集成学习+泰坦尼克号案例+红酒品质预测
集成学习简介
学习目标:
1.知道集成学习是什么?
2.了解集成学习的分类
3.理解bagging集成的思想
4.理解boosting集成的思想
【知道】集成学习是什么?
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型成为弱学习器(基学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。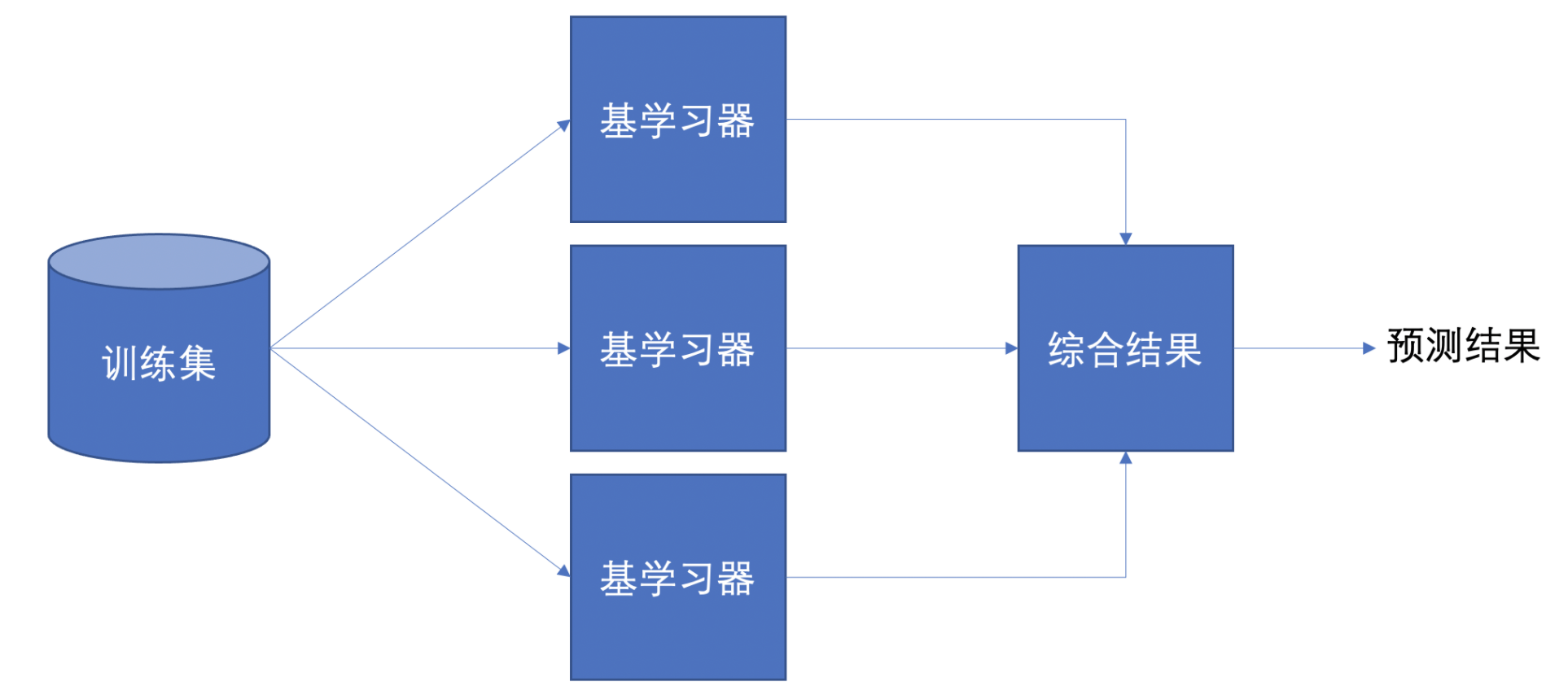
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮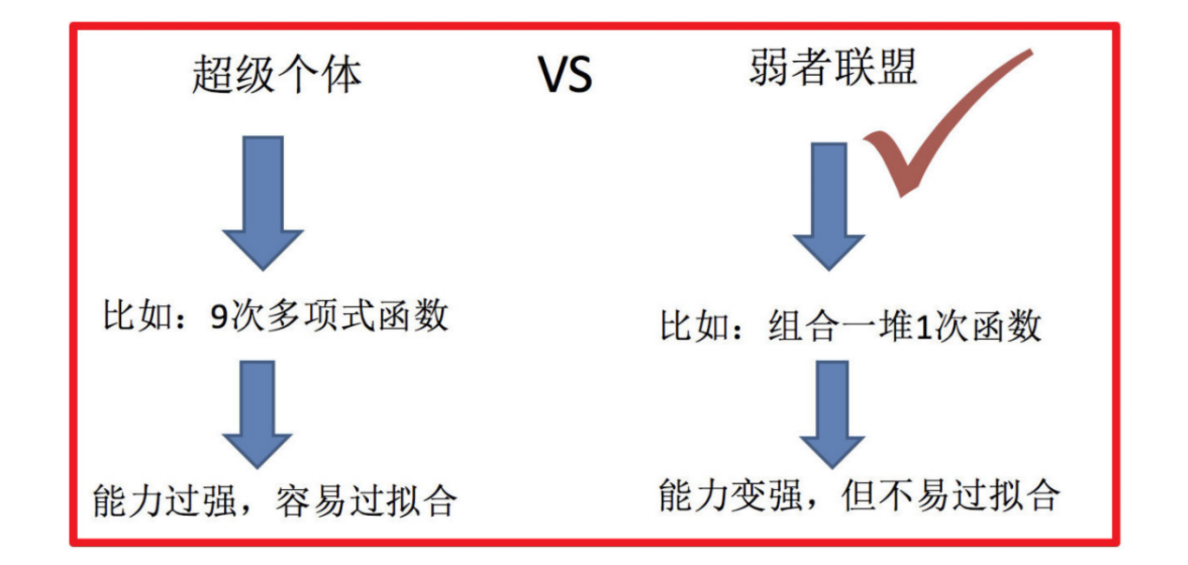
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是 生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
【了解】集成学习分类
集成学习算法一般分为:bagging和boosting。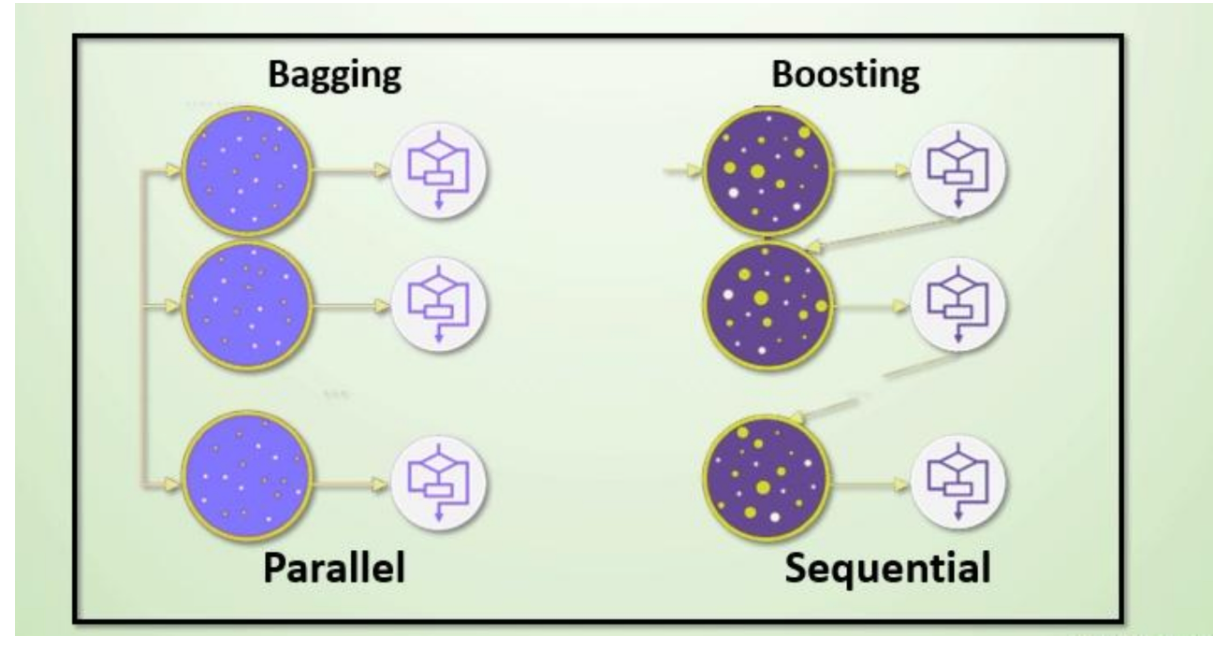
【理解】bagging集成
Baggging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。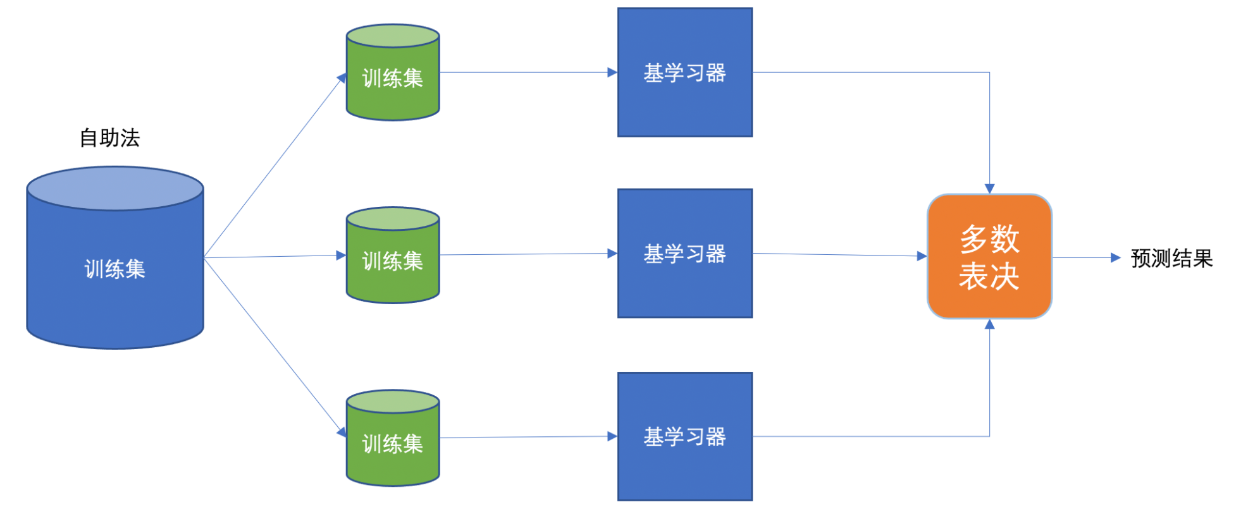
例子:
目标:把下面的圈和方块进行分类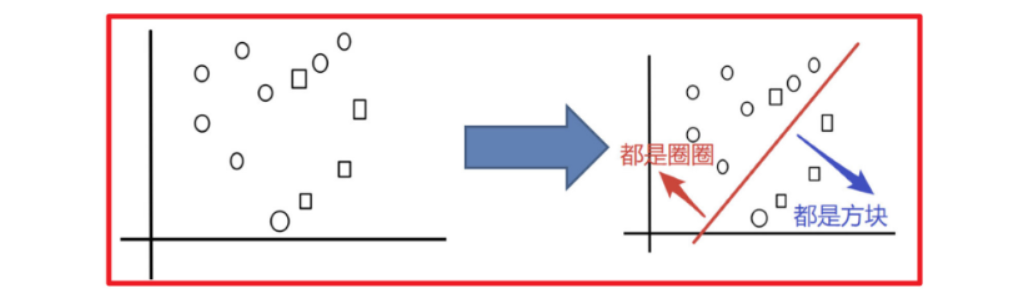
-
采样不同数据集
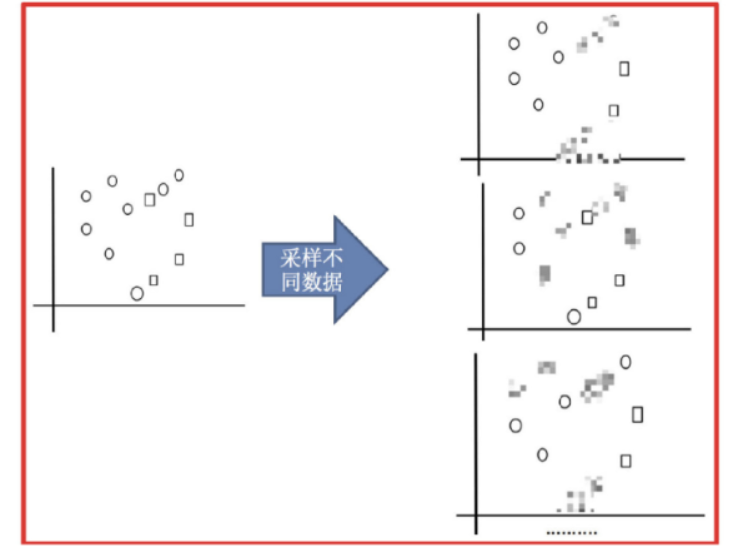
2)训练分类器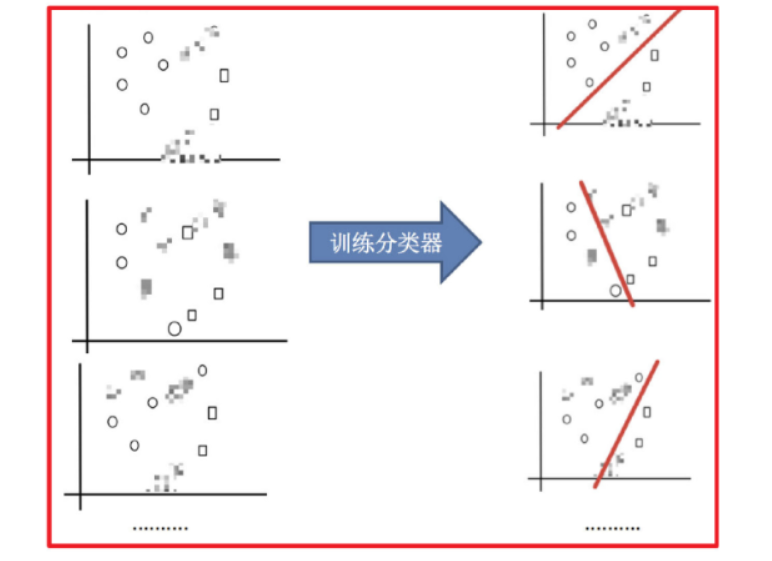
3)平权投票,获取最终结果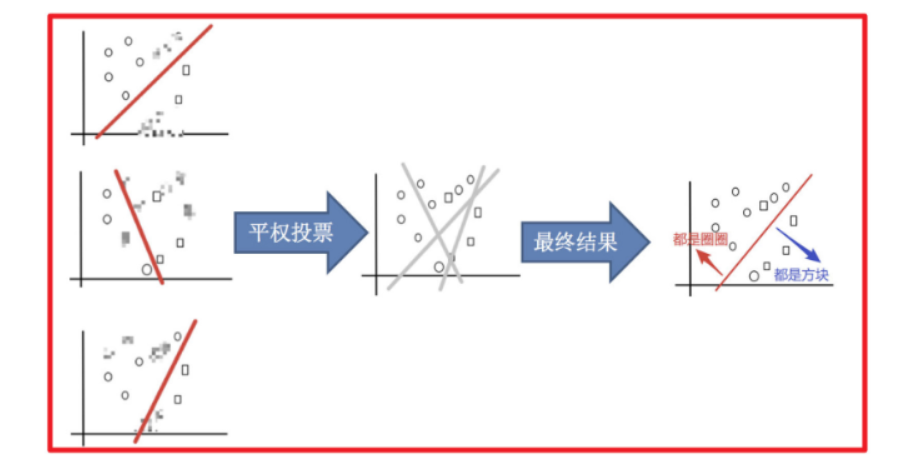
4)主要实现过程小结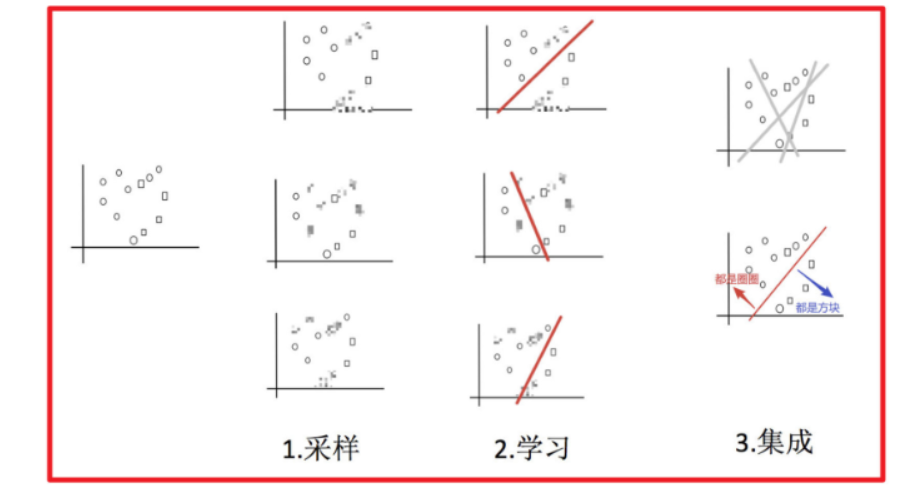
【理解】boosting集成
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。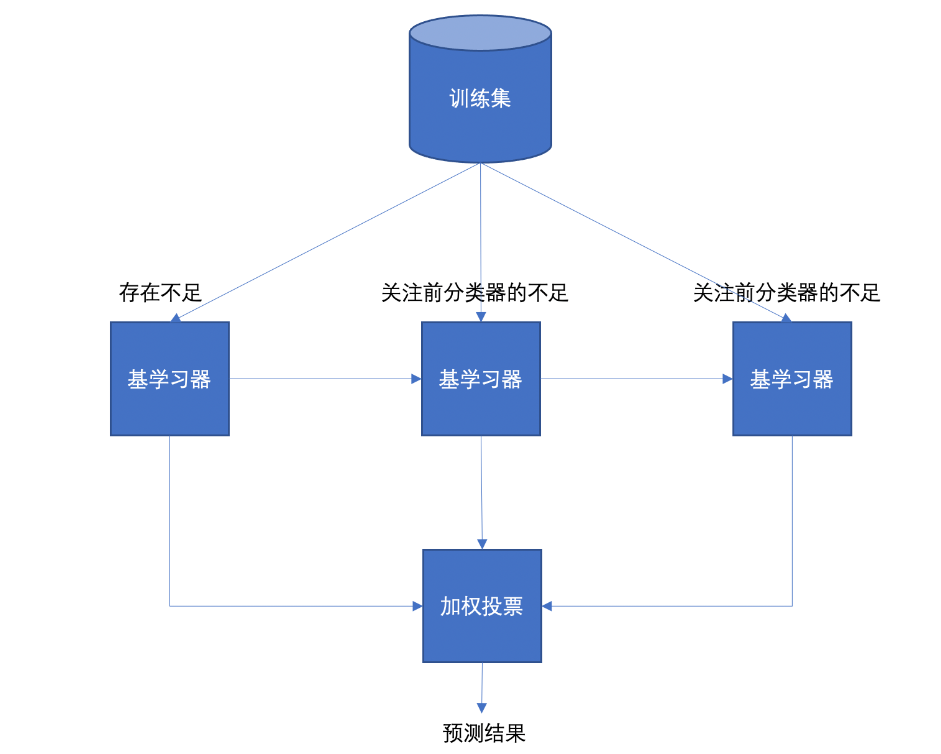
Boosting是一组可将弱学习器升为强学习器算法。这类算法的工作机制类似:
1.先从初始训练集训练出一个基学习器
2.在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续得到最大的关注。
3.然后基于调整后的样本分布来训练下一个基学习器;
4.如此重复进行,直至基学习器数目达到实现指定的值T为止。
5.再将这T个基学习器进行加权结合得到集成学习器。
简而言之:每新加入一个弱学习器,整体能力就会得到提升
Bagging 与 Boosting
区别一:数据方面
-
Bagging:有放回采样
-
Boosting:全部数据集, 重点关注前一个弱学习器不足
区别二:投票方面
-
Bagging:平权投票
-
Boosting:加权投票
区别三:学习顺序
-
Bagging的学习是并行的,每个学习器没有依赖关系
-
Boosting学习是串行,学习有先后顺序
随机森林
学习目标:
1.理解随机森林的构建方法
2.知道随机森林的API
3.能够使用随机森林完成分类任务
【理解】算法思想
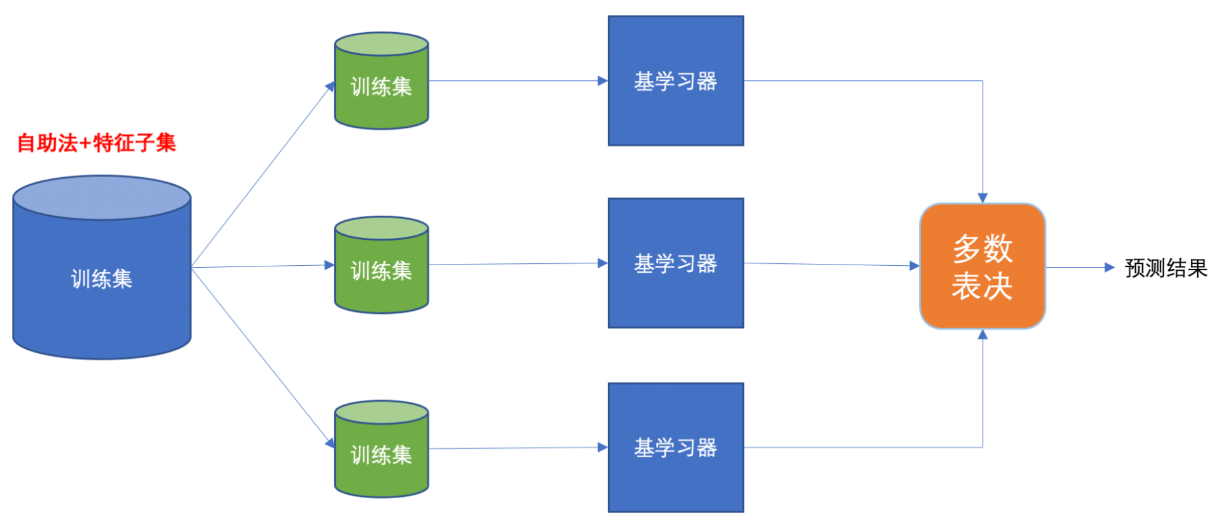
随机森林是基于 Bagging 思想实现的一种集成学习算法,它采用决策树模型作为每一个基学习器。其构造过程:
-
训练:
-
有放回的产生训练样本
-
随机挑选 n 个特征(n 小于总特征数量)
-
-
预测:平权投票,多数表决输出预测结果
随机森林的步骤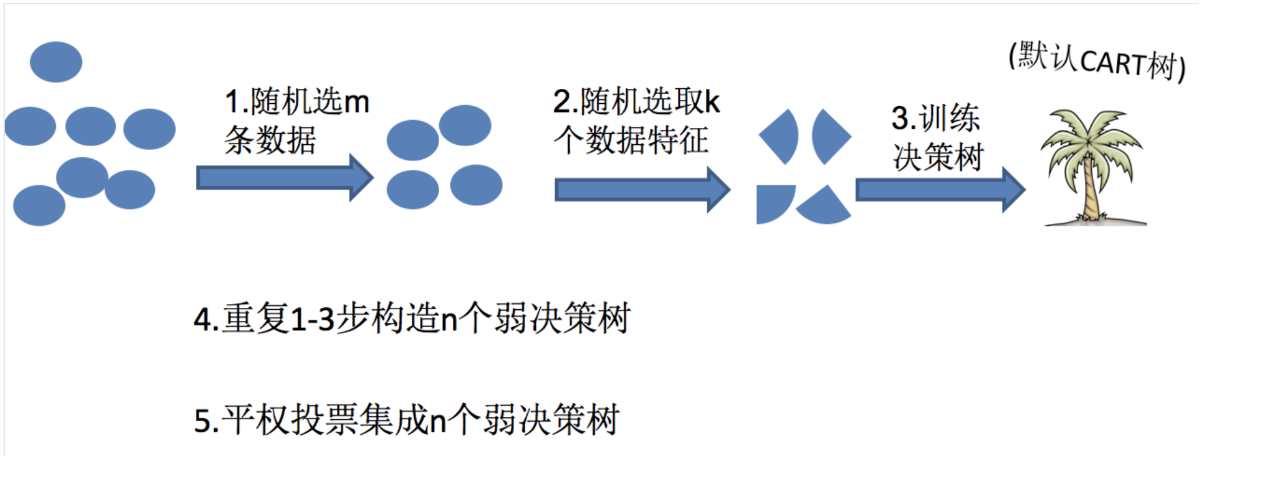
如上图:
首先,对样本数据进行有放回的抽样,得到多个样本集。具体来讲就是每次从原来的N个训练样本中有放回地随机抽取m个样本(包括可能重复样本)。
然后,从候选的特征中随机抽取k个特征,作为当前节点下决策的备选特征,从这些特征中选择最好地划分训练样本的特征。用每个样本集作为训练样本构造决策树。单个决策树在产生样本集和确定特征后,使用CART算法计算,不剪枝。
最后,得到所需数目的决策树后,随机森林方法对这些树的输出进行投票,以得票最多的类作为随机森林的决策。
说明:
(1)随机森林的方法即对训练样本进行了采样,又对特征进行了采样,充分保证了所构建的每个树之间的独立性,使得投票结果更准确。
(2)随机森林的随机性体现在每棵树的训练样本是随机的,树中每个节点的分裂属性也是随机选择的。有了这2个随机因素,即使每棵决策树没有进行剪枝,随机森林也不会产生过拟合的现象。
随机森林中有两个可控制参数:
-
森林中树的数量(一般选取值较大)
-
抽取的属性值m的大小。
思考
-
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
-
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”,也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
【知道】随机森林 API
sklearn.ensemble.RandomForestClassifier()
n_estimators:决策树数量,(default = 10)
Criterion:entropy、或者 gini, (default = gini)
max_depth:指定树的最大深度,(default = None 表示树会尽可能的生长)
max_features="auto”, 决策树构建时使用的最大特征数量
-
If "auto", then
max_features=sqrt(n_features). -
If "sqrt", then
max_features=sqrt(n_features)(same as "auto"). -
If "log2", then
max_features=log2(n_features). -
If None, then
max_features=n_features.
bootstrap:是否采用有放回抽样,如果为 False 将会使用全部训练样本,(default = True)
min_samples_split: 结点分裂所需最小样本数,(default = 2)
-
如果节点样本数少于min_samples_split,则不会再进行划分.
-
如果样本量不大,不需要设置这个值.
-
如果样本量数量级非常大,则推荐增大这个值.
min_samples_leaf: 叶子节点的最小样本数,(default = 1)
-
如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝.
-
较小的叶子结点样本数量使模型更容易捕捉训练数据中的噪声.
min_impurity_split: 节点划分最小不纯度
-
如果某节点的不纯度(基尼系数,均方差)小于这个阈值,则该节点不再生成子节点,并变为叶子节点.
-
一般不推荐改动默认值1e-7。
【实践】 随机森林泰坦尼克号生存预测
这泰坦尼克号案例实战:
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块从互联网中收集泰坦尼克号数据集
titanic=pd.read_csv("data/泰坦尼克号.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
X = pd.get_dummies(X)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)
#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
dtc.score(X_test,y_test)
#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(max_depth=6,random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
rfc.score(X_test,y_test)
#6.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))超参数选择代码:
# 随机森林去进行预测
# 1 实例化随机森林
rf = RandomForestClassifier()
# 2 定义超参数的选择列表
param={"n_estimators":[80,100,200], "max_depth": [2,4,6,8,10,12],"random_state":[9]}
# 超参数调优
# 3 使用GridSearchCV进行网格搜索
from sklearn.model_selection import GridSearchCV
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("随机森林预测的准确率为:", gc.score(X_test, y_test))Adaboost
学习目标:
1、理解adaboost算法的思想
2、知道adaboost的构建过程
3、实践泰坦尼克号生存预测案例
【知道】adaboost算法简介
Adaptive Boosting(自适应提升)基于 Boosting思想实现的一种集成学习算法核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。弱分类器的性能比随机猜测强就行,即可构造出一个非常准确的强分类器。其特点是:训练时,样本具有权重,并且在训练过程中动态调整。被分错的样本的样本会加大权重,算法更加关注难分的样本。
Adaboost自适应在于:“关注”被错分的样本,“器重”性能好的弱分类器:(观察下图)
(1)不同的训练集--->调整样本权重
(2)“关注”--->增加错分样本权重
(3)“器重”--->好的分类器权重大
(4) 样本权重间接影响分类器权重
主要过程演示如下: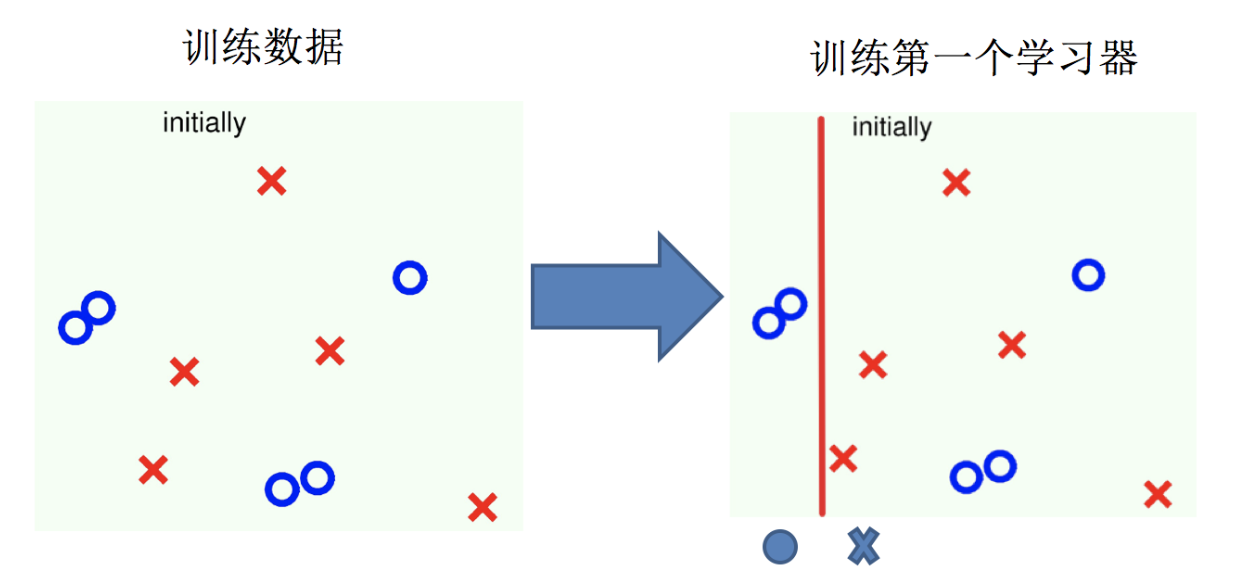
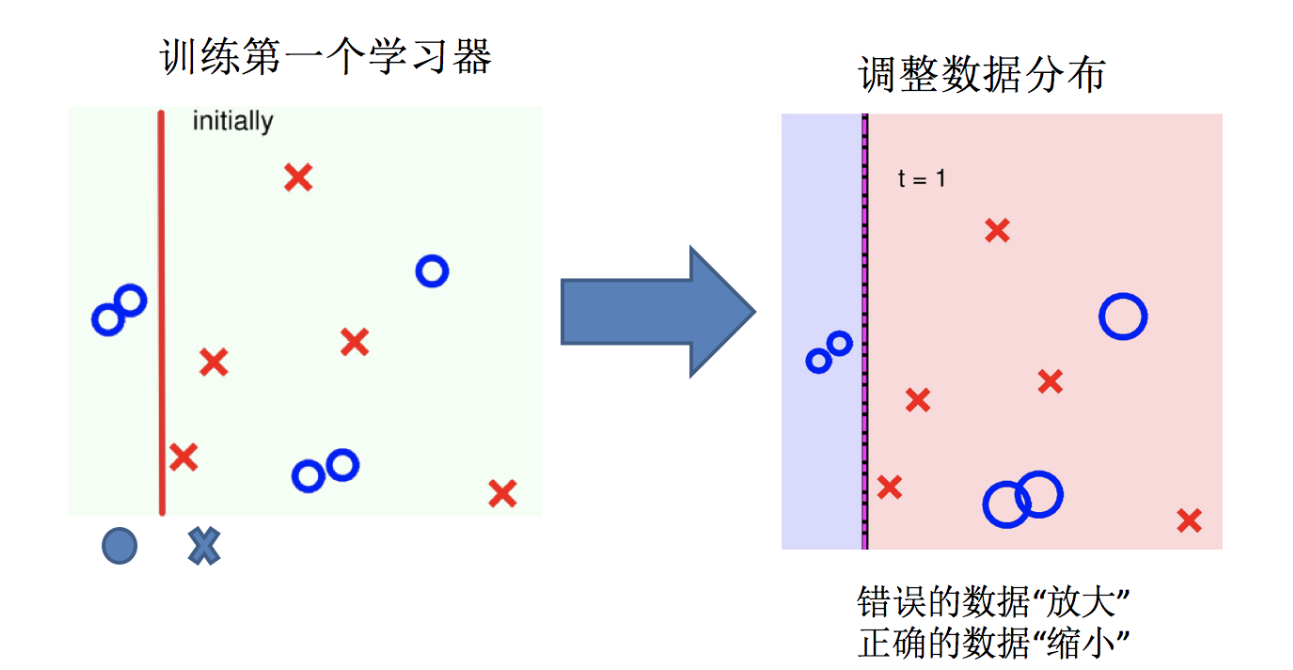
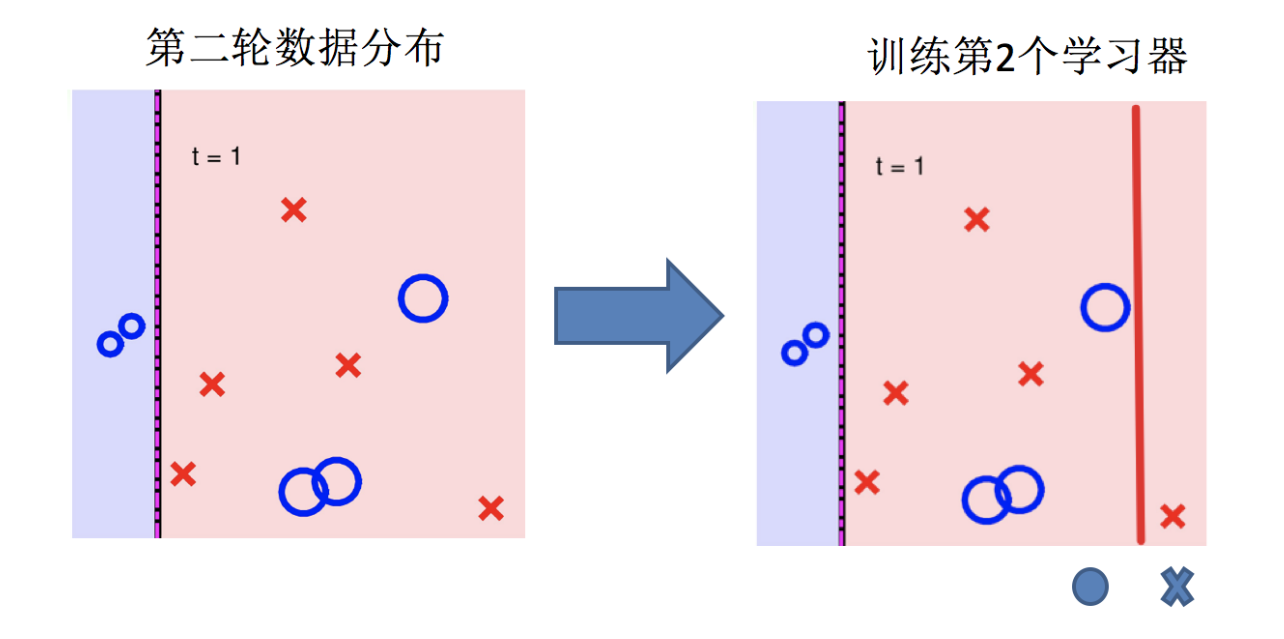
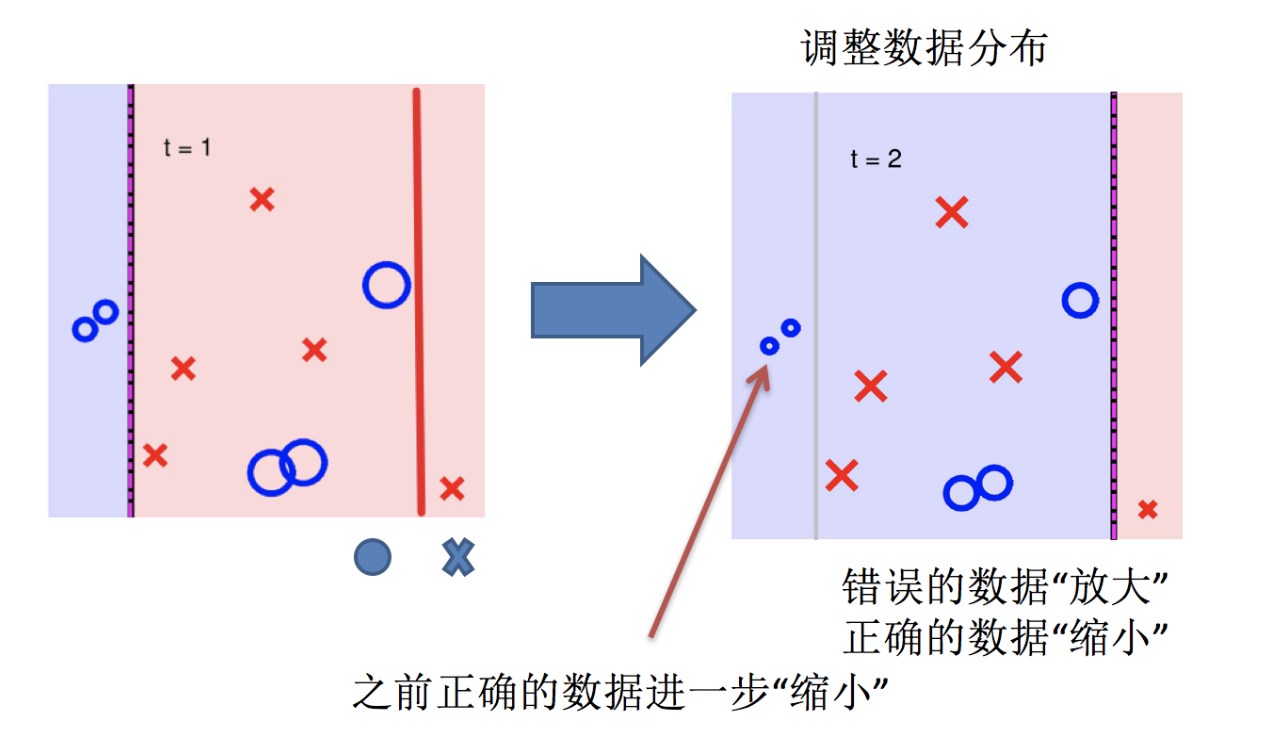
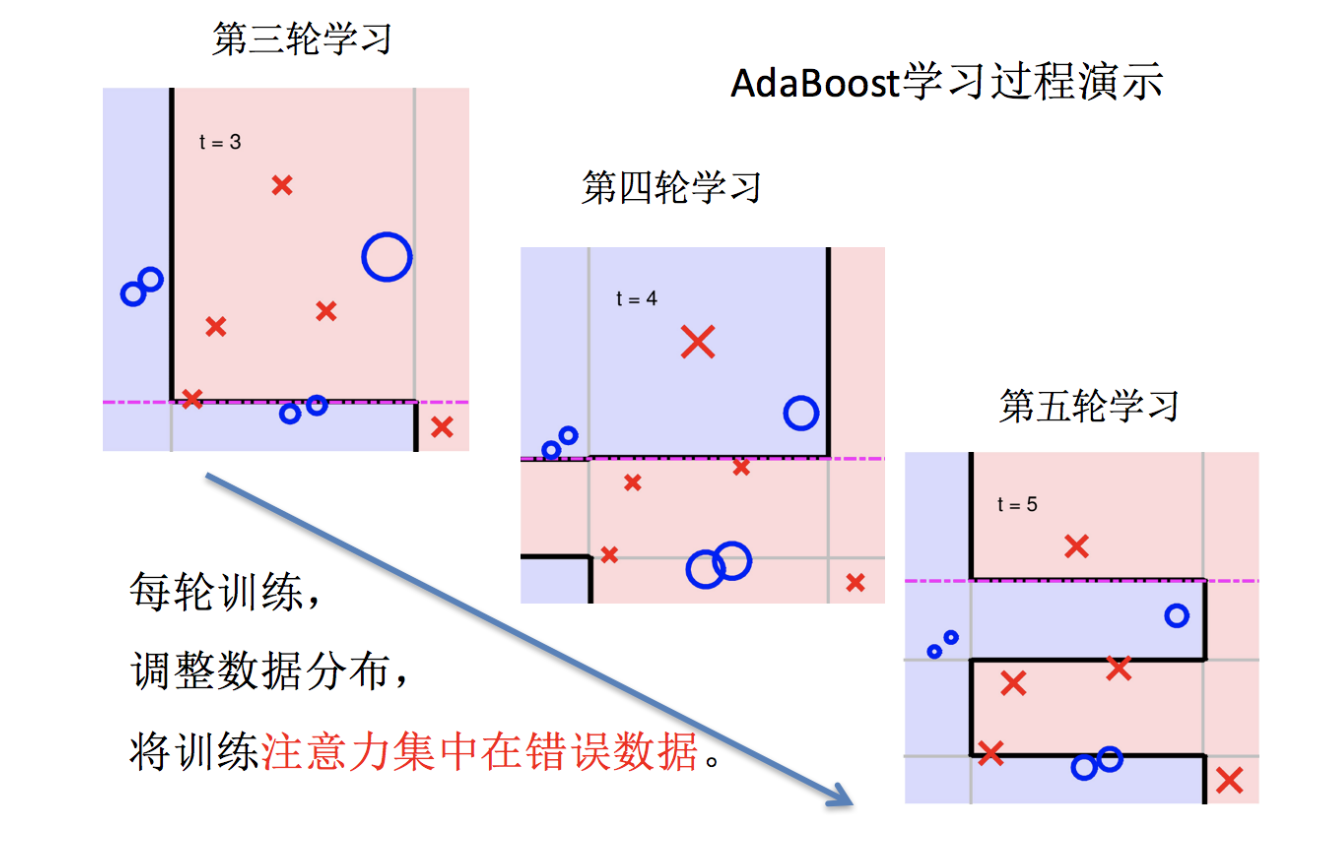
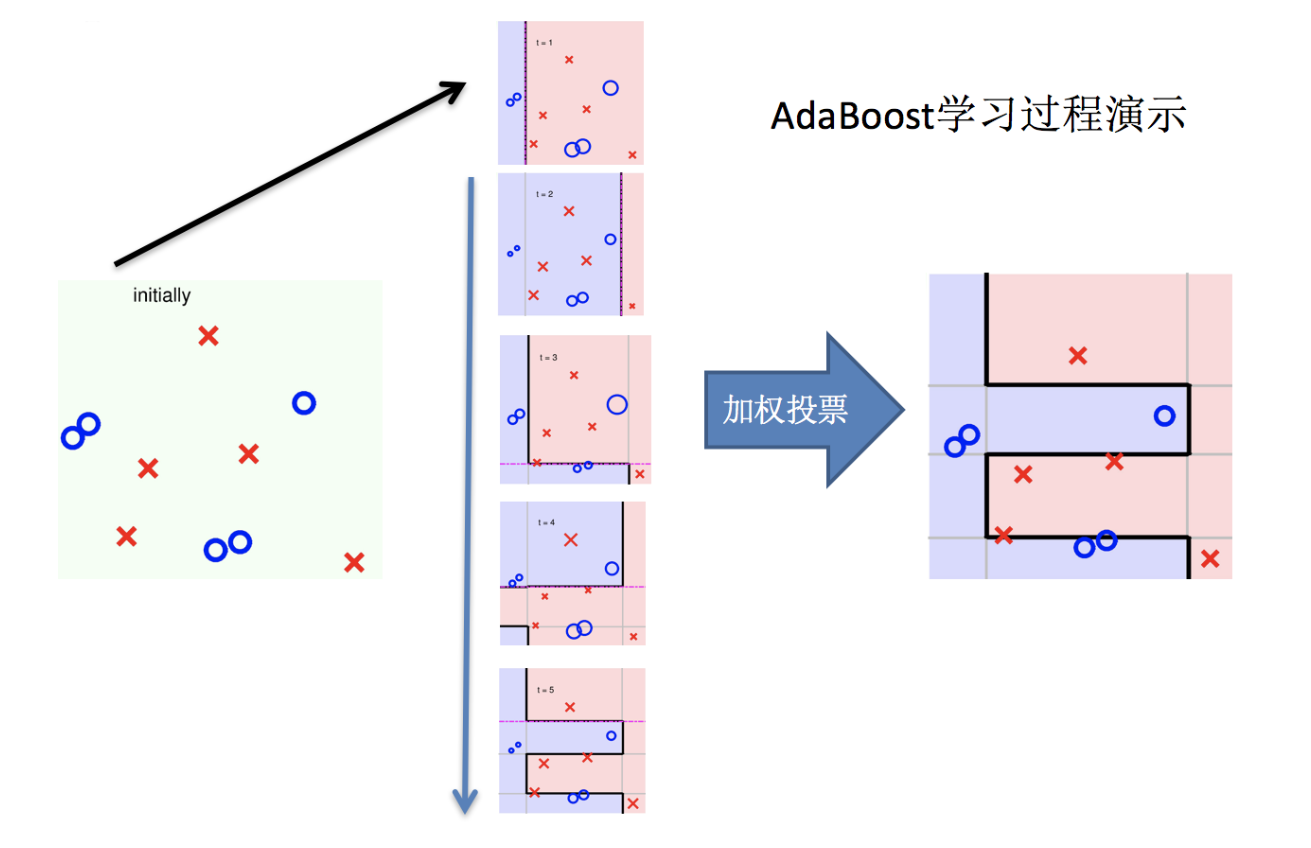
AdaBoost算法的两个核心步骤:
权值调整: AdaBoost算法提高那些被前一轮基分类器错误分类样本的权值,而降低那些被正确分类样本的权值。从而使得那些没有得到正确分类的样本,由于权值的加大而受到后一轮基分类器的更大关注。
基分类器组合: AdaBoost采用加权多数表决的方法。
-
分类误差率较小的弱分类器的权值大,在表决中起较大作用。
-
分类误差率较大的弱分类器的权值小,在表决中起较小作用。
【理解】AdaBoost算法推导
AdaBoost 模型公式中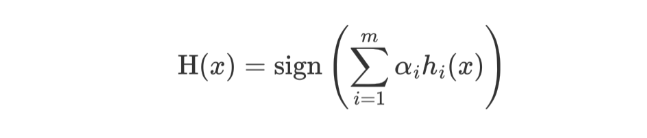
-
α 为模型的权重
-
m 为弱学习器数量
-
hi(x) 表示弱学习器
-
H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。
AdaBoost 权重更新公式:
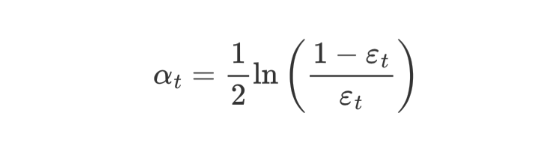
εt 表示第 t 个弱学习器的错误率
AdaBoost 样本权重更新公式: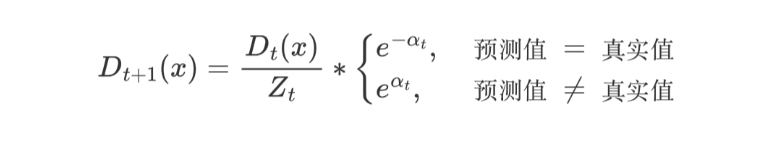
-
Zt 为归一化值(所有样本权重的总和)
-
Dt(x) 为样本权重
-
αt 为模型权重。
【理解】 AdaBoost 构建过程
下面为训练数数据,假设弱分类器由 x 产生,其阈值 v 使该分类器在训练数据集上的分类误差率最低,试用 Adaboost 算法学习一个强分类器。
-
构建第一个弱学习器
-
初始化工作:初始化 10 个样本的权重,每个样本的权重为:0.1
-
构建第一个基学习器:
-
寻找最优分裂点
-
对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
-
当以 0.5 为分裂点时,有 5 个样本分类错误
-
当以 1.5 为分裂点时,有 4 个样本分类错误
-
当以 2.5 为分裂点时,有 3 个样本分类错误
-
当以 3.5 为分裂点时,有 4 个样本分类错误
-
当以 4.5 为分裂点时,有 5 个样本分类错误
-
当以 5.5 为分裂点时,有 4 个样本分类错误
-
当以 6.5 为分裂点时,有 5 个样本分类错误
-
当以 7.5 为分裂点时,有 4 个样本分类错误
-
当以 8.5 为分裂点时,有 3 个样本分类错误
-
最终,选择以 2.5 作为分裂点,计算得出基学习器错误率为:3/10=0.3
-
-
计算模型权重:
1/2 * np.log((1-0.3)/0.3)=0.4236 -
更新样本权重:
-
分类正确样本为:1、2、3、4、5、6、10 共 7 个,其计算公式为:e-αt,则正确样本权重变化系数为:e-0.4236 = 0.6547
-
分类错误样本为:7、8、9 共 3 个,其计算公式为:eαt,则错误样本权重变化系数为:e0.4236 = 1.5275
-
样本 1、2、3、4、5、6、10 权重值为:
0.06547 -
样本 7、8、9 的样本权重值为:
0.15275 -
归一化 Zt 值为:
0.06547 * 7 + 0.15275 * 3 = 0.9165 -
样本 1、2、3、4、5、6、10 最终权重值为:
0.07143 -
样本 7、8、9 的样本权重值为:
0.1667
-
-
此时得到:

-
-
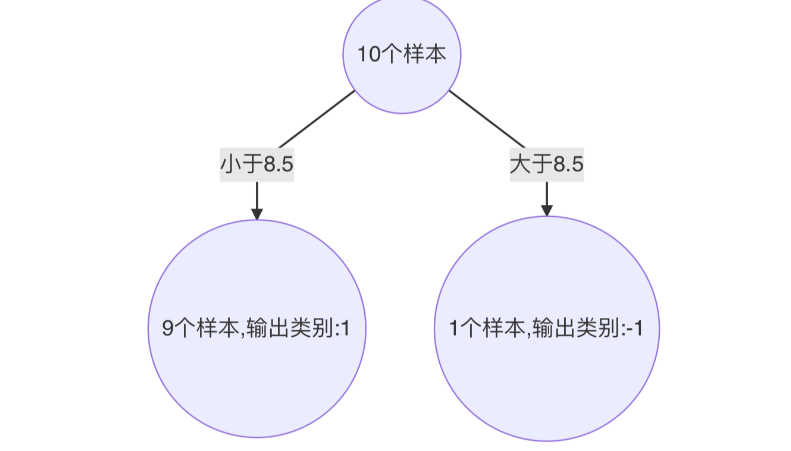
构建第二个弱学习器
-
寻找最优分裂点:
-
对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
-
当以 0.5 为分裂点时,有 5 个样本分类错误,错误率为:0.07143 * 5 = 0.35715
-
当以 1.5 为分裂点时,有 4 个样本分类错误,错误率为:0.07143 * 1 + 0.16667 * 3 = 0.57144
-
当以 2.5 为分裂点时,有 3 个样本分类错误,错误率为:0.16667 * 3 = 0.57144
。。。 。。。
-
当以 8.5 为分裂点时,有 3 个样本分类错误,错误率为:0.07143 * 3 = 0.21429
-
最终,选择以 8.5 作为分裂点,计算得出基学习器错误率为:0.21429
-
-
计算模型权重:
1/2 * np.log((1-0.21429)/0.21429)=0.64963 -
分类正确的样本:1、2、3、7、8、9、10,其权重调整系数为:0.5222
-
分类错误的样本:4、5、6,其权重调整系数为:1.9148
-
分类正确样本权重值:
-
样本 0、1、2、、9 为:0.0373
-
样本 6、7、8 为:0.087
-
-
分类错误样本权重值:0.1368
-
归一化 Zt 值为:
0.0373 * 4 + 0.087 * 3 + 0.1368 * 3 = 0.8206 -
最终权重:
-
样本 0、1、2、9 为 :0.0455
-
样本 6、7、8 为:0.1060
-
样本 3、4、5 为:0.1667
-
-
此时得到:

-
构建第三个弱学习器
错误率:0.1820,模型权重:0.7514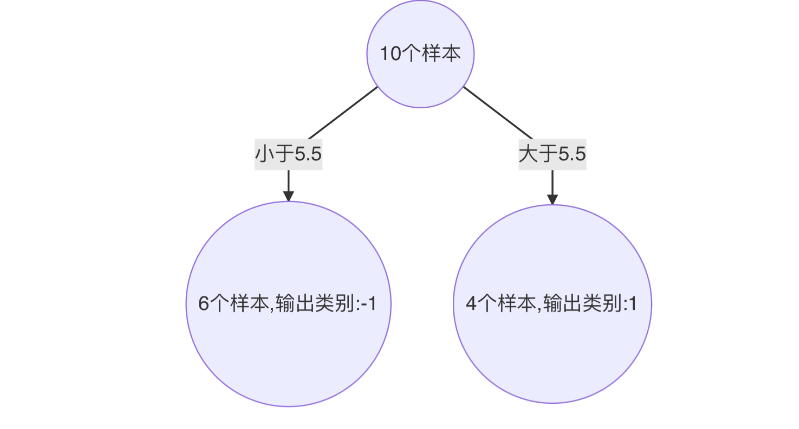
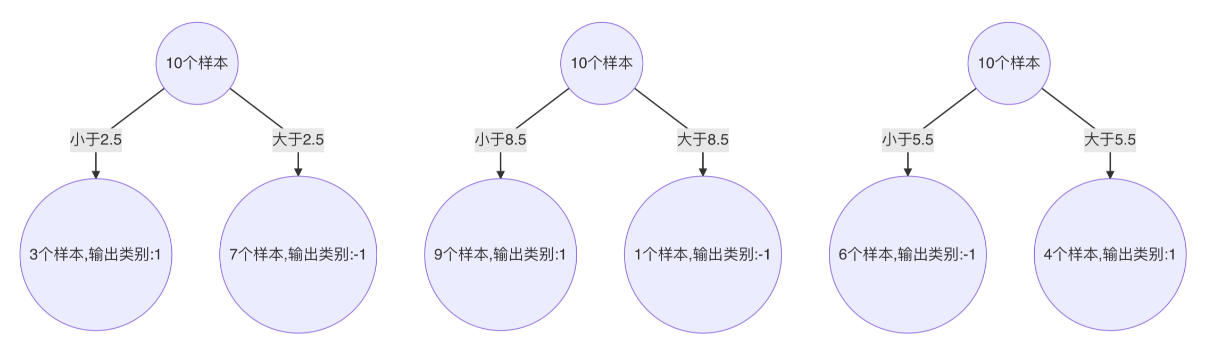
-
强学习器
【实践】AdaBoost实战葡萄酒数据
葡萄酒分为白葡萄酒和红葡萄酒两类。 该分析涉及白葡萄酒,并基于数据集中显示的13个变量/特征: 固定酸度,挥发性酸度,柠檬酸,残留糖,氯化物,游离二氧化硫,总二氧化硫,密度,pH值,硫酸盐,酒精,质量等。为了评估葡萄酒的质量,我们提出的方法就是根据酒的物理化学性质与质量的关系,找出高品质的葡萄酒具体与什么性质密切相关,这些性质又是如何影响葡萄酒的质量。
# 获取数据
import pandas as pd
df_wine = pd.read_csv('data/wine.data')
# 修改列名
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
# 去掉一类(1,2,3)
df_wine = df_wine[df_wine['Class label'] != 1]
# 获取特征值和目标值
X = df_wine[['Alcohol', 'Hue']].values
y = df_wine['Class label'].values
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# 类别转化 (2,3)=>(0,1)
le = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
# 机器学习(决策树和AdaBoost)
tree = DecisionTreeClassifier(criterion='entropy',max_depth=1,random_state=0)
ada= AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=0)
from sklearn.metrics import accuracy_score
# 决策树和AdaBoost分类器性能评估
# 决策树性能评估
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# Decision tree train/test accuracies 0.845/0.854
# AdaBoost性能评估
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# Adaboost train/test accuracies 1/0.875 总结:AdaBosst预测准确了所有的训练集类标,与单层决策树相比,它在测试机上表现稍微好一些。单决策树对于训练数据过拟合的程度更加严重一些。总之,我们可以发现Adaboost分类器能够些许提高分类器性能,并且与bagging分类器的准确率接近.
GBDT
学习目标:
-
掌握提升树的算法原理思想
-
了解梯度提升树的原理思想
【理解】 提升树(Boosting Tree)
梯度提升树(Gradient Boosting Decision Tre)是提升树(Boosting Decision Tree)的一种改进算法,所以在讲梯度提升树之前先来介绍一下提升树。
假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。最后将每次拟合的岁数加起来便是模型输出的结果。
【理解】梯度提升树
梯度提升树不再使用拟合残差,而是利用最速下降的近似方法,利用损失函数的负梯度作为提升树算法中的残差近似值。
假设:
-
我们前一轮迭代得到的强学习器是:fi-1(x)
-
损失函数是:L(y,fi−1(x))
-
本轮迭代的目标是找到一个弱学习器:hi(x)
-
让本轮的损失最小化: L(y, fi(x))=L(y, fi−1(x)) + hi(x))
当采用平方损失函数时: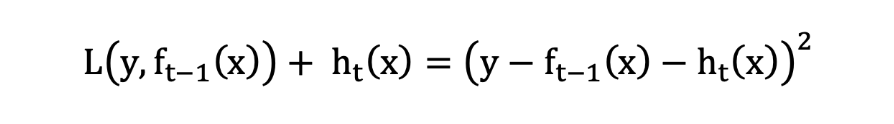
则: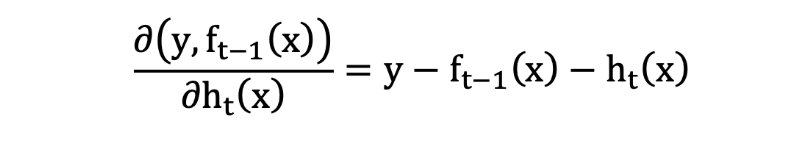
损失函数为平方损失, 则每个样本要拟合的负梯度为: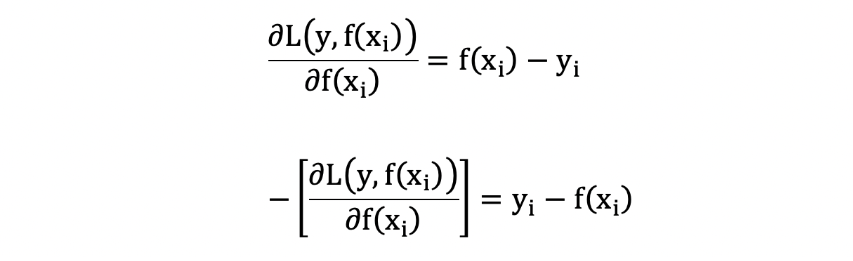
此时, 我们发现 GBDT 拟合的负梯度就是残差,或者说对于回归问题,拟合的目标值就是残差。
如果我们的 GBDT 进行的是分类问题,则损失函数变为 logloss,此时拟合的目标值就是该损失函数的负梯度值。
【理解】GBDT例子
-
初始化弱学习器(CART树)
我们通过计算当模型预测值为何值时,会使得第一个基学习器的平方误差最小,即:求损失函数对 f(xi) 的导数,并令导数为0.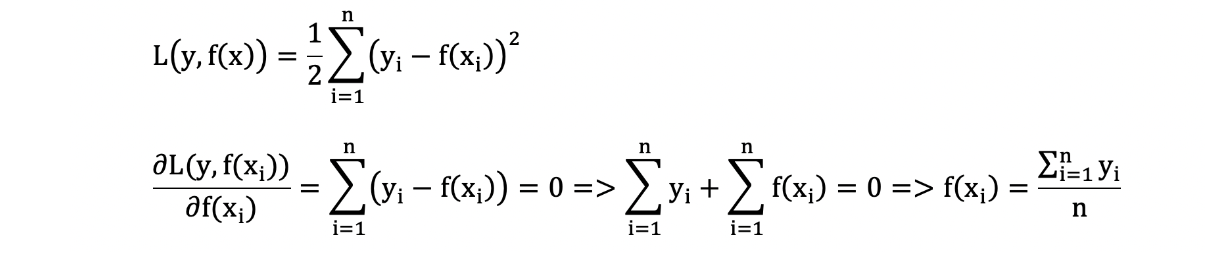

