2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(3卷)任务书
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(3卷)任务书
- 背景描述:
- 模块A:大数据平台搭建(容器环境)(15分)
- 任务一:Hadoop HA安装部署
- 任务二:Hive安装配置
- 任务三:Kafka安装配置
- 模块B:离线数据处理(25分)
- 任务一:数据抽取
- 任务二:数据清洗
- 模块C:数据挖掘(10分)
- 任务一:特征工程
- 任务二:推荐系统
- 模块D:数据采集与实时计算(20分)
- 任务一:实时数据采集
- 任务二:使用Flink处理Kafka中的数据
- 模块E:数据可视化(15分)
- 任务一:用柱状图展示消费额最高的国家
- 任务二:用饼状图展示各地区消费能力
- 任务三:用散点图展示总消费额变化
- 任务四:用条形图展示平均消费额最高的国家
- 任务五:用折柱混合图展示地区平均消费额和国家平均消费额
- 需要培训私信博主,资源环境也可以(包拿奖)!!
背景描述:
大数据时代背景下,电商经营模式发生很大改变。在传统运营模式中,缺乏数据积累,人们在做出一些决策行为过程中,更多是凭借个人经验和直觉,发展路径比较自我封闭。而大数据时代,为人们提供一种全新的思路,通过大量的数据分析得出的结果将更加现实和准确。商家可以对客户的消费行为信息数据进行收集和整理,比如消费者购买产品的花费、选择产品的渠道、偏好产品的类型、产品回购周期、购买产品的目的、消费者家庭背景、工作和生活环境、个人消费观和价值观等。通过数据追踪,知道顾客从哪儿来,是看了某网站投放的广告还是通过朋友推荐链接,是新访客还是老用户,喜欢浏览什么产品,购物车有无商品,是否清空,还有每一笔交易记录,精准锁定一定年龄、收入、对产品有兴趣的顾客,对顾客进行分组、标签化,通过不同标签组合运用,获得不同目标群体,以此开展精准推送。
因数据驱动的零售新时代已经到来,没有大数据,我们无法为消费者提供这些体验,为完成电商的大数据分析工作,你所在的小组将应用大数据技术,以Scala作为整个项目的基础开发语言,基于大数据平台综合利用Hudi、Spark、Flink、Vue.js等技术,对数据进行处理、分析及可视化呈现,你们作为该小组的技术人员,请按照下面任务完成本次工作。
模块A:大数据平台搭建(容器环境)(15分)
环境说明:
服务端登录地址详见各模块服务端说明。
补充说明:宿主机可通过Asbru工具或SSH客户端进行SSH访问;
相关软件安装包在宿主机的/opt目录下,请选择对应的安装包进行安装,用不到的可忽略;
所有模块中应用命令必须采用绝对路径;
从本地仓库中拉取镜像,并启动3个容器
进入Master节点的方式为
docker exec –it master /bin/bash
进入Slave1节点的方式为
docker exec –it slave1 /bin/bash
进入Slave2节点的方式为
docker exec –it slave2 /bin/bash
同时将/opt目录下的所有安装包移动到3个容器节点中。
任务一:Hadoop HA安装部署
本环节需要使用root用户完成相关配置,安装Hadoop需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
1、将Master节点JDK安装包解压并移动到/usr/local/src路径下,将命令复制并粘贴至对应报告中;
2、请完成host相关配置,将三个节点分别命名为master、slave1、slave2,配置SSH免密登录,从Master节点复制JDK环境变量文件以及JDK解压后的安装文件到Slave1、Slave2节点,配置java环境变量,配置完毕后在Master节点分别执行“java”和“javac”命令,将命令行执行结果分别截图并粘贴至对应报告中;
3、Zookeeper配置完毕后,分发Zookeeper,分别在3个节点启动Zookeeper,并在Slave2节点查看ZooKeeper运行状态,将查看命令和结果复制并粘贴至对应报告中;
4、ZooKeeper、Hadoop HA配置完毕后,请将dfs.ha.namenodes.hadoopcluster设置为nn1,nn2并在Master节点启动Hadoop,并查看服务(nn1,nn2)进程状态,并将查看命令及结果复制并粘贴至对应报告中;
5、Hadoop HA配置完毕后,在Slave1节点查看服务进程,将查看命令及结果复制并粘贴至对应报告中。
任务二:Hive安装配置
本环节需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
1、将Master节点Hive安装包解压到/opt目录下,将命令复制并粘贴至对应报告中;
2、设置Hive环境变量,并使环境变量生效,并将环境变量配置内容复制并粘贴至对应报告中;
3、完成相关配置并添加所依赖包,将MySQL数据库作为Hive元数据库。初始化Hive元数据,并通过schematool相关命令执行初始化,将初始化结果复制粘贴至对应报告中。
任务三:Kafka安装配置
本环节需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
1、修改Kafka的server.properties文件,并将修改的内容复制粘贴至对应报告中;
完善其他配置并分发kafka文件到slave1,slave2中,并在每个节点启动Kafka,将Master节点的Kafka启动命令复制粘贴至对应报告中。
模块B:离线数据处理(25分)
环境说明:
服务端登录地址详见各模块服务端说明。
补充说明:各主机可通过Asbru工具或SSH客户端进行SSH访问;
Master节点MySQL数据库用户名/密码:root/123456(已配置远程连接);
Hive的元数据启动命令为:
nohup hive --service metastore &
Hive的配置文件位于/opt/apache-hive-2.3.4-bin/conf/
Spark任务在Yarn上用Client运行,方便观察日志。
任务一:数据抽取
请使用Sqoop工具,将MySQL的shtd_store库中表CUSTOMER、NATION、PART、PARTSUPP、REGION、SUPPLIER的数据全量抽取到Hive的ods库中对应表customer,nation,part,partsupp,region,supplier中,将表ORDERS、LINEITEM的数据增量抽取到Hive的ods库中对应表ORDERS,LINEITEM中。
1、抽取shtd_store库中CUSTOMER的全量数据进入Hive的ods库中表customer。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.customer命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
