MySQL表的增删改查进阶版
Mysql
- 1、数据库的约束
- 1.1约束类型
- 1.2 NULL约束
- 1.3 UNIQUE:唯一约束
- 1.4 DEFAULT:默认值约束
- 1.5 PRIMARY KEY:主键约束(重点)
- 1.6 FOREIGN KEY:外键约束(重点)
- 2.表的设计
- 2.1一对一
- 2.2一对多
- 2.3多对多
- 3.新增
- 4.查询
- 4.1聚合查询
- 4.1.1聚合函数
- 4.1.2GROUP BY 子句
- 4.1.3HAVING
- 4.2联合查询
- 4.2.1内连接
- 4.2.2外连接
- 4.2.3自连接
- 4.2.4子查询
- 4.2.5合并查询
1、数据库的约束
1.1约束类型
什么是约束?
约束是数据库自动对数据进行合法性校验检查的一系列机制,目的是为了数据库中能避免被插入/修改一些非法的数据,数据库引入约束后执行效率会受影响,效率会降低很多
NOT NULL:知识某列不能存储NULL值UNIQUE:保证某列的每行必须有唯一的值,unique会让后续插入/修改数据时都先触发一次查询操作,确定当前记录是否存在DEFAULT:规定没有给列赋值时的默认值PRIMARY KEY:NOT NULL和UNIQUE的结合,确保某列有唯一标识,有助于更快速地找到表中的一个特定的记录,一张表中只能有一个primary keyFOREIGN KEY:保证一个表中数据匹配另一个表中的值的参照完整性CHECK:保证列中的值符合指定的条件
下面我们来进行逐一解释
1.2 NULL约束
创建表时,可以指定某列不为空
mysql> create table student
(id int not null,sn int,name varchar(20),qq_mail varchar(20));
-- 如果id列插入null类型的数据,则会报错
mysql> insert into student values(null,1,'lisi','ddd');
ERROR 1048 (23000): Column 'id' cannot be null
1.3 UNIQUE:唯一约束
指定sn列是唯一的,不重复的
mysql> create table student
(id int not null,sn int unique,name varchar(20),qq_mail varchar(20));
Query OK, 0 rows affected (0.02 sec)
-- 我们可以在以下代码看到,sn只能插入一次相同的值,重复插入会报错
mysql> insert into student values(1,1,'qqq','qqq');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(1,1,'qqq','qqq');
ERROR 1062 (23000): Duplicate entry '1' for key 'sn'
mysql>
1.4 DEFAULT:默认值约束
指定插入数据时,name列为空,则默认值为unkown
create table student
(id int not null,sn int unique,name varchar(20) default 'unkown',qq_mail varchar(20));
-- 在下列代码可以看到name列没被插入,系统自动补成unkown
mysql> insert into student(id ,sn,qq_mail) values(2,2,'qqq');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+--------+---------+
| id | sn | name | qq_mail |
+----+------+--------+---------+
| 2 | 2 | unkown | qqq |
+----+------+--------+---------+
1 row in set (0.00 sec)
1.5 PRIMARY KEY:主键约束(重点)
指定id列为主键
mysql> create table student
(id int not null primary key,name varchar(20));
Query OK, 0 rows affected (0.01 sec)
如何保证主键唯一呢?
MySQL提供一种“自增主键”这样的机制,主键经常使用int/big int,我们插入数据的时候,不必手动指定主键值,由数据库服务器自己分配一个主键,从1开始,依次递增的分配主键的值
对于整数类型的主键,常搭配子增长auto_increment来使用,插入数据对应字段不给值时(null,这里写作null其实是交给数据库服务器自行分配),使用最大值+1(相当于使用了一个变量来保存当前表的ID最大值,后续分配自增主键都是根据这个最大值分配的,如果手动指定的id也会更新最大值)
自动分配也有一定的局限性,如果是单个MySQL没问题,如果是一个分布式系统有多个MySQL服务器构成的集群,这个时候自增主键就不行了
-- 主键是NOT NULL和UNIQUE的结合,可以不用NOT NULL
create table student1
(id int primary key auto_increment,name varchar(20));
Query OK, 0 rows affected (0.01 sec)
-- 插入多条数据,不指定id,我们来看一下效果
mysql> insert into student1(name) values('qqq');
mysql> insert into student1(name) values('qqq');
mysql> insert into student1(name) values('qqq');
mysql> insert into student1(name) values('qqq');
mysql> select * from student1;
+----+------+
| id | name |
+----+------+
| 1 | qqq |
| 2 | qqq |
| 3 | qqq |
| 4 | qqq |
+----+------+
4 rows in set (0.00 sec)-- 当我们指定了一个id,自增主键会更新最大值,我们来看下效果
mysql> insert into student1 values(11,'qqq');
Query OK, 1 row affected (0.00 sec)mysql> insert into student1(name) values('qqq');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student1;
+----+------+
| id | name |
+----+------+
| 1 | qqq |
| 2 | qqq |
| 3 | qqq |
| 4 | qqq |
| 11 | qqq |
| 12 | qqq |
+----+------+
6 rows in set (0.00 sec)
分布式唯一id:=时间戳+主机编号/机房编号+随机因子
+指的是字符串拼接,不是算数相加
1.6 FOREIGN KEY:外键约束(重点)
外键用于关联其他表的主键或唯一键,描述了两个表之间的关联关系,只有用到的才受约束。
语法:
foreign key (子表的列) reference 主表(列);
进一步解释:子表的列表示当前哪个表的哪个列被约束,主表(列)表示数据是被谁约束,也就是说,子表的列要出自于主表后括号中的那一列,references表示当前这个表的这一列中的数据应该是出自另一个表的哪一列
- 例:classes表中的数据约束了student表中的数据,classes称为父表(约束别人的表),student称为子表(被人约束的表)
创建班级表classes,id为主键:
mysql> create table classes
(id int primary key auto_increment,
name varchar(20),
`desc` varchar(100));
创建学生表student,一个学生对应一个班级,一个班级对应多个学生,使用id为主键,classes_id为外键,关联班级表id
mysql> create table student
(id int primary key auto_increment,
sn int unique,
name varchar(20) default 'unkown',
qq_mail varchar(20),
classes_id int,
foreign key (classes_id) references classes(id));
Query OK, 0 rows affected (0.02 sec)-- 我们可以看到如下代码
mysql> insert into classes(name,`desc`) values('qqq','aaa');
Query OK, 1 row affected (0.00 sec)
mysql> select * from classes;
+----+------+------+
| id | name | desc |
+----+------+------+
| 1 | qqq | aaa |
+----+------+------+
1 row in set (0.00 sec)
-- 在这里我们发现把一个学生的班级设置为2会错误,因为classes表中没有id为2这个班级
