SQL 语句基础(增删改查)
文章目录
- 一、SQL 基础概念
- 1. SQL 简介
- 2. 数据库系统的层次结构
- 二、SQL 语句分类
- 1. DDL(Data Definition Language 数据定义语言)
- 1.1 CREATE
- 1.1.1 创建数据库
- 1.1.2 创建数据表
- 1.1.3 创建用户
- 1.2 ALTER
- 1.2.1 AlTER 添加字段名
- 1.2.2 ALTER 修改字段名
- 1.2.3 ALTER 修改数据库和数据表
- 1.2.4 ALTER 添加约束
- 1.3. DROP
- 1.3.1 DROP 删除字段名
- 1.3.2 DROP 删除数据库、数据表和用户
- 1.3.3 DROP 删除约束
- 1.4 TRUNCATE
- 1.4.1 TRUNCATE 清空表数据
- 2. DML(Data Manipulation Language 数据操作语言)
- 2.1 INSERT
- INSERT INTO 语句的两种形式
- 2.2 UPDATE
- 2.3 DELETE
- 3. DCL(Data Control Language 数据控制语言)
- 3.1 GRANT
- 3.2 REVOKE
- 4. DQL(Data Query Language 数据查询语言)
- 4.1 SELECT
- 4.2 WHERE
- 4.2.1 AND(并且)
- 4.2.2 OR(或者)
- 4.2.3 同时出现 AND && OR
- 4.2.4 BETWEEN...AND...(区间范围)
- 4.2.5 IN(多值匹配)
- 4.2.6 LIKE 模糊查询
- 4.2.7 `%` 通配符(百分号)
- 4.2.8 `_` 通配符(下划线)
- 4.3 GROUP BY
- 4.4 聚合函数
- 4.5 HAVING
- 4.6 ORDER BY
- 4.7 LIMIT
- 4.8 子查询
- 4.8.1 WHERE子查询(单值比较)
- 4.8.2 WHERE子查询(多值IN)
- 4.8.3 FROM子查询(派生表)
- 4.9 联表查询
- 4.9.1 等值连接 和 非等值连接
- 等值连接(最常用)
- 非等值连接(范围连接)
- 两种连接的对比
- 4.9.2 内连接(INNER JOIN)
- 内连接示例
- 4.9.3 左连接(LEFT JOIN)
- 左连接示例
- 4.9.4 右连接(RIGTH JOIN)
- 外连接示例
- 附录(其他部分)
- MySQL 错误代码分类速查表
- SQL 执行流程
- SQL查询执行顺序简明对照表
- 执行流程
- 2.1 举例:SQL查询顺序:学生成绩管理(类比)
- 📝 2.1.1 写SQL的顺序(写法顺序)
- ⚙️ 2.1.2 数据库实际处理的顺序(执行顺序)
- 常用的数据类型(部分)
- 1.常用的数据类型表格
- SQL 中 真(TRUE)与假(FALSE)判断标准表格
- 数据库权限授权常用表格
- 特殊权限说明
- 六、数据表参照
仅供参考
一、SQL 基础概念
1. SQL 简介
- SQL(Structured Query Language,结构化查询语言)是一种用于管理和操作关系型数据库的标准编程语言。
- 它允许用户从数据库中查询、插入、更新和删除数据,还可以创建和修改数据库结构(如表、索引等)。
2. 数据库系统的层次结构
数据库系统的层次结构从大到小依次为:数据库系统 → 数据库 → 表 → 字段名(列) → 数据(行)。
- 数据库系统(Database System)
- 管理多个数据库的软件系统
- 包含数据库管理系统(DBMS)如 MySQL、Oracle、SQL Server 等
- 提供数据存储、检索、更新和安全等功能
- 数据库(Database)
- 存储数据的容器
- 一个数据库系统可以管理多个数据库
- 例如:学生管理数据库、电子商务数据库等
- 表(Table)
- 数据库中的主要数据结构
- 由行和列组成的二维结构
- 例如:学生表、课程表、成绩表等
- 字段名/列(Field/Column)
- 表中的每一列代表一个属性
- 有特定的数据类型(如整数、字符串、日期等)
- 例如:学生表中的"学号"、“姓名”、"年龄"等字段名
- 数据/行(Data/Row)
- 表中的每一行代表一条具体记录
- 例如:学生表中的一行表示一个学生的完整信息
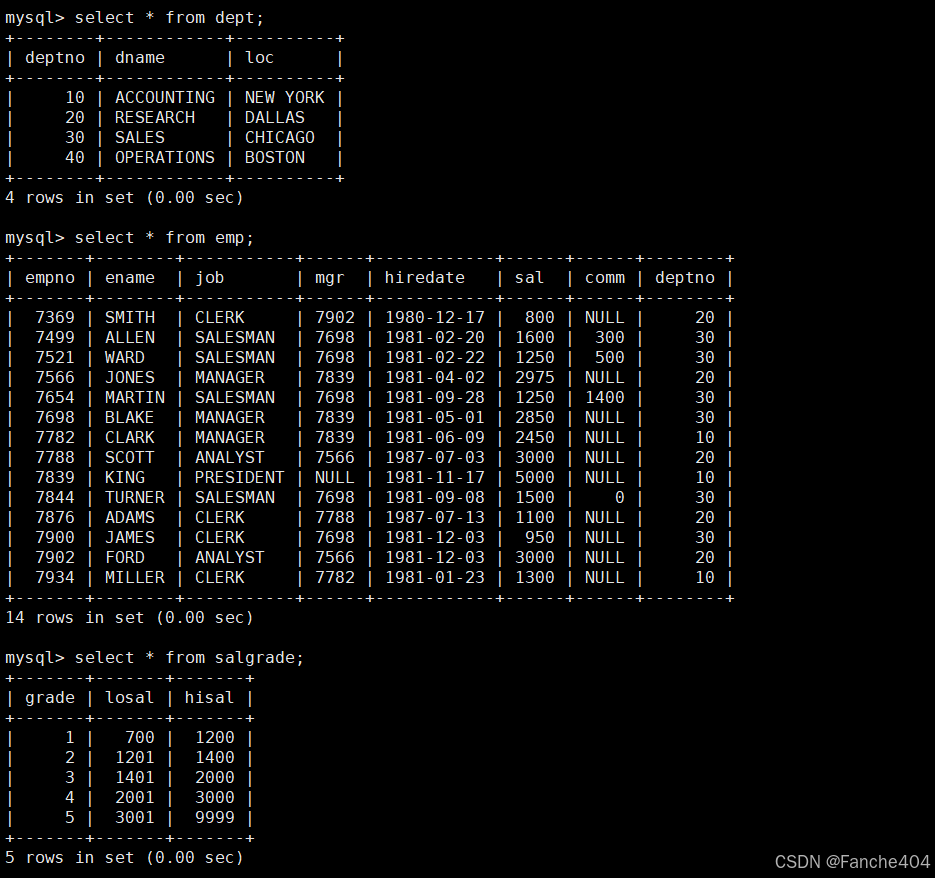
# 数据库系统层次结构实例说明(基于部门-员工数据库)/* 数据库系统层次结构:数据库系统 → 数据库 → 表 → 字段 → 数据记录
*/-- 层次1:数据库系统(MySQL系统)
/*- 当前运行的MySQL数据库管理系统- 管理着包括员工数据库在内的多个数据库- 提供SQL接口执行这些查询
*/-- 层次2:数据库(员工管理数据库)
/*- 包含dept/emp/salgrade三个表的数据库- 示例名称可能是hr_database或employee_db
*/-- 层次3:表(部门表dept)
/*
+---------------------+
| dept表 |
+---------------------+
| 存储所有部门信息 |
| 包含3个字段 |
| 已有4条部门记录 |
+---------------------+
*/-- 层次4:字段(dept表的字段)
/*
+--------+-------------+----------------+
| Field | Type | 说明 |
+--------+-------------+----------------+
| deptno | int(11) | 部门编号(主键) |
| dname | varchar(14) | 部门名称 |
| loc | varchar(13) | 部门所在地 |
+--------+-------------+----------------+
*/-- 层次5:数据(dept表的具体记录)
/*
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
*/-- 完整层级关系示例
/*
数据库系统(MySQL)└─ 数据库(hr_database)├─ 表(dept)│ ├─ 字段(deptno/dname/loc)│ └─ 数据(10/ACCOUNTING/NEW YORK等)├─ 表(emp)│ ├─ 字段(empno/ename/job等)│ └─ 数据(7369/SMITH/CLERK等)└─ 表(salgrade)├─ 字段(grade/losal/hisal)└─ 数据(1/700/1200等)
*/
二、SQL 语句分类
备注:SQL 语句使用格式带
[]都是可选项,根据实际情况来。
1. DDL(Data Definition Language 数据定义语言)
- 作用:用来定义或修改数据库的结构(比如创建表、修改表结构等)。
- 类比:就像盖房子时设计房子的结构(比如有几层楼、每层有几个房间)。
- 常见操作:
CREATE:创建数据库或表。ALTER:修改表的结构(比如添加一列)。DROP:删除数据库或表。TRUNCATE:清空表中的所有数据(但保留表结构)。RENAME:重命名表。
1.1 CREATE
CREATE 是 SQL 中的 数据定义语言(DDL) 命令,用于 创建数据库对象(如表、数据库、索引等)。
1.1.1 创建数据库
-- 使用格式:创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名称
[CHARACTER SET 字符集名称]
[COLLATE 排序规则];
-- 选择使用数据库
USE 数据库名;-- 查看所有数据库
SHOW DATABASES;
1.1.2 创建数据表
附录: 三、常用的数据类型(部分)
-- 使用格式:创建数据表(字段名建议英文)
CREATE TABLE [IF NOT EXISTS] 表名称 (字段名1 数据类型 [约束条件],字段名2 数据类型 [约束条件],...[表级约束条件]
)
[ENGINE=存储引擎]
[CHARACTER SET 字符集]
[COMMENT '表注释'];-- 查看所有表
SHOW TABLES;-- 查看表结构
DESC 表名;-- 查看建表SQL(验证细节)
SHOW CREATE TABLE 表名;
创建表示例
-- 创建员工表示例
CREATE TABLE emp(empno int PRIMARY KEY, -- 员工编号,整数类型,作为表的主键ename VARCHAR(10), -- 员工姓名,字符串类型,最大长度为10个字符job VARCHAR(9), -- 职位名称,字符串类型,最大长度为9个字符mgr int, -- 直接上级的员工编号,整数类型hiredate DATE, -- 入职日期,日期类型sal double, -- 薪水,双精度浮点数类型comm double, -- 佣金,双精度浮点数类型deptno int -- 部门编号,整数类型
) ENGINE=InnoDB -- 使用InnoDB存储引擎
CHARACTER SET utf8mb4 -- 使用utf8mb4字符集
COMMENT='员工信息表'; -- 表注释
1.1.3 创建用户
-- 1. 创建用户(指定主机)
create user '用户名'@'主机地址' identified by '密码';-- 2. 仅允许本地访问
create user '用户名'@'localhost' identified by '密码';-- 3. 允许任意主机访问
create user '用户名'@'%' identified by '密码';
1.2 ALTER
ALTER 是 SQL 中的 数据定义语言(DDL) 命令之一,用于修改现有数据库对象的结构。 (也有其他特殊用法)
备注:
ALTER对表结构做操作,不对表数据做操作
1.2.1 AlTER 添加字段名
-- 1. 添加字段名(在末尾添加字段名)
alter table 表名 add 新字段名 数据类型;-- 2. 添加字段名(在开头添加字段名)
alter table 表名 add 新字段名 数据类型 first;-- 3. 添加字段名(在中间添加字段名)
alter table 表名 add 新字段名 数据类型 after 旧字段名;-- 4. 添加多个字段名
alter table 表名add 新字段名 数据类型 [约束条件],add 新字段名 数据类型 [约束条件];
1.2.2 ALTER 修改字段名
-- 1. 修改字段名( 修改字段名的数据类型)
alter table 表名 modify 字段名 新数据类型;-- 2. 修改字段名 (修改字段名和数据类型)
alter table 表名 change 字段名 新字段名 新数据类型;-- 3. 修改字段名(修改字段名的数据类型和长度)
alter table 表名 modify 字段名 数据类型(新长度);-- 4. 重命名字段列
alter table 表名 rename column 旧字段名 to 新字段名;
1.2.3 ALTER 修改数据库和数据表
-- 1. 修改库的编码格式
alter database 数据库名 character set utf8;-- 2. 修改表的编码格式(仅修改表的默认编码,不影响已有数据)
alter table 表名 character set utf8mb4;-- 3. 修改表的编码格式(修改表的默认编码,并将已有数据转换为新编码)
alter table 表名 convert to character set utf8mb4;-- 4. 修改表的存储引擎
alter table 表名 engine = 存储引擎名;
1.2.4 ALTER 添加约束
-- 1. 添加主键约束
alter table 表名 add primary key (字段名);-- 2. 添加外键约束
alter table 表名 add constraint 约束名 foreign key (字段名) references 其他表名(其他字段名);-- 3. 添加唯一约束
alter table 表名 add unique (字段名);-- 4. 添加非空约束
alter table 表名 modify 字段名 数据类型 not null;-- 5. 添加/设置默认值
alter table 表名 alter column 字段名 set default 默认值;-- 6. 添加自增属性
alter table 表名 modify 字段名 数据类型 auto_increment;
1.3. DROP
DROP 是 SQL 中的一个 数据定义语言(DDL) 命令,用于删除数据库中的各种对象,如表、视图、索引、存储过程、函数、触发器或整个数据库。
1.3.1 DROP 删除字段名
-- 1. 删除字段名
alter table 表名 drop column 字段名;-- 2. 删除多个字段名
alter table 表名drop column 字段名1,drop column 字段名2;
1.3.2 DROP 删除数据库、数据表和用户
-- 1. 删除数据库
drop database 数据库名;-- 2. 删除数据表
drop table 表名;
drop table 表名1, 表名2, 表名3;-- 3. 删除用户
drop user 用户名;
1.3.3 DROP 删除约束
-- 使用格式:删除约束
alter table 表名 drop constraint 约束名;-- 1. 删除主键约束
alter table 表名 drop primary key;-- 2. 删除外键约束
alter table 表名 drop foreign key 约束名;-- 3. 删除非空约束
alter table 表名 modify 字段名 数据类型 null;-- 4. 删除默认值
alter table 表名 alter column 字段名 drop default;-- 5. 删除自增属性
alter table 表名 modify 字段名 数据类型;
1.4 TRUNCATE
1.4.1 TRUNCATE 清空表数据
truncate 是 SQL中的 数据定义语言(DDL) 命令,用于 快速删除表中的所有数据,但保留表结构(列、约束、索引等)。
使用格式
-- 使用格式(TABLE关键字可省略)
TRUNCATE [TABLE] 表名称;
2. DML(Data Manipulation Language 数据操作语言)
- 作用:用来操作数据库中的数据(比如插入、更新、删除数据)。
- 类比:就像往房子里搬家具、更换家具或扔掉家具。
- 常见操作:
INSERT:插入新数据。UPDATE:更新数据。DELETE:删除数据。
2.1 INSERT
INSERT 是 SQL 中最基础的 数据操作语言(DML) 命令之一,用于向数据库表中添加新记录。
注意:MySQL 里面没有全部为
NULL的记录,NULL只是一个空白,不是一个值(更不可能是0)!
INSERT INTO 语句的两种形式
使用 INSERT INTO 语句向目标表格中插入数据时,需要确保表格的字段名和数据类型与目标数据一致,否则可能会导致插入失败或数据错误。
使用格式
-- 第一种形式:完整字段插入
INSERT INTO 表名称 (字段1, 字段2, ...)
VALUES (值1, 值2, ...); -- 值与字段顺序对应-- 第一种形式:简写形式(需按表字段顺序提供所有值)
INSERT INTO 表名称
VALUES (值1, 值2, ...);-- 指定列名插入多条记录
insert into 表名 (字段1, 字段2) values
(值1, 值2),
(值3, 值4),
(值5, 值6);
2.2 UPDATE
UPDATE 是 SQL 中的 数据操作语言(DML) 命令,用于修改表中现有的单行或者多行记录。
备注:
UPDATE对表数据中的数据做操作,不对表结构做操作
使用格式
-- 使用格式
UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ... [WHERE 条件] ;
-- 1. 单字段更新(精确条件)
update 表名 set 字段名1=新值1 where 主键字段=值;-- 2. 多字段更新(多条件)
update 表名 set 字段名1=新值1, 字段名2=新值2 where 条件1 and 条件2;-- 3. 批量条件更新(IN语句)
update 表名 set 状态字段='新值' where id in (1,3,5);
2.3 DELETE
delete 是 SQL 中的 数据操纵语言(DML) 命令,用于从数据库表中删除一行或多行记录。
小数据量或有条件删除用
delete,快速清空大表用truncate(需确保不需要回滚)
使用格式
-- 使用格式:WHERE是可选的,但建议使用!
DELETE FROM 表名称 [WHERE 条件表达式];
-- 1. 删除单条/多条记录(条件可使用AND或者OR或者区间范围删除)
delete from 表名 where 条件表达式;-- 2. 删除多条记录(范围条件)
delete from 表名 where 数字字段 between 值1 and 值2;-- 3. 多条件删除(AND组合)
delete from 表名 where 字段1=值1 and 字段2=值2;-- 4. 批量条件删除(OR组合)
delete from 表名 where 字段名 in (值1, 值2, 值3);-- 7. 清空表数据(慎用)
delete from 表名;
3. DCL(Data Control Language 数据控制语言)
- 作用:用来控制数据库的访问权限(比如谁可以查看或修改数据)。
- 类比:就像给房子的不同房间分配钥匙(比如谁可以进客厅,谁可以进卧室)。
- 常见操作:
GRANT:授予用户权限。REVOKE:撤销用户权限。
3.1 GRANT
GRANT 是 SQL 中的 数据控制语言(DCL) 命令,用于授予用户或角色对数据库对象的访问权限。
跳转到附录: 五、数据库权限授权常用表格
-- 查看用户已有权限
SHOW GRANTS FOR 'user'@'host';
使用格式
-- 基础授权(推荐显式指定权限)
GRANT 权限类型 ON 数据库名.表名 TO '用户名'@'主机';-- 授予所有权限(需谨慎)
GRANT ALL PRIVILEGES ON *.* TO '用户名'@'主机';
-- 1. 授予查询权限(select)
grant select on 数据库名.表名 to '用户名'@'主机';-- 2. 授予增删改查组合权限
grant select, insert, update, delete on 数据库名.表名 to '用户名'@'主机';-- 3. 授予权限并允许转授权(增删改查)
grant select, insert, update, delete on 数据库名.表名 to '用户名'@'主机' with grant option;
备注:执行后可能需要
flush privileges;使更改生效
3.2 REVOKE
REVOKE 是 SQL 中用于撤销权限的关键命令,与 GRANT 相对应,同属于数据控制语言(DCL)。它用于移除之前授予用户或角色的数据库访问权限。
-- 查看用户已有权限
SHOW GRANTS FOR 'user'@'host';
使用格式
-- 基础使用(*.* 代表所有数据库和数据表)
REVOKE 权限类型 ON 数据库对象 FROM '用户名'@'主机';-- 撤销所有权限
REVOKE ALL PRIVILEGES ON *.* FROM '用户名'@'主机';
-- 1. 撤销查询权限(select)
revoke select on 数据库名.表名 from '用户名'@'主机';-- 2. 撤销增删改查组合权限
revoke select, insert, update, delete on 数据库名.表名 from '用户名'@'主机';-- 3. 撤销权限转授能力(增删改查)
revoke grant option for select, insert, update, delete on 数据库名.表名 from '用户名'@'主机';
备注:执行后可能需要
flush privileges;使更改生效
4. DQL(Data Query Language 数据查询语言)
-
作用:用来查询数据库中的数据。
-
类比:就像在房子里查找某件家具(比如找沙发在哪里)。
-
常见操作:
SELECT:查询数据。WHERE:过滤数据。GROUP BY:分组数据。HAVING:过滤分组后的数据。ORDER BY:排序数据。LIMIT:限制查询结果的数量。
4.1 SELECT
SELECT 是 SQL 中最核心的 数据查询语言(DQL) 命令,用于从数据库中检索数据。它是所有 SQL 查询的基础,使用频率最高。
使用
SELECT查询数据是不会对数据进行任何改动操作。
-- 标准使用格式(可选)
SELECT 字段名1, 字段名2,[聚合函数(字段名3) AS 别名,]...
FROM 表名
[WHERE 基础过滤条件]
[GROUP BY 分组列1, 分组列2, ...]
[HAVING 分组后过滤条件]
[ORDER BY 排序列1 [ASC|DESC], 排序列2 [ASC|DESC], ...]
[LIMIT [偏移量,] 行数];
-- 1. 基本查询条件
select 字段名1, 字段名2 from 表名 where 条件表达式;-- 2. 多条件组合查询
select 字段名1, 字段名2 from 表名 where 条件表达式1 and|or 条件表达式2;-- 3. 模糊条件查询
select 字段名1, 字段名2 from 表名 where 字段名 like '模式';-- 4. 空值条件查询
select 字段名1, 字段名2 from 表名 where 字段名 is null;
select 字段名1, 字段名2 from 表名 where 字段名 is not null;-- 5. 分组条件查询
select 字段名1, count(*) from 表名 where 条件表达式 group by 字段名1 having count(*) > 1;-- 6. 排序条件查询
select 字段名1, 字段名2 from 表名 where 条件表达式 order by 字段名1 asc|desc;-- 7. 分页条件查询
select 字段名1, 字段名2 from 表名 where 条件表达式 limit 偏移量, 行数;
4.2 WHERE
WHERE 是 SQL 中最核心的 数据查询语言(DQL) 查询条件子句,用于筛选满足特定条件的记录。通常与 SELECT、UPDATE、DELETE 等语句配合使用。
-- 使用表达式
SELECT 字段列表 FROM 表名 WHERE 条件表达式;
使用示例
-- 1. 基本查询条件
-- 查询部门20的员工
select empno, ename from emp where deptno = 20;-- 2. 多条件组合查询
-- 查询部门20且薪资大于1500的员工
select empno, ename, sal from emp where deptno = 20 and sal > 1500;-- 3. 模糊条件查询
-- 查询姓名以s开头的员工
select empno, ename from emp where ename like 's%';-- 4. 空值条件查询
-- 查询有奖金的员工
select empno, ename, comm from emp where comm is not null;
4.2.1 AND(并且)
AND 是数据库查询中常用的逻辑运算符。在构建查询条件时,它用于串联多个条件,只有当通过 AND 连接的每一个条件都满足(即逻辑值为真 )时 ,整个由 AND 组合的条件表达式才为真。
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
附录: SQL 中真(TRUE)与假(FALSE)判断标准表格
-- 1. AND 基础用法(必须同时满足多个条件)
SELECT 字段名1,字段名2, ... FROM 表名 WHERE 条件1 AND 条件2 ...
使用示例
-- 1. 基础AND用法(必须同时满足多个条件)
-- 查询部门号为20且职位是CLERK的员工
select empno, ename, deptno, job from emp where deptno = 20 and job = 'CLERK';-- 2. 多条件AND组合(必须全部满足)
-- 查询部门号为10、职位是MANAGER且薪资大于2000的员工
select empno, ename, deptno, job, sal from emp where deptno = 10 and job = 'MANAGER' and sal > 2000;-- 3. 字符串条件AND