2、抽取shtd_store库中NATION的全量数据进入Hive的ods库中表nation。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.nation命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
3、抽取shtd_store库中PART的全量数据进入Hive的ods库中表part。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.part命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
4、抽取shtd_store库中PARTSUPP的全量数据进入Hive的ods库中表partsupp。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.partsupp命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
5、抽取shtd_store库中REGION的全量数据进入Hive的ods库中表region。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.region命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
6、抽取shtd_store库中SUPPLIER的全量数据进入Hive的ods库中表supplier。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.supplier命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
7、抽取shtd_store库中ORDERS的增量数据进入Hive的ods库中表orders,要求只取某年某月某日及之后的数据(包括某年某月某日),根据ORDERS表中ORDERKEY作为增量字段(提示:对比MySQL和Hive中的表的ORDERKEY大小),只将新增的数据抽入,字段类型不变,同时添加动态分区,分区字段类型为String,且值为ORDERDATE字段的内容(ORDERDATE的格式为yyyy-MM-dd,分区字段格式为yyyyMMdd),。并在hive cli执行select count(distinct(dealdate)) from ods.orders命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中;
8、抽取shtd_store库中LINEITEM的增量数据进入Hive的ods库中表lineitem,根据LINEITEM表中orderkey作为增量字段,只将新增的数据抽入,字段类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.lineitem命令,将Sqoop提交命令及hive cli的执行结果分别截图复制粘贴至对应报告中。
任务二:数据清洗
编写Java工程代码,使用MR引擎,将ods库中相应表数据全量抽取到Hive的dwd库中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
1、将ods库中customer表数据抽取到dwd库中dim_customer的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照cust_key顺序排序,查询dim_customer前1条数据,将MR jar包提交命令截图及hive cli的执行结果内容分别复制粘贴至对应报告中;
2、将ods库中part表数据抽取到dwd库中dim_part的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照part_key顺序排序,查询dim_part前1条数据,将MR jar包提交命令截图及hive cli的执行结果内容分别复制粘贴至对应报告中;
3、将ods库中nation表数据抽取到dwd库中dim_nation的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照nation_key顺序排序,查询dim_nation前1条数据,将MR jar包提交命令截图及hive cli的执行结果内容分别复制粘贴至对应报告中;
4、将ods库中region表数据抽取到dwd库中dim_region的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中 dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照region_key顺序排序,查询dim_region表前1条数据,将MR jar包提交命令截图及hive cli的执行结果内容分别复制粘贴至对应报告中;
5、将ods库中orders表数据抽取到dwd库中fact_orders的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在执行hive cli执行select count(distinct(dealdate)) from dwd.fact_orders命令,将MR jar包提交命令截图及hive cli的执行结果内容分别复制粘贴至对应报告中;
6、待任务5完成以后,需删除ods.orders中的分区,仅保留最近的三个分区。并在hive cli执行show partitions ods.orders命令,将结果截图粘贴至对应报告中;
7、将ods库中lineitem表数据抽取到dwd库中fact_lineitem的分区表,分区字段为etldate且值与ods库的相对应表该值相等,抽取的条件为根据orderkey和partkey进行去重,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli执行show partitions dwd.fact_lineitem命令,将MR jar包提交命令截图及hive cli的执行结果内容分别复制粘贴至对应报告中。
任务三:指标计算
编写Scala代码在Spark集群中运行,统计相关指标。
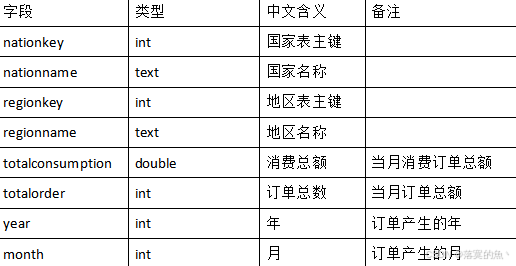
1、根据dwd层表统计每个地区、每个国家、每个月下单的数量和下单的总金额,存入MySQL数据库shtd_store的nationeverymonth表(表结构如下)中,然后在Linux的MySQL命令行中根据订单总数、消费总额、国家表主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中;
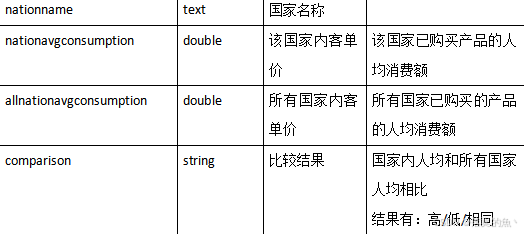
2、请根据dwd层表计算出某年每个国家的平均消费额和所有国家平均消费额相比较结果(“高/低/相同”),存入MySQL数据库shtd_store的nationavgcmp表(表结构如下)中,然后在Linux的MySQL命令行中根据订单总数、消费总额、国家表主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中;

