ELK+Filebeat 深度部署指南与实战测试全解析
一、介绍
ELK: ELasticsearch ,Logstash,Kibana三大开源框架首字母简写,市面上也被称为Elastic Stack。
- Elasticsearch 是一个基于 Lucene 的分布式搜索平台框架,通过 Restful 方式进行交互,具备近实时搜索能力。像百度、Google 这类大数据全文搜索引擎的场景,都能使用 Elasticsearch 作为底层支持框架,其强大的搜索能力可见一斑。在市面上,我们通常将 Elasticsearch 简称为 ES ;
- Logstash(读音:lao ge si ta shi)是 ELK 的中央数据流引擎。它能够从不同目标(如文件、数据存储、MQ)收集各类数据,在经过过滤处理后,支持输出到不同的目的地(例如文件、MQ、Redis、Elasticsearch、Kafka 等 );
- Kibana 能够将 Elasticsearch 的数据以友好的页面形式展示出来,并提供实时分析功能。
(实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集场景,日志分析和收集只是更具代表性.并非唯一性)
Filebeat:是一个轻量级的日志采集器,是 Elastic Stack(ELK)的一部分,主要用于收集服务器上的日志文件并将其发送到 Logstash 或 Elasticsearch 中进行处理和分析。
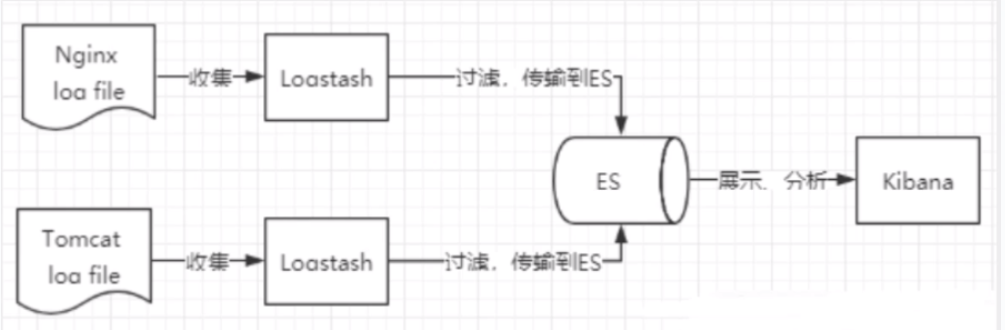
(工作流程:收集清洗数据(Logstash) ==> 搜索,存储(ELasticsearch) ==> 展示(Kibanna))
二、部署
1.规划
| 192.168.60.10 | node1.com node1 | JDK,ELasticsearch,Logstash,Kibana |
| 192.168.60.20 | node2.com node2 | JDK,ELasticsearch |
| 192.168.60.30 | node3.com node3 | JDK,ELasticsearch |
| 192.168.60.40 | node4.com node4 | Apache+filebeat |
2.环境准备
(1)selinux、firewall 关闭
(2)时间同步
(3)主机名修改
(4)主机名解析
#!/bin/bash#交互式设置ip地址和主机名
read -p "请输入要初始化成的ip地址:" ip_address
read -p "请输入要初始化的主机名:" name#设置ip地址
cat > /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="5ad929c2-d3eb-4504-bbf8-58d80652cd75"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=$ip_address
PREFIX=24
GATEWAY=192.168.60.2
DNS1=114.114.114.114
EOF#设置主机名
hostnamectl set-hostname ${name}.com#解析主机名
cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
$ip_address ${name}.com
EOF#关闭防火墙
systemctl stop firewalld
systemctl disabled firewalld#关闭selinux
setenforce 0
cat > /etc/selinux/config << EOF
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
EOF#时间同步
ntpdate ntp.aliyun.com(使用initialize.sh初始化脚本完成前四条的环境准备)
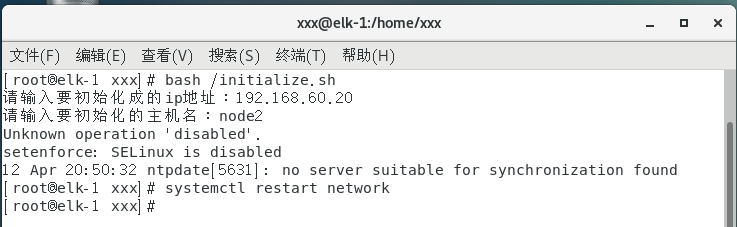
(5)设置时间计划任务
(每个节点都要配置)
[root@node1 /]# crontab -e
*/30 * * * * /usr/sbin/ntpdate 120.25.115.20 &> /dev/null(6)ssh互信
[root@node1 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.60.10 node1.com node1
192.168.60.20 node2.com node2
192.168.60.30 node3.com node3
192.168.60.40 node4.com node4
 [root@node1 ~]# scp /etc/hosts 192.168.60.20:/etc/
[root@node1 ~]# scp /etc/hosts 192.168.60.20:/etc/
[root@node1 ~]# scp /etc/hosts 192.168.60.30:/etc/
[root@node1 ~]# scp /etc/hosts 192.168.60.40:/etc/
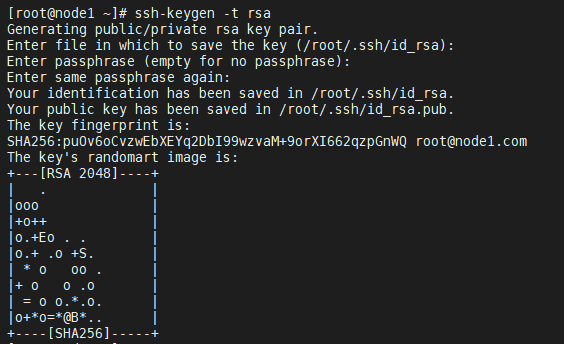
[root@node1 ~]# ssh-keygen -t rsa
[root@node1 ~]# mv /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.60.20:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.60.30:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.60.40:/root/
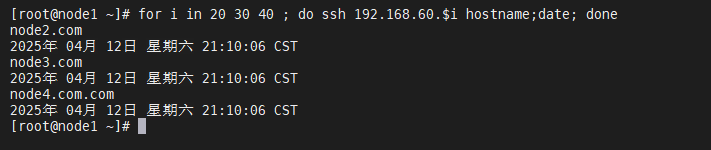
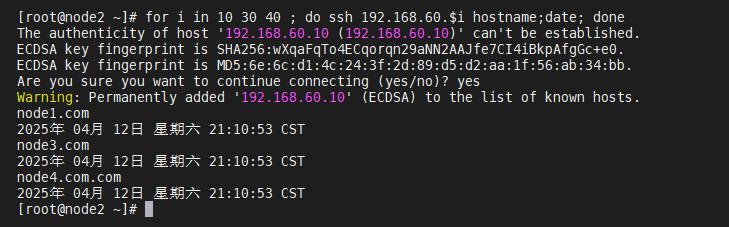
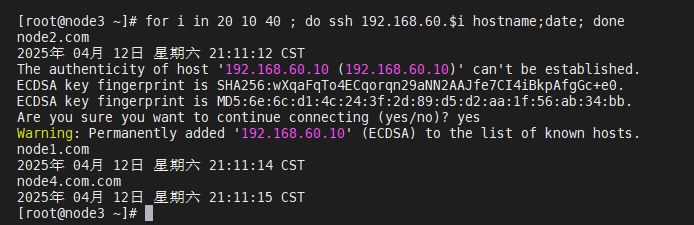
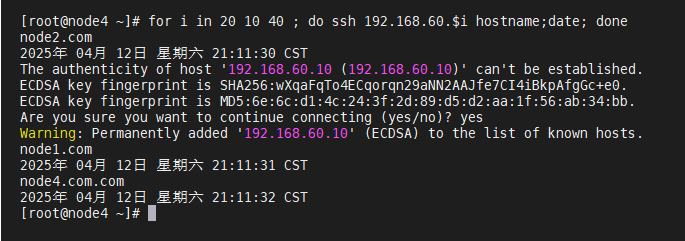
(ssh互信配置成功!)
(7)修改打开文件最大数
(在node2、node3、node4都做以下的操作来修改打开文件的最大数)
[root@node1 ~]# vim /etc/security/limits.conf #另外三个节点都要做下面这些操作
* soft nproc 655350
* hard nproc 655350
* soft nofile 655350
* hard nofile 655350
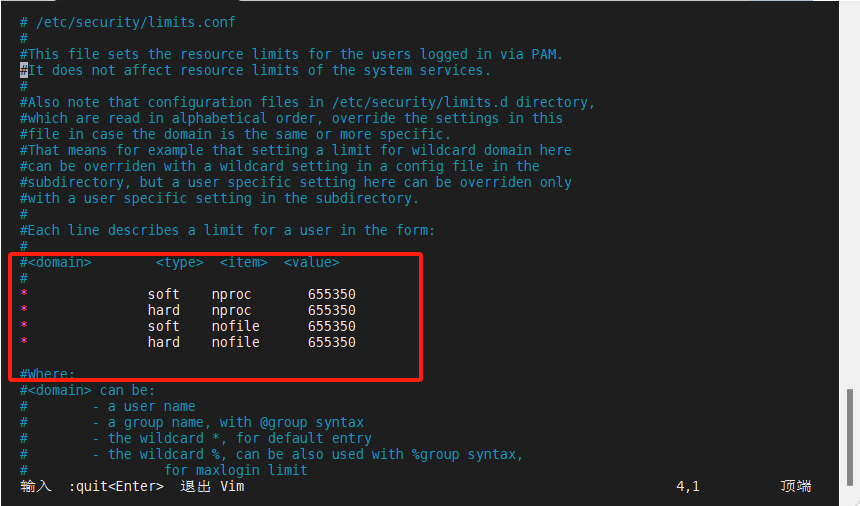
[root@node1 ~]# ulimit -SHn 655350 #设置用户软、硬文件描述符上限
[root@node1 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144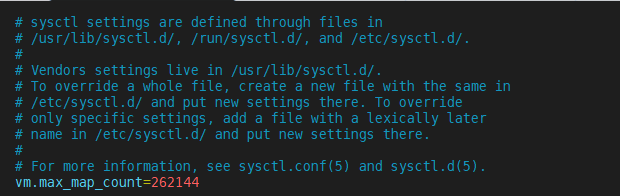
[root@node1 ~]# sysctl -p #刷新生效
3.配置JDK环境
(四个节点都要进行下述的操作来配置JDK环境)
(1)下载
我用夸克网盘分享了「jdk-8u391-linux-x64.rpm」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/41b52e5a593e

