Docker 安装 Flink 实现数据实时统计 - 华为云
概述
案例介绍
Apache Flink 是一个开源的流处理框架,具有高吞吐、低延迟、可容错等特点,可同时支持批处理和流处理,为数据处理提供了强大而灵活的解决方案,Flink 在 Docker 中的应用场景主要是为了简化集群的部署和管理,特别是在开发、测试以及小规模生产环境中。使用 Docker 可以快速启动、停止和重启集群,避免手动配置和依赖管理的复杂性。
Flink 实时统计功能可以应用在以下场景:
- 实时数据清洗和转换:在数据进入存储或分析系统之前,需要对原始数据进行清洗和转换,以确保数据的质量和一致性。
- 实时事件监测与告警:在实时监控系统中,当某些事件满足特定条件时触发告警。
- 实时推荐系统:根据用户的实时行为和偏好,为用户提供个性化推荐。
本案例通过云主机进行 Docker 部署和安装 Flink,在 CodeArts IDE 编辑器进行代码开发实现数据的实时统计。
通过实际操作,让大家深入了解如何方便快捷的使用 Flink。在这个过程中,大家将学习到 Docker 的安装、Flink 的安装部署以及简单的 Flink 代码开发,从而掌握 Flink 的基本使用方法,体验其在应用开发中的优势。
使用 Docker 可简化集群部署和管理,适合开发、测试及小规模生产环境。
华为云链接:华为云
适用对象
- 企业
- 个人开发者
- 高校学生
案例流程
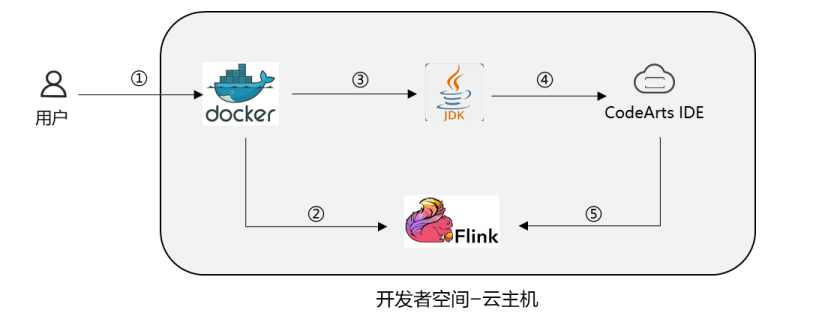
说明:
① 登录云主机,安装 Docker;
② 在 Docker 安装 Flink;
③ 安装 JDK1.8;
④ 打开 CodeArts IDE 编写wordCount 代码;
⑤ 代码打包到 Flink 运行。
资源总览
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
|---|---|---|---|
| 云主机 | 2 vCPUs |4GB X86 | 免费 | 60 |
Docker 安装 Flink 实现数据实时统计
1、安装 Docker
本案例中,使用 Docker 简化集群的部署和管理,提高开发效率、保证环境一致性、降低成本、提高安全性和可靠性,同时也支持复杂的架构和部署模式。
# 打开云主机命令行窗口输入以下命令,更新软件包
sudo apt update && sudo apt upgrade -y# 卸载旧版本 Docker(如果已安装)。
sudo apt-get remove docker docker-engine docker.io containerd runc# 安装必要的依赖
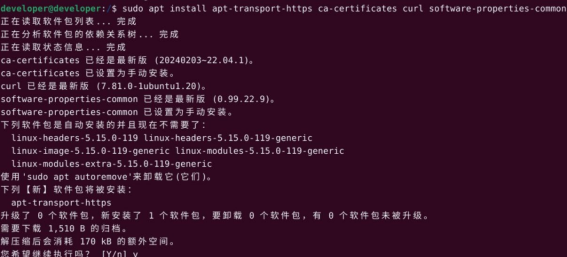
sudo apt install apt-transport-https ca-certificates curl software-properties-common
# 添加 Docker GPG 密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -

# 添加 Docker APT 源
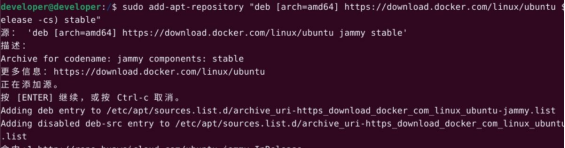
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu$(lsb_release -cs) stable"
执行命令后需要按”ENTER“键继续执行命令。
# 更新 APT 包索引
sudo apt update# 安装 Docker CE
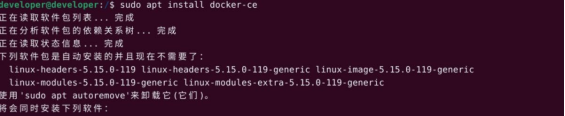
sudo apt update && sudo apt install docker-ce
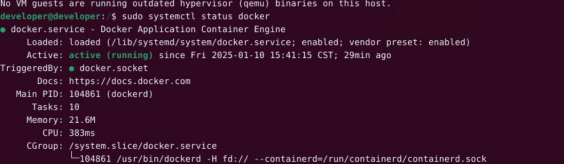
# 验证安装
sudo systemctl status docker
# 设置 Docker 开机自启
sudo systemctl enable docker# 安装 docker-compose
sudo apt-get install docker-compose

