高并发内存池(三):PageCache(页缓存)的实现
前言:
在前两期内容中,我们深入探讨了内存管理机制中在 ThreadCache 和 CentralCache两个层级进行内存申请的具体实现。这两层缓存作为高效的内存分配策略,能够快速响应线程的内存需求,减少锁竞争,提升程序性能。
本期文章将继续沿着这一脉络,聚焦于PageCache层级的内存申请逻辑。作为内存分配体系的更高层级,PageCache承担着从操作系统获取大块内存,并对其进行管理和再分配的重要职责。通过对PageCache内存申请流程的剖析,我们将完整地勾勒出整个内存分配体系的工作流程。这不仅有助于我们理解内存分配的底层机制,也为后续深入探讨内存释放策略奠定了基础。
接下来,让我们一同走进PageCache的内存世界。
目录
一、PageCache的概述
二、PageCache结构
三、内存申请的核心流程
四、PageCache类的设计
五、代码实现
1.GetOneSpan的实现
2.NewSpan的实现
3.加锁保护
六、源码
一、PageCache的概述
⻚缓存是在central cache缓存上⾯的⼀层缓存,存储的内存是以⻚为单位存储及分配的。当central cache没有内存对象时,从page cache分配出⼀定数量的page,并切割成定⻓⼤⼩的⼩块内存,分配给central cache。当⼀个span的⼏个跨度⻚的对象都回收以后,page cache会回收central cache满⾜条件的span对象,并且合并相邻的⻚,组成更⼤的⻚,缓解内存碎⽚的问题。
二、PageCache结构
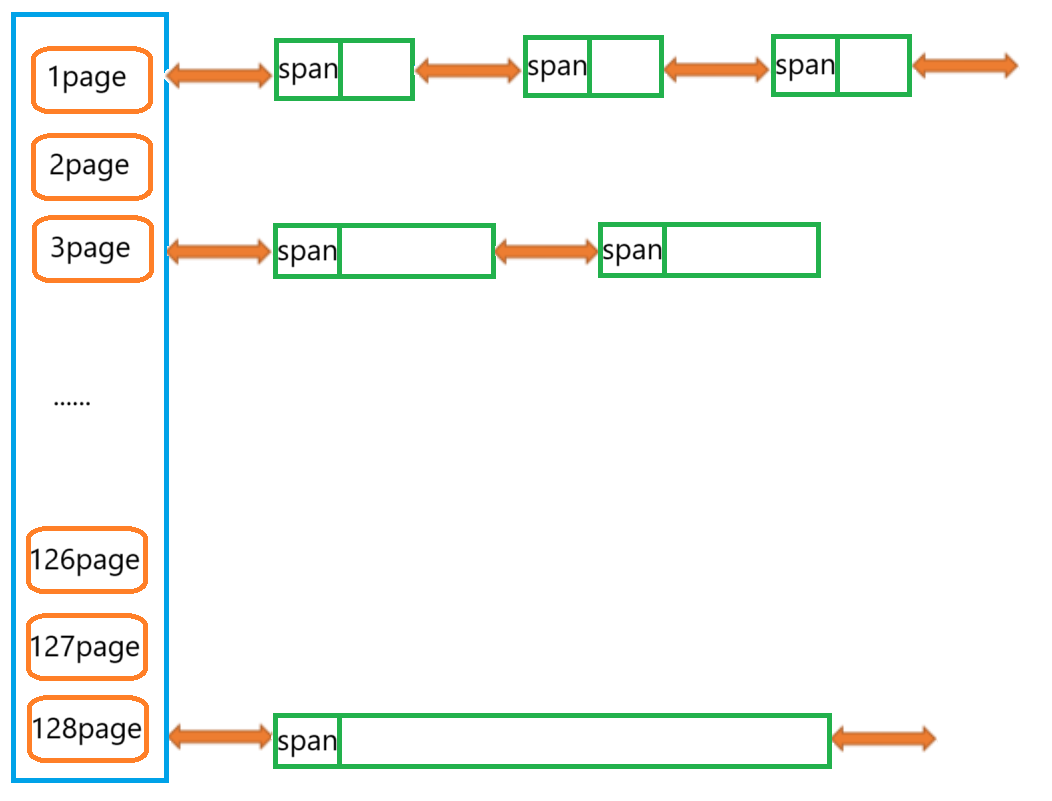
PageCache的结构是一个哈希表,如上图所示,也就是一个储存span双链表的数组,这一点和CentralCache的结构完全类似,区别在于这里的Span是大块的页(1页~128页)没有进行分割,而CentralCache中的Span是分割好的小块内存(自由链表),这样做的好处是方便页与页之间的分割与合并,有效的缓解内存外碎片,在下文会详细讲解。
PageCache结构的哈希映射方法是直接定址法,下标为n的位置储存的Span双链表中每个节点有n个页。
这个哈希表也是所有线程共用一个,属于临界资源需要加锁,但不是桶锁,而是一整个大锁,为什么呢?同样在下文细讲。
注:通常以4KB或8KB为一页,这里我们以8KB为一页。
三、内存申请的核心流程
- ThreadCache
CentralCache
当ThreadCache的自由链表内没有内存时,会向CentralCache中的一个Span申请,如果没有可用的Span,就向PageCache申请一个Span大块页,如果没有Span大块页了,最后才会向系统申请。
那么CentralCache具体是如何向PageCache申请内存的呢?
同样的PageCache一次只给一个Span,然后把这个Span切割成小块连接到CentralCache的哈希桶中,要给几页的Span呢?,这需要根据要将它切割成多大为单位的小块内存来进行具体分配,如果要切较小的内存块,页数就给小一些,如果要切大内存块,页数就给多一些。这里我们就先记为n页的Span。
因为PageCache中的哈希映射是直接定址法,所以直接找到n下标位置的Span链,如果有Span则取出并切成小块连接到CentralCache的哈希桶中。
如果没有n页的Span并不是直接去系统申请,而是到更大的页单位去找Span。比如找到有(n+k)页的Span,k>0,n+k<=128,那么把(n+k)拆开为n页与k页,并连接到相应位置。这样就有了n页的Span,把它切割和连接就行。
如果直到找到128页也没有找到可用的Span那么就向系统申请128页的内存,即128*8*1024字节,然后再执行上面逻辑。这就是整个在PageCache申请内存的逻辑。
处理临界资源互斥问题
如上,PageCache的哈希桶中各个桶是互相联动的,主要体现在这三方面:
- 当前桶没Span要往后找。
- 后面的桶切割Span后要连接到前面的桶。
- 在内存回收时又需要前面桶的Span合并成大页的Span连接到后面的桶。
所以这里不像CentralCache结构的桶相互独立,如果用桶锁会造成频繁的锁申请和释放,效率反而变得很低。用一个大锁来管理整个哈希桶更为合理。
四、PageCache类的设计
把这个类的设计放在头文件PageCache.h里,它核心就两个成员变量:锁和哈希桶,然后再声明一个用来申请Span的成员函数,如下:
class PageCache
{
public:Span* NewSpan(size_t k);std::mutex _pageMtx;
private:SpanList _spanLists[NPAGES];
};- Span* NewSpan(size_t k):申请一个k页的Span
- mutex _pageMtx:锁,因为它要在外部使用,所以设为public。
- SpanList _spanLists[NPAGES]:哈希桶,其中NPAGES是一个静态全局变量为129,在Common.h中定义。设为129是因为哈希表中存1页~128页的Span,要通过页数直接定址的方式找到Span链表,就需要开辟129大小的数组。
PageCache类和CentralCache类一样所有线程共用一份,所以把它创建为单例模式,它分为以下几步:
- 把构造函数设为私有。
- 把拷贝构造禁用。
- 声明静态的PageCache对象,并在PageCache.cpp中定义。