(2)安装
[root@node1 /]# rpm -ivh jdk-8u391-linux-x64.rpm
(3)配置环境变量
[root@node1 /]# vim /etc/profile
JAVA_HOME=/usr/lib/jvm/jdk-1.8-oracle-x64
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH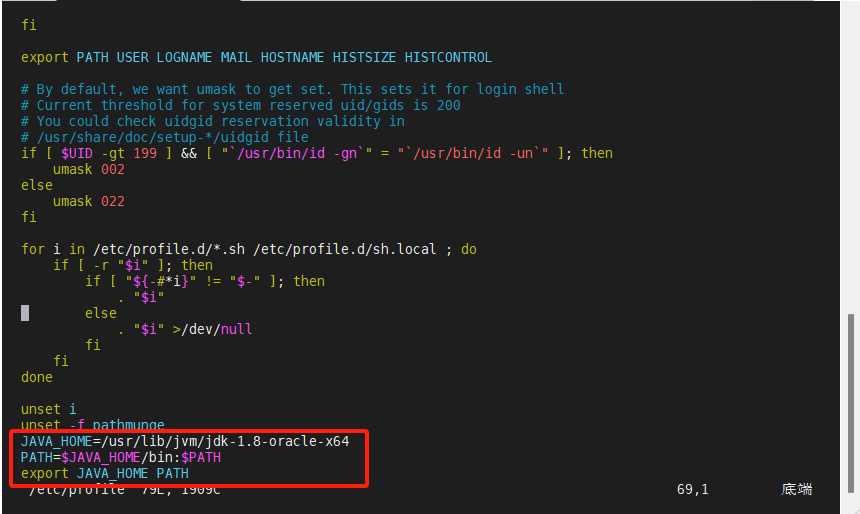
[root@node1 /]# source /etc/profile #生效配置
[root@node1 ~]# for i in 10 20 30 40; do ssh 192.168.60.$i hostname;java -version; done;
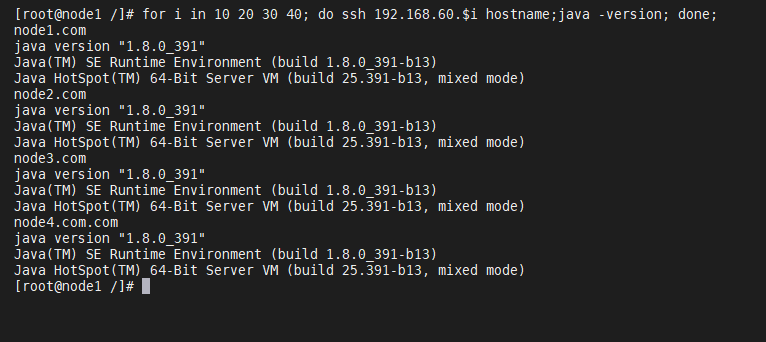
(配置成功!)
4.Elasticsearch 的安装过程
(1)相关介绍
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
什么是Lucene?
Lucene是一款非常优秀且成熟的开源免费全文索引检索工具包,完全基于Java语言开发。 全文检索,指的是计算机索引程序逐词扫描文章,为每个词构建索引,记录该词在文章中的出现次数与位置。当用户发起查询时,检索程序依据预先建立的索引展开查找,并将结果反馈给用户。
(2)节点类型说明
- Master node
- 负责集群自身的管理操作;例如创建索引、添加节点、删除节点
- node.master: true
- Data node
- 负责数据读写
- 建议实际部署时,使用高内存、高硬盘的服务器
- node.data: true
- Ingest node
- 预处理节点
- 负责数据预处理(解密、压缩、格式转换)
- Client node
- 负责路由用户的操作请求
- node.master: false
- node.data: false
(3)node1节点
①下载
[root@node1 /]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.0-linux-x86_64.tar.gz
②配置安装
(Elastic Search安装时不要使用root用户,需要创建一个普通用户elasticsearch来安装,后面执行命令都是以elasticsearch用户来执行的,需要提高权限的地方使用sudo来执行)
[root@node1 /]# groupadd es
[root@node1 /]# useradd -g es es
[root@node1 /]# echo "es ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/es
[root@node1 /]# chmod 0440 /etc/sudoers.d/es
[root@node1 /]# su - es
[es@node1 ~]$ sudo mkdir /usr/local/setup
[es@node1 ~]$ sudo chown -R es.es /usr/local/setup/
[es@node1 ~]$ sudo cp /elasticsearch-8.6.0-linux-x86_64.tar.gz /usr/local/setup/
[es@node1 ~]$ tar -xvf /usr/local/setup/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup
[es@node1 ~]$ sudo mkdir -p /data/es/{logs,data}
[es@node1 ~]$ sudo chown -R es.es /data/
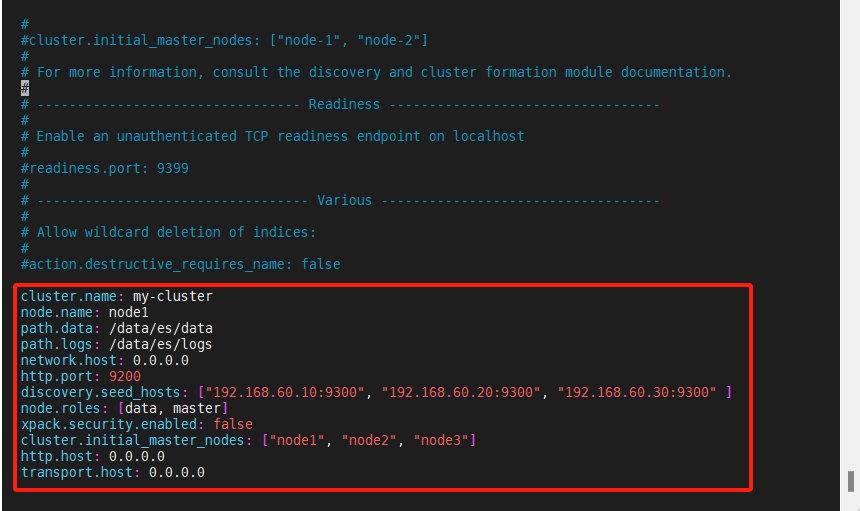
[es@node1 ~]$ sudo vim /usr/local/setup/elasticsearch-8.6.0/config/elasticsearch.yml
cluster.name: my-cluster
node.name: node1
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ]
node.roles: [data, master]
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
(配置说明)
cluster.name: my-cluster #集群名, 如果做集群,只需要在启一个节点相同的集群名
node.name: node1 #集群中的节点名,最好和主机名一致
path.data: /data/es/data #数据存储位置,默认
path.logs: /data/es/logs #日志存储位置,默认
network.host: 0.0.0.0 #监听地址,这里是为了使用elasticsearch-head
http.port: 9200 #监听端口
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ] #集群发现
node.roles: [data, master] #节点角色
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]#集群初始化Master节点,会在第一次选举中进行计算 必须使用短主机名
http.host: 0.0.0.0
transport.host: 0.0.0.0
(4)node2节点
①下载
[es@node1 /]$ sudo scp /elasticsearch-8.6.0-linux-x86_64.tar.gz 192.168.60.20:/
②配置安装
[root@node2 /]# groupadd es
[root@node2 /]# useradd -g es es
[root@node2 /]# echo "es ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/es
[root@node2 /]# chmod 0440 /etc/sudoers.d/es
[root@node2 /]# su - es
[es@node2 ~]$ sudo mkdir /usr/local/setup
[es@node2 ~]$ sudo chown -R es.es /usr/local/setup/
[es@node2 ~]$ sudo cp /elasticsearch-8.6.0-linux-x86_64.tar.gz /usr/local/setup/
[es@node2 ~]$ sudo tar -xvf /usr/local/setup/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup
[es@node2 ~]$ sudo mkdir -p /data/es/{logs,data}
[es@node2 ~]$ sudo chown -R es.es /data/
[es@node2 ~]$ sudo vim /usr/local/setup/elasticsearch-8.6.0/config/elasticsearch.yml
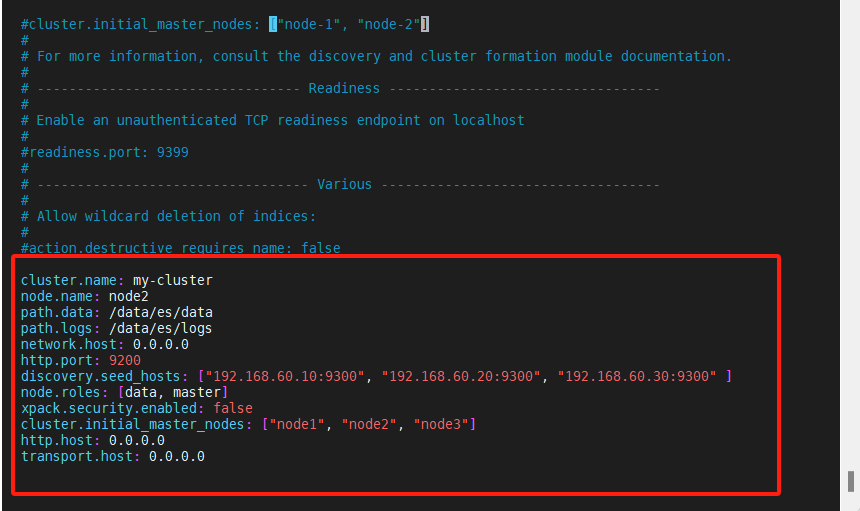
cluster.name: my-cluster
node.name: node2
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ]
node.roles: [data, master]
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
(5)node3节点
①下载
[es@node1 /]$ sudo scp /elasticsearch-8.6.0-linux-x86_64.tar.gz 192.168.60.30:/
②配置安装
[root@node3 ~]# groupadd es
[root@node3 ~]# useradd -g es es
[root@node3 ~]# echo "es ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/es
[root@node3 ~]# chmod 0440 /etc/sudoers.d/es
[root@node3 ~]# su - es
[es@node3 ~]$ sudo mkdir /usr/local/setup
[es@node3 ~]$ sudo chown -R es.es /usr/local/setup/
[es@node3 ~]$ sudo cp /elasticsearch-8.6.0-linux-x86_64.tar.gz /usr/local/setup/
[es@node3 ~]$ sudo tar -xvf /usr/local/setup/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup
[es@node3 ~]$ sudo mkdir -p /data/es/{logs,data}
[es@node3 ~]$ sudo chown -R es.es /data/
[es@node3 ~]$ sudo vim /usr/local/setup/elasticsearch-8.6.0/config/elasticsearch.yml
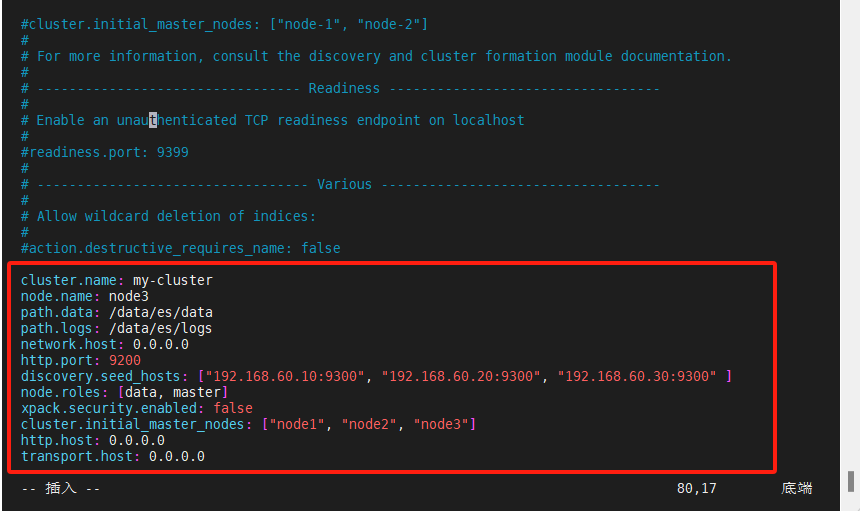
cluster.name: my-cluster
node.name: node3
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ]
node.roles: [data, master]
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
(6)启动每个节点
node1:
[es@node1 /]$ cd /usr/local/setup/elasticsearch-8.6.0/bin
[es@node1 /]$ ./elasticsearch -d
node2:
[es@node2 /]$ cd /usr/local/setup/elasticsearch-8.6.0/bin
[es@node2 /]$ ./elasticsearch -d
node3:
[es@node3 /]$ cd /usr/local/setup/elasticsearch-8.6.0/bin
[es@node3 /]$ ./elasticsearch -d
(7)测试
[root@node4 ~]# curl http://192.168.60.10:9200/_cat/health?v

