【Reinforcement Learning For Quadruped Control】1
强化学习(RL)是一种机器学习范式,代理通过与环境的互动来学习做出决策。强化学习的核心概念围绕以下几个方面展开:a) 代理agent,做出决策;b) 环境environment,响应代理的决策;c) 状态states,环境的当前条件;d) 动作action,代理做出的决策;e) 奖励reward,是反馈信号,用于引导学习。强化学习的目标是学习一个策略,以最大化在整个时间内积累的总奖励。这一学习过程依赖于试错法,其中代理根据环境中的状态和动作获得奖励,并力求最大化未来的回报。
强化学习的目标,是找到一套策略(Policy),使得智能体在长期交互中所获得的累计奖励最大化。它不是靠人类提供明确的输入输出映射来学习,而是靠自己在环境中“摸索”,一步步试出来。这种能力使它在传统监督学习难以覆盖的场景中展现出巨大价值——比如那些无法精确建模的系统,或者对任务反馈具有长期依赖性的决策过程。强化学习最强大的地方,在于它将“决策”建模为一个动态过程,而不是一个静态的分类问题。这使它天然适合处理连续决策问题、延迟反馈任务和交互式场景。也正因如此,它在机器人学中得到了广泛应用,比如四足机器人学习行走策略、机械臂抓取目标物体等。此外,它还在博弈(如围棋、Dota2)、金融资产配置、智能医疗诊断等复杂领域取得了令人惊叹的成果。
强化学习(RL)的数学基础通常被建模为马尔可夫决策过程(MDP): ( s , a , f , r t , p 0 , γ ) (s, a, f, r_t, p_0, \gamma) (s,a,f,rt,p0,γ),其中 s s s是状态空间, a a a是动作空间, f ( s , a ) f(s, a) f(s,a)是系统dynamics, r t ( s t , a t , s t + 1 ) r_t(s_t, a_t, s_{t+1}) rt(st,at,st+1)是奖励函数, p 0 p_0 p0是初始状态分布, γ \gamma γ是折扣因子。MDP假设马尔可夫性质,即未来的状态仅依赖于当前状态和动作,而不依赖于导致当前状态的事件序列。这使得MDP成为建模顺序问题的强大工具,强化学习可以基于累计奖励进行优化。深度强化学习(DRL)的目标是找到策略 ( π θ : S → A ) (\pi_{\theta}: S \rightarrow A) (πθ:S→A)的最优参数 θ \theta θ,以最大化在整个回合时间 T T T内的期望折扣回报 J ( θ ) J(\theta) J(θ)(参见公式(1))。
J ( θ ) = E π θ [ ∑ t = 0 T − 1 γ t r t ] (1) J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \sum_{t=0}^{T-1} \gamma^t r_t \right] \ \ \ \ \ \ \text{(1)} J(θ)=Eπθ[t=0∑T−1γtrt] (1)
尽管MDP框架为强化学习(RL)提供了强大的基础,但传统的强化学习方法(Q-learning,SARSA)在面对复杂的高维环境时仍然存在困难,因为准确表示状态和动作非常困难。这导致了深度强化学习(DRL)的发展,DRL结合了强化学习和深度神经网络(DNN)的学习能力。
