打造AI应用基础设施:Milvus向量数据库部署与运维
目录
- 打造AI应用基础设施:Milvus向量数据库部署与运维
- 1. Milvus介绍
- 1.1 什么是向量数据库?
- 1.2 Milvus主要特点
- 2. Milvus部署方案对比
- 2.1 Milvus Lite
- 2.2 Milvus Standalone
- 2.3 Milvus Distributed
- 2.4 部署方案对比表
- 3. Milvus部署操作命令实战
- 3.1 Milvus Lite部署
- 3.2 Milvus Standalone Docker部署
- 3.3 Milvus Distributed Kubernetes部署
- 3.3.1 使用Helm安装Milvus Operator
- 3.3.2 使用kubectl安装Milvus Operator
- 3.3.3 部署Milvus集群
- 3.3.4 检查Milvus集群状态
- 3.3.5 端口转发以便本地访问
- 3.3.6 卸载Milvus集群
- 4. Milvus部署后的使用
- 4.1 基本概念
- 4.1.1 集合(Collection)
- 4.1.2 模式(Schema)和字段(Fields)
- 4.1.3 主键(Primary Key)和自动ID(AutoId)
- 4.2 Python代码示例
- 4.3 基本操作流程
- 4.4 高级功能
- 5. Milvus运维方案
- 5.1 Prometheus监控
- 5.1.1 部署Prometheus监控服务
- 5.1.2 为Milvus启用ServiceMonitor
- 5.2 可视化和管理工具
- 5.3 备份和恢复
- 5.4 集群扩容
- 5.5 升级Milvus版本
- 6. 总结
- 参考资料
打造AI应用基础设施:Milvus向量数据库部署与运维
1. Milvus介绍
Milvus是一款高性能、可扩展的开源向量数据库,专为管理和检索向量数据而设计。它支持从Jupyter Notebook本地演示到处理数十亿向量的大规模Kubernetes集群的各种规模用例。
1.1 什么是向量数据库?
向量数据库是专门设计用于存储、管理和检索向量嵌入(embeddings)的数据库系统。在AI和机器学习领域,向量嵌入是将文本、图像、音频等转换为数值向量的过程,这些向量可以用于相似性搜索。Milvus可以高效地执行相似性搜索操作,是AI应用(如语义搜索、推荐系统、图像识别等)的理想选择。
1.2 Milvus主要特点
- 高性能:支持数十亿规模的向量管理和高效的相似性搜索
- 可扩展:提供从轻量级到分布式集群的多种部署方案
- 多模态支持:支持多种数据类型,包括稠密向量、稀疏向量、二进制向量等
- 高级搜索能力:支持ANN搜索、元数据过滤、范围搜索、混合搜索等
- 灵活部署:提供多种部署模式,适应不同规模和场景的需求
- 开源生态:拥有丰富的工具和集成选项,如WebUI、备份工具等
2. Milvus部署方案对比
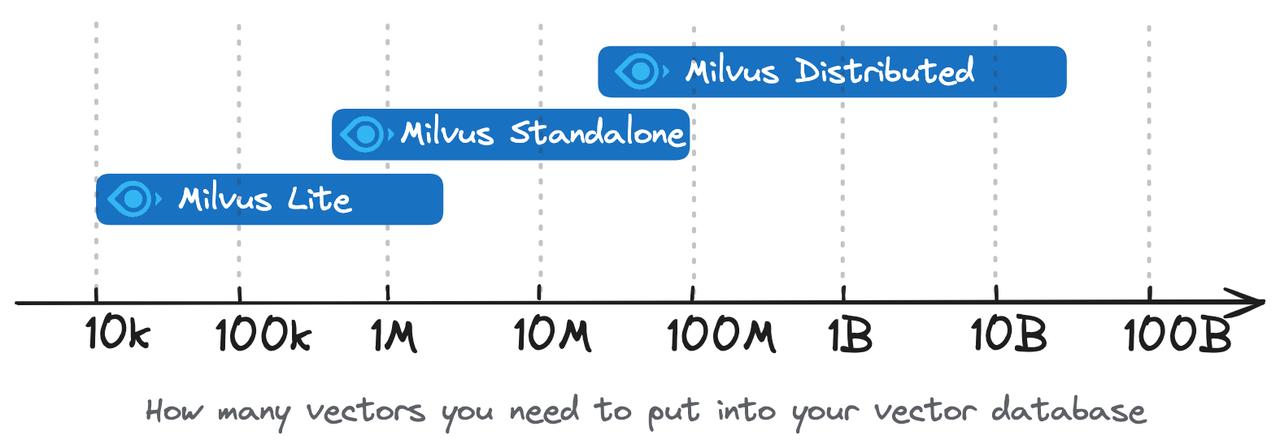
目前,Milvus提供了三种主要的部署选项:Milvus Lite、Milvus Standalone和Milvus Distributed。
2.1 Milvus Lite
Milvus Lite是一个Python库,可以直接导入到应用程序中。作为Milvus的轻量级版本,它非常适合在Jupyter Notebook中快速原型设计或在资源有限的智能设备上运行。
特点:
- 轻量级,仅需通过pip安装
- 适用于小型数据集(建议不超过几百万向量)
- 简单易用,适合快速原型设计和学习
- 与其他Milvus部署模式共享相同的API
适用场景:
- 快速原型开发(RAG演示、AI聊天机器人、多模态搜索等)
- Jupyter Notebook或Google Colab环境
- 边缘设备上的本地搜索
- 处理私密或敏感数据
2.2 Milvus Standalone
Milvus Standalone是单机服务器部署。所有组件都打包到一个Docker镜像中,便于部署。
特点:
- 单一Docker镜像,部署简便
- 适合中等规模数据集(可扩展至1亿向量)
- 通过主从复制支持高可用性
- 比集群部署需要更少的DevOps工作
适用场景:
- 早期生产环境
- 产品市场适应性测试阶段
- 灵活性比可扩展性更重要的场景
- 中等规模的生产部署
2.3 Milvus Distributed
Milvus Distributed可以部署在Kubernetes集群上,具有云原生架构,摄取负载和搜索查询由独立节点单独处理,允许关键组件冗余。
