spark(二)
本节课接上节课继续对于RDD进行学习,首先是对于创建RDD的不同方式,接着学习了RDD的三种转换算子:Value类型、双Value类型、Key-Value类型,以及各个转换算子的不同使用方式。
学习到如下的区别:
map 与 mapPartitions:前者是逐条处理数据,后者以分区为单位进行批处理,性能上后者可能更高,但内存占用也更大。
map 与 flatMap:map 是一对一映射,flatMap 先扁平化再映射,可能会改变数据的数量。
reduceByKey 与 groupByKey:reduceByKey 可在 shuffle 前预聚合,减少落盘数据量,性能更好;groupByKey 仅能分组,不能聚合。
reduceByKey、foldByKey、aggregateByKey、combineByKey:它们在对第一个数据的处理方式、分区内和分区间的计算规则方面存在差异
创建RDD
在 scala 文件夹下创建一个新的 Scala 文件,CreateRDD.scala
import org.apache.spark.rdd.RDD
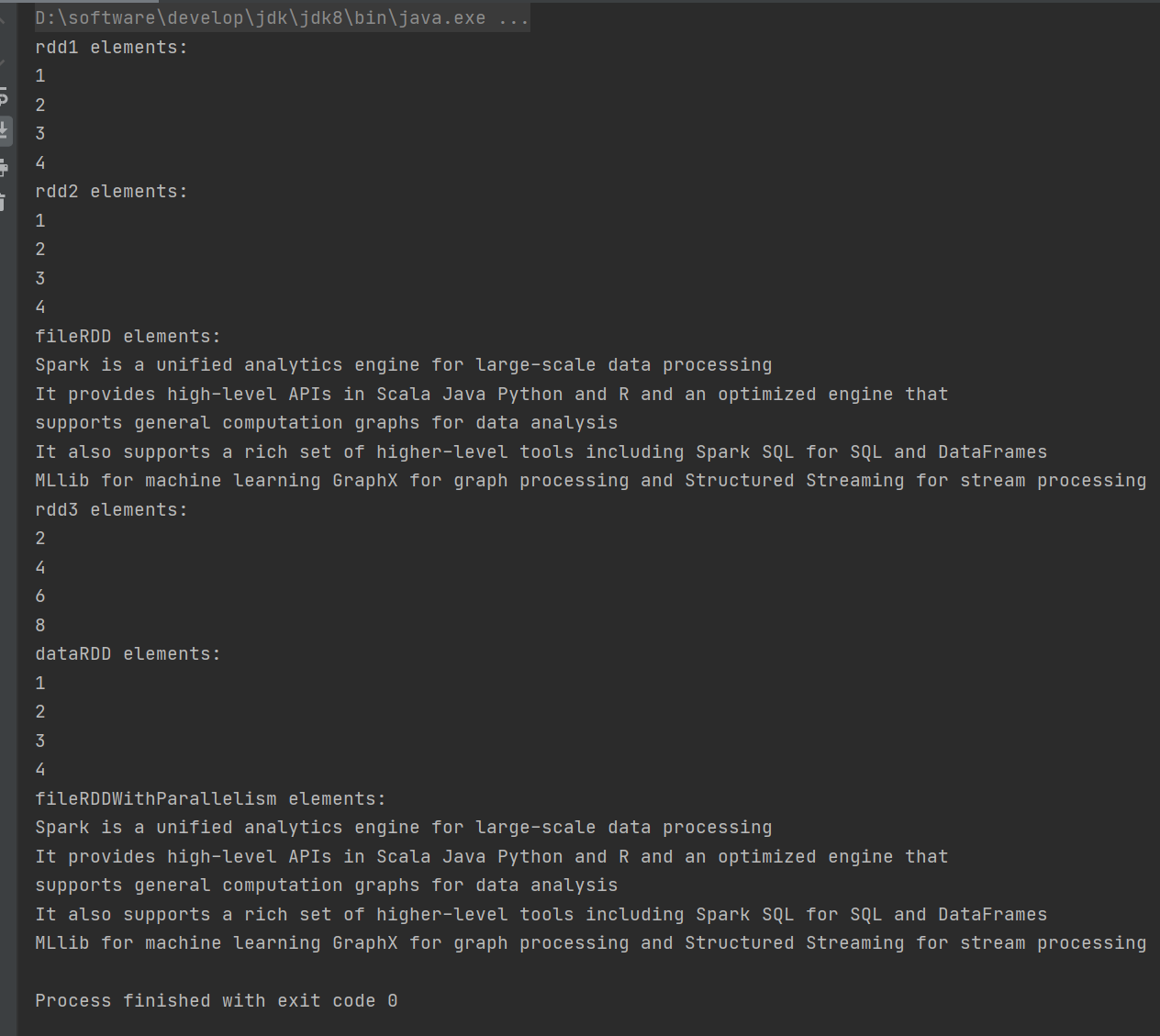
import org.apache.spark.{SparkConf, SparkContext}object CreateRDD {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")val sparkContext = new SparkContext(sparkConf)// 1) 从集合(内存)中创建 RDDval rdd1 = sparkContext.parallelize(List(1, 2, 3, 4))val rdd2 = sparkContext.makeRDD(List(1, 2, 3, 4))println("rdd1 elements:")rdd1.collect().foreach(println)println("rdd2 elements:")rdd2.collect().foreach(println)// 2) 从外部存储(文件)创建 RDDval fileRDD: RDD[String] = sparkContext.textFile("spark-core/input")println("fileRDD elements:")fileRDD.collect().foreach(println)// 3) 从其他 RDD 创建val rdd3 = rdd1.map(_ * 2)println("rdd3 elements:")rdd3.collect().foreach(println)// 4) 直接创建 RDD(new),一般由 Spark 框架自身使用,这里不做演示// RDD 并行度与分区val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 4)val fileRDDWithParallelism: RDD[String] = sparkContext.textFile("spark-core/input", 2)println("dataRDD elements:")dataRDD.collect().foreach(println)println("fileRDDWithParallelism elements:")fileRDDWithParallelism.collect().foreach(println)sparkContext.stop()}
} 
RDD转换算子
Value类型
首先添加以下前提
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object RDDTransformations {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_function")val sparkContext = new SparkContext(sparkConf)sparkContext.stop()
}}RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型
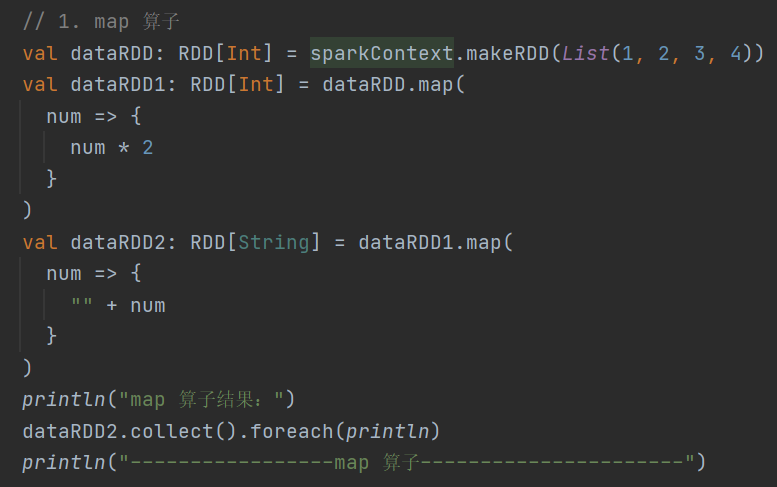
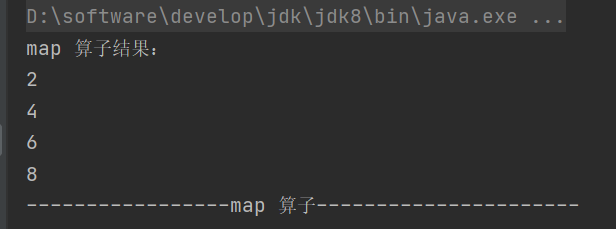
1.map
def map[U: ClassTag](f: T => U): RDD[U]对 RDD 里的数据逐条进行映射转换,能够实现类型或者值的转换
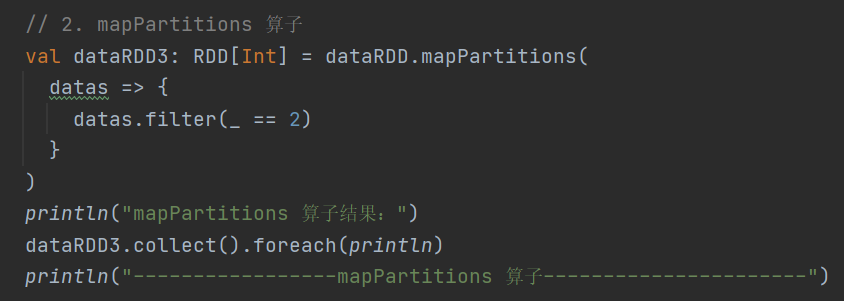
2.mapPartitions
def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U],preservesPartitioning: Boolean = false): RDD[U]以分区为单位对数据进行批处理操作,可在计算节点上对数据开展任意处理