-- 查询姓名以'S'开头且职位是'ANALYST'的员工
select empno, ename, job from emp where ename like 'S%' and job = 'ANALYST';-- 4. 数值范围AND(与BETWEEN等效写法)
-- 查询薪资在2000到3000之间的员工
select empno, ename, sal from emp where sal >= 2000 and sal <= 3000;-- 5. 空值判断AND
-- 查询有奖金且奖金不为0的员工
select empno, ename, comm from emp where comm is not null and comm <> 0;
4.2.2 OR(或者)
OR 同样是逻辑运算符。与 AND 不同,在连接多个条件时,只要通过 OR 连接的条件中有一个条件成立(逻辑值为真 ) ,整个由 OR 组成的条件表达式就为真。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
附录: SQL 中真(TRUE)与假(FALSE)判断标准表格
-- OR 基础用法(满足任意条件即可)
SELECT 字段名1, 字段名2, ... FROM 表名 WHERE 条件1 OR 条件2 ...
使用示例
-- 1. 基础OR用法(满足任一条件)
-- 查询部门号为10或20的员工信息
select empno, ename, deptno from emp where deptno = 10 or deptno = 20;-- 2. 多条件OR组合
-- 查询部门号为10或20或30的员工信息
select empno, ename, deptno from emp where deptno = 10 or deptno = 20 or deptno = 30;-- 3. 字符串条件OR
-- 查询职位是'MANAGER'或'ANALYST'的员工
select empno, ename, job from emp where job = 'MANAGER' or job = 'ANALYST';-- 4. 数值范围OR
-- 查询薪资低于1000或高于3000的员工
select empno, ename, sal from emp where sal < 1000 or sal > 3000;-- 5. 与IN运算符等效写法
-- 查询部门号为10、20或30的员工(等同于IN写法)
select empno, ename, deptno from emp where deptno = 10 or deptno = 20 or deptno = 30;-- 6. 空值判断OR
-- 查询没有奖金(comm为null)或奖金为0的员工
select empno, ename, comm from emp where comm is null or comm = 0;
4.2.3 同时出现 AND && OR
优先级:AND的优先级比OR优先级更高。除非有括号。优先处理有括号里的条件,不管括号里面是否为OR,一律优先括号内的条件。
- AND的优先级高于OR
例如:条件1 OR 条件2 AND 条件3会被解释为条件1 OR (条件2 AND 条件3) - 括号可以改变优先级
括号内的条件总是优先计算,例如:(条件1 OR 条件2) AND 条件3
-- 同时使用 AND 和 OR 的基础用法(满足任意条件即可)
SELECT字段名1,字段名2,...
FROM 表名
WHERE 条件1 AND (条件2 OR 条件3)...
使用示例
-- 1. AND优先于OR(默认优先级)
-- 查询部门20的员工,或者部门30且薪资大于2000的员工
select empno, ename, deptno, sal
from emp
where deptno = 20 or deptno = 30 and sal > 2000;-- 2. 使用括号改变优先级
-- 查询(部门20或30)且薪资大于2000的员工
select empno, ename, deptno, sal
from emp
where (deptno = 20 or deptno = 30) and sal > 2000;-- 3. 复杂条件组合
-- 查询(部门10且职位是MANAGER)或(部门20且薪资大于2500)的员工
select empno, ename, deptno, job, sal
from emp
where (deptno = 10 and job = 'MANAGER') or (deptno = 20 and sal > 2500);-- 4. 多层级嵌套条件
-- 查询部门10的员工,且(职位是MANAGER或PRESIDENT),且(薪资大于2000或没有奖金)
select empno, ename, deptno, job, sal, comm
from emp
where deptno = 10 and (job = 'MANAGER' or job = 'PRESIDENT') and (sal > 2000 or comm is null);
4.2.4 BETWEEN…AND…(区间范围)
用于指定一个范围,查询结果会返回在这个范围内的值。
-- 使用格式
SELECT 字段名1, 字段名2, ... FROM 表名 WHERE 字段名1 BETWEEN 值1 AND 值2...
使用示例
-- 1. 基础范围查询(数值区间)
-- 查询薪资在2000到3000之间的员工信息
select empno, ename, sal from emp where sal between 2000 and 3000;-- 2. 字符串范围查询(按字母顺序)
-- 查询姓名首字母在A到M之间的员工信息
select empno, ename from emp where ename between 'A' and 'M';-- 3. 与NOT组合使用(范围外查询)
-- 查询薪资不在2000到3000之间的员工信息
select empno, ename, sal from emp where sal not between 2000 and 3000;
4.2.5 IN(多值匹配)
用于指定一组不连续的、具体的数值。查询结果会返回在这些值中的任意一个值。(IN 包含多个值,不是一个区间,而是 IN 里面有什么值,就会匹配什么值)
-- 使用格式
SELECT 字段名1, 字段名2 FROM 表名 WHERE 字段名 IN (值1, 值2, 值3); -- 匹配括号内任意值
使用示例
-- 1. 基础IN用法(多值匹配)
-- 查找部门号为10或20的员工信息
select empno, ename, deptno from emp where deptno in (10, 20);-- 2. 与NOT组合使用
-- 查找不在部门10和20的员工信息
select empno, ename, deptno from emp where deptno not in (10, 20);-- 3. 子查询结果匹配
-- 查找薪资高于平均薪资的员工信息
select empno, ename, sal from emp where sal in (select sal from emp where sal > (select avg(sal) from emp));-- 4. 与其它条件组合
-- 查找部门号为10或20且薪资大于2000的员工信息
select empno, ename, deptno, sal from emp where deptno in (10, 20) and sal > 2000;
4.2.6 LIKE 模糊查询
模糊查询是SQL中用于在不确定完整信息时查找那些与特定模式相匹配的数据的一种查询方式,主要通过模式匹配来实现。当不确切知晓要查询的数据的完整内容时,就可以借助模糊查询,按照某种模式来查找数据。在 SQL 中,模糊查询一般借助LIKE操作符,搭配通配符来达成。
-- 使用格式
SELECT 字段名1, 字段名2, ... FROM 表名 WHERE 字段名 LIKE '模式字符串';
4.2.7 % 通配符(百分号)
作用:匹配任意长度的字符串(包括0个字符)
-- 使用格式
SELECT * FROM 表名 WHERE 字段名 LIKE '%值';
-- 1. 匹配任意前缀(后缀包含"值"的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '%值';-- 2. 匹配任意后缀(前缀包含"值"的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '值%';-- 3. 匹配包含特定子串(任意位置包含"值"的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '%值%';-- 4. 匹配固定前后缀(以"A"开头,"B"结尾的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like 'A%B';-- 5. 匹配特定格式(第二个字符为"值"的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '_值%';-- 6. 组合使用(包含"值"且长度至少3字符的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '_%值%_';-- 7. 转义百分号字符(查找包含百分号的数据)
select 字段名1, 字段名2 from 表名 where 字段名 like '%\%%' escape '\';--'
-- 8. 匹配邮箱域名(所有@example.com结尾的邮箱)
select 字段名1, 字段名2 from 表名 where 邮箱字段 like '%@example.com';
4.2.8 _ 通配符(下划线)
作用:精确匹配单个字符
-- 使用格式
SELECT * FROM 表名 WHERE 字段名 LIKE '_值';
-- 1. 匹配单个任意字符(第二位是"值"的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '_值';-- 2. 匹配固定长度模式(匹配A开头B结尾的4字符值)
select 字段名1, 字段名2 from 表名 where 字段名 like 'A__B'; -- 3. 匹配特定位置字符(匹配"张"姓两字姓名)
select 字段名1, 字段名2 from 表名 where 字段名 like '张_'; -- -- 4. 与%通配符组合使用(匹配第二位是"值"的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '_值%'; -- -- 5. 匹配特定格式(匹配A、B、C间隔一个字符的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like 'A_B_C'; -- -- 6. 转义下划线字符(匹配以下划线开头的字符串)
select 字段名1, 字段名2 from 表名 where 字段名 like '\_%' escape '\'; -- 反斜杠将下划线转义为普通字符而非通配符。--'
-- 7. 匹配电话号码模式(匹配138开头1234结尾的11位手机号)
select 字段名1, 字段名2 from 表名 where 电话字段 like '138____1234'; -- 8. 匹配产品编码格式(匹配PRD-4位数字-2023格式)
select 字段名1, 字段名2 from 表名 where 产品编码 like 'PRD-____-2023';
4.3 GROUP BY
GROUP BY 是 SQL 中用于对查询结果进行分组的关键子句,它通常与聚合函数一起使用来生成分组汇总数据。
-- 使用格式
SELECT 字段名1, 字段名2, 聚合函数(字段名3), ...
FROM 表名
[WHERE 条件]
GROUP BY 分组列1, 分组列2, ...
[HAVING 分组条件]
[ORDER BY 排序列];
使用示例
-- 1. 基础分组查询
-- 统计各部门员工数量
select deptno, count(*) from emp group by deptno;-- 2. 多字段分组
-- 统计各部门各职位的平均薪资
select deptno, job, avg(sal) from emp group by deptno, job;-- 3. 带WHERE条件的分组
-- 统计1981年之后入职的各部门薪资总额
select deptno, sum(sal) from emp where hiredate >= '1981-01-01' group by deptno;-- 4. 分组后过滤(HAVING)
-- 查询平均薪资大于2000的部门
select deptno, avg(sal) from emp group by deptno having avg(sal) > 2000;-- 5. 分组后排序
-- 统计各职位人数并按人数降序排列
select job, count(*) as emp_count from emp group by job order by emp_count desc;
4.4 聚合函数
聚合函数(Aggregate Functions)是SQL中对一组值执行计算并返回单一值的函数。它们对多行数据进行汇总统计,常用于SELECT 语句的 GROUP BY 子句中。 注意:不能跟在 where 后面!!!
聚合函数示例使用
1. count 计数(统计非空值数量)
select count(字段名) from 表名;
2. sum 求和(计算总和)
select sum(字段名) from 表名;
3. avg 求平均值(计算算术平均数)
select avg(字段名) from 表名;
4. max 求最大值(找出最大数值)
select max(字段名) from 表名;
5. min 求最小值(找出最小数值)
select min(字段名) from 表名;
4.5 HAVING
HAVING 用于对 GROUP BY 子句分组后的结果进行过滤。HAVING 通常与聚合函数一起使用,以便对分组数据应用条件。 (类似WHERE,但针对分组)
备注:能不用
HAVING尽量不用HAVING。实在是WHERE解决不了的情况下再使用HAVING。
HAVING 与 WHERE的区别:
| 特性 | WHERE | HAVING |
|---|---|---|
| 执行时机 | 在分组前过滤数据 | 在分组后过滤数据 |
| 可用的条件 | 不能使用聚合函数 | 可以使用聚合函数 |
| 性能影响 | 先过滤后分组,通常更高效 | 先分组后过滤,可能更耗资源 |
-- 使用格式
SELECT 字段名1, 聚合函数(字段名2), ...
FROM 表名
[WHERE 条件]
GROUP BY 分组列
HAVING 聚合函数条件
[ORDER BY 排序列];
-- 多表分组过滤
select t1.字段名1, -- 选择表1中的字段名1sum(t2.字段名2) -- 计算表2中字段名2的总和
from 表名1 t1 join 表名2 t2 -- 从表1和表2中进行连接查询
on t1.字段名=t2.字段名 -- 指定连接条件,即表1和表2中字段名相同的记录进行连接
group by t1.字段名1 -- 按照表1中的字段名1进行分组
having sum(t2.字段名2) > 1000; -- 筛选出分组后,字段名2总和大于1000的记录
使用示例
-- 1. 基础HAVING用法
-- 统计各部门员工数量,筛选出员工数大于3的部门
select deptno, count(*) as employee_count from emp group by deptno having count(*) > 3;-- 2. 使用聚合函数条件
-- 查询各部门平均薪资大于2000的部门
select deptno, avg(sal) as avg_salaryfrom empgroup by deptnohaving avg(sal) > 2000;-- 3. 多条件组合
-- 查询各部门各职位的薪资总额大于5000且人数少于5的组合
select deptno, job, sum(sal) as total_salaryfrom emp
group by deptno, job
having sum(sal) > 5000 and count(*) < 5;-- 4. 与WHERE配合使用
-- 查询1981年后入职的员工中,各部门最高薪资高于公司平均薪资的部门
select deptno, max(sal) as max_salary
from emp
where hiredate >= '1981-01-01'
group by deptno
having max(sal) > (select avg(sal) from emp);-- 5. 使用别名
-- 查询各部门人数大于3的部门(使用别名筛选)
select deptno, count(*) as emp_count from emp group by deptno having emp_count > 3;
4.6 ORDER BY
ORDER BY 是 SQL 中用于对查询结果进行排序的关键字,它可以按照一个或多个列对结果集进行升序或降序排列。
-- 使用格式(ASC:默认升序,DESC:降序。)
SELECT 字段名1, 字段名2, ...
FROM 表名
[WHERE 条件]
[GROUP BY 分组列]
[HAVING 分组条件]
ORDER BY 排序字段1 [ASC|DESC], 排序字段2 [ASC|DESC], ...
使用示例
-- 1. 单字段降序排序(默认升序)
-- 按薪资降序查看员工信息
select empno, ename, sal from emp order by sal desc;-- 2. 多字段排序
-- 先按部门升序,再按薪资降序排列员工
select deptno, ename, sal from emp order by deptno asc, sal desc;-- 3. 排序带条件查询
-- 查询部门30的员工并按薪资升序排列
select ename, job, sal from emp where deptno = 30 order by sal;-- 4. 排序分组结果
-- 统计各部门人数并按人数降序排列
select deptno, count(*) as emp_count from emp group by deptno order by emp_count desc;-- 5. 按字段位置排序(按第2列排序)
-- 按员工姓名排序(结果集的第2列)
select empno, ename, job from emp order by 2;-- 6. 排序限制结果数量
-- 获取薪资最高的5名员工
select ename, sal from emp order by sal desc limit 5;
4.7 LIMIT
LIMIT 子句用于限制 SQL 查询结果返回的行数,常用于分页查询或限制结果集大小。
偏移量(offset)在SQL的LIMIT子句中表示要跳过的记录数量,它是分页查询的核心参数之一
-- 使用格式(ASC:默认升序,DESC:降序。)
SELECT 字段名1, 字段名2, ...
FROM 表名
[WHERE 条件]
[GROUP BY 分组列]
[HAVING 分组条件]
ORDER BY 排序字段1 [ASC|DESC], 排序字段2 [ASC|DESC], ...
[LIMIT [偏移量,] 行数];
使用示例
-- 1. 限制返回行数(基础用法)
-- 获取前5名员工的信息
select empno, ename, job from emp limit 5;-- 2. 分页查询(带偏移量)
-- 获取第6-10名员工的信息(每页5条,第二页)
select empno, ename, job from emp limit 5, 5;-- 3. 排序后限制结果
-- 获取薪资最高的3名员工
select ename, sal from emp order by sal desc limit 3;-- 4. 带条件的限制查询
-- 获取部门20的前2名员工
select empno, ename, deptno from emp where deptno = 20 limit 2;-- 5. 与其他子句组合使用
-- 获取薪资在2000-3000之间的员工,按入职日期升序排列,跳过前2条,取接下来的3条
select ename, sal, hiredate from emp where sal between 2000 and 3000 order by hiredate limit 2, 3;
4.8 子查询
💡 记住:子查询就是"查询里面套查询",先想清楚要查什么数据,再决定放在WHERE还是FROM里。
不确定怎么写时,可以分步执行:
- 先单独运行括号里的子查询
- 确认子查询结果正确后
- 再套到主查询中
子查询对比
| 类型 | 查几个值 | 像什么 | 常用场景 |
|---|---|---|---|
| WHERE子查询(单值比较) | 1个值 | 先算答案再比较 | 和平均值/最大值比较 |
| WHERE子查询(多值IN) | 多个值 | 先列清单再查详情 | 查有XX记录的数据 |
| FROM子查询(派生表) | 多行多列 | 先加工数据再查结果 | 复杂统计后二次筛选 |
4.8.1 WHERE子查询(单值比较)
WHERE单值子查询:用一个查询结果作为条件值
-- 使用格式
SELECT 字段名1, 字段名2
FROM 表名
WHERE 字段名 比较运算符 (SELECT 单值字段 FROM 子表 WHERE 子条件);
示例:查比平均工资高的员工
-- 查询薪资高于公司平均薪资的员工信息
SELECT e.empno AS '工号', -- 选取员工编号字段,显示为"工号"e.ename AS '姓名', -- 选取员工姓名字段,显示为"姓名"e.sal AS '薪资' -- 选取薪资字段,显示为"薪资"
FROM emp e -- 数据来源:员工表(使用别名e)
WHERE -- 筛选条件:薪资高于公司平均薪资e.sal > (-- 子查询:计算全体员工平均薪资SELECT AVG(sal) FROM emp)
-- 结果按薪资从高到低排序
ORDER BY e.sal DESC; -- DESC表示降序排列
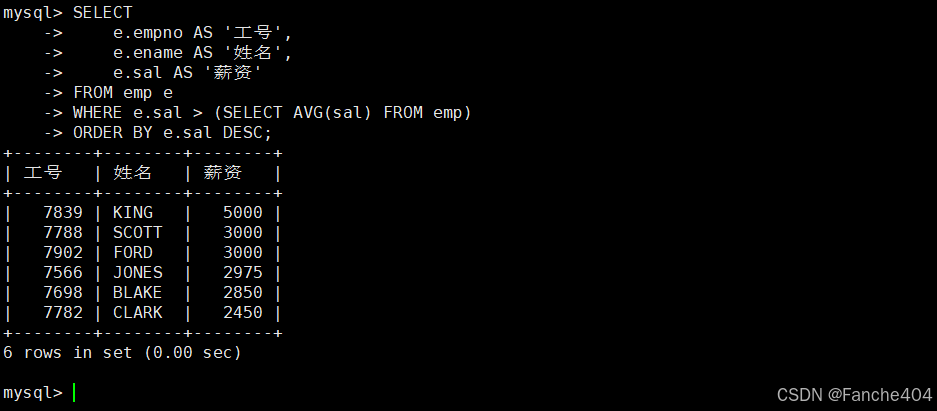
示例:查和SCOTT同部门的人
-- 2. 查询与SCOTT同部门的所有其他员工信息
SELECT e.empno AS '工号', -- 选择员工编号字段,显示为"工号"e.ename AS '姓名', -- 选择员工姓名字段,显示为"姓名" e.job AS '职位' -- 选择职位字段,显示为"职位"
FROM emp e -- 数据来源:员工表(使用别名e)
WHERE -- 部门筛选条件:部门编号等于SCOTT所在部门e.deptno = (-- 子查询:获取SCOTT员工的部门编号SELECT deptno -- 选择部门编号字段FROM emp -- 从员工表查询WHERE ename = 'SCOTT' -- 限定员工姓名为SCOTT)-- 附加条件:排除SCOTT本人AND e.ename != 'SCOTT'
-- 结果按员工编号升序排列
ORDER BY e.empno;
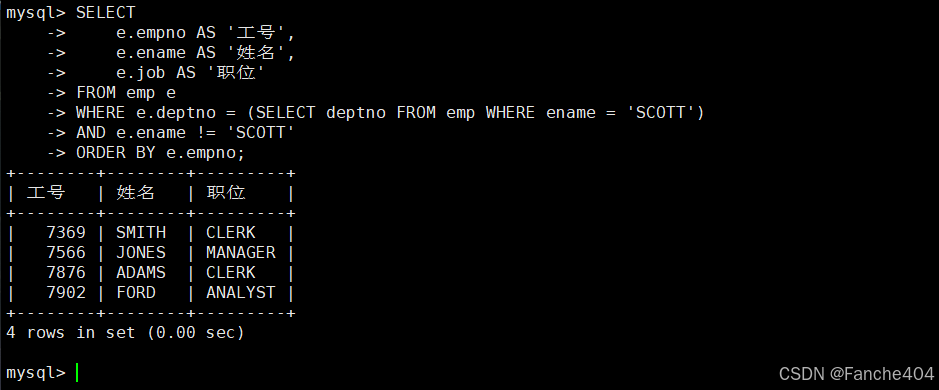
4.8.2 WHERE子查询(多值IN)
WHERE多值子查询(IN):用一个查询结果作为条件列表
-- 使用格式
SELECT 字段名1, 字段名2
FROM 表名
WHERE 字段名 IN (SELECT 多值字段 FROM 子表 WHERE 子条件);
示例:查在NEW YORK工作的员工
-- 1. 查在NEW YORK工作的员工
-- 主查询:查询在NEW YORK地区工作的员工信息
SELECT e.empno AS '员工编号', -- 从员工表获取员工编号,显示为"员工编号"e.ename AS '员工姓名', -- 从员工表获取员工姓名,显示为"员工姓名"e.job AS '职位' -- 从员工表获取职位信息,显示为"职位"
FROM emp e -- 数据来源:员工表(使用别名e简化引用)
WHERE -- 使用IN子查询筛选部门e.deptno IN (-- 子查询:获取位于NEW YORK的部门编号SELECT deptno -- 查询部门编号字段FROM dept -- 从部门表查询WHERE loc = 'NEW YORK' -- 限定工作地点为NEW YORK)
-- 结果按员工编号升序排列
ORDER BY e.empno;

