zk基础—zk实现分布式功能
1.zk实现数据发布订阅
(1)发布订阅系统一般有推模式和拉模式
推模式:服务端主动将更新的数据发送给所有订阅的客户端。
拉模式:客户端主动发起请求来获取最新数据(定时轮询拉取)。
(2)zk采用了推拉相结合来实现发布订阅
首先客户端需要向服务端注册自己关注的节点(添加Watcher事件)。一旦该节点发生变更,服务端就会向客户端发送Watcher事件通知。客户端接收到消息通知后,需要主动到服务端获取最新的数据。所以,zk的Watcher机制有一个缺点就是:客户端不能定制服务端回调,需要客户端收到Watcher通知后再次向服务端发起请求获取数据,多进行一次网络交互。
如果将配置信息放到zk上进行集中管理,那么:
一.应用启动时需主动到zk服务端获取配置信息,然后在指定节点上注册一个Watcher监听。
二.只要配置信息发生变更,zk服务端就会实时通知所有订阅的应用,让应用能实时获取到订阅的配置信息节点已发生变更的消息。
注意:原生zk客户端可以通过getData()、exists()、getChildren()三个方法,向zk服务端注册Watcher监听,而且注册的Watcher监听具有一次性,所以zk客户端获得服务端的节点变更通知后需要再次注册Watcher。
(3)使用zk来实现数据发布订阅总结
步骤一:将配置信息存储到zk的节点上。
步骤二:应用启动时首先从zk节点上获取配置信息,然后再向该zk节点注册一个数据变更的Watcher监听。一旦该zk节点数据发生变更,所有订阅的客户端就能收到数据变更通知。
步骤三:应用收到zk服务端发过来的数据变更通知后重新获取最新数据。
(4)zk原生实现分布式配置(也就是实现注册发现或者数据发布订阅)
配置可以使用数据库、Redis、或者任何一种可以共享的存储位置。使用zk的目的,主要就是利用它的回调机制。任何zk的使用方不需要去轮询zk,Redis或者数据库可能就需要主动轮询去看看数据是否发生改变。使用zk最大的优势是只要对数据添加Watcher,数据发生修改时zk就会回调指定的方法。注意:new一个zk实例和向zk获取数据都是异步的。
如下的做法其实是一种Reactor响应式编程:使用CoundownLatch阻塞及通过调用一次数据来触发回调更新本地的conf。我们并没有每个场景都线性写一个方法堆砌起来,而是用相应的回调和Watcher事件来粘连起来。其实就是把所有事件发生前后要做的事情粘连起来,等着回调来触发。
一.先定义一个工具类可以获取zk实例
public class ZKUtils {private static ZooKeeper zk;private static String address = "192.168.150.11:2181,192.168.150.12:2181,192.168.150.13:2181,192.168.150.14:2181/test";private static DefaultWatcher defaultWatcher = new DefaultWatcher();private static CountDownLatch countDownLatch = new CountDownLatch(1);public static ZooKeeper getZK() {try {zk = new ZooKeeper(address, 1000, defaultWatcher);defaultWatcher.setCountDownLatch(countDownLatch);//阻塞直到建立好连接拿到可用的zkcountDownLatch.await();} catch (Exception e) {e.printStackTrace();}return zk;}
}二.定义和zk建立连接时的Watcher
public class DefaultWatcher implements Watcher {CountDownLatch countDownLatch ;public void setCountDownLatch(CountDownLatch countDownLatch) {this.countDownLatch = countDownLatch;}@Overridepublic void process(WatchedEvent event) {System.out.println(event.toString());switch (event.getState()) {case Unknown:break;case Disconnected:break;case NoSyncConnected:break;case SyncConnected:countDownLatch.countDown();break;case AuthFailed:break;case ConnectedReadOnly:break;case SaslAuthenticated:break;case Expired:break;}}
