A Causal Inference Look at Unsupervised Video Anomaly Detection

标题:无监督视频异常检测的因果推断视角
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/20053
发表:AAAI-2022
文章目录
- 摘要
- 引言
- 相关工作
- 无监督视频异常检测
- 因果推断
- 方法
- 问题公式化
- 一般设置
- 强基线模型
- 无监督视频异常检测的因果推断视角
- 分析
- 通过因果干预进行去混杂训练
- 基于反事实的长程时间上下文集成
- 总体公式化
- 去混杂训练
- 反事实时间上下文集成
- 自监督伪标签学习
- 实验
- 实现细节
- 训练和评估
- 评估数据集和指标
- 消融研究
- 与先前最先进结果的比较
- 定量结果
- 定性结果
- 结论
摘要
无监督视频异常检测是一项在工业应用和学术研究中都极具挑战性但又非常重要的任务,它不需要任何形式的已标注正常/异常训练数据。现有方法通常遵循迭代伪标签生成过程。然而,它们缺乏对这种伪标签生成对训练影响的原则性分析。此外,长程时间依赖关系也被忽视了,这是不合理的,因为异常事件的定义依赖于长程时间上下文。为此,首先,我们提出一个因果图来分析伪标签生成过程的混杂效应。然后,我们引入一个简单而有效的基于因果推断的框架,以消除噪声伪标签的影响。最后,我们进行基于反事实的模型集成,在推理过程中将长程时间上下文与局部图像上下文相结合,以进行最终的异常检测。在六个标准基准数据集上的大量实验表明,我们提出的方法显著优于以前的最先进方法,证明了我们框架的有效性。
引言
视频异常检测(VAD)是指在视频帧中检测异常事件的任务,例如不寻常的行人运动模式、交通事故和投掷物体等,这些事件与观察到的正常日常活动有显著差异。这项任务的实际重要性吸引了工业界和学术界的广泛研究。大多数此类研究都有一个典型的设置,即数据集中有一组已标注的异常事件,或者训练数据集必须仅包含正常视频,这限制了这类研究的广泛应用。相反,另一类研究则专注于设计完全无监督设置的算法,即不提供任何形式的已标注正常/异常训练数据。在本文中,我们关注的就是这种无监督视频异常检测(UVAD)。为了监督训练,通常采用通过迭代伪标签生成进行自训练的方法,这种技术在无监督学习中得到了广泛研究和应用(Giorno, Bagnell, and Hebert 2016; Ionescu et al. 2017; Wang et al. 2018; Pang et al. 2020)。这种流程背后的关键工作原理有两个方面:第一,由于现实世界中异常事件很少见,学习到的表征会偏向于正常事件,使得异常事件的表征更具判别力;第二,通过启发式设计生成的大多数伪标签足够准确,例如在(Wang et al. 2018)中基于自动编码器的重建和在(Pang et al. 2020)中的Sp + iForest等。
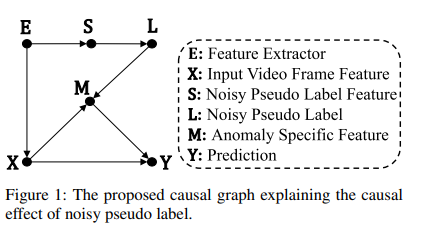
尽管使用上述伪标签训练的异常检测模型表现出有竞争力的性能,但其性能提升主要来自正确的伪标签。如果没有对错误伪标签带来的负面影响进行原则性分析,进一步的性能提升将受到限制。为了更好地理解噪声伪标签的影响并深入了解这一现象,我们从因果推断的角度来解决这个问题。根据图1,UVAD任务是学习一个模型,该模型可以估计 P ( Y ∣ X , M ) P(Y | X, M) P(Y∣X,M)。伪标签生成过程( ( E → S → L ) (E \to S \to L) (E→S→L))产生噪声伪标签集 L L L,用于监督 P ( Y ∣ X , M ) P(Y | X, M) P(Y∣X,M)中异常特定特征表示 M M M的训练。一方面,正确的伪标签有利于异常特定特征表示学习 M M M,从而显著提高性能。这在图1中表示为中介因果路径( ( X → M → Y ) (X \to M \to Y) (X→M→Y))。另一方面,错误的伪标签通过后门路径( ( X ← E → S → L → M → Y ) (X \leftarrow E \to S \to L \to M \to Y) (X←E→S→L→M→Y))混淆了 X X X和 Y Y Y。后门路径被定义为路径的一端有一个箭头指向 X X X,另一端指向 Y Y Y,使得 X X X和 Y Y Y产生虚假依赖。换句话说,这条因果路径有一个有害影响,它将一些异常/正常事件与正常/异常标签错误地关联起来,从而误导分类器做出错误的预测。因此,我们推测上述两条因果路径的混合因果效应是性能瓶颈的主要原因之一。此外,长程时间上下文与图像帧外观本身之间的交互对于判别异常视频帧至关重要。现有方法通过收集一小范围的相邻视频帧作为输入来进行这种交互,但由于短范围的时间上下文涉及不一致的时间上下文信息(Yu et al. 2020; Pang et al. 2020; Ionescu et al. 2017; Giorno, Bagnell, and Hebert 2016; Wang et al. 2018),它们缺乏充分利用视频活动中长程时间上下文的能力。
根据上述分析,我们提出了一种新的基于两阶段因果推断的流程,旨在消除噪声伪标签的影响并融入长程时间上下文。具体来说,在第一阶段,我们进行去混杂训练,保留有益的中介路径,同时去除后门路径,如图3所示。然后,我们进行基于反事实的模型集成,将第一阶段训练的模型预测与同一模型在输入替换为基于长程滑动窗口的上下文特征(同时保持中介变量 M M M不变)时的预测相加,如图4所示。需要注意的是,第二阶段不需要额外的训练,这意味着我们只需要进行两次推理就可以获得反事实模型集成预测,这种方式轻量级且无额外成本。整个流程如图5所示。
综上所述,本文有以下贡献:
- 据我们所知,我们首次从因果推断的角度研究了无监督视频异常检测中噪声伪标签的影响,并确定伪标签生成包含一种混杂效应,限制了性能的进一步提升。
- 我们引入了一个基于迭代两阶段因果推断的框架来消除噪声伪标签的影响。具体来说,我们采用因果干预进行去混杂训练,去除有害的后门因果路径,并使用训练好的模型进行基于反事实的长程时间上下文集成。
- 我们的方法明显优于所有先前的方法,在六个标准数据集上实现了新的最先进性能。
相关工作
无监督视频异常检测
Giorno等人(Giorno, Bagnell, and Hebert 2016)介绍了UVAD问题,并提出使用排列检验来检测帧序列中的变化,以确定哪些帧与之前的所有帧不同。Ionescu等人(Ionescu et al. 2017)取消了排列检验,而是应用去掩蔽方法,根据分类准确率的变化来衡量异常程度。Wang等人(Wang et al. 2018)从自动编码器的角度解决UVAD任务。与我们的工作最相似的是(Pang et al. 2020),该研究首先采用Sp + iForest(Liu, Ting, and Zhou 2012)生成视频帧的伪标签,然后以端到端的方式迭代训练一个自监督深度有序回归模型。然而,我们的工作在以下方面有所不同:(1)我们从因果推断的角度分析了(Pang et al. 2020)中伪标签生成的作用,并确定它对 P ( Y ∣ X , M ) P(Y | X, M) P(Y∣X,M)有混杂效应。(2)我们提出利用后门调整方法,通过对伪标签特征 S S S进行分层(干预)来明确消除混杂效应,阻断 X ← E → S → L → M → Y X \leftarrow E \to S \to L \to M \to Y X←E→S→L→M→Y路径。(3)我们通过基于反事实的模型集成,以可忽略的计算成本将长程时间上下文先验信息注入到模型预测中。
因果推断
