scikit-learn 开源框架在机器学习中的应用
文章目录
- scikit-learn 开源框架介绍
- 1. 框架概述
- 1.1 基本介绍
- 1.2 版本信息
- 2. 核心功能模块
- 2.1 监督学习
- 2.2 无监督学习
- 2.3 数据处理
- 3. 关键设计理念
- 3.1 统一API设计
- 3.2 流水线(Pipeline)
- 4. 重要辅助功能
- 4.1 模型选择
- 4.2 评估指标
- 5. 性能优化技巧
- 5.1 并行计算
- 5.2 内存优化
- 6. 行业应用案例
- 6.1 金融风控
- 6.2 医疗诊断
- 7. 学习资源推荐
- 实验
- 准备
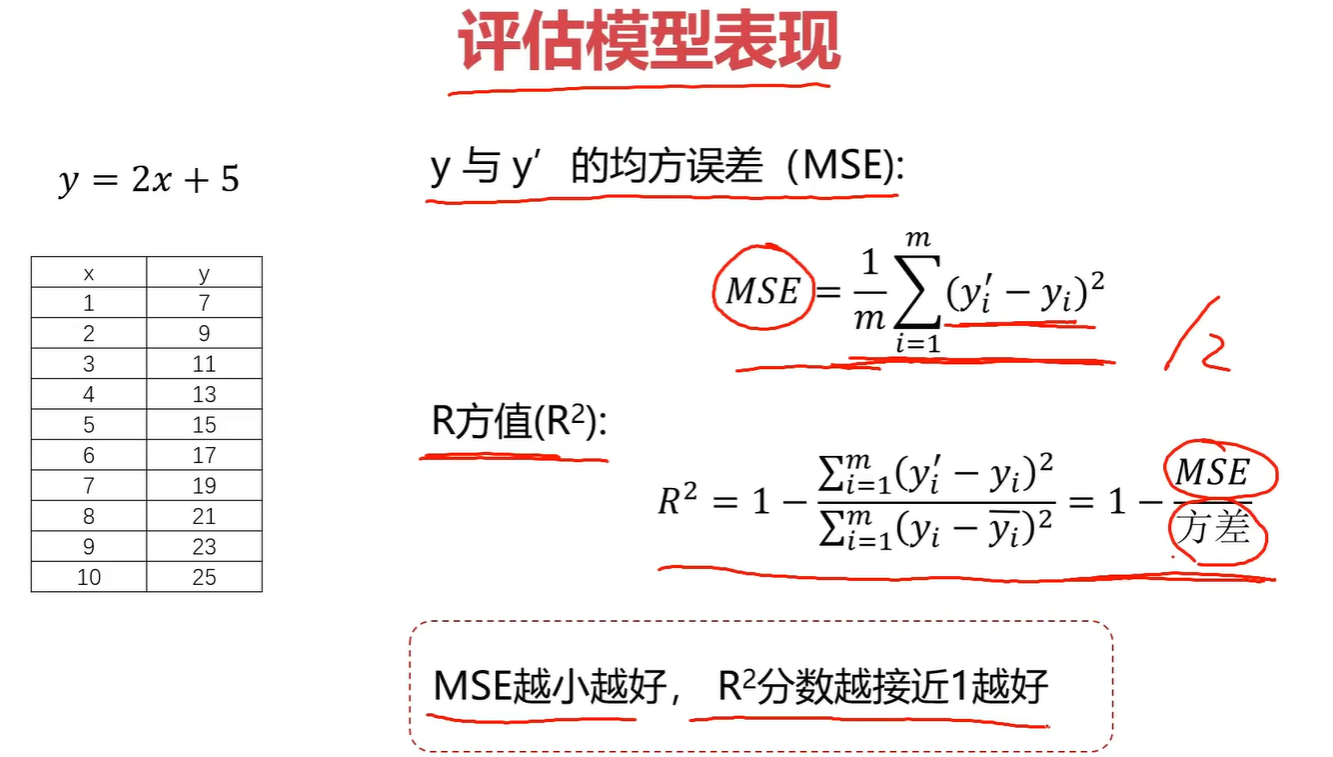
- 1.线性回归实验结果:
- 2.逻辑回归训练结果
- 逻辑回归的代码示例如下:
scikit-learn 开源框架介绍
用于自己复习,好记性不如懒笔头
1. 框架概述
1.1 基本介绍
scikit-learn (简称sklearn) 是Python最流行的机器学习开源库,具有以下核心特点:
- 基于NumPy/SciPy构建的算法实现
- 统一的API设计(fit/predict/transform)
- 完善的文档和社区支持
- BSD开源协议(可商用)
1.2 版本信息
import sklearn
print("当前版本:", sklearn.__version__) # 要求≥1.0版本
2. 核心功能模块
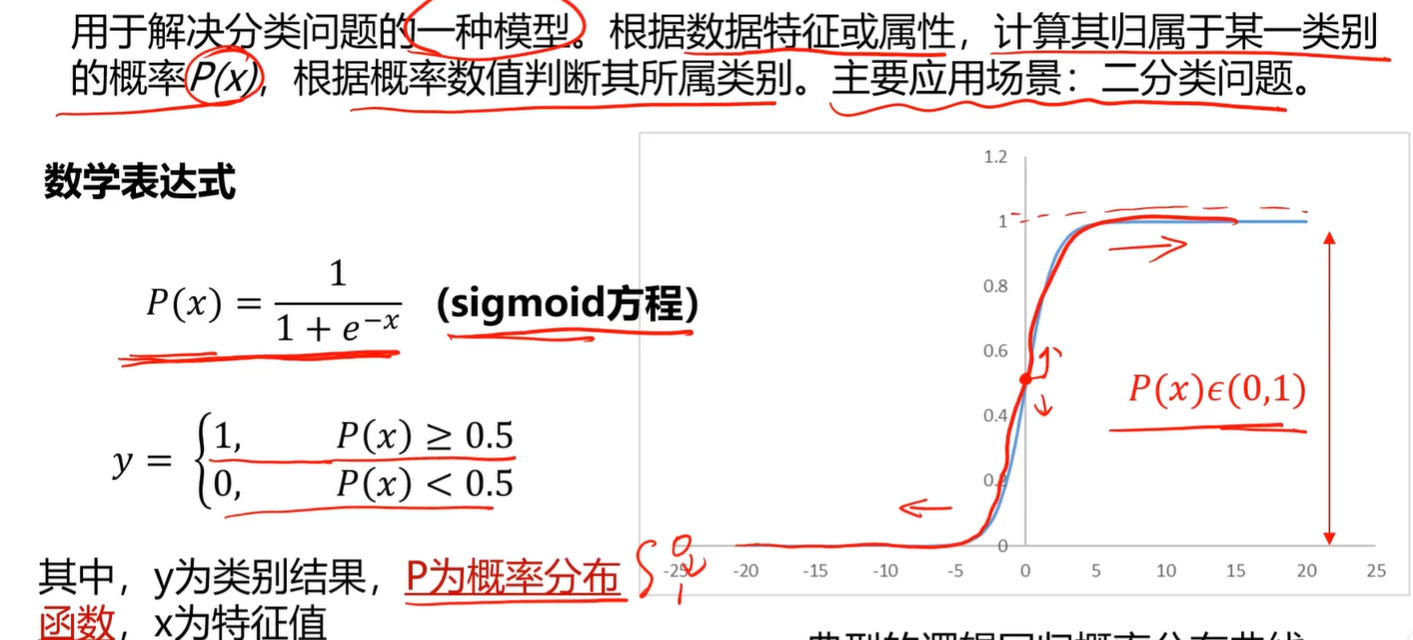
2.1 监督学习
| 算法类别 | 典型算法 | 导入方式 |
|---|---|---|
| 线性模型 | LinearRegression, LogisticRegression | from sklearn.linear_model import ... |
| 树模型 | DecisionTree, RandomForest | from sklearn.ensemble import ... |
| SVM | SVC, SVR | from sklearn.svm import ... |
线性回归的调用方法:


逻辑回归的说明:
2.2 无监督学习
from sklearn.cluster import KMeans # 聚类
from sklearn.decomposition import PCA # 降维
2.3 数据处理
| 功能 | 类/函数 | 示例 |
|---|---|---|
| 标准化 | StandardScaler | scaler.fit_transform(X) |
| 特征编码 | OneHotEncoder | encoder.fit_transform(cat_features) |
| 缺失值处理 | SimpleImputer | imputer.fit_transform(X_missing) |
3. 关键设计理念
3.1 统一API设计
所有算法类都实现以下核心方法:
model.fit(X_train, y_train) # 训练
model.predict(X_test) # 预测
model.score(X_test, y_test) # 评估
3.2 流水线(Pipeline)
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(StandardScaler(),PCA(n_components=2),LogisticRegression()
)
pipe.fit(X_train, y_train)
4. 重要辅助功能
4.1 模型选择
from sklearn.model_selection import (train_test_split,GridSearchCV,cross_val_score
)
4.2 评估指标
from sklearn.metrics import (accuracy_score, # 分类准确率mean_squared_error, # 回归MSEconfusion_matrix # 混淆矩阵
)
5. 性能优化技巧
5.1 并行计算
RandomForestClassifier(n_jobs=-1) # 使用所有CPU核心
5.2 内存优化
PCA(svd_solver='randomized') # 大数据集降维
6. 行业应用案例
6.1 金融风控
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier() # 用于信用评分
6.2 医疗诊断
from sklearn.svm import SVC
clf = SVC(kernel='rbf', probability=True) # 疾病预测
7. 学习资源推荐
- 官方文档:scikit-learn.org
- 代码示例库:
sklearn.datasets.load_* - 交互式学习:scikit-learn教程
实验
准备
本人随机生成了两组数据,余额50元以上的,结果是购买电影票;50元以下的,结果是不够买电影票。
我将用线性回归和逻辑回归根据账号余额预测是否会购买电影票进行模型训练
1.线性回归实验结果:
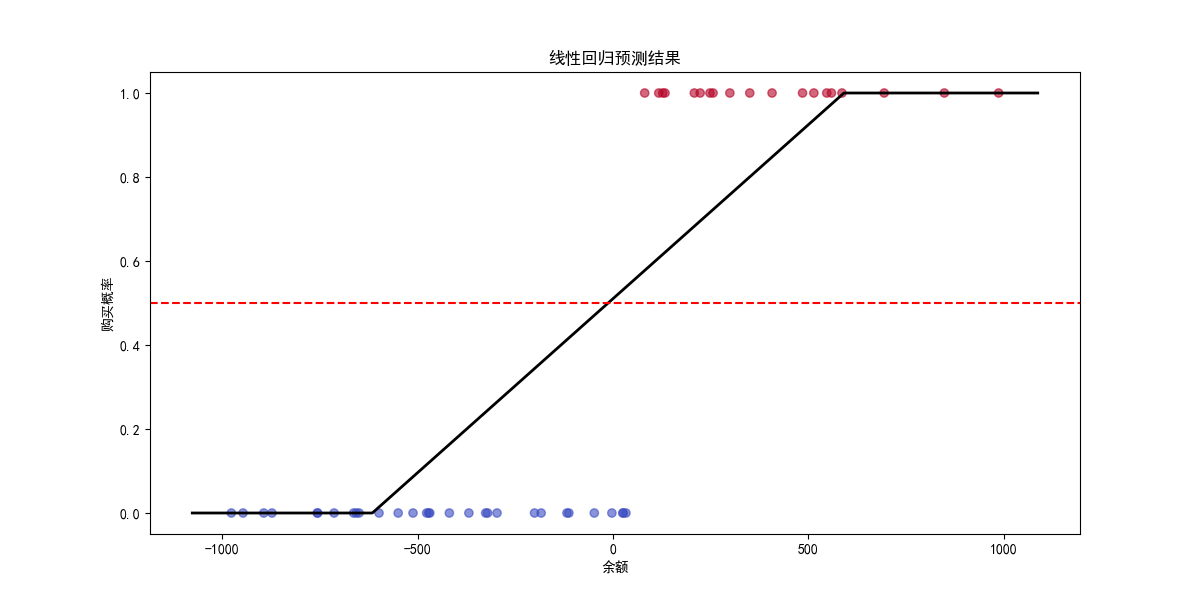
标准化后的线性回归方程
y ^ = 0.4155 + 0.4152 × x 标准化 \hat{y} = 0.4155 + 0.4152 \times x_{标准化} y^=0.4155+0.4152×x标准化
其中:
y ^ \hat{y} y^ 是预测的购买概率
x 标准化 x_{标准化} x标准化 是标准化后的余额值
0.4155 是截距
0.4152 是标准化余额的系数
原始数据的线性回归方程
由于我们使用了StandardScaler进行标准化,原始数据的方程可以表示为:
y ^ = 0.4155 + 0.4152 × ( x − μ σ ) \hat{y} = 0.4155 + 0.4152 \times \left(\frac{x - \mu}{\sigma}\right) y^=0.4155+0.4152×(σx−μ)
其中:
x x x 是原始余额值
μ = − 114.57 \mu = -114.57 μ=−114.57 是原始数据的均值
σ = 506.39 \sigma = 506.39 σ=506.39 是原始数据的标准差
预测阈值