}三.定义分布式配置的核心类WatcherCallBack
这个WatcherCallBack类不仅实现了Watcher,还实现了两个异步回调。
首先通过zk.exists()方法判断配置的znode是否存在并添加监听(自己) + 回调(自己),然后通过countDownLatch.await()方法进行阻塞。
在回调中如果发现存在配置的znode,则设置配置并执行countDown()方法不再进行阻塞。
在监听中如果发现数据变化,则会调用zk.getData()方法获取配置的数据,并且获取配置的数据时也会继续监听(自己) + 回调(自己)。
public class WatcherCallBack implements Watcher, AsyncCallback.StatCallback, AsyncCallback.DataCallback {ZooKeeper zk;MyConf conf;CountDownLatch countDownLatch = new CountDownLatch(1);public MyConf getConf() {return conf;}public void setConf(MyConf conf) {this.conf = conf;}public ZooKeeper getZk() {return zk;}public void setZk(ZooKeeper zk) {this.zk = zk;}//判断配置是否存在并监听配置的znodepublic void aWait(){ zk.exists("/AppConf", this, this ,"ABC");try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}}//回调自己,这是执行完zk.exists()方法或者zk.getData()方法的回调//在回调中如果发现存在配置的znode,则设置配置并执行countDown()方法不再进行阻塞。@Overridepublic void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {if (data != null) {String s = new String(data);conf.setConf(s);countDownLatch.countDown();}}//监听自己,这是执行zk.exists()方法或者zk.getData()方法时添加的Watcher监听//在监听中如果发现数据变化,则会继续调用zk.getData()方法获取配置的数据,并且获取配置的数据时也会继续监听(自己) + 回调(自己)@Overridepublic void processResult(int rc, String path, Object ctx, Stat stat) {if (stat != null) {//stat不为空, 代表节点已经存在zk.getData("/AppConf", this, this, "sdfs");}}@Overridepublic void process(WatchedEvent event) {switch (event.getType()) {case None:break;case NodeCreated://调用一次数据, 这会触发回调更新本地的confzk.getData("/AppConf", this, this, "sdfs");break;case NodeDeleted://容忍性, 节点被删除, 把本地conf清空, 并且恢复阻塞conf.setConf("");countDownLatch = new CountDownLatch(1);break;case NodeDataChanged://数据发生变更, 需要重新获取调用一次数据, 这会触发回调更新本地的confzk.getData("/AppConf", this, this, "sdfs");break;case NodeChildrenChanged:break;}}
}分布式配置的核心配置类:
//MyConf是配置中心的配置
public class MyConf {private String conf ;public String getConf() {return conf;}public void setConf(String conf) {this.conf = conf;}
}四.通过WatcherCallBack的方法判断配置是否存在并尝试获取数据