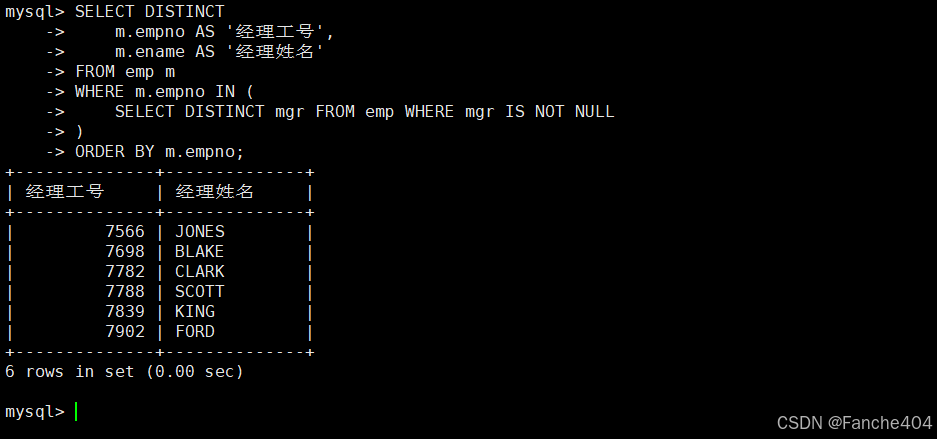
示例:查有下属的经理
-- 主查询:查询有下属的经理信息
SELECT DISTINCTm.empno AS '经理工号', -- 从员工表获取经理编号,显示为"经理工号"m.ename AS '经理姓名' -- 从员工表获取经理姓名,显示为"经理姓名"
FROM emp m -- 数据来源:员工表(使用别名m表示经理)
WHERE -- 使用IN子查询筛选有下属的经理m.empno IN (-- 子查询:获取所有有下属的经理编号SELECT DISTINCT mgr -- 查询上级经理编号字段(去掉重复的)FROM emp -- 从员工表查询WHERE mgr IS NOT NULL -- 排除mgr为NULL的记录(确保是有效经理))
-- 结果按经理工号升序排列
ORDER BY m.empno;
4.8.3 FROM子查询(派生表)
FROM子查询:把查询结果当临时表用
-- 使用格式
SELECT a.字段名1, a.字段名2
FROM (SELECT 字段名1, 字段名2 FROM 子表 WHERE 子条件) AS a
WHERE a.条件;
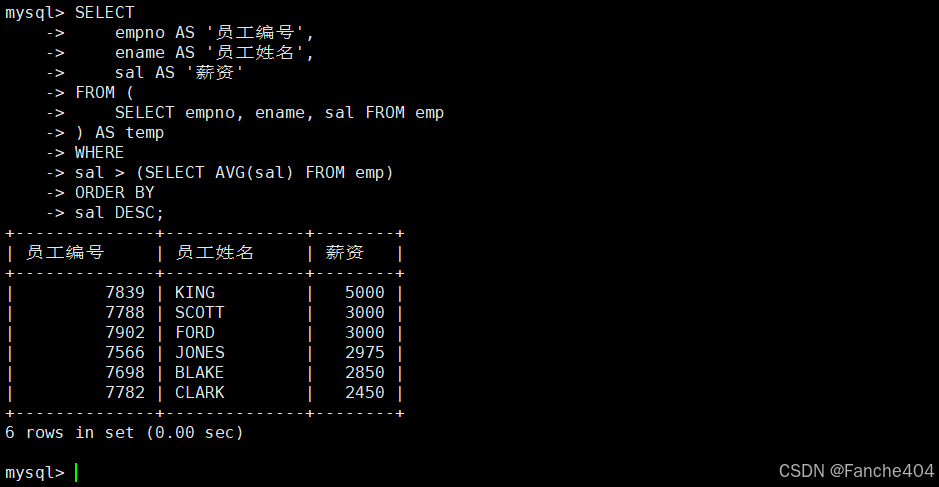
示例:查询工资高于平均工资的员工
-- 1. 查询工资高于公司平均工资的员工信息
SELECT empno AS '员工编号', -- 选择员工编号字段,显示为"员工编号"ename AS '员工姓名', -- 选择员工姓名字段,显示为"员工姓名"sal AS '薪资' -- 选择薪资字段,显示为"薪资"
FROM (-- 子查询:从员工表中获取员工编号、姓名和薪资信息-- 创建一个临时结果集temp,包含这三个字段SELECT empno, -- 员工编号ename, -- 员工姓名sal -- 薪资FROM emp -- 数据来源:员工表
) AS temp -- 为子查询结果命名为temp(派生表)
WHERE -- 筛选条件:薪资大于公司平均薪资sal > (-- 子查询:计算公司全体员工的平均薪资SELECT AVG(sal) -- 计算薪资平均值FROM emp -- 从员工表计算)
-- 结果按薪资从高到低排序
ORDER BY sal DESC; -- DESC表示降序排列
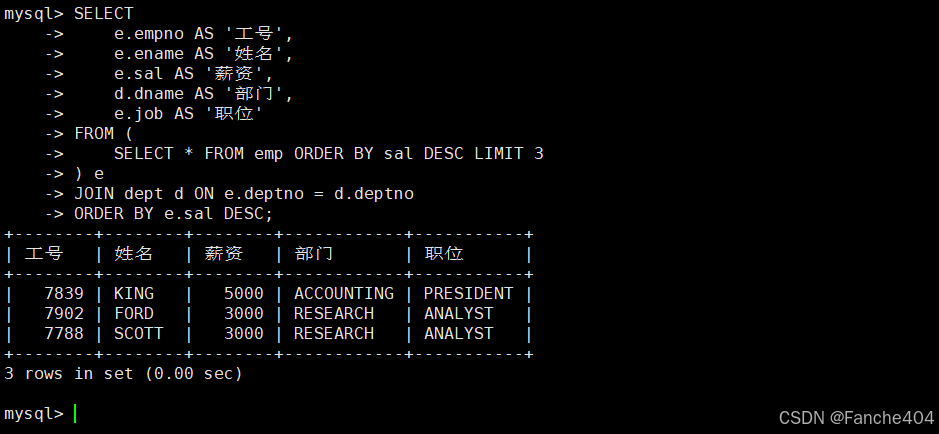
示例:查工资前3名的员工
-- 2. 查工资前3名的员工
-- 主查询:查询薪资最高的前3名员工及其部门信息
SELECT e.empno AS '工号', -- 员工编号,显示为"工号"e.ename AS '姓名', -- 员工姓名,显示为"姓名"e.sal AS '薪资', -- 员工薪资,显示为"薪资"d.dname AS '部门', -- 部门名称,显示为"部门"e.job AS '职位' -- 职位信息,显示为"职位"
FROM (-- 子查询/派生表:获取薪资最高的3名员工-- 先按薪资降序排序,然后限制结果为3条记录SELECT * FROM emp ORDER BY sal DESC LIMIT 3
) e -- 将子查询结果命名为e(派生表别名)
JOIN dept d -- 连接部门表,别名为d
ON e.deptno = d.deptno -- 连接条件:员工部门编号=部门编号
-- 最终结果按薪资降序排列(从高到低)
ORDER BY e.sal DESC;
4.9 联表查询
联表查询 (Join) 是SQL中用于从多个表中组合数据的操作,它通过两个或多个表之间的关联列将数据连接起来,联表次数越少越好。 (确保连接条件正确,避免笛卡尔积)
联表查询就像把多张Excel表格用VLOOKUP合并起来查看。比如:
- 员工表存员工信息
- 部门表存部门信息
- 通过"部门编号"把两张表连起来,就能同时看到员工和所属部门
4.9.1 等值连接 和 非等值连接
等值连接(最常用)
什么是等值连接?当两个表的关联条件是字段值相等(使用=号)时,就是等值连接。
🔑 特点:用
=号连接,就像"找相同编号的记录配对"
等值连接特点:
- 使用
=作为连接条件 - 关联字段通常是一对一或一对多关系
- 性能最好,最常用
等值连接示例:
示例:员工表和部门表通过deptno相等连接(因为员工表和部门表都有 deptno 这个字段)
-- 查询1:查询员工及其所属部门信息(等值连接)
-- 功能:通过部门编号关联员工表和部门表
SELECT e.ename, -- 员工姓名d.dname -- 部门名称
FROM emp e -- 员工表(别名e)
JOIN dept d -- 部门表(别名d)
ON -- 等值连接条件:员工部门编号=部门编号e.deptno = d.deptno;
-- 查询2:查询员工及其直接上级经理信息(自连接)
-- 功能:通过经理ID关联员工表自身
SELECT e.ename, -- 员工姓名m.ename AS manager -- 经理姓名(显示为manager)
FROM emp e -- 员工表(别名e,代表普通员工)
JOIN emp m -- 员工表自连接(别名m,代表经理)
ON-- 等值连接条件:员工的经理ID=经理的员工IDe.mgr = m.empno;
非等值连接(范围连接)
什么是非等值连接?当连接条件不是简单的相等关系,而是使用>, <, BETWEEN等比较运算符时,就是非等值连接。
🔑 特点:用
BETWEEN/>/<连接,适合范围匹配
非等值连接特点:
- 使用
>,<,>=,<=,BETWEEN,!=等运算符 - 常用于范围匹配、区间查询
- 性能通常比等值连接差
非等值连接示例:
示例:将员工薪资与薪资等级表中的范围进行匹配(范围连接)
-- 将员工薪资与薪资等级表中的范围进行匹配(范围连接)
SELECT e.ename, -- 员工姓名e.sal, -- 员工薪资s.grade -- 薪资等级
FROM emp e -- 员工表(别名e)
JOIN salgrade s -- 薪资等级表(别名s)
ON -- 连接条件:员工薪资在等级表的薪资范围内e.sal BETWEEN s.losal AND s.hisal; -- 使用BETWEEN进行范围匹配
两种连接的对比
| 对比项 | 等值连接 | 非等值连接 |
|---|---|---|
| 连接条件 | 使用=号 | 使用>,<,BETWEEN等 |
| 使用频率 | 最常用(约80%场景) | 较少用(约20%场景) |
| 性能 | 通常更好 | 通常较差 |
| 典型场景 | 主外键关联、代码表关联 | 范围查询、区间匹配 |
| 示例 | ON a.id = b.id | ON a.sal BETWEEN b.min AND b.max |
4.9.2 内连接(INNER JOIN)
使用格式
-- 使用格式:内连接(只返回两表匹配的记录)
SELECT 表1.字段名, 表2.字段名
FROM 表1
INNER JOIN 表2
ON 表1.关联字段 = 表2.关联字段
[WHERE 条件] ...
内连接示例
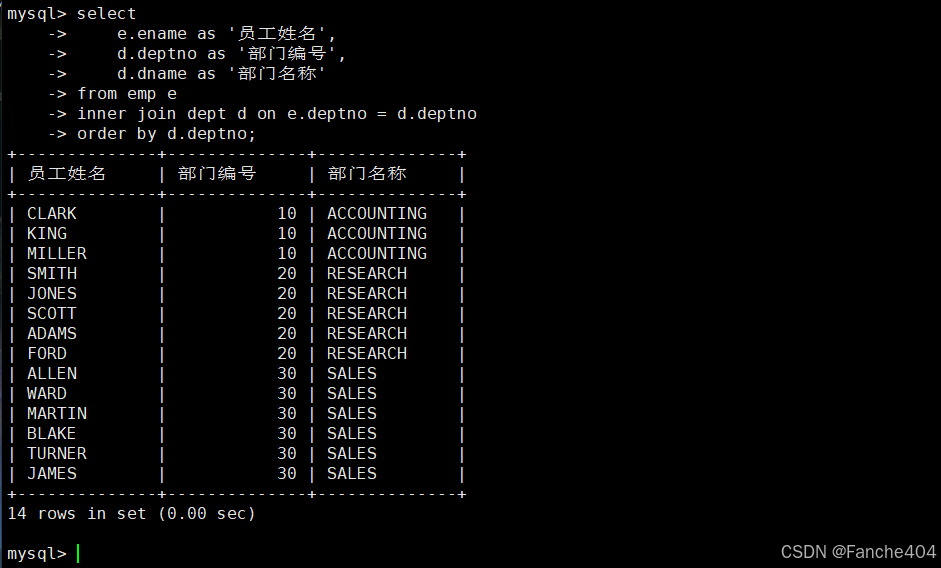
示例:查询员工及其部门信息(只显示有部门的员工)
-- 查询员工及其所属部门信息(只显示有有效部门的员工)
SELECT e.ename AS '员工姓名', -- 从员工表获取员工姓名,显示为"员工姓名"d.deptno AS '部门编号', -- 从部门表获取部门编号,显示为"部门编号" d.dname AS '部门名称' -- 从部门表获取部门名称,显示为"部门名称"
FROM emp e -- 员工表(别名e)
INNER JOIN -- 内连接:只返回有匹配部门的员工记录dept d -- 部门表(别名d)
ON e.deptno = d.deptno -- 连接条件:员工部门编号=部门编号
ORDER BY d.deptno; -- 按部门编号升序排序
示例:查询员工及其工资等级
-- 示例:查询员工及其工资等级(范围连接)
SELECT e.ename AS '员工姓名', -- 从员工表获取员工姓名,显示为"员工姓名"e.sal AS '薪资', -- 从员工表获取薪资,显示为"薪资"s.grade AS '薪资等级' -- 从薪资等级表获取等级,显示为"薪资等级"
FROM emp e -- 员工表(使用别名e)
INNER JOIN salgrade s -- 薪资等级表(使用别名s)
ON -- 非等值连接条件:员工薪资在等级表的薪资范围内e.sal BETWEEN s.losal AND s.hisal -- 使用BETWEEN进行范围匹配
ORDER BY e.sal; -- 按薪资升序排列