强化学习大致可以分为两种主要方法:基于模型和无模型。选择基于模型还是无模型的方法取决于环境的复杂性、数据的可用性、训练所需的计算能力以及所需的性能水平。在基于模型的强化学习中,代理根据当前的状态-动作对学习一个模型,能够预测下一个状态和奖励。模型使得代理能够通过模拟不同的动作及其潜在结果来提前规划。与此不同,在无模型的强化学习中,代理通过与环境的互动直接学习,而不需要显式建模。它专注于学习一个策略 π θ ( s ) \pi_{\theta}(s) πθ(s),将状态映射到动作(基于策略的Policy-based),或学习一个动作值函数 Q ( s , a ) Q(s, a) Q(s,a),它估计在某状态下采取某个动作的总奖励(基于值的Value-based))。
在使用深度强化学习(DRL)设计控制器时,动作空间的性质(离散或连续)是一个至关重要的考虑因素。离散动作空间意味着代理在任何给定时刻都拥有有限的一组动作。例子包括二进制动作(例如,前进、后退)或类别动作(例如,移动到特定位置、切换不同的控制策略,如平地和楼梯的控制策略)。尽管这些离散的动作空间相对容易表示和学习,但离散动作本身固有地限制了代理通过动作进行细粒度控制的能力。相比之下,连续动作空间允许代理选择在定义边界内平滑变化的动作。这一点在四足机器人中有所体现,例如,机器人的腿部关节的连续运动范围或可调节的扭矩水平。然而,在连续动作空间中进行学习会面临更大的挑战。
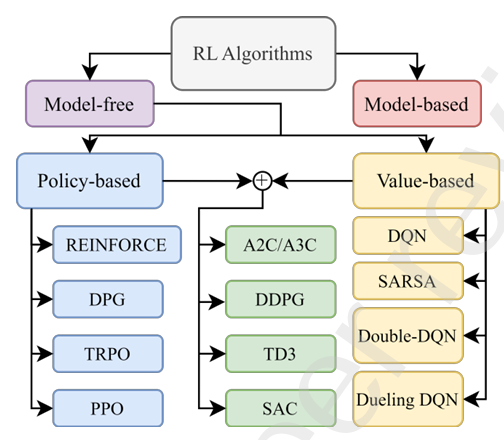
深度Q网络(DQN)。一种基于值的深度强化学习算法,通过近似最优的动作值函数,即Q值,来操作,Q值表示在给定状态下采取某个动作的期望回报。这个近似通过深度神经网络(DNN)进行学习。网络将当前状态作为输入,并输出所有可能动作的Q值。然后,代理选择具有最高Q值的动作。DQN依赖于离散的动作空间,限制了其在复杂四足控制任务中的应用。离散化的连续动作空间可能导致次优性能,并且DQN的探索策略可能受到限制。此外,DQN还面临过度估计偏差的问题,其中代理倾向于选择由于Q值膨胀而导致的非最优动作。这些因素导致了DQN在四足控制中的应用受限。
深度确定性策略梯度(DDPG)Deep Deterministic Policy Gradient。是一种为连续动作空间设计的演员-评论家actor-critic 算法。它扩展了DQN,通过使用确定性策略梯度来处理连续动作。DDPG采用一个critic network来估计Q值函数,并使用一个 actor network来学习策略。DDPG可能会遇到一些问题,如探索挑战和训练过程中的不稳定性。此外,由于其确定性本质,DDPG可能会限制其适应复杂和动态环境的能力。
信任区域策略优化(TRPO)Trust Region Policy Optimization.。 是一种基于策略的强化学习算法,与基于值的算法,如DQN不同,TRPO避免了对动作值的直接估计,而是通过直接学习映射状态到动作的策略。这种直接方法对需要精确运动控制的任务具有优势,因为它生成了连续输出的动作。与可能在训练过程中表现出不稳定性的DDPG不同,TRPO通过确保策略的单调改进来强调稳定性。这是通过将策略更新限制在信任区域内来实现的,从而防止偏离最优轨迹。尽管TRPO在理论上保证了策略的改进,但其计算复杂性和实现挑战限制了其广泛采用,导致了PPO的出现。