特点:
- 高可扩展性和高可用性
- 灵活定制每个组件的资源分配
- 适合大规模数据集(从1亿到数百亿向量)
- 企业级生产环境的首选
适用场景:
- 大规模生产部署
- 数据规模超出单台服务器容量的业务
- 需要定制化负载处理的环境(如高读取、低写入或高写入、低读取)
2.4 部署方案对比表
| 特性 | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| 部署方式 | Python库 | Docker容器 | Kubernetes集群 |
| 适用数据规模 | 数百万向量 | 高达1亿向量 | 1亿至数百亿向量 |
| SDK支持 | Python、gRPC | Python、Go、Java、Node.js、C#、RESTful | Python、Java、Go、Node.js、C#、RESTful |
| 资源要求 | 最低 | 中等 | 高 |
| 运维复杂度 | 简单 | 中等 | 复杂 |
| 一致性级别 | 强一致性 | 强一致性、有界陈旧、会话一致性、最终一致性 | 强一致性、有界陈旧、会话一致性、最终一致性 |
| 高级数据管理 | 不支持 | 访问控制、分区、分区键 | 访问控制、分区、分区键、物理资源分组 |
3. Milvus部署操作命令实战
3.1 Milvus Lite部署
Milvus Lite作为Python库,部署非常简单:
# 安装pymilvus(包含Milvus Lite)
pip install -U pymilvus# 在Python代码中使用
from pymilvus import MilvusClient# 使用本地文件初始化Milvus Lite实例
client = MilvusClient("./milvus_demo.db")
3.2 Milvus Standalone Docker部署
Milvus提供了一个安装脚本,可以轻松地将其作为Docker容器安装:
# 下载安装脚本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh# 启动Docker容器
bash standalone_embed.sh start
安装后:
- Milvus容器在端口19530上启动
- 一个嵌入式etcd与Milvus一起安装在同一容器中,端口为2379
- 可通过修改当前文件夹中的user.yaml文件来更改默认Milvus配置
- Milvus数据卷映射到当前文件夹中的volumes/milvus目录
停止和删除Milvus:
# 停止Milvus
bash standalone_embed.sh stop# 删除Milvus数据
bash standalone_embed.sh delete
升级Milvus版本:
# 升级Milvus
bash standalone_embed.sh upgrade
3.3 Milvus Distributed Kubernetes部署
使用Milvus Operator在Kubernetes上部署Milvus集群:
3.3.1 使用Helm安装Milvus Operator
helm install milvus-operator \-n milvus-operator --create-namespace \--wait --wait-for-jobs \https://github.com/zilliztech/milvus-operator/releases/download/v1.2.0/milvus-operator-1.2.0.tgz
3.3.2 使用kubectl安装Milvus Operator
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/deploy/manifests/deployment.yaml
3.3.3 部署Milvus集群
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/config/samples/milvus_cluster_default.yaml
3.3.4 检查Milvus集群状态
kubectl get milvus my-release -o yaml
3.3.5 端口转发以便本地访问
# 转发Milvus服务端口
kubectl port-forward service/my-release-milvus 27017:19530# 转发WebUI端口
