深度学习模型的概述与应用
📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
深度学习作为人工智能领域的重要分支,近年来已经被广泛应用于图像识别、自然语言处理、语音识别等多个领域。随着计算能力的提升和数据量的增加,深度学习模型的训练与应用变得越来越便利和高效。本文将深入探讨深度学习模型的基本组成、常见模型及其应用场景,为想要了解和学习深度学习的读者提供一个全面的视角。
一. 深度学习模型的基本组成
深度学习模型是人工智能领域中的强大工具,其设计和实现一般由多个核心组成部分构成。这些组成部分相互协作,使得模型能够有效地从数据中学习和提取特征。以下是深度学习模型的基本组成部分的详细介绍。
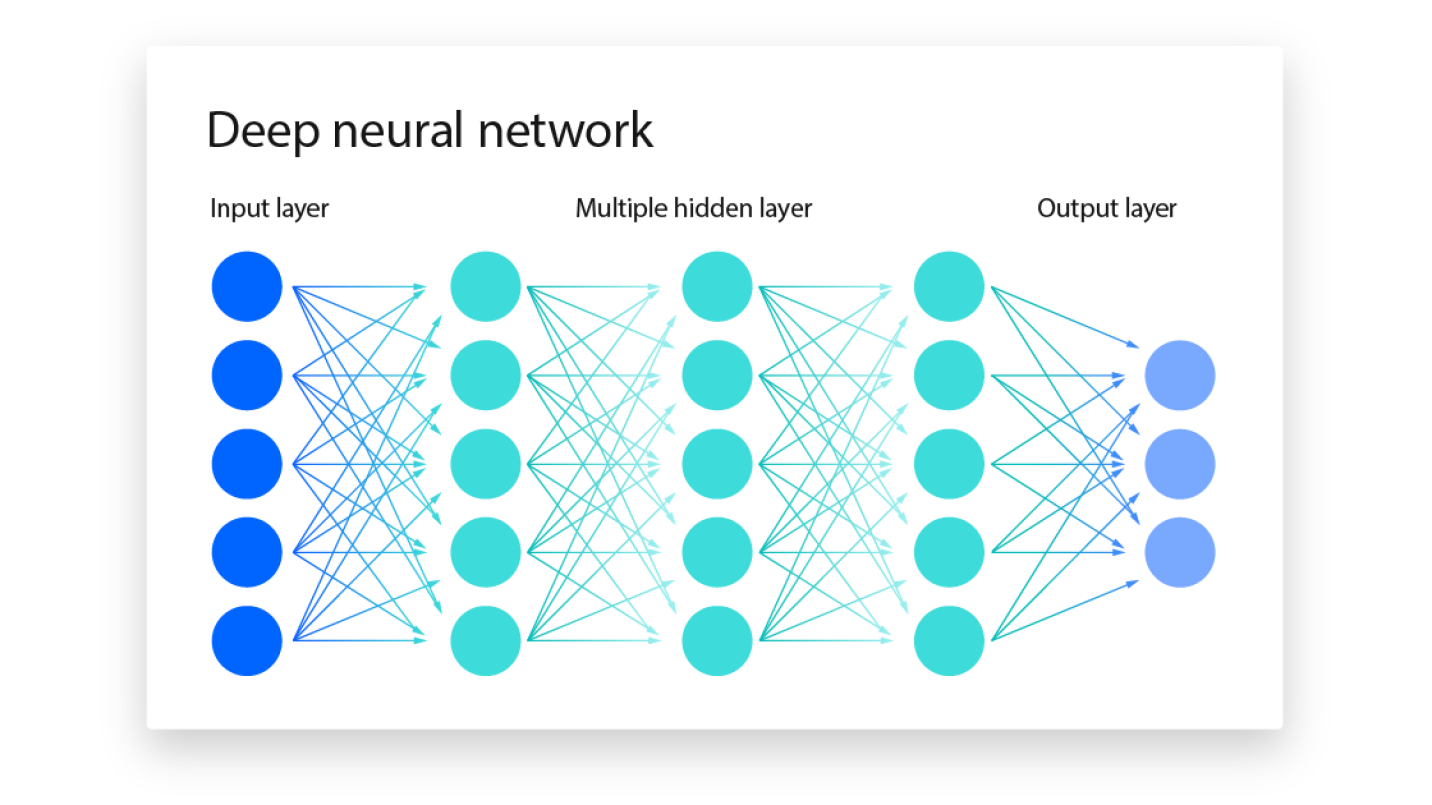
1.1 神经元(Neuron)
神经元是神经网络的基本计算单元,借鉴于生物神经系统的工作原理。每个神经元通过接收输入信号(来自前一层神经元或输入数据),进行加权求和,然后通过激活函数计算输出。
1.1.1 权重与偏置
每个输入信号都被分配一个权重,反映了该输入在模型预测中的重要性。偏置是另一个参数,用于调整模型的输出,使得模型更具有灵活性。神经元的输出计算公式可表示为:
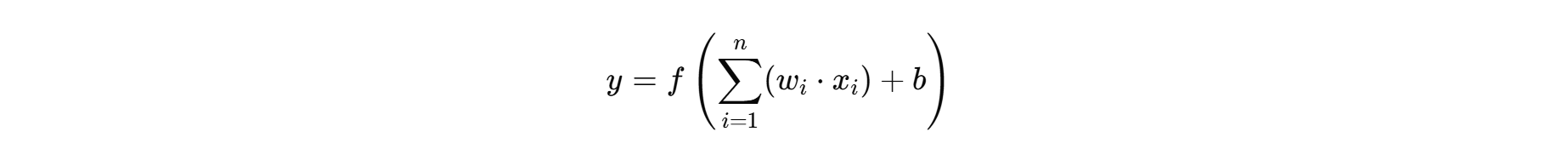
其中:
- y 是输出
- f是激活函数
- wi是权重
- xi是输入
- b是偏置
1.1.2 激活函数
激活函数决定了神经元的输出是否活跃,常见的激活函数包括:
-
ReLU(修正线性单元) :在输入大于0时返回输入值,小于0时返回0。有效地解决了梯度消失问题,促进了深层神经网络的训练。
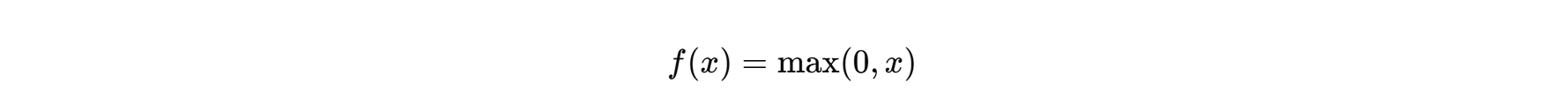
-
Sigmoid:映射到0和1之间,适用于二分类问题,但在深层网络中容易导致梯度消失。
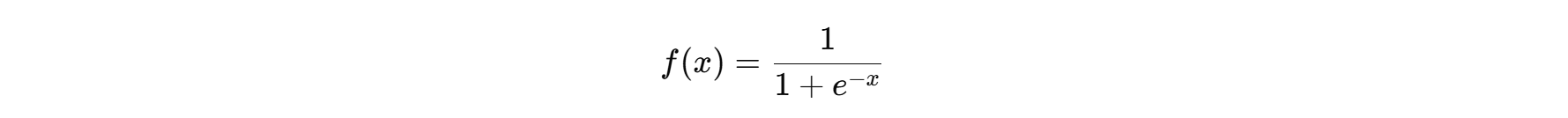
-
Tanh(双曲正切) :输出范围在-1到1之间,相比Sigmoid有更好的性能,能有效避免梯度消失问题。
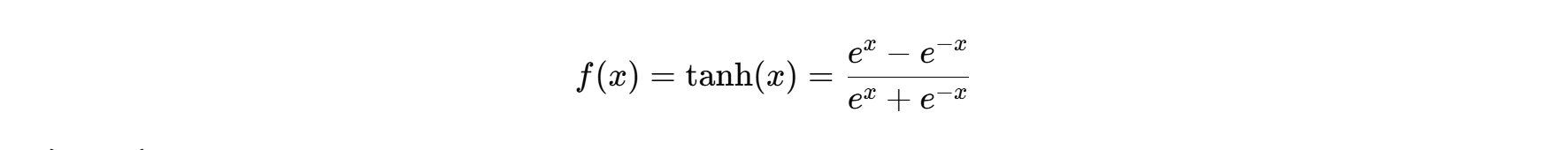
1.2 层(Layer)
层是由多个神经元组成的集合,深度学习模型通过多个层的堆叠,形成前馈结构。深度学习模型通常由以下几类层组成:
1.2.1 输入层(Input Layer)
输入层是神经网络的第一层,负责接收输入数据。对于图像数据,输入通常是一个多维数组,例如一个图像的高度、宽度和颜色通道构成的三维张量。对于文本数据,输入可能是分词后的词向量。
1.2.2 隐藏层(Hidden Layer)
隐藏层是介于输入层和输出层之间的层,负责进行特征提取和信息映射。通过多层次的不同行为组合,隐含层能够学习复杂的数据模式。可以有多个隐藏层,并且每一层的神经元数目可以不同。
-
前馈层:标准的隐藏层,通过全连接的方式将前一层的每个神经元与当前层的每个神经元相连接。
-
卷积层:常用于卷积神经网络(CNN),用于提取局部特征,并通过卷积运算显著减少参数数量。
-
循环层:用于递归神经网络(RNN),能够维护序列数据的信息,适合于时序数据处理。
1.2.3 输出层(Output Layer)
输出层是神经网络的最后一层,负责生成模型的最终结果。根据任务类型的不同,输出层的构成也有所不同:
-
分类任务:输出层通常由Softmax激活函数组成,以计算每个类别的概率分布,并选择最高概率的类别。
-
回归任务:输出层可能是一个线性单元,输出连续值。
1.3 网络结构(Network Architecture)
网络结构是指神经网络的整体框架和连接方式,决定了神经网络如何处理输入数据并产生输出。常见的网络结构包括:
1.3.1 前馈神经网络(Feedforward Neural Network)
前馈神经网络是最基础的深度学习网络结构,信息在网络中单向流动,没有反馈连接。它由多个层次堆叠而成,每一层都仅与上一层和下一层相连。
1.3.2 卷积神经网络(Convolutional Neural Network, CNN)
CNN在处理图像数据时有效,通过卷积层提取图像的局部特征。卷积运算能够保持局部空间关系,同时通过池化层减少维度和计算量。CNN在图像分类、目标检测和分割任务中表现出色。
1.3.3 循环神经网络(Recurrent Neural Network, RNN)
RNN特别适合处理序列数据,其自循环结构允许神经网络“记住”信息的序列。LSTM和GRU是RNN的改进版本,解决了长期依赖问题,广泛应用于自然语言处理和时间序列预测任务。
1.3.4 Transformer
Transformer通过自注意力机制有效处理长距离依赖关系,取代了传统的RNN结构,取得了卓越的性能。Transformer模型在处理序列的任务(如文本机器翻译)中,已经成为主流选择。