[root@node4 ~]# curl -X GET "http://192.168.60.10:9200/_cluster/health?pretty"
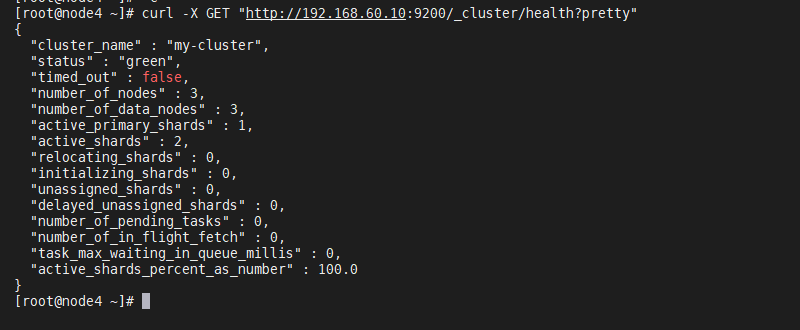
(可以看到集群的健康状况良好!)
问题解决
① 运行时权限不足
报错——
[es@node1 /]$ ./elasticsearch -d
warning: ignoring JAVA_HOME=/usr/lib/jvm/jdk-1.8-oracle-x64; using bundled JDK
./elasticsearch-cli:行14: /usr/local/setup/elasticsearch-8.6.0/jdk/bin/java: 权限不够
解决——
[es@node1 /]$ sudo chown -R es.es /usr/local/setup/
#添加一下权限
② 测试没有到主机的路由
报错——
[root@node4 ~]# curl http://192.168.60.10:9200/_cat/health?v
curl: (7) Failed connect to 192.168.60.10:9200; 没有到主机的路由
解决——
[es@node1 /]$ sudo iptables -F
[es@node1 /]$ sudo systemctl stop firewalld.service
[es@node1 /]$ sudo systemctl disable firewalld
#关闭防火墙以及清空iptables规则
5.Kibana的安装过程
(1)相关介绍
Kibana是为Elasticsearch设计的开源分析和可视化平台。你可以使用Kibana来搜索,查看存储在Elasticsearch索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
(这个只需要在node1节点上安装配置)
(2)下载
官网:Kibana Guide | Elastic
下载地址: Past Releases of Elastic Stack Software | Elastic
[root@node1 /]# wget https://artifacts.elastic.co/downloads/kibana/kibana-8.6.0-linux-x86_64.tar.gz
(3)配置安装
[root@node1 /]# tar -xvf kibana-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup/
[root@node1 /]# vim /usr/local/setup/kibana-8.6.0/config/kibana.yml
server.port: 5601
server.host: "192.168.60.10"
elasticsearch.hosts: ["http://192.168.60.10:9200"]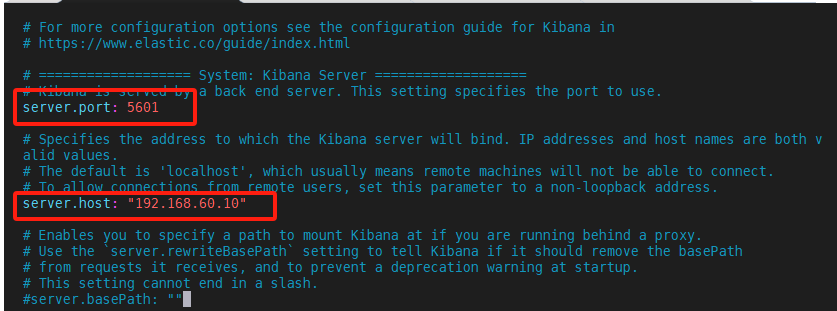

(4)启动
[root@node1 /]# chown -R es.es /usr/local/setup/kibana-8.6.0/
[root@node1 /]# su - es
[es@node1 ~]$ nohup /usr/local/setup/kibana-8.6.0/bin/kibana &
[es@node1 ~]$ ps -ef | grep kibana
[es@node1 ~]$ ss -anplt
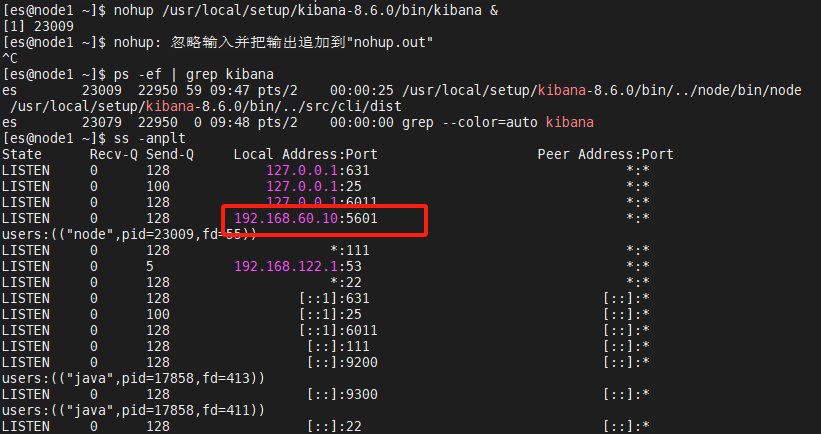
(5)访问
访问192.168.60.10:5601
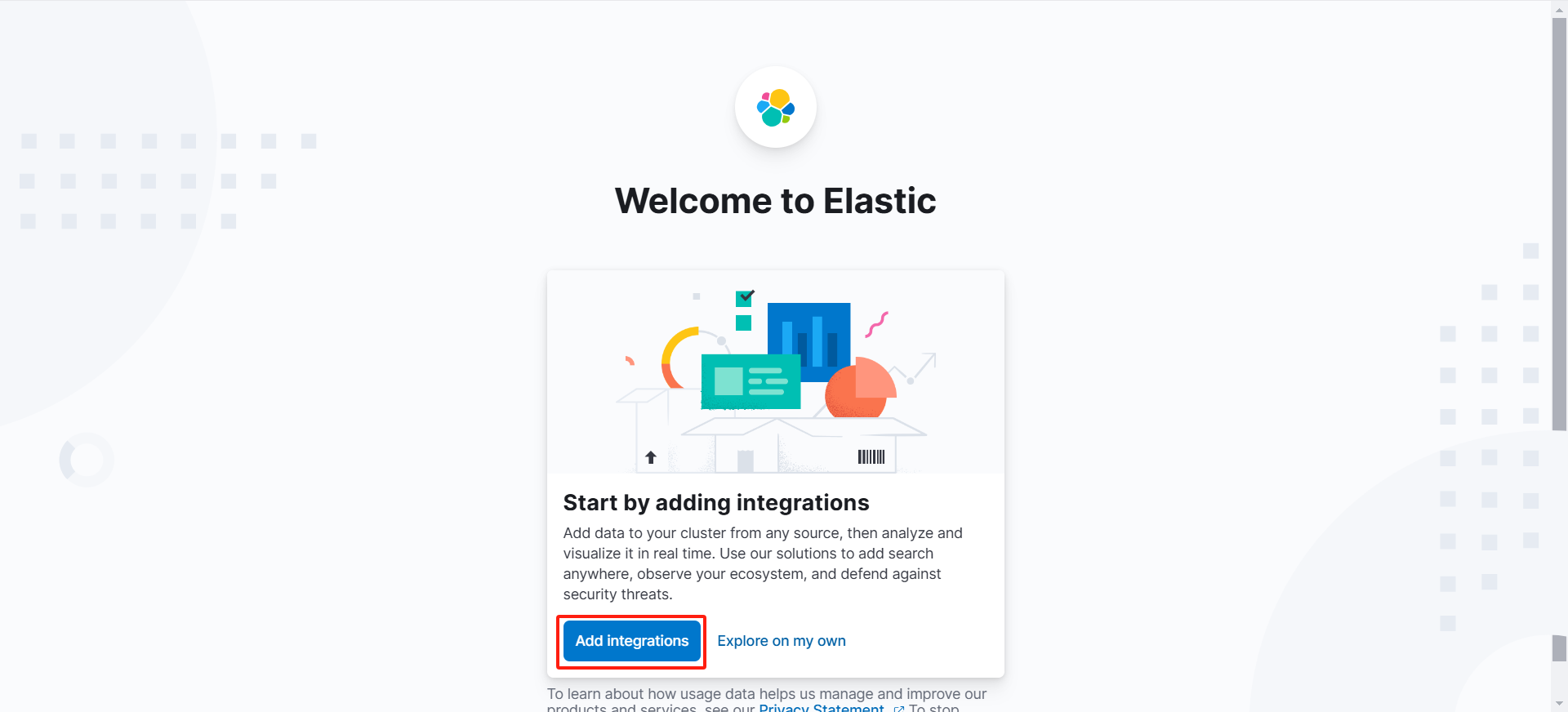
(安装成功!)
6.安装部署filebeat
(1)相关介绍
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
filebeat和logstash的关系
Logstash基于JVM运行,资源消耗较大。因此,其作者后来用Golang编写了一个轻量级的Logstash-Forwarder,功能相对较少,但资源消耗也更低。当时作者独自进行开发,后来他加入了Elastic公司(官网为http://elastic.co )。Elastic公司此前还收购了一个用Golang开发的开源项目Packetbeat,并且有专门的团队负责维护。鉴于此,Elastic公司决定将Logstash-Forwarder的开发工作整合到这个Golang团队中,于是新的项目Filebeat应运而生 。
(这个只需要在node4节点上安装配置)
(2)下载
官网:Filebeat Reference | Elastic
下载地址: Past Releases of Elastic Stack Software | Elastic
[root@node4 /]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.6.0-linux-x86_64.tar.gz
(3) 配置安装
[root@node4 /]# tar -xvf filebeat-8.6.0-linux-x86_64.tar.gz -C /usr/local/
[root@node4 /]# cp /usr/local/filebeat-8.6.0-linux-x86_64/filebeat.yml /usr/local/filebeat-8.6.0-linux-x86_64/filebeat.yml.bak
[root@node4 /]# vim /usr/local/filebeat-8.6.0-linux-x86_64/filebeat.yml
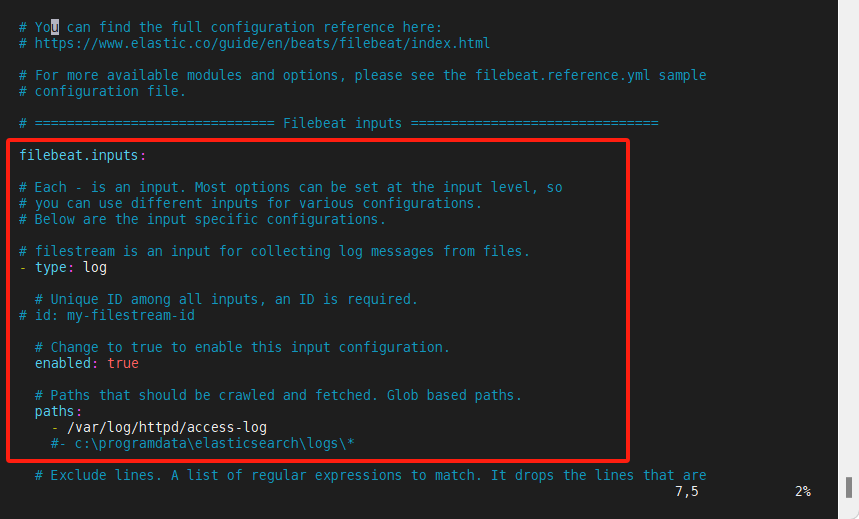
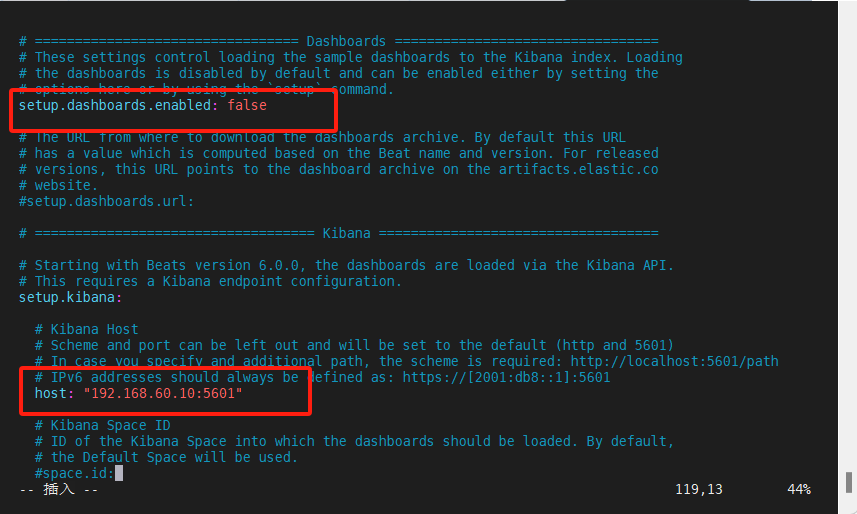
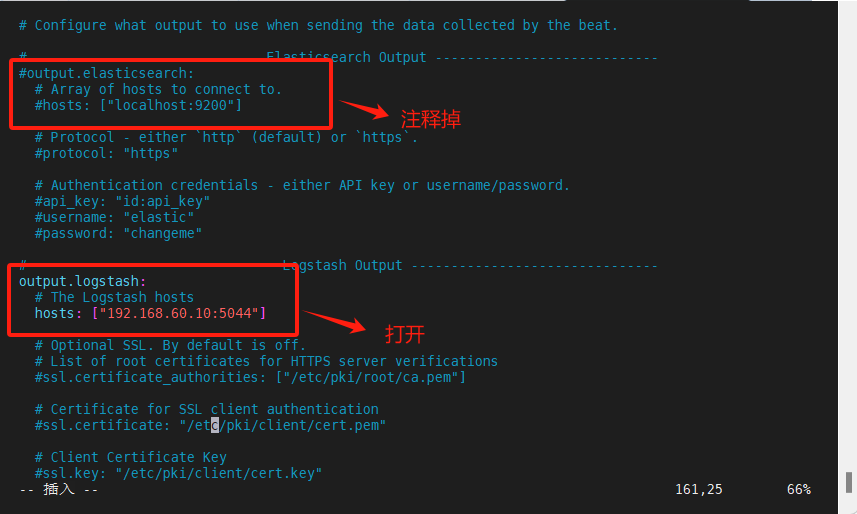
(4)启动
[root@node4 /]# yum install httpd -y #安装apache
[root@node4 /]# systemctl restart httpd
[root@node4 /]# curl 192.168.60.40 #访问产生日志
[root@node4 /]# cd /var/log/httpd/ #修改日志名
[root@node4 httpd]# mv access_log access-log
[root@node4 httpd]# mv error_log error-log
[root@node4 httpd]# vim /etc/httpd/conf/httpd.conf #修改日志配置
ErrorLog "logs/error-log"
CustomLog "logs/access-log" combined
(就是把 - 下划线改成 - 横杠)
[root@node4 /]# cd /usr/local/filebeat-8.6.0-linux-x86_64/ #启动
[root@node4 filebeat-8.6.0-linux-x86_64]# nohup ./filebeat -c filebeat.yml &

