #mermaid-svg-6tGuE…...
)
软件设计师2009-2022历年真题与答案解析(附pdf下载)
软考在即,现在给大家分享一下软件设计师2009-2022真题与答案解析 pdf全套,文末提供大家免费下载,大家都知道在软考备考过程中,拥有一套全面且实用的考试资料对于考生来说至关重要。目录如下: 历年真题及详解2004-2019 …...

前端 React 弹窗式 滑动验证码实现
目录 一、安装依赖 1、rc-slider-captcha 2、create-puzzle 二、个人封装好的组件拿去用 三、效果展示 一、安装依赖 这里需要引入两个依赖,若有后端图片接入,可以不引入第二个依赖 1、rc-slider-captcha 滑动验证码生成的库 国内网:…...

【触想智能】工业触摸一体机在金融智能设备领域上应用的优势
工业触摸一体机在金融智能设备领域上具有许多独特的优势。这些设备结合了工业级的强度和耐用性,以及先进的触控技术和高性能处理能力,为金融机构提供全面可靠的解决方案。下面将介绍工业触摸一体机在金融智能设备领域上的应用优势。 触想嵌入式工业触摸一…...

本地实现Rtsp视频流推送
简言:使用ffmpeg实现本地视频流推送 srs存储(延时推送) 准备工作 安装包: ffmpeg:http://ffmpeg.org/download.html EasyDarwin:EasyDarwin流媒体音视频资源汇总 srs安装教程地址:http://…...
综述)
人工智能中的卷积神经网络(CNN)综述
文章目录 前言 1. CNN的基本原理 1.1 卷积层 1.2 池化层 1.3 全连接层 2. CNN的发展历程 2.1 LeNet-5 2.2 AlexNet 2.3 VGGNet 2.4 ResNet 3. CNN的主要应用 3.1 图像分类 3.2 目标检测 3.3 语义分割 3.4 自然语言处理 4. 未来研究方向 4.1 模型压缩与加速 4.2 自监督学习 4.3 …...

Mac电脑交叉编译iphone设备可以运行的redsocks, openssl, libsevent
准备:intel x86_64芯片的mac电脑,系统为mac os15.3.1,iphone为6s的ios14.4(rootful越狱) 第一步:准备工具链(推荐使用 theos clang) 如果你已经安装过 Theos(或 NewTheos)&#x…...
-----点灯大师梦开始的地方)
入门51单片机(1)-----点灯大师梦开始的地方
前言 这一次的博客主要是要记录一下学习的记录的,方便以后去复习一下的,当然这篇博客还是针于零基础的伙伴萌,看完这篇博客,大家就可以学会点灯了。 安装软件 方法一下一下来教!!萌新宝贝萌可以学会的!帮…...

[1-01-09].第08节:基础语法 - 数组常见算法 + Arrays工具类 + 数组中常见异常
一、 数组的常见算法 1.1 数值型数组特征值统计 这里的特征值涉及到:平均值、最大值、最小值、总和等 **举例1:**数组统计:求总和、均值 public class TestArrayElementSum {public static void main(String[] args) {int[] arr {4,5,6,…...

dnf install openssl失败的原因和解决办法
网上有很多编译OpenSSL源码(3.x版本)为RPM包的文章,这些文章在安装RPM包时都是执行rpm -ivh openssl-xxx.rpm --nodeps --force 这个命令能在缺少依赖包的情况下能强行执行安装 其实根据Centos的文档,安装RPM包一般是执行yum install或dnf install。后者…...
 和模拟网格体 是如何关联的?为什么模拟网格体 可以驱动渲染网格体?)
UE5 Chaos :官方文献总结 + 渲染网格体 (Render Mesh) 和模拟网格体 是如何关联的?为什么模拟网格体 可以驱动渲染网格体?
官方文献:https://dev.epicgames.com/community/learning/tutorials/pv7x/unreal-engine-panel-cloth-editor 1. 流程概述 本文档介绍了如何通过面板编辑器(Panel Editor)在Unreal Engine中生成基于面板的布料资源。流程主要包含从Marvelou…...