1.4 损失函数(Loss Function)
损失函数是深度学习中评估模型性能的重要工具,它衡量了模型预测值与真实值之间的差异。在训练过程中,深度学习模型通过优化损失函数不断调整参数,以提高预测精度。常见的损失函数包括:
-
均方误差(Mean Squared Error, MSE) :常用于回归问题,计算预测值与真实值之间的平方差的平均值。
-
交叉熵损失(Cross-Entropy Loss) :常用于分类问题,计算分类结果概率分布与真实标签分布之间的差异,尤其在多分类任务中表现良好。
1.5 优化算法(Optimization Algorithm)
优化算法用于调整模型的参数,以最小化损失函数。常见的优化算法有:
-
随机梯度下降(Stochastic Gradient Descent, SGD) :在每次迭代中使用一个样本来更新模型参数,收敛较慢,但能逃离局部最优解。
-
Adam(Adaptive Moment Estimation) :结合了动量法和RMSProp,通过调整学习率自适应地更新参数,是目前广泛使用的优化算法之一。
深度学习模型的基本组成部分相互作用,构成了完整的学习系统。了解每一个组成部分的功能、重要性及如何相互配合,有助于读者更深入地理解深度学习的核心原理。这不仅为设计和实现深度学习模型奠定基础,也为解决实际问题提供了强有力的工具和理念。通过不断学习和实践,读者将能在深度学习的世界中游刃有余。
二. 常见深度学习模型
随着深度学习技术的迅速发展,出现了多种强大的模型,这些模型在各个领域取得了显著的成绩。下面将详细介绍几种常见的深度学习模型,包括它们的结构特点、优缺点以及应用场景。
2.1 卷积神经网络(Convolutional Neural Network, CNN)
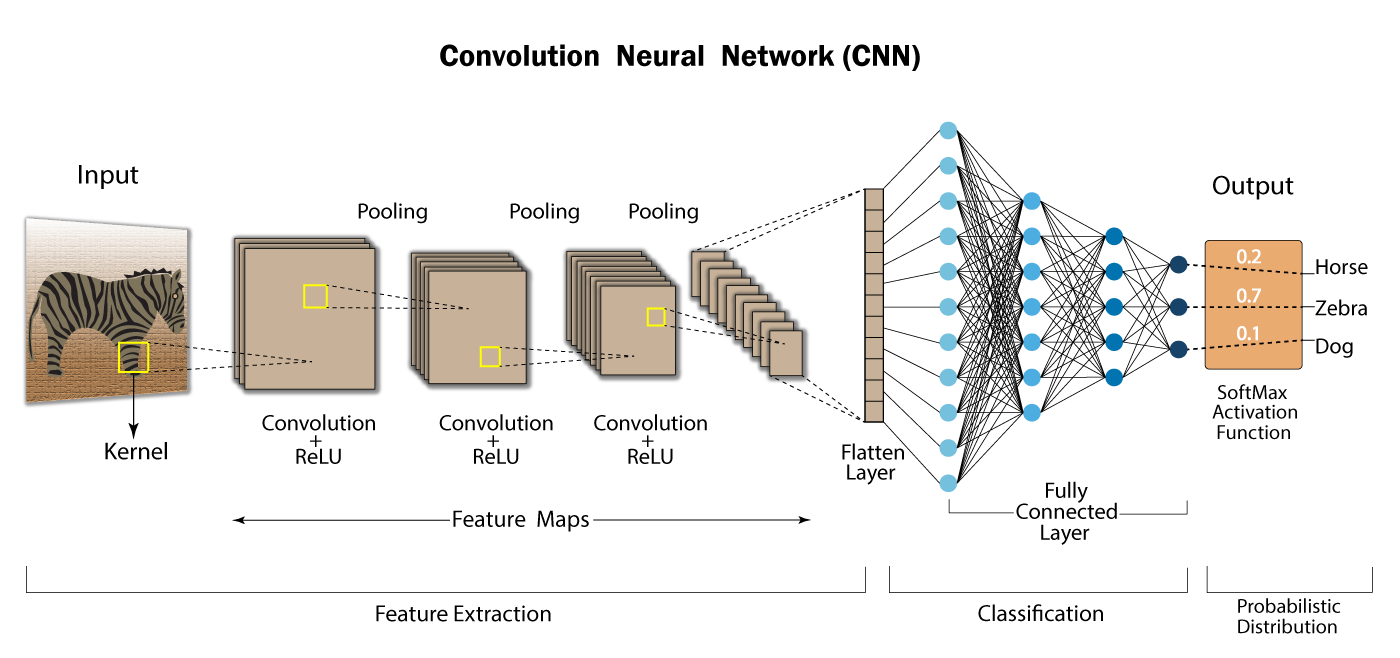
2.1.1 结构特点
卷积神经网络(CNN)专为处理图像数据而设计,其核心思想是通过卷积操作和池化操作提取特征。CNN的基本结构包括以下几个部分:
-
卷积层:通过若干个卷积核对输入图像进行卷积操作,从而提取局部特征。卷积操作能有效降低参数数量,同时保留空间信息。
-
激活层:通常在卷积层后面连接激活函数(如ReLU),引入非线性因素,使得模型能够学习更复杂的特征。
-
池化层:通过最大池化或平均池化操作,减少特征图的尺寸,缩减计算量,并防止过拟合。
-
全连接层:在经过多层卷积和池化后,将最终的特征图展平,并通过全连接层映射到输出类别。
2.1.2 优缺点
-
优点:
- 能够有效提取图像特征,特别是在大型数据集上表现出色。
- 参数共享和局部连接减少了计算复杂度和内存使用。
- 适用于多种视觉应用,如图像分类、目标检测等。
-
缺点:
- 对于小型数据集,容易过拟合。
- 对旋转、缩放等图像变换的鲁棒性有限。
- 对于某些结构化数据,如文本,应用效果不佳。
2.1.3 应用场景
- 图像分类(如MNIST手写数字识别、ImageNet识别任务)
- 目标检测(如YOLO、Faster R-CNN)
- 图像分割(如U-Net、Mask R-CNN)
- 风格迁移和图像生成(如生成对抗网络中的卷积层)
2.2 递归神经网络(Recurrent Neural Network, RNN)
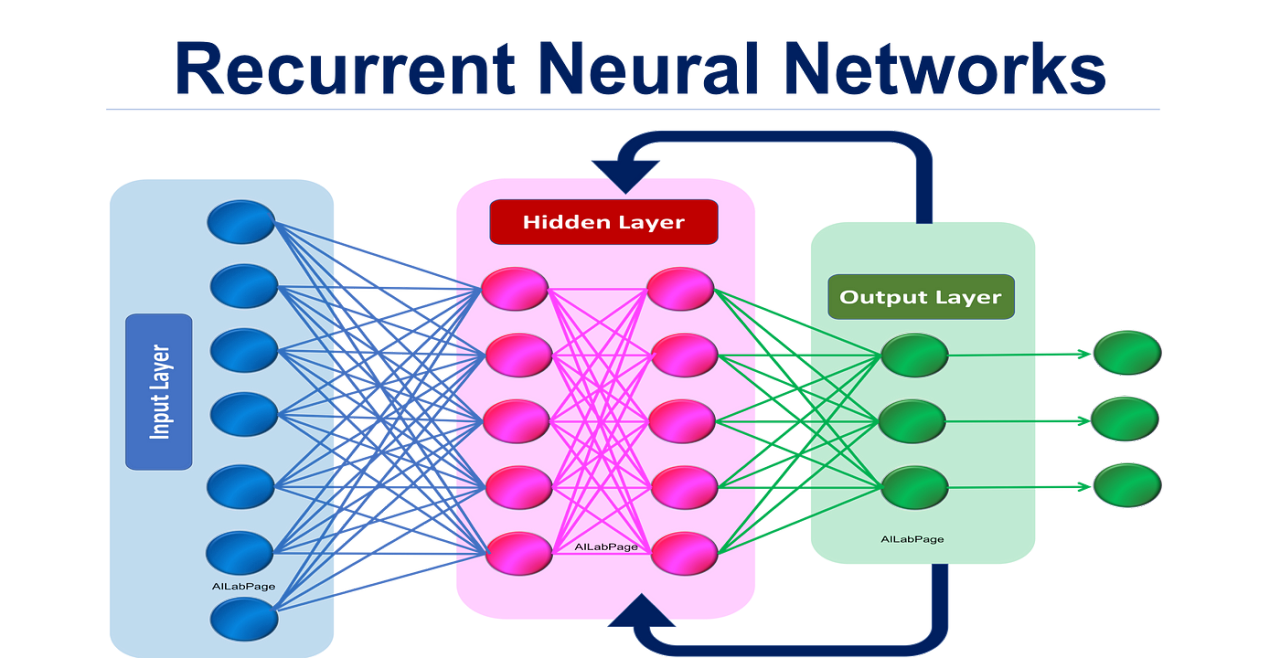
2.2.1 结构特点
递归神经网络(RNN)主要用于处理序列数据,其核心特性是通过自反馈连接保存信息。RNN的基本结构包括:
-
输入层:接收序列数据的每一个时间步输入。
-
隐藏层:包含循环连接,当前时间步的输入和前一时间步的状态共同决定当前状态。
-
输出层:根据当前状态生成输出,可以是每个时间步都有输出,也可以仅在序列结束时输出一次。
2.2.2 优缺点
-
优点:
- 能够有效处理时间序列数据,适合自然语言处理和时间序列预测等任务。
- 内部状态的循环连接使模型具有记忆能力,能够保留先前的信息。
-
缺点:
- 难以捕捉长期依赖关系,容易导致梯度消失或爆炸问题。
- 训练时计算复杂度高,不易并行化。
2.2.3 应用场景
- 自然语言处理(如机器翻译、情感分析)
- 时间序列预测(如股票价格预测、气象预测)
- 语音识别(如语音转文本)
- 音乐生成与合成(如乐谱生成)
2.3 长短期记忆网络(Long Short-Term Memory, LSTM)
2.3.1 结构特点
长短期记忆网络(LSTM)是对传统RNN的一种改进,专门设计用于解决长距离依赖问题。LSTM通过引入记忆单元和三个门控机制(输入门、遗忘门和输出门)来控制信息的流动。
-
记忆单元:存储长期信息,有助于模型记忆较早的信息。
-
三个门:
- 输入门:决定当前输入的信息可以写入记忆单元的多少。
- 遗忘门:决定当前记忆单元中的信息可以保留多少。
- 输出门:决定从记忆单元中读取多少信息并输出。
2.3.2 优缺点
-
优点:
- 有效解决了RNN在处理长序列时的梯度消失问题,适合处理长距离依赖问题。
- 模型灵活性高,能够学习复杂的时间序列模式。
-
缺点:
- 计算复杂度高,参数数量相对较大,训练时间较长。
- 结构较为复杂,相对难于调试和理解。
2.3.3 应用场景
- 机器翻译(如将英语句子翻译为法语)
- 语音识别(如将语音数据转为文字)
- 文本生成(如自动写诗、写小说)
- 视频分析(如运动预测和行为识别)
2.4 生成对抗网络(Generative Adversarial Network, GAN)
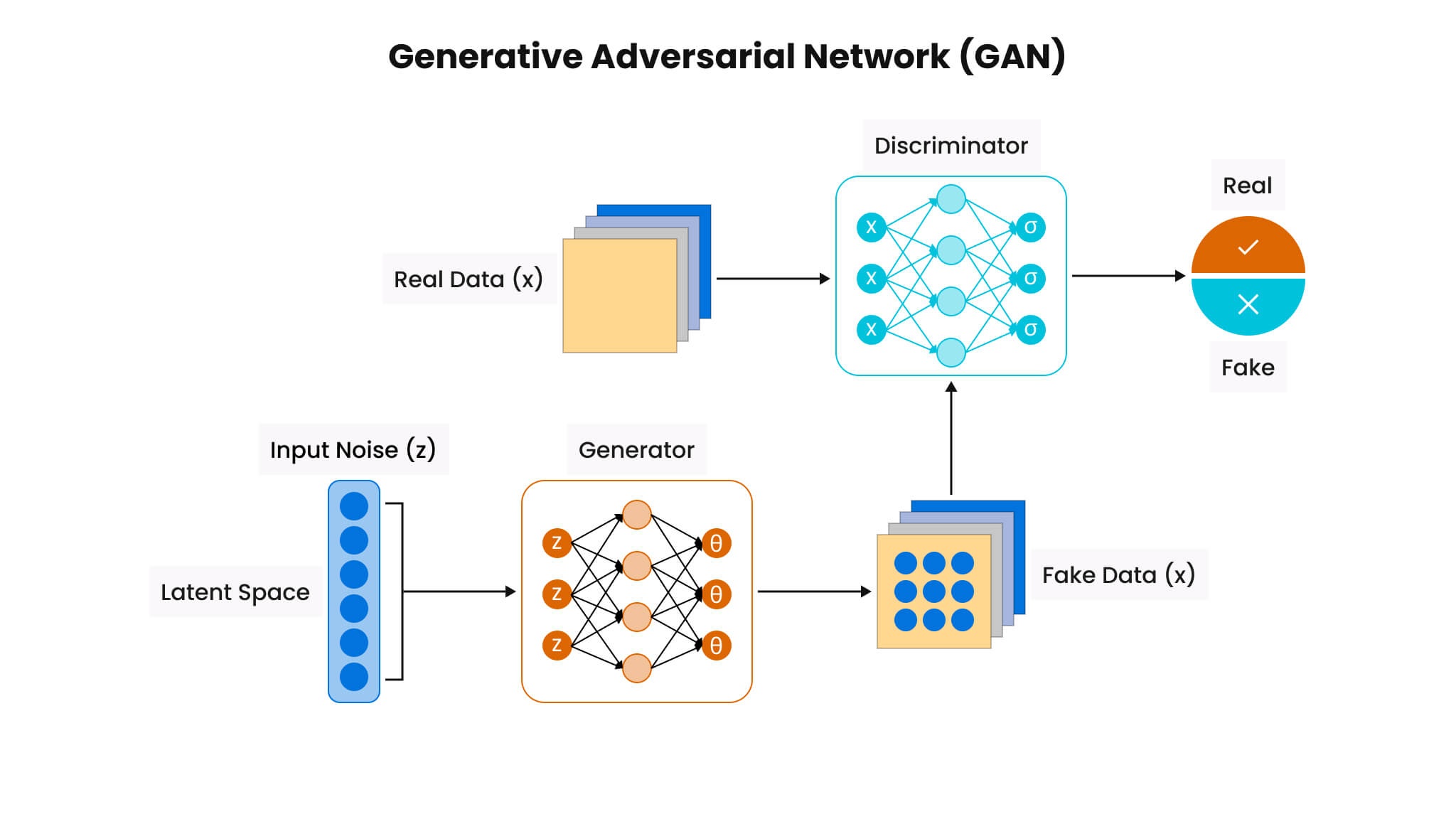
2.4.1 结构特点
生成对抗网络(GAN)采用了对抗性训练机制,包含两个主要组件:生成器(Generator)和判别器(Discriminator)。
-
生成器:负责从随机噪声中生成数据,目的是尽量生成看起来真实的数据。
-
判别器:负责区分真实数据和生成器生成的数据,输出真假概率。
两者通过相互博弈来提升性能,生成器不断改进以生成更真实的数据,而判别器则越来越擅长于识别虚假数据。
2.4.2 优缺点
-
优点:
- 能够生成高质量、高多样性的样本,尤其在图像生成领域表现突出。
- 可用于数据增强和半监督学习场景。
-
缺点:
- 训练过程不稳定,容易导致生成器和判别器之间的失衡(例如,判别器过强导致生成器无法学习)。
- 需要大量的计算资源,训练时间较长。
2.4.3 应用场景
- 图像生成(如艺术作品生成、人脸生成)
- 数据增强(如合成训练样本)
- 图像修复(如去噪声、图像补全)
- 文本生成与风格迁移(如自动生成图文内容)
2.5 转换器模型(Transformer)
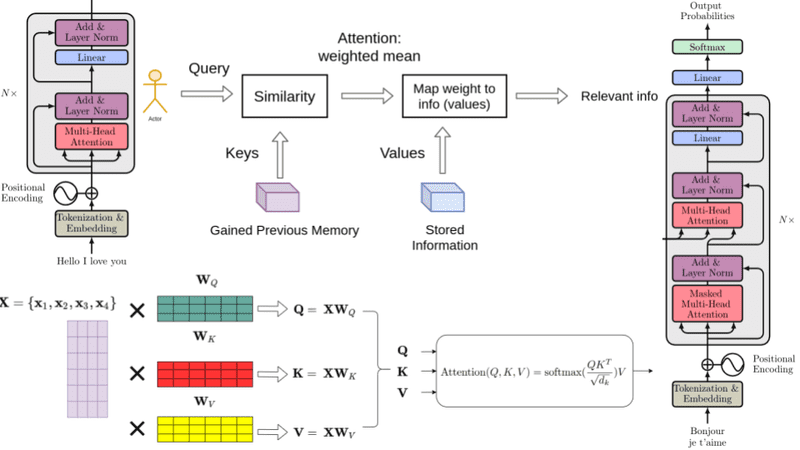
2.5.1 结构特点
转换器模型(Transformer)是解决序列到序列问题的有效结构,取消了传统RNN/LSTM的序列处理方式,引入了自注意力机制(Self-Attention),使得模型能够一次性处理整个序列,不再依赖于递归。
-
自注意力机制:计算每个单词与其他单词在输入序列中的相对重要性,从而动态地加权信息。
-
编码器-解码器架构:编码器将输入序列编码为上下文向量,解码器根据上下文向量生成输出序列。
2.5.2 优缺点
-
优点:
- 处理长序列时效率高,能够并行处理每个时间步的数据。
- 通过自注意力机制增强了模型对上下文信息的理解能力。
-
缺点:
- 需要较大的计算资源和内存,尤其在处理长序列时。
- 模型复杂性较高,超参数较多,调试较困难。
2.5.3 应用场景
- 自然语言处理(如BERT、GPT模型在文本生成和问答系统中的应用)
- 机器翻译(如使用Transformer模型进行英语翻译为其他语言)
- 情感分析(通过上下文了解文本情感)
- 图像生成与处理(通过视觉Transformer对图像进行分析和生成)
深度学习模型的类型多样,各种模型在特定领域和任务中展示了其独特的优势。随着研究的不断深入,新的架构和方法持续涌现,为解决实际问题提供了更丰富的工具。
三. 深度学习模型的训练
训练深度学习模型是一个关键过程,直接影响模型的性能和实际应用效果。深度学习模型的训练通常包括数据准备、模型选择与构建、超参数调整、训练与评估以及模型优化等多个步骤。下面将对每一个步骤进行详细阐述。
3.1 数据准备
数据是深度学习成功的基础,合适的数据集能够显著提高模型的性能。数据准备包括以下几个具体步骤:
3.1.1 数据收集
数据收集是构建深度学习模型的第一步。数据可以通过各种渠道获取,例如:
- 公开数据集:许多领域的公开数据集(如MNIST、CIFAR-10、ImageNet、COCO等)可以为模型提供良好的基准。
- 爬虫技术:如果公开数据集无法满足需求,可以使用网络爬虫程序收集数据。
- 业务数据:对于一些特定应用,可以利用企业内部数据库或日志系统收集数据。
3.1.2 数据预处理
数据预处理是确保数据质量的重要环节,主要包括:
- 数据清洗:去除重复、错误和不完整的数据条目,以提高数据的准确性。
- 数据格式转换:将数据转换为适合模型输入的格式,如将图像数据转为张量,文本数据转为词向量等。
- 数据归一化:将数据缩放到相同的范围内(如[0, 1]或[-1, 1]),确保不同特征对模型训练的影响一致。
- 数据增强:在图像分类任务中,可以对训练样本进行随机旋转、平移、剪切等操作,增加样本多样性,提升模型的泛化能力。
3.1.3 数据划分
将数据集划分为训练集、验证集和测试集是训练深度学习模型的标准做法:
- 训练集:用于模型的训练,模型通过此数据学习特征和模式。
- 验证集:用于模型训练过程中的参数调优和性能评估,防止过拟合。
- 测试集:用于对最终模型的性能进行评估,确保模型在新的、未见过的数据上的表现。
3.2 模型选择与构建
选择适合的问题背景和任务类型的深度学习模型是训练过程的重要环节。这一过程包括:
3.2.1 模型选择
基于数据类型和问题需求,选择适当的深度学习模型,如CNN、RNN或Transformer等。对于具体任务,可以考虑:
- 图像识别任务:选择卷积神经网络(CNN),如ResNet、Inception等。
- 序列数据处理:选择递归神经网络(RNN)或长短期记忆网络(LSTM)。
- 自然语言处理:选择基于Transformer架构的模型,如BERT、GPT等。
3.2.2 模型构建
使用深度学习框架(如TensorFlow、PyTorch)构建模型。模型的构建过程包括:
- 定义层结构:根据选择的模型,定义每层的类型、数量及其参数,如卷积层的卷积核大小、激活函数选择等。
- 初始化参数:合理选择权重初始化方法,以加速训练收敛过程,例如使用Xavier初始化或He初始化。
- 编译模型:设置损失函数、优化器和评价指标,准备进行模型训练。
3.3 超参数调整
超参数是影响深度学习模型训练效果的关键因素,常见的超参数包括:
- 学习率(Learning Rate) :控制权重更新幅度。较高的学习率可能导致收敛不稳定,而较低的学习率则可能导致收敛速度过慢。
- 批次大小(Batch Size) :每次训练所用样本的数量。批次大小的选择影响到模型的训练稳定性和内存使用。
- 训练轮数(Epochs) :整个训练集被用来训练网络的次数。过多的训练轮数可能导致过拟合。
- 正则化参数:如L2正则化权重或Dropout比例,这些对防止过拟合至关重要。
3.3.1 网格搜索与随机搜索
为找到最佳的超参数组合,可以使用网格搜索和随机搜索等方法:
- 网格搜索:尝试所有可能的参数组合,通常计算量大,但可保证找到最佳结果。
- 随机搜索:随机选择超参数组合进行尝试,相较于网格搜索计算量小,有时能取得更好的效果。
3.3.2 贝叶斯优化
贝叶斯优化是一种更为高效的超参数调优方法,通过建立代理模型,根据历史试验结果来指导新参数选择,能够减少计算成本并提高优化效果。
3.4 模型训练与评估
模型训练是深度学习的核心步骤,这一过程包括:
3.4.1 训练过程
模型训练的过程通常是迭代进行的,其中一轮迭代的基本步骤包括:
- 前向传播(Forward Propagation) :输入数据经过网络层层传递,计算出输出。
- 损失计算:根据输出和真实标签,计算损失函数值,用于衡量模型性能。
- 反向传播(Backward Propagation) :通过链式法则计算损失对各层权重的梯度,并更新权重。
3.4.2 验证与监控
在训练过程中,利用验证集监控模型的性能,以检测是否发生过拟合。监控指标通常包括:
- 损失曲线:观察训练和验证的损失值趋势,评估模型训练的效果。
- 准确率(Accuracy) :分类模型的正确率,验证集上的准确率提升通常说明模型学习良好。
3.5 模型优化
经过初步训练后,可能需要进一步优化模型以提高性能。优化的方法包括:
3.5.1 早停法(Early Stopping)
在验证集上监控模型的表现,当验证损失不再下降时,提早终止训练。这可以防止过拟合并节省计算时间。
3.5.2 模型调整
- 改变网络结构:增加或减少网络层数、改变神经元数量、应用不同类型的激活函数等。
- 正则化策略:使用Dropout、L2正则化等方法降低过拟合风险。
- 预训练模型:可以考虑迁移学习,使用已经在大规模数据集上训练好的模型进行微调,以实现更好的效果。
3.5.3 重新训练
在进行调整后,可能需要重新启动整个训练过程,利用更新后的参数进行新的训练。
深度学习模型的训练过程是一个复杂而循序渐进的过程。通过严谨的数据准备、合理的模型选择、细致的超参数调整及有效的优化手段,模型的性能将不断提升。掌握这些训练流程,不仅能优化模型效果,更能加深对深度学习理论的理解,为在实际问题中应用深度学习技术奠定坚实基础。
四. 深度学习模型的应用实例
4.1.2 目标检测
目标检测是识别图像中特定对象的位置和类别的任务。现代目标检测算法通常基于CNN,并通过引入区域候选网络(如R-CNN)进行检测。
4.1.3 图像分割
图像分割任务旨在将图像划分为多个部分,以便更好地进行分析。常见的模型包括U-Net和Mask R-CNN。
4.2 自然语言处理
自然语言处理是深度学习的另一大应用领域,许多任务如文本分类、机器翻译等均得益于深度学习模型的应用。
4.2.1 机器翻译
基于序列到序列架构的模型,如LSTM和后来的Transformer模型,显著提高了机器翻译的质量。
4.2.2 文本生成
文本生成是指根据输入生成相关的文本内容。深度学习模型,尤其是Transformer,在这一任务中表现突出。
4.2.3 情感分析
情感分析是自然语言处理任务之一,通常用于判断一段文本的情感倾向(正面、负面或中性)。
4.3 语音识别
语音识别是将口语转化为文本的技术,深度学习的引入极大提升了其准确性。
4.3.1 语音到文本
基于循环神经网络(RNN)和长短期记忆网络(LSTM)模型的应用,使得语音识别在自然语言理解上取得了显著成就。
