【中大厂面试题】TCP 校招 java 后端最新面试题
TCL(一面)
1. Spring 初始化Bean前要做什么?有几种方式
在 Spring 容器调用 Bean 的初始化方法(如 init-method、@PostConstruct 等)之前,会按顺序完成以下关键步骤:实例化 → 属性注入 → Aware 接口回调 → BeanPostProcessor 前置处理。
-
实例化:通过构造函数或工厂方法创建 Bean 的实例。
-
属性注入:通过
setter方法、字段注入(如@Autowired)或构造器注入,完成 Bean 的依赖注入。 -
Aware 接口回调:如果 Bean 实现了 Spring 的
Aware接口,Spring 会调用对应的回调方法,使 Bean 能感知容器信息。 -
BeanPostProcessor 的前置处理:调用所有注册的
BeanPostProcessor的postProcessBeforeInitialization()方法,允许对 Bean 进行自定义修改(如代理增强)。
在初始化阶段(即上述步骤完成后),Spring 提供了以下三种主要方式来定义 Bean 的初始化逻辑:
-
使用
@PostConstruct注解:在方法上添加@PostConstruct注解,Spring 会在依赖注入完成后调用该方法。
@Component
public class MyBean {@PostConstructpublic void init() {// 初始化逻辑}
}
-
实现
InitializingBean接口:实现InitializingBean接口,并重写afterPropertiesSet()方法。
@Component
public class MyBean implements InitializingBean {@Overridepublic void afterPropertiesSet() {// 初始化逻辑}
}
-
配置
init-method:在 XML 或 Java 配置中指定自定义的初始化方法。XML 示例:
<bean id="myBean" class="com.example.MyBean" init-method="customInit"/>
Java 注解配置示例:
@Bean(initMethod = "customInit")
public MyBean myBean() {return new MyBean();
}
2. 微服务和单体的区别与优势是什么?
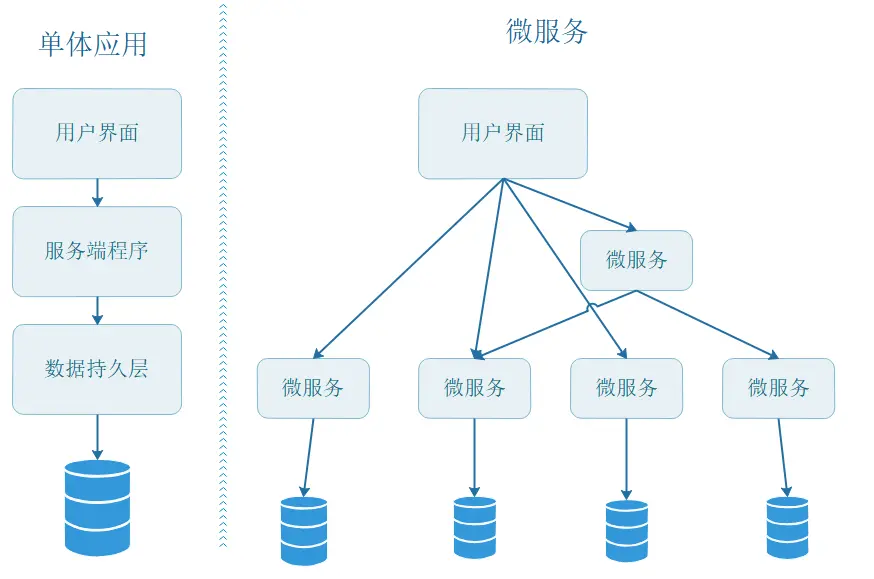
-
所有功能模块(如用户管理、订单处理、支付等)集中在一个单一的代码库中,编译为一个可执行文件或服务,共享同一个数据库和资源。单体架构适合业务简单、团队小的场景,优势是开发效率高、性能好,不过随着随着业务增长,代码库臃肿,维护会变的更困难,而且任何修改都可能影响全局,回归测试成本高。
-
将应用拆分为多个独立的、松耦合的小型服务,每个服务专注于单一业务功能,拥有独立的代码库、数据库和进程,通过API(如REST或gRPC)通信。微服务通过解耦服务实现灵活扩展和独立部署,但复杂度高,适合大型系统(如电商平台、社交网络)。
3. Spring Cloud组件有哪些?
我项目用的是Spring Cloud Alibaba,我简单说一下Spring Cloud Alibaba组件:
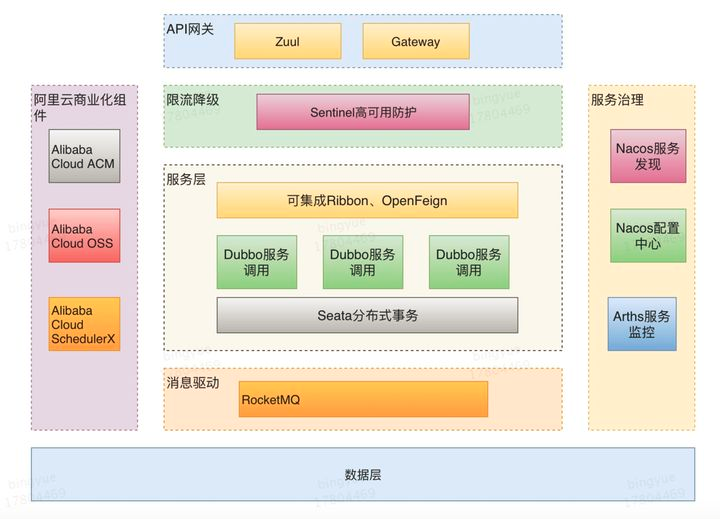
-
Nacos:其服务注册和发现功能能让服务提供者将自身服务信息注册到 Nacos 服务器,服务消费者从服务器获取服务列表,此外,Nacos 还支持配置的动态更新,可实现服务的快速上下线和配置的实时生效。
-
Sentinel:负责流量控制与熔断降级,Sentinel 可以通过配置规则对服务的流量进行精准控制,防止服务因流量过大而崩溃。同时,当服务出现异常时,它能快速进行熔断降级,保障系统的稳定性。
-
Seata;分布式事务,支持AT模式(自动补偿)、TCC、Saga等, 可以帮助开发者在微服务架构中处理分布式事务问题,确保数据的一致性。通过 Seata,开发者可以像处理本地事务一样处理分布式事务,降低了开发的复杂度。
-
RocketMQ:分布式消息队列,支持顺序消息、事务消息、延迟消息,开发者可以方便地在微服务之间进行异步通信,实现解耦和流量削峰。例如,在电商系统中,订单服务可以通过 RocketMQ 向库存服务发送消息,实现库存的扣减。
-
Dubbo:提供了高效的远程服务调用能力,支持多种协议和负载均衡策略。在微服务架构中,使用 Dubbo 可以方便地实现服务之间的远程调用,提高系统的性能和可扩展性。
-
Arthas:开源的Java动态追踪工具,基于字节码增强技术,功能非常强大。
4. Kafka 分区和消费者的关系是怎样的?
Kafka 的主题(Topic)可以被划分为多个分区(Partition),分区是物理上的概念,每个分区是一个有序的、不可变的消息序列。分区分布在不同的 broker 上,以此实现数据的分布式存储。
消费者从 Kafka 的主题中读取消息,消费者可以组成消费者组(Consumer Group),每个消费者组内有多个消费者实例。
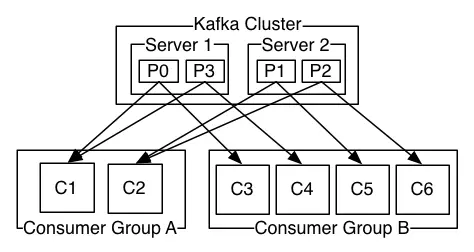
在一个消费者组内,一个分区只能被一个消费者实例消费。这种设计保证了分区内消息消费的顺序性,因为一个分区的消息只能由一个消费者按顺序处理。比如,一个主题有 3 个分区,一个消费者组中有 3 个消费者,那么这 3 个消费者会分别对应一个分区进行消息消费。
如果两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的偏移量,就有可能C1才读到2,而C1读到1,C1还没处理完,C2已经读到3了,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序。
如果消费者数量 > 分区数,多余消费者闲置,比如主题 orders 有 3 个分区(P0、P1、P2),消费者组 group-1 有 3 个消费者(C1、C2、C3):
P0 → C1
P1 → C2
P2 → C3
如果消费者组扩容到 4 个消费者,第 4 个消费者(C4)将无法分配到分区,处于空闲状态。
5. Kafka 如何批量拉取消息?
可以通过调整配置参数来实现 Kafka 批量拉取消息:
-
设置
max.poll.records:该参数用于设定一次poll操作最多拉取的消息数量。例如,在 Java 中创建KafkaConsumer实例时,通过props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 100);将其设置为 100,意味着每次poll最多拉取 100 条消息。 -
调整