[root@node4 filebeat-8.6.0-linux-x86_64]# ps -elf | grep filebeat

(启动成功!)
7.安装部署Logstash
(1)相关介绍
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
(使用Logstash的版本号与elasticsearch版本号需要保持一致,JDK需要预先装好)
(这个只需要在node1节点上安装配置)
(2)下载
官网:Download Logstash Free | Get Started Now | Elastic
下载地址: Past Releases of Elastic Stack Software | Elastic
[root@node1 /]# wget https://artifacts.elastic.co/downloads/logstash/logstash-8.6.0-linux-x86_64.tar.gz
(3)配置安装
[root@node1 /]# tar -xvf logstash-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup/
[root@node1 /]# cp /usr/local/setup/logstash-8.6.0/config/logstash-sample.conf /usr/local/setup/logstash-8.6.0/config/logstash.conf
[root@node1 /]# vim /usr/local/setup/logstash-8.6.0/config/logstash.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.input {beats {port => 5044}
}filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}
}output {elasticsearch {hosts => ["http://192.168.60.10:9200"]index => "httpd-access-%{+YYYY.MM.dd}"#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"#user => "elastic"#password => "changeme"}
}
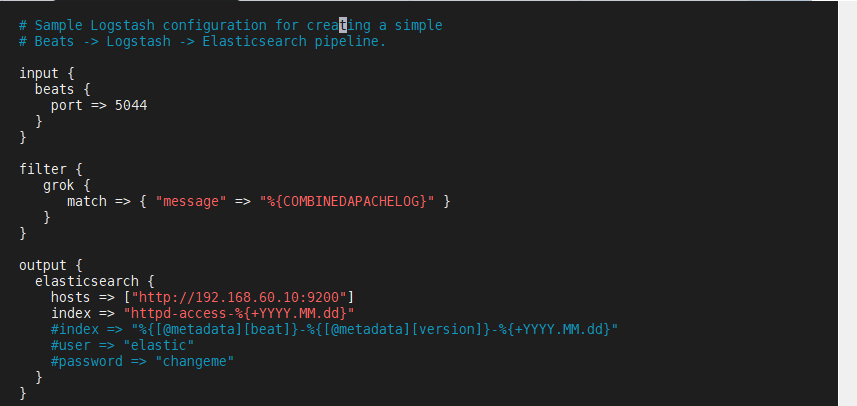
[root@node1 /]# vim /usr/local/setup/logstash-8.6.0/config/jvm.options #修改jvm的配置
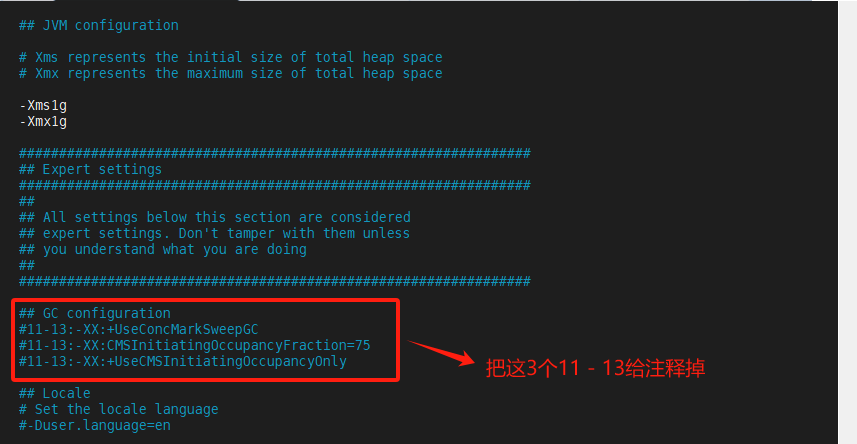
(4)启动
[root@node1 /]# nohup /usr/local/setup/logstash-8.6.0/bin/logstash -f /usr/local/setup/logstash-8.6.0/config/logstash.conf &
[root@node1 /]# ps -ef | grep logstash
[root@node1 /]# netstat -tunlp | grep 5044
 (启动成功!)
(启动成功!)
8.测试
(1)基本功能
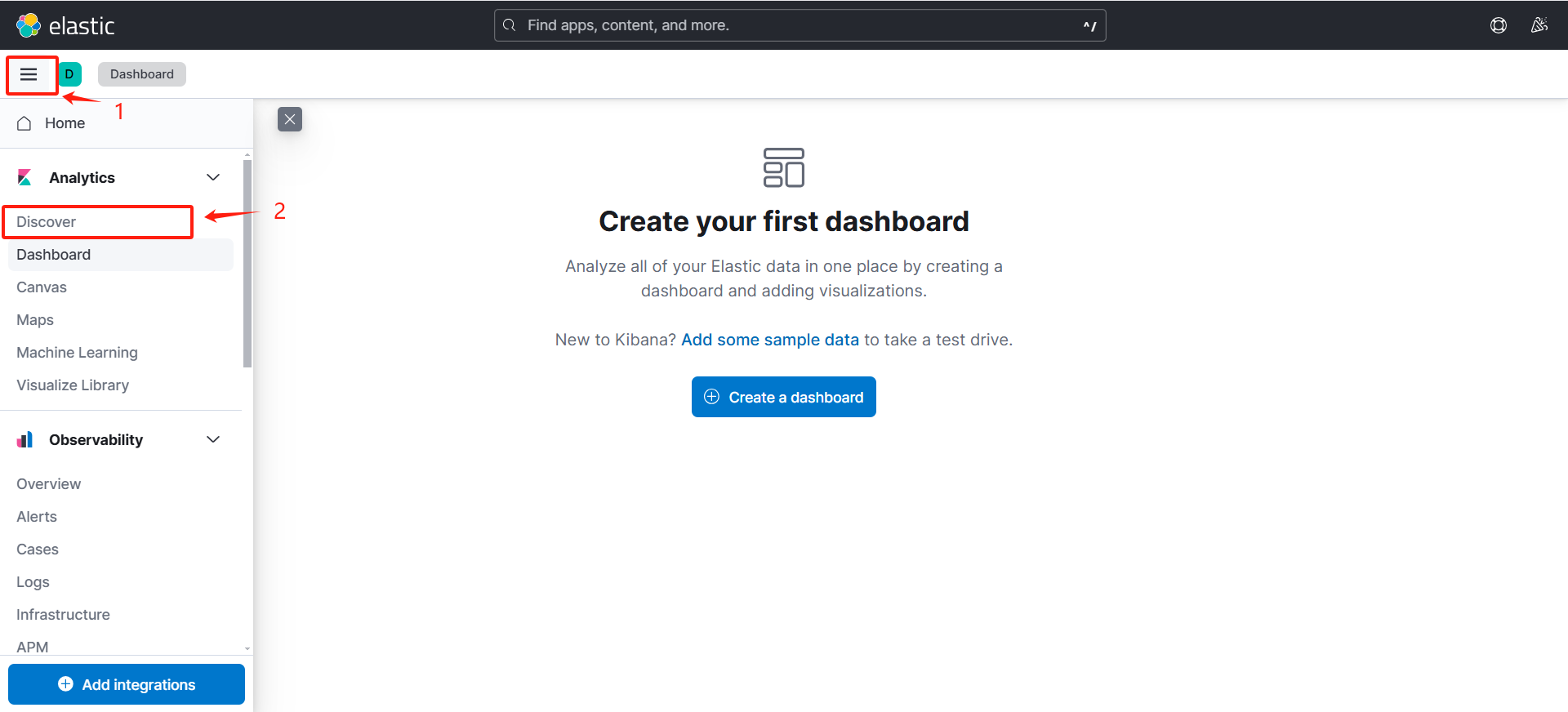