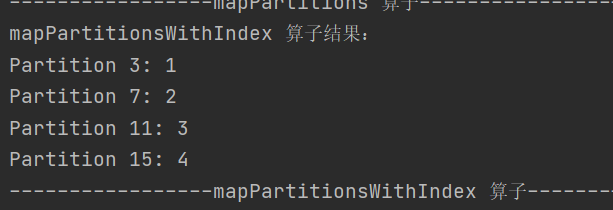
3.mapPartitionsWithIndex
def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false): RDD[U]和 mapPartitions 类似,不过在处理时能获取当前分区的索引

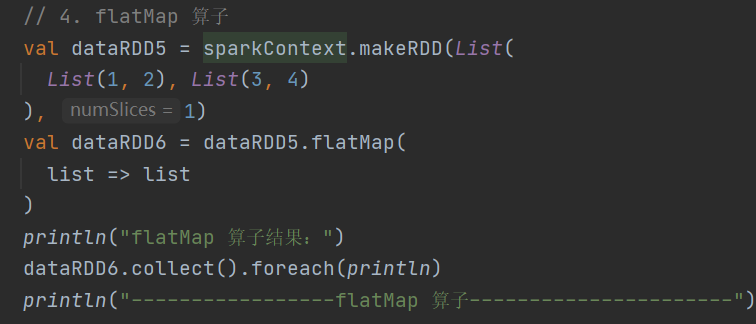
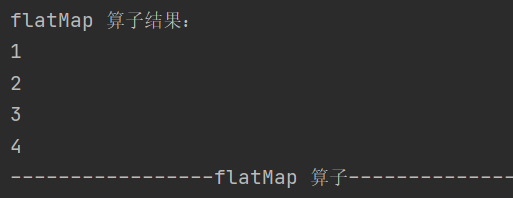
4.flatMap
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]先对数据进行扁平化处理,再进行映射操作
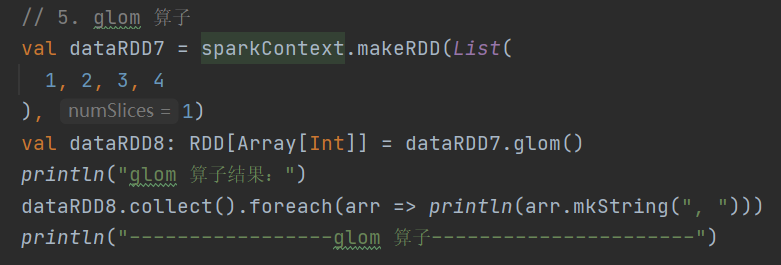
5.glom
def glom(): RDD[Array[T]]把同一个分区的数据转换为相同类型的内存数组,分区保持不变
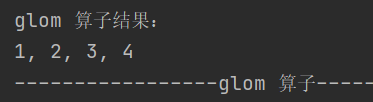
6.groupBy
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]按照指定规则对数据进行分组,会产生 shuffle 操作

