本节课课堂总结
课堂总结:
Spark运行架构:
运行架构:
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
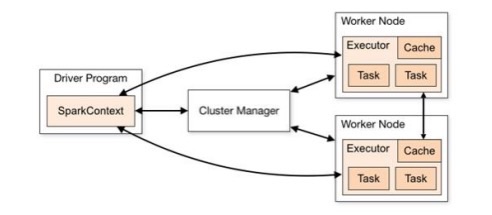
核心组件:
由上图可以看出,对于 Spark 框架有两个核心组件:
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
➢ 将用户程序转化为作业(job)
➢ 在 Executor 之间调度任务(task)
➢ 跟踪 Executor 的执行情况
➢ 通过 UI 展示查询运行情况
实际上,我们无法准确地描述 Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
Executor:
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
➢ 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
➢ 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Master & Worker:
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。
核心概念:
Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
提交流程:
所谓的提交流程,其实就是开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以这里提到的提交流程是基于 Yarn 环境的。
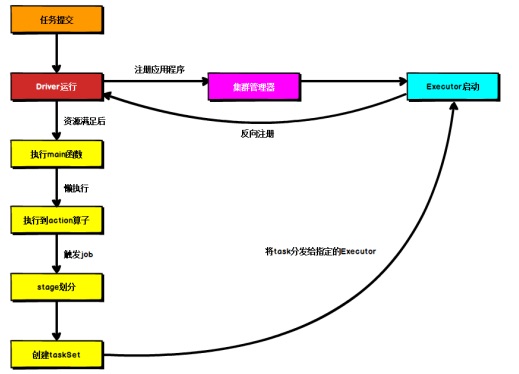
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
Yarn Client 模式:
Client 模式将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
➢ Driver 在任务提交的本地机器上运行
➢ Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster
➢ ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,负责向 ResourceManager 申请 Executor 内存
➢ ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
Yarn Cluster 模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
➢ 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster。
➢ 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
➢ Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动Executor 进程。
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数。
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
RDD相关概念:
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
➢ RDD : 弹性分布式数据集
➢ 累加器:分布式共享只写变量
➢ 广播变量:分布式共享只读变量
RDD:
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
➢ 弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
核心属性:
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
➢ 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算。
➢ RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。
➢ 分区器(可选)
当数据为 K-V 类型数据时,可以通过设定分区器自定义数据的分区。
➢ 首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算。
执行原理:
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 序列化:
1) 闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
2) 序列化方法和属性
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行
3) Kryo 序列化框架
Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。
RDD 依赖关系:
1) RDD 血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2) RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系。包括打印依赖、shuffle依赖等。
3) RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
4) RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
5) RDD 阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。
6) RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task
⚫ Application:初始化一个 SparkContext 即生成一个 Application;
⚫ Job:一个 Action 算子就会生成一个 Job;
⚫ Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
⚫ Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
RDD 持久化:
1) RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部 Partition。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
2) RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
3) 缓存和检查点区别
··1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
·2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
·3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
RDD 分区器:
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
➢ 只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
➢ 每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
1)Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余。
2)Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
RDD 文件读取与保存:
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
➢ text 文件
➢ sequence 文件
SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对而设计的一种平面文件(Flat File)。在 SparkContext 中,可以调用 sequenceFile[keyClass, valueClass](path)。
➢ object 对象文件
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。可以通过 objectFile[T: ClassTag](path)函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
相关文章:

本节课课堂总结
课堂总结: Spark运行架构: 运行架构: Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master&…...

MyBatis中特殊符号处理总结
前言 MyBatis 是一款流行的Java持久层框架,广泛应用于各种类型的项目中。因为我们在日常代码 MyBatis 动态拼接语句时,会经常使用到 大于(>,>)、小于(<,<)、不等于(<>、!)操作符号。由于此符号包含了尖括号,而 MyBatis 使用…...
)
【零基础实战】Ubuntu搭建DVWA漏洞靶场全流程详解(附渗透测试示例)
【零基础实战】Ubuntu搭建DVWA漏洞靶场全流程详解(附渗透测试示例) 一、DVWA靶场简介 DVWA(Damn Vulnerable Web Application)是专为网络安全学习者设计的漏洞演练平台,包含SQL注入、XSS、文件包含等10大Web漏洞模块&…...