kubectl port-forward service/my-release-milvus 27018:9091
3.3.6 卸载Milvus集群
kubectl delete milvus my-release
4. Milvus部署后的使用
4.1 基本概念
4.1.1 集合(Collection)
集合是Milvus中的基本数据组织单位,类似于关系数据库中的表。集合是具有固定列和可变行的二维表。每列代表一个字段,每行代表一个实体。
4.1.2 模式(Schema)和字段(Fields)
模式定义了集合中字段的属性(如数据类型、向量维度等)。每个字段都有各种约束属性,如数据类型和向量字段的维度。
4.1.3 主键(Primary Key)和自动ID(AutoId)
主键字段用于区分实体,每个值在全局范围内是唯一的。主键字段只接受整数或字符串。如果启用了AutoId,Milvus将在数据插入时自动生成这些值。
4.2 Python代码示例
以下是使用Milvus进行文本搜索的简单演示:
from pymilvus import MilvusClient
import numpy as np# 连接到Milvus
client = MilvusClient("./milvus_demo.db") # Milvus Lite本地文件
# 或者连接到Milvus服务器
# client = MilvusClient(uri="http://localhost:19530", token="username:password")# 创建集合
client.create_collection(collection_name="demo_collection",dimension=384 # 本例中向量维度为384
)# 示例文本
docs = ["Artificial intelligence was founded as an academic discipline in 1956.","Alan Turing was the first person to conduct substantial research in AI.","Born in Maida Vale, London, Turing was raised in southern England.",
]# 生成示例向量(实际应用中应使用真实的嵌入模型)
vectors = [[ np.random.uniform(-1, 1) for _ in range(384) ] for _ in range(len(docs)) ]
data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ]# 插入数据
res = client.insert(collection_name="demo_collection",data=data
)# 执行带过滤条件的搜索
res = client.search(collection_name="demo_collection",data=[vectors[0]],filter="subject == 'history'",limit=2,output_fields=["text", "subject"],
)
print(res)# 查询匹配过滤表达式的所有实体
res = client.query(collection_name="demo_collection",filter="subject == 'history'",output_fields=["text", "subject"],
)
print(res)# 删除数据
res = client.delete(collection_name="demo_collection",filter="subject == 'history'",
)
print(res)
4.3 基本操作流程
- 创建集合:定义向量和标量字段的集合模式
- 插入数据:将向量和元数据插入集合
- 创建索引:为向量字段创建索引以加速搜索
- 加载集合:将集合加载到内存中以准备搜索
- 执行搜索/查询:执行相似度搜索或基于标量条件的查询
- 释放集合:不使用时释放内存资源
4.4 高级功能
- 分区(Partition):集合的子集,共享相同的字段集,每个分区包含实体的子集
- 分片(Shard):集合的水平切片,每个分片对应一个数据输入通道
- 别名(Alias):为集合创建别名,便于管理
- 一致性级别:定义跨数据节点和副本的数据一致性级别
5. Milvus运维方案
5.1 Prometheus监控
