使用Python从零开始构建端到端文本到图像 Transformer大模型
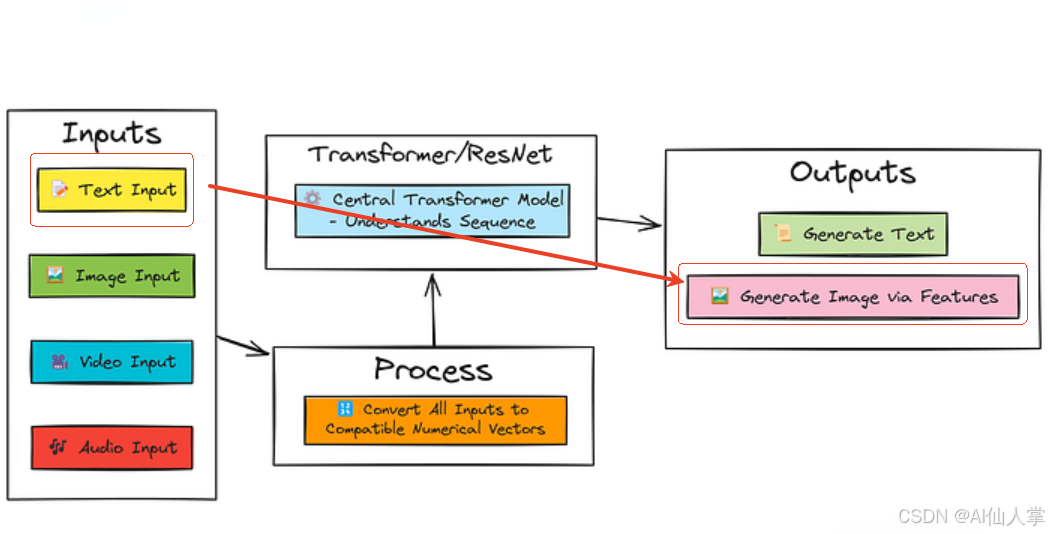
简介:通过特征向量从文本生成图像
回顾:多模态 Transformer
在使用Python从零实现一个端到端多模态 Transformer大模型中,我们调整了字符级 Transformer 以处理图像(通过 ResNet 特征)和文本提示,用于视觉描述等任务。我们将状态保存到 saved_models/multimodal_model.pt 中,包括文本处理组件、分词器和视觉特征投影层。
文本到图像的挑战(简化版)
直接从文本生成逼真图像是一项复杂的任务,通常涉及生成对抗网络(GANs)或扩散模型等专门架构。为了保持在 Transformer 框架内,我们将处理一个简化版本:
- 目标:给定文本提示(例如“一个蓝色方块”),生成表示描述图像的图像特征向量。
- 为什么使用特征向量? 使用基本 Transformer 自回归生成原始像素既困难又计算昂贵。生成固定大小的特征向量(如 ResNet 中的特征向量)是一个更易管理的中间步骤。
- 图像重建:生成特征向量后,我们将使用简单的最近邻方法在已知的训练图像上可视化结果。模型预测特征向量,我们找到训练图像(红色方块、蓝色方块、绿色圆圈)中特征向量最相似的图像并显示它。
我们的方法:用于特征预测的 Transformer
- 加载组件:我们从
multimodal_model.pt中加载文本 Transformer 组件(嵌入、位置编码、注意力/FFN 块、最终层归一化)和分词器。我们还加载冻结的 ResNet-18 特征提取器以在训练期间获取目标特征。 - 调整架构:输入现在仅为文本。我们将用一个新的线性层替换最终输出层(之前预测文本标记),该线性层将 Transformer 的最终隐藏状态映射到 ResNet 图像特征的维度(例如 512)。
- 训练数据:我们需要(文本提示,目标图像)对。我们将使用之前创建的简单图像的描述性提示。
- 训练过程:模型读取提示,通过 Transformer 块处理它,并使用新的输出层预测图像特征向量。损失(MSE)将此预测向量与目标图像的实际特征向量进行比较。
- 推理(生成):输入文本提示,从模型中获取预测的特征向量,找到最接近的已知图像特征,并显示相应的图像。
内联实现风格
我们继续以理论为基础的极其详细、逐步的内联实现,避免使用函数和类。
步骤 0:设置 - 库、加载、数据、特征提取
目标:准备环境,从之前的多模态模型中加载相关组件,定义文本-图像对数据,并提取目标图像特征。
步骤 0.1:导入库
理论:导入必要的库。我们需要 torch、torchvision、PIL、math、os、numpy。我们稍后还需要 scipy.spatial.distance 或 torch.nn.functional.cosine_similarity 来在生成过程中找到最接近的特征向量。
# 导入必要的库
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from PIL import Image, ImageDraw
import math
import os
import numpy as np
# 用于后续寻找最近向量
from scipy.spatial import distance as scipy_distance # 为了可重复性
torch.manual_seed(123)
np.random.seed(123)print(f"PyTorch version: {torch.__version__}")
print(f"Torchvision version: {torchvision.__version__}")
print("Libraries imported.")# --- 设备配置 ---
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
步骤 0.2:从多模态模型加载相关状态
理论:从 multimodal_model.pt 加载状态字典。我们需要配置参数、分词器、文本 Transformer 组件(嵌入层、注意力块等)以及 ResNet 特征提取器(保持冻结状态)。
# --- 加载保存的多模态模型状态 ---
print("\nStep 0.2: Loading state from multi-modal model...")
model_load_path = 'saved_models/multimodal_model.pt'
if not os.path.exists(model_load_path):raise FileNotFoundError(f"Error: Model file not found at {model_load_path}. Please ensure 'multimodal.ipynb' was run and saved the model.")loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"Loaded state dictionary from '{model_load_path}'.")# --- Extract Config and Tokenizer ---
config = loaded_state_dict['config']
vocab_size = config['vocab_size'] # Includes special tokens
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
# 使用加载配置中的block_size,后续可能根据文本提示长度需求调整
block_size = config['block_size']
vision_feature_dim = config['vision_feature_dim'] # ResNet特征维度(例如512)
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
pad_token_id = char_to_int.get('<PAD>', -1) # Get PAD token ID
if pad_token_id == -1:print("Warning: PAD token not found in loaded tokenizer!")print("Extracted model configuration and tokenizer:")
print(f" vocab_size: {vocab_size}")
print(f" d_model: {d_model}")
print(f" n_layers: {n_layers}")
print(f" n_heads: {n_heads}")
print(f" d_ff: {d_ff}")
print(f" block_size: {block_size}")
print(f" vision_feature_dim: {vision_feature_dim}")
print(f" PAD token ID: {pad_token_id}")# --- Load Positional Encoding ---
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
# 验证块大小一致性
if positional_encoding.shape[1] != block_size:print(f"Warning: Loaded PE size ({positional_encoding.shape[1]}) doesn't match loaded block_size ({block_size}). Using loaded PE size.")# block_size = positional_encoding.shape[1] # 选项1: 使用PE的大小# 选项2: 如有必要重新计算PE(像之前一样),但先尝试切片/填充
print(f"Loaded positional encoding with shape: {positional_encoding.shape}")# --- 加载文本Transformer组件(仅加载权重,后续创建结构) ---
loaded_embedding_dict = loaded_state_dict['token_embedding_table']
loaded_ln1_dicts = loaded_state_dict['layer_norms_1']
loaded_qkv_dicts = loaded_state_dict['mha_qkv_linears']
loaded_mha_out_dicts = loaded_state_dict['mha_output_linears']
loaded_ln2_dicts = loaded_state_dict['layer_norms_2']
loaded_ffn1_dicts = loaded_state_dict['ffn_linear_1']
loaded_ffn2_dicts = loaded_state_dict['ffn_linear_2']
loaded_final_ln_dict = loaded_state_dict['final_layer_norm']
print("Stored state dicts for text transformer components.")# --- 加载视觉特征提取器(ResNet) ---
# 重新加载之前使用的ResNet-18模型并保持冻结状态
print("Loading pre-trained vision model (ResNet-18) for target feature extraction...")
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
vision_model.fc = nn.Identity() # 移除分类器
vision_model = vision_model.to(device)
vision_model.eval() # 保持评估模式
# 冻结ResNet参数 - 非常重要
for param in vision_model.parameters():param.requires_grad = False
print(f"Loaded and froze ResNet-18 feature extractor on device: {device}")# --- Define Image Transformations (same as before) ---
image_transforms = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
print("Defined image transformations.")
步骤 0.3:定义示例文本-图像数据
理论:创建(描述性文本提示,目标图像路径)对。使用之前 notebook 生成的相同简单图像。
print("\nStep 0.3: Defining sample text-to-image data...")# --- Image Paths (Assuming they exist from multimodal.ipynb) ---
sample_data_dir = "sample_multimodal_data"
image_paths = {"red_square": os.path.join(sample_data_dir, "red_square.png"),"blue_square": os.path.join(sample_data_dir, "blue_square.png"),"green_circle": os.path.join(sample_data_dir, "green_circle.png")
}
# Verify paths exist
for key, path in image_paths.items():if not os.path.exists(path):print(f"Warning: Image file not found at {path}. Attempting to recreate.")if key == "red_square":img_ = Image.new('RGB', (64, 64), color = 'red')img_.save(path)elif key == "blue_square":img_ = Image.new('RGB', (64, 64), color = 'blue')img_.save(path)elif key == "green_circle":img_ = Image.new('RGB', (64, 64), color = 'white')draw = ImageDraw.Draw(img_)draw.ellipse((4, 4, 60, 60), fill='green', outline='green')img_.save(path)else:print(f"Error: Cannot recreate unknown image key '{key}'.")# --- Define Text Prompt -> Image Path Pairs ---
