【Linux网络与网络编程】09.传输层协议TCP
前言
TCP 即 传输控制协议 (Transmission Control Protocol),该协议要对数据的传输进行一个详细的控制(数据传输时什么时候传输,一次发多少,怎么发,出错了怎么办……)
本篇博客将从下面这张TCP协议格式图展开:
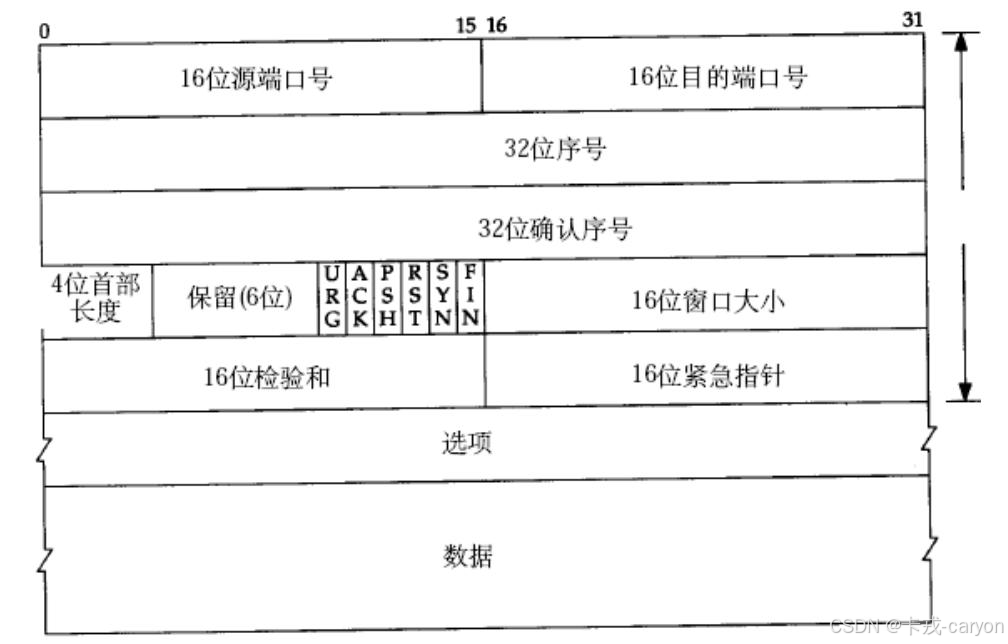
可以看到整体格式为:固定大小 20 字节的报头 + 扩展选项 +数据。
各部分的功能(整体认识,下文依次展开):
• 源/目的端口号:表示数据是从哪个进程来,到哪个进程去
• 32 位序号/32 位确认序号:下文详细讲
• 4 位 TCP 报头长度:表示该 TCP 头部有多少个4 字节
• 标志位:
○ URG:紧急指针是否有效
○ ACK:确认号是否有效
○ PSH:提示接收端应用程序立刻从 TCP 缓冲区把数据读走
○ RST:对方要求重新建立连接。我们把携带 RST 标识的称为复位报文段
○ SYN:请求建立连接。我们把携带 SYN 标识的称为同步报文段
○ FIN : 通知对方本端要关闭了。我们称携带 FIN 标识的为结束报文段
• 16 位窗口大小: 下文详细讲
• 16 位校验和:发送端填充,CRC 校验,接收端校验不通过则认为数据有问题。此处的检验和不光包含 TCP 首部,也包含 TCP 数据部分
• 16 位紧急指针:标识哪部分数据是紧急数据
• 选项: 暂时忽略
TCP是如何完成解包,如何完成分用的?
首先读取报头的20字节,拿到其中的4位首部长度(其基本单位为4字节)就能分离出 报头+选项 与 数据。而后通过目的端口号完成分用。
下面是Linux中的TCP报头部分源码:
struct tcphdr {__u16 source;__u16 dest;__u32 seq;__u32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)__u16 res1:4,doff:4,fin:1,syn:1,rst:1,psh:1,ack:1,urg:1,ece:1,cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)__u16 doff:4,res1:4,cwr:1,ece:1,urg:1,ack:1,psh:1,rst:1,syn:1,fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif __u16 window;__u16 check;__u16 urg_ptr;
};
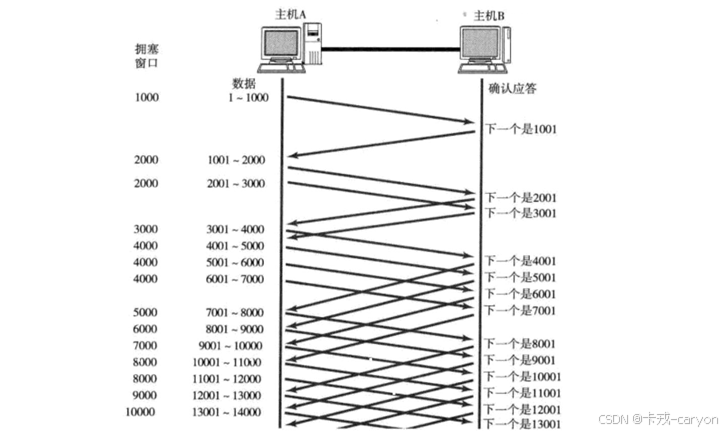
1. 确认应答机制——可靠性问题
主机A通过网络给主机B发了条消息,这条消息在网络中的传输也是要花费时间的并且主机A不能确定主机B是否收到了消息,因此TCP要求对接收到的消息做一次应答。只要主机A接收到了应答就能确保对端已经接收到了消息,这一机制就是确认应答。
但是与此同时我们也产生了新的问题:主机B给主机A发送应答,我怎么知道主机A是否接收到了呢?这就需要主机A对主机B做出的应答再次应答。不过这样的话岂不是无休止了吗?
所以我们可以有这样的结论:长距离通信时没有100%的可靠性,因为总有最新的一条消息是没有应答的。但是对于已经应答过的消息能做到100%可靠的。可靠性指的是历史消息的可靠性。
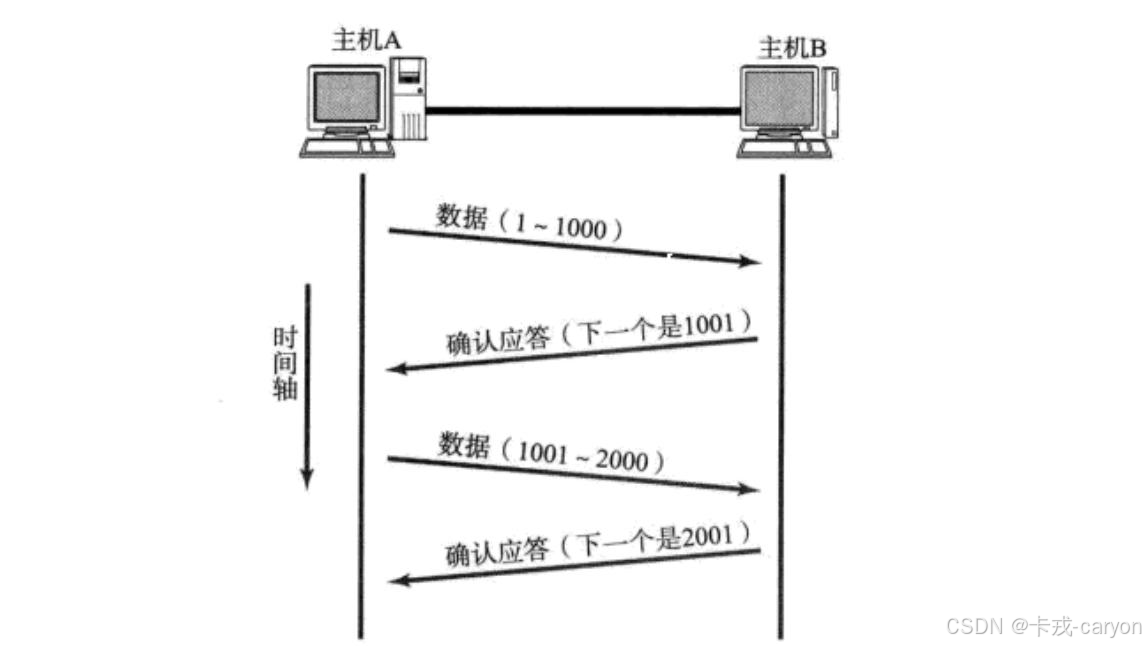
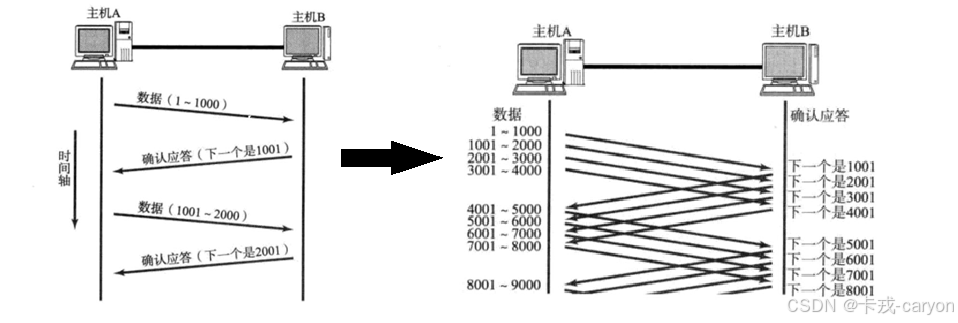
在上图中我们可以看到,收发消息的动作是串行的,但是这样的效率未免也太低了吧,只有当我接收应答之后我才能发送下一条消息?TCP协议在设计时就考虑到了这一点,因此真实情况下是并行的。并行的话客户端会收到很多的应答,可是客户端怎么能知道这些应答是对那条消息的应答呢?所以要给每个报文都带上编号,这也就是32位序号;同理,确认应答也对应一个编号,即32位确认序号。