fetch.max.bytes:此参数用于设置一次fetch请求能够拉取的最大数据量。如果消息体较大,可适当调大该参数,以确保能拉取到足够数量的消息。在 Java 中可通过props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 1024 * 1024);将其设置为 1MB。
6. Redis分布式锁实现原理?
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
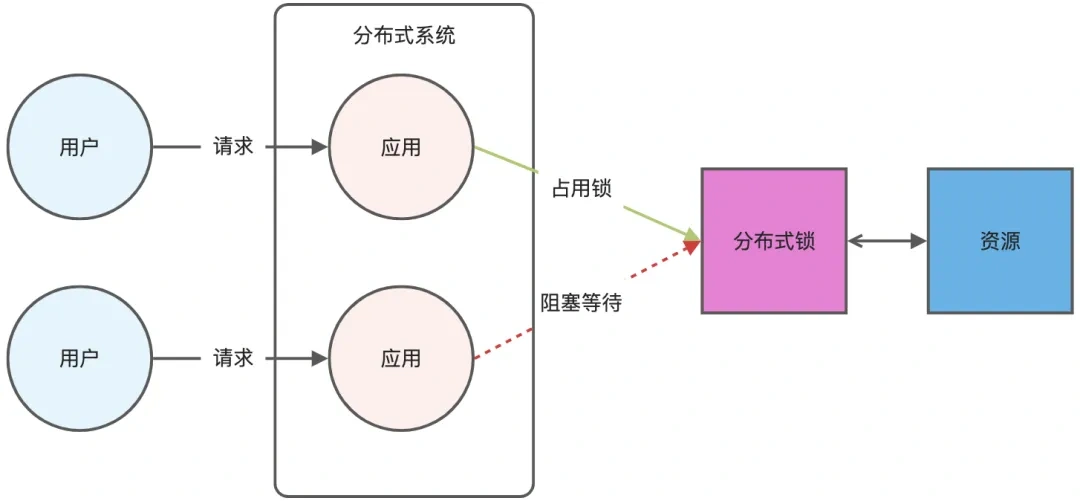
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁,而且 Redis 的读写性能高,可以应对高并发的锁操作场景。Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
-
如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
-
如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
-
加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
-
锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
-
锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
-
lock_key 就是 key 键;
-
unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
-
NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
-
PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
7. Redision使用方式是什么?
Redisson 是一个基于 Redis 的 Java 客户端,提供了丰富的分布式数据结构和服务,其中 分布式锁是其核心功能之一,以下是 Redisson 实现分布式锁的完整方式。
-
引入依赖:如果你使用 Maven 项目,可在
pom.xml里添加以下依赖:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.16.2</version> <!-- 选择合适的版本 -->
</dependency>
-
配置客户端:要使用 Redisson,得先创建一个
RedissonClient实例。以下是一个简单的单机 Redis 配置示例:
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonConfigExample {public static RedissonClient getRedissonClient() {Config config = new Config();// 单机模式config.useSingleServer().setAddress("redis://127.0.0.1:6379");return Redisson.create(config);}
}
-
实现分布式锁代码:Redisson 提供了多种分布式数据结构,例如分布式锁、分布式集合等。下面是使用分布式锁的示例:
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;publicclass RedissonLockExample {public static void main(String[] args) {RedissonClient redisson = RedissonConfigExample.getRedissonClient();// 获取锁对象RLock lock = redisson.getLock("myLock");try {// 尝试加锁,最多等待100秒,锁的持有时间为10秒boolean isLocked = lock.tryLock(100, 10, java.util.concurrent.TimeUnit.SECONDS);if (isLocked) {try {// 模拟业务操作System.out.println("获得锁,开始执行任务");Thread.sleep(5000);} finally {// 释放锁lock.unlock();System.out.println("释放锁");}}} catch (InterruptedException e) {e.printStackTrace();} finally {// 关闭 Redisson 客户端redisson.shutdown();}}
}
8. MySQL索引底层结构是什么?有什么优势?
MySQL InnoDB 引擎是用了B+树作为了索引的数据结构。
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示:
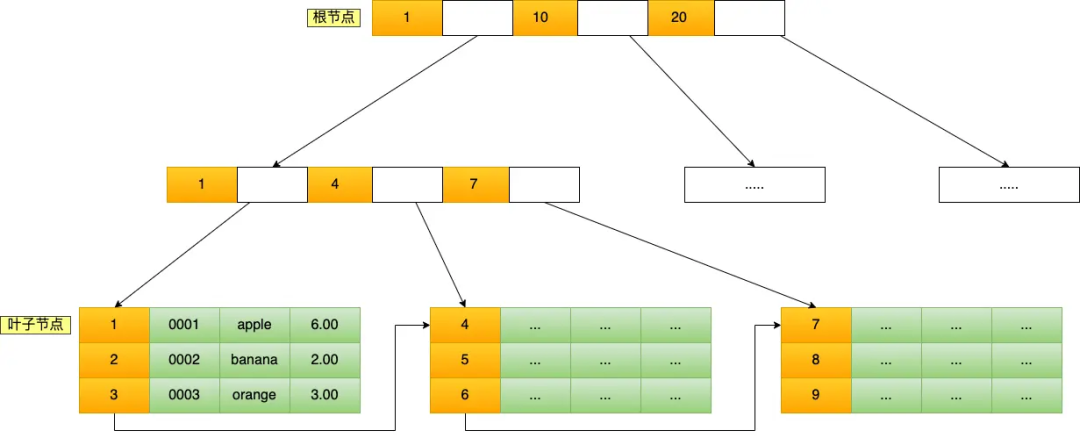
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
-
将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
-
在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
-
在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
9. 联合索引的失效场景你知道哪些?
6 种会发生索引失效的情况:
-
当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
-
当我们在查询条件中对索引列使用函数,就会导致索引失效。
-
当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
-
MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
-
联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
-
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
10. mysql Explain 执行计划中 key 和possible_key的区别是什么?
explain 是查看 sql 的执行计划,主要用来分析 sql 语句的执行过程,比如有没有走索引,有没有外部排序,有没有索引覆盖等等。
如下图,就是一个没有使用索引,并且是一个全表扫描的查询语句。