- 提供一个获取PageCache对象的静态成员函数,并设为public。
代码示例:
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}Span* NewSpan(size_t k);std::mutex _pageMtx;
private:PageCache() {}PageCache(const PageCache&) = delete;SpanList _spanLists[NPAGES];static PageCache _sInst;
};五、代码实现
1.GetOneSpan的实现
回顾上一期我们只是假设通过GetOneSpan从CentralCache中取到了Span,然后继续做后面的处理。接下来我们一起来实现GetOneSpan函数。
因为要在Span链表中取一个有用的Span节点,所以需要遍历Span链表,那么可以模拟一个迭代器。我们在SpanList类中封装这两个函数:
Span* Begin()
{return _head->_next;
}
Span* End()
{return _head;
}注:SpanList是一个带头双向环形链表。
接下来遍历链表找到可用的Span并返回,如果没有则到PageCache中申请。
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}it = it->_next;}//走到这里说明没有可用的Span了,向PageCache中申请。//......
}- SpanList& list:指定的一个哈希桶,即一个Span链表的头结点。
- size_t size:进行内存对齐后实际需要申请的字节大小。
注意在PageCache中申请的是大块的Span页,还需要把它切割,然后连接到CentralCache的桶中并返回。
在PageCache类中我们准备实现的函数NewSpan就是用来实现这个功能,现在需要考虑的是要传入的参数是多少,即要申请多少页的Span。
这里我们是以8KB为一页,即 1页=8*1024字节(2^13字节)为方便后面做位运算,我们在Common.h文件定义一个这样一个变量:
static int const PAGE_SHIFT = 13;
当然了这里也可以做成宏定义。
接下来在SizeClass类里封装一个函数NumMovePage用来计算一个size需要申请几页的Span,如下:
//用来计算ThreadCache向CentralCache申请几个小内存块
static inline size_t NumMoveSize(size_t size)
{int ret = MAX_BYTES / size;if (ret < 2) ret = 2;if (ret > 512) ret = 512;return ret;
}
//用来计算CentralCache向PageCache申请几个页的Span
static inline size_t NumMovePage(size_t size)
{int num = NumMoveSize(size);int npage = num * size;npage >>= PAGE_SHIFT; //除以8KBif (npage < 1) npage = 1;return npage;
}在此,大家无需过度纠结于该设计背后的原理。这或许是相关领域的资深专家在历经大量测试与实践后,所总结提炼出的有效策略,我们继续走下面的逻辑。
//申请Span
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
//切割Span
//......NewSpan函数我们待会再设计,现在假设已经申请到一个Span的大块页,接下来就是进行切割。
首先我们需要得到的是这个页的起始地址与终止地址,在这个范围内以size的跨度切割。
用char*的指针变量start,end分别来储存起始地址和终止地址,用char*类型是因为char*类型指针变量加多少,就移动多少字节,方便后面做切割运算。
起始页地址的获取:
取到Span的页号,用页号乘以8KB(2^13字节)就能得到页的起始地址,即:
char* start = (char*)(span->_pageId << PAGE_SHIFT);
终止页地址的获取:
取到Span的页数,用页数乘以8KB再加上起始页地址就能得到终止页地址,即:
int bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
注:页号是通过申请到的内存的虚拟地址除以8KB得到的。
接下来把start连接到Span的自由链表中,然后使用循环把[start,end]这块内存以size为跨度进行切割,如下:
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}it = it->_next;}//申请SpanSpan* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));//切割Spanchar* start = (char*)(span->_pageId << PAGE_SHIFT);int bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;span->_freeList = start;while (start < end){Nextobj(start) = start + size;start = (char*)Nextobj(start);}Nextobj(end) = nullptr;//连接到CentralCache中list.PushFront(span);return span;