mysql> insert into student(name,classes_id) values('qqq',2);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`db_test`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classes_id`) REFERENCES `classes` (`id`))
-- 班级设置为1则正确
mysql> insert into student(name,classes_id) values('qqq',1);
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+------+---------+------------+
| id | sn | name | qq_mail | classes_id |
+----+------+------+---------+------------+
| 2 | NULL | qqq | NULL | 1 |
+----+------+------+---------+------------+
1 row in set (0.00 sec)
要对父表进行修改/删除操作,如果当前被修改/删除的值已经被子表引用了,这样的操作会失败,外键约束始终要保持子表中的数据要在对应的父表的列中存在,此时万一把父表这条数据删除了,就打破刚才的约束了,所以删除会报错
若想删除关联的表,只能先删除子表,再删父表
2.表的设计
根据实际的需求场景,明确当前要创建几个表,每个表啥样子,这些表之间是否存在一定联系
一般来说,每个实体都需要安排一个表,表的列就对应到实体的各个属性
- 三大范式
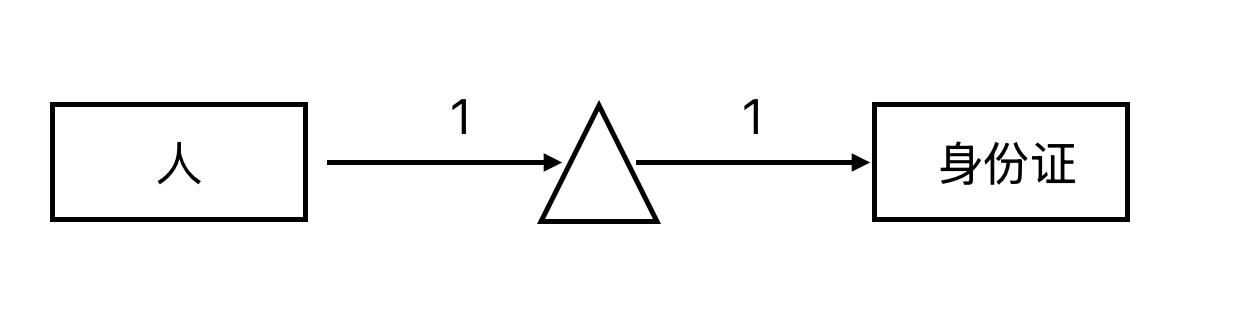
2.1一对一
一个学生只能拥有***一个***账号
一个账号只能被***一个***学生拥有
2.2一对多
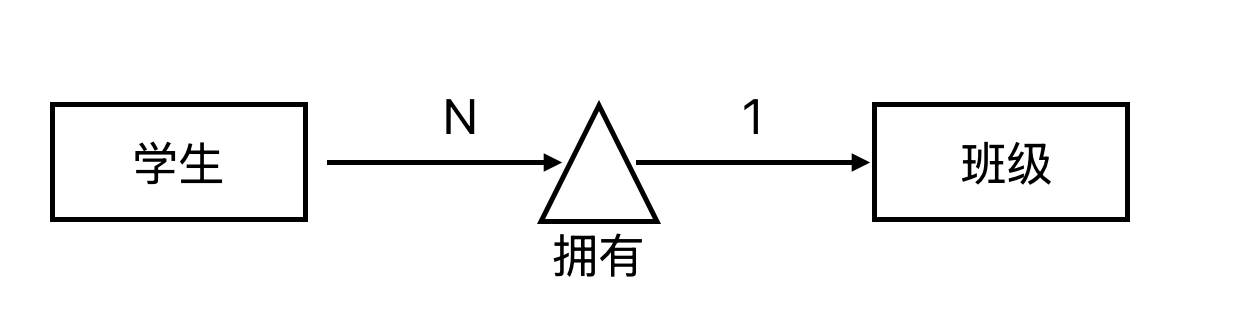
一个学生只能在***一个***班级中
一个班级可以包括***多个***学生
2.3多对多
一个学生可以选择***多门***课程
一门课程也可以包含***多个***学生
3.新增
把查询语句的查询结果作为插入的数值
语法:
insert into 表名 select * from 表名;
- 例:设计一张用户表,把已有的学生数据复制进来
mysql> insert into test_user(name) select name from student1;
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
-- 我们可以看到,学生姓名已经被成功的复制进来
mysql> select * from test_user;
+----+------+------+
| id | name | age |
+----+------+------+
| 1 | qqq | NULL |
| 2 | aaa | NULL |
| 3 | bbb | NULL |
| 4 | ccc | NULL |
| 5 | ddd | NULL |
| 6 | eee | NULL |
+----+------+------+
6 rows in set (0.00 sec)
4.查询
4.1聚合查询
表达式查询是针对列和列之间进行运算的,
聚合查询是相当于行和行之间进行运算的。
4.1.1聚合函数
SQL中提供了聚合函数,常见的统计总数,计算平均值等操作,可以使用聚合函数来实现,以下是常见的聚合函数:
| 函数 | 说明 |
|---|---|
| COUNT(expr) | 返回查询到的数据的数量,查询出来结果是集的行数 |
| SUM(expr) | 返回查询到的数据的总和,只能针对数字,把这一列的若干行求和,算术运算 |
| AVG(expr) | 返回查询到的数据的平均值 |
| MAX(expr) | 返回查询到的数据的最大值 |
| MIN(expr) | 返回查询到的数据的最小值 |
COUNT
-- 插入测试数据
mysql> insert into test_user (name) values('张三'),('李四'),('王五'),('赵六');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
-- 查询(用*查询不可进行去重,NULL也算进去)
mysql> select count(*) from test_user;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
mysql> select count(0) from test_user;
+----------+
| count(0) |
+----------+
| 4 |
+----------+
1 row in set (0.01 sec)
-- 再插入几组年龄数据,姓名为空
mysql> insert into test_user (age) values(10),(12),(13);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 我们先查询一下
mysql> select * from test_user;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 8 | 张三 | NULL |
| 9 | 李四 | NULL |
| 10 | 王五 | NULL |
| 11 | 赵六 | NULL |
| 12 | NULL | 10 |
| 13 | NULL | 12 |
| 14 | NULL | 13 |
+----+--------+------+
7 rows in set (0.00 sec)
-- 统计班级收集的年龄信息有多少个,年龄为NULL不会计入结果,也可进行去重
mysql> select count(age) from test_user;
+------------+
| count(age) |
+------------+
| 3 |
+------------+
1 row in set (0.00 sec)
SUM
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)mysql> select sum(chinese) from exam_result;
+--------------+
| sum(chinese) |
+--------------+
| 525.0 |
+--------------+
1 row in set (0.00 sec)
sum函数中也可以使用表达式,先把对应列相加,得到的临时表再把这个临时表的结果进行相加,举例如下
mysql> select sum(chinese + math) from exam_result;
+---------------------+
| sum(chinese + math) |
+---------------------+
| 1106.5 |
+---------------------+
1 row in set (0.00 sec)
AVG
mysql> select avg(chinese+english+ math) as 平均总分 from exam_result;
+--------------+
| 平均总分 |
+--------------+
| 221.42857 |
+--------------+
1 row in set (0.00 sec)
MAX
mysql> select max(english) as 英语最高分 from exam_result;
+-----------------+
| 英语最高分 |
+-----------------+
| 90.0 |
+-----------------+
1 row in set (0.00 sec)
MIN
mysql> select min(math) as 数学最低分 from exam_result;
+-----------------+
| 数学最低分 |
+-----------------+
| 65.0 |
+-----------------+
1 row in set (0.00 sec)
4.1.2GROUP BY 子句
针对指定列进行分组,把这一列中值相同的行,分到一组中,然后得到若干个组,针对这些组分别使用聚合函数
语法
select column1,sum(column2)…… from table group by column1,column3;
- 例:准备测试表和数据
mysql> insert into emp(name, role, salary) values-> ('马云','服务员', 1000.20),-> ('马化腾','游戏陪玩', 2000.99),-> ('孙悟空','游戏角色', 999.11),-> ('猪无能','游戏角色', 333.5),-> ('沙和尚','游戏角色', 700.33),-> ('隔壁老王','董事长', 12000.66);
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0+----+--------------+--------------+----------+
| id | name | role | salary |
+----+--------------+--------------+----------+
| 1 | 马云 | 服务员 | 1000.20 |
| 2 | 马化腾 | 游戏陪玩 | 2000.99 |
| 3 | 孙悟空 | 游戏角色 | 999.11 |
| 4 | 猪无能 | 游戏角色 | 333.50 |
| 5 | 沙和尚 | 游戏角色 | 700.33 |
| 6 | 隔壁老王 | 董事长 | 12000.66 |
+----+--------------+--------------+----------+