text_to_image_data = [{"prompt": "a red square", "image_path": image_paths["red_square"]},{"prompt": "the square is red", "image_path": image_paths["red_square"]},{"prompt": "show a blue square", "image_path": image_paths["blue_square"]},{"prompt": "blue shape, square", "image_path": image_paths["blue_square"]},{"prompt": "a green circle", "image_path": image_paths["green_circle"]},{"prompt": "the circle, it is green", "image_path": image_paths["green_circle"]},# Add maybe one more variation{"prompt": "make a square that is red", "image_path": image_paths["red_square"]}
]num_samples = len(text_to_image_data)
print(f"Defined {num_samples} sample text-to-image data points.")
# print(f"Sample 0: {text_to_image_data[0]}")
步骤 0.4:提取目标图像特征
理论:使用冻结的 ResNet 预计算数据集中所有唯一图像的目标特征向量。存储这些特征向量,建立图像路径到特征张量的映射,并另存为(path, feature)列表供生成阶段最近邻查找使用。
print("\nStep 0.4: Extracting target image features...")
target_image_features = {} # Dict: {image_path: feature_tensor}
known_features_list = [] # List: [(path, feature_tensor)] for generation lookup# --- Loop Through Unique Image Paths in this dataset ---
unique_image_paths_in_data = sorted(list(set(d["image_path"] for d in text_to_image_data)))
print(f"Found {len(unique_image_paths_in_data)} unique target images to process.")for img_path in unique_image_paths_in_data:# Avoid re-extracting if already done (e.g., if loading from multimodal)# if img_path in extracted_image_features: # Check previous notebook's dict# feature_vector_squeezed = extracted_image_features[img_path]# print(f" Using pre-extracted features for '{os.path.basename(img_path)}'")# else: # --- Load Image --- try:img = Image.open(img_path).convert('RGB')except FileNotFoundError:print(f"Error: Image file not found at {img_path}. Skipping.")continue# --- Apply Transformations ---img_tensor = image_transforms(img).unsqueeze(0).to(device) # (1, 3, 224, 224)# --- Extract Features (using frozen vision_model) ---with torch.no_grad():feature_vector = vision_model(img_tensor) # (1, vision_feature_dim)feature_vector_squeezed = feature_vector.squeeze(0) # (vision_feature_dim,)print(f" Extracted features for '{os.path.basename(img_path)}', shape: {feature_vector_squeezed.shape}")# --- Store Features ---target_image_features[img_path] = feature_vector_squeezedknown_features_list.append((img_path, feature_vector_squeezed))if not target_image_features:raise ValueError("No target image features were extracted. Cannot proceed.")print("Finished extracting and storing target image features.")
print(f"Stored {len(known_features_list)} known (path, feature) pairs for generation lookup.")
步骤 0.5:定义训练超参数
理论:为此特定任务调整超参数。可能需要不同的学习率或训练轮数。此处的 block_size 主要与预期的最大提示长度相关。
print("\nStep 0.5: Defining training hyperparameters for text-to-image...")# Use block_size from loaded config, ensure it's adequate for prompts
max_prompt_len = max(len(d["prompt"]) for d in text_to_image_data)
if block_size < max_prompt_len + 1: # +1 for potential special tokens like <EOS> if used in promptprint(f"Warning: Loaded block_size ({block_size}) might be small for max prompt length ({max_prompt_len}). Consider increasing block_size if issues arise.")# Adjust block_size if needed, and recompute PE / causal mask# block_size = max_prompt_len + 5 # Example adjustment# print(f"Adjusted block_size to {block_size}")# Need to recompute PE and causal_mask if block_size changes# Recreate causal mask just in case block_size was adjusted, or use loaded size
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
print(f"Using block_size: {block_size}")learning_rate = 1e-4 # Potentially lower LR for fine-tuning
batch_size = 4 # Keep small due to limited data
epochs = 5000 # Number of training iterations
eval_interval = 500print(f" Training Params: LR={learning_rate}, BatchSize={batch_size}, Epochs={epochs}")
步骤 1:模型适配与初始化
目标:使用加载的权重重建文本 Transformer 组件,并初始化新的输出投影层。
步骤 1.1:初始化文本 Transformer 组件
理论:创建嵌入层、LayerNorms 和 Transformer 块的线性层实例,然后从步骤 0.2 存储的字典中加载预训练权重。
print("\nStep 1.1: Initializing Text Transformer components and loading weights...")# --- Token Embedding Table ---
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_embedding_dict)
print(f" Loaded Token Embedding Table, shape: {token_embedding_table.weight.shape}")# --- Transformer Blocks Components ---
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []for i in range(n_layers):# LayerNorm 1ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_ln1_dicts[i])layer_norms_1.append(ln1)# MHA QKV Linear (Check bias presence)qkv_dict = loaded_qkv_dicts[i]has_bias = 'bias' in qkv_dictqkv_linear = nn.Linear(d_model, 3 * d_model, bias=has_bias).to(device)qkv_linear.load_state_dict(qkv_dict)mha_qkv_linears.append(qkv_linear)# MHA Output Linear (Check bias presence)mha_out_dict = loaded_mha_out_dicts[i]has_bias = 'bias' in mha_out_dictoutput_linear_mha = nn.Linear(d_model, d_model, bias=has_bias).to(device)output_linear_mha.load_state_dict(mha_out_dict)mha_output_linears.append(output_linear_mha)# LayerNorm 2ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_ln2_dicts[i])layer_norms_2.append(ln2)# FFN Linear 1 (Check bias presence)ffn1_dict = loaded_ffn1_dicts[i]has_bias = 'bias' in ffn1_dictlin1 = nn.Linear(d_model, d_ff, bias=has_bias).to(device)lin1.load_state_dict(ffn1_dict)ffn_linear_1.append(lin1)# FFN Linear 2 (Check bias presence)ffn2_dict = loaded_ffn2_dicts[i]has_bias = 'bias' in ffn2_dictlin2 = nn.Linear(d_ff, d_model, bias=has_bias).to(device)lin2.load_state_dict(ffn2_dict)ffn_linear_2.append(lin2)print(f" Loaded components for {n_layers} Transformer Layers.")# --- Final LayerNorm ---
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_final_ln_dict)
print(" Loaded Final LayerNorm.")print("Finished initializing and loading weights for text transformer components.")
步骤 1.2:初始化新的输出投影层
理论:创建一个新的线性层,将 Transformer 的最终隐藏状态(d_model)映射到图像特征向量的维度(vision_feature_dim)。该层的权重将随机初始化并进行训练。
print("\nStep 1.2: Initializing new output projection layer (Text -> Image Feature)...")text_to_image_feature_layer = nn.Linear(d_model, vision_feature_dim).to(device)print(f" Initialized Text-to-Image-Feature Output Layer: {d_model} -> {vision_feature_dim}. Device: {device}")
步骤 2:文本到图像训练的数据准备
目标:对文本提示进行分词和填充,并将其与对应的目标图像特征向量配对。
步骤 2.1:分词和填充提示
理论:使用 char_to_int 将文本提示转换为 token ID 序列。使用 pad_token_id 将每个序列填充到 block_size 长度。同时创建对应的注意力掩码(1 表示真实 token,0 表示填充部分)。