对于执行计划,比较重要的参数有:
-
possible_keys 字段表示可能用到的索引;
-
key 字段表示实际用的索引,它是从
possible_keys所列出的索引中挑选出来的,如果这一项为 NULL,说明没有使用索引; -
key_len 表示索引的长度;
-
rows 表示扫描的数据行数。
-
type 表示数据扫描类型
11. 追问:那 extra中出现 Using index condition、Using filesort是为什么?
-
Using index condition:表示使用了索引条件下推优化,当查询条件中的部分列使用了索引,但还有其他条件无法通过索引直接过滤时,就会出现
Using index condition。数据库会先利用索引来获取满足索引条件的记录,然后再在存储引擎层根据剩余的条件对这些记录进行过滤,而不是像以前那样先把所有满足索引条件的记录都读取到服务器层,再进行过滤。例如,有一个复合索引idx_country_industry,查询语句为SELECT * FROM c WHERE country = 'Ukraine' AND industry = 'banking',如果只使用country列的索引来查询,那么就会先通过索引找到所有country为Ukraine的记录,然后在存储引擎层再根据industry = 'banking'这个条件进一步过滤,此时Extra列就会显示Using index condition,这样可以减少存储引擎和服务器层之间的数据传输,以及回表的次数,提高查询性能。 -
Using filesort :当查询语句中包含 group by 操作,而且无法利用索引完成排序操作的时候, 这时不得不选择相应的排序算法进行,甚至可能会通过文件排序,效率是很低的,所以要避免这种问题的出现。
12. TCP四次挥手中 第三步FIN丢失,会进入什么状态?
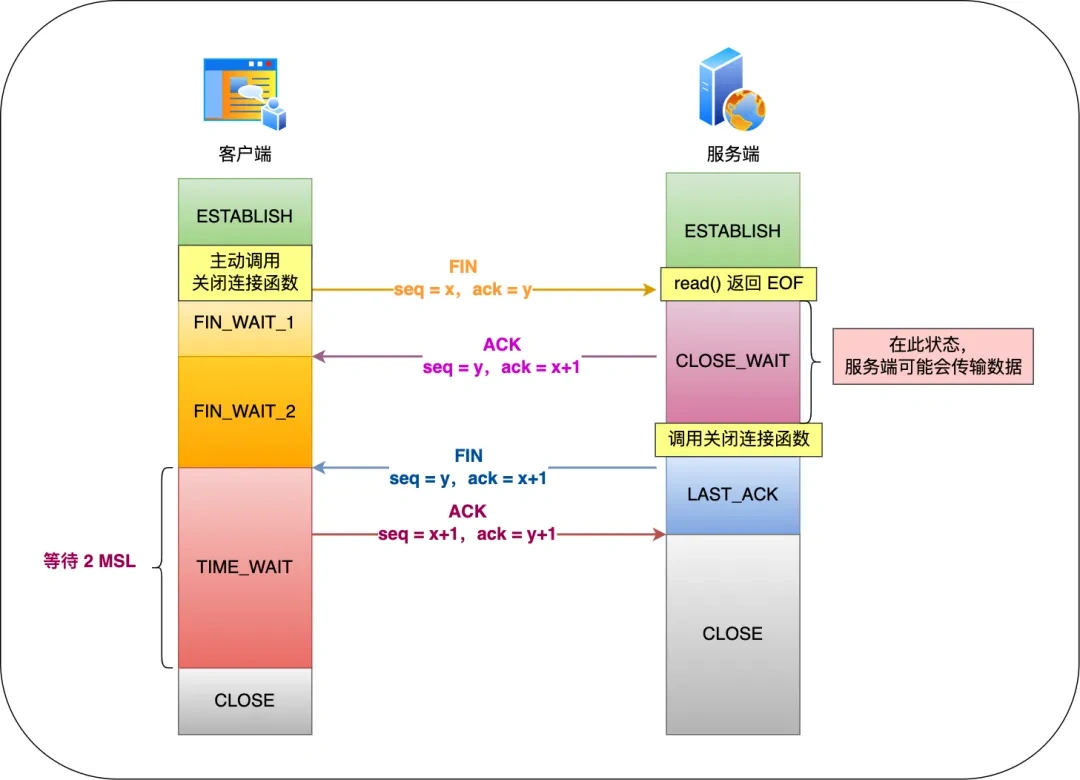
在 TCP 四次挥手中,如果第三步的 FIN 丢失,相关方会进入以下状态:
-
服务端(被动关闭方):服务端发送 FIN 后会进入 LAST_ACK 状态。由于 FIN 丢失,服务端收不到客户端的 ACK 确认,会触发超时重传机制,重新发送 FIN 报文,直到收到客户端的 ACK 或者达到最大重传次数。如果达到最大重传次数后仍未收到 ACK,服务端最终会进入 CLOSED 状态,释放连接资源。
-
客户端(主动关闭方):客户端处于 FIN_WAIT_2 状态,等待服务端的 FIN 报文。因为未收到服务端的 FIN,客户端会一直保持 FIN_WAIT_2 状态。如果客户端的应用程序没有设置超时时间,那么这个连接可能会一直处于 FIN_WAIT_2 状态,导致资源无法释放。不过,在实际应用中,通常会设置超时机制,当超过一定时间未收到服务端的 FIN 报文,客户端会认为连接出现异常,从而主动释放连接,进入 CLOSED 状态。
13. 了解哪些网络编程框架?
了解过 netty,它是基于 Java NIO 的高性能、异步事件驱动的网络应用框架,netty有以下特点:
-
高性能:基于 Java NIO 实现,单线程可处理万级并发连接,吞吐量达百万级 QPS。
-
低延迟:零拷贝技术减少内存复制,ByteBuf 动态扩展优化内存分配。
-
易用性:通过高度抽象的 API 屏蔽底层 NIO 细节,降低开发门槛。
-
协议扩展性:内置 HTTP、WebSocket、MQTT 等协议支持,支持自定义私有协议。