6 rows in set (0.00 sec)
查询每个角色的最高工资、最低工资和平均工资
mysql> select role,max(salary),min(salary),avg(salary) from emp group by role;
+--------------+-------------+-------------+--------------+
| role | max(salary) | min(salary) | avg(salary) |
+--------------+-------------+-------------+--------------+
| 服务员 | 1000.20 | 1000.20 | 1000.200000 |
| 游戏角色 | 999.11 | 333.50 | 677.646667 |
| 游戏陪玩 | 2000.99 | 2000.99 | 2000.990000 |
| 董事长 | 12000.66 | 12000.66 | 12000.660000 |
+--------------+-------------+-------------+--------------+
4 rows in set (0.01 sec)
由于role这一列是group by指定的列,每一组的所有记录的role一定是相同的
如果分组之后不使用聚合函数,此时的结果就是查询出每一组中的某个代表数据,往往要搭配聚合函数使用,否则这里的查询结果就是没有意义的
- 在group by中,可以一个SQL同时完成这两个类的筛选
注意:可搭配条件需要区分清楚,该条件是分组之前的条件还是分组之后的条件
分组之前:直接使用where即可,where子句一般写在group by前
分组之后:查询每个岗位的平均薪资,但是排除平均薪资超过2w的结果,须使用下列的HAVING描述条件
4.1.3HAVING
GROUP BY子句进行分组之后,需要对分组结果再进行条件过滤时,不能使用where语句,而需要用HAVING
having语句一般写在group by 的后面
- 显示平均工资低于1500的角色和他的平均工资
mysql> select role,max(salary),min(salary),avg(salary) from emp group by role having avg(salary)<1500;
+--------------+-------------+-------------+-------------+
| role | max(salary) | min(salary) | avg(salary) |
+--------------+-------------+-------------+-------------+
| 服务员 | 1000.20 | 1000.20 | 1000.200000 |
| 游戏角色 | 999.11 | 333.50 | 677.646667 |
+--------------+-------------+-------------+-------------+
2 rows in set (0.00 sec)
4.2联合查询
(面试大概率考,但是实际开发中,而是要非常限制的使用,有时候使用起来很爽,但又不能广泛而不加节制的使用)
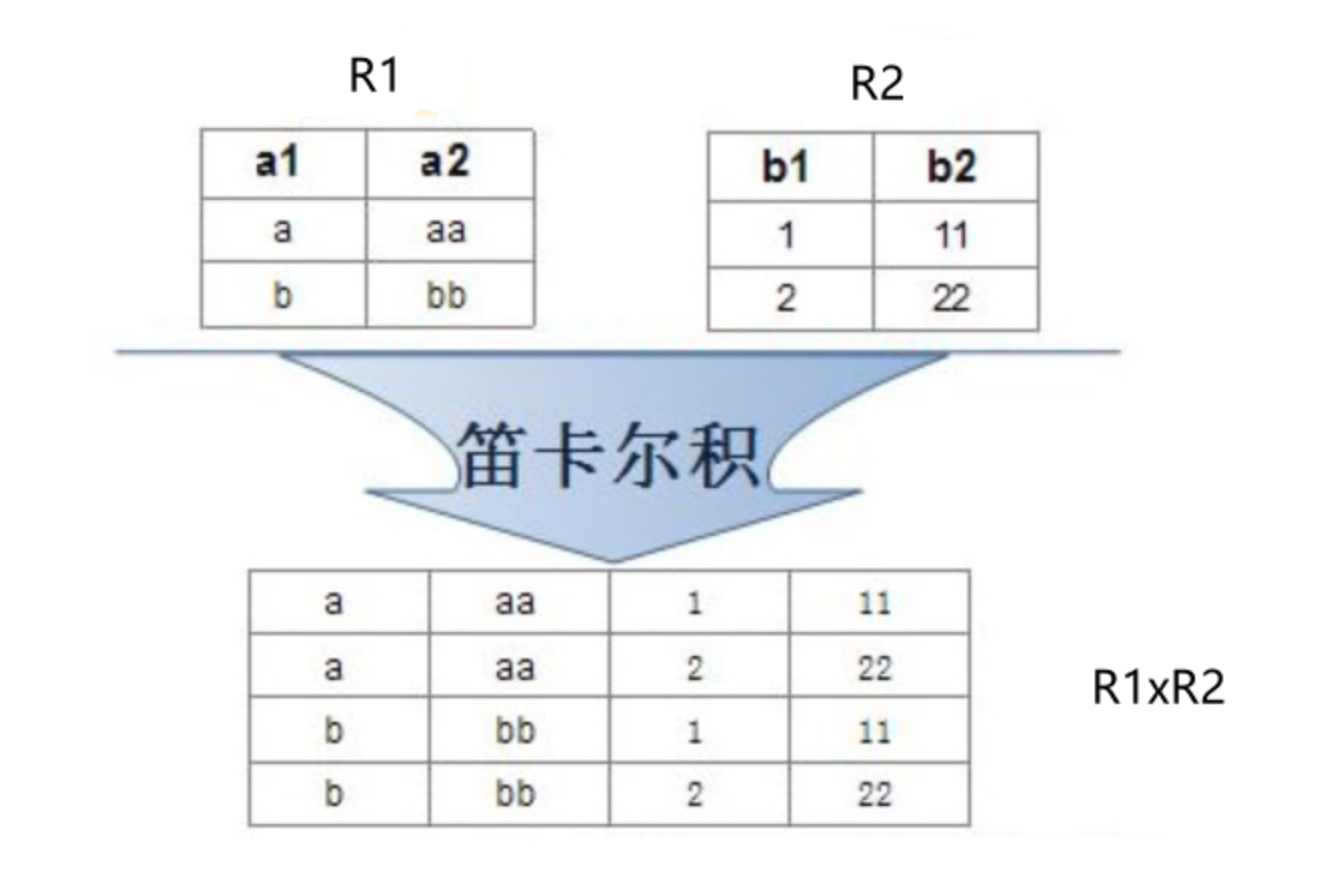
- 关键思路:理解笛卡尔积的工作原理
笛卡尔积:通过排列组合的方式得到一张更大的表,笛卡尔积的行数(列数)是这两个表的行数相加(列数相加),如果仔细观察可以看到其中有些数据是非法的(不符合实际情况,无意义),进行多表查询时,需要把有意义的数据筛选出来,无意义的数据过滤掉
4.2.1内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件
- 例:查询许仙同学的成绩
步骤:
- 先把两个表进行笛卡尔积
mysql> select * from student,score ;
- 加上连接条件,筛选出有效数据
mysql> select * from student,score where student.id = score.student_id;
- 结合需求添加条件,针对结果进行筛选
mysql> select * from student,score where student.id = score.student_id and student.name = '许仙';
+----+------+--------+---------------+------------+----+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | id | score | student_id | course_id |
+----+------+--------+---------------+------------+----+-------+------------+-----------+
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 10 | 67.0 | 4 | 1 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 11 | 23.0 | 4 | 3 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 12 | 56.0 | 4 | 5 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 13 | 72.0 | 4 | 6 |
+----+------+--------+---------------+------------+----+-------+------------+-----------+
4 rows in set (0.00 sec)
- 针对查询到的列进行精简
mysql> select student.name,score.score course from student,score where student.id = score.student_id and name = '许仙';
+--------+--------+
| name | course |
+--------+--------+
| 许仙 | 67.0 |
| 许仙 | 23.0 |
| 许仙 | 56.0 |
| 许仙 | 72.0 |
+--------+--------+
4 rows in set (0.00 sec)
- 例:查询所有同学的总成绩,及同学的个人信息
此时同学的成绩是按照行来组织的,此处就是多行数据进行加和,聚合函数还需按同学进行分组
- 先进行笛卡尔积
mysql> select * from student,score where student.id = score.student_id;
- 指定连接条件
mysql> select * from student,score where student.id = score.student_id;
- 先精简列
mysql> select student.name,sum(score.score) from student,score where student.id = score.student_id;
- 针对上述结果进行group by聚合查询
mysql> select student.name,sum(score.score) from student,score where student.id = score.student_id group by name;
+-----------------+------------------+
| name | sum(score.score) |
+-----------------+------------------+
| tellme | 172.0 |
| 不想毕业 | 118.0 |
| 好好说话 | 178.0 |
| 白素贞 | 200.0 |
| 菩提老祖 | 119.5 |
| 许仙 | 218.0 |
| 黑旋风李逵 | 300.0 |
+-----------------+------------------+
7 rows in set (0.01 sec)
- 例:查询所有同学的成绩以及个人信息
列出每个同学,每门课程的的课程名字和分数
- 先进行笛卡尔积
mysql> select * from student,score,course;
- 指定连接条件筛选数据
mysql> select * from student,score,course where student.id = score.student_id and course.id = score.course_id;
- 进行列的精简
mysql> select student.name,course.name,score.score from student,score,course where student.id = score.student_id and course.id = score.course_id;
+-----------------+--------------------+-------+
| name | name | score |
+-----------------+--------------------+-------+
| 黑旋风李逵 | Java | 70.5 |
| 菩提老祖 | Java | 60.0 |
| 白素贞 | Java | 33.0 |
| 许仙 | Java | 67.0 |
| 不想毕业 | Java | 81.0 |
| 好好说话 | 中国传统文化 | 56.0 |
