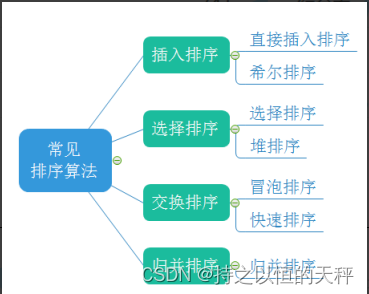
详细介绍7大排序算法
1.排序的概念及其运用
1.1 排序的概念
1.2 常见的排序算法
1.3 排序接口的实现
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>void PrintArray(int* a, int n);
void InsertSort(int* a, int n);
void ShellSort(int* a, int n);
void BubbleSort(int* a, int n);
void SelectSort(int* a, int n);
void BubblleSort(int* a, int n);
void SelectSort(int* a, int n);
void HeapSort(int* a, int n);
void QuickSort(int* a, int begin, int end);2.常见排序算法的实现
2.1 插入排序
插入排序是一种简单的插入排序算法,基本思想是:
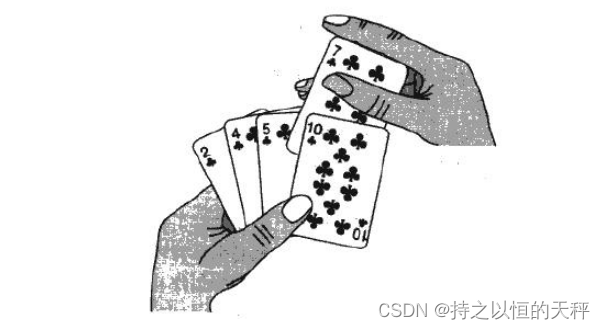
2.2.1直接插入排序

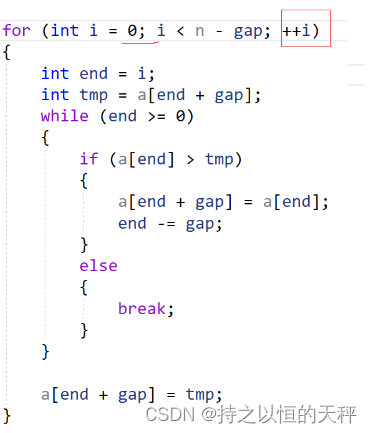
void InsertSort(int* a, int n)
{//[0,end]有序,插入tmp依旧有序for (int i = 1; i < n; i++){int end = i - 1;int tmp = a[i];while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}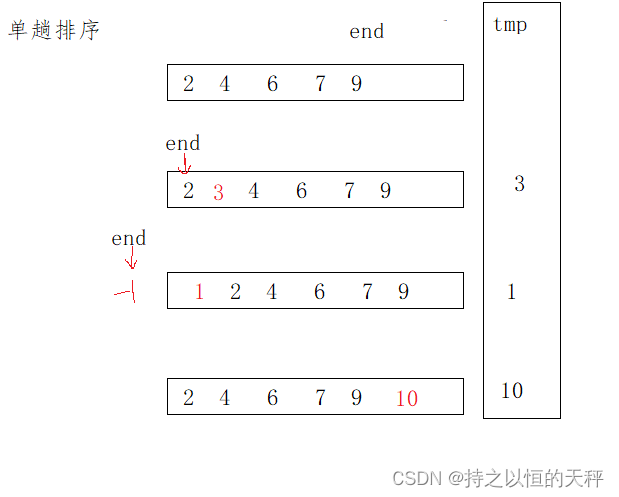
如果从头开始比较的话,我们想象一下摸牌的过程,当我们摸了第一张牌的时候,那么这张牌就是有序的,摸第二张牌的时候要跟第一张牌进行比较,如果小就放在前面,比它大就放在后面。摸第三张牌就跟第二张进行比较,以此类推,摸第n张牌就跟第n-1张进行比较。其中第一张牌就是end,要摸的牌就是tmp,依次比较就要end--,我们要以计算机的思路进行比较,实际生活中我们一眼就能看出牌应该在哪个位置。OK,这就是插入排序的逻辑思路了。
2.2.2 希尔排序







通过上面的图片我们来讨论一下gap的取值该怎样取呢 ?
我们令gap=n,gap=gap/3+1。加1的原因是保证最后一次一定是1。当gap==1时就是直接插入排序。当然你也可以用gap/2,这样不管是奇数还是偶数都能保证最后一次一定是1.
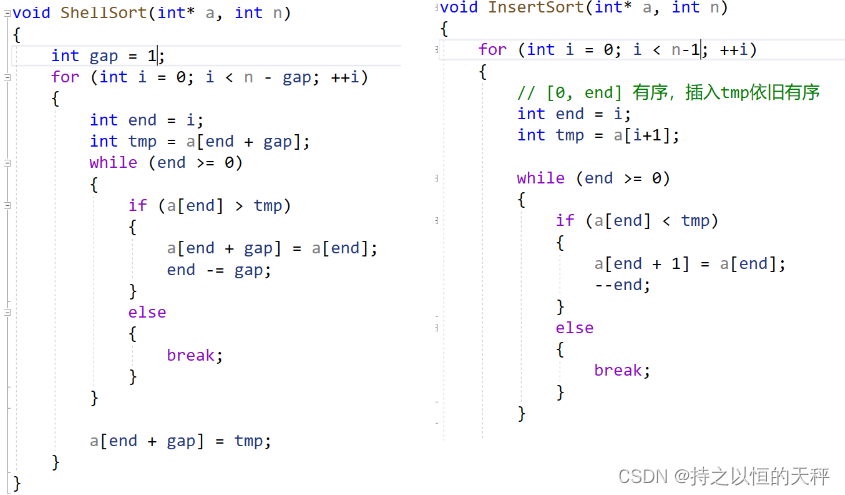
代码示例:
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//加1保证最后一次一定是1for (int j = 0; j < gap; j++){for (int i = j; i < n - gap; i += gap)//i<n时会有越界的风险{int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}
}2.2 选择排序
2.2.1基本思想
2.2.2 直接选择排序