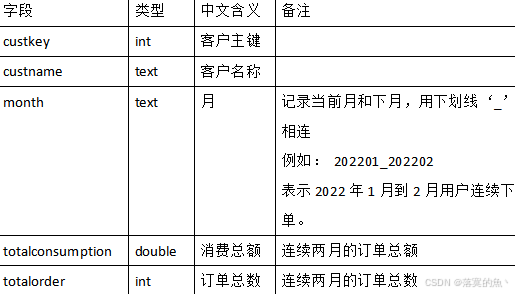
3、根据dwd层表统计连续两个月下单并且下单金额保持增长的用户,订单发生时间限制为大于等于某年,存入MySQL数据库shtd_store的usercontinueorder表(表结构如下)中。然后在Linux的MySQL命令行中根据订单总数、消费总额、客户主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中。
模块C:数据挖掘(10分)
环境说明:
服务端登录地址详见各模块服务端说明。
补充说明:各主机可通过Asbru工具或SSH客户端进行SSH访问;
Master节点MySQL数据库用户名/密码:root/123456(已配置远程连接);
Hive的元数据启动命令为:
nohup hive --service metastore &
Hive的配置文件位于/opt/apache-hive-2.3.4-bin/conf/
Spark任务在Yarn上用Client运行,方便观察日志。
该模块均使用Scala编写,利用Spark相关库完成。
任务一:特征工程
1、根据dwd库中fact_orders表,将其转换为以下类型矩阵:其中A表示用户A,B表示用户B,矩阵中的【0,1】值为1表示A用户与B用户之间购买了1个相同的零件,0表示A用户与B用户之间没有购买过相同的零件。将矩阵保存为txt文件格式并存储在HDFS上,使用命令查看文件前2行,将执行结果截图粘贴至对应报告中;

