Proximal Policy Optimization (PPO)2017
2.1 策略梯度方法
策略梯度方法计算策略梯度的估计值并将其插入到随机梯度上升算法中。最常用的梯度估计器的形式如下:
g ^ = E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] (1) \hat{g} = \mathbb{E}_t \left[ \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \hat{A}_t \right] \tag{1} g^=Et[∇θlogπθ(at∣st)A^t](1)
其中 π θ \pi_{\theta} πθ是一个随机策略, A ^ t \hat{A}_t A^t是时间步 t t t时刻优势函数的估计值。这里,期望 E t [ ⋅ ] \mathbb{E}_t[\cdot] Et[⋅]表示在有限样本批次上的经验平均,算法在采样和优化之间交替进行。使用自动微分软件的实现通过构造目标函数,其梯度为策略梯度估计器;估计器 g ^ \hat{g} g^是通过对目标进行微分得到的。
L P G ( θ ) = E t [ log π θ ( a t ∣ s t ) A ^ t ] (2) L^{PG}(\theta) = \mathbb{E}_t \left[ \log \pi_{\theta}(a_t | s_t) \hat{A}_t \right] \tag{2} LPG(θ)=Et[logπθ(at∣st)A^t](2)
尽管执行多步优化以最小化此损失 L P G L^{PG} LPG看起来是有吸引力的,但这样做并不合理,从经验上看,这往往会导致破坏性的较大策略更新
2.2 信任域方法Trust Region Methods
在TRPO中,目标函数(即“替代”目标)在对策略更新的大小施加约束的条件下进行最大化。具体而言,
maximize θ E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t ] (3) \text{maximize}_{\theta} \mathbb{E}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t \right] \tag{3} maximizeθEt[πθold(at∣st)πθ(at∣st)A^t](3)
同时满足约束条件:
E t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ≤ δ (4) \mathbb{E}_t \left[ \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)] \right] \leq \delta \tag{4} Et[KL[πθold(⋅∣st),πθ(⋅∣st)]]≤δ(4)
其中, θ old \theta_{\text{old}} θold是更新前的策略参数向量。该问题可以通过共轭梯度算法高效求解,首先对目标函数进行线性逼近,并对约束条件进行二次逼近。
理论上,TRPO的正当性实际上建议使用惩罚项而不是约束条件,即解决无约束优化问题为某个系数 β \beta β。
maximize θ E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (5) \text{maximize}_{\theta} \mathbb{E}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t - \beta \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)] \right] \tag{5} maximizeθEt[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]](5)
这一理论依据源自于某些替代目标(它计算状态上的最大KL,而不是均值)形成了策略性能的下界(即悲观边界)。TRPO使用硬约束而不是惩罚项,因为选择一个在不同问题上表现良好的 β \beta β值是困难的,甚至在单一问题中,由于特征在学习过程中会发生变化。因此,为了实现目标,即使用一阶算法来模拟TRPO的单调改进,实验表明,仅仅选择一个固定的惩罚系数 β \beta β并优化带有惩罚项的目标函数(方程(5))与SGD方法相结合是不够的;需要进行额外的修改。
3 裁剪的替代目标
设 r t ( θ ) r_t(\theta) rt(θ)表示概率比率 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),因此 r ( θ old ) = 1 r(\theta_{\text{old}}) = 1 r(θold)=1。TRPO最大化一个“替代”目标:
L C P I ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t ] = E ^ t [ r t ( θ ) A ^ t ] (6) L^{CPI}(\theta) = \hat{\mathbb{E}}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t \right] = \hat{\mathbb{E}}_t \left[ r_t(\theta) \hat{A}_t \right] \tag{6} LCPI(θ)=E^t[πθold(at∣st)πθ(at∣st)A^t]=E^t[rt(θ)A^t](6)
上标 C P I CPI CPI表示保守策略迭代(Conservative Policy Iteration),这是该目标提出的背景。在没有约束的情况下,最大化 L C P I L^{CPI} LCPI会导致过大的策略更新;因此,我们现在考虑如何修改目标,惩罚那些将 r t ( θ ) r_t(\theta) rt(θ)从1移开的策略变化。
我们提出的主要目标如下:
L C L I P ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] (7) L^{CLIP}(\theta) = \hat{\mathbb{E}}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right] \tag{7} LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)](7)
其中, ϵ \epsilon ϵ是一个超参数,例如 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2。这个目标函数的动机如下:最小值内的第一项是 L C P I L^{CPI} LCPI。第二项, clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_t clip(rt(θ),1−ϵ,1+ϵ)A^t,通过裁剪概率比率来修改替代目标,这样可以移除策略更新时 r t ( θ ) r_t(\theta) rt(θ) 超出区间 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ]的激励。最后,我们取裁剪和未裁剪目标的最小值,因此最终目标是未裁剪目标的下界(即悲观边界)。在这种方案中,我们仅在使目标变差时忽略概率比率的变化,并且当它使目标变坏时,我们会将其包括在内。注意, L C L I P ( θ ) = L C P I ( θ ) L^{CLIP}(\theta) = L^{CPI}(\theta) LCLIP(θ)=LCPI(θ)对于 θ \theta θ的第一次逼近(即 r = 1 r = 1 r=1)是相同的,但随着 θ \theta θ偏离 θ old \theta_{\text{old}} θold,它们变得不同。图1绘制了 L C L I P L^{CLIP} LCLIP中的单个项(即,单个 t t t);请注意,概率比率 r r r会裁剪为 1 − ϵ 1 - \epsilon 1−ϵ或 1 + ϵ 1 + \epsilon 1+ϵ,这取决于优势是否为正或负。
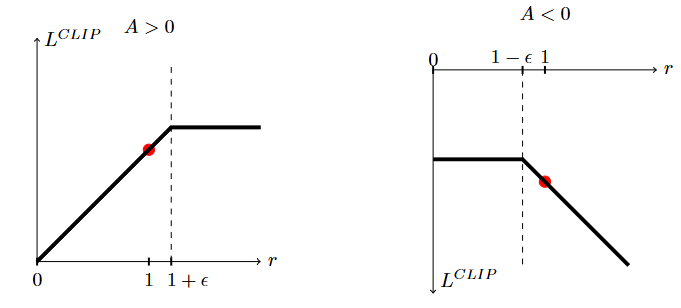 图1:绘制了替代目标函数 L C L I P L^{CLIP} LCLIP的单个项(即,单个时间步)相对于概率比率 r r r的图形,其中左侧表示正优势,右侧表示负优势。每个图上的红色圆圈表示优化的起始点,即 r = 1 r = 1 r=1。注意, L C L I P L^{CLIP} LCLIP是这些项的总和。
图1:绘制了替代目标函数 L C L I P L^{CLIP} LCLIP的单个项(即,单个时间步)相对于概率比率 r r r的图形,其中左侧表示正优势,右侧表示负优势。每个图上的红色圆圈表示优化的起始点,即 r = 1 r = 1 r=1。注意, L C L I P L^{CLIP} LCLIP是这些项的总和。
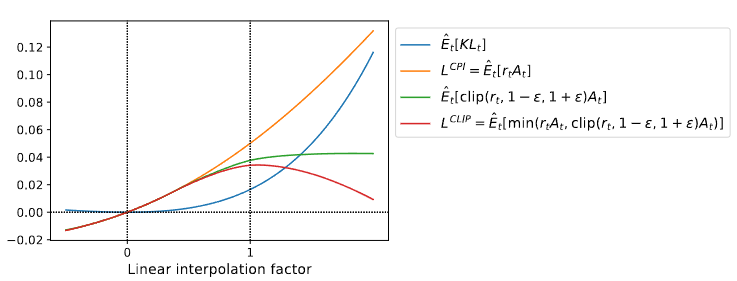
图2提供了关于替代目标 L C L I P L^{CLIP} LCLIP的另一个直观理解。它展示了当我们沿着策略更新方向进行插值时,多个目标是如何变化的,这个方向是通过近端策略优化在一个连续控制问题上获得的。我们可以看到, L C L I P L^{CLIP} LCLIP是 L C P I L^{CPI} LCPI的下界,并且对于策略更新过大有惩罚。
4 自适应KL惩罚系数
另一种方法,可以作为裁剪替代目标的替代方案,或作为附加方案,是对KL散度施加惩罚,并调整惩罚系数,以便在每次策略更新时实现KL散度的目标值 d t a r g d_{targ} dtarg。在我们的实验中,我们发现KL惩罚方法的表现优于裁剪的替代目标,然而我们仍将其包含在这里,因为它是一个重要的基线。
在该算法的最简单实现中,我们在每次策略更新时执行以下步骤:
- 使用几轮小批量SGD,优化KL惩罚目标:
L K L P E N ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (8) L^{KL PEN}(\theta) = \hat{\mathbb{E}}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t - \beta \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)] \right] \tag{8} LKLPEN(θ)=E^t[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]](8)
-
计算 d = E ^ t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] d = \hat{\mathbb{E}}_t[\text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)]] d=E^t[KL[πθold(⋅∣st),πθ(⋅∣st)]]
- 如果 d < d t a r g / 1.5 d < d_{targ}/1.5 d<dtarg/1.5,则 β ← β / 2 \beta \leftarrow \beta / 2 β←β/2
- 如果 d > d t a r g × 1.5 d > d_{targ} \times 1.5 d>dtarg×1.5,则 β ← β × 2 \beta \leftarrow \beta \times 2 β←β×2
更新后的 β \beta β将用于下一个策略更新。使用这种方案,我们偶尔会看到策略更新,其中KL散度与 d t a r g d_{targ} dtarg显著不同,但这些情况很少见,并且 β \beta β会快速调整。参数1.5和2是通过启发式选择的,但算法对它们并不特别敏感。 β \beta β的初始值是另一个超参数,但在实践中并不重要,因为算法会快速调整它。
5 算法
前面章节中的替代损失函数可以通过对典型的策略梯度实现进行少量修改来计算和求导。对于使用自动微分的实现,只需构造损失 L C L I P L^{CLIP} LCLIP或 L K L P E N L^{KL PEN} LKLPEN,代替 L P G L^{PG} LPG,然后对该目标执行多个随机梯度上升步骤。