}这里直接以尾插的方式切,好处在于用户在使用内存时是连在一块的,相关的数据会被一并载入寄存器中,可以增加高速缓存命中率,提高效率。
最后实现一个类方法PushFront,用来把Span连接到哈希桶里。
void PushFront(Span* node)
{//在Begin()前插入node,即头插Insert(Begin(), node);
}2.NewSpan的实现
NewSpan我们放在源文件PageCache.cpp中实现。
查找当前桶
首先可以用assert断言页数的有效性,然后直接定址找到Span链,如果不为空返回一个Span节点,如果为空到后面的大页去找,如下:
Span* PageCache::NewSpan(size_t k)
{//判断页数的有效性assert(k > 0 && k < NPAGES);if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}//到后面更大块的Span页切割//......//向系统申请内存//......
}到大页切割
当k号桶没有Span后,从k+1号桶开始往后找,比如找到i号桶不为空,则把Span节点取出来,记为nSpan,然后切割为k页和i-k页,切割的本质就是改变页数_n和页号_pageId。
new一个Span空间,用kSpan变量指向,然后把nSpan头k个页切出来储存到一个kSpan中,即:
- kSpan->_pageId = nSpan->_pageId:更新kSpan的页号。
- kSpan->_n = k:更新kSpan的页数。
- nSpan->_pageId += k:原nSpan的页起始页号后移k位。
- nSpan->_n -= k:原nSpan的页数减少k。
这样就相当于把原来大块的nSpan切割成了两块,最后把割剩下的nSpan插入到对应的哈希桶中,把kSpan返回。
for (int i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}向系统申请
当k号桶往后的桶都是空的,那么我们就需要向系统申请内存了,直接申请一个128的页,放在128号桶,再执行上面的逻辑。
对于内存申请,在windows下我们使用VirtualAlloc函数,与malloc相比VirtualAlloc直接与操作系统交互,无额外开销,效率高,通常用来申请超大块内存。
VirtualAlloc的声明
LPVOID VirtualAlloc(LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect );
- LPVOID lpAddress:期望的起始地址(通常设为0由系统决定)
- SIZE_T dwSize:分配的内存大小(字节)
- DWORD flAllocationType: 分配的类型(如保留或提交)
- DWORD flProtect:内存保护选项(如读写权限)
返回值:LPVOID ,本质是void*,需强制类型转换后使用。
flAllocationType
MEM_COMMIT:提交内存,使其可用。
MEM_RESERVE:保留地址空间,暂不分配物理内存。二者可组合使用(
MEM_RESERVE | MEM_COMMIT),同时保留并提交。flProtect
控制内存访问权限,常用选项:
PAGE_READWRITE:可读/写。
PAGE_NOACCESS:禁止访问(触发访问违规)。
PAGE_EXECUTE_READ:可执行/读。
因为还要考虑其他系统的需求,我们在Common.h内封装一个向系统申请内存的函数,并使用条件编译来选择不同的函数调用,如下:
#ifdef _WIN32#include <windows.h>
#else//Linux...
#endifinline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();//抛异常return ptr;
}接下来继续NewSpan的执行逻辑,向系统申请内存后,new一个Span储存相关的页信息,即计算页号(地址/8KB),填写页数,然后把Span连接到128号哈希桶,最后需要做的就是把它切割为k页的Span和(128-k)页的Span和前面的逻辑一模一样,为提高代码复用率以递归的方式返回。如下:
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}for (int i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}//向系统申请内存Span* span = new Span;void* ptr = SystemAlloc(NPAGES - 1);span->_pageId = (PANGE_ID)ptr>>PAGE_SHIFT;span->_n = NPAGES - 1;_spanLists[span->_n].PushFront(span);return NewSpan(k);
}3.加锁保护
PageCache哈希桶是临界资源,需要对它进行加锁保护。上文已经讲过只用加一个大锁,而不是用桶锁。
因为NewSpan函数涉及递归,需要使用递归锁,这样比较高效。但这里也可以把锁加到NewSpan外面,也就是GetOneSpan函数里,如下:

其次有一个优化的点:线程进入PageCache这一层之前是先进入了CentralCache的,并在这一层加了桶锁,那么此时CentralCache的哈希桶它暂时不用,但可能其他线程要用,可以先把锁释放掉,等从PageCache申请完内存后再去申请锁。
虽然说线程走到PageCache这一层说明CentralCache的哈希桶已经没有内存了,其他线程来了也申请不到内存,但别忘了还有内存的释放呢。把桶锁释放了,其他线程释放内存对象回来,就不会阻塞。如下:

六、源码
代码量比较大,就不放在这里了,需要的小伙伴到我的gitee上取:
PageCache/PageCache · 敲上瘾/ConcurrentMemoryPool - 码云 - 开源中国
相关文章:
:PageCache(页缓存)的实现)
高并发内存池(三):PageCache(页缓存)的实现
前言: 在前两期内容中,我们深入探讨了内存管理机制中在 ThreadCache 和 CentralCache两个层级进行内存申请的具体实现。这两层缓存作为高效的内存分配策略,能够快速响应线程的内存需求,减少锁竞争,提升程序性能。 本期…...

使用pybind11开发可供python使用的c++扩展模块
在做紫微斗数程序的时候用到了padas库,不过也只用了它下面几个功能: 1、读入csv文件,构造DataFrame; 2、通过行列标题查找数据; 3、通过行标题读取一行数据。 用这几个功能却导入了pandas、numpy、dateutil、pytz等一堆库,多少有点划不来,于是想用c++开发一个实现这几…...
)
系统与网络安全------网络通信原理(5)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 传输层解析 传输层 传输层的作用 IP层提供点到点的连接传输层提供端到端的连接 端口到端口的连接(不同端口号,代表不同的应用程序) TCP协议概述 TCP(Transm…...