void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int maxi = begin, mini = begin;for (int i = begin; i <= end; i++){if (a[i] > a[maxi])maxi = i;if (a[i] < a[mini])mini = i;}Swap(&a[begin], &a[mini]);if (begin == maxi)maxi = mini;Swap(&a[end], &a[maxi]);++begin;--end;}
}2.2.3 堆排序
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child + 1] > a[child])//child+1防止越界{++child;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void HeapSort(int* a, int n)
{//建大堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}2.3 交换排序
2.3.1 基本思想
2.3.2 冒泡排序
冒泡排序是我们最熟悉的一种排序算法了,就不过多介绍了。直接给出代码
void BubbleSort(int* a, int n)
{for (int j = 0; j < n; ++j){bool exchange = false;for (int i = 1; i < n - j; i++){if (a[i - 1] > a[i]){int tmp = a[i];a[i] = a[i - 1];a[i - 1] = tmp;exchange = true;}}if (exchange == false){break;}}
}动图演示:

2.3.3 快速排序


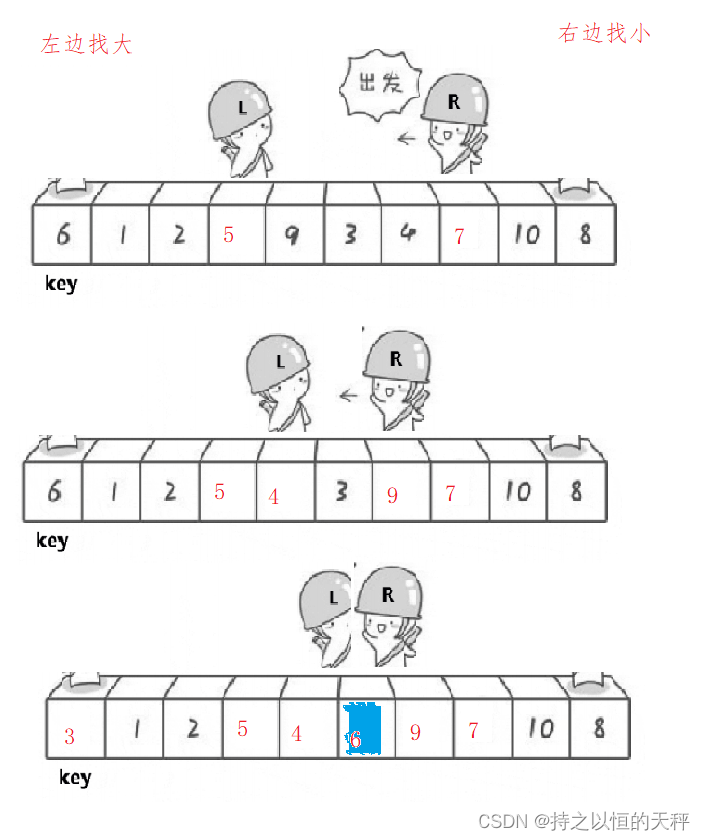
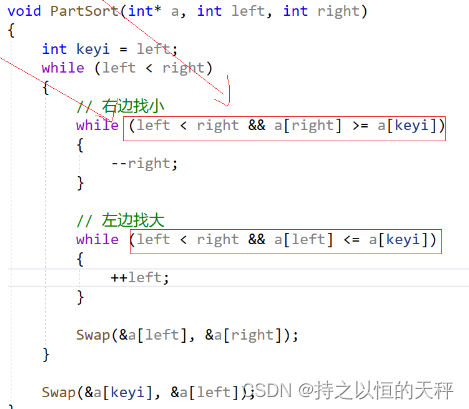
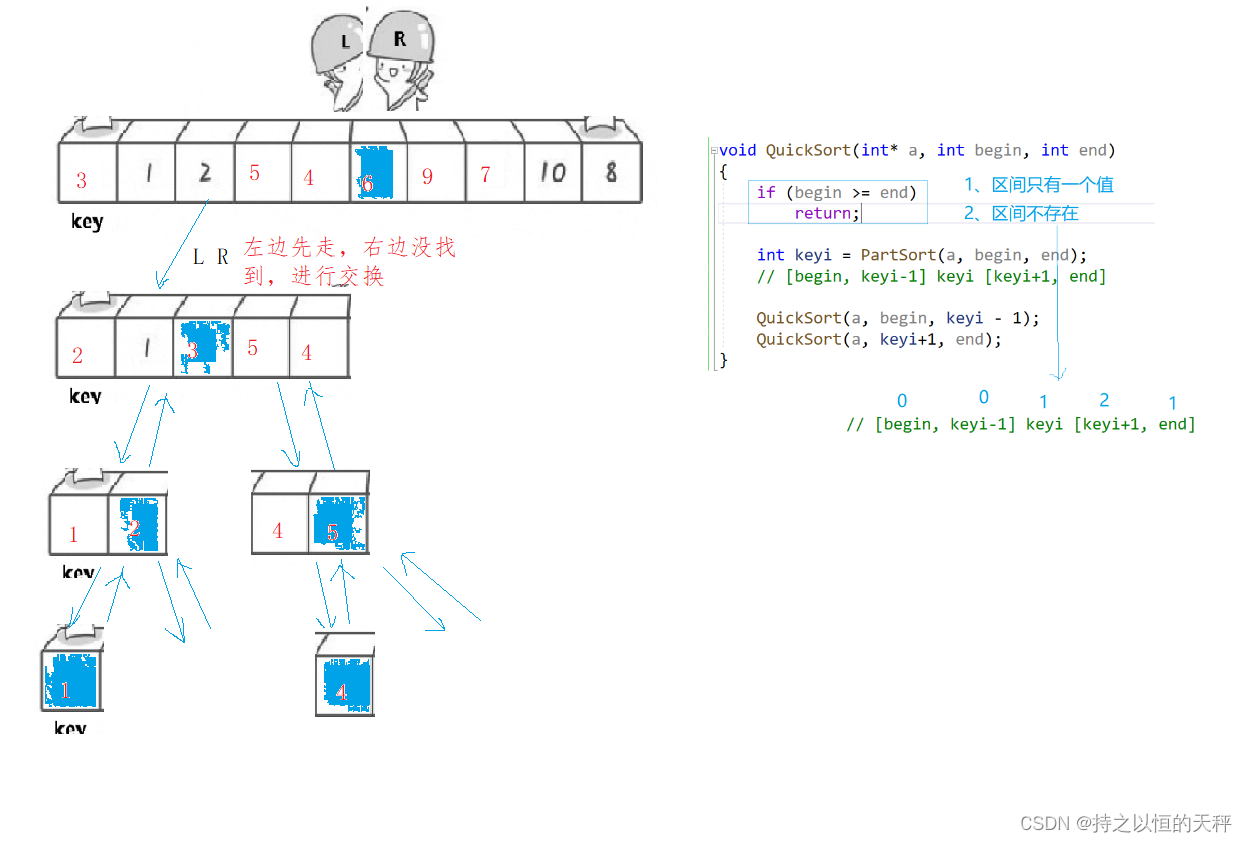
int PartSort1(int* a, int left, int right)
{int keyi = left;while (left < right){//右边找小while (left < right && a[right] >= a[keyi]){--right;}//左边找大while (left < right && a[left] <= a[keyi]){++left;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);//相遇就交换keyi和leftreturn left;
}void QuickSort(int* a, int begin, int end)
{if (begin > end)return;int keyi = PartSort1(a, begin, end);//int keyi = PartSort2(a, begin, end);//int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}这里面有些问题需要注意,如何保证相遇位置就一定比key小
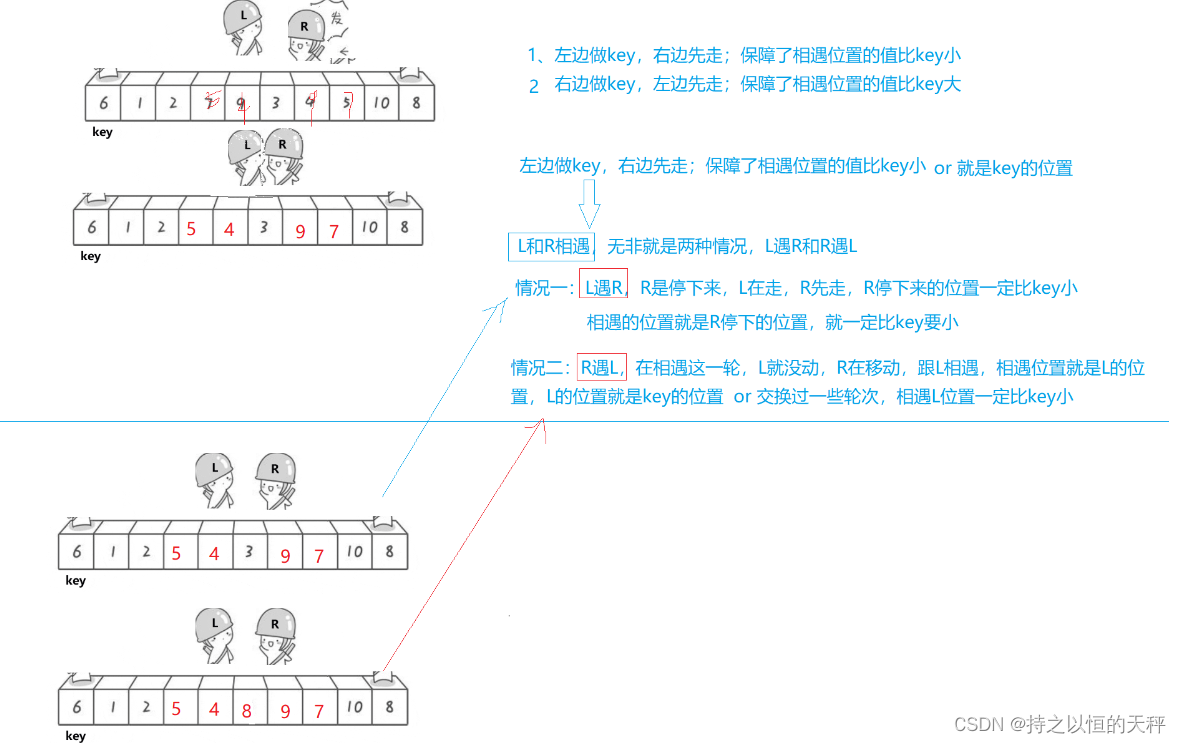
2.挖坑法
动图示例:


挖坑法比较好理解,就不用过多解释了
代码示例:
//挖坑法
int PartSort2(int* a, int left, int right)
{int key = a[left];int hole = left;while (left < right){while (left < right && a[right] >= key){--right;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}3.前后指针法
动图演示:

思想:1.最开始prev和cur是相邻的。
2.当cur遇到比key大的值以后,它们之间的值都是比key大的值
3.cur找小,找到小的以后,先++prev,然后交换prev的位置和cur的位置,相当于把大的翻滚式往右边推的同时把小的换到左边
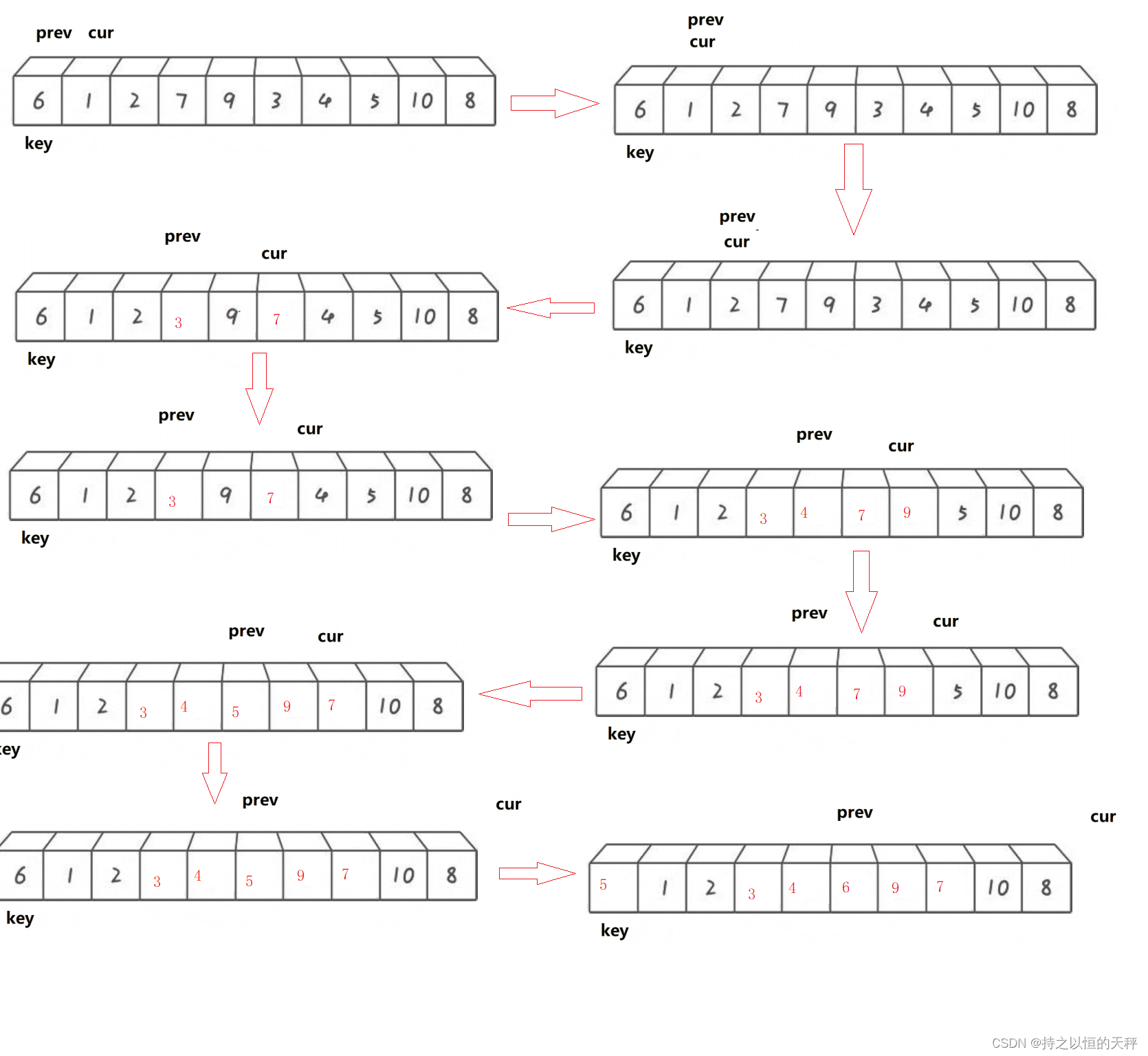
代码示例:
int PartSort3(int* a, int left, int right)
{int prev = left;int cur = left + 1;int keyi = left;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}快速排序优化:
每次选key都是中位数,效率就很好。当数据有序的时候,变成最坏,时间复杂度是O(N^2)。
解决方法是1.随机数选key 2.三数取中
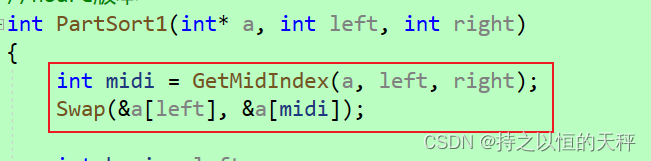
三数取中代码
//三数取中
int GetMidIndex(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right])return mid;else if (a[left] < a[right])return right;elsereturn left;}else{if (a[mid] > a[right])return mid;else if (a[left] > a[right])return right;elsereturn left;}
}然后再三个版本中加入这2行代码
2.3.4 快速排序的非递归实现
void QuickSortNonR(int* a, int begin, int end)
{ST st;STInit(&st);STPush(&st,end);STPush(&st,begin);while (!STEmpty(&st)){int left = STTop(&st);STPop(&st);int right = STTop(&st);STPop(&st);int keyi = PartSort1(a, left, right);// [left, keyi-1] keyi [keyi+1, right]if (keyi + 1 < right){STPush(&st, right);STPush(&st, keyi+1);}if (left < keyi - 1){STPush(&st, keyi - 1);STPush(&st, left);}}STDestroy(&st);
}2.3.5 各种排序算法的比较
我们可以用10万个数据来看一看这几种排序的时间差异,看一下哪种算法好
void TestOP()
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();BubbleSort(a3, N);int end3 = clock();int begin4 = clock();SelectSort(a4, N);int end4 = clock();int begin5 = clock();HeapSort(a5, N);int end5 = clock();int begin6 = clock();QuickSort(a6, 0, N - 1);int end6 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("BubbleSort:%d\n", end3 - begin3);printf("SelcetSort:%d\n", end4 - begin4);printf("HeapSort:%d\n", end5 - begin5);printf("QuickSort:%d\n", end6 - begin6);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);
}
2.4 归并排序
2.4.1概念
- 分割:将待排序的序列不断地⼆分为两个⼦序列,直到每个⼦序列只剩下⼀个元素。
- 归并:将两个有序⼦序列合并为⼀个有序序列。
2.4.2 基本思想
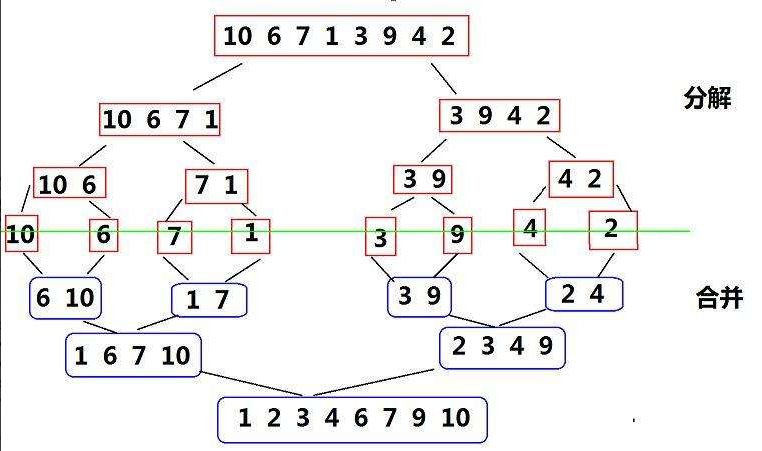