当 y ^ = 0.5 \hat{y} = 0.5 y^=0.5 时,对应的余额阈值为:
x = 0.5 − 0.4155 0.4152 × σ + μ = − 12.54 元 x = \frac{0.5 - 0.4155}{0.4152} \times \sigma + \mu = -12.54 \text{元} x=0.41520.5−0.4155×σ+μ=−12.54元
这意味着:
当余额 > -12.54元时,预测购买概率 > 0.5
当余额 < -12.54元时,预测购买概率 < 0.5
2.逻辑回归训练结果
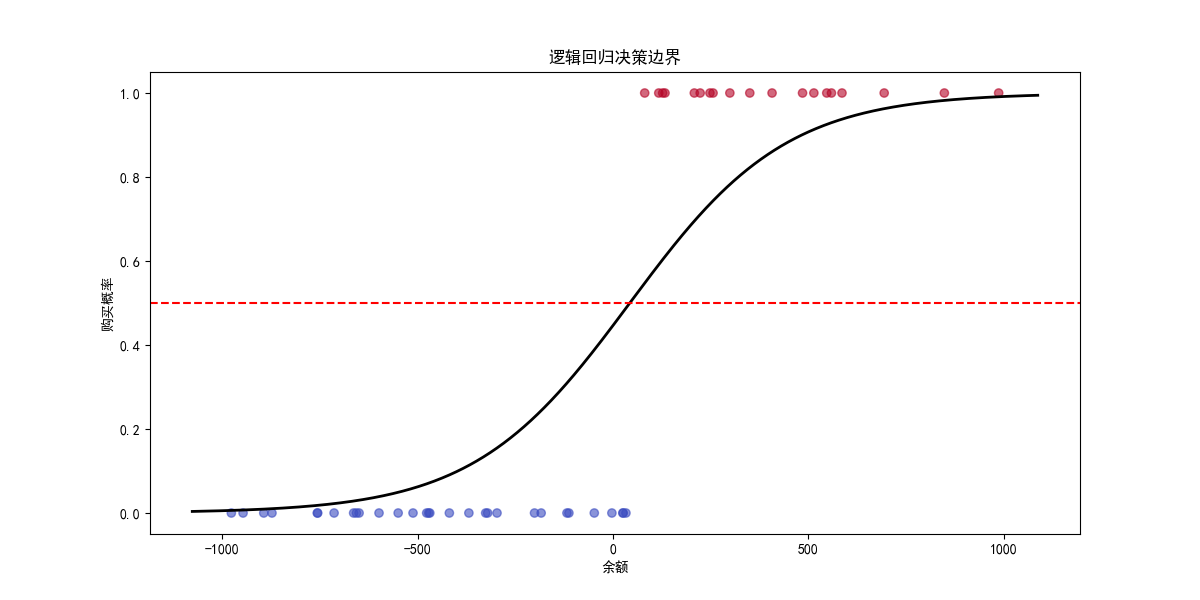
标准化后的逻辑回归方程
P ( y = 1 ∣ x ) = 1 1 + e − ( − 0.7862 + 2.5021 × x 标准化 ) P(y=1|x) = \frac{1}{1 + e^{-(-0.7862 + 2.5021 \times x_{标准化})}} P(y=1∣x)=1+e−(−0.7862+2.5021×x标准化)1
其中:
P ( y = 1 ∣ x ) P(y=1|x) P(y=1∣x) 是购买电影票的概率
x 标准化 x_{标准化} x标准化 是标准化后的余额值
-0.7862 是截距
2.5021 是标准化余额的系数
原始数据的逻辑回归方程
由于我们使用了StandardScaler进行标准化,原始数据的方程可以表示为:
P ( y = 1 ∣ x ) = 1 1 + e − ( − 0.7862 + 2.5021 × x − μ σ ) P(y=1|x) = \frac{1}{1 + e^{-(-0.7862 + 2.5021 \times \frac{x - \mu}{\sigma})}} P(y=1∣x)=1+e−(−0.7862+2.5021×σx−μ)1
其中:
x x x 是原始余额值
μ = − 114.57 \mu = -114.57 μ=−114.57 是原始数据的均值
σ = 506.39 \sigma = 506.39 σ=506.39 是原始数据的标准差
预测阈值
当 P ( y = 1 ∣ x ) = 0.5 P(y=1|x) = 0.5 P(y=1∣x)=0.5 时,对应的余额阈值为:
x = 0.5 − ( − 0.7862 ) 2.5021 × σ + μ = 44.54 元 x = \frac{0.5 - (-0.7862)}{2.5021} \times \sigma + \mu = 44.54 \text{元} x=2.50210.5−(−0.7862)×σ+μ=44.54元
这意味着:
当余额 > 44.54元时,预测购买概率 > 0.5
当余额 < 44.54元时,预测购买概率 < 0.5
比较两个结果,显然分类问题,用逻辑回归模型的准确度会更大些
逻辑回归的代码示例如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, roc_curve, auc
from sklearn.preprocessing import StandardScaler# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef load_and_preprocess_data():"""加载并预处理数据"""# 读取数据df = pd.read_excel('balance.xlsx')# 将"是"/"否"转换为1/0df['是否买电影票'] = df['是否买电影票'].map({'是': 1, '否': 0})# 数据标准化scaler = StandardScaler()df['小明的余额_标准化'] = scaler.fit_transform(df[['小明的余额']])return df, scalerdef visualize_data(df):"""数据可视化"""# 1. 余额分布图plt.figure(figsize=(12, 6))sns.histplot(data=df, x='小明的余额', hue='是否买电影票', bins=20)plt.title('余额分布与购买行为')plt.xlabel('余额')plt.ylabel('频次')plt.savefig('余额分布图.png')plt.close()# 2. 