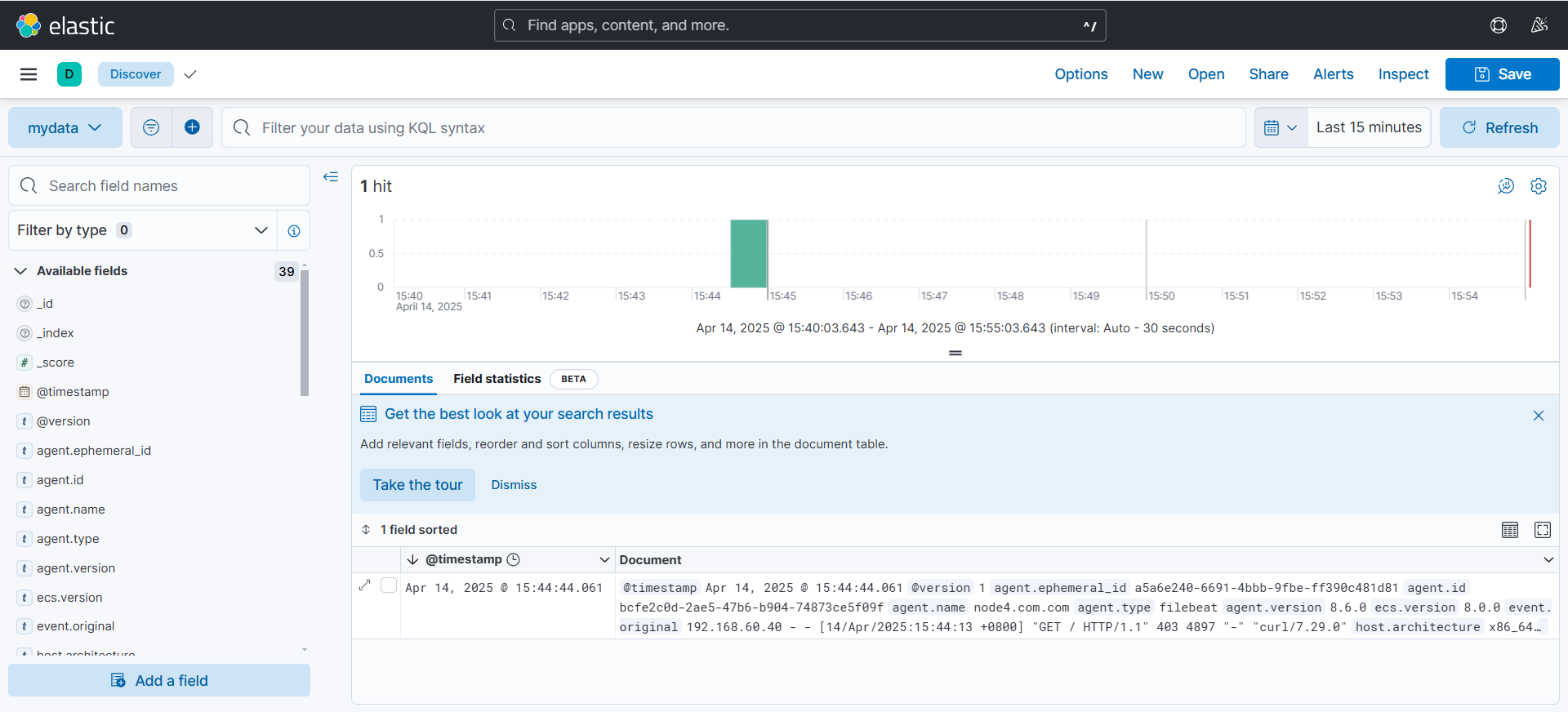
(可以看到可以采集到日志数据)
[root@node4 /]# echo hello >> /var/www/html/index.html #生成新的日志
[root@node1 /]# for i in {1..10000}; do curl 192.168.60.40; done
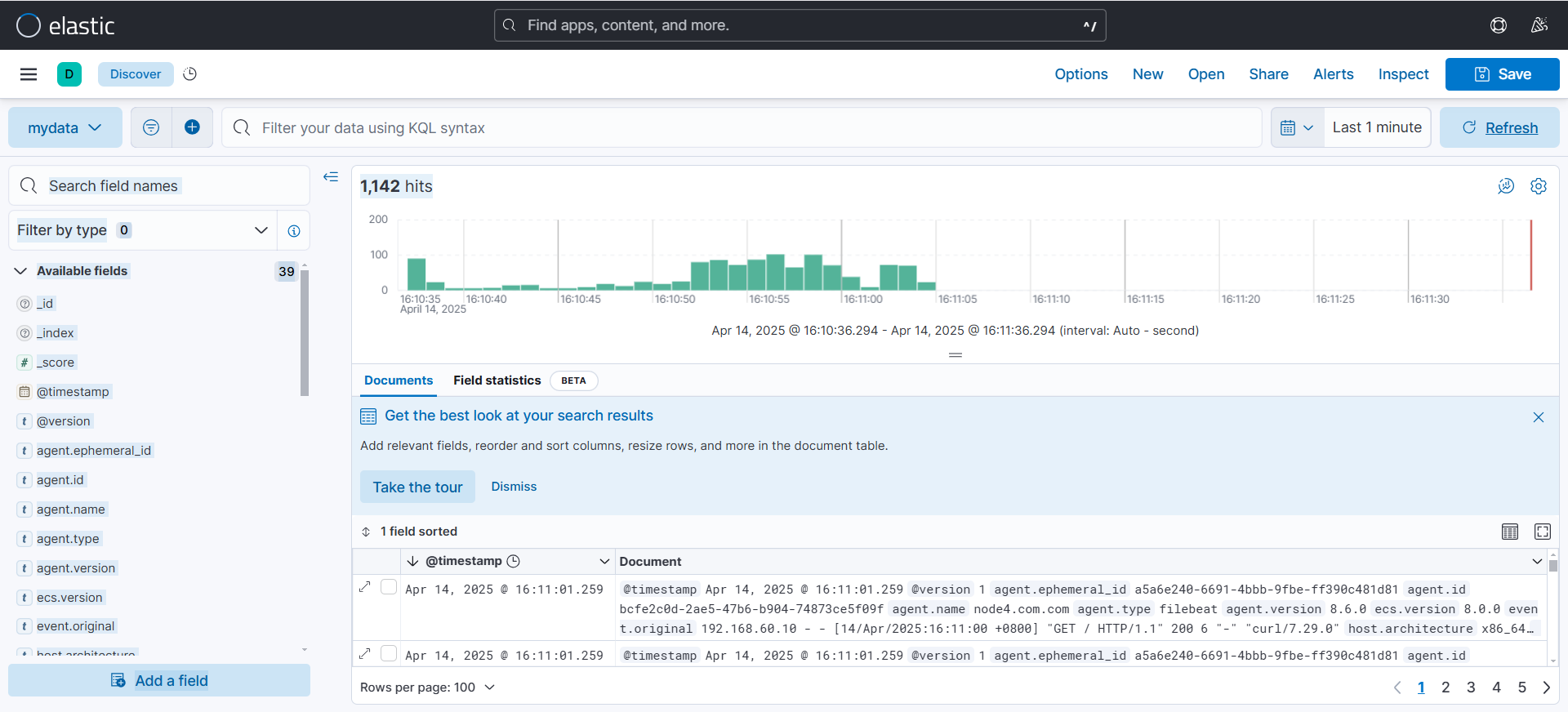 (可以看到可以日志数据随着访问在不断发生变化)
(可以看到可以日志数据随着访问在不断发生变化)
(2)设置图形
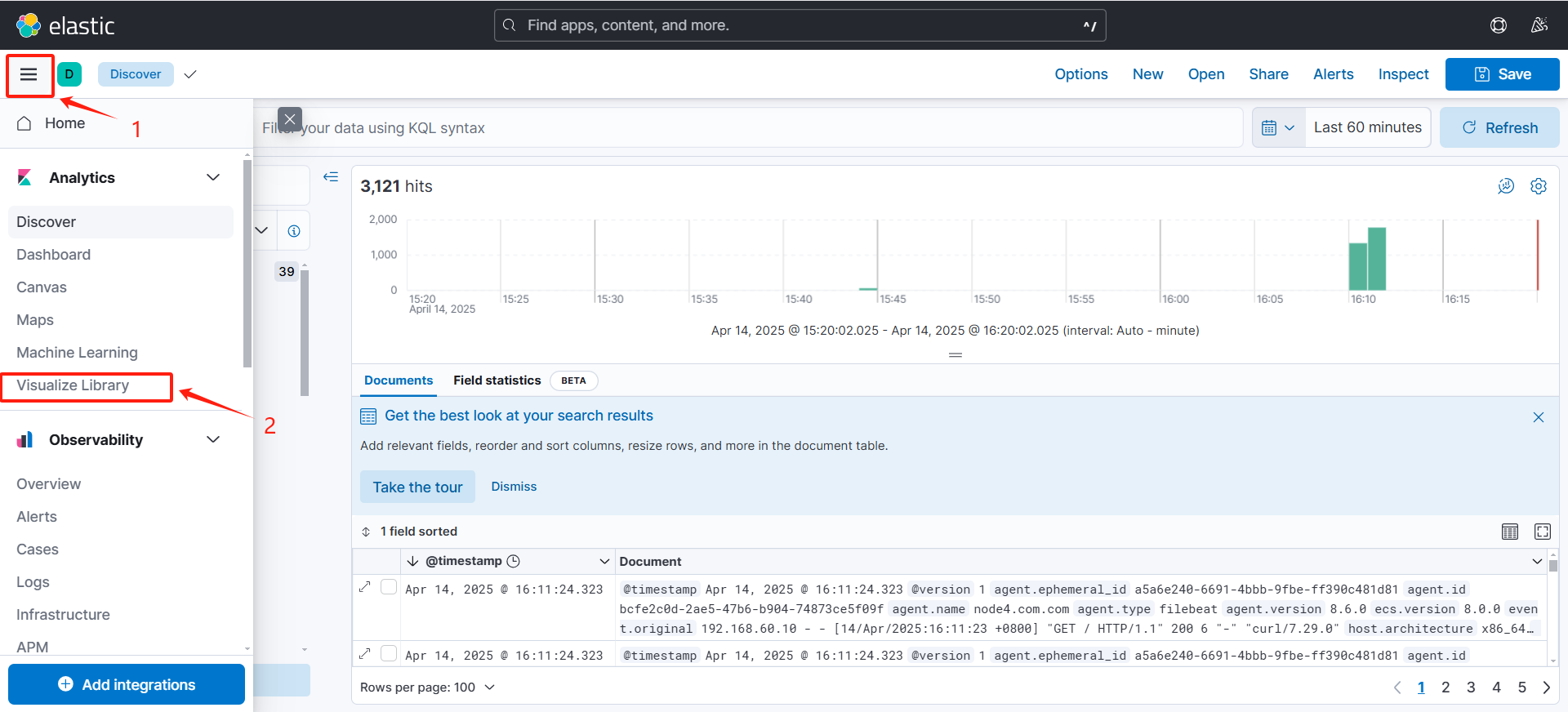
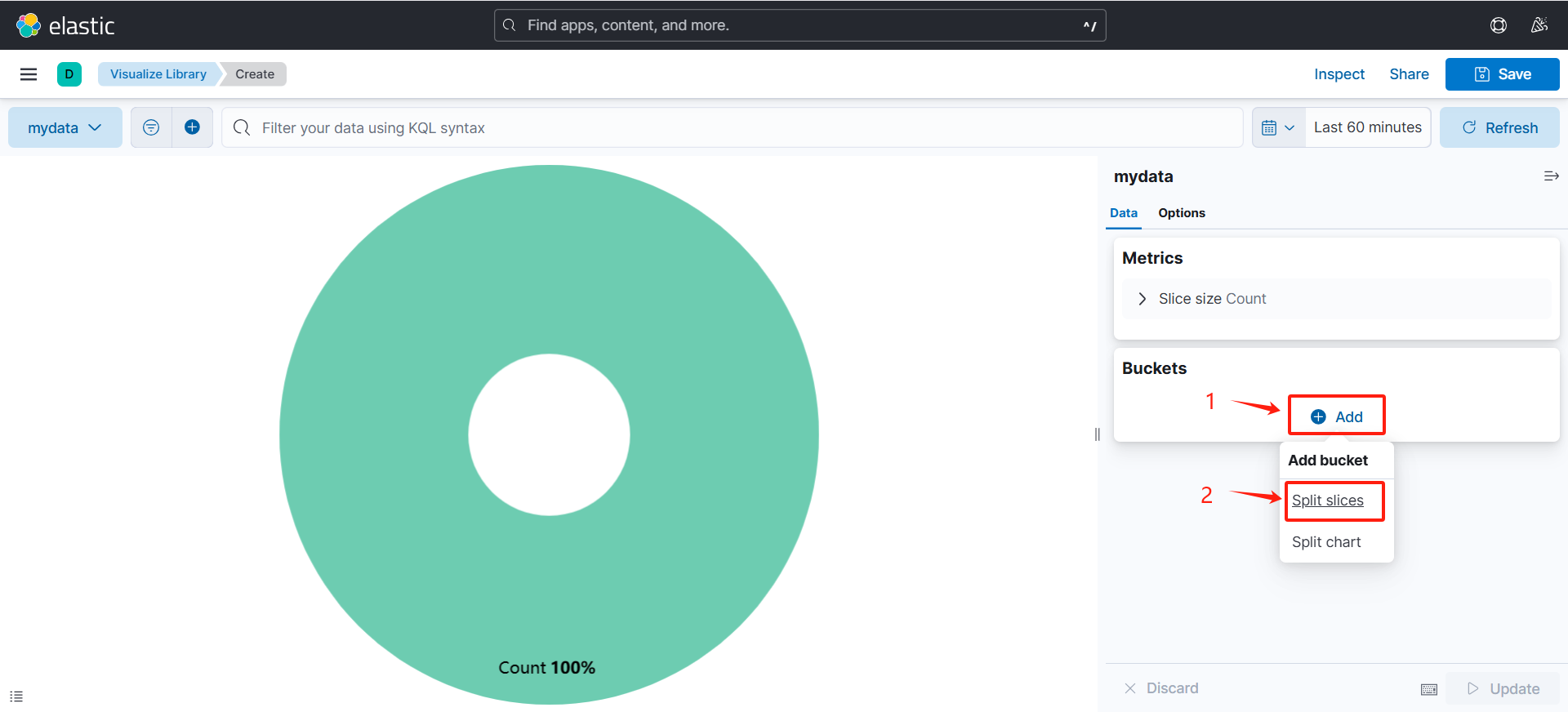
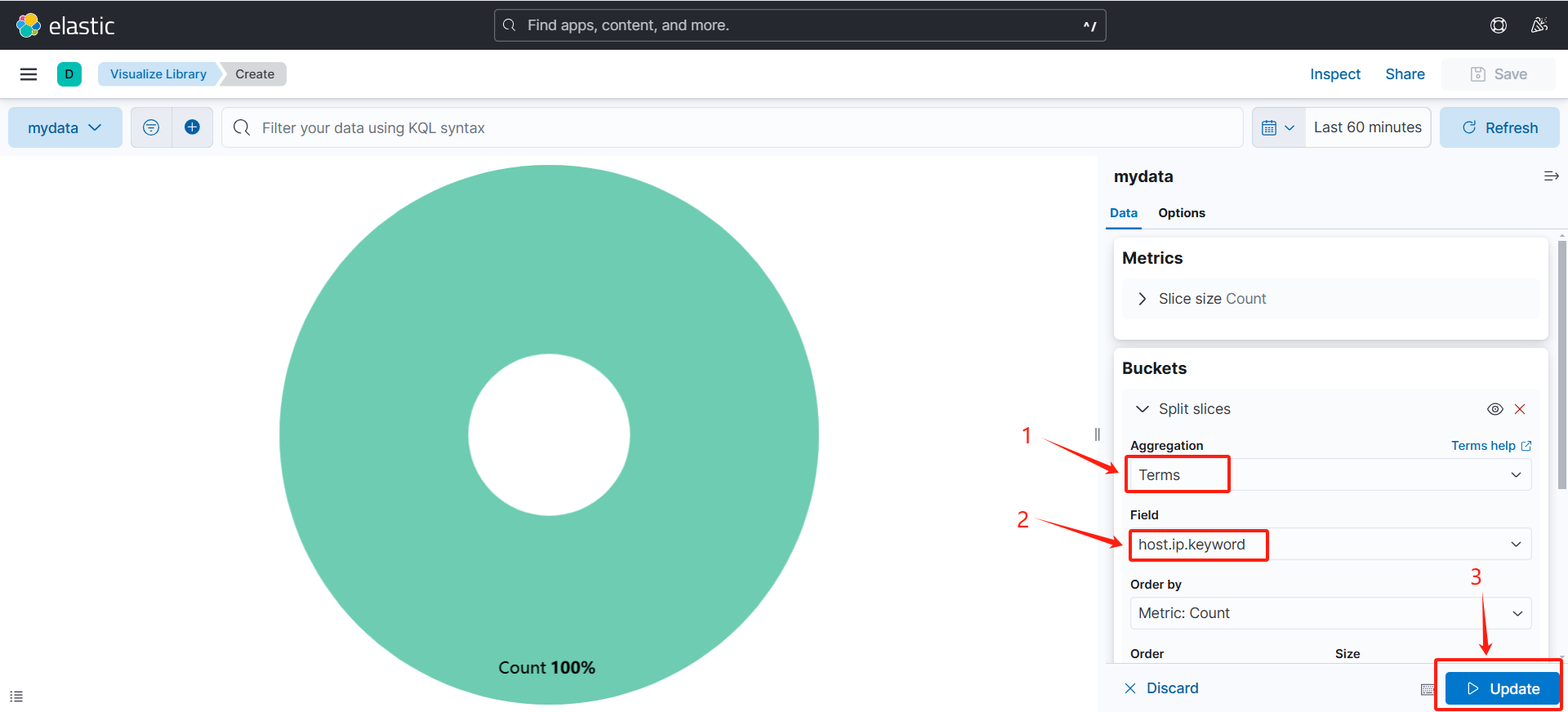
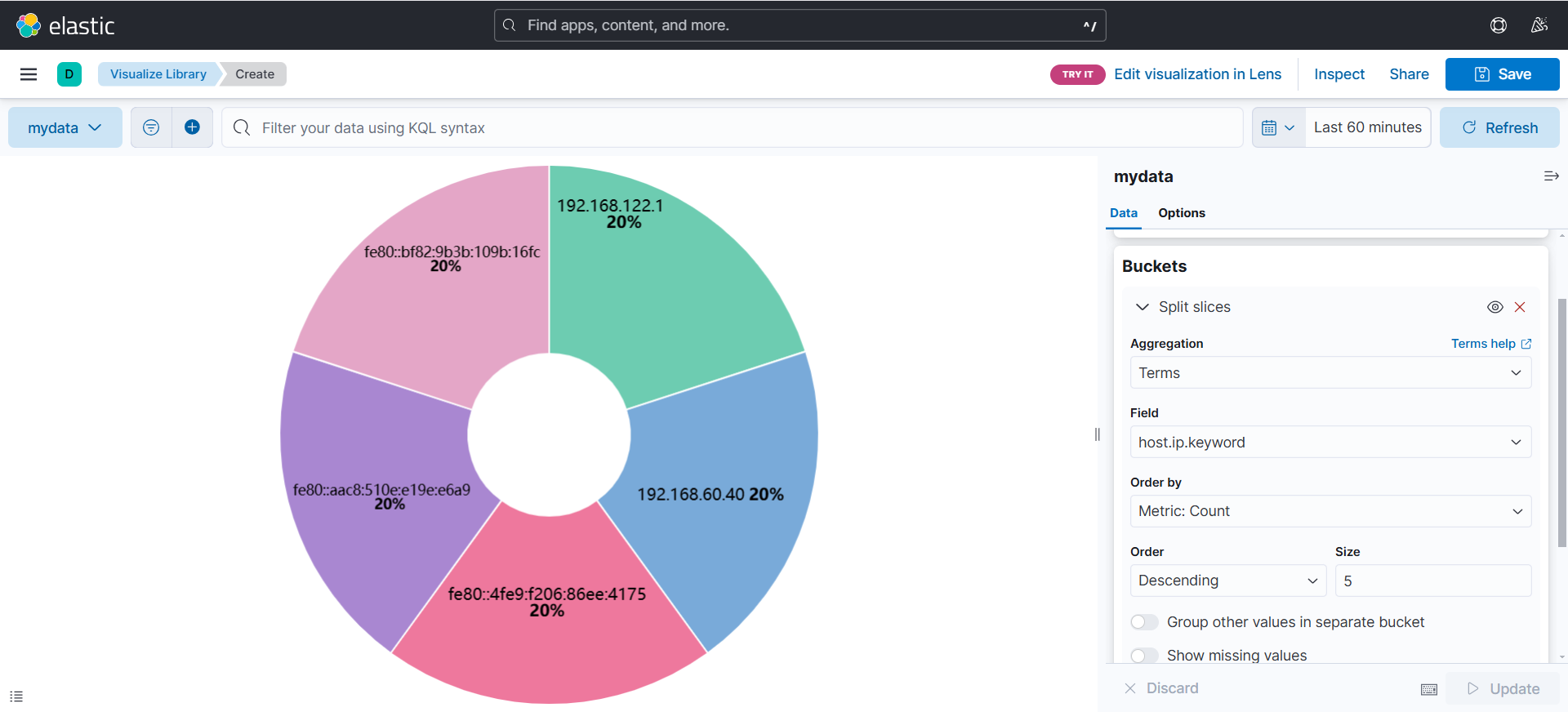 (可以看到根据ip划分出来的饼状图)
(可以看到根据ip划分出来的饼状图)
(但是如果想看其他的数据怎么办,比如说时间戳,我想知道访问量最多的时间段)
(可以通过修改Field,如下面的示例)
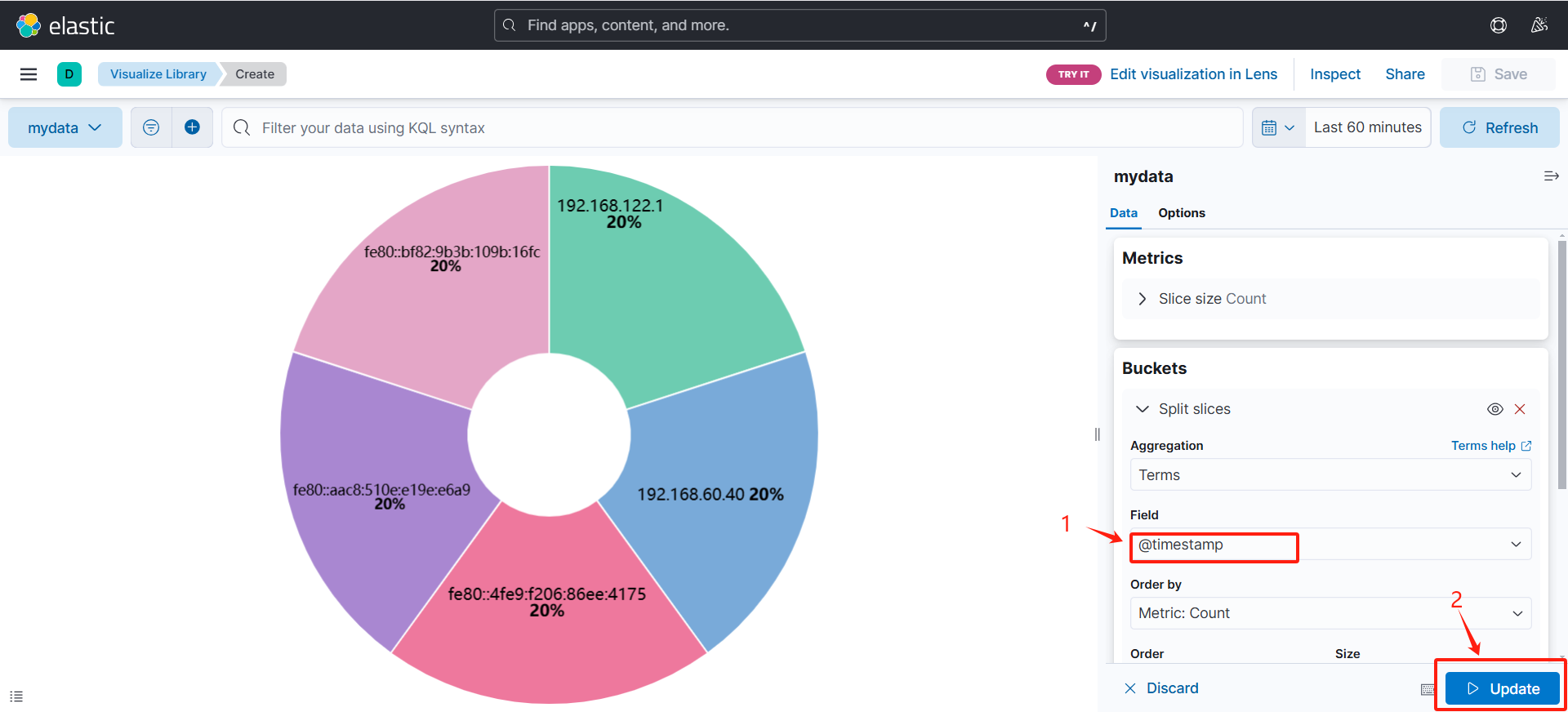
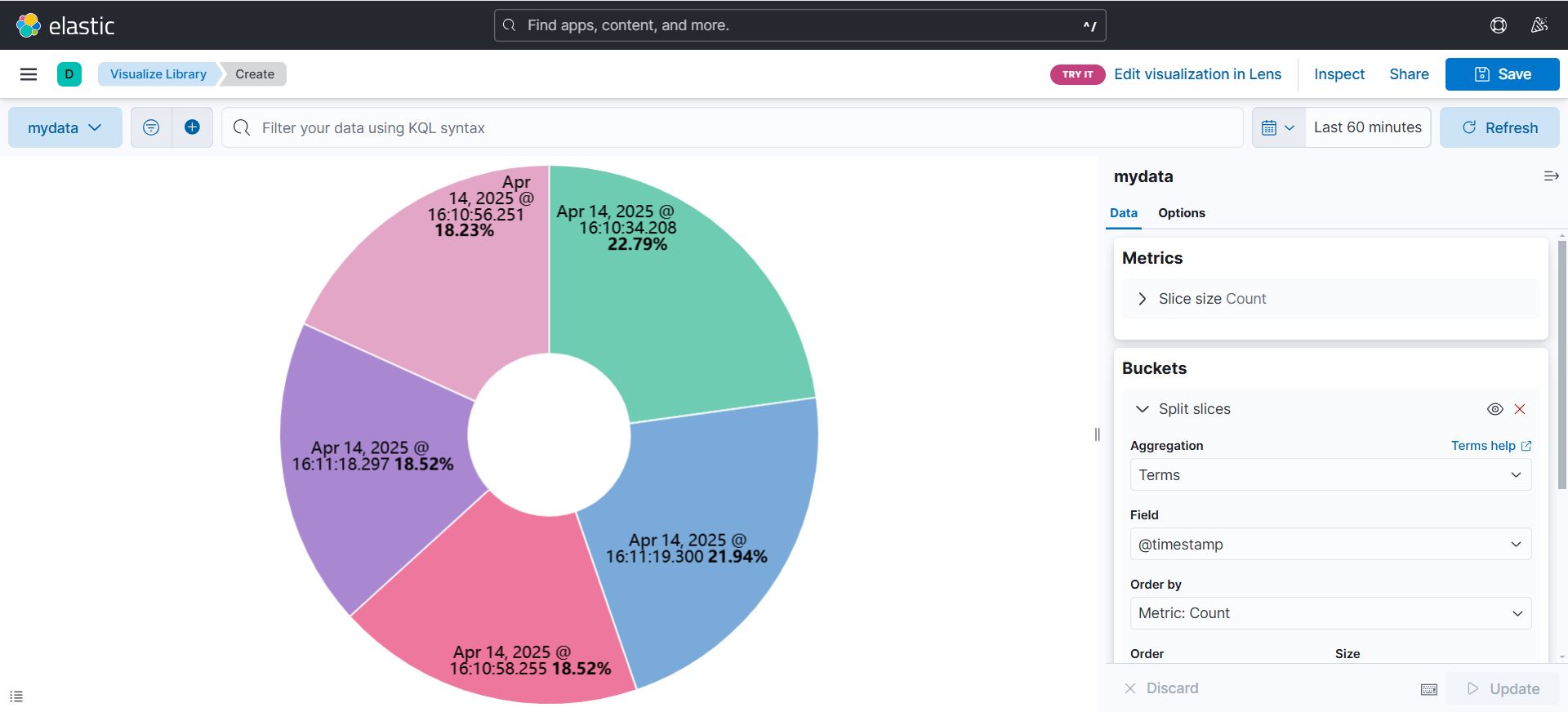 (可以看到根据时间戳划分出来的饼状图)
(可以看到根据时间戳划分出来的饼状图)
(当然不仅仅是饼状图,也可以修改成其他各种类型的视图,具体设置都和饼状图类似)
(3)过滤
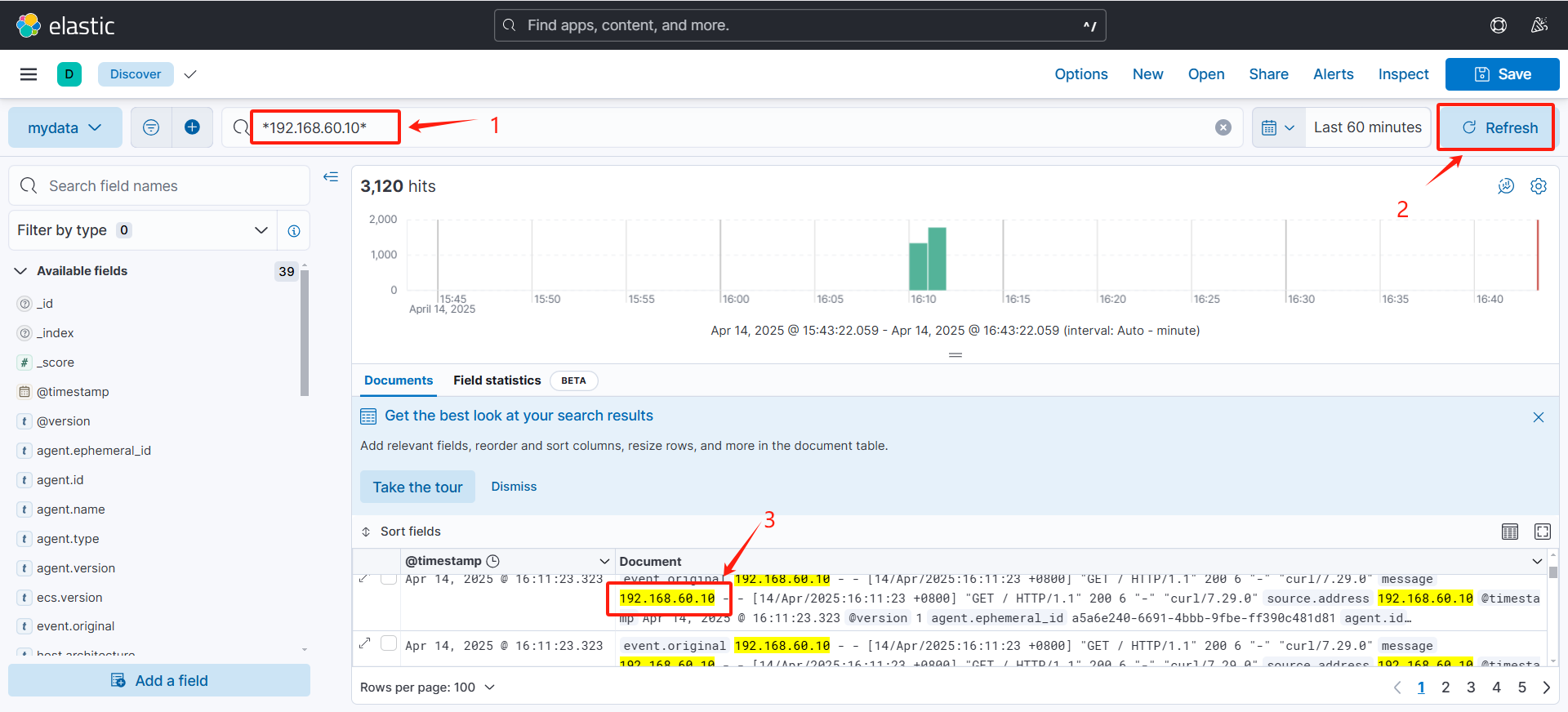
(过滤IP为192.168.60.10的数据)
相关文章:

ELK+Filebeat 深度部署指南与实战测试全解析
一、介绍 ELK: ELasticsearch ,Logstash,Kibana三大开源框架首字母简写,市面上也被称为Elastic Stack。 Elasticsearch 是一个基于 Lucene 的分布式搜索平台框架,通过 Restful 方式进行交互,具备近实时搜索能力。像百度、Google 这类大数据全…...

Java设计模式之中介者模式:从入门到架构级实践
一、什么是中介者模式? 中介者模式(Mediator Pattern)是一种行为型设计模式,其核心思想是通过引入一个中介对象来封装多个对象之间的交互关系。这种模式将原本复杂的网状通信结构转换为星型结构,类似于现实生活中的机…...

L2TP通道基础实验
目录 实验拓扑: 一、需求配置LAC设置: 界面设置: 编辑LNS设置: 建立静态路由:编辑 策略配置: 二、测试 通讯测试: 实验拓扑: 一、需求配置 LAC设置: [LAC]l2…...
软件的详解、核心功能以及与同类产品的对比分析)
关于字节跳动旗下的豆包(DouBao)软件的详解、核心功能以及与同类产品的对比分析
以下是关于豆包(DouBao)软件的详解、核心功能以及与同类产品的对比分析: 一、豆包(DouBao)详解 豆包是字节跳动推出的一款多功能人工智能助手,主打“智能助手场景化工具”结合,覆盖日常生活、…...

如何在本地修改 Git 项目的远程仓库地址
✅ 场景说明 你当前的 Git 项目地址是: http://192.168.0.16/xxx.git你希望把它改成: http://192.168.0.22:8099/xxx.git🧩 操作步骤 步骤 ①:进入项目所在目录 你已经在正确路径下了: cd C:\Develop\xxx确认这个…...

Gitea 1.23.7 速配
复用容器内的postgresql CREATE USER gitea WITH PASSWORD gitea; CREATE DATABASE gitea; GRANT ALL PRIVILEGES ON DATABASE gitea TO gitea; docker-compose.yml 内容 gitea:image: gitea/gitea:latestcontainer_name: giteaenvironment:- GITEA__server__HTTP_ADDR0.0.0.…...

JavaScript — 函数定义
介绍 JavaScript函数是执行特定任务的代码块,可通过多种方式定义。传统函数声明使用function关键字,后接函数名和参数列表,这种声明会被提升至作用域顶部。函数表达式则将匿名或具名函数赋值给变量,遵循变量作用域规则࿰…...

Allure安装与使用【macOS】
安装: brew install allure 安装插件: pip install allure-pytest2.8.16 生成一个html格式的报告,步骤: 执行生成json,制定结果保存目录 pytest --alluredirreport test_demo.py 查看测试保报告方式 将json转成h…...

FireCrawl爬虫工具, Craw4ai
FireCrawl是一款开源的AI爬虫工具,专门用于Web数据提取,并将其转换为Markdown格式或其他结构化数据。FireCrawl特别适合处理使用JavaScript动态生成的网站,能够自动抓取网站及其所有可访问的子页面内容,并将其转换为适合大语言…...

【Python爬虫】详细入门指南
目录 一、简单介绍 二、详细工作流程以及组成部分 三、 简单案例实现 一、简单介绍 在当今数字化信息飞速发展的时代,数据的获取与分析变得愈发重要,而网络爬虫技术作为一种能够从互联网海量信息中自动抓取所需数据的有效手段,正逐渐走入…...

Cesium.Cesium3DTileset设置贴地,tileset.readyPromise.then报错
tileset.readyPromise.then(function(tileset) { }); 用的readyPromise函数,却报错了,通过参考别人的博客内容发现最终修改的是 modelMatrix这个参数的内容,所以直接舍弃使用readyPromise函数,在代码中等 viewer.scene.primitiv…...

卫星电话扬帆智慧海洋,构筑蓝海通信新生态
海洋,承载着全球90%的贸易运输量,更是我国“向海图强”战略的核心战场。但是,全球95%的海洋区域仍处于蜂窝网络覆盖的“真空地带”,近海信号不稳、远洋通信中断的难题长期制约着海洋经济的纵深发展。技术革新是推动发展的强大引擎…...

大模型不是在推理,只是在复述??
目的 看见一篇论文Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?,论文中建立了一个推理题库,通过将推理问题进行改写(通过只改写几个字,颠覆整个问题…...

安全编码课程 实验7 并发
实验项目:C 多线程中的数据竞争与同步机制 实验要求: 1. 编写基础代码:模拟账户余额取款 创建一个全局共享变量 int balance 100,表示初始余额; 创建两个线程 Thread A 和 Thread B,尝试各自取出 100 元&a…...

【vue】2.16简单案例
一、高亮显示点击文字 使用vue绑定页面 设置默认样式 使用for循环数组数据展示,并取得索引 创建点击事件并传承,创建num变量 方法中num传进来的参数, 在内容中使用:class和三元运算符,当numkey时是true显示,…...
)
多线程进阶知识篇(一)
文章目录 一、开启线程1. start()2. run() 二、单核/多核CPU1. 单核CPU2. 多核CPU3.烧水问题 三、操作线程的命令四、并发的本质五、线程上下文切换1. 定义2. 原因 一、开启线程 1. start() 调用 start() 方法会启动一个新的线程,每次调用 start(),线程…...