JavaScript防抖与节流
目录 防抖(Debounce) 一、防抖的定义 二、防抖的实现原理 三、防抖的代码实现 四、代码解析 五、使用示例 1. 输入框实时搜索(延迟执行模式) 2. 按钮防重复点击(立即执行模式) 六、总结 节流&…...
)
Java网络编程实战(多人聊天室-CS模式)
一、C/S模式核心原理 1.1 基本架构 C/S(Client/Server)模式采用客户端-服务器架构: 服务器端:持续运行,负责消息路由和广播客户端:用户交互界面,连接服务器进行通信通信协议:TCP&…...

Vue3.5 + Vite6.x 项目的完整 Stylelint 配置方案,支持 .vue/.html 内联样式、Less/SCSS/CSS 等多种文件类
Vue3.5 Vite6.x 项目的完整 Stylelint 配置方案,支持 .vue/.html 内联样式、Less/SCSS/CSS 等多种文件类型 一、完整依赖安装 npm install --save-dev stylelint stylelint-config-standard postcss-html # 解析 Vue/HTML 文件中的样式postcss-scss …...
)
23种设计模式Java版(带脑图,带示例源码)
设计模式 1、创建型 1.1、单例模式(Singleton pattern) 确保一个类只有一个实例,并提供该实例的全局访问点。 1.2、工厂方法(Factory Method) 它定义了一个创建对象的接口,但由子类决定要实例化哪个类。工厂方法把实例化操作推迟到子类。 1.3、抽象…...

mapbox高阶,使用graphology、graphology-shortest-path前端插件和本地geojson数据纯前端实现路径规划
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️graphology 插件1.3.1 ☘️概念1.3.2 ☘…...

【已解决】vscode升级后连接远程异常:“远程主机可能不符合XXX的先决条件”解决方法
vscode提示升级,每次都升了,突然某次关闭后无法连接远程,查询资料是因为从VS Code 1.86.1版本开始(2024年1月)要求glibc版本>2.28。 命令“ ldd --version”可查看glibc版本为2.27: rootXXXXXXX:~$ ld…...

Springboot整合JAVAFX
Springboot整合JAVAFX 实体与VO设计 pom.xml文件如下: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xs…...

【算法】——一键解决动态规划
前言 动态规划是一种高效解决重叠子问题和最优子结构问题的算法思想。它通过分治记忆化,将复杂问题分解为子问题,并存储中间结果,避免重复计算,从而大幅提升效率。 为什么重要? 优化…...

Git使用与管理
一.基本操作 1.创建本地仓库 在对应文件目录下进行: git init 输入完上面的代码,所在文件目录下就会多一个名为 .git 的隐藏文件,该文件是Git用来跟踪和管理仓库的。 我们可以使用 tree 命令(注意要先下载tree插件)…...

npm、nvm、nrm
NVM (Node Version Manager) 常见指令 NVM 是一个用于管理 Node.js 版本的流行工具,允许你在同一台机器上安装和切换不同版本的 Node.js。以下是 NVM 的常见指令: 安装与卸载 nvm install <version> - 安装指定版本的 Node.js 例如:…...

Java 文件内容转换为MD5哈希值
若要把读取到的 files 列表里的内容转换为 MD5 哈希值,你可以逐个遍历 files 列表中的元素,将每个元素的内容计算成 MD5 哈希值。 以下是一个完整的 Java 示例代码,展示了如何实现这一功能: import java.io.BufferedInputStream…...