Milvus支持使用Prometheus进行监控,提供了各组件的指标,可通过http://<component-host>:9091/metrics端点导出。
5.1.1 部署Prometheus监控服务
使用kube-prometheus部署监控服务:
# 克隆kube-prometheus仓库
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus# 创建监控栈
kubectl apply --server-side -f manifests/setup
kubectl wait \--for condition=Established \--all CustomResourceDefinition \--namespace=monitoring
kubectl apply -f manifests/# 修补prometheus-k8s clusterrole以获取Milvus指标
kubectl patch clusterrole prometheus-k8s --type=json -p='[{"op": "add", "path": "/rules/-", "value": {"apiGroups": [""], "resources": ["pods", "services", "endpoints"], "verbs": ["get", "watch", "list"]}}]'# 端口转发Prometheus和Grafana服务
kubectl --namespace monitoring --address 0.0.0.0 port-forward svc/prometheus-k8s 9090
kubectl --namespace monitoring --address 0.0.0.0 port-forward svc/grafana 3000
5.1.2 为Milvus启用ServiceMonitor
通过Helm参数启用ServiceMonitor:
helm upgrade my-release milvus/milvus --set metrics.serviceMonitor.enabled=true --reuse-values
检查ServiceMonitor资源:
kubectl get servicemonitor
5.2 可视化和管理工具
Milvus提供了多种工具来帮助可视化和管理:
-
Milvus WebUI:通过浏览器访问的内置GUI工具,提供系统可观察性和简单的界面。可通过
http://127.0.0.1:9091/webui/访问。 -
Milvus Backup:开源工具,用于Milvus数据备份。
-
Birdwatcher:开源工具,用于调试Milvus和动态配置更新。
-
Attu:开源GUI工具,用于直观的Milvus管理。
5.3 备份和恢复
Milvus Lite提供了命令行工具,可以将数据导出到JSON文件中:
# 安装带bulk_writer的pymilvus
pip install -U "pymilvus[bulk_writer]"# 导出数据
milvus-lite dump -d ./milvus_demo.db -c demo_collection -p ./data_dir
使用导出的文件,可以通过以下方式上传数据:
- 通过数据导入功能上传到Zilliz Cloud
- 通过批量插入功能上传到Milvus服务器
5.4 集群扩容
对于Milvus Distributed,可以通过修改Kubernetes配置来扩展集群:
- 调整资源请求和限制
- 增加副本数量
- 添加更多节点到Kubernetes集群
5.5 升级Milvus版本
- Milvus Standalone:使用
bash standalone_embed.sh upgrade命令 - Milvus Distributed:使用Helm或Milvus Operator进行升级
6. 总结
Milvus是一款功能强大的向量数据库,提供了从轻量级到分布式集群的多种部署选项,适应不同规模和场景的需求。通过本博客,我们介绍了Milvus的基本概念、部署方案对比、部署操作实战、使用方法和运维方案。
无论您是在进行快速原型设计、构建小型生产应用还是需要大规模向量搜索系统,Milvus都能提供灵活而强大的解决方案。根据您的项目阶段和规模选择合适的Milvus部署模式,可以获得最佳的性能和资源利用效率。
参考资料
- Milvus官方文档
- Milvus安装概述
- Milvus Lite文档
- Milvus集合管理
- Milvus监控指南
相关文章:

打造AI应用基础设施:Milvus向量数据库部署与运维
目录 打造AI应用基础设施:Milvus向量数据库部署与运维1. Milvus介绍1.1 什么是向量数据库?1.2 Milvus主要特点 2. Milvus部署方案对比2.1 Milvus Lite2.2 Milvus Standalone2.3 Milvus Distributed2.4 部署方案对比表 3. Milvus部署操作命令实战3.1 Milv…...

使用WindSurf生成贪吃蛇小游戏:从零开始的开发之旅
在当今数字化时代,编程已经成为一项必备技能,而创建游戏无疑是学习编程过程中最具趣味性的项目之一。今天,我将向大家介绍如何使用WindSurf这款强大的代码生成工具来快速生成一个经典的贪吃蛇小游戏。从下载软件到运行游戏,我们将…...

论文学习:《EVlncRNA-net:一种双通道深度学习方法,用于对实验验证的lncRNA进行准确预测》
原文标题:EVlncRNA-net: A dual-channel deep learning approach for accurate prediction of experimentally validated lncRNAs 原文链接:https://www.sciencedirect.com/science/article/pii/S0141813025020896 长链非编码RNA( long non-coding RNAs&…...

LLM Post-Training
1. LLM的后训练分类 Fine-tuning Reinforcement Learning Test-time Scaling 方法 优点 缺点 Fine-tuning 任务适应性:能够针对特定任务或领域进行优化,提升模型在该任务上的性能。 数据驱动优化:利用标注数据直接调整模型参数&#x…...

【LLM】解锁Agent协作:深入了解谷歌 A2A 协议与 Python 实现
人工智能(AI)智能体正迅速成为企业提高生产力、自动化工作流程和增强运营能力的关键工具。从处理日常重复性任务到协助复杂的决策,智能体的潜力巨大。然而,当这些智能体来自不同的供应商、使用不同的框架或被限制在孤立的数据系统…...

FileWriter 详细解析与记忆方法
FileWriter 详细解析与记忆方法 一、FileWriter 核心概念 FileWriter 是 Java 中用于向文件写入字符数据的类,继承自 OutputStreamWriter,属于字符流体系。 1. 核心特点 特性说明继承关系Writer → OutputStreamWriter → FileWriter数据单位字符&am…...
)
Java笔记5——面向对象(下)
目录 一、抽象类和接口 1-1、抽象类(包含抽象方法的类) 1-2、接口 编辑编辑 二、多态 编辑 1. 自动类型转换(向上转型) 示例: 注意: 2. 强制类型转换(向下转型) 示…...

c++------模板进阶
目录 一、模板 1.1 非类型模板参数 二、模板的特化 2.1 概念 2.2 函数模板特化 2.3 类模板特化 全特化 偏特化 (1)部分特化 (2)参数更进一步的限制 三、模板分离编译 3.1 什么是分离编译 3.2 模板的分离编译 3.3 解决…...

《轨道力学讲义》——第四讲:轨道计算与预测
第四讲:轨道计算与预测 引言 在轨道力学的研究中,轨道计算与预测是将理论付诸实践的关键环节。当我们掌握了轨道运动的基本规律和数学描述后,下一步便是要能够准确地计算航天器在任意时刻的位置和速度,并对其未来的运动轨迹进行…...

鸿蒙开发-页面跳转
1.路由使用 //1.引入路由 import router from ohos.router//2.使用跳转router.pushUrl({url: "pages/Show"})2.页面跳转 import { router } from kit.ArkUI;Entry Component struct LoginPage {State message: string 登陆页;build() {Row() {Column() {Text(this…...

数据大屏只能撑撑场面?
很多人对数据大屏的看法就是“没有用”、“花架子”,实际上,它的作用绝不止于此。 业财猫全新升级的经营驾舱模块,以精准的行业洞察与场景化设计,重新定义了这一工具的价值。 作为专为财税代账行业打造的一站式运营管理平台&…...

第十九讲 | XGBoost 与集成学习:精准高效的地学建模新范式
🟨 一、为什么要学习集成学习? 集成学习(Ensemble Learning) 是一种将多个弱学习器(如决策树)组合成一个强学习器的策略。它在地理学、生态学、遥感分类等领域表现尤为突出。 📌 应用优势&#…...

大数据面试问答-批处理性能优化
1. 数据存储角度 1.1 存储优化 列式存储格式:使用Parquet/ORC代替CSV/JSON,减少I/O并提升压缩率。 df.write.parquet("hdfs://path/output.parquet")列式存储减少I/O的核心机制: 列裁剪(Column Pruning) …...

关于 软件开发模型 的分类、核心特点及详细对比分析,涵盖传统模型、迭代模型、敏捷模型等主流类型
以下是关于 软件开发模型 的分类、核心特点及详细对比分析,涵盖传统模型、迭代模型、敏捷模型等主流类型: 一、软件开发模型分类及核心特点 1. 瀑布模型(Waterfall Model) 核心特点: 线性阶段划分:需求分…...