4.4 推荐系统
深度学习在推荐系统中的应用正越来越普遍,利用用户数据和行为信息,为用户提供个性化推荐。
4.4.1 基于内容的推荐
推荐系统根据用户过去的选择和行为,为其推荐相似的内容。
4.4.2 协同过滤
协同过滤方法依赖用户的交互行为(如评分、点击等),为相似用户推荐相似的内容。
4.5 生成模型
深度学习生成模型的应用场景多种多样,不仅可以生成图像,还可以生成音乐和艺术作品。
4.5.1 图像生成
生成对抗网络(GAN)在图像生成领域显示出极高的潜力,能够生成高质量的逼真图像。
4.5.2 音乐生成
深度学习也被用于音乐创作,生成音乐作品。
-
深度学习模型因其强大的特征学习能力,已被广泛应用于多个领域,产生了显著的效果。以下将详细介绍若干深度学习模型在各个应用场景中的实例,涵盖计算机视觉、自然语言处理、语音识别等领域。
4.1 计算机视觉
计算机视觉是深度学习应用的重要领域,许多经典的深度学习模型在此领域取得了突破性进展。
4.1.1 图像分类
图像分类任务是指将输入图像分配给特定类别。例如,在手写数字识别中,使用卷积神经网络(CNN)可以达到高性能。
- 应用实例:MNIST数据集是手写数字识别的标准 benchmark,使用CNN模型,如LeNet,能够将准确率提高到99%以上。
- 扩展应用:在ImageNet上,AlexNet、VGGNet等模型的成功使得深度学习在图像分类任务中取得了重大进展,深度分类模型能够识别多达1000类别的物体。
- 应用实例:YOLO(You Only Look Once)是一种高效的目标检测方法,它通过将检测过程转化为回归问题,实现了实时检测,可在视频流中检测多个目标。
- 扩展应用:Faster R-CNN通过共享卷积层加速了计算,成为检测精度和速度均佼佼者的算法,被广泛用于无人驾驶、监控和安防领域。
- 应用实例:U-Net模型被广泛应用于医学图像分割(如肿瘤检测),其通过跳跃连接在特征层之间传递信息,能够精确分割出目标区域。
- 扩展应用:Mask R-CNN在场景分割中表现优异,能够在处理图像时为每个对象生成精准的分割掩码,在自动驾驶、图像编辑等多种语境中应用。
- 应用实例:Google翻译使用基于神经网络的翻译模型,结合了RNN和注意力机制,能够更加准确地翻译多种语言。
- 扩展应用:BERT等预训练模型进一步提升了翻译质量,通过丰富的上下文理解,改变了机器翻译的实现方式。
- 应用实例:OpenAI的GPT系列模型(如GPT-3)具有强大的文本生成能力,能够生成自然流畅的段落,广泛应用于内容创作、对话生成等。
- 扩展应用:利用LSTM和变体生成诗歌、故事等创意内容,带来了前所未有的文本生成体验。
- 应用实例:基于LSTM的情感分析模型能够以高达90%以上的准确率对影评、社交媒体内容等进行情感分类。
- 扩展应用:BERT等预训练模型提升了情感分析的效果,目前在舆情监控和市场情绪分析中应用广泛。
- 应用实例:Google的语音识别系统广泛应用于Android设备,能够实时识别并转录用户的语音指令。
- 扩展应用:语音助手(如Siri和Alexa)依赖深度学习模型对用户语音进行理解和响应,提供信息查询、设备控制等服务。
- 应用实例:Netflix使用基于内容的推荐算法分析用户观看历史,匹配相似内容,从而提高用户留存率。
- 扩展应用:结合CNN和RNN的深度推荐系统,不仅考虑内容特征,还考虑用户行为序列,提升推荐质量。
- 应用实例:Amazon的推荐系统通过分析用户的购买行为和评分,推荐用户可能喜欢的产品,提升了销售额。
- 扩展应用:混合模型结合了基于内容的推荐和协同过滤,使用深度学习增强了推荐算法的效果,处理冷启动问题。
- 应用实例:StyleGAN,能根据输入样式生成高分辨率的人脸图像,广泛应用于艺术创作和虚拟角色生成。
- 扩展应用:CycleGAN能够实现无监督图像转化,如风格转换,应用于图像编辑和增强等场景。
- 应用实例:OpenAI’s MuseNet,能够基于用户输入生成多种风格的音乐,展现了深度学习在创意领域的无限可能。
- 扩展应用:Magenta是一个开源项目,使用深度学习技术生成、演奏和学会音乐,致力于艺术与技术的融合。
总之,深度学习的应用实例覆盖了方方面面,从计算机视觉、自然语言处理到语音识别,再到推荐系统和生成模型,这些领域的进展显著推动了技术的演变,改变了人们的生活与工作。在未来,随着理论和算法的持续创新,深度学习将进一步拓展应用范围,带来更多的可能性,为各行各业创造更大的价值。通过对这些实例的了解,读者可以更好地把握深度学习的应用前景并激发创新思维。
五. 结语
深度学习模型的快速发展与应用,极大地推动了人工智能技术的进步。未来,随着技术的不断演进和优化,深度学习将在更多领域展现出更强大的能力。希望通过本文的介绍,读者能够对深度学习模型的基本概念与应用有更深入的理解,激发出更多的探索与实践。
相关文章:

深度学习模型的概述与应用
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

基于Ubuntu系统搭建51单片机开发环境的详细教程
一、环境搭建 1. 安装SDCC编译器 SDCC(Small Device C Compiler)是Linux下常用的开源51单片机编译器,支持多种芯片架构。 安装命令: sudo apt update sudo apt install sdcc 验证安装:输入 sdcc -v,若显…...

通义灵码助力Neo4J开发:快速上手与智能编码技巧
在 Web 应用开发中,Neo4J 作为一种图数据库,用于存储节点及节点间的关系。当图结构复杂化时,关系型数据库的查找效率会显著降低,甚至无法有效查找,这时 Neo4J 的优势便凸显出来。然而,由于其独特的应用场景…...

项目班——0408
qt的多线程开发 一、并发、并行的概念: 1. 并发:多个任务在同一时间段内交替执行(可能共享同一资源),但不一定同时发生。 核心思想:通过快速切换任务(例如时间片轮转)模拟“同时进…...
)
【Linux】42.网络基础(2.4)
文章目录 2.3 TCP协议2.3.10 拥塞控制2.3.11 延迟应答2.3.12 捎带应答2.3.13 面向字节流2.3.14 粘包问题2.3.15 TCP异常情况2.3.16 TCP小结2.3.17 基于TCP应用层协议 2.3 TCP协议 2.3.10 拥塞控制 虽然TCP有了滑动窗口这个大杀器, 能够高效可靠的发送大量的数据. 但是如果在刚…...

大模型在直肠癌诊疗全流程预测及应用研究报告
目录 一、引言 1.1 研究背景与目的 1.2 国内外研究现状 1.3 研究方法与创新点 二、大模型预测直肠癌的原理与技术基础 2.1 大模型技术概述 2.2 用于直肠癌预测的数据来源 2.3 模型构建与训练过程 三、术前预测 3.1 肿瘤分期预测 3.1.1 基于影像组学的 T 分期预测模型…...