近端策略优化(PPO)Proximal Policy Optimization。在其前身TRPO的基础上进行了改进,通过简化优化过程并保持性能保证。它采用了剪切的替代目标函数来约束策略更新,防止了可能导致不稳定的大幅度策略变化。这使得PPO在实际应用中更具可行性。PPO在各种四足控制任务中取得了成功,如学习复杂的步态、适应不同的地形和执行动态机动。其能够处理连续动作空间,并结合稳定的训练过程,推动了它在该领域的广泛采用。这是四足机器人领域中使用最广泛的优化算法。
软演员-评论家(SAC)Soft Actor-Critic。是一种基于策略的强化学习算法,它结合了最大熵强化学习和演员-评论家方法的优势。它旨在学习一个随机策略,最大化期望回报和熵,从而鼓励探索和鲁棒行为。由于其有效处理复杂状态和动作空间的能力,SAC特别适合处理复杂状态的连续控制任务。与PPO相比,SAC在处理大量输入状态时表现更好,而PPO在处理少量输入状态时表现更佳。通过将熵项纳入目标函数,SAC促进了探索,防止了过早收敛到次优解。这对于四足控制至关重要,因为四足机器人通常需要在适应不同地形和挑战时表现出多样的行为。SAC在学习复杂且鲁棒的运动模式方面,特别是在四足机器人领域,显示出了良好的效果。
四足运动问题可以使用动态系统建模,其中下一个状态 s t + 1 s_{t+1} st+1依赖于当前状态 s t s_t st和当前动作 a t a_t at。系统的动态模型可以写为: s t + 1 = f ( s t , a t ) + ϵ s_{t+1} = f(s_t, a_t) + \epsilon st+1=f(st,at)+ϵ,其中 f ( s t , a t ) f(s_t, a_t) f(st,at)是描述系统动态的函数, ϵ \epsilon ϵ表示过渡中的噪声或不确定性。在马尔可夫决策过程(MDP)中,系统的动态通过转移概率 P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t, a_t) P(st+1∣st,at)表示,该概率可以是确定性的(如果系统是完全已知的)或随机的(如果存在不确定性)。由于控制问题可以被表述为MDP,强化学习(RL)可以用于解决四足运动问题。
使用深度强化学习(DRL)解决四足运动的关键组成部分如图中的分类法所示。输入或观察空间包括RL agent可以获取的信息,涵盖了内感受(内部状态)和外感受(外部传感器)数据。动作空间指agent可以采取的动作集合,例如关节扭矩或步态指令。奖励函数提供了对agent在环境中动作的反馈,引导其学习过程。此外,模拟到现实的差距突出显示了仿真与现实世界之间的差异,包括物理、建模误差、噪声以及其他环境变量等因素。
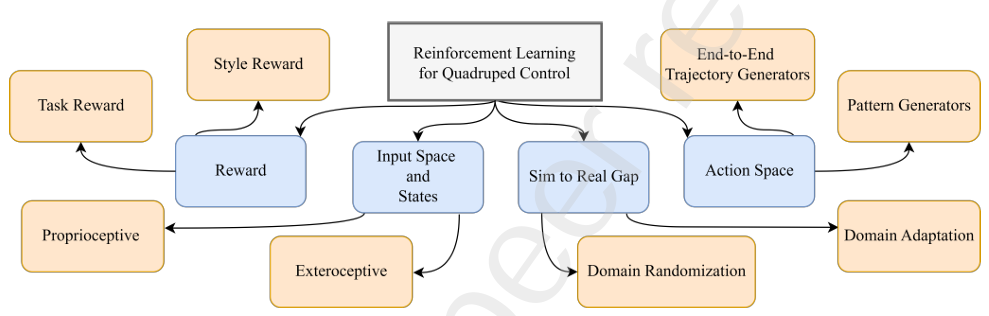
在动态系统中,状态代表了描述系统演化所需的最小物理量集合。尽管MDP共享这一概念,但这里的状态在时间域上是离散化的,当前状态封装了系统的历史。因此,未来状态仅依赖于两个因素:当前状态和对环境采取的动作。
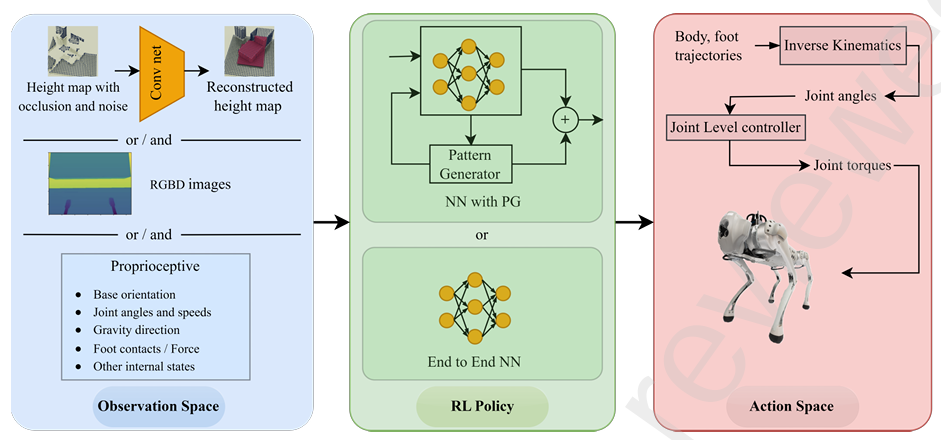
