【大模型理论篇】Search-R1: 通过强化学习训练LLM推理与利⽤搜索引擎
最近基于强化学习框架来实现大模型在推理和检索能力增强的项目很多,也是Deep Research技术持续演进的缩影。之前我们讨论过《R1-Searcher:通过强化学习激励llm的搜索能⼒》,今天我们分析下Search-R1【1】。
1. 研究背景与问题
- 检索增强⽣成(RAG):基于输⼊查询检索相关段落,并将它们与查询⼀起输⼊到LLM中⽣成响应。虽然简单,但常常检索不到相关信息或⽆法提供⾜够有⽤的上下⽂。
- 将搜索引擎作为⼯具:通过提⽰或微调LLM来使⽤搜索引擎作为⼯具。基于提⽰的⽅法泛化能⼒弱,而基于训练的⽅法依赖⼤规模⾼质量的标注轨迹。
OpenAI在4月11日开源BrowseComp, 这是专门用于智能体浏览器功能的测试基准。这个测试基准非常有难度,连OpenAI自己的GPT-4o、GPT-4.5准确率只有0.6%和0.9%几乎为0,即便使用带浏览器功能的GPT-4o也只有1.9%。但OpenAI最新发布的Agent模型Deep Research准确率高达51.5%。
将强化学习(RL)应⽤于搜索和推理场景⾯临三个主要挑战:
1. RL框架和稳定性:如何有效地将搜索引擎集成到LLM的RL⽅法中,同时确保优化稳定性,特别是在引⼊检索上下⽂时。2. 多轮交错推理和搜索:理想情况下,LLM应能进⾏迭代推理和搜索引擎调⽤,根据问题复杂性动态调整检索策略。3. 奖励设计:为搜索和推理任务设计有效的奖励函数是⼀个基本挑战,尚不清楚简单的基于结果的奖励是否⾜以引导LLM学习有意义和⼀致的搜索⾏为。
2. Search-R1框架概述
1. 搜索引擎作为环境的⼀部分:将搜索引擎建模为环境的⼀部分,使采样的轨迹序列能够交错LLM的token⽣成与搜索引擎检索。Search-R1兼容各种RL算法,包括PPO和GRPO,并应⽤检索token掩码以确保优化稳定。2. 多轮检索和推理⽀持:⽀持多轮检索和推理,通过特定tokens(<search> 和 </search>) 显式触发搜索调⽤。检索内容⽤<information> 和 </information> tokens包围,而LLM推理步骤⽤<think>和</think> tokens包装。最终答案使⽤<answer>和</answer> tokens格式化。3. 简单的基于结果的奖励函数:采⽤简单的基于结果的奖励函数,避免基于过程的奖励的复杂性。结果表明,这种最小奖励设计在搜索和推理场景中是有效的。
3. 强化学习在Search-R1中的应⽤
3.1 RL⽬标函数
![]()
3.2 检索令牌损失掩码
3.3 基于PPO的Search-R1

