【深度学习】PyTorch实现VGG16模型及网络层数学原理
一、Demo概述
代码已附在文末
1.1 代码功能
- ✅ 实现VGG16网络结构
- ✅ 在CIFAR10数据集上训练分类模型
1.2 环境配置
详见【深度学习】Windows系统Anaconda + CUDA + cuDNN + Pytorch环境配置
二、各网络层概念
2.1 卷积层(nn.Conv2d)
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
| 参数 | 含义 | 作用说明 |
|---|---|---|
in_channels | 输入通道数(如RGB图为3) | 接收输入的维度 |
out_channels | 输出通道数(卷积核数量) | 提取不同特征类型的数量 |
kernel_size | 卷积核尺寸(如3x3) | 决定感知的局部区域大小 |
padding | 边缘填充像素数 | 保持输出尺寸与输入一致 |
作用:通过滑动窗口提取局部特征(如边缘、颜色分布)
示例: 输入3通道224x224图片 → 通过64个3x3卷积核 → 输出64通道224x224特征图
1)卷积后的输出尺寸:
卷积后的输出尺寸由以下公式决定:
输出尺寸 = 输入尺寸 − 卷积核尺寸 + 2 × 填充 步长 + 1 \text{输出尺寸} = \frac{\text{输入尺寸} - \text{卷积核尺寸} + 2 \times \text{填充}}{\text{步长}} + 1 输出尺寸=步长输入尺寸−卷积核尺寸+2×填充+1
在代码中:
- 输入尺寸:224x224
- 卷积核尺寸:3x3 → (k=3)
- 填充 (padding):1 → (p=1)
- 步长 (stride):1 → (s=1)(默认值)
代入公式:
输出尺寸 = 224 − 3 + 2 × 1 1 + 1 = 224 \text{输出尺寸} = \frac{224 - 3 + 2 \times 1}{1} + 1 = 224 输出尺寸=1224−3+2×1+1=224
因此,宽度和高度保持不变(仍为224x224)。
2)64个卷积核的输出不同
- 参数初始化差异
- 初始权重随机:每个卷积核的权重矩阵在训练前通过随机初始化生成(如正态分布)
- 示例:
- 卷积核1初始权重可能偏向检测水平边缘
- 卷积核2初始权重可能随机偏向检测红色区域
- 反向传播差异:每个卷积核根据其当前权重计算出的梯度不同
数学表达:
Δ W k = − η ∂ L ∂ W k \Delta W_k = -\eta \frac{\partial \mathcal{L}}{\partial W_k} ΔWk=−η∂Wk∂L- W k W_k Wk:第k个卷积核的权重
- η \eta η:学习率
- 不同位置的梯度导致权重更新方向不同
3)卷积核参数的「通道敏感度」
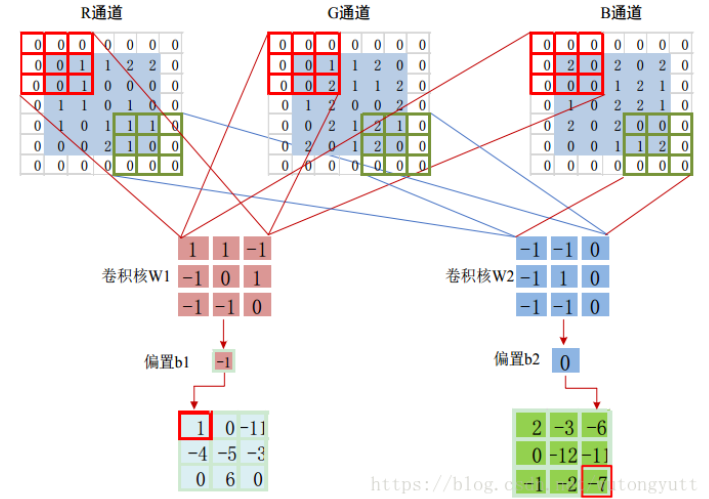
卷积操作的完整计算式为:
输出 = ∑ c = 1 C in ( 输入通道 c ∗ 卷积核权重 c ) + 偏置 \text{输出} = \sum_{c=1}^{C_{\text{in}}} (\text{输入通道}_c \ast \text{卷积核权重}_c) + \text{偏置} 输出=c=1∑Cin(输入通道c∗卷积核权重c)+偏置
其中:
- C in C_{\text{in}} Cin:输入通道数(例如RGB图为3)
- ∗ \ast ∗ 表示卷积运算
- 偏置的意义在于允许激活非零特征
- 不同的卷积核权重决定了通道敏感度,比如RGB三个通道,R通道权重放大即偏好红色特征,红色通道的输入会被加强
4)卷积核参数的「空间敏感度」
- 卷积核矩阵决定空间关注模式,每个卷积核的权重矩阵就像一张「特征检测模板」,决定了在图像中的哪些空间位置组合能激活该核的输出。
[ [ − 1 , 0 , 1 ] , [ − 2 , 0 , 2 ] , [ − 1 , 0 , 1 ] ] [[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]] [[−1,0,1],[−2,0,2],[−1,0,1]] - 这是一个经典的Sobel水平边缘检测核,当输入图像在水平方向有明暗变化时(如水平边缘),左右两侧的权重差异会放大响应值
5)参数协同工作
例. 综合检测红色水平边缘
假设一个卷积核的参数如下:
- 空间权重(与之前Sobel核相同):
[[-1, 0, 1],[-2, 0, 2],[-1, 0, 1]] - 通道权重:
- 红色:0.9, 绿色:0.1, 蓝色:-0.2
- 在红色通道中检测水平边缘 → 高响应
- 在绿色/蓝色通道的同类边缘 → 响应被抑制
- 最终输出:红色物体的水平边缘被突出显示
2.2 激活函数(nn.ReLU)
没有激活函数的神经网络等效于单层线性模型
nn.ReLU(inplace=True)
激活函数有很多种,这里是最简单的一种ReLU

