哈希表的封装
目录
引入
哈希表封装
修改哈希表参数
修改哈希表成员
修改%时使用的变量
修改读取时获得的变量
迭代器的实现
迭代器的定义
迭代器++
迭代器*解引用
迭代器->成员访问
迭代器重载==和!=
封装迭代器
HashTable迭代器封装
非const版本
const版本
unordered_set迭代器封装
unordered_map迭代器封装
修改insert的返回值
unordered_map的[ ]解引用重载
代码汇总
引入
unordered_set和unordered_map是由哈希表封装而来的。前面介绍了解决哈希冲突的两种方式:开散列和闭散列。此篇博客将会采用开散列进行封装,模拟实现unordered_set和unordered_map。
哈希表(开散列)的实现-CSDN博客文章浏览阅读523次,点赞24次,收藏26次。通过除留余数法确定数据位置,再根据开散列的方法解决哈希冲突。本篇博客对哈希表开散列的实现进行细致剖析,帮助读者理解哈希表性能的优缺点。https://blog.csdn.net/2401_87944878/article/details/146923387哈希表(闭散列)的实现-CSDN博客文章浏览阅读925次,点赞43次,收藏44次。通过除留余数法确定数据位置,再根据闭散列的方法解决哈希冲突。本篇博客对哈希表闭散列的实现进行细致剖析,帮助读者理解哈希表性能的优缺点。
https://blog.csdn.net/2401_87944878/article/details/146922720
此处贴出哈希表开散列的代码,如有疑问可以参考。我们将借助一下代码对哈希表进行封装。
template<class K,class V>
struct HashNode
{//默认构造HashNode(const pair<K,V>& kv=pair()):_kv(kv),_next(nullptr){ }pair<K, V> _kv;HashNode* _next;
};template<class K,class V>
class HashTable
{typedef HashNode<K, V> Node;
public://默认构造HashTable(){_table.resize(10); //初始情况下数组有10个空间_n = 0;}//扩容void More(){if ((double)_n / _table.size() >= 1){//进行扩容HashTable newtable;size_t newsize = 2 * _table.size();newtable._table.resize(newsize); //扩容两倍扩size_t hashi = 0;while (hashi < _table.size()){if (_table[hashi]){//将数据进行头插Node* pcur = _table[hashi];while (pcur){Node* next = pcur->_next;pcur->_next = newtable._table[hashi];newtable._table[hashi] = pcur;pcur = next;}}hashi++;}_table.swap(newtable._table);}}//插入bool insert(const pair<K, V>& kv){//扩容More();size_t hashi = kv.first % _table.size();Node* newnode = new Node(kv);//将数据头插到对应映射的位置newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;}//查找bool Find(const K& key){size_t hashi = key % _table.size();Node* pcur = _table[hashi];while (pcur){if (pcur->_kv.first == key){return true;}pcur = pcur->_next;}return false;}//删除bool Erase(const K& key){size_t hashi = key % _table.size();Node* pcur = _table[hashi];Node* parent = nullptr;while (pcur){if (pcur->_kv.first == key){if (parent == nullptr){delete pcur;pcur = nullptr;_table[hashi] = nullptr;}else{parent->_next = pcur->_next;delete pcur;}return true;}pcur = pcur->_next;}return false;}private:vector<Node*> _table;size_t _n; //存储有效数据
};哈希表封装
哈希表的封装与红黑树的封装异曲同工之妙,没看过红黑树封装的可以看看,此处贴链接:
set和map封装-CSDN博客文章浏览阅读1k次,点赞51次,收藏29次。本文对set和map的底层实现进行深度剖析,分析如何通过相同的底层逻辑红黑树来封装出不同的容器,对set和map的迭代器进行底层实现,对库中封装的逻辑进行详细分析,帮助读者理解两种容器的结构以及实现逻辑。https://blog.csdn.net/2401_87944878/article/details/146424819
修改哈希表参数
哈希表的模板参数就现在看来需要两个:1)确定查找数据的类型;2)用于存储数据的类型。
注意:关于哈希表的模板参数并不止这两种,在后面还需要添加。
对于unordered_set来说:查找数据的类型和存储数据的类型是一样的,都是T。
而对于unordered_map来说:查找数据的类型是key,而存储数据的类型是pair。
template<class T>
class set
{typedef HashTable<T, T> Hash;
public:private:Hash _hash;
};template<class K, class V>
class map
{typedef HashTable<K, pair<K, V>> Hash;
public:private:Hash _hash;
};修改哈希表成员
此时哈希表的成员不再是pair了,而要使用date来实现泛型编程。
template<class T>
struct HashNode
{//默认构造HashNode(const T& date = T()):_date(date), _next(nullptr){}T _date;HashNode* _next;
};将哈希表中的pair全部用date取代。
修改%时使用的变量
当哈希表中存储的时string类型时,就不能取模。所以需要通过仿函数来实现对string类型的取模。
通过添加模板参数来决定%取模的方式。
对于string类型来说:采用将字符串的每一个字符相加作为其返回的整形;通过在每次相加前乘以131可以保证对于不同顺序的字符串可以返回不同的整形进而降低了哈希冲突
template<class K>
struct HashFunc //用于普通整形返回
{//对于普通整形进行返回size_t operator()(const K& key){return (size_t)key; // 转化为size_t 类型后,还能保证负数也可以找到对应下标位置}
};struct HashString //用于string返回整形