2、拉取 Flink 镜像
Apache Flink 是一个功能强大的流处理框架,适用于各种实时数据处理和分析场景,它提供了强大的功能和丰富的 API,支持分布式、高性能、低延迟和精确一次的处理,在现代数据处理领域发挥着重要的作用。
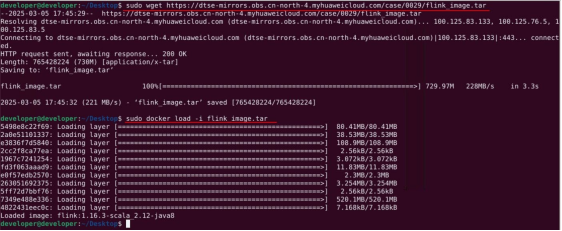
# 使用以下命令从 OBS 下载指定版本的 Flink 镜像,并将镜像加载到本地的 Docker 镜像库中。
# 下载并加载 Flink 镜像
sudo wget https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0029/flink_image.tar
sudo docker load -i flink_image.tar
# 创建一个目录用于存放 Flink 集群的相关文件。
mkdir ~/flink && cd ~/flink# 创建 docker-compose.yml 文件
vim docker-compose.yml
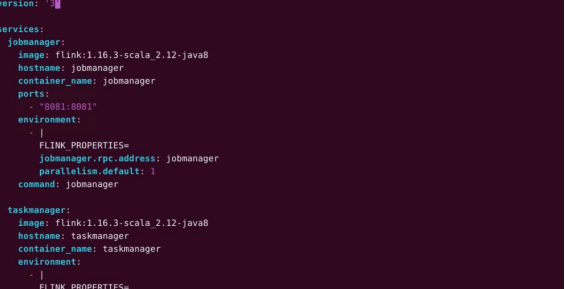
文件内容如下:
version: '3'services:jobmanager:image: flink:1.16.3-scala_2.12-java8hostname: jobmanagercontainer_name: jobmanagerports:- "8081:8081"environment:- |FLINK_PROPERTIES=jobmanager.rpc.address: jobmanagerparallelism.default: 1command: jobmanagertaskmanager:image: flink:1.16.3-scala_2.12-java8hostname: taskmanagercontainer_name: taskmanagerenvironment:- |FLINK_PROPERTIES=jobmanager.rpc.address: jobmanagertaskmanager.numberOfTaskSlots: 2parallelism.default: 1depends_on:- jobmanagercommand: taskmanager
# 配置代理
# 在 Docker 的配置文件中添加华为镜像加速器。sudo vim /etc/docker/daemon.json# 配置信息如下
{"registry-mirrors": [ "https://7046a839d8b94ca190169bc6f8b55644.mirror.swr.myhuaweicloud.com" ]
}# 重启 docker。
sudo systemctl restart docker# 启动 Flink 集群
# 通过以下命令启动 Flink 集群:
sudo docker-compose up -d

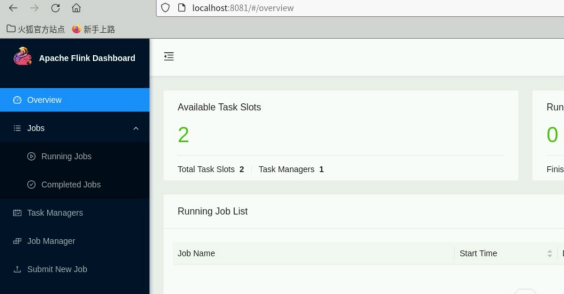
等待容器启动后,你可以通过访问 http://localhost:8081 来打开 Flink 的 Web 界面,以检查集群是否成功启动。
# 修改配置文件,保证日志正常打印
# 执行如下命令复制 taskmanager 下的 docker-entrypoint.sh 脚本。
sudo docker cp taskmanager:/docker-entrypoint.sh ./docker-entrypoint.sh# 替换配置文件。
vim docker-entrypoint.sh# 配置文件增加如下内容:$FLINK_HOME/bin/taskmanager.sh start "$@"
fi
sleep 1
exec /bin/bash -c "tail -f $FLINK_HOME/log/*.log" args=("${args[@]}")
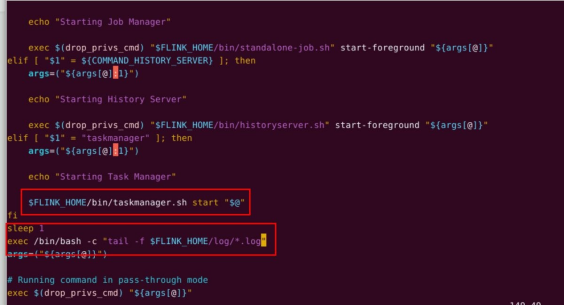
# 将修改后的配置文件再上传到 taskmanager。
sudo docker cp ./docker-entrypoint.sh taskmanager:/docker-entrypoint.sh# 重启服务。
sudo docker-compose restart# 查看服务状态。
sudo docker ps -a
3、安装 Java 环境
jdk1.8 的安装包如下,请把压缩格式的文件 jdk-8u431-linux-x64.tar.gz 下载到云主机复制下面链接到浏览器下载。
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0001/jdk-8u431-linux-x64.tar.gz

