卷积神经网络CNN
目录
一、图像基础知识
图像基本概念
图像的加载
二、CNN概述
CNN概述
三、卷积层
卷积计算
Padding
Stride
多通道卷积计算
PyTorch卷积层API
四、池化层
池化层计算
Stride
Padding
多通道池化层计算
PyTorch 池化 API
五、图像分类案例
CIFAR10 数据集
搭建图像分类网络
编写训练函数
编写预测函数
总体代码
一、图像基础知识
图像基本概念
图像是由像素点组成的,每个像素点的取值范围为: [0, 255] 。像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。
在深度学习中,我们使用的图像大多是彩色图,彩色图由RGB3个通道组成,如下图所示
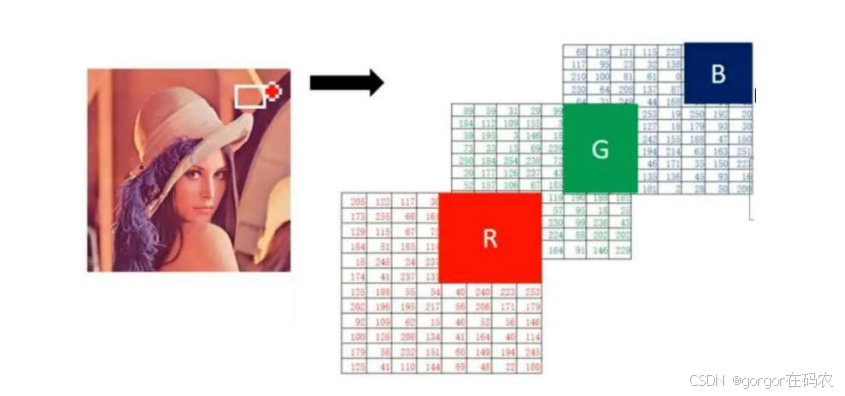
图像的加载
使用 matplotlib 库来实际理解下上面讲解的图像知识。
import numpy as np
import matplotlib.pyplot as plt
# 像素值的理解
def test01():# 全0数组是黑色的图像img = np.zeros([200, 200, 3])# 展示图像plt.imshow(img)plt.show()# 全255数组是白色的图像img = np.full([200, 200, 3], 255)# 展示图像plt.imshow(img)plt.show()test01()
# 图像的加载
def test02():# 读取图像img = plt.imread("data/yy.jpg")# 图像形状 高,宽,通道print("图像的形状(H, W, C):\n", img.shape)# 展示图像plt.imshow(img)plt.axis("off")plt.show()
test02()
二、CNN概述
CNN概述
- 卷积层负责提取图像中的局部特征;
- 池化层用来大幅降低参数量级(降维);
- 全连接层用来输出想要的结果。

三、卷积层
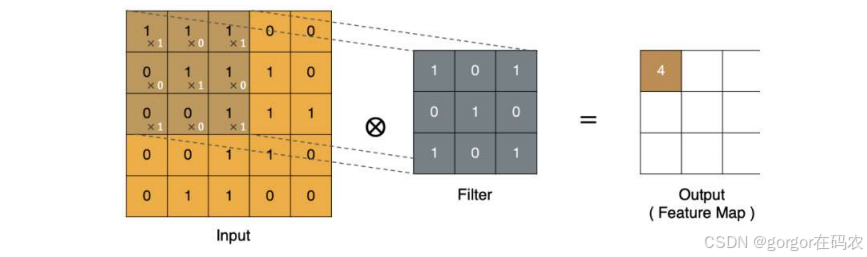
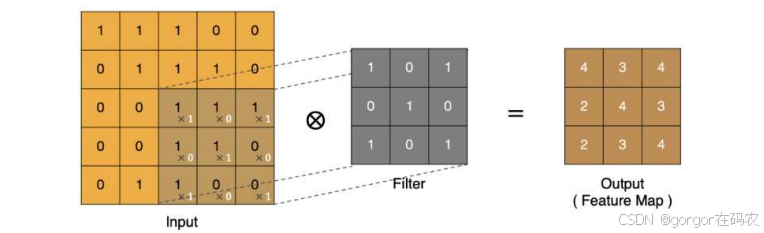
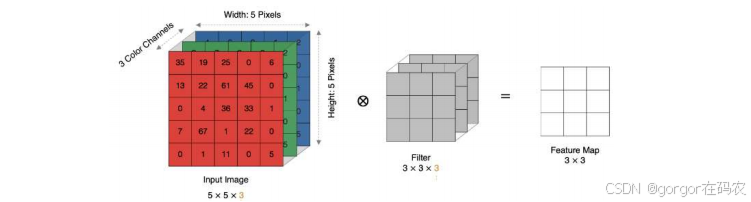
卷积计算
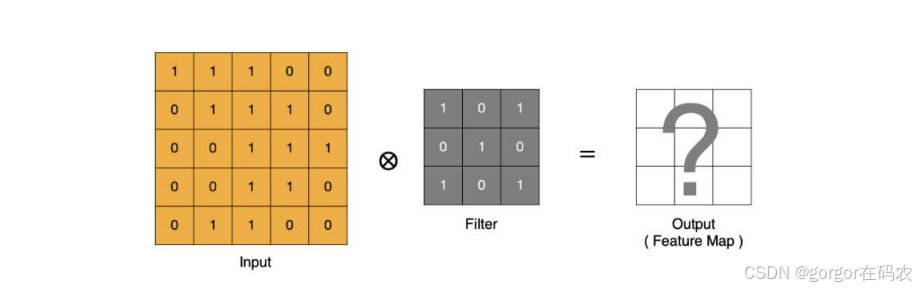
- input 表示输入的图像
- filter 表示卷积核, 也叫做卷积核(滤波矩阵)
- input 经过 filter 得到输出为最右侧的图像,该图叫做特征图
Padding
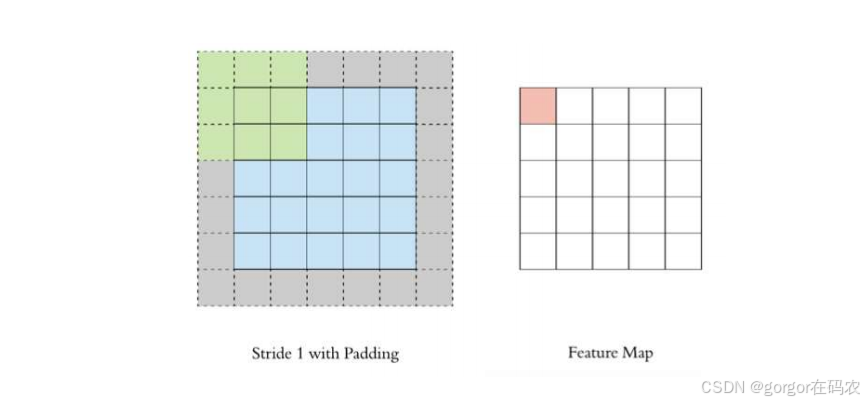
Stride