2.4.3 非递归实现方式
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);int gap = 1;while (gap < n){int j = 0;for (int i = 0; i < n; i += 2 * gap){// 每组的合并数据int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;if (end1 >= n || begin2 >= n){break;}// 修正if (end2 >= n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}// 归并一组,拷贝一组memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}free(tmp);
}
2.3.4 递归方式实现
void _MergeSort(int* a,int begin, int end,int* tmp)
{if (begin == end)return;int mid = (begin + end) / 2;// [begin, mid] [mid+1, end]_MergeSort(a, begin, mid, tmp);_MergeSort(a, mid+1, end, tmp);int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(a, 0, n - 1, tmp);free(tmp);
}- 非递归方式实现的空间复杂度更低:递归⽅式需要使⽤系统栈来保存函数调⽤信息,当递归深度较大时,可能会导致栈溢出。而非递归⽅式可以使⽤循环和迭代来实现,不需要使⽤额外的空间,因此空间复杂度更低。
- 非递归方式实现的效率更⾼:递归⽅式需要频繁地进行函数调⽤和返回操作,每次调⽤和返回都会带来额外的开销。而非递归方式只需要进⾏简单的循环和迭代,效率更高。
- ⾮递归方式实现的代码更易于理解和调试:递归方式实现的代码⽐较难以理解和调试,因为递归过程中函数的调⽤顺序⽐较复杂。而非递归方式实现的代码结构更加清晰,易于理解和调试。
相关文章:

详细介绍7大排序算法
1.排序的概念及其运用 1.1 排序的概念 排序 :所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性 :假定在待排序的记录序列中,存在多个具有相同的关键字的记…...

TGCTF web
AAA偷渡阴平 这个题是一个非预期的无参RCE <?php$tgctf2025$_GET[tgctf2025];if(!preg_match("/0|1|[3-9]|\~|\|\|\#|\\$|\%|\^|\&|\*|\(|\)|\-|\|\|\{|\[|\]|\}|\:|\|\"|\,|\<|\.|\>|\/|\?|\\\\/i", $tgctf2025)){//hi…...