# 把安装包上传到/home/developer/Downloads 的目录下执行如下命令:
# 创建/usr/lib/jvm 目录用来存放 JDK 文件
sudo mkdir -p /usr/lib/jvm# 把 JDK 文件解压到/usr/lib/jvm 目录下
sudo tar -zxvf /home/developer/Downloads/jdk-8u431-linux-x64.tar.gz -C /usr/lib/jvm # JDK 文件解压缩以后,可以执行如下命令到/usr/lib/jvm 目录查看一下:
cd /usr/lib/jvm
ls# 可以看到,在/usr/lib/jvm 目录下有个 jdk1.8.0_371 目录。下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc# 使用 vim 编辑器,打开了 developer 这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_431
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH# 保存.bashrc 文件并退出 vim 编辑器。然后,继续执行如下命令让.bashrc 文件的配置立即生效:
source ~/.bashrc# 这时,可以使用如下命令查看是否安装成功:
java -version
如果能够在屏幕上返回如下信息,则说明安装成功:

至此,就成功安装了 Java 环境。
4、代码开发
双击打开桌面上的 CodeArts IDE for JAVA。

点击新建工程。
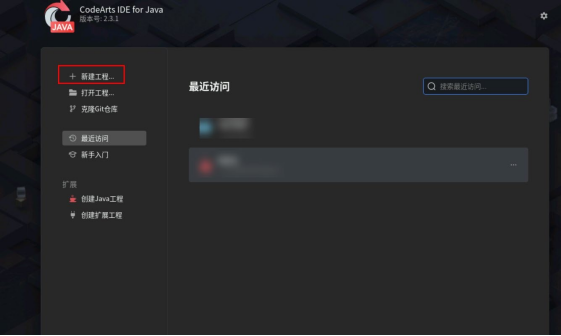
工程信息如下:
名称:自定义
位置:默认
构建系统:Maven
JDK:1.8
# 配置 settings.xml 文件,在命令行执行:
vim /home/developer/.m2/settings.xml
# 将内容替换如下:
<?xml version="1.0" encoding="UTF-8"?>
<settingsxmlns="http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"><!-- 默认的值是${user.home}/.m2/repository --><!--<localRepository></localRepository>--><!-- 如果 Maven 要试图与用户交互来得到输入就设置为 true,否则就设置为 false,默认为 true。 --><!--<interactiveMode>true</interactiveMode>--><!-- 如果 Maven 使用${user.home}/.m2/plugin-registry.xml 来管理 plugin 的版本,就设置为 true,默认为 false。 --><!--<usePluginRegistry>false</usePluginRegistry>--><!-- 如果构建系统要在离线模式下工作,设置为 true,默认为 false。 如果构建服务器因为网络故障或者安全问题不能与远程仓库相连,那么这个设置是非常有用的。 --><!--<offline>false</offline>--><servers><!-- server | Specifies the authentication information to use when connecting to a particu
lar server,identified by| a unique name within the system (referred to by the 'id' attribute below).| | NOTE: You should either specify username/password OR privateKey/passphras
e, since these pairingsare| used together.| --><!-- server 标签的作用 ,如下 --><!-- 使用 mvn install 时,会把项目打的包安装到本地 maven 仓库 --><!-- 使用 mvn deploye 时,会把项目打的包部署到远程 maven 仓库,这样有权限访问远程仓库的人都可以访问你的 jar 包 --><!-- 通过在 pom.xml 中使用 distributionManagement 标签,来告知 maven 部署的远程仓库地址--></servers><mirrors><mirror><id>huaweiyun</id><mirrorOf>*</mirrorOf><!--*代表所有的 jar 包都到华为云下载--><!--<mirrorOf>central</mirrorOf>--><!--central 代表只有中央仓库的 jar 包才到华为云下载--><!-- maven 会有默认的 id 为 “central” 的中央仓库--><name>huaweiyun-maven</name><url>https://mirrors.huaweicloud.com/repository/maven/</url></mirror></mirrors><!-- settings.xml 中的 profile 是 pom.xml 中的 profile 的简洁形式。它包含了激活(activation),仓库(repositories),插件仓库(pluginRepositories)和属性(properties)元素。profile 元素仅包含这四个元素是因为他们涉及到整个的构建系统,而不是个别的 POM 配置。如果 settings 中的 profile 被激活,那么它的值将重载 POM 或者 profiles.xml 中的任何相等 ID 的 profiles。 --><!-- 如果 setting 中配置了 repository,则等于项目的 pom 中配置了 --><profiles><profile><!-- 指定该 profile 的 id --><id>dev</id><!-- 远程仓库--><repositories><!-- 华为云远程仓库--><repository><id>huaweicloud</id><name>huaweicloud maven Repository</name><url>https://mirrors.huaweicloud.com/repository/maven/</url><!-- 只从该仓库下载 release 版本 --><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-milestone</id><name>Spring Milestone Repository</name><url>https://repo.spring.io/milestone</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots><layout>default</layout></repository><repository><id>spring-snapshot</id><name>Spring Snapshot Repository</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots><layout>default</layout></repository></repositories><pluginRepositories><!-- 插件仓库。插件从这些仓库下载 --><pluginRepository><id>huaweicloud</id><url>https://mirrors.huaweicloud.com/repository/maven/</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots></pluginRepository></pluginRepositories></profile></profiles><!-- activations 是 profile 的关键,就像 POM 中的 profiles,profile 的能力在于它在特定情况下可以修改一些值。而这些情况是通过 activation 来指定的。 --><!-- <activeProfiles/> --><activeProfiles><activeProfile>dev</activeProfile></activeProfiles>