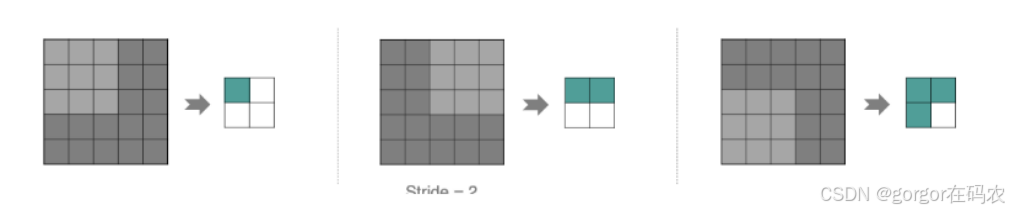
多通道卷积计算

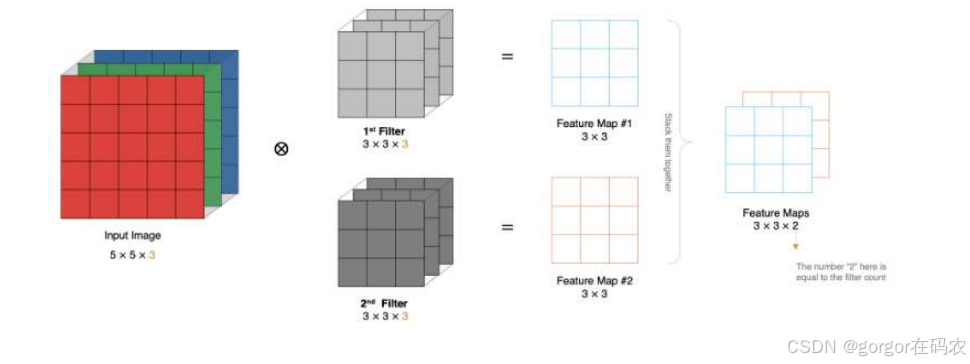
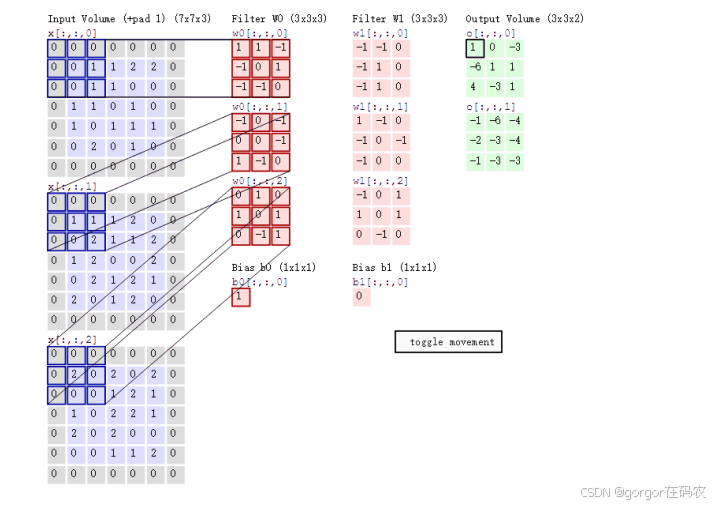
- size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1*1 、3*3、5*5
- Padding: 零填充的方式
- Stride: 步长
- 输入图像大小: W x W
- 卷积核大小: F x F
- Stride: S
- Padding: P
- 输出图像大小: N x N
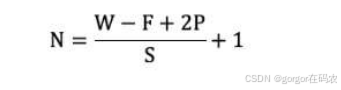
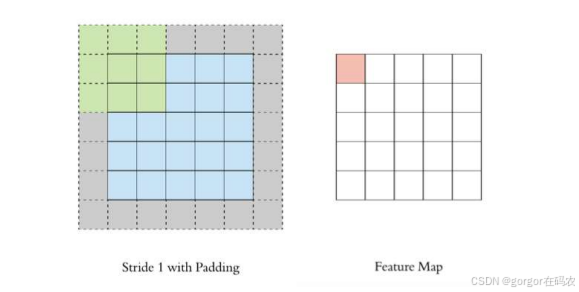
- 图像大小: 5 x 5
- 卷积核大小: 3 x 3
- Stride: 1
- Padding: 1
- (5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
PyTorch卷积层API
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)"""参数说明:in_channels: 输入通道数,out_channels: 输出通道,也可以理解为卷积核 kernel 的数量kernel_size :卷积核的高和宽设置,一般为 3,5,7...stride :卷积核移动的步长padding :在四周加入 padding 的数量,默认补 0"""
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
def test():# 读取图像, 形状: (640, 640, 3)img = plt.imread('data/yy.jpg')plt.imshow(img)plt.axis('off')plt.show()# 构建卷积层# out_channels表示卷积核个数# 修改out_channels,stride,padding观察特征图的变化情况conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=2, padding=0)# 输入形状: (BatchSize, Channel, Height, Width)# mg形状: torch.Size([3, 640, 640])img = torch.tensor(img).permute(2, 0, 1)# img 形状: torch.Size([1, 3, 640, 640])img = img.unsqueeze(0)# 将图像送入卷积层中feature_map_img = conv(img.to(torch.float32))# 打印特征图的形状print(feature_map_img.shape)if __name__ == '__main__':test()四、池化层
池化层计算
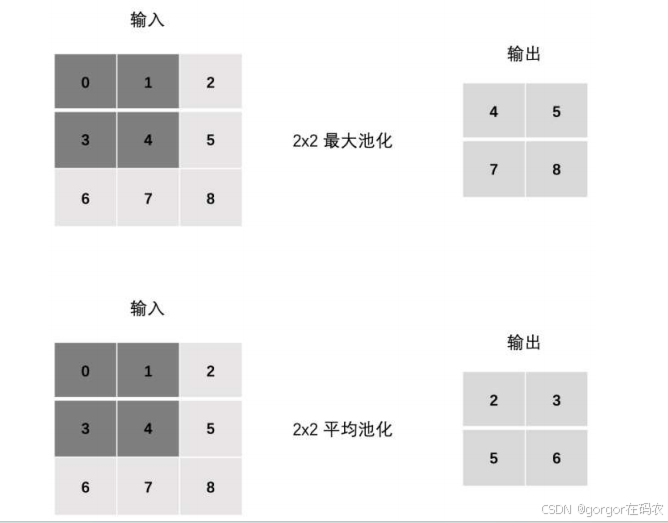