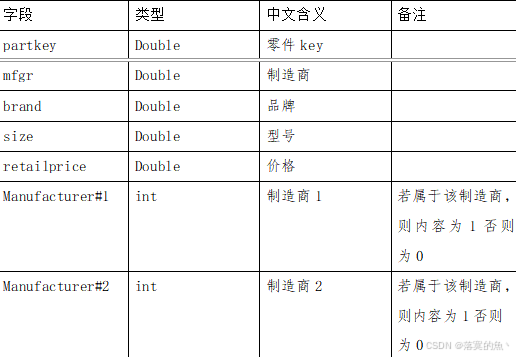
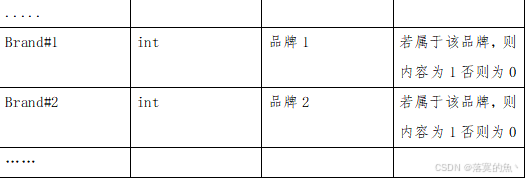
2、对dwd库中dim_part获取partkey 、mfgr、brand、size、retailprice五个字段并进行数据预处理,再进行归一化并保存至dwd.fact_part_machinelearning_data中,对制造商与品牌字段进行one-hot编码处理(将制造商与品牌的值转换成列名添加至表尾部,若该零部件属于该品牌则置为1,否则置为0),并按照partkey,size进行顺序排序,然后在Hive cli中执行命令desc dwd.fact_part_machinelearning_data 中查询出结果,将SQL语句与执行结果截图粘贴至对应报告中。
任务二:推荐系统
1、根据任务一的结果,获取与该用户相似度(矩阵内的值最高)最高的前10个用户,并结合hive中dwd层的fact_orders表、fact_lineitem表、fact_part_machine_data表,获取到这10位用户已购买过的零部件,并剔除该用户已购买的零部件,并通过计算用户已购买产品与该数据集中余弦相似度累加,输出前5零部件key作为推荐使用。将输出结果保存至MySQL的part_machine表中。然后在Linux的MySQL命令行中查询出前5条数据,将SQL语句与执行结果截图粘贴至对应报告中。
模块D:数据采集与实时计算(20分)
环境说明:
服务端登录地址详见各模块服务端说明。
补充说明:各主机可通过Asbru工具或SSH客户端进行SSH访问;
请先检查ZooKeeper、Kafka、Redis端口看是否已启动,若未启动则各启动命令如下:
ZK启动(netstat -ntlp查看2181端口是否打开)
/usr/zk/zookeeper-3.4.6/bin/zkServer.sh start
Redis启动(netstat -ntlp查看6379端口是否打开)
/usr/redis/bin/redis-server /usr/redis/bin/redis.conf
Kafka启动(netstat -ntlp查看9092端口是否打开)
/opt/kafka/kafka_2.11-2.0.0/bin/kafka-server-start.sh -daemon(空格连接下行)/opt/kafka/kafka_2.11-2.0.0/config/server.properties
Flink任务在Yarn上用per job模式(即Job分离模式,不采用Session模式),方便Yarn回收资源。
任务一:实时数据采集
1、在Master节点使用Flume采集实时数据生成器26001端口的socket数据,将数据存入到Kafka的Topic中(topic名称为order,分区数为4),将Flume的配置截图粘贴至对应报告中;
2、Flume接收数据注入kafka 的同时,将数据备份到HDFS目录/user/test/flumebackup下,将备份结果截图粘贴至对应报告中。
任务二:使用Flink处理Kafka中的数据
编写Scala工程代码,使用Flink消费Kafka中Topic为order的数据并进行相应的数据统计计算。
1、使用Flink消费Kafka中的数据,统计个人实时订单总额,将key设置成totalprice存入Redis中(再使用hash数据格式,key存放为用户id,value存放为该用户消费总额),使用redis cli以get key方式获取totalprice值,将结果截图粘贴至对应报告中,需两次截图,第一次截图和第二次截图间隔一分钟以上,第一次截图放前面,第二次放后面。
2、在任务1进行的同时需监控若发现ORDERSTATUS字段为F,将数据存入MySQL表alarmdata中(可考虑侧边流的实现),然后在Linux的MySQL命令行中根据ORDERKEY逆序排序,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中;
3、使用Flink消费kafka中的数据,统计每分钟下单的数量,将key设置成totalorder存入redis中。使用redis cli以get key方式获取totalorder值,将结果粘贴至对应报告中,需两次截图,第一次截图(应该在job启动2分钟数据稳定后再截图)和第二次截图时间间隔应达一分钟以上,第一次截图放前面,第二次放后面。(注:流数据中,时间未精确到时分秒,建议StreamTimeCharacteristic设置成ProcessingTime(默认)或IngestionTime。)
模块E:数据可视化(15分)
环境说明:
数据接口地址及接口描述详见各模块服务端说明。
任务一:用柱状图展示消费额最高的国家
编写Vue工程代码,根据接口,用柱状图展示某年某月消费额最高的5个国家,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至对应报告中。
任务二:用饼状图展示各地区消费能力
编写Vue工程代码,根据接口,用饼状图展示某年第一季度各地区的消费总额占比,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至对应报告中。
任务三:用散点图展示总消费额变化
编写Vue工程代码,根据接口,用散点图展示某年上半年商城总消费额的变化情况,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至对应报告中。
任务四:用条形图展示平均消费额最高的国家
编写Vue工程代码,根据接口,用条形图展示某年平均消费额最高的5个国家,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至对应报告中。
任务五:用折柱混合图展示地区平均消费额和国家平均消费额
编写Vue工程代码,根据接口,用折柱混合图展示某年地区平均消费额和国家平均消费额的对比情况,柱状图展示平均消费额最高的5个国家,折线图展示每个国家所在的地区的平均消费额变化,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至对应报告中。
需要培训私信博主,资源环境也可以(包拿奖)!!