</settings>
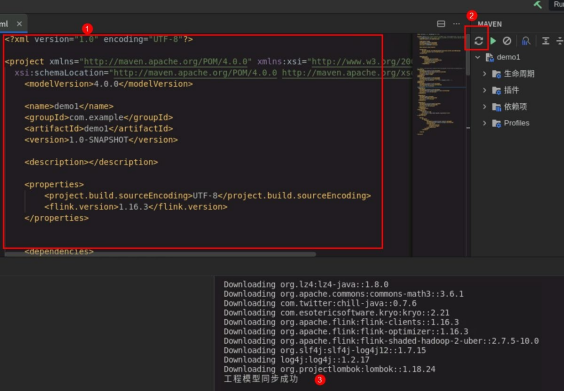
配置 pom 文件:
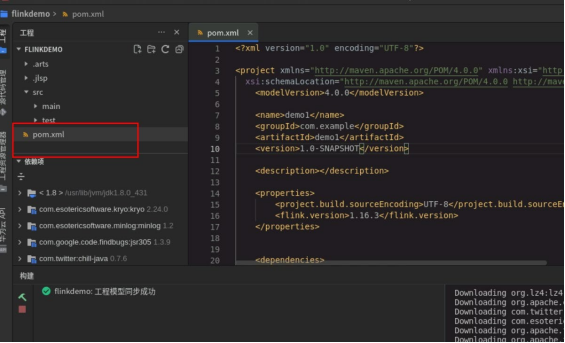
# 文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><name>demo1</name><groupId>com.example</groupId><artifactId>flinkdemo</artifactId><version>1.0-SNAPSHOT</version><description></description><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.16.3</flink.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>1.16.3</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.16.3</version><!-- 根据实际需求选择版本 --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.16.3</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies><repositories><repository><id>central</id><url>https://repo.maven.apache.org/maven2/</url></repository></repositories><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>8</source><target>8</target></configuration></plugin></plugins></build>
</project>
配置完之后,点击右边 MAVEN 刷新按钮,下载依赖。
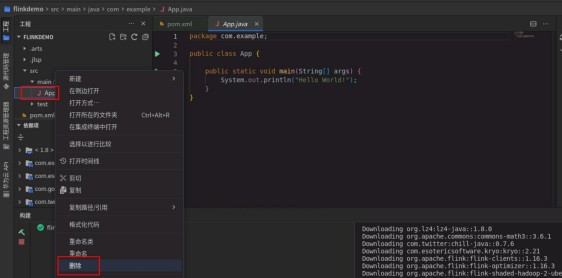
打开项目工程,删除 App.java。
新建 WordCount.java 类。
代码如下:
package com.example;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
//import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Random;
public class WordCount
{/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception{// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 后续的数据源、转换、操作等代码// env.execute("WordCount01");// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 定义一个用于生成随机单词的数组/* String[] words = {"apple", "banana", "cherry", "date", "elderberry"};Random random = new Random();// 这里使用一个无限循环来模拟持续生成数据while (true) {// 随机选择一个单词String word = words[random.nextInt(words.length)]; */// DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream < String > dataStream01 = env.socketTextStream("10.12.164.220", 9999);DataStream < String > flatMapStream = dataStream01.flatMap(new FlatMapFunction < String, String > (){@Overridepublic void flatMap(String line, Collector < String > collector) throws Exception{String[] arr = line.split(" ");for(String word: arr){// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的 DataStreamcollector.collect(word);}}});//flatMapStream.print();// Tuple2 指的是 2 元组DataStream < Tuple2 < String, Integer >> mapStream = flatMapStream.map(new MapFunction < String, Tuple2 < String, Integer >> (){@Overridepublic Tuple2 < String, Integer > map(String word) throws Exception{return Tuple2.of(word, 1); // ("hello",1)}});DataStream < Tuple2 < String, Integer >> sumResult = mapStream.keyBy(new KeySelector < Tuple2 < String, Integer > , String > (){@Overridepublic String getKey(Tuple2 < String, Integer > tuple2) throws Exception{return tuple2.f0;}// 此处的 1 指的是元组的第二个元素,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute("WordCount01");/*env.setParallelism(2); // 设置全局并行度dataStream.keyBy(0).sum(1).setParallelism(2); // 设置单个操作的并行度*/}
}
打开命令行输入命令查看云主机本地 ip。
ifconfig
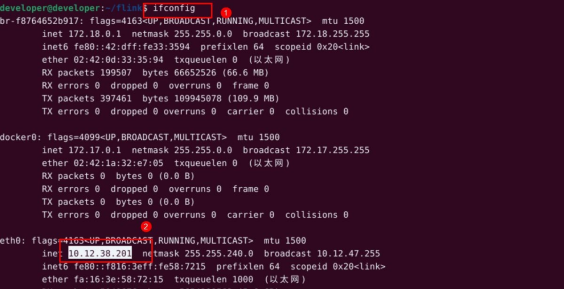
将得到的 ip 填入代码中。
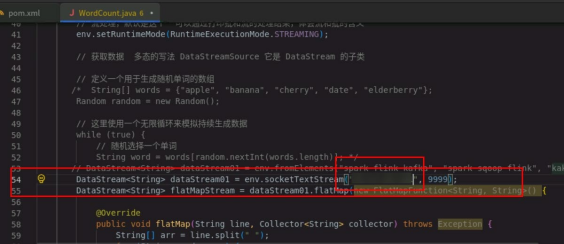
打包代码。
右侧项目 target 目录下生成 jar 包。
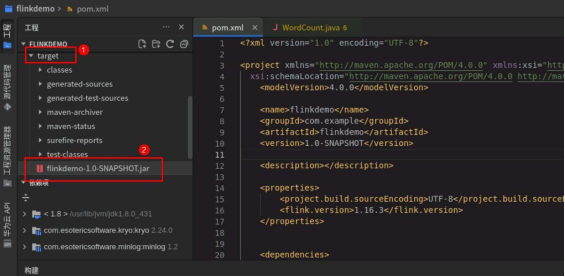
5、运行代码
在命令行窗口输入命令打开监听:
nc -l 9999