3.4 基于GRPO的Search-R1
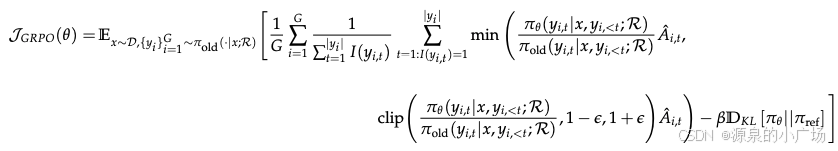
3.5 强化学习⽅法的⽐较
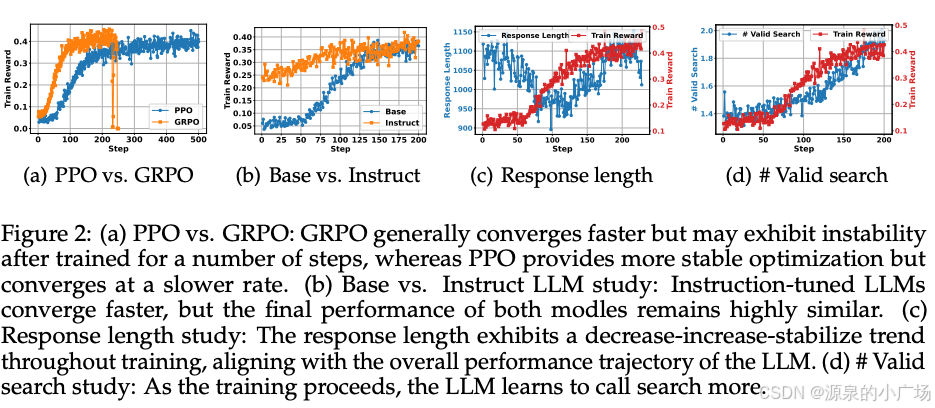
收敛速度:GRPO收敛速度更快,因为PPO依赖于需要预热的critic模型。训练稳定性:PPO提供更稳定的训练⾏为,GRPO在训练较多步骤后可能出现奖励崩溃。最终性能:两种⽅法达到的最终训练奖励相当,也就是说它们在优化Search-R1⽅⾯都是有效的。
4. 系统架构与⼯作流程
4.1 多轮搜索引擎调⽤⽣成
1. 系统指导LLM在需要外部检索时使⽤特定的搜索调⽤标记(<search>和 </search>)来封装搜索查询。2. 当系统在⽣成序列中检测到这些token时,会提取搜索查询,查询搜索引擎,并检索相关结果。3. 检索到的信息被封装在特殊的检索标记(<information>和</information>)内,并附加到正在进⾏的展开序列中,作为下⼀个⽣成步骤的附加上下⽂。4. 这个过程迭代进⾏,直到:(1)达到最⼤动作数,或(2)模型⽣成最终响应,该响应被封装在指定的答案标记(<answer>和</answer>)之间。
4.2 训练模板
Answer the given question. You must conduct reasoning inside <think> and </think> first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a search engine by <search> query </search>, and it will return the topsearched results between <information> and </information>. You can search as many times as you want. If you find no further external knowledge needed, you can directly provide the answer inside <answer> and </answer> without detailed illustrations. For example,<answer> xxx </answer>. Question: question.
4.3 响应⽣成的交互过程
算法 1: LLM Response Rollout with Multi-Turn Search Engine Calls输⼊ : 输⼊查询 x, 策略模型 π, 搜索引擎 R, 最⼤动作预算 B输出 : 最终响应 y1: 初始化展开序列 y ← ∅2: 初始化动作计数 b ← 03: while b < B do4: 初始化当前动作 LLM 展开序列 yb ← ∅5: while True do6: ⽣成响应token yt ∼ π(·|x, y + yb)7: 将yt 附加到展开序列 yb ← yb + yt8: if yt in [</search>, </answer>, <eos>] then break9: end if10: end while11: y ← y + yb12: if <search> </search> detected in yb then13: 提取搜索查询q ← Parse(yb, <search>, </search>)14: 检索搜索结果d = R(q)15: 将d 插⼊到展开 y ← y + <information>d</information>16: else if <answer> </answer> detected in yb then17: return 最终⽣成的响应 y18: else19: 请求重新思考y ← y+ "My action is not correct. Let me rethink."20: end if21: 增加动作计数 b ← b + 122: end while23: return 最终⽣成的响应 y
4.4 奖励建模
![]()
5. 训练与评测⽅法
5.1 数据集
5.2 基线⽅法
5.3 实验设置
- PPO变体:策略LLM学习率为1e-6,值LLM学习率为1e-5。训练500步,策略和价值模型的预热⽐例分别为0.285和0.015。
- GRPO训练:策略LLM学习率为1e-6,每个提⽰采样5个响应。模型训练500步,学习率预热⽐例为0.285。
- 通⽤设置:使⽤8个H100 GPU,总批量⼤小为512,最⼤序列⻓度为4,096个标记,最⼤响应⻓度为500。
- 奖励计算:使⽤精确匹配(EM)计算结果奖励。
6. 实验结果与分析
6.1 主要性能结果
6.2 不同RL⽅法的⽐较
6.3 基础模型与指令模型的对⽐
6.4 响应⻓度和有效搜索研究
1. 早期阶段(前100步):响应⻓度急剧减少,而训练奖励略有增加。在此阶段,基础模型学会消除过多的填充词,并开始适应任务需求。2. 后期阶段(100步后):响应⻓度和训练奖励都显著增加。此时,LLM学会频繁调⽤搜索引擎,由于检索到的段落,导致响应更⻓。随着模型更有效地利⽤搜索结果,训练奖励⼤幅提⾼。3. 随着训练的进⾏,LLM学会更多次地调⽤搜索引擎。
6.5 检索token损失掩码
7. 参考材料
【1】Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
相关文章:

【大模型理论篇】Search-R1: 通过强化学习训练LLM推理与利⽤搜索引擎
最近基于强化学习框架来实现大模型在推理和检索能力增强的项目很多,也是Deep Research技术持续演进的缩影。之前我们讨论过《R1-Searcher:通过强化学习激励llm的搜索能⼒》,今天我们分析下Search-R1【1】。 1. 研究背景与问题 ⼤模型(LLM&a…...

错误码code:9568282 error: install releaseType target not same怎么处理?
目录 1.背景 2.解决方案 1.背景 当前是由于应用从4.1版本升级到5.0版本,然后安装应用会报错9568282 ,如果签名是一致的&#...
)
qt联动其他库实现一个客户端(本章主要是概述如何实现)
一.服务器功能 1.能连接多个客户端通信 2.负责统计与手机客户端的数据 3.遇到客户端请求数据时能检索数据库并发送对应数据 4.服务器需要能连接到公网 5.服务器需要有账号密码登录功能 6.服务器要有日志与管理员系统能统计信息 二.客户端 1.客户端需要有登录界面 2.客户端需要…...

爱普生FC1610AN5G手机中替代传统晶振的理想之选
在 5G 技术引领的通信新时代,手机性能面临前所未有的挑战与机遇。从高速数据传输到多任务高效处理,从长时间续航到紧凑轻薄设计,每一项提升都离不开内部精密组件的协同优化。晶振,作为为手机各系统提供稳定时钟信号的关键元件&…...
)
SpringMVC基础二(RestFul、接收数据、视图跳转)
ReauestMapping ReauestMapping注解用于映射url到控制器类或一个特定的处理程序方法。可用于类或方法上,用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。 创建一个新项目:设置为web项目 编写web.xml(此配置也几…...
)
BERT - 段嵌入(Segment Embedding)
1. 段嵌入(Segment Embedding)的作用 在BERT模型中,段嵌入的主要作用是区分不同的句子。具体来说: 单句任务:所有位置的段嵌入都是0。 句子对任务:第一个句子的所有位置使用段嵌入0,第二个句子…...
)
Kaggle-Disaster Tweets-(二分类+NLP+模型融合)
Disaster Tweets 题意: 就是给出一个dataframe包含text这一列代表着文本,文本会有一些词,问对于每条记录中的text是真关于灾难的还是假关于灾难的。 比如我们说今天作业真多,这真是一场灾难。实际上这个灾难只是我们调侃而言的。…...

关于哈希冲突的讨论
文章目录 1. 什么是哈希冲突?2. 为什么会产生哈希冲突?3. 如何解决哈希冲突?4. 为什么哈希算法一定会产生冲突?5. 存在不发生冲突的哈希算法吗?6. 为什么不用无冲突的哈希算法(如完美哈希)&…...

傅利叶发布首款开源人形机器人N1:开发者可实现完整复刻
2025年4月11日,上海——通用机器人公司傅利叶正式发布首款开源人形机器人 Fourier N1,并同步开放涵盖物料清单、设计图纸、装配指南、基础操作软件在内的完整本体资源包。作为傅利叶 “Nexus 开源生态矩阵” 的首个落地项目(“N1” 即 “Nexu…...

2020年INS SCI1区TOP:平衡复合运动优化算法BCMO,深度解析+性能实测
目录 1.摘要2.算法原理3.结果展示4.参考文献5.代码获取 1.摘要 元启发式算法因其强大的鲁棒性和简便的编程方式,在优化领域中发挥着重要作用。本文提出了一种基于平衡复合运动优化算法BCMO,其核心思想是在解空间中平衡个体的复合运动特性。通过概率选择…...
任务书)
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(3卷)任务书
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(3卷)任务书 背景描述:模块A:大数据平台搭建(容器环境)(15分)任务一:Hadoop HA安装部署任务二&#x…...
详解:从零开始掌握(4))
Express中间件(Middleware)详解:从零开始掌握(4)
下面我将为你提供四个实战项目的完整实现代码,每个项目都展示了Express中间件的实际应用场景。 1. API网关实现 const express require(express); const rateLimit require(express-rate-limit); const helmet require(helmet); const morgan require(morgan)…...

