(一)基于云平台微调大模型,以deepseek-coder-6.7b为例
一、租借rtx4090卡并创建示例
如下图,我们进入jupyter界面,然后创建笔记本

二、提前下载好模型到本地
为了节省时间,我们需要提前下好模型deepseek-ai/deepseek-coder-6.7b-instruct,然后再上传到autodl上直接本地加载。
下载方法推荐用命令行下载,比浏览器一个个下载快:
步骤 1:安装 CLI 工具
在你本地电脑的终端运行(需要 Python 环境,推荐用虚拟环境):
pip install huggingface_hub
步骤 2:登录 Hugging Face(可选,如果模型需要认证)
huggingface-cli login
会提示你输入你的 Hugging Face Token,在这里获取。
步骤 3:下载整个模型文件夹
huggingface-cli download deepseek-ai/deepseek-coder-6.7b-instruct --local-dir deepseek-coder-6.7b-instruct --local-dir-use-symlinks False
这条命令会把模型完整下载到你当前目录下的 deepseek-coder-6.7b-instruct/ 文件夹中。完整模型大约 13GB,请确保磁盘空间充足。
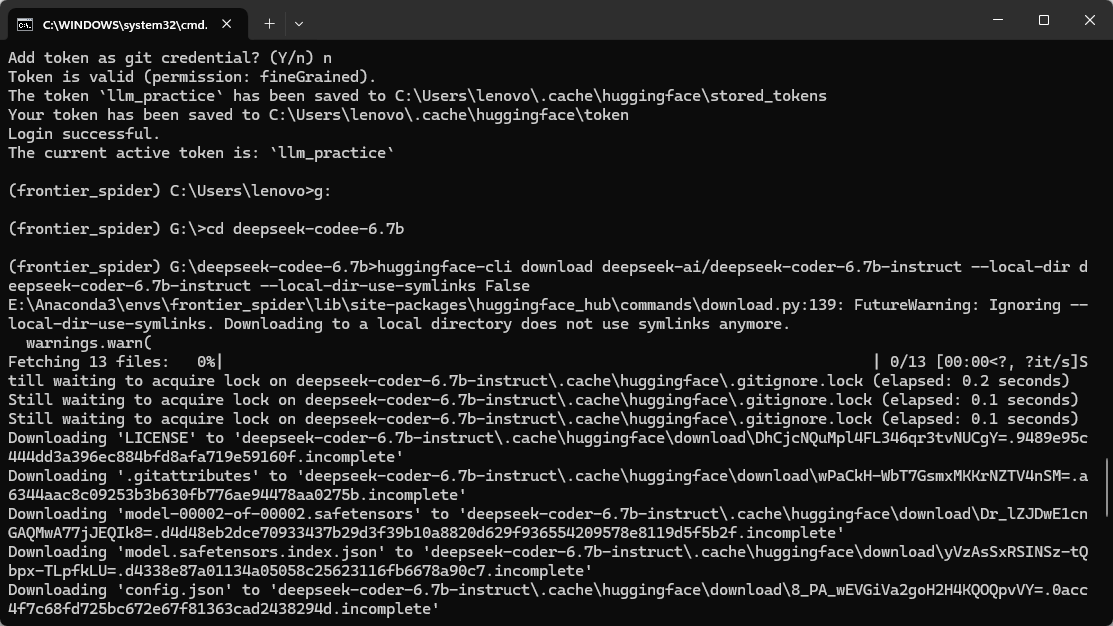
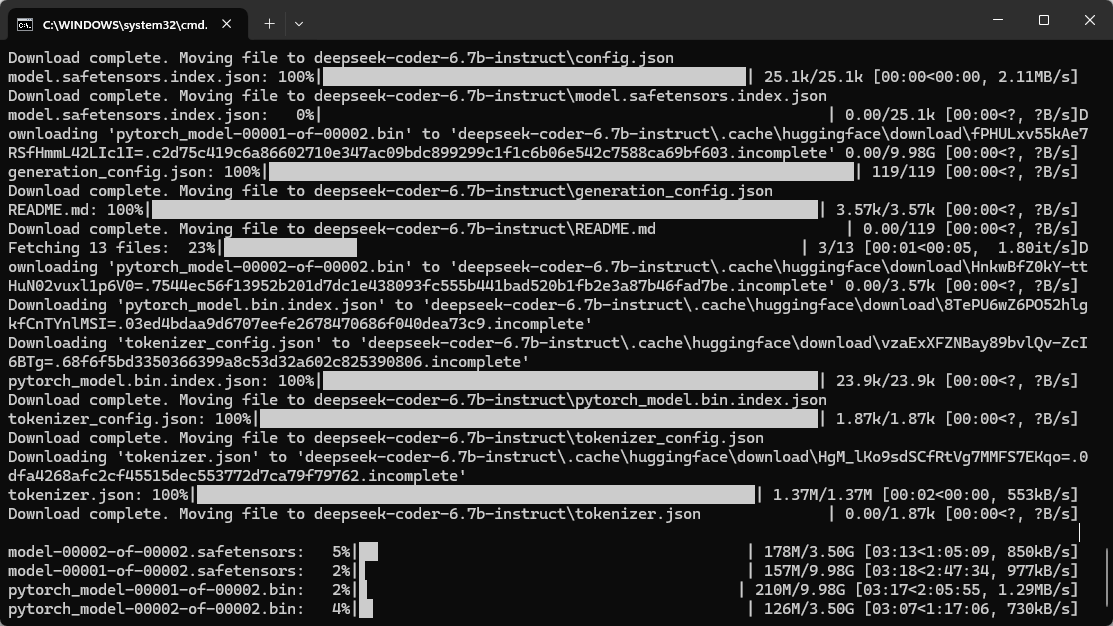
当然从本地上传到autodl是很慢的,所以推荐使用kaggle里面有的模型,用下面的方式直接下载到autodl的实例中。
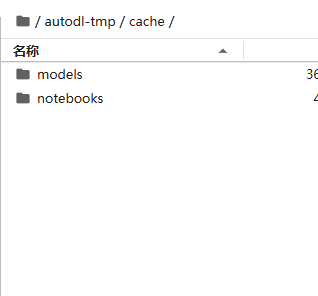
我们指定缓存路径,这样下载的时候就会下载到我们的数据盘了
import os
import kagglehub# 设置缓存路径
os.environ["KAGGLEHUB_CACHE"] = '/root/autodl-tmp/cache'
model_path = kagglehub.model_download("deepseek-ai/deepseek-r1/Transformers/deepseek-r1-distill-qwen-7b/1")print("模型保存路径:", model_path)可以看到都保存到数据盘了
那么接下来我们就可以加载模型了,下面详细讲解每个步骤(这里我加载模型用于生成svg代码)
三、加载模型用于生成svg代码
首先我们给出完整代码,然后讲解每个步骤。
import concurrent
import io
import logging
import re
import re2import cairosvg
import kagglehub
import torch
from lxml import etree
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfigsvg_constraints = kagglehub.package_import('metric/svg-constraints')DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")class Model:def __init__(self):# 模型量化相关配置quantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.float16,)self.model_path = '/root/autodl-tmp/cache/models/deepseek-ai/deepseek-r1/Transformers/deepseek-r1-distill-qwen-7b/1'self.tokenizer = AutoTokenizer.from_pretrained(self.model_path)self.model = AutoModelForCausalLM.from_pretrained(self.model_path,device_map="auto",quantization_config=quantization_config,)self.prompt_template = """Generate SVG code to visually represent the following text description, while respecting the given constraints.