相关文章:
任务书)
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(3卷)任务书
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(3卷)任务书 背景描述:模块A:大数据平台搭建(容器环境)(15分)任务一:Hadoop HA安装部署任务二&#x…...
详解:从零开始掌握(4))
Express中间件(Middleware)详解:从零开始掌握(4)
下面我将为你提供四个实战项目的完整实现代码,每个项目都展示了Express中间件的实际应用场景。 1. API网关实现 const express require(express); const rateLimit require(express-rate-limit); const helmet require(helmet); const morgan require(morgan)…...

Ubuntu22环境下,Docker部署阿里FunASR的gpu版本
番外: 随着deepseek的爆火,人工智能相关的开发变得异常火爆,相关的大模型开发很常见的agent智能体需要ASR语音识别的功能,阿里开源的FunASR几乎是把一个商业的项目放给我们使用了。那么我们项目中的生产环境怎么部署gpu版本的语音识别服务呢?经过跟deepseek的一上午的极限…...

vue springboot 案例 收集
vue springboot 案例 收集 SpringbootVue前后端分离项目-管理系统 https://blog.csdn.net/m0_56308072/article/details/130893828...

Windows环境下本地部署deepseek-r1或其他大模型 【保姆级教程】
目录 背景准备工作开始部署下载olloma安装olloma下载deepseek-r1模型使用如何使用 结束语 背景 最近deepseek本地部署的概念越来越火,勾起了我学习的兴趣。 我就在思考如何使用家用机或者平时打游戏的机器来本地部署deepseek,给自己开发个智能体来辅佐…...

ubuntu20.04系统安装apollo10.0系统
文章目录 前言一、安装基础软件1、更新相关软件2 安装 Docker Engine 二、获取 GPU 支持1、安装显卡驱动2、安装 Nvidia container toolkit 三、安装 Apollo 环境管理工具1、安装依赖软件2、在宿主机添加 Apollo 软件源的 gpg key,并设置好源和更新3、安装aem 四、安…...

图片文本识别OCR+DeepSeekapi实现提取图片关键信息
用到的技术: 通过腾讯OCR文字识别,deepseek的api实现 目录 需求分析: 文字识别(OCR)具体实现步骤 起步工作 代码编写 deepseek整合消息,返回文本关键信息 起步工作 编写工具类 具体调用实现 具体…...

minio改成https+域名访问
思路有两个: 方式一:通过nginx反向代理,将https配置在nginx,内部的MinIO还是使用HTTP;方式二:MinIO服务端直接配置成HTTPS; 注意: 私钥需要命名为:private.key 公钥需要…...
)
unity与usb串口通信(web版)
一、本文介绍在web环境下unity与usb串口进行通信的代码 本篇使用本地服务器作为unity与串口的中介,unity发送数据到服务器,服务器发送给串口收到响应并解析返回给uinty。 使用websocket协议。 注: 1.我的硬件是检测磁阻液位,用…...

UE5每次都打开上一次的工程文件 , 如何取消?
点击左上角 - 文件 点击 打开项目 取消勾选 - 启动时固定加载上次打开的项目...