public class TestConfig {ZooKeeper zk;@Beforepublic void conn () {zk = ZKUtils.getZK();}@Afterpublic void close () {try {zk.close();} catch (InterruptedException e) {e.printStackTrace();}}@Testpublic void getConf() {WatchCallBack watchCallBack = new WatchCallBack();//传入zk和配置confwatchCallBack.setZk(zk);MyConf myConf = new MyConf();watchCallBack.setConf(myConf);//节点不存在和节点存在, 都尝试去取数据, 取到了才往下走watchCallBack.aWait();while(true) {if (myConf.getConf().equals("")) {System.out.println("conf diu le ......");watchCallBack.aWait();} else {System.out.println(myConf.getConf());}try {Thread.sleep(200);} catch (InterruptedException e) {e.printStackTrace();}}}
}2.zk实现负载均衡
(1)负载均衡算法
常用的负载均衡算法有:轮询法、随机法、原地址哈希法、加权轮询法、加权随机法、最小连接数法。
一.轮询法
轮询法是最为简单的负载均衡算法。当接收到客户端请求后,负载均衡服务器会按顺序逐个分配给后端服务。比如集群中有3台服务器,分别是server1、server2、server3,轮询法会按照sever1、server2、server3顺序依次分发请求给每个服务器。当第一次轮询结束后,会重新开始下一轮的循环。
二.随机法
随机法是指负载均衡服务器在接收到来自客户端请求后,根据随机算法选中后台集群中的一台服务器来处理这次请求。由于当集群中的机器变得越来越多时,每台机器被抽中的概率基本相等,因此随机法的实际效果越来越趋近轮询法。
三.原地址哈希法
原地址哈希法是根据客户端的IP地址进行哈希计算,对计算结果进行取模,然后根据最终结果选择服务器地址列表中的一台机器来处理请求。这种算法每次都会分配同一台服务器来处理同一IP的客户端请求。
四.加权轮询法
由于一个分布式系统中的机器可能部署在不同的网络环境中,每台机器的配置性能各不相同,因此其处理和响应请求的能力也各不相同。
如果采用上面几种负载均衡算法,都不太合适。这会造成能力强的服务器在处理完业务后过早进入空闲状态,而性能差或网络环境不好的服务器一直忙于处理请求造成任务积压。
为了解决这个问题,可以采用加权轮询法。加权轮询法的方式与轮询法的方式很相似,唯一的不同在于选择机器时,不只是单纯按照顺序的方式去选择,还要根据机器的配置和性能高低有所侧重,让配置性能好的机器优先分配。
五.加权随机法
加权随机法和上面提到的随机法一样,在采用随机法选举服务器时,会考虑系统性能作为权值条件。
六.最小连接数法
最小连接数法是指:根据后台处理客户端的请求数,计算应该把新请求分配给哪一台服务器。一般认为请求数最少的机器,会作为最优先分配的对象。
(2)使用zk来实现负载均衡
实现负载均衡服务器的关键是:探测和发现业务服务器的运行状态 + 分配请求给最合适的业务服务器。
一.状态收集之实现zk的业务服务器列表
首先利用zk的临时子节点来标记业务服务器的状态。在业务服务器上线时:通过向zk服务器创建临时子节点来实现服务注册,表示业务服务器已上线。在业务服务器下线时:通过删除临时节点或者与zk服务器断开连接来进行服务剔除。最后通过统计临时节点的数量,来了解业务服务器的运行情况。
在代码层面的实现中,首先定义一个BlanceSever接口类。该类用于业务服务器启动或关闭后:第一.向zk服务器地址列表注册或注销服务,第二.根据接收到的请求动态更新负载均衡情况。
public class BlanceSever {//向zk服务器地址列表进行注册服务public void register()//向zk服务器地址列表进行注销服务public void unregister()//根据接收到的请求动态更新负载均衡情况public void addBlanceCount()public void takeBlanceCount()
}之后创建BlanceSever接口的实现类BlanceSeverImpl,在BlanceSeverImpl类中首先定义:业务服务器运行的Session超时时间、会话连接超时时间、zk客户端地址、服务器地址列表节点SERVER_PATH等基本参数。并通过构造函数,在类被引用时进行初始化zk客户端对象实例。