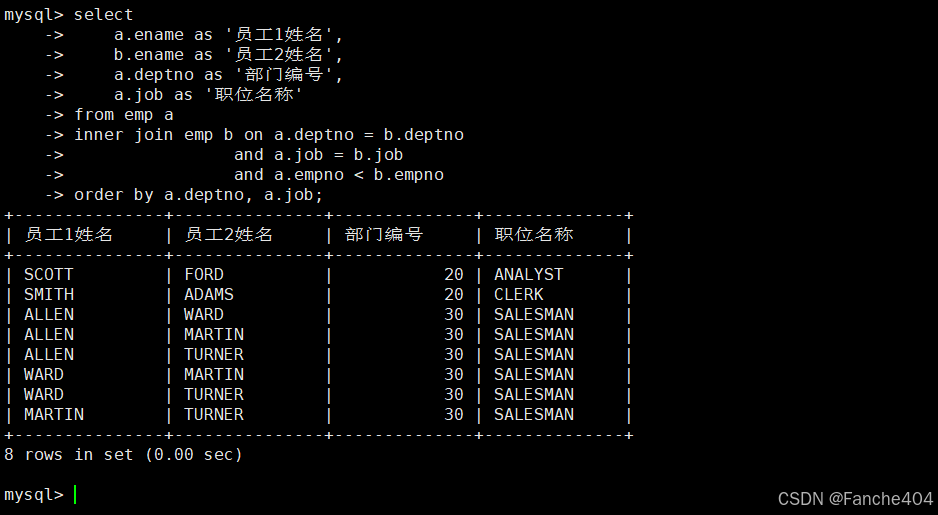
示例:同部门同职位员工组合
-- 查询同部门同职位的员工组合(排除重复组合)
SELECTa.ename AS '员工1姓名', -- 第一个员工姓名b.ename AS '员工2姓名', -- 第二个员工姓名a.deptno AS '部门编号', -- 所属部门编号a.job AS '职位名称' -- 职位名称
FROM emp a -- 员工表(别名a代表第一个员工)
INNER JOIN emp b -- 员工表自连接(别名b代表第二个员工)
ON a.deptno = b.deptno -- 连接条件1:同部门AND a.job = b.job -- 连接条件2:同职位AND a.empno < b.empno -- 连接条件3:确保不重复组合(a.empno < b.empno)
ORDER BY a.deptno, a.job; -- 结果按部门编号和职位名称排序
4.9.3 左连接(LEFT JOIN)
返回左表所有记录,即使右表没有匹配。以左表为"主角",右表只是"配角",主角全部出场,配角没匹配到就用 NULL 补位
使用格式
-- 使用格式:左连接(保留左表所有记录,右表无匹配则显示NULL)
SELECT 表1.字段名, 表2.字段名
FROM 表1
LEFT JOIN 表2
ON 表1.关联字段 = 表2.关联字段
[WHERE 条件] ...
左连接示例
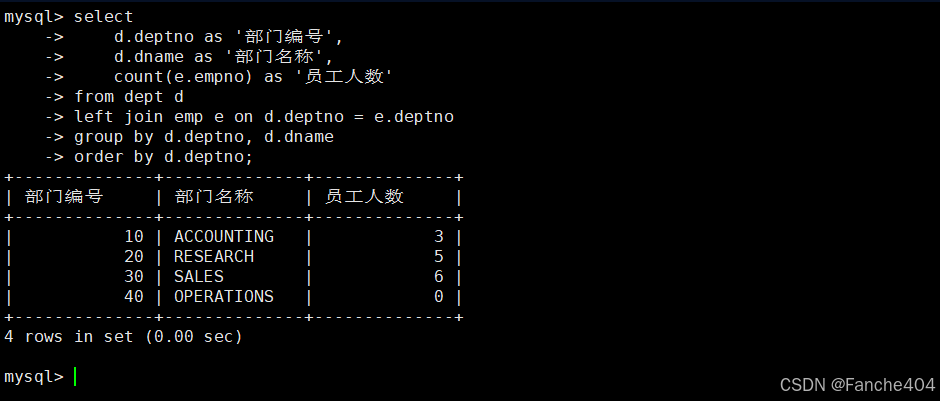
示例:各部门人数统计
-- 查询各部门员工人数统计(包含无员工的部门)
SELECT d.deptno AS '部门编号', -- 部门编号字段,显示为"部门编号"d.dname AS '部门名称', -- 部门名称字段,显示为"部门名称"COUNT(e.empno) AS '员工人数' -- 统计员工数量,显示为"员工人数"
FROM dept d -- 部门表(别名d)
LEFT JOIN -- 左连接:保留所有部门记录emp e -- 员工表(别名e)
ON d.deptno = e.deptno -- 连接条件:部门编号匹配
GROUP BY d.deptno, d.dname -- 按部门编号和名称分组
ORDER BY d.deptno; -- 按部门编号升序排序
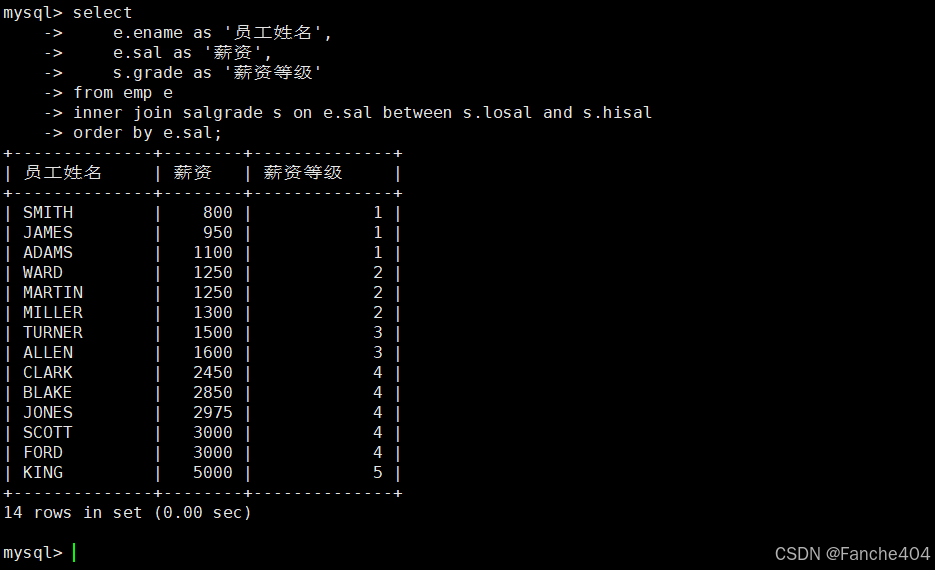
示例:查询所有员工工资等级(包括工资不在等级范围内的)
备注:这里使用的是范围连接(非等值连接),用工资范围判断属于哪个等级。
-- 查询所有员工及其薪资等级(包含无等级匹配的员工)
SELECT e.ename AS '员工姓名', -- 从员工表获取员工姓名,显示为"员工姓名"e.sal AS '薪资', -- 从员工表获取薪资数额,显示为"薪资"s.grade AS '薪资等级' -- 从薪资等级表获取等级,显示为"薪资等级"(可能为NULL)
FROM emp e -- 员工表(别名e)
LEFT JOIN -- 左连接:保留所有员工记录salgrade s -- 薪资等级表(别名s)
ON -- 非等值连接条件:员工薪资在等级范围内e.sal BETWEEN s.losal AND s.hisal -- 使用BETWEEN范围匹配
ORDER BY e.sal; -- 按薪资升序排列
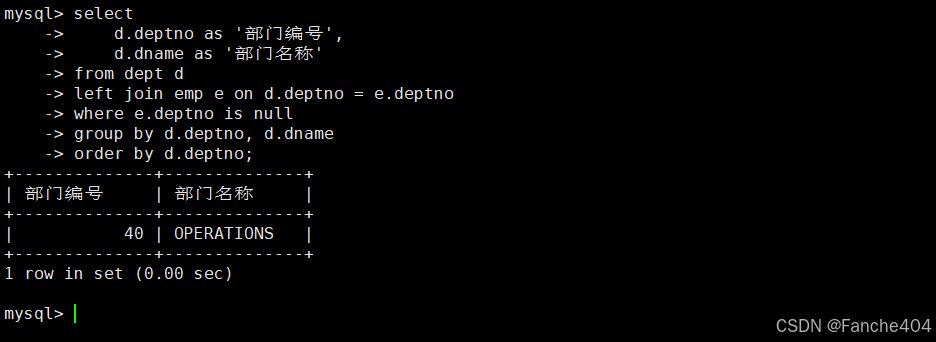
示例:快速找出空部门(没有员工的部门)
-- 查询没有员工的部门信息
SELECTd.deptno AS '部门编号', -- 部门编号字段,显示为"部门编号"d.dname AS '部门名称' -- 部门名称字段,显示为"部门名称"
FROMdept d -- 部门表(别名d)
LEFT JOIN -- 左连接:保留所有部门记录emp e -- 员工表(别名e)
ONd.deptno = e.deptno -- 连接条件:部门编号匹配
WHEREe.deptno IS NULL -- 筛选条件:没有匹配到员工的部门
GROUP BYd.deptno, d.dname -- 按部门编号和名称分组(去重)
ORDER BYd.deptno; -- 按部门编号升序排序
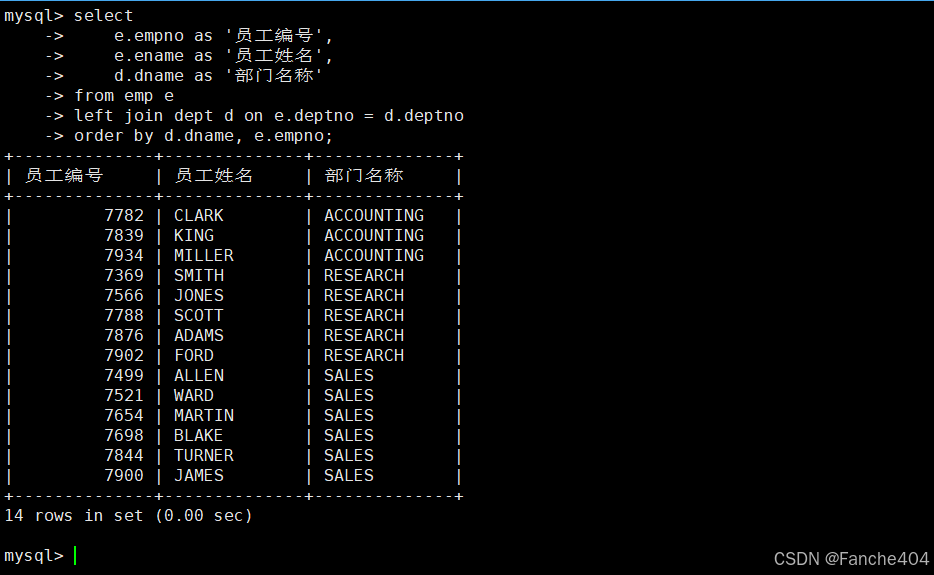
示例:查询所有员工信息(包括没有部门的员工)
-- 查询所有员工及其所属部门信息(包含未分配部门的员工)
SELECTe.empno AS '员工编号', -- 从员工表获取员工编号,显示为"员工编号"e.ename AS '员工姓名', -- 从员工表获取员工姓名,显示为"员工姓名"d.dname AS '部门名称' -- 从部门表获取部门名称,显示为"部门名称"(可能为NULL)
FROMemp e -- 员工表(别名e)
LEFT JOIN -- 左连接:保留所有员工记录dept d -- 部门表(别名d)
ONe.deptno = d.deptno -- 连接条件:部门编号匹配
ORDER BYd.dname, -- 优先按部门名称排序(NULL值会排在最前)e.empno; -- 其次按员工编号排序
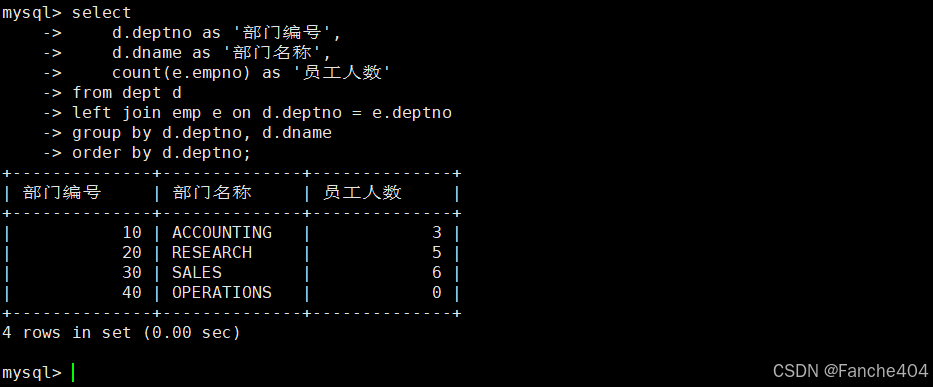
示例:部门人数统计
-- 查询各部门员工人数统计(包含无员工的部门)
SELECT d.deptno AS '部门编号', -- 部门编号字段,显示为"部门编号"d.dname AS '部门名称', -- 部门名称字段,显示为"部门名称"COUNT(e.empno) AS '员工人数' -- 统计员工数量,显示为"员工人数"
FROM dept d -- 部门表(别名d)
LEFT JOIN -- 左连接:保留所有部门记录emp e -- 员工表(别名e)
ON d.deptno = e.deptno -- 连接条件:部门编号匹配
GROUP BY d.deptno, d.dname -- 按部门编号和名称分组
ORDER BY d.deptno; -- 按部门编号升序排序
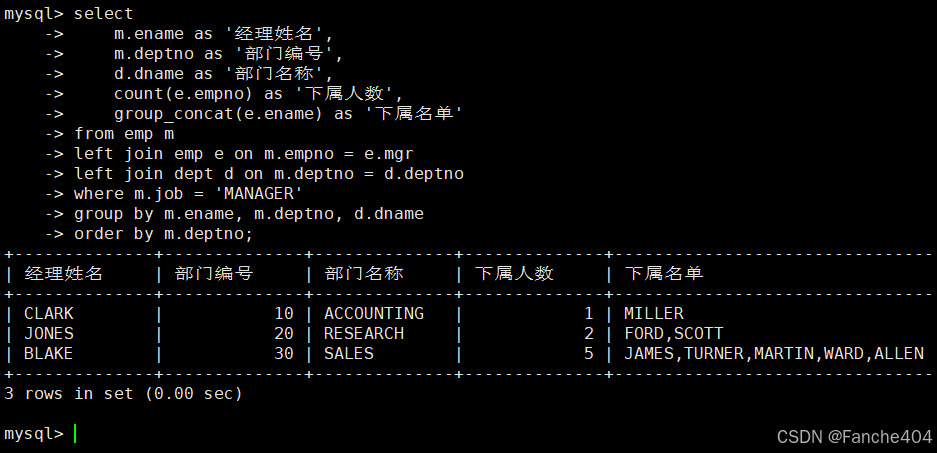
示例:经理及其下属(按部门分组统计)
采用两次左连接
-- 查询各经理及其下属信息统计
SELECT m.ename AS '经理姓名', -- 经理姓名字段,显示为"经理姓名"m.deptno AS '部门编号', -- 部门编号字段,显示为"部门编号"d.dname AS '部门名称', -- 部门名称字段,显示为"部门名称"COUNT(e.empno) AS '下属人数', -- 统计下属员工数量,显示为"下属人数"GROUP_CONCAT(e.ename) AS '下属名单' -- 合并下属姓名,显示为"下属名单"
FROM emp m -- 经理表(别名m)
LEFT JOIN -- 左连接:保留所有经理记录emp e -- 下属员工表(别名e)
ON m.empno = e.mgr -- 连接条件:经理编号=员工经理编号
LEFT JOIN -- 左连接:保留所有经理记录dept d -- 部门表(别名d)
ON m.deptno = d.deptno -- 连接条件:部门编号匹配
WHERE m.job = 'MANAGER' -- 筛选条件:职位为经理
GROUP BY m.ename, m.deptno, d.dname -- 按经理姓名、部门编号和名称分组
ORDER BY m.deptno; -- 按部门编号升序排序
4.9.4 右连接(RIGTH JOIN)
返回右表所有记录,即使左表没有匹配。以右表为"主角",左表是"配角"
-- 使用格式:右连接(保留右表所有记录,左表无匹配则显示NULL)
SELECT 表1.字段名, 表2.字段名
FROM 表1
RIGHT JOIN 表2
ON 表1.关联字段 = 表2.关联字段
[WHERE 条件] ...
外连接示例
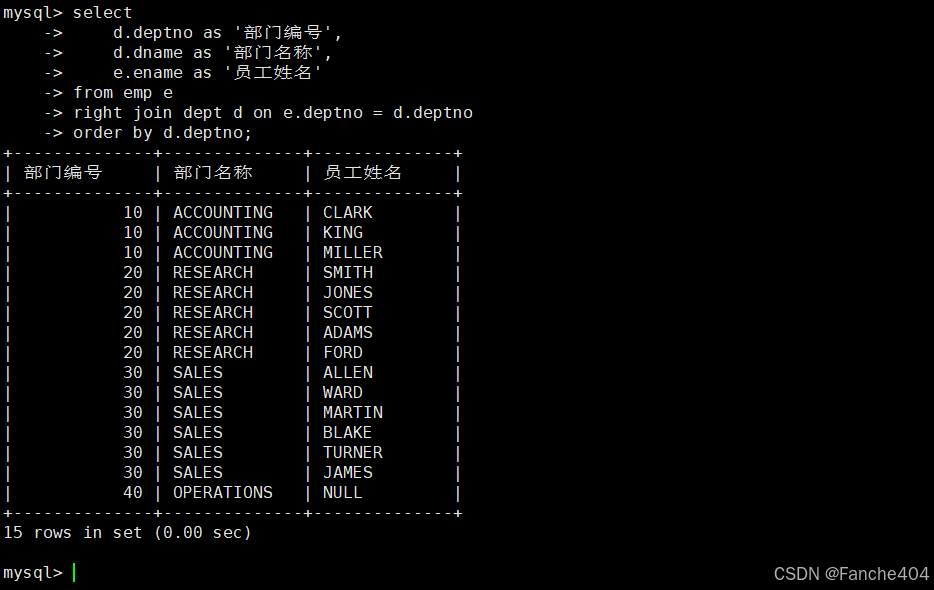
示例:查询所有部门及员工(含无员工部门)
-- 示例:查询所有部门信息(包括没有员工的部门)
selectd.deptno as '部门编号',d.dname as '部门名称',e.ename as '员工姓名'
from emp e
right join dept d on e.deptno = d.deptno
order by d.deptno;
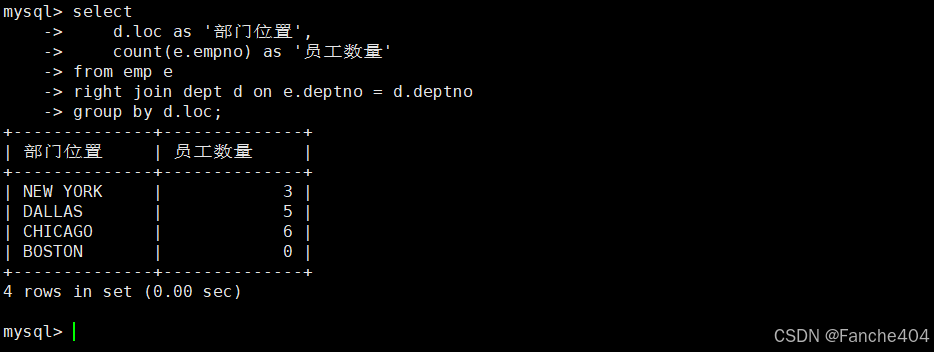
示例:查询所有工作地点及员工数(包括无员工的地点)
selectd.loc as '部门位置',count(e.empno) as '员工数量'
from emp e
right join dept d on e.deptno = d.deptno
group by d.loc;
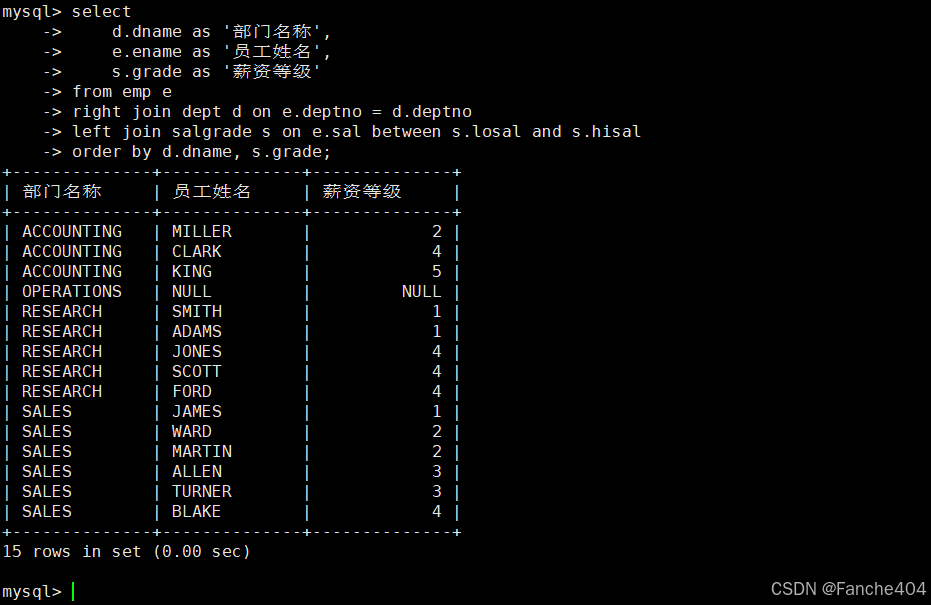
示例:完整部门-员工-薪资等级查询
selectd.dname as '部门名称',e.ename as '员工姓名',s.grade as '薪资等级'
from emp e
right join dept d on e.deptno = d.deptno
left join salgrade s on e.sal between s.losal and s.hisal
order by d.dname, s.grade;
附录(其他部分)
MySQL 错误代码分类速查表
| 错误代码 | 错误类型 | 典型原因 | 解决方案 |
|---|---|---|---|
| 1005 | 创建表失败 | 外键约束问题 | 检查外键引用的表/字段名是否存在 |
| 1045 | 访问拒绝 | 用户名/密码错误或权限不足 | 检查授权信息,使用GRANT命令授权 |
| 1054 | 未知列 | 查询的字段名不存在 | 检查字段名拼写和大小写 |
| 1062 | 重复键 | 违反唯一约束/主键约束 | 检查重复数据或使用INSERT IGNORE |
| 1064 | 语法错误 | SQL语句语法问题 | 检查SQL拼写、引号、括号等 |
| 1146 | 表不存在 | 查询的表名错误 | 检查表名或使用SHOW TABLES查看 |
| 1215 | 外键约束 | 无法添加外键约束 | 检查数据类型是否匹配 |
| 1216 | 外键约束 | 无法更新/删除父表记录 | 先处理子表相关记录 |
| 1451 | 外键约束 | 不能删除被引用的记录 | 先删除或修改引用记录 |
| 2002 | 连接错误 | 无法连接到MySQL服务器 | 检查MySQL服务是否运行 |
| 2003 | 连接错误 | 无法连接到指定端口 | 检查防火墙和端口设置 |
SQL 执行流程
SQL查询执行顺序简明对照表
| 顺序 | 关键字 | 书写顺序 | 执行顺序 | 关键说明 |
|---|---|---|---|---|
| 1 | SELECT | 1 | 7 | 最后选择输出列,可使用别名 |
| 2 | FROM | 2 | 1 | 查询的起点表 |
| 3 | JOIN | 3 | 2 | 加载关联表数据 |
| 4 | ON | 4 | 3 | 应用连接条件 |
| 5 | WHERE | 5 | 4 | 初步数据过滤,不能用别名 |
| 6 | GROUP BY | 6 | 5 | 数据分组计算 |
| 7 | HAVING | 7 | 6 | 筛选分组结果,可用聚合函数 |
| 8 | ORDER BY | 8 | 8 | 最终结果排序,可用别名 |
| 9 | LIMIT | 9 | 9 | 结果行数限制 |
执行流程
| 阶段 | 执行顺序 | 对应关键字 | 数据处理过程 | 类比场景 |
|---|---|---|---|---|
| 准备 | 1-3 | FROM-JOIN-ON | 加载数据并建立表关联 | 🏭 从各仓库调货并匹配订单 |
| 过滤 | 4-6 | WHERE-GROUP BY-HAVING | 逐层筛选数据 | 🧹 质检→分类装箱→整箱检查 |