Stride
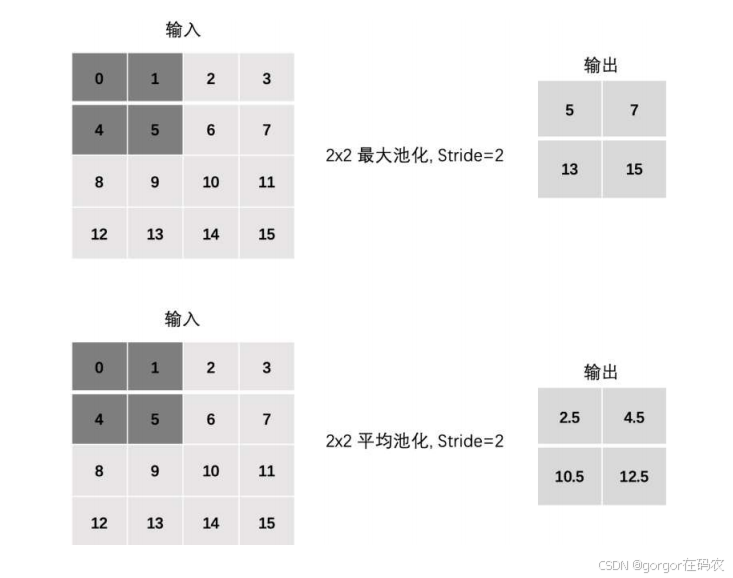
Padding
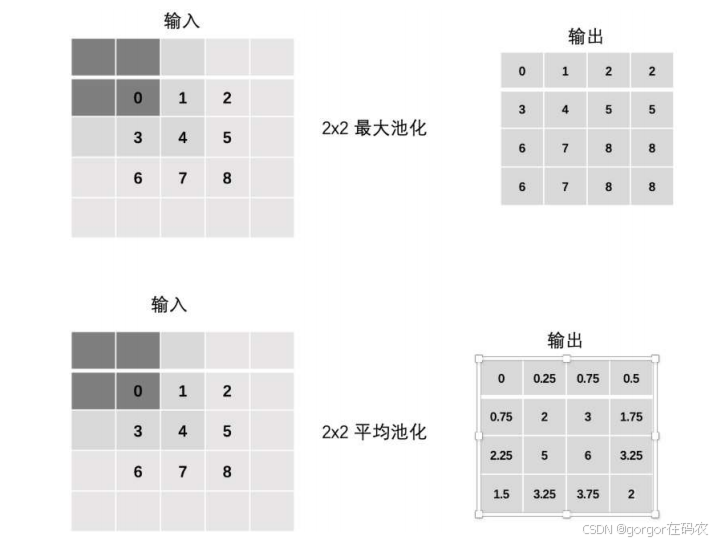
多通道池化层计算
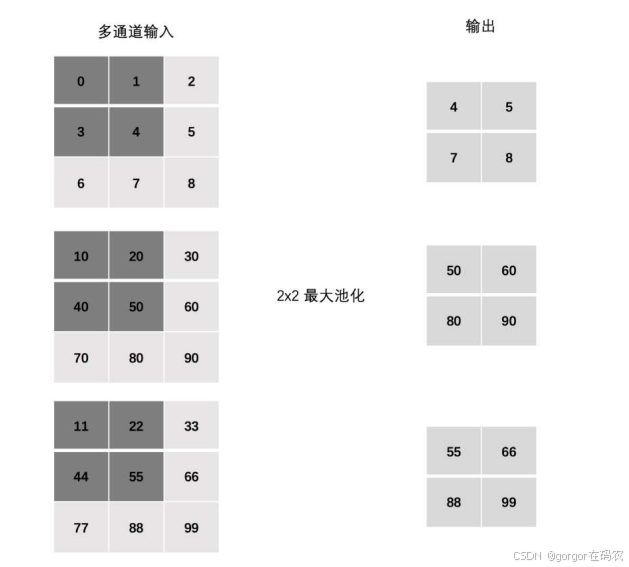
PyTorch 池化 API
# 最大池化nn.MaxPool2d(kernel_size=2, stride=2, padding=1)# 平均池化nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
import torch
import torch.nn as nn
"""
1. 单通道池化
"""
def test01():# 定义输入输数据 【1,3,3 】inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]]]).float()# 修改stride,padding观察效果# 1. 最大池化polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)output = polling(inputs)print("最大池化:\n", output)# 2. 平均池化polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=0)output = polling(inputs)print("平均池化:\n", output)"""
2. 多通道池化
"""
def test02():# 定义输入输数据 【3,3,3 】inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],[[10, 20, 30], [40, 50, 60], [70, 80, 90]],[[11, 22, 33], [44, 55, 66], [77, 88, 99]]]).float()# 最大池化polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)output = polling(inputs)print("多通道池化:\n", output)
if __name__ == '__main__':test01()test02()输出结果
最大池化:
tensor([[[4., 5.],
[7., 8.]]])
平均池化:
tensor([[[2., 3.],
[5., 6.]]])
多通道池化:
tensor([[[ 4., 5.],
[ 7., 8.]],[[50., 60.],
[80., 90.]],[[55., 66.],
[88., 99.]]])
五、图像分类案例
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.transforms import Compose
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
BATCH_SIZE = 8CIFAR10 数据集