这是一张Netty官网关于Netty的核心架构图:
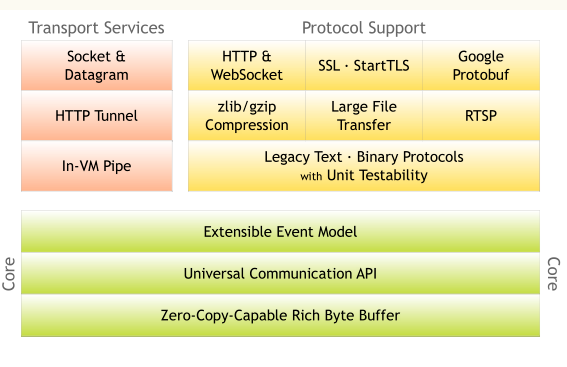
可以看到Netty由以下三个核心部分构成:
-
传输服务:传输服务层提供了网络传输能力的定义和实现方法。它支持 Socket、HTTP 隧道、虚拟机管道等传输方式。Netty 对 TCP、UDP 等数据传输做了抽象和封装,用户可以更聚焦在业务逻辑实现上,而不必关系底层数据传输的细节。
-
协议支持:Netty支持多种常见的数据传输协议,包括:HTTP、WebSocket、SSL、zlib/gzip、二进制、文本等,还支持自定义编解码实现的协议。Netty丰富的协议支持降低了开发成本,基于 Netty 我们可以快速开发 HTTP、WebSocket 等服务。
-
Core核心:Netty的核心,提供了底层网络通信的通用抽象和实现,包括:可扩展的事件驱动模型、通用的通信API、支持零拷贝的Buffer缓冲对象。
介绍完 Netty 的模块结构,我们再来看一下它的处理架构:
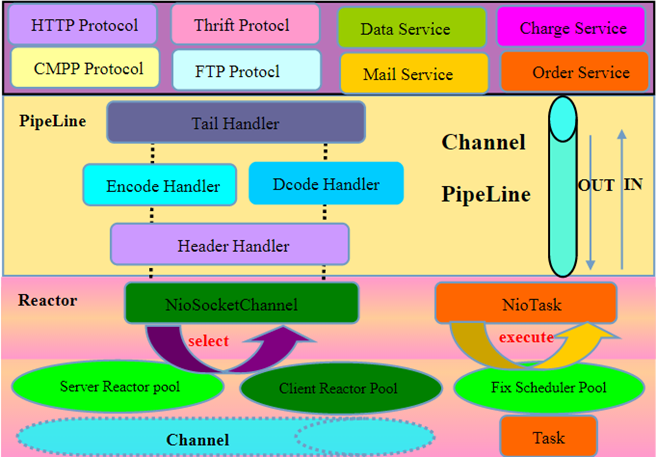
Netty 的架构也很清晰,就三层:
-
底层 IO 复用层,负责实现多路复用。
-
通用数据处理层,主要对传输层的数据在进和出两个方向进行拦截处理,如编/解码,粘包处理等。
-
应用实现层,开发者在使用 Netty 的时候基本就在这一层上折腾,同时 Netty 本身已经在这一层提供了一些常用的实现,如 HTTP 协议,FTP 协议等。
一般来说,数据从网络传递给 IO 复用层,IO 复用层收到数据后会将数据传递给上层进行处理,这一层会通过一系列的处理 Handler 以及应用服务对数据进行处理,然后返回给 IO 复用层,通过它再传回网络。
在 Netty 处理架构图中,可以看到在 IO 复用层上标注了一个「Reactor」:
这个「Reactor」代表的就是其 IO 复用层具体的实现模式 -- Reactor 模式,Netty 主要采用了 主从 Reactor 多线程模型:
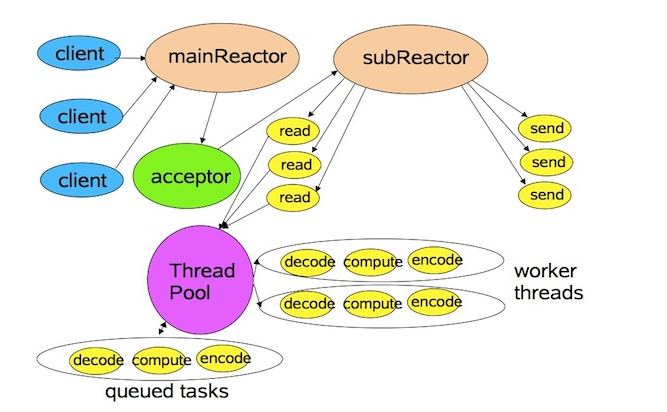
在 Reactor 模式中,分为主反应组(MainReactor)和子反应组(subReactor)以及 ThreadPool,主反应组(MainReactor)负责处理连接,连接建立完成以后由主线程对应的 acceptor 将后续的数据处理(read/write)分发给子反应组(subReactor)进行处理,而 Threadpool 对应的是业务处理线程池。
服务端处理请求流程:
-
Reactor主线程对象通过seletct监听连接事件,收到事件后,通过Acceptor处理连接事件
-
当Acceptor处理连接事件后,主Reactor线程将连接分配给子Reactor线程
-
Reactor子线程将连接加入连接队列进行监听,并创建handler进行各种事件处理
-
当有新事件发生时,子Reactor线程会调用对应的handler进行处理
-
handler读取数据分发给worker线程池分配一个独立的线程进行业务处理,并返回结果给handler
-
handler收到响应的结果后,通过send将结果返回给客户端
该模型虽然编程复杂度高,但是其优势比较明显,体现在:
-
主从线程职责分明,主线程只需要接收新请求,子线程完成后续的业务处理
-
主从线程数据交互简单,主线程只需要把新连接传给子线程
相关文章:

【中大厂面试题】TCP 校招 java 后端最新面试题
TCL(一面) 1. Spring 初始化Bean前要做什么?有几种方式 在 Spring 容器调用 Bean 的初始化方法(如 init-method、PostConstruct 等)之前,会按顺序完成以下关键步骤:实例化 → 属性注入 → Aw…...

【教学类-102-11】蝴蝶外轮廓01——Python对黑白图片进行PS填充三种颜色+图案描边+图案填充白色+制作1图2图6图24图
背景需求: 用Python,对白色255背景的图片进行了透明化、制作点状或线段的描边裁剪线 【教学类-102-10】剪纸图案全套代码09——Python线条虚线优化版04(原图放大白背景)+制作1图2图6图24图-CSDN博客文章浏览阅读1k次,点赞27次,收藏8次。【教学类-102-10】剪纸图案全套代…...
视图(超详细))
【数据库系统概论】第3章 SQL(四)视图(超详细)
视图(View)是数据库中的虚拟表 通过执行查询定义并存储在数据库中,可以像普通表一样被查询和使用。 视图本身并不存储数据,而是基于一个或多个表的查询结果动态生成。 视图的概念 视图( View )是由其它表或视图上的查询所定义…...

HTTP:六.HTTP代理相关介绍
什么是HTTP代理 代理是指获授权代表他人执行操作的人员,代理服务器在在线世界中提供此操作。 代理服务器 充当用户和互联网之间的网关,并防止访问网络以外的任何人。通过 Web 浏览器定期访问互联网,使用户能够直接与网站连接。但是代理充当中间人,代表用户与网页通信。 当…...