打开 flink web 上传 jar 包运行代码。点击左边栏 Submit New Job。
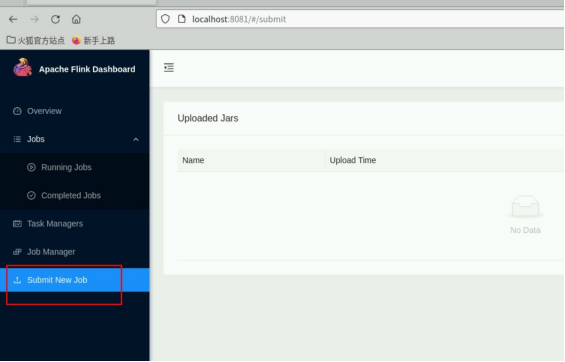
点击右边 Add New 。
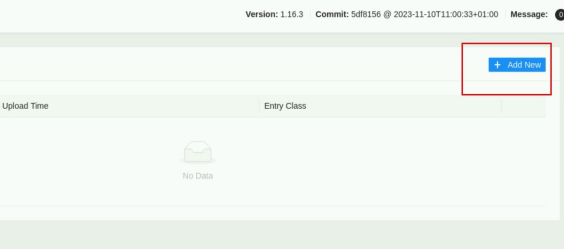
上传 jar 包。
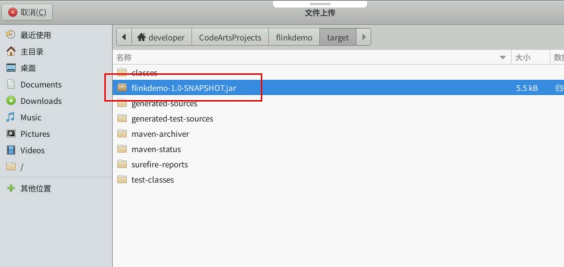
填写任务运行参数。填写主类:com.example.WordCount,点击 Submit 运行。
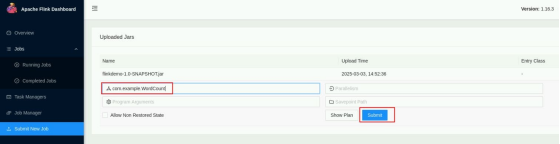
在命令行监听输入单词。

打开 flink web Task Managers。
点击 Stdout 可以看到打印出刚刚输出的单词数量,根据相同单词数据进行累加统计。

不再进行监听的时候,进入命令行,按下 Ctrl+C 停止命令行监听窗口。
如果想了解更多 docker 内容可以访问:https://www.docker.com/
想了解更多关于 flink 内容的可以访问:https://flink.apache.org/
相关文章:

Docker 安装 Flink 实现数据实时统计 - 华为云
概述 案例介绍 Apache Flink 是一个开源的流处理框架,具有高吞吐、低延迟、可容错等特点,可同时支持批处理和流处理,为数据处理提供了强大而灵活的解决方案,Flink 在 Docker 中的应用场景主要是为了简化集群的部署和管理&#x…...
_46)
LeetCode算法题(Go语言实现)_46
题目 给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。 另有一些以数组 queries 表示的问题,其中 querie…...

AJAX与Axios基础
目录 一、AJAX 核心概念解析 1.1 AJAX 的核心概念 1.2 AJAX 工作原理 1.3 AJAX 局限性 二、axios 库介绍 2.1 Axios 核心特性 2.2 快速上手 2.3 核心配置项 2.4 错误处理标准方案 三、Axios 核心配置项 3.1 常用核心配置项 1. url 2. method 3. params 4. data …...