1)ReLU 的数学原理
ReLU(Rectified Linear Unit)的数学定义非常简单:
f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
-
正向传播:
- 当输入 x > 0 x > 0 x>0 时,输出 f ( x ) = x f(x) = x f(x)=x(直接传递信号)。
- 当输入 x < = 0 x <= 0 x<=0 时,输出 f ( x ) = 0 f(x) = 0 f(x)=0(完全抑制信号)。
-
反向传播:
- 在 x > 0 x > 0 x>0 时,梯度为 ∂ f ∂ x = 1 \frac{\partial f}{\partial x} = 1 ∂x∂f=1(梯度无衰减)。
- 在 x < = 0 x <= 0 x<=0 时,梯度为 ∂ f ∂ x = 0 \frac{\partial f}{\partial x} = 0 ∂x∂f=0(梯度归零)。
2)引入非线性
如果神经网络只使用线性激活函数(如 ( f(x) = x )),无论堆叠多少层,最终等效于单层线性变换(( W_{\text{total}} = W_1 W_2 \cdots W_n )),无法建模复杂函数。
- ReLU 的非线性:通过分段处理(保留正信号、抑制负信号),打破线性组合,使网络能够学习非线性决策边界。
- 实际意义:ReLU 允许网络在不同区域使用不同的线性函数(正区间为线性,负区间为常数),从而组合出复杂的非线性函数。
3)缓解梯度消失
梯度消失问题通常发生在深层网络中,当反向传播时梯度逐层衰减,导致浅层参数无法更新。
ReLU 的缓解机制如下:
-
导数值恒为 1(正区间): 相比于 Sigmoid(导数最大 0.25)、Tanh(导数最大 1),ReLU 在正区间的梯度恒为 1,避免梯度随网络深度指数级衰减。
-
稀疏激活性: ReLU 会抑制负值信号(输出 0),导致部分神经元“死亡”,但活跃的神经元梯度保持完整,使有效路径的梯度稳定传递。
-
对比其他激活函数: Sigmoid:导数 ( f’(x) = f(x)(1-f(x)) ),当 ( |x| ) 较大时,导数趋近 0。 ReLU:仅需判断 ( x > 0 ),计算高效且梯度稳定。
4)输入与输出
我们输入张量尺寸为 [Channels=64, Height=224, Width=224]:
- 维度不变性:
- ReLU 是逐元素操作(element-wise),不会改变输入输出的形状,输出尺寸仍为 64×224×224。
- 数值变化:
- 正区间:保留原始值,维持特征强度。
- 负区间:置零,可能造成特征稀疏性(部分像素/通道信息丢失)。
- 实际影响:
- 如果输入中存在大量负值(如未规范化的数据),ReLU 会过滤掉这些信息,可能影响模型性能。
- 通常需配合批归一化(BatchNorm) 使用,将输入调整到以 0 为中心,减少负值抑制。
5)局限性与拓展
- 神经元死亡(Dead ReLU):
- 当输入恒为负时,梯度为 0,导致神经元永久失效。
- 解决方案:
- 使用 Leaky ReLU:允许负区间有微小梯度(如 ( f(x) = \max(0.01x, x) ))。
- Parametric ReLU (PReLU):将负区间的斜率作为可学习参数。
2.3 池化层(nn.MaxPool2d)
nn.MaxPool2d(kernel_size=2, stride=2)
1)数学原理
最大池化(Max Pooling)是一种非线性下采样操作,其核心是对输入张量的局部区域取最大值。以参数 kernel_size=2, stride=2 为例:
- 窗口划分:在输入张量的每个通道上,以
2×2的窗口(无重叠)滑动。 - 步长操作:每次滑动
2个像素(横向和纵向均移动 2 步),确保窗口不重叠。 - 计算规则:每个窗口内的最大值作为输出。
示例:
输入矩阵(2×2 窗口,步长 2):
输入 (4×4):
[[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]]输出 (2×2):
[[6, 8],[14, 16]]
- 第一个窗口(左上角)的值为
[1,2;5,6]→ 最大值 6 - 第二个窗口(右上角)的值为
[3,4;7,8]→ 最大值 8 - 依此类推。
2)核心作用
-
降维(下采样):
- 降低特征图的空间分辨率(高度和宽度),减少后续层的计算量和内存消耗。
- 例如,输入尺寸
64×224×224→ 输出64×112×112(通道数不变)。
-
特征不变性增强:
- 平移不变性:即使目标在输入中有轻微平移,最大池化仍能捕捉到其主要特征。
- 旋转/缩放鲁棒性:通过保留局部最显著特征,降低对细节变化的敏感度。
-
防止过拟合:
- 减少参数量的同时,抑制噪声对模型的影响。
-
扩大感受野:
- 通过逐步下采样,后续层的神经元能覆盖输入图像中更大的区域。
3)对输入输出的影响
以 PyTorch 的 nn.MaxPool2d(kernel_size=2, stride=2) 为例:
-
输入尺寸:
[Batch, Channels, Height, Width](如64×3×224×224)。 -
输出尺寸:
输出高度 = ⌊ 输入高度 − kernel_size stride ⌋ + 1 \text{输出高度} = \left\lfloor \frac{\text{输入高度} - \text{kernel\_size}}{\text{stride}} \right\rfloor + 1 输出高度=⌊stride输入高度−kernel_size⌋+1
同理计算宽度。- 若输入为
224×224→ 输出为112×112((224-2)/2 +1 = 112)。
- 若输入为
-
通道数不变:池化操作独立作用于每个通道,不改变通道数。
-
数值变化:
- 每个窗口仅保留最大值,其余数值被丢弃。
- 输出张量的值域与输入一致,但稀疏性可能增加(大量低值被过滤)。
4)与卷积层的区别
| 特性 | 卷积层 (nn.Conv2d) | 最大池化层 (nn.MaxPool2d) |
|---|---|---|
| 可学习参数 | 是(权重和偏置) | 否(固定操作) |
| 作用 | 提取局部特征并组合 | 下采样,保留显著特征 |
| 输出通道数 | 可自定义(通过 out_channels) | 与输入通道数相同 |
| 非线性 | 需配合激活函数(如 ReLU) | 自带非线性(取最大值) |
2.4 全连接层(nn.Linear)
nn.Linear(512*7*7, 4096)
1)数学原理
全连接层(Fully Connected Layer)的数学本质是线性变换 + 偏置,其公式为:
y = W x + b y = Wx + b y=Wx+b
-
输入向量 x ∈ R n x \in \mathbb{R}^{n} x∈Rn:将输入张量展平为一维向量(例如
512×7×7→ 512 × 7 × 7 = 25088 512 \times 7 \times 7 = 25088 512×7×7=25088维)。 -
权重矩阵 W ∈ R m × n W \in \mathbb{R}^{m \times n} W∈Rm×n:维度为
[输出维度, 输入维度],即 4096 × 25088 4096 \times 25088 4096×25088。 -
偏置向量 b ∈ R m b \in \mathbb{R}^{m} b∈Rm:维度为
4096。 -
输出向量 y ∈ R m y \in \mathbb{R}^{m} y∈Rm:维度为
4096。 -