{size_t operator()(const string& st){//此处采用将字符串的每一个字符相加作为其返回的整形size_t hashi = 0;for (auto e : st){hashi *= 131; //通过在相加前乘以131可以保证对于不同顺序的字符串可以返回不同的整形//进而降低了哈希冲突hashi += e;}return hashi;}
};此处也可以使用模板特化来代替使用多个类型。
template<class K>
struct HashFunc //用于普通整形返回
{//对于普通整形进行返回size_t operator()(const K& key){return (size_t)key; // 转化为size_t 类型后,还能保证负数也可以找到对应下标位置}
};template<>
struct HashFunc<string>
{size_t operator()(const string& st){size_t hashi = 0;for (auto e : st){hashi *= 131; hashi += e;}return hashi;}
};template<class K, class T,class Func=HashFunc<K>>
class HashTable
{//....
}将每次对K进行%取模前,使用仿函数获取整形,以下是部分处理方式。
Func func;
size_t hashi = func(date) % _table.size();修改读取时获得的变量
在查找时要进行数据的比较,对于set来说只有T一种类型,可以直接进行比较。而对于map来说,其存储的是pair,比较时要用pair的第一个参数first进行比较。所以需要增加一个内部类来实现取出比较元素。
在set和map中分别实现内部类,来获取其比较是用的数据;对于set来说返回的就是T,而对于map来说返回的则是pair中存储的first。在RBTree添加一个模板参数用来保存内部类即可。
template<class T>
class set
{struct SetofK{const T& operator()(const T& key){return key;}};typedef HashTable<T, T,SetofK> Hash;private:Hash _hash;
};
template<class K, class V>
class map
{struct MapofK{const K& operator()(const pair<K, V>& kv){return kv.first;}};typedef HashTable<K, pair<K, V>,MapofK> Hash;
public:private:Hash _hash;
};template<class K, class T,class TofK, class Func=HashFunc<K>>
class HashTable
{//....
}在进行比较前使用仿函数获取进行处理的数据,如以下代码。
Func func;
TofK getkey;
size_t hashi = func(getkey(date)) % _table.size();
迭代器的实现
哈希表中存储的是节点,所以其迭代器底层是存储每一个节点的结构体。
其结构体成员有节点指针,还需要哈希表。因为在对迭代器进行++时,可能会出现从一个链表跳转到另一个链表。
迭代器的定义
template<class K, class T,class Ref,class Ptr ,class TofK>
struct HashIterator
{typedef HashTable<K, T, TofK> HashTable;typedef HashNode<T> Node;typedef HashIterator<K, T, Ref, Ptr, TofK> Self;//构造//构造HashIterator(Node* node,HashTable* hash):_node(node),_hash(hash){}Node* _node;HashTable* _hash;
};迭代器++
迭代器++分为两种情况:1)当前节点有下一个节点,返回下一个节点即可;2)当前节点没有下一个节点,从当前节点对应的哈希表位置向后找,找到不为空的位置。
在迭代器中需要访问哈希表的vector,所以需要将迭代器置为HashTable的友元。
//迭代器++
Self operator++()
{HashFunc<K> func;if (_node->_next){_node = _node->_next;return *this;}else{TofK getkey;size_t hashi = func(getkey(_node->_date));hashi = hashi % _hash->_table.size();++hashi;while (hashi < _hash->_table.size()){if (_hash->_table[hashi]){_node = _hash->_table[hashi];return *this;}else{++hashi;}}//结尾了_node = nullptr;return *this;}
}迭代器*解引用
Ref operator*()
{return _node->_date;
}迭代器->成员访问
Ptr operator->()
{return &(_node->_date);
}迭代器重载==和!=
//等于
bool operator==(Self& it)
{return _node == it._node;
}//不等于
bool operator!=(Self& it)
{return _node != it._node;
}封装迭代器
HashTable迭代器封装
非const版本
template<class K, class T,class TofK, class Func=HashFunc<K>>
class HashTable
{typedef HashNode<T> Node;
public:typedef HashIterator<K, T, T&, T*, TofK> iterator;typedef HashIterator<K, T, const T&, const T*, TofK> const_iterator;//beginiterator begin(){//找到哈希表中第一个不为空的位置size_t hashi = 0;while (hashi<_table.size()){if (_table[hashi]){return iterator(_table[hashi], this);}++hashi;}return iterator(nullptr, this);}//enditerator end(){return iterator(nullptr, this);}
}const版本
//begin
const_iterator begin()const
{//找到哈希表中第一个不为空的位置size_t hashi = 0;while (hashi < _table.size()){if (_table[hashi]){return iterator(_table[hashi], this);}++hashi;}return iterator(nullptr, this);
}//end
const_iterator end()const
{return iterator(nullptr, this);
}unordered_set迭代器封装
