【KWDB创作者计划】_KWDB应用之实战案例
【KWDB 2025 创作者计划】_KWDB应用之实战案例
本文是在完成KWDB数据库安装的情况下的操作篇,关于KWDB的介绍与安装部署,可以查看上一篇博客:
https://blog.itpub.net/70045384/viewspace-3081187/
https://blog.csdn.net/m0_38139250/article/details/147234176
本文更多KWDB的SQL操作参考如下:
https://www.kaiwudb.com/kaiwudb_docs/#/oss_v2.2.0/sql-reference/overview.html
开启并连接KWDB
进入已经按照好kwdb的服务器
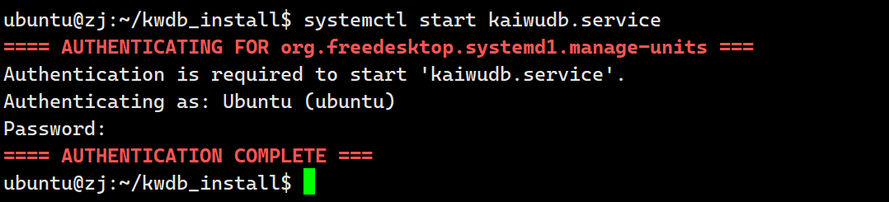
1.启动kwdb
systemctl start kaiwudb.service
输出如下:
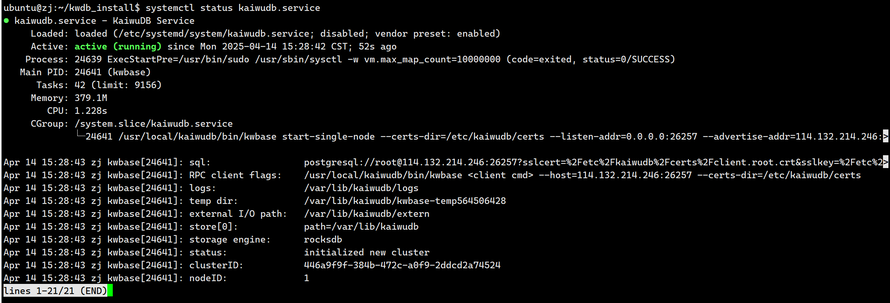
查看状态:
systemctl status kaiwudb.service
输出如下
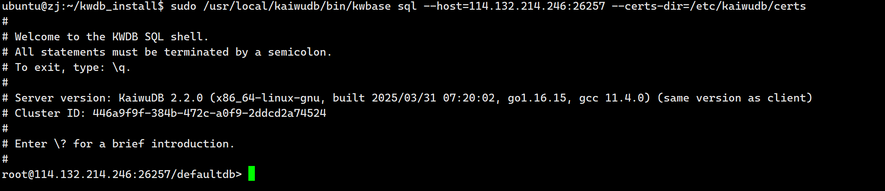
2.登录到命令行的kwdb
执行 add_user.sh 脚本创建数据库用户。如果跳过该步骤,系统将默认使用 root 用户,且无需密码访问数据库。
sudo /usr/local/kaiwudb/bin/kwbase sql --host=114.132.214.246:26257 --certs- dir = /etc/kaiwudb/certs
输出如下:
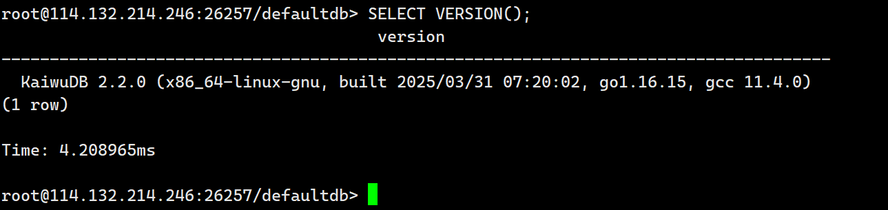
3.查看当前的KWDB版本
SELECT version();
输出如下:
KWDB数据库操作
1.创建数据库
KWDB 时序数据库支持在创建数据库的时候设置数据库的生命周期和分区时间范围。数据库生命周期和分区时间范围的设置与系统的存储空间密切相关。生命周期越长,分区时间范围越大,系统所需的存储空间也越大。有关存储空间的计算公式,参见 预估磁盘使用量。当用户单独指定或者修改数据库内某一时序表的生命周期或分区时间范围时,该配置只适用于该时序表。
生命周期的配置不适用于当前分区。当生命周期的取值小于分区时间范围的取值时,即使数据库的生命周期已到期,由于数据存储在当前分区中,用户仍然可以查询数据。当时间分区的所有数据超过生命周期时间点( now() - retention time)时,系统尝试删除该分区的数据。如果此时用户正在读写该分区的数据,或者系统正在对该分区进行压缩或统计信息处理等操作,系统无法立即删除该分区的数据。系统会在下一次生命周期调度时再次尝试删除数据(默认情况下,每小时调度一次)。
前提条件
用户具有 Admin 角色。默认情况下,root 用户具有 Admin 角色。创建成功后,用户拥有该数据库的全部权限。
语法格式
CREATE TS DATABASE <db_name> [RETENTIONS <keep_duration>] [PARTITION INTERVAL <interval>];

创建一个名为 ts_db_temp 的数据库,并将数据库的生命周期设置为 1年。
CREATE TS DATABASE ts_db_temp RETENTIONS 1Y;
输出如下:

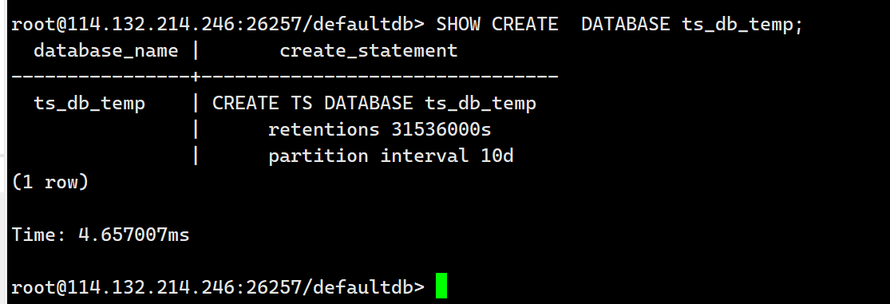
2.查看数据库的建库语句
SHOW CREATE DATABASE ts_db_temp;
输出如下:
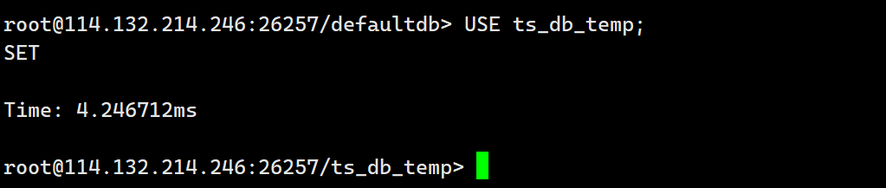
3.切换数据库
USE ts_db_temp;
输出如下:
KWDB数据表操作
1.建表操作
语句格式如下
CREATE TABLE <table_name> (<column_list>)
[TAGS|ATTRIBUTES] (<tag_list>)
PRIMARY [TAGS|ATTRIBUTES] (<primary_tag_list>)
[RETENTIONS <keep_duration>]
[ACTIVETIME <active_duration>]
[PARTITION INTERVAL <interval>]
[DICT ENCODING];
参数如下:

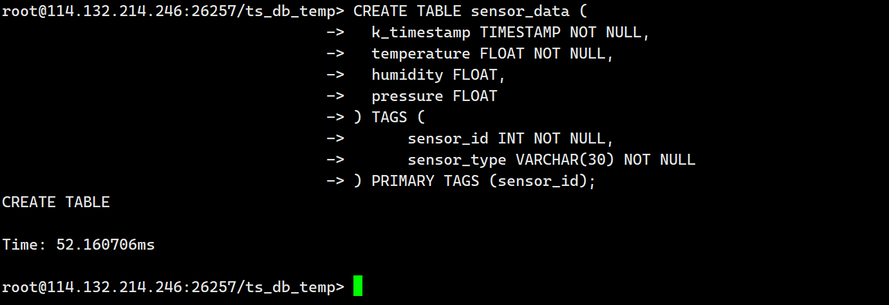
以下示例创建一个名为 sensor_data 的时序表。
- 创建 sensor_data 时序表。
CREATE TABLE sensor_data (k_timestamp TIMESTAMP NOT NULL,temperature FLOAT NOT NULL,humidity FLOAT,pressure FLOAT
) TAGS (sensor_id INT NOT NULL,sensor_type VARCHAR(30) NOT NULL
) PRIMARY TAGS (sensor_id);
输出如下:
- 给sensor_data 时序表添加注释信息。
语法格式,注意注释用单引号。
COMMENT ON [DATABASE <database_name> | TABLE <table_name> | COLUMN <column_name> ] IS <comment_text>;
添加注释的语句
COMMENT ON COLUMN sensor_data.k_timestamp IS '时间戳';
COMMENT ON COLUMN sensor_data.temperature IS '温度';
COMMENT ON COLUMN sensor_data.humidity IS '湿度';
COMMENT ON COLUMN sensor_data.pressure IS '压力';
输出如下:
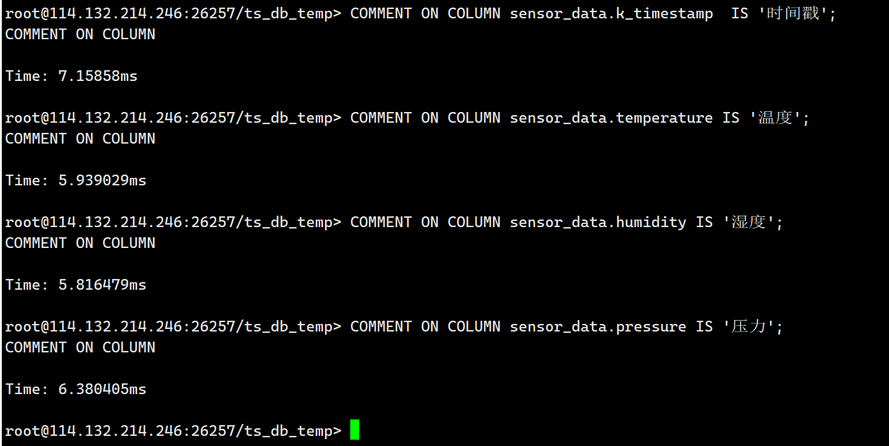
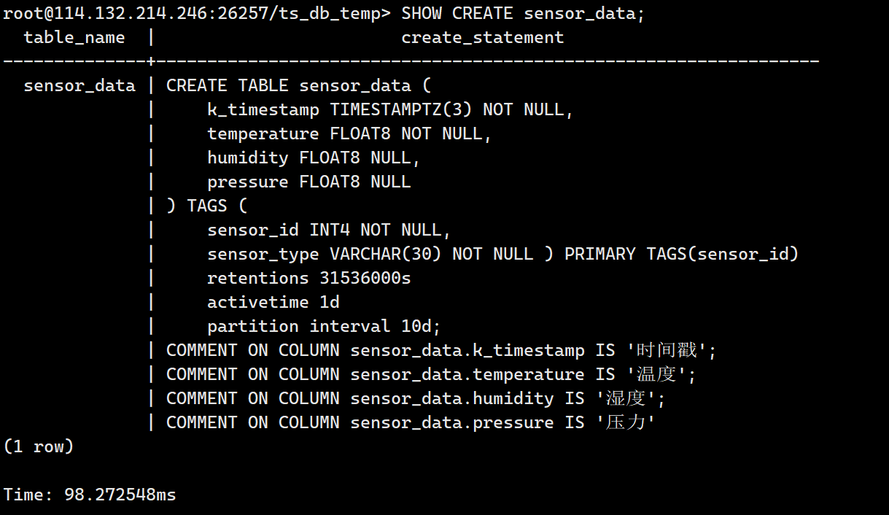
3.查看sensor_data的建表语句
SHOW CREATE sensor_data;
输出如下:
2.插入数据
更多内容参考官网文档
语法如下:
INSERT INTO ts_db_temp. sensor_data VALUES ('2023-07-13 14:06:32.272', 20.0, 0.50, 200, 100,'100数据中心');
输出如下:

基于python生成100条插入语句,包含100和102的两个id,python代码如下:
import random
from datetime import datetime, timedelta
# 定义函数生成时间戳序列
def generate_timestamps(start_time, count):timestamps = []current_time = start_timefor _ in range(count):timestamps.append(current_time.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]) # 保留到毫秒current_time += timedelta(seconds=10) # 每条记录间隔10秒return timestamps
# 定义温度、湿度和压力的正常范围
def generate_normal_values():temperature = round(random.uniform(18.0, 25.0), 1)humidity = round(random.uniform(0.4, 0.6), 2)pressure = random.randint(190, 210)return temperature, humidity, pressure
# 插入异常值
def generate_abnormal_temperature():return round(random.uniform(30.0, 40.0), 1) if random.random() > 0.5 else round(random.uniform(10.0, 15.0), 1)
# 生成插入语句
def generate_insert_statements(data_center, sensor_id, count, abnormal_count):statements = []timestamps = generate_timestamps(datetime(2023, 7, 13, 14, 6, 32), count)# 随机选择异常值的位置abnormal_indices = random.sample(range(count), abnormal_count)for i in range(count):timestamp = timestamps[i]if i in abnormal_indices:temperature = generate_abnormal_temperature()else:temperature, humidity, pressure = generate_normal_values()humidity = round(random.uniform(0.4, 0.6), 2) if i not in abnormal_indices else round(random.uniform(0.4, 0.6), 2)pressure = random.randint(190, 210) if i not in abnormal_indices else random.randint(190, 210)statement = f"INSERT INTO ts_db_temp.sensor_data VALUES ('{timestamp}', {temperature}, {humidity}, {pressure}, {sensor_id}, '{data_center}');"statements.append(statement)return statements
# 主函数
if __name__ == "__main__":# 生成100数据中心的数据data_center_100 = generate_insert_statements("100数据中心", 100, 50, random.randint(1, 2))# 生成102数据中心的数据data_center_102 = generate_insert_statements("102数据中心", 102, 50, random.randint(1, 2))# 合并结果all_statements = data_center_100 + data_center_102# 输出到文件或打印with open("insert_statements.sql", "w",encoding="UTF8") as f:for statement in all_statements:f.write(statement + "\n")print("SQL插入语句已生成并保存到 insert_statements.sql 文件中!")
生成的内容如下:
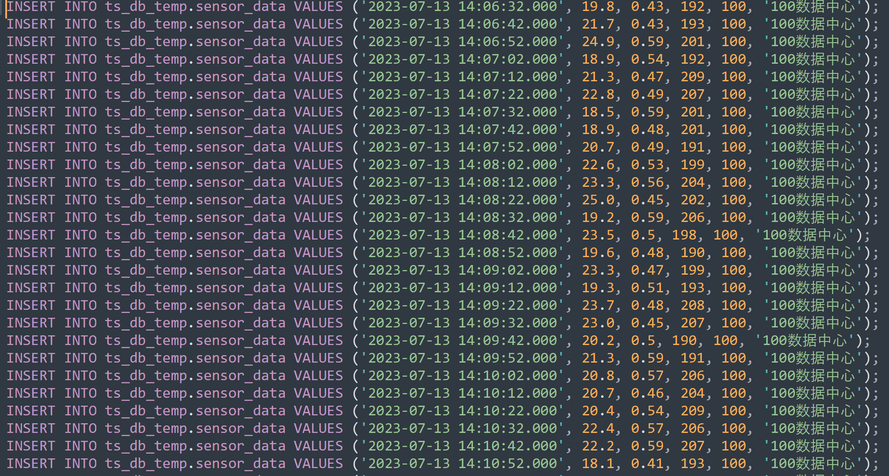
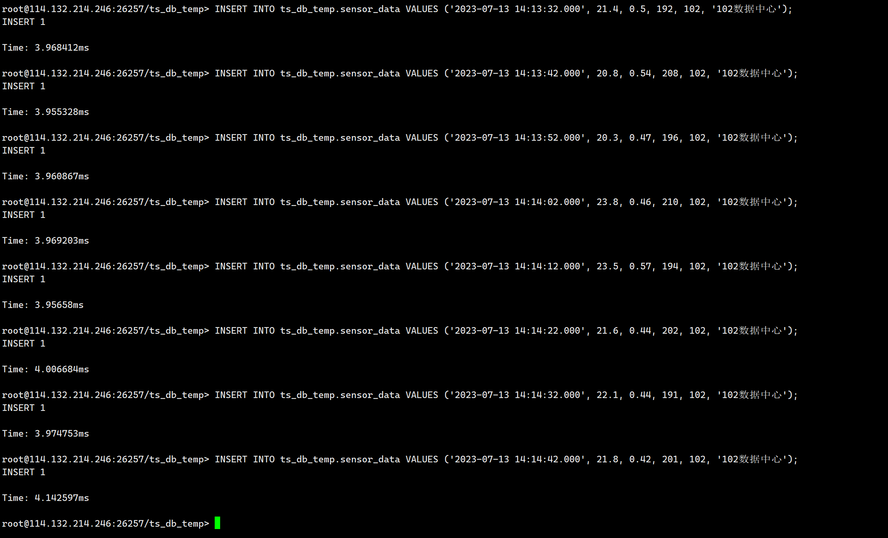
把代码复制到KWDB的客户端,并执行
输出如下:
3.查询数据
查看100的数据
SELECT * FROM ts_db_temp.sensor_data WHERE sensor_id=100;
输出如下:
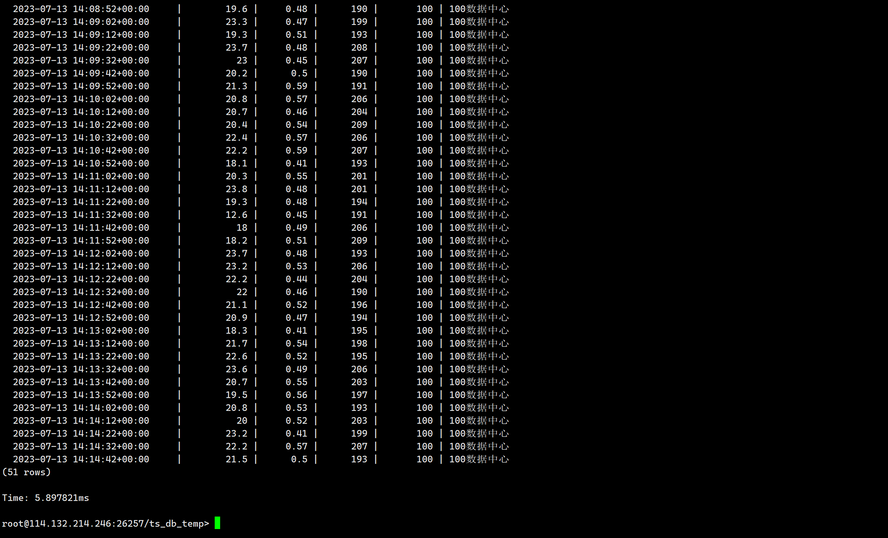
查看101的数据
SELECT * FROM ts_db_temp.sensor_data WHERE sensor_id=102;
输出如下:
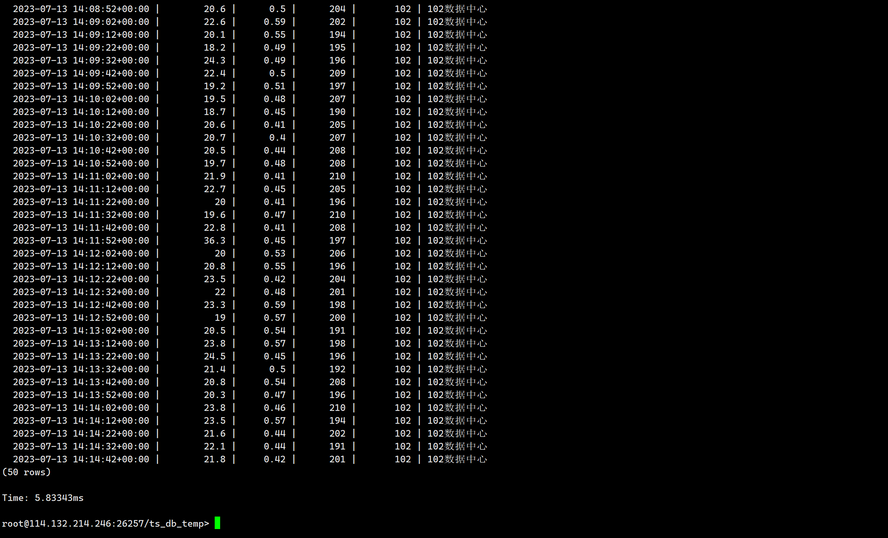
4.删除数据
DELETE FROM ts_db_temp.sensor_data WHERE k_timestamp in ('2023-07-13 14:14:02', '2023-07-13 14:15:42');
输出如下:

5.复杂查询
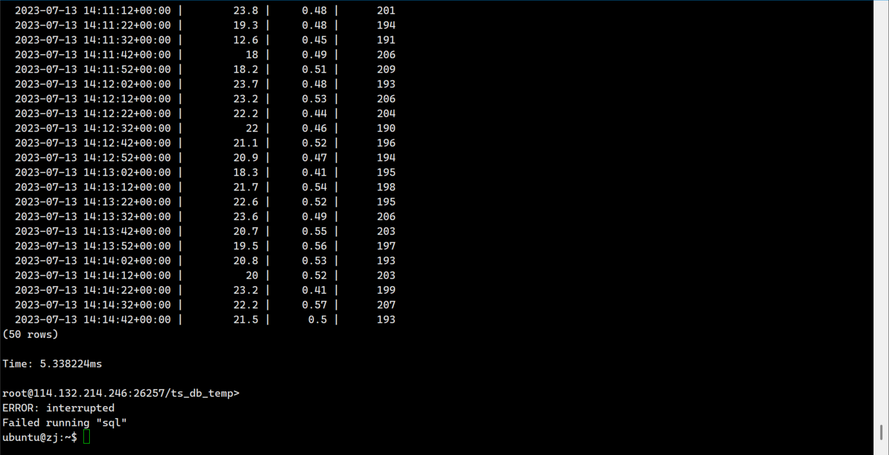
对sensor_id为100的进行按照k_timestamp进行排序
SELECT k_timestamp,temperature,humidity,pressure FROM ts_db_temp.sensor_data WHERE sensor_id=100 ORDER BY k_timestamp;
输出如下:
2023-07-13 14:14:22+00:00 | 23.2 | 0.41 | 199
2023-07-13 14:14:32+00:00 | 22.2 | 0.57 | 207
2023-07-13 14:14:42+00:00 | 21.5 | 0.5 | 193
(50 rows)
Time: 5.338224ms
按照temperature进行分组,并统计每个temperature出现的次数,然后按照temperature排序
SELECT temperature,count(temperature) FROM ts_db_temp.sensor_data WHERE sensor_id=100 GROUP BY temperature ORDER BY temperature;
输出如下:
root@114.132.214.246:26257/ts_db_temp> SELECT temperature,count(temperature) FROM ts_db_temp.sensor_data WHERE sensor_id=100 GROUP BY temperature ORDER BY temperature;
temperature | count
--------------±-------
12.6 | 118 | 118.1 | 118.2 | 118.3 | 118.5 | 118.9 | 2...24.9 | 125 | 1
(37 rows)
Time: 6.048762ms
按照temperature进行分组,并统计每个temperature出现的次数,然后按照temperature 出现的次数降序排序
SELECT temperature,count(temperature) AS tem_nums FROM ts_db_temp.sensor_data WHERE sensor_id=100 GROUP BY temperature ORDER BY tem_nums DESC;
输出如下:
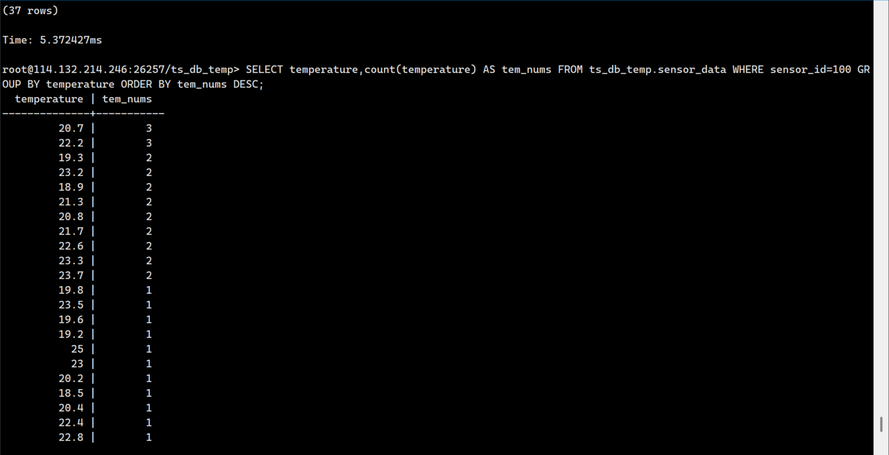
Python操作KWDB数据库
基于编程语言访问操作KWDB数据库的方法可以参考如下:
https://www.kaiwudb.com/kaiwudb_docs/#/development/overview.html
1.安装Python依赖
Psycopg 是PostgreSQL 数据库适配器,专为 Python 编程语言而设计。Psycopg 完全遵循 Python DB API 2.0 规范,支持线程安全,允许多个线程共享同一连接,特别适合高并发和多线程的应用场景。
KaiwuDB 支持用户通过 Psycopg 3 连接数据库,并执行创建、插入和查询操作。本示例演示了如何通过 Psycopg 3 驱动连接和使用 KaiwuDB。
本示例使用的 Python 版本为 Python 3.12。
pip3 install "psycopg[binary]"
输出如下:
Installing collected packages: tzdata, typing-extensions, psycopg-binary, psycopg
Successfully installed psycopg-3.2.6 psycopg-binary-3.2.6 typing-extensions-4.13.2 tzdata-2025.2
创建名为 example-psycopg3-app.ipynb 文件
2.KWDB数据库设置密码
Python连接KWDB数据库时,需要指定密码,现在给KWDB设置密码。
1)root 用户登录 defaultdb 数据库。
2)root 用户创建用户并为用户设置密码。
以下示例创建 user1 用户,并为 user1 用户设置密码。
CREATE USER user1 WITH PASSWORD '11aa!!AA';
3)给user1用户配置基于密码的认证参数。
授权的语法格式如图所示
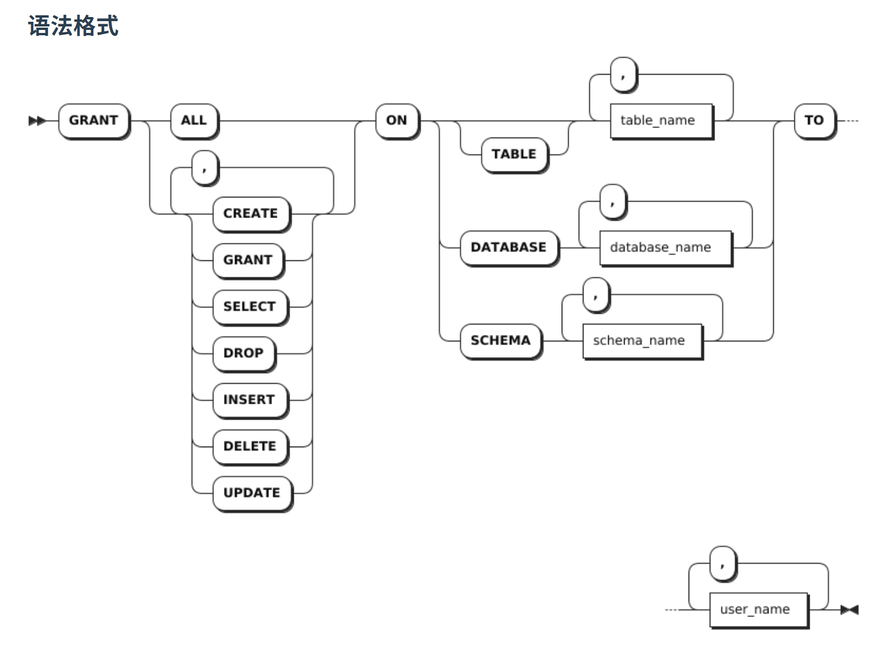
以下示例允许 user1 用户使用密码登录 ts_db_temp 数据库。
GRANT ALL ON DATABASE ts_db_temp, defaultdb TO user1;
输出如下:

查看数据库权限
SHOW GRANTS ON DATABASE ts_db_temp;
以下示例允许 user1 用户使用密码访问 ts_db_temp 数据库的sensor_data表。
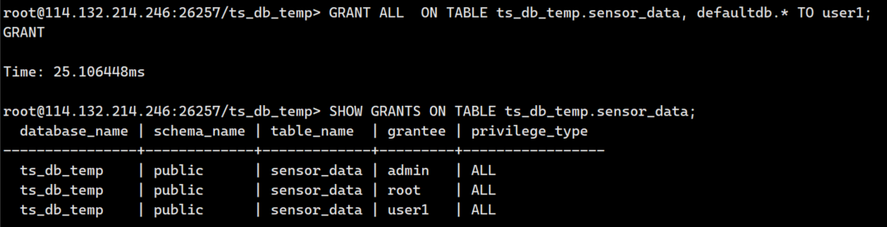
GRANT ALL ON TABLE ts_db_temp.sensor_data, defaultdb.* TO user1;
查看 sensor_data表的权限:
SHOW GRANTS ON TABLE ts_db_temp.sensor_data;
输出如下:
3.Python连接KWDB数据库
python代码如下:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import psycopg
def main():con=Nonecur=None# 指定数据库url user1是用户名 11aa!!AA是密码url = "postgresql://user1:11aa!!AA@114.132.214.246:26257/ts_db_temp"# for secure connection mode# url = "postgresql://root@127.0.0.1:26257/defaultdb"# url += "?sslrootcert=D:\\Tools\\test\\example-app-c\\example-app-cpp\\ca.crt"# url += "&sslcert=D:\\Tools\\test\\example-app-c\\example-app-cpp\\client.root.crt"# url += "&sslkey=D:\\Tools\\test\\example-app-c\\example-app-cpp\\client.root.key"print(url)try:# 连接数据库con = psycopg.connect(url, autocommit=True)print(" 连接数据库 Connected!")cur = con.cursor()except psycopg.Error as e:# 连接数据库失败print(f"连接 Kaiwudb 失败: {e}")# 建表语句# Failed to create db/table: only users with the admin role are allowed to CREATE DATABASE# sql_db = "CREATE DATABASE IF NOT EXISTS ts_db_temp"# sql_table = "CREATE TABLE IF NOT EXISTS ts_db_temp.table1 \# (k_timestamp timestamp NOT NULL, \# voltage double, \# current double, \# temperature double \# ) TAGS ( \# number int NOT NULL) \# PRIMARY TAGS(number) \# ACTIVETIME 3h"# try:# cur.execute(sql_db)# cur.execute(sql_table)# except psycopg.Error as e:# print(f"Failed to create db/table: {e}")# 插入数据sql_insert = "INSERT INTO ts_db_temp.sensor_data VALUES ('2023-07-14 14:14:42.000', 21.8, 0.42, 201, 102, '102数据中心');"try:cur.execute(sql_insert)except psycopg.Error as e:print(f"Failed to insert data: {e}")sql_seclet = "SELECT * from ts_db_temp.sensor_data"try:cur.execute(sql_seclet)rows = cur.fetchall()for row in rows:print(f"k_timestamp: {row[0]}, temperature: {row[1]}, humidity: {row[2]}, pressure: {row[3]}, sensor_id: {row[4]}, sensor_type: {row[5]}")except psycopg.Error as e:print(f"Failed to insert data: {e}")cur.close()con.close()return
if __name__ == "__main__":main()
输出如下:

实战案例Python读取KWDB数据库,并完成时序数据预测
Python已经完成的KWDB数据库的连接测试,下面进行一个案例模拟:
生成1000条插入输入数据,要求包含100数据中心,时间戳以每小时粒度生成一条数据,其中每间隔7天,当天的温度出现5-8次的异常值,
生成数据的Python代码如下:
import random
from datetime import datetime, timedelta
# 定义函数生成时间戳序列
def generate_timestamps(start_time, count):timestamps = []current_time = start_timefor _ in range(count):timestamps.append(current_time.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]) # 保留到毫秒current_time += timedelta(hours=1) # 每条记录间隔1小时return timestamps
# 定义温度、湿度和压力的正常范围
def generate_normal_values():temperature = round(random.uniform(18.0, 25.0), 1)humidity = round(random.uniform(0.4, 0.6), 2)pressure = random.randint(190, 210)return temperature, humidity, pressure
# 插入异常值
def generate_abnormal_temperature():return round(random.uniform(30.0, 40.0), 1) if random.random() > 0.5 else round(random.uniform(10.0, 15.0), 1)
# 主函数
if __name__ == "__main__":# 初始参数start_time = datetime(2023, 7, 13, 14, 0, 0) # 起始时间total_records = 1000 # 总记录数sensor_id = 100data_center = "100数据中心"# 生成时间戳timestamps = generate_timestamps(start_time, total_records)# 初始化结果列表insert_statements = []# 遍历时间戳并生成数据for i, timestamp in enumerate(timestamps):# 判断是否是每隔7天的当天is_seventh_day = (start_time + timedelta(hours=i)).day % 7 == 0if is_seventh_day:# 每隔7天的当天,随机生成5-8次异常值abnormal_count = random.randint(5, 8)if i % 24 < abnormal_count: # 前 abnormal_count 条为异常值temperature = generate_abnormal_temperature()else:temperature, humidity, pressure = generate_normal_values()else:# 正常值temperature, humidity, pressure = generate_normal_values()# 构造插入语句statement = (f"INSERT INTO ts_db_temp.sensor_data VALUES ('{timestamp}', {temperature}, {humidity}, {pressure}, "f"{sensor_id}, '{data_center}');")insert_statements.append(statement)# 输出到文件或打印with open("insert_statements.sql", "w",encoding="UTF8") as f:for statement in insert_statements:f.write(statement + "\n")print("SQL插入语句已生成并保存到 insert_statements.sql 文件中!")
生成的插入语句部分如下
– 正常数据
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-13 14:00:00.000’, 20.0, 0.50, 200, 100, ‘100数据中心’);
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-13 15:00:00.000’, 21.5, 0.55, 201, 100, ‘100数据中心’);
– 第7天的异常数据
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-20 00:00:00.000’, 35.0, 0.50, 200, 100, ‘100数据中心’); – 异常值
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-20 01:00:00.000’, 10.0, 0.50, 200, 100, ‘100数据中心’); – 异常值
…
– 第14天的正常数据
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-27 14:00:00.000’, 22.0, 0.45, 205, 100, ‘100数据中心’);
…
安装python的依赖库
pip install pandas matplotlib statsmodels -i https://pypi.tuna.tsinghua.edu.cn/simple
输出如下:
Successfully installed contourpy-1.3.1 cycler-0.12.1 fonttools-4.57.0 kiwisolver-1.4.8 matplotlib-3.10.1 numpy-2.2.4 packaging-24.2 pandas-2.2.3 patsy-1.0.1 pillow-11.2.1 pyparsing-3.2.3 python-dateutil-2.9.0.post0 pytz-2025.2 scipy-1.15.2 six-1.17.0 statsmodels-0.14.4
把数据插入到KWDB中,然后用Python读取,并进行时间预测,如下:
首先连接数据库
import psycopg
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
con=None
cur=None
# 指定数据库url user1是用户名 11aa!!AA是密码
url = "postgresql://user1:11aa!!AA@114.132.214.246:26257/ts_db_temp"
try:# 连接数据库con = psycopg.connect(url, autocommit=True)print(" 连接数据库 Connected!")cur = con.cursor()