# 1. 数据集基本信息
def create_dataset():# 加载数据集:训练集数据和测试数据train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]), download=True)valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]), download=True)# 返回数据集结果return train, valid
if __name__ == '__main__':# 数据集加载train_dataset, valid_dataset = create_dataset()# 数据集类别print("数据集类别:", train_dataset.class_to_idx)# 数据集中的图像数据print("训练集数据集:", train_dataset.data.shape)print("测试集数据集:", valid_dataset.data.shape)# 图像展示plt.figure(figsize=(2, 2))plt.imshow(train_dataset.data[1])plt.title(train_dataset.targets[1])plt.show()搭建图像分类网络
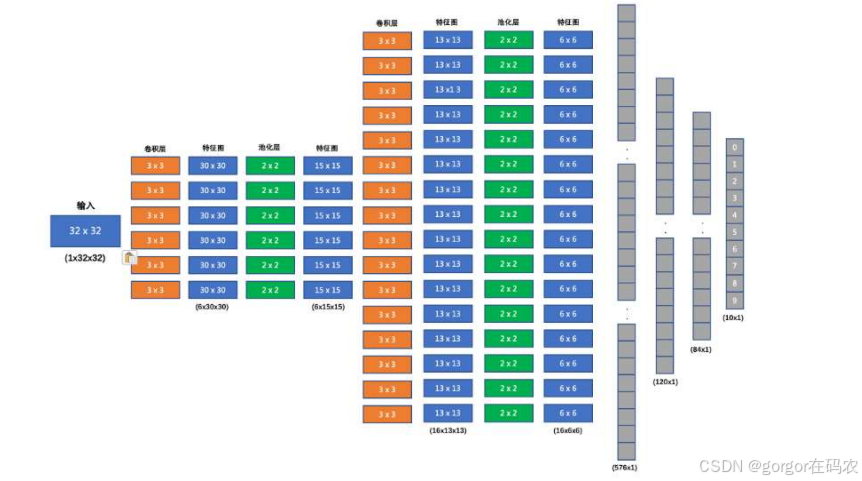
- 输入形状: 32x32
- 第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
- 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
- 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
- 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
- 第一个全连接层输入 576 维, 输出 120 维
- 第二个全连接层输入 120 维, 输出 84 维
- 最后的输出层输入 84 维, 输出 10 维
# 2.模型构建
class ImageClassification(nn.Module):# 定义网络结构def __init__(self):super(ImageClassification, self).__init__()# 定义网络层:卷积层+池化层self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)# 全连接层self.linear1 = nn.Linear(576, 120)self.linear2 = nn.Linear(120, 84)self.out = nn.Linear(84, 10)# 定义前向传播def forward(self, x):# 卷积+relu+池化x = torch.relu(self.conv1(x))x = self.pool1(x)# 卷积+relu+池化x = torch.relu(self.conv2(x))x = self.pool2(x)# 将特征图做成以为向量的形式:相当于特征向量x = x.reshape(x.size(0), -1)# 全连接层x = torch.relu(self.linear1(x))x = torch.relu(self.linear2(x))# 返回输出结果return self.out(x)if __name__ == '__main__':# 模型实例化model = ImageClassification()summary(model,input_size=(3,32,32),batch_size=1)编写训练函数
# 3.训练模型
def train(model,train_dataset):criterion = nn.CrossEntropyLoss() # 构建损失函数optimizer = optim.Adam(model.parameters(), lr=1e-3) # 构建优化方法epoch = 100 # 训练轮数for epoch_idx in range(epoch):# 构建数据加载器dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)sam_num = 0 # 样本数量total_loss = 0.0 # 损失总和start = time.time() # 开始时间# 遍历数据进行网络训练for x, y in dataloader:output = model(x)loss = criterion(output, y) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 参数更新total_loss += loss.item() # 统计损失和sam_num += 1print('epoch:%2s loss:%.5f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,time.time() - start))# 模型保存torch.save(model.state_dict(), 'data/image_classification.pth')if __name__ == '__main__':# 数据集加载train_dataset, valid_dataset = create_dataset()# 模型实例化model = ImageClassification()# 模型训练train(model,train_dataset)编写预测函数
def test(valid_dataset):# 构建数据加载器dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True)# 加载模型并加载训练好的权重model = ImageClassification()model.load_state_dict(torch.load('data/image_classification.pth'))model.eval()# 计算精度total_correct = 0total_samples = 0# 遍历每个batch的数据,获取预测结果,计算精度for x, y in dataloader:output = model(x)total_correct += (torch.argmax(output, dim=-1) == y).sum()total_samples += len(y)# 打印精度print('Acc: %.2f' % (total_correct / total_samples))总体代码