箱线图plt.figure(figsize=(12, 6))sns.boxplot(x='是否买电影票', y='小明的余额', data=df)plt.title('不同购买决策下的余额分布')plt.savefig('余额箱线图.png')plt.close()# 3. 散点图plt.figure(figsize=(12, 6))sns.scatterplot(x='小明的余额', y='是否买电影票', data=df)plt.title('余额与购买行为的关系')plt.savefig('余额散点图.png')plt.close()def train_and_evaluate_model(df):"""训练和评估模型"""# 准备数据X = df[['小明的余额_标准化']]y = df['是否买电影票']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型model = LogisticRegression()model.fit(X_train, y_train)# 预测y_pred = model.predict(X_test)y_pred_proba = model.predict_proba(X_test)[:, 1]# 评估模型accuracy = accuracy_score(y_test, y_pred)report = classification_report(y_test, y_pred)# 计算ROC曲线fpr, tpr, _ = roc_curve(y_test, y_pred_proba)roc_auc = auc(fpr, tpr)# 绘制ROC曲线plt.figure(figsize=(10, 6))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.2f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('假正例率')plt.ylabel('真正例率')plt.title('ROC曲线')plt.legend(loc="lower right")plt.savefig('ROC曲线.png')plt.close()return model, accuracy, report, roc_aucdef plot_decision_boundary(df, model, scaler):"""绘制决策边界"""# 生成测试数据x_min, x_max = df['小明的余额'].min() - 100, df['小明的余额'].max() + 100xx = np.linspace(x_min, x_max, 1000)xx_scaled = scaler.transform(xx.reshape(-1, 1))# 预测概率proba = model.predict_proba(xx_scaled)[:, 1]# 绘制决策边界plt.figure(figsize=(12, 6))plt.scatter(df['小明的余额'], df['是否买电影票'], c=df['是否买电影票'], cmap='coolwarm', alpha=0.6)plt.plot(xx, proba, 'k-', linewidth=2)plt.axhline(y=0.5, color='r', linestyle='--')plt.title('逻辑回归决策边界')plt.xlabel('余额')plt.ylabel('购买概率')plt.savefig('决策边界.png')plt.close()def main():# 加载和预处理数据df, scaler = load_and_preprocess_data()# 数据可视化visualize_data(df)# 训练和评估模型model, accuracy, report, roc_auc = train_and_evaluate_model(df)# 绘制决策边界plot_decision_boundary(df, model, scaler)if __name__ == "__main__":main()
相关文章:

scikit-learn 开源框架在机器学习中的应用
文章目录 scikit-learn 开源框架介绍1. 框架概述1.1 基本介绍1.2 版本信息 2. 核心功能模块2.1 监督学习2.2 无监督学习2.3 数据处理 3. 关键设计理念3.1 统一API设计3.2 流水线(Pipeline) 4. 重要辅助功能4.1 模型选择4.2 评估指标 5. 性能优化技巧5.1 并行计算5.2 内存优化 6…...

GPT-4、Grok 3与Gemini 2.0 Pro:三大AI模型的语气、风格与能力深度对比
更新后的完整CSDN博客文章 以下是基于您的要求,包含修正后的幻觉率部分并保留原始信息的完整CSDN博客风格文章。幻觉率已调整为更符合逻辑的描述,其他部分保持不变。 GPT-4、Grok 3与Gemini 2.0 Pro:三大AI模型的语气、风格与能力深度对比 …...

Cyber Weekly #51
赛博新闻 1、英伟达开源新模型,性能直逼DeepSeek-R1 本周,英伟达开源了基于Meta早期Llama-3.1-405B-Instruct模型开发的Llama-3.1-Nemotron-Ultra-253B-v1大语言模型,该模型拥有2530亿参数,在多项基准测试中展现出与6710亿参数的…...

QT聊天项目开发DAY02
1.添加输入密码的保密性 LoginWidget::LoginWidget(QDialog*parent): QDialog(parent) {ui.setupUi(this);ui.PassWord_Edit->setEchoMode(QLineEdit::Password);BindSlots(); }2.添加密码的验证提示 3.修复内存泄漏,并嵌套UI子窗口到主窗口里面 之前并没有设置…...

Spring AI高级RAG功能查询重写和查询翻译
1、创建查询重写转换器 // 创建查询重写转换器queryTransformer RewriteQueryTransformer.builder().chatClientBuilder(openAiChatClient.mutate()).build(); 查询重写是RAG系统中的一个重要优化技术,它能够将用户的原始查询转换成更加结构化和明确的形式。这种转…...

速盾:高防CDN的原理和高防IP一样吗?
随着互联网的发展,网络安全威胁日益严重,尤其是DDoS攻击、CC攻击等恶意行为,给企业带来了巨大的风险。为了应对这些挑战,许多企业开始采用高防CDN(内容分发网络)和高防IP作为防御措施。尽管两者都能提供一定…...

SQLite-Web:一个轻量级的SQLite数据库管理工具
SQLite-Web 是一个基于 Web 浏览器的轻量级 SQLite 数据库管理工具。它基于 Python 开发,免费开源,无需复杂的安装或配置,适合快速搭建本地或内网的 SQLite 管理和开发环境。 SQLite-Web 支持常见的 SQLite 数据库管理和开发任务,…...

数智读书笔记系列028 《奇点更近》
一、引言 在科技飞速发展的今天,我们对未来的好奇与日俱增。科技将如何改变我们的生活、社会乃至人类本身?雷・库兹韦尔的《奇点更近》为我们提供了深刻的见解和大胆的预测,让我们得以一窥未来几十年的科技蓝图。这本书不仅是对未来科技趋势…...

