[reinforcement learning] 是什么 | 应用场景 | Andrew Barto and Richard Sutton
目录
什么是强化学习?
强化学习的应用场景
广告和推荐
对话系统
强化学习的主流算法
纽约时报:Turing Award Goes to 2 Pioneers of Artificial Intelligence
wiki
资料混合:youtube, wiki, github
今天下午上课刷到了不少,整合放一起叭,之后有时间每天了解一点(´・ω・`)
2024.5 图灵奖颁给了两位 强化学习先驱:Andrew Barto and Richard Sutton
- For developing the conceptual and algorithmic foundations of reinforcement learning
- 未来将会是怎样的呢?

什么是强化学习?
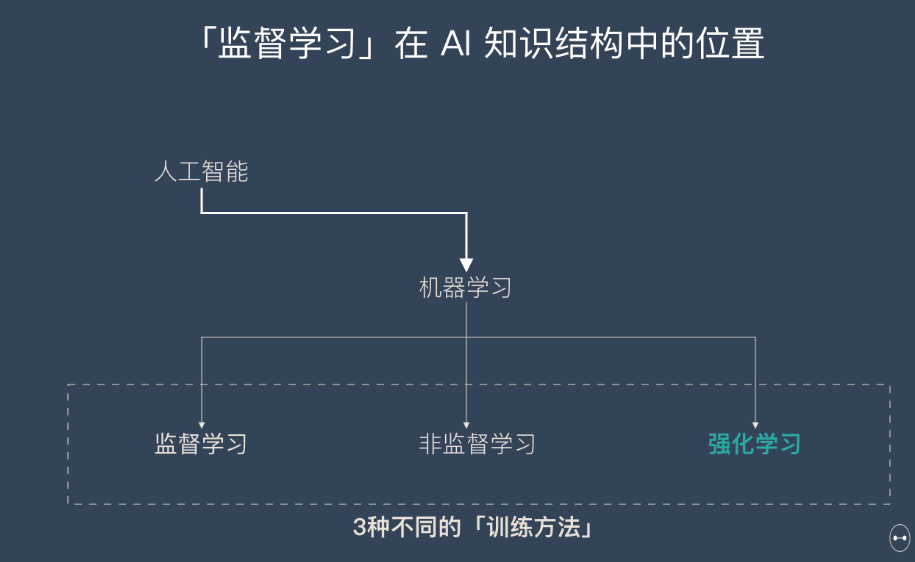
- 强化学习并不是某一种特定的算法,而是一类算法的统称。
- 如果用来做对比的话,他跟监督学习,无监督学习 是类似的,是一种统称的学习方式。
- 强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步“强化”这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种“绩效奖励”非常类似。我们平时也常常用这样的策略来提高自己的游戏水平。
- 在 Flappy bird 这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞的越远越好,因为飞的越远就能获得更高的积分奖励。
这就是一个典型的强化学习场景:
- 机器有一个明确的小鸟角色——代理
- 需要控制小鸟飞的更远——目标
- 整个游戏过程中需要躲避各种水管——环境
- 躲避水管的方法是让小鸟用力飞一下——行动
- 飞的越远,就会获得越多的积分——奖励

你会发现,强化学习和监督学习、无监督学习 最大的不同就是不需要大量的“数据喂养”。而是通过自己不停的尝试来学会某些技能。
强化学习的应用场景
- 强化学习目前还不够成熟,应用场景也比较局限。最大的应用场景就是游戏了。
游戏