DRL策略的输入状态数量是一个设计选择,并没有固定的经验法则。使用过少的状态可能导致部分可观察的MDP,表现不佳。相反,过多的状态信息可能导致在仿真环境中过拟合,并且在真实环境中表现不可靠。内感受测量,指的是机器人内部状态,通常足以学习一个有效的控制器来应对较简单的任务。这些测量包括IMU数据、足部接触状态、速度和足部接触力等。
外感受数据则提供了关于外部环境的信息。这包括传感器数据,如LiDAR点云、深度图像和高度图等。复杂的任务,如地形感知导航或类似跑酷的任务,通常需要结合内感受和外感受测量。当使用高维输入时,直接将输入与策略集成可能会在RL训练环境中带来不利影响。因此,一些压缩技术,如编码器和 belief states,用于压缩这些高维输入。
动作空间。动作空间代表了RL策略的输出,作为输入提供给环境,从而引起环境的变化。在使用深度强化学习(DRL)进行四足运动控制时,可以识别出两种主要的动作生成方法:a) 端到端直接轨迹生成器(TG)Trajectory Generators,其中质心(CoM)、足部位置或关节角度的轨迹直接由DNN策略生成;b) 由DNN策略调节的模式生成器 Pattern Generators,其中模式生成器生成预定义的有节奏的足部或关节角度轨迹,而DNN通过输入信号调节模式生成器的输出。在这两种方法中,生成的模式通过低级控制器以更高的频率执行,低级控制器通常使用基于PID的控制器或全身控制器作为支撑。
当RL策略作为端到端轨迹生成器时,它将输入数据直接映射到输出的关节角度,之后通过低级控制器进行处理。这些端到端的TG通常关注质心、足部或关节角度的轨迹。在生成的轨迹不能直接表示为关节角度的情况下,会使用逆向运动学。生成质心的加速度,可以提高机器人灵活性。模型直接生成关节角度可能会限制高动态,因为在训练过程中缺乏样本效率。然而,近年来仿真技术的进展,导致了更快速的仿真平台的发展,促进了这一领域的进步。最近的进展探索了直接控制关节扭矩,以便为机器人提供更动态的运动,但在这种情况下,策略需要以更高的频率(100 Hz至1 kHz范围)进行评估,以生成扭矩指令,因为电机扭矩是低级指令,且策略必须快速评估以平稳地处理电机的dynamics。
样本效率Sample efficiency是这些端到端学习策略的主要挑战,因为DNN策略必须通过试错法在奖励函数的引导下学习自然的腿部运动。这个过程并不高效。在这方面,存在一些技术,如课程学习、模仿学习和元学习,用于引导机器人朝着更高效的样本路径学习,最终达到目标。端到端策略的另一个主要问题是promoting exploration。使用鼓励探索的算法,如SAC,或者向动作空间的输出添加高斯扰动,是解决这一问题的一些方法。这个方法鼓励策略探索更广泛的动作范围,从而提高其发现最优解的能力。
或者,可以使用预定义的轨迹生成器来提高RL策略的样本效率。例如,中央模式生成器(CPGs)是生成独立于感觉反馈的节律性运动模式的系统之一。这些模式通常是重复的,形成如行走等运动。虽然感觉反馈可以影响CPG生成模式的相位和整体运动,但基本的节律是内部生成的。在四足运动中使用的CPGs可以在笛卡尔空间或关节空间中,生成行走所需的模式。
通常在四足运动控制中,CPGs常常涉及所有四条腿之间的显式耦合,这可能会限制机器人的多功能性和适应性,因此研究人员探索了解耦的方法。受动物启发,关节角度的修正是通过DNN策略根据感觉反馈生成的。这些角度修正随后被加到从CPG提取的关节角度上,以增强鲁棒性。
参考资料来源网络,仅供学习使用
如有侵权,联系删除
相关文章:

【Reinforcement Learning For Quadruped Control】1
强化学习(RL)是一种机器学习范式,代理通过与环境的互动来学习做出决策。强化学习的核心概念围绕以下几个方面展开:a) 代理agent,做出决策;b) 环境environment,响应代理的决策;c) 状态…...

工程企业如何实现四算联动?预算-核算-决算系统解析
在工程行业,项目管理的高效性直接决定了企业的盈利能力和市场竞争力。尤其是在EPC(工程总承包)模式下,工程企业面临着复杂的业务场景和多维度的成本管控需求。如何通过“四算联动”(概算、预算、核算、决算)…...

【SpringBoot】处理actuator风险漏洞
最近给系统做渗透测试,扫描出了一个actuator风险漏洞,属于高危级别,通过actuator接口可以拿到用户敏感信息。这个问题处理起来倒也简单,禁用actuator或者限制访问就可以了 # 禁用actuator接口配置 management:server:port: -1# 限…...

MACOS15版本安装 python mysqlclient 以连接mysql 8.0
MACOS14/15 版本安装 python mysqlclient 以连接mysql 8.0 主要用于macos django4 mysql8.0 开发项目 准备材料 macos > 13.0 python > 3.10.0 (不强制) mysql > 8.0 安装步骤 安装 brew 使用国内源安装brew /bin/zsh -c "$(curl -f…...

KV Cache大模型推理加速功能
KV Cache KV Cache是大模型标配的推理加速功能,也是推理过程中,显存资源巨大开销的元凶之一。在模型推理时,KV Cache在显存占用量可达30%以上。 目前大部分针对KV Cache的优化工作,主要集中在工程上。比如著名的VLLM,…...
)
Windows下安装WSL2下的Ubuntu、docker容器的IP地址(上)
既然容器支持多个应用,那么容易想到应该有对应的ip地址和端口,这样才能和Ubuntu主机进行通讯,ubuntu访问外网也应该有ip能连接到外网才行,要搞清楚这些ip地址的关系才行。 前面两篇文章中说了怎么实现windows和wsl2下的ubuntu的文…...

vue实现中英文切换
第一步:安装插件vue-i18n,npm install vue-i18n 第二步:在src下新建locales文件夹,并在locales下新建index.js、EN.js、CN.js文件 第三步:在EN.js和CN.js文件下配置你想要的字段,例如: //CN.js…...
 API)
探索 Vue 3 中 vue-router 的 router.resolve () API
一、router.resolve() 是什么 router.resolve() 就好比是一个精准的 “导航参谋”。当我们在 Vue 3 应用里需要明确某个路由地址对应的详细信息时,它就能派上用场。我们给它传入路由信息,像路径、参数等,它会解析出对应的路由对象࿰…...

Excel 插件推荐:提升Excel能力的效率神器!
一、Excel玩家的觉醒时刻 在财务部的深夜加班现场,李师傅的咖啡杯上凝结着第3圈水渍。眼前的Excel窗口堆叠如俄罗斯方块:重复值删除进度15%、VLOOKUP公式报错3处、合并单元格序号乱成毛线团…这场景是否也戳中了你的痛点? 每个Excel高手都经…...

leetcode_383. 赎金信_java
383. 赎金信https://leetcode.cn/problems/ransom-note/ 1、题目 给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true ;否则返回 false 。 magazine 中的每个字…...
之三)
应用安全系列之四十五:日志伪造(Log_Forging)之三
1、简介 针对Java的日志系统有多种,本文主要描述如何通过修改配置文件来解决logback和log4j的日志伪造问题。 2、logback 2.1、系统提供的解决方案 在logback.xml中配置编码器自动转义特殊字符: 复制 <configuration><appender name"C…...

FTPClient开发遇到的坑
1. 生成文件夹乱序 这里用分隔符把路径划分开,意在一层一层创建目录 这里可能会出现乱序 正确的代码 先换一下分隔符 再一次生成所有路径 2.ftpClient 需要指定被动模式才能绕开端口限制 有些 服务器没有打开指定端口,上传文件会出现 425 Canno…...

leetcode0155. 最小栈-medium
1 题目:最小栈 官方标定难度:中 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。 void push(int val) 将元素val推入堆栈。 void pop() 删…...

操作系统 3.6-内存换出
换出算法总览 页面置换算法 FIFO(先进先出): 最简单的页面置换算法,淘汰最早进入内存的页面。 优点:实现简单。 缺点:可能会导致Belady异常,即增加内存反而降低性能。如果刚换入的页面马上又要…...