【STL】set
在 C C C S T L STL STL 标准库中, s e t set set 是一个关联式容器,表示一个集合,用于存储唯一元素的容器。 s e t set set 中的元素会自动按照一定的顺序排序(默认情况下是升序)。这意味着在 s e t set set 中不能…...

信奥还能考吗?未来三年科技特长生政策变化
近年来,科技特长生已成为名校录取的“黄金敲门砖”。 从CSP-J/S到NOI,编程竞赛成绩直接关联升学优势。 未来三年,政策将如何调整?家长该如何提前布局? 一、科技特长生政策趋势:2025-2027关键变化 1. 竞…...

几何建模基础-拓扑命名实现及优化
1.背景介绍 1.1 什么是拓扑? 拓扑是研究几何图形或空间在连续改变形状后还能保持不变的一些性质的一个学科。它只考虑物体间的位置关系而不考虑它们的形状和大小。 Body对象的拓扑可以理解为面(Face)与边(Edge)、边…...

浙江大学DeepSeek系列专题线上公开课第二季第五期即将上线!deepseek音乐创作最强玩法来了!
浙江大学DeepSeek系列专题线上公开课第二季第5期即将在今晚进行直播! 其中,今晚8点10分左右,浙大AI大佬张克俊教授将带来硬核的deepseek公开课讲座。 讲座 主题: 人工智能与音乐创作 主讲人: 张克俊 教授 人工智能作…...

electron-builder参数详解
electron-builder 是一个用于打包和构建 Electron 应用的工具,支持 macOS、Windows 和 Linux 平台,并提供了丰富的参数配置选项。 1、安装: npm install electron-builder --save-dev2、参数详解 命令: electron-builder build…...

PVE+CEPH+HA部署搭建测试
一、基本概念介绍 Proxmox VE Proxmox Virtual Environment (Proxmox VE) 是一款开源的虚拟化管理平台,基于 Debian Linux 开发,支持虚拟机和容器的混合部署。它提供基于 Web 的集中管理界面,简化了计算、存储和网络资源的配置与监控。P…...

Android Studio 日志系统详解
文章目录 一、Android 日志系统基础1. Log 类2. 日志级别 二、Android Studio 中的 Logcat1. 打开 Logcat2. Logcat 界面组成3. 常用 Logcat 命令 三、高级日志技巧1. 自定义日志工具类2. 打印方法调用栈3. 打印长日志4. JSON 和 XML 格式化输出 四、Logcat 高级功能1. 自定义日…...

【LLM】A2A 与 MCP:剖析 AI Agent 互联时代的两种关键协议
随着人工智能技术的飞速发展,AI Agent(智能体)正从理论走向实践,有望成为提升生产力的关键。然而,正如历史上任何新兴技术领域一样,标准的缺失导致了“筒仓效应”——不同来源、不同框架构建的 Agent 难以有…...

解析大尺寸液晶屏视觉检测,装配错位如何避免?
在3C电子产品种类飞速发展的今天,大尺寸液晶屏已成为市场主流,消费刚需。消费者对手机屏幕的视觉体验要求不断攀升,屏占比的提升成为各大手机厂商竞争的焦点。然而,大尺寸液晶屏在生产过程中面临着诸多检测难题,严重影…...

巴法云平台-TCP设备云-微信小程序实时接收显示数据-原理
微信小程序通过WebSocket或HTTP长轮询连接平台(而非直接使用TCP)!!! 物联网平台对协议层的一种封装设计——将底层通信协议(如TCP)与应用层业务逻辑(如主题路由)解耦&am…...

ElementNotInteractableException原因及解决办法
在自动化测试中,ElementNotInteractableException是一个常见的异常,它通常发生在尝试与网页上的某个元素进行交互(例如点击、输入等操作)时,但由于该元素当前不可交互。这可能由多种原因引起,以下是一些常见的原因及其解决方法: 元素未完全加载 如果尝试与页面上的元素交…...
)
信息系统项目管理师-工具名词解释(上)
本文章记录学习过程中,重要的知识点,是否为重点的依据,来源于官方教材和历年考题,持续更新共勉 本文章记录学习过程中,重要的知识点,是否为重点的依据,来源于官方教材和历年考题,持续更新共勉 数据收集 头脑风暴 在短时间内获得大量创意,适用于团队环境,需要引导者…...