确认序号 = 序号 + 1 ,表示在确认序号之前的内容已经全部收到了。
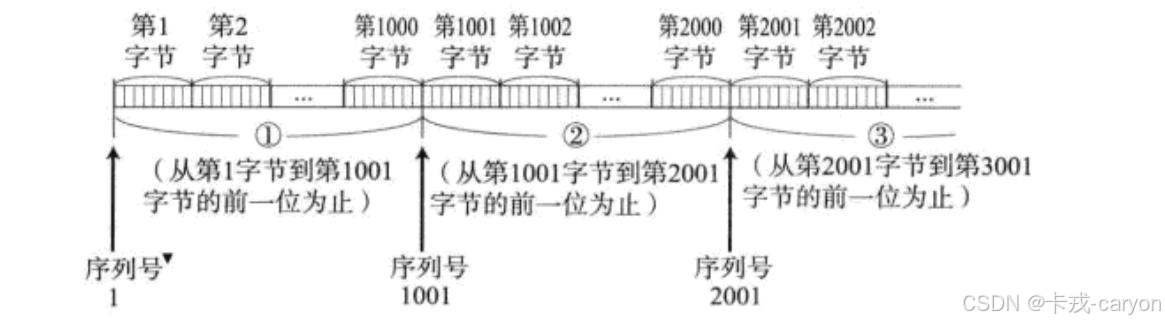
如何理解序号与确认序号?
TCP报头中不存在描述数据长度的字段,这是因为TCP时面向字节流的,它不对报文做任何完整性检测。即在接收到报文之后,它会将报头去掉,剩下的数据放到接收缓冲区中,随着缓冲区数据的不断增多就形成了流式结构,TCP的发送和接收缓冲区大小一般是确定的(16位窗口大小),于是TCP的缓冲区就可以理解为char类型的数组,因此就产生了序号。
收发消息就是典型的生产者消费者模型。
为什么要有两个序号呢?
请求的报文一般是tcphdr+有效载荷,而确认的报文一般是裸的tcphdr。但是其实在确认报头中也可以添加数据,这种机制称为捎带应带机制。这也很大概率上说明了tcp报文就是应答又是数据,故而存在的序号和确认序号更符合实际情况。
2. 超时重传机制——丢包问题
在TCP中丢包可以分为两种情况:1. 数据丢了 2. 应答丢了
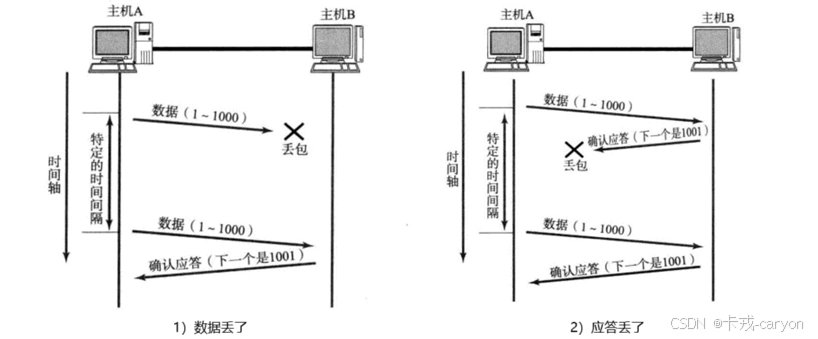
但是主机A怎么能确认是数据丢了还是应答丢了吗?不能,因为从主机A来看都是没有收到应答。那么主机A真的能确定自己的报文丢了吗?也不能,因此TCP只能规定超时重传。
这又产生了一个新的问题:如果主机A发送的数据因为网络问题导致超时了,而主机A又重新发了一遍,这不会导致数据重复吗?
报文 = 报头 + 有效载荷 ,在报头中包含的序号字段可以用来去重。
那么超时的时间如何确定呢?
最理想的情况下,找到一个最小的时间来保证 "确认应答一定能在这个时间内返回"。但是这个时间的长短随着网络环境的不同是有差异的,如果超时时间设的太长则会影响整体的重传效率;如果超时时间设的太短则有可能会频繁发送重复的包。TCP为了保证无论在任何环境下都能比较高性能的通信会动态计算这个最大超时时间。
Linux 中(BSD Unix 和 Windows 也是如此)超时以 500ms 为一个单位进行控制,每次判定超时重发的超时时间都是 500ms 的整数倍。如果重发一次之后仍然得不到应答,将会等待 2*500ms 后再进行重传,如果仍然得不到应答,就会等待 4*500ms 进行重传。依次类推,以指数形式递增,累计到一定的重传次数之后,TCP 认为网络或者对端主机出现异常就会强制关闭连接。
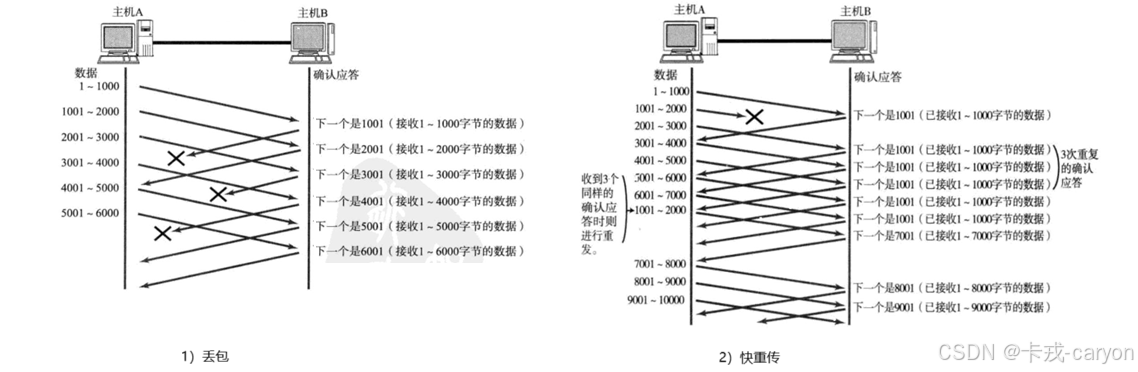
当某一段报文段丢失之后,发送端会一直收到 1001 这样的 ACK,这就像是在提醒发送端 "我想要的是 1001" 一样。如果发送端主机连续三次收到了同样一个 "1001" 这样的应答,就会将对应的数据 1001 - 2000 重新发送。这个时候接收端收到了 1001 之后,再次返回的 ACK 就是7001了,(因为 2001 - 7000)接收端其实之前就已经收到了,被放到了接收端操作系统内核的接收缓冲区中。这种机制被称为 "高速重发控制" (也叫 "快重传")
3. 连接管理机制
在正常情况下,TCP 要经过三次握手建立连接,四次挥手断开连接。
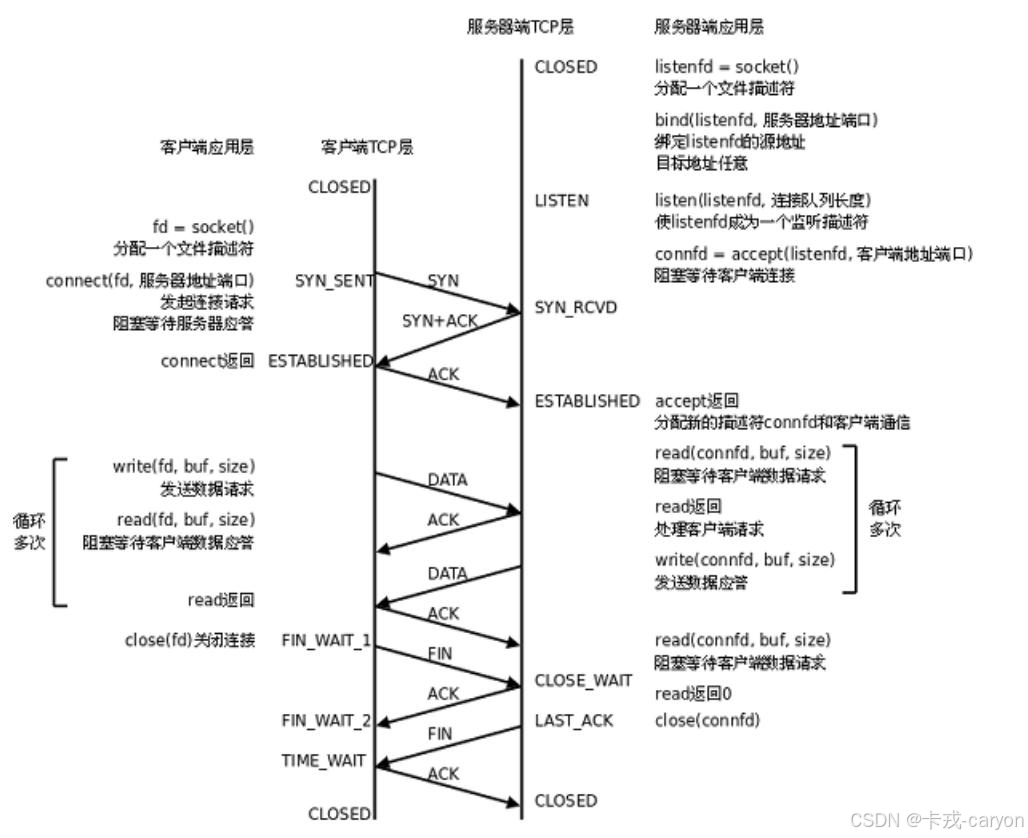
三次握手是双方的操作系统自动完成的。三次握手也是存在赌得成分的,赌得是最后一个ACK被对方收到了,如果失败就会发送一个将报头中RST置1的报头,重新建立联系。
四次挥手是由应用层的close触发的。四次挥手断开连接可以看出是需要双方同意的,因为TCP是全双工的,需要关闭两个朝向上的连接。
为什么是三次握手?
三次握手实质上来讲就是四次握手,只不过服务端的ACK和SYN合并形成了捎带应答。
三次握手建立了双方主机的通信意愿,同时验证了全双工通信的流畅性。
三次握手之后我们就建立起了连接,什么是连接?
一个连接一定和一个文件相对应,因为一个连接对应一个sockfd(fd)。连接在操作系统内部肯定会存在很多个,于是操作系统就要对这些连接进行管理——先描述后组织。所以连接就是结构。
状态转化示意:

看到这里各位或许有一个问题:客户端已经关闭连接了,但是服务端还想发送数据怎么办呢?
这里就引出了另一个关闭文件描述符的函数:
int shutdown(int sockfd, int how);这里的how就是关闭方式,有SHUT_WR,SHUT_RDWR,SHUT_RD。
3.1 TIME_WAIT状态
首先我们来看这样一个现象:
caryon@VM-24-10-ubuntu:~/linux/TCP_Socket/EchoSever$ ./sever_tcp
[2025-3-13 12:9:15] [INFO] [2444134] [TCPSever.hpp] [114] - socket succeed
[2025-3-13 12:9:15] [INFO] [2444134] [TCPSever.hpp] [122] - bind succeed
[2025-3-13 12:9:15] [INFO] [2444134] [TCPSever.hpp] [130] - listen succeed
[2025-3-13 12:10:14] [INFO] [2444134] [TCPSever.hpp] [221] - accept succeed connected is 111.61.198.165:29564 sockfd is 4...
^C
caryon@VM-24-10-ubuntu:~/linux/TCP_Socket/EchoSever$ ./sever_tcp
[2025-3-13 12:10:28] [INFO] [2444504] [TCPSever.hpp] [114] - socket succeed
[2025-3-13 12:10:28] [FATAL] [2444504] [TCPSever.hpp] [119] - bind failed
caryon@VM-24-10-ubuntu:~/linux/TCP_Socket/EchoSever$ netstat -tap
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 localhost:33060 0.0.0.0:* LISTEN -
tcp 0 0 localhost:mysql 0.0.0.0:* LISTEN -
tcp 0 0 _localdnsstub:domain 0.0.0.0:* LISTEN -
tcp 0 0 _localdnsproxy:domain 0.0.0.0:* LISTEN -
tcp 0 0 localhost:6010 0.0.0.0:* LISTEN -
tcp 0 0 VM-24-10-ubuntu:8888 111.61.198.165:29564 TIME_WAIT -
tcp 0 0 VM-24-10-ubuntu:51530 169.254.0.55:5574 ESTABLISHED -
tcp 1 0 VM-24-10-ubuntu:60092 169.254.0.3:http CLOSE_WAIT -
tcp 0 0 VM-24-10-ubuntu:51538 169.254.0.55:5574 ESTABLISHED -
tcp 0 0 VM-24-10-ubuntu:54608 169.254.0.138:8186 ESTABLISHED -
tcp 0 0 VM-24-10-ubuntu:52032 169.254.0.4:http TIME_WAIT -
tcp6 0 0 [::]:ssh [::]:* LISTEN -
tcp6 0 0 ip6-localhost:6010 [::]:* LISTEN -
tcp6 0 804 VM-24-10-ubuntu:ssh 111.61.198.165:28845 ESTABLISHED -
经过上述操作之后8888号端口变成了TIME_WAIT状态。
这是因为TCP 协议规定:主动关闭连接的一方要处于 TIME_ WAIT 状态等待两个 MSL(maximum segment lifetime)的时间后才能回到 CLOSED 状态。我们使用 Ctrl-C 终止了 server,所以 server 是主动关闭连接的一方,在 TIME_WAIT 期间仍然不能再次监听同样的 server 端口。
至于MSL 在 RFC1122 中规定为两分钟,但是各操作系统的实现不同,在 Centos7 上 默认配置的值是 60s。可以通过 cat /proc/sys/net/ipv4/tcp_fin_timeout 查看 msl 的值。
那么为什么 TIME_WAIT 的时间是 2MSL?
MSL 是 TCP 报文的最大生存时间,因此 TIME_WAIT 持续存在 2MSL 的话就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启,可能会收到来自上一个进程的迟到的数据,但是这种数据很可能是错误的)。同时也是在理论上保证最后一个报文可靠到达(假设最后一个 ACK 丢失,那么服务器会再重发一个 FIN。这时虽然客户端的进程不在了,但是 TCP 连接还在,仍然可以重发 LAST_ACK)。
在上面的现象展示中我们还可以看到 bind 失败了,这是因为在 server 的 TCP 连接没有完全断开之前不允许重新监听。服务器需要处理非常大量的客户端的连接(每个连接的生存时间可能很短,但是每秒都有很大数量的客户端来请求)。这个时候如果由服务器端主动关闭连接(比如某些客户端不活跃,就需要被服务器端主动清理掉) 就会产生大量 TIME_WAIT 连接。由于我们的请求量很大,这就可能导致 TIME_WAIT 的连接数很多,并且每个连接都会占用一个通信五元组(源 ip、源端口、目的 ip、目的端口、协议),其中服务器的 ip 、端口和协议是固定的,如果新来的客户端连接的 ip 和端口号和 TIME_WAIT 占用的连接重复了就会出现问题。
使用 setsockopt()设置 socket 描述符的选项 SO_REUSEADDR 为 1 表示允许创建端口号相同但 IP 地址不同的多个 socket 描述符。