【benepar】benepar安装会自动更新pytorch
直接pip install benepar,安装benepar0.2.0时会自动更新torch的版本 解决方法:去https://pypi.org/project/benepar/0.1.3/找历史版本 我的适配版本:python3.9,torch1.11.0(cuda11.3),对应的ben…...

智能云图库-1-项目初始化
项目中的异常处理 自定义异常 在exception包下新建错误码枚举类: Getter public enum ErrorCode {SUCCESS(0, "ok"),PARAMS_ERROR(40000, "请求参数错误"),NOT_LOGIN_ERROR(40100, "未登录"),NO_AUTH_ERROR(40101, "无权限&q…...

每日算法-250414
每日算法学习记录 - 240414 记录今天学习和解决的两道 LeetCode 算法题,主要涉及二分查找的应用。 162. 寻找峰值 题目描述 思路分析 核心思想:二分查找 题目要求找到数组中的任意一个峰值。峰值定义为比其相邻元素都大的元素。题目还隐含了一个条件…...
)
鸿蒙NEXT开发格式化工具类(ArkTs)
import { i18n } from kit.LocalizationKit;/*** 格式化工具类* 提供电话号码格式化、归属地查询、字符转换等功能。* author: 鸿蒙布道师* since: 2025/04/14*/ export class FormatUtil {/*** 判断传入的电话号码格式是否正确。* param phone - 待验证的电话号码* param coun…...

HarmonyOS 第2章 Ability的开发,鸿蒙HarmonyOS 应用开发入门
第2章 Ability的开发 本章内容 本章介绍HarmonyOS的核心组件Ability的开发。 2.1 Ability概述 2.2 FA模型介绍 2.3 Stage模型介绍 2.4 Ability内页面的跳转和数据传递 2.5 Want概述 2.6 实战:显式Want启动Ability 2.7 实战:隐式Want打开应用管理 2.8 小结 2.9 习题 2.1 Abili…...

CS5346 - Interactivity in Visualization 可视化中的交互
文章目录 Visualization representation interactionInteraction (交互)Benefits (好处)Typical Interaction Techniques(交互技术)SelectFilteringAbstract / Elaborate几何放缩(Geometric zoom)语义放缩࿰…...

AI与我共创WEB界面
记录一次压测后的自我技术提升 这事儿得从机房停电说起。那天吭哧吭哧做完并发压测,正准备截Zabbix监控图写报告,突然发现监控曲线神秘失踪——系统组小哥挠着头说:“上次停电后,zabbix服务好像就没起来过…” 我盯着空荡荡的图表界面,大脑的CPU温度可能比服务器还高。 其…...

python蓝桥杯备赛常用算法模板
一、python基础 (一)集合操作 s1 {1,2,3} s2{3,4,5} print(s1|s2)#求并集 print(s1&s2)#求交集 #结果 #{1, 2, 3, 4, 5} #{3}(二)对多维列表排序 1.新建列表 list1[[1,2,3],[2,3,4],[0,3,2]] #提取每个小列表的下标为2的…...

代码随想录第17天:二叉树
一、二叉搜索树的最近公共祖先(Leetcode 235) 由于是二叉搜索树,节点的值有严格的顺序关系:左子树的节点值都小于父节点,右子树的节点值都大于父节点。利用这一点,可以在树中更高效地找到最低公共祖先。 c…...

第8篇:Linux程序访问控制FPGA端HEX<一>
Q:如何从DE1-SoC_Computer系统的ARM A9处理器访问FPGA端的七段数码管呢? A:DE1-SoC_Computer系统中有2个连接FPGA端HEX外设的并行端口HEX5_HEX4和HEX3_HEX0,每个端口有一个32位只读Data寄存器。地址为0xFF200020的寄存器驱动4个数…...

Android 添加一个自己的系统服务SystemService
Android 系统服务(System Services)是 Android 操作系统的核心组件,运行在系统层面,为应用程序提供底层硬件访问、系统资源管理以及跨应用功能支持。这些服务在后台持续运行,由系统进程(如 system_server&a…...
)
git安装(windows)
通过网盘分享的文件:资料(1) 链接: https://pan.baidu.com/s/1MAenYzcQ436MlKbIYQidoQ 提取码: evu6 点击next 可修改安装路径 默认就行 一般从命令行调用,所以不用创建。 用vscode,所以这么选择。...

C# visionpro联合编程中遇到的问题之 R6025 - pure virtual function call
C# visionpro联合编程中遇到的问题之 R6025 - pure virtual function call R6025 pure virtual function call解决方法步骤 1: 获取所有相机步骤 2: 遍历并关闭相机完整代码 R6025 pure virtual function call 如果错误 “R6025 - pure virtual function call” 发生在关闭窗体…...
:原理与实现方案)
OTA技术(一):原理与实现方案
目录 一.引言 二.核心原理 2.1 定义与分类 2.2 系统架构 2.3 典型的升级流程 三.嵌入式系统中的OTA实现方案 3.1 存储空间划分 3.2 关键技术 一.引言 在智能手机上点击系统更新、电动汽车解锁新功能、智能家居设备自动修复漏洞……这些场景背后都离不开一项关键技术——…...

strings.LastIndexAny 使用详解
目录 1. 官方包 2. 支持版本 3. 官方说明 4. 作用 5. 实现原理 6. 推荐使用场景和不推荐使用场景 推荐场景 不推荐场景 7. 使用场景示例 示例1:官方示例 示例2:日志清洗(去除末尾的乱码或非法字符) 8. 性能对比 性能…...

大型商场运营新变革:AcrelCloud - 3200 预付费系统应用全解析
一、方案概述 在现代商业运营和物业管理中,大型商场、商业小区以及大集团和大物业面临着复杂的费用收取和管理难题。安科瑞的 AcrelCloud - 3200 远程预付费管控云平台,借助先进的预付费电表等设备,为解决这些问题提供了高效的一体化解决方案…...

鸿蒙开发07-interface
在 ArkTS(HarmonyOS Ability Runtime TypeScript)中,interface(接口)是一种强大的类型工具,它主要用于定义对象的结构,为对象的属性和方法提供类型约束,帮助开发者编写更加规范、可维…...
之旅——方法的使用⑤)
Java从入门到“放弃”(精通)之旅——方法的使用⑤
Java从入门到“放弃”(精通)之旅🚀——方法的使用⑤ 📖引言: 在编程领域,代码如同精密的齿轮相互咬合驱动程序运转。随着项目规模渐长,重复的代码片段如同冗余的齿轮,不仅增加负重…...

5 C 程序全流程解析:编写、预处理、编译、汇编、链接、运行与 GCC 指令详解
1 C 程序运行机制流程概述 通过以上步骤,我们可以将一个 C 语言源代码文件逐步转换为一个可执行的二进制程序。这一过程涉及多个关键工具和步骤,每一步都承担着特定的任务,发挥着独特的作用。深入理解这些步骤,不仅有助于我们更好…...
)
leetcode:1351. 统计有序矩阵中的负数(python3解法)
难度:简单 给你一个 m * n 的矩阵 grid,矩阵中的元素无论是按行还是按列,都以非严格递减顺序排列。 请你统计并返回 grid 中 负数 的数目。 示例 1: 输入:grid [[4,3,2,-1],[3,2,1,-1],[1,1,-1,-2],[-1,-1,-2,-3]] 输…...

hive数仓要点总结
1.OLTP和OLAP区别 OLTP(On-Line Transaction Processing)即联机事务处理,也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用…...

LeetCode[541]反转字符串Ⅱ
思路: 题目给我们加了几个规则,剩余长度小于2k,大于等于k就反转k个,小于k就全部反转,我们按照这个逻辑来就行。 第一就是大于等于k就反转k个,我们for循环肯定是i2k了,接下来就是判断是否大于等于…...
)
瑞幸微RK系列平台的YOLO部署(上篇)
🎇环境配置 🎉前言 部署的第一步是对环境的配置,不同的平台的平台需要依赖的环境不同,之前在英伟达的Jetson系列部署过,其主要是需要配置CUDA和CUDNN的环境,需要加速推理的话可能还需要TensorRT的环境。 …...

HarmonyOS:页面滚动时标题悬浮、背景渐变
一、需求场景 进入到app首页或者分页列表首页时,随着页面滚动,分类tab要求固定悬浮在顶部。进入到app首页、者分页列表首页、商品详情页时,页面滚动时,顶部导航栏(菜单、标题)背景渐变。 二、相关技术知识点…...

无人设备遥控器之安全防护与预警篇
无人设备遥控器的安全防护与预警是保障无人机、无人船、无人车等无人系统安全运行的关键环节。随着无人设备在农业、测绘、物流、安防等领域的广泛应用,其遥控器的安全性与可靠性显得尤为重要。 一、安全防护 1. 物理安全防护 外壳防护:采用防水、防尘…...

win10win11启用组策略编辑器
今天发现家庭版的win11系统没有组策略编辑器, 桌面新建txt文件,打开 编写以下脚本: echo off pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >Li…...

谷歌浏览器的开发者模式如何开启及安装教程
在谷歌浏览器(Google Chrome)中开启开发者模式并安装扩展程序(如未上架商店的插件或自定义扩展)的步骤如下: 一、开启开发者模式 打开扩展管理页面 在浏览器地址栏输入:chrome://extensions/ 或通过菜单进入…...

WebRTC实时通话EasyRTC嵌入式音视频通信SDK,构建智慧医疗远程会诊高效方案
一、方案背景 当前医疗领域,医疗资源分布不均问题尤为突出,大城市和发达地区优质医疗资源集中,偏远地区医疗设施陈旧、人才稀缺,患者难以获得高质量的医疗服务,制约医疗事业均衡发展。 EasyRTC技术基于WebRTC等先进技…...
)
C++性能优化实战:从瓶颈定位到高并发架构重构(第一章)
在高并发编程的世界中,性能瓶颈往往潜伏在代码的深处,悄无声息地吞噬着系统的吞吐量。想象一下,你正在开发一个游戏服务器,需要在每毫秒内为数千名玩家分配和释放内存,任何微小的延迟都可能导致玩家体验的崩塌。你是否曾遇到过这样的困惑:增加了线程数,期待性能翻倍,结…...

Terraform 迷思:当优雅的模块 terraform-aws-eks 与现实碰撞
大家好,今天想和大家聊聊一个可能很多技术人都经历过的场景——面对看似完美的工具或代码库,却陷入意想不到的困境,甚至开始有点怀疑人生的时刻。 启程:雄心勃勃的 EKS 模块优化 故事的开端往往充满希望。就像我今天࿰…...

路由器端口映射的意思、使用场景、及内网ip让公网访问常见问题和解决方法
一、端口映射是什么意思 端口映射是将内网主机的IP地址端口映射到公网中,内部机器提供相应的互联网服务。当异地用户访问该这个端口时,会自动将请求映射到对应局域网内部的机器上。 二、端口映射常见使用场景 1,远程访问需求。当有…...
)
【MySQL 数据库】增删查改操作CRUD(下)
🔥博客主页🔥:【 坊钰_CSDN博客 】 欢迎各位点赞👍评论✍收藏⭐ 目录 1. 聚合函数 1.1 常见聚合函数 1.1.1 COUNT 1.1.2 SUM 1.1.3 AVG 1.1.4 MAX 2. Group by 分组 2.1 分组示例 3. having 语句 3.1 having 过滤结果 3…...

Android 日志输出模块
Android 日志输出模块 本文主要记录下封装的日志输出模块. 1: 主要功能 日志模块初始化,并设置日志级别支持将日志写入文件日志文件单个限制200M,按天记录到指定文件,文件达到阈值后,记录新的日志文件.支持导出日志文件zip. 2: 具体实现 日志整体初始化使用静态内部类的方式…...

群辉搭建静态网站
写在前面,本文章主要是记录自己搭建过程以备后来需要时温习下! 1.安装并打开web station 2. 2.打开 File Station 找到web文件夹 把静态导航网站的代码下载下来,并上传到上面 web 文件夹下 3. 在Web Station 套件里面,在网页服…...