| tellme | 中国传统文化 | 80.0 |
| 黑旋风李逵 | 计算机原理 | 98.5 |
| 白素贞 | 计算机原理 | 68.0 |
| 许仙 | 计算机原理 | 23.0 |
| 好好说话 | 语文 | 43.0 |
| 黑旋风李逵 | 高阶数学 | 33.0 |
| 菩提老祖 | 高阶数学 | 59.5 |
| 白素贞 | 高阶数学 | 99.0 |
| 许仙 | 高阶数学 | 56.0 |
| 不想毕业 | 高阶数学 | 37.0 |
| 黑旋风李逵 | 英文 | 98.0 |
| 许仙 | 英文 | 72.0 |
| 好好说话 | 英文 | 79.0 |
| tellme | 英文 | 92.0 |
+-----------------+--------------------+-------+
20 rows in set (0.00 sec)
笛卡尔积的缺点:要提前考虑好表的数量,一旦表数量大或数目多,笛卡尔积大,如果对大表进行笛卡尔积,会产生大量临时结果,耗费时间,如果多表查询的数目非常多,SQL复杂,可读性差
4.2.2外连接
如果两个表里的记录都是存在对应关系,内外连接的结果一定是一致的,如果不存在对应关系,内外链接就会出现差别
外连接分为左外连接和右外连接,如果联合查询,左侧的表完全显示我们就说是左外连接,右侧的表完全显示我们就说是右外连接
左外连接就是以左侧的表为基准,保证左侧的表的每个数据都会在最终的结果里,如果在右侧表中不存在,对应的列就填成NULL
右外连接就是以右侧的表为基准,保证右侧的表的每个数据都会在最终的结果里,如果在右侧表中不存在,对应的列就填成NULL
语法:
-- 左外连接,表1完全显示
select 字段 from 表名1 left join 表名2 on 连接条件-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件
- 例:查询所有同学的成绩以及个人信息,如果同学没有成绩,也需要表示
-- “老外学中文”同学没有考试成绩也显示出来了-- 左外连接mysql> select * from student stu left join score sco on stu.id = sco.student_id;
+----+-------+-----------------+------------------+------------+------+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | id | score | student_id | course_id |
+----+-------+-----------------+------------------+------------+------+-------+------------+-----------+
| 1 | 9982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 1 | 70.5 | 1 | 1 |
| 1 | 9982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 2 | 98.5 | 1 | 3 |
| 1 | 9982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 3 | 33.0 | 1 | 5 |
| 1 | 9982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 4 | 98.0 | 1 | 6 |
| 2 | 835 | 菩提老祖 | NULL | 1 | 5 | 60.0 | 2 | 1 |
| 2 | 835 | 菩提老祖 | NULL | 1 | 6 | 59.5 | 2 | 5 |
| 3 | 391 | 白素贞 | NULL | 1 | 7 | 33.0 | 3 | 1 |
| 3 | 391 | 白素贞 | NULL | 1 | 8 | 68.0 | 3 | 3 |
| 3 | 391 | 白素贞 | NULL | 1 | 9 | 99.0 | 3 | 5 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 10 | 67.0 | 4 | 1 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 11 | 23.0 | 4 | 3 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 12 | 56.0 | 4 | 5 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 | 13 | 72.0 | 4 | 6 |
| 5 | 54 | 不想毕业 | NULL | 1 | 14 | 81.0 | 5 | 1 |
| 5 | 54 | 不想毕业 | NULL | 1 | 15 | 37.0 | 5 | 5 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 16 | 56.0 | 6 | 2 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 17 | 43.0 | 6 | 4 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 18 | 79.0 | 6 | 6 |
| 7 | 83223 | tellme | NULL | 2 | 19 | 80.0 | 7 | 2 |
| 7 | 83223 | tellme | NULL | 2 | 20 | 92.0 | 7 | 6 |
| 8 | 9527 | 老外学中文 | foreigner@qq.com | 2 | NULL | NULL | NULL | NULL |
+----+-------+-----------------+------------------+------------+------+-------+------------+-----------+
21 rows in set (0.00 sec)
4.2.3自连接
自己和自己进行笛卡尔积,有时需要进行行和行的比较,而SQL只能进行行和列进行比较,此时就可以使用自连接,把行关系转成列关系
- 例:查询成绩表中计算机原理成绩比Java成绩好的信息
mysql> select s1.student_id,s1.score,s2.score from score as s1,score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;
+------------+-------+-------+
| student_id | score | score |
+------------+-------+-------+
| 1 | 98.5 | 70.5 |
| 3 | 68.0 | 33.0 |
+------------+-------+-------+
2 rows in set (0.01 sec)
4.2.4子查询
子查询的本质是套娃,把多个简单的SQL拼接成一个复杂的SQL,违背了一贯的变成原则
- 例:查询与“不想毕业”的同班同学
mysql> select * from student where classes_id = (select classes_id from student where name = '不想毕业');
+----+------+-----------------+-----------------+------------+
| id | sn | name | qq_mail | classes_id |
+----+------+-----------------+-----------------+------------+
| 1 | 9982 | 黑旋风李逵 | xuanfeng@qq.com | 1 |
| 2 | 835 | 菩提老祖 | NULL | 1 |
| 3 | 391 | 白素贞 | NULL | 1 |
| 4 | 31 | 许仙 | xuxian@qq.com | 1 |
| 5 | 54 | 不想毕业 | NULL | 1 |
+----+------+-----------------+-----------------+------------+
5 rows in set (0.00 sec)
4.2.5合并查询
把多个SQL的查询结果集合合并到一起
在实际应用中,为了合并多个select的执行结果,可以使用操作符union,union all。使用这两个时,前后查询的结果集中,字段需要一致
union:该操作符用于取得两个结果集的并集,当使用该操作符时,会自动去掉结果集中的重复行
- 例:查询id小于3,或者名字为“英文”的课程
mysql> select * from course where id < 3 union select * from course where name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)
合并的两个SQL的结果集的列的个数和类型需要一致,union允许把两个不同的表查询结果合并到一起,并进行去重,若不想去重则使用union all
union all:不会去掉结果集中的重复行
- 例:查询id小于3,或者名字为“Java”的课程
mysql> select * from course where id < 3 union all select * from course where name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)
相关文章:

MySQL表的增删改查进阶版
Mysql 1、数据库的约束1.1约束类型1.2 NULL约束1.3 UNIQUE:唯一约束1.4 DEFAULT:默认值约束1.5 PRIMARY KEY:主键约束(重点)1.6 FOREIGN KEY:外键约束(重点) 2.表的设计2.1一对一2.2…...

【C#】Socket通信的使用
在C#中,Socket通信是一种用于实现网络通信的底层技术。通过Socket,程序可以在网络上与其他设备进行数据交换。以下是如何使用C#中的System.Net.Sockets命名空间来实现Socket通信的详细步骤。 1. Socket通信的基本概念 Socket: 一个Socket是网络通信的端…...

linux以C方式和内核交互监听键盘[香橙派搞机日记]
最近在深入研究我的香橙派,不可避免的遇到了怎么认识和使用Linux内核的问题。 我给自己留了一个简单的任务:使用原生C来监听内核,实现读取键盘的消息。 CSDN上也有其他文章来解决这个问题,不过要么是技术不达标(直接和…...
 指针-深浅copy)
【C++初学】课后作业汇总复习(七) 指针-深浅copy
1、 HugeInt类:构造、、cout Description: 32位整数的计算机可以表示整数的范围近似为-20亿到+20亿。在这个范围内操作一般不会出现问题,但是有的应用程序可能需要使用超出上述范围的整数。C可以满足这个需求,创建功能强大的新的…...