<constraints>
* **Allowed Elements:** `svg`, `path`, `circle`, `rect`, `ellipse`, `line`, `polyline`, `polygon`, `g`, `linearGradient`, `radialGradient`, `stop`, `defs`
* **Allowed Attributes:** `viewBox`, `width`, `height`, `fill`, `stroke`, `stroke-width`, `d`, `cx`, `cy`, `r`, `x`, `y`, `rx`, `ry`, `x1`, `y1`, `x2`, `y2`, `points`, `transform`, `opacity`
</constraints><example>
<description>"A red circle with a blue square inside"</description>
```svg
<svg viewBox="0 0 256 256" width="256" height="256"><circle cx="50" cy="50" r="40" fill="red"/><rect x="30" y="30" width="40" height="40" fill="blue"/>
</svg>
```
</example>Please ensure that the generated SVG code is well-formed, valid, and strictly adheres to these constraints. Focus on a clear and concise representation of the input description within the given limitations. Always give the complete SVG code with nothing omitted. Never use an ellipsis.<description>"{}"</description>
```svg
<svg viewBox="0 0 256 256" width="256" height="256">
"""self.default_svg = """<svg width="256" height="256" viewBox="0 0 256 256"><circle cx="50" cy="50" r="40" fill="red" /></svg>"""self.constraints = svg_constraints.SVGConstraints()self.timeout_seconds = 90# You could try increasing `max_new_tokens`def predict(self, description: str, max_new_tokens=512) -> str:def generate_svg():try:prompt = self.prompt_template.format(description)inputs = self.tokenizer(text=prompt, return_tensors="pt").to(DEVICE)with torch.no_grad():output = self.model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=True,)output_decoded = self.tokenizer.decode(output[0], skip_special_tokens=True)logging.debug('Output decoded from model: %s', output_decoded)matches = re.findall(r"<svg.*?</svg>", output_decoded, re.DOTALL | re.IGNORECASE)if matches:svg = matches[-1]else:return self.default_svglogging.debug('Unprocessed SVG: %s', svg)svg = self.enforce_constraints(svg)logging.debug('Processed SVG: %s', svg)# Ensure the generated code can be converted by cairosvgcairosvg.svg2png(bytestring=svg.encode('utf-8'))return svgexcept Exception as e:logging.error('Exception during SVG generation: %s', e)return self.default_svg# Execute SVG generation in a new thread to enforce time constraintswith concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor:future = executor.submit(generate_svg)try:return future.result(timeout=self.timeout_seconds)except concurrent.futures.TimeoutError:logging.warning("Prediction timed out after %s seconds.", self.timeout_seconds)return self.default_svgexcept Exception as e:logging.error(f"An unexpected error occurred: {e}")return self.default_svgdef enforce_constraints(self, svg_string: str) -> str:"""Enforces constraints on an SVG string, removing disallowed elementsand attributes.Parameters----------svg_string : strThe SVG string to process.Returns-------strThe processed SVG string, or the default SVG if constraintscannot be satisfied."""logging.info('Sanitizing SVG...')try:parser = etree.XMLParser(remove_blank_text=True, remove_comments=True)root = etree.fromstring(svg_string, parser=parser)except etree.ParseError as e:logging.error('SVG Parse Error: %s. Returning default SVG.', e)return self.default_svgelements_to_remove = []for element in root.iter():tag_name = etree.QName(element.tag).localname# Remove disallowed elementsif tag_name not in self.constraints.allowed_elements:elements_to_remove.append(element)continue# Remove disallowed attributes and check attribute valuesattrs_to_remove = []for attr, value in element.attrib.items():attr_name = etree.QName(attr).localnameif (attr_name not in self.constraints.allowed_elements[tag_name]and attr_name not in self.constraints.allowed_elements['common']):attrs_to_remove.append(attr)else:# Check if color attributes are valid CSS colorsif attr_name in ['fill', 'stroke'] and not self.is_valid_css_color(value):attrs_to_remove.append(attr)# Check if dimensions are positive numbersif attr_name in ['width', 'height', 'r', 'x', 'y', 'cx', 'cy', 'rx', 'ry'] and not self.is_positive_number(value):attrs_to_remove.append(attr)# Check if opacity is within the valid rangeif attr_name == 'opacity' and not self.is_valid_opacity(value):attrs_to_remove.append(attr)for attr in attrs_to_remove:logging.debug('Attribute "%s" for element "%s" not allowed. Removing.', attr, tag_name)del element.attrib[attr]# Remove elements marked for removalfor element in elements_to_remove:if element.getparent() is not None:element.getparent().remove(element)logging.debug('Removed element: %s', element.tag)try:cleaned_svg_string = etree.tostring(root, encoding='unicode')return cleaned_svg_stringexcept ValueError as e:logging.error('SVG could not be sanitized to meet constraints: %s', e)return self.default_svgdef is_valid_css_color(self, color: str) -> bool:# Implement a simple check for valid CSS color valuesreturn re.match(r'^#(?:[0-9a-fA-F]{3}){1,2}$', color) is not None or color in ['red', 'blue', 'green', 'black', 'white']def is_positive_number(self, value: str) -> bool:try:return float(value) > 0except ValueError:return Falsedef is_valid_opacity(self, value: str) -> bool:try:return 0 <= float(value) <= 1except ValueError:return False3.1 量化配置
下面的量化配置都是啥意思呢,我们在加载大模型的时候有一些策略是可以进行推理加速和显存优化的,让大模型回答的速度更快,使用显卡的效率更高,这就是量化的目的,具体怎么实现呢?