Swift观察机制新突破:如何用AsyncSequence实现原子化数据监听?
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

Lombok库
文章目录 Lombok1.介绍2.主要注解2.1如何使用 Lombok2.1.1添加依赖2.1.2 使用Lombok注解2.1.3Lombok的其他常用注解ValueBuilderGoF23种设计模式之一:建造模式使用Builder注解自动生成建造模式的代码 SingularSlf4j使用选择合适的注解 Lombok 1.介绍 Lombok 是一个…...

算法思想之模拟
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之模拟 发布时间:2025.4.14 隶属专栏:算法 目录 滑动窗口算法介绍核心特点常见问题优化方向 例题替换所有的问号题目链接题目描述算法思路代码实现 提莫攻击题目链接题目描述算法思路…...

Windows 系统如何使用Redis 服务
前言 在学习过程中,我们长期接触到的是Mysql 关系型数据库,也是够我们平时练习项目用的,但是后面肯定会有大型数据的访问就要借助新的新的工具。 一、什么是Redis Redis(Remote Dictionary Server)是一个基于内存的 键…...
)
2025年常见渗透测试面试题-红队面试宝典上(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 一、如何判断是否是域环境? 二、定位域控的 IP 三、定位域管所在机器 四、Kerberos 核心…...

Base64在线编码解码 - 加菲工具
Base64在线编码解码 - 加菲工具 打开网站 加菲工具 选择“Base64 在线编码解码” 或者直接打开https://www.orcc.top/tools/base64 输入需要编码/解码的内容,点击“编码”/“解码”按钮 编码: 解码: 复制已经编码/解码后的内容。...

前端面试宝典---闭包
闭包介绍 使用闭包: 在函数内声明一个变量,避免外部访问在该函数内再声明一个函数访问上述变量(闭包)返回函数内部的函数使用完毕建议闭包函数null;译放内存 function createCounter() {let count 0;return function () {coun…...

算法:有一个整数数组,长度为n。她希望通过一系列操作将数组变成一个回文数组。
小红有一个整数数组,长度为n。她希望通过一系列操作将数组变成一个回文数组。每次操作可以选择数组中任意两个相邻的元素 ai和 ai1,将它们的值同时加一。请你计算至少需要多少次操作使得数组变成一个回文数组。如果不可能,则输出-1。否则输出…...
)
数字人:开启医疗领域的智慧变革新时代(5/10)
摘要:数字人技术作为医疗变革的基石,通过多学科融合实现虚拟医生、手术模拟、医学教育等多元应用,贯穿诊前、术中、术后全流程,显著提升医疗效率、优化资源分配、推动个性化服务。尽管面临技术、伦理、数据安全等挑战,…...
 - 加菲工具)
正则表达式在线校验(RegExp) - 加菲工具
正则表达式在线校验 - 加菲工具 打开网站 加菲工具 选择“正则表达式在线校验” 或者直接打开https://www.orcc.top/tools/regexp 输入待校验的源文本与正则表达式,点击“校验”按钮 需要注意检验后的内容可能存在多空格,可以拉下去看看~...

某车企面试备忘
记录两个关于Binder的问题,我感觉面试官提的非常好,作一下备忘。 1.通过Binder进行的IPC(进程间通信)是线程阻塞的吗? 参考答案: Binder是Android平台的一种跨进程通信(IPC)机制&…...

从Ampere到Hopper:GPU架构演进对AI模型训练的颠覆性影响
一、GPU架构演进的底层逻辑 AI大模型训练效率的提升始终与GPU架构的迭代深度绑定。从Ampere到Hopper的演进路径中,英伟达通过张量核心升级、显存架构优化、计算范式革新三大技术路线,将LLM(大语言模型)训练效率提升至…...

【JavaEE】SpringBoot 统一功能处理
目录 一、拦截器1.1 使用1.1 定义拦截器1.2 注册配置拦截器 1.2 拦截器详解1.2.1 拦截路径1.2.2 拦截器执⾏流程 1.3 适配器模式 二、统一数据返回格式2.1 简单用法2.2 问题及解决 三、统一异常处理 一、拦截器 拦截器:拦截器是Spring框架提供的核⼼功能之⼀&#…...
)
杨辉三角(力扣 118)
118. 杨辉三角 - 力扣(LeetCode) 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2: 输入: numRows 1 输出: [[1]] vector<vector<int>> generate(int numRows) { //生成有numRows个元素(vector<in…...