因果推断是一种统计工具,它使模型能够推断感兴趣变量之间的因果效应。它在统计学、心理学、经济学和社会学等领域得到了广泛研究和应用(Morgan and Winship 2014; Chernozhukov, Fern´andez-Val, and Melly 2009; Rubin 2005; Petersen, Sinisi, and van der Laan 2006; Pearl 2001)。近年来,将因果推断应用于许多计算机相关问题的研究越来越多,包括自然语言处理(Liu et al. 2021; Keith, Jensen, and O’Connor 2020)、计算机视觉(Tang et al. 2020; Zhang et al. 2020; Wang et al. 2020)、机器人学(Ahmed et al. 2021)等。我们遵循Pearl图形模型(Pearl 2009)中的相同图形符号。然而,我们为UVAD任务提出了一个定制的因果图,据我们所知,这是首次尝试研究UVAD中伪标签生成过程的混杂效应。此外,我们通过基于反事实的特征替换对长程时间上下文与局部图像帧外观之间的交互进行建模。
方法
问题公式化
一般设置
给定一组视频帧 I = { I i } i = 1 K \mathbb{I}=\{I_{i}\}_{i = 1}^{K} I={Ii}i=1K,其中 K K K是视频帧的总数,提取的特征集表示为 X = { x i } i = 1 K X = \{x_{i}\}_{i = 1}^{K} X={xi}i=1K,其中 x i ∈ R D b x_{i} \in \mathbb{R}^{D_{b}} xi∈RDb。我们将整体噪声伪标签集定义为 L = A ∪ N = { l i ∣ l i = c , c ∈ C = { 0 , 1 } } i = 1 K L = A \cup N = \{l_{i} | l_{i} = c, c \in C = \{0, 1\}\}_{i = 1}^{K} L=A∪N={li∣li=c,c∈C={0,1}}i=1K,其中伪异常标签集为 A A A,伪正常标签集为 N N N, c c c表示标签集,0表示正常事件,1表示异常事件。我们将UVAD任务公式化为:
F = a r g m i n Θ ∑ I ∈ I L f o c ( y ^ = ϕ ( m = φ ( x = f ( I ) ) ) , l ) (1) \mathcal{F}=\underset{\Theta}{arg min } \sum_{I \in \mathbb{I}} \mathcal{L}_{f o c}(\hat{y}=\phi(m=\varphi(x=f(I))), l) \tag{1} F=ΘargminI∈I∑Lfoc(y^=ϕ(m=φ(x=f(I))),l)(1)
其中,我们旨在通过卷积神经网络学习一个异常检测器 F \mathcal{F} F,该网络由一个骨干网络 f ( ⋅ ; Θ b ) : R H × W × 3 ↦ R D b f(\cdot ; \Theta_{b}): \mathbb{R}^{H ×W ×3} \mapsto \mathbb{R}^{D_{b}} f(⋅;Θb):RH×W×3↦RDb(将输入视频帧 I I I转换为特征 x x x)、一个异常表示学习模块 φ ( ⋅ ; Θ a ) : R D b ↦ R D a \varphi(\cdot ; \Theta_{a}): \mathbb{R}^{D_{b}} \mapsto \mathbb{R}^{D_{a}} φ(⋅;Θa):RDb↦RDa(将 x x x转换为异常特定表示 m m m)和一个异常分数回归层 ϕ ( ⋅ ; Θ s ) : R D s ↦ R \phi(\cdot ; \Theta_{s}): \mathbb{R}^{D_{s}} \mapsto \mathbb{R} ϕ(⋅;Θs):RDs↦R(学习将 m m m预测为异常分数 y y y)组成。整体参数 Θ = { Θ b , Θ a , Θ s } \Theta = \{\Theta_{b}, \Theta_{a}, \Theta_{s}\} Θ={Θb,Θa,Θs}通过焦点损失(Lin et al. 2017) L f o c L_{foc } Lfoc进行优化:
L f o c ( y ^ , l ) = α 1 l ( 1 − σ ( y ^ ) ) 2 log σ ( y ^ ) + α 2 ( 1 − l ) σ ( y ^ ) 2 log ( 1 − σ ( y ^ ) ) (2) \begin{gathered} \mathcal{L}_{f o c}(\hat{y}, l)=\alpha_{1} l(1-\sigma(\hat{y}))^{2} \log \sigma(\hat{y}) \\+\alpha_{2}(1 - l)\sigma(\hat{y})^{2} \log (1 - \sigma(\hat{y})) \end{gathered} \tag{2} Lfoc(y^,l)=α1l(1−σ(y^))2logσ(y^)+α2(1−l)σ(y^)2log(1−σ(y^))(2)
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅)是标准的sigmoid函数, α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2是超参数。
强基线模型
然后,我们按照(Pang et al. 2020)中的相同逻辑介绍强基线异常检测器 F \mathcal{F} F的训练。
- 第0轮:初始伪标签集生成:我们使用在ImageNet上预训练的ResNet - 50 CNN(He et al. 2016)作为 f ( ⋅ ) f(\cdot) f(⋅)来提取 X X X。然后,采用一种无监督算法为 L 0 L_{0} L0生成初始伪标签。确实,有许多算法可用于此任务,例如自动编码器网络(Wang et al. 2018)。然而,为了与(Pang et al. 2020)进行公平比较,我们采用隔离森林算法(Liu, Ting, and Zhou 2012)。它通过随机选择一个特征,然后在所选特征的最大值和最小值之间随机选择一个分割值来隔离异常事件。这相当于构建一个随机树森林,其中每个树节点的特征和分割点都是随机选择的。一个样本被隔离所需的分割次数等于从根节点到终止节点的路径长度。在这样的随机树森林中,路径长度的平均值是衡量正常程度的指标。具体来说,给定一个随机子集 R ⊂ X R \subset X R⊂X和 x ∈ R x \in R x∈R, x x x的异常分数定义为:
z = P C A ( x ) z = PCA(x) z=PCA(x)
s c o r e ( z ) = 2 − E ( h ( z ) ) / τ ( ∣ R ∣ ) score(z) = 2^{−E(h(z)) / \tau(|R|)} score(z)=2−E(h(z))/τ(∣R∣)
τ ( n ) = 2 H a r ( n − 1 ) − ( 2 ( n − 1 ) / n ) (3) \tau(n)=2 Har(n - 1)-(2(n - 1) / n) \tag{3} τ(n)=2Har(n−1)−(2(n−1)/n)(3)
其中 P C A ( ⋅ ) PCA(\cdot) PCA(⋅)是主成分分析函数,保留99%的解释方差量。 h ( z ) h(z) h(z)表示 z z z从根节点到叶节点遍历隔离树所经过的边数。 E ( h ( z ) ) E(h(z)) E(h(z))是来自一组隔离树的 h ( z ) h(z) h(z)的平均值。 ∣ R ∣ |R| ∣R∣表示 R R R中的总样本数, H a r ( ⋅ ) Har(\cdot) Har(⋅)是调和数, τ ( ⋅ ) \tau(\cdot) τ(⋅)是归一化项。 - 第1轮:使用 L 0 L_{0} L0进行学习:利用上一轮计算得到的 L 0 L_{0} L0,我们使用公式(1)进行学习,得到 F 1 \mathcal{F}_{1} F1。然后,我们使用 F 1 \mathcal{F}_{1} F1重新采样伪标签集 L 1 L_{1} L1。
- 第2轮到第T轮:自监督伪标签学习过程:通过迭代伪标签生成进行自训练,以逐步提高 L L L的质量。具体来说,使用训练好的 F t \mathcal{F}_{t} Ft生成的新伪标签集 L t L_{t} Lt用于训练新的 F t + 1 \mathcal{F}_{t + 1} Ft+1。这个过程迭代 T T T轮,直到性能达到平稳。