| 输出 | 7-9 | SELECT-ORDER BY-LIMIT | 生成最终结果 | 🏷️ 打单→装车→控制发货量 |
“写查连筛组选排限”(书写顺序)
SELECT→FROM→JOIN→WHERE→GROUP BY→HAVING→ORDER BY→LIMIT
“读连筛组选排限”(执行顺序)
FROM→JOIN→WHERE→GROUP BY→HAVING→SELECT→ORDER BY→LIMIT
这个SQL语句查询能运行吗?
错误原因是:在WHERE子句执行时,AVG聚合计算尚未发生,avg_score别名也还不存在。
SELECT student_name,AVG(score) AS avg_score -- 步骤5:这里才创建avg_score别名
FROM grades
WHERE avg_score > 80 -- 这里错误!步骤2:WHERE时avg_score还不存在!
GROUP BY student_name; -- 步骤3:分组在WHERE之后
- SQL执行顺序 ≠ 书写顺序
- 虽然我们按
SELECT → FROM → WHERE → GROUP BY → HAVING的顺序写SQL - 但实际执行顺序是:
FROM → WHERE → GROUP BY → HAVING → SELECT - 这就是为什么WHERE不能使用SELECT阶段创建的别名或聚合函数
- 虽然我们按
- WHERE与HAVING的本质区别
WHERE:在分组前对原始数据行进行过滤(只能使用原始列)HAVING:在分组后对聚合结果进行过滤(可以使用聚合函数和别名)
- 聚合函数的生命周期
- 聚合计算(如AVG/SUM/COUNT等)只在GROUP BY之后才生效
- 在WHERE阶段,数据库还不知道分组结果,自然无法计算平均值
- 别名的作用时机
- 列别名(如
avg_score)是在SELECT阶段创建的 - 在SELECT之前的阶段(WHERE/GROUP BY)都不能引用这些别名
- 列别名(如
应该使用HAVING来筛选聚合结果:
-- 正确写法
SELECT student_name,AVG(score) AS avg_score
FROM grades
GROUP BY student_name
HAVING AVG(score) > 80;
2.1 举例:SQL查询顺序:学生成绩管理(类比)
📝 2.1.1 写SQL的顺序(写法顺序)
-- 就像老师要求统计成绩:
-- 1.要什么数据 2.从哪来 3.条件 4.呈现方式
SELECT student_name, AVG(test_score) AS average_score -- 1.要查学生姓名和平均分
FROM student_records -- 2.从学生成绩表
JOIN test_results ON student_records.id = test_results.student_id -- 3.关联考试成绩
WHERE semester = '2023秋季学期' -- 4.筛选特定学期
GROUP BY student_name -- 5.按学生姓名分组
HAVING AVG(test_score) > 85 -- 6.筛选平均分85以上的
ORDER BY average_score DESC -- 7.按平均分降序排列
LIMIT 10; -- 8.只显示前10名
⚙️ 2.1.2 数据库实际处理的顺序(执行顺序)
1. 先确定成绩表(FROM student_records) → 教务处先拿出所有学生档案
2. 关联考试成绩(JOIN test_results) → 再去考试中心调取考试记录
3. 匹配学生ID(ON student_records.id=test_results.student_id) → 确认哪些成绩属于哪些学生
4. 筛选学期(WHERE semester='2023秋季学期') → 只保留秋季学期的记录
5. 按学生分组(GROUP BY student_name) → 把每个学生的所有考试成绩归到一起
6. 过滤低分学生(HAVING AVG(test_score)>85) → 淘汰平均分低于85的学生
7. 计算显示字段名(SELECT...) → 准备最终要显示的姓名和平均分
8. 成绩排名(ORDER BY average_score DESC) → 按平均分从高到低排序
9. 取前十名(LIMIT 10) → 只公布成绩最好的10位学生
常用的数据类型(部分)
1.常用的数据类型表格
SQL语句分类: 1.1.2 创建数据表
| 数据类型 | 说明 | 示例 |
|---|---|---|
int | 整数类型,4字节存储空间,范围约±21亿 | age int |
smallint | 小整数类型,2字节存储空间,范围-32,768到32,767 | status smallint |
bigint | 大整数类型,8字节存储空间,范围约±922京 | id bigint |
float(m,n) | 浮点数类型,m表示总位数,n表示小数位数 | price float(8,2) |
decimal(m,n) | 精确小数类型,适合存储精确数值如金额,m总位数,n小数位 | amount decimal(10,2) |
char(n) | 定长字符串,固定占用n个字符空间,适合存储长度固定的数据 | code char(10) |
varchar(n) | 变长字符串,最大可存储n个字符,实际占用空间根据内容长度变化 | name varchar(50) |
text | 长文本数据类型,适合存储大段文字 | content text |
date | 日期类型,格式为YYYY-MM-DD | birth date |
datetime | 日期时间类型,格式为YYYY-MM-DD HH:MM:SS | create_time datetime |
timestamp | 时间戳类型,自动记录数据修改时间 | update_time timestamp |
boolean | 布尔值类型,存储true或false | is_active boolean |
SQL 中 真(TRUE)与假(FALSE)判断标准表格
到SQL语句分类:4.2.1 AND(并且)
到SQL语句分类:4.2.2 OR(或者)
| 数据类型 | 为真(TRUE)的条件 | 为假(FALSE)的条件 |
|---|---|---|
| 布尔值 | TRUE | FALSE |
| 数值 | 任何非零数值(1, -5, 0.1, 100) | 零值(0, 0.0) |
| 字符串 | 非空字符串(‘a’, ‘hello’, ’ ') | 空字符串(‘’) |
| 集合 | 非空集合([1], [1,2], 非空数组) | 空集合([], 空数组) |
| 比较 | 条件成立(id=1, age>18, name LIKE ‘A%’) | 条件不成立(id=0, age<=18) |
| NULL | 不适用 | 不适用 |
数据库权限授权常用表格
跳转到SQL语句分类: 3.1 GRANT
以下是常见数据库权限的授权参考表格,适用于大多数关系型数据库(MySQL, PostgreSQL, Oracle, SQL Server等):
| 权限类型 | 语法示例 | 适用对象 | 说明 |
|---|---|---|---|
| SELECT | GRANT SELECT ON 表名 TO 用户名 | 表/视图 | 允许查询数据 |
| INSERT | GRANT INSERT ON 表名 TO 用户名 | 表/视图 | 允许插入数据 |
| UPDATE | GRANT UPDATE ON 表名 TO 用户名 | 表/视图 | 允许修改数据 |
| DELETE | GRANT DELETE ON 表名 TO 用户名 | 表/视图 | 允许删除数据 |
| ALL PRIVILEGES | GRANT ALL PRIVILEGES ON 数据库.* TO 用户名 | 数据库/表 | 授予所有权限 |
| CREATE | GRANT CREATE ON DATABASE 数据库名 TO 用户名 | 数据库 | 允许创建对象 |
| ALTER | GRANT ALTER ON 表名 TO 用户名 | 表 | 允许修改表结构 |
| DROP | GRANT DROP ON 数据库名 TO 用户名 | 数据库/表 | 允许删除对象 |
| EXECUTE | GRANT EXECUTE ON PROCEDURE 存储过程名 TO 用户名 | 存储过程/函数 | 允许执行 |
| REFERENCES | GRANT REFERENCES ON 表名 TO 用户名 | 表 | 允许创建外键约束 |
| INDEX | GRANT INDEX ON 表名 TO 用户名 | 表 | 允许创建索引 |
| WITH GRANT OPTION | GRANT SELECT ON 表名 TO 用户名 WITH GRANT OPTION | 任意 | 允许用户授权他人 |
特殊权限说明
| 权限 | 说明 |
|---|---|
GRANT CREATE USER | 允许创建用户(通常仅管理员) |
GRANT SUPER | 高级管理权限(MySQL) |
GRANT DBA | 数据库管理员权限(Oracle) |
GRANT CONNECT | 允许连接数据库 |
GRANT RESOURCE | 允许创建对象(Oracle) |
六、数据表参照
子查询: 返回
联表查询: 返回
关系表(字段)
| 表名 | 关联字段 | 关联说明 |
|---|---|---|
| emp(员工表) | deptno | 关联dept表的deptno字段 |
| dept(部门表) | deptno | 被emp表关联的主键字段 |
| salgrade(工资等级表) | - | 通过emp.sal与salgrade.losal/hisal范围关联 |
-- 部门表(dept)字段注释
+--------+---------------------+
| 字段名 | 注释说明 |
+--------+---------------------+
| deptno | 部门编号(主键) |
| dname | 部门名称 |
| loc | 部门所在地 |
+--------+---------------------+-- 员工表(emp)字段注释
+----------+--------------------------------+
| 字段名 | 注释说明 |
+----------+--------------------------------+
| empno | 员工编号(主键) |
| ename | 员工姓名 |
| job | 职位(CLERK/SALESMAN等) |
| mgr | 直属领导编号(关联empno) |
| hiredate | 入职日期(YYYY-MM-DD) |
| sal | 基本工资 |
| comm | 佣金/奖金(销售岗位特有) |
| deptno | 所属部门编号(关联dept.deptno) |
+----------+--------------------------------+-- 薪资等级表(salgrade)字段注释
+-------+---------------------+
| 字段名 | 注释说明 |
+-------+---------------------+
| grade | 薪资等级(1-5级) |
| losal | 该等级最低工资标准 |
| hisal | 该等级最高工资标准 |
+-------+---------------------+
相关文章:
)
SQL 语句基础(增删改查)
文章目录 一、SQL 基础概念1. SQL 简介2. 数据库系统的层次结构 二、SQL 语句分类1. DDL(Data Definition Language 数据定义语言)1.1 CREATE1.1.1 创建数据库1.1.2 创建数据表1.1.3 创建用户 1.2 ALTER1.2.1 AlTER 添加字段名1.2.2 ALTER 修改字段名1.2…...