2016年:AlphaGo Master 击败李世石,使用强化学习的 AlphaGo Zero 仅花了40天时间,就击败了自己的前辈 AlphaGo Master。
《被科学家誉为“世界壮举”的AlphaGo Zero, 对普通人意味着什么?》
2019年1月25日:AlphaStar 在《星际争霸2》中以 10:1 击败了人类顶级职业玩家。
《星际争霸2人类1:10输给AI!DeepMind “AlphaStar”进化神速》
2019年4月13日:OpenAI 在《Dota2》的比赛中战胜了人类世界冠军。
《2:0!Dota2世界冠军OG,被OpenAI按在地上摩擦》
机器人
机器人很像强化学习里的“代理”,在机器人领域,强化学习也可以发挥巨大的作用。
《机器人通过强化学习,可以实现像人一样的平衡控制》
《深度学习与强化学习相结合,谷歌训练机械臂的长期推理能力》
《伯克利强化学习新研究:机器人只用几分钟随机数据就能学会轨迹跟踪》
其他
强化学习在推荐系统,对话系统,教育培训,广告,金融等领域也有一些应用:
《强化学习与推荐系统的强强联合》
《基于深度强化学习的对话管理中的策略自适应》
《强化学习在业界的实际应用》
广告和推荐
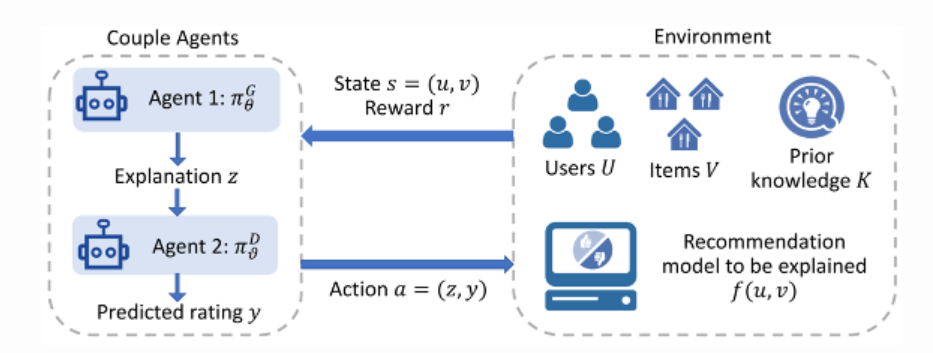
图片来源:A Reinforcement Learning Framework for Explainable Recommendation
对话系统
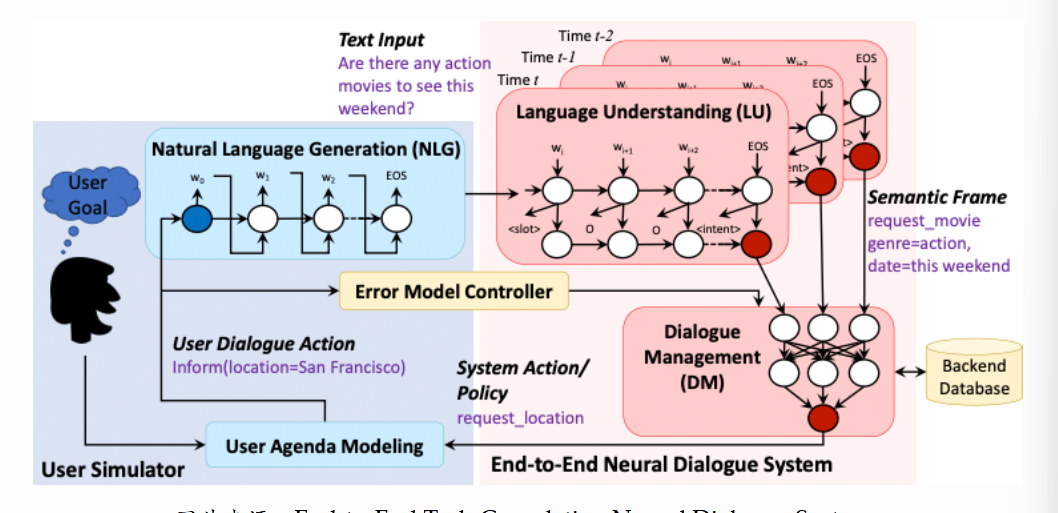
图片来源:End-to-End Task-Completion Neural Dialogue Systems
强化学习的主流算法
免模型学习(Model-Free) vs 有模型学习(Model-Based)
在介绍详细算法之前,我们先来了解一下强化学习算法的2大分类。这2个分类的重要差异是:智能体是否能完整了解或学习到所在环境的模型
有模型学习(Model-Based)对环境有提前的认知,可以提前考虑规划,但是缺点是如果模型跟真实世界不一致,那么在实际使用场景下会表现的不好。
免模型学习(Model-Free)放弃了模型学习,在效率上不如前者,但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。
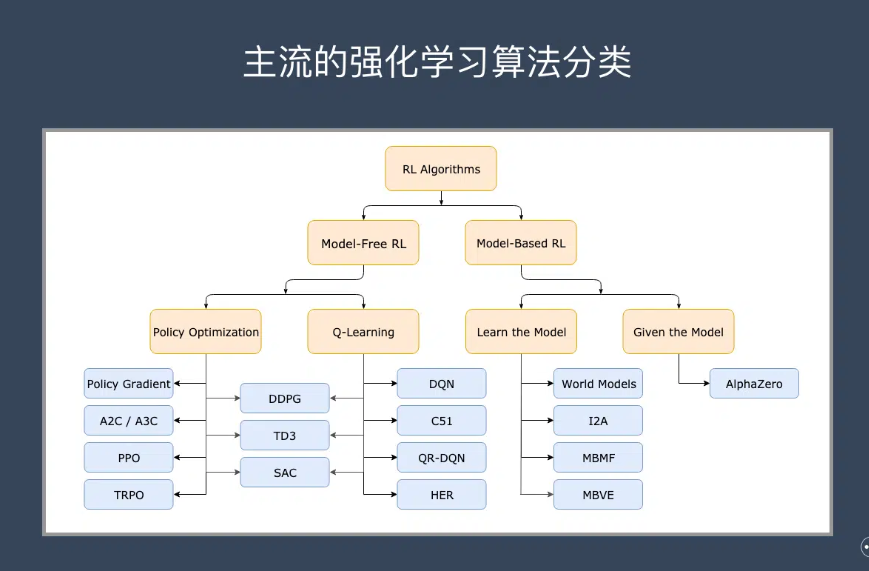
除了免模型学习和有模型学习的分类外,强化学习还有其他几种分类方式:
- 基于概率 VS 基于价值
- 回合更新 VS 单步更新
- 在线学习 VS 离线学习
纽约时报:Turing Award Goes to 2 Pioneers of Artificial Intelligence
Andrew Barto and Richard Sutton developed reinforcement learning, a technique vital to chatbots like ChatGPT.
Andrew Barto 和 Richard Sutton 开发了强化学习,这是一种对 ChatGPT 等聊天机器人至关重要的技术。
In 1977, Andrew Barto, as a researcher at the University of Massachusetts, Amherst, began exploring a new theory that neurons behaved like hedonists. The basic idea was that the human brain was driven by billions of nerve cells that were each trying to maximize pleasure and minimize pain.
1977 年,马萨诸塞大学阿默斯特分校的研究员安德鲁·巴托 (Andrew Barto) 开始探索一种新理论,即神经元的行为类似于享乐主义者。基本思想是,人脑由数十亿个神经细胞驱动,每个神经细胞都试图最大限度地提高快乐和减少痛苦。
A year later, he was joined by another young researcher, Richard Sutton. Together, they worked to explain human intelligence using this simple concept and applied it to artificial intelligence. The result was “reinforcement learning,” a way for A.I. systems to learn from the digital equivalent of pleasure and pain.
一年后,另一位年轻的研究人员理查德·萨顿 (Richard Sutton) 加入了他的行列。他们一起努力使用这个简单的概念来解释人类智能,并将其应用于人工智能。结果是“强化学习”,一种人工智能系统从数字等价物的快乐和痛苦中学习的方法。
On Wednesday, the Association for Computing Machinery, the world’s largest society of computing professionals, announced that Dr. Barto and Dr. Sutton had won this year’s Turing Award for their work on reinforcement learning. The Turing Award, which was introduced in 1966, is often called the Nobel Prize of computing. The two scientists will share the $1 million prize that comes with the award.
周三,世界上最大的计算机专业人士协会(Association for Computing Machinery)宣布,巴托博士和萨顿博士因其在强化学习方面的工作而获得了今年的图灵奖。图灵奖于 1966 年推出,通常被称为计算界的诺贝尔奖。这两位科学家将分享该奖项附带的 100 万美元奖金。
Over the past decade, reinforcement learning has played a vital role in the rise of artificial intelligence, including breakthrough technologies such as Google’s AlphaGo and OpenAI’s ChatGPT. The techniques that powered these systems were rooted in the work of Dr. Barto and Dr. Sutton.
在过去的十年中,强化学习在人工智能的兴起中发挥了至关重要的作用,包括谷歌的 AlphaGo 和 OpenAI 的 ChatGPT 等突破性技术。为这些系统提供动力的技术植根于 Barto 博士和 Sutton 博士的工作。
“They are the undisputed pioneers of reinforcement learning,” said Oren Etzioni, a professor emeritus of computer science at the University of Washington and founding chief executive of the Allen Institute for Artificial Intelligence. “They generated the key ideas — and they wrote the book on the subject.”