CodeReview工具集合
codereview 工具集合 在现代软件开发中,代码审查(Code Review) 已成为保障代码质量和团队协作效率的关键流程。一个合适的 Code Review 工具,不仅能帮助团队发现潜在问题,还能促进知识共享与规范统一。 本文整理了一些…...
_45)
LeetCode算法题(Go语言实现)_45
题目 n 座城市,从 0 到 n-1 编号,其间共有 n-1 条路线。因此,要想在两座不同城市之间旅行只有唯一一条路线可供选择(路线网形成一颗树)。去年,交通运输部决定重新规划路线,以改变交通拥堵的状况…...
]] 属性)
C++23 新特性:[[assume(expression)]] 属性
文章目录 语法与基本用法作用与优化原理使用注意事项未满足假设时的行为使用场景 示例代码总结 C23 引入了一个新的属性 [[assume(expression)]],它为程序员提供了一种向编译器传递额外信息的机制,从而让编译器能够生成更高效的代码。 语法与基本用法 …...

AI IDE 提示词
好的,这就将之前的分析内容整理成一篇适合发布在 CSDN 上的博客文章。 告别代码生成混乱:AI IDE 提示词模式权威指南 作者: (你的名字/昵称) 日期: 2025年4月14日 前言 随着人工智能技术的飞速发展,AI 助手(如 GitHub Copilot…...

Framework Binder架构分解
整个 Binder 架构所涉及的总共有以下 5 个目录: 1. /framework/base/core/java/(Java) 2. /framework/base/core/jni/ (JNI) 3,/framework/native/libs/binder (Native) 4,/framework/native/cmds/servicemanager/ (Native) 5,…...
实现各个实训室电脑网络可互通,原本是独立局域网)
三层交换机SVI功能(交换机虚拟接口)实现各个实训室电脑网络可互通,原本是独立局域网
三层交换机 SVI功能(交换机虚拟接口) 实现VLAN路由 需求 :各实训室使用独立局域网,即每个实训有自己的IP网段, 每个实训室只有内部互相访问。 需求:为了加强各实训室学生的交流,学校要求我们…...

Spark-SQL核心编程:DataFrame、DataSet与RDD深度解析
在大数据处理领域,Spark-SQL是极为重要的工具。今天就来深入探讨Spark-SQL中DataFrame、DataSet和RDD这三个关键数据结构。 Spark-SQL的前身是Shark,它摆脱了对Hive的过度依赖,在数据兼容、性能优化和组件扩展上有显著提升。DataFrame是基于R…...

腾讯云COS直传,官方后端demo,GO语言转JAVA
腾讯云COS直传,官方后端demo,GO写的,我们台是JAVA所以转一下,已跑通。废话不多说,直接上代码: Controller类如下: import com.ruoyi.web.core.config.CosConfig; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.Ht…...
)
c语言坦克对战(前言)
实现C语言中的“坦克大战”游戏逻辑,可以按照以下步骤进行: 游戏初始化 定义游戏窗口:设置游戏窗口的大小和标题。加载资源:加载坦克、子弹、敌人等图像资源。初始化游戏状态:设置初始分数、生命值、坦克位置等。 游…...
)
空间信息可视化——WebGIS前端实例(一)
技术栈:原生HTML 源代码:CUGLin/WebGIS: This is a project of Spatial information visualization 4 全国贫困县可视化系统 4.1 系统设计思想 党的十九大报告明确指出,要“确保到2020年我国现行标准下农村贫困人口实现脱贫,贫困县全部摘帽,解决区域…...
:量子封神·用鸿蒙编译器重铸天道法则)
JVM考古现场(十九):量子封神·用鸿蒙编译器重铸天道法则
楔子:代码鸿蒙劫 "警告!警告!昆仑山服务器集群出现量子纠缠现象!"凌霄殿监控中心警报响彻云霄。全息投影中,Java线程在四维时空中编织出克莱因瓶拓扑结构,GC日志里闪烁着霍金辐射般的奇点事件。本…...

思维与算法共舞:AIGC语言模型的艺术与科学
云边有个稻草人-个人主页 热门文章_云边有个稻草人的博客-本篇文章所属专栏~ 目录 引言:AIGC与文本生成概述 一、AIGC基础:语言模型的基本原理 1. 什么是语言模型? 2. 预训练与微调 二、AIGC的应用领域:文本生成的具体应用 …...

C++之 多继承
在学校里有老师和学生,他们都是人,我么应该创建一个名为 Person 的基类和两个名为 Teacher 和Student 的子类,后两者是从前者继承来的 有一部分学生还教课挣钱(助教),也就是同时存在着两个”是一个”关系&…...

AI模型的主要分类及其详细对比,涵盖任务类型、架构、数据需求、应用场景等维度,并附上典型代表模型
以下是 AI模型的主要分类及其详细对比,涵盖任务类型、架构、数据需求、应用场景等维度,并附上典型代表模型: 一、AI模型的主要分类 1. 按任务类型分类 分类定义特点代表模型应用场景推理模型专注于逻辑推理、问题解决、因果关系分析的模型…...

TypeScript 快速入门
TypeScript 快速入门 1. 初识 TypeScript 1.1 TS 是什么? 以 JavaScript 为基础构建的语言;一个 JavaScript 的超集;可以在任何支持 JavaScript 的平台执行;TypeScript 扩展了 JavaScript 并添加了类型;TS 不能被 J…...