【蓝桥杯 CA 好串的数目】题解
题目链接 考虑令 p r e [ i ] pre[i] pre[i] 表示 [ p r e [ i ] , i ] [pre[i], i] [pre[i],i] 是连续非递减子串,这可以类似双指针 O ( n ) O(n) O(n) 预处理: std::vector<int> pre(n); for (int r 1, l 0; r < n; r) {if (s[r] ! s[…...
——Linux命令)
Oracle for Linux安装和配置(11)——Linux命令
11.1. Linux命令 Linux是目前比较常用和流行的操作系统,现在很多生产环境就会用到它。随着其功能、性能、稳定性和可靠性等方面的日渐增强和完善,加之其成本上的优势,其市场占有率逐日攀升,也得到越来越多广大用户的关注和青睐。但作为一种操作系统,其安装、配置、管理和…...

Linux基础7
一、逻辑卷管理 查看所有物理卷:pvs 查看当前系统卷组:vgs 查看所有逻辑卷:lvs 新创建系统卷组:vgcreate [参数] [volume name] url/sdb[1-2] eg:vgcreate vg_Test /dev/sdb{1,2} >…...

C#打开文件及目录脚本
如果每天开始工作前都要做一些准备工作,比如打开文件或文件夹,我们可以使用代码一键完成。 using System.Diagnostics; using System.IO;namespace OpenFile {internal class Program{static void Main(string[] args){Console.WriteLine("Hello, …...