print("\nStep 2.1: Tokenizing and padding text prompts...")prepared_prompts = []
target_features_ordered = [] # Store target features in the same orderfor sample in text_to_image_data:prompt = sample["prompt"]image_path = sample["image_path"]# --- Tokenize Prompt --- prompt_ids_no_pad = [char_to_int[ch] for ch in prompt]# --- Padding --- current_len = len(prompt_ids_no_pad)pad_len = block_size - current_lenif pad_len < 0:print(f"Warning: Prompt length ({current_len}) exceeds block_size ({block_size}). Truncating prompt.")prompt_ids = prompt_ids_no_pad[:block_size]pad_len = 0current_len = block_sizeelse:prompt_ids = prompt_ids_no_pad + ([pad_token_id] * pad_len)# --- Create Attention Mask --- attention_mask = ([1] * current_len) + ([0] * pad_len)# --- Store Prompt Data --- prepared_prompts.append({"input_ids": torch.tensor(prompt_ids, dtype=torch.long),"attention_mask": torch.tensor(attention_mask, dtype=torch.long)})# --- Store Corresponding Target Feature --- if image_path in target_image_features:target_features_ordered.append(target_image_features[image_path])else:print(f"Error: Target feature not found for {image_path}. Data mismatch?")# Handle error - maybe skip this sample or raise exceptiontarget_features_ordered.append(torch.zeros(vision_feature_dim, device=device)) # Placeholder# --- Stack into Tensors ---
all_prompt_input_ids = torch.stack([p['input_ids'] for p in prepared_prompts])
all_prompt_attention_masks = torch.stack([p['attention_mask'] for p in prepared_prompts])
all_target_features = torch.stack(target_features_ordered)num_sequences_available = all_prompt_input_ids.shape[0]
print(f"Created {num_sequences_available} padded prompt sequences and gathered target features.")
print(f" Prompt Input IDs shape: {all_prompt_input_ids.shape}") # (num_samples, block_size)
print(f" Prompt Attention Mask shape: {all_prompt_attention_masks.shape}") # (num_samples, block_size)
print(f" Target Features shape: {all_target_features.shape}") # (num_samples, vision_feature_dim)
步骤 2.2:批处理策略(随机采样)
理论:设置训练期间的随机批次采样。我们将选择随机索引并获取相应的提示 ID、掩码和目标图像特征。
print("\nStep 2.2: Preparing for batching text-to-image data...")# Check batch size feasibility
if num_sequences_available < batch_size:print(f"Warning: Number of sequences ({num_sequences_available}) is less than batch size ({batch_size}). Adjusting batch size.")batch_size = num_sequences_availableprint(f"Data ready for training. Will sample batches of size {batch_size} randomly.")
# In the training loop, we will use random indices to get:
# xb_prompt_ids = all_prompt_input_ids[indices]
# batch_prompt_masks = all_prompt_attention_masks[indices]
# yb_target_features = all_target_features[indices]
步骤 3:文本到图像训练循环(内联)
目标:训练模型将文本提示映射到图像特征向量。
步骤 3.1:定义优化器和损失函数
理论:收集可训练参数(Transformer 组件+新的输出层)。定义优化器(AdamW)。定义损失函数 - 均方误差(MSE)适用于比较预测和目标特征向量。
print("\nStep 3.1: Defining Optimizer and Loss Function for text-to-image...")# --- Gather Trainable Parameters ---
# Includes Transformer components and the new output layer
all_trainable_parameters_t2i = list(token_embedding_table.parameters())
for i in range(n_layers):all_trainable_parameters_t2i.extend(list(layer_norms_1[i].parameters()))all_trainable_parameters_t2i.extend(list(mha_qkv_linears[i].parameters()))all_trainable_parameters_t2i.extend(list(mha_output_linears[i].parameters()))all_trainable_parameters_t2i.extend(list(layer_norms_2[i].parameters()))all_trainable_parameters_t2i.extend(list(ffn_linear_1[i].parameters()))all_trainable_parameters_t2i.extend(list(ffn_linear_2[i].parameters()))
all_trainable_parameters_t2i.extend(list(final_layer_norm.parameters()))
all_trainable_parameters_t2i.extend(list(text_to_image_feature_layer.parameters())) # Add the new layer# --- Define Optimizer ---
optimizer = optim.AdamW(all_trainable_parameters_t2i, lr=learning_rate)
print(f" Optimizer defined: AdamW with lr={learning_rate}")
print(f" Managing {len(all_trainable_parameters_t2i)} parameter groups/tensors.")# --- Define Loss Function ---
# Theory: MSE loss compares the predicted feature vector to the target feature vector.
criterion = nn.MSELoss()
print(f" Loss function defined: {type(criterion).__name__}")
步骤 3.2:训练循环
理论:迭代 epochs 次。每一步:
- 选择批次(提示 ID、掩码、目标特征)。
- 执行前向传播:嵌入提示,添加位置编码,通过 Transformer 块传递,应用最终层归一化,使用
text_to_image_feature_layer投影到图像特征维度。 - 计算预测和目标特征向量之间的 MSE 损失。
- 反向传播并更新权重。
print("\nStep 3.2: 开始文本到图像训练循环...")t2i_losses = []# --- Set Trainable Layers to Training Mode ---
token_embedding_table.train()
for i in range(n_layers):layer_norms_1[i].train()mha_qkv_linears[i].train()mha_output_linears[i].train()layer_norms_2[i].train()ffn_linear_1[i].train()ffn_linear_2[i].train()
final_layer_norm.train()
text_to_image_feature_layer.train() # New layer also needs training mode
# vision_model remains in eval() mode# --- Training Loop ---
for epoch in range(epochs):# --- 1. 批次选择 --- indices = torch.randint(0, num_sequences_available, (batch_size,))xb_prompt_ids = all_prompt_input_ids[indices].to(device) # (B, T)batch_prompt_masks = all_prompt_attention_masks[indices].to(device) # (B, T)yb_target_features = all_target_features[indices].to(device) # (B, vision_feature_dim)# --- 2. 前向传播 --- B, T = xb_prompt_ids.shapeC = d_model# --- 嵌入 + 位置编码 ---token_embed = token_embedding_table(xb_prompt_ids) # (B, T, C)pos_enc_slice = positional_encoding[:, :T, :] # (1, T, C)x = token_embed + pos_enc_slice # (B, T, C)# --- Transformer块 --- # 创建注意力掩码(因果掩码+提示的填充掩码)padding_mask_expanded = batch_prompt_masks.unsqueeze(1).unsqueeze(2) # (B, 1, 1, T)combined_attn_mask = causal_mask[:,:,:T,:T] * padding_mask_expanded # (B, 1, T, T)for i in range(n_layers):x_input_block = x# Pre-LN MHAx_ln1 = layer_norms_1[i](x_input_block)qkv = mha_qkv_linears[i](x_ln1)qkv = qkv.view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3)q, k, v = qkv.chunk(3, dim=-1)attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked = attn_scores.masked_fill(combined_attn_mask == 0, float('-inf'))attention_weights = F.softmax(attn_scores_masked, dim=-1)attention_weights = torch.nan_to_num(attention_weights)attn_output = attention_weights @ vattn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(B, T, C)mha_result = mha_output_linears[i](attn_output)x = x_input_block + mha_result # Residual 1# Pre-LN FFNx_input_ffn = xx_ln2 = layer_norms_2[i](x_input_ffn)ffn_hidden = ffn_linear_1[i](x_ln2)ffn_activated = F.relu(ffn_hidden)ffn_output = ffn_linear_2[i](ffn_activated)x = x_input_ffn + ffn_output # Residual 2# --- Final LayerNorm --- final_norm_output = final_layer_norm(x) # (B, T, C)# --- 选择用于预测的隐藏状态 --- # 理论:我们需要每个序列一个向量来预测图像特征向量。