深入理解linux操作系统---第4讲 用户、组和密码管理
4.1 UNIX系统的用户和组 4.1.1 用户与UID UID定义:用户身份唯一标识符,16位或32位整数,范围0-65535。系统用户UID为0(root)、1-999(系统服务),普通用户从1000开始分配特殊UID&…...
))
系统设计模块之安全架构设计(常见攻击防御(SQL注入、XSS、CSRF、DDoS))
一、SQL注入攻击防御 SQL注入是通过恶意输入篡改数据库查询逻辑的攻击方式,可能导致数据泄露或数据库破坏。防御核心在于隔离用户输入与SQL代码,具体措施包括: 参数化查询(预编译语句) 原理:将SQL语句与用…...

redission锁释放失败处理
redission锁释放失败处理 https://www.jianshu.com/p/055ae798547a 就是可以删除 锁的key 这样锁就释放了,但是 还是要结合业务,这种是 非正规的处理方式,还是要在代码层面进行处理。...

Visual Studio Code 在.S汇编文件中添加调试断点及功能简介
目录 一、VS Code汇编文件添加断点二、VS Code断点调试功能简介1. 设置断点(1) 单行断点(2) 条件断点(3) 日志断点 2. 查看断点列表3. 调试时的断点控制4. 禁用/启用断点5. 删除断点6. 条件断点的使用7. 多线程调试8. 远程调试9. 调试配置文件 一、VS Code汇编文件添加断点 最…...

计算视觉与数学结构及AI拓展
在快速发展的计算视觉领域,算法、图像处理、神经网络和数学结构的交叉融合,在提升我们对视觉感知和分析的理解与能力方面发挥着关键作用。本文探讨了支撑计算视觉的基本概念和框架,强调了数学结构在开发鲁棒的算法和模型中的重要性。 AI拓展…...

Vue2 老项目升级 Vue3 深度解析教程
Vue2 老项目升级 Vue3 深度解析教程 摘要 Vue3 带来了诸多改进和新特性,如性能提升、组合式 API、更好的 TypeScript 支持等,将 Vue2 老项目升级到 Vue3 可以让项目获得这些优势。本文将深入解析升级过程,涵盖升级前的准备工作、具体升级步骤…...

器件封装-2025.4.13
1.器件网格设置要与原理图一致,同时器件符号要与数据手册一致 2.或者通过向导进行编辑,同时电机高级符号向导进行修改符号名称 2.封装一般尺寸大小要比数据手册大2倍到1.5倍 焊盘是在顶层绘制,每个焊盘距离要用智能尺子测量是否跟数据手册一…...

Python 基础语法汇总
Python 语法 │ ├── 基本结构 │ ├── 语句(Statements) │ │ ├── 表达式语句(如赋值、算术运算) │ │ ├── 控制流语句(if, for, while) │ │ ├── 定义语句(def…...

Java函数式编程魔法:Stream API的10种妙用
在Java 8中引入的Stream API为函数式编程提供了一种全新的方式。它允许我们以声明式的方式处理数据集合,使代码更加简洁、易读且易于维护。本文将介绍Stream API的10种妙用,帮助你更好地理解和应用这一强大的工具。 1. 过滤操作:筛选符合条件…...
编辑距离)
【力扣hot100题】(094)编辑距离
记得最初做这题完全没思路,这次凭印象随便写了一版居然对了。 感觉这题真的有点为出题而出题的意思,谁拿到这题会往动态规划方向想啊jpg 也算是总结出规律了,凡是遇到这种比较俩字符串的十有八九是动态规划,而且是二维动态规划&…...

穿透三层内网VPC2
网络拓扑 目标出网web地址:192.168.139.4 信息收集端口扫描: 打开8080端口是一个tomcat的服务 版本是Apache Tomcat/7.0.92 很熟悉了,可能存在弱口令 tomcat/tomcat 成功登录 用哥斯拉生成马子,上传war包,进入后台 C…...

AI数字消费第一股,重构商业版图的新物种
伍易德带领团队发布“天天送AI数字商业引擎”,重新定义流量与消费的关系 【2025年4月,深圳】在人工智能浪潮席卷全球之际,深圳天天送网络科技有限公司于深圳大中华喜来登酒店重磅召开“AI数字消费第一股”发布盛典。公司创始人伍易德首次系统…...

Unity 基于navMesh的怪物追踪惯性系统
今天做项目适合 策划想要实现一个在现有的怪物追踪系统上实现怪物拥有惯性功能 以下是解决方案分享: 怪物基类代码: using UnityEngine; using UnityEngine.AI;[RequireComponent(typeof(NavMeshAgent))] [RequireComponent(typeof(AudioSource))] …...

【OpenCV】【XTerminal】talk程序运用和linux进程之间通信程序编写,opencv图像库编程联系
目录 一、talk程序的运用&Linux进程间通信程序的编写 1.1使用talk程序和其他用户交流 1.2用c语言写一个linux进程之间通信(聊天)的简单程序 1.服务器端程序socket_server.c编写 2.客户端程序socket_client.c编写 3.程序编译与使用 二、编写一个…...