大多数计算方差减少的优势函数估计的方法使用学习的状态值函数 V ( s ) V(s) V(s);例如,广义优势估计[Sch+15a],或[Mini+16]中的有限时域估计方法。如果使用共享策略和价值函数参数的神经网络架构,则必须使用结合策略替代函数和价值函数误差项的损失函数。该目标还可以通过添加一个熵奖励来进一步增强,以确保足够的探索,如过去的工作中所建议的[Wil92; Mini+16]。将这些项结合起来,我们得到如下目标函数,每次迭代时(大致)最大化:
L t C L I P + V F + S ( θ ) = E ^ t [ L t C L I P ( θ ) − c 1 L t V F ( θ ) + c 2 S [ π θ ] ( s t ) ] (9) L^{CLIP+VF+S}_t(\theta) = \hat{\mathbb{E}}_t \left[ L^{CLIP}_t(\theta) - c_1 L^{VF}_t(\theta) + c_2 S[\pi_{\theta}](s_t) \right] \tag{9} LtCLIP+VF+S(θ)=E^t[LtCLIP(θ)−c1LtVF(θ)+c2S[πθ](st)](9)
其中, c 1 c_1 c1和 c 2 c_2 c2是系数, S S S表示熵奖励, L t V F L^{VF}_t LtVF是平方误差损失 ( V θ ( s t ) − V t target ) 2 (V_{\theta}(s_t) - V_t^{\text{target}})^2 (Vθ(st)−Vttarget)2。
一种策略梯度实现方式,在[Mini+16]中流行并且适合与递归神经网络一起使用,为每个时间步运行策略(其中 T T T远小于回合长度),并使用收集到的样本进行更新。该方式需要一个不超出时间步 T T T的优势估计器。由[Mini+16]使用的估计器为:
A ^ t = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) (10) \hat{A}_t = -V(s_t) + r_t + \gamma r_{t+1} + \cdots + \gamma^{T - t + 1} r_{T-1} + \gamma^{T - t} V(s_T) \tag{10} A^t=−V(st)+rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)(10)
其中 t t t指定时间索引范围为 [ 0 , T ] [0, T] [0,T],在给定长度为 T T T的轨迹段内。推广此选择,我们可以使用广义优势估计的截断版本,当 λ = 1 \lambda = 1 λ=1时简化为方程(10):
A ^ t = δ t + ( γ λ ) δ t + 1 + ⋯ + ( γ λ ) T − t + 1 δ T − 1 , (11) \hat{A}_t = \delta_t + (\gamma \lambda) \delta_{t+1} + \cdots + (\gamma \lambda)^{T - t + 1} \delta_{T-1}, \tag{11} A^t=δt+(γλ)δt+1+⋯+(γλ)T−t+1δT−1,(11)
其中,
δ t = r t + γ V ( s t + 1 ) − V ( s t ) (12) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) \tag{12} δt=rt+γV(st+1)−V(st)(12)
一种使用固定长度轨迹段的近端策略优化(PPO)算法如下所示。在每次迭代中,每个 N N N(并行)演员收集 T T T时间步的数据。然后我们在这些 N T NT NT时间步的数据上构造替代损失,并使用小批量SGD(或通常为更好的性能,使用Adam [KB14])优化它,进行 K K K轮迭代。
算法1 PPO,Actor-Critic Style
for iteration=1, 2, ... dofor actor=1, 2, ..., N do# 在环境中运行策略$\pi_{\text{old}}$,共$T$时间步Run policy $\pi_{\text{old}}$ in environment for $T$ timesteps# 计算优势估计$\hat{A}_1, \dots, \hat{A}_T$Compute advantage estimates $\hat{A}_1, \dots, \hat{A}_T$end for# 优化替代目标$L$,与$\theta$,进行$K$轮,并使用小批量大小$M \leq NT$Optimize surrogate $L$ wrt $\theta$, with $K$ epochs and minibatch size $M \leq NT$# 更新$\theta_{\text{old}} \leftarrow \theta$$\theta_{\text{old}} \leftarrow \theta$end for
参考文献:Proximal Policy Optimization Algorithms
仅用于学习,如有侵权,联系删除
相关文章:
2017)
Proximal Policy Optimization (PPO)2017
2.1 策略梯度方法 策略梯度方法计算策略梯度的估计值并将其插入到随机梯度上升算法中。最常用的梯度估计器的形式如下: g ^ E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] (1) \hat{g} \mathbb{E}_t \left[ \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \h…...
)
使用 Google ML Kit 实现图片文字识别(提取美国驾照信息)
Google ML Kit 是一个现代、功能强大、跨平台的机器学习 SDK。在这篇文章中,我们将使用 ML Kit 在 Android 应用中识别图片文字,以提取美国驾照上的关键信息:DL(驾照号) 和 EXP(有效日期)。 &am…...