# 我们可以取*最后一个非填充*标记的隐藏状态。# 找到批次中每个序列的最后一个非填充标记的索引。# batch_prompt_masks的形状为(B, T),值为1表示非填充,0表示填充。# `torch.sum(mask, 1) - 1`给出了最后一个'1'的索引。last_token_indices = torch.sum(batch_prompt_masks, 1) - 1 # Shape: (B,)# 确保索引在边界内(处理全部是填充的情况,虽然不太可能)last_token_indices = torch.clamp(last_token_indices, min=0)# 收集对应于这些最后标记的隐藏状态。# 我们需要索引final_norm_output[batch_index, token_index, :]batch_indices = torch.arange(B, device=device)last_token_hidden_states = final_norm_output[batch_indices, last_token_indices, :] # (B, C)# --- 投影到图像特征维度 --- # 理论:使用新的输出层预测图像特征向量。predicted_image_features = text_to_image_feature_layer(last_token_hidden_states) # (B, vision_feature_dim)# --- 3. 计算损失 --- # 理论:计算预测特征和目标特征之间的MSE。loss = criterion(predicted_image_features, yb_target_features)# --- 4. Zero Gradients --- optimizer.zero_grad()# --- 5. Backward Pass --- if not torch.isnan(loss) and not torch.isinf(loss):loss.backward()# Optional: Gradient Clipping# torch.nn.utils.clip_grad_norm_(all_trainable_parameters_t2i, max_norm=1.0)# --- 6. Update Parameters --- optimizer.step()else:print(f"Warning: Invalid loss detected (NaN or Inf) at epoch {epoch+1}. Skipping optimizer step.")loss = None# --- Logging --- if loss is not None:current_loss = loss.item()t2i_losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" Epoch {epoch+1}/{epochs}, MSE Loss: {current_loss:.6f}")elif epoch % eval_interval == 0 or epoch == epochs - 1:print(f" Epoch {epoch+1}/{epochs}, Loss: Invalid (NaN/Inf)")print("--- Text-to-Image Training Loop Completed ---\n")# Optional: Plot losses
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(t2i_losses)
plt.title("Text-to-Image Training Loss (MSE)")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.grid(True)
plt.show()
步骤 4:文本到图像生成(内联实现)
目标:使用训练好的模型从文本提示生成图像特征向量,并找到最接近的已知图像。
步骤 4.1:准备输入提示
理论:定义新的文本提示,进行分词处理,并填充到 block_size 长度。
print("\nStep 4.1: Preparing input prompt for generation...")# --- Input Prompt ---
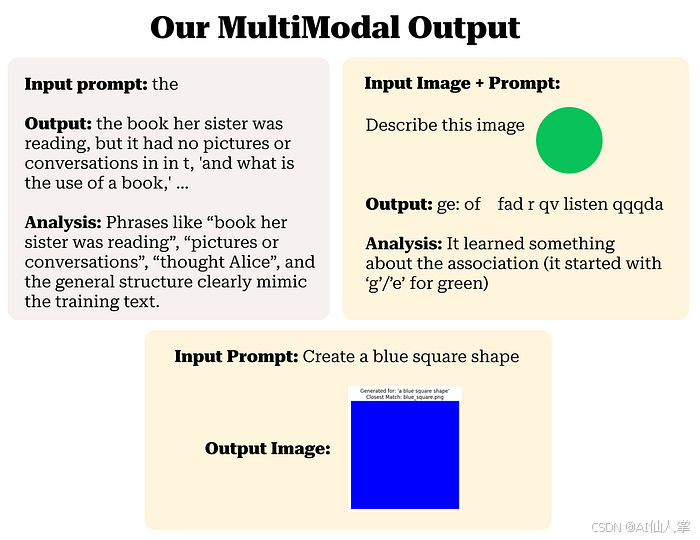
generation_prompt_text = "a blue square shape"
print(f"Input Prompt: '{generation_prompt_text}'")# --- Tokenize and Pad ---
gen_prompt_ids_no_pad = [char_to_int.get(ch, pad_token_id) for ch in generation_prompt_text] # Use get with default for safety
gen_current_len = len(gen_prompt_ids_no_pad)
gen_pad_len = block_size - gen_current_lenif gen_pad_len < 0:print(f"Warning: Generation prompt length ({gen_current_len}) exceeds block_size ({block_size}). Truncating.")gen_prompt_ids = gen_prompt_ids_no_pad[:block_size]gen_pad_len = 0gen_current_len = block_size
else:gen_prompt_ids = gen_prompt_ids_no_pad + ([pad_token_id] * gen_pad_len)# --- Create Attention Mask ---
gen_attention_mask = ([1] * gen_current_len) + ([0] * gen_pad_len)# --- Convert to Tensor ---
xb_gen_prompt_ids = torch.tensor([gen_prompt_ids], dtype=torch.long, device=device) # Add batch dim B=1
batch_gen_prompt_masks = torch.tensor([gen_attention_mask], dtype=torch.long, device=device) # Add batch dim B=1print(f"Prepared prompt tensor shape: {xb_gen_prompt_ids.shape}")
print(f"Prepared mask tensor shape: {batch_gen_prompt_masks.shape}")
步骤 4.2:生成图像特征向量
理论:使用训练好的模型(在评估模式下)对输入提示进行前向传播,获取预测的图像特征向量。
print("\nStep 4.2: Generating image feature vector...")# --- Set Model to Evaluation Mode ---
token_embedding_table.eval()
for i in range(n_layers):layer_norms_1[i].eval()mha_qkv_linears[i].eval()mha_output_linears[i].eval()layer_norms_2[i].eval()ffn_linear_1[i].eval()ffn_linear_2[i].eval()
final_layer_norm.eval()
text_to_image_feature_layer.eval()# --- Forward Pass ---
with torch.no_grad():B_gen, T_gen = xb_gen_prompt_ids.shapeC_gen = d_model# Embeddings + PEtoken_embed_gen = token_embedding_table(xb_gen_prompt_ids)pos_enc_slice_gen = positional_encoding[:, :T_gen, :]x_gen = token_embed_gen + pos_enc_slice_gen# Transformer Blockspadding_mask_expanded_gen = batch_gen_prompt_masks.unsqueeze(1).unsqueeze(2)combined_attn_mask_gen = causal_mask[:,:,:T_gen,:T_gen] * padding_mask_expanded_genfor i in range(n_layers):x_input_block_gen = x_gen# Pre-LN MHAx_ln1_gen = layer_norms_1[i](x_input_block_gen)qkv_gen = mha_qkv_linears[i](x_ln1_gen)qkv_gen = qkv_gen.view(B_gen, T_gen, n_heads, 3 * d_k).permute(0, 2, 1, 3)q_gen, k_gen, v_gen = qkv_gen.chunk(3, dim=-1)attn_scores_gen = (q_gen @ k_gen.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked_gen = attn_scores_gen.masked_fill(combined_attn_mask_gen == 0, float('-inf'))attention_weights_gen = F.softmax(attn_scores_masked_gen, dim=-1)attention_weights_gen = torch.nan_to_num(attention_weights_gen)attn_output_gen = attention_weights_gen @ v_genattn_output_gen = attn_output_gen.permute(0, 2, 1, 3).contiguous().view(B_gen, T_gen, C_gen)mha_result_gen = mha_output_linears[i](attn_output_gen)x_gen = x_input_block_gen + mha_result_gen # Residual 1# Pre-LN FFNx_input_ffn_gen = x_genx_ln2_gen = layer_norms_2[i](x_input_ffn_gen)ffn_hidden_gen = ffn_linear_1[i](x_ln2_gen)ffn_activated_gen = F.relu(ffn_hidden_gen)ffn_output_gen = ffn_linear_2[i](ffn_activated_gen)x_gen = x_input_ffn_gen + ffn_output_gen # Residual 2# Final LayerNormfinal_norm_output_gen = final_layer_norm(x_gen)# Select Hidden State (use last non-padding token's state)last_token_indices_gen = torch.sum(batch_gen_prompt_masks, 1) - 1last_token_indices_gen = torch.clamp(last_token_indices_gen, min=0)batch_indices_gen = torch.arange(B_gen, device=device)last_token_hidden_states_gen = final_norm_output_gen[batch_indices_gen, last_token_indices_gen, :]# Project to Image Feature Dimensionpredicted_feature_vector = text_to_image_feature_layer(last_token_hidden_states_gen)print(f"Generated predicted feature vector with shape: {predicted_feature_vector.shape}") # Should be (1, vision_feature_dim)