第一章 计算机网络和因特网
1.1 什么是因特网(Internet) 在博客这一系列文章中,我们使用一种特定的计算机网络,即公共因特网作为讨论计算机网络及其协议的主要载体。什么是因特网?可以用两种方式来回答这个问题:其一,我们能够通过因特网的具体构…...

【uni-app】axios 报错:Error: Adapter ‘http‘ is not available in the build
在 uni-app 中使用 axios 会报错:Error: Adapter ‘http‘ is not available in the build 解决方法:为 axios 添加 adapter 适配器。 import axios from axios; import settle from ../../node_modules/axios/lib/core/settle; import buildURL from …...

【路由交换方向IE认证】BGP选路原则之Weight属性
文章目录 一、路由器BGP路由的处理过程控制平面和转发平面选路工具 二、BGP的选路顺序选路的前提选路顺序 三、Wight属性选路原则规则9与规则11的潜移默化使用Weight值进行选路直接更改Weight值进行选路配合使用route-map进行选路 四、BGP邻居建立配置 一、路由器BGP路由的处理…...

思科模拟器的单臂路由,交换机,路由器,路由器只要两个端口的话,连接三台电脑该怎么办,划分VLAN,dotlq协议
单臂路由 1. 需求:让三台电脑互通 2. 在二层交换机划分vlan,并加入; 3. 将连接二层交换机和路由器的端口f0/4改为trunk模式 4. 路由器:进入连接路由器的f0/0端口将端口开启 5. 进入每个vlan设dotlq协议并设网络IP(…...

计算机视觉与深度学习 | 基于Matlab的钢筋计数
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 基于Matlab的钢筋计数 1、引言2、方法设计2.1 整体流程2.2 关键技术2…...
)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(三)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(三) 7. 实现条件WGAN-GP # 训练条件WGAN-GP def train_conditional_wgan_gp():# 用于记录损失d_losses []g_losses []# 用于记录生成样本的多样性(通过类别分…...

MySQL 用 limit 影响性能的优化方案
一.使用索引覆盖扫描 如果我们只需要查询部分字段,而不是所有字段,我们可以尝试使用索引覆盖扫描,也就是让查询所需的所有字段都在索引中,这样就不需要再访问数据页,减少了随机 I/O 操作。 例如,如果我们…...

粉末冶金齿轮学习笔记分享
有一段小段时间没有更新了,不知道小伙们有没有忘记我。最近总听到粉末冶金齿轮这个概念,花点时间来学习一下,总结一篇笔记分享给大家。废话不多说,直接开始: “粉末冶金”是一种制造工艺,包括在高压下压实…...

数据结构第五版【李春葆】
数据结构教程上机实验指导第5版(李春葆主编).pdf 数据结构教程(第5版)(李春葆).pdf 数据结构教程(第五版)课后习题参考答案(李春葆).pdf 数据结构教…...

深入解析区块链技术:原理、应用与未来展望
1 区块链技术原理 1.1 基本概念 区块链本质上是一个分布式账本,它由一系列按照时间顺序排列的数据块组成,每个数据块包含了一定时间内的交易信息。这些数据块通过密码学技术相互链接,形成一个不可篡改的链条。其核心特点包括去中心化、不可篡…...

SAX解析XML:Java程序员的“刑侦破案式“数据处理
各位XML侦探们!今天我们要化身代码界的福尔摩斯,学习用SAX解析XML——这种一边读文件一边破译线索的技术,就像在凶案现场逐帧查看监控录像,内存占用比你的咖啡杯还小!(DOM解析?那叫把整个监控室…...
)
Spring - 13 ( 11000 字 Spring 入门级教程 )
一: Spring AOP 备注:之前学习 Spring 学到 AOP 就去梳理之前学习的知识点了,后面因为各种原因导致 Spring AOP 的博客一直搁置。。。。。。下面开始正式的讲解。 学习完 Spring 的统一功能后,我们就进入了 Spring AOP 的学习。…...

SQL 解析 with as dual sysdate level
目录 sql的运行顺序 with as EXTRACT 编辑 dual sysdate level 编辑 编辑 Oracle中的日期存储 核心部分 拆解字符串并计算最小值 关联子查询 NVL 函数 REGEXP_SUBSTR() sql的运行顺序 <select id"getTrendList" parameterType"java.util.H…...

苍穹外卖day03
店铺状态接口 引入Redis,因为像存储店铺状态这种只有一个字段(没必要存储在数据库),且登录后台就要被访问的数据(加快查询速度,减少数据库压力) 使用步骤:导入相关maven依赖、配置…...
 v5 备考学习资源汇总)
精品整理 | 云安全知识证书 (CCSK) v5 备考学习资源汇总
云安全知识证书 (CCSK) v5 备考学习资源,包含课件、视频、习题及CSA学习指南,共12章。 1.云计算的概念和架构 2.云治理 3.风险、审计与合规 4.组织管理 5.身份和访问管理 6.云安全监控 7.云基础设施和网络安全 8.云工作负载安全 9.云数据安全 10.云应用…...