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.transforms import Compose
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
BATCH_SIZE = 8# 1. 数据集基本信息
def create_dataset():# 加载数据集:训练集数据和测试数据train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]), download=True)valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]), download=True)# 返回数据集结果return train, valid
# if __name__ == '__main__':
# # 数据集加载
# train_dataset, valid_dataset = create_dataset()
# # 数据集类别
# print("数据集类别:", train_dataset.class_to_idx)
# # 数据集中的图像数据
# print("训练集数据集:", train_dataset.data.shape)
# print("测试集数据集:", valid_dataset.data.shape)
# # 图像展示
# plt.figure(figsize=(2, 2))
# plt.imshow(train_dataset.data[1])
# plt.title(train_dataset.targets[1])
# plt.show()# 2.模型构建
class ImageClassification(nn.Module):# 定义网络结构def __init__(self):super(ImageClassification, self).__init__()# 定义网络层:卷积层+池化层self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)# 全连接层self.linear1 = nn.Linear(576, 120)self.linear2 = nn.Linear(120, 84)self.out = nn.Linear(84, 10)# 定义前向传播def forward(self, x):# 卷积+relu+池化x = torch.relu(self.conv1(x))x = self.pool1(x)# 卷积+relu+池化x = torch.relu(self.conv2(x))x = self.pool2(x)# 将特征图做成以为向量的形式:相当于特征向量x = x.reshape(x.size(0), -1)# 全连接层x = torch.relu(self.linear1(x))x = torch.relu(self.linear2(x))# 返回输出结果return self.out(x)# 3.训练模型
def train(model,train_dataset):criterion = nn.CrossEntropyLoss() # 构建损失函数optimizer = optim.Adam(model.parameters(), lr=1e-3) # 构建优化方法epoch = 100 # 训练轮数for epoch_idx in range(epoch):# 构建数据加载器dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)sam_num = 0 # 样本数量total_loss = 0.0 # 损失总和start = time.time() # 开始时间# 遍历数据进行网络训练for x, y in dataloader:output = model(x)loss = criterion(output, y) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 参数更新total_loss += loss.item() # 统计损失和sam_num += 1print('epoch:%2s loss:%.5f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,time.time() - start))# 模型保存torch.save(model.state_dict(), 'data/image_classification.pth')# 4.预测模型
def test(valid_dataset):# 构建数据加载器dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True)# 加载模型并加载训练好的权重model = ImageClassification()model.load_state_dict(torch.load('data/image_classification.pth'))model.eval()# 计算精度total_correct = 0total_samples = 0# 遍历每个batch的数据,获取预测结果,计算精度for x, y in dataloader:output = model(x)total_correct += (torch.argmax(output, dim=-1) == y).sum()total_samples += len(y)# 打印精度print('Acc: %.2f' % (total_correct / total_samples))if __name__ == '__main__':#1.数据集加载train_dataset, valid_dataset = create_dataset()#2.模型实例化model = ImageClassification()#3.模型训练train(model, train_dataset)#4.预测模型test(valid_dataset)相关文章:

卷积神经网络CNN
目录 一、图像基础知识 图像基本概念 图像的加载 二、CNN概述 CNN概述 三、卷积层 卷积计算 Padding Stride 多通道卷积计算 PyTorch卷积层API 四、池化层 池化层计算 Stride Padding 多通道池化层计算 PyTorch 池化 API 五、图像分类案例 CIFAR10 数据集 …...

【大数据生态】Hive的metadata服务未开启
解决办法 进入到Hive的bin目录下,键入命令: #启动元服务 [atguiguhadoop102 bin]$ pwd /opt/module/hive-3.1.2/bin [atguiguhadoop102 bin]$ ./hive --service metastore & #启动hive [atguiguhadoop102 hive-3.1.2]$ pwd /opt/module/hive-3.1.2 [atguiguhadoop102 hiv…...

【RabbitMQ】死信队列
1.概述 死信,顾名思义就是无法被消费的消息,也就是没有被传到消费者的消息,或者即使传到了也没有被消费。当然有死信就有死信队列。死信队列就是用来存储死信的。 它的应用场景就是保证订单业务的消息数据不丢失,当消息消费发 生…...

区间 dp 系列 题解
1.洛谷 P4342 IOI1998 Polygon 我的博客 2.洛谷 P4290 HAOI2008 玩具取名 题意 某人有一套玩具,并想法给玩具命名。首先他选择 W, I, N, G 四个字母中的任意一个字母作为玩具的基本名字。然后他会根据自己的喜好,将名字中任意一个字母用 W, I, N, G …...

Typora使用笔记
文章目录 主题自动编号字体设置两端对齐Step1Step 2 代码块显示行号设置快捷键参考文献 主题自动编号 typora-theme-auto-numbering 字体设置两端对齐 Step1 切记从typora的偏好设置中打开主题所在的文件夹,并修改对应的css文件。(以 github.css 为例…...

k8s部署grafana
先决条件 这里部署过程的前提是已经部署好storageclass,所以pv会根据pvc自动创建. 详情参考:k8s-StoargClass的使用-基于nfs_a volume that contains injected data from multiple-CSDN博客 直接开始: 部署pvc [rootmodule /zpf/grafana]$cat pvc.yml apiVersion: v1 kind…...

第三章:SQL 高级功能与性能优化
1. 窗口函数(Window Functions) 用于在结果集的“窗口”(指定行范围)内执行计算,保留原数据行的同时生成聚合或排序结果。 1.1 核心语法 SELECT column1,column2,[窗口函数] OVER (PARTITION BY 分组列…...
 | getline(cin,s))
[ACM_3] n组数据 | getchar() | getline(cin,s)
目录 14. 第⼀⾏是⼀个整数n,表示⼀共有n组测试数据, 之后输⼊n⾏ 字符串 15. 第⼀⾏是⼀个整数n,然后是n组数据,每组数据2⾏,每⾏ 为⼀个字符串,为每组数据输出⼀个字符串,每组输出占⼀⾏ 16. 多组测试…...

富士相机照片 RAF 格式如何快速批量转为 JPG 格式教程
富士(Fujifilm)相机拍摄的 RAW 格式文件(RAF)因其高质量和丰富的图像信息而受到摄影师的喜爱。然而,RAF 文件通常体积较大且不易于分享或直接使用。为了方便处理,许多人选择将其转换为更通用的 JPG 格式。在…...
[特殊字符])
[特殊字符]【高并发实战】Java Socket + 线程池实现高性能文件上传服务器(附完整源码)[特殊字符]
大家好!今天给大家分享一个 Java Socket 线程池 实现的高性能文件上传服务器,支持 多客户端并发上传,代码可直接运行,适合 面试、项目实战、性能优化 学习! 📌 本文亮点: ✅ 完整可运行代码&a…...

2025 年天津消防设施操作员考试攻略:深挖地区特色考点
天津作为重要的港口城市与工业基地,消防安全形势复杂多样,其消防设施操作员考试也带有鲜明的地区特色。 地区特色考点解析:天津化工产业发达,涉及众多危化品场所。因此,危化品储存场所的消防设施配置与应急处置成为…...

chrome extension开发框架WXT之Browser.runtime
以下是对 Browser.runtime API 中主要方法的参数、返回值、作用及运用场景的详细解释: 1. 连接与通信方法 connect(connectInfo?: ConnectInfo) / connect(extensionId: string, connectInfo?: ConnectInfo) 参数: extensionId(可选):目标扩展的 ID,未指定时默认连接当…...

dav_1_MySQL数据库排查cpu消耗高的sql
CPU消耗高sql定位 以下从2个维度进行分析,一个是当前cpu高占用排查,一个是历史sql占用高排查 一.当前cpu占用高排查 1 从os资源消耗逐步到mysql查询 1.1 输入top 然后按大P 使之进程按照消耗cpu排序 比如3889为mysql进程ID,接下来再用它查…...

数据结构刷题之贪心算法
贪心算法(Greedy Algorithm) 是一种在每个步骤中都选择当前最优解的算法设计策略。它通常用于解决优化问题,例如最小化成本或最大化收益。贪心算法的核心思想是:在每一步选择中,都做出局部最优的选择,希望…...
暴力娱乐篇23)
每日一题(小白)暴力娱乐篇23
由题意得知给我们一串数字,我们每次交换两位,最少交换多少次成功得到有顺序的数组。我们以平常的思维去思考,加入给你一串数字获得最少的交换次数,意味着你的交换后续基本不会变,比如说2 1 3 5 4 中1与2交换后不变&…...

回归预测 | Matlab实现RIME-CNN-GRU-Attention霜冰优化卷积门控循环单元注意力机制多变量回归预测
回归预测 | Matlab实现RIME-CNN-GRU-Attention霜冰优化卷积门控循环单元注意力机制多变量回归预测 目录 回归预测 | Matlab实现RIME-CNN-GRU-Attention霜冰优化卷积门控循环单元注意力机制多变量回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现RIME…...