对于插入到哈希表中的数据来说,用于比较的数据是不能被修改的,所以对set来说其存储的key值不能进行修改,所以unordered_set的普通迭代器的实质还是const迭代器。
_hash.begin()返回的是普通迭代器,而set的普通迭代器实际上还是const迭代器,普通迭代器和const迭代器虽然是来自同一个模板,但是其是完全不同的两个类,所以此处需要用返回的普通迭代器中的数据来构造一个const迭代器。
template<class T>
class set
{typedef HashTable<T, T,SetofK> Hash;typedef typename Hash::iterator Iterator; //普通迭代器
public:typedef typename Hash::const_iterator iterator; //const迭代器typedef typename Hash::const_iterator const_iterator; //const迭代器iterator begin(){Iterator ret = _hash.begin();return iterator(ret._node,&_hash);}iterator end(){Iterator ret = _hash.end();return iterator(ret._node,&_hash);}private:Hash _hash;
};unordered_map迭代器封装
unordered_map的K也不能进行修改,但是T可以进行修改,所以map普通迭代器不变,但是还需要实现对Key值的不能修改,此处的实现就比较简单了,可以直接在pair的模板参数中使用const Key即可。
template<class K, class V>
class map
{typedef HashTable<K, pair<const K, V>,MapofK> Hash;
public:typedef typename Hash::iterator iterator;typedef typename Hash::const_iterator const_iterator;iterator begin(){return _hash.begin();}iterator end(){return _hash.end();}private:Hash _hash;
};修改insert的返回值
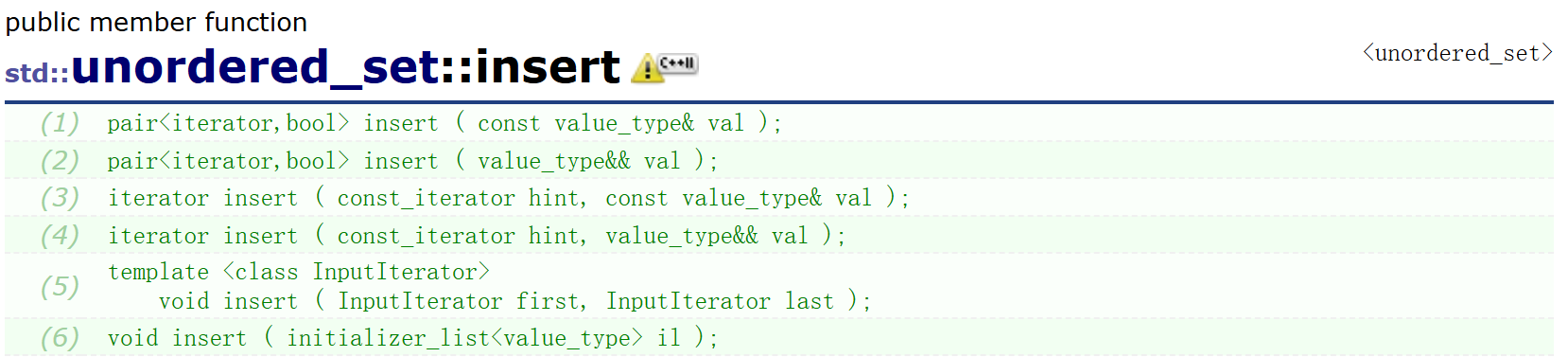
可以看到在库中,insert的返回值是pair,所以此处对返回值进行修改。将原本的bool,改为pair类型即可。
将return true改为return make_pair(iterator(newnode,this), true);即可。
对于unordered_set的insert返回值还是需要先保留再转化。
pair<iterator, bool> insert(const T& val)
{pair<Iterator, bool> it = _hash.insert(val);return make_pair(iterator(it.first._node, &_hash), it.second);
}unordered_map的[ ]解引用重载
unordered_map的解引用重载的实现,底层还是insert,对没有的数据进行插入,对已经存在的数据返回T。
V& operator[](const K& key)
{pair<iterator, bool> it = _hash.insert(make_pair(key, V()));return it.first._node->_date.second;
}代码汇总
<HashTable>
template<class T>
struct HashNode
{//默认构造HashNode(const T& date = T()):_date(date), _next(nullptr){}T _date;HashNode* _next;
};template<class K>
struct HashFunc //用于普通整形返回
{//对于普通整形进行返回size_t operator()(const K& key){return (size_t)key; // 转化为size_t 类型后,还能保证负数也可以找到对应下标位置}
};template<>
struct HashFunc<string>
{size_t operator()(const string& st){size_t hashi = 0;for (auto e : st){hashi *= 131; hashi += e;}return hashi;}
};struct HashString //用于string返回整形
{size_t operator()(const string& st){//此处采用将字符串的每一个字符相加作为其返回的整形size_t hashi = 0;for (auto e : st){hashi *= 131; //通过在相加前乘以131可以保证对于不同顺序的字符串可以返回不同的整形//进而降低了哈希冲突hashi += e;}return hashi;}
};template<class K, class T, class Ref, class Ptr, class TofK>
struct HashIterator;template<class K, class T,class TofK, class Func=HashFunc<K>>
class HashTable
{typedef HashNode<T> Node;
public:typedef HashIterator<K, T, T&, T*, TofK> iterator;typedef HashIterator<K, T, const T&, const T*, TofK> const_iterator;//beginiterator begin(){//找到哈希表中第一个不为空的位置size_t hashi = 0;while (hashi<_table.size()){if (_table[hashi]){return iterator(_table[hashi], this);}++hashi;}return iterator(nullptr, this);}//enditerator end(){return iterator(nullptr, this);}//beginconst_iterator begin()const{//找到哈希表中第一个不为空的位置size_t hashi = 0;while (hashi < _table.size()){if (_table[hashi]){return iterator(_table[hashi], this);}++hashi;}return iterator(nullptr, this);}//endconst_iterator end()const{return iterator(nullptr, this);}//默认构造HashTable(){_table.resize(10); //初始情况下数组有10个空间_n = 0;}//扩容void More(){if ((double)_n / _table.size() >= 1){//进行扩容HashTable newtable;size_t newsize = 2 * _table.size();newtable._table.resize(newsize); //扩容两倍扩size_t hashi = 0;while (hashi < _table.size()){if (_table[hashi]){//将数据进行头插Node* pcur = _table[hashi];while (pcur){Node* next = pcur->_next;pcur->_next = newtable._table[hashi];newtable._table[hashi] = pcur;pcur = next;}}hashi++;}_table.swap(newtable._table);}}//插入pair<iterator ,bool> insert(const T& date){//扩容More();Func func;TofK getkey;size_t hashi = func(getkey(date)) % _table.size();Node* newnode = new Node(date);//将数据头插到对应映射的位置newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return make_pair(iterator(newnode,this), true);}//查找bool Find(const K& key){TofK getkey;Func func;size_t hashi = func(getkey(key)) % _table.size();Node* pcur = _table[hashi];while (pcur){if (pcur-> _date == key){return true;}pcur = pcur->_next;}return false;}//删除bool Erase(const K& key){Func func;TofK getkey;size_t hashi = func(key) % _table.size();Node* pcur = _table[hashi];Node* parent = nullptr;while (pcur){if (getkey(pcur->date) == key){if (parent == nullptr){delete pcur;pcur = nullptr;_table[hashi] = nullptr;}else{parent->_next = pcur->_next;delete pcur;}return true;}pcur = pcur->_next;}return false;}template<class K, class T, class Ref, class Ptr, class TofK>friend struct HashIterator;
private:vector<Node*> _table;size_t _n; //存储有效数据
};template<class K, class T,class Ref,class Ptr ,class TofK>
struct HashIterator
{typedef HashTable<K, T, TofK> HashTable;typedef HashNode<T> Node;typedef HashIterator<K, T, Ref, Ptr, TofK> Self;//构造HashIterator(Node* node,HashTable* hash):_node(node),_hash(hash){}//迭代器++Self operator++(){HashFunc<K> func; if (_node->_next){_node = _node->_next;return *this;}else{TofK getkey;size_t hashi = func(getkey(_node->_date));hashi = hashi % _hash->_table.size();++hashi;while (hashi < _hash->_table.size()){if (_hash->_table[hashi]){_node = _hash->_table[hashi];return *this;}else{++hashi;}}//结尾了_node = nullptr;return *this;}}Ref operator*(){return _node->_date;}Ptr operator->(){return &(_node->_date);}//等于bool operator==(Self& it){return _node == it._node;}//不等于bool operator!=(Self& it){return _node != it._node;}Node* _node;HashTable* _hash;
};<unordered_set>
template<class T>
class set
{struct SetofK{const T& operator()(const T& key){return key;}};typedef HashTable<T, T,SetofK> Hash;typedef typename Hash::iterator Iterator; //普通迭代器
public:typedef typename Hash::const_iterator iterator; //const迭代器typedef typename Hash::const_iterator const_iterator; //const迭代器iterator begin(){Iterator ret = _hash.begin();return iterator(ret._node,&_hash);}iterator end(){Iterator ret = _hash.end();return iterator(ret._node,&_hash);}pair<iterator, bool> insert(const T& val){pair<Iterator, bool> it = _hash.insert(val);return make_pair(iterator(it.first._node, &_hash), it.second);}private:Hash _hash;
};<unordered_map>
template<class K, class V>
class map
{struct MapofK{const K& operator()(const pair<K, V>& kv){return kv.first;}};typedef HashTable<K, pair<const K, V>,MapofK> Hash;
public:typedef typename Hash::iterator iterator;typedef typename Hash::const_iterator const_iterator;iterator begin(){return _hash.begin();}iterator end(){return _hash.end();}pair<iterator,bool> insert(const pair<K, V> kv){pair<iterator,bool> it = _hash.insert(kv);return make_pair(iterator(it.first._node,&_hash), it.second);}V& operator[](const K& key){pair<iterator, bool> it = _hash.insert(make_pair(key, V()));return it.first._node->_date.second;}private:Hash _hash;
};相关文章:

哈希表的封装
目录 引入 哈希表封装 修改哈希表参数 修改哈希表成员 修改%时使用的变量 修改读取时获得的变量 迭代器的实现 迭代器的定义 迭代器 迭代器*解引用 迭代器->成员访问 迭代器重载和! 封装迭代器 HashTable迭代器封装 非const版本 const版本 unordered_set迭…...

2025年认证杯数模竞赛赛题浅析-快速选题
赛题浅析 认证杯作为国内最早的数学建模论坛、唯一一个全部公开参赛论文的竞赛、国内最大的数学建模竞赛之一、唯一一个对非学生群里开放的数学建模竞赛、国内唯二的支持高中生参赛的大学生数模竞赛。在数模界一直被视为国赛之前较好的练手赛,本文将初步简略得介绍…...

【网络安全】Linux 常见命令
未经许可,不得转载。 文章目录 正文系统信息查看用户与权限管理进程管理网络配置与检测文件操作日志查看与分析权限审计与安全检测正文 在网络安全工作中,熟练掌握 Linux 系统中的常用命令,对于日常运维、日志分析、安全排查等工作至关重要。 以下为常用命令汇总,供参考。…...

电脑卡顿严重怎么办 电脑卡顿的处理指南
电脑突然卡顿比较严重,这是很多用户都曾经遇到过的问题,鼠标一直转圈圈,无法进行任何操作。电脑卡顿,电脑卡顿不仅会降低工作效率,还可能导致数据丢失,数据无法保存。很多用户解决电脑卡顿的方法就是直接一…...
之测试前后端连接)
山东大学软件学院创新项目实训开发日志(9)之测试前后端连接
在正式开始前后端功能开发前,在队友的帮助下,成功完成了前后端测试连接: 首先在后端编写一个测试相应程序: 然后在前端创建vue 并且在index.js中添加一下元素: 然后进行测试,测试成功: 后续可…...

H.264 NVMPI解码性能优化策略
H.264 NVMPI解码性能优化策略 1. 硬件与驱动配置 JetPack版本匹配:确保NVIDIA Jetson设备的JetPack SDK版本与CUDA驱动兼容,避免因驱动不匹配导致硬件解码性能下降8。显存分配优化:调整FFmpeg的-hwaccel_device参数指定GPU…...

汽车软件开发常用的需求管理工具汇总
目录 往期推荐 DOORS(IBM ) 行业应用企业: 应用背景: 主要特点: Polarion ALM(Siemens) 行业应用企业: 应用背景: 主要特点: Codebeamer ALM&#x…...

如何从零构建一个自己的 CentOS 基础镜像
如何从零构建一个自己的 CentOS 基础镜像 从零构建一个基于 CentOS 的基础镜像是一个很好的实践,可以帮助你理解 Docker 镜像的底层原理。以下是以 CentOS 为例,从零开始(不依赖现有镜像)构建基础镜像的详细步骤。我们将使用 yum…...

mongodb和clickhouse比较
好问题——MongoDB 也能处理这种高写入 定期删除的时间序列场景,尤其从 MongoDB 5.0 开始支持了专门的 Time Series Collections(时间序列集合),对你的需求其实挺对口的。 不过它有些优点和局限,需要具体分析下你场景…...

C#容器源码分析 --- List
List是一个非常常用的泛型集合类,它位于 System.Collections.Generic 命名空间下,本质上是一个动态数组,它提供了一系列方便的方法来管理和操作元素,例如添加、删除、查找等。与传统的数组相比,List可以根据需要动态调…...