-
构建第一个弱学习器(CART树)
由于我们拟合的是样本的负梯度,即: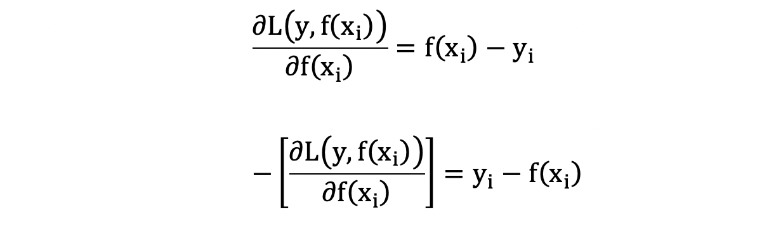
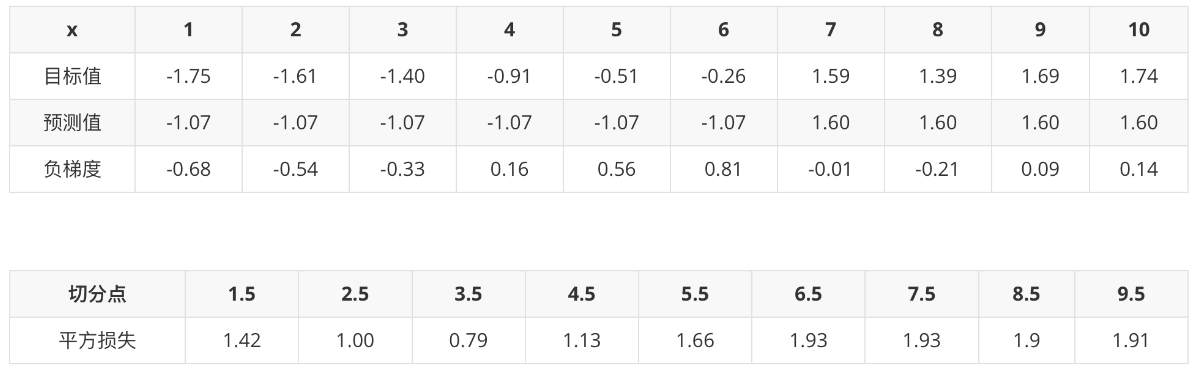
由此得到数据表如下:

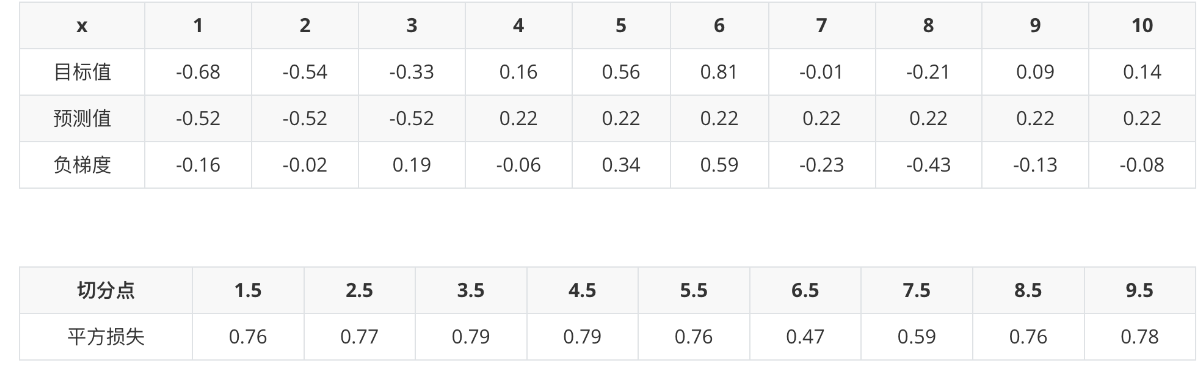
上表中平方损失计算过程说明(以切分点1.5为例):
切分点1.5 将数据集分成两份 [5.56],[5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9. 9.05]
第一份的平均值为5.56 第二份数据的平均值为(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9 = 7.5011
由于是回归树,每份数据的平均值即为预测值,则可以计算误差,第一份数据的误差为0,第二份数据的平方误差为 :
$(5.70-7.5011)^2+(5.91-7.5011)^2+...+(9.05-7.5011)^2 = 15.72308$
以 6.5 作为切分点损失最小,构建决策树如下: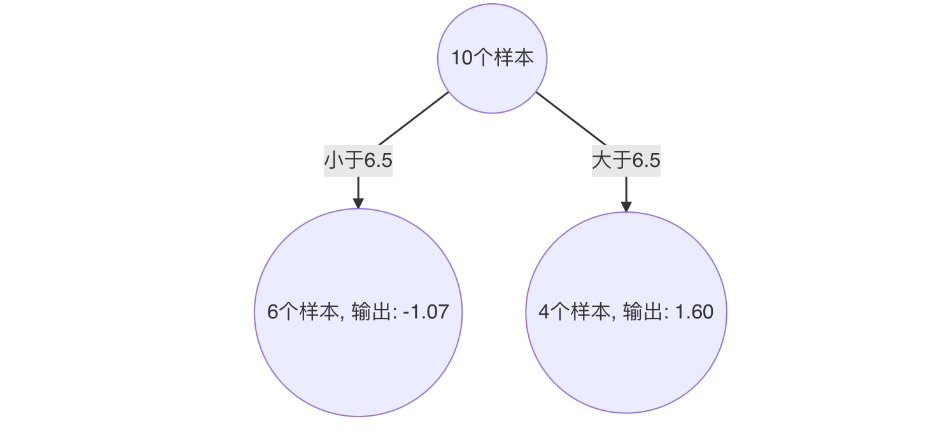
-
构建第二个弱学习器(CART树)
以 3.5 作为切分点损失最小,构建决策树如下: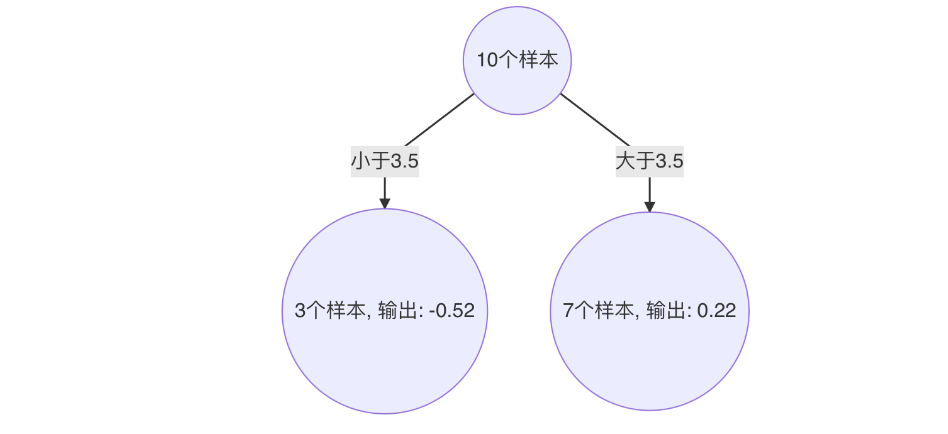
-
构建第三个弱学习器(CART树)
以 6.5 作为切分点损失最小,构建决策树如下: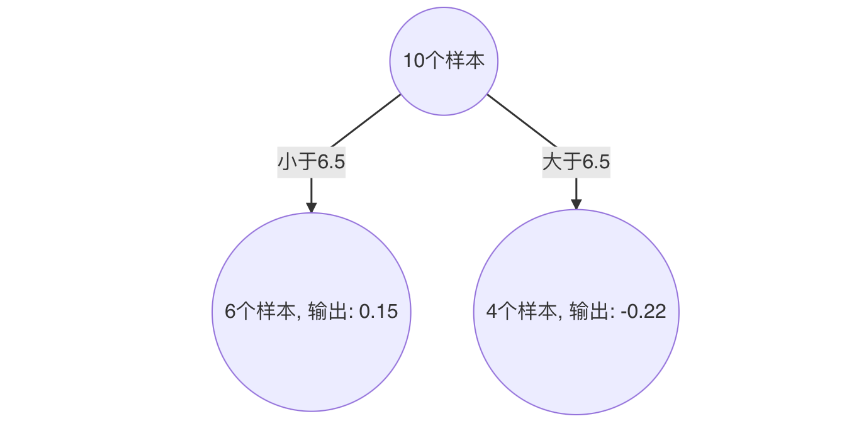
-
最终强学习器
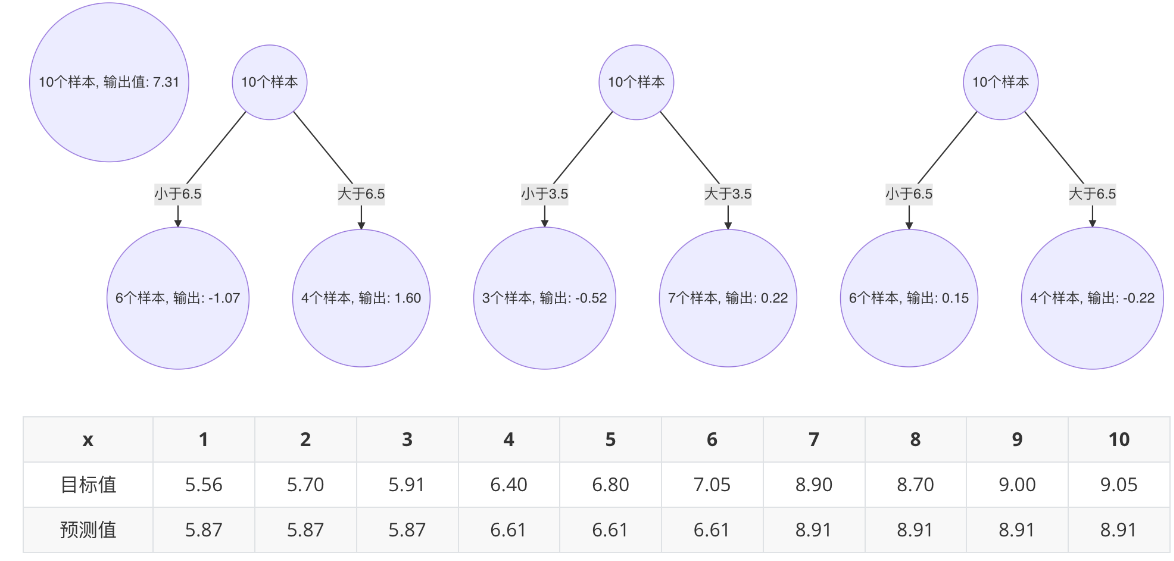
-
GBDT算法流程
1 初始化弱学习器(目标值的均值作为预测值)
2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度
3 直到达到指定的学习器个数
4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出
【实践】泰坦尼克号案例实战
该案例是在随机森林的基础上修改的,可以对比理解
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块泰坦尼克号数据集
titanic=pd.read_csv("../data/泰坦尼克号数据集.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)
#将数据转化为特征向量
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='records'))
X_test=vec.transform(X_test.to_dict(orient='records'))
#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
print("score",dtc.score(X_test,y_test))
#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
print("score:forest",rfc.score(X_test,y_test))
#6.GBDT进行模型的训练和预测分析
from sklearn.ensemble import GradientBoostingClassifier
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_pred=gbc.predict(X_test)
print("score:GradientBoosting",gbc.score(X_test,y_test))
#7.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))
print("gbc_report:",classification_report(gbc_y_pred,y_test))XGBoost
学习目标:
1.知道XGBoost算法的思想
2.理解XGBoost目标函数
3.了解XGBoost的算法API
4.实现红酒品质预测案例
XGBoost(Extreme Gradient Boosting)全名叫极端梯度提升树,XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost。
XGBoost在绝大多数的回归和分类问题上表现的十分顶尖
【知道】XGBoost算法思想
XGBoost 是对GBDT的改进:
-
求解损失函数极值时使用泰勒二阶展开
-
在损失函数中加入了正则化项
-
XGB 自创一个树节点分裂指标。这个分裂指标就是从损失函数推导出来的。XGB 分裂树时考虑到了树的复杂度。
构建最优模型的方法是最小化训练数据的损失函数 。
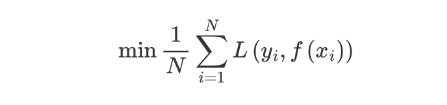
预测值和真实值经过某个函数计算出损失,并求解所有样本的平均损失,并且使得损失最小。这种方法训练得到的模型复杂度较高,很容易出现过拟合。因此,为了降低模型的复杂度,在损失函数中添加了正则化项,如下所示::
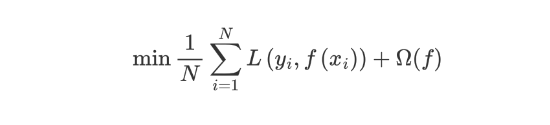
提高模型对未知数据的泛化能力。
【理解】XGboost的目标函数
XGBoost(Extreme Gradient Boosting)是对梯度提升树的改进,并且在损失函数中加入了正则化项。
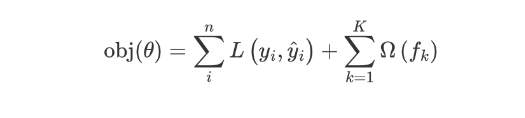
目标函数的第一项表示整个强学习器的损失,第二部分表示强学习器中 K 个弱学习器的复杂度。
xgboost 每一个弱学习器的复杂度主要从两个方面来考量:
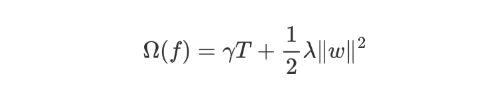
-
γT 中的 T 表示一棵树的叶子结点数量,γ 是对该项的调节系数
-
λ||w||2 中的 w 表示叶子结点输出值组成的向量,λ 是对该项的调节系数
-
模型复杂度的介绍
假设我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,如下图所示: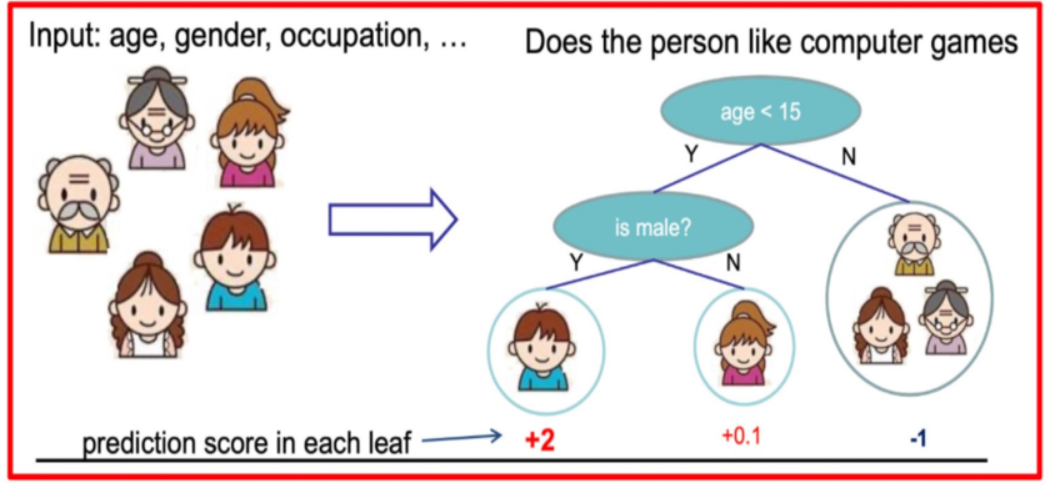
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以:
-
小男孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。
-
爷爷的预测分数同理:-1 + 0.9 = -0.1。
具体如下图所示: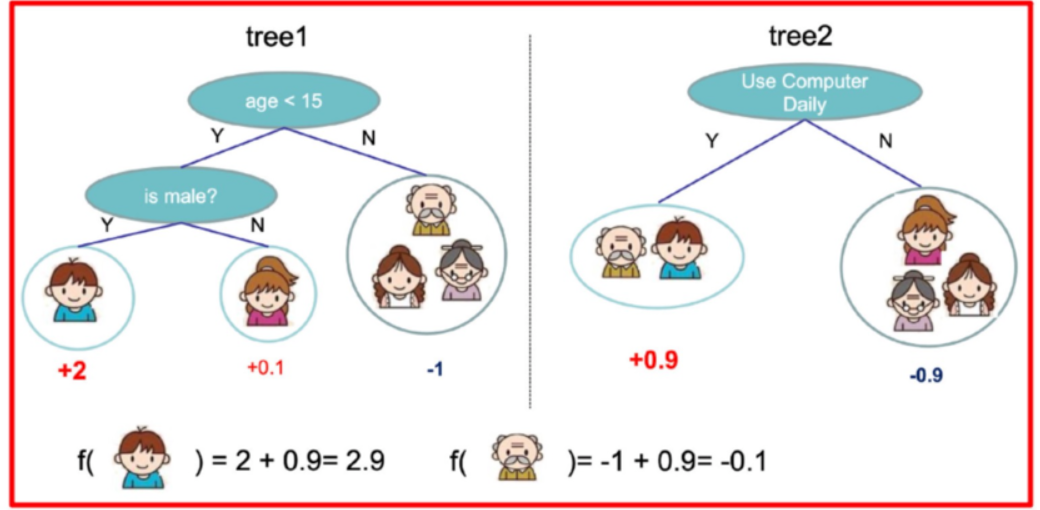
如下树tree1的复杂度表示为: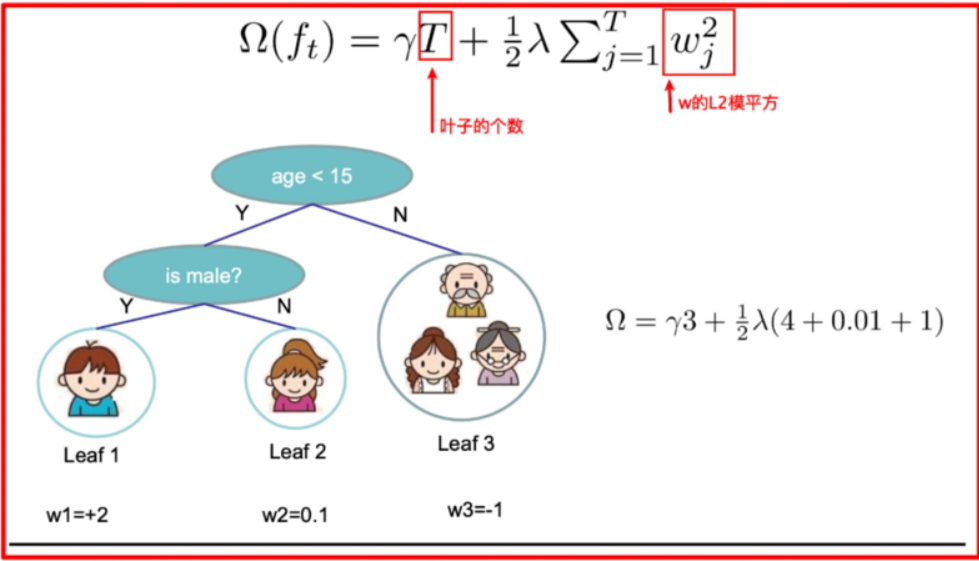
-
泰勒公式展开
我们直接对目标函数求解比较困难,通过泰勒展开将目标函数换一种近似的表示方式。接下来对 yi(t-1) 进行泰勒二阶展开,得到如下近似表示的公式: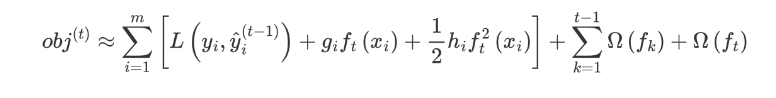
其中,gi 和 hi 的分别为损失函数的一阶导、二阶导:
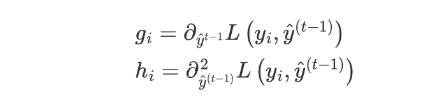
-
化简目标函数
我们观察目标函数,发现以下两项都是常数项,我们可以将其去掉。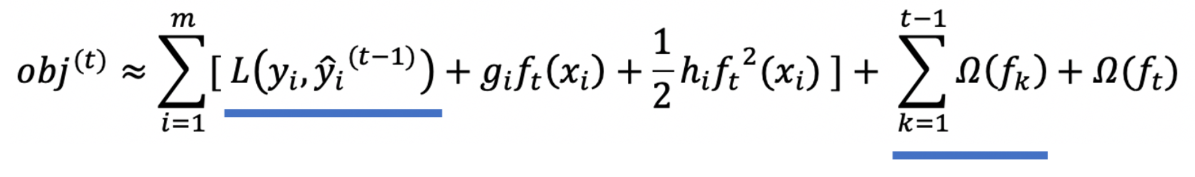
为什么说是常数项呢?这是因为当前学习器之前的学习器都已经训练完了,可以直接通过样本得出结果。化简之后的结果为:
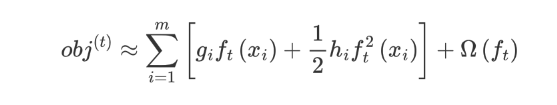
我们再将 Ω(ft) 展开,结果如下:
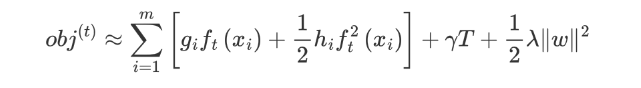
这个公式中只有 ft ,该公式可以理解为,当前这棵树如何构建能够降低损失。
-
问题再次转换
我们再次理解下这个公式表示的含义:
-
gi 表示每个样本的一阶导,hi 表示每个样本的二阶导
-
ft(xi) 表示样本的预测值
-
T 表示叶子结点的数目
-
||w||2 由叶子结点值组成向量的模
现在,我们发现公式的各个部分考虑的角度不同,有的从样本角度来看,例如:ft(xi) ,有的从叶子结点的角度来看,例如:T、||w||2。我们下面就要将其转换为相同角度的问题,这样方便进一步合并项、化简公式。我们统一将其转换为从叶子角度的问题: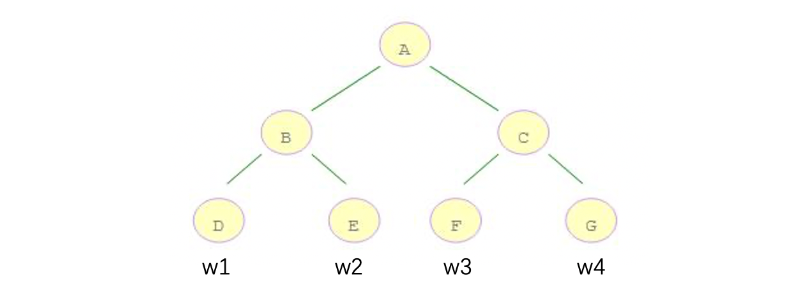
例如:10 个样本,落在 D 结点 3 个样本,落在 E 结点 2 个样本,落在 F 结点 2 个样本,落在 G 结点 3 个样本
-
D 结点计算: w1 * gi1 + w1 * gi2 + w1 * gi3 = (gi1 + gi2 + gi3) * w1
-
E 结点计算: w2 * gi4 + w2 * gi5 = (gi4 + gi5) * w2
-
F 结点计算: w3 * gi6 + w3 * gi6 = (gi6 + gi7) * w3
-
G 节点计算:w4 * gi8 + w4 * gi9 + w4 * gi10 = (gi8 + gi9 + gi10) * w4
gi ft(xi) 表示样本的预测值,我们将其转换为如下形式:
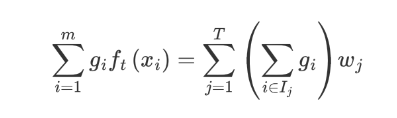
-
wj 表示第 j 个叶子结点的值
-
gi 表示每个样本的一阶导
hift2(xi) 转换从叶子结点的问题,如下:
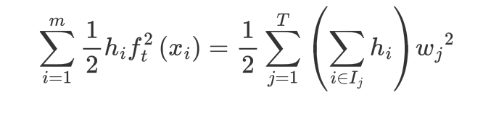
λ||w||2 由于本身就是从叶子角度来看,我们将其转换一种表示形式:

我们重新梳理下整理后的公式,如下: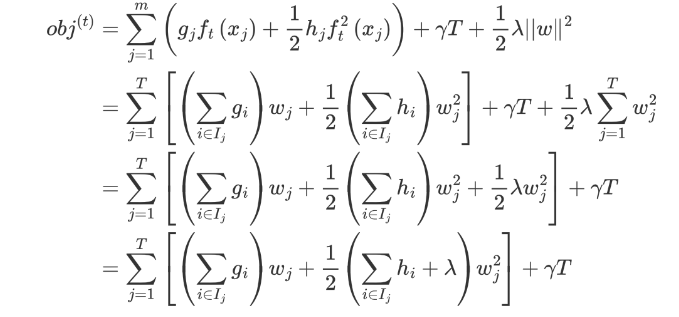
上面的公式太复杂了,我们令:
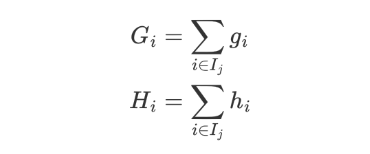
Gi 表示样本的一阶导之和,Hi 表示样本的二阶导之和,当确定损失函数时,就可以通过计算得到结果。
现在我们的公式变为:
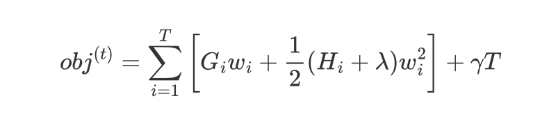
-
对叶子结点求导
此时,公式可以看作是关于叶子结点 w 的一元二次函数,我们可以对 w 求导并令其等于 0,可得到 w 的最优值,将其代入到公式中,即可再次化简上面的公式。
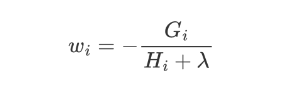
将 wj 代入到公式中,即可得到: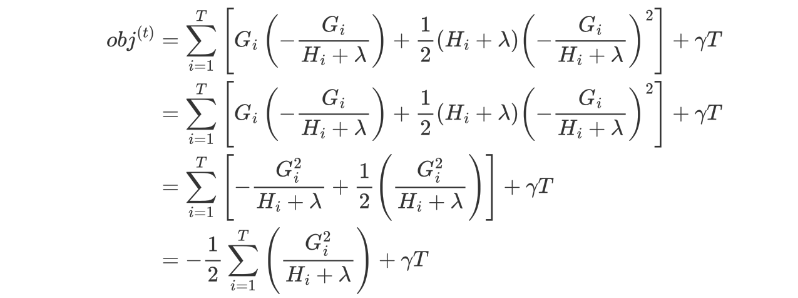
-
XGBoost的树构建方法
该公式也叫做打分函数 (scoring function),它可以从树的损失函数、树的复杂度两个角度来衡量一棵树的优劣。
这个公式,我们怎么用呢?
当我们构建树时,可以用来选择树的最佳划分点。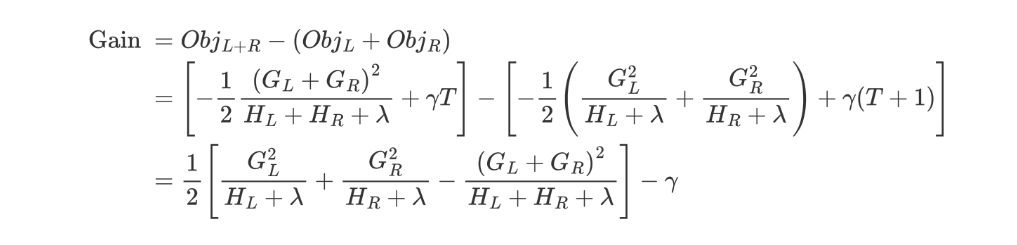
其过程如下:
-
对树中的每个叶子结点尝试进行分裂
-
计算分裂前 - 分裂后的分数:
-
如果gain > 0,则分裂之后树的损失更小,我们会考虑此次分裂
-
如果gain< 0,说明分裂后的分数比分裂前的分数大,此时不建议分裂
-
-
当触发以下条件时停止分裂:
-
达到最大深度
-
叶子结点样本数量低于某个阈值
-
等等...
-