“他们是强化学习无可争议的先驱,”华盛顿大学(University of Washington)计算机科学名誉教授、艾伦人工智能研究所(Allen Institute for Artificial Intelligence)的创始首席执行官奥伦·埃齐奥尼(Oren Etzioni)说。“他们提出了关键思想——他们写了一本关于这个主题的书。”
Their book, “Reinforcement Learning: An Introduction,” which was published in 1998, remains the definitive exploration of an idea that many experts say is only beginning to realize its potential.
他们的著作《强化学习:导论》(Reinforcement Learning: An Introduction)于 1998 年出版,至今仍是对这一观点的权威探索,许多专家表示,这一观点才刚刚开始实现其潜力。
Psychologists have long studied the ways that humans and animals learn from their experiences. In the 1940s, the pioneering British computer scientist Alan Turing suggested that machines could learn in much the same way.
心理学家长期以来一直在研究人类和动物从他们的经历中学习的方式。在 1940 年代,英国计算机科学家先驱艾伦·图灵 (Alan Turing) 提出,机器可以以大致相同的方式学习。
But it was Dr. Barto and Dr. Sutton who began exploring the mathematics of how this might work, building on a theory that A. Harry Klopf, a computer scientist working for the government, had proposed. Dr. Barto went on to build a lab at UMass Amherst dedicated to the idea, while Dr. Sutton founded a similar kind of lab at the University of Alberta in Canada.
但正是巴托博士和萨顿博士开始探索这如何运作的数学原理,他们以为政府工作的计算机科学家 A. Harry Klopf 提出的理论为基础。巴托博士继续在马萨诸塞大学阿默斯特分校建立了一个专门研究这个想法的实验室,而萨顿博士在加拿大阿尔伯塔大学建立了一个类似的实验室。
“It is kind of an obvious idea when you’re talking about humans and animals,” said Dr. Sutton, who is also a research scientist at Keen Technologies, an A.I. start-up, and a fellow at the Alberta Machine Intelligence Institute, one of Canada’s three national A.I. labs. “As we revived it, it was about machines.”
“当你谈论人类和动物时,这是一个显而易见的想法,”萨顿博士说,他也是人工智能初创公司Keen Technologies的研究科学家,也是加拿大三个国家人工智能实验室之一的阿尔伯塔省机器智能研究所(Alberta Machine Intelligence Institute)的研究员。“当我们复兴它时,它与机器有关。”
This remained an academic pursuit until the arrival of AlphaGo in 2016. Most experts believed that another 10 years would pass before anyone built an A.I. system that could beat the world’s best players at the game of Go.
在 2016 年 AlphaGo 到来之前,这仍然是一个学术追求。大多数专家认为,再过 10 年,才会有人构建出可以在围棋比赛中击败世界上最好的棋手的人工智能系统。
But during a match in Seoul, South Korea, AlphaGo beat Lee Sedol, the best Go player of the past decade. The trick was that the system had played millions of games against itself, learning by trial and error. It learned which moves brought success (pleasure) and which brought failure (pain).
但在韩国首尔的一场比赛中,AlphaGo 击败了过去十年中最好的围棋选手李世石。诀窍在于,该系统已经与自己对弈了数百万次,通过反复试验来学习。它了解哪些动作会带来成功(快乐),哪些动作会带来失败(痛苦)。
The Google team that built the system was led by David Silver, a researcher who had studied reinforcement learning under Dr. Sutton at the University of Alberta.
构建该系统的 Google 团队由大卫·西尔弗 (David Silver) 领导,他是一名研究员,曾在阿尔伯塔大学 (University of Alberta) 的萨顿 (Sutton) 博士的指导下研究强化学习。
Many experts still question whether reinforcement learning could work outside of games. Game winnings are determined by points, which makes it easy for machines to distinguish between success and failure.
许多专家仍然质疑强化学习是否可以在游戏之外发挥作用。游戏赢利由积分决定,这使得机器很容易区分成功和失败。
But reinforcement learning has also played an essential role in online chatbots.
但强化学习在在线聊天机器人中也发挥了重要作用。
Leading up to the release of ChatGPT in the fall of 2022, OpenAI hired hundreds of people to use an early version and provide precise suggestions that could hone its skills. They showed the chatbot how to respond to particular questions, rated its responses and corrected its mistakes. By analyzing those suggestions, ChatGPT learned to be a better chatbot.