3.1.1 精度
BitsAndBytesConfig 是 HuggingFace 的 transformers 库中用于配置 bitsandbytes 量化加载的类,能以 4bit/8bit 精度加载模型,减少显存使用,同时保持尽量高的精度。这里就需要讲解一下什么是精度了。在深度学习中,精度指的是表示一个数时使用的bit数,有4,8,16等。
| 精度类型 | 每个数占用大小 | 举例 |
|---|---|---|
| float32 | 32 bit(4字节) | 标准浮点数,训练常用 |
| float16 | 16 bit(2字节) | 精度稍低,但更省资源 |
| bfloat16 | 16 bit | 精度类似float32,但范围大 |
| int8 | 8 bit(1字节) | 只表示整数,低精度 |
| 4 bit(nf4等) | 4 bit(0.5字节) | 极低精度,用于推理优化 |
需要注意,不同精度对显存的使用不同,数值越精确,占用的存储位数越多。举个例子:你要表示 3.1415926 这个数:
-
float32可以表示到 7 位有效数字 -
float16只能表示到 3~4 位 -
4bit可能只能表示成类似 3.1 或 3.0
所以:用 float32:一个参数占 4 字节;用 4bit:一个参数只占 0.5 字节(减少 8 倍 显存!)
假设一个模型有 10 亿个参数,则:
-
float32:≈ 4GB 显存
-
float16:≈ 2GB
-
4bit:≈ 0.5GB
而低精度虽然省显存,但容易影响模型效果(准确率、鲁棒性)。模型本身在训练时是用高精度 (float32) 完成的,转换为低精度时可能出现:参数失真(例如小数被截断)、数值不稳定(容易梯度爆炸或消失)、推理效果变差(回答不准确)等问题,所以有很多技术压缩精度又尽量不影响性能。
quantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.float16,)上面代码4个参数分别表示:
1.load_in_4bit=True,表示使用4bit精度压缩存储模型参数,但是这个是只在存储的时候压缩使用,在训练和推理的时候说了,要用高精度。
2.bnb_4bit_quant_type,表示使用nf4, 代表normal float4,这个是一种专为量化设计的4bit浮点格式,比普通的浮点4和int4精度更好。
3.bnb_4bit_use_double_quant,表示使用二次量化,意思是先将模型权重分组,然后对每组的量化比例因子再次进行量化,可以理解为再一次压缩,减少存储空间
4.bnb_4bit_compute_compute_dtype,表示计算过程中使用的数据类型是float16,意思是在GPU上进行前向传播推理的时候,使用float16来还原并计算量化后的参数。这里注意的是,参数存储阶段用4bit精度将模型权重存储在显存中,极大节省显存空间;但是推理计算的时候,会动态的、逐层的把模型进行逐层加盟计算,在需要加载的时候加载成float16参与计算。
总结就是,这段代码告诉模型加载逻辑:“请用4bit的NF4量化方式加载模型参数,用双量化压缩进一步减少显存消耗,计算时用float16精度执行”。
3.1.2 量化基本概念
量化的核心思想是将原本连续的实数如32位浮点数映射到有限的离散数值如8位整数,从而减少数据占用的存储空间
在不同阶段,有不同的量化技术:
1.在训练阶段,有量化感知训练(QAT),是指在训练过程中模拟低精度量化的影响,以使得模型在训练时适应低精度计算。通过量化感知训练,模型可以适应低精度带来的误差,最大程度地保留精度。训练时的精度损失较少,推理时表现更加稳定。
2.在保存阶段,把训练好的模型进行压缩。权重量化(Weight Quantization):将模型的权重从 float32 转换为 int8 或其他低精度格式。激活量化(Activation Quantization):在推理时,输入和输出(激活)也会被量化为低精度格式。量化偏置(Bias Quantization):一般情况下,偏置保持为 float32,因为它对结果的影响相对较小。
3.在推理阶段,首先是量化保存到内存,减少对显存的需求,使得一些大模型可以在显存较小的GPU上面运行;然后在计算的时候还原成高精度推理。
相关文章:
基于云平台微调大模型,以deepseek-coder-6.7b为例)
(一)基于云平台微调大模型,以deepseek-coder-6.7b为例
一、租借rtx4090卡并创建示例 如下图,我们进入jupyter界面,然后创建笔记本 二、提前下载好模型到本地 为了节省时间,我们需要提前下好模型deepseek-ai/deepseek-coder-6.7b-instruct,然后再上传到autodl上直接本地加载。 下载方…...