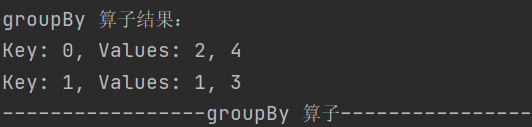
7.filter
def filter(f: T => Boolean): RDD[T]依据指定规则筛选过滤数据,符合规则的数据会被保留
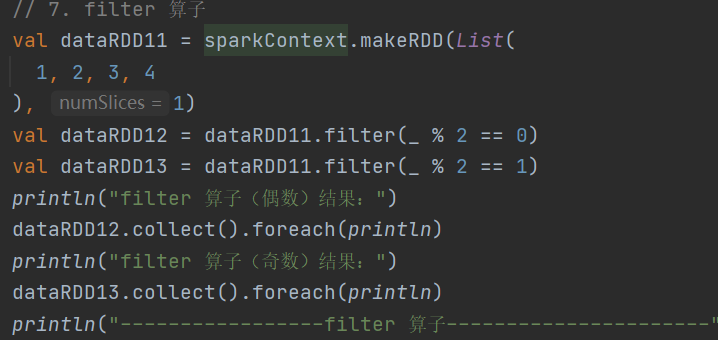
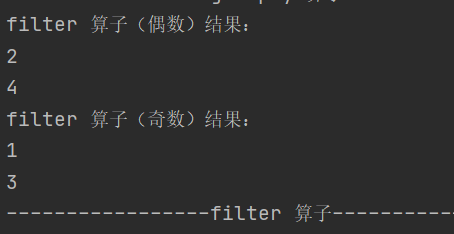
8.sample
def sample(withReplacement: Boolean,fraction: Double,seed: Long = Utils.random.nextLong): RDD[T]按照指定规则从数据集中抽取数据,支持放回和不放回抽样
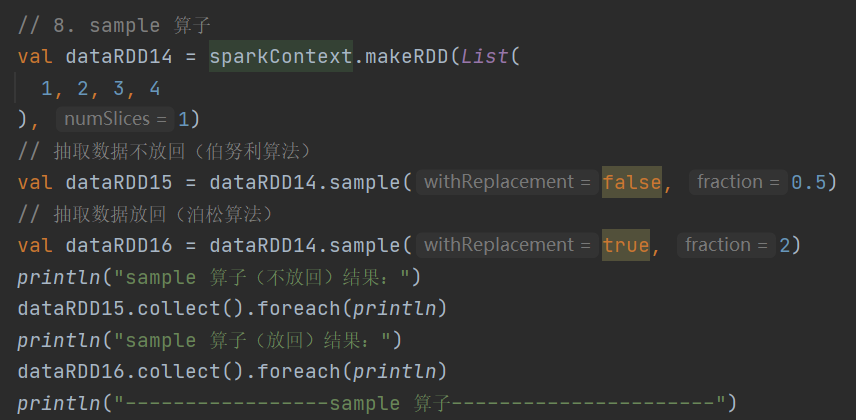

9.distinct
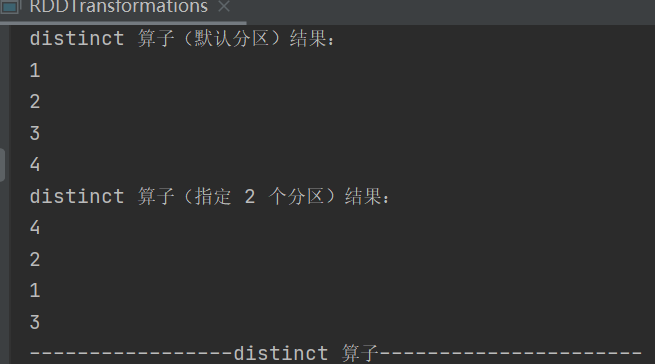
def distinct()(implicit ord: Ordering[T] = null): RDD[T]def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]去除数据集中的重复数据