RTPS数据包分析
DDS-RTPS 常见子消息_dds pdp消息-CSDN博客Fast RTPS原理与代码分析(3):动态发现协议之端点发现协议EDP_fast-rtps 原理-CSDN博客 在RTPS(Real-Time Publish-Subscribe,实时发布订阅)协议中,DATA(r)和DATA是两种不同的…...

go语言gRPC使用流程
1. 安装工具和依赖 安装 Protocol Buffers 编译器 (protoc) 下载地址:https://github.com/protocolbuffers/protobuf/releases 使用说明:https://protobuf.dev/ 【centos环境】yum方式安装:protoc[rootlocalhost demo-first]# yum install …...

回溯算法的要点
可以用树结构(解空间树)来表示用回溯法解决的问题的所有选项。 叶节点则对应着最终的状态. 回溯过程:深度遍历,在任意时刻,算法只保存从根结点到当前结点的路径。 “剪枝”:当某一节点不包含问题的解&am…...
)
爬虫: 一文掌握 pycurl 的详细使用(更接近底层,性能更高)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、PycURL概述1.1 PycURL介绍1.2 基本安装1.3 安装依赖(Linux/macOS)1.4 常用选项参考二、基本使用2.1 简单 GET 请求2.2 获取响应信息2.3 设置请求头2.4 超时设置2.5 跟随重定向三、高级功能3.1 POST 请求3.2 文件上…...

大模型文生图
提示词分4个部分:质量,主体,元素,风格 质量:杰作,高质量,超细节,完美的精度,高分辨率,大师级的; 权重:把图片加括号,&am…...

c# AI编程助手 — Fitten Code
前言 前有Copilot各种酷炫操作,今有国产软件杀出重围。给大家介绍的是一款国内的国产编程神器,可与微软GitHub Copilot比比身手。关键它还是完全免费。它就是:非十团队国产自主研发的Fitten Code。此工具的速度是GitHub Copilot的两倍&#x…...

《植物大战僵尸融合版v2.4.1》,塔防与创新融合的完美碰撞
《植物大战僵尸融合版》是基于经典塔防游戏《植物大战僵尸》的创意同人改版,由“蓝飘飘fly”等开发者主导制作。它在保留原版核心玩法的基础上,引入了独特的植物融合机制,玩家可以将不同的植物进行组合,创造出全新的植物种类&…...
)
深度学习总结(12)
层:深度学习的基础模块 神经网络的基本数据结构是层。层是一个数据处理模块,它接收一个或多个张量作为输入,并输出一个或多个张量。有些层是无状态的,但大多数层具有状态,即层的权重。权重是利用随机梯度下降学到的一个或多个张量…...

pyqt环境配置
文章目录 1 概述2 PyQt6和PySide6区别3 环境配置4 配置PySide65 配置PyQt66 配置外部工具7 添加模板8 使用pyside6-project构建工程9 常见错误10 相关地址 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 …...

YOLO11改进——融合BAM注意力机制增强图像分类与目标检测能力
深度学习在计算机视觉领域的应用取得了显著进展,尤其是在目标检测(Object Detection)和图像分类(Image Classification)任务中。YOLO(You Only Look Once)系列算法凭借其高效的单阶段检测框架和…...

考研单词笔记 2025.04.14
amount n数量,数额v(数量)达到,总计(to),意味着,相当于 couple n一对,一双,一些,几个,夫妻,情侣v连接,结合 …...

AI云游戏盒子:未来娱乐的新纪元
AI云游戏盒子:未来娱乐的新纪元 随着科技的不断进步,人工智能(AI)与云计算技术的结合正在重新定义我们享受数字娱乐的方式。2025年,一款名为“AI云游戏盒子”的产品正逐渐成为家庭娱乐的核心设备,它不仅集…...

第八章 文件操作
第八章 文件操作 文章目录 第八章 文件操作1 文件读取1 将文件整个读取内存2 按字节读取文件 1 文件读取 1 将文件整个读取内存 类似于python的 with open(filename, modert, encodingutf-8) as f:res f.read()go中的书写方式: 方式一: package ma…...

《extern:如何在编译时“暗通款曲“》
C中extern关键字的完整用法总结 extern是C中管理链接性(linkage)的重要关键字,主要用于声明外部定义的变量或函数。以下是详细的用法分类和完整示例: 一、基本用法 1. 声明外部全局变量 // globals.cpp int g_globalVar 42; …...

活动图与流程图的区别与联系:深入理解两种建模工具
目录 前言1. 活动图概述1.1 活动图的定义1.2 活动图的基本构成要素1.3 活动图的应用场景 2. 流程图概述2.1 流程图的定义2.2 流程图的基本构成要素2.3 流程图的应用场景 3. 活动图与流程图的联系4. 活动图与流程图的区别4.1 所属体系不同4.2 表达能力差异4.3 使用目的与语境4.4…...

FinanceRAG获奖方案解读:ACM-ICAIF ’24的FinanceRAG挑战赛
ACM-ICAIF 24 FinanceRAG Challenge提供一套整合的文本和表格财务数据集。这些数据集旨在测试系统检索和推理财务数据的能力。参与者将受益于 Github 上的基线示例和官方提交代码,其位于FinanceRAG,以及在 huggingface 上的简化的数据集访问,…...
)
Linux LED驱动(gpio子系统)
0. gpio子系统 gpio子系统是linux内核当中用于管理GPIO资源的一套系统,它提供了很多GPIO相关的API接口,驱动程序中使用GPIO之前需要向gpio子系统申请。 gpio子系统的主要目的就是方便驱动开发者使用gpio,驱动开发者在设备树中添加gpio相关信息…...