except psycopg.Error as e:# 连接数据库失败print(f"连接 Kaiwudb 失败: {e}")
# 数据库查询代码
sql_select = "SELECT * FROM ts_db_temp.sensor_data"
输出如下:
连接数据库 Connected!
df=None
# 数据库查询代码
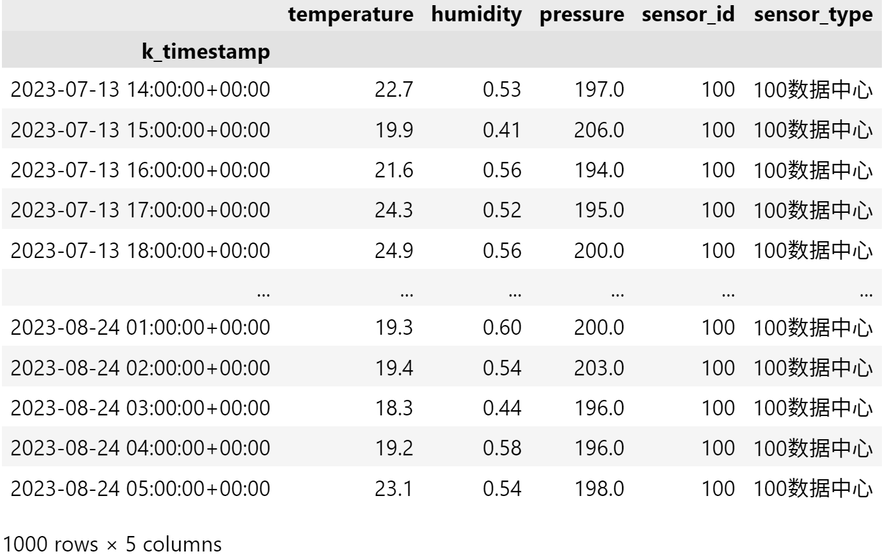
try:# 假设已经建立数据库连接 conn 和游标 curcur.execute(sql_select)rows = cur.fetchall()# 将查询结果转换为 Pandas DataFramedf = pd.DataFrame(rows, columns=["k_timestamp", "temperature", "humidity", "pressure", "sensor_id", "sensor_type"])# 确保时间戳列为 datetime 类型df["k_timestamp"] = pd.to_datetime(df["k_timestamp"])# 设置时间戳为索引df.set_index("k_timestamp", inplace=True)print("数据加载成功!")
except psycopg.Error as e:print(f"Failed to fetch data: {e}")
df
输出如下:
数据加载成功!
异常与窗口检测
# 异常检测函数
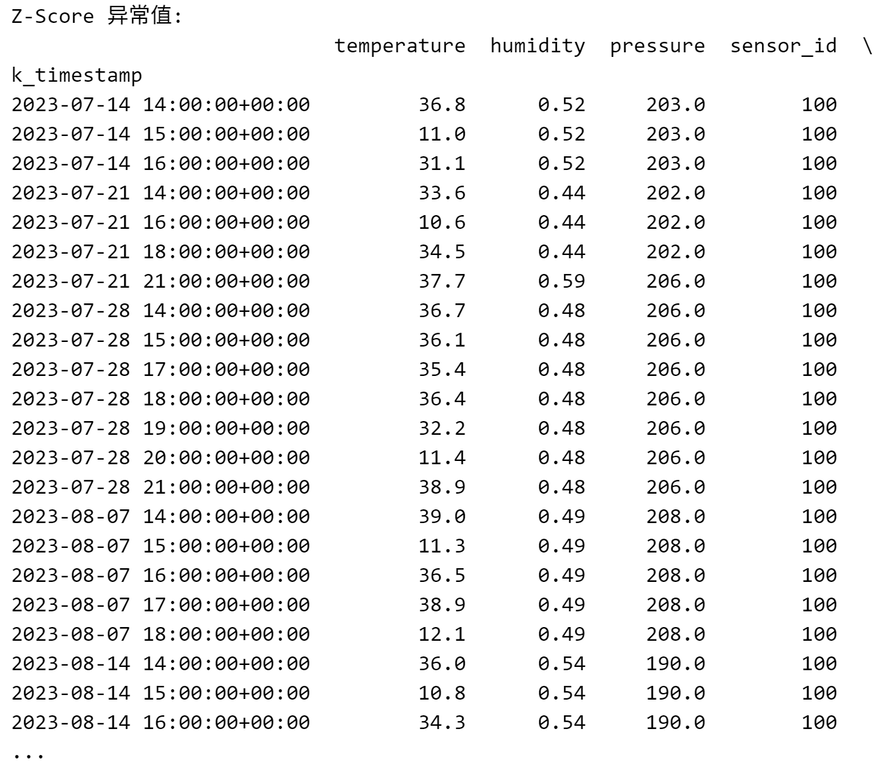
def detect_anomalies_zscore(data, threshold=3):mean = data.mean() # 计算数据的平均值std = data.std() # 计算数据的标准差anomalies = data[(data - mean).abs() > threshold * std] # 找出与平均值差异超过阈值倍标准差的点return anomalies # 返回异常值
def detect_anomalies_rolling(data, window=24, threshold=2):rolling_mean = data.rolling(window=window).mean() # 计算滚动窗口的平均值rolling_std = data.rolling(window=window).std() # 计算滚动窗口的标准差anomalies = data[(data - rolling_mean).abs() > threshold * rolling_std] # 找出偏离滚动均值超过阈值倍标准差的值return anomalies # 返回异常值
检测与查看异常值
# 检测异常值
df["anomaly_zscore"] = detect_anomalies_zscore(df["temperature"])
df["anomaly_rolling"] = detect_anomalies_rolling(df["temperature"])
# 查看异常值
print("Z-Score 异常值:")
print(df[df["anomaly_zscore"].notnull()])
print("\n滚动窗口异常值:")
print(df[df["anomaly_rolling"].notnull()])
输出如下:
划分训练集与测试集
# 时间序列预测
temperature_series = df["temperature"]
train_size = int(len(temperature_series) * 0.8)
train, test = temperature_series[:train_size], temperature_series[train_size:]
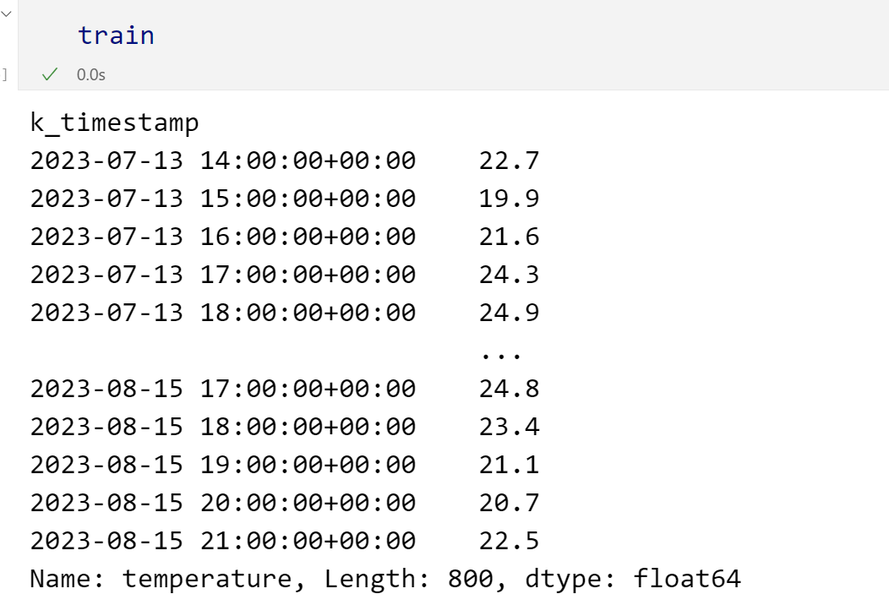
查看训练集train
输出如下:
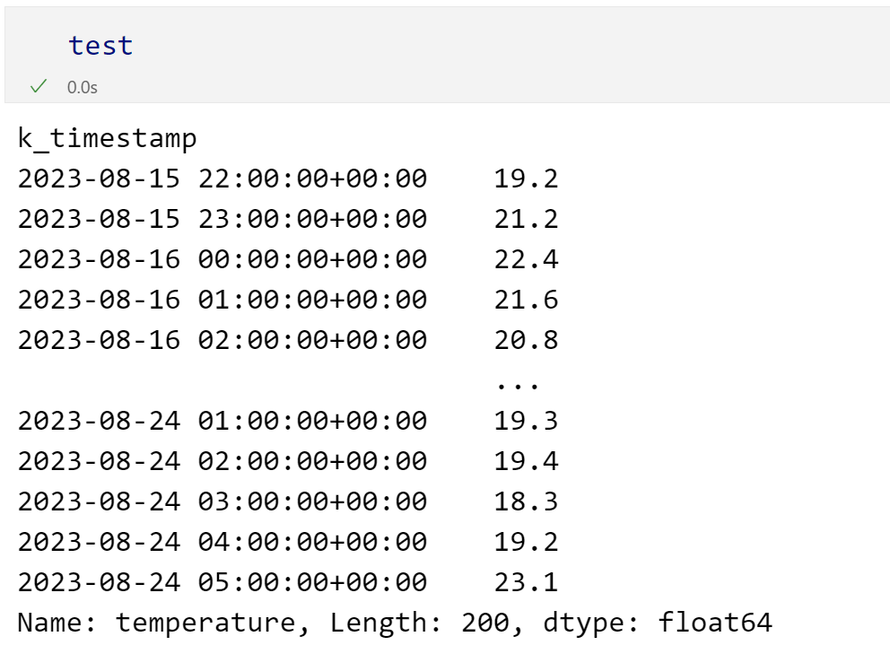
查看测试集
test
输出如下:
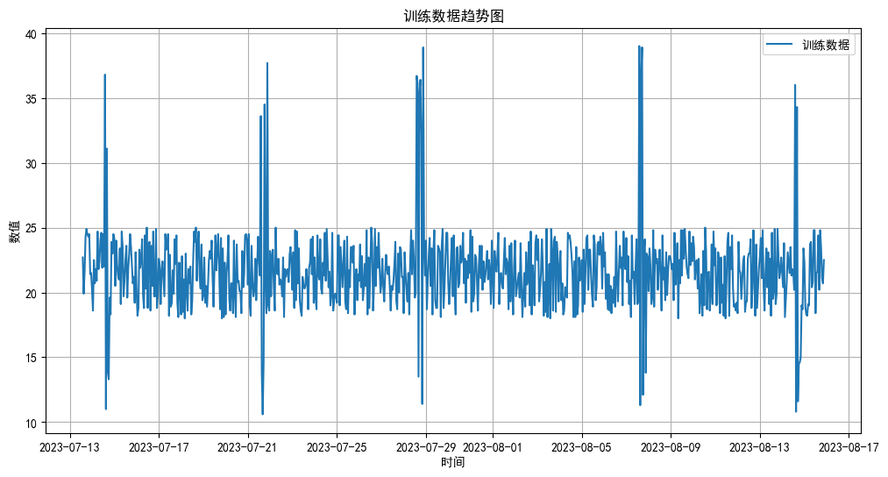
对训练数据进行可视化操作
# 训练数据可视化
# 设置中文显示和负数显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(12, 6))
plt.plot(train, label='训练数据')
plt.title('训练数据趋势图')
plt.xlabel('时间')
plt.ylabel('数值')
plt.legend()
plt.grid(True)
plt.show()
输出如下:
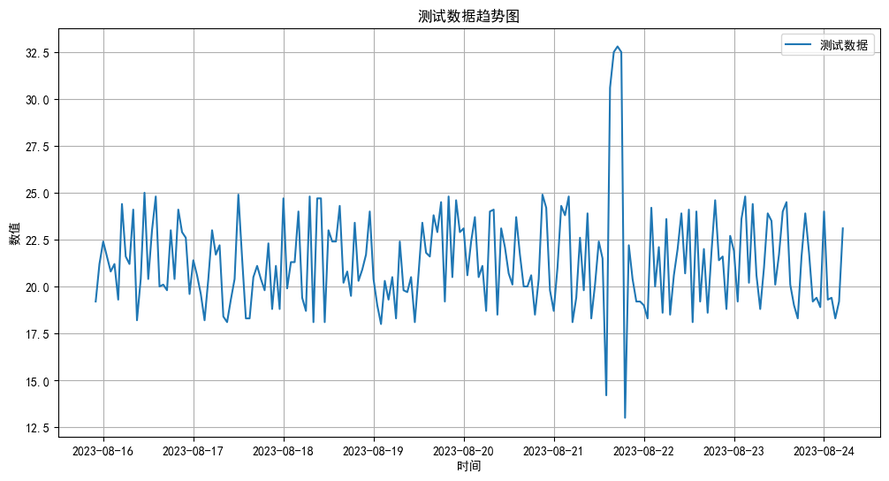
对测试集进行可视化操作
# 训练数据可视化
# 设置中文显示和负数显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(12, 6))
plt.plot(test, label='测试数据')
plt.title('测试数据趋势图')
plt.xlabel('时间')
plt.ylabel('数值')
plt.legend()
plt.grid(True)
plt.show()
输出如下:
查看季节性分解
# 方案2:季节性分解
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df["temperature"], model='additive', period=24)
result.plot()
# 可以看到存在季节性
输出如下:
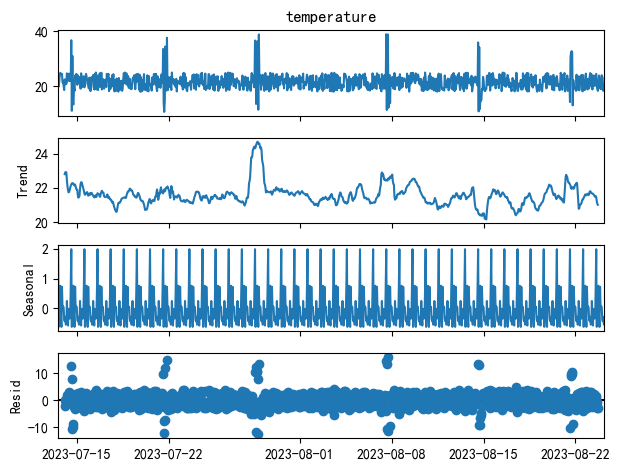
使用季节性算法
from statsmodels.tsa.statespace.sarimax import SARIMAX
# (p,d,q)为非季节性参数,(P,D,Q,24)为季节性参数
model = SARIMAX(train.asfreq('h'), order=(1,1,1), seasonal_order=(1,1,1,24))
model_fit = model.fit()
预测未来值
预测未来值
forecast_steps = len(test)
forecast = model_fit.forecast(steps=forecast_steps)
查看预测结果
# 可视化预测结果
plt.figure(figsize=(12, 6))
plt.plot(test.index, test, label="实际值")
plt.plot(test.index, forecast, label="预测值", color="red")
plt.title("温度预测")
plt.xlabel("时间")
plt.ylabel("温度")
plt.legend()
plt.show()
输出如下:
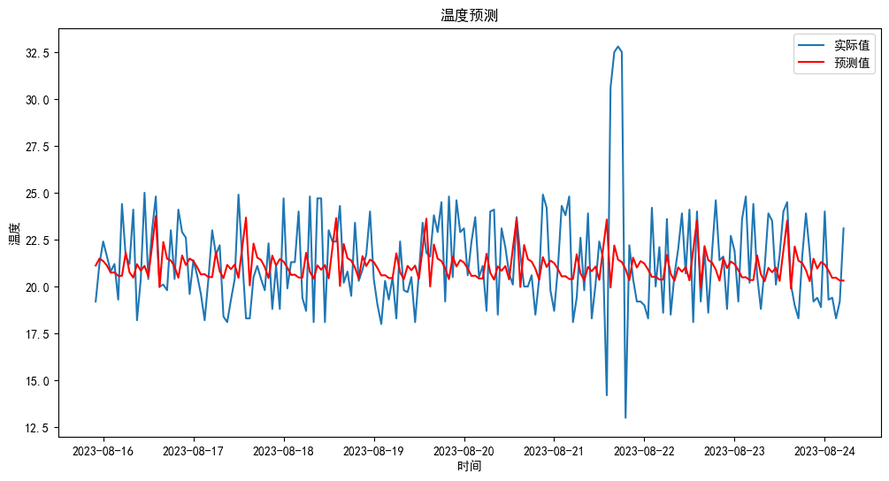
到此基于Python针对KWDB中的时序数据的完整预测过程已经完成,进一步的优化步骤,这里不再拓展
打完收工,感谢你看到这了,这个博客花了很久,未来在使用过程中,再进一步分享。
相关文章:

【KWDB创作者计划】_KWDB应用之实战案例
【KWDB 2025 创作者计划】_KWDB应用之实战案例 本文是在完成KWDB数据库安装的情况下的操作篇,关于KWDB的介绍与安装部署,可以查看上一篇博客: https://blog.itpub.net/70045384/viewspace-3081187/ https://blog.csdn.net/m0_38139250/article/details/…...

JavaScript中的运算符与语句:深入理解编程的基础构建块
# JavaScript中的运算符与语句:深入理解编程的基础构建块 在JavaScript编程的世界里,运算符和语句就像是构建大厦的基石,它们是编写高效、灵活代码的基础。今天,我们就来深入了解一下这些重要的元素。 ## 一、运算符:…...
)
MySQL——学习InnoDB(1)
MySQL——学习InnoDB(1) 文章目录 MySQL——学习InnoDB(1)1. InnoDB的前世今生1.1 诞生发展1.2 核心设计1.3 关键进化 2. InnoDB和MyISAM在性能和安全上的区别2.1 性能对比2.2 安全对比 3. InnoDB架构图(内存结构磁盘结…...

QT中多线程写法
转自个人博客:QT中多线程写法 1. QThread及moveToThread() 使用情况: 多使用于需要将有着复杂逻辑或需要一直占用并运行的类放入子线程中执行的情况,moveToThread是将整个类的对象移入子线程。 优缺点: 优点:更符合…...

css 二维码始终显示在按钮的正下方,并且根据不同的屏幕分辨率自动调整位置
一、需求 “求职入口” 下面的浮窗位置在其正下方,并且浏览器分辨的改变(拖动浏览器),位置依旧在最下方 二、实现 <div class"btn_box"><div class"btn_link id"js-apply">求职入口<di…...

STM32 认识STM32
目录 什么是嵌入式? 认识STM32单片机 开发环境安装 安装开发环境 开发板资源介绍 单片机开发模式 创建工程的方式 烧录STM32程序 什么是嵌入式? 1.智能手环项目 主要功能有: 彩色触摸屏 显示时间 健康信息:心率&#…...
 和 智能体功能 的具体说明及对比分析)
关于 CSDN的C知道功能模块 的详细解析,包括 新增的AI搜索(可选深度思考) 和 智能体功能 的具体说明及对比分析
以下是关于 CSDN的C知道功能模块 的详细解析,包括 新增的AI搜索(可选深度思考) 和 智能体功能 的具体说明及对比分析: 一、C知道核心功能模块详解(基础功能) (参考前文内容,此处略…...

Vue--组件练习案例
图片轮播案例: <!DOCTYPE html><html lang"en"><head><meta charset"UTF-8"><title>Title</title></head><body><!--轮播图片--><div id"app"><h1>轮播图</h1…...

Sentinel源码—1.使用演示和简介一
大纲 1.Sentinel流量治理框架简介 2.Sentinel源码编译及Demo演示 3.Dashboard功能介绍 4.流控规则使用演示 5.熔断规则使用演示 6.热点规则使用演示 7.授权规则使用演示 8.系统规则使用演示 9.集群流控使用演示 1.Sentinel流量治理框架简介 (1)与Sentinel相关的问题 …...
)
空间信息可视化——WebGIS前端实例(二)
技术栈:原生HTML 源代码:CUGLin/WebGIS: This is a project of Spatial information visualization 5 水质情况实时监测预警系统 5.1 系统设计思想 水安全是涉及国家长治久安的大事。多年来,为相应国家战略,诸多地理信息领域的…...
)
高并发内存池(前言介绍)
高并发内存池项目介绍 1.项目介绍2.项目的知识储备要求3.了解池化技术及内存池4.本次项目中内存池解决的问题5.malloc 1.项目介绍 此项目是实现一个高并发的内存池,它的原型是google的一个开源项目tcmalloc,tcmalloc全程Thread-Caching Mallocÿ…...

误译、值对象和DDD伪创新-《分析模式》漫谈56
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 “Analysis Patterns”的第14章“类型模型设计模板模式”原文: Examples of such object types are the classic built-in data types of programming environments: inte…...

Java单例模式:实现全局唯一对象的艺术
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、什么是单例模式? 单例模式(Singleton Pattern)是一种创建型设计模式,确保一个类只有一个实例,…...

机器学习项目二:帕金森病检测
目录 下载数据 一、导入相关包 二、数据加载 三、特征工程 四、构建模型 五、评估与可视化 六、程序流程 七、完整代码 一、导入相关包 # 导入库部分 import numpy as np # 数值计算基础库 import pandas as pd # 数据处理库 from sklearn.preprocessing import MinMaxS…...

FreeDogs:AI、区块链与迷因文化的深度融合
引言 在 Web3 时代,人工智能(AI)、区块链技术和迷因文化的结合催生了一种全新的去中心化生态系统。FreeDogs 项目作为这一领域的创新代表,通过独特的技术与文化融合模式迅速受到关注。它利用 AI 驱动的智能营销网络推动迷因文化的…...

《组合优于继承:构建高内聚低耦合模块的最佳实践》
《组合优于继承:构建高内聚低耦合模块的最佳实践》 一、引言:编程范式中的选择 在软件设计中,继承和组合是两个重要的设计模式。继承(Inheritance)常被用来实现代码复用,但滥用继承容易导致脆弱的类层次结构,增加耦合度和维护成本。而组合(Composition)通过将功能分解…...

机器学习02——RNN
一、RNN的基本概念 定义 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络架构。它与传统的前馈神经网络(如多层感知机)不同,RNN具有“记忆”功能,能够利用前一时…...

Java基础——面试自我总结
1、String类中常用方法和equals区别 答:对于和equals这两个都是用来比较判断是否相等,其中用来判断两个变量的值是否相等,变量的值的类型分为基本数据类型和引用数据类型。对于,基本数据类型是直接进行值比较,而对于引…...
)
低功耗设计:Level Shift的种类(以SAED EDK 32/28nm工艺库为例)
在多电压设计中,当信号从一个电压域跨越到另一个电压域时,需要使用电压转换器(Level Shift)。它的工作方式类似于缓冲器,但其输入和输出使用不同的电压,作用是将一个逻辑信号从一个电压转换为另一个电压,并在输入到输出…...
 和模拟网格体 是如何关联的?为什么模拟网格体 可以驱动渲染网格体?)
UE5 Chaos :渲染网格体 (Render Mesh) 和模拟网格体 是如何关联的?为什么模拟网格体 可以驱动渲染网格体?
官方文献:https://dev.epicgames.com/community/learning/tutorials/pv7x/unreal-engine-panel-cloth-editor 这背后的核心是一种常见的计算机图形学技术,通常称为代理绑定 (Proxy Binding) 或 表面变形传递 (Surface Deformation Transfer)。 关联机制…...

Fiddler为什么可以看到一次HTTP请求数据?
1、作为代理服务器 Fiddler作为代理服务器,拦截了设备与互联网服务器之间的所有HTTP和HTTPS流量。当客户端(如浏览器)发送请求时,请求先到达Fiddler,然后由Fiddler转发到目标服务器;服务器的响应也会返回给…...
召回算法是检索增强生成模型中的关键组件)
RAG(Retrieval-Augmented Generation)召回算法是检索增强生成模型中的关键组件
RAG(Retrieval-Augmented Generation)召回算法是检索增强生成模型中的关键组件,其核心目标是从大规模文档库中高效检索与输入查询相关的信息,以辅助生成模型产生更准确的回答。以下是该算法的关键点解析: ### 1. **核…...

[NOIP 2003 普及组] 栈 Java
import java.io.*;public class Main {public static void main(String[] args) throws IOException {BufferedReader br new BufferedReader(new InputStreamReader(System.in));int n Integer.parseInt(br.readLine());int[] dp new int[n 1];dp[0] 1; // 空序列只有一种…...

5.5 GitHub数据秒级分析核心揭秘:三层提示工程架构设计解析
GitHub Sentinel Agent 分析报告功能设计与实现 关键词:GitHub 数据分析, 提示工程设计, Pull Request 分析, Issues 跟踪, 竞品对比 项目进展报告生成功能设计 报告生成模块是 GitHub Sentinel 的核心功能,通过三层嵌套式提示工程架构实现深度分析: #mermaid-svg-vdHRUan…...
绑定导入表)
PE文件(十五)绑定导入表
我们在分析Windows自带的一些程序时,常常发现有的程序,如notepad,他的IAT表在文件加载内存前已经完成绑定,存储了函数的地址。这样做可以使得程序是无需修改IAT表而直接启动,这时程序启动速度变快。但这种方式只适用于…...

