【pytorch图像视觉】lesson17深度视觉应用(上)构建自己的深度视觉项目
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、 数据
- 1、认识经典数据
- 1.1入门数据:MNIST、其他数字与字母识别
- (1)数据加载
- (2)查看数据的特征和标签
- 方式一:.data/.targets查看数据特征和标签
- 方式二:通过查看某一个索引值的方式来查看特征和标签
- 方式三:万能方法
- (3)数据可以化
- 方式一:PIL直接可视化
- 方式二:用一个万能公式来随机可视化五张图
- 1.2竞赛数据:ImageNet、COCO、VOC、LSUN
- 1.3景物、人脸、通用、其他
- 总结
前言
内容来源于【菜菜&九天深度学习实战课程】上班以后时间少,为了提高效率,通过抄课件的方式加深记忆,而非听课。所以所有笔记仅仅是学习工具,并非抄袭!
在传统机器学习中,通常会区分有监督、无监督、分类、回归、聚类等人物类别,在不同的任务重会指向不同形式的标签、不同的评估指标、不同的损失函数,这些内容会影响我们的训练和建模流程。在深度视觉以外,除了区分“回归、分类”之外,还需要区分众多的、视觉应用类别。如果只考虑图像的内容,至少有常见的三种任务:识别(recognition) 、检测(detection)、分割(segmentation)。
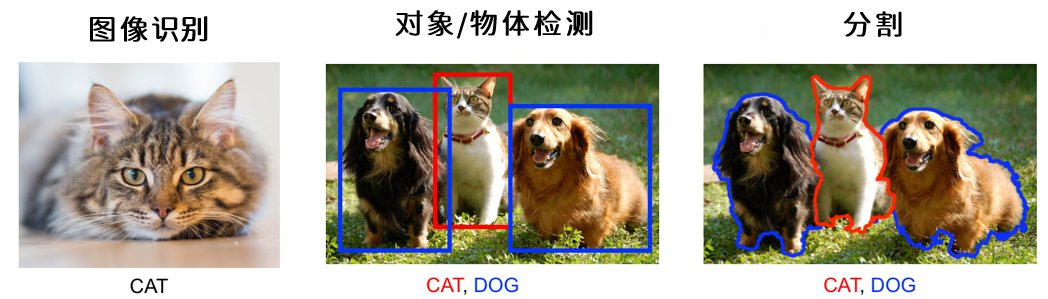
图像识别以图像中的单一对象为核心,采集信息并作出判断,任何超过单一对象的任务都不是单纯的图像识别。用于图像识别的数据集往往比较规整、比较简单,被识别物体基本轮廓完整、拍摄清晰、是图像中最容易被人眼注意到的对象。因此,图像识别适用于机场人脸识别这种简单的应用场景。
检测任务和分割任务是针对图像中多个或者单个对象进行判断的任务。因此分割和检测所使用的图像往往复杂很多。在检测任务重,首先要使用边界框(Bounding Box, bbx)对图像中的多个对象所在位置进行判断,在一个边界框容纳一个对象的前提下,再对边界框内每一个单一对象进行图像识别。因此。
检测任务的标签有两个:(1)以坐标方式确定的边界框的位置;(2)每个边界框中的物体属性。检测任务的训练流程也氛围两步:(1)定位;(2)判断。检测任务的训练数据也都是带边框的。我们可以只使用其中一个标签进行训练,但是检测任务同时训练两个标签才是最常见的情况。检测任务比较适用于大规模动态影像的识别,比如识别道路车辆、识别景区人群等。检测也是现在实际应用最为广泛的视觉任务。
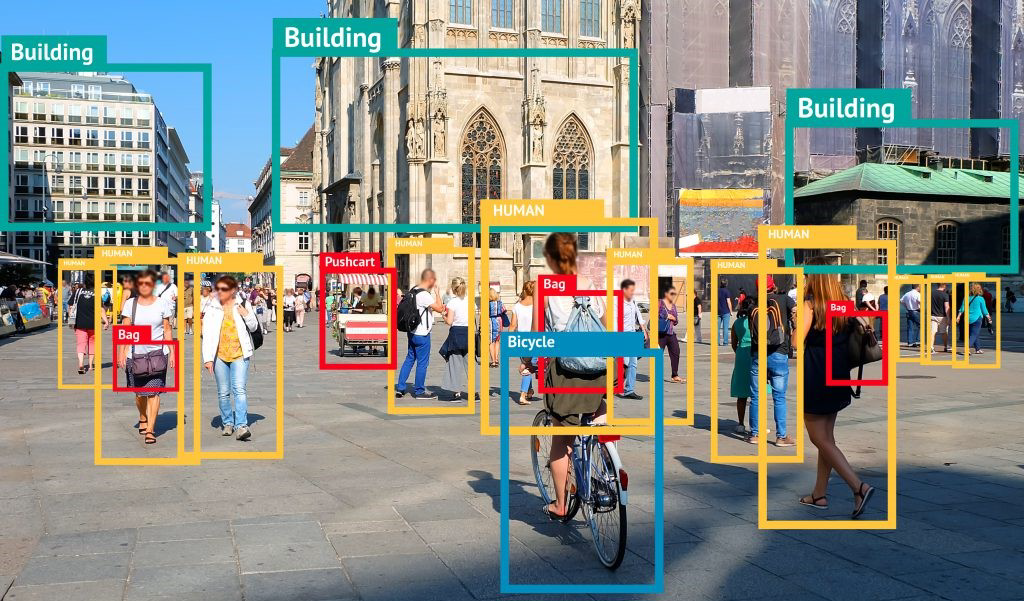
分割任务是像素级别的密集任务,需要对图像中的每个像素进行分类,因此不需要定义边界框就能够找到每个对象的“精准边界”。分割任务的标签往往只有一个,通常是对象的定义或性质(比如,这个像素是猫,这个像素是蓝天),但是标签中的类别会非常对,对于复杂的图像,标签类别可能成百上千。分割任务是现在图像领域对“理解图像”探索的前沿部分,许多具体的困难还未解决,同时,在许多实际应用场景并不需要分割任务这么”精准“的判断,因此分割的实际落地场景并不如检测来的多。比较知名的实际落地场景是美颜相机、抖音换脸特效等。
综上所述,三种任务在输出的结果及标签有所不同,但它们在一定程度上共享训练数据集,这主要是因为图像中的“对象”概念是可以人为定义的。用于图像识别的训练数据只要有适当的标签,也可以被用来检测和分割。例如,对于只有一张人脸的图像,只要训练数据存在边界框,那标签中就可以进行检测。相对的,用于检测和分割的数据如果含有大量的对象,可以被标注为“人群”这样的标签来进行识别(不过,用于检测、分割的数据拥有可以作为识别数据的标签非常少,因为检测分割数据集往往是多对象的)。