无监督视频异常检测的因果推断视角
分析
我们提出如图1所示的因果图来分析上述 F \mathcal{F} F训练过程中的问题。在这里,我们简要介绍一下因果图的定义。图1中的因果图由六个感兴趣的变量组成:特征提取器( E E E)、噪声伪标签特征( S S S)、噪声伪标签( L L L)、输入视频帧特征( X X X)、异常特定特征表示( M M M)和模型预测( Y Y Y)。它主要包含两个部分:(1)通过链路 E → S → L E \to S \to L E→S→L的伪标签生成部分,代表第0轮及后续轮次的伪标签生成;(2)模型训练部分,通过链路 E → X E \to X E→X(表示公式(1)中的 x = f ( I ) x = f(I) x=f(I))、链路 X → M → Y X \to M \to Y X→M→Y(表示 y ^ = ϕ ( m = φ ( x = f ( I ) ) ) \hat{y}=\phi(m=\varphi(x=f(I))) y^=ϕ(m=φ(x=f(I))))和链路 L → M ← X L \to M \leftarrow X L→M←X(表示 L f o c ( y ^ , l ) L_{foc }(\hat{y}, l) Lfoc(y^,l))。此外,链路 X → Y X \to Y X→Y是我们期望实现的 X X X和 Y Y Y之间的直接因果效应。
正如上一节所讨论的,学习到的模型 F \mathcal{F} F的性能并不能暗示 X X X和 Y Y Y之间的直接因果效应,因为明显的后门路径 X ← E → S → L → M → Y X \leftarrow E \to S \to L \to M \to Y X←E→S→L→M→Y使 X X X和 Y Y Y产生虚假依赖。正确的伪标签通过 X → M → Y X \to M \to Y X→M→Y帮助 F \mathcal{F} F学习更好的异常特定表示空间,而错误的伪标签则通过后门路径扭曲这个空间。因此,这为进一步提高性能提供了潜力。
通过因果干预进行去混杂训练
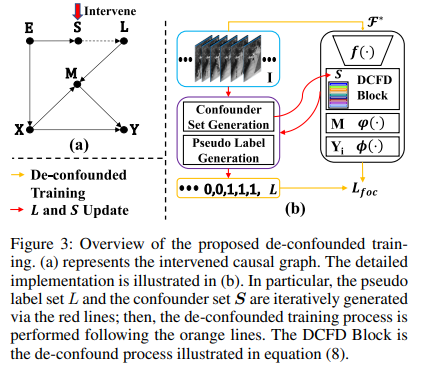
为了解决上述问题,我们提出一个干预后的因果图来解决伪标签生成过程的混杂偏差,如图3所示。调整后的因果图通过阻断因果链路 X ← E → S → L → M → Y X \leftarrow E \to S \to L \to M \to Y X←E→S→L→M→Y来阻断混杂路径,这使得伪标签生成过程与模型学习之间不会产生虚假相关性。因此,使用这个因果图进行学习可以产生 X X X和 Y Y Y之间的直接因果效应,表示为 P ( Y ∣ d o ( X ) , M ) = ∑ s P ( Y ∣ X , M , S = s ) P ( s ) P(Y | do(X), M)=\sum_{s} P(Y | X, M, S = s) P(s) P(Y∣do(X),M)=∑sP(Y∣X,M,S=s)P(s)。这种技术称为后门调整(Pearl 2001),它相当于将总体划分为相对于 S S S同质的组,评估每个同质组中 X X X对 Y Y Y的影响,然后对结果进行平均。请注意,我们选择 S S S是因为它是唯一可行的可用于划分以进行后门调整的变量,而特征提取器 E E E和噪声伪标签 L L L难以进行划分。为此,我们将使用 P ( Y ∣ d o ( X ) , M ) P(Y | do(X), M) P(Y∣do(X),M)定义的学习模型记为 F ∗ \mathcal{F}^{*} F∗, P ( Y ∣ d o ( X ) , M ) P(Y | do(X), M) P(Y∣do(X),M)的实现为:
P ( Y = c ∣ d o ( X = x ) , M = m ) = E s [ σ ( F ∗ ( x , m , s ) ) ] ≈ σ ( E s [ F ∗ ( x , m , s ) ] ) (4) \begin{aligned} P(Y=c | d o(X=x), M=m) & =\mathbb{E}_{s}\left[\sigma\left(\mathcal{F}^{*}(x, m, s)\right)\right] \\ & \approx \sigma\left(\mathbb{E}_{s}\left[\mathcal{F}^{*}(x, m, s)\right]\right) \end{aligned} \tag{4} P(Y=c∣do(X=x),M=m)=Es[σ(F∗(x,m,s))]≈σ(Es[F∗(x,m,s)])(4)
其中 F ∗ \mathcal{F}^{*} F∗输出 x x x属于类别 c c c的无偏预测对数几率。由于 E s [ ⋅ ] \mathbb{E}_{s}[\cdot] Es[⋅]需要计算成本高昂的采样,因此我们进行公式(7)所示的近似。
基于反事实的长程时间上下文集成
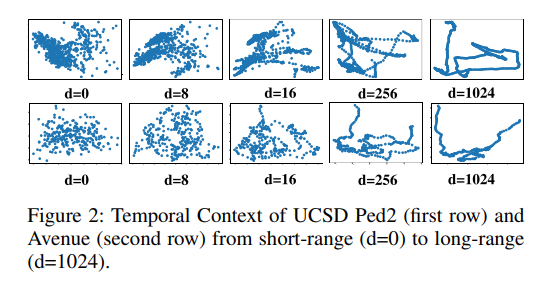
借助上述经过去混杂训练得到的模型,我们通过在模型预测中融入长程时间上下文先验信息,进一步提升模型的能力。在视频异常检测(VAD)中,提取稳健的时间上下文对于判定异常事件至关重要。现有方法常常将时间上下文建模为一小段相邻视频帧,却忽略了长程时间上下文。不同的短程时间上下文表示可能差异巨大,且变化无常,这不利于获取稳健的时间上下文表示。相反,长程时间上下文表示更为稳定,并且随着视频播放变化较小。这种现象在图2中有所体现,我们绘制了随着相邻帧数增加时间上下文特征的变化情况:(1)最左边一列表示投影到二维图像平面的短程(0个相邻帧)时间上下文特征;(2)最右边一列展示了投影到二维图像平面的长程(1024个相邻帧)时间上下文特征。显然,短程时间上下文特征表示比长程对应特征的噪声更多,而长程时间上下文呈现出更平滑、更清晰的模式。为此,我们通过图4第二部分所示的反事实特征替换来对长程时间上下文进行建模。由于正常预测对数几率和长程时间上下文预测对数几率的大小不同,在将它们相加以进行模型集成之前,我们对来自 F ∗ \mathcal{F}^{*} F∗的正常预测和长程预测的预测对数几率进行归一化处理。最终类别c的异常预测分数 O ( ⋅ ) O(\cdot) O(⋅)定义如下:
O ( Y = c ) = σ ( N o r m ( E s [ F ∗ ( x , m , s ) ] ) + N o r m ( E s [ F ∗ ( x a , m , s ) ] ) ) (5) \begin{array}{r}O(Y = c)=\sigma\left(Norm\left(\mathbb{E}_{s}\left[\mathcal{F}^{*}(x, m, s)\right]\right)+\right.\\ \left.Norm\left(\mathbb{E}_{s}\left[\mathcal{F}^{*}\left(x_{a}, m, s\right)\right]\right)\right)\end{array}\tag{5} O(Y=c)=σ(Norm(Es[F∗(x,m,s)])+Norm(Es[F∗(xa,m,s)]))(5)
其中 x a = ∑ i = − d d x i 2 d x_{a}=\frac{\sum_{i=-d}^{d} x_{i}}{2d} xa=2d∑i=−ddxi是以x为中心、窗口大小为d的滑动窗口的平均特征, N o r m ( l o g i t ) = l o g i t − μ δ Norm(logit)=\frac{logit - \mu}{\delta} Norm(logit)=δlogit−μ, μ \mu μ是所有帧的所有对数几率的平均值, δ \delta δ是所有帧的所有对数几率的标准差。
总体公式化
异常预测问题的总体公式定义为对 O ( ⋅ ) O(\cdot) O(⋅)分数的度量:
arg max c ∈ C O ( Y = c ) (6) \arg\max_{c \in \mathcal{C}} O(Y=c)\tag{6} argc∈CmaxO(Y=c)(6)