VR体验馆如何用小程序高效引流?3步打造线上预约+团购裂变系统
VR体验馆如何用小程序高效引流?3步打造线上预约团购裂变系统 一、线上预约的核心价值:优化体验,提升转化 减少客户等待时间 通过小程序预约功能,客户可提前选择体验时段,避免到店排队。数据显示&#…...
)
前端知识(vue3)
1.Vue3 1.1 介绍 Vue(读音 /vjuː/, 类似于 view)是一款用于构建用户界面的渐进式的JavaScript框架 官网:https://cn.vuejs.org 1.2 常见指令 指令:指的是HTML 标签上带有 v- 前缀的特殊属性,不同指令具有不同含义…...

nginx 代理 https 接口
代码中需要真实访问的接口是:https://sdk2.028lk.com/application-localizationdev.yml文件中配置: url: http:/111.34.80.138:18100/sdk2.028lk.com/该服务器111.34.80.138上 18100端口监听,配置信息为: location /sdk2.028lk.c…...

网络带宽测速工具选择指南iperf3 nttcp tcpburn jperf使用详解
简介 本文主要介绍内网(局域网)与外网(互联网)的网络带宽测速工具下载地址、选择指南、参数对比、基本使用。 测速工具快速选择指南 测速工具下载地址 iperf 官网下载链接:iperf.fr/iperf-download.php该链接提供了不…...