在单个任务重,也可能会遇到不同的“标签”。例如,对人脸数据,我们可以进行“属性识别”(attribute recognition)、“个体识别”(identity recognition)、“情绪识别”(emotion recognition)等不同的任务,对于同一张图像,我们的识别结果可能完全不同。

在情绪识别中,我们只拥有“情绪”这一标签,但标签类别中包含不同的情绪。在属性识别中,我们可以执行属性有限的多分类任务,也可以让每一种属性都有一个单独的标签,针对一个标签来完成二分类任务。而个体识别则是经典的人脸识别,在CelebA数据中我们使用人名作为标签来进行判断。
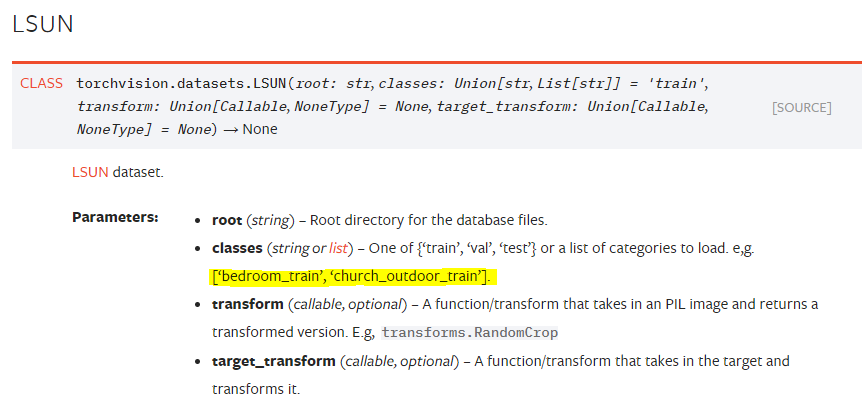
同样的,在场景识别、物体识别数据下(比如大规模场景识别数据LSUN),我们可能无法使用全部的数据集,因为全数据集可能会非常巨大并且包含许多我们不需要的信息。在这种情况下,标签可能是分层的,例如,场景可能分为室内和室外两种,而室内又分为卧式、客厅、厨房,室外则分为自然精光、教堂、其他建筑等,在这种情况下,室内和室外就是“上层标签”,具体的房间或景色则被认为是“下层标签”。我们通常会选择某个下层标签下的数据进行学习,例如:在LSUN中选择“教堂”或“卧室”标签进行学习:

对检测任务,我们也可能会检测不同的对象,例如:检测车牌号和检测车辆就是完全不同的标签,我们也需要从可以选择的标签中进行挑选。对于分割,则有更多的选项,我们可以执行将不同性质的物体分割开来的”语义分割“,也可以执行将每个独立对象都分割开来的”实例分割“,还可以执行使用多边形或颜色进行分割的分割方法。同时,根据分割的“细致程度”,还可以分为“粗粒度分割”(Coarse)和“细粒度分割”(Fine-grained),具体的分割程度由训练图像而定。

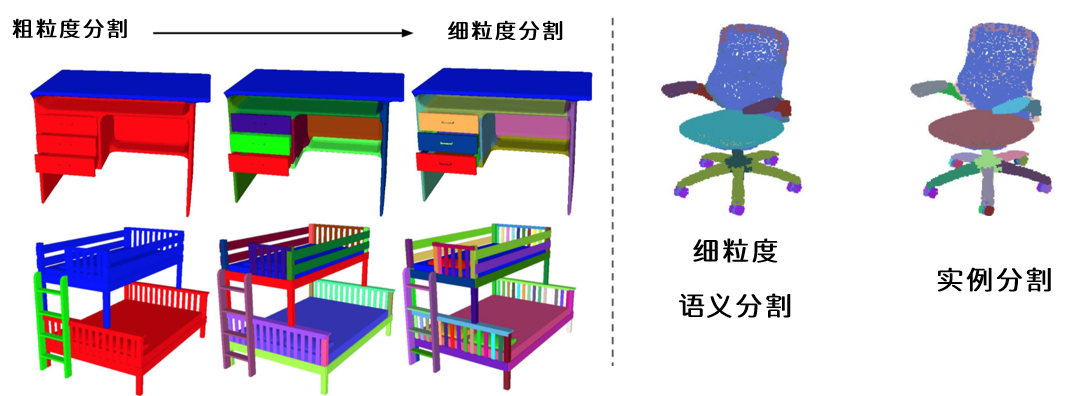
因此,在图像数据集的读取过程中,可能会发现一个图像数据集会带有很多个指向不同任务的标签、甚至很多个不同任务的训练集。遗憾的是,数据集本身并不会说明数据集所指向的任务,因此我们必须从中辨别出自己所需要的部分。torchvision.datasets模块中自带的CelebA人脸数据集就是这种情
况。如下图所示,类datasets.CelebA下没有任何文字说明,只有一个指向数据源的链接,光看PyTorch官网,我们并不能判断这个数据集是什么样的数据集。不过,这个类由参数“target_type”,这个参数可以控制标签的类型,四种标签类型分别是属性(attr)、个体(identity)、边界框(bbox)和特征(landmarks)。根据参数说明,可以看出属性是40个二分类标签,可以从中选择一个进行分类,个体是判断这个人类是哪个具体任务,这两个标签指向的是识别任务。边界框和特征都以坐标形式表示,这两个标签都指向检测任务。