步骤 4.3:查找最接近的已知图像(简化重建)
理论:将预测的特征向量与我们已知训练图像的预计算特征向量(known_features_list)进行比较。找到特征向量与预测向量距离最小(如欧几里得距离或余弦距离)的已知图像,并显示该图像。
print("\n步骤4.3:寻找最接近的已知图像...")# --- 计算距离 ---
# 理论:计算预测向量与每个已知向量之间的距离。
# 我们使用余弦距离:1 - 余弦相似度。距离越小越好。
predicted_vec = predicted_feature_vector.squeeze(0).cpu().numpy() # 移至CPU并转换为numpy供scipy使用min_distance = float('inf')
closest_image_path = Nonefor known_path, known_vec_tensor in known_features_list:known_vec = known_vec_tensor.cpu().numpy()# 计算余弦距离# dist = scipy_distance.cosine(predicted_vec, known_vec)# 或者计算欧几里得距离(L2范数)dist = scipy_distance.euclidean(predicted_vec, known_vec)# print(f" 到 {os.path.basename(known_path)} 的距离: {dist:.4f}") # 可选:打印距离if dist < min_distance:min_distance = distclosest_image_path = known_path# --- 显示结果 ---
if closest_image_path:print(f"Closest match found: '{os.path.basename(closest_image_path)}' with distance {min_distance:.4f}")# 使用PIL或matplotlib显示图像try:matched_img = Image.open(closest_image_path)print("Displaying the closest matching image:")# 在notebook环境中,简单地显示对象通常就可以工作:# matched_img # 或者使用matplotlib:import matplotlib.pyplot as pltplt.imshow(matched_img)plt.title(f"Generated for: '{generation_prompt_text}'\nClosest Match: {os.path.basename(closest_image_path)}")plt.axis('off')plt.show()except FileNotFoundError:print(f"Error: Could not load the matched image file at {closest_image_path}")except Exception as e:print(f"Error displaying image: {e}")
else:print("Could not determine the closest image.")
步骤 5:保存模型状态(可选)
要保存我们的文本到图像生成模型,您需要创建一个包含所有模型组件和配置的字典,然后使用 torch.save()。具体方法如下:
import os# 如果目录不存在则创建
save_dir = 'saved_models'
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, 'text_to_image_model.pt')# 创建包含所有相关组件和配置的字典
text_to_image_state_dict = {# 配置'config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'d_ff': d_ff,'block_size': block_size,'vision_feature_dim': vision_feature_dim},# 分词器'tokenizer': {'char_to_int': char_to_int,'int_to_char': int_to_char},# 模型权重(可训练部分)'token_embedding_table': token_embedding_table.state_dict(),'positional_encoding': positional_encoding, # 未训练,但重建时需要'layer_norms_1': [ln.state_dict() for ln in layer_norms_1],'mha_qkv_linears': [l.state_dict() for l in mha_qkv_linears],'mha_output_linears': [l.state_dict() for l in mha_output_linears],'layer_norms_2': [ln.state_dict() for ln in layer_norms_2],'ffn_linear_1': [l.state_dict() for l in ffn_linear_1],'ffn_linear_2': [l.state_dict() for l in ffn_linear_2],'final_layer_norm': final_layer_norm.state_dict(),'text_to_image_feature_layer': text_to_image_feature_layer.state_dict() # 新的输出层# 注意:我们不在这里保存冻结的vision_model权重,# 因为我们假设它在使用时会从torchvision单独加载。
}# 保存到文件
torch.save(text_to_image_state_dict, save_path)
print(f"文本到图像模型已保存到 {save_path}")
加载保存的文本到图像模型
要加载模型,您需要逆转保存过程:
# 加载保存的文本到图像模型# 加载保存的状态字典
load_path = 'saved_models/text_to_image_model.pt'
if os.path.exists(load_path):loaded_t2i_state = torch.load(load_path, map_location=device)print(f"从'{load_path}'加载状态字典。")# 提取配置和分词器config = loaded_t2i_state['config']vocab_size = config['vocab_size']d_model = config['d_model']n_heads = config['n_heads']n_layers = config['n_layers']d_ff = config['d_ff']block_size = config['block_size']vision_feature_dim = config['vision_feature_dim']d_k = d_model // n_headschar_to_int = loaded_t2i_state['tokenizer']['char_to_int']int_to_char = loaded_t2i_state['tokenizer']['int_to_char']# 重新创建因果掩码causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)# 重建并加载模型组件token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)token_embedding_table.load_state_dict(loaded_t2i_state['token_embedding_table'])positional_encoding = loaded_t2i_state['positional_encoding'].to(device)layer_norms_1 = []mha_qkv_linears = []mha_output_linears = []layer_norms_2 = []ffn_linear_1 = []ffn_linear_2 = []for i in range(n_layers):# Load Layer Norm 1ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_t2i_state['layer_norms_1'][i])layer_norms_1.append(ln1)# Load MHA QKV Linearqkv_dict = loaded_t2i_state['mha_qkv_linears'][i]has_bias = 'bias' in qkv_dictqkv = nn.Linear(d_model, 3 * d_model, bias=has_bias).to(device)qkv.load_state_dict(qkv_dict)mha_qkv_linears.append(qkv)# Load MHA Output Linearmha_out_dict = loaded_t2i_state['mha_output_linears'][i]has_bias = 'bias' in mha_out_dictmha_out = nn.Linear(d_model, d_model, bias=has_bias).to(device)mha_out.load_state_dict(mha_out_dict)mha_output_linears.append(mha_out)# Load Layer Norm 2ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_t2i_state['layer_norms_2'][i])layer_norms_2.append(ln2)# Load FFN Linear 1ffn1_dict = loaded_t2i_state['ffn_linear_1'][i]has_bias = 'bias' in ffn1_dictff1 = nn.Linear(d_model, d_ff, bias=has_bias).to(device)ff1.load_state_dict(ffn1_dict)ffn_linear_1.append(ff1)# Load FFN Linear 2ffn2_dict = loaded_t2i_state['ffn_linear_2'][i]has_bias = 'bias' in ffn2_dictff2 = nn.Linear(d_ff, d_model, bias=has_bias).to(device)ff2.load_state_dict(ffn2_dict)ffn_linear_2.append(ff2)# Load Final LayerNormfinal_layer_norm = nn.LayerNorm(d_model).to(device)final_layer_norm.load_state_dict(loaded_t2i_state['final_layer_norm'])# Load Text-to-Image Feature Layert2i_out_dict = loaded_t2i_state['text_to_image_feature_layer']has_bias = 'bias' in t2i_out_dicttext_to_image_feature_layer = nn.Linear(d_model, vision_feature_dim, bias=has_bias).to(device)text_to_image_feature_layer.load_state_dict(t2i_out_dict)print("文本到图像模型组件加载成功。")else:print(f"在{load_path}未找到模型文件。无法加载模型。")
第六步:总结
关键步骤包括:
- 加载:重用之前多模态模型中的文本 Transformer 组件和 ResNet 特征提取器。
- 数据:定义与目标图像配对的文本提示,并使用冻结的 ResNet 预提取目标图像特征向量。
- 架构调整:将 Transformer 的最终输出层替换为新的线性层,将隐藏状态投影到图像特征维度。
- 训练:训练 Transformer 组件和新输出层,以最小化给定文本提示的预测图像特征向量与目标图像特征向量之间的均方误差(MSE)。
- 生成与简化重建:使用训练好的模型从新的文本提示中预测特征向量,然后找到实际特征向量与预测向量最接近的训练图像(使用欧几里得距离)并显示该图像。
该方法展示了在保持内联实现约束的同时,使用 Transformer 进行跨模态生成(文本到视觉表示)的概念。它避免了直接像素生成(GANs、扩散模型)的显著复杂性,但通过在已知图像的特征空间中进行最近邻搜索,提供了一个有形的基础视觉输出。现实中的文本到图像模型要复杂得多,通常结合不同的架构并在海量数据集上进行训练。
相关文章:
使用Python从零开始构建端到端文本到图像 Transformer大模型
简介:通过特征向量从文本生成图像 回顾:多模态 Transformer 在使用Python从零实现一个端到端多模态 Transformer大模型中,我们调整了字符级 Transformer 以处理图像(通过 ResNet 特征)和文本提示,用于视觉…...