【iOS】UIPageViewController学习
UIPageViewController学习 前言创建一个UIPageViewController最简单的使用 UIPageViewController的方法说明:效果展示 UIPageViewController的协议方法 前言 笔者最近在写项目时想实现一个翻书效果,上网学习到了UIPageViewController今天写本篇博客总结…...

GDB 调试命令详解:高效掌握常用调试技巧
🐞 GDB 调试命令详解:高效掌握常用调试技巧 GNU Debugger(GDB)是 Linux 下最强大的 C/C 调试工具。本文将系统梳理 GDB 的常用命令,覆盖运行控制、断点管理、变量查看、线程与进程调试等核心功能,助你快速掌…...

实验二 用递归下降法分析表达式实验
【实验目的】 1.掌握用递归下降分析法进行语法分析的方法。加深对自顶向下语法分析原理的理解。 2.掌握设计、编制并调试自顶向下语法分析程序的思想和方法。 3.本实验是高级语言程序设计、数据结构和编译原理中词法分析、自顶向下语法分析原理等知 识的综合。由于语法分析…...

【随身wifi】青龙面板保姆级教程
0.操作前必看 本教程基于Debian系统,从Docker环境。面板安装,到最后拉取脚本的使用。 可以拉库跑狗东京豆,elm红包等等,也可以跑写自己写的脚本,自行探索 重要的号别搞,容易黑号,黑号自己负责…...

从一到无穷大 #45:InfluxDB MCP Server 构建:从工程实践到价值重构
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 工程实践遇到的问题MCP Host选择开发流程 结果展现可能性展望工作生活带来的变化 MCP…...

app逆向专题五:新快报app数据采集
app逆向专题五:新快报app数据采集 一、抓包寻找数据接口二、编写代码三、完整代码一、抓包寻找数据接口 打开charles,并在手机端打开新快报app,点击“广州”或者“经济”等选项卡,抓包,寻找数据接口,如图所示: 二、编写代码 这里介绍一种简便的代码编写方法,在数据…...

使用 lm-eval 评估模型时报错:TypeError: ‘NoneType’ object is not callable 的解决方案
问题描述 在使用 lm-evaluation-harness 进行多 GPU 模型评估时,使用如下命令: accelerate launch --multi-gpu --num_processes 2 \-m lm_eval --model hf \--model_args pretrained${local_model_path} \--tasks mmlu \--batch_size 8 \--log_sample…...
:图像处理中的强大工具)
脉冲耦合神经网络(PCNN):图像处理中的强大工具
文章目录 一、PCNN 的起源与背景二、PCNN 的基本原理(一)模型结构(二)工作方式(三)动态阈值与脉冲特征三、PCNN 在图像处理中的应用(一)图像分割(二)边缘检测(三)纹理分析四、PCNN 的实现与优化环境准备PCNN 类定义图像分割示例在图像处理和计算机视觉领域,神经网…...

【Git】从零开始使用git --- git 的基本使用
哪怕是野火焚烧,哪怕是冰霜覆盖, 依然是志向不改,依然是信念不衰。 --- 《悟空传》--- 从零开始使用git 了解 Gitgit创建本地仓库初步理解git结构版本回退 了解 Git 开发场景中,文档可能会经历若干版本的迭代。假如我们不进行…...

React Hooks 的使用
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

【NIO番外篇】之组件 Channel
目录 一、什么是NIO Channel?二、常见的Channel组件及其用法1. FileChannel2. SocketChannel3. ServerSocketChannel4. DatagramChannel 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下&a…...