三周年创作纪念日
文章目录 回顾与收获三年收获的五个维度未来的展望致谢与呼唤 亲爱的社区朋友们,大家好! 今天是 2025 年 4 月 14 日,距离我在 2022 年 4 月 14 日发布第一篇技术博客《SonarQube 部署》整整 1,095 天。在这条创作之路上,我既感慨…...
)
[c语言日记]轮转数组算法(力扣189)
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...

【Unity笔记】Unity超时检测器开发:支持自定义重试次数与事件触发
在Unity游戏或应用开发中,我们经常会遇到需要检测超时的场景,比如: 等待用户在限定时间内完成某个交互;等待网络请求或资源加载是否在规定时间内返回;控制AI角色等待某个事件发生,超时后执行备选逻辑。 在…...

【微服务管理】注册中心:分布式系统的基石
在分布式系统日益普及的当下,如何高效地管理众多服务实例成为关键问题。注册中心应运而生,它犹如分布式系统的 “指挥中枢”,承担着服务注册、发现等核心任务,为整个系统的稳定运行和高效协作提供坚实保障。本文将深入探讨注册中心…...

P10413 [蓝桥杯 2023 国 A] 圆上的连线
题意: 给定一个圆,圆上有 n2023 个点从 1 到 n 依次编号。 问有多少种不同的连线方式,使得完全没有连线相交。当两个方案连线的数量不同或任何一个点连接的点在另一个方案中编号不同时,两个方案视为不同。 答案可能很大&#x…...

计算机操作系统——存储器管理
系列文章目录 1.存储器的层次结构 2.程序的装入和链接 3.连续分配存储管理方式(内存够用) 4.对换(Swapping)(内存不够用) 5.分页存储管理方式 6.分段存储管理方式 文章目录 系列文章目录前言一、存储器的存储结构寄存器&…...

TCPIP详解 卷1协议 四 地址解析协议
4.1——地址解析协议(ARP) 对于TCP/IP网络,地址解析协议(ARP)[RFC0826]提供了一种在IPv4地址和各种网络技术使用的硬件地址之间的映射。ARP仅用于IPv4。IPv6使用邻居发现协议,它被合并入ICMPv6。当两个局域网的主机之间传输的以太…...
)
履带小车+六轴机械臂(2)
本次介绍原理图部分 开发板部分,电源供电部分,六路舵机,PS2手柄接收器,HC-05蓝牙模块,蜂鸣器,串口,TB6612电机驱动模块,LDO线性稳压电路,按键部分 1、开发板部分 需要注…...

耘想WinNAS:以聊天交互重构NAS生态,开启AI时代的存储革命
一、传统NAS的交互困境与范式瓶颈 在传统NAS(网络附加存储)领域,用户需通过复杂的图形界面或命令行工具完成文件管理、权限配置、数据检索等操作,学习成本高且效率低下。例如,用户若需搜索特定文件,需手动…...

如何通过自动化解决方案提升企业运营效率?
引言 在现代企业中,运营效率直接影响着企业的成本、速度与竞争力。尤其是随着科技的不断发展,传统手工操作和低效的流程逐渐无法满足企业的需求。自动化解决方案正成为企业提升运营效率、降低成本和提高生产力的关键。无论是大型跨国公司,还…...

【笔记ing】AI大模型-03深度学习基础理论
神经网络:A neural network is a network or circuit of neurons,or in a modern sense,an artificial neural network,composed of artificial neurons or nodes.神经网络是神经元的网络或回路,或者在现在意义上来说,是一个由人工神经元或节…...

Spring-注解编程
注解基础概念 1.什么是注解编程 指的是在类或者方法上加入特定的注解(XXX) 完成特定功能的开发 Component public classXXX{} 2.为什么要讲注解编程 1.注解开发方便 代码简洁 开发速度大大提高 2.Spring开发潮流 Spring2.x引入注解 Spring3.x完善注解 Springboot普及 推广注解…...