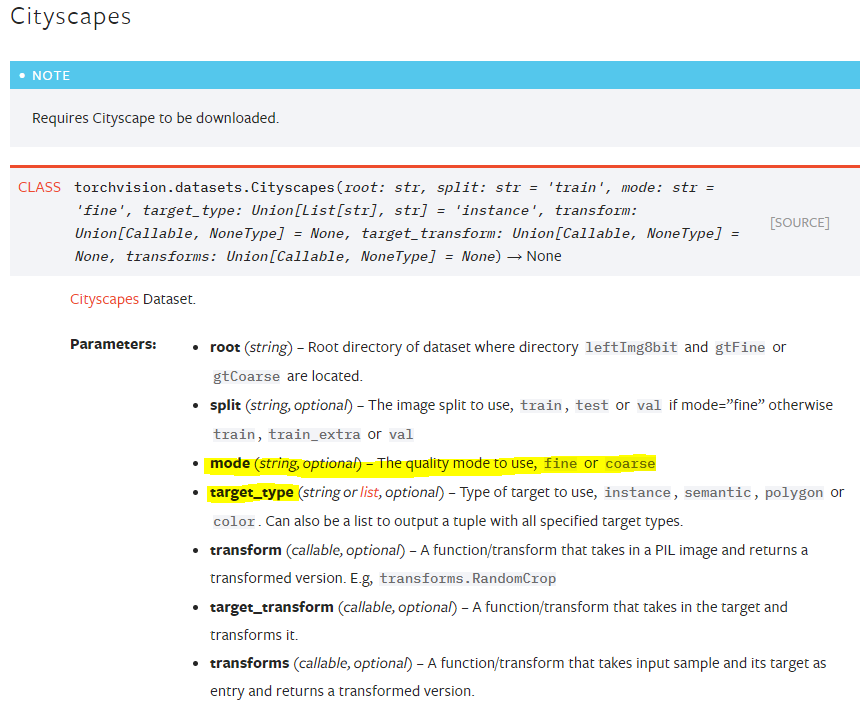
同样情况的还有Cityscapes,这个数据集的类dataset.Cityscapes下没有任何说明,但它含有参数mode和target_type,其中mode由两个模式:fine以及coarse,这两个模式表示Cityscape是一个用于分割任务额度数据集。同时,targe-type下面还有instance(实例分割)、semantic(语义分割)、polygon(多边形分割)、color(颜色分割)四种选项,所以要清晰了解自己的需求以及每种分割的含义才能正确填写这些参数。同时,我们可以一次性训练导入多个标签进行使用,如何混用这些标签来达成训练目标也成为难点之一。
再看看LSUN数据集,需要自己填写标签名称的情况:
现在我们对视觉任务有了一定了解:图像数据丰富多样,在具体任务不明确的情况下,我们连最基本的数据导入都存在问题。基于对图像任务的理解,本课内容将分为上、下两部分。上以图像识别任务为主,下以视觉任务中的其他任务为主。
一、 数据
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
1、认识经典数据
1.1入门数据:MNIST、其他数字与字母识别
第一部分要介绍的是最适合用于教学和实验、几乎对所有的电脑都无负担的MNIST一族。MNIST一族是数据和字母识别的最基本的数据集,这些数据集户全都是小尺寸图像的简单识别,可以被轻松放入任意神经网络中进行训练。具体如下:
| 数据名称 | 数据说明 |
|---|---|
| FashionMINST | 衣物用品数据集 |
| MINST | 手写数字数据集 |
| KuzushijiMNIST | 日语手写平假名识别,包含48个平假名字符和一个平假名迭代标记,一个高度 |
| 不平衡的数据集 | |
| QMNIST | 与MNIST高度相似的手写数字数据集 |
| EMNIST | 与MNIST高度相似,在MNIST的基础上拓展的手写数字数据集 |
| Omniglot | 全语种手写字母数据集,包含来自50个不同字母的1623个不同的手写字符,专用于“一次性学习" |
| USPS | 另一个体系的手写数字数据集,常用来与MNIST对比 |
| SVHN | 实拍街景数字数据集(Street View House Number),是数字识别和检测中非常不同的一个数据集。有原始尺寸数据集可以下载,但在PyTorch中内置的是32x32的识别数据。注意,使用本数据需要SciPy模块的支持。 |

在PyTorch中,提供了三个与MNIST数据集相对比的数据集,分别是用于一次性学习的字母识别数据集Omniglot,另一个体系的手写数据集USPS,以及SVHN实拍街景数字数据集。这几个数据集与MNIST的区别如下图。

在深度视觉的研究中,我们很少专门就MNIST进行研究,但我们在这些简单识别数据集上设置了其他值得研究的问题。比如,在我们撰写论文或检验自己的架构时,MNIST一族是很好的基准线——他们尺寸很小,容易训练,很简单却又没有那么“简单”。一流的架构往往能够在MNIST数据集上取得99%以上的高分,而发表论文时,MNIST数据集的结果低于97%是不能接受的。单一机器学习算法能够在Fashion-MNIST数据集上取得的分数基本都在90%左右,而一流的深度学习架构至少需要达到95%以上的水准。再比如,我们常常使用平假名识别的数据集来研究深度学习中的样本不平衡问题,我们还使用Omniglot数据集来研究人脸识别(主要是个体识别 identity recognition)中常见的“一次性学习”问题(one-shot learning)。我们来重点讲讲这个“一次性学习”的问题。