若依前后端分离版本从mysql切换到postgresql数据库
一、修改依赖: 修改admin模块pom.xml中的依赖,屏蔽或删除mysql依赖,增加postgresql依赖。 <!-- Mysql驱动包 --> <!--<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> &l…...
 E. Rendez-vous de Marian et Robin)
【补题】Codeforces Round 974 (Div. 3) E. Rendez-vous de Marian et Robin
题意:给个图,两个人分别从点1和点n出发,问最早在哪个点可以相遇,其中某些点有马,骑上去之后可以在接下来剩余的时间内都可以将路程所需时间缩短一半。 关于题目数据见原题,这里说明太累了想偷懒Problem - 2…...

MySQL集群技术
当有数据时添加slave2 #从master节点备份数据 mysqldump -uroot -ptiminglee 1 > timinglee.sql 生产环境中备份时需要锁表,保证备份前后的数据一致 mysql> FLUSH TABLES WITH READ LOCK; 备份后再解锁 mysql> UNLOCK TABLES; mysqldump命令备份的数…...

Java 中的字节码
🔍 什么是 Java 字节码(Bytecode)? 字节码是 Java 源码(.java 文件)被编译后生成的中间代码(.class 文件),它不是机器码,而是一种 面向 JVM 的指令集。 可以…...
)
json 转 txt 用于 yolo 训练(可适用多边形标注框_python)
json 转 txt 用于 yolo 训练(可适用多边形标注框_python) import json import os import argparse from tqdm import tqdmdef convert_label_json(json_dir, save_dir, classes):json_paths os.listdir(json_dir)classes classes.split(,)for json_pa…...
)
SQL注入(SQL Injection)
目录 SQL注入(SQL Injection)是什么SQL注入的危害SQL注入的常见方式1. 经典注入(Error-Based Injection)2. 联合查询注入(Union-Based Injection)3. 时间盲注(Time-Based Blind Injection)4. 布尔盲注(Boolean-Based Blind Injection)5. 堆叠注入(Stacked Queries I…...

智慧厨房的秘密:当大模型遇见智能体
智慧厨房的秘密:当大模型遇见智能体 想象一下,一家餐厅里,顾客点了一份特别定制的菜肴。厨师不仅需要知道如何制作这道菜,还得根据当天的食材情况灵活调整配方,甚至考虑到顾客的口味偏好做出微调。这一切背后…...

IDEA遇到问题汇总
问题1:【异常】IDEA中报错:无效的目标发行版本 IDEA 报错:无效的源发行版-CSDN博客 【异常】IDEA中报错:无效的目标发行版本-CSDN博客 原因是:版本不兼容不一致,需要修改jdk、maven、以及目标字节码使之相一…...

状态管理组件Pinia 简介与底层原理 、Pinia 与其他状态管理库对比、Vue3 + Element Plus + Pinia 安装配置详解
一、Pinia 简介与底层原理 1. Pinia 简介 Pinia 是 Vue3 官方推荐的状态管理库,由 Vue 核心团队开发,旨在替代 Vue2 的 Vuex。其核心目标是提供一种更简洁、直观的状态管理方案,同时充分利用 Vue3 的响应式系统和 Composition API。 2. 底…...

本地部署 opik
本地部署 opik 1. 安装2. 访问 1. 安装 克隆代码, git clone https://github.com/comet-ml/opik.git使用 Docker compose 启动, cd opik/deployment/docker-compose docker compose up -d2. 访问 启动后,您可以在浏览器中访问 localhost:…...
)
操作系统之进程与线程的理解(一)
对进程的理解 进程是可以并发执行的程序在某个数据集合上的运行过程,是系统进行资源分配和调度的基本单位。进程由三部分组成,程序,数据和进程控制块(简称PCB)。简单的说,进程就是程序的一次执行 为确保进…...