未来郴州:科技与自然的交响诗篇
故事背景 故事发生在中国湖南郴州,描绘了未来城市中科技与自然共生共荣的奇妙图景。通过六个充满诗意的场景,展现雾能转化系统、立体生态书库、智能稻田等创新设计,编织出一曲人类智慧与自然韵律共鸣的未来交响。 故事内容 在东江湖的晨雾中&…...

UE5 运行时动态将玩家手部模型设置为相机的子物体
在编辑器里,我们虽然可以手动添加相机,但是无法将网格体设置为相机的子物体,只能将相机设置为网格体的子物体 但是为了使用方便,我们希望将网格体设置为相机的子物体,这样我们直接旋转相机就可以旋转网格体࿰…...

Ubuntu系统下的包管理器APT
Ubuntu系统下的包管理器APT 在Linux操作系统生态中,软件包管理工具是连接用户与系统功能的桥梁。Ubuntu作为基于Debian的流行发行版,其强大的包管理系统APT(Advanced Packaging Tool)为开发者与系统管理员提供了便捷的软件生命周…...

超级码科技发布镂空AI保险胶带,重塑包装防伪新标准
在酒类、物流、奢侈品、电子产品等领域,包装安全与防伪需求日益迫切。传统封箱胶带易被转移或重复利用,导致商品被仿冒的风险居高不下。 为此,超级码科技推出镂空型防揭AI数字身份保险封箱胶带——一款集结构防伪、信息追踪与增值服务于一体的…...

微软Exchange管理中心全球范围宕机
微软已确认Exchange管理中心(Exchange Admin Center,EAC)发生全球性服务中断,导致管理员无法访问关键管理工具。该故障被标记为关键服务事件(编号EX1051697),对依赖Exchange Online的企业造成广…...

前端通信库fetch-event-source实现丰富的SSE
环境:SpringBoot3.4.0 + Vue3 1. 简介 SSE(Server-Sent Events)是一种基于HTTP的服务器向客户端单向推送实时数据的轻量级协议,配合浏览器原生EventSource API,可实现高效实时通信。前端通过创建EventSource对象订阅服务端流,自动处理连接、重试与数据解析;服务端设置C…...

JVM 中Minor GC、Major GC、Full GC 的区别?
Minor GC、Major GC 和 Full GC 是 Java 虚拟机 (JVM) 垃圾回收 (Garbage Collection) 中的不同类型的 GC 事件,它们在范围、触发条件、停顿时间等方面有所不同。 1. Minor GC (Young GC): 范围: 只针对新生代 (Young Generation) 进行垃圾回收。触发条…...

2747. 统计没有收到请求的服务器数目
文章目录 题意思路代码 题意 题目链接 思路 代码 class Solution { public:vector<int> countServers(int n, vector<vector<int>>& logs, int x, vector<int>& queries) {sort(logs.begin(), logs.end(), [](vector<int> &a, v…...

设计模式:抽象工厂 - 掌控多产品族的创建之道
一、什么是抽象工厂模式? 抽象工厂模式是一种创建型设计模式,提供一个接口,用于创建一系列相关或相互依赖的对象,而无需指定它们的具体类。 核心思想 1.定义多个产品的抽象接口,统一管理具体产品和工厂的创建逻辑。…...

图神经网络+多模态:视频动作分割的轻量高效新解法
一、引言 在智能监控、自动驾驶、人机交互等领域,准确理解视频中的动作序列至关重要。然而,传统方法依赖复杂的视觉模型,计算成本高且难以捕捉长时依赖。近期,一项名为 Semantic2Graph 的研究通过图神经网络(GNN&am…...
)
技术与情感交织的一生 (五)
目录 初入“江湖” 分工 陌生 CraneOffice 内功 宝典 枪手 回到大二 通关 小聚 唱一首歌 初入“江湖” 分工 软件工作室是坐落在和平区宜昌道的一间民房,和我想象中的公司形象多少有些偏差。天津的道路有点凌乱,初次的时候不太好找…...
)
简单-快速-高效——模块化解析Pulid(实现不同风格下的人脸一致)
资源 论文:https://arxiv.org/abs/2404.16022 github:https://github.com/ToTheBeginning/PuLID?tabreadme-ov-file comfyui插件:https://github.com/sipie800/ComfyUI-PuLID-Flux-Enhanced 讲解参考 https://zhuanlan.zhihu.com/p/69684…...