【Python爬虫】详细工作流程以及组成部分
目录 一、Python爬虫的详细工作流程 确定起始网页 发送 HTTP 请求 解析 HTML 处理数据 跟踪链接 递归抓取 存储数据 二、Python爬虫的组成部分 请求模块 解析模块 数据处理模块 存储模块 调度模块 反爬虫处理模块 一、Python爬虫的详细工作流程 在进行网络爬虫工…...

深入解析UML图:版本演变、静态图与动态图详解
目录 前言1 UML的版本演变1.1 UML 1.x阶段:统一的开始1.2 UML 2.x阶段:功能的扩展与深化 2 UML图的分类概述3 UML静态图详解3.1 类图(Class Diagram)3.2 对象图(Object Diagram)3.3 组件图(Comp…...

老旧测试用例生成平台异步任务与用户通知优化
在现代 Web 开发中,异步任务处理和用户通知是两个重要的功能。由于老旧测试平台【测试用例生成平台,源码分享】进行智能化升级后,未采用异步任务处理,大模型推理时间较长,导致任务阻塞,无法处理其他任务&am…...

数据结构初阶:队列
本篇博客主要讲解队列的相关知识。 目录 1.队列 1.1 概念与结构 1.2 队列头文件(Queue.h) 1.2.1 定义队列结点结构 1.2.2 定义队列的结构 1.3 队列源代码(Queue.h) 1.3.1 队列的初始化 1.3.2 队列的销毁 1.3.3 入队---队尾 1…...

苍穹外卖。12 数据统计
12.1 工作台 12.1.1 需求分析与设计 12.1.2 代码导入 12.1.3 测试 测试通过 12.2 Apache POI 12.2.1 需求分析与设计 12.2.2 案例 column表示索引行...

WebSocket 和 HTTP长轮询
一、HTTP长轮询(Long Polling) 1. 工作原理 传统轮询(低效):客户端每隔几秒向服务器发一次请求,问“有新数据吗?”,即使服务器没有数据也会立即返回“无”。长轮询(改进…...

高等数学同步测试卷 同济7版 试卷部分 上 做题记录 第三章微分中值定理与导数的应用同步测试卷 B 卷
第三章微分中值定理与导数的应用同步测试卷 B 卷 一、单项选择题(本大题共5小题,每小题3分,总计15分) 1. 2. 3. 4. 5. 二、填空题(本大题共5小题,每小题3分,总计15 分) 6. 7. 8. 9. 10. 三、求解下列各题(本大题共5小题,每小题6分,总计 3…...
发展史与行业标准演变)
生成式引擎优化(GEO)发展史与行业标准演变
一、生成式引擎优化(GEO)发展史与行业标准演变 随着 ChatGPT、Bard、Claude、文心一言等生成式AI搜索产品快速发展,GEO(Generative Engine Optimization,生成式引擎优化)也应运而生,成为继SEO、…...

美客多自养号测评技术解析:如何低成本打造安全稳定的测评体系
美客多(MercadoLibre)自养号测评系统的搭建需综合考虑硬件、软件、网络环境及操作流程的合规性,以下是基于多篇行业指南整理的核心步骤与要点: 一、前期规划与准备 1. 明确目标与规则 • 确定测评目的(如提升产品曝…...

STM32单片机入门学习——第36节: [11-1] SPI通信协议
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.14 STM32开发板学习——第36节: [11-1] SPI通信协议 前言开发板说明引用解答和科普一…...

Qt QML - qmldir使用方法详解
以实际例子看qmldir的使用 1.搞一个qmldir2.让QML找到你的qmldir (重点).pro 工程文件QQmlApplicationEngine加载主QML处 3.用起来你的模块 qmldir是Qt QML模块化的基石,其设计初衷是为解决QML文件的组织、复用和依赖管理问题,。只需要在每个…...

AI大模型赋能工业制造:智能工厂的全新跃迁路径
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言:从自动化到智造化,工业领域的AI革命正悄然发生 在过去几十年中,制造业经历了机械化、电气化和自动化三次浪潮。如今,第四次工业革命——以人工智能、大数据、云计算、物联网为代表的“工业…...

LanDiff:赋能视频创作,语言与扩散模型的融合力量
自从 Wan 2.1 发布以来,AI 视频生成领域似乎进入了一个发展瓶颈期,但这也让人隐隐感到:“DeepSeek 时刻”即将到来!就在前几天,浙江大学与月之暗面联合推出了一款全新的文本到视频(T2V)生成模型…...

Windows 图形显示驱动开发-WDDM 1.2功能~显示设备的容器id支持
容器 ID 设备驱动程序接口 (DDI) 在显示微型端口驱动程序中实现此函数和结构: DxgkDdiGetChildContainerIdDXGK_CHILD_CONTAINER_ID 容器 ID 说明 监视设备中的新功能可以提供更好的用户体验。 具体而言,通用串行总线 (USB) 集线器是监视器上用于连…...