在 2022 年秋季发布 ChatGPT 之前,OpenAI 聘请了数百人使用早期版本并提供可以磨练其技能的精确建议。他们向聊天机器人展示了如何回答特定问题,对其回答进行评分并纠正错误。通过分析这些建议,ChatGPT 学会了成为一个更好的聊天机器人。
Researchers call this “reinforcement learning from human feedback,” or R.L.H.F. And it is one of the key reasons that today’s chatbots respond in surprisingly lifelike ways.
研究人员称之为“来自人类反馈的强化学习”,或 R.L.H.F.。这也是当今聊天机器人以令人惊讶的逼真方式做出响应的关键原因之一。
(The New York Times has sued OpenAI and its partner, Microsoft, for copyright infringement of news content related to A.I. systems. OpenAI and Microsoft have denied those claims.)
(《纽约时报》起诉 OpenAI 及其合作伙伴 Microsoft 侵犯与 AI 系统相关的新闻内容的版权。OpenAI 和 Microsoft 否认了这些指控。
More recently, companies like OpenAI and the Chinese start-up DeepSeek have developed a form of reinforcement learning that allows chatbots to learn from themselves — much as AlphaGo did. By working through various math problems, for instance, a chatbot can learn which methods lead to the right answer and which do not.
最近,OpenAI 和中国初创公司 DeepSeek 等公司开发了一种强化学习形式,允许聊天机器人从自己身上学习——就像 AlphaGo 所做的那样。例如,通过解决各种数学问题,聊天机器人可以学习哪些方法会导致正确答案,哪些方法不会。
If it repeats this process with an enormously large set of problems, the bot can learn to mimic the way humans reason — at least in some ways. The result is so-called reasoning systems like OpenAI’s o1 or DeepSeek’s R1.
如果它用大量的问题重复这个过程,机器人就可以学会模仿人类的推理方式——至少在某些方面是这样。结果是所谓的推理系统,如 OpenAI 的 o1 或 DeepSeek 的 R1。
Dr. Barto and Dr. Sutton say these systems hint at the ways machines will learn in the future. Eventually, they say, robots imbued with A.I. will learn from trial and error in the real world, as humans and animals do.
巴托博士和萨顿博士说,这些系统暗示了机器未来将如何学习。他们说,最终,充满人工智能的机器人将像人类和动物一样,从现实世界的试错中学习。
“Learning to control a body through reinforcement learning — that is a very natural thing,” Dr. Barto said.
“通过强化学习来学习控制身体——这是一件非常自然的事情,”巴托博士说。
wiki
For reinforcement learning in psychology, see Reinforcement and Operant conditioning.
Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent should take actions in a dynamic environment in order to maximize a reward signal. Reinforcement learning is one of the three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
强化学习 (RL) 是机器学习和最优控制的一个跨学科领域,涉及智能代理应该如何在动态环境中采取行动,以最大限度地提高奖励信号。强化学习是三种基本的机器学习范式之一,另外两个是监督学习和无监督学习。
Reinforcement learning differs from supervised learning in not needing labelled input-output pairs to be presented, and in not needing sub-optimal actions to be explicitly corrected. Instead, the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge) with the goal of maximizing the cumulative reward (the feedback of which might be incomplete or delayed).[1] The search for this balance is known as the exploration–exploitation dilemma.
强化学习与监督学习的不同之处在于,不需要呈现标记的输入-输出对,也不需要明确纠正次优作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡,目标是最大化累积奖励(其反馈可能不完整或延迟)。[1] 寻找这种平衡被称为勘探-开发困境。
The environment is typically stated in the form of a Markov decision process (MDP), as many reinforcement learning algorithms use dynamic programming techniques.[2] The main difference between classical dynamic programming methods and reinforcement learning algorithms is that the latter do not assume knowledge of an exact mathematical model of the Markov decision process, and they target large MDPs where exact methods become infeasible.[3]
环境通常以马尔可夫决策过程 (MDP) 的形式表示,因为许多强化学习算法使用动态编程技术。[2] 经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设了解马尔可夫决策过程的精确数学模型,并且它们针对精确方法变得不可行的大型 MDP。[3]
相关文章:

[reinforcement learning] 是什么 | 应用场景 | Andrew Barto and Richard Sutton
目录 什么是强化学习? 强化学习的应用场景 广告和推荐 对话系统 强化学习的主流算法 纽约时报:Turing Award Goes to 2 Pioneers of Artificial Intelligence wiki 资料混合:youtube, wiki, github 今天下午上课刷到了不少࿰…...

【VsCode】设置文件自动保存
目录 一、前言 二、操作步骤 一、前言 VSCode中开启自动保存功能可以通过访问设置、修改settings.json文件、使用自动保存延迟功能来实现。这些方法能有效提升编程效率、避免数据丢失、实时同步更改。 二、操作步骤 在 Visual Studio Code (VS Code) 中设置自动保存功能非…...

16:00开始面试,16:08就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到4月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...

深入理解 PyTorch:从入门到精通的深度学习框架
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

子串-滑动窗口的最大值
滑动窗口的最大值 给你一个整数数组 nums,有一个大小为 k 的滑动窗 口从数组的最左侧移动到数组的最右侧。你只可以看 到在滑动窗口内的 k 个数字。滑动窗口每次只向右移 动一位。 返回 滑动窗口中的最大值 。输入:整型数组,最大值k 输出&am…...

老龄化遇上数字化丨适老化改造:操作做“减法”,服务做“加法”
当中国 60 岁以上人口突破 2.8 亿,银发浪潮与数字时代的碰撞催生了一道必答题:如何让技术红利真正惠及老年人?传统适老化改造常陷入 "技术崇拜" 误区。 智能设备功能复杂如 "科技迷宫",操作界面充满 "数…...
)
【计算机网络】网络基础(协议,网络传输流程、Mac/IP地址 、端口号)
目录 1.协议简述2.网络分层结构2.1 软件分层2.2 网络分层为什么? 是什么?OSI七层模型TCP/IP五层(或四层)结构 3. 网络与操作系统之间的关系4.从语言角度理解协议5.网络如何传输局域网通信(同一网段) 不同网…...

【Java编程】【计算机视觉】一种简单的图片加/解密算法
by Li y.c. 一、内容简介 本文介绍一种简单的图片加/解密算法,算法的基本原理十分简单,即逐个(逐行、逐列)地获取图片的像素点颜色值,对其进行一些简单的算数运算操作进行加密,解密过程则相应地为加密运算…...

61.评论日记
老人摔倒无人扶最终死亡,家属将路人告上法庭,法院这样宣判!_哔哩哔哩_bilibili 2025年4月14日16:01:25...