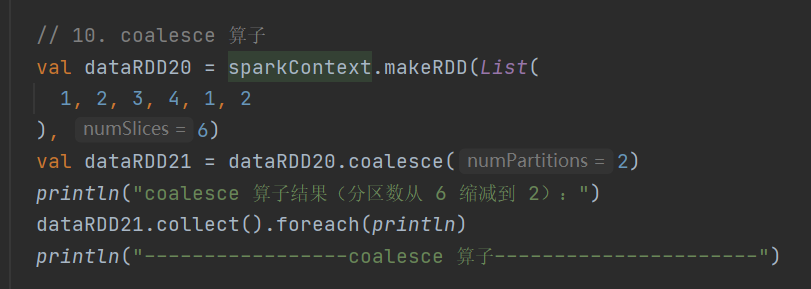
10.coalesce
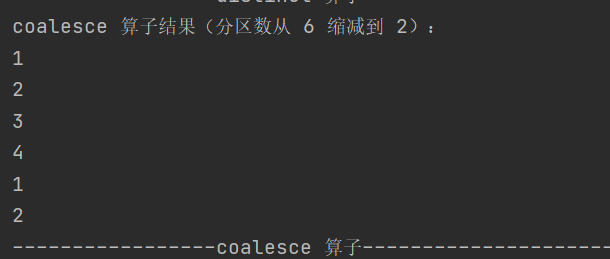
def coalesce(numPartitions: Int, shuffle: Boolean = false,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]根据数据量缩减分区,降低任务调度成本
11.repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]可增加或减少分区数,内部会进行 shuffle 操作
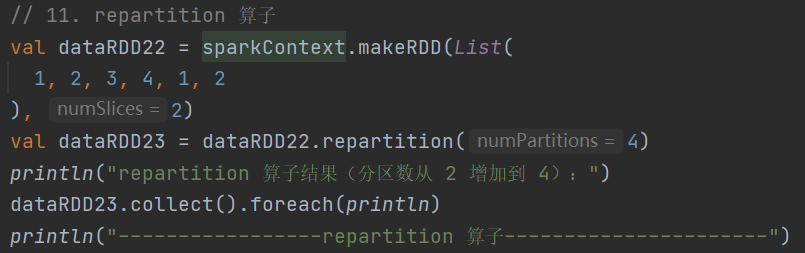
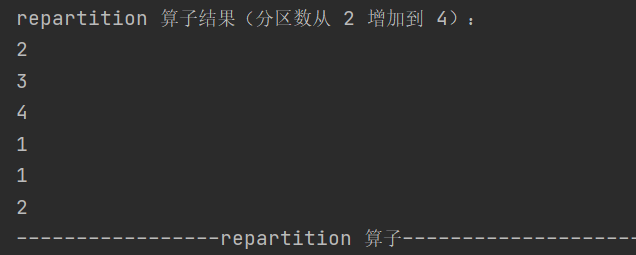
12.sortBy
def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]对数据进行排序,可指定排序规则和分区数
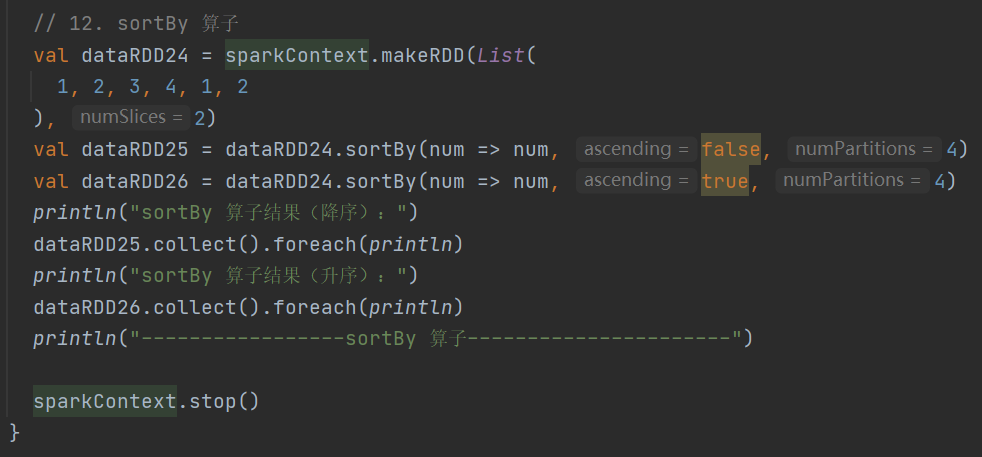
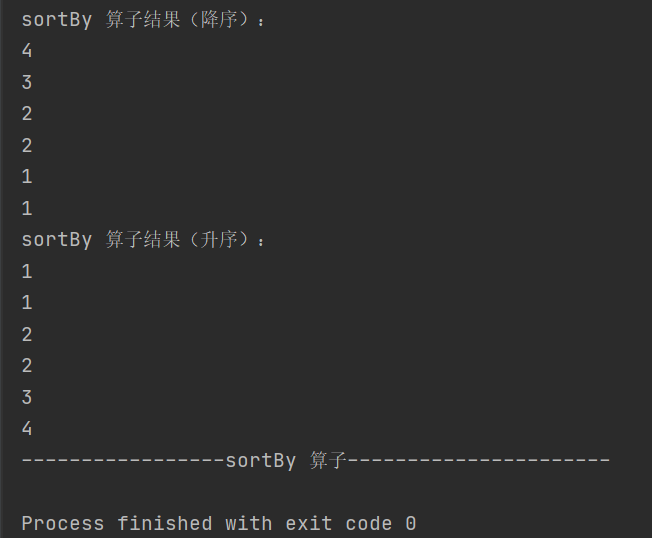
双Value类型
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object RDDDoubleValueTransformations {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDDoubleValue_function")val sparkContext = new SparkContext(sparkConf)
sparkContext.stop()}
}1. intersection
def intersection(other: RDD[T]): RDD[T]求两个 RDD 的交集
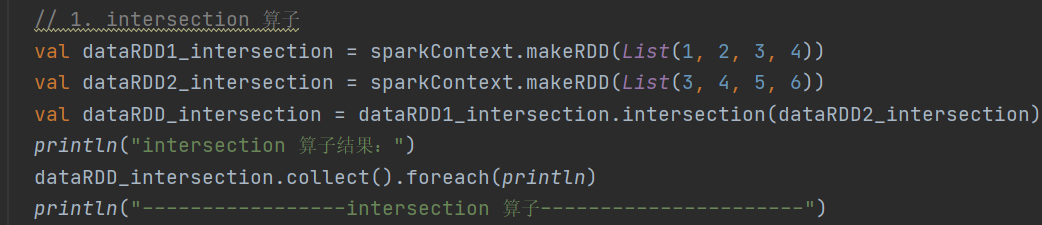
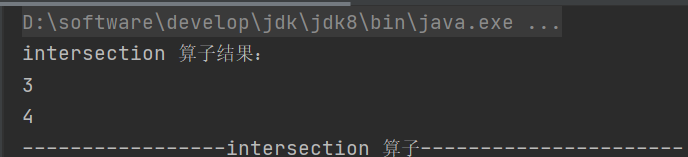
2.union
def union(other: RDD[T]): RDD[T]求两个 RDD 的并集,重复数据不会去重
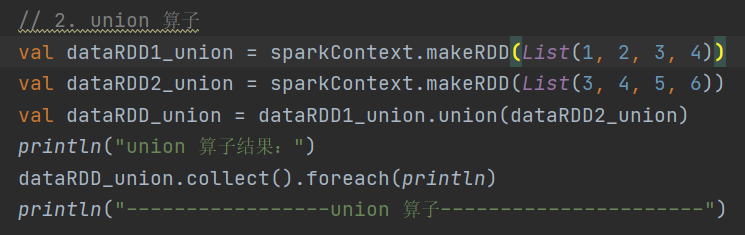
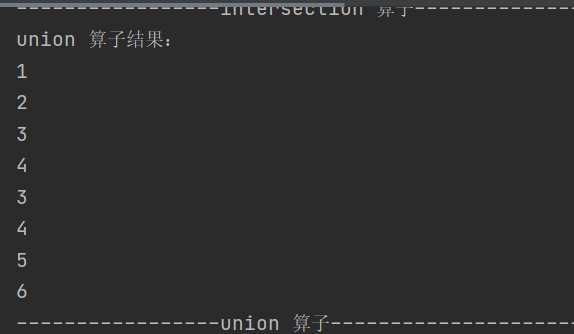
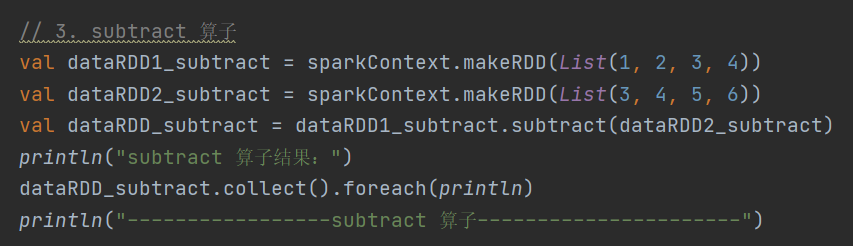
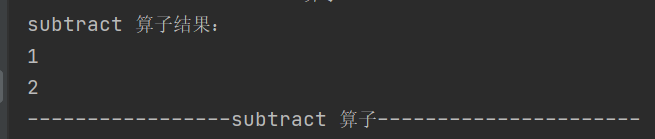
3.subtract
def subtract(other: RDD[T]): RDD[T]以源 RDD 元素为主,去除两个 RDD 中的重复元素,保留源 RDD 的其他元素
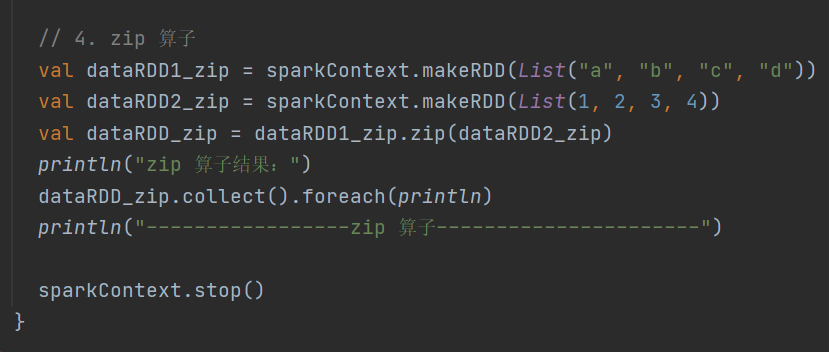
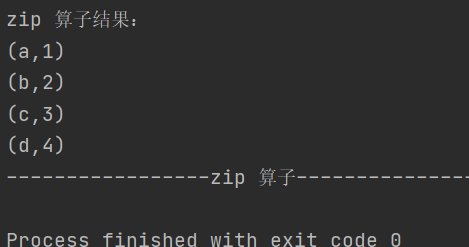
4.zip
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]将两个 RDD 中的元素以键值对的形式合并
Key-Value类型
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}object RDDKeyValueTransformations {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDKeyValue_function")val sc = new SparkContext(sparkConf)sc.stop()}
}1.partitionBy
def partitionBy(partitioner: Partitioner): RDD[(K, V)]按照指定的 Partitioner 对数据重新分区