去混杂训练
如前一小节所讨论的,我们建议使用后门调整来推导去混杂模型。关键思路是对变量E、S或L中的一个进行分层(干预),以阻断后门路径。然而,伪标签生成过程的分层可以通过对伪标签特征S进行分层来实现,因为L仅由E生成的特征集S决定,对L或E进行分层操作难度较大。因此,我们将S的分层定义为 S = { s i } i = 1 N s S = \{s_{i}\}_{i = 1}^{N_{s}} S={si}i=1Ns,其中 s i ∈ R D b s_{i} \in \mathbb{R}^{D_{b}} si∈RDb, N s N_{s} Ns是表示混杂集S大小的超参数。由于实际中噪声伪标签特征的数量庞大,在实现过程中,我们利用带有 P C A ( ⋅ ) PCA(\cdot) PCA(⋅)的K-Means算法来学习混杂集s。因此,公式(4)的总体公式为:
P ( Y ∣ d o ( X ) ) = ∑ s P ( Y ∣ X = x , M = m , S = s ) P ( s ) ≈ P ( Y ∣ X , m = ∑ s g ( x = f ( I ) , s ) P ( s ) ) (7) \begin{aligned}P(Y | do(X)) & =\sum_{s} P(Y | X=x, M=m, S=s) P(s) \\& \approx P\left(Y | X, m=\sum_{s} g(x=f(I), s) P(s)\right)\end{aligned}\tag{7} P(Y∣do(X))=s∑P(Y∣X=x,M=m,S=s)P(s)≈P(Y∣X,m=s∑g(x=f(I),s)P(s))(7)
其中近似是通过归一化加权几何平均(Xu et al. 2015b)实现的(见补充文档)。阻断后门路径使得X有公平的机会将每个s纳入对Y的预测中,并受到先验P(s)的约束。 g ( ⋅ ) g(\cdot) g(⋅)定义如下:
m = g ( x , S ) P ( S ) = ∑ s g ( x , s ) P ( s ) = softmax ( ( W 1 x ) T ( W 2 S ) D h ) S \begin{aligned}m & =g(x, S) P(S)=\sum_{s} g(x, s) P(s) \\& =\text{softmax}\left(\frac{\left(W_{1}x\right)^{T}\left(W_{2}S\right)}{\sqrt{D_{h}}}\right) S\end{aligned} m=g(x,S)P(S)=s∑g(x,s)P(s)=softmax(Dh(W1x)T(W2S))S
其中 P ( s i ) = ∣ s i ∣ ∑ j ∣ s j ∣ P(s_{i})=\frac{|s_{i}|}{\sum_{j}|s_{j}|} P(si)=∑j∣sj∣∣si∣, ∣ s i ∣ |s_{i}| ∣si∣是聚类 s i s_{i} si中的样本数量, W 1 W_{1} W1, W 2 ∈ R D h × D b W_{2} \in \mathbb{R}^{D_{h} ×D_{b}} W2∈RDh×Db是可学习参数,用于将x和 s i s_{i} si投影到联合空间。 D h \sqrt{D_{h}} Dh是用于特征归一化的常数缩放因子。在实际实现中,为了更好地表示异常特定特征,我们进一步设置 M = m ⊕ M = m^{\oplus} M=m⊕,其中 m ⊕ = concat ( x , m ) m^{\oplus}=\text{concat}(x, m) m⊕=concat(x,m)。
最后,本节定义的模型 F ∗ \mathcal{F}^{*} F∗使用 L f o c L_{foc } Lfoc进行训练。
反事实时间上下文集成
利用上一小节训练的模型 F ∗ \mathcal{F}^{*} F∗,我们旨在将长程时间上下文先验信息注入到模型预测中。给定一个输入视频帧(I),公式(5)中的第一项是通过以 x = f ( I ) x = f(I) x=f(I)为输入进行正常推理得到的,因此 m ⊕ = concat ( x , m ) m^{\oplus}=\text{concat}(x, m) m⊕=concat(x,m)。公式(5)中的第二项通过反事实特征替换来实现。换句话说,我们设置 m a ⊕ = concat ( x a , m ) m_{a}^{\oplus}=\text{concat}(x_{a}, m) ma⊕=concat(xa,m) ,随后是后期融合层。也就是将输入设置为以(I)为中心的滑动窗口的平均特征 x a x_{a} xa,同时保持其他所有内容不变。这种实现方式模拟了长程时间上下文 x a x_{a} xa和局部图像上下文 m m m之间的交互。通过这种解耦设计,第一项保持去混杂后的异常预测,第二项融入了长程时间上下文和局部图像上下文之间的交互。将它们相加类似于进行模型集成。公式(5)的实现定义为:
O ( Y = c ) = σ ( N o r m ( E s [ F ∗ ( x , m ⊕ , s ) ] ) + N o r m ( E s [ F ∗ ( x a , m a ⊕ , s ) ] ) ) \begin{array}{r}O(Y = c)=\sigma\left(Norm\left(\mathbb{E}_{s}\left[\mathcal{F}^{*}\left(x, m^{\oplus}, s\right)\right]\right)+\right.\\ \left.Norm\left(\mathbb{E}_{s}\left[\mathcal{F}^{*}\left(x_{a}, m_{a}^{\oplus}, s\right)\right]\right)\right)\end{array} O(Y=c)=σ(Norm(Es[F∗(x,m⊕,s)])+Norm(Es[F∗(xa,ma⊕,s)]))
自监督伪标签学习
至此,我们已经介绍了去混杂训练模块和基于反事实的长程时间上下文集成模块。遵循(Pang et al. 2020),我们采用与强基线相同的自监督伪标签学习设置。具体而言,在第0轮,我们使用上述隔离森林算法将伪标签L初始化为 L 0 L_{0} L0。混杂集S首先使用骨干网络 f ( ⋅ ) f(\cdot) f(⋅)初始化为 S 0 S_{0} S0。然后,在第1轮,我们进行去混杂训练以获得优化的模型参数 F 1 ∗ \mathcal{F}_{1}^{*} F1∗,接着通过反事实时间上下文集成模块将S更新为 S 1 S_{1} S1,将 L 0 L_{0} L0更新为 L 1 L_{1} L1。在第2轮及以后,这个自监督伪标签学习过程重复(T)轮。一般来说,虽然我们的框架属于自监督伪学习范式,但我们的贡献在于明确消除了伪标签生成过程引起的混杂偏差,并以反事实的方式融入了长程时间上下文先验信息。后续实验进一步表明,我们的模型性能显著超越了以前的最优方法。
实验
实现细节
训练和评估
由于在实际应用中异常事件较为罕见,如果仅使用这些数据集的测试集则不符合实际情况,因此遵循(Pang et al. 2020),我们将训练集和测试集合并构建完整的数据集。我们在采样的训练集上训练模型,并在完整数据集上评估模型,评估时仅使用真实标签。为了获得可靠的训练伪标签,我们通过保留异常分数排名前(a%)的帧作为异常帧来构建伪异常标签集(A),并根据异常分数选择最正常的(b%)的帧来构建伪正常标签集(N)。(a)和(b)通常分别设置为5和20。这两个截止阈值是默认设置,因为它们在具有不同异常率的数据集上始终能显著提升性能。将(b)设置为较高的值通常有助于获得高质量的(N),因为在现实世界的数据集中正常帧占主导地位。更多实现细节请参考补充文档。
评估数据集和指标