3.2 CLOSE_WAIT状态
以我们之前写过的TCP服务器为例,当我们不close掉sockfd时而客户端退出时,可以看到8888号端口对应的服务端状态为CLOSE_WAIT:
caryon@VM-24-10-ubuntu:~$ netstat -tap
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 2480011/./sever_tcp
tcp 0 0 localhost:33060 0.0.0.0:* LISTEN -
tcp 0 0 localhost:mysql 0.0.0.0:* LISTEN -
tcp 0 0 _localdnsstub:domain 0.0.0.0:* LISTEN -
tcp 0 0 _localdnsproxy:domain 0.0.0.0:* LISTEN -
tcp 0 0 localhost:6010 0.0.0.0:* LISTEN -
tcp 0 0 localhost:6011 0.0.0.0:* LISTEN -
tcp 0 0 VM-24-10-ubuntu:51530 169.254.0.55:5574 ESTABLISHED -
tcp 1 0 VM-24-10-ubuntu:60092 169.254.0.3:http CLOSE_WAIT -
tcp 0 0 VM-24-10-ubuntu:51538 169.254.0.55:5574 ESTABLISHED -
tcp 0 0 VM-24-10-ubuntu:8888 111.61.198.169:31802 CLOSE_WAIT 2480011/./sever_tcp
tcp 0 0 VM-24-10-ubuntu:54608 169.254.0.138:8186 ESTABLISHED -
tcp6 0 0 [::]:ssh [::]:* LISTEN -
tcp6 0 0 ip6-localhost:6010 [::]:* LISTEN -
tcp6 0 0 ip6-localhost:6011 [::]:* LISTEN -
tcp6 0 0 VM-24-10-ubuntu:ssh 111.61.198.169:31668 ESTABLISHED -
tcp6 0 280 VM-24-10-ubuntu:ssh 111.61.198.169:31786 ESTABLISHED - 而当我们关闭之后则不会有这样的显示:
caryon@VM-24-10-ubuntu:~$ netstat -tap
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 2482667/./sever_tcp
tcp 0 0 localhost:33060 0.0.0.0:* LISTEN -
tcp 0 0 localhost:mysql 0.0.0.0:* LISTEN -
tcp 0 0 _localdnsstub:domain 0.0.0.0:* LISTEN -
tcp 0 0 _localdnsproxy:domain 0.0.0.0:* LISTEN -
tcp 0 0 localhost:33689 0.0.0.0:* LISTEN 2481073/code-494970
tcp 0 0 localhost:6010 0.0.0.0:* LISTEN -
tcp 0 0 localhost:6011 0.0.0.0:* LISTEN -
tcp 0 0 localhost:60080 localhost:33689 ESTABLISHED -
tcp 0 0 VM-24-10-ubuntu:51530 169.254.0.55:5574 ESTABLISHED -
tcp 1 0 VM-24-10-ubuntu:60092 169.254.0.3:http CLOSE_WAIT -
tcp 0 0 VM-24-10-ubuntu:51538 169.254.0.55:5574 ESTABLISHED -
tcp 0 0 localhost:33689 localhost:60080 ESTABLISHED 2481073/code-494970
tcp 0 0 VM-24-10-ubuntu:54608 169.254.0.138:8186 ESTABLISHED -
tcp6 0 0 [::]:ssh [::]:* LISTEN -
tcp6 0 0 ip6-localhost:6010 [::]:* LISTEN -
tcp6 0 0 ip6-localhost:6011 [::]:* LISTEN -
tcp6 0 0 VM-24-10-ubuntu:ssh 111.61.198.169:31668 ESTABLISHED -
tcp6 0 0 VM-24-10-ubuntu:ssh 111.61.198.169:31905 ESTABLISHED -
tcp6 0 376 VM-24-10-ubuntu:ssh 111.61.198.169:31786 ESTABLISHED - 这也是在警示我们服务端使用完毕的sockfd一定要及时关闭。
4. 流量控制——滑动窗口问题
这里我们抛出一个问题:客户端可能会给服务端发送大量的数据,但是服务端来不及接收怎么办?
正常来讲就只能丢弃掉了,但是这个也没什么的,因为客户端会重发,可以重发可是会浪费时间和空间的啊,操作系统可不会做这样的事情,所以操作系统的角度就会想,既然来不及接收了,那我们就应该减少客户端发送的数据量,这样的操作我们称为流量控制。但是客户端凭什么进行流量控制呢?客户端是怎么知道服务端来不及接收了呢?这就需要明确服务端的接收能力有什么决定,很显然是由接收方的接收缓冲区的剩余大小决定的。因此在服务端应答时,报头中有一个16位窗口大小的属性,它会将自己的接收缓冲区的大小填入其中,服务端接收到报头也就会明确了。
刚才我们在讨论确认应答策略时对每一个发送的数据段,都要给一个 ACK 确认应答。在收到 ACK 后再发送下一个数据段,这样做有一个比较大的缺点,就是性能较差。尤其是数据往返的时间较长的时候。既然这样一发一收的方式性能较低,那么我们一次发送多条数据就可以大大的提高性能(其实是将多个段的等待时间重叠在一起了)。
窗口大小指的是无需等待确认应答而可以继续发送数据的最大值,上图的窗口大小就是 4000 个字节(四个段)。在发送前四个段时不需要等待任何 ACK即可直接发送。在收到第一个 ACK 后,滑动窗口向后移动,继续发送第五个段的数据…… 操作系统内核为了维护这个滑动窗口,需要开辟发送缓冲区来记录当前还有哪些数据没有应答,只有确认应答过的数据才能从缓冲区删掉,窗口越大,则网络的吞吐率就越高。
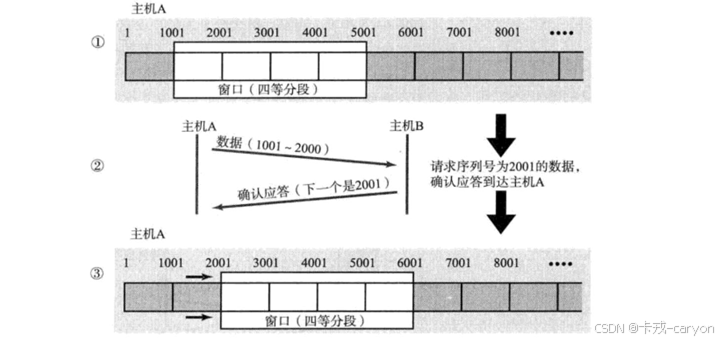
如何理解滑动窗口?