public class BlanceSeverImpl implements BlanceSever {private static final Integer SESSION_TIME_OUT;private static final Integer CONNECTION_TIME_OUT;private final ZkClient zkclient;private static final SERVER_PATH = "/Severs";public BlanceSeverImpl() {init...}
}接下来定义,业务服务器启动时,向zk注册服务的register方法。
在如下代码中,会通过在SERVER_PATH路径下创建临时子节点的方式来注册服务。首先获取业务服务器的IP地址,然后利用IP地址作为临时节点的path来创建临时节点。
public register() throws Exception {//首先获取业务服务器的IP地址InetAddress address = InetAddress.getLocalHost();String serverIp = address.getHostAddress();//然后利用IP地址作为临时节点的path来创建临时节点zkclient.createEphemeral(SERVER_PATH + serverIp);
}接下来定义,业务服务器关机或不对外提供服务时的unregister()方法。通过调用unregister()方法,注销该台业务服务器在zk服务器列表中的信息。注销后的机器不会被负载均衡服务器分发处理会话。在如下代码中,会通过删除SERVER_PATH路径下临时节点的方式来注销业务服务器。
public unregister() throws Exception {zkclient.delete(SERVER_PATH + serverIp);
}二.请求分配之如何选择业务服务器
以最小连接数法为例,来确定如何均衡地分配请求给业务服务器,整个实现步骤如下:
步骤一:首先负载均衡服务器在接收到客户端的请求后,通过getData()方法获取已成功注册的业务服务器列表,也就是"/Servers"节点下的各个临时节点,这些临时节点都存储了当前服务器的连接数。
步骤二:然后选取连接数最少的业务服务器作为处理当前请求的业务服务器,并通过setData()方法将该业务服务器对应的节点值(连接数)加1。
步骤三:当该业务服务器处理完请求后,调用setData()方法将该节点值(连接数)减1。
下面定义,当业务服务器接收到请求后,增加连接数的addBlance()方法。在如下代码中,首先通过readData()方法获取服务器最新的连接数,然后将该连接数加1。接着通过writeData()方法将最新的连接数写入到该业务服务器对应的临时节点。
public void addBlance() throws Exception {InetAddress address = InetAddress.getLocalHost();String serverIp = address.getHostAddress();Integer con_count = zkClient.readData(SERVER_PATH + serverIp);++con_count;zkClient.writeData(SERVER_PATH + serverIp, con_count);
}3.zk实现分布式命名服务
命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体可以是集群中的机器、提供的服务地址等。例如,Java中的JNDI便是一种典型的命名服务。
(1)ID编码的特性
分布式ID生成器就是通过分布式的方式,自动生成ID编码的程序或服务。生成的ID编码一般具有唯一性、递增性、安全性、扩展性这几个特性。
(2)通过UUID方式生成分布式ID
UUID能非常简便地保证分布式环境中ID的唯一性。它由32位字符和4个短线字符组成,比如e70f1357-f260-46ff-a32d-53a086c57ade。
由于UUID在本地应用中生成,所以生成速度比较快,不依赖其他服务和网络。但缺点是:长度过长、含义不明、不满足递增性。
(3)通过TDDL生成分布式ID
MySQL的自增主键是一种有序的ID生成方式,还有一种性能更好的数据库序列生成方式:TDDL中的ID生成方式。TDDL是Taobao Distributed Data Layer的缩写,是一种数据库中间件,主要应用于数据库分库分表的应用场景中。