【Docker基础】全面解析 Docker 镜像:构建、使用与管理
文章目录 一、Docker 镜像(Docker Image)详解1.1 Docker 镜像的结构1.2 Docker 镜像的每一层(Layer)1.3 镜像的构建过程1.4 镜像的使用1.5 镜像的优势 二、为什么需要镜像三、镜像命令3.1 命令清单3.2 详细解释 四、docker 操作案…...

3. git config
文章目录 基本概述配置级别基本用法设置配置项查看配置项删除配置项 常用配置项 基本概述 git config 的作用是:设置用户信息、编辑器、别名、仓库行为等。 配置级别 级别作用范围配置文件路径命令选项仓库级别(Local)当前仓库.git/config…...

docker 运行自定义化的服务-前端
运行自定义化的前端服务 具体如下: ①打包前端项目,形成dist包 ②编写dockerfile文件,文件内容如下: # 基础镜像(镜像名:版本号TAG) FROM nginx:1.0 # 镜像作者和相关元数据 LABEL maintainer"Atb" \version"1.0…...

error: RPC failed; HTTP 408 curl 22 The requested URL returned error: 408
在git push时报错:error: RPC failed; HTTP 408 curl 22 The requested URL returned error: 408 原因:可能是推送的文件太大,要么是缓存不够,要么是网络不行。 解决方法: 将本地 http.postBuffer 数值调整到500MB&…...

JMH 基准测试实战:Java 性能对比的正确打开方式!
📖 摘要 在Java开发中,我们经常需要比较不同实现方式的性能差异。但如何科学、准确地进行性能测试呢?本文将带你深入理解JMH(Java Microbenchmark Harness)工具,通过实战演示如何正确编写和运行基准测试&a…...

etf可以T+0交易吗?
在我国的A股市场中,部分ETF基金支持T0交易,这为投资者提供了更灵活的交易策略。 支持T0交易的ETF基金类型包括: 货币型ETF:主要投资于货币市场工具,如短期债券和银行存款,具有较高的流动性。 债券型ETF&…...

解决问题:Vscode 自动更新不匹配远程服务器版本
避免自动更新: 1. 打开:文件 - 首选项 - 设置 - 应用程序 - 更新; 2. 设置下列选项: 如果已自动更新,如何回退至原有的历史版本 : 去官网下载所需的历史版本,然后直接按流程安装,…...

【Leetcode-Hot100】盛最多水的容器
题目 解答 目的是求面积最大,面积是由两个下标和对应的最小值得到,因此唯一的问题就是如何遍历这两个下标。我采用begin和end两个变量,确保begin是小于end的,使用它们二者求面积,代码如下: 很不幸 出错了…...

FFMEPG常见命令查询
基本参数 表格1:主要参数 参数说明-i设定输入流-f设定输出格式(format) 高于后缀名-ss开始时间-t时间长度codec编解码 表格2:音频参数 参数说明-aframes设置要输出的音频帧数-f音频帧深度-b:a音频码率-ar设定采样率-ac设定声音的Channel数-acodec设定…...

欢迎来到 Codigger Store:Boby周边专区
亲爱的 Codigger 用户们,感谢你们一直以来的支持与热爱!你们的每一次代码跳跃、每一次项目成功,都离不开你们对编程的热情和对 Codigger 的信任。为了回馈大家的厚爱,我们在 Codigger Store 中特别开设了 Boby 周边专区࿰…...

决策树模型
决策树(TDS) 注意1:决策树有很多种算法,比如:ID3算法,C4.5算法,CART算法,这三个算法的区别是选择最优划分属性的方法不同,第一个是根据信息增益来选;第二个是找出信息增益高于平均水…...

解锁深度学习激活函数
在深度学习的广袤天地里,激活函数宛如隐匿于神经网络架构中的神奇密码,掌控着模型学习与表达的关键力量。今天,就让我们一同深入探究这些激活函数的奇妙世界,揭开它们神秘的面纱。 一、激活函数为何不可或缺? 想象一…...