Docker 镜像 的常用命令介绍
拉取镜像 $ docker pull imageName[:tag][:tag] tag 不写时,拉取的 是 latest 的镜像查看镜像 查看所有本地镜像 docker images or docker images -a查看完整的镜像的数字签名 docker images --digests查看完整的镜像ID docker images --no-trunc只查看所有的…...

Python数组学习之旅:数据结构的奇妙冒险
Python数组学习之旅:数据结构的奇妙冒险 第一天:初识数组的惊喜 阳光透过窗帘缝隙洒进李明的房间,照亮了他桌上摊开的笔记本和笔记本电脑。作为一名刚刚转行的金融分析师,李明已经坚持学习Python编程一个月了。他的眼睛因为昨晚熬夜编程而微微发红,但脸上却挂着期待的微…...

Vue 3 和 Vue 2 的区别及优点
Vue.js 是一个流行的 JavaScript 框架,广泛用于构建用户界面和单页应用。自 Vue 3 发布以来,很多开发者开始探索 Vue 3 相较于 Vue 2 的新特性和优势。Vue 3 引入了许多改进,优化了性能、增强了功能、提升了开发体验。本文将详细介绍 Vue 2 和…...

特殊定制版,太给力了!
今天给大家分享一款超棒的免费录屏软件,真的是录屏的好帮手! 这款软件功能可以录制 MP4、AVI、WMV 格式的标清、高清、原画视频,满足你各种需求。 云豹录屏大师 多功能录屏神器 它的界面特别简洁,上手超快,用起来很顺…...