在人脸识别中,我们有两种识别策略:
第一种策略是以人名为标签进行多分类,在训练样本中包含大量的同一个人的照片,测试集中也包含这个人的照片,看CNN能否正确预测出这个人的名字;而第二种策略则是一种二分类策略,在训练样本中给与算法两张照片,通过计算距离或计算某种相似性,来判断两张照片是否是同一个人,输出的标签为“是/否相似或一致”,在这种策略中,测试集的样本也是两张照片,并且测试集的样本不需要出现在训练集中。
如果基于第一种策略来执行人脸识别,则机场、火车站的人脸识别算法必须把全国人民的人脸数据都学习一遍才可能进行正确的判断。而在第二种策略中,算法只需要采集身份证/护照上的照片信息,再把它与摄像头中拍摄到的影像进行对比,就可以进行人脸识别了。这种“看图A,判断图B上的人是否与图A上的人是同一人”的学习方法,就叫做一次性学习,因为对于单一样本,算法仅仅见过一张图A而已。不难想象,实际落地的人脸识别项目都是基于一次性学习完成的。Omniglot数据集就是专门训练一次性学习的数据集。从上图可以看出,Omniglot数据集中的字母/符号对我们而言是完全陌生的,因此我们并无法判断出算法是否执行了正确的“识别”结果。而在Omniglot数据集上,算法是通过学习图像与图像之间的相似性来判断两个符号是否是一致的符号,至于这个符号是什么,代表什么含义,对Omniglot数据集来说并无意义。
字母和数字识别的数据集的尺寸都较小,因此PyTorch对以上每个数据集都提供了下载接口,因此我们无需自行下载数据,就可以使用torchvision.datasets.xxxx的方式来对他们进行调用。在网速没有太大问题的情况下,只要将download设置为True,并确定VPN是关闭状态,就可以顺利下载。注意:下载之后最好将download参数设置为False,否则只要调用目录写错,就会重新进行下载,费时也费流量。
(1)数据加载
方式一:通过torchvision.datasets.MNIST下载数据
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transformstrain_data = torchvision.datasets.MNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,transform=transforms.ToTensor(),download=True)test_data = torchvision.datasets.MNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,transform=transforms.ToTensor(),download=True)
方式二:下载了数据存储在自己电脑上并调用:
import torchvision
import torchvision.transforms as transformsfminst = torchvision.datasets.FashionMNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,download=False,transform=transforms.ToTensor())svhn = torchvision.datasets.SVHN(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/SVHN',split="train",download=False,transform=transforms.ToTensor())omniglot = torchvision.datasets.Omniglot(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',background=True, #在ominglot论文中,作者将训练集称为background,因此background代表训练集download=False,transform=transforms.ToTensor())print(fminst)
'''
Dataset FashionMNISTNumber of datapoints: 60000Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_datasetSplit: TrainStandardTransform
Transform: ToTensor()'''
print(svhn)
'''
Dataset SVHNNumber of datapoints: 73257Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/SVHNSplit: trainStandardTransform
Transform: ToTensor()
'''
print(omniglot)
'''
Dataset OmniglotNumber of datapoints: 19280Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/omniglot-pyStandardTransform
'''
(2)查看数据的特征和标签
需要注意的是:由于深度视觉中的数据属性均有不同,如果简单得调用.data或者.targets很容易报错。本小结最后给出了一个万能方式。
方式一:.data/.targets查看数据特征和标签
当我们查看数据集时,只给出了Number of datapoints、Root location等,但我们想了解的是数据集的输入和标签,针对fminst来说,可以通过调.data的方式查看特征,.target的方式查看标签。
print(fminst.data)
'''
tensor([[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],...,[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)
'''
print(fminst.targets)
'''
tensor([9, 0, 0, ..., 3, 0, 5])
'''
但是并不是所有的数据集都可以通过这种方式来查阅。这是因为:当面临的任务不同时,每个数据集的标签排布方式和意义也都不同,因此不太可能使用相同的API进行调用。
for i in [fminst, svhn, omniglot]:print(i.data.shape)
'''
torch.Size([60000, 28, 28])
(73257, 3, 32, 32)
AttributeError: 'Omniglot' object has no attribute 'data'
'''for i in [fminst, svhn, omniglot]:print(i.targets.shape)
'''
tensor([9, 0, 0, ..., 3, 0, 5])
torch.Size([60000])
AttributeError: 'SVHN' object has no attribute 'targets'
'''
方式二:通过查看某一个索引值的方式来查看特征和标签
因此,我们可以看到omniglot数据并没有data和targets属性,那么我们应该如何查看omniglot数据呢?——通过索引的方式查看某一个单独的数据
#方式一:查看某一个索引的情况
print(omniglot[0])
'''
(tensor([[[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],...,[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.]]]), 0)
'''
#由此可以看出omniglot的每个索引是一个元组#紧接着我们可以调用每个元组中的第一个切片来查看图像数据的特征和形状
print(omniglot[0][0])
'''
tensor([[[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],...,[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.]]])
'''
print(omniglot[0][0].shape)
#torch.Size([1, 105, 105]) ,omniglot数据的图像仅有一个通道,图片的形状是105*105#查看样本量
print(len(omniglot)) #19280
方式三:万能方法
如果通过索引的方式还是报错,那就要使用报错概率最低的方式:
for i in [fminst, svhn, omniglot]:for x,y in i:print(x.shape, y)break
'''
torch.Size([1, 28, 28]) 9
torch.Size([3, 32, 32]) 1
torch.Size([1, 105, 105]) 0
'''
(3)数据可以化
方式一:PIL直接可视化
如果需要查看图片,可以通过去掉transforms.Totensor()来查看
fminst = torchvision.datasets.FashionMNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,download=False)#transform=transforms.ToTensor())#print(fminst)
#print(fminst[0])
#(<PIL.Image.Image image mode=L size=28x28 at 0x7FB843C23BB0>, 9)
print(fminst[0][0]) #(<PIL.Image.Image image mode=L size=28x28 at 0x7FB843C23BB0>, 9)
image = fminst[0][0]
image.show()