Kubernetes 深入浅出系列 | 容器剖析之容器安全
目录 1、容器真的需要privileged权限吗?一、什么是 --privileged 权限?二、privileged 的风险到底有多大?三、常见需求场景及更安全的替代方式四、如何判断容器是否真正需要特权? 2、不以 Root 用户运行容器,真的更安全吗&#x…...

Spring Boot应用中可能出现的Full GC问题
Full GC的原理与触发条件 原理 标记-清除:首先遍历所有对象,标记可达的对象,然后清除不可达的对象。复制算法:将内存分为两部分,每次只使用其中一部分。当这部分内存用完时,将存活的对象复制到另一部分&a…...
)
Maven 的安装与配置(IDEA)
2025/4/9 向 一、什么是Maven Maven 是一个基于项目对象模型(Project Object Model,POM)概念的项目构建工具(所以就是一个工具),它主要用于自动化项目的构建过程,包括编译、测试、打包、部署等…...

软考中级-软件设计师 2022年下半年上午题真题解析:通关秘籍+避坑指南
📚 目录(快速跳转) 选择题(上午题)(每题1分,共75分)一、 计算机系统基础知识 🖥️💻 题目1:计算机硬件基础知识 - RISC(精简指令集计算…...

全栈开发套件Telerik DevCraft——赋能现代化应用构建
Telerik DevCraft包含一个完整的产品栈来构建您下一个Web、移动和桌面应用程序。它使用HTML和每个.NET平台的UI库,加快开发速度。Telerik DevCraft提供完整的工具箱,用于构建现代和面向未来的业务应用程序,目前提供UI for ASP.NET MVC、Kendo…...

Windows + vmware + ubuntu+docker + docker-android实现Android模拟器构建和启动
文章目录 引言编译启动过程玩下adb最后 引言 Windows vmware ubuntudockerdocker-android实现Android模拟器启动 编译启动过程 #下载docker-android git clone https://github.com/budtmo/docker-android.gitmaqiubuntu:~/docker-android$ git remote -v origin https://…...

远程团队协作效率低,如何优化
在远程工作的环境中,团队协作效率低下成为许多企业面临的一大挑战。随着全球化和技术进步,远程团队的出现成为企业的常态,但由于沟通不畅、任务管理不明确、缺乏团队凝聚力等问题,往往会影响团队的整体效率。为了优化远程团队的协…...
)
Oracle 19C 通过 ODBC 连接 SQL Server 数据库指南 (Red Hat 7)
前言 本指南详细说明如何在 Red Hat Enterprise Linux 7 系统上配置 Oracle 19C 通过 ODBC 连接 SQL Server 数据库。这种异构数据库连接方式称为 Oracle Heterogeneous Services,允许 Oracle 数据库直接访问非 Oracle 数据源。 系统要求 操作系统:Red Hat Enterprise Linu…...

【MYSQL从入门到精通】数据类型及建表
一些基础操作语句 1.使用客户端工具连接数据库服务器:mysql -uroot -p 2.查看所有数据库:show databases; 3.创建属于自己的数据库: create database 数据库名;create database if not exists 数据库名; 强烈建议大家在建立数据库时指定编…...

鸿蒙开发中的并发与多线程
文章目录 前言异步并发 (Promise和async/await)多线程并发并发能力选择耗时任务并发执行场景常见业务场景 常驻任务并发执行场景常见业务场景 传统共享内存并发业务长时任务并发执行场景常见业务场景 并发任务管理线程间通信同语言线程间通信(ArkTS内)线…...

ruby self
在 Ruby 中,self 是一个指向当前对象的特殊变量,它的值根据代码的上下文动态变化。理解 self 的指向是掌握 Ruby 面向对象编程的关键。以下是详细解析: 一、self 的核心规则 self 始终指向当前方法的执行者(即调用方法的对象&…...

Kotlin 学习-集合
/*** kotlin 集合* List:是一个有序列表,可通过索引(下标)访问元素。元素可以在list中出现多次、元素可重复* Set:是元素唯一的集合。一般来说 set中的元素顺序并不重要、无序集合* Map:(字典)是一组键值对。键是唯一的…...