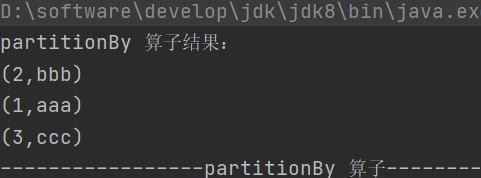
2.groupByKey
def groupByKey(): RDD[(K, Iterable[V])]def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]依据 key 对 value 进行分组

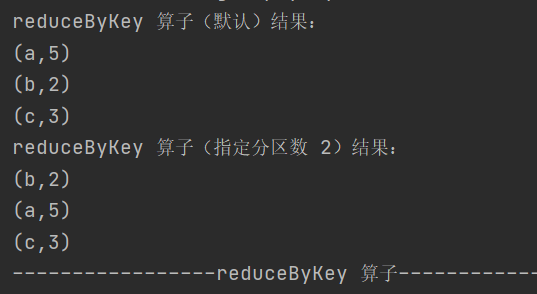
3.reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]按照相同的 key 对 value 进行聚合,可在 shuffle 前进行预聚合,性能较高

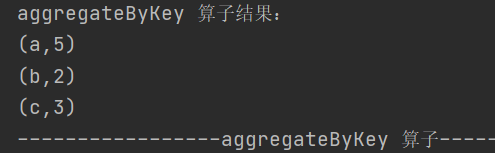
4.aggregateByKey
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]按照不同规则进行分区内和分区间的计算

5.foldByKey
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]当分区内和分区间的计算规则相同时,可简化 aggregateByKey 的使用
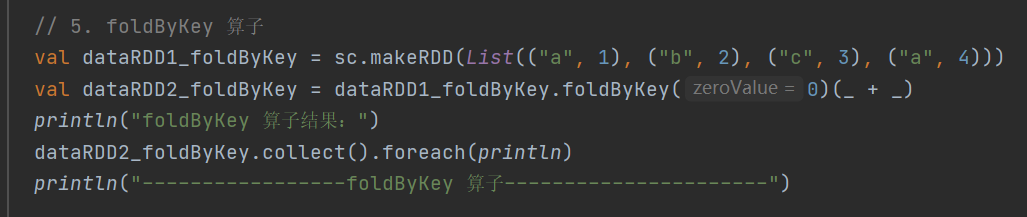
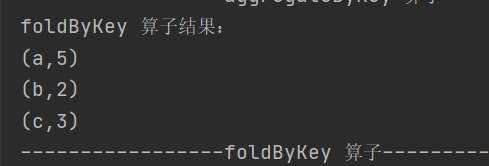
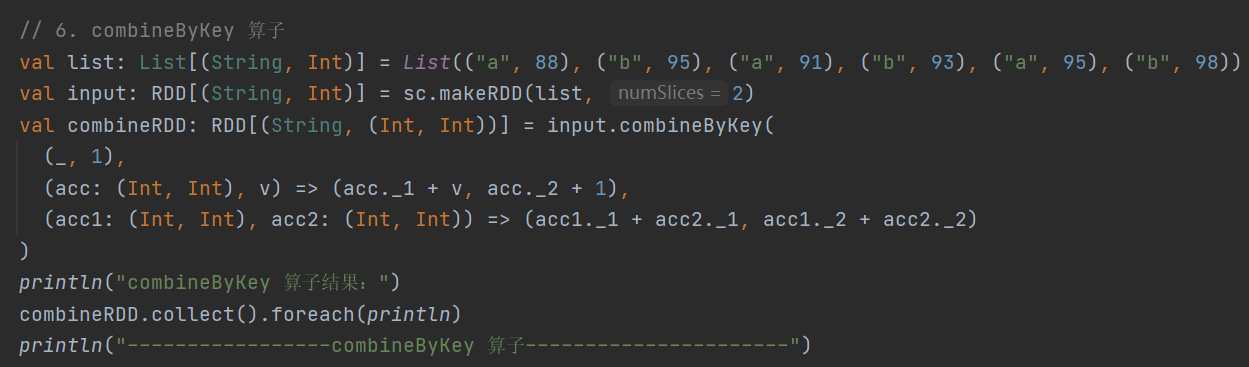
6.combineByKey
def combineByKey[C](createCombiner: V => C,//将当前值作为参数进行附加操作并返回mergeValue: (C, V) => C,// 在分区内部进行,将新元素V合并到第一步操作得到的C中mergeCombiners: (C, C) => C): RDD[(K, C)]//将第二步操作得到的C进行分区间计算最通用的对 key - value 型 RDD 进行聚集操作的函数,允许返回值类型与输入不同
示例:现有数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),求每个key的总值及每个key对应键值对的个数