方式二:用一个万能公式来随机可视化五张图
注意:该方法要求已经将图片转换为tensor格式,即要求含有tansform = transforms.ToTensor()
def plotsample(data):fig, axs = plt.subplots(1,5,figsize=(10,10)) #建立子图for i in range(5):num = random.randint(0,len(data)-1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签#将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0)))axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴#%%plotsample(omniglot)
plt.show()

plotsample(svhn)
plt.show()
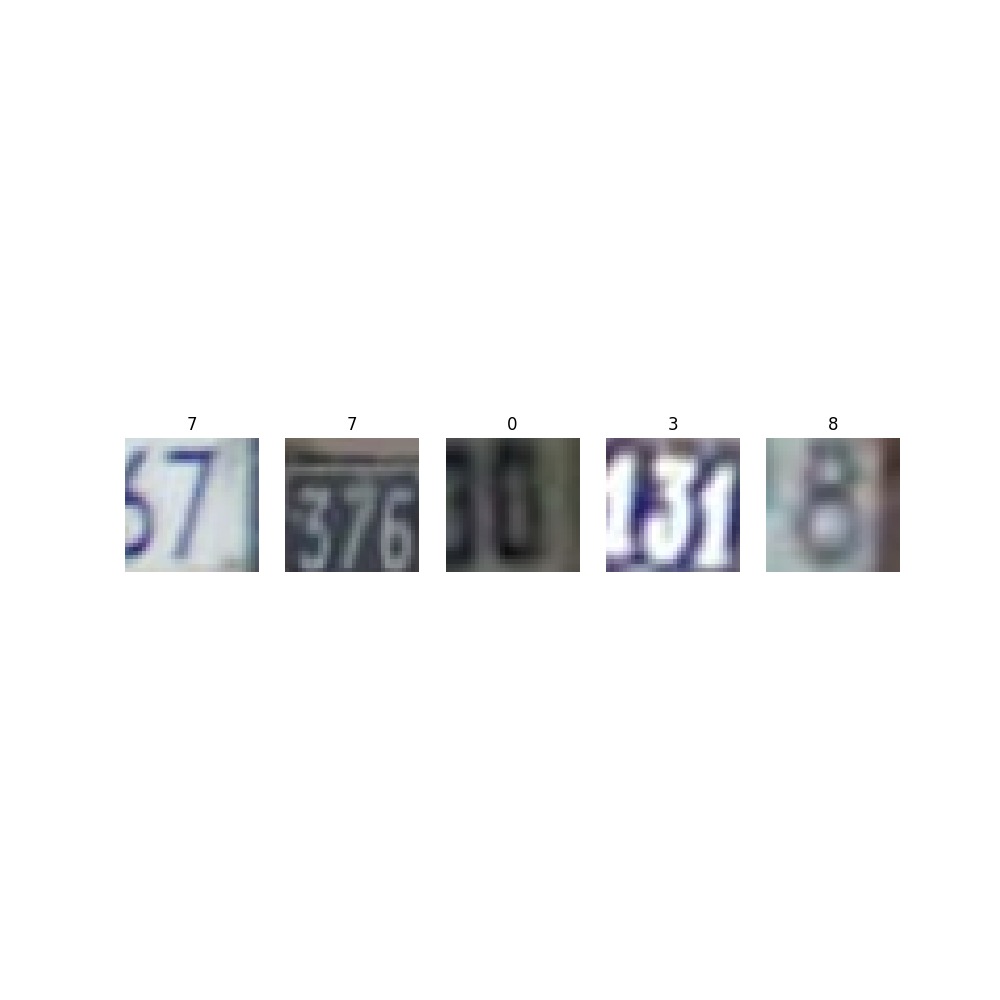
plotsample(fminst)
plt.show()

根据类的不同,参数train可能变为split,还可能增加一些其他的参数,具体可以参照datasets页面。MNIST一组的数据集户都可以被用于简单的识别项目,是测试架构的最佳数据。在提出新架构或新方法时,学者们总会在MNIST或Fashion-MNIST数据集上进行测试,并将这些数据拿到高分(>95%)作为新架构有效的证明之一。
1.2竞赛数据:ImageNet、COCO、VOC、LSUN
除了数字和字母识别以外,最熟悉且最瞩目的就是各大竞赛的主力数据。之前在讲解大规模视觉挑战赛ILSVRC的时候,介绍过ImageNet数据集,和ImageNet数据一样,竞赛数据往往诞生于顶尖大学、顶尖科研机构或大型互联网公司的人工智能实验室,属于推动整个深度学习向前发展的数据集,因此这些数据集通畅数据量巨大、涵盖类别广泛、标签异常丰富、可以被用于各类图像任务,并且每年会更新迭代,且在相关竞赛停止或关闭之后会下架数据集。作为计算机视觉的学习者,我们没有用过这些数据,但是必须要知道它们的名字和基本信息。作为计算机视觉工程师,在每个项目上线之前,都需要使用这些数据来进行测试。现在就来了解一下这些数据集吧。
| 数据名称 | 数据说明 |
|---|---|
| ImageNet2012 | ImageNet大规模视觉挑战赛(ILSVRC)在2012年所使用的比赛数据。1000分类通用数据,涵盖了动植物、人类、生活用品、食物、景色、交通工具等类别。任何互联网大厂在深度学习模型上线之前必用的数据集。2012年版本数据集由于版权原因已在全网下架,现只分享给拥有官方学术头衔的机构或个人(这意味着,在申请数据集时必须使用xxx@xxx.edu的电子邮件,任何免费的、非学术机构性质的电子邮件地址都不能获得数据申请。因此,PyTorch中的torchvision.datasets.ImageNet类已经失效。 |
| ImageNet2019 | ILSVRC在2017年之后就取消了识别任务,并将比赛赚到Kagg了上举办,现在ImageNet2019版本可以在Kaggle上免费现在,主要用于检测任务。 |
| PASCAL VOCSegmentation PASCAL VOCDetection | 模式分析,统计建模和计算机学习大赛(Pattern Analysis, Statistical Modeling and Computation Learning, PSACAL),视觉对象分类(Visual Object Classes)数据集。与ImageNet类型相似,覆盖动植物、人类、生活用品、食物、交通等类别,但数据量相对较小。在PyTorch中被分为VOCSegementation与VOCDetection两个类,分别支持分割和检测任务,虽然带有类别标签但基本不支持识别任务。同时,PyTorch支持从2007到2012年的五个版本的下载,通畅我们都是用最新版本。 |
| CocoCaptions CocoDetection | 微软Microsoft Common Objects in Context数据集,是大规模场景理解挑战赛(Large-scale Scene Understanding challenge,LSUN)中的核心数据,主要覆盖复杂的日常场景,是继ImageNet之后,最受关注的物体检测、语义分割、图像理解(Caption)方面的数据集,也是唯一关注图像理解的大规模挑战赛。其中,用于图像理解的部分是2015年之前的数据,用于检测和分割的则是2017年及之后的版本。需要安装COCO API才可以调用。PyTorch没有提供用于分割的API,但我们依然可以自己下载数据集用于分割。 |
| LSUN | 城市景观、城市建筑、人文风光数据集,包含10中场景、20中对象的大猩猩数据集。其中,场景图像被用于LSUN大规模题场景理解挑战赛。20分类包含交通工具、动物、人类等图像,可用于识别任务。在我们导入数据时,我们会选择LSUN中的某一个场景或对象进行训练,因此个人给予LSUN进行的识别任务是二分类的。 |
1.3景物、人脸、通用、其他
17.3.2将二维表及其他结构转换为四维tensor
要点1:多项式升维:from sklearn.preprocessing import PolynomialFeatures as PF. 在多项式升维中,维度指的是特征维度,而非张量的维度。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
相关文章:
构建自己的深度视觉项目)
【pytorch图像视觉】lesson17深度视觉应用(上)构建自己的深度视觉项目
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、 数据1、认识经典数据1.1入门数据:MNIST、其他数字与字母识别(1)数据加载(2)查看数据的特征和标…...