场外期权交易和结算方式的区别是什么?
场外期权交易的核心在于双方协商一致的合约条款。这些条款包括但不限于期权的类型(看涨或看跌)、执行价格、到期日、合约规模以及支付的期权费。由于每份合约都是独一无二的,因此交易双方需要具备高度的专业知识和谈判技巧,下文为…...

自注意力的机制内涵和设计逻辑
在自注意力机制中,查询(Q)、键(K)和值(V)的交互过程是核心设计,其背后的数学和语义内涵可以从以下角度理解: 1. 数学视角:动态加权聚合 自注意力机制的公式可…...

VIM学习笔记
1. ex模式 vim中,按:触发的命令行模式,称为 ex模式,具体命令参见如下笔记: https://blog.csdn.net/u010250151/article/details/51868751?ops_request_misc%257B%2522request%255Fid%2522%253A%2522814b671a9898c95…...
)
Windows系统docker desktop安装(学习记录)
目前在学习docker,在网上扒了很多老师的教程,终于装好了,于是决定再装一遍做个记录,省的以后再这么麻烦 一:什么是docker Docker 是一个开源的应用容器引擎,它可以让开发者打包他们的应用以及依赖包到一个…...

操作系统学习笔记——[特殊字符]超详细 | 如何唤醒被阻塞的 socket 线程?线程阻塞原理、线程池、fork/vfork彻底讲明白!
💡超详细 | 如何唤醒被阻塞的 socket 线程?线程阻塞原理、线程池、fork/vfork彻底讲明白! 一、什么是阻塞?为什么线程会阻塞?二、socket线程被阻塞的典型场景🧠 解法思路: 三、线程的几种阻塞状…...

GIC驱动程序对中断的处理流程
承接上一篇,我们来讲讲GIC的处理流程: 我们先来看看老版本的CPU是怎么去处理中断的: 这种的话,基本上就是一开始就确定你有多少个中断,就为你分配好了多少个irq_desc,这样子每一个硬件中断,也就…...

罗庚机器人:机器人打磨领域的先行者
近日,记者在广东罗庚机器人有限公司(以下简称罗庚机器人)总经理蒲小平处了解到,该公司是一家研发与为客户提供高精度自适应机器人打磨抛光集成工艺的高科技企业,是机器人打磨领域的先行者。在国内外机器人打磨抛光应用…...
)
如何在 Java 中对 PDF 文件进行数字签名(教程)
Java 本身并不原生支持 PDF 文件,因此若要对 PDF 进行数字签名,您需要使用一些专用的软件。本教程将演示如何使用 JPedal PDF 库来对 PDF 文件进行数字签名。 步骤: • 下载 JPedal 并将 Jar 文件添加到项目中 • 创建一个 PKCS#12 密…...

一文了解:北斗短报文终端是什么,有哪些应用场景?
在通信技术飞速发展的今天,人们已习惯于依赖地面基站和互联网实现即时通信。然而,当自然灾害突发、远洋航行遇险或深入无人区勘探时,传统通信手段往往失效。北斗短报文终端——这一由中国自主研发的卫星通信技术,正以“无网络通信…...

【KWDB创作者计划】_KWDB应用之实战案例
【KWDB 2025 创作者计划】_KWDB应用之实战案例 本文是在完成KWDB数据库安装的情况下的操作篇,关于KWDB的介绍与安装部署,可以查看上一篇博客: https://blog.itpub.net/70045384/viewspace-3081187/ https://blog.csdn.net/m0_38139250/article/details/…...

JavaScript中的运算符与语句:深入理解编程的基础构建块
# JavaScript中的运算符与语句:深入理解编程的基础构建块 在JavaScript编程的世界里,运算符和语句就像是构建大厦的基石,它们是编写高效、灵活代码的基础。今天,我们就来深入了解一下这些重要的元素。 ## 一、运算符:…...
)
MySQL——学习InnoDB(1)
MySQL——学习InnoDB(1) 文章目录 MySQL——学习InnoDB(1)1. InnoDB的前世今生1.1 诞生发展1.2 核心设计1.3 关键进化 2. InnoDB和MyISAM在性能和安全上的区别2.1 性能对比2.2 安全对比 3. InnoDB架构图(内存结构磁盘结…...

QT中多线程写法
转自个人博客:QT中多线程写法 1. QThread及moveToThread() 使用情况: 多使用于需要将有着复杂逻辑或需要一直占用并运行的类放入子线程中执行的情况,moveToThread是将整个类的对象移入子线程。 优缺点: 优点:更符合…...

css 二维码始终显示在按钮的正下方,并且根据不同的屏幕分辨率自动调整位置
一、需求 “求职入口” 下面的浮窗位置在其正下方,并且浏览器分辨的改变(拖动浏览器),位置依旧在最下方 二、实现 <div class"btn_box"><div class"btn_link id"js-apply">求职入口<di…...

STM32 认识STM32
目录 什么是嵌入式? 认识STM32单片机 开发环境安装 安装开发环境 开发板资源介绍 单片机开发模式 创建工程的方式 烧录STM32程序 什么是嵌入式? 1.智能手环项目 主要功能有: 彩色触摸屏 显示时间 健康信息:心率&#…...
 和 智能体功能 的具体说明及对比分析)
关于 CSDN的C知道功能模块 的详细解析,包括 新增的AI搜索(可选深度思考) 和 智能体功能 的具体说明及对比分析
以下是关于 CSDN的C知道功能模块 的详细解析,包括 新增的AI搜索(可选深度思考) 和 智能体功能 的具体说明及对比分析: 一、C知道核心功能模块详解(基础功能) (参考前文内容,此处略…...