JS 箭头函数
只能用于声明函数表达式更简洁。替代匿名函数 设置取消点击事件的默认行为 在这里插入图片描述...

Mb,Kb,byte,bits
1MB1024KB; 1KB1024byte(字节); 1byte8bits(位); 小蓝准备用 256MB 的内存空间开一个数组,数组的每个元素都是 32 位 二进制整数,如果不考虑程序占用的空间和维护内存需要的辅助空间…...

x265 中 aqMode 和 hevcAq 的深度解析与应用技巧
aqMode 和 hevcAq 介绍 在 x265 中基本继承了 x264 中 aqmode 的思想,此外还引入了 hevcAq 算法工具,在 x265_param 结构体中有这两个参数变量开关相关解释。从声明注释可以理解,aqMode 和 x264 中 aqmode 的思想完全相似,也扩展了些功能,属于通用型自适应量化方法,基于 …...
基于云平台微调大模型,以deepseek-coder-6.7b为例)
(一)基于云平台微调大模型,以deepseek-coder-6.7b为例
一、租借rtx4090卡并创建示例 如下图,我们进入jupyter界面,然后创建笔记本 二、提前下载好模型到本地 为了节省时间,我们需要提前下好模型deepseek-ai/deepseek-coder-6.7b-instruct,然后再上传到autodl上直接本地加载。 下载方…...

【Docker基础】全面解析 Docker 镜像:构建、使用与管理
文章目录 一、Docker 镜像(Docker Image)详解1.1 Docker 镜像的结构1.2 Docker 镜像的每一层(Layer)1.3 镜像的构建过程1.4 镜像的使用1.5 镜像的优势 二、为什么需要镜像三、镜像命令3.1 命令清单3.2 详细解释 四、docker 操作案…...

3. git config
文章目录 基本概述配置级别基本用法设置配置项查看配置项删除配置项 常用配置项 基本概述 git config 的作用是:设置用户信息、编辑器、别名、仓库行为等。 配置级别 级别作用范围配置文件路径命令选项仓库级别(Local)当前仓库.git/config…...

docker 运行自定义化的服务-前端
运行自定义化的前端服务 具体如下: ①打包前端项目,形成dist包 ②编写dockerfile文件,文件内容如下: # 基础镜像(镜像名:版本号TAG) FROM nginx:1.0 # 镜像作者和相关元数据 LABEL maintainer"Atb" \version"1.0…...

error: RPC failed; HTTP 408 curl 22 The requested URL returned error: 408
在git push时报错:error: RPC failed; HTTP 408 curl 22 The requested URL returned error: 408 原因:可能是推送的文件太大,要么是缓存不够,要么是网络不行。 解决方法: 将本地 http.postBuffer 数值调整到500MB&…...

JMH 基准测试实战:Java 性能对比的正确打开方式!
📖 摘要 在Java开发中,我们经常需要比较不同实现方式的性能差异。但如何科学、准确地进行性能测试呢?本文将带你深入理解JMH(Java Microbenchmark Harness)工具,通过实战演示如何正确编写和运行基准测试&a…...

etf可以T+0交易吗?
在我国的A股市场中,部分ETF基金支持T0交易,这为投资者提供了更灵活的交易策略。 支持T0交易的ETF基金类型包括: 货币型ETF:主要投资于货币市场工具,如短期债券和银行存款,具有较高的流动性。 债券型ETF&…...

解决问题:Vscode 自动更新不匹配远程服务器版本
避免自动更新: 1. 打开:文件 - 首选项 - 设置 - 应用程序 - 更新; 2. 设置下列选项: 如果已自动更新,如何回退至原有的历史版本 : 去官网下载所需的历史版本,然后直接按流程安装,…...

【Leetcode-Hot100】盛最多水的容器
题目 解答 目的是求面积最大,面积是由两个下标和对应的最小值得到,因此唯一的问题就是如何遍历这两个下标。我采用begin和end两个变量,确保begin是小于end的,使用它们二者求面积,代码如下: 很不幸 出错了…...