基于PyQt5和OpenCV的传统图像分割应用UI程序
目录 1. 程序概述 2. 用户界面设计 主窗口布局 图像显示区域 控制面板区域 3. 核心功能实现 图像处理功能 关键方法 4. 特色实现 区域生长算法改进 分水岭算法改进 GrabCut算法改进 5. 用户体验优化 6. 技术栈 7. 使用说明 8. 完整代码 9. 测试结果 本文实现了…...

java使用HTTP实现多线程爬取数据
Java中使用HTTP多线程爬取数据。首先,我得理解他们的需求。可能想要高效地抓取大量网页数据,而单线程可能不够快,所以需要多线程来提高效率。不过,多线程爬虫需要考虑的问题挺多的,比如线程安全、请求频率控制、异常处…...
:收发数据包+数据校验)
08【基础学习】串口通信(三):收发数据包+数据校验
收发数据包数据校验 1、和校验异或校验1.1、HEX固定长度数据包校验1.2、HEX不固定长度数据包校验 2、CRC校验 1、和校验异或校验 和校验:将接收到的数据全部相加后,取结果的最后一个字节的数据 异或校验:将接收到的数据全部相异或后ÿ…...

已开源!CMU提出NavRL :基于强化学习的无人机自主导航和动态避障新方案
导读在无人机技术快速发展的今天,如何确保无人机在复杂动态环境中的安全飞行成为一个关键挑战。传统的导航方法通常将决策过程分解为预测和规划两个独立模块,这种手工设计的系统虽然在特定环境中表现良好,但当环境条件发生变化时,…...
)
C++ (类的设计,对象的创建,this指针,构造函数)
类的设计 C对结构体是有增强的 可以包含函数作为结构体成员 可以直接定义变量 在结构体成员函数里面可以直接访问结构体成员变量 struct student{string name;int age;float score;void play_game(const string &name);}void student::play_game(const string game){}…...

【C++】——lambda表达式
🌟 前言:C Lambda表达式,当函数开始"叛逆期" 你是否有过这样的崩溃瞬间? 为了写个只用到一次的排序规则,被迫定义了一个类在std::for_each里塞函数指针,代码瞬间变成"古董级"写法看着层的循环…...

DHCP简单例子
本文描述了使用ENsp模拟DHCP Global和DHCP 中继两种简单配置过程。 拓朴图 DHCP全局配置 此配置较为简单,因为全局既支持局域网,也支持跨网络分配。 # DHCP Server1 <Huawei>system-view [Huawei]sysname server1 [server1]dhcp enable …...

Spark-SQL简介及核心编程
Spark-SQL概述:是Spark用于结构化数据处理的模块,前身是Shark。Shark基于Hive开发,使SQL-on-Hadoop性能大幅提升,但对Hive依赖制约了Spark发展。SparkSQL汲取Shark优点并重新开发,在数据兼容、性能优化和组件扩展上优势…...

LDAP渗透测试
LDAP渗透测试 1.LDAP协议概述2.LDAP写公钥3.暴力破解LDAP4.LDAP信息收集ldapdomaindumpwindapsearch工具ldapsearch 1.LDAP协议概述 LDAP(Lightweight Directory Access Protocol,轻量目录访问协议)是一种访问和管理目录服务的应用层协议&am…...
)
观察者模式(行为模式)
观察者模式 观察者模式属于行为模式,个人理解:和发布订阅者魔模式是有区别的 细分有两种:推模式和拉模式两种,具体区别在于推模式会自带推送参数,拉模式是在接收通知后要自己获取更新参数 观察者模式(Obs…...

Spark SQL
Spark SQL Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 Spark SQL特点 易整合。无缝的整合了 SQL 查询和 Spark 编程 统一的数据访问。使用相同的方式连接不同的数据源 兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL 标准数据连接。通过 JDBC…...
)
周末学习笔记:Python文件操作(结构化数据转换与文件处理)
目录 一、任务目标 二、实现步骤与代码解析 2.1 数据准备阶段 关键点解析: 2.2 数据转换核心代码 三、关键技术解析 3.1 字符串处理方法 3.2 数据结构转换 3.3 文件写入技巧 四、执行结果验证 输入文件t1.txt内容: 输出文件t2.txt内容&am…...

【PCIE736-0】基于 PCIE X16 总线架构的 4 路 QSFP28 100G 光纤通道处理平台
产品概述 PCIE736-0 是一款基于 PCIE 总线架构的 4 路 QSFP28 100G 光纤通道适配器,该板卡具有 1 个 PCIe Gen3x16 主机接口、一共 4个 QSFP28 100G 光纤接口,可以实现 4 路 QSFP28 100G 光纤的数据实时采集、实时缓存与 PCIE 高速传输。该板卡采用 Xil…...

PyCharm 开发工具 修改背景颜色
PyCharm 开发工具 修改背景颜色 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是有学习/理解关联性,希望对您有用~ PyCharm 开发工具 修改背景颜色 文章目录 PyCharm 开…...
)
linux Shell编程之循环语句(三)
目录 一. for 循环语句 1. for语句的结构 2. for 语句应用示例 (1) 根据姓名列表批量添加用户 (2) 根据 IP 地址列表检查主机状态 二. 使用 while 循环语句 1. while 语句的结构 2. while 语句应用示例 (1) 批量添加规律编号的用户 (2) 猜价格游戏 三. until 循环语…...

GCC和GDB基础知识
1 GCC和G 一套开源的编译器,支持 C、C、Fortran 等语言。它负责将人类编写的源代码(如 .c 文件)翻译成计算机能执行的二进制文件(如 .exe)。 核心作用: 预处理:处理宏…...
)
网络复习二(TCP【3】)
一、为什么TIME_WAIT等待的时间是2MSL? MSL:报文最大生存时间 我们要知道TCP报文是基于IP协议生存的,而在IP头中有一个TTL(经过路由跳数),当TTL为0使,数据报被丢失,同时发送ICMP报…...