NDT和ICP构建点云地图 |【点云建图、Ubuntu、ROS】
### 本博客记录学习NDT,ICP构建点云地图的实验过程,参考的以下两篇博客: 无人驾驶汽车系统入门(十三)——正态分布变换(NDT)配准与无人车定位_settransformationepsilon-CSDN博客 PCL中点云配…...

第 1 篇✅ 用 AI 编程之前,你得先搞清楚你和 AI 是啥关系
程序员不是被替代的,是要学会主导 AI 的人 🧠 那些把 AI 当兄弟的程序员,后来都踩了坑 最近的一次线下开发者聚会,我们聊到“AI 编程”,现场笑声不断,也点醒了不少人。 有个朋友说: “我让 AI 写一个 Web 服务,它写得飞快,我一激动就上线了,结果上线后一堆坑,日志…...

Android Jetpack Compose 高级开发核心技术
Android Compose 高级技术总结 1. 性能优化 1.1 状态管理优化 状态提升原则:将状态提升到共享的最近共同父组件derivedStateOf:当需要基于多个状态计算派生状态时使用 val scrollState rememberScrollState() val showButton by remember {derivedS…...
)
Go小技巧易错点100例(二十五)
本期分享: 1. 使用atomic包实现无锁并发控制 2. Gin框架的中间件机制 3. 搞懂nil切片和空切片 使用atomic包实现无锁并发控制 sync/atomic包提供了原子操作,用于在多goroutine环境下安全地操作共享变量,避免使用锁带来的性能开销。 代码…...