从“被动跳闸”到“主动预警”:智慧用电系统守护老旧小区安全
安科瑞顾强 近年来,老旧小区电气火灾事故频发,成为威胁居民生命财产安全的重要隐患。据统计,我国居住场所火灾伤亡人数远超其他场所,仅今年一季度就发生8.3万起住宅火灾,造成503人遇难。这些建筑多建于上世纪&#x…...

2.1 全栈运维管理:Proxmox VE单节点配置桥接、VLAN和Bonding的详细实验指南
本文是Proxmox VE 全栈管理体系的系列文章之一,如果对 Proxmox VE 全栈管理感兴趣,可以关注“Proxmox VE 全栈管理”专栏,后续文章将围绕该体系,从多个维度深入展开。 概要:本文介绍 Proxmox VE 单节点网络配置。桥接基…...

docker面试题
1.docker网络 Docker网络是Docker容器之间进行通信的关键功能。Docker提供了多种网络模式和驱动,以满足不同的网络需求。以下是Docker网络的详细介绍: 1.Docker网络模式 Docker提供了以下几种网络模式,每种模式适用于不同的场景:…...

计算机视觉——基于YOLOV8 的人体姿态估计训练与推理
概述 自 Ultralytics 发布 YOLOV5 之后,YOLO 的应用方向和使用方式变得更加多样化且简单易用。从图像分类、目标检测、图像分割、目标跟踪到关键点检测,YOLO 几乎涵盖了计算机视觉的各个领域,似乎已经成为计算机视觉领域的“万能工具”。 Y…...

【本地图床搭建】宝塔+Docker+MinIO+PicGo+cpolar:打造本地化“黑科技”图床方案
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言宝塔安装DockerMinIO 安装与设置cploar内网穿透PicGo下载与安装typora安装总结互动…...
】家政平台性能蜕变:性能测试与优化全解析)
【家政平台开发(41)】家政平台性能蜕变:性能测试与优化全解析
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...

监控docker中的java应用
1)进入指定的容器 docker exec -it demo /bin/bash 2)下载curl root89a67e345354:/# apt install curl -y 3)下载arthas root89a67e345354:/# curl -O https://arthas.aliyun.com/arthas-boot.jar 4)运行 root89a67e345354:/# java -jar arthas-boot.jar 5)监控 […...

Android游戏辅助工具开发详解
文章目录 第一部分:概述与基础准备1.1 游戏辅助工具的定义与用途1.2 开发环境准备1.3 项目创建与配置 第二部分:核心功能实现2.1 屏幕点击功能实现2.1.1 基础点击功能2.1.2 多点触控实现 2.2 滑动功能实现2.2.1 基础滑动功能2.2.2 曲线滑动实现 2.3 屏幕…...

重生之外卖配送时被投诉后的反思
重生之外卖配送时被投诉后的反思 写苍穹外卖时 我们发现在每一次调用sql语句时 insert update语句总会需要在service的实现类里加入例如create_time,create_user , update_time , update_user的填充 每次赋值都要重新编写代码,会造成代码冗余 ; 序号字…...

计算机基础复习资料整理
计算机基础复习资料整理 一、操作系统 (一)定义 操作系统(Operating System,OS)是介于计算机硬件和用户(程序或人)之间的接口。作为通用管理程序,它管理计算机系统中每个部件的活动…...

Profibus DP主站网关数据映射全解析!
Profibus DP主站网关数据映射全解析! 在工业自动化领域,Profibus DP主站网关作为一种关键的通讯设备,其数据映射的精准度和效率对整个控制系统的性能有着至关重要的影响。本文旨在深入探讨Profibus DP主站网关的数据映射过程,揭示…...

ocr-不动产权识别
目录 一、在阿里云申请ocr识别服务 二、创建springboot项目 三、后续 一、在阿里云申请ocr识别服务 在线体验:房产证图片上传 [阿里官方]不动产权证OCR文字识别_API专区_云市场-阿里云 (aliyun.com) 可以选择一毛500次这个 当然也可以白嫖100 下面有个在线调试…...

leetcode 198. House Robber
本题是动态规划问题。 第一步,明确并理解dp数组以及下标的含义 dp[i]表示从第0号房间一直到第i号房间(包含第i号房间)可以偷到的最大金额,具体怎么偷这里不考虑,第i1号及之后的房间也不考虑。换句话说,dp[i]也就是只考虑[0,i]号…...
)
【2025软考高级架构师】——软件架构设计(4)
摘要 本文主要介绍了几种软件架构设计相关的概念和方法。包括C2架构风格的规则,模型驱动架构(MDA)的起源、目标、核心模型及各模型之间的关系;软件架构复用的概念、历史发展、维度、类型及相关过程;特定领域架构&…...

分发饼干问题——用贪心算法解决
目录 一:问题描述 二:解决思路 贪心策略(C语言)算法复习总结3——贪心算法-CSDN博客 三:代码实现 四:复杂度分析 一:问题描述 分发饼干问题是一个经典的可以使用贪心算法解决的问题…...