【5G通信】通过RRC重配实现功率调整的可能性
在5G网络中,通过解析UE Capability Information消息中的RF Parameters字段实现终端发射功率的动态调整,需要结合协议规范、射频特性及网络控制策略。以下是技术实现流程及示例: 一、RF Parameters关键字段解析 根据3GPP TS 38.331和TS 38.10…...

UE 使用事件分发器设计程序
【双字精译】虚幻引擎中的设计模式:观察者模式——Ali Elzoheiry|游戏开发游戏编程模式游戏设计模式虚幻蓝图编程事件分发器UnrealEngineUE5_哔哩哔哩_bilibili 创建一个事件分发器,这里是放在死亡事件里 比如计算场景中的敌人数量,这个UI是…...

前端面试宝典---原型链
引言----感谢大佬的讲解 大佬链接 原型链示意图 原型链问题中需要记住一句话:一切变量和函数都可以并且只能通过__proto__去找它所在原型链上的属性与方法 原型链需要注意的点 看上图可以发现 函数(构造函数)也可以通过__proto__去找到原…...

ViT 模型讲解
文章目录 一、模型的诞生背景1.1 背景1.2 ViT 的提出(2020年) 二、模型架构2.1 patch2.2 模型结构2.2.1 数据 shape 变化2.2.2 代码示例2.2.3 模型结构图 2.3 关于空间信息 三、实验3.1 主要实验3.2 消融实验 四、先验问题4.1 归纳偏置4.2 先验or大数据&…...

【技术文章的标准结构与内容指南】
技术文章的标准结构与内容指南 技术文章是传递专业知识、分享实践经验的重要媒介。一篇高质量的技术文章不仅能够帮助读者解决问题,还能促进技术交流与创新。以下是技术文章通常包含的核心内容与结构指南。 1. 标题 一个好的技术文章标题应当: 简洁明…...

Mysql概述
一、数据库相关概念 1.数据库(Data Base ,简称DB)是长期存储在计算机中有组织、可管理、可共享的数据集合。 2.数据库管理系统(Database Management System,简称为 DBMS)是管理数据库的系统软件 3.MySQL数据库全称为MySQL数据库管理系统 3.SQL语言(S…...
))
系统设计模块之安全架构设计(身份认证与授权(OAuth2.0、JWT、RBAC/ABAC))
一、OAuth 2.0:开放授权框架 OAuth 2.0 是一种标准化的授权协议,允许第三方应用在用户授权下访问其资源,而无需直接暴露用户密码。其核心目标是 分离身份验证与授权,提升安全性与灵活性。 1. 核心概念与流程 角色划分ÿ…...

如何管理“灰色时间”导致的成本漏洞
明确时间记录机制、优化流程透明度、应用自动化工具、强化绩效考核机制、提高员工时间意识 来有效管理。其中,明确时间记录机制 是最关键的一步。通过统一的时间记录平台,例如Toggl Track、Clockify或企业级工时系统,不仅可以实时掌握员工工作…...
:4A广告代理公司与行业资质解读)
程序化广告行业(84/89):4A广告代理公司与行业资质解读
程序化广告行业(84/89):4A广告代理公司与行业资质解读 大家好!在探索程序化广告行业的道路上,每一次知识的分享都是我们共同进步的阶梯。一直以来,我都希望能和大家携手前行,深入了解这个充满机…...

MTK Android12-13 -Intent Filter Verification Service 停止运行
MTK Android12-13 -Intent Filter Verification Service 停止运行 问题修复 文章目录 参考资料解决方案-修改文件源码分析源码 StatementService配置加载config_appsNotReportingCrashesActivityManagerService -retrieveSettings 加载配置AppErrors-loadAppsNotReportingCrash…...

Sentinel源码—1.使用演示和简介二
大纲 1.Sentinel流量治理框架简介 2.Sentinel源码编译及Demo演示 3.Dashboard功能介绍 4.流控规则使用演示 5.熔断规则使用演示 6.热点规则使用演示 7.授权规则使用演示 8.系统规则使用演示 9.集群流控使用演示 5.熔断规则使用演示 (1)案例说明熔断和降级 (2)Sentin…...

基于Geotools的PostGIS原始操作之CQL过滤及按属性名称生成面属性时间-以湖北省地级市行政区划为例
目录 前言 背景与意义 技术方法概述 一、CQL查询实现 1、CQL查询原理 2、Geotools中的CQL实现 二、SLD编程式样式生成 1、获取唯一的分类值 2、生成不同颜色分类 3、集成生成SLD的Style文件 三、总结 前言 随着地理信息系统(GIS)技术的快速发展…...

Linux内核中struct net_protocol的early_demux字段解析
背景问题 在内核版本4.19.0-25的头文件中,struct net_protocol结构体的定义未显式包含early_demux字段。然而,在内核版本4.19的源代码中可以看到tcp_protocol实例化时却对该字段进行了赋值: static struct net_protocol tcp_protocol = {.early_demux = tcp_v4_earl…...

TLS协议四次握手原理详解,密钥套件采用DH密钥交换算法
目录 1.TLS协议握手概述 2.TLS协议握手具体步骤 2.1.TLS第一次握手 2.2.TLS第二次握手 2.3.TLS第三次握手 2.4.TLS第四次握手 3.DH密钥交换算法 1.TLS协议握手概述 第一步客户端会发起一个消息,携带了TLS的版本号,客户端随机数,密码套…...

React 更新state中的对象
更新 state 中的对象 state 中可以保存任意类型的 JavaScript 值,包括对象。但是,你不应该直接修改存放在 React state 中的对象。相反,当你想要更新一个对象时,你需要创建一个新的对象(或者将其拷贝一份)…...