假设输入向量 x ∈ R 25088 x \in \mathbb{R}^{25088} x∈R25088,权重矩阵 W ∈ R 4096 × 25088 W \in \mathbb{R}^{4096 \times 25088} W∈R4096×25088,偏置 b ∈ R 4096 b \in \mathbb{R}^{4096} b∈R4096,则输出向量的第 i i i 个元素为:
y i = ∑ j = 1 25088 W i , j ⋅ x j + b i y_i = \sum_{j=1}^{25088} W_{i,j} \cdot x_j + b_i yi=j=1∑25088Wi,j⋅xj+bi
每个输出元素是输入向量的加权和,权重矩阵的每一行定义了一个“特征选择器”。
2)核心作用
-
全局特征整合:
- 将卷积层提取的局部特征(如边缘、纹理)通过矩阵乘法整合为全局语义信息(如物体类别)。
- 例如:将
512×7×7的特征图(对应图像不同区域的特征)映射到更高维度的抽象语义空间(如“猫”“狗”的分类特征)。
-
非线性建模能力:
- 通常配合激活函数(如 ReLU)使用,增强网络的非线性表达能力。
-
维度压缩/扩展:
- 通过调整输出维度(如
4096),实现特征压缩(降维)或扩展(升维)。
- 通过调整输出维度(如
3)对输入输出的影响
以 nn.Linear(512*7*7, 4096) 为例:
-
输入尺寸:
- 假设输入为
[Batch=64, Channels=512, Height=7, Width=7],需先展平为[64, 512×7×7=25088]。
- 假设输入为
-
输出尺寸:
- 输出为
[Batch=64, 4096],即每个样本被映射到4096维的特征空间。
- 输出为
-
参数数量:
- 权重矩阵参数: 25088 × 4096 = 102 , 760 , 448 25088 \times 4096 = 102,760,448 25088×4096=102,760,448
- 偏置参数: 4096 4096 4096
- 总计:102,764,544 个可训练参数。
4)适用场景与局限性
-
适用场景:
- 传统卷积网络(如 AlexNet、VGG)的分类头部。
- 需要全局特征交互的任务(如语义分割中的上下文建模)。
-
局限性:
- 参数量过大:例如本例中超过 1 亿参数,易导致过拟合和计算成本高。
- 空间信息丢失:展平操作破坏特征图的空间结构,不适合需要保留位置信息的任务(如目标检测)。
-
替代方案:
- 全局平均池化(GAP):将
512×7×7压缩为512×1×1,再输入全连接层,大幅减少参数(例如 ResNet)。 - 1×1 卷积:保留空间维度,实现局部特征交互。
- 全局平均池化(GAP):将
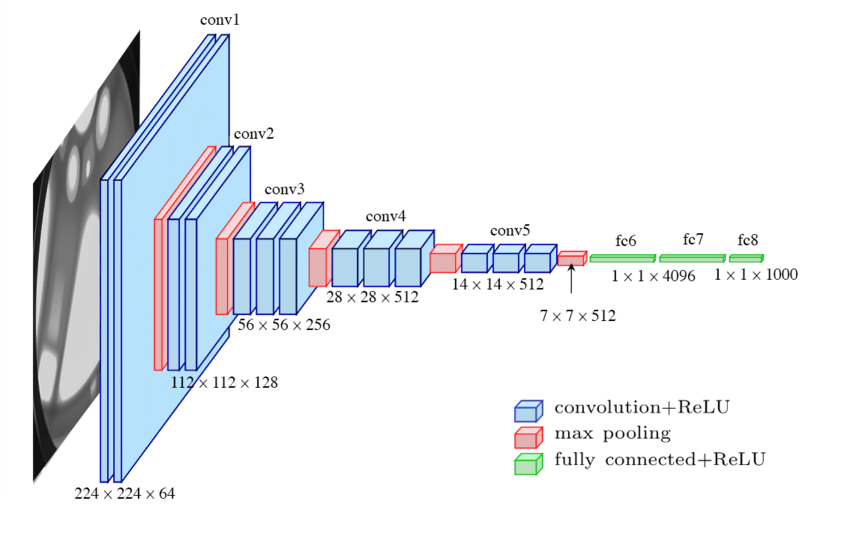
三、VGG16网络结构实现
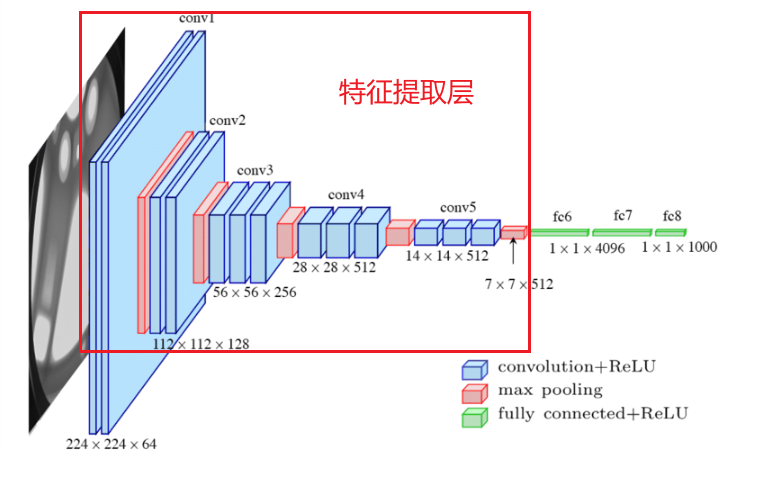
3.1 特征提取层
self.features = nn.Sequential(# Block 1 (2 conv layers)nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 输出尺寸112x112# 后续Block结构类似,此处省略...
)
3.1.1 特征提取的作用
- 特征提取的本质:通过卷积核的局部计算、ReLU的非线性激活、池化的降维,将原始像素逐步抽象为高层语义特征。
- 数学公式的递进:
像素 → 卷积+ReLU 边缘 → 卷积+ReLU 纹理 → 池化 物体部件 → ... 语义特征 \text{像素} \xrightarrow{\text{卷积+ReLU}} \text{边缘} \xrightarrow{\text{卷积+ReLU}} \text{纹理} \xrightarrow{\text{池化}} \text{物体部件} \xrightarrow{\text{...}} \text{语义特征} 像素卷积+ReLU边缘卷积+ReLU纹理池化物体部件...语义特征 - 对输入的影响:空间分辨率降低,通道数增加,特征语义逐步抽象化。
3.1.2 数学原理
-
卷积层(核心操作):
每个卷积核(如3×3)在输入特征图上滑动,计算局部区域的加权和:
输出 ( x , y ) = ∑ i = − 1 1 ∑ j = − 1 1 输入 ( x + i , y + j ) ⋅ 权重 ( i , j ) + 偏置 \text{输出}(x,y) = \sum_{i=-1}^{1}\sum_{j=-1}^{1} \text{输入}(x+i, y+j) \cdot \text{权重}(i,j) + \text{偏置} 输出(x,y)=i=−1∑1j=−1∑1输入(x+i,y+j)⋅权重(i,j)+偏置- 权重共享:同一卷积核在不同位置使用相同权重,捕捉空间不变性特征。
- 多通道:每个卷积核输出一个通道,多个卷积核组合可提取多维度特征。
-
ReLU 激活函数:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)- 作用:引入非线性,增强模型对复杂特征的表达能力。
-
最大池化层:
输出 ( x , y ) = max i , j ∈ 窗口 输入 ( x + i , y + j ) \text{输出}(x,y) = \max_{i,j \in \text{窗口}} \text{输入}(x+i, y+j) 输出(x,y)=i,j∈窗口max输入(x+i,y+j)- 作用:降维并保留最显著特征,提升模型对位置变化的鲁棒性。
以输入图像 [Batch, 3, 224, 224] 为例,逐层分析变化:
| 层类型 | 输入尺寸 | 输出尺寸 | 数学影响 |
|---|---|---|---|
| Conv2d(3→64) | [B,3,224,224] | [B,64,224,224] | 提取 64 种基础特征(边缘/颜色) |
| ReLU | [B,64,224,224] | [B,64,224,224] | 非线性激活,抑制负响应 |
| Conv2d(64→64) | [B,64,224,224] | [B,64,224,224] | 细化特征,增强局部模式组合 |
| MaxPool2d | [B,64,224,224] | [B,64,112,112] | 下采样,保留最显著特征 |
| 重复块(128→256→512) | … | … | 逐层增加通道数,提取更复杂特征 |
| 最终输出 | [B,512,7,7] | [B,512,7,7] | 高层语义特征,输入分类器或检测头 |
- 通道数变化:
3 → 64 → 128 → 256 → 512,表示特征复杂度递增。 - 空间分辨率下降:
224x224 → 7x7,通过池化逐步聚焦全局语义。
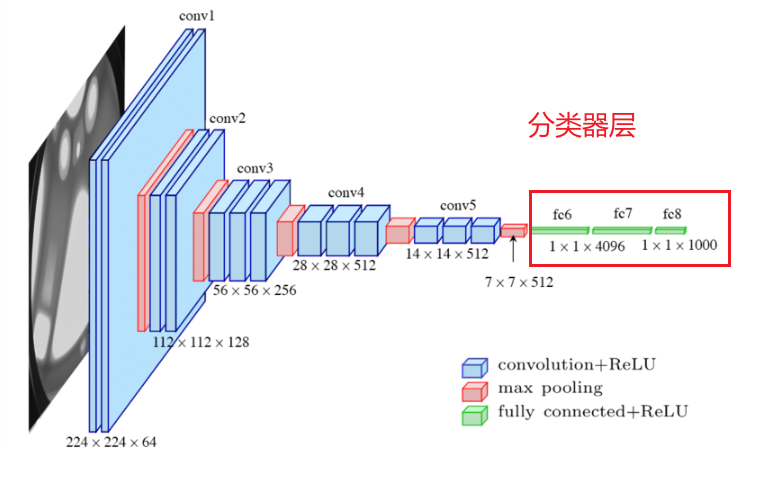
3.2 分类器层
self.classifier = nn.Sequential(nn.Dropout(p=0.5), # 防止过拟合nn.Linear(512*7*7, 4096), # 特征图维度计算nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes)
)
3.2.1 分类器层作用
分类器层(Classifier)是网络的最后阶段,负责将卷积层提取的高级语义特征映射到类别概率空间。其核心功能包括:
- 特征整合:将全局特征转化为与任务相关的判别性表示。
- 分类决策:通过全连接层(Linear)和激活函数(ReLU)生成类别得分。
- 正则化:通过Dropout减少过拟合,提升模型泛化能力。
3.2.2 数学原理