以太坊区块大小的决定因素:深入解析区块 Gas 限制及其影响
以太坊(Ethereum)作为全球领先的区块链平台,其区块大小并非固定的物理尺寸,而是由区块 Gas 限制(Block Gas Limit)所决定。理解区块 Gas 限制及其影响因素,对于深入掌握以太坊网络的运行机制至…...

利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“…...

智慧养老实训基地建设方案:如何以科技赋能养老实操培训
在人口老龄化加剧的当下,智慧养老产业蓬勃发展,对专业技能型人才的需求愈发迫切。智慧养老实训基地建设意义非凡,它为培育具备实操能力与创新思维的养老人才搭建关键平台,有助于填补行业人才缺口,推动养老服务从传统模…...
实战:漏洞拦截与威胁情报集成)
基于AI的Web应用防火墙(AppWall)实战:漏洞拦截与威胁情报集成
摘要:针对Web应用面临的OWASP、CVE等漏洞攻击,本文结合群联AI云防护系统的AppWall模块,详解AI规则双引擎的防御原理,并提供漏洞拦截配置与威胁情报集成代码示例。 一、Web应用安全挑战与AppWall优势 传统WAF依赖规则库更新滞后&a…...

什么是采购管理?如何做好采购管理的持续优化?
你是不是也遇到过这种情况: 公司采购部刚换了新供应商,结果原材料质量忽高忽低,生产线上三天两头出状况;行政采购的办公用品,月初买回来月底就堆在仓库吃灰;财务部天天追着问采购成本怎么又超支了... 这些…...

Unity 设置弹窗Tips位置
根据鼠标位于屏幕的区域,设置弹窗锚点以及位置 public static void TipsPos(Transform tf) {//获取ui相机var uiCamera GetUICamera();var popup tf.GetComponent<RectTransform>();//获取鼠标位置Vector2 mousePos Input.mousePosition;float screenWidt…...

区块链知识点5-Solidity编程基础
1. 全局变量名 具体描述 msg.sender 返回当前调用函数的调用者的地址 msg.value 当前消息所附带的以太币,单位为wei 2.变量的用法 默认存储位置修饰符 函数的返回值 memory 函数内部的局…...

OLAP与OLTP架构设计原理对比
OLAP与OLTP架构设计原理对比 一、核心区别 维度OLTPOLAP设计目标支持高并发、低延迟的事务操作(增删改查)支持复杂分析查询(聚合、多维度统计)数据模型规范化模型(3NF),减少冗余维度模型&…...
)
ubuntu20.04在mid360部署direct_lidar_odometry(DLO)
editor:1034Robotics-yy time:2025.4.10 1.下载DLO,mid360需要的一些...: 1.1 在工作空间/src下 下载DLO: git clone https://github.com/vectr-ucla/direct_lidar_odometry 1.2 在工作空间/src下 下载livox_ros_driver2&…...
架构深度解析:突破大模型边界的工程实践)
检索增强生成(RAG)架构深度解析:突破大模型边界的工程实践
一、RAG技术架构设计哲学 1.1 范式演进:从静态模型到动态知识系统 graph LR A[传统LLM架构] -->|问题| B[依赖预训练参数] B --> C[知识固化风险] C --> D[领域适配困难]A -->|解决方案| E[RAG增强架构] E --> F[实时知识检索] F --> G[动态上下…...

线代第四课:行列式的性质
行列式性质 转置行列式 把行列式的第一行转置成第一列,使用表示 如果在转置一下: 性质一: 行列地位相同,对行性质,对列性质 性质二: 交换D的两行(列),D值变符号 性…...

【语音识别】vLLM 部署 Whisper 语音识别模型指南
目录 1. 模型下载 2. 环境安装 3. 部署脚本 4. 服务测试 语音识别技术在现代人工智能应用中扮演着重要角色,OpenAI开源的Whisper模型以其出色的识别准确率和多语言支持能力成为当前最先进的语音识别解决方案之一。本文将详细介绍如何使用vLLM(一个高…...

Python | kelvin波的水平空间结构
写在前面 简单记录一下之前想画的一个图: 思路 整体比较简单,两个子图,本质上就是一个带有投影,一个不带投影,通常用在EOF的空间模态和时间序列的绘制中,可以看看之前的几个详细的画法。 Python | El Ni…...

什么叫行列式
《行列式:数学中的重要概念及其应用》 行列式是数学中的一个重要概念,主要用于描述线性方程组、向量空间等方面的性质。以下是关于它的详细介绍: 定义 行列式是由排成正方形的一组数(称为元素)按照特定的规则计算得…...