CSI-external-provisioner
main() 这段Go代码是一个CSI(容器存储接口)Provisioner(供应器)的实现,用于在Kubernetes集群中动态提供持久卷。代码涉及多个组件和步骤,下面是对关键部分的解释: 初始化和配置 命令行标志和…...

OpenAI为抢跑AI,安全底线成牺牲品?
几年前,如果你问任何一个AI从业者,安全测试需要多长时间,他们可能会淡定地告诉你:“至少几个月吧,毕竟这玩意儿可能改变世界,也可能毁了它。”而现在,OpenAI用实际行动给出了一个新答案——几天…...

单片机任意普通IO引脚使用定时器扩展外部中断的巧妙方法
在嵌入式系统中,将任意一个IO端口配置为外部中断源是一种常见的需求,尤其是在硬件资源有限的情况下。通过定时器扩展外部中断的方法,可以在不依赖专用中断引脚的情况下,实现对外部信号的实时响应。以下是一种基于定时器扩展外部中…...
)
arcgis几何与游标(1)
本节我们对几何进行展开学习 ArcPy 的几何对象 在 ArcPy 中,几何对象是表示地理空间数据的核心。它包括点(Point)、多点(Multipoint)、线(Polyline)和面(Polygon)等类型…...

安全密码处理实践
1. 引言 在现代应用程序中,密码存储和验证的安全性 直接关系到用户数据的保护。密码泄露事件频繁发生,通常是由于不安全的存储方式 或 弱加密处理 导致的。为了提高密码的安全性,开发者需要遵循一系列安全密码处理 的最佳实践。 本篇文章将详细介绍如何在应用程序中安全地…...

can‘t set boot order in virtualbox
Boot order setting is ignored if UEFI is enabled https://forums.virtualbox.org/viewtopic.php?t99121 如果勾选EFI boot order就是灰色的 传统BIOS就是可选的 然后选中任意介质,通过右边的上下箭头调节顺序,最上面的应该是优先级最高的 然后就…...

电池分选机详细介绍
在当今这个科技飞速发展的时代,电池作为能源存储的重要载体,其性能的一致性和稳定性对于各类电子设备和电动汽车等应用至关重要。而电池分选机,作为电池生产过程中的关键环节,正扮演着越来越重要的角色。本文将带您深入了解电池分…...

深入理解浏览器的 Cookie:全面解析与实践指南
在现代 Web 开发中,Cookie 扮演着举足轻重的角色。它不仅用于管理用户会话、记录用户偏好,还在行为追踪、广告投放以及安全防护等诸多方面发挥着重要作用。随着互联网应用场景的不断丰富,Cookie 的使用和管理也日趋复杂,如何在保障…...

浙江大学DeepSeek系列专题线上公开课第二季第五期即将上线!deepseek人文艺术之美专场来啦!
浙江大学DeepSeek系列专题线上公开课第二季第五期即将重磅上线! 其中,今晚7点半,浙大AI大神陈为教授将带来硬核的deepseek公开课讲座。 讲座 主题: DeepSeek时代,让AI更懂中国文化的美与善 主讲人: 陈为 …...

5分钟学会接口自动化测试框架
今天,我们来聊聊接口自动化测试。 接口自动化测试是什么?如何开始?接口自动化测试框架如何搭建? 自动化测试 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发…...
:窗口计算、水位线与状态编程)
Flink DataStream API深度解析(Scala版):窗口计算、水位线与状态编程
在前面的文章中Flink 编程基础:Scala 版 DataStream API 入门-CSDN博客,我们已经介绍了 Flink 的 Datastream API 编程模型、窗口划分以及时间语义(处理时间、事件时间等)。本篇文章将深入讲解窗口计算的进阶内容,包括…...