解决TF-IDF增量学习问题的思路与方案
TF-IDF的传统实现面临增量学习困难,因为IDF计算依赖全局文档统计信息。但是实际的工作当中往往数据是增量的,并且定期增量和不定期增量混合,所以为了实际考虑,还是有必要思考如何解决TF-IDF增量问题的。 一、增量学习核心挑战 ID…...

【亲测】Linux 使用 Matplotlib 显示中文
文章目录 安装中文字体在Matplotlib中使用该字体来显示中文 在 Linux 系统中使用 Matplotlib 绘制图表时,如果需要显示中文,可能会遇到中文字符显示为方块或者乱码的问题。这是因为Matplotlib 默认使用的字体不支持中文。本文手把手带你解决这个问题。 …...

git clone阻塞问题
问题描述 git clone采用的ssh协议,在克隆仓库的时候,会经常卡一下,亦或是直接卡死不动。 最开始以为是公司电脑配置的问题,想着自己实在解决不了找it帮忙。 查阅资料发现,最终发现是git版本的问题,这个是…...

Json快速入门
引言 Jsoncpp 库主要是用于实现 Json 格式数据的序列化和反序列化,它实现了将多个数据对象组织成 为Json格式字符串,以及将 Json 格式字符串解析得到多个数据对象的功能,独立于开发语言。 Json数据对象 Json数据对象类的表示: …...

【QT】学习笔记1
QT概述 Qt是一个1991年由QtCompany开发的跨平台C图形用户界面应用程序开发框架。它既可以开发GUI程序,也可用于开发非GUI程序,比如控制台工具和服务器。Qt是面向对象的框架,使用特殊的代码生成扩展(称为元对象编译器(…...

【Kafka基础】生产者命令行操作指南:从基础到高级配置
Kafka作为分布式消息系统,其生产者是数据管道的起点。掌握kafka-console-producer.sh工具的使用对于开发测试和运维都至关重要。本文将系统介绍该工具的各种用法,帮助您高效地向Kafka发送消息。 1 基础消息生产 1.1 最简单的消息发送 /export/home/kafk…...

【Java面试系列】Spring Boot中自动配置原理与自定义Starter开发实践详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Boot中自动配置原理与自定义Starter开发实践详解 - 3-5年Java开发必备知识 引言 Spring Boot作为Java生态中最流行的框架之一,其自动配置机制和Starter开发是面试中的高频考点。对于3-5年经验的Java开发者来说,深入理解这些原理…...
)
reid查找余弦相似度计算修正(二)
上一篇文章 reid查找余弦相似度计算(一) 上一篇的遗留问题就是reid 的结果部分正确,我们参考一下 fast-reid的demo,把里面的抽取特征提取出来 修改提取特征 首先发现图像改变大小的不同,fast 使用的是[128,384], 如…...

嵌入式---加速度计
一、基本概念与定义 定义 加速度计(Accelerometer)是一种测量物体加速度(线性加速度或振动加速度)的传感器,可检测物体运动状态、振动幅度、倾斜角度等,输出与加速度成比例的电信号(模拟或数字信…...

Redis如何判断哨兵模式下节点之间数据是否一致
在哨兵模式下判断两个Redis节点的数据一致性,可以通过以下几种方法实现: 一、检查主从复制偏移量 使用INFO replication命令 分别在主节点和从节点执行该命令,比较两者的master_repl_offset(主节点)和slave_repl_offs…...