TDDL生成ID编码的大致过程如下:首先数据库中有一张Sequence序列化表,记录当前已被占用的ID最大值。然后每个需要ID编码的客户端在请求TDDL的ID编码生成器后,TDDL都会返回给该客户端一段ID编码,并更新Sequence表中的信息。
客户端接收到一段ID编码后,会将该段编码存储在内存中。在本机需要使用ID编码时,会首先使用内存中的ID编码。如果内存中的ID编码已经完全被占用,则再重新向编码服务器获取。
TDDL通过分批获取ID编码的方式,减少了客户端访问服务器的频率,避免了网络波动所造成的影响,并减轻了服务器的内存压力。不过TDDL高度依赖数据库,不能作为独立的分布式ID生成器对外提供服务。
(4)通过zk生成分布式ID
每个需要ID编码的业务服务器可以看作是zk的客户端,ID编码生成器可以看作是zk的服务端,可以利用zk数据模型中的顺序节点作为ID编码。
客户端通过create()方法来创建一个顺序子节点。服务端成功创建节点后会响应客户端请求,把创建好的节点发送给客户端。客户端以顺序节点名称为基础进行ID编码,生成ID后就可以进行业务操作。
(5)SnowFlake算法
SnowFlake算法是Twitter开源的一种用来生成分布式ID的算法,通过SnowFlake算法生成的编码会是一个64位的二进制数。
第一个bit不用,接下来的41个bit用来存储毫秒时间戳,再接下来的10个bit用来存储机器ID,剩余的12个bit用来存储流水号和0。

SnowFlake算法主要的实现手段就是对二进制数位的操作,SnowFlake算法理论上每秒可以生成400多万个ID编码,SnowFlake是业界普遍采用的分布式ID生成算法。
4.zk实现分布式协调(Master-Worker协同)
(1)Master-Worker架构
Master-Work是一个广泛使用的分布式架构,系统中有一个Master负责监控Worker的状态,并为Worker分配任务。
说明一:在任何时刻,系统中最多只能有一个Master。不可以出现两个Master,多个Master共存会导致脑裂。
说明二:系统中除了Active状态的Master还有一个Bakcup的Master。如果Active失败,Backup可以很快进入Active状态。
说明三:Master实时监控Worker的状态,能够及时收到Worker成员变化的通知。Master在收到Worker成员变化通知时,会重新进行任务分配。
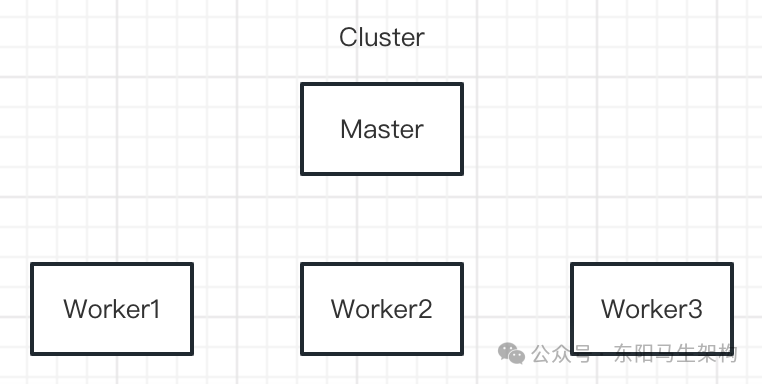
(2)Master-Worker架构示例—HBase
HBase采用的就是Master-Worker的架构。HMBase是系统中的Master,HRegionServer是系统中的Worker。HMBase会监控HBase Cluster中Worker的成员变化,HMBase会把region分配给各个HRegionServer。系统中有一个HMaster处于Active状态,其他HMaster处于备用状态。

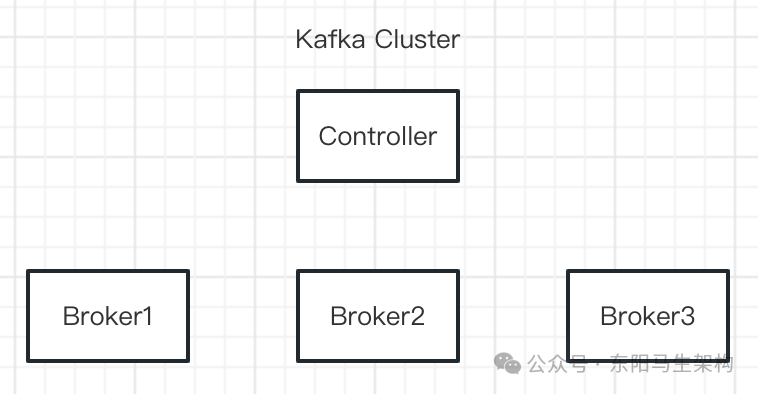
(3)Master-Worker架构示例—Kafka
一个Kafka集群由多个Broker组成,这些Borker是系统中的Worker,Kafka会从这些Worker选举出一个Controller。这个Controlle是系统中的Master,负责把Topic Partition分配给各个Broker。
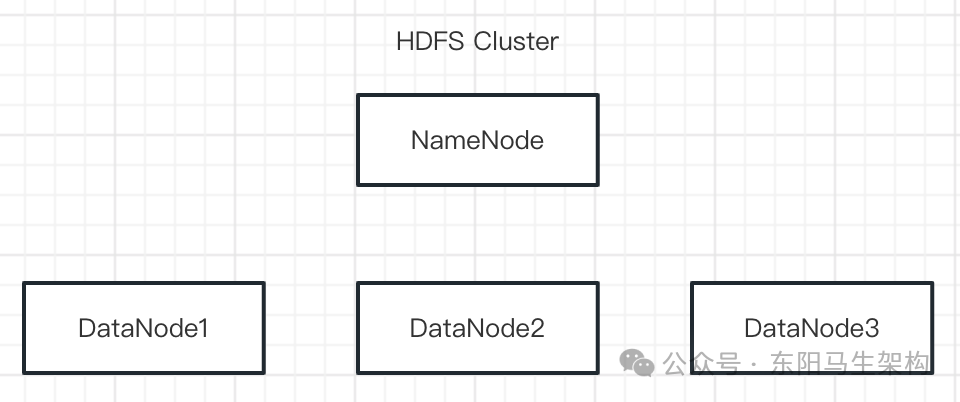
(4)Master-Worker架构示例—HDFS
HDFS采用的也是一个Master-Worker的架构。NameNode是系统中的Master,DataNode是系统中的Worker。NameNode用来保存整个分布式文件系统的MetaData,并把数据块分配给Cluster中的DataNode进行保存。
(5)如何使用zk实现Master-Worker
步骤1:使用一个临时节点"/master"表示Master。Master在行使Master的职能之前,首先要创建这个znode。如果创建成功,进入Active状态,开始行使Master职能。如果创建失败,则进入Backup状态,并使用Watcher机制监听"/master"。假设系统中有一个Active Master和一个Backup Master。如果Active Master故障了,那么它创建的"/master"就会被zk自动删除。这时Backup Master会收到通知,再次创建"/master"成为新Active Master。
步骤2:使用一个持久节点"/workers"下的临时子节点来表示Worker,Worker通过在"/workers"节点下创建临时节点来加入集群。