假设输入特征为 x ∈ R 512 × 7 × 7 x \in \mathbb{R}^{512 \times 7 \times 7} x∈R512×7×7(展平后为25088维),分类器层的计算流程如下:
-
Dropout层(训练阶段):
x drop = Dropout ( x , p = 0.5 ) x_{\text{drop}} = \text{Dropout}(x, p=0.5) xdrop=Dropout(x,p=0.5)- 随机将50%的神经元输出置零,防止过拟合。
-
全连接层1(降维):
y 1 = W 1 x drop + b 1 ( W 1 ∈ R 4096 × 25088 , b 1 ∈ R 4096 ) y_1 = W_1 x_{\text{drop}} + b_1 \quad (W_1 \in \mathbb{R}^{4096 \times 25088}, \, b_1 \in \mathbb{R}^{4096}) y1=W1xdrop+b1(W1∈R4096×25088,b1∈R4096)- 将25088维特征压缩到4096维。
-
ReLU激活:
a 1 = max ( 0 , y 1 ) a_1 = \max(0, y_1) a1=max(0,y1) -
重复Dropout和全连接层:
y 2 = W 2 ( Dropout ( a 1 ) ) + b 2 ( W 2 ∈ R 4096 × 4096 ) y_2 = W_2 (\text{Dropout}(a_1)) + b_2 \quad (W_2 \in \mathbb{R}^{4096 \times 4096}) y2=W2(Dropout(a1))+b2(W2∈R4096×4096)
a 2 = max ( 0 , y 2 ) a_2 = \max(0, y_2) a2=max(0,y2) -
最终分类层:
y logits = W 3 a 2 + b 3 ( W 3 ∈ R 10 × 4096 ) y_{\text{logits}} = W_3 a_2 + b_3 \quad (W_3 \in \mathbb{R}^{10 \times 4096}) ylogits=W3a2+b3(W3∈R10×4096)- 输出10维向量(CIFAR-10的类别数)。
3.2.3 与特征提取层的对比
| 特性 | 特征提取层(卷积层) | 分类器层(全连接层) |
|---|---|---|
| 输入类型 | 原始像素或低级特征 | 高级语义特征(如512×7×7) |
| 操作类型 | 局部卷积、池化 | 全局线性变换、非线性激活 |
| 参数分布 | 权重共享(卷积核) | 全连接权重(无共享) |
| 主要功能 | 提取空间局部特征(边缘→纹理→语义部件) | 整合全局特征,输出类别概率 |
| 维度变化 | 通道数增加,空间分辨率降低 | 特征维度压缩,最终输出类别数 |
三,完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import time# 数据预处理
# 将CIFAR-10的32x32图像缩放至224x224(VGG16的标准输入尺寸)。
# 使用ImageNet的均值和标准差进行归一化。
# 缺少数据增强(如随机裁剪、翻转等)。
transform = transforms.Compose([transforms.Resize(224), # VGG16 需要 224x224 的输入transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载 CIFAR-10 数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)# 定义 VGG16 模型
# 自定义VGG16模型,包含13个卷积层和3个全连接层。
# 输入尺寸为224x224,经过5次最大池化后特征图尺寸为7x7,全连接层输入维度为512 * 7 * 7=25088,符合原版VGG16设计。
# 特征提取层:13个卷积层(含ReLU激活)+ 5个最大池化层
# 分类层:3个全连接层(含Dropout)
# 输出维度:num_classes(CIFAR-10为10)
class VGG16(nn.Module):def __init__(self, num_classes=10):super(VGG16, self).__init__()# VGG16 的卷积层部分self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))# VGG16 的全连接层部分self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x) # 通过卷积层x = torch.flatten(x, 1) # 展平x = self.classifier(x) # 通过全连接层return x# 实例化模型
model = VGG16(num_classes=10)# 使用 GPU 如果可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练函数
def train(model, train_loader, criterion, optimizer, num_epochs=10):model.train() # 切换到训练模式epoch_times = []for epoch in range(num_epochs):start_time = time.time()running_loss = 0.0correct = 0total = 0for i, (inputs, labels) in enumerate(train_loader):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad() # 清空梯度outputs = model(inputs)loss = criterion(outputs, labels)loss.backward() # 反向传播optimizer.step() # 参数更新running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()epoch_loss = running_loss / len(train_loader)epoch_acc = 100. * correct / totalepoch_end_time = time.time()epoch_duration = epoch_end_time - start_timeepoch_times.append(epoch_duration)print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%, Time: {epoch_duration:.2f}s')avg_epoch_time = sum(epoch_times) / num_epochsprint(f'\nAverage Epoch Time: {avg_epoch_time:.2f}s')# 测试函数
def test(model, test_loader):model.eval() # 切换到评估模式correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()accuracy = 100. * correct / totalprint(f'Test Accuracy: {accuracy:.2f}%')# 训练和测试模型
train(model, train_loader, criterion, optimizer, num_epochs=10)
test(model, test_loader)相关文章:

【深度学习】PyTorch实现VGG16模型及网络层数学原理
一、Demo概述 代码已附在文末 1.1 代码功能 ✅ 实现VGG16网络结构✅ 在CIFAR10数据集上训练分类模型 1.2 环境配置 详见【深度学习】Windows系统Anaconda CUDA cuDNN Pytorch环境配置 二、各网络层概念 2.1 卷积层(nn.Conv2d) nn.Conv2d(in_cha…...

Spring 事务
29.Spring管理事务的方式有几种? Spring中的事务分为编程式事务和声明式事务。 编程式事务是在代码中硬编码,通过 TransactionTemplate或者 TransactionManager 手动管理事务,事务范围过大会出现事务未提交导致超时,比较适合分布…...
GPT - TransformerDecoderBlock
本节代码定义了一个 TransformerDecoderBlock 类,它是 Transformer 架构中解码器的一个基本模块。这个模块包含了多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Lay…...
(C语言完结篇))
【C语言】预处理(预编译)(C语言完结篇)
一、预定义符号 前面我们学习了C语言的编译和链接。 在C语言中设置了一些预定义符号,其可以直接使用,预定义符号也是在预处理期间处理的。 如下: 可以看到上面的预定义符号,其都有两个短下划线,要注意的是ÿ…...