AI大模型与人类未来的协作图景:从工具到“数字共生体”
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:技术跃迁与文明重塑的十字路口 2020年代以来,人工智能特别是**AI大语言模型(Large Language Models, LLMs)**的迅猛发展,正在从根本上改变人类与技术的关系。从最初的“智能写作助手”到今日…...

C++ I/O 性能优化指南
在高性能计算和大规模数据处理中,I/O 性能优化是提升系统整体效率的关键环节。C 作为一种高性能编程语言,提供了丰富的工具和机制来优化 I/O 操作。本文将详细介绍在 Linux 环境下,如何通过代码层面的优化、系统调用的选择以及多线程技术等手…...

Idea忽略已提交文件
全局忽略 项目根目录下新增.gitignore文件,写入想要忽略的信息,以下可参考 **/src/main/resources/application-local.yamltarget/ !.mvn/wrapper/maven-wrapper.jar !**/src/main/**/target/ !**/src/test/**/target/### IntelliJ IDEA ### .idea/mod…...

Mamba原理及在low-level vision的工作[持续更新]
文章目录 Mamba原理选择性扫描(Selective Retain Information):选择有关/无关信息状态空间模型(SSM)Mamba的选择性保留信息Mamba的扫描操作(The Scan Operation) 硬件感知(Hardware-…...

openlayers入门02 -- 地图控件
地图控件 1.视图跳转控件(ZoomToExtent) 视图跳转控件用于将地图快速跳转到指定的范围。示例: // 视图跳转控件(extent这里用的是学校的经纬度范围,可以按照需要修改) const ZoomToExtent new ol.contro…...
)
Python 装饰器(Decorator)
文章目录 代码解析1. 装饰器定义 timer(func)2. 应用装饰器 timer **执行流程****关键点****实际应用场景****改进版本(带 functools.wraps)** 这是一个 Python 装饰器(Decorator) 的示例,用于测量函数的执行时间。下…...

UE的AI判断队伍归属的机制:IGenericTeamAgentInterface接口
从官方论坛老哥那学来的,优点在于使用项目设置,像配置碰撞一样,能配置碰撞通道对其他碰撞通道的反应,如阻挡,忽略,重叠,全局配置队伍归属,也能配置当前队伍对其他队伍的身份识别&…...

安宝特新闻丨Vuzix Core™波导助力AR,视角可调、高效传输,优化开发流程
Vuzix Core™ 光波导技术 近期,Vuzix Core™光波导技术赋能AR新视界!该系列镜片支持定制化宽高比调节及20至40视场角范围,可灵活适配各类显示引擎。通过创新的衍射光波导架构,Vuzix Core™实现了光学传输效率与图像质量的双重突破…...

基于springboot留守儿童网站的设计与实现 docx
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...

AST 技术进行 JavaScript 反混淆实战
一、AST 技术核心原理 抽象语法树(AST) 是代码的“骨架”,它把代码拆解成一个个节点,就像把一棵大树拆成树枝、树叶一样。通过分析和修改这些节点,我们可以精准地还原代码的逻辑。 二、实战案例 1:还原字…...
,源码可白嫖!)
基于ECharts+Spark的疫情防控数据分析平台(源码+lw+部署文档+讲解),源码可白嫖!
摘要 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,特别是近几年来,新冠疫情出现以来,疫情防控数据分析平台当然不能排除在外。我本次开发的疫情防控数据分析平台是在…...

wireshark过滤器表达式的规则
1.抓包过滤器语法和实例 抓包过滤器类型Type(host、net、port)、方向Dir(src、dst)、协议Proto(ether、ip、tcp、udp、http、icmp、ftp等)、逻辑运算符(&&与、|| 或、!非&am…...

使用 Python 扫描 Windows 下的 Wi-Fi 网络实例演示
使用 Python 扫描 Windows 下的 Wi-Fi 网络 代码实现代码解析 1. 导入库2. 解码混合编码3. 扫描 Wi-Fi 网络4. 运行函数 这是我当前电脑的 wifi 连接界面。 这个是运行的效果图: 代码实现 我们使用了 Python 的 subprocess 模块来调用 Windows 的内置命令 netsh…...
详解)
Redis 字符串(String)详解
1. 什么是字符串类型 在 Redis 中,字符串(String) 是最基本的数据类型。它可以包含任何数据,比如文本、JSON、甚至二进制数据(如图片的 Base64 编码),最大长度为 512 MB。 字符串在 Redis 中不…...