XYZ to xyY 求解
免责声明:本文所提供的信息和内容仅供参考。作者对本文内容的准确性、完整性、及时性或适用性不作任何明示或暗示的保证。在任何情况下,作者不对因使用本文内容而导致的任何直接或间接损失承担责任,包括但不限于数据丢失、业务中断或其他经济…...

科技自然的协奏曲-深圳
故事背景 故事发生在中国广东深圳的现代城市环境,这里呈现出未来科技与自然生态共生的独特图景。没有具体的角色,却通过多样的场景描绘,展现出未来生活的活力与创新,反映出社会创新与人类情感的紧密结合。 故事内容 在未来的深…...

idea 创建 maven-scala项目
文章目录 idea 创建 maven-scala项目1、创建普通maven项目并且配置pom.xml文件2、修改项目结构1)创建scala目录并标记成【源目录】2)导入scala环境3)测试环境 idea 创建 maven-scala项目 1、创建普通maven项目并且配置pom.xml文件 maven依赖…...

C++项目:高并发内存池_下
目录 8. thread cache回收内存 9. central cache回收内存 10. page cache回收内存 11. 大于256KB的内存申请和释放 11.1 申请 11.2 释放 12. 使用定长内存池脱离使用new 13. 释放对象时优化成不传对象大小 14. 多线程环境下对比malloc测试 15. 调试和复杂问题的调试技…...

【UE5】RTS游戏的框选功能+行军线效果实现
目录 效果 步骤 一、项目准备 二、框选NPC并移动到指定地点 三、框选效果 四、行军线效果 效果 步骤 一、项目准备 1. 新建一个俯视角游戏工程 2. 新建一个pawn、玩家控制器和游戏模式,这里分别命名为“MyPawn”、“MyController”和“MyGameMode” 3. 打开“MyGam…...

多图超详细:Docker安装知识库AI客服RAGFlow的详细步骤、使用教程及注意事项:
RAGFlow 介绍 RAGFlow 是一款基于深度文档理解的开源检索增强生成(RAG)引擎,通过结合信息检索与生成式 AI 技术,解决复杂场景下的数据处理和可信问答问题。其核心设计目标是提供透明化、可控化的文档处理流程,并通过多…...

docker compose安装智能体平台N8N
使用 docker volume create n8n_data 创建了一个名为 n8n_data 的数据卷。你通过 docker run 启动容器,映射了端口 5678,并挂载了 n8n_data 数据卷。 以下是对应的 docker-compose.yml 配置文件: version: "3.7"services:n8n:ima…...

FRP调用本地摄像头完成远程拍照
from flask import Flask, Response import cv2app Flask(__name__)# 基础文字回复 app.route(/) def hello_world():return <h1>你好啊世界</h1><img src"/camera" width"640" /># 摄像头拍照并返回图像 app.route(/camera) def captu…...

【Linux】39.一个基础的HTTP Web服务器
文章目录 1. 实现一个基础的HTTP Web服务器1.1 功能实现:1.2 Log.hpp-日志记录器1.3 HttpServer.hpp-网页服务器1.4 Socket.hpp-网络通信器1.5 HttpServer.cc-服务器启动器 1. 实现一个基础的HTTP Web服务器 1.1 功能实现: 总体功能: 提供We…...
)
蓝桥杯-小明的背包(动态规划-Java)
0/1背包问题介绍 0/1背包问题是经典的动态规划问题,具体描述如下: 解题思路: 输入数据 首先,程序通过 Scanner 从输入中读取数据: n 表示物品的数量。 v 表示背包的最大容量。 接着读取每个物品的重量和价值ÿ…...
Dart 中的空安全与 `late` 关键字教程)
(四十一)Dart 中的空安全与 `late` 关键字教程
Dart 中的空安全与 late 关键字教程 空安全简介 空安全(Null Safety)是 Dart 语言的一项重要特性,旨在帮助开发者避免空指针异常(NullPointerException)。空安全通过在编译时检查变量是否可能为 null,从而…...