如何用海伦公式快速判断点在直线的哪一侧
一、海伦公式的定义与推导 1. 海伦公式的定义 海伦公式(Heron’s Formula)是用于计算三角形面积的一种方法,适用于已知三角形三边长度的情况。公式如下: S s ( s − a ) ( s − b ) ( s − c ) S \sqrt{s(s - a)(s - b)(s - c…...

【异常处理】Clion IDE中cmake时头文件找不到 头文件飘红
如图所示是我的clion项目目录 我自定义的data_structure.h和func_declaration.h在unit_test.c中无法检索到 cmakelists.txt配置文件如下所示: cmake_minimum_required(VERSION 3.30) project(noc C) #设置头文件的目录 include_directories(${CMAKE_SOURCE_DIR}/…...

自动驾驶技术关键技术梳理
一、硬件 1、 传感器系统设计主要注意以下几个问题: 1.时间同步 一般包括多传感器之间时钟同源、帧同步触发的问题。首先要解决时钟同源问题,然后为了帧同步触发,可以让所有传感器整秒触发。常用GPS(最多分2路)给激光雷…...

MySQL索引介绍
索引的定义 扇区:磁盘存储的最小单位,扇区一般大小为512Byte。磁盘块:文件系统与磁盘交互的的最小单位(计算机系统读写磁盘的最小单位),一个磁盘块由连续几个(2^n)扇区组成…...
)
2025认证杯一阶段各题需要使用的模型或算法(冲刺阶段)
A题(小行星轨迹预测) 问题一:三角测量法、最小二乘法、空间几何算法、最优化方法 问题二:Gauss/Laplace轨道确定方法、差分校正法、数值积分算法(如Runge-Kutta法)、卡尔曼滤波器 B题(谣言在…...
:touch)
每天学一个 Linux 命令(13):touch
Linux 文件管理命令:touch touch 是 Linux 中一个简单但高频使用的命令,主要用于创建空文件或修改文件的时间戳(访问时间、修改时间)。它是文件管理和脚本操作的实用工具。 1. 命令作用 创建空文件:快速生成一个或多个空白文件。更新时间戳:修改文件的访问时间(Access …...

Flutter常用组件实践
Flutter常用组件实践 1、MaterialApp 和 Center(组件居中)2、Scaffold3、Container(容器)4、BoxDecoration(装饰器)5、Column(纵向布局)及Icon(图标)6、Column/Row(横向/横向布局)+CloseButton/BackButton/IconButton(简单按钮)7、Expanded和Flexible8、Stack和Po…...

Python 实现最小插件框架
文章目录 Python 实现最小插件框架1. 基础实现项目结构plugin_base.py - 插件基类plugins/hello.py - 示例插件1plugins/goodbye.py - 示例插件2main.py - 主程序 2. 更高级的特性扩展2.1 插件配置支持2.2 插件依赖管理2.3 插件热加载 3. 使用 setuptools 的入口点发现插件3.1 …...

AUTOSAR_SWS_MemoryDriver图解
AUTOSAR 存储驱动程序(Memory Driver)详解 AUTOSAR存储驱动规范 - 技术解析与架构详解 目录 1. 概述2. Memory Driver架构设计 2.1 整体架构 3. Memory Driver核心组件4. 作业管理5. Memory Driver错误处理6. 时序流程7. 配置与设置8. 总结 1. 概述 A…...

AI结合VBA提升EXCEL办公效率尝试
文章目录 前言一、开始VBA编程二、主要代码三、添加到所有EXCEL四、运行效果五、AI扩展 前言 EXCEL右击菜单添加一个选项,点击执行自己逻辑的功能。 然后让DeepSeek帮我把我的想法生成VBA代码 一、开始VBA编程 我的excel主菜单没有’开发工具‘ 选项,…...

Python中NumPy的索引和切片
在数据科学和科学计算领域,NumPy是一个功能强大且广泛使用的Python库。它提供了高效的多维数组对象以及丰富的数组操作函数,其中索引和切片是NumPy的核心功能之一。通过灵活运用索引和切片操作,我们可以轻松访问和操作数组中的元素࿰…...
)
普通通话CSFB方式(2g/3g)
一、CSFB的触发条件 当模块(或手机)驻留在 4G LTE网络 时,若发生以下事件,会触发CSFB流程: 主叫场景:用户主动拨打电话。被叫场景:接收到来电(MT Call)。紧急呼叫&…...

daily routines 日常生活
总结 🛏 起床相关(Waking Up) 动作常用表达示例句子醒来wake upI usually wake up around 6:30.起床(离床)get up / get out of bedI got out of bed at 6:45.赖床stay in bed / lay thereI stayed in bed for another 10 minutes.关闭闹钟turn off the alarm / hit snoo…...

系分论文《论面向服务开发方法在设备租赁行业的应用》
系统分析师论文系列 【摘要】 2022年5月,我司承接某工程机械租赁企业"智能租赁运营管理平台"建设项目,我作为系统分析师主导系统架构设计。该项目需整合8大类2000余台设备资产,覆盖全国15个区域运营中心与300家代理商,实…...

深度解析python生成器和关键字yield
一、生成器概述 生成器(Generator)是Python中用于创建迭代器的工具,通过yield关键字实现。与普通函数不同,生成器函数返回的是迭代器对象,具有以下核心特性: 内存效率:只在需要时生成值&#x…...

蓝桥杯大模板
init.c void System_Init() {P0 0x00; //关闭蜂鸣器和继电器P2 P2 & 0x1f | 0xa0;P2 & 0x1f;P0 0x00; //关闭LEDP2 P2 & 0x1f | 0x80;P2 & 0x1f; } led.c #include <LED.H>idata unsigned char temp_1 0x00; idata unsigned char temp_old…...

Python装饰器的基本使用详解
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 装饰器是Python中的一个强大且灵活的特性,它允许我们在不修改函数代码的情况下为其添加额外功能。装饰器广泛应用于日志记录、性能测试、权限验证等场景。本文将详细介绍装饰器的基本使用&…...

5Why分析法
1. 基本概念 5Why分析法是一种通过连续追问"为什么"来探究问题根本原因的思考工具,由丰田生产方式创始人丰田喜一郎提出。其核心思想是:通过至少5次连续的"为什么"追问,穿透表面现象,直达问题本质。 2. 实施…...

AI Agent入门指南
图片来源网络 一、开箱暴击:你以为的"智障音箱",其实是赛博世界的007 1.1 从人工智障到智能叛逃:Agent进化史堪比《甄嬛传》 青铜时代(2006-2015) “小娜同学,关灯” “抱歉&…...

华为机试—最大最小路
题目 对于给定的无向无根树,第 i 个节点上有一个权值 wi 。我们定义一条简单路径是好的,当且仅当:路径上的点的点权最小值小于等于 a ,路径上的点的点权最大值大于等于 b 。 保证给定的 a<b,你需要计算有多少条简…...

java之多线程
目录 创建多线程的三种创建方式 常用的成员方法 守护线程 多线程的声明周期 编辑 同步代码块编辑 同步方法 死锁 等待唤醒机制(线程协调) 线程池 创建多线程的三种创建方式 继承 Thread 类 通过继承 Thread 类并重写 run() 方法创建线程。 …...

php伪协议
PHP 伪协议(PHP Stream Wrapper) PHP 的伪协议(Protocol Wrapper)是一种机制,允许开发者通过统一的文件访问函数(如 file_get_contents、fopen、include 等)访问不同类型的数据源,包…...

六、测试分类
设计测试用例 万能公式:功能测试性能测试界面测试兼容性测试安全性测试易用性测试 弱网测试:fiddler上行速率和下行速率 安装卸载测试 在工作中: 1.基于需求文档来设计测试用例(粗粒度) 输入字段长度为6~15位 功…...

【AM2634】启动和调试
目录 【AM2634】启动和调试1. 上电流程1.1 BootFlow and Bootloader1.2 Rom Code1.2.1 功能介绍1.2.2 模式选择1.2.2.1 QSPI Boot1.2.2.2 UART Boot1.2.2.3 Dev Boot 1.3 SBL1.3.1 文件构成1.3.2 文件构建1.3.3 appimage解析和core启动流程 1.4 Appimage1.4.1 RPRC文件构成1.4.…...