我们在四个基准数据集上评估我们的方法,即UCSD数据集(Mahadevan et al. 2010)、地铁监控数据集(Adam et al. 2008)、UMN数据集(Mehran, Oyama, and Shah 2009)和Avenue数据集(Lu, Shi, and Jia 2013)。遵循(Sugiyama and Borgwardt 2013; Giorno, Bagnell, and Hebert 2016; Ionescu et al. 2017; Luo, Liu, and Gao 2017; Sultani, Chen, and Shah 2018; Wang et al. 2018; Liu, W. Luo, and Gao 2018; Pang et al. 2020),我们使用ROC曲线和相应的曲线下面积(AUC)作为评估指标,该指标是根据帧级别的真实注释计算得出的。更多数据集的详细信息,请参考补充文档。
消融研究
我们开展了广泛的实验,从以下几个方面验证我们模型的有效性:(1)组件有效性;(2)反事实集成的变体;(3)损失函数设计;(4)骨干网络的稳健性;(5)超参数调整。为了进行公平比较,我们选择由ResNet - 50作为(f(\cdot)),两个连续的FC - BN - ReLU作为(\varphi(\cdot)),后跟一个单独的FC作为(\phi(\cdot))的基线模型进行所有实验。在(4)中,我们进一步测试C3D(Tran et al. 2015)、I3D(Carreira and Zisserman 2017,仅以RGB图像作为输入)和VGG(Simonyan and Zisserman 2015)作为(f(\cdot))。所有实验都在具有挑战性的UCSD数据集上进行,并采用自监督伪标签学习。我们将UCSD数据集的默认设置设为:(N_{s}=16),(d = 1024),((a %, b %)=(5 %, 20 %)),以平衡计算成本和性能。每次通过改变一个参数进行消融实验。
- 组件有效性:根据表2,我们进行实验1、2、3以验证每个提出组件的有效性。实验1是提出的强基线模型。通过实验2、3,仅添加去混杂因果流分解(DCFD)训练,在UCSD Ped1数据集上比强基线模型性能提高了3.2%,在Ped2数据集上提高了16.7%。同时添加DCFD训练和反事实时间上下文集成(CTCE)后,在UCSD Ped1和Ped2数据集上,该模型比仅使用DCFD训练的模型分别进一步提高了11%和1.5%。
- 反事实集成的变体:我们进行表2中的实验3、4、5以验证CTCE的设计选择。具体来说,我们构建了两个变体:(1)CTCE V1:对(X)对(Y)的总体影响,不对中介变量(M)进行进一步的反事实干预。我们放弃反事实特征替换设计,将模型输入设置为(x_{a})。公式(5)中的中介变量(M)不再是固定值,而是根据(x_{a})实时计算。(2)CTCE V2:将滑动窗口平均特征设计改为零特征设计,即不使用滑动窗口。我们进一步通过将(x_{a})替换为(x_{0} \in \mathbb{R}^{D_{b}})(一个零特征向量)来验证使用(x_{a})作为反事实输入的效果。结果表明,使用(x_{a})进行反事实特征替换的效果最好,显示了我们设计的优越性。
- 损失函数设计:我们使用另外两种损失函数,均方误差损失(L_{mse })和二元交叉熵损失(L_{bce }),来验证使用焦点损失(L_{foc })的有效性。表2中实验3、6、7的性能表明,焦点损失会自动惩罚学习良好的样本,并专注于难以学习的样本,在这三种损失函数中性能最佳。
- 骨干网络的稳健性:表2中的实验3、8、9、10表明,随着使用更先进的骨干网络,我们方法的性能会提高,这表明我们的方法不依赖于对(f(\cdot))的精心选择。
- 超参数调整:一般来说,我们模型中有四种类型的超参数:(1)构建伪标签集时的(a%)和(b %);(2)混杂集(s)的大小(N_{s});(3)滑动窗口大小(d);(4)训练轮数(T)。与VAD中的大多数工作一样,我们报告所有超参数设置的评估结果。对于(1),根据表3,我们在实验1、2、3、4、5中将异常与正常样本的采样比例设置为1 : 2、1 : 3、1 : 4、1 : 5、1 : 6,评估结果表明,将比例设置为较小的值会产生更好的性能,因为现实世界中的异常事件很少见。对于(2),为了确定混杂集(N_{s})的大小,我们在实验6、7、8、9中将(N_{s})设置为4、16、64和128,结果表明混杂集(S)的粒度很重要。将(N_{s})设置为能够很好地表示训练数据中(X)分布的值有利于去混杂训练。对于(3),我们将窗口大小从短程值设置为长程值,结果表明较大的窗口大小始终优于较小的窗口大小,这表明长程时间上下文对于稳健的上下文表示至关重要。对于(4),我们绘制图6中的AUC性能以显示自监督伪标签学习过程的总体趋势。具体来说,结果表明AUC在(t = 0 - 8)之间逐渐提高,通常在(t = 8)时达到平稳。我们将(T = 8)以平衡计算成本和性能。此外,从初始化到第1轮的学习过程代表了从传统无监督方法到深度神经网络模型的学习。性能的急剧提升揭示了一个事实,即深度神经网络倾向于先学习简单模式,然后再拟合伪标签噪声,正如(Li, Socher, and Hoi 2020; Arpit et al. 2017)所证明的那样。从第2轮开始,学习过程转变为表示细化过程,因为我们的模型是在前一轮训练的模型基础上进行微调,导致性能提升不那么明显。
与先前最先进结果的比较
定量结果
根据表1,我们在四个标准基准数据集上,将我们的方法与16种在训练中需要已标注正常数据的VAD方法,以及7种不需要任何形式已标注数据的UVAD方法进行比较。我们展示了五种不同配置的模型:(1)实验22中使用从ResNet - 50提取的图像特征的隔离森林(iForest),作为简单基线;(2)强基线模型 F \mathcal{F} F, f ( ⋅ ) f(\cdot) f(⋅)设置为ResNet - 50,除了训练损失替换为 L f o c L_{foc } Lfoc之外,几乎与(Pang et al. 2020)相同;(3)Ours(ResNet - 50) + DCFD,与(2)的不同之处在于添加了去混杂训练模块;(4)Ours(ResNet - 50) + DCFD + CTCE,与(3)的不同之处在于添加了反事实时间上下文集成模块;(5)Ours(I3D) + DCFD + CTCE,与(4)的不同之处在于将 f ( ⋅ ) f(\cdot) f(⋅)更改为I3D。总体而言,我们的方法显著优于所有先前的UVAD方法,甚至比一些VAD方法的性能还要高。具体来说,我们分别分析每个数据集上的性能提升。UCSD:我们的方法显著超越了所有先前的UVAD方法,与表现最好的模型(Wang et al. 2018)相比,在Ped1数据集上高出7.1%,在Ped2数据集上高出3.0%(通过比较实验25和20)。对于VAD,我们的方法在Ped2数据集上优于所有VAD方法,在Ped1数据集上也达到了较高的排名,展示了我们方法的竞争力。地铁监控数据集:我们的结果在入口和出口基准测试中均超越了所有先前的UVAD方法。UMN:显然,我们方法的性能高于所有先前的UVAD方法,并且与有监督方法相比也具有竞争力。具体而言,我们在所有场景中达到了100%(比(Pang et al. 2020)高出2.6%)。Avenue:通过比较实验26和20,我们的方法比先前的UVAD最优方法(Wang et al. 2018)高出5%。该性能也高于大多数VAD方法,排名第二。
定性结果
图7展示了我们模型在4个示例基准数据集上的定性结果。与隔离森林基线相比,很明显我们提出的方法在事件异常时能够产生更好的异常分数。大量实验表明,我们的方法可以逐步提高伪标签质量(通过正确的正常/异常帧数除以总正常/异常帧数来计算),如图8所示。
结论
我们从因果推断的角度分析了无监督视频异常检测中噪声伪标签和长程时间上下文的影响。然后,我们提出了去混杂训练和反事实时间上下文集成,以增强无监督视频异常检测中常用的自监督伪标签学习过程。整体框架简单,计算量小,并且对噪声伪标签具有鲁棒性。我们广泛验证了所提出流程的有效性,六个基准数据集上的实验结果表明,我们的方法显著优于所有先前的方法,展示了我们方法的优越性。尽管如此,设计更好的因果图或特征解耦方法可能会进一步提高模型在无监督视频异常检测中的性能。
相关文章:

A Causal Inference Look at Unsupervised Video Anomaly Detection
标题:无监督视频异常检测的因果推断视角 原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/20053 发表:AAAI-2022 文章目录 摘要引言相关工作无监督视频异常检测因果推断 方法问题公式化一般设置强基线模型 无监督视频异常检测的因…...
)
MQ(RabbitMQ.1)
MQ的含义及面试题 MQMQ的含义MQ之间的调用的方式MQ的作用MQ的几种产品RabbitMQRabbitMQ的安装RabbitMQ的使用RabbitMQ⼯作流程 AMQPWeb界面操作用户相关操作虚拟主机相关操作 RabbitMQ的代码应用编写生产者代码编写消费者代码 生产者代码消费者代码 MQ MQ的含义 MQ࿰…...

cursor+高德MCP:制作一份旅游攻略
高德开放平台 | 高德地图API (amap.com) 1.注册成为开发者 2.进入控制台选择应用管理----->我的应用 3.新建应用 4.点击添加Key 5.在高德开发平台找到MCP的文档 6.按照快速接入的步骤,进行操作 一定要按照最新版的cursor, 如果之前已经安装旧的版本卸载掉重新安…...
——时钟组)
FPGA时序分析与约束(11)——时钟组
目录 一、同步时钟与异步时钟 二、逻辑与物理独立时钟 2.1 逻辑独立时钟 2.2 物理独立时钟 三、如何设置时钟组 四、注意事项 专栏目录: FPGA时序分析与约束(0)——目录与传送门https://ztzhang.blog.csdn.net/article/details/134893…...