每日一题——云服务计费问题
云服务计费问题(哈希表 排序)| 附详细 C源码解析 一、题目描述二、输入描述三、输出描述四、样例输入输出输入示例:输出示例:说明: 五、解题思路分析六、C实现源码详解(完整)七、复杂度分析 一…...

android-根据java文件一键生成dex文件脚本
安装7z命令 7-Zip官方下载网址 生成dex脚本文件 echo off setlocal enabledelayedexpansion:: 获取当前日期和时间 for /f "tokens2 delims" %%i in ("wmic os get localdatetime /value | findstr LocalDateTime") do set datetime%%i:: 提取年、月、日…...

OpenCV直方图均衡化全面解析:从灰度到彩色图像的增强技术
目录 一、直方图均衡化基础:原理与核心思想 二、彩色图像的直方图均衡化:挑战与解决方案 三、进阶技巧与注意事项 四、应用场景与典型案 一、直方图均衡化基础:原理与核心思想 1. 直方图的本质与作用 直方图是图像像素强度分布的统计图表…...

Node.js技术原理分析系列7——Node.js模块加载方式分析
Node.js 是一个开源的、跨平台的JavaScript运行时环境,它允许开发者在服务器端运行JavaScript代码。Node.js 是基于Chrome V8引擎构建的,专为高性能、高并发的网络应用而设计,广泛应用于构建服务器端应用程序、网络应用、命令行工具等。 本系…...

BFD:网络链路检测与联动配置全攻略
目录 BFD简介 BFD会话建立方式和检测机制 BFD会话建立过程 BFD工作流程 联动功能 BFD与OSPF联动配置需求 BFD与OSPF联动配置实现 BFD与VRRP联动配置需求 BFD与VRRP联动配置实现 单臂回声 BFD默认参数及调整方法 BFD简介 一种全网统一、检测迅速、监控网络中链…...

预防WIFI攻击,保证网络安全
文章总结(帮你们节约时间) WiFi协议存在多种安全漏洞,从去认证攻击到KRACK和PMKID攻击,这些都源于协议设计中的历史遗留问题。ESP32S3微控制器结合Arduino环境,成为强大的WiFi安全研究平台,可用于网络扫描…...

循环神经网络 - 门控循环单元网络
为了解决循环神经网络在学习过程中的长程依赖问题,即梯度消失或爆炸问题,一种非常好的解决方案是在简单循环网络的基础上引入门控机制来控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息。这一类网络可…...

Java 正则表达式综合实战:URL 匹配与源码解析
在 Web 应用开发中,我们经常需要对 URL 进行格式验证。今天我们结合 Java 的 Pattern 和 Matcher 类,深入理解正则表达式在实际应用中的强大功能,并剖析一段实际的 Java 示例源码。 package com.RegExpInfo;import java.util.regex.Matcher; …...

TCPIP详解 卷1协议 六 DHCP和自动配置
6.1——DHCP和自动配置 为了使用 TCP/IP 协议族,每台主机和路由器需要一定的配置信息。基本上采用3种方法:手工获得信息;通过一个系统获得使用的网络服务;使用某种算法自动确定。 拥有一个IP 地址和子网掩码,以及 DN…...
-01)
面试宝典(C++基础)-01
文章目录 1. C++基础1.1 C++特点1.2 说说C语言和C++的区别1.3 说说 C++中 struct 和 class 的区别1.4 include头文件的顺序以及双引号""和尖括号<>的区别1.5 说说C++结构体和C结构体的区别1.6 导入C函数的关键字是什么,C++编译时和C有什么不同?1.7 C++从代码…...

【笔记ing】AI大模型-04逻辑回归模型
一个神经网络结构,其中的一个神经网络层,本质就是一个逻辑回归模型 深度神经网络的本质就是多层逻辑回归模型互相连接或采用一定的特殊连接的方式连接在一起构成的。其中每一个层本质就是一个逻辑回归模型。 逻辑回归模型基本原理 逻辑回归࿰…...

【Android】常用参数实践 用户界面UI 布局文件XML
本文将系统总结 Android XML 布局的通用参数和常用布局类型的专属规则 一、通用布局参数 这些参数适用于所有 View 和 ViewGroup,是布局设计的基石。 1. 尺寸控制 android:layout_width 与 android:layout_height 定义视图的宽度和高度,可选值…...

音乐产业新玩法:NFTs如何颠覆传统与挑战未来?
音乐产业新玩法:NFTs如何颠覆传统与挑战未来? 近年来,NFT(Non-Fungible Token,非同质化代币)像一颗新星,迅速在数字艺术、游戏等领域掀起了革命。而在音乐产业,NFT不仅是一种数字所…...

测试基础笔记第三天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 ⼀、缺陷介绍定义:软件中使⽤中任何问题都为缺陷,简称:bug 二、缺陷编写三、注册模块测试点练习 ⼀、缺陷介绍 定义:…...