发送缓冲区可以可以理解为一个 char buff [N]; 的环形结构(基于环形队列的生产者消费者模型),所谓的滑动窗口就是有开始序号到结束序号之间的一段空间区域。滑动窗口的滑动是通过ACK返回的确认序列号和窗口大小决定,因此它是动态变化的。滑动窗口只能向右滑动,因为序列号是连续的。
滑动窗口的大小?
滑动窗口的大小 = min( 对方缓冲区剩余空间的大小,拥塞窗口的大小)。那么问题来了。16位数字最大表示 65535,那么 TCP 窗口最大就是 65535 字节么?实际上,TCP 首部 40 字节选项中还包含了一个窗口扩大因子 M,实际窗口大小是窗口字段的值左移 M 位。
滑动窗口里面的数据为什么是一段一段的?直接干成一个大报文不行吗?
不行,因为数据链路层不允许发送大报文。
5. 拥塞控制——网络问题
虽然 TCP 有了滑动窗口这个大杀器能够高效可靠的发送大量的数据。但是如果在刚开始阶段就发送大量的数据仍然可能引发问题。因为网络上有很多的计算机,可能当前的网络状态就已经比较拥堵,在不清楚当前网络状态下,贸然发送大量的数据是很有可能引起雪上加霜的。于是TCP 引入慢启动机制,先发少量的数据探探路,摸清当前的网络拥堵状态后再决定按照多大的速度传输数据。
实际情况如图所示,发送的数据是慢增长的:
拥塞窗口:
在发送开始的时候,定义拥塞窗口大小为 1,每次收到一个 ACK 应答之后拥塞窗口加 1。每次发送数据包的时候,将拥塞窗口和接收端主机反馈的窗口大小做比较,取较小的值作为实际发送的窗口。像下面这样的拥塞窗口增长速度是指数级别的。"慢启动" 只是指初始时慢,但是增长速度非常快。为了不增长的那么快,因此不能使拥塞窗口单纯的加倍,当拥塞窗口超过慢启动的阈值时,不再按照指数方式增长, 而是按照线性方式增长。
当 TCP 开始启动的时候,慢启动阈值等于窗口最大值,在每次超时重发的时候,慢启动阈值会变成原来的一半,同时拥塞窗口置回 1。
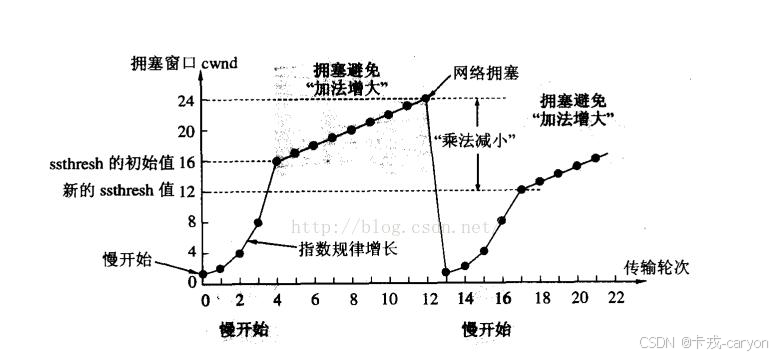
面对少量的丢包,我们仅仅是触发超时重传,而面对大量的丢包,我们就认为网络拥塞。当 TCP 通信开始后网络吞吐量会逐渐上升,随着网络发生拥堵,吞吐量会立刻下降。拥塞控制归根结底是 TCP 协议想尽可能快的把数据传输给对方,但是又要避免给网络造成太大压力的折中方案。
6. 延迟应答机制
如果接收数据的主机立刻返回 ACK 应答,这时候返回的窗口可能比较小。假设接收端缓冲区为 1M,一次收到了 500K 的数据,如果立刻应答,返回的窗口就是 500K。但实际上可能处理端处理的速度很快,10ms 之内就把 500K 数据从缓冲区消费掉了。在这种情况下,接收端处理还远没有达到自己的极限,即使窗口再放大一些也能处理过来。如果接收端稍微等一会再应答,比如等待200ms再应答,那么这个时候返回的窗口大小就是 1M。窗口越大,网络吞吐量就越大,传输效率就越高。
我们的目标是在保证网络不拥塞的情况下尽量提高传输效率,那么所有的包都可以延迟应答吗? 肯定也不是
• 数量限制:每隔 N 个包就应答一次
• 时间限制:超过最大延迟时间就应答一次
具体的数量和超时时间,由于操作系统的不同而不同。一般 N 取 2,超时时间取 200ms。
7. 面向字节流——粘包问题
创建一个 TCP 的 socket 的同时会在内核中创建一个发送缓冲区和一个接收缓冲区。在调用 write 时,数据会先写入发送缓冲区中,如果发送的字节数太长的话会被拆分成多个 TCP 的数据包发出;如果发送的字节数太短就会先在缓冲区里等待,等到缓冲区长度差不多了或者其他合适的时机发送出去。在接收数据的时候,数据也是从网卡驱动程序到达内核的接收缓冲区,然后应用程序可以调用 read 从接收缓冲区拿数据。
TCP 的一个连接,既有发送缓冲区也有接收缓冲区,那么对于这一个连接的话既可以读数据,也可以写数据,这个概念叫做全双工。
由于缓冲区的存在使得TCP 程序的读和写不需要一一匹配,例如: 写 100 个字节数据时可以调用一次 write 写 100 个字节,也可以调用 100 次 write,每次写一个字节;读 100 个字节数据时也完全不需要考虑写的时候是怎么写的,既可以一次 read 100 个字节,也可以一次 read 一个字节重复100 次。
正是由于TCP的面向字节流的特性,使得存在着粘包问题。
首先要明确,粘包问题中的"包"指的是应用层的数据包。在 TCP 的协议头中没有如同 UDP 一样的 "报文长度" 这样的字段,但是有一个序号这样的字段。这可以使得站在传输层的角度来看,TCP 是一个一个报文过来,并按照序号排好序放在缓冲区中;而站在应用层的角度来看,看到的只是一串连续的字节数据。
应用程序看到了这么一连串的字节数据压根就不知道从哪个部分开始到哪个部分结束,一个完整的应用层数据包如何避免粘包问题呢? 归根结底就是一句话,明确两个包之间的边界。
对于定长的包,保证每次都按固定大小读取即可;对于变长的包,可以在包头的位置约定一个包总长度的字段,从而就知道了包的结束位置,还可以在包和包之间使用明确的分隔符(应用层协议是程序猿自己来定的,只要保证分隔符不和正文冲突即可)。
思考:对于 UDP 协议来说,是否也存在 "粘包问题" 呢?
对于 UDP,如果还没有上层交付数据,那么UDP 的报文长度仍然在。同时,UDP 是一个一个把数据交付给应用层的,这就有很明确的数据边界。站在应用层的角度,在使用 UDP 时要么收到完整的 UDP 报文,要么不收,不会出现"半个"的情况。
8. TCP异常情况
• 进程终止:进程终止会释放文件描述符,仍然可以发送 FIN ,这个和正常关闭没有什么区别。
• 机器重启:和进程终止的情况相同
• 机器掉电/网线断开:接收端认为连接还在,一旦接收端有写入操作就会发现连接已经不在了,就会进行 reset。即使没有写入操作,TCP 自己也内置了一个保活定时器,会定期询问对方是否还在,如果对方不在的话会把连接释放。
9. 基于 TCP 应用层协议
• HTTP
• HTTPS
• SSH
• Telnet
• FTP
• SMTP
• 自定义的基于TCP的应用层协议
10. 小结
TCP 这么复杂是因为要保证可靠性的同时又尽可能的提高性能。
可靠性:
• 校验和
• 序列号
• 确认应答
• 超时重发
• 连接管理
• 流量控制
• 拥塞控制
提高性能:
• 滑动窗口
• 快速重传
• 延迟应答
• 捎带应答
其他:
• 定时器(超时重传定时器, 保活定时器, TIME_WAIT 定时器等)
11. TCP/UDP 对比
我们说了 TCP 是可靠连接,那么是 TCP 是不是一定就优于 UDP 呢?
TCP 和 UDP 之间的优点和缺点不能简单的、绝对的进行比较。
• TCP 用于可靠传输的情况,应用于文件传输、重要状态更新等场景
• UDP 用于对高速传输和实时性要求较高的通信领域。例如:早期的 QQ、视频传输等场景,另外 UDP 可以用于广播
归根结底,TCP 和 UDP 都是程序员的工具。什么时机用,具体怎么用,还是要根据具体的需求场景去判定。
相关文章:

【Linux网络与网络编程】09.传输层协议TCP
前言 TCP 即 传输控制协议 (Transmission Control Protocol),该协议要对数据的传输进行一个详细的控制(数据传输时什么时候传输,一次发多少,怎么发,出错了怎么办……) 本篇博客将从下面这张TCP协议格式图…...

08.unity 游戏开发-unity编辑器资源的导入导出分享
08.unity 游戏开发-unity编辑器资源的导入导出分享 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望对您有用~ unity简介…...

Docker Swarm 集群
Docker Swarm 集群 本文档介绍了 Docker Swarm 集群的基本概念、工作原理以及相关命令使用示例,包括如何在服务调度中使用自定义标签。本文档适用于需要管理和扩展 Docker 容器化应用程序的生产环境场景。 1. 什么是 Docker Swarm Docker Swarm 是用于管理 Docker…...

数据中台、数据湖和数据仓库 区别
1. 核心定义与定位 数据仓库(Data Warehouse) 定义:面向主题的、集成的、历史性且稳定的结构化数据集合,主要用于支持管理决策和深度分析。定位:服务于管理层和数据分析师,通过历史数据生成报表和商业智能…...
官网示例(五)可撤销操作、拆分视图、斑马条纹)
【CodeMirror】系列(二)官网示例(五)可撤销操作、拆分视图、斑马条纹
一、可撤销操作 默认情况下,history 历史记录扩展仅跟踪文档和选择的更改,撤销操作只会回滚这些更改,而不会影响编辑器状态的其他部分。 不过你也可以将其他的操作定义成可撤销的。如果把这些操作看作状态效果,就可以把相关功能整…...

SpringBoot 动态路由菜单 权限系统开发 菜单权限 数据库设计 不同角色对应不同权限
介绍 系统中的路由配置可以根据用户的身份、角色或其他权限信息动态生成,而不是固定在系统中。不同的用户根据其权限会看到不同的路由,访问不同的页面。对应各部门不同的权限。 效果 [{"id": 1,"menuName": "用户管理"…...

scikit-learn 开源框架在机器学习中的应用
文章目录 scikit-learn 开源框架介绍1. 框架概述1.1 基本介绍1.2 版本信息 2. 核心功能模块2.1 监督学习2.2 无监督学习2.3 数据处理 3. 关键设计理念3.1 统一API设计3.2 流水线(Pipeline) 4. 重要辅助功能4.1 模型选择4.2 评估指标 5. 性能优化技巧5.1 并行计算5.2 内存优化 6…...

GPT-4、Grok 3与Gemini 2.0 Pro:三大AI模型的语气、风格与能力深度对比
更新后的完整CSDN博客文章 以下是基于您的要求,包含修正后的幻觉率部分并保留原始信息的完整CSDN博客风格文章。幻觉率已调整为更符合逻辑的描述,其他部分保持不变。 GPT-4、Grok 3与Gemini 2.0 Pro:三大AI模型的语气、风格与能力深度对比 …...

Cyber Weekly #51
赛博新闻 1、英伟达开源新模型,性能直逼DeepSeek-R1 本周,英伟达开源了基于Meta早期Llama-3.1-405B-Instruct模型开发的Llama-3.1-Nemotron-Ultra-253B-v1大语言模型,该模型拥有2530亿参数,在多项基准测试中展现出与6710亿参数的…...

QT聊天项目开发DAY02
1.添加输入密码的保密性 LoginWidget::LoginWidget(QDialog*parent): QDialog(parent) {ui.setupUi(this);ui.PassWord_Edit->setEchoMode(QLineEdit::Password);BindSlots(); }2.添加密码的验证提示 3.修复内存泄漏,并嵌套UI子窗口到主窗口里面 之前并没有设置…...