【了解】XGboost API
bst = XGBClassifier(n_estimators, max_depth, learning_rate, objective) 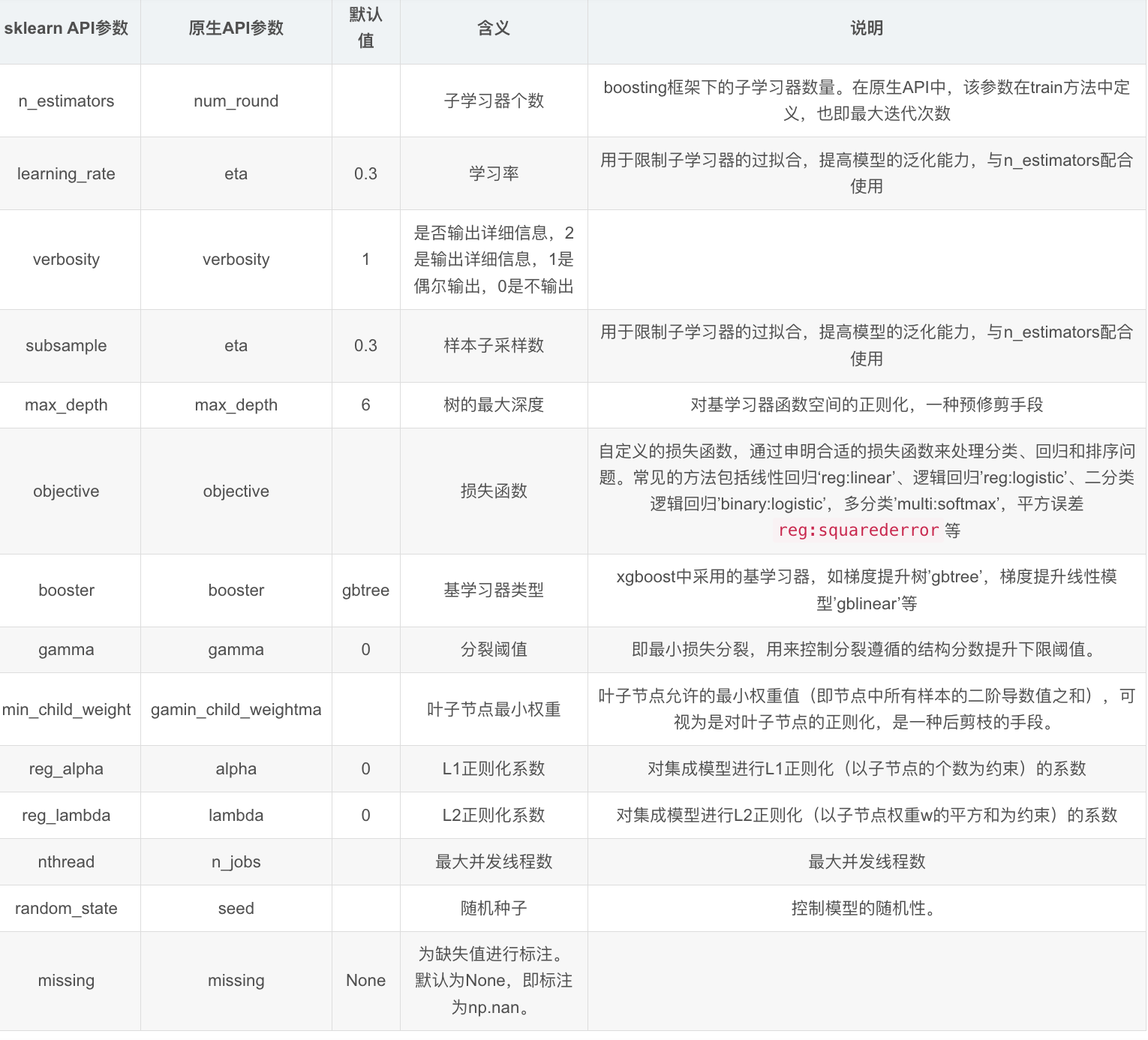
【实践】红酒品质预测
数据集介绍
数据集共包含 11 个特征,共计 3269 条数据. 我们通过训练模型来预测红酒的品质, 品质共有 6 个各类别,分别使用数字: 1、2、3、4、5 来表示。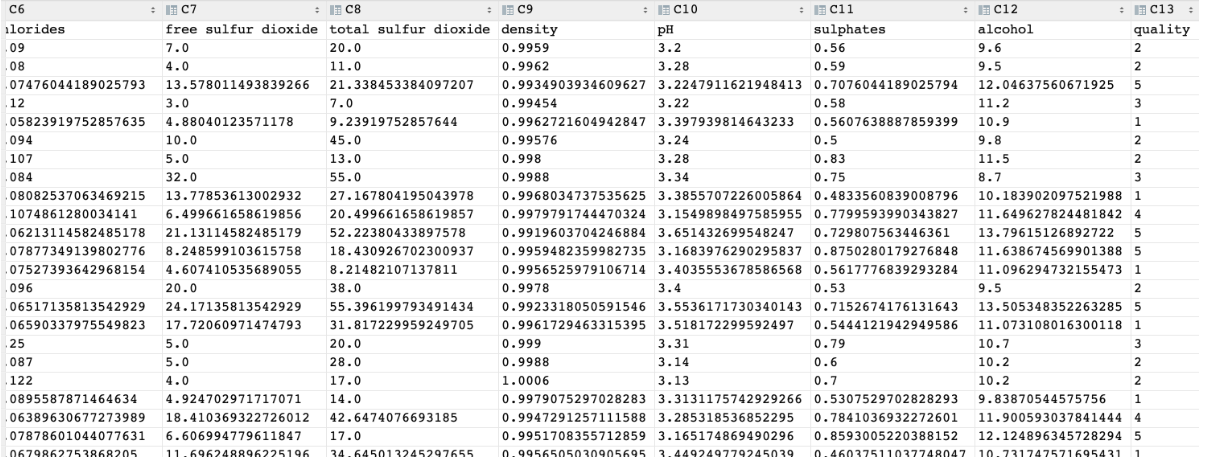
案例实现
-
导入需要的库文件
import joblib
import numpy as np
import xgboost as xgb
import pandas as pd
import numpy as np
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.model_selection import StratifiedKFold-
数据基本处理
def test01():
# 1. 加载训练数据data = pd.read_csv('data/红酒品质分类.csv')x = data.iloc[:, :-1]y = data.iloc[:, -1] - 3
# 2. 数据集分割x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, stratify=y, random_state=22)
# 3. 存储数据pd.concat([x_train, y_train], axis=1).to_csv('data/红酒品质分类-train.csv')pd.concat([x_valid, y_valid], axis=1).to_csv('data/红酒品质分类-valid.csv')-
模型基本训练
def test02():
# 1. 加载训练数据train_data = pd.read_csv('data/红酒品质分类-train.csv')valid_data = pd.read_csv('data/红酒品质分类-valid.csv')
# 训练集x_train = train_data.iloc[:, :-1]y_train = train_data.iloc[:, -1]
# 测试集x_valid = valid_data.iloc[:, :-1]y_valid = valid_data.iloc[:, -1]
# 2. XGBoost模型训练estimator = xgb.XGBClassifier(n_estimators=100,objective='multi:softmax',eval_metric='merror',eta=0.1,use_label_encoder=False,random_state=22)estimator.fit(x_train, y_train)
# 3. 模型评估y_pred = estimator.predict(x_valid)print(classification_report(y_true=y_valid, y_pred=y_pred))
# 4. 模型保存joblib.dump(estimator, 'model/xgboost.pth')-
模型参数调优
# 样本不均衡问题处理
from sklearn.utils import class_weight
classes_weights = class_weight.compute_sample_weight(class_weight='balanced',y=y_train)
# 训练的时候,指定样本的权重
estimator.fit(x_train, y_train,sample_weight = classes_weights)
y_pred = estimator.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))
# 交叉验证,网格搜索
train_data = pd.read_csv('data/红酒品质分类-train.csv')
valid_data = pd.read_csv('data/红酒品质分类-valid.csv')
# 训练集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
# 测试集
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
spliter = StratifiedKFold(n_splits=5, shuffle=True)
# 2. 定义超参数
param_grid = {'max_depth': np.arange(3, 5, 1),'n_estimators': np.arange(50, 150, 50),'eta': np.arange(0.1, 1, 0.3)}
estimator = xgb.XGBClassifier(n_estimators=100,objective='multi:softmax',eval_metric='merror',eta=0.1,use_label_encoder=False,random_state=22)
cv = GridSearchCV(estimator,param_grid,cv=spliter)
y_pred = cv.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))相关文章:

集成学习+泰坦尼克号案例+红酒品质预测
集成学习简介 学习目标: 1.知道集成学习是什么? 2.了解集成学习的分类 3.理解bagging集成的思想 4.理解boosting集成的思想 【知道】集成学习是什么? 集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高…...

SpringBoot 基础知识,HTTP 概述
1. 概述 1.1 Spring Spring 提供若干个子项目,每个项目用于完成特定功能 Spring 的若干个子项目都基于一个基础的框架:Spring Framework 框架类似于 房屋的地基 但 Spring Framework 配置繁琐,入门难度大 1.2 Spring Boot 于是…...
实现)
背包问题(java)实现
1、01背包 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scannew Scanner(System.in);int nscan.nextInt();int mscan.nextInt();int[][] dpnew int[n1][m1];int[] vnew int[n1];int[] wnew int[n1];for(int i1;i<n;i) {v…...
)
HDCP(一)
HDCP的核心目标解析 1. 数字内容版权保护 HDCP(高带宽数字内容保护)的核心目标是防止未经授权的设备对高清音视频内容进行非法复制或截取。它通过加密技术保护数字信号在传输链路(如HDMI、DisplayPort、DVI等接口)中的安全性&am…...

HTTP 1.0 时代,第一次优化
HTTP 是 “HyperText Transfer Protocol” 的缩写,即超文本传输协议。 相较于最初的设计,1.0增加了以下特性: 增加head,post等新方法。 引入新方法是为了扩充语义,其中 head 方法可以只拿元信息,不必传输…...

【吾爱出品】[Windows] 鼠标或键盘可自定义可同时多按键连点工具
[Windows] 鼠标或键盘连点工具 链接:https://pan.xunlei.com/s/VONSFKLNpyVDeYEmOCBY3WZJA1?pwduik5# [Windows] 鼠标或键盘可自定义可同时多按键连点工具 就是个连点工具,功能如图所示,本人系统win11其他系统未做测试,自己玩…...

计算机网络起源
互联网的起源和发展是一个充满创新、突破和变革的历程,从20世纪60年代到1989年,这段时期为互联网的诞生和普及奠定了坚实的基础。让我们详细回顾这一段激动人心的历史。 计算机的发展与ARPANET的建立(20世纪60年代) 互联网的诞生…...