封装方法的辨析
equals //字符串 str1.equals(str2); //list的两个实现类 list1.equals(list2); //map的两个实现类 //比较所有的键值对是否相同 map1.equals(map2); //数组(包括string类型) //比较内容是否相同 Arrays.equals(array1, array2); contains 基本都有…...

解决 IntelliJ IDEA 中 Maven 项目左侧项目视图未显示顶层目录问题的详细步骤说明
以下是解决 IntelliJ IDEA 中 Maven 项目左侧项目视图未显示顶层目录问题的详细步骤说明: 1. 切换项目视图模式 默认情况下,IDEA 的项目视图可能处于 Packages 模式,仅显示代码包结构,而非物理目录。 操作步骤: 点击…...

CMIP6数据分析与可视化、降尺度技术与气候变化的区域影响、极端气候分析
当前的CMIP6计划相较于前代模型,在空间分辨率、物理过程表达和地球系统组件耦合等方面均有显著提升。 一:气候变化研究的AI新视角 1、气候模型基础与全球气候模型(GCM) 全球气候(环流)模型的基本原理、发…...

如何精准控制大模型的推理深度
论文标题 ThinkEdit: Interpretable Weight Editing to Mitigate Overly Short Thinking in Reasoning Models 论文地址 https://arxiv.org/pdf/2503.22048 代码地址 https://github.com/Trustworthy-ML-Lab/ThinkEdit 作者背景 加州大学圣迭戈分校 动机 链式推理能显…...

1. Git 下载和安装
文章目录 Git 下载Git 安装(以windows为例)Git 使用(以windows为例) Git 下载 1.进 Git 官网 https://git-scm.com/downloads 2.选择对应的操作系统 3.选择对应的操作系统位数 Git 安装(以windows为例)…...

git回滚指定版本并操作
你可以通过以下步骤切换到第三个版本。根据你的需求,有两种主要方法: 方法 1:临时查看第三个版本(不修改当前分支) 适用于仅查看或测试旧版本,不保留后续修改: 找到第三个版本的提交哈希&#…...

FastAdmin和thinkPHP学习文档
介绍 - FastAdmin框架文档 - FastAdmin开发文档https://doc.fastadmin.net/doc目录结构 ThinkPHP5.0完全开发手册 看云ThinkPHP V5.0是一个为API开发而设计的高性能框架——是一个颠覆和重构版本,采用全新的架构思想,引入了很多的PHP新特性,…...

通过HTTP协议实现Git免密操作的解决方案
工作中会遇到这样的问题的。 通过HTTP协议实现Git免密操作的解决方案 方法一:启用全局凭据存储(推荐) 配置凭证存储 执行以下命令,让Git永久保存账号密码(首次操作后生效): git config --g…...

git 查看某一文件夹下所有文件 修改记录
git: 如何查询某个文件或者某个目录的更新历史_git 查看指定文件夹的记录-CSDN博客 git log --follow path/to/your/file git log -p --follow path/to/your/file git log --stat --follow path/to/your/file这是最常用的方法,可以显示指定文件的所有提交历史…...
)
测试(一)
软件的生命周期: 需求分析——计划——设计——编码——测试——运行维护 常见的开发模型: 瀑布模型: 最基本的开发模型,绝大多数开发模型的基本框架。 特点:线性的开发流程 使用场景:需求固定ÿ…...

解决华硕主板Z890m下载ubuntu20.04后没有以太网问题
问题描述: 华硕主板Z890m下载双系统ubuntu20.04后,发现ubuntu不能打开以太网。 问题原因: 华硕主板的网卡驱动是r8125,而ubuntu20.04的驱动版本是r8169,所以是网卡驱动不匹配造成 解决方案 开机界面按下F2进入BOIS模式&#…...

从零推导飞机小扰动运动线性方程——0. 学习目录
第0期文章——学习目录 如图,本专栏将连载以下学习内容,带你从零开始学习飞机小扰动方程!...

Agentic AI 干货!DeepSeek + OpenAI SDK 构建 Agent 实战
引言: DeepSeek-R1、OpenAI-o1 等具备内化的假设、反思、验证等优秀推理能力的 LLM 大型推理模型将 AI 发展推进到智能体 AI 时代,将使 AI Agent 迸发出远超上一代由外化的手搓式简单推理 Agent 不可比拟的发展势能。 在 GTC2025 大会上,英伟…...