第1章 对大型语言模型的介绍
人类正处在一个关键转折点。自2012年起,基于深度神经网络的人工智能系统研发进入快速通道,将这一技术推向了新高度:至2019年底,首个能够撰写与人类文章真假难辨的软件系统问世,这个名为GPT-2(生成型预训练变…...

PGA 简介
PGA(Programmable Gain Amplifier,可编程增益放大器)是一种可以通过外部控制信号改变增益大小的放大器,常用于需要灵活调节信号放大倍数的应用中,比如在模拟信号采集、数据转换(如 ADC 之前)、传…...

2025年CCF-C NCA:导航变量多目标粒子群算法NMOPSO,深度解析+性能实测
目录 1.摘要2.运动学模型和约束3.路径规划目标函数3.多目标粒子群算法4.结果展示5.参考文献6.代码获取 1.摘要 路径规划是无人机(UAV)任务执行的核心,因为它决定了无人机完成任务所需的飞行路径。为了解决这一问题,本文提出了一种…...

FFMpeg音视频解码实战
音频解码 一、初始化阶段 avformat_open_input 打开输入媒体文件。avformat_find_stream_info 读取媒体流信息,查找音频流。avcodec_find_decoder 查找对应的解码器(如 AAC、MP3 解码器)。avcodec_alloc_context3 分配解码器上下文。avcodec…...

day25学习Pandas库
文章目录 三、Pandas库4.函数计算7.合并8.随机抽样9.空值处理9.1检测空值9.2填充空值9.3删除空值行/列 5.读取CSV文件5.1 to_csv()5.2 read_csv() 6.绘图 三、Pandas库 4.函数计算 7.合并 merge 函数用于将两个 DataFrame 对象根据一个或多个键进行合并 函数: …...

去除Mysql表中的空格、回车、换行符和特殊字符
系列文章目录 文章目录 系列文章目录前言一、示例1.sql层面2.java层面 前言 一、示例 1.sql层面 参考 ## 例子1 ## CHAR(10) 表示换行符 ## CHAR(13) 表示回车UPDATE 表名 SET 列名 REPLACE(REPLACE(列名, CHAR(10), ), CHAR(13), )## 例子2 ## 删除字段中的空格、换行符、…...

以普通用户身份启动pure-ftpd服务端
Pureftp的优点包括 : 高性能,适用于大容量数据传输。安全性强,通过SSL/TLS加密和身份验证机制保证文件传输安全。易用性高,具有直观的用户界面。灵活性强,支持多种文件存储方式。没有漏洞,便于维护 基于Centos 9的pu…...

国内下载不了镜像,可以用国外机器下载完成,打成tar文件,在国内机器上重新加载
可以在 已经拉取过镜像的机器上打包(导出)镜像文件,然后 拷贝到另一台机器上导入使用。这是离线部署 Docker 镜像的常用方法,非常适合网络受限的环境。 🛠️ 步骤如下: ✅ 1. 在已有镜像的机器上打包镜像 …...

【Java】Java 中不同类型的类详解
目录 Java 中不同类型的类详解一、基础类类型1. 普通类(Concrete Class)2. 抽象类(Abstract Class)3. 接口(Interface)4. 枚举类(Enum Class) 二、嵌套类与特殊类5. 内部类ÿ…...

Cadence学习笔记之---热风焊盘制作
目录 01 | 前 言 02 | 环境描述 03 | 热风焊盘 04 | 规则热风焊盘制作 05 | 不规则热风焊盘制作 06 | 总 结 01 | 前 言 在上一篇Cadence小记中讲述了如何制作贴片(SMD)焊盘、通孔焊盘、以及过孔;本篇关于Cadence的小记主要讲如何制作热风焊盘。 上篇小记&a…...

518. Coin Change II
这是完全背包问题。 由于求的是组合数,所以外层循环只能是对硬币遍历,内层循环只能是对总金额的遍历。 另外,虽然题目数据保证结果符合 32 位带符号整数。但是第28个测试用例,dp[j]dp[j-conis[i]]中间结果会整数溢出,…...

GPIO子系统与Pinctrl子系统的交互
我们前面呢,已经讲过GPIO子系统的数据结构以及他的设备树信息是怎么转换成我们的C代码存储在结构体里面了,我们知道,如果想去使用一个GPIO,避免不了得把这个引脚复用成GPIO功能,那么就避不开Pinctrl子系统,…...

DeepSeek实用操作及行业应用系列2
DeepSeek的本地化部署与AI通识教育之未来 DeepSeek之火,可以燎原 面向审计行业DeepSeek大模型操作指南v1.0 DeepSeek提示词设计、幻觉避免与应用(大数据百家讲坛) DeepSeek 搞钱教程(0基础入门) DeepSeek基础知识…...

面向数据库场景的大模型交互微调数据集
关键要点 研究表明,面向数据库场景的大模型交互微调数据集通常包括数据库模式、自然语言查询和对应的SQL查询。证据倾向于认为,数据集应以JSON格式组织,覆盖多种查询类型,并确保高质量和多样性。对于自定义数据库,建议…...

解锁ChatGPT-4o文生图潜力:精选提示词收集整理更新中
示例一:按元素和描述要求生成图片 示例二:“吉卜力”风格 示例三:3D Q版风格 示例四:生成指定布局和主题图片 具体的提示词参考,陆续更新中:https://blog.luler.top/d/25...