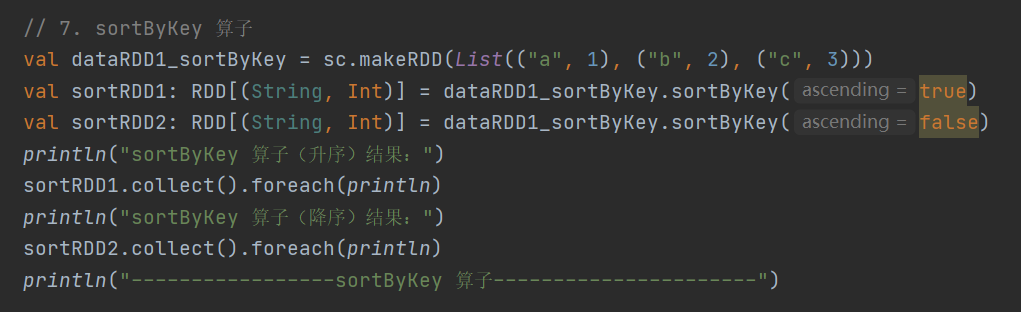
7.sortByKey
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]按照 key 对 RDD 进行排序
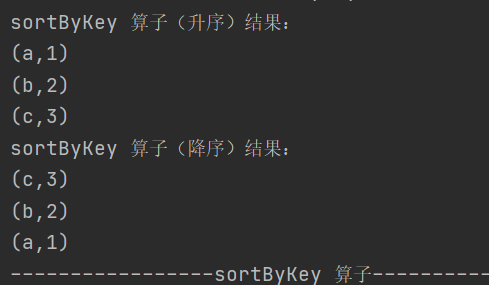
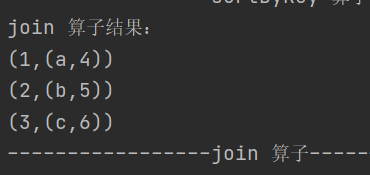
8. join
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]对两个类型为 (K, V) 和 (K, W) 的 RDD 进行连接操作

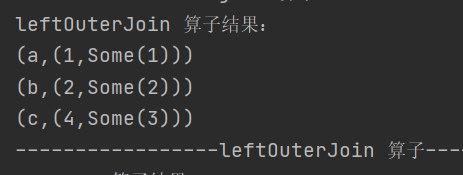
9. leftOuterJoin
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]类似于 SQL 中的左外连接

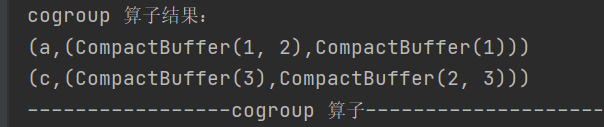
10.cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]对两个类型为 (K, V) 和 (K, W) 的 RDD 进行分组操作
相关文章:
)
spark(二)
本节课接上节课继续对于RDD进行学习,首先是对于创建RDD的不同方式,接着学习了RDD的三种转换算子:Value类型、双Value类型、Key-Value类型,以及各个转换算子的不同使用方式。 学习到如下的区别: map 与 mapPartitions…...

Fay 数字人部署环境需求
D:\ai\Fay>python main.py pygame 2.6.1 (SDL 2.28.4, Python 3.11.9) Hello from the pygame community. https://www.pygame.org/contribute.html [2025-04-11 00:10:16.7][系统] 注册命令... [2025-04-11 00:10:16.8][系统] restart 重启服务 [2025-04-11 00:10:16.8][…...
)
【Harmony】端云一体化(云函数)
一、云函数的概述 1、什么是云函数 官方解释 云函数是一项Serverless计算服务,提供FaaS(Function as a Service)能力,一方面云函数将开发测试的对象聚焦到函数级别,可以帮助您大幅简化应用开发与运维相关的事务&…...

利用大模型和聚类算法找出 Excel 文件中重复或相似度高的数据,并使用 FastAPI 进行封装的详细方案
以下是一个利用大模型和聚类算法找出 Excel 文件中重复或相似度高的数据,并使用 FastAPI 进行封装的详细方案: 方案流程 数据读取:从 Excel 文件中读取数据。文本向量化:使用大模型将文本数据转换为向量表示。聚类分析:运用聚类算法对向量进行分组,将相似度高的数据归为…...

通过远程桌面连接wsl2中安装的ubuntu24.04
要介绍的这种方式其实跟直接用wsl来执行命令差不多,是在终端去操作ubuntu。WSL2 默认只提供命令行界面,本文安装xrdp后通过windows远程桌面连接过去。 1、更新软件包列表 sudo apt update 确保你的软件包列表是最新的,否则可能找不到某些包…...

对接和使用国内稳定无水印的 Suno API
随着 AI 的应用日益广泛,各种 AI 程序已经融入我们的日常生活。从最早的写作,到医疗、教育,如今甚至扩展到了音乐领域。 Suno 是一个专注于高质量 AI 歌曲和音乐创作的平台。用户只需输入简单的文本提示词,便可以按照流派风格和歌…...
_38)
LeetCode算法题(Go语言实现)_38
我将按照您提供的文档结构为您整理二叉树最近公共祖先(LCA)问题的解决方案: 一、代码实现 type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode }func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {if root nil ||…...

Linux学习笔记 1
1.发展史 略...... 2.xshell的使用方法 2.1登录 ssh root公网地址 输入密码,用 uname -r 指令来鉴定是否登录成功。之后就可以进行命令行操作了。 alt enter 全屏、退出 设置多用户指令,新建用户 adduser 名字 passwd 密码 销毁用户…...

微信小程序跳4
formatMillisecondsTime: function(milliseconds, formatStr) { // 创建一个新的Date对象,传入毫秒值 const date new Date(milliseconds); // 获取年月日时分秒,并确保它们都是两位数 const year date.getFullYear(); const month (date.getMonth() …...

STM32单片机入门学习——第31节: [10-1] I2C通信协议
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.10 STM32开发板学习——第31节: [10-1] I2C通信协议 前言开发板说明引用解答和科普一…...
图像滤波-----双边滤波函数bilateralFilter())
OpenCV 图形API(24)图像滤波-----双边滤波函数bilateralFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 应用双边滤波到图像。 该函数对输入图像应用双边滤波,如 http://www.dai.ed.ac.uk/CVonline/LOCAL_COPIES/MANDUCHI1/Bilateral_Fil…...

【图像处理基石】什么是影调?并用python实现一个哈苏色彩影调
影调是摄影语言的核心,通过控制明暗、虚实与色彩,可精准传达创作意图。实际选择需结合主题情感、光线条件及画面结构,灵活运用高调、低调或冷暖色调,以强化视觉表现力。 一、影调的定义 影调指画面中明暗、虚实、色彩的层次与对比…...