探秘 Ruby 与 JavaScript:动态语言的多面风采
1 语法特性对比:简洁与灵活 1.1 Ruby 的语法优雅 Ruby 的语法设计旨在让代码读起来像自然语言一样流畅。它拥有简洁而富有表现力的语法结构,例如代码块、符号等。 以下是一个使用 Ruby 进行数组操作的简单示例: # 定义一个数组 numbers [1…...
基本总结回顾21)
高频面试题(含笔试高频算法整理)基本总结回顾21
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...

深入浅出一下Python函数的核心概念与进阶应用
本篇技术博文摘要 🌟 本文系统梳理了Python函数的核心知识点,从基础概念到高级特性,构建了完整的函数编程知识体系。内容涵盖:变量作用域的局部与全局划分、函数注释的规范写法、参数传递中值与引用的区别、匿名函数的灵活应用&am…...
)
【漫话机器学习系列】198.异常值(Outlier)
异常值(Outlier)全面指南 —— 检测、分析与处理 作者:Chris Albon(图源) 场景:数据清洗与特征工程必备技能 一、什么是异常值(Outlier) 定义 异常值(Outlier࿰…...

React 记账本项目实战:多页面路由、Context 全局
在本文中,我们将分享一个使用 React 开发的「记账本」项目的实战经验。该项目通过 VS Code 完成,包含首页、添加记录页、编辑页等多个功能页面,采用了 React Router 实现路由导航,使用 Context API 管理全局的交易记录状态,并引入数据可视化组件呈现不同月份的支出情况。项…...

[React] 如何用 Zustand 构建一个响应式 Enum Store?附 RTKQ 实战与 TS 架构落地
[React] 如何用 Zustand 构建一个响应式 Enum Store?附 RTKQ 实战与 TS 架构落地 本文所有案例与数据为作者自行构建,所有内容均为技术抽象示例,不涉及任何实际商业项目 自从之前尝试了一下 zustand 之后,就发现 zustand 是一个轻…...

DeepSeek在职场办公中的高效指令运用与策略优化
摘要 随着人工智能技术的飞速发展,大型语言模型在各个领域的应用日益广泛。DeepSeek作为一款具有影响力的AI产品,为职场办公带来了新的变革与机遇。本文深入剖析DeepSeek在职场办公场景下的提示词指令运用,通过对提示词概念、作用、设计原则的…...

mysql事务脏读 不可重复读 幻读 事务隔离级别关系
看了很多文档,发现针对事务并发执行过程中的数据一致性问题,即脏读、不可重复读、幻读的解释一塌糊涂,这也不能说什么,因为官方SQL标准中的定义也模糊不清。 按照mysql中遵循的事务隔离级别,可以梳理一下其中的关系 隔…...

Fork/Join框架与线程池对比分析
Fork/Join框架与线程池对比分析 1. 概述 线程池(如ThreadPoolExecutor)是Java并发编程中用于管理线程生命周期的通用工具,适用于处理大量独立任务。Fork/Join框架(基于ForkJoinPool)是Java 7引入的专用框架ÿ…...

docker 安装 Gitlab
GitLab 安装 #创建容器数据卷映射目录 mkdir -p /usr/docker/gitlab/config mkdir -p /usr/docker/gitlab/logs mkdir -p /usr/docker/gitlab/data #目录授权 chmod 777 -R /usr/docker/gitlab/*#直接复制可用(记得改下宿主机ipv4,不知道怎么看,输入i…...

【贪心之摆动序列】
题目: 分析: 这里我们使用题目中给的第二个实例来进行分析 题目中要求我们序列当中有多少个摆动序列,摆动序列满足一上一下,一下一上,这样是摆动序列,并且要输出摆动序列的最长长度 通过上面的图我们可以…...

kubectl修改资源时添加注解
kubectl修改资源时添加注解 kubectl修改资源时添加注解老版本的注解(变化注解)删除Annotations查看Annotations信息 查看发布记录回滚 kubectl修改资源时添加注解 参考: 为什么我们要使用kubectl apply 修改资源时,在命令行后添加 --save-configtrue ,就会自动添加此次修改的…...
 复数类与运算符重载)
【C++初学】课后作业汇总复习(四) 复数类与运算符重载
1、复数类输出 如题,要求实现: 1、复数类含两个参数的构造函数,一个为实部,一个为虚部 2、用Show()现实复数的值。 输出 (23i) //如题,要求实现: // //1、复数类含两个参数的构造函数&…...

十四、C++速通秘籍—函数式编程
目录 上一章节: 一、引言 一、函数式编程基础 三、Lambda 表达式 作用: Lambda 表达式捕获值的方式: 注意: 四、函数对象 函数对象与普通函数对比: 五、函数适配器 1、适配普通函数 2、适配 Lambda 表达式 …...

复刻系列-星穹铁道 3.2 版本先行展示页
复刻星穹铁道 3.2 版本先行展示页 0. 视频 手搓~星穹铁道~展示页~~~ 1. 基本信息 作者: 啊是特嗷桃系列: 复刻系列官方的网站: 《崩坏:星穹铁道》3.2版本「走过安眠地的花丛」专题展示页现已上线复刻的网…...

阿里云备案有必要选择备案管家服务吗?自己ICP备案可以吗?
阿里云备案有必要选择备案管家服务吗?新手可以选择备案管家,备案管家不需要自己手动操作,可以高效顺利通过ICP备案。自己ICP备案可以吗?自己备案也可以的,也很简单,适合动手能力强的同学。 阿里云备案管家…...
--以postersql为例)
SQL语言基础(二)--以postersql为例
上次教程我们讲述了数据库中的增,删,改语句,今天我们来学习最后一个–‘改’的语句。 1.select语法 数据库查询只有select一个句子,但select语法相对复杂,其功能丰富,使用方式也很灵活 SELECT [ALL|Dist…...