中断的硬件框架
今天呢,我们来讲讲中断的硬件框架,这里会去举3个开发板,去了解中断的硬件框架: 中断路径上的3个部件: 中断源 中断源多种多样,比如GPIO、定时器、UART、DMA等等。 它们都有自己的寄存器,可以…...

大数据面试问答-Hadoop/Hive/HDFS/Yarn
1. Hadoop 1.1 MapReduce 1.1.1 Hive语句转MapReduce过程 可分为 SQL解析阶段、语义分析阶段、逻辑计划生成阶段、逻辑优化阶段、物理计划生成阶段。 SQL解析阶段 词法分析(Lexical Analysis):使用Antlr3将SQL字符串拆分为有意义的token序列 语法分析(Syntax An…...
第五期)
【小沐学GIS】基于C++绘制三维数字地球Earth(QT5、OpenGL、GIS、卫星)第五期
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第二期3【小沐学GIS】…...
)
初始图形学(3)
昨天休息了一天,今天继续图形学的学习 向场景发射光线 现在我们我们准备做一个光线追踪器。其核心在于,光线追踪程序通过每个像素发送光线。这意味着对于图像中的每个像素点,程序都会计算一天从观察者出发,穿过该像素的光线。并…...

如果想在 bean 创建出来之前和销毁之前做一些自定义操作可以怎么来实现呢?
使用生命周期扩展接口(最灵活) 创建前拦截可以通过实现 InstantiationAwareBeanPostProcessor 接口的 postProcessBeforeInstantiation 方法,在Bean实例化前执行逻辑 在销毁前拦截可以通过实现 DestructionAwareBean 接口的 postProcessBe…...

【甲子光年】DeepSeek开启AI算法变革元年
目录 引言人工智能的发展拐点算力拐点:DeepSeek的突破数据拐点:低参数量模型的兴起算法创新循环算法变革推动AI普惠应用全球AI科技竞争进入G2时代结论 引言 2025年,人工智能的发展已经走到了一个战略拐点。随着技术能力的不断提升࿰…...

Go语言--语法基础4--基本数据类型--整数类型
整型是所有编程语言里最基础的数据类型。 Go 语言支持如下所示的这些整型类型。 需要注意的是, int 和 int32 在 Go 语言里被认为是两种不同的类型,编译器也不会帮你自动做类型转换, 比如以下的例子会有编译错误: var value2 in…...

MCP基础学习计划详细总结
MCP基础学习计划详细总结 1.MCP概述与基础 • MCP(Model Context Protocol):由Anthropic公司于2024年11月推出,旨在实现大型语言模型(LLM)与外部数据源和工具的无缝集成。 • 核心功能: • 资…...

大模型到底是怎么产生的?一文揭秘大模型诞生全过程
前言 大模型到底是怎么产生的呢? 本文将从最基础的概念开始,逐步深入,用通俗易懂的语言为大家揭开大模型的神秘面纱。 大家好,我是大 F,深耕AI算法十余年,互联网大厂核心技术岗。 知行合一,不写水文,喜欢可关注,分享AI算法干货、技术心得。 【专栏介绍】: 欢迎关注《…...

Node.js介绍
一、Node.js 核心定义 本质:基于 Chrome V8 引擎构建的 JavaScript 运行时环境,用于在服务器端执行 JavaScript 代码。 定位:非阻塞、事件驱动的 I/O 模型,专为高并发、实时应用设计。 诞生:2009 年由 Ryan Dahl 发布…...

DRABP_NSGA2最新算法神圣宗教算法优化BP做代理模型,NSGA2反求最优因变量和对应的最佳自变量组合,Matlab代码
一、神圣宗教算法(DRA)优化BP代理模型 1. DRA的核心原理 DRA是一种模拟宗教社会层级互动的元启发式算法,通过“追随者学习”、“传教士传播”和“领导者引导”三种行为模式优化搜索过程。在BP神经网络优化中,DRA通过以下步骤调整…...

Android Studio 在 Windows 上的完整安装与使用指南
Android Studio 在 Windows 上的完整安装与使用指南—目录 一、Android Studio 简介二、下载与安装1. 下载 Android Studio2. 安装前的依赖准备3. 安装步骤 三、基础使用指南1. 首次启动配置2. 创建第一个项目3. 运行应用4. 核心功能 四、进阶功能配置1. 配置 SDK 和工具2. 自定…...

Matlab学习笔记五十:循环语句和条件语句的用法
1.说明 循环语句:for…end,while…end 条件语句:if…end,switch…case…end 其中if语句语法还可以是:for…else…end,for…elseif…else…end 2.简单for程序实例 for x1:5 %循环遍历1~5 yx5 end [1…...

大漠流光:科技牧歌的未来-内蒙古鄂尔多斯
故事背景 故事发生在中国内蒙古鄂尔多斯,这里是蒙古族文化的摇篮,也是科技与自然交织的未来舞台。在这片广袤的土地上,蒙古族少女、老牧人和工程师们共同谱写着一曲科技与传统共生的赞歌。未来的鄂尔多斯,不再是单一的沙漠或草原…...