步骤3:处于Active状态的Master会通过Watcher机制,监控"/workers"下的子节点列表来实时获取Worker成员的变化。
5.zk实现分布式通信
在大部分的分布式系统中,机器间的通信有三种类型:心跳检测、工作进度汇报、系统调度。
(1)心跳检测
机器间的心跳检测是指:在分布式环境中,不同机器间需要检测彼此是否还在正常运行。其中,心跳检测有如下三种方法。
方法一:通常会通过机器间是否可以相互PING通来判断对方是否正常运行。
方法二:在机器间建立长连接,通过TCP连接固有的心跳检测机制来实现上层机器的心跳检测。
方法三:基于zk的临时子节点来实现心跳检测,让不同的机器都在zk的一个指定节点下创建临时子节点,不同机器间可以根据这个临时子节点来判断对应的客户端是否存活。基于zk的临时节点来实现的心跳检测,可以大大减少系统的耦合。因为检测系统和被检测系统之间不需要直接关联,只需要通过zk临时节点间接关联。
(2)工作进度汇报
在一个任务分发系统中,任务被分发到不同的机器上执行后,需要实时地将自己的任务执行进度汇报给分发系统。
通过zk的临时子节点来实现工作进度汇报:可以在zk上选择一个节点,每个任务机器都在该节点下创建临时子节点。然后通过判断临时子节点是否存在来确定任务机器是否存活,各个任务机器会实时地将自己的任务执行进度写到其对应的临时节点上,以便中心系统能够实时获取到任务的执行进度。
(3)系统调度
一个分布式系统由控制台和一些客户端系统组成,控制台的职责是将一些指令信息发送给所有客户端。
使用zk实现系统调度时:先让控制台的一些操作指令对应到zk的某些节点数据,然后让客户端系统注册对这些节点数据的监听。当控制台进行一些操作时,便会触发修改这些节点的数据,而zk会将这些节点数据的变更以事件通知的形式发送给监听的客户端。
这样就能省去大量底层网络通信和协议设计上的重复工作了,也大大降低了系统间的耦合,方便实现异构系统的灵活通信。
6.zk实现Master选举
Master选举的需求是:在集群的所有机器中选举出一台机器作为Master。
(1)通过创建临时节点实现
集群的所有机器都往zk上创建一个临时节点如"/master"。在这个过程中只会有一个机器能成功创建该节点,则该机器便成为Master。同时其他没有成功创建节点的机器会在"/master"节点上注册Watcher监听,一旦当前Master机器挂了,那么其他机器就会重新往zk上创建临时节点。
(2)通过临时顺序子节点来实现
使用临时顺序子节点来表示集群中的机器发起的选举请求,然后让创建最小后缀数字节点的机器成为Master。
7.zk实现分布式锁
可以利用zk的临时节点来解决死锁问题,可以利用zk的Watcher监听机制实现锁释放后重新竞争锁,可以利用zk数据节点的版本来实现乐观锁。
(1)死锁的解决方案
在单机环境下,多线程之间会产生死锁问题。同样,在分布式系统环境下,也会产生分布式死锁的问题。常用的解决死锁问题的方法有超时方法和死锁检测。
一.超时方法
在解决死锁问题时,超时方法可能是最简单的处理方式了。超时方式是在创建分布式线程时,对每个线程都设置一个超时时间。当该线程的超时时间到期后,无论该线程是否执行完毕,都要关闭该线程并释放该线程所占用的系统资源,之后其他线程就可以访问该线程释放的资源,这样就不会造成死锁问题。
但这种设置超时时间的方法最大的缺点是很难设置一个合适的超时时间。如果时间设置过短,可能造成线程未执行完相关的处理逻辑,就因为超时时间到期就被迫关闭,最终导致程序执行出错。
二.死锁检测
死锁检测是处理死锁问题的另一种方法,它解决了超时方法的缺陷。死锁检测方法会主动检测发现线程死锁,在控制死锁问题上更加灵活准确。
可以把死锁检测理解为一个运行在各服务器系统上的线程或方法,该方法专门用来发现应用服务上的线程是否发生死锁。如果发生死锁,那么就会触发相应的预设处理方案。
(2)zk如何实现排他锁
一.获取锁
获取排他锁时,所有的客户端都会试图通过调用create()方法,在"/exclusive_lock"节点下创建临时子节点"/exclusive_lock/lock"。zk会保证所有的客户端中只有一个客户端能创建临时节点成功,从而获得锁。没有创建临时节点成功的客户端也就没能获得锁,需要到"/exclusive_lock"节点上,注册一个子节点变更的Watcher监听,以便可以实时监听lock节点的变更情况。
二.释放锁
如果获取锁的客户端宕机,那么zk上的这个临时节点(lock节点)就会被移除。如果获取锁的客户端执行完,也会主动删除自己创建的临时节点(lock节点)。
(3)zk如何实现共享锁(读写锁)
一.获取锁