Ceph块存储
#### 一、Ceph块存储 ##### 镜像快照管理 > 实现数据备份、恢复和测试等操作,而不影响原始数据,提高系统的可靠性和可用性。 shell # 创建镜像 rbd create img1 --size 10G # 映射镜像到本地并格式化挂载 rbd map img1 mkfs -t xfs /dev/rbd0 moun…...

【转载翻译】Open3D和PCL的一些比较
转自个人博客:【转载翻译】Open3D和PCL的一些比较 本人在逛Github时,发现一个解答Open3D和PCL对比的小文章,还挺有参考价值的 原文:https://github.com/LaplaceKorea/investigate_open3d_vs_pcl/blob/main/README.rst#whats-the-s…...
)
ebpf: CO-RE, BTF, and Libbpf(二)
本文内容主要来源于Learning eBPF,可阅读原文了解更全面的内容。 本文涉及源码也来自于书中对应的github:https://github.com/lizrice/learning-ebpf/ 概述 上篇文章主要讲了CO-RE最关键的一环:BTF,了解其如何记录内核中的数据结…...

RHCE第五章:NFS服务器
一、NFS(network file system) 网络文件系统:在互联网中共享服务器中的文件资源(用于Linux主机共享文件的协议)。 使用nfs服务需要安装:nfs-utils 以及 rpcbind nfs-utils : 提供nfs服务的程序 rpcbind :…...
 手动配置moc生成规则)
qt(vs2010) 手动配置moc生成规则
在 Visual Studio 2010 中写QT项目时,有时需要 手动配置 MOC 生成规则 操作步骤: 右键 .h 文件 → Properties。在 Configuration Properties > Custom Build Tool 中: Command Line:"$(QTDIR)\bin\moc.exe" "%(FullPath)…...

mongodb 安装配置
1.下载 官网下载地址:MongoDB Community Download | MongoDB 2.使用解压包 解压包安装:https://pan.baidu.com/s/1Er56twK9UfxoExuCPlJjhg 提取码: 26aj 3.配置环境: (1)mongodb安装包位置: …...

Java多态课堂练习题
Java多态课堂练习题 题目:动物乐园的多态展示 背景设定: 设计一个动物乐园程序,展示不同类型动物的行为特点,要求使用多态特性实现。 1. 基础类设计(已给出部分代码) // 基类:动物 abstract…...

Android Studio 实现自定义全局悬浮按钮
文章目录 一、基础实现方案1. 使用 WindowManager 实现全局悬浮窗2. 布局文件 (res/layout/floating_button.xml)3. 圆形背景 (res/drawable/circle_background.xml)4. 启动服务 二、权限处理1. AndroidManifest.xml 中添加权限2. 检查并请求权限 三、高级功能扩展1. 添加动画效…...

Android Studio 中文字大小的单位详解
文章目录 一、Android 中的尺寸单位1. dp (Density-independent Pixels - 密度无关像素)2. sp (Scale-independent Pixels - 可缩放像素)3. px (Pixels - 像素)4. pt (Points - 磅)5. mm (Millimeters - 毫米) 和 in (Inches - 英寸) 二、文字大小单位的最佳实践1. 始终使用 sp…...

Project ERROR: liblightdm-qt5-3 development package not found问题的解决方法
问题描述:使用make命令进行ukui-greeter-Debian构建时出现Project ERROR: liblightdm-qt5-3 development package not found错误,具体如图: 问题原因:缺乏liblightdm-qt5-3 development软件包 解决方法:安装liblightd…...
+SQLServer实现(WinForm)超市管理系统)
基于QT(C++)+SQLServer实现(WinForm)超市管理系统
超市库存管理系 使用 QT 开发,SQLserver 数据库配置 ODBC 数据源:QSQLServer 超市库存管理系统需求规格说明书 1 引言 校园超市的库存物资管理往往是很复杂、很繁琐的。由于所掌握的物资种类众多,订货、管理的渠道各有差异,各个校园超市之间的管理体制…...
)
06 - 多线程-JUC并发编程-原子类(二)
上一章,讲解java (java.util.concurrent.atomic) 包中的 支持基本数据类型的原子类,以及支持数组类型的原子类,这一章继续讲解支持对实体类的原子类,以及原子类型的修改器。 还有最后java (java…...

HTML:网页的骨架 — 入门详解教程
HTML:网页的骨架 — 入门详解教程 HTML(HyperText Markup Language,超文本标记语言)是构建网页的基础语言,负责定义网页的结构和内容。无论是简单的个人博客,还是复杂的企业网站,HTML都是不可或…...
)
Oracle 分析函数(Analytic Functions)
Oracle 的分析函数(Analytic Functions)是一类特殊的函数,用于在查询结果的窗口(window)内执行计算(如排名、累计求和、移动平均等),不会聚合结果行,而是为每一行返回一个…...

全新电脑如何快速安装nvm,npm,pnpm
以下是全新电脑快速安装 nvm、npm 和 pnpm 的详细步骤,覆盖 Windows/macOS/Linux 系统: 一、安装 nvm(Node Version Manager) 1. Windows 系统 下载安装包: 访问 nvm-windows 官方仓库,下载 nvm-setup.ex…...

风丘年度活动:2025年横滨汽车工程展览会
| 展会简介: 2025年横滨汽车工程展览会,是由日本汽车工程师学会(JSAE)精心主办的一场行业盛会。预计届时将汇聚超550家参展商,设置1300个展位,展览面积超过20000平方米。展会受众广泛,面向汽车…...

springBoot接入文心一言
文章目录 效果接入步骤项目接入配置类:WenXinYiYan前端vue代码js代码 后端mapper层service层controller层 测试代码 效果 先来看一下最后实现的效果 (1)未点击前的功能页面 (2)点击后的页面 (3ÿ…...

力扣HOT100——无重复字符的最长子字符串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 思路: 滑动窗口。遍历整个字符串,…...

Python高级爬虫之JS逆向+安卓逆向1.4节:数据运算
目录 引言: 1.4.1 赋值运算 1.4.2 算术运算 1.4.3 关系运算 1.4.4 逻辑运算 1.4.5 标识运算 1.4.6 爬虫接单赚了10块钱 引言: 大神薯条老师的高级爬虫安卓逆向教程: 这套爬虫教程会系统讲解爬虫的初级,中级,高…...

微信小程序无缝衔接弹幕效果纯CSS
效果图 主要运用蒙层、动画延迟 .wxml <view wx:for"{{detail}}" wx:key"{{index}}" class"container" style"--s:{{item.s}}s" ><view wx:for"{{2}}" wx:key"{{index}}" class"container-item&q…...
)
vue3:十一、主页面布局(增加左上角系统名称)
一、实现效果 侧边栏可平滑折叠/展开,带有过渡动画 折叠时隐藏Logo文字,只显示图标 优化滚动区域,避免标题栏随菜单滚动 解决折叠/展开时出现的滚动条闪烁问题 二、 实现 1、可以使用 SCSS(Sass 的一种语法) 首先…...

孟加拉slot游戏出海代投FB脸书广告策略
对于在孟加拉进行游戏出海代投的广告策略,可以考虑以下方面: 定位目标受众:确定目标受众群体,包括他们的年龄、兴趣爱好、消费习惯等信息,以便精准定位广告投放对象。 优质创意设计:设计吸引人眼球的广告素…...
:子集)
算法题(125):子集
审题: 本题需要我们将题目给定数组的所有子集枚举起来 思路: 方法一:二进制枚举 枚举对象:0到1<<n -1的整形数据 枚举顺序:顺序 枚举方式:二进制枚举 在解释二进制枚举的方法之前,我们先看…...