Spring 核心注解深度解析:@Autowired、@Repository 与它们的协作关系
引言 在 Spring 框架中,依赖注入(DI) 是实现松耦合架构的核心机制。Autowired 和 Repository 作为两个高频使用的注解,分别承担着 依赖装配 和 数据访问层标识 的关键职责。本文将深入探讨它们的功能特性、协作模式…...

LeetCode541反转字符串②
思路: 关键是判断反转的右边界, ①当剩余字符数<k,是反转当前所有字符,右边界就是rightlen-1,不可以超过len-1,会越界; ②当剩余字符数>k且<2k,反转k个字符,右边界就是righ…...
之2)
Ubuntu 22 Linux上部署DeepSeek+RAG知识库操作详解(Dify方式)之2
上一篇在ubuntu上通过docker拉取了dify并启动与它相关的服务,本篇主要介绍两个知识点: 一是配置模型,使用之前通过Xinference搭建的本地deepseek模型,启动过程参考前期文档,这里就不做介绍了。(注意一点&a…...

如何在多线程中安全地使用 PyAudio
1. 背景介绍 在多线程环境下使用 PyAudio 可能会导致段错误(Segmentation Fault)或其他不可预期的行为。这是因为 PyAudio 在多线程环境下可能会出现资源冲突或线程安全问题。 PyAudio 是一个用于音频输入输出的 Python 库,它依赖于 PortAu…...

Spring MVC与Spring Boot文件上传配置项对比
Spring MVC与Spring Boot文件上传配置项对比 一、Spring MVC配置项(基于不同MultipartResolver实现) 1. 使用 CommonsMultipartResolver(Apache Commons FileUpload) Bean public MultipartResolver multipartResolver() {Common…...
)
多类型医疗自助终端智能化升级路径(代码版.上)
大型医疗自助终端的智能化升级是医疗信息化发展的重要方向,其思维链一体化路径需要围绕技术架构、数据流协同、算法优化和用户体验展开: 一、技术架构层:分布式边缘计算与云端协同 以下针对技术架构层的分布式边缘计算与云端协同模块,提供具体编程实现方案: 一、边缘节点…...

Chrome 浏览器插件收录
1. Responsive Viewer 可以在同个窗口内,针对同一网站,添加多个不同设备屏幕显示。 在前端开发,需要多端适配,尤其是移动端响应式适配的网站开发中,可以同时测试多个不同屏幕的适配效果。 2. VisBug 提供工具栏&#x…...
_python版本)
力扣hot100_回溯(2)_python版本
一、39. 组合总和(中等) 代码: class Solution:def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:ans []path []def dfs(i: int, left: int) -> None:if left 0:# 找到一个合法组合ans.append(pa…...

文档大模型
处理流程: 对表格或者文章文档切分成chunk,将其存入DB根据chunk文档内容,通过prompt生成问题(qwen)通过sentencetransformer生成embbedding(Text embedding 模型 stella_large 模型,长文本编码), 第二步 抽…...

基于分布式指纹引擎的矩阵运营技术实践:突破平台风控的工程化解决方案
一、矩阵运营的技术痛点与市场现状 风控机制升级 主流平台通过复合指纹识别(Canvas渲染哈希WebGL元数据AudioContext频率分析)检测多账号关联传统方案成本:单个亚马逊店铺因关联封号月均损失$5000,矩阵规模越大风险指数级增长 …...

SpringBoot 统一功能处理
1.拦截器 1.1什么是拦截器 拦截器是Spring框架提供的核心功能之一,主要是用来拦截用户的请求,在用户请求指定的方法执行前后,可以根据业务需要执行实现预定的代码。 通过拦截器,开发人员就可以根据需求针对一些特殊的请求&#…...