【语法】C++的list
目录 为什么会有list? 迭代器失效: list和vector的迭代器不同的地方: list的大部分用法和vector都很像,例如push_back,构造,析构,赋值重载这些就不再废话了,本篇主要讲的是和vecto…...

Java接口性能优化面试问题集锦:高频考点与深度解析
1. 如何定位接口性能瓶颈?常用哪些工具? 考察点:性能分析工具的使用与问题定位能力。 核心答案: 工具:Arthas(在线诊断)、JProfiler(内存与CPU分析)、VisualVM、Prometh…...
)
基于STM32与应变片的协作机械臂力反馈控制系统设计与实现---5.2 工业机械臂系统性能测试全方案(专业工程级)
5.2 工业机械臂系统性能测试全方案(专业工程级) 一、测试体系架构设计 1.1 三级测试体系 #mermaid-svg-A55VxjZ7ENKNWAli {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-A55VxjZ7ENKNWAli .error-icon{fill:#55…...

VM——相机拍照失败
1、问题:相机频闪触发,在MVS中正常出图,在VM中出现拍照失败 2、解决: 1、首先排查网络设置(巨帧是否设置) 2、电脑的所有防火墙是否关闭 3、在MVS中恢复相机的设置参数为默认参数,删除VM中的全…...

图解力扣回溯及剪枝问题的模板应用
文章目录 选哪个的问题17. 电话号码的字母组合题目描述解题代码图解复杂度 选不选的问题78. 子集题目描述解题代码图解复杂度 两相转化77. 组合题目描述解题代码法一:按选哪个的思路法二:按选不选的思路 图解选哪个:选不选 复杂度 选哪个的问…...

Trae + LangGPT 生成结构化 Prompt
Trae LangGPT 生成结构化 Prompt 0. 引言1. 安装 Trae2. 克隆 LangGPT3. Trae 和 LangGPT 联动4. 集成到 Dify 中 0. 引言 Github 上 LangGPT 这个项目,主要向我们介绍了写结构化Prompt的一些方法和示例,我们怎么直接使用这个项目,辅助我们…...

模糊测试究竟在干什么
目录 1.软件漏洞和缺陷 2.模糊测试与传统测试 3.汽车领域中的模糊测试 4.常见工具总结 1.软件漏洞和缺陷 提单、上票、拒收,这是开发和测试的日常博弈。大多数时候,我们是根据自己对需求的理解来进行开发和测试,这基本是属于功能层级。 …...

【RTD200P04 MCAL 篇3】 S32M244 PWM PDB ADC控制
【RTD200P04 MCAL 篇3】 S32M244 PWM PDB ADC控制 一,文档简介二,PWMTRGMUXPDBADC 2ch 软件配置与实现2.1 软硬件版本平台2.2 MCAL工程以及模块配置2.2.1 Dio 模块配置2.2.2 Adc模块配置2.2.3 Mcu模块配置2.2.4 Platform模块配置2.2.5 Port模块配置2.2.6…...

03--Deepseek服务器部署与cjson解析
一、ollama部署deepseek模型 1、Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。 Ollama 教程:从 0 到 1 全面指南 教程【全文两万字保姆级详细讲解】 -CSDN博客 1.下载o…...

实现抗隐私泄漏的AI人工智能推理
目录 什么是私人AI? 什么是可信执行环境? TEE 如何在 AI 推理期间保护数据? 使用 TEE 是否存在风险? 有哪些风险? Atoma 如何应对这些风险 为什么去中心化网络是解决方案 人工智能推理过程中还有其他保护隐私的方法吗? 私人人工智能可以实现什么? 隐私驱动的应…...

Kotlin 学习--数组
一、关于数组的基础知识和常用方式 /*** kotlin 数组* 使用arrayOf创建数组,必须指定数组的元素,可以是任意类型* */val arrayNumber arrayOf(1, 2, 3, 4)/*** 集合中的元素可以是任意类型* kotlin 中的Any 等价于 java 中的Object 对象的意思* */val a…...

Spring Boot 启动后自动执行 Service 方法终极指南
**导语:**在 Spring Boot 开发中,我们经常需要在应用启动后立即执行初始化任务(如加载配置、预热缓存、启动定时任务)。本文将深度解析 5 种主流实现方案,包含完整代码示例、执行顺序控制技巧和避坑指南&a…...