【从零实现高并发内存池】内存池整体框架设计 及 thread cache实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

#MES系统中的一些相关的名词
📌MES系统 部分 术语表 缩写英文全称中文名称详细解释MESManufacturing Execution System制造执行系统用于连接计划系统与生产现场,实时管理和控制整个生产过程,覆盖物料、人员、设备、质量、指令等。ERPEnterprise Resource Planning企业资…...

《灵活的接口设计:如何支持多种后端数据存取实现》
《灵活的接口设计:如何支持多种后端数据存取实现》 一、引言:从单一适配到多样需求 在现代软件开发中,系统通常需要与不同的数据存储后端进行交互,例如关系型数据库(MySQL、PostgreSQL)、NoSQL 数据库(MongoDB、Redis)或文件存储(JSON、CSV)。为了增强系统的可扩展性…...
)
Spark-SQL核心编程(一)
一、Spark-SQL 基础概念 1.定义与起源:Spark SQL 是 Spark 用于结构化数据处理的模块,前身是 Shark。Shark 基于 Hive 开发,提升了 SQL-on-Hadoop 的性能,但因对 Hive 依赖过多限制了 Spark 发展,后被 SparkSQL 取代&…...

Qt:解决MSVC编译器下qDebug输出中文乱码的问题
问题描述: 使用msvc编译器,通过qDebug输出打印信息为乱码(显示问号或者乱码) 百度到以下方案,但是没有效果 最终解决: 在.pro文件中添加如下,重新构建运行即可显示中文内容 msvc:QMAKE_CXXFLAGS -exec…...

Go:接口
接口既约定 Go 语言中接口是抽象类型 ,与具体类型不同 ,不暴露数据布局、内部结构及基本操作 ,仅提供一些方法 ,拿到接口类型的值 ,只能知道它能做什么 ,即提供了哪些方法 。 func Fprintf(w io.Writer, …...

js | 网页上的 json 数据怎么保存到本地表格中?
1.思路 json 转为 csv 保存到本地或者:json 转为 html 显示到网页中,然后复制到excel中。 (2) 数据 wjl{"code":1,"data":[{"chrmiRNA":"chr1","0":"chr1","startmiRNA":&quo…...
:架构优化与安全增强)
智能Todo协作系统开发日志(二):架构优化与安全增强
📅 2025年4月14日 | 作者:Aphelios380 🌟 今日优化目标 在原Todo单机版基础上进行三大核心升级: 组件化架构改造 - 提升代码可维护性 本地数据加密存储 - 增强隐私安全性 无障碍访问支持 - 践行W3C标准 一、组件化架构改造 …...
)
buctoj_算法设计与分析(5)
问题 A: 没有上司的舞会 题目描述 Ural大学有N名职员,编号为1~N。 他们的关系就像一棵以校长为根的树,父节点就是子节点的直接上司。 每个职员有一个快乐指数,用整数 HiHi 给出,其中 1≤i≤N。 现在要召开一场周年庆宴会&#x…...

VUE项目中的package.json中的启动脚本
"scripts": {"dev": "vite","build:prod": "vite build","build:stage": "vite build --mode staging","preview": "vite preview"}vite build 和 vite build --mode staging 是 V…...

目标追踪数据标注
在将 YOLO(目标检测) 和 DeepSORT(目标追踪) 结合时,数据标注需要同时满足 检测 和 追踪 的需求。以下是具体的分阶段标注策略和操作指南: 一、标注的核心要求 检测标注:每帧中目标的 边界框&a…...

详细介绍7大排序算法
1.排序的概念及其运用 1.1 排序的概念 排序 :所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性 :假定在待排序的记录序列中,存在多个具有相同的关键字的记…...

TGCTF web
AAA偷渡阴平 这个题是一个非预期的无参RCE <?php$tgctf2025$_GET[tgctf2025];if(!preg_match("/0|1|[3-9]|\~|\|\|\#|\\$|\%|\^|\&|\*|\(|\)|\-|\|\|\{|\[|\]|\}|\:|\|\"|\,|\<|\.|\>|\/|\?|\\\\/i", $tgctf2025)){//hi…...