Ubuntu22环境下,Docker部署阿里FunASR的gpu版本
番外: 随着deepseek的爆火,人工智能相关的开发变得异常火爆,相关的大模型开发很常见的agent智能体需要ASR语音识别的功能,阿里开源的FunASR几乎是把一个商业的项目放给我们使用了。那么我们项目中的生产环境怎么部署gpu版本的语音识别服务呢?经过跟deepseek的一上午的极限…...

vue springboot 案例 收集
vue springboot 案例 收集 SpringbootVue前后端分离项目-管理系统 https://blog.csdn.net/m0_56308072/article/details/130893828...

Windows环境下本地部署deepseek-r1或其他大模型 【保姆级教程】
目录 背景准备工作开始部署下载olloma安装olloma下载deepseek-r1模型使用如何使用 结束语 背景 最近deepseek本地部署的概念越来越火,勾起了我学习的兴趣。 我就在思考如何使用家用机或者平时打游戏的机器来本地部署deepseek,给自己开发个智能体来辅佐…...

ubuntu20.04系统安装apollo10.0系统
文章目录 前言一、安装基础软件1、更新相关软件2 安装 Docker Engine 二、获取 GPU 支持1、安装显卡驱动2、安装 Nvidia container toolkit 三、安装 Apollo 环境管理工具1、安装依赖软件2、在宿主机添加 Apollo 软件源的 gpg key,并设置好源和更新3、安装aem 四、安…...

图片文本识别OCR+DeepSeekapi实现提取图片关键信息
用到的技术: 通过腾讯OCR文字识别,deepseek的api实现 目录 需求分析: 文字识别(OCR)具体实现步骤 起步工作 代码编写 deepseek整合消息,返回文本关键信息 起步工作 编写工具类 具体调用实现 具体…...

minio改成https+域名访问
思路有两个: 方式一:通过nginx反向代理,将https配置在nginx,内部的MinIO还是使用HTTP;方式二:MinIO服务端直接配置成HTTPS; 注意: 私钥需要命名为:private.key 公钥需要…...
)
unity与usb串口通信(web版)
一、本文介绍在web环境下unity与usb串口进行通信的代码 本篇使用本地服务器作为unity与串口的中介,unity发送数据到服务器,服务器发送给串口收到响应并解析返回给uinty。 使用websocket协议。 注: 1.我的硬件是检测磁阻液位,用…...

UE5每次都打开上一次的工程文件 , 如何取消?
点击左上角 - 文件 点击 打开项目 取消勾选 - 启动时固定加载上次打开的项目...

AI大模型与人类未来的协作图景:从工具到“数字共生体”
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:技术跃迁与文明重塑的十字路口 2020年代以来,人工智能特别是**AI大语言模型(Large Language Models, LLMs)**的迅猛发展,正在从根本上改变人类与技术的关系。从最初的“智能写作助手”到今日…...

C++ I/O 性能优化指南
在高性能计算和大规模数据处理中,I/O 性能优化是提升系统整体效率的关键环节。C 作为一种高性能编程语言,提供了丰富的工具和机制来优化 I/O 操作。本文将详细介绍在 Linux 环境下,如何通过代码层面的优化、系统调用的选择以及多线程技术等手…...

Idea忽略已提交文件
全局忽略 项目根目录下新增.gitignore文件,写入想要忽略的信息,以下可参考 **/src/main/resources/application-local.yamltarget/ !.mvn/wrapper/maven-wrapper.jar !**/src/main/**/target/ !**/src/test/**/target/### IntelliJ IDEA ### .idea/mod…...