获取共享锁时,所有客户端会到"/shared_lock"下创建一个临时顺序节点。如果是读请求,那么就创建"/shared_lock/read001"的临时顺序节点。如果是写请求,那么就创建"/shared_lock/write002"的临时顺序节点。
二.判断读写顺序
步骤一:客户端在创建完节点后,会获取"/shared_lock"节点下的所有子节点,并对"/shared_lock"节点注册子节点变更的Watcher监听。
步骤二:然后确定自己的节点序号在所有子节点中的顺序(包括读节点和写节点)。
步骤三:对于读请求:如果没有比自己序号小的写请求子节点,或所有比自己小的子节点都是读请求,那么表明可以成功获取共享锁。如果有比自己序号小的子节点是写请求,那么就需要进入等待。对于写请求:如果自己不是序号最小的子节点,那么就需要进入等待。
步骤四:如果客户端在等待过程中接收到Watcher通知,则重复步骤一。
三.释放锁
如果获取锁的客户端宕机,那么zk上的对应的临时顺序节点就会被移除。如果获取锁的客户端执行完,也会主动删除自己创建的临时顺序节点。
(4)羊群效应
一.排他锁的羊群效应
如果有大量的客户端在等待锁的释放,那么就会出现大量的Watcher通知。然后这些客户端又会发起创建请求,但最后只有一个客户端能创建成功。这个Watcher事件通知其实对绝大部分客户端都不起作用,极端情况可能会出现zk短时间向其余客户端发送大量的事件通知,这就是羊群效应。出现羊群效应的根源在于:没有找准客户端真正的关注点。
二.共享锁的羊群效应
如果有大量的客户端在等待锁的释放,那么不仅会出现大量的Watcher通知,还会出现大量的获取"/shared_lock"的子节点列表的请求,但最后大部分客户端都会判断出自己并非是序号最小的节点。所以客户端会接收过多和自己无关的通知和发起过多查询节点列表的请求,这就是羊群效应。出现羊群效应的根源在于:没有找准客户端真正的关注点。
(5)改进后的排他锁
使用临时顺序节点来表示获取锁的请求,让创建出后缀数字最小的节点的客户端成功拿到锁。
步骤一:首先客户端调用create()方法在"/exclusive_lock"下创建一个临时顺序节点。
步骤二:然后客户端调用getChildren()方法返回"/exclusive_lock"下的所有子节点,接着对这些子节点进行排序。
步骤三:排序后,看看是否有后缀比自己小的节点。如果没有,则当前客户端便成功获取到排他锁。如果有,则调用exist()方法对排在自己前面的那个节点注册Watcher监听。
步骤四:当客户端收到Watcher通知前面的节点不存在,则重复步骤二。
(6)改进后的共享锁
步骤一:客户端调用create()方法在"/shared_lock"节点下创建临时顺序节点。如果是读请求,那么就创建"/shared_lock/read001"的临时顺序节点。如果是写请求,那么就创建"/shared_lock/write002"的临时顺序节点。
步骤二:然后调用getChildren()方法返回"/shared_lock"下的所有子节点,接着对这些子节点进行排序。
步骤三:对于读请求:如果排序后发现有比自己序号小的写请求子节点,则需要等待,且需要向比自己序号小的最后一个写请求子节点注册Watcher监听。对于写请求:如果排序后发现自己不是序号最小的子节点,则需要等待,并且需要向比自己序号小的最后一个请求子节点注册Watcher监听。注意:这里注册Watcher监听也是调用exist()方法。此外,不满足上述条件则表示成功获取共享锁。
步骤四:如果客户端在等待过程中接收到Watcher通知,则重复步骤二。
(7)zk原生实现分布式锁的示例
一.分布式锁的实现步骤
步骤一:每个线程都通过"临时顺序节点 + zk.create()方法 + 添加回调"去创建节点。
步骤二:线程执行完创建临时顺序节点后,先通过CountDownLatch.await()方法进行阻塞。然后在创建成功的回调中,通过zk.getChildren()方法获取根目录并继续回调。
步骤三:某线程在获取根目录成功后的回调中,会对目录排序。排序后如果发现其创建的节点排第一,那么就执行countDown()方法不再阻塞,表示获取锁成功。排序后如果发现其创建的节点不是第一,则通过zk.exists()方法监听前一节点。
步骤四:获取到锁的线程会通过zk.delete()方法来删除其对应的节点实现释放锁。在等候获取锁的线程掉线时其对应的节点也会被删除。而一旦节点被删除,那些监听根目录的线程就会重新zk.getChildren()方法,获取成功后其回调又会进行排序以及通过zk.exists()方法监听前一节点。
二WatchCallBack对分布式锁的具体实现