深入详解MYSQL的MVCC机制
参考资料: 参考视频(注意第二个视频关于幻读的讲解是错误的,详情见本文) redoLog的结构详解 参考资料 学习内容: 1. MVCC要解决的问题 MVCC要解决的问题是,在不产生脏读等数据库问题的前提下,数据库的查询语句和更改语句不相互阻塞的情况; 在InnoDB中,MVCC仅仅存…...

DNS域名解析
目录 一.DNS 1.1DNS的简介 1.2DNS的背景 1.3DNS的架构 1.4实现DNS的方式 1.5DNS的查询类型 1.6DNS解析的基本流程 二.主从复制 2.1定义 2.2优缺点 三.DNS服务软件 3.1bind 3.1.1定义 3.1.2bind相关文件 3.2DNS服务器的核心文件 3.2.1主配置文件 3.2.2域名文件 …...

Java基础:一文讲清多线程和线程池和线程同步
01-概述 02-线程创建 继承Thread 实现Runnable(任务对象) 实现Callable接口 public class ThreadDemo3 {public static void main(String[] args) throws ExecutionException, InterruptedException {// 目标:线程创建3// 需求:求1-100的和Callable<…...

ubuntu 20.04 连不上蓝牙耳机/蓝牙鼠标
sudo gedit /etc/bluetooth/main.conf改为 ControllerMode dual然后重启蓝牙服务 sudo service bluetooth restart...

SaaS、Paas、IaaS、MaaS、BaaS五大云计算服务模式
科普版:通俗理解五大云计算服务模式 1. SaaS(软件即服务) 一句话解释:像“租用公寓”,直接使用现成的软件,无需操心维护。 案例:使用钉钉办公、在网页版WPS编辑文档。服务提供商负责软件更新和…...

【深拷贝、浅拷贝】golang函数参数传递,变量复制后,操作变量参数,是否影响原有数据?全面解析
Golang中深拷贝与浅拷贝的详细解析,以及变量复制、函数参数传递等场景下对新旧变量影响的总结: 一拷贝与浅拷贝的核心区别 1. 浅拷贝(Shallow Copy) • 定义:仅复制数据的顶层结构,对引用类型字段&#x…...

c语言编程经典习题详解3
21. 求给定正整数 n 以内的素数之积 定义:找出小于给定正整数n的所有素数,并将它们相乘。要点:使用双层for循环,外层循环遍历小于n的数,内层循环判断是否为素数,若是则累乘。应用:在数论研究、密码学等领域有应用。c #include <stdio.h>int isPrime(int num) {if…...

【HD-RK3576-PI】Docker搭建与使用
硬件:HD-RK3576-PI 软件:Linux6.1Ubuntu22.04 1. 安装Docker Docker安装脚本下载: roothd-rk3576-pi:~ $ curl -fsSL https://test.docker.com -o test-docker.sh 可以直接执行安装 roothd-rk3576-pi:~ $ sh test-docker.sh 2. 配置国内镜…...

C++进阶——异常
目录 1、异常的概念及使用 1.1 异常的概念 1.2 异常的抛出和捕获 1.3 栈展开 1.4 查找匹配的处理代码 1.5 异常的重新抛出 1.6 异常的安全问题 1.7 异常的规范 2、标准库的异常(了解) 1、异常的概念及使用 1.1 异常的概念 C语言,出错了,就报错…...

Linux安装开源版MQTT Broker——EMQX服务器环境从零到一的详细搭建教程
零、EMQX各个版本的区别 EMQX各个版本的功能对比详情https://docs.emqx.com/zh/emqx/latest/getting-started/feature-comparison.html...

C++ 编程指南36 - 使用Pimpl模式实现稳定的ABI接口
一:概述 C 的类布局(尤其是私有成员变量)直接影响它的 ABI(应用二进制接口)。如果你在类中添加或修改了私有成员,即使接口不变,编译器生成的二进制布局也会变,从而导致 ABI 不兼容。…...

笔记本电脑突然无法开机电源灯亮但是屏幕无法点亮
现象 按电源键,电源灯点亮,屏幕没动静 风扇开始运转,然后一会儿就不转了;屏幕一直没动静,屏幕没有任何反应(没有系统启动画面,没有徽标显示,就一点反应也没用) 这个问…...

mongodb 4.0+多文档事务的实现原理
1. 副本集事务实现(4.0) 非严格依赖二阶段提交 MongoDB 4.0 在副本集环境中通过 全局逻辑时钟(Logical Clock) 和 快照隔离(Snapshot Isolation) 实现多文档事务,事务提交时通过…...
)
decompiled.class file bytecode version50(java 6)
idea运行项目报错,跳到具体的.class中,idea会给出提示下载源码,点击下载报错,具体报错信息我没记录了(反正就是无法看到源码) 解决方式: 1、网上说下载scala插件,重启idea即可 但是…...

CSS 列表样式学习笔记
CSS 列表样式提供了强大的功能,用于定制 HTML 列表的外观。通过 CSS,可以轻松地改变列表项的标记类型、位置,甚至使用图像作为列表项标记。以下是对 CSS 列表样式的详细学习笔记。 一、HTML 列表类型 在 HTML 中,主要有两种类型…...

linux网络设置
ifconfig 查看ip地址 查看当前的liunx系统的网络参数ip地址 Ubuntu需要安装 Apt install -y net-tools 查看网络信息 Ifconfig 只能看到开启的网卡 Ifconfig -a 看到所有的网卡包括开启和关闭的 Ifconfig 网卡名称 up 开启网卡 Ifconfig 网卡名称 down 关闭网卡 If…...

抗干扰CAN总线通信技术在分布式电力系统中的应用
摘要:随着分布式电力系统的广泛应用,其通信系统的可靠性与稳定性受到了前所未有的挑战。CAN总线通信技术以其卓越的抗干扰性能和可靠性,在众多通信技术中脱颖而出,成为解决分布式电力系统通信问题的关键。本文深入剖析了CAN总线通…...
——extension和depency的区别)
Maven工具学习使用(十二)——extension和depency的区别
在 Maven 中,extensions 和 dependencies 是两个不同的概念,它们在项目构建和依赖管理中扮演着不同的角色。 1、Dependencies dependencies 是 Maven 项目中用于管理项目所需的库和模块的部分。这些依赖可以是本地仓库中的,也可以是远程仓库…...