鲁大师绿色版,纯净无广告
鲁大师是我们常用的硬件跑分软件,可以非常准确的识别电脑硬件,对电脑性能进行评估 但他的流氓行为:广告弹窗,捆绑下载其他软件,疯狂的吃硬件性能,无法卸载等因素,又使我们大家既享用又不敢用 我为大家整理了一款纯净的绿色版鲁大师 主要实现了以下功能: 01屏蔽了…...
学习之旅:数据结构的奇妙冒险)
Python数组(array)学习之旅:数据结构的奇妙冒险
Python数组学习之旅:数据结构的奇妙冒险 第一天:初识数组的惊喜 阳光透过窗帘缝隙洒进李明的房间,照亮了他桌上摊开的笔记本和笔记本电脑。作为一名刚刚转行的金融分析师,李明已经坚持学习Python编程一个月了。他的眼睛因为昨晚熬夜编程而微微发红,但脸上却挂着期待的微…...

spring cloud微服务API网关详解及各种解决方案详解
微服务API网关详解 1. 核心概念 定义:API网关作为微服务的统一入口,负责请求路由、认证、限流、监控等功能,简化客户端与后端服务的交互。核心功能: 路由与转发:将请求分发到对应服务。协议转换:HTTP/HTTP…...

工程师 - 场效应管分类
What Are the Different Types of FETs? Pulse Octopart Staff Jul 31, 2021 Field effect transistors (FETs) are today’s workhorses for digital logic, but they enjoy plenty of applications outside of digital integrated circuits, everything from motor driver…...

asm汇编源代码之按键处理相关函数
提供5个子程序: 1. 发送按键 sendkey 2. 检测是否有按键 testkey 3. 读取按键 getkey 4. 判断键盘缓冲区是否为空 bufempty 5. 判断键盘缓冲区是否已满 buffull 具体功能及参数描述如下 sendkey proc far ; axcharcode testkey proc far ; out: ; zf1 buff empt…...
:多因素交织下的行业剖析与展望)
程序化广告行业(78/89):多因素交织下的行业剖析与展望
程序化广告行业(78/89):多因素交织下的行业剖析与展望 在程序化广告这片充满活力又不断变化的领域,持续学习和知识共享是我们紧跟潮流、实现突破的关键。一直以来,我都渴望能与大家一同探索这个行业的奥秘,…...

如何使用MaxScript+dotNet在UI中显示图像?
在MaxScript中,你可以使用dotNetControl来显示图像。以下是一个简单的示例脚本,它创建一个UI窗口并在其中显示logo.jpg图像: rollout logoRollout "Logo Display" width:300 height:300 (dotNetControl logoPicture "System.Windows.Forms.PictureBox"…...

BitMap和RoaringBitmap:极致高效的大数据结构
目录 1、引言 2、BitMap:基础 2.1、核心原理 2.2、BitMap的优势 2.3、BitMap的局限性 3、RoaringBitmap:进化 3.1、分段策略 3.2、三种容器类型 3.2.1. ArrayContainer(数组容器) 3.2.2. BitMapContainer(位图容器) 3.2.3. RunContainer(行程容器) 3.3、行…...

Java高性能并发利器-VarHandle
1. 什么是 VarHandle? VarHandle 是 Java 9 引入的类,用于对变量(对象字段、数组元素、静态变量等)进行低级别、高性能的原子操作(如 CAS、原子读写)。它是 java.util.concurrent.atomic 和 sun.misc.…...

关于读完《毛泽东选集》的一些思考迭代
看完毛选前四卷,从革命初期一直讲到抗战胜利,共75.8W字,花费67个小时读完。从1925年发表的“中国社会各阶级的分析”,跨越100年,通过67个小时向主席学习到: 实事求是 从实践中来再到实践中去 用辩证与发展…...

机器学习 第一章
🧠 机器学习 第一章 一、什么是机器学习 (Machine Learning) 让计算机自己从数据中学习出规律,无需人手写规则 输入: 特征 x输出: 标签 y学习目标: 学习出 f(x) 等价于 y 二、三大类型任务 类型英文特点示例回归Regression输出是连续值房价预测分类Cla…...

LVS+Keepalived+DNS 高可用项目
项目架构 主机规划 主机IP角色软件lb-master172.25.250.105主备负载均衡器ipvsadm,keepalivedlb-backup172.25.250.106同时做web和dns调度ipvsadm,keepaliveddns-master172.25.250.107VIP:172.25.250.100binddns-slave172.25.250.108LVS DNS…...

app逆向专题三:adb工具的使用
app逆向专题三:adb工具的使用 一、adb工具的配置二、adb工具的下载与安装 一、adb工具的配置 adb它是一个通用命令行工具,它可以作为Android与PC端连接的一个桥梁,所以adb又成为Android调试桥,用户可以通过adb在电脑上对Android设…...

CAD导入arcgis中保持面积不变的方法
1、加载CAD数据,选择面数据,如下: 2、加载进来后,右键导出数据,导出成面shp数据,如下: 3、选择存储路径,导出面后计算面积,如下: 4、与CAD中的闭合线面积核对…...
)
提示词 (Prompt)
引言 在生成式 AI 应用中,Prompt(提示)是与大型语言模型(LLM)交互的核心输入格式。Prompt 的设计不仅决定了模型理解任务的准确度,还直接影响生成结果的风格、长度、结构与可控性。随着模型能力和应用场景…...
)
并查集(Java模板及优化点解析)
并查集 一、核心思想 并查集(Union-Find)是一种处理不相交集合合并与查询的高效数据结构,核心功能包括: 合并(Union):将两个不相交集合合并为一个集合。查询(Find)&am…...
)
本地部署大模型(ollama模式)
分享记录一下本地部署大模型步骤。 大模型应用部署可以选择 ollama 或者 LM Studio。本文介绍ollama本地部署 ollama官网为:https://ollama.com/ 进入官网,下载ollama。 ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型&…...

【JavaEE】TCP流套接字编程
目录 API 1.Socket类(客户端) 2.ServerSocket类(服务端) 创建回显服务器-客户端 服务器引入多线程 服务器引入线程池 解疑惑 长短连接 在Java中,TCP流套接字是基于TCP协议实现的网络通信方式,提供面向连接、可靠、有序的双向字节流传输。 API T…...
——分析方法1)
SQL问题分析与诊断(8)——分析方法1
8.4. 方法 8.4.1. 分析Cost方法 8.4.1.1. 方法说明 SQL Server中,通过阅读和分析SQL语句的评估查询计划,才是现实SQL优化工作中经常被采用的方法。然而,与Oracle等关系库类似,我们对SQL语句的查询计划进行阅读和分析时,首先要做的就是对SQL语句的整个查询计划进行快速的…...

【深度学习基础】神经网络入门:从感知机到反向传播
摘要 神经网络是深度学习的核心!本文将带你从零开始理解神经网络的基本原理,包括感知机模型、激活函数选择、反向传播算法等核心概念,并通过Python实现一个简单的全连接神经网络。文末提供《神经网络公式推导手册》和实战项目资源包…...

linux RCU技术
RCU(Read-Copy-Update)是Linux内核中的一种同步机制,用于在多核处理器环境中实现无锁读取和延迟更新。Linux RCU(Read-Copy-Update)技术通过一种高效的同步机制来处理并发冲突,确保在多核环境中读者和写者对…...