Vue3 watch 与 watchEffect 深度解析
Vue3 watch 与 watchEffect 深度解析 一、响应式监听的基石作用 在Vue3的响应式系统中,watch和watchEffect是构建复杂状态逻辑的关键工具。它们实现了对响应式数据的精准监听,支撑着现代前端开发中的状态管理、副作用处理等核心功能。 1.1 演变 Optio…...

服务器信息收集
信息收集又叫打点,打仗也要侦探敌情,攻防更是如此。 但要获取哪些信息呢? 目录 一. 获取公网IP 如何知道一个网站用了CDN? 如何绕过CDN? 二. 旁站信息收集 三. C段主机查询 四. 子域名信息收集 五. 端口信息收…...

Java设计模式之装饰器模式:从入门到架构级实践
一、开篇:为什么需要装饰器模式? 在软件开发中,我们经常面临这样的困境:如何在不修改原有对象结构的情况下,动态地扩展对象的功能?当系统需要为对象添加多种可能的扩展功能时,如果直接使用继承…...

Vue3性能优化全攻略:从原理到极致性能实战
一、性能瓶颈深度诊断 1.1 关键性能指标分析 1.2 性能剖析工具矩阵 工具类型典型工具适用场景检测维度综合检测工具Lighthouse首屏加载性能分析加载评分/优化建议运行时监控工具Web Vitals页面交互性能监控FCP/LCP/TTI等框架专项工具Vue Devtools组件渲染性能分析渲染耗时/更…...

阿里云 AI 搜索开放平台:从算法到业务——AI 搜索驱动企业智能化升级
——已获知乎作者【GitHub Daily】授权转载 目前大模型的强大能力,使其成为一些企业和行业的主要创新驱动力,企业亟需重新审视和调整现有的创新机制,以适应AI技术和大数据的快速发展。目前很多企业已经开始尝试大模型在业务中进行赋能&#x…...

特权FPGA之AT24C02 IIC实现
0 简介 IIC的物理层 IIC一共有只有两个总线: 一条是双向的串行数据线SDA,一条是串行时钟线SCL. SDA(Serial data)是数据线,D代表Data也就是数据,Send Data …...

Docker 容器内运行程序的性能开销
在 Docker 容器内运行程序通常会有一定的性能开销,但具体损失多少取决于多个因素。以下是详细分析: 1. CPU 性能 理论开销:容器直接共享宿主机的内核,CPU 调度由宿主机管理,因此 CPU 运算性能几乎与原生环境一致&…...

SpringBoot依赖冲突引发的 log4j 日志打印问题及解决方法
依赖冲突引发的 log4j 日志打印问题及解决方法 在软件开发过程中,依赖管理是至关重要的一环。然而,时常会遇到依赖冲突的情况,其中就包括影响日志框架正常使用,比如因依赖冲突导致无法正常打印 log4j 日志的问题。 问题描述 当…...

MacOS中的鼠标、触控板的设置研究
一、背景和写这篇文章的原因 想搞清楚和配置好鼠标,比如解决好为什么我的滚动那么难用?怎么设置滚轮的方向跟windows相同?调整双击速度,调整鼠标滚轮左右拨动的"冷却时间"。 二、各种设置之详细解释 1. MacOS设置 -&…...

Clickhouse试用单机版部署
问题 最近需要试用clklog数据收集的社区版,clklog用数据库是Clickhouse。这就需要我先单机部署一个Clickhouse数据库,先试用试用。 步骤 这里假设我们已经拥有一台Ubuntu的服务器了,现在我们需要在这台机器上面安装Clickhouse数据库。Clic…...

【运维 | 硬件】服务器中常见的存储插槽类型、对应的传输协议及其特性总结
Why:最近更换设备,具体了解一下。 传输协议对比 协议 底层接口 最大带宽 队列深度 典型延迟 适用场景 AHCI SATA 6 Gbps (~600 MB/s) 单队列(32命令) 较高 传统 HDD/SATA SSD SAS SAS 24 Gbps (~2.4 GB/s) 单队列&…...

本地laravel项目【dcat-admin】部署到liunx服务器
文章目录 前言一、部署流程1、数据库搬迁2、宝塔创建网站,配置php3、修改nginx配置4、在public目录设置软连接5、修改env配置、刷新缓存 二、其他问题1.后台登陆失败问题2.完美解决接口跨域问题 总结 前言 laravel新手记录 差不多一个月,总算用laravel…...

DeepSeek:AI如何重构搜索引擎时代的原创内容生态
一、当生成式AI遇上搜索引擎:一场效率与价值的博弈 2023年,全球搜索引擎处理了超过2万亿次查询,其中超40%涉及复杂问题解答。而与此同时,Google的"Helpful Content Update"算法升级直接淘汰了26%的低质AI生成页面。这场…...

在docker里装rocketmq-console
首先要到github下载(这个一般是需要你有梯子) GitHub - apache/rocketmq-externals at release-rocketmq-console-1.0.0 如果没有梯子,用下面这个百度网盘链接下 http://链接: https://pan.baidu.com/s/1x8WQVmaOBjTjss-3g01UPQ 提取码: fu…...
【小白适用】)
蓝桥杯C++组算法知识点整理 · 考前突击(上)【小白适用】
【背景说明】本文的作者是一名算法竞赛小白,在第一次参加蓝桥杯之前希望整理一下自己会了哪些算法,于是有了本文的诞生。分享在这里也希望与众多学子共勉。如果时间允许的话,这一系列会分为上中下三部分和大家见面,祝大家竞赛顺利…...

Docker 是什么? Docker 基本观念介绍与容器和虚拟机的比较
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:历代文学,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编程,高并发设计…...

Docker:安装与部署 Nacos 的技术指南
1、简述 Nacos(Dynamic Naming and Configuration Service)是阿里巴巴开源的一个动态服务发现、配置管理和服务治理的综合解决方案,适用于微服务架构。 Nacos 主要功能: 服务发现与注册:支持 Dubbo、Spring Cloud 等主流微服务框架的服务发现与注册。动态配置管理:支持…...

UE5 RPC调用示例详解
文章目录 前言一、示例场景二、代码实现三、关键点解析3.1 RPC类型选择3.2 可靠性设置3.3 权限控制3.4 输入处理 四、测试与验证总结 前言 在UE5中,RPC(远程过程调用)是实现多人游戏逻辑同步的核心机制。以下通过一个玩家跳跃的示例…...

MATLAB在工程领域的实际应用案例
文章目录 前言自动驾驶汽车路径规划系统汽车先进驾驶辅助系统(ADAS)开发控制电气系统设计与优化桥梁结构分析与安全性评估 前言 MATLAB 在工程领域应用广泛,能解决复杂问题、优化系统设计。下面从不同工程领域选取了具有代表性的案例&#x…...

【完美解决】VSCode连接HPC节点,已配置密钥却还是提示需要输入密码
目录 问题描述软件版本原因分析错误逻辑链 解决方案总结 问题描述 本人在使用 VSCode Remote-SSH 插件连接超算集群节点时,遇到以下问题:已正确配置 SSH 密钥,且 VSCode 能识别密钥文件(如图1),但在…...

智能物联网网关策略部署
实训背景 某智慧工厂需部署物联网网关,实现以下工业级安全管控需求: 设备准入控制:仅允许注册MAC地址的传感器接入(白名单:AA:BB:CC:DD:EE:FF)。协议合规性:禁止非Modbus TCP(端口…...

玩转代理 IP :实战爬虫案例
在现代互联网环境下,爬虫不仅是数据获取的利器,也成为应对网站反爬机制的技术博弈。而在这场博弈中,"代理 IP" 是核心武器之一。本文将以高匿名的代理ip为核心,结合 Python 实战、代理策略设计、高匿技巧与反封锁优化&a…...

Deepseek解锁科研绘图新方式
在科研领域,一张清晰、准确且美观的图片往往能比冗长的文字更有效地传达研究成果。从展示实验数据的图表,到阐述理论模型的示意图,科研绘图贯穿于研究的各个环节。然而,传统的科研绘图工具往往操作复杂,学习成本高&…...
)
【unity游戏开发入门到精通——动画篇】Animator反向动力学(IK)
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、…...

【JavaScript】十八、页面加载事件和页面滚动事件
文章目录 1、页面加载事件1.1 load1.2 DOMContentLoaded 2、页面滚动事件2.1 语法2.2 获取滚动位置 3、案例:页面滚动显示隐藏侧边栏 1、页面加载事件 script标签在html中的位置一般在</body>标签上方,这是因为代码从上往下执行,在htm…...

Solana链开发全景指南:从环境搭建到生态实践
——2025年高性能区块链开发技术栈深度解析 一、Solana核心优势与技术特性 1. 突破性技术架构 历史证明(PoH):通过时间戳序列化交易,实现并行处理能力,支持5万TPS的吞吐量 并行执行引擎(Sealevel…...

这是一个文章标题
# Markdown 全语法示例手册本文档将全面演示 Markdown 的语法元素,包含 **标题**、**列表**、**代码块**、**表格**、**数学公式** 等 18 种核心功能。所有示例均附带实际应用场景说明。---## 一、基础文本格式### 1.1 标题层级 markdown # H1 (使用 #) ## H2 (使用…...

预言机与数据聚合器:DeFi的数据桥梁与风险博弈
一、核心机制与价值定位 预言机(Oracle)与数据聚合器是DeFi生态的“数据基建层”,解决链上-链下数据互通与链上数据可读性两大问题: 数据输入层(预言机):将现实世界数据(价格、天气…...

通过百度OCR在线API识别带水印扫描图片文字
目录 0 环境准备 1 百度OCR API申请 1.1 登录百度智能云 1.2 创建应用 1.3 获取API key和secret key 2 创建项目python环境 2.1 conda创建python环境 2.2 在pycharm中创建项目 2.3 激活python环境 2.4 安装项目依赖包 3 程序逻辑实现 3.1 导入依赖包 3.2 定义百度k…...

ocr python库
ocr python库 上手Git、Gitee和Github!watt toolkit...

Node 处理 request 的过程中,都会更新哪些 metadata 和 property
什么是 Metadata? 用于描述帧状态、控制参数、处理结果等 是随 request 流动的结构,通常是 PerFrameMetaData,每一帧一份 属于 HAL3 metadata 树的组成部分 什么是 Property? 是 CamX 内部定义的一种帧级别的轻量信息块 不一…...

基于labview的多功能数据采集系统
基于labview的多功能数据采集系统(可定制功能) 包含基于NI温度采集卡。电流采集卡。电压采集卡的数据采集功能 数据存储 报表存储 数据处理与分析 生产者消费者架构 有需要可联系...

李沐《动手学深度学习》 | 线性神经网络-线性回归
文章目录 线性回归1.确定模型2.衡量预估质量-损失函数3.深度学习的基础优化算法随机梯度下降小批量随机梯度下降 从线性回归到深度网络 线性回归从0开始实现构造一个人造数据集创建数据集可视化数据集 读取数据-随机抽取样本模型定义模型参数初始化定义模型定义损失函数定义优化…...

LabVIEW 中 “Flatten To Json String” VI 应用及优势
在 LabVIEW 开发涉及机器人数据等场景时,常需将数据以特定 JSON 格式输出。“Flatten To Json String” VI 在此过程中能发挥重要作用,相比 LabVIEW 系统自带的 JSON 处理方式,它具备独特优势。以下将介绍其获取、使用方法及相较系统自带方式…...

关于 Spring Boot 后端项目使用 Maven 打包命令、JAR/WAR 对比、内嵌服务器与第三方服务器对比,以及热部署配置的详细说明
以下是关于 Spring Boot 后端项目使用 Maven 打包命令、JAR/WAR 对比、内嵌服务器与第三方服务器对比,以及热部署配置的详细说明: 一、Maven 打包命令详解 1. 基础命令 1.1 清理并打包 mvn clean packageclean:删除 target 目录中的旧构建文…...

用labview写crc8校验
crc8校验有好几种,我这里写的是不带任何后缀的crc8。 首先,我们百度一下crc8的计算方式 一般搜索出来下面还有c语言写的crc8可以做为参考。 下面便是根据百度的计算方式写的crc8,已校验过,无问题。 写完后,可以输入下…...

阿里云CDN与DCDN主动推送静态资源至边缘服务器的ASP.NET WEB实例
一、CDN,需要调用PushObjectCache接口进行URL预热,以下是操作步骤: 1. 准备工作 首先,安装阿里云SDK NuGet包: Install-Package Aliyun.NET.SDK.CDN -Version 3.0.0 Install-Package Aliyun.NET.SDK.Core -Version 3.0.0 2. 创建ASP.NET Web页面代码 CDNPreheat.aspx…...
)
LangChain-提示模板 (Prompt Templates)
提示模板是LangChain的核心组件,用于构建发送给语言模型的输入。本文档详细介绍了提示模板的类型、功能和最佳实践。 概述 提示工程是使用大型语言模型的关键技术。通过精心设计的提示,可以显著提高模型的输出质量和相关性。LangChain的提示模板系统提…...

多线程中的互斥与同步
多线程中的互斥与同步 1. 互斥与同步的区别 互斥:确保某一资源在同一时刻只能被一个线程访问。其主要目的是保证资源的唯一性和排他性,但无法控制访问的顺序。同步:在互斥的基础上,进一步通过其他机制保证访问资源的有序性。 2…...

ValueError: Cannot handle batch sizes > 1 if no padding token is defined`
ValueError: Cannot handle batch sizes > 1 if no padding token is defined` batch sizes > 1 进行掩码填充:pad_token,eos_token 在处理自然语言处理任务时,尤其是在使用批量数据进行训练或推理时,经常需要对输入文本进行填充(padding),以确保每个输入序列具…...

Gemma 3模型:Google 开源新星,大语言模型未来探索
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、快速发展的AI世界:为何关注Gemma 3&#x…...

先占个日常,等会写。
引入一个重要的概念 “struct” (译为中文:结构体) 可用作设出比较复杂的一些变量类型 语法 :struct point name { int x; int y; int z;} point 和 name是任意命名的名字,含义是,声明一个变量类型为st…...

PyTorch Tensor维度变换实战:view/squeeze/expand/repeat全解析
本文从图像数据处理、模型输入适配等实际场景出发,系统讲解PyTorch中view、squeeze、expand和repeat四大维度变换方法。通过代码演示对比不同方法的适用性,助您掌握数据维度调整的核心技巧。 一、基础维度操作方法 1. view:内存连续的形状重…...