构建高可用大数据平台:Hadoop与Spark分布式集群搭建指南
想象一下,你手握海量数据,却因为测试环境不稳定,频频遭遇宕机和数据丢失的噩梦。Hadoop和Spark作为大数据处理的“黄金搭档”,如何在分布式高可用(HA)环境下稳如磐石地运行?答案就在于一个精心构…...
)
[leetcode]211. 添加与搜索单词(Trie+DFS)
题目链接 题意 实现词典类 WordDictionary : WordDictionary() 初始化词典对象void addWord(word) 将 word 添加到数据结构中,之后可以对它进行匹配bool search(word) 如果数据结构中存在字符串与 word 匹配,则返回 true ;否则…...

AI | 字节跳动 AI 中文IDE编辑器 Trae 初体验
Trae 简介与安装 🔦 什么是 Trae Trae 是大厂字节跳动出品的国内首个 AI IDE,深度理解中文开发场景。AI 高度集成于 IDE 环境之中,为你带来比 AI 插件更加流畅、准确、优质的开发体验。说是能够不用写代码,全靠一张嘴跟 AI 聊天…...

【开发经验】结合实际问题解决详述HTTPS通信过程
最近的开发调试过程中涉及到了HTTPS发送与接收,遇到实际问题才发现对这部分尚属于一知半解。结合实际问题的解决过程来详细整理以下HTTPS通信过程。 需要调试的功能为BMC作为客户端向搭建好的Web服务器发送HTTPS请求,Web服务器负责接收处理发送过来的HT…...
)
灵霄破茧:仙途启幕 - 灵霄门新篇-(4)
重建之路,风云再起 灵霄门内一片萧瑟,残垣断壁间弥漫着悲伤与凝重。弟子们忙碌地清理着战场,救治伤员,每个人的脸上都带着劫后余生的疲惫。陈霄日夜守在玄风真人的榻前,眼中满是自责与担忧。玄风真人的伤势极重&#…...

微信小程序事件绑定基本语法
微信小程序使用 bind 或 catch 前缀绑定事件,语法如下: <组件 bind事件名"处理函数" catch事件名"处理函数"></组件> bind:事件绑定,允许事件冒泡(向父组件传递)。 catc…...

vscode 连不上 Ubuntu 18 server 的解决方案
下载 vscode 历史版本 18.5(windows请装在 系统盘 C 盘) 打开 vdcode,将 自动更新 设置为 None (很关键,否则容易前功尽弃) 重命名(删除) 服务器上的 .vscode-server 文件夹 重新…...

OSPF接口的网络类型和不规则区域
网络类型(数据链路层所使用的协议所构建的二层网络类型) 1、MA --- 多点接入网络 BMA --- 支持广播的多点接入网络 NBMA --- 不支持广播的多点接入网络 2、P2P --- 点到点网络 以太网 --- 以太网最主要的特点是需要基于MAC地址进行物理寻址,主要是因为以太网接口所连…...

基于Flask的勒索病毒应急响应平台架构设计与实践
基于Flask的勒索病毒应急响应平台架构设计与实践 序言:安全工程师的防御视角 作为从业十年的网络安全工程师,我深刻理解勒索病毒防御的黄金时间法则——应急响应速度每提升1分钟,数据恢复成功率将提高17%。本文介绍的应急响应平台ÿ…...

0410 | 软考高项笔记:项目管理概述
以下是不同组织结构中项目经理的角色、工作特点以及快速记忆的方法: 不同组织结构中项目经理的角色和工作特点 组织结构项目经理的角色工作特点职能型组织项目协调者、辅助管理者权力有限,主要负责协调部门间的工作,项目成员向部门经理汇报…...
:拖拽加载与基础图像处理功能实现)
基于 Qt 的图片处理工具开发(一):拖拽加载与基础图像处理功能实现
一、引言 在桌面应用开发中,图片处理工具的核心挑战在于用户交互的流畅性和异常处理的健壮性。本文以 Qt为框架,深度解析如何实现一个支持拖拽加载、亮度调节、角度旋转的图片处理工具。通过严谨的文件格式校验、分层的架构设计和用户友好的交互逻辑&am…...
:6G技术加速落地与全连接生态构建)
2025年4月通信科技领域周报(3.31-4.06):6G技术加速落地与全连接生态构建
2025年4月通信科技领域周报(3.31-4.06):6G技术加速落地与全连接生态构建 目录 一、本周热点回顾二、技术进展深度解析三、产业动态全景扫描四、行业生态与政策风向五、专业术语解释六、免责声明 一、本周热点回顾 1. 华为发布6G全场景技术…...
)
Codeforces-CF816B-Karen and Coffee(差分/前缀和)
题目翻译: Karen 喜欢咖啡。 她有 n 本食谱,第 i 本食谱包含两个数 li,ri,表示这本食谱推荐用 [li,ri] 之间的温度(包含 li.ri)来煮咖啡。 Karen 认为一个温度 a 是可接受的当且仅当有 ≥k 本食谱推荐用 …...