Vue--组件练习案例
图片轮播案例: <!DOCTYPE html><html lang"en"><head><meta charset"UTF-8"><title>Title</title></head><body><!--轮播图片--><div id"app"><h1>轮播图</h1…...

Sentinel源码—1.使用演示和简介一
大纲 1.Sentinel流量治理框架简介 2.Sentinel源码编译及Demo演示 3.Dashboard功能介绍 4.流控规则使用演示 5.熔断规则使用演示 6.热点规则使用演示 7.授权规则使用演示 8.系统规则使用演示 9.集群流控使用演示 1.Sentinel流量治理框架简介 (1)与Sentinel相关的问题 …...
)
空间信息可视化——WebGIS前端实例(二)
技术栈:原生HTML 源代码:CUGLin/WebGIS: This is a project of Spatial information visualization 5 水质情况实时监测预警系统 5.1 系统设计思想 水安全是涉及国家长治久安的大事。多年来,为相应国家战略,诸多地理信息领域的…...
)
高并发内存池(前言介绍)
高并发内存池项目介绍 1.项目介绍2.项目的知识储备要求3.了解池化技术及内存池4.本次项目中内存池解决的问题5.malloc 1.项目介绍 此项目是实现一个高并发的内存池,它的原型是google的一个开源项目tcmalloc,tcmalloc全程Thread-Caching Mallocÿ…...

误译、值对象和DDD伪创新-《分析模式》漫谈56
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 “Analysis Patterns”的第14章“类型模型设计模板模式”原文: Examples of such object types are the classic built-in data types of programming environments: inte…...

Java单例模式:实现全局唯一对象的艺术
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、什么是单例模式? 单例模式(Singleton Pattern)是一种创建型设计模式,确保一个类只有一个实例,…...

机器学习项目二:帕金森病检测
目录 下载数据 一、导入相关包 二、数据加载 三、特征工程 四、构建模型 五、评估与可视化 六、程序流程 七、完整代码 一、导入相关包 # 导入库部分 import numpy as np # 数值计算基础库 import pandas as pd # 数据处理库 from sklearn.preprocessing import MinMaxS…...

FreeDogs:AI、区块链与迷因文化的深度融合
引言 在 Web3 时代,人工智能(AI)、区块链技术和迷因文化的结合催生了一种全新的去中心化生态系统。FreeDogs 项目作为这一领域的创新代表,通过独特的技术与文化融合模式迅速受到关注。它利用 AI 驱动的智能营销网络推动迷因文化的…...

《组合优于继承:构建高内聚低耦合模块的最佳实践》
《组合优于继承:构建高内聚低耦合模块的最佳实践》 一、引言:编程范式中的选择 在软件设计中,继承和组合是两个重要的设计模式。继承(Inheritance)常被用来实现代码复用,但滥用继承容易导致脆弱的类层次结构,增加耦合度和维护成本。而组合(Composition)通过将功能分解…...

机器学习02——RNN
一、RNN的基本概念 定义 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络架构。它与传统的前馈神经网络(如多层感知机)不同,RNN具有“记忆”功能,能够利用前一时…...

Java基础——面试自我总结
1、String类中常用方法和equals区别 答:对于和equals这两个都是用来比较判断是否相等,其中用来判断两个变量的值是否相等,变量的值的类型分为基本数据类型和引用数据类型。对于,基本数据类型是直接进行值比较,而对于引…...
)
低功耗设计:Level Shift的种类(以SAED EDK 32/28nm工艺库为例)
在多电压设计中,当信号从一个电压域跨越到另一个电压域时,需要使用电压转换器(Level Shift)。它的工作方式类似于缓冲器,但其输入和输出使用不同的电压,作用是将一个逻辑信号从一个电压转换为另一个电压,并在输入到输出…...
 和模拟网格体 是如何关联的?为什么模拟网格体 可以驱动渲染网格体?)
UE5 Chaos :渲染网格体 (Render Mesh) 和模拟网格体 是如何关联的?为什么模拟网格体 可以驱动渲染网格体?
官方文献:https://dev.epicgames.com/community/learning/tutorials/pv7x/unreal-engine-panel-cloth-editor 这背后的核心是一种常见的计算机图形学技术,通常称为代理绑定 (Proxy Binding) 或 表面变形传递 (Surface Deformation Transfer)。 关联机制…...

Fiddler为什么可以看到一次HTTP请求数据?
1、作为代理服务器 Fiddler作为代理服务器,拦截了设备与互联网服务器之间的所有HTTP和HTTPS流量。当客户端(如浏览器)发送请求时,请求先到达Fiddler,然后由Fiddler转发到目标服务器;服务器的响应也会返回给…...
召回算法是检索增强生成模型中的关键组件)
RAG(Retrieval-Augmented Generation)召回算法是检索增强生成模型中的关键组件
RAG(Retrieval-Augmented Generation)召回算法是检索增强生成模型中的关键组件,其核心目标是从大规模文档库中高效检索与输入查询相关的信息,以辅助生成模型产生更准确的回答。以下是该算法的关键点解析: ### 1. **核…...