Python中的数值运算函数及math库详解
文章目录 Python中的数值运算函数及math库详解一、内置数值运算函数1. 基本数值运算函数2. 类型转换函数3. 进制转换函数 二、math库中的数学常数三、math库常用数学函数1. 数论与表示函数2. 幂函数与对数函数3. 三角函数4. 角度转换5. 双曲函数6. 特殊函数 四、实际应用示例1.…...

安卓开发提示Android Gradle plugin错误
The project is using an incompatible version (AGP 8.9.1) of the Android Gradle plugin. Latest supported version is AGP 8.8.0-alpha05 See Android Studio & AGP compatibility options. 改模块级 build.gradle(如果有独立配置):…...

《Uniapp-Vue 3-TS 实战开发》一键授权登录
在使用 UniApp 结合 Vue 3 和 TypeScript 开发时,实现一键授权登录功能通常涉及到调用微信小程序的授权接口(如 wx.getUserProfile 或 wx.login)来获取用户信息和登录凭证,然后将这些信息发送到后端进行验证和处理。以下是一个完整的实现示例,展示如何在 UniApp 中实现一键…...

Windows 图形显示驱动开发-WDDM 1.2功能_WDDM 1.2 和 Windows 8
简介 WDDM 是随 Windows Vista 一起引入的,以取代 Windows XP 或 Windows 2000 显示驱动程序模型 (XDDM) 。 随着 Windows Vista 中的引入,WDDM 体系结构提供了启用新功能的功能,例如桌面组合、增强的容错、视频内存管理器、GPU 计划程序、D…...

155.最小栈
1.题目解析 题目是让我们设计一个栈,它于STL库中栈的区别是支持检索到了最小元素的栈但是需要时间复杂度为常数,我们很容易想到的是记录最小值。但是如果中途删除的话最小值可能失效,所以我们选择用2个栈来实现。 2.算法原理 我们创建2个栈…...

[C语言笔记]10、字符串
前言: C语言的相关知识点的笔记均在下面的专栏链接中,欢迎订阅! c语言笔记_1zero10的博客-CSDN博客 10-1字符数组与字符串 1、字符数组就是一个数组,数组的每一个元素都是一个字符 首先利用字符数组,回顾以前学过…...

Windows系统备份和还原点
一、简介 系统的还原点存储了当前系统的主要状态,包括一些关键的配置信息和参数(包括注册表、系统服务设置、设备驱动程序设置等)。将此时的状态进行备份,在系统发生故障时,可以还原到此还原点的状态中,这…...

内联汇编知识点earlyclobber=
arm64内联汇编格式: asm volatile ("汇编指令1\n\t""汇编指令2\n\t""汇编指令3": 输出操作数列表: 输入操作数列表: 可能被修改的寄存器列表 );示例1:简单的寄存器操作 uint64_t add_numbers(uint64_t a, uint64_t b) {…...

修改ESP32CAM的示例CameraWebServer里的camera_index.h的方法
在这里,默认你已经会使用Arduino IDE或者PlatformIO通过烧录底座对ESP32CAM(如下图)进行烧录,并能通过浏览器对其进行访问。 我们访问到下图的界面时,不禁有个疑问,这个界面是如何生成的,如果我…...
(字符串))
Python学习笔记(二)(字符串)
文章目录 编写简单的程序一、标识符 (Identifiers)及关键字命名规则:命名惯例:关键字 二、变量与赋值 (Variables & Assignment)变量定义:多重赋值:变量交换:(很方便哟) 三、输入与输出 (In…...

ViewModel vs AndroidViewModel:核心区别与使用场景详解
在 Android 的 MVVM 架构中,ViewModel 和 AndroidViewModel 都是用于管理 UI 相关数据的组件,但二者有一些关键区别: 1. ViewModel 基本用途:用于存储和管理与 UI 相关的数据,生命周期与 Activity/Fragment 解耦&…...

Windows环境下 全屏显示某个字符串
case WM_PAINT: {PAINTSTRUCT ps;HDC hdc BeginPaint(hWnd, &ps);// 获取完整客户区尺寸RECT rc;GetClientRect(hWnd, &rc);// 全屏时:整个窗口作为显示区域RECT displayRect rc;// 纯黑背景FillRect(hdc, &displayRect, (HBRUSH) GetStockObject(BLA…...