Mamba原理及在low-level vision的工作[持续更新]
文章目录 Mamba原理选择性扫描(Selective Retain Information):选择有关/无关信息状态空间模型(SSM)Mamba的选择性保留信息Mamba的扫描操作(The Scan Operation) 硬件感知(Hardware-…...

openlayers入门02 -- 地图控件
地图控件 1.视图跳转控件(ZoomToExtent) 视图跳转控件用于将地图快速跳转到指定的范围。示例: // 视图跳转控件(extent这里用的是学校的经纬度范围,可以按照需要修改) const ZoomToExtent new ol.contro…...
)
Python 装饰器(Decorator)
文章目录 代码解析1. 装饰器定义 timer(func)2. 应用装饰器 timer **执行流程****关键点****实际应用场景****改进版本(带 functools.wraps)** 这是一个 Python 装饰器(Decorator) 的示例,用于测量函数的执行时间。下…...

UE的AI判断队伍归属的机制:IGenericTeamAgentInterface接口
从官方论坛老哥那学来的,优点在于使用项目设置,像配置碰撞一样,能配置碰撞通道对其他碰撞通道的反应,如阻挡,忽略,重叠,全局配置队伍归属,也能配置当前队伍对其他队伍的身份识别&…...

安宝特新闻丨Vuzix Core™波导助力AR,视角可调、高效传输,优化开发流程
Vuzix Core™ 光波导技术 近期,Vuzix Core™光波导技术赋能AR新视界!该系列镜片支持定制化宽高比调节及20至40视场角范围,可灵活适配各类显示引擎。通过创新的衍射光波导架构,Vuzix Core™实现了光学传输效率与图像质量的双重突破…...

基于springboot留守儿童网站的设计与实现 docx
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...

AST 技术进行 JavaScript 反混淆实战
一、AST 技术核心原理 抽象语法树(AST) 是代码的“骨架”,它把代码拆解成一个个节点,就像把一棵大树拆成树枝、树叶一样。通过分析和修改这些节点,我们可以精准地还原代码的逻辑。 二、实战案例 1:还原字…...
,源码可白嫖!)
基于ECharts+Spark的疫情防控数据分析平台(源码+lw+部署文档+讲解),源码可白嫖!
摘要 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,特别是近几年来,新冠疫情出现以来,疫情防控数据分析平台当然不能排除在外。我本次开发的疫情防控数据分析平台是在…...

wireshark过滤器表达式的规则
1.抓包过滤器语法和实例 抓包过滤器类型Type(host、net、port)、方向Dir(src、dst)、协议Proto(ether、ip、tcp、udp、http、icmp、ftp等)、逻辑运算符(&&与、|| 或、!非&am…...

使用 Python 扫描 Windows 下的 Wi-Fi 网络实例演示
使用 Python 扫描 Windows 下的 Wi-Fi 网络 代码实现代码解析 1. 导入库2. 解码混合编码3. 扫描 Wi-Fi 网络4. 运行函数 这是我当前电脑的 wifi 连接界面。 这个是运行的效果图: 代码实现 我们使用了 Python 的 subprocess 模块来调用 Windows 的内置命令 netsh…...
详解)
Redis 字符串(String)详解
1. 什么是字符串类型 在 Redis 中,字符串(String) 是最基本的数据类型。它可以包含任何数据,比如文本、JSON、甚至二进制数据(如图片的 Base64 编码),最大长度为 512 MB。 字符串在 Redis 中不…...

【Taro3.x + Vue3】搭建微信小程序
IOS环境为例 打开终端环境有多种办法,例举一个:在访达里新建一个文件夹,鼠标右键选择。 一、先安装Taro的环境 npm install -g tarojs/cli安装完成后,可以输入命令检验是否安装成功: taro --version二、创建项目 …...

P8668 [蓝桥杯 2018 省 B] 螺旋折线
题目 思路 一眼找规律题,都 1 0 9 10^9 109说明枚举必然超时,找规律,每个点找好像没有什么规律,尝试找一下特殊点,比如:对角线上的点 4 16 36(右上角) 4k^2,看在第几层(…...

【14】数据结构之哈夫曼树篇章
目录标题 哈夫曼树哈夫曼树的定义哈夫曼树的构造哈夫曼编码哈夫曼树的实现 哈夫曼树 哈夫曼树的定义 路径:从一个结点到另一个结点的路线树的路径长度:从树根到树中每个结点的路径长度之和结点的权:在一些应用中,赋予树中结点的…...
)
初识SpringAI(接入硅基流动deepseek)
①创建项目 ②application.yml spring:application:name: pgs-aiai:openai:api-key: sk-vrozloxjpjgkozaggtodbmwyfmubmxqpdpbvbbxpcgleanugbase-url: https://api.siliconflow.cn/chat:options:model: deepseek-ai/DeepSeek-V3 api-key:去硅基流动官网生成你的密钥…...