4.DJI-PSDK云台x-port控制:
DJI-PSDK云台x-port控制: X-Port 功能控制,即控制 X-Port 云台,头文件为 dji_xport.h 使用PSDK 的“云台控制”功能,开发者需要先设计负载设备的云台并开发出控制云台的程序,将云台的控制函数注册到PSDK 指定的接口后…...

大语言模型中的幻觉现象深度解析
一、幻觉的定义及出现的原因 1. 基本定义 幻觉(Hallucination) 指大语言模型在自然语言处理过程中产生的与客观事实或既定输入相悖的响应,主要表现为信息失准与逻辑矛盾。 2. 幻觉类型与机制 2.1 事实性幻觉 定义:生成内容与可验证…...
(springboot+ssm+vue+mysql)含运行文档)
衣橱管理助手系统(衣服推荐系统)(springboot+ssm+vue+mysql)含运行文档
衣橱管理助手系统(衣服推荐系统)(springbootssmvuemysql)含运行文档 该系统名为衣橱管理助手,是一个衣物搭配管理系统,主要功能包括衣物档案管理、衣物搭配推荐、搭配收藏以及套装智能推荐。用户可以通过系统进行衣物的搭配和收藏管理,系统提…...

视觉对象 - 数据可视化解读
Power BI 提供了丰富的视觉对象(Visuals),帮助用户以直观的方式呈现和分析数据。以下是 32 个常用视觉对象的解读及案例分享,涵盖核心功能、适用场景和注意事项。内容基于实际应用场景整理,便于快速理解。 一、数据比较类视觉对象 这类视觉对象主要用于比较不同类别、组别…...
详解)
使用物联网卡的烟感(NB-IoT/4G烟感)详解
基于物联网卡(NB-IoT/4G)的智能烟感是一种无线联网型火灾报警设备,相比传统烟感,它能够实时上报火警信息,适用于无人值守场所、智慧消防、远程监控等场景。 1. 物联网卡烟感的核心功能 功能说明实时报警探测到烟雾后&…...
网络学习之堡垒机)
(2)网络学习之堡垒机
堡垒机和防火墙的区别: 1.功能定位 防火墙主要负责抵御外部攻击,就像一道坚固的城墙,防止黑客进入内部网络。堡垒机则专注于内部管理,监控和记录运维人员的操作行为,确保内部网络的安全。 2.部署位置与作用范围 防…...

FlinkSQL的常用语言
FlinkSQL 常用语言指南 FlinkSQL 是 Apache Flink 提供的 SQL 接口,允许用户使用标准 SQL 或扩展的 SQL 语法来处理流式和批式数据。以下是 FlinkSQL 的常用语言元素和操作: 基本查询 -- 选择查询 SELECT * FROM table_name;-- 带条件的查询 SELECT c…...

Go语言编写一个进销存Web软件的demo
Go语言编写一个进销存Web软件的demo 用户现在要求用。之前他们已经讨论了用Django实现的方案,现在突然切换到Go,可能有几个原因。首先,用户可能对Go语言感兴趣,或者他们公司的技术栈转向了Go。其次,用户可能希望比较不…...
)
架构设计之Redisson分布式锁-可重入同步锁(一)
架构设计之Redisson分布式锁-可重入同步锁(一) Redisson分布式锁官方博客地址 1、Redisson是什么 Redisson 是一个基于 Redis 的 Java 分布式工具库,它提供了 分布式锁、集合、队列、缓存、Map、限流、任务调度 等高级数据结构和功能,极大地简化了 Ja…...

使用libcurl编写爬虫程序指南
用户想知道用Curl库编写的爬虫程序是什么样的。首先,我需要明确Curl本身是一个命令行工具和库,用于传输数据,支持多种协议。而用户提到的“Curl库”可能指的是libcurl,这是一个客户端URL传输库,可以用在C、C等编程语言…...
·解析数据难点)
【数据结构】排序算法(下篇·终结)·解析数据难点
前引:归并排序作为一种高效排序方法,掌握起来还是有点困难的,何况需要先接受递归的熏陶,这正是编程的浪漫之处,我们不断探索出新的可能,如果给你一串数据让其变得有序?是选择简单的冒泡、插入排…...

Django 使用 Celery 完成异步任务或定时任务
1 介绍 Celery是一个分布式任务队列,由三个主要组件组成:Celery worker、Celery beat 和消息代理(例如 Redis 或 RabbitMQ)。这些组件一起协作,让开发者能够轻松地执行异步任务和定时任务。 Celery worker࿱…...

Excel 自动执行全局宏
Excel 自动执行全局宏 25.04.09 步骤 1:创建个人宏工作簿(Personal.xlsb) 生成Personal.xlsb (如尚未存在): 打开Excel → 开发工具 → 录制宏 → 选择“保存到个人宏工作簿” → 停止录制。按 Alt F11 进…...