【Kubernetes】Kubernetes 如何进行日志管理?Fluentd / Loki / ELK 适用于什么场景?
由于 Kubernetes 运行在容器化的环境中,应用程序和系统日志通常分布在多个容器和节点上,传统的日志管理方法(例如直接访问每个节点的日志文件)在 Kubernetes 中不适用。 因此,Kubernetes 引入了集中式日志管理方案&am…...

从 SaaS 到 MCP:构建 AI Agent 生态的标准化服务升级之路
从 SaaS 到 MCP:构建 AI Agent 生态的标准化服务升级之路 —— 以数据连接器 dslink 的技术改造实践为例 引言:AI Agent 时代的 SaaS 服务范式转型 在生成式 AI 爆发式发展的 2025 年,AI Agent 已从概念验证走向企业级应用落地,…...

Linux 入门五:Makefile—— 从手动编译到工程自动化的蜕变
一、概述:Makefile—— 工程编译的 “智能指挥官” 1. 为什么需要 Makefile? 手动编译的痛点:当工程包含数十个源文件时,每次修改都需重复输入冗长的编译命令(如gcc file1.c file2.c -o app),…...

CST入门教程:如何从SYZ参数提取电容C和电感L --- 双端口
上期解释了单端口计算S参数,然后后处理很容易提取L或C,已经满足基本需求。 这期我们看复杂一点的情况,电路中放两个端口,比如S2P: 或集总电路: 或导入SPICE: 两个端口的Y和Z参数就是四个量了,Y…...

桌面版本及服务器版本怎么查看网络源软件包的url下载路径
服务器版本: ### 利用yumdownloader工具 - 首先安装yum-utils软件包,它包含yumdownloader工具。执行命令: bash yum install yum-utils - 安装完成后,使用yumdownloader --urls <package_name>命令来获取软件包的下载UR…...

汽车零部件产线节能提效,工业网关解锁数据采集 “密码”
在汽车零部件生产领域,高效的生产监控与精准的数据采集至关重要。工业网关作为智能工厂的关键枢纽,正发挥着不可替代的作用,助力产线实现电表等多种仪表数据的采集与高效监控。 背景简析 汽车零部件产线涉及众多设备与环节,各类电…...

量化策略分类、优劣势及对抗风险解析
一、常见量化策略分类及优劣势 1. 趋势跟踪策略(Trend Following) 原理:通过捕捉价格趋势(如均线突破、动量指标)进行交易。 代表模型:海龟交易法则、Dual Thrust。 优势: 在强趋势市场&am…...

Linux调试工具——gdb/cgdb
📝前言: 这篇文章我们来讲讲Linux调试工具——gdb/cgdb: 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 🌄其他专栏:C学习笔记,C…...

SQLite + Redis = Redka
Redka 是一个基于 SQLite 实现的 Redis 替代产品,实现了 Redis 的核心功能,并且完全兼容 Redis API。它可以用于轻量级缓存、嵌入式系统、快速原型开发以及需要事务 ACID 特性的键值操作等场景。 功能特性 Redka 的主要特点包括: 使用 SQLi…...

使用 Terraform 部署 Azure landing zone
Azure 登陆区是架构完善的环境,遵循 Microsoft 针对 Azure 云架构的最佳实践。它们为团队运行工作负载提供了良好管理的基础,从而提供了可扩展性并促进了云的采用。 如果您有兴趣部署 Azure 登陆区,Terraform 是一个不错的选择。本教程概述的…...

【搭建博客网站】老旧笔记本“零成本逆袭”
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言博客网站搭建免费域名本地主机安装虚拟机安装宝塔及配置花生壳内网穿透 磁盘扩容 …...

XHR、FetchAxios详解网络相关大片文件上传下载
以下是 XHR(XMLHttpRequest) 与 Fetch API 的全面对比分析,涵盖语法、功能、兼容性等核心差异: 一、语法与代码风格 XHR(基于事件驱动) 需要手动管理请求状态(如 onreadystatechange 事件)和错误处理,代码冗长且易出现回调地狱。 const xhr = new XMLHttpRequest(); x…...
)
共享内存(与消息队列相似)
目录 共享内存概述 共享内存函数 (1)shmget函数 功能概述 函数原型 参数解释 返回值 示例 结果 (2)shmat函数 功能概述 函数原型 参数解释 返回值 (3)shmdt函数 功能概述 函数原型 参数解释…...