MySQL行列转换
创建一个sc表并插入数据 方法一: select distinct uid, (select score from sc where s.uiduid and course语文)语文, (select score from sc where s.uiduid and course数学)数学, (select score from sc where s.uiduid and course英语)英语 from sc s; 方法二: select * fro…...

cookie和session哪个生成的时间早
Cookie 和 Session 的出现时间都可以追溯到 Web 开发的早期阶段,但它们的生成顺序在实际应用中通常是先生成 Session,然后通过 Cookie 来存储 Session ID。 详细解释: Session 的生成过程 • 用户请求服务器: • 用户首次访问网…...

sh脚本删除指定后缀.txt的文件,保留6个月的数据
1、linux下脚本删除指定后缀.txt和.path的文件,保留6个月的数据: 下面代码内容: #!/bin/bash # 指定要删除文件的路径列表 paths("/data/fail")# 获取当前系统日期6个月之前的日期 six_months_ago$(date -d "-6 months"…...

嵌入式Linux按键监控模块详解:实现设备重启与长按检测
嵌入式Linux按键监控模块详解:实现设备重启与长按检测 在嵌入式Linux设备开发中,物理按键仍然是用户与设备交互的重要方式。本文将分享一个轻量级但功能完整的按键监控模块,它可以精确识别按键的短按和长按事件,并执行对应操作如…...

[错误经验 坑]关于UDP服务器和客户端通信使用的recvfrom的输出型参数len没有被初始化导致的问题
[错误经验 坑]关于UDP服务器和客户端通信使用的recvfrom的输出型参数len没有被初始化导致的问题 水墨不写bug 文章目录 一、困惑:二、解答:(1)函数原型1. int sockfd2. void *buf3. size_t len4. int flags5. struct sockaddr *sr…...

KaiwuDB:面向AIoT场景的多模融合数据库,赋能企业数字化转型
引言 在万物互联的AIoT时代,企业面临着海量时序数据处理、多模数据融合和实时分析等挑战。KaiwuDB应运而生,作为一款面向AIoT场景的分布式、多模融合、支持原生AI的数据库产品,为企业提供了一站式数据管理解决方案。 产品概述 KaiwuDB是一…...

Web3 的云基础设施正在成型,Polkadot 2.0 用三项技术改写“上链成本”
在Web3基础设施内卷加剧的今天,“如何以更低成本、更大灵活性部署一条高性能应用链”正成为开发者们最关心的问题。而刚刚走出“技术慢热”误区的Polkadot,正在用一套名为 Polkadot 2.0 的架构升级方案,重新定义这一问题的解法。 这套升级最…...

Elasticsearch 学习规划
Elasticsearch 学习规划 明确学习目标与动机 场景化需求分析 - **S**:掌握Elasticsearch架构体系,熟练使用Elasticsearch 进行数据分析,Elasticsearch结合java 项目落地案例 - **M**:搜索和Elasticsearch相关GitHub项目 - **A**:每…...
)
OpenHarmony如何编译安装系统应用(以settings设置为例)
开发环境 1.OpenHarmony 2.DevEco Studio 3 .Full Sdk 实现步骤 1.获取设置应用源码 https://gitee.com/openharmony/applications_settings/tree/OpenHarmony-v5.0.0-Release/ 2,使用 DevEco Studio 和 Full SDK对系统应用进行签名,默认工程是未配置签名的状态,所构建…...

手撕 STL 之—— list
目录 引言 1, list_node类及其构造函数 2, list类的创建 3, list基本功能函数 3_1, 构造函数 3_2,push_back 3_3,push_front 3_4, pop_back 3_5,pop_front 4,迭代器 (重点) 4_1,如何设…...

Med-R1论文阅读理解
论文介绍 这篇论文介绍了一个名为 Med-R1 的新方法,用于提升多模态视觉语言模型(VLM)在医学图像理解和推理任务中的泛化能力和可解释性。下面是对整篇论文的简洁总结: ⸻ 🧠 核心思想 • 当前医学 VLM 多依赖于监督…...

微服务相关
1.SpringCloud有哪些常用组件?分别是什么作用? 注册中心:nacos 负载均衡:rabbion/LoadBalancer 网关:gateway 服务熔断:sential 服务调用:Feign 2.服务注册发现的基本流程是怎样的&#x…...

Linux vagrant 导入Centos到virtualbox
前言 vagrant 导入centos 虚拟机 前提要求 安装 virtualbox 和vagrant<vagrant-disksize> (Linux 方式 Windows 方式) 创建一键部署centos 虚拟机 /opt/vagrant 安装目录/opt/VirtualBox 安装目录/opt/centos8/Vagrantfile (可配置网络IP,内存…...
)
Spring Boot MongoDB 分页工具类封装 (新手指南)
Spring Boot MongoDB 分页工具类封装 (新手指南) 目录 引言:为何需要分页工具类?工具类一:PaginationUtils - 简化 Pageable 创建 设计目标代码实现 (PaginationUtils.java)如何使用 PaginationUtils 工具类二:PageResponse<…...

第七章 指针
2024-04 2023-10 A 2023-04 2022-10 2022-04 2021-10 2021-04 2020-10 2020-04...

20年AB1解码java
P8706 [蓝桥杯 2020 省 AB1] 解码 - 洛谷 详细代码如下: import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner innew Scanner(System.in); // 接收输入的字符串char [] c in.next().toCharArray(); // 接收 还原的字符…...

《Java实战:密码加密算法实现与代码解析》
文章目录 一、需求背景二、代码逐模块解析1. 主程序入口2. 密码输入模块3. 加密处理模块4. 结果拼接模块 三、完整代码示例四、运行示例五、优化方向(下篇预告) 一、需求背景 实现一个4位数字密码的简单加密系统,规则如下: 输入…...

AllData数据中台升级发布 | 支持K8S数据平台2.0版本
🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。 ✨杭州奥零数据科技官网…...

Jupyter notebook使用技巧
一、打开指定文件夹 在快捷方式目标中,使用如下代码 anaconda3\python.exe anaconda3\cwp.py anaconda3 anaconda3\python.exe anaconda3\Scripts\jupyter-notebook-script.py --notebook-dirD:\code\python...

6.3es新特性web worker
Web Worker 是 HTML5 提供的多线程技术,允许在浏览器后台创建独立线程执行 JavaScript 代码,解决主线程因耗时任务导致的 界面卡顿 问题。 核心特性 线程隔离:Worker 线程无法直接操作 DOM 或访问 window 对象通信机制:通过 pos…...