Vue事件修饰符课堂练习
Vue事件修饰符课堂练习 题目:基于 Vue 2.0,使用事件修饰符 .stop、.prevent、.capture、.self 和 .once,为按钮绑定 click 事件,并展示每个修饰符的作用。 要求: 创建一个 Vue 实例,并绑定到一个 HT…...

Y1——ST表
知识点 ST表 只能询问,不能修改 ST表的预处理: 使用了DP的思想,设a是要求区间最值的数列,f(i,j)表示从第i个数起连续2^j个数中的最大值 状态转移方程 f [ i , j ]max( f [ i , j-1 ], f [ i 2 ^ j-1,j - 1]) 建立ST表 vo…...

Python Cookbook-5.14 给字典类型增加排名功能
任务 你需要用字典存储一些键和“分数”的映射关系。你经常需要以自然顺序(即以分数的升序)访问键和分数值,并能够根据那个顺序检查一个键的排名。对这个问题,用dict 似乎不太合适。 解决方案 我们可以使用 dict 的子类,根据需要增加或者重…...

第二十二: go与k8s、docker相关编写dockerfile
实战演示k8s部署go服务,实现滚动更新、重新创建、蓝绿部署、金丝雀发布-CSDN博客 go 编写k8s命令: 怎么在go语言中编写k8s命令 • Worktile社区 k8s中如何使用go 在K8s编程中如何使用Go-阿里云开发者社区 go build - o : -o:指定输出文件…...

Servlet、HTTP与Spring Boot Web全面解析与整合指南
目录 第一部分:HTTP协议与Servlet基础 1. HTTP协议核心知识 2. Servlet核心机制 第二部分:Spring Boot Web深度整合 1. Spring Boot Web架构 2. 创建Spring Boot Web应用 3. 控制器开发实践 4. 请求与响应处理 第三部分:高级特性与最…...

事件过滤器
1.简介 事件过滤器是指在程序分发到event事件之前进行的一次高级拦截。 2.使用步骤 给控件安装事件过滤器重写eventfilter事件 3.具体实现 3.1安装事件过滤器 代码: //给label1安装事件过滤器ui->label->installEventFilter(this); 3.2重写eventfilter…...

AI识别与雾炮联动:工地尘雾治理新途径
利用视觉分析的AI识别用于设备联动雾炮方案 背景 在建筑工地场景中,人工操作、机械作业以及环境因素常常导致局部出现大量尘雾。传统监管方式存在诸多弊端,如效率低、资源分散、监控功能单一、人力效率低等,难以完美适配现代工程需求。例如…...
)
Kubernetes nodeName Manual Scheduling practice (K8S节点名称绑定以及手工调度)
Manual Scheduling 在 Kubernetes 中,手动调度框架允许您将 Pod 分配到特定节点,而无需依赖默认调度器。这对于测试、调试或处理特定工作负载非常有用。您可以通过在 Pod 的规范中设置 nodeName 字段来实现手动调度。以下是一个示例: apiVe…...

Nacos注册中心
Nacos注册中心 本地环境搭建 准备挂载的文件夹 在拉取 Nacos 镜像之前,在 E:\docker 文件夹下,创建一个 /nacos 文件夹,等会运行容器时,用于将 Nacos 容器中的配置文件、持久化文件挂载出来,防止容器重启时数据丢失…...
,还有CAUSAL_LM,QUESTION_ANS)
除了 `task_type=“SEQ_CLS“`(序列分类),还有CAUSAL_LM,QUESTION_ANS
task_type="SEQ_CLS"是什么意思:QUESTION_ANS 我是qwen,不同模型是不一样的 SEQ_CLS, SEQ_2_SEQ_LM, CAUSAL_LM, TOKEN_CLS, QUESTION_ANS, FEATURE_EXTRACTION. task_type="SEQ_CLS" 通常用于自然语言处理(NLP)任务中,SEQ_CLS 是 Sequence Classif…...

二战蓝桥杯所感
🌴 前言 今天是2025年4月12日,第十六届蓝桥杯结束,作为二战的老手,心中还是颇有不甘的。一方面,今年的题目比去年简单很多,另一方面我感觉并没有把能拿的分都拿到手,这是我觉得最遗憾的地方。不…...

深度解析自动化工作流工具:n8n 与 Dify 的对比分析
深度解析自动化工作流工具:n8n 与 Dify 的对比分析 随着企业数字化转型的加速,自动化工具在提高工作效率、降低人工成本方面扮演着越来越重要的角色。市面上有多种自动化工作流工具可供选择,其中 n8n 和 Dify 是两个备受关注的开源和商业产品…...

深度剖析Python中的生成器:高效迭代的秘密武器
深度剖析Python中的生成器:高效迭代的秘密武器 在Python的编程世界里,生成器(Generator)是一个强大而又迷人的特性,它为开发者提供了一种高效处理大量数据的方式,尤其在涉及到迭代操作时,能显著…...

Mac 下载 PicGo 的踩坑指南
Mac 下载 PicGo 的踩坑指南 一、安装问题 下载地址:https://github.com/Molunerfinn/PicGo/releases 下载之后直接安装即可,此时打开会报错:Picgo.app 文件已损坏,您应该将它移到废纸篓。 这是因为 macOS 为了保护用户不受恶意…...

网页布局汇总
1. 盒模型 容器大小 内容大小 内边距(padding) 边框大小 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0">&l…...

基于 Maven 构建的 Thingsboard 3.8.1 项目结构
一、生命周期(Lifecycle) Maven 的生命周期定义了项目构建和部署的各个阶段,图中列出了标准的生命周期阶段: clean:清理项目,删除之前构建生成的临时文件和输出文件。validate:验证项目配置是否…...
)
MySQL 中为产品添加灵活的自定义属性(如 color/size)
方案 1:EAV 模型(最灵活但较复杂) 适合需要无限扩展自定义属性的场景 -- 产品表 CREATE TABLE products (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(100),price DECIMAL(10,2) );-- 属性名表 CREATE TABLE attributes (id INT PRIMA…...

C++语言程序设计——02 变量与数据类型
目录 一、变量与数据类型(一)变量的数据类型(二)变量命名规则(三)定义变量(四)变量赋值(五)查看数据类型 二、ASCII码三、进制表示与转换(一&…...

第三篇:Python数据结构深度解析与工程实践
第一章:列表与字典 1.1 列表的工程级应用 1.1.1 动态数组实现机制 Python列表底层采用动态数组结构,初始分配8个元素空间,当空间不足时按0,4,8,16,25,35...的公式扩容,每次扩容增加约12.5%的容量 通过sys模块可验证扩容过程&a…...

dcsdsds
我将为您在页面顶部添加欢迎内容,同时保持整体风格的一致性。以下是修改后的代码,主要修改了模板部分和对应的样式: vue 复制 <template><div class"main-wrapper"><!-- 新增欢迎部分 --><div class"…...

Vitis: 使用自定义IP时 Makefile错误 导致编译报错
参考文章: 【小梅哥FPGA】 Vitis开发中自定义IP的Makefile路径问题解决方案 Vitis IDE自定义IP Makefile错误(arm-xilinx-eabi-gcc.exe: error: *.c: Invalid argument)解决方法 Vitis 使用自定义IP时: Makefile 文件里的语句是需要修改的,…...

应急响应练习靶机-web1
1)背景 小李在值守的过程中,发现有CPU占用飙升,出于胆子小,就立刻将服务器关机,这是他的服务器系统,请你找出以下内容,并作为通关条件: 1.攻击者的shell密码 2.攻击者的IP地址 3.攻击…...
 browserscan检测原理逆向分析)
cdp-(Chrome DevTools Protocol) browserscan检测原理逆向分析
https://www.browserscan.net/zh/bot-detection 首先,打开devtools后访问网址,检测结果网页显示红色Robot,标签插入位置,确定断点位置可以hook该方法,也可以使用插件等方式找到这个位置,本篇不讨论. Robot标签是通过insertBefore插入的. 再往上追栈可以发现一个32长度数组,里面…...

MCU刷写——Hex文件格式详解及Python代码
工作之余来写写关于MCU的Bootloader刷写的相关知识,以免忘记。今天就来聊聊Hex这种文件的格式,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走一波!感谢…...
)
SpringBoot(一)
快速入门 1.概念 SpringBoot 简单、快速地创建一个独立的、生产级别的 Spring 应用(说明SpringBoot底层是Spring) 大多数 SpringBoot 应用只需要编写少量配置即可快速整合 Spring 平台以及第三方技术 特性: 快速创建独立 Spring 应用 SSM&…...

学习Mysql对库和表的操作以及对数据的操作
对库操作 SHOW DATABASES;可以查看数据库服务器中有哪些数据库(注意databases最后的s不要忘记) SELECT DATABASE();可以查看到目前是在哪个数据库下。 CREATE DATABASE 库名;可以创建一个数据库 DROP DATABASE 库名;可以删除一个数据库 USE 库名;切换到当前数据库 对表操…...

微软office填表无法打勾✔,解决办法!
最近在使用office 填表的时候,碰到需要在选择框中打勾的情况,但是找了半天发现找不到打勾的按钮。为此,记录该问题解决办法: 以这个界面为例,如果点击打勾发现无法✔。 这里因为office和wps的编写不一样,所…...

Python实现链接KS3,并批量下载KS3文件数据到本地
前言 本文是该专栏的第56篇,后面会持续分享python的各种干货知识,值得关注。 在本专栏的上篇文章《Python实现链接KS3,并将文件数据批量上传到KS3》中,笔者有详细介绍基于Python,实现链接KS3并将文件数据批量上传。而本文,笔者将基于在上一篇文章的基础之上,实现链接KS…...

构建智能期货交易策略分析应用:MCP与AI的无缝集成
引言 随着金融科技的快速发展,数据驱动的交易决策已成为期货交易领域的重要趋势。本文将深入探讨一个结合了Model Content Protocol (MCP)和AI技术的期货交易策略分析应用——Futures MCP。该应用不仅提供了丰富的技术分析工具,还通过MCP协议与大型语言…...

区块链点燃游戏行业新未来——技术变革与实践指南
区块链点燃游戏行业新未来——技术变革与实践指南 在数字时代,游戏行业无疑是创新的热土。从简单像素风的街机游戏到沉浸式的虚拟现实,我们见证了技术如何一步步塑造游戏的样貌。然而,在传统游戏模式中,玩家权益往往无法得到保障…...

Jmeter中如何实现关联?
在JMeter中实现关联(Correlation)是性能测试中处理动态数据(如Session ID、Token、动态参数等)的核心技能。以下是详细操作指南,涵盖原理、工具和实战示例: 一、关联的本质与场景 作用:从服务器响应中提取动态数据,供后续请求复用(如登录Token、订单ID、验证码等)。 …...

在MATLAB中使用MPI进行并行编程
在MATLAB中使用MPI进行并行编程 MATLAB支持通过MPI (Message Passing Interface) 进行并行编程,这通常通过Parallel Computing Toolbox和MATLAB Parallel Server实现。以下是使用MPI进行并行编程的基本方法: 基本设置 确保安装了必要的工具箱ÿ…...

15.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--单体转微服务--如何拆分单体
单体应用(Monolithic Application)是指将所有功能模块集中在一个代码库中构建的应用程序。它通常是一个完整的、不可分割的整体,所有模块共享相同的运行环境和数据库。这种架构开发初期较为简单,部署也较为方便,但随着…...

C++: char类型既不是signed char也不是unsigned char
对于 int, short, long, long long 类型, 增加 signed, 类型不变。 对于 char 类型, 增加 signed, 类型变了。 char 既不是 signed char, 也不是 unsigned char。 虽然 char 的取值范围, 一定是࿱…...

测试第二课-------测试分类
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

16.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--单体转微服务--微服务的部署与运维
部署与运维是微服务架构成功实施的关键环节。一个良好的部署与运维体系能够保障微服务的高可用性、可扩展性和可靠性。在这一阶段,重点包括微服务的容器化与编排、API 网关的实现以及日志与监控体系的建设。 一、容器化与编排 1.1 使用 Docker 容器化微服务 容器…...

什么是供应链金融
供应链金融(Supply Chain Finance) 是一种基于供应链上下游真实交易场景的金融服务模式,通过整合物流、信息流、资金流和数据流,为核心企业及其上下游中小企业提供灵活、高效的融资解决方案。其核心目标是优化供应链资金周转效率&…...

个人博客系统后端 - 注册登录功能实现指南
一、功能概述 个人博客系统的注册登录功能包括: 用户注册:新用户可以通过提供用户名、密码、邮箱等信息创建账号用户登录:已注册用户可以通过用户名和密码进行身份验证,获取JWT令牌身份验证:使用JWT令牌访问需要认证…...

微信小程序运行机制详解
微信小程序运行机制详解 微信小程序是介于 Web 和原生 App 之间的一种应用形态,具有无需安装、用完即走、体验流畅的特点。本文将从架构层面、运行环境、通信机制等方面深入剖析微信小程序的运行机制。 一、小程序运行架构概览 微信小程序采用双线程模型ÿ…...
)
GGML源码逐行调试(中)
目录 前言1. 简述2. 加载模型超参数3. 加载词汇表4. 初始化计算上下文5. 初始化计算后端6. 创建模型张量7. 分配缓冲区8. 加载模型权重结语下载链接参考 前言 学习 UP 主 比飞鸟贵重的多_HKL 的 GGML源码逐行调试 视频,记录下个人学习笔记,仅供自己参考&…...

高阶函数/柯里化/纯函数
本篇文章主要是介绍一下标题里面的概念,在面试的时候经常文档,结合阅读到的资料,结合本人的个人见解出品了该文章,如有写的不好的地方或理解有误的,还望阁下多多指教。 1、高阶函数 什么是高阶函数? 接受…...