【3D开发SDK】HOOPS SDKS如何在BIM行业运用?
Tech Soft 3D提供了支持核心功能的软件开发工具,使开发人员可以使用Windows,Linux,OSX和移动平台等广泛的平台来构建巨大而复杂的建筑和BIM应用程序。HOOPS SDK支持多种格式的CAD导入和3D查看技术。这些技术受到了Trimble,RIB&…...

纳米软件矿用电源模块自动化测试方案分享
矿用电源模块主要是用于矿井等危险环境的一种电源系统,它可以为矿井中的仪器提供充足的电力支持。由于矿用电源经常用在危险环境中,因此对于矿用电源的稳定性要求极为严格。 纳米软件矿用电源模块自动化测试方案 测试需求分析 矿用电源模块作为矿井作业…...

pycharm中安装Charm-Crypto
一、安装依赖 1、安装gcc、make、perl sudo apt-get install gcc sudo apt-get install make sudo apt-get install perl #检查版本 gcc -v make -v perl -v 2、安装依赖库m4、flex、bison(如果前面安装过pypbc的话,应该已经装过这些包了) sudo apt-get update sudo apt…...

RTX30系显卡运行Tensorflow 1.15 GPU版本
30系显卡只支持cuda11.0及以上版本,但很多tensorflow项目用的仍然是1.1x版本,这些版本需要cuda10或者以下版本,这就导致在30系显卡上无法正常运1.1x版本的tensorflow,最近几天我也因为这个问题头疼不已,网上一番搜索…...

adb|scrcpy的安装和配置方法|手机投屏电脑|手机声音投电脑|adb连接模拟器或手机
adb|scrcpy的安装和配置方法手机投屏电脑|手机声音投电脑|adb连接模拟器或手机或电视 引言 在数字设备交织的现代生活中,adb(Android Debug Bridge)与 scrcpy 宛如隐匿的强大工具,极大地拓展了我们操控手机、模拟器乃至智能电视等…...
:Chat、流式与文生图模型功能)
LangChain4j(2):Chat、流式与文生图模型功能
本文将探讨 LangChain4j 的聊天对话、流式对话以及文生图这三种常见且实用的功能,以及实际代码示例 一、聊天对话(ChatLanguageModel) 在 LangChain4j 中,使用ChatLanguageModel进行基本的聊天对话简单直观。以下是一段示例代码&a…...

Uniapp当中的async/await的作用
一、原始代码的行为(使用 async/await) const getUserMessagePlan async () > {// 等待两个异步操作完成const tabsList await message.getTagesList(); // 等待获取标签列表const tagsStateList await message.getTagsStateList(); // 等…...

JS包装类型Array
reduce()函数 没有起始值的执行过程 有初始值的执行过程 计算对象 是对象数组的情况 数组类型 方法...

Cursor + MCP让Blender实现自动建模
先决条件 Blender 3.0 或更新版本 Python 3.10 或更高版本 uv Blender安装 && 插件安装 下载Blender,版本最好是3.x以上的版本,选择适合自己的平台,地址:Download — blender.org 安装插件 从https://g…...

websocket深入-webflux+websocket
文章目录 背景版本约定配置文件代码使用webflux使用websocket配置文件handler基类实现类注册路由 背景 基于更复杂的情况和更高的开发要求,我们可能会遇到必须同时要使用webflux和websocket的情况。 版本约定 JDK21Springboot 3.2.0Fastjson2lombok 配置文件 &…...
)
LangChain-输出解析器 (Output Parsers)
输出解析器是LangChain的重要组件,用于将语言模型的原始文本输出转换为结构化数据。本文档详细介绍了输出解析器的类型、功能和最佳实践。 概述 语言模型通常输出自然语言文本,但在应用开发中,我们经常需要将这些文本转换为结构化的数据格式…...

wsl2+ubuntu22.04安装blenderproc教程
本章教程,介绍如何在windows操作系统上通过wsl2+Ubuntu22.04上安装blenderproc。 一、pipi安装方式 推荐使用minconda3安装Python环境。 pip install Blenderproc二、源码安装 1、下载源码 git clone https://github.com/DLR-RM/BlenderProc2、安装依赖 cd BlenderProc &am…...

矩阵热图】】
一、基础热图绘制 import matplotlib.pyplot as plt import numpy as np# 模拟数据生成 matching_history [np.random.randint(0, 2, (5, 3)) for _ in range(4)] # 5个UE,3个边缘服务器,4次迭代# 绘制最终匹配矩阵 plt.figure(figsize(10, 6)) plt.i…...

opencv人脸性别年龄检测
一、引言 在计算机视觉领域,人脸分析是一个热门且应用广泛的研究方向。其中,人脸性别年龄检测能够自动识别图像或视频流中人脸的性别和年龄信息,具有诸多实际应用场景,如市场调研、安防监控、用户个性化体验等。OpenCV 作为一个强…...

idea里面不能运行 node 命令 cmd 里面可以运行咋回事啊
idea里面不能运行 node 命令 cmd 里面可以运行咋回事啊 在 IntelliJ IDEA(或其他 JetBrains 系列 IDE)中无法运行某些命令,但在系统的命令提示符(CMD)中可以正常运行,这种情况通常是由于以下原因之一导致的…...