public class WatchCallBack implements Watcher, AsyncCallback.StringCallback, AsyncCallback.Children2Callback, AsyncCallback.StatCallback {ZooKeeper zk ;String threadName;CountDownLatch countDownLatch = new CountDownLatch(1);String pathName;public String getPathName() {return pathName;}public void setPathName(String pathName) {this.pathName = pathName;}public String getThreadName() {return threadName;}public void setThreadName(String threadName) {this.threadName = threadName;}public ZooKeeper getZk() {return zk;}public void setZk(ZooKeeper zk) {this.zk = zk;}public void tryLock() {try {System.out.println(threadName + " create....");//创建一个临时的有序的节点zk.create("/lock", threadName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL, this, "abc");countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}}//当前线程释放锁, 删除节点public void unLock() {try {zk.delete(pathName, -1);System.out.println(threadName + " over work....");} catch (InterruptedException e) {e.printStackTrace();} catch (KeeperException e) {e.printStackTrace();}}//上面zk.create()方法的回调//创建临时顺序节点后的回调, 10个线程都能同时创建节点//创建完后获取根目录下的子节点, 也就是这10个线程创建的节点列表, 这个不用watch了, 但获取成功后要执行回调//这个回调就是每个线程用来执行节点排序, 看谁是第一就认为谁获得了锁@Overridepublic void processResult(int rc, String path, Object ctx, String name) {if (name != null ) {System.out.println(threadName + " create node : " + name );setPathName(name);//一定能看到自己前边的, 所以这里的watch要是falsezk.getChildren("/", false, this ,"sdf");}}//核心方法: 各个线程获取根目录下的节点时, 上面zk.getChildren("/", false, this ,"sdf")的回调@Overridepublic void processResult(int rc, String path, Object ctx, List<String> children, Stat stat) {//一定能看到自己前边的节点System.out.println(threadName + "look locks...");for (String child : children) {System.out.println(child);}//根目录下的节点排序Collections.sort(children);//获取当前线程创建的节点在根目录中排第几int i = children.indexOf(pathName.substring(1));//是不是第一个, 如果是则说明抢锁成功; 如果不是, 则watch当前线程创建节点的前一个节点是否被删除(删除);if (i == 0) {System.out.println(threadName + " i am first...");try {//这里的作用就是不让第一个线程获得锁释放锁跑得太快, 导致后面的线程还没建立完监听第一个节点就被删了zk.setData("/", threadName.getBytes(), -1);countDownLatch.countDown();} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}} else {//9个没有获