Spring AI高级RAG功能查询重写和查询翻译
1、创建查询重写转换器 // 创建查询重写转换器queryTransformer RewriteQueryTransformer.builder().chatClientBuilder(openAiChatClient.mutate()).build(); 查询重写是RAG系统中的一个重要优化技术,它能够将用户的原始查询转换成更加结构化和明确的形式。这种转…...

速盾:高防CDN的原理和高防IP一样吗?
随着互联网的发展,网络安全威胁日益严重,尤其是DDoS攻击、CC攻击等恶意行为,给企业带来了巨大的风险。为了应对这些挑战,许多企业开始采用高防CDN(内容分发网络)和高防IP作为防御措施。尽管两者都能提供一定…...

SQLite-Web:一个轻量级的SQLite数据库管理工具
SQLite-Web 是一个基于 Web 浏览器的轻量级 SQLite 数据库管理工具。它基于 Python 开发,免费开源,无需复杂的安装或配置,适合快速搭建本地或内网的 SQLite 管理和开发环境。 SQLite-Web 支持常见的 SQLite 数据库管理和开发任务,…...

数智读书笔记系列028 《奇点更近》
一、引言 在科技飞速发展的今天,我们对未来的好奇与日俱增。科技将如何改变我们的生活、社会乃至人类本身?雷・库兹韦尔的《奇点更近》为我们提供了深刻的见解和大胆的预测,让我们得以一窥未来几十年的科技蓝图。这本书不仅是对未来科技趋势…...

深入理解linux操作系统---第4讲 用户、组和密码管理
4.1 UNIX系统的用户和组 4.1.1 用户与UID UID定义:用户身份唯一标识符,16位或32位整数,范围0-65535。系统用户UID为0(root)、1-999(系统服务),普通用户从1000开始分配特殊UID&…...
))
系统设计模块之安全架构设计(常见攻击防御(SQL注入、XSS、CSRF、DDoS))
一、SQL注入攻击防御 SQL注入是通过恶意输入篡改数据库查询逻辑的攻击方式,可能导致数据泄露或数据库破坏。防御核心在于隔离用户输入与SQL代码,具体措施包括: 参数化查询(预编译语句) 原理:将SQL语句与用…...

redission锁释放失败处理
redission锁释放失败处理 https://www.jianshu.com/p/055ae798547a 就是可以删除 锁的key 这样锁就释放了,但是 还是要结合业务,这种是 非正规的处理方式,还是要在代码层面进行处理。...

Visual Studio Code 在.S汇编文件中添加调试断点及功能简介
目录 一、VS Code汇编文件添加断点二、VS Code断点调试功能简介1. 设置断点(1) 单行断点(2) 条件断点(3) 日志断点 2. 查看断点列表3. 调试时的断点控制4. 禁用/启用断点5. 删除断点6. 条件断点的使用7. 多线程调试8. 远程调试9. 调试配置文件 一、VS Code汇编文件添加断点 最…...

计算视觉与数学结构及AI拓展
在快速发展的计算视觉领域,算法、图像处理、神经网络和数学结构的交叉融合,在提升我们对视觉感知和分析的理解与能力方面发挥着关键作用。本文探讨了支撑计算视觉的基本概念和框架,强调了数学结构在开发鲁棒的算法和模型中的重要性。 AI拓展…...

Vue2 老项目升级 Vue3 深度解析教程
Vue2 老项目升级 Vue3 深度解析教程 摘要 Vue3 带来了诸多改进和新特性,如性能提升、组合式 API、更好的 TypeScript 支持等,将 Vue2 老项目升级到 Vue3 可以让项目获得这些优势。本文将深入解析升级过程,涵盖升级前的准备工作、具体升级步骤…...

器件封装-2025.4.13
1.器件网格设置要与原理图一致,同时器件符号要与数据手册一致 2.或者通过向导进行编辑,同时电机高级符号向导进行修改符号名称 2.封装一般尺寸大小要比数据手册大2倍到1.5倍 焊盘是在顶层绘制,每个焊盘距离要用智能尺子测量是否跟数据手册一…...

Python 基础语法汇总
Python 语法 │ ├── 基本结构 │ ├── 语句(Statements) │ │ ├── 表达式语句(如赋值、算术运算) │ │ ├── 控制流语句(if, for, while) │ │ ├── 定义语句(def…...

Java函数式编程魔法:Stream API的10种妙用
在Java 8中引入的Stream API为函数式编程提供了一种全新的方式。它允许我们以声明式的方式处理数据集合,使代码更加简洁、易读且易于维护。本文将介绍Stream API的10种妙用,帮助你更好地理解和应用这一强大的工具。 1. 过滤操作:筛选符合条件…...
编辑距离)
【力扣hot100题】(094)编辑距离
记得最初做这题完全没思路,这次凭印象随便写了一版居然对了。 感觉这题真的有点为出题而出题的意思,谁拿到这题会往动态规划方向想啊jpg 也算是总结出规律了,凡是遇到这种比较俩字符串的十有八九是动态规划,而且是二维动态规划&…...

穿透三层内网VPC2
网络拓扑 目标出网web地址:192.168.139.4 信息收集端口扫描: 打开8080端口是一个tomcat的服务 版本是Apache Tomcat/7.0.92 很熟悉了,可能存在弱口令 tomcat/tomcat 成功登录 用哥斯拉生成马子,上传war包,进入后台 C…...

AI数字消费第一股,重构商业版图的新物种
伍易德带领团队发布“天天送AI数字商业引擎”,重新定义流量与消费的关系 【2025年4月,深圳】在人工智能浪潮席卷全球之际,深圳天天送网络科技有限公司于深圳大中华喜来登酒店重磅召开“AI数字消费第一股”发布盛典。公司创始人伍易德首次系统…...

Unity 基于navMesh的怪物追踪惯性系统
今天做项目适合 策划想要实现一个在现有的怪物追踪系统上实现怪物拥有惯性功能 以下是解决方案分享: 怪物基类代码: using UnityEngine; using UnityEngine.AI;[RequireComponent(typeof(NavMeshAgent))] [RequireComponent(typeof(AudioSource))] …...

【OpenCV】【XTerminal】talk程序运用和linux进程之间通信程序编写,opencv图像库编程联系
目录 一、talk程序的运用&Linux进程间通信程序的编写 1.1使用talk程序和其他用户交流 1.2用c语言写一个linux进程之间通信(聊天)的简单程序 1.服务器端程序socket_server.c编写 2.客户端程序socket_client.c编写 3.程序编译与使用 二、编写一个…...

中断的硬件框架
今天呢,我们来讲讲中断的硬件框架,这里会去举3个开发板,去了解中断的硬件框架: 中断路径上的3个部件: 中断源 中断源多种多样,比如GPIO、定时器、UART、DMA等等。 它们都有自己的寄存器,可以…...