MySQL与Oracle深度对比
MySQL与Oracle深度对比:数据类型与SQL差异 一、数据类型差异 1. 数值类型对比 数据类型MySQLOracle整数TINYINT, SMALLINT, MEDIUMINT, INT, BIGINTNUMBER(精度) 或直接INT(内部仍为NUMBER)小数DECIMAL(p,s), FLOAT, DOUBLENUMBER(p,s), FLOAT, BINARY_FLOAT, BI…...
))
GESP2023年12月认证C++七级( 第一部分选择题(6-10))
选择题第八题: #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int MAXN 1005; // 假设字符串长度不超过1000 char s1[MAXN], s2[MAXN]; int dp[MAXN]; // 一维DP数组int main() {while (cin >>…...

腾势品牌欧洲市场冲锋,科技豪华席卷米兰
在时尚与艺术的交汇点,米兰设计周的舞台上,一场汽车界的超级风暴正在酝酿,腾势品牌如一头勇猛无畏的雄狮,以雷霆万钧之势正式向欧洲市场发起了冲锋。其最新力作——腾势Z9GT的登场,仿佛是一道闪电划破夜空,…...

双指针、滑动窗口
一、双指针 双指针是指在算法中使用两个指针(通常是索引或迭代器)来解决问题,通过移动这两个指针来扫描数据结构(如数组或链表),从而达到高效的目的。双指针的核心思想是利用两个指针的相对位置或移动方式…...

《数据密集型应用系统设计》读书笔记:第二章
我们继续拆解 第2章:数据模型与查询语言。这章讲的是如何组织数据、如何访问数据,也是你选择数据库种类的根本依据。 第2章:数据模型与查询语言 一、为何数据模型重要? Martin 开篇就强调,数据模型影响: …...

ubuntu24.04LTS安装向日葵解决方案
去向日葵官方下载ubuntu使用的deb包 向日葵 输入如下命令安装,将具体版本修改成自己下载的版本 andrew in ~/下载 λ sudo dpkg -i SunloginClient_15.2.0.63064_amd64.deb 正在选中未选择的软件包 sunloginclient。 (正在读取数据库 ... 系统当前共安装有 290947…...

Python基础语法1
目录 1、认识Python 1.1、计算机 1.2、编程 1.3、编程语言的类别 1.4、Python背景 1.5、Python的应用场景 1.6、Python的优缺点 1.7、Python前景 1.8、Python 环境 2、常量和表达式 3、变量和类型 3.1、定义变量 3.2、使用变量 3.3、变量的类型 3.3.1、整形 3.3…...

深度学习中多机训练概念下的DP与DDP
在进行单机多卡/多机多卡训练时,通常会遇到DP与DDP的概念,为此基于kimi大模型对二者的差异进行梳理。使用DP/DPP的核心是数据并行,也就是根据显卡数量对数据集进行分治,每一个显卡都有一个独立完整的模型和一个局部数据。在多个显…...
-桥接模式)
设计模式(结构型)-桥接模式
目录 摘要 定义 类图 角色 具体实现 优缺点 优点 缺点 使用场景 使用案例 JDBC 和桥接模式 总结 摘要 在软件开发领域,随着系统规模和复杂性的不断攀升,如何设计出具有良好扩展性、灵活性以及可维护性的软件架构成为关键挑战。桥接模式作为一…...
)
精品推荐 | 湖仓一体电商数据分析平台实践教程合集(视频教程+设计文档+完整项目代码)
精品推荐,湖仓一体电商数据分析平台实践教程合集,包含视频教程、设计文档及完整项目代码等资料,供大家学习。 1、项目背景介绍及项目架构 2、项目使用技术版本及组件搭建 3、项目数据种类与采集 4、实时业务统计指标分析一——ODS分层设计与数…...

【LangChain少样本提示工程实战】FewShotPromptTemplate原理与应用解析——附运行代码
目录 引言 重点提炼 一、FewShotPromptTemplate作用 1. 整合示例与模板,构建结构化提示 2. 引导模型理解任务逻辑 3. 提升少样本场景下的模型性能 4. 支持动态示例选择(扩展功能) 5. 与其他模块…...

基于LSTM的文本分类3——模型训练
前言 之前已经完成了模型搭建和文本数据处理,现在做一下模型训练。 源码 # -*- coding: UTF-8 -*- import numpy as np import torch import torch.nn as nn import torch.nn.functional as F from sklearn import metrics # 导入评估指标 import time from uti…...

【JS】关于原型/原型链
本文会讲解什么是原型,什么是原型链,以及查找原型的方法,最后会实现一个函数:判断某对象是否有某属性。 定义 原型:函数都有prototype属性,称作原型/原型对象 原型可以放一些方法和属性,共享…...

猫咪如厕检测与分类识别系统系列【五】信息存储数据库改进+添加猫咪页面制作+猫咪躯体匹配算法架构更新
前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠的如…...