【Taro3.x + Vue3】搭建微信小程序
IOS环境为例 打开终端环境有多种办法,例举一个:在访达里新建一个文件夹,鼠标右键选择。 一、先安装Taro的环境 npm install -g tarojs/cli安装完成后,可以输入命令检验是否安装成功: taro --version二、创建项目 …...

P8668 [蓝桥杯 2018 省 B] 螺旋折线
题目 思路 一眼找规律题,都 1 0 9 10^9 109说明枚举必然超时,找规律,每个点找好像没有什么规律,尝试找一下特殊点,比如:对角线上的点 4 16 36(右上角) 4k^2,看在第几层(…...

【14】数据结构之哈夫曼树篇章
目录标题 哈夫曼树哈夫曼树的定义哈夫曼树的构造哈夫曼编码哈夫曼树的实现 哈夫曼树 哈夫曼树的定义 路径:从一个结点到另一个结点的路线树的路径长度:从树根到树中每个结点的路径长度之和结点的权:在一些应用中,赋予树中结点的…...
)
初识SpringAI(接入硅基流动deepseek)
①创建项目 ②application.yml spring:application:name: pgs-aiai:openai:api-key: sk-vrozloxjpjgkozaggtodbmwyfmubmxqpdpbvbbxpcgleanugbase-url: https://api.siliconflow.cn/chat:options:model: deepseek-ai/DeepSeek-V3 api-key:去硅基流动官网生成你的密钥…...

两个有序序列合并算法分析
一 问题背景 合并两个有序序列是常见操作,例如在归并排序中。传统方法需要额外空间,时间复杂度为 O(n)。但若要求原地合并(不占用额外内存),则需借助 手摇算法(或称内存反转或三次反转算法)。 二 手摇算法原理 手摇算法通过三次反转操作,实现数组片段的原…...

Robot---SPLITTER行星探测机器人
1 背景 先给各位读者朋友普及一个航天小知识,截止到目前为止,登陆火星的火星车有哪些?结果比较令人吃惊:当前只有美国和中国登陆过火星。 “勇气”号(Spirit):2004年1月4日,美国国家…...

kafka的topic扩容分区会对topic任务有什么影响么
在 Kafka 中对 Topic 进行扩容分区会对相关任务产生多方面的影响,下面为你详细介绍: 积极影响 增强并发处理能力:Kafka 中数据是以分区为单位进行并行处理的,增加分区数量意味着可以让更多的消费者并行消费数据。比如࿰…...
模拟娱乐篇27)
每日一题(小白)模拟娱乐篇27
由题意可以得知这是一道暴力模拟的题目,我们只需要根据题意说的模拟整个过程即可。首先需用循环接收n个数字,每次判断这个数字是否出现过,若没有出现则为对应的负值,若出现过则需要将这个坐标减去之前坐标的值再减一返回ÿ…...

进行性核上性麻痹患者,饮食 “稳” 健康
进行性核上性麻痹作为一种复杂且罕见的神经系统退行性疾病,给患者的身体机能和日常生活带来严重挑战。在积极接受专业治疗的同时,合理的饮食安排对于维持患者营养状况、缓解症状及提升生活质量起着关键作用。以下为患者提供一些健康饮食建议。 首先&…...
)
GitLab之搭建(Building GitLab)
GitLab之搭建 “ 在企业开发过程中,GitLab凭借其强大的版本管理、CI/CD集成和项目管理功能,成为许多团队的首选工具。本文将探讨GitLab的基础介绍、搭建过程、权限管理、代码审查以及团队知识管理等方面。通过详细的步骤和实用的技巧,旨在帮…...

R 语言科研绘图第 38 期 --- 饼状图-玫瑰
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

array和list在sql中的foreach写法
在MyBatis中,<foreach>标签用于处理集合或数组类型的参数,以便在SQL语句中动态生成IN子句或其他需要遍历集合的场景。以下是array和list在SQL中的<foreach>写法总结。 <if test"taskIds ! null and taskIds.length > 0">…...

国内MCP服务有哪些?MCP服务器搜索引擎哪家好?
随着MCP(Model Context Protocol)协议的广泛应用,国内出现了越来越多的MCP服务提供商,这些服务覆盖了从开发工具、数据科学到金融、游戏等多个领域。 如果你对MCP协议和相关开发感兴趣,可以访问AIbase(htt…...