如何快速部署基于Docker 的 OBDIAG 开发环境
很多开发者对 OceanBase的 SIG社区小组很有兴趣,但如何将OceanBase的各类工具部署在开发环境,对于不少开发者而言都是比较蛮烦的事情。例如,像OBDIAG,其在WINDOWS系统上配置较繁琐,需要单独搭建C开发环境。此外&#x…...

Multimodal-CoT与MCP的融合医疗AI编程路线探析
引言 在医疗AI领域,多模态数据融合与模块化系统设计是提升诊断精度和临床实用性的关键。Multimodal Chain-of-Thought(Multimodal-CoT)通过构建多源数据的推理链增强决策透明度,而Model Context Protocol(MCP)作为标准化接口协议,为AI系统提供灵活的数据源集成能力。两…...

基于单片机的智能养生油炸炉系统设计与实现
标题:基于单片机的智能养生油炸炉系统设计与实现 内容:1.摘要 本文针对传统油炸炉功能单一、无法满足现代养生需求的问题,设计并实现了基于单片机的智能养生油炸炉系统。通过采用STC89C52单片机作为控制核心,结合温度传感器、液位传感器、继电器等硬件&…...

MySQL流程控制
一:介绍 在 MySQL 中,流程控制语句用于控制存储过程和自定义函数中的程序流程。主要的流程控制语句包括:IF 语句、CASE 语句、LOOP 语句、LEAVE 语句、ITERATE 语句、REPEAT 语句和 WHILE 语句 (1):if条件…...

在思科模拟器show IP route 发现Gateway of last resort is not set没有设置最后的通道
如果在show ip route的时候出现没有设置最后的通道Gateway of last resort is not set Switch#show ip route Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA exte…...

Java雪花算法
以下是用Java实现的雪花算法代码示例,包含详细注释和异常处理: 代码下面有解析 public class SnowflakeIdGenerator {// 起始时间戳(2020-01-01 00:00:00)private static final long START_TIMESTAMP 1577836800000L;// 各部分…...

【中大厂面试题】TCP 校招 java 后端最新面试题
TCL(一面) 1. Spring 初始化Bean前要做什么?有几种方式 在 Spring 容器调用 Bean 的初始化方法(如 init-method、PostConstruct 等)之前,会按顺序完成以下关键步骤:实例化 → 属性注入 → Aw…...

【教学类-102-11】蝴蝶外轮廓01——Python对黑白图片进行PS填充三种颜色+图案描边+图案填充白色+制作1图2图6图24图
背景需求: 用Python,对白色255背景的图片进行了透明化、制作点状或线段的描边裁剪线 【教学类-102-10】剪纸图案全套代码09——Python线条虚线优化版04(原图放大白背景)+制作1图2图6图24图-CSDN博客文章浏览阅读1k次,点赞27次,收藏8次。【教学类-102-10】剪纸图案全套代…...
视图(超详细))
【数据库系统概论】第3章 SQL(四)视图(超详细)
视图(View)是数据库中的虚拟表 通过执行查询定义并存储在数据库中,可以像普通表一样被查询和使用。 视图本身并不存储数据,而是基于一个或多个表的查询结果动态生成。 视图的概念 视图( View )是由其它表或视图上的查询所定义…...

HTTP:六.HTTP代理相关介绍
什么是HTTP代理 代理是指获授权代表他人执行操作的人员,代理服务器在在线世界中提供此操作。 代理服务器 充当用户和互联网之间的网关,并防止访问网络以外的任何人。通过 Web 浏览器定期访问互联网,使用户能够直接与网站连接。但是代理充当中间人,代表用户与网页通信。 当…...

【Python爬虫】详细工作流程以及组成部分
目录 一、Python爬虫的详细工作流程 确定起始网页 发送 HTTP 请求 解析 HTML 处理数据 跟踪链接 递归抓取 存储数据 二、Python爬虫的组成部分 请求模块 解析模块 数据处理模块 存储模块 调度模块 反爬虫处理模块 一、Python爬虫的详细工作流程 在进行网络爬虫工…...

深入解析UML图:版本演变、静态图与动态图详解
目录 前言1 UML的版本演变1.1 UML 1.x阶段:统一的开始1.2 UML 2.x阶段:功能的扩展与深化 2 UML图的分类概述3 UML静态图详解3.1 类图(Class Diagram)3.2 对象图(Object Diagram)3.3 组件图(Comp…...

老旧测试用例生成平台异步任务与用户通知优化
在现代 Web 开发中,异步任务处理和用户通知是两个重要的功能。由于老旧测试平台【测试用例生成平台,源码分享】进行智能化升级后,未采用异步任务处理,大模型推理时间较长,导致任务阻塞,无法处理其他任务&am…...

数据结构初阶:队列
本篇博客主要讲解队列的相关知识。 目录 1.队列 1.1 概念与结构 1.2 队列头文件(Queue.h) 1.2.1 定义队列结点结构 1.2.2 定义队列的结构 1.3 队列源代码(Queue.h) 1.3.1 队列的初始化 1.3.2 队列的销毁 1.3.3 入队---队尾 1…...

苍穹外卖。12 数据统计
12.1 工作台 12.1.1 需求分析与设计 12.1.2 代码导入 12.1.3 测试 测试通过 12.2 Apache POI 12.2.1 需求分析与设计 12.2.2 案例 column表示索引行...

WebSocket 和 HTTP长轮询
一、HTTP长轮询(Long Polling) 1. 工作原理 传统轮询(低效):客户端每隔几秒向服务器发一次请求,问“有新数据吗?”,即使服务器没有数据也会立即返回“无”。长轮询(改进…...

高等数学同步测试卷 同济7版 试卷部分 上 做题记录 第三章微分中值定理与导数的应用同步测试卷 B 卷
第三章微分中值定理与导数的应用同步测试卷 B 卷 一、单项选择题(本大题共5小题,每小题3分,总计15分) 1. 2. 3. 4. 5. 二、填空题(本大题共5小题,每小题3分,总计15 分) 6. 7. 8. 9. 10. 三、求解下列各题(本大题共5小题,每小题6分,总计 3…...
发展史与行业标准演变)
生成式引擎优化(GEO)发展史与行业标准演变
一、生成式引擎优化(GEO)发展史与行业标准演变 随着 ChatGPT、Bard、Claude、文心一言等生成式AI搜索产品快速发展,GEO(Generative Engine Optimization,生成式引擎优化)也应运而生,成为继SEO、…...

美客多自养号测评技术解析:如何低成本打造安全稳定的测评体系
美客多(MercadoLibre)自养号测评系统的搭建需综合考虑硬件、软件、网络环境及操作流程的合规性,以下是基于多篇行业指南整理的核心步骤与要点: 一、前期规划与准备 1. 明确目标与规则 • 确定测评目的(如提升产品曝…...

STM32单片机入门学习——第36节: [11-1] SPI通信协议
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.14 STM32开发板学习——第36节: [11-1] SPI通信协议 前言开发板说明引用解答和科普一…...

Qt QML - qmldir使用方法详解
以实际例子看qmldir的使用 1.搞一个qmldir2.让QML找到你的qmldir (重点).pro 工程文件QQmlApplicationEngine加载主QML处 3.用起来你的模块 qmldir是Qt QML模块化的基石,其设计初衷是为解决QML文件的组织、复用和依赖管理问题,。只需要在每个…...

AI大模型赋能工业制造:智能工厂的全新跃迁路径
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言:从自动化到智造化,工业领域的AI革命正悄然发生 在过去几十年中,制造业经历了机械化、电气化和自动化三次浪潮。如今,第四次工业革命——以人工智能、大数据、云计算、物联网为代表的“工业…...

LanDiff:赋能视频创作,语言与扩散模型的融合力量
自从 Wan 2.1 发布以来,AI 视频生成领域似乎进入了一个发展瓶颈期,但这也让人隐隐感到:“DeepSeek 时刻”即将到来!就在前几天,浙江大学与月之暗面联合推出了一款全新的文本到视频(T2V)生成模型…...

Windows 图形显示驱动开发-WDDM 1.2功能~显示设备的容器id支持
容器 ID 设备驱动程序接口 (DDI) 在显示微型端口驱动程序中实现此函数和结构: DxgkDdiGetChildContainerIdDXGK_CHILD_CONTAINER_ID 容器 ID 说明 监视设备中的新功能可以提供更好的用户体验。 具体而言,通用串行总线 (USB) 集线器是监视器上用于连…...

基于PyQt5和OpenCV的传统图像分割应用UI程序
目录 1. 程序概述 2. 用户界面设计 主窗口布局 图像显示区域 控制面板区域 3. 核心功能实现 图像处理功能 关键方法 4. 特色实现 区域生长算法改进 分水岭算法改进 GrabCut算法改进 5. 用户体验优化 6. 技术栈 7. 使用说明 8. 完整代码 9. 测试结果 本文实现了…...