编程思想——FP、OOP、FRP、AOP、IOC、DI、MVC、DTO、DAO
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

使用SSH开通Linux服务器账号
文章目录 1. 通过SSH连接到服务器2. 创建账号3. 将用户设置为管理员(可选)4. 设置SSH登录权限(可选)(1)切换到该用户目录(2)创建.ssh目录并设置适当的权限 1. 通过SSH连接到服务器 …...

【C++】内存分配与释放、内存碎片、内存泄漏、栈溢出
C内存分配方式 内存分配方式区别 特性 静态分配 栈分配 堆分配 分配时机 编译期 函数调用时 运行期(new) 释放方式 自动释放 函数结束自动释放 手动delete释放 内存区域 静态存储区 栈 堆(自由存储区) 大小灵活性…...

论文:Generalized Category Discovery with Large Language Models in the Loop
论文下载地址:Generalized Category Discovery with Large Language Models in the Loop - ACL Anthology 1、研究背景 尽管现代机器学习系统在许多任务上取得了优异的性能,绝大多数都遵循封闭世界的设置,假设训练和测试数据来自同一组预定义…...

k8s亲和力和非亲和力
在 Kubernetes 中,亲和力(Affinity)和非亲和力(Anti-Affinity)是用于控制 Pod 调度策略的机制,它们可以帮助优化资源利用率、提高应用性能和可用性。以下是亲和力和非亲和力的详细解释: 亲和力…...

Redis几个基本的全局指令
目录 1.set和get 2.keys 3.exists 4.del 5.expire 6.ttl 7.type 我们都知道Redis存的内容都是键值对,key是String,value有很多类型,像string(字符串),hash(哈希),…...

Flutter中如何判断一个计算任务是否耗时?
在 Flutter 里,判断一个计算任务是否耗时可从以下几个角度着手: 1. 任务复杂度分析 数学运算复杂度:依据算法的时间复杂度来初步判断。例如,简单的加法、乘法运算时间复杂度为 O ( 1 ) O(1) O(1),这类任务通常不耗时…...
)
LeetCode面试热题150中6-11题学习笔记(用Java语言描述)
Day 02 6、轮转数组 需求:给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 方法一 核心思想 使用额外的数组来将每个元素放至正确的位置。用 n 表示数组的长度,遍历原数组,将原数组下标…...
:设备模型 ≈ 运行时的适配器机制)
驱动开发硬核特训 · Day 10 (理论上篇):设备模型 ≈ 运行时的适配器机制
🔍 B站相应的视屏教程: 📌 内核:博文视频 - 总线驱动模型实战全解析 敬请关注,记得标为原始粉丝。 在 Linux 驱动开发中,设备模型(Device Model)是理解驱动架构的核心。而从软件工程…...

4.13日总结
javafx中实现发送qq邮箱验证码: 手动导入jar包方法: 第一步:开启QQ邮箱的 POP3/IMAP 或者 SMTP/IMAP 服务 打开qq邮箱(电脑端),找到设置里的账号与安全的安全设置,往下滑就可以找到 POP3/IMAP 或者 SMTP…...

python 微博爬虫 01
起因, 目的: ✅下载单个视频,完成。✅ 获取某用户的视频列表,完成。剩下的就是, 根据视频列表,逐个下载视频,我没做,没意思。获取视频的评论,以后再说。 关键点记录: 1. 对一个视…...

CST1017.基于Spring Boot+Vue共享单车管理系统
计算机/JAVA毕业设计 【CST1017.基于Spring BootVue共享单车管理系统】 【项目介绍】 共享单车管理系统,基于 Spring Boot Vue 实现,功能丰富、界面精美 【业务模块】 系统共有四类用户,分别是:监管用户、运营用户、调度用户、普…...

小刚说C语言刷题——第23讲 字符数组
前面,我们学习了一维数组和二维数组的概念。今天我们学习一种特殊的数组,字符数组。 1.字符数组的概念 字符数组就是指元素类型为字符的数组。字符数组是用来存放字符序列或者字符串的。 2.字符数组的定义及语法 char ch[5]; 3.字符数组的初始化及赋…...

c++11--std::forwaord--完美转发
std::forword的作用 完美转发的核心目的是保持参数的原始类型(包括const/volatile限定符和左值/右值性质)不变地传递给其他函数。 为什么需要完美转发 在没有完美转发之前,我们面临以下问题: 模板参数传递中的值类别丢失 当参数…...
学习率)
机器学习的一百个概念(12)学习率
前言 本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见[《机器学习的一百个概念》 ima 知识库 知识库广场搜索: 知识库创建人机器学习@Shockang机器学习数学基础@Shocka…...

java异常 与 泛型<T>
文章目录 异常认识异常什么是异常?Java的异常体系异常的基本处理异常的作用? 自定义异常编译时异常自定义运行时异常 异常的处理方案 泛型认识泛型泛型类泛型接口泛型方法、通配符、上下限泛型支持的类型包装类包装类具备的其他功能总结 异常 认识异常 …...

齐次坐标系统:什么是齐次坐标?为什么要引入齐次坐标?
齐次坐标系统:计算机图形学的基础 在计算机图形学、计算机视觉、相机标定、三维建模等领域,齐次坐标是一个非常重要的数学工具。本文将介绍:齐次坐标的基本概念、数学原理、我们为什么要引入齐次坐标、及其在实际应用中的价值。 文章目录 齐…...