HTML5 Web 存储:超越 Cookie 的本地存储新选择
一、引言 在当今的 Web 开发领域,对于用户数据的本地存储需求日益增长。HTML5 带来了一种比传统 cookie 更强大、更安全、更高效的本地存储方式 ——Web 存储。本文将深入探讨 HTML5 Web 存储的相关知识,包括其基本概念、浏览器支持情况、localStorage …...

基于 DB、EAST、SAST 的文本检测算法详解及应用综述
摘要 近年来,随着深度学习在计算机视觉领域的广泛应用,自然场景文字检测技术取得了飞速发展。针对复杂背景、任意形状、多角度文本等问题,学术界和工业界陆续提出了 DB、EAST、SAST 等多种算法。本文详细介绍了这几种主流文本检测方法的原理…...

牙刷生产中的视觉检测,让刷毛缺陷检测高效便捷!
在日常口腔护理中,一把优质牙刷至关重要,而刷毛质量直接决定了牙刷品质。从生产端来看,牙刷制造行业正面临着品质管控的严峻挑战。人工目检在检测刷毛缺陷时,不仅效率低下,还极易因主观因素导致漏检、误检,…...
核心概念进阶)
面向对象编程(OOP)核心概念进阶
面向对象编程(OOP)核心概念进阶 final 关键字 行为特征:作为终结者关键字,用于限制类、方法、变量的可修改性 三层控制力: - 修饰类: 定义不可继承的最终类(如 String、Integer 等不可变类核…...

AI与教育的协奏曲:重构未来学习生态
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言:教育的“智变”来临 在经历了千年的教与学之后,教育终于迎来了最大规模的技术变革浪潮。随着ChatGPT、DeepSeek、Grok 等大语言模型的诞生与不断演进,AI正以前所未有的方式深入影响每一个学生、老师…...

性能炸裂的数据可视化分析工具:DataEase!
今天分享一款开源的数据可视化分析工具,帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。支持丰富的数据源连接,能够通过拖拉拽方式快速制作图表,并可以方便地与他人分享。 技术栈 前端:Vue.js、Elemen…...

9.thinkphp的请求
请求对象 当前的请求对象由think\Request类负责,该类不需要单独实例化调用,通常使用依赖注入即可。在其它场合则可以使用think\facade\Request静态类操作。 项目里面应该使用app\Request对象,该对象继承了系统的think\Request对象ÿ…...

UBUNTU20.04安装ros2
ubuntu20.04安装ROS2 详细教程_ubuntu20.04 ros2-CSDN博客...

数据可视化工具LightningChart .NET v12.2.1全新发布——支持新的 .NET 目标框架
LightningChart.NET完全由GPU加速,并且性能经过优化,可用于实时显示海量数据-超过10亿个数据点。 LightningChart包括广泛的2D,高级3D,Polar,Smith,3D饼/甜甜圈,地理地图和GIS图表以及适用于科学…...

Python + Playwright:规避常见的UI自动化测试反模式
Python + Playwright:规避常见的UI自动化测试反模式 前言反模式一:整体式页面对象(POM)反模式二:具有逻辑的页面对象 - POM 的“越界”行为反模式三:基于 UI 的测试设置 - 缓慢且脆弱的“舞台搭建”反模式四:功能测试过载 - “试图覆盖一切”的测试反模式之间的关联与核…...

蓝宝石狼组织升级攻击工具包,利用新型紫水晶窃密软件瞄准能源企业
网络安全专家发现,被称为"蓝宝石狼"(Sapphire Werewolf)的威胁组织正在使用升级版"紫水晶"(Amethyst)窃密软件,对能源行业企业发起复杂攻击活动。此次攻击标志着该组织能力显著提升&am…...

高光谱相机:温室盆栽高通量植物表型光谱成像研究
传统植物表型测量依赖人工观察与手工记录,存在效率低、主观性强、无法获取多维数据(如生化成分、三维形态)等缺陷。例如,叶片氮含量需破坏性取样检测,根系表型需挖掘植株,导致数据不连续且难以规模化。此外…...

Android Studio安装平板的虚拟机
其实很简单,但是我刚开始也是一窍不通,所以也查了好多资料才会的,本文仅作为个人学习笔记分享,有跟我一样的小白可以当做一个参考,有什么问题也欢迎大家提出建议,俺会虚心接受并改进的~ 首先我们打开项目&…...

Redis 常问知识
1.Redis 缓存穿透问题 缓存穿透:当请求的数据在缓存和数据库中不存在时,该请求就跳出我们使用缓存的架构(先从缓存找,再从数据库查找、这样就导致了一直去数据库中找),因为这个数据缓存中永远也不会存在。…...