Redis到底能不能做主数据库?
张三拍案而起:“Redis 是缓存数据库,怎么能当主数据库用?简直是天方夜谭!” 李四冷笑回应:“你没用过,凭什么说不行?我已经用 Redis 做主数据库好几年了,系统稳定得像铁板一块&…...

C++ 基础进阶
C 基础进阶 内容概述: 函数重载:int add(int x, inty);,long long add(long long x, long long y);,double add(double x, double y);模板函数:template<typename T> 或 template<class T>结构体&#x…...

从C语言到Go语言:新手快速入门指南
对于刚学会C语言的新手来说,学习Go语言(Golang)可能是一个既有趣又有挑战性的过程。Go语言由Google开发,以简洁、高效和并发支持著称,被广泛用于现代软件开发。相比C语言,Go语言在语法上更加现代化…...

Vue.js 中 v-model 的使用及其原理
在 Vue.js 开发中,v-model是一个非常重要且常用的指令。它极大地简化了表单元素与数据之间的双向绑定操作,让开发者能够更高效地处理用户输入和数据更新。接下来,我们将深入探讨v-model的使用场景及其背后的工作原理。 一、v-model 的基本…...
)
深入解析哈希表:从原理到实现(拉链法详解)
哈希表(Hash Table)是计算机科学中最重要的数据结构之一,它能够在平均 O(1) 时间内完成数据的插入、删除和查找操作。本文将围绕**拉链法(Chaining)**的实现,结合代码示例和图示,深入讲解哈希表…...

okcc呼叫中心系统坐席签入长签和普通签入的区别
在OKCC呼叫中心系统中,坐席的长签(持久签入)与普通签入(常规签入)是两种不同的登录模式,主要区别体现在 会话保持时长、资源占用、业务场景适配性 等方面。以下是具体对比: 一、核心区别对比 维…...

2024年博客之星的省域空间分布展示-以全网Top300为例
目录 前言 一、2024博客之星 1、所有排名数据 2、空间属性管理 二、数据抓取与处理 1、相关业务表的设计 2、数据抓取处理 3、空间查询分析实践 三、数据成果挖掘 1、省域分布解读 2、技术开发活跃 四、总结 前言 2024年博客之星的评选活动已经过去了一个月…...
)
7.3 在通知中显示图片或视频(UNNotificationAttachment)
在iOS通知中显示富媒体内容可以显著提升用户体验。通过UNNotificationAttachment,我们可以为本地和远程通知添加图片、音频、视频等内容。 基本实现方法 1. 创建带附件的通知 func scheduleNotificationWithImage() {// 1. 创建通知内容let content UNMutableNo…...

1.5-APP的架构\微信小程序的架构
1.5-APP的架构\微信小程序的架构 APP的三种开发架构: 原生态APP类型 APP-开发架构-原生态-IDEA 演示:remusic项目源码 NP管理器: http://normalplayer.top/ HttpCanary:https://github.com/mingww64/HttpCanary-SSL-Magisk 安全影…...

Python缩进完全指南:语法规则、使用场景与最佳实践
一、Python缩进的核心概念 Python的缩进不仅是代码风格问题,更是语法的一部分,这是Python区别于其他编程语言最显著的特征之一。 1.1 什么是缩进? 缩进是指在代码行前添加空格或制表符来实现代码块的层级结构。在Python中,缩进…...

高通音频数据从HAL到DSP
概述 参考高通平台8155 从数据流的角度整理下安卓平台音频数据从HAL层到达DSP这个流程; 以 MultiMedia22 --> QUIN_TDM_RX_0 播放为例; 主要关注pcm数据写到dsp, 以及将前后端路由信息告知dsp两个点。 <!-- more --> [Platform:高通 8155 gvmq Android 11] [Ker…...

第六天 开始Unity Shader的学习之Unity中的基础光照之漫反射光照模型
Unity Shader的学习笔记 第六天 开始Unity Shader的学习之Unity中的基础光照之漫反射光照模型 文章目录 Unity Shader的学习笔记前言一、漫反射光照模型1.逐像素光照① 更改v2f② 传递法线信息给片元着色器③ 片元着色器计算漫反射光照模型 二.半兰伯特模型总结 前言 提示&am…...