WHAT - React 进一步学习推荐
书籍 adevnadia 的《Advanced React》TejasKumar_ 的《Fluent React》addyosmani 和 djirdehh 的《Building Large Scale Web Apps》 面试准备 reactjs-interview-questions 文章:最佳实践 如果你想了解最佳实践并学习技巧,请务必关注以下专家&…...

有关串口的知识点
轻微了解 一般都是 前这俩01 Ren1才能接受 开局T1 R1要给0 所以就是0x50的起手 终端服务是接受的 ———————————————————————————— 进入实际引用 使用的时候1 初始化 2要给个500ms的延时函数即可...

无线插卡话机如何接入呼叫中心系统?
一、接入原理与技术架构 无线插卡话机通过内置SIM卡模块(支持GSM/CDMA/4G/5G等网络制式),将移动网络信号转化为语音通信信号,再通过SIP协议或专用网关与呼叫中心系统对接。其核心流程包括: 1、网络信号…...

prometheus有几种数据类型
Prometheus 数据类型主要有以下四种: Counter(计数器): 单调递增的数值,表示某个事件发生的次数。计数器的值只会增加,除非被重置为0(例如在系统重启时)。示例:HTTP 请求…...

C++设计模式+异常处理
#include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory> #include <stdexcept> // 包含异常类using namespace std;// 该作业要求各位写一…...
神奇数 (数学)DNA序列 (固定长度的滑动窗口))
字符串替换 (模拟)神奇数 (数学)DNA序列 (固定长度的滑动窗口)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 字符串替换 (模拟)神奇数 (数学)DNA序列 (固定长度的滑动窗口&am…...

echarts地图详解
获取地图坐标json数据 <template><div id"china-map" style"width:500px;height:500px"></div> </template> <script>import * as echarts from echarts;// 坐标jsonimport chinaJson from "/assets/china.json" …...

Redis 哨兵模式:告别手动故障转移!
目录 前言一、 Redis哨兵模式是啥?🤔二、 为什么需要哨兵模式?🤷♀️三、 哨兵模式的原理是什么?🤝1. 监控(Monitoring)2. 信息共享与客观下线判断3. 哨兵领导者选举4. 故障转移5.…...

地理数据输出
为了便于数据共享和交换,可以将地理数据库中的要素数据输出为Shapefiles或者Coverage,将相应的属性表输出为Info或者dBase格式的数据文件。 1.输出为 Shapefile (1)在AreCatalog目录树或者内容栏中,右键点击需要输出的地理要素类,…...

springboot + security + redis + jwt 实现验证登录上
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...

SomeIP通讯机制
在SOME/IP协议中,通讯方式主要围绕服务的交互模式进行的设计,核心机制包括Event(时间)、Method(方法)以及其变种Fire-and-Forget(FF)。以下是SOME/IP中所有通信方式的总结࿱…...

线代第三课:n阶行列式
引言 行标取自然排列 不同行不同列的3个元素相乘 列标取排列的所有可能 列标排列的逆序数的奇偶性决定符号,- n阶行列式 第一种:按行展开 (1) 行标取自然排列 (2) 列标取排列的所有可能 (PS:可以理解为随意取) (3) 从…...

人工智能在高中教育中的应用现状剖析与挑战应对
第一章:绪论 1.1 研究背景与意义 随着全球化的加速和科技的飞速发展,高中教育在培养未来社会所需人才方面的重要性日益凸显。高中阶段是学生知识体系构建和思维能力发展的关键时期,然而,当前高中教育面临着诸多挑战,…...

如何在powerbi使用自定义SQL
我们在刚使用到powerbi的时候发现当直接连接到数据库的时候我们只能使用数据库中已存在的表,我们没有办法使用自定义SQL来准备数据,这给我们的开发造成很大的困扰;我目前使用的是vertica数据库,首先我们需要在本地有vertica的驱动…...

边缘计算盒子是什么?
边缘计算盒子是一种小型的硬件设备,通常集成了处理器、存储器和网络接口等关键组件,具备一定的计算能力和存储资源,并能够连接到网络。它与传统的云计算不同,数据处理和分析直接在设备本地完成,而不是上传到云端&#…...
:探寻构造函数的幽微之境)
【C++面向对象】封装(上):探寻构造函数的幽微之境
每文一诗 💪🏼 我本将心向明月,奈何明月照沟渠 —— 元/高明《琵琶记》 译文:我本是以真诚的心来对待你,就像明月一样纯洁无瑕;然而,你却像沟渠里的污水一样,对这份心意无动于衷&a…...

物联网|无人自助台球厅源码|哪些框架支持多设备连接?
在无人自助台球厅的智能化管理中,物联网(IoT)技术是核心支撑。如何实现不同设备(如智能门锁、环境传感器、支付终端、灯光控制系统等)的高效连接与协同工作,是系统开发的关键挑战。本文将带大家探讨支持多设…...
和四旋翼无人机优势对比)
单旋翼无人机(直升机)和四旋翼无人机优势对比
以下是无人机直升机(单旋翼无人机)与四旋翼无人机的优势对比分析,分场景阐述两者的核心差异: 一、无人机直升机(单旋翼无人机)的优势 1. 高能量效率,长续航 动力设计:单…...

微服务之间调用外键“翻译”的方法概述
写在前面的话:减少strean流操作,减少多层嵌套for循环。使用普通for循环和map的方式进行转换, 第一步查询数据 List<Student> findList studentDao.findList(findMap); 第二步准备遍历和赋值 if(CollectionUtil.isNotEmpty(findLis…...