禅道MCP Server开发实践与功能全解析
一、简介 1、MCP Server核心定义 MCP Server(Meta Command Protocol Server)是一种基于客户端-服务器架构的轻量级服务程序,采用统一的mcp协议格式,通过连接多样化数据源和工具为AI应用提供扩展能力。它作为中间层,实…...

Vue.js组件安全开发实战:从架构设计到攻防对抗
目录 开篇总述:安全视角下的Vue组件开发新范式 一、Vue.js组件开发现状全景扫描 二、安全驱动的Vue组件创新架构 三、工程化组件体系构建指南 四、深度攻防对抗实战解析 五、安全性能平衡策略 结语:安全基因注入前端开发的未来展望 下期预告&…...

代发考试战报:4月份最新锐捷RCNA RCNP 考试通过战报
锐捷 RCNA云计算 R4111 考试通过,RCNA 安全 R3111 考试通过,RCNP无线 R5211考试通过,RCNP路由考试通过,等等 成绩单战报...

卫星互联网技术加速发展,遨游卫星电话为生命添一份“保险”
卫星互联网通过高中低轨卫星组网,实现了对海洋、沙漠、极地等“信息盲区”的全域覆盖。据国际电信联盟(ITU)统计,截至2024年底,全球在轨卫星数量已突破1万颗,其中我国“千帆星座”“GW星座”等低轨计划加速…...
)
文件IO7(中文字库的原理与应用/目录检索原理与应用/并发编程的原理与应用)
中文字库的原理与应用 ⦁ 基本概念 一般在项目中都会显示汉字,都采用中文简体字符集,计算机早期只有ANSI组织设计的ANSII码,其实也属于字符集,这套字符集并未收录中文,只收录256个字符。 所以后期中国国家标准总局设…...
)
达梦数据库-学习-16-常用SQL记录(持续更新)
目录 一、环境信息 二、介绍 三、查询SQL 1、数据库的总使用空间大小 2、各个表空间的总大小 3、使用空间最大的50个对象 4、使用率最高的50个sequence 5、使用空间率最高的50个自增列 6、定位锁 7、支持HINT 8、表数据页使用率 9、备份文件相关信息 10、初始化库参…...

使用setTimeout模拟setInterval
const SECOND 1000 const MINUTE 60 * SECOND const HOUR 60 * MINUTE const DAY 24 * HOUR/*** description: 根据传入的毫秒值格式化为时间* param {*} time:毫秒值* returns:{days, hours, minutes, seconds, milliseconds}*/ function parseTime…...

Cesium实现鹰眼图和主地图联动
本文是vuets实现的,想要转为react,只需要修改以下几部分内容 1. 将 reactive 定义的数据直接改写为 let定义 2. 将 watch 监听的内容改成对应的监听写法 3. 将 ref 定义的字段改写为对应的写法 该模块实现的功能: 通过点击鹰眼图的某一位置…...
)
文件IO6(开机动画的显示原理/触摸屏的原理与应用)
开机动画的显示原理 ⦁ 基本原理 一般电子产品在开机之后都会加深用户印象,一般开机之后都会播放一段开机动画(视频、GIF…),不管哪种采用形式,内部原理都是相同,都是利用人类的眼睛的视觉暂留效应实现的…...

Linux内核分页——线性地址结构
每个进程通过一个指针(即进程的mm_struct→pgd)指向其专属的页全局目录(PGD),该目录本身存储在一个物理页框中。这个页框包含一个类型为pgd_t的数组,该类型是与架构相关的数据结构,定义在<as…...

每日算法-250411
这是我今天的 LeetCode 刷题记录和心得,主要涉及了二分查找的应用。 3143. 正方形中的最多点数 题目简述: 思路 本题的核心思路是 二分查找。 解题过程 为什么可以二分? 我们可以对正方形的半边长 len 进行二分。当正方形的半边长 len 越大时&…...