大数据面试问答-Hadoop/Hive/HDFS/Yarn
1. Hadoop 1.1 MapReduce 1.1.1 Hive语句转MapReduce过程 可分为 SQL解析阶段、语义分析阶段、逻辑计划生成阶段、逻辑优化阶段、物理计划生成阶段。 SQL解析阶段 词法分析(Lexical Analysis):使用Antlr3将SQL字符串拆分为有意义的token序列 语法分析(Syntax An…...
第五期)
【小沐学GIS】基于C++绘制三维数字地球Earth(QT5、OpenGL、GIS、卫星)第五期
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第二期3【小沐学GIS】…...
)
初始图形学(3)
昨天休息了一天,今天继续图形学的学习 向场景发射光线 现在我们我们准备做一个光线追踪器。其核心在于,光线追踪程序通过每个像素发送光线。这意味着对于图像中的每个像素点,程序都会计算一天从观察者出发,穿过该像素的光线。并…...

如果想在 bean 创建出来之前和销毁之前做一些自定义操作可以怎么来实现呢?
使用生命周期扩展接口(最灵活) 创建前拦截可以通过实现 InstantiationAwareBeanPostProcessor 接口的 postProcessBeforeInstantiation 方法,在Bean实例化前执行逻辑 在销毁前拦截可以通过实现 DestructionAwareBean 接口的 postProcessBe…...

【甲子光年】DeepSeek开启AI算法变革元年
目录 引言人工智能的发展拐点算力拐点:DeepSeek的突破数据拐点:低参数量模型的兴起算法创新循环算法变革推动AI普惠应用全球AI科技竞争进入G2时代结论 引言 2025年,人工智能的发展已经走到了一个战略拐点。随着技术能力的不断提升࿰…...

Go语言--语法基础4--基本数据类型--整数类型
整型是所有编程语言里最基础的数据类型。 Go 语言支持如下所示的这些整型类型。 需要注意的是, int 和 int32 在 Go 语言里被认为是两种不同的类型,编译器也不会帮你自动做类型转换, 比如以下的例子会有编译错误: var value2 in…...

MCP基础学习计划详细总结
MCP基础学习计划详细总结 1.MCP概述与基础 • MCP(Model Context Protocol):由Anthropic公司于2024年11月推出,旨在实现大型语言模型(LLM)与外部数据源和工具的无缝集成。 • 核心功能: • 资…...

大模型到底是怎么产生的?一文揭秘大模型诞生全过程
前言 大模型到底是怎么产生的呢? 本文将从最基础的概念开始,逐步深入,用通俗易懂的语言为大家揭开大模型的神秘面纱。 大家好,我是大 F,深耕AI算法十余年,互联网大厂核心技术岗。 知行合一,不写水文,喜欢可关注,分享AI算法干货、技术心得。 【专栏介绍】: 欢迎关注《…...

Node.js介绍
一、Node.js 核心定义 本质:基于 Chrome V8 引擎构建的 JavaScript 运行时环境,用于在服务器端执行 JavaScript 代码。 定位:非阻塞、事件驱动的 I/O 模型,专为高并发、实时应用设计。 诞生:2009 年由 Ryan Dahl 发布…...

DRABP_NSGA2最新算法神圣宗教算法优化BP做代理模型,NSGA2反求最优因变量和对应的最佳自变量组合,Matlab代码
一、神圣宗教算法(DRA)优化BP代理模型 1. DRA的核心原理 DRA是一种模拟宗教社会层级互动的元启发式算法,通过“追随者学习”、“传教士传播”和“领导者引导”三种行为模式优化搜索过程。在BP神经网络优化中,DRA通过以下步骤调整…...

Android Studio 在 Windows 上的完整安装与使用指南
Android Studio 在 Windows 上的完整安装与使用指南—目录 一、Android Studio 简介二、下载与安装1. 下载 Android Studio2. 安装前的依赖准备3. 安装步骤 三、基础使用指南1. 首次启动配置2. 创建第一个项目3. 运行应用4. 核心功能 四、进阶功能配置1. 配置 SDK 和工具2. 自定…...

Matlab学习笔记五十:循环语句和条件语句的用法
1.说明 循环语句:for…end,while…end 条件语句:if…end,switch…case…end 其中if语句语法还可以是:for…else…end,for…elseif…else…end 2.简单for程序实例 for x1:5 %循环遍历1~5 yx5 end [1…...

大漠流光:科技牧歌的未来-内蒙古鄂尔多斯
故事背景 故事发生在中国内蒙古鄂尔多斯,这里是蒙古族文化的摇篮,也是科技与自然交织的未来舞台。在这片广袤的土地上,蒙古族少女、老牧人和工程师们共同谱写着一曲科技与传统共生的赞歌。未来的鄂尔多斯,不再是单一的沙漠或草原…...

MySQL与Oracle深度对比
MySQL与Oracle深度对比:数据类型与SQL差异 一、数据类型差异 1. 数值类型对比 数据类型MySQLOracle整数TINYINT, SMALLINT, MEDIUMINT, INT, BIGINTNUMBER(精度) 或直接INT(内部仍为NUMBER)小数DECIMAL(p,s), FLOAT, DOUBLENUMBER(p,s), FLOAT, BINARY_FLOAT, BI…...
))
GESP2023年12月认证C++七级( 第一部分选择题(6-10))
选择题第八题: #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int MAXN 1005; // 假设字符串长度不超过1000 char s1[MAXN], s2[MAXN]; int dp[MAXN]; // 一维DP数组int main() {while (cin >>…...

腾势品牌欧洲市场冲锋,科技豪华席卷米兰
在时尚与艺术的交汇点,米兰设计周的舞台上,一场汽车界的超级风暴正在酝酿,腾势品牌如一头勇猛无畏的雄狮,以雷霆万钧之势正式向欧洲市场发起了冲锋。其最新力作——腾势Z9GT的登场,仿佛是一道闪电划破夜空,…...

双指针、滑动窗口
一、双指针 双指针是指在算法中使用两个指针(通常是索引或迭代器)来解决问题,通过移动这两个指针来扫描数据结构(如数组或链表),从而达到高效的目的。双指针的核心思想是利用两个指针的相对位置或移动方式…...

《数据密集型应用系统设计》读书笔记:第二章
我们继续拆解 第2章:数据模型与查询语言。这章讲的是如何组织数据、如何访问数据,也是你选择数据库种类的根本依据。 第2章:数据模型与查询语言 一、为何数据模型重要? Martin 开篇就强调,数据模型影响: …...

ubuntu24.04LTS安装向日葵解决方案
去向日葵官方下载ubuntu使用的deb包 向日葵 输入如下命令安装,将具体版本修改成自己下载的版本 andrew in ~/下载 λ sudo dpkg -i SunloginClient_15.2.0.63064_amd64.deb 正在选中未选择的软件包 sunloginclient。 (正在读取数据库 ... 系统当前共安装有 290947…...

Python基础语法1
目录 1、认识Python 1.1、计算机 1.2、编程 1.3、编程语言的类别 1.4、Python背景 1.5、Python的应用场景 1.6、Python的优缺点 1.7、Python前景 1.8、Python 环境 2、常量和表达式 3、变量和类型 3.1、定义变量 3.2、使用变量 3.3、变量的类型 3.3.1、整形 3.3…...

深度学习中多机训练概念下的DP与DDP
在进行单机多卡/多机多卡训练时,通常会遇到DP与DDP的概念,为此基于kimi大模型对二者的差异进行梳理。使用DP/DPP的核心是数据并行,也就是根据显卡数量对数据集进行分治,每一个显卡都有一个独立完整的模型和一个局部数据。在多个显…...