GaussDB使用指南
目录 1. GaussDB 概述 1.1 GaussDB 简介 1.2 核心技术架构 1.3 适用场景与行业案例 2. GaussDB 安装与部署 2.1 环境准备与依赖检查 2.2 单机版安装(Linux) 2.3 分布式集群部署 3. GaussDB 基础操作与语法 3.1 数据库连接与用户管理 3.2 DDL …...
)
算法训练之动态规划(一)
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

dubbo配置中心
配置中心 简介 配置中心(config-center)在dubbo中可承担两类职责: 外部化配置:启动配置的集中式存储。流量治理规则存储。 Dubbo动态配置中心定义了两个不同层次的隔离选项,分别是namespace和group。 namespace&a…...

移动端六大语言速记:第11部分 - 内存管理
移动端六大语言速记:第11部分 - 内存管理 本文将对比Java、Kotlin、Flutter(Dart)、Python、ArkTS和Swift这六种移动端开发语言在内存管理方面的特性,帮助开发者理解和掌握各语言的内存管理机制。 11. 内存管理 11.1 垃圾回收机制对比 各语言垃圾回收…...

对象的创建方式有哪些?在虚拟机中具体的创建过程是怎样的?
在Java中,对象的创建方式及其在虚拟机中的具体过程如下: 一、对象的创建方式 使用 new 关键字 最常见的对象创建方式,直接调用类的构造方法。 MyClass obj new MyClass();反射(Reflection) 通过 Class 或 Constructor…...

openwrt软路由配置3
1.启用sftp文件连接 使用ssh连接openwrt时,我发现无法打开sftp windows进行上传和下载文件,提示 sftp channel closed by server: stderr:ash /usr/libexec/sftp-server:not found 原因是系统刚刚装好后,没有安装openssh-sftp-server包 opk…...

C语言for循环嵌套if相关题目
一、题目引入 以下代码程序运行结果是多少? 二、思路解析 进入一个for循环 a<100 进入第一个if b1不大于20为假 进入第二个if b4 a这时a自增为2 当b4时,满足第二个if条件 1.b4,a2 当b7时,满足第二个if条件 2.bb37,a3 当b10时,满足第二个if条件 …...

Redis与Mysql双写一致性如何保证?
我们在面试的时候redis与mysql双写一致性是一个常考的问题,今天我们就一起探讨一下吧 所谓的一致性就是数据的一致性,在分布式系统中,可以理解为多个节点中数据的值是一致的。 强一致性: 这种一致性级别是最符合用户直觉的&…...

STM32 CRC校验与芯片ID应用全解析:从原理到实践 | 零基础入门STM32第九十七步
主题内容教学目的/扩展视频CRC与芯片ID原理实现CRC校验和读取芯片ID为单片机应用提供数据验证和身份识别的功能。 师从洋桃电子,杜洋老师 📑文章目录 一、CRC校验功能解析1.1 CRC基本原理1.2 核心功能对比 二、CRC校验应用实战2.1 典型应用场景2.2 程序实…...

《微服务与事件驱动架构》读书分享
《微服务与事件驱动架构》读书分享 Building Event-Driver Microservices 英文原版由 OReilly Media, Inc. 出版,2020 作者:[加] 亚当 • 贝勒马尔 译者:温正东 作者简介: 这本书由亚当贝勒马尔(Adam Bellemare…...
基础)
⼤模型(LLMs)基础
⼤模型(LLMs)基础 ⽬前 主流的开源模型体系 有哪些?prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么?⼤模型LLM的 训练⽬标 是什么?涌现能⼒是啥原因?为何现在的⼤模型⼤部分是Decoder o…...

IDEA :物联网ThingsBoard-gateway配置,运行Python版本,连接thingsboard,接入 MQTT 设备
准备阶段(教程只针对本地操作,未涉及虚拟机环境) Thingsboard源码编译并运行 没有操作过的小伙伴,可以看我上一篇文章 物联网ThingsBoard源码本地编译篇,超详细教程,小白看过来!_thingsboard…...

面向大模型的开发框架LangChain
这篇文章会带给你 如何使用 LangChain:一套在大模型能力上封装的工具框架如何用几行代码实现一个复杂的 AI 应用面向大模型的流程开发的过程抽象 文章目录 这篇文章会带给你写在前面LangChain 的核心组件文档(以 Python 版为例)模型 I/O 封装…...