【RabbitMQ】队列模型
1.概述 RabbitMQ作为消息队列,有6种队列模型,分别在不同的场景进行使用,分别是Hello World,Work queues,Publish/Subscribe,Routing,Topics,RPC。 下面就分别对几个模型进行讲述。…...

【Java设计模式】第3章 软件设计七大原则
3-1 本章导航 学习开辟原则(基础原则)依赖倒置原则单一职责原则接口隔离原则迪米特法则(最少知道原则)里氏替换原则合成复用原则(组合复用原则)核心思想: 设计原则需结合实际场景平衡,避免过度设计。设计模式中可能部分遵循原则,需灵活取舍。3-2 开闭原则讲解 定义 软…...
: 列表展示)
Axure中继器(Repeater): 列表展示
文章目录 引言I 中继器说明中继器的作用中继器的结构中继器例子II 中继器基础应用:列表展示表头制作列表内容表头中的列与中继器的列绑定填充数据内容引言 中继器是Axure RP 7.0推出的新功能,用于快速设计一些复杂的交互界面(制作“高保真”的动态原型)。 I 中继器说明 中…...

mybatis的第五天学习笔记
12. 动态SQL 12.1 动态SQL概述 新增内容: 动态SQL执行流程 MyBatis如何解析动态SQLSQL语句构建过程参数绑定机制 新增示例 // 动态条件查询接口示例 List<User> searchUsers(Param("name") String name,Param("age") Integer age,Para…...

LeetCode 941 有效的山脉数组
算法探索:如何精准判断有效山脉数组 在计算机科学领域,算法和数据结构堪称基石,它们不仅是解决复杂问题的有力工具,更是衡量程序员技术水平的重要指标。数组作为最基础、应用最广泛的数据结构之一,围绕它衍生出了大量…...

java设计模式-单例模式
单例模式 1、饿汉式(静态常量) Slf4j public class SingletonTest01 {public static void main(String[] args) {Singleton singleton Singleton.getInstance();Singleton singleton2 Singleton.getInstance();log.info("比对结果:{}",singletonsingl…...

对抗Prompt工程:构建AI安全护栏的攻防实践
大语言模型的开放性与自然语言交互特性使其面临前所未有的Prompt工程攻击威胁。本文通过分析2021-2023年间157个真实越狱案例,揭示语义混淆、上下文劫持、多模态组合三重攻击路径的技术原理,提出融合动态意图拓扑分析(DITA)、对抗…...

CentOS 环境下 MySQL 数据库全部备份的操作指南
最近阿里云个人服务到期,因为是很久之前买的测试机器,配置较低,上面运行的有技术博客 和以往的测试项目,所以准备放弃掉。 需要备份下上面的表结构和数据、以及代码仓库。 下面是一个完整的 CentOS 环境下 MySQL 数据库全部备份…...

回溯算法补充leetcode
1. 组合 leetcode题目链接:77. 组合 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 示例 1: 输入:n 4, k 2 输出: [[2,4],[3,4],[2,3],[1,2],[1,3],[1,4], ] 示…...

利用 AI 实现雷池 WAF 自动化运维
欢迎加入雷池社区:雷池 WAF | 下一代 Web 应用防火墙 | 免费使用 已经升级到 8.4.0 的兄弟们应该会发现雷池又多了一些 AI 能力,8.4.0 更新公告。 感谢 Web2GPT 为雷池提供的 AI 能力支持。 主要变化 右下角多了一个 AI 小助手 按钮右上角多了一个 连…...

【嵌入式面试】
1、如果中断函数中有耗时较长的内容,会导致以下问题,如何解决? 对系统实时性的影响 阻塞低优先级中断:中断函数执行时间过长,会阻塞其他低优先级中断的响应。例如,如果一个高优先级中断处理程序中包含耗时…...