【ROS】软件包后期添加依赖
【ROS】软件包后期添加依赖 前言整体思路修改 package.xml1. 构建依赖(build_depend)2. 构建导出依赖(build_export_depend)3. 运行依赖(exec_depend)如何修改 修改 CMakeLists.txt修改 find_package其他修…...
)
十三届蓝桥杯Java省赛 B组(持续更新..)
目录 十三届蓝桥杯Java省赛 B组第一题:星期计算第二题:山第三题:字符统计第四题:最少刷题数第五题:求阶乘第六题:最大子矩阵第七题:数组切分第八题:回忆迷宫第九题:红绿灯…...

生成式人工智能的价值回归:重塑技术、社会与个体的发展轨迹
在数字化浪潮的席卷之下,生成式人工智能(Generative AI)正以前所未有的速度重塑人类社会的面貌。这项技术不仅被视为人工智能发展的新阶段,更被赋予了推动生产力跃升、加速社会形态变革的历史使命。生成式人工智能的价值回归,不仅体现在技术本身的革新与突破,更在于其对个…...

【工具开发教程】通过批量OCR识别PDF扫描件中的文本,给PDF批量重命名,基于WPF和阿里云的实现方案,超详细
以下是基于WPF和阿里云实现批量OCR识别PDF扫描件中的文本,并给PDF批量重命名的项目方案,包含项目背景、界面设计、代码步骤和开发总结。 一、项目背景 在日常办公或学习中,处理大量PDF扫描件时,常常需要手动提取文件中的文本内容并重命名文件。这种方式效率低下且容易出错…...

AI 重构 Java 遗留系统:从静态方法到 Spring Bean 注入的自动化升级
在当今快速发展的软件行业中,许多企业都面临着 Java 遗留系统的维护和升级难题。这些老旧系统往往采用了大量静态方法,随着业务的不断发展,其局限性日益凸显。而飞算 JavaAI 作为一款强大的 AI 工具,为 Java 遗留系统的重构提供了…...

JS—同源策略:2分钟掌握同源策略
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–什么是“同源”?三–同源策略的限制范围四–允许跨源的场景五–如何绕过同源策略(安全方式)六–同源策略的安全意义七–总结 二. 什么是“同源”? …...

【C++】关于scanf是否需要使用的快速记忆
在 C 语言中,scanf 函数用于从标准输入读取数据并存储到变量中。scanf 函数需要知道变量的内存地址,以便将输入的数据存储到正确的内存位置。这就是为什么在大多数情况下需要使用 & 符号的原因。 1. 为什么需要使用& & 符号用于获取变量的内…...
)
BUUCTF-web刷题篇(19)
28.CheckIn 源码: #index.php <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><meta http-equiv&q…...

国家优青ppt美化_青年科学基金项目B类ppt案例模板
国家优青 国家优青,全称“国家优秀青年基金获得者”。2025改名青年科学基金B类。 作为自然基金人才资助类型,支持青年学者在基础研究方面自主选择研究方向开展创新研究。它是通往更高层次科研荣誉的重要阶梯,是准杰青梯队。 / WordinPPT /…...

【HTML】动态背景效果前端页面
下面是一个带有多种动态背景效果的现代化前端页面,包含粒子效果、渐变波浪和星空背景三种可选动态背景。直接上代码!! <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name&quo…...

前端面试宝典---创建对象的配置
Object.create 对整个对象的多个属性值进行配置 创建对象 不可更改属性值 // 创建对象 不可更改属性值 let obj Object.create({}, {name: {value: lisi,writable: false,},age: {value: 20,writable: true,} })console.log(初始化obj, obj) obj.name wangwu console.log(…...
)
Linux重启命令(Linux Restart Command)
Linux重启命令:深入了解reboot、shutdown、init和systemctl 在Linux系统中,重启系统是一个常见的操作,可以通过多种命令来实现。以下是一些常用的重启命令及其区别: reboot 这是一个非常通用的命令,用于重启系统。 它…...
序列图)
UML-饮料自助销售系统(饮料已售完)序列图
一、题目: 在饮料自动销售系统中,顾客选择想要的饮料。系统提示需要投入的金额,顾客从机器的前端钱币口投入钱币,钱币到达钱币记录仪,记录仪更新自己的选择。正常时记录仪通知分配器分发饮料到机器前端,但可…...

第7课:智能体安全与可靠性保障
智能体安全与可靠性保障:从攻击防御到隐私保护的全栈实践 一、引言:当智能体走向开放世界:安全为何成为协作的“生命线” 随着多智能体系统(MAS)在金融、医疗、自动驾驶等关键领域的落地,安全风险呈指数级…...

前端性能优化核弹级方案:CSS分层渲染+Wasm,首屏提速300%!
前端性能优化核弹级方案:CSS分层渲染Wasm实现首屏提速300%的终极指南 在当今Web应用日益复杂的背景下,性能优化已成为前端开发的核心竞争力。本文将深入剖析两种革命性的前端性能优化技术——CSS分层渲染与WebAssembly(Wasm)的协同应用,揭示…...

有一个服务器能做什么?
服务器对于程序员来说就是一个超级便利的机器,可以用自己的知识来做出许多的使用场景。 搭建网站和应用程序 个人网站:可以创建个人博客、作品集网站或简历网站等,用于展示个人才华、分享经验和知识。 企业网站:为企业搭建官方…...

华为RH2288H V3服务器极速重装:从RedHat到openEuler 24超详细重装指南
1 登录iBMC口 2 配置启动项 点击:配置,点击:系统启动项 点击:单次有效,选择:光驱,点击:保存 3 进Remote Contro 点击:远程控制,进入如下界面 点击࿱…...

AI集群设计
关键要素 硬件选型 计算节点:通常选用配备高性能 GPU(如 NVIDIA A100、H100 等)的服务器,以提供强大的并行计算能力,加速深度学习模型的训练和推理过程。网络设备:采用高速网络,如 InfiniBand …...