二叉树的应用
目录 一、二叉树遍历算法的应用 二、树的存储结构 1、双亲表示法 2、孩子表示法 带双亲的孩子链表 3、孩子兄弟表示法(左孩子、右兄弟)较为普遍 三、森林与二叉树的转换 四、哈夫曼树 哈夫曼(Huffman)树的构造 一、二叉树…...

【LaTeX】
基本使用 \documentclass 类型:文章(article)、报告(report)、书(book) 中文的文章是ctexart,中文字体是UTF8 \documentclass[UTF8]{ctexart} []说明可以省略不写的意思…...
)
Java基础 - 泛型(基本概念)
文章目录 基本概念参数化类型类型安全和编译时检查 为什么需要泛型?解决类型安全问题避免重复代码提高可读性和维护性 泛型(Generics)是编程语言中一种支持参数化类型的特性,允许在定义类、接口、方法时使用类型参数(T…...

面试之《前端信息加密》
前端代码是直接暴漏给用户的,请求的接口也可以通过控制台network看到参数,这是不够安全的,如果遇到坏人想要破坏,可以直接修改参数,或者频繁访问导致系统崩溃,或数据毁坏。 所以信息加密在某些场合就变得非…...

【含文档+PPT+源码】基于微信小程序的小区物业收费管理系统
项目视频介绍: 毕业作品基于微信小程序的小区物业收费管理系统 课程简介: 本课程演示的是一款基于微信小程序的小区物业收费管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目…...

KDD 2025 顶会最新力作,多变量时间序列预测登顶!
在多变量时间序列预测领域,如何高效捕捉时间分布变化和通道间复杂关系是两大核心挑战。传统方法往往难以同时处理时间模式的异质性和通道间的噪声影响。近期,基于时频结合的方法在这一领域取得了显著进展。本文总结了两篇创新性论文,分别从时…...

for循环的优化方式、循环的种类、使用及平替方案。
本篇文章主要围绕for循环,来讲解循环处理数据中常见的六种方式及其特点,性能。通过本篇文章你可以快速了解循环的概念,以及循环在实际使用过程中的调优方案。 作者:任聪聪 日期:2025年4月11日 一、循环的种类 1.1 默认有以下类型 原始 for 循环 for(i = 0;i<10;i++){…...

OpenFeign 的实现原理详解
前言 OpenFeign 是一个声明式的 HTTP 客户端,它简化了服务间的 HTTP 调用。通过简单的注解和接口定义,开发者可以轻松调用远程服务,而无需手动编写复杂的 HTTP 请求代码。本文将深入探讨 OpenFeign 的实现原理,并结合源码分析其核…...

const关键字理解
const关键字主要的作用是告诉编译器这个东西是个常量,不可被修改。 或者是用来和指针玩一些奇奇怪怪的东西,这玩意面试八股文常青树。 const int* p://表示指针指向的内容不能更改,指针可以更改。 int* const p: //表示指针不能…...

操作系统 4.3-生磁盘的使用
磁盘的物理组成 盘面: 磁盘由多个盘面组成,每个盘面上都有数据存储的区域。 磁道: 每个盘面上都有若干个同心圆,这些同心圆称为磁道。磁道是数据存储的路径。 扇区: 磁道被进一步划分为若干个扇区,扇区…...

Uniapp Vue 实现当前日期到给定日期的倒计时组件开发
应用场景与需求分析 在移动端应用开发中,倒计时功能是常见的交互需求,例如限时促销活动、订单超时提醒、考试倒计时等场景。本文将基于 Uniapp 框架,实现一个从当前日期到给定日期的倒计时组件,支持显示 HH:mm:ss 格式的剩余时间…...

3dmax标准材质/vr/cr材质贴图转PBR材质贴图插件,支持多维子材质转换
3dmax标准材质/vr/cr材质贴图转PBR材质贴图插件,支持多维子材质转换 3dmax标准材质/vr/cr材质贴图转PBR材质贴图插件,支持多维子材质转换...

操作系统 3.3-多级页表和快表
分页的问题 这张幻灯片讨论了操作系统中内存管理的一个核心问题:页大小与页表大小之间的权衡。 页(Page)是内存管理中的一个基本概念,指的是将虚拟内存分割成固定大小的块,以便于管理和访问。页的大小直接影响内存空间…...