FFMEPG常见命令查询
基本参数 表格1:主要参数 参数说明-i设定输入流-f设定输出格式(format) 高于后缀名-ss开始时间-t时间长度codec编解码 表格2:音频参数 参数说明-aframes设置要输出的音频帧数-f音频帧深度-b:a音频码率-ar设定采样率-ac设定声音的Channel数-acodec设定…...

欢迎来到 Codigger Store:Boby周边专区
亲爱的 Codigger 用户们,感谢你们一直以来的支持与热爱!你们的每一次代码跳跃、每一次项目成功,都离不开你们对编程的热情和对 Codigger 的信任。为了回馈大家的厚爱,我们在 Codigger Store 中特别开设了 Boby 周边专区࿰…...

决策树模型
决策树(TDS) 注意1:决策树有很多种算法,比如:ID3算法,C4.5算法,CART算法,这三个算法的区别是选择最优划分属性的方法不同,第一个是根据信息增益来选;第二个是找出信息增益高于平均水…...

解锁深度学习激活函数
在深度学习的广袤天地里,激活函数宛如隐匿于神经网络架构中的神奇密码,掌控着模型学习与表达的关键力量。今天,就让我们一同深入探究这些激活函数的奇妙世界,揭开它们神秘的面纱。 一、激活函数为何不可或缺? 想象一…...

Kubernetes 深入浅出系列 | 容器剖析之容器安全
目录 1、容器真的需要privileged权限吗?一、什么是 --privileged 权限?二、privileged 的风险到底有多大?三、常见需求场景及更安全的替代方式四、如何判断容器是否真正需要特权? 2、不以 Root 用户运行容器,真的更安全吗&#x…...

Spring Boot应用中可能出现的Full GC问题
Full GC的原理与触发条件 原理 标记-清除:首先遍历所有对象,标记可达的对象,然后清除不可达的对象。复制算法:将内存分为两部分,每次只使用其中一部分。当这部分内存用完时,将存活的对象复制到另一部分&a…...
)
Maven 的安装与配置(IDEA)
2025/4/9 向 一、什么是Maven Maven 是一个基于项目对象模型(Project Object Model,POM)概念的项目构建工具(所以就是一个工具),它主要用于自动化项目的构建过程,包括编译、测试、打包、部署等…...

软考中级-软件设计师 2022年下半年上午题真题解析:通关秘籍+避坑指南
📚 目录(快速跳转) 选择题(上午题)(每题1分,共75分)一、 计算机系统基础知识 🖥️💻 题目1:计算机硬件基础知识 - RISC(精简指令集计算…...

全栈开发套件Telerik DevCraft——赋能现代化应用构建
Telerik DevCraft包含一个完整的产品栈来构建您下一个Web、移动和桌面应用程序。它使用HTML和每个.NET平台的UI库,加快开发速度。Telerik DevCraft提供完整的工具箱,用于构建现代和面向未来的业务应用程序,目前提供UI for ASP.NET MVC、Kendo…...

Windows + vmware + ubuntu+docker + docker-android实现Android模拟器构建和启动
文章目录 引言编译启动过程玩下adb最后 引言 Windows vmware ubuntudockerdocker-android实现Android模拟器启动 编译启动过程 #下载docker-android git clone https://github.com/budtmo/docker-android.gitmaqiubuntu:~/docker-android$ git remote -v origin https://…...

远程团队协作效率低,如何优化
在远程工作的环境中,团队协作效率低下成为许多企业面临的一大挑战。随着全球化和技术进步,远程团队的出现成为企业的常态,但由于沟通不畅、任务管理不明确、缺乏团队凝聚力等问题,往往会影响团队的整体效率。为了优化远程团队的协…...
)
Oracle 19C 通过 ODBC 连接 SQL Server 数据库指南 (Red Hat 7)
前言 本指南详细说明如何在 Red Hat Enterprise Linux 7 系统上配置 Oracle 19C 通过 ODBC 连接 SQL Server 数据库。这种异构数据库连接方式称为 Oracle Heterogeneous Services,允许 Oracle 数据库直接访问非 Oracle 数据源。 系统要求 操作系统:Red Hat Enterprise Linu…...