虚幻基础:碰撞帧运算
能帮到你的话,就给个赞吧 😘 文章目录 碰撞碰撞盒线段检测 帧运算:每个程序流就是一帧的计算结果速度过快时(10000),导致每帧移动过大(83),从而导致碰撞盒错过而没有碰撞速度快的碰撞要用线段检测 碰撞 碰撞盒 线段检…...

AI反检测如何在TikTok养号中发挥关键作用?
在 TikTok 这个全球性的短视频平台上,账号的养成和管理成为了创作者和品牌不可忽视的一环。随着平台对内容和账号行为的监管越来越严格,传统的养号方法已经难以适应新的挑战。在这一背景下,AI 反检测技术应运而生,它通过模拟人类行…...

鸿蒙案例---生肖抽卡
案例源码: Zodiac_cards: 鸿蒙生肖抽奖卡片 效果演示 初始布局 1. Badge 角标组件 此处为语雀内容卡片,点击链接查看:https://www.yuque.com/kevin-nzthp/lvl039/rccg0o4pkp3v6nua 2. Grid 布局 // 定义接口 interface ImageCount {url:…...

【AI编程技术爆发:从辅助工具到生产力革命】
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现运行结果验证 三、性能对比测试方法论量化数据对比(2023年数据)结果分析 四、最…...

【前后端】npm包mysql2的使用__nodejs mysql包升级版
不定期更新,建议关注收藏点赞。 目录 简介使用说明 还在用mysql包吗?已经过时啦! 简介 mysql2 是一个用于 Node.js 的 MySQL 数据库驱动,它是 mysql 包的升级版,性能更好,支持 Promise 和 async/await&…...

基于LangChain的Native RAG简单样例
本文代码: Github 文章目录 1. 概述2. Native RAG 概述3. 实战:基于LangChain实现简单的Native RAG概述环境配置文档分割定义Embedding模型构建向量数据库与LLM交互 参考文献 1. 概述 众所周知, 大模型可以回答它知道的内容。但如果用户问的是它不知道…...
)
数据结构基础(2)
1.什么是算法? 算法:算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。 算法定义中,提到了指令,指令能被人或机器等计算装置执行。它可以是计算机指令&a…...

慢查询解决思路
1. 复现问题 慢查询的出现是常态还是偶尔?是否在业务允许范围内? "不要过早优化,先 Make it work / right,再 Make it fast。" 建议先将查询语句及其触发条件记录下来,便于后续测试、分析和对比。 2. 定位问题 2.1 单机数据库: explain查询执行计划 数据库默…...

前端下载文件时浏览器右上角没有保存弹窗及显示进度,下载完之后才会显示保存弹窗的问题定位及解决方案
需求背景 在开发过程中会发现,有的时候下载后端返回的文件,浏览器右上角不会进行保存弹窗的弹出及下载进度,而是接口响应后文件下载完才会弹出保存并且没有进度条效果,这就导致在点击下载后用户是不知道文件下载到什么进度了&…...

Streamlit在测试领域中的应用:构建自动化测试报告生成器
引言 Streamlit 在开发大模型AI测试工具方面具有显著的重要性,尤其是在简化开发流程、增强交互性以及促进快速迭代等方面。以下是几个关键点,说明了 Streamlit 对于构建大模型AI测试工具的重要性: 1. 快速原型设计和迭代 对于大模型AI测试…...

IP组播技术与internet
1.MAC地址分为三类:广播地址;组播地址;单播地址 2.由一个源向一组主机发送信息的传输方式称为组播。 3.组播MAC地址,第一个字节的最后一位为1; 单播MAC地址,第一个字节的最后一位为0; 4.不能…...

[Java基础]StringBuilder解析
StringBuilder简单总结与源码预览。 之前写StringBuilder对象默认简写为sb,被说是骂人不让用了,现在写成strBuilder了。大家一般写什么呢 StringBuilder预留空间设计 已知Redis的String结构是通过预留空间的形式来避免频繁地分配空间。 那么Java中有没有…...

国内智能外呼系统市场概况及技术发展趋势
根据最新行业报告和用户评价,国内智能外呼系统市场呈现快速增长态势,预计2025年市场规模将达到180亿元人民币,年复合增长率约20%。主要驱动因素包括AI技术成熟、企业降本增效需求以及政策扶持(如工信部《智能语音产业发展行动计划…...