Python学生信息查询
利用字典设置学生信息,将这些信息放入列表中进行存储,根据输入的姓名查询展示对应的学生信息。 Student1{no:202001,name:zyt,score:87} Student2Student1.copy() Student3Student2.copy()Student2[no]202002 Student3[no]202003Student2[name]zwh Stud…...
做了一个配色网站)
一天时间,我用AI(deepseek)做了一个配色网站
前言 最近在开发颜色搭配主题的相关H5和小程序,想到需要补充一个web网站,因此有了这篇文章。 一、确定需求 向AI要答案之前,一定要清楚自己想要做什么。如果你没有100%了解自己的需求,可以先让AI帮你理清逻辑和思路,…...
体系详解)
MQ(消息队列)体系详解
消息队列(MQ,Message Queue) 是一种基于消息传递的异步通信机制,用于不同系统、服务之间进行数据传递和交互。它通常用来解耦生产者和消费者,提供高可用、高吞吐量和可靠的消息传递。 一、消息队列用途 1.系统解耦 …...

【GESP真题解析】第 3 集 GESP一级样题卷编程题 2:闰年求和
大家好,我是莫小特。 这篇文章给大家分享 GESP 一级样题卷编程题第 2 题:闰年求和。 题目链接 洛谷链接:B3846 闰年求和 一、完成输入 根据题目要求,我们需要输入两个整数,分别表示起始年份和终止年份。 要求计算…...

Windows Server 2019 安装 Docker 完整指南
博主本人使用的是离线安装 1. 安装前准备 系统要求 操作系统:Windows Server 2019(或 2016/2022)权限:管理员权限的 PowerShell网络:可访问互联网(或离线安装包) 启用容器功能 Install-Win…...

JetBrains PhpStorm v2024.3.1 Mac PHP开发工具
JetBrains PhpStorm v2024.3.1 Mac PHP开发工具 一、介绍 JetBrains PhpStorm 2024 mac,是一款PHP开发工具,直接开始编码,无需安装和配置大量插件。PhpStorm 从一开始就已包含 PHP、JavaScript 和 TypeScript 开发所需的一切,还…...
在AI驱动测试通过数据驱动的智能决策显著提升测试效率、覆盖率和准确性。)
机器学习(ML)在AI驱动测试通过数据驱动的智能决策显著提升测试效率、覆盖率和准确性。
机器学习(ML)在AI驱动测试中扮演着 核心引擎 的角色,通过数据驱动的智能决策显著提升测试效率、覆盖率和准确性。以下是机器学习在测试各环节的具体作用及实现方案: 一、机器学习在测试生命周期中的作用 #mermaid-svg-u4vgPE6O2jugiZFB {font-family:"trebuchet ms&qu…...

0x06.Redis 中常见的数据类型有哪些?
回答重点 Redis 常见的数据结构主要有五种,这五种类型分别为:String(字符串)、List(列表)、Hash、Set(集合)、Zset(有序集合,也叫sorted set)。 String 字符串是Redis中最基本的数据类型,可以存储任何类型的数据,包括文本、数字和二进制数据。它的最大长度为512MB。 使…...

本地缓存方案Guava Cache
Guava Cache 是 Google 的 Guava 库提供的一个高效内存缓存解决方案,适用于需要快速访问且不频繁变更的数据。 // 普通缓存 Cache<Key, Value> cache CacheBuilder.newBuilder().maximumSize(1000) // 最大条目数.expireAfterWrite(10, TimeUnit.MINUTES) /…...

A Causal Inference Look at Unsupervised Video Anomaly Detection
标题:无监督视频异常检测的因果推断视角 原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/20053 发表:AAAI-2022 文章目录 摘要引言相关工作无监督视频异常检测因果推断 方法问题公式化一般设置强基线模型 无监督视频异常检测的因…...
)
MQ(RabbitMQ.1)
MQ的含义及面试题 MQMQ的含义MQ之间的调用的方式MQ的作用MQ的几种产品RabbitMQRabbitMQ的安装RabbitMQ的使用RabbitMQ⼯作流程 AMQPWeb界面操作用户相关操作虚拟主机相关操作 RabbitMQ的代码应用编写生产者代码编写消费者代码 生产者代码消费者代码 MQ MQ的含义 MQ࿰…...

cursor+高德MCP:制作一份旅游攻略
高德开放平台 | 高德地图API (amap.com) 1.注册成为开发者 2.进入控制台选择应用管理----->我的应用 3.新建应用 4.点击添加Key 5.在高德开发平台找到MCP的文档 6.按照快速接入的步骤,进行操作 一定要按照最新版的cursor, 如果之前已经安装旧的版本卸载掉重新安…...
——时钟组)
FPGA时序分析与约束(11)——时钟组
目录 一、同步时钟与异步时钟 二、逻辑与物理独立时钟 2.1 逻辑独立时钟 2.2 物理独立时钟 三、如何设置时钟组 四、注意事项 专栏目录: FPGA时序分析与约束(0)——目录与传送门https://ztzhang.blog.csdn.net/article/details/134893…...

opencv 识别运动物体
import cv2 import numpy as npcap cv2.VideoCapture(video.mp4) try:import cv2backSub cv2.createBackgroundSubtractorMOG2() except AttributeError:backSub cv2.bgsegm.createBackgroundSubtractorMOG()#形态学kernel kernel cv2.getStructuringElement(cv2.MORPH_REC…...

opencv实际应用--银行卡号识别
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,主要用于图像和视频处理、目标检测、特征提取、3D重建以及机器学习任务。它支持多种编程语言(如C、Python),提供丰富的算法和工具&a…...

【软考系统架构设计师】系统架构设计知识点
1、 从需求分析到软件设计之间的过渡过程称为软件架构。 软件架构为软件系统提供了一个结构、行为和属性的高级抽象,由构件的描述、构件的相互作用(连接件)、指导构件集成的模式以及这些模式的约束组成。 软件架构不仅指定了系统的组织结构和…...