【MYSQL从入门到精通】数据类型及建表
一些基础操作语句 1.使用客户端工具连接数据库服务器:mysql -uroot -p 2.查看所有数据库:show databases; 3.创建属于自己的数据库: create database 数据库名;create database if not exists 数据库名; 强烈建议大家在建立数据库时指定编…...

鸿蒙开发中的并发与多线程
文章目录 前言异步并发 (Promise和async/await)多线程并发并发能力选择耗时任务并发执行场景常见业务场景 常驻任务并发执行场景常见业务场景 传统共享内存并发业务长时任务并发执行场景常见业务场景 并发任务管理线程间通信同语言线程间通信(ArkTS内)线…...

ruby self
在 Ruby 中,self 是一个指向当前对象的特殊变量,它的值根据代码的上下文动态变化。理解 self 的指向是掌握 Ruby 面向对象编程的关键。以下是详细解析: 一、self 的核心规则 self 始终指向当前方法的执行者(即调用方法的对象&…...

Kotlin 学习-集合
/*** kotlin 集合* List:是一个有序列表,可通过索引(下标)访问元素。元素可以在list中出现多次、元素可重复* Set:是元素唯一的集合。一般来说 set中的元素顺序并不重要、无序集合* Map:(字典)是一组键值对。键是唯一的…...

封装方法的辨析
equals //字符串 str1.equals(str2); //list的两个实现类 list1.equals(list2); //map的两个实现类 //比较所有的键值对是否相同 map1.equals(map2); //数组(包括string类型) //比较内容是否相同 Arrays.equals(array1, array2); contains 基本都有…...

解决 IntelliJ IDEA 中 Maven 项目左侧项目视图未显示顶层目录问题的详细步骤说明
以下是解决 IntelliJ IDEA 中 Maven 项目左侧项目视图未显示顶层目录问题的详细步骤说明: 1. 切换项目视图模式 默认情况下,IDEA 的项目视图可能处于 Packages 模式,仅显示代码包结构,而非物理目录。 操作步骤: 点击…...

CMIP6数据分析与可视化、降尺度技术与气候变化的区域影响、极端气候分析
当前的CMIP6计划相较于前代模型,在空间分辨率、物理过程表达和地球系统组件耦合等方面均有显著提升。 一:气候变化研究的AI新视角 1、气候模型基础与全球气候模型(GCM) 全球气候(环流)模型的基本原理、发…...

如何精准控制大模型的推理深度
论文标题 ThinkEdit: Interpretable Weight Editing to Mitigate Overly Short Thinking in Reasoning Models 论文地址 https://arxiv.org/pdf/2503.22048 代码地址 https://github.com/Trustworthy-ML-Lab/ThinkEdit 作者背景 加州大学圣迭戈分校 动机 链式推理能显…...

1. Git 下载和安装
文章目录 Git 下载Git 安装(以windows为例)Git 使用(以windows为例) Git 下载 1.进 Git 官网 https://git-scm.com/downloads 2.选择对应的操作系统 3.选择对应的操作系统位数 Git 安装(以windows为例)…...

git回滚指定版本并操作
你可以通过以下步骤切换到第三个版本。根据你的需求,有两种主要方法: 方法 1:临时查看第三个版本(不修改当前分支) 适用于仅查看或测试旧版本,不保留后续修改: 找到第三个版本的提交哈希&#…...

FastAdmin和thinkPHP学习文档
介绍 - FastAdmin框架文档 - FastAdmin开发文档https://doc.fastadmin.net/doc目录结构 ThinkPHP5.0完全开发手册 看云ThinkPHP V5.0是一个为API开发而设计的高性能框架——是一个颠覆和重构版本,采用全新的架构思想,引入了很多的PHP新特性,…...

通过HTTP协议实现Git免密操作的解决方案
工作中会遇到这样的问题的。 通过HTTP协议实现Git免密操作的解决方案 方法一:启用全局凭据存储(推荐) 配置凭证存储 执行以下命令,让Git永久保存账号密码(首次操作后生效): git config --g…...