基于 OpenHarmony 5.0 的星闪轻量型设备应用开发——Ch3 设备驱动开发
写在前面:本篇是系列文章《基于 OpenHarmony 5.0 的星闪轻量型设备应用开发》的第 3 章。本篇从 GPIO、PWM、I2C、UART 以及 ADC 等方面对基于 OpenHarmony 5.0 的 WS63 设备驱动开发进行了详细的介绍。本篇的篇幅较长,建议先收藏再阅读。 3.1 OpenHarmo…...

iphone各个机型尺寸
以下是苹果(Apple)历代 iPhone 机型 的屏幕尺寸、分辨率及其他关键参数汇总(截至 2023年10月,数据基于官方发布信息): 一、标准屏 iPhone(非Pro系列) 机型屏幕尺寸(英寸…...

OfficePlus去掉PDF文件右键菜单里的PDF转换
今天在吾爱破解论坛看到一个求助帖,说是OfficePlus,安装后,PDF文件的右键菜单里多了PDF转换,想去掉,不知道怎么弄。底下的回复基本都是百度复制或者AI搜索出的答案,大致就是找注册表里CLASSID下的菜单栏相关…...
- DRM驱动程序设计)
Linux驱动开发进阶(七)- DRM驱动程序设计
文章目录 1、前言2、DRAM(KMS、GEM)2.1、KMS2.2、GEM 3、DRM3.1、驱动结构体3.2、设备结构体3.3、DRM驱动注册3.4、DRM模式设置3.4.1、plane初始化3.4.2、crtc初始化3.4.3、encoder初始化3.4.4、connect初始化 4、示例说明5、DRM Simple Display框架6、DRM热插拔7、DRM中的plan…...

Parasoft C++Test软件单元测试_条件宏和断言宏使用方法的详细介绍
系列文章目录 Parasoft C++Test软件静态分析:操作指南(编码规范、质量度量)、常见问题及处理 Parasoft C++Test软件单元测试:操作指南、实例讲解、常见问题及处理 Parasoft C++Test软件集成测试:操作指南、实例讲解、常见问题及处理 进阶扩展:自动生成静态分析文档、自动…...
)
vue辅助工具(vue系列二)
目录 第一章、安装周边库1.1)状态管理:Pinia1.2)路由管理:Router1.3)HTTP 客户端:Axios1.4)UI 组件库:Element 第二章、下载Vue插件并安装2.1)安装开发者工具2.1.1&#…...

WPF 五子棋项目文档
WPF 五子棋项目文档 1. 项目概述 本项目是一个使用 Windows Presentation Foundation (WPF) 技术栈和 C# 语言实现的桌面版五子棋(Gomoku)游戏。它遵循 MVVM(Model-View-ViewModel)设计模式,旨在提供一个结构清晰、可…...

UniApp 实现兼容 H5 和小程序的拖拽排序组件
如何使用 UniApp 实现一个兼容 H5 和小程序的 九宫格拖拽排序组件,实现思路和关键步骤。 一、实现目标 支持拖动菜单项改变顺序拖拽过程实时预览移动位置拖拽松开后自动吸附回网格兼容 H5 和小程序平台 二、功能结构拆解以及完整代码 完整代码: <…...

谷歌推出统一安全平台-一个平台实现跨云网端主动防护
👋 今天要给大家带来一个超级棒的消息!谷歌云推出了全新的“谷歌统一安全平台”,感觉我们的网络安全问题有救啦!😄 随着企业基础设施变得越来越复杂,保护它们也变得越来越难。攻击面不断扩大,安…...

众趣科技丨沉浸式 VR 体验,助力酒店民宿数字化营销宣传
随着旅游季的到来,各地的旅游景区开始“摩拳擦掌”推出各种活动,吸引更多游客来此游玩。 自去年以来,冰雪游热度持续上升,尤其是对于满心期待的南方游客来说,哈尔滨仍是冰雪旅游的热门目的地。据美团数据显示ÿ…...

DAY05:【pytorch】图像预处理
1、torchvision 功能:计算视觉工具包 torchvision.transforms:常用的图像预处理方法torchvision.datasets:常用数据集的 dataset 实战,MINIST,CIFAR-10,ImageNet等torchvision.model:常用的模…...

真实企业级K8S故障案例:ETCD集群断电恢复与数据保障实践
背景描述 某跨境电商平台生产环境使用Kubernetes(v1.23.17)管理500微服务。某日机房突发市电中断,UPS未能及时接管导致: 3节点ETCD集群(v3.5.4)全部异常掉电 Control-Plane节点无法启动api-server 业务P…...

rbd块设备的id修改
背景 看到有这个需求,具体碰到什么场景了不太清楚,之前做过rbd的重构的研究,既然能重构,那么修改应该是比重构还要简单一点的,我们具体看下怎么操作 数据结构分析 rbd的元数据信息 [rootlab104 ~]# rbd create tes…...

WP最主题专业的wordpress主题开发
WP最主题(wpzui.com) WP最主题是一个提供高品质WordPress主题的平台。它注重主题的设计和功能,旨在为用户提供美观且实用的主题选择。其主题通常具有良好的用户体验、丰富的自定义选项以及优化的性能,能够满足不同类型的网站搭建…...

HomeAssistant本地化部署结合内网穿透打造跨网络智能家居中枢
文章目录 前言1. 添加镜像源2. 部署HomeAssistant3. HA系统初始化配置4. HA系统添加智能设备4.1 添加已发现的设备4.2 添加HACS插件安装设备 5. 安装cpolar内网穿透5.1 配置HA公网地址 6. 配置固定公网地址 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂…...

# 实时人脸性别与年龄识别:基于OpenCV与深度学习模型的实现
实时人脸性别与年龄识别:基于OpenCV与深度学习模型的实现 在当今数字化时代,计算机视觉技术正以前所未有的速度改变着我们的生活与工作方式。其中,人脸检测与分析作为计算机视觉领域的重要分支,已广泛应用于安防监控、智能交互、…...

SAP-ABAP:SAP的Open SQL和Native SQL详细对比
在SAP ABAP开发中,Open SQL和Native SQL是两种操作数据库的方式,它们的核心区别在于可移植性、功能范围及底层实现机制。以下是详细对比: 1. Open SQL:深入解析 1.1 核心特性 数据库抽象层 Open SQL 由 SAP 内核的 Database Interface (DBI) 转换为目标数据库的 SQL(如 …...