两个有序序列合并算法分析
一 问题背景 合并两个有序序列是常见操作,例如在归并排序中。传统方法需要额外空间,时间复杂度为 O(n)。但若要求原地合并(不占用额外内存),则需借助 手摇算法(或称内存反转或三次反转算法)。 二 手摇算法原理 手摇算法通过三次反转操作,实现数组片段的原…...

Robot---SPLITTER行星探测机器人
1 背景 先给各位读者朋友普及一个航天小知识,截止到目前为止,登陆火星的火星车有哪些?结果比较令人吃惊:当前只有美国和中国登陆过火星。 “勇气”号(Spirit):2004年1月4日,美国国家…...

kafka的topic扩容分区会对topic任务有什么影响么
在 Kafka 中对 Topic 进行扩容分区会对相关任务产生多方面的影响,下面为你详细介绍: 积极影响 增强并发处理能力:Kafka 中数据是以分区为单位进行并行处理的,增加分区数量意味着可以让更多的消费者并行消费数据。比如࿰…...
模拟娱乐篇27)
每日一题(小白)模拟娱乐篇27
由题意可以得知这是一道暴力模拟的题目,我们只需要根据题意说的模拟整个过程即可。首先需用循环接收n个数字,每次判断这个数字是否出现过,若没有出现则为对应的负值,若出现过则需要将这个坐标减去之前坐标的值再减一返回ÿ…...

进行性核上性麻痹患者,饮食 “稳” 健康
进行性核上性麻痹作为一种复杂且罕见的神经系统退行性疾病,给患者的身体机能和日常生活带来严重挑战。在积极接受专业治疗的同时,合理的饮食安排对于维持患者营养状况、缓解症状及提升生活质量起着关键作用。以下为患者提供一些健康饮食建议。 首先&…...
)
GitLab之搭建(Building GitLab)
GitLab之搭建 “ 在企业开发过程中,GitLab凭借其强大的版本管理、CI/CD集成和项目管理功能,成为许多团队的首选工具。本文将探讨GitLab的基础介绍、搭建过程、权限管理、代码审查以及团队知识管理等方面。通过详细的步骤和实用的技巧,旨在帮…...

R 语言科研绘图第 38 期 --- 饼状图-玫瑰
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

array和list在sql中的foreach写法
在MyBatis中,<foreach>标签用于处理集合或数组类型的参数,以便在SQL语句中动态生成IN子句或其他需要遍历集合的场景。以下是array和list在SQL中的<foreach>写法总结。 <if test"taskIds ! null and taskIds.length > 0">…...

国内MCP服务有哪些?MCP服务器搜索引擎哪家好?
随着MCP(Model Context Protocol)协议的广泛应用,国内出现了越来越多的MCP服务提供商,这些服务覆盖了从开发工具、数据科学到金融、游戏等多个领域。 如果你对MCP协议和相关开发感兴趣,可以访问AIbase(htt…...

二叉树的应用
目录 一、二叉树遍历算法的应用 二、树的存储结构 1、双亲表示法 2、孩子表示法 带双亲的孩子链表 3、孩子兄弟表示法(左孩子、右兄弟)较为普遍 三、森林与二叉树的转换 四、哈夫曼树 哈夫曼(Huffman)树的构造 一、二叉树…...

【LaTeX】
基本使用 \documentclass 类型:文章(article)、报告(report)、书(book) 中文的文章是ctexart,中文字体是UTF8 \documentclass[UTF8]{ctexart} []说明可以省略不写的意思…...
)
Java基础 - 泛型(基本概念)
文章目录 基本概念参数化类型类型安全和编译时检查 为什么需要泛型?解决类型安全问题避免重复代码提高可读性和维护性 泛型(Generics)是编程语言中一种支持参数化类型的特性,允许在定义类、接口、方法时使用类型参数(T…...