opencv 识别运动物体
import cv2 import numpy as npcap cv2.VideoCapture(video.mp4) try:import cv2backSub cv2.createBackgroundSubtractorMOG2() except AttributeError:backSub cv2.bgsegm.createBackgroundSubtractorMOG()#形态学kernel kernel cv2.getStructuringElement(cv2.MORPH_REC…...

opencv实际应用--银行卡号识别
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,主要用于图像和视频处理、目标检测、特征提取、3D重建以及机器学习任务。它支持多种编程语言(如C、Python),提供丰富的算法和工具&a…...

【软考系统架构设计师】系统架构设计知识点
1、 从需求分析到软件设计之间的过渡过程称为软件架构。 软件架构为软件系统提供了一个结构、行为和属性的高级抽象,由构件的描述、构件的相互作用(连接件)、指导构件集成的模式以及这些模式的约束组成。 软件架构不仅指定了系统的组织结构和…...

GPT - 2 文本生成任务全流程
数据集下载 数据预处理 import json import pandas as pdall_data []with open("part-00018.jsonl",encoding"utf-8") as f:for line in f.readlines():data json.loads(line)all_data.append(data["text"])batch_size 10000for i in ran…...

重返JAVA之路——面向对象
目录 面向对象 1.什么是面向对象? 2.面向对象的特点有哪些? 3.什么是对象? 4.什么是类? 5.什么是构造方法? 6.构造方法的特性有哪些? 封装 1.什么是封装? 2.封装有哪些特点? 数据隐…...

docker 安装 jenkins
拉取镜像 docker pull jenkins/jenkins:2.426.3-lts-jdk17 创建数据卷 # 创建时即设置安全权限(SGID确保组权限继承) sudo mkdir -p /var/jenkins_home sudo chmod -R 777 /var/jenkins_home 拉取镜像并运行容器 # 生产环境推荐(JDK17…...

sql 向Java的映射
优化建议,可以在SQL中控制它的类型 在 MyBatis 中,如果返回值类型设置为 java.util.Map,默认情况下可以返回 多行多列的数据...

探索Streamlit在测试领域的高效应用:文档读取与大模型用例生成的完美前奏
大模型用例生成前置工作之文档读取——构建你的自动化测试基础 在群友的极力推荐下,开始了streamlit的学习之旅。本文将介绍如何使用Streamlit开发一个多功能文档处理工具,支持读取、预览、格式转换和导出多种测试相关文档(YAML、JSON、DOCX…...

Python中数值计算、表格处理和可视化的应用
1.数值计算:Numpy import numpy as np 1.1创建数组 import numpy as np arr1 np.array([[1,2,3,4,5]]) print(arr1) print(type(arr1)) print("数组形状",arr1.shape) arr2 np.array([[1,2,3],[2,3,4]]) print(arr2) print(type(arr1)) print("…...

【数据可视化艺术·实战篇】视频AI+人流可视化:如何让数据“动”起来?
景区游玩,密密麻麻全是人,想找个拍照的好位置都难;上下班高峰挤地铁,被汹涌的人潮裹挟着,只能被动 “随波逐流”。这样的场景,相信很多人都再熟悉不过。其实,这些看似杂乱无章的人群流动现象&am…...

038-flatbuffers
flatbuffers FlatBuffers技术调研报告 一、核心原理与优势 FlatBuffers通过内存直接访问技术实现零拷贝序列化,其核心优势如下: 内存布局:数据以连续二进制块存储,包含VTable(虚拟表)和Data Object&…...

探索 Go 与 Python:性能、适用场景与开发效率对比
1 性能对比:执行速度与资源占用 1.1 Go 的性能优势 Go 语言被设计为具有高效的执行速度和低资源占用。它编译后生成的是机器码,能够直接在硬件上运行,避免了 Python 解释执行的开销。 以下是一个用 Go 实现的简单循环计算代码: …...

Pinia最基本用法
1. 定义 Store 首先,定义一个 Pinia Store,使用组合式 API 风格和 ref 来管理状态。 示例:stores/ids.js import { defineStore } from pinia; import { ref } from vue;export const useIdsStore defineStore(ids, () > {const ids …...

MySQL中的UNION和UNION ALL【简单易懂】
一、前言 UNION 和 UNION ALL 是 SQL 中用于合并多个查询结果集的关键字。 二、核心作用 两者均用于将多个 SELECT 语句的结果集纵向合并(列结构需相同),但行为存在关键差异: 三、使用场景对比 需要去重时:例如合并…...

ConcurrentHashMap 源码分析
摘要 介绍线程安全集合类 ConcurrentHashMap 源码,包括扩容,协助扩容,红黑树节点读写线程同步,插入元素后累加键值对数量操作原子性实现。 1 成员变量及其对应的数据结构 底层由数组红黑树链表实现volatile long baseCount 和 v…...

一种基于学习的多尺度方法及其在非弹性碰撞问题中的应用
A learning-based multiscale method and its application to inelastic impact problems 摘要: 我们在工程应用中观察和利用的材料宏观特性,源于电子、原子、缺陷、域等多尺度物理机制间复杂的相互作用。多尺度建模旨在通过利用固有的层次化结构来理解…...

【DE2-115】Verilog实现DDS+Quartus仿真波形
【DE2-115】Verilog实现DDSQuartus仿真波形 一、任务要求二、实现步骤2.1 相位累加器2.2 波形存储器ROM2.2.1 方波模块2.2.2 正弦波形存储器 2.3 3锁相环倍频电路2.4 顶层电路设计 三、设计实现四、实验总结 一、任务要求 采用数字频率合成(Direct Digital Frequen…...

StickyNotes,简单便签超实用
日常工作中是不是经常需要记点东西,但又不想用太复杂的工具?今天给你推荐一款超简单的桌面便签软件——StickyNotes。 下面是动图: 简单到极致的便签工具 StickyNotes真的是简单到不能再简单了。打开软件,直接输入你的便签内容&a…...

深度探索 C 语言:指针与内存管理的精妙艺术
C 语言作为一门历史悠久且功能强大的编程语言,以其高效的性能和灵活的底层控制能力,在计算机科学领域占据着举足轻重的地位。 指针和内存管理是 C 语言的核心特性,也是其最具挑战性和魅力的部分。深入理解指针与内存管理,不仅能够…...

【C++】深拷贝与浅拷贝
重开也不是不可能 ~.~ 浅拷贝 #include <iostream> #include <cstring>class ShallowCopyExample { public:int m_nValue;int* m_pData;// 构造函数,初始化指针成员ShallowCopyExample(int value) : m_nValue(value) {m_pData new int(0);*m_pData va…...

【3】k8s集群管理系列--包应用管理器helm之chart资源打包并推送到harbor镜像仓库
一、chart资源打包 helm package ./web-chart # 当前目录会生成一个tgz的压缩文件二、安装help push插件(用于推送前面打包的文件,到镜像仓库) .1 下载help-push二进制文件 wget https://github.com/chartmuseum/helm-push/releases/down…...

React与Vue:选择哪个框架入门?
React与Vue:选择哪个框架入门? 作为前端开发者,我在React和Vue两个框架间切换多次,常被新手问到应该从哪个入手。不同于网上那些详尽的技术比较,这里我想从实用角度给你一个简明对比。 两大框架核心差异 特性ReactV…...

pycharm已有python3.7,如何新增Run Configurations中的Python interpreter为python 3.9
在 PyCharm 中,如果你已经安装了 Python 3.9,并且希望在 Run Configurations 中新增一个 Python 3.9 的解释器,可以按照以下步骤操作: 步骤 1:打开 PyCharm 设置 点击 PyCharm 左上角的 File 菜单。选择 Settings&am…...
)
STL之迭代器(iterator)
迭代器的基本概念 迭代器(iterator)模式又称为游标(Cursor)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式&#…...

Mysql5.7配置文件
Mysql5.7配置文件 初始化数据库之前修改my.cnf----配置持久化键(persistence key) 初始化数据库之前修改my.cnf----配置持久化键(persistence key) 使用utf8mb4而不是utf8: https://blog.csdn.net/omaidb/article/details/106481406 https://blog.csdn.net/fdipzo…...