探索 Rust 语言:高效、安全与并发的完美融合
在当今的编程语言领域,Rust 正以其独特的魅力吸引着越来越多开发者的目光。它诞生于 Mozilla 实验室,旨在解决系统编程中长久以来存在的难题,如今已成为构建可靠、高效软件的有力工具。 1 内存安全 Rust 通过所有权(ownership&a…...

最大公约数和最小倍数 java
在Java中,计算两个数的最大公约数(Greatest Common Divisor, GCD)和最小公倍数(Least Common Multiple, LCM)是常见的编程问题。以下是具体的实现方法和代码示例。 --- ### **1. 最大公约数 (GCD)** 最大公约数是指…...
:相机设备输入输出(ArkTS))
OpenHarmony Camera开发指导(三):相机设备输入输出(ArkTS)
相机应用可通过创建相机输入流调用并控制相机设备,创建不同类型的输出流,进而实现预览、拍照、录像等基础功能。 开发步骤 在创建相机设备输入之前需要先完成相机设备管理,详细开发步骤可参考上一篇文章。 创建相机输入流 通过cameraMana…...

通过分治策略解决内存限制问题完成大型Hive表数据的去重的PySpark代码实现
在Hive集群中,有一张历史交易记录表,要从这张历史交易记录表中抽取一年的数据按某些字段进行Spark去重,由于这一年的数据超过整个集群的内存容量,需要分解成每个月的数据,分别用Spark去重,并保存为Parquet文…...

融媒体中心智能语音识别系统设计与实现
县级融媒体中心智能语音识别系统设计与实现 序言 随着融媒体时代的快速发展,新闻采编、专题节目制作对语音转写效率的要求日益提高。作为基层融媒体中心的技术工程师,我们在实际工作中常面临以下痛点: 采访录音整理耗时:传统人…...

学习笔记九——Rust所有权机制
🦀 Rust 所有权机制 📚 目录 什么是值类型和引用类型?值语义和引用语义?什么是所有权?为什么 Rust 需要它?所有权的三大原则(修正版)移动语义 vs 复制语义:变量赋值到底…...
)
计算机视觉算法实现——电梯禁止电瓶车进入检测:原理、实现与行业应用(主页有源码)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 电梯安全检测领域概述 近年来,随着电动自行车(以下简称"电瓶车"&…...

扩散模型 Diffusion Model 整体流程详解
🧠 Diffusion Model 思路、疑问和代码 文章目录 🧠 Diffusion Model 思路、疑问和代码🔄 一、核心思想:从噪声到图像📦 二、正向过程:加噪🧠 三、反向过程:学习去噪🎯 目…...

[Spark]深入解密Spark SQL源码:Catalyst框架如何优雅地解析你的SQL
本文内容组织形式 总结具体例子执行语句解析层优化层物理计划层执行层 猜你喜欢PS 总结 先写个总结,接下来会分别产出各个部分的源码解析,Spark SQL主要分为以下五个执行部分。 具体例子 接下来举个具体的例子来说明 执行语句 SELECT name, age FR…...
)
【数据结构_7】栈和队列(上)
一、概念 栈和队列,也是基于顺序表和链表实现的 栈是一种特殊的线性表,其只允许在固定的一段进行插入和删除元素操作。 遵循后进先出的原则 此处所见到的栈,本质上就是一个顺序表/链表,但是,实在顺序表/链表的基础…...

Linux中的cat命令常见用法
在 Linux 中,cat 命令是 concatenate(连接)的缩写,意思是“连接”或“串联”。 基本功能 cat 命令的主要功能是用于查看、合并和创建文件。它会将一个或多个文件的内容输出到标准输出设备(通常是终端屏幕)…...
简单粗暴几行代码搞定!)
css - 实现三角形 div 容器,用css画一个三角形(提供示例源码)简单粗暴几行代码搞定!
效果图 如下图所示,让一个 div 变成三角形,并且可随意更改大小, 本文提供了可运行示例源码,直接复制即可。 实现源码 建议创建一个 demo.html 文件,一键复制代码运行。 <style> .div{width: 0px;height: 0px…...

springboot 项目 jmeter简单测试流程
测试内容为 主机地址随机数 package com.hainiu.example;import lombok.extern.slf4j.Slf4j; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotat…...

设计模式实践:模板方法、观察者与策略模式详解
目录 1 模板方法1.1 模板方法基本概念1.2 实验1.2.1 未使用模板方法实现代码1.2.2 使用模板方法的代码 2 观察者模式2.1 观察者模式基本概念2.2 实验 3 策略模式3.1 策略模式基本概念3.2 实验 1 模板方法 1.1 模板方法基本概念 定义:一个操作中的算法的骨架 &…...

Google的AI模型Gemini和Gemini网络协议
粉丝私信问我:gemini如何访问? "Gemini如何访问"需明确区分两种完全不同的技术体系:Google的AI模型Gemini和Gemini网络协议。以下是两者的访问方式详解: 一、访问Google的Gemini AI模型 1. 通过Web应用 地址…...

HTTP实现心跳模块
HTTP实现心跳模块 使用轻量级的cHTTP库cpp-httplib重现实现HTTP心跳模块 头文件HttplibHeartbeat.h #ifndef HTTPLIB_HEARTBEAT_H #define HTTPLIB_HEARTBEAT_H#include <string> #include <thread> #include <atomic> #include <chrono> #include …...
,源码可白嫖!)
基于web的民宿信息系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 随着信息时代的来临,民宿过去的民宿信息方式的缺点逐渐暴露,对过去的民宿信息的缺点进行分析,采取计算机方式构建民宿信息系统。本文通过阅读相关文献,研究国内外相关技术,提出了一种民宿信息管理、民宿信息管理…...
实现一个星系漫游)
使用OpenSceneGraph (osg)实现一个星系漫游
简介 使用OpenSceneGraph (osg)实现了一个太阳系漫游的程序,具有以下特点: 1.通过按键控制飞行器前进后退、空间姿态; 2.星系渲染; 3.背景星空渲染; 效果 提供了一张超大的星空背景图 代码示例 int main(int a…...