UnityUI:Canvas框架获取鼠标悬浮UI
将下面脚本挂在主体Canvas上,Canvas会对下面所有Image挂上PointerHandler脚本,并且可以通过GetPointEnter方法判断当前鼠标是否悬停在UI上 public class BaseCanvas : MonoBehaviour {public static BaseCanvas Main;private void Awake(){Main this;I…...
:RNN英文名国家分类)
NLP实战(3):RNN英文名国家分类
目录 1. 项目需求 2. 模型解析 2.1 网络模型 2.2 准备数据 2.3 双向循环神经网络 3. 代码解析 4. 完整代码 5. 结果 1. 项目需求 对名字的分类,几千个名字,总共来自于18个国家 2. 模型解析 对于自然语言处理来说,输入是一个序列&am…...

东方博宜OJ ——1335 - 土地分割
递归 入门 ————1335 - 土地分割 1335 - 土地分割题目描述输入输出样例问题分析递归解法(欧几里得算法)代码实现总结 1335 - 土地分割 题目描述 把一块m * n米的土地分割成同样大的正方形,如果要求没有土地剩余,分割出的正方形…...

在轨道交通控制系统中如何实现μs级任务同步
轨道交通作为现代城市化进程中的重要支柱,承载着数以亿计的乘客出行需求,同时也是城市经济运行的命脉。无论是地铁、轻轨还是高速铁路,其控制系统的稳定性和可靠性直接关系到运营安全和效率。在这样一个高风险、高复杂度的环境中,…...

【C++教程】进制转换的实现方法
在C中进行进制转换可以通过标准库函数或自定义算法实现。以下是两种常见场景的转换方法及示例代码: 一、使用C标准库函数 任意进制转十进制 #include <string> #include <iostream>int main() {std::string num "1A3F"; // 十六进制数int…...

日志文件爆满_配置使用logback_只保留3天日志文件_每天定时生成一个日志文件---SpringCloud工作笔记206
日志文件爆满,springCloud微服务架构中的,日志爆满如何解决,使用脚本直接删除,会导致, 如果要删除的日志文件,还正在被进程占用,那么你即使使用脚本定时删除了,这个日志文件,那么这个日志文件实际上还是不会删除的,他的大小,依然占用磁盘,就是因为,有进程还在占用它,所以之前说…...
)
DICOM通讯(ACSE->DIMSE->Worklist)
DICOM 通讯协议中的 ACSE → DIMSE → Worklist 这条通讯链路。DICOM 通讯栈本身是一个多层的协议结构,就像 OSI 模型一样,逐层封装功能。 一、DICOM 通讯协议栈总体架构 DICOM 通讯使用 TCP/IP 建立连接,其上面封装了多个协议层次…...
)
QML与C++:基于ListView调用外部模型进行增删改查(附自定义组件)
目录 引言相关阅读项目结构文件组织 核心技术实现1. 数据模型设计联系人项目类 (datamodel.h)数据模型类 (datamodel.h)数据模型实现 (datamodel.cpp) 2. 主程序入口点 (main.cpp)3. 主界面设计 (Main.qml)4. 联系人对话框 (ContactDialog.qml)5. 自定义组件CustomTextField.qm…...

# linux 设置宽容模式
linux 设置宽容模式 在Linux系统中,通常没有直接称为“宽容模式”的设置选项,但你可以通过几种方式来模拟或调整系统行为,使其表现得更加“宽容”,特别是在处理错误、权限问题或其他潜在问题时。以下是一些常见的方法:…...

#1 理解物联网
物联不是一个新概念,物联网如其中文译名, 虚拟和物的对应和联接。 对于人类的梦想而言,总是希望自己无比强大,但受限于外部条件而只能为此悻悻念念。 所以人们的目光聚焦在,上世纪70年代发展的传感器、大规模电路、通…...
)
物联网场景实战:智能电表数据管理与分析(二)
数据管理 数据清洗与预处理 智能电表在数据采集、传输和存储过程中,不可避免地会引入噪声、出现缺失值和异常值等问题,这些问题会严重影响数据的质量和后续分析的准确性,因此数据清洗至关重要。 噪声数据通常是由于测量误差、通信干扰等原…...

linux一次启动多个jar包
linux一次启动多个jar包并且可以自定义路径和端口号 代码使用 分享公司大神使用的一个脚步,可以一次启动多个jar包,也可以指定启动jar包 代码 #! /bin/sh # 端口号 PORTS(8080 8081 8082 8083) # 模块 MODULES(gateway auth system file) # 模块名称 MODULE_NAMES(网关服务 认…...

自然语言交互:NAS进化的下一站革命
自然语言交互:NAS进化的下一站革命 在数据爆炸式增长的数字时代,网络附加存储设备(NAS)早已突破企业级应用的边界,成为个人数字资产管理的核心枢纽。当全球NAS市场年复合增长率稳定在15%之际,耘想科技推出…...