HarmonyOS-ArkUI V2装饰器: @Provider和@Consumer装饰器:跨组件层级双向同步
作用 我们在之前学习的那些控件中,各有特点,也各有缺陷,至今没有痛痛快快的出现过真正能跨组件的双向绑定的装饰器。 比如 @Local装饰器,不能跨组件@Param装饰器呢,能跨组件传递,但是仅仅就是下一层组件接收参数。另外,它是单向传递,不可被重新赋值。如果您非要改值则…...

【HarmonyOS 5】敏感信息本地存储详解
【HarmonyOS 5】敏感信息本地存储详解 前言 鸿蒙其实自身已经通过多层次的安全机制,确保用户敏感信息本地存储安全。不过再此基础上,用户敏感信息一般三方应用还需要再进行加密存储。 本文章会从鸿蒙自身的安全机制进行展开,最后再说明本地…...

0x03.Redis 通常应用于哪些场景?
回答重点 1)缓存(Cache): Redis 最常用的场景是作为缓存层,以减少数据库的负载,提高数据读取速度。例如,常用的用户会话数据和页面渲染结果可以存储在 Redis 中。2)分布式锁(Distributed Lock): Redis 可以用作分布式锁的实现,确保在分布式系统中资源的安全访问,避免…...

Keil创建自定义的STM32标准库工程
注:以下工程创建将以STM32F103ZET6为例 1 下载需要的资料包 1.1 下载 Keil 的 STM32F103 芯片支持包 1.1.1 手动下载安装包 Keil官网:https://www.keil.com/ (1)进入官网,点击 Download。 (2…...
基础入门)
React(1)基础入门
React(1)基础入门 Author: Once Day Date: 2025年4月10日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: FullStack开发_Once-Day的博客-CSDN博客 …...

Mysql8配置文件
Mysql8配置文件 修改my.cnf----配置持久化键(persistence key)配置表名不区分大小写 修改my.cnf----配置持久化键(persistence key) MySQL8初始化数据库之前配置好这些变量值,初始化数据库之后可能无法修改这个值。 # 服务端配置 [mysqld] ######## 数据目录和基…...

c/c++ 使用libgeotiff读取全球高程数据ETOPO
#include <geotiff.h> #include <geotiffio.h> #include <tiffio.h> #include <iostream> #include <xtiffio.h> void MyTIFFErrorHandler(const char* module, const char* fmt, va_list args) {// 格式化错误消息char buffer[1024];vsnprintf(…...

Spring Boot集成Nacos
1. 添加依赖 在pom.xml文件中添加Nacos相关依赖。根据Spring Boot版本选择合适的依赖版本: Spring Boot 3.2.x版本 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artif…...

CAP理论 与 BASE理论
一、分布式系统存在的问题 1.分布式系统 20世纪90年代,随着互联网应用的快速扩张,传统单机系统难以支撑高并发、跨地域的数据处理需求。分布式系统(Distributed System) 逐渐成为主流架构,分布式系统是由多台计算机&…...
—类和对象(下) ⑥匿名对象)
C++(21)—类和对象(下) ⑥匿名对象
文章目录 一、匿名对象的定义与基本特性二、匿名对象与有名对象的对比1. 有名对象2. 匿名对象 三、匿名对象的构造与析构时机1. 构造与析构规则2. 示例分析 四、匿名对象的适用场景1. 临时调用对象方法2. 作为函数参数 五、总结 一、匿名对象的定义与基本特性 匿名对象&#x…...

Go环境变量配置
Go环境变量配置 一、下载 进入The Go Programming Language 点击下载对应操作系统的 安装成功界面如下图,默认安装到: usr/local/go/ 安装完成之后,在终端运行 go version,如果显示类似下面的信息,表明安装成功(备注:darwin(其实…...

AI推理强,思维模型也有功劳【58】二八定律思维
giszz的理解:二八定律,我们说的和听的都比较多。20%的关键,是事物本质,做人不要贪心,也不要胡子眉毛一把抓。当然,也不要轻视那80%。 一、定义 二八定律思维模型,也被称为帕累托法则࿰…...

文件上传靶场
文件上传靶场 项目结构 upload-lab/ ├── Dockerfile └── www├── index.php└── upload└── flag.txt执行命令流程(逐行执行) 创建目录结构 # 创建目录结构 mkdir upload-lab;cd upload-lab mkdir -p www/upload# 创建flag文件 echo &qu…...

RV1106 OCR 识别算法
一 题记 目标是在某款 RV1106 低算力小板下跑通OCR文字识别算法,做个简单的应用,RK 官方模型库rk_model_zoo 有PP-OCR 的例子,但在 rv1106 上尚未支持。于是便打算折腾一吧。 二 方案甄选 参考国外某大佬的比较: 对比了几种方案…...

Linux实现翻译以及群通信功能
1.翻译功能实现 UdpServer.hpp文件 构造函数 接收一个端口号和一个回调函数,回调函数是传入一个执行方法,比如翻译方法。 UdpServer(uint16_t port,func_t func):_sockfd(defaultfd),_port(port),_isrunning(false),_func(func){}Init函数 首先创建了…...

[MRCTF2020]ezpop wp
本题考点:php反序列化的pop链 首先来了解一下pop链是什么,它类似于多米诺骨牌一环套一环,要调用这个成员方法然后去找能调用这个方法的魔术方法,最后一环接一环,完成一个链子,最终形成payload。 那么来了解一下这些魔术方法 __construct() //类的构造函数࿰…...

机器学习入门之Sklearn基本操作
、 Sklearn全称:Scipy-toolkit Learn是 一个基于scipy实现的的开源机器学习库。它提供了大量的算法和工具,用于数据挖掘和数据分析,包括分类、回归、聚类等多种任务。本文我将带你了解并入门Sklearn在机器学习中的基本用法。 获取方式 pip install sc…...
安卓开发中的数据存储之SQLite简单使用)
(二十二)安卓开发中的数据存储之SQLite简单使用
在Android开发中,SQLite是一种非常常用的数据库存储方式。它轻量、简单,非常适合移动设备上的数据管理。本文将通过通俗易懂的语言,结合代码示例和具体场景,详细讲解SQLite在Android中的使用。 1. 什么是SQLite? SQLite是一个开…...

docker compose搭建博客wordpress
一、前言 docker安装等入门知识见我之前的这篇文章 https://blog.csdn.net/m0_73118788/article/details/146986119?fromshareblogdetail&sharetypeblogdetail&sharerId146986119&sharereferPC&sharesourcem0_73118788&sharefromfrom_link 1.1 docker co…...

信息学奥赛一本通 1498:Roadblocks | 洛谷 P2865 [USACO06NOV] Roadblocks G
【题目链接】 ybt 1498:Roadblocks 洛谷 P2865 [USACO06NOV] Roadblocks G 【题目考点】 1. 图论:严格次短路径 严格次短路的路径长度必须大于最短路的路径长度。 非严格次短路的路径长度大于等于最短路的路径长度。 【解题思路】 每个交叉路口是一…...
)
学习笔记—C++—类和对象(三)
目录 类和对象 再探构造函数 类型转换 隐式类型转换 显式类型转换 C语言风格类型转换 C风格类型转换 static_cast dynamic_cast const_cast reinterpret_cast static成员 友元 友元函数 友元类 友元成员函数 内部类 匿名对象 匿名对象的使用场景:…...