深度学习中的数值稳定性处理详解:以SimCLR损失为例
文章目录 1. 问题背景SimCLR的原始公式 2. 数值溢出问题为什么会出现数值溢出?浮点数的表示范围 3. 数值稳定性处理方法核心思想数学推导 4. 代码实现分解代码与公式的对应关系 5. 具体数值示例示例:相似度矩阵方法1:直接计算exp(x)方法2&…...

查看linux中是否安装了tiktoken
在 Linux 中检查 tiktoken 是否安装的完整方法 通过 pip 命令检查 查看已安装的 Python 包列表: pip list | grep tiktoken 若输出包含 tiktoken,则表示已安装。 获取包详细信息: pip show tiktoken 若显示包版本、安装路径…...
)
从源码看无界 1.0.28:为何说它是 qiankun 的 “轻量化替代方案”(二)
我们接着上一节的《从源码看无界 1.0.28:为何说它是 qiankun 的 “轻量化替代方案”》内容继续往下。 生命周期图 sandbox.active 方法 我们找到 packages/wujie-core/src/sandbox.ts 文件的第 275 行: //.../** 激活子应用* 1、同步路由* 2、动态修改iframe的fetch* 3、准…...

SQL注入之时间盲注攻击流程详解
目录 一、时间盲注原理 二、完整攻击流程 1. 注入点确认 2. 基础条件判断 3. 系统信息收集 (1)获取数据库版本 (2)获取当前数据库名 4. 数据提取技术 (1)表名枚举 (2)列名猜…...

【NIO番外篇】之组件 Selector
目录 一、Selector:网络世界的“机场管制塔” / “总机接线员” 📡什么是 Selector?它的作用是什么? 二、Selector 的工作流程:塔台是怎么指挥飞机的?1. 飞机就位 (准备 Channel):2. 向塔台报到…...

对接印度尼西亚股票数据源API
随着对东南亚市场的关注增加,获取印度尼西亚(IDX)股票市场的实时和历史数据变得尤为重要。本文将指导您如何使用Spring Boot框架对接一个假定的印尼股票数据源API(例如,StockTV),以便开发者能够…...
:创建数据库,表,简单)
SQL(9):创建数据库,表,简单
1、创建数据库,一句SQL语句搞定 CREATE DATDBASE 数据库名 CREATE DATABASE my_db;2、创建表 CREATE TABLE 表名(字段名 类型) CREATE TABLE Persons ( PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255)…...
:一项综述|文献速递-深度学习医疗AI最新文献)
医学成像中的对比语言-图像预训练模型(CLIP):一项综述|文献速递-深度学习医疗AI最新文献
Title 题目 CLIP in medical imaging: A survey 医学成像中的对比语言-图像预训练模型(CLIP):一项综述 01 文献速递介绍 尽管在过去十年中视觉智能领域取得了重大进展(何恺明等人,2016;塔尔瓦宁和瓦尔…...

KEGG注释脚本kofam2kegg.py--脚本010
采用kofam结合kegg官网htxt进行注释 用法: python kofam2kegg.py kofam.out ath00001.keg my_kegg_output code: import sys from collections import defaultdictdef parse_kofam_file(kofam_file):ko_to_genes defaultdict(list)with open(kofam_file) as f:…...

hevc编码芯片学习-VLSI实现
在Fan等工作中,根据特定算法设计了整像素运动估计引擎,最终的BD-Rate损失非常小,但是硬件开销比较大,搜索算法缺少灵活性,本次设计优化了硬件设计架构, 微代码 取像素 压缩 水平参考像素存储器 寻址控制 转…...

选导师原理
总述 一句话总结:是雷一定要避,好的一定要抢。方向契合最好,不契合适当取舍。 首先明确自身需求: 我要学东西!青年导师,好沟通,有冲劲,高压力。 我要摆烂!中老年男性教…...

2.5亿像素卷帘快门CMOS大幅面扫描相机
规格说明书 主要特征 ◎ 卷帘快门CMOS 传感器 ◎ 2.46 亿像素分辨率 ◎ 全分辨率最高帧率达5fps ◎ 高灵敏度及低噪声 ◎ ROI 区域设置 ◎ 曝光时间灵活控制(外触发,自由运行) ◎ 输出像素格式8/10/12bit 可选 ◎ 自动坏像素校正、平场校正…...
友元和内部类)
CD27.【C++ Dev】类和对象(18)友元和内部类
目录 1.友元 友元函数 几个特点 友元类 格式 代码示例 2.内部类(了解即可) 计算有内部类的类的大小 分析 注意:内部类不能直接定义 内部类是外部类的友元类 3.练习 承接CD21.【C Dev】类和对象(12) 流插入运算符的重载文章 1.友元 友元函数 在CD21.【C Dev】类和…...

企业级硬盘的测试流程
测试硬盘流程 找一个有Linux操作系统的服务器,配置好管理ip的接口,连接上linux服务器,执行lsblk命令来查看设备的情况 使用mkfs命令格式化要测试的硬盘,格式化之前务必把数据进行备份,可以使用blkid命令查看硬盘的文件…...

std::enable_shared_from_this 模板类的作用是什么?
我们以Connection类的shared智能指针为例说明,std::enable_shared_from_this<Connection> 是一个标准库模板类,它的作用是让一个类的对象能够安全地生成指向自身的 std::shared_ptr,即使该对象最初是通过普通指针或其他方式创建的。 作…...

鸿蒙开发-ArkUi控件使用
2.0控件-按钮 2.1.控件-文本框 Text(this.message).fontSize(40) // 设置文本的文字大小.fontWeight(FontWeight.Bolder) // 设置文本的粗细.fontColor(Color.Red) // 设置文本的颜色------------------------------------------------------------------------- //设置边框Tex…...

大数据学习栈记——MongoDB编程
本文介绍NoSQL技术:MongoDB用Java来连接数据库,执行常见的数据库操作,使用环境:IntelliJ IDEA、Ubuntu24.04。 配置Maven 我们需要使用“MongoDB Driver”,所以先打开“MongoDB Java Driver”项目,但是提…...
:A Machine-Learning-Guided Framework for Fault-Tolerant DNNs)
体系结构论文(六十七):A Machine-Learning-Guided Framework for Fault-Tolerant DNNs
A Machine-Learning-Guided Framework for Fault-Tolerant DNNs DATE 2024 研究动机 深度神经网络(DNN)虽然对某些扰动具有天然的容错性,但在面对硬件故障(如软错误、老化、环境干扰等)时,仍会出现输出错…...

qt designer 创建窗体选择哪种屏幕大小
1. 新建窗体时选择QVGA还是VGA 下面这个图展示了区别 这里我还是选择默认,因为没有特殊需求,只是在PC端使用...

游戏引擎学习第225天
只能说太难了 回顾当前的进度 我们正在进行一个完整游戏的开发,并在直播中同步推进。上周我们刚刚完成了过场动画系统的初步实现,把开场动画基本拼接完成,整体效果非常流畅。看到动画顺利呈现,令人十分满意,整个系统…...

sql工具怎么选最适合自己的?
sql工具怎么选? 为什么大多数主流工具又贵又难用?有没有一款免费好用的sql工具?像大多数朋友经常用的sql工具应该都遇到过这种情况,用着用着收到了来自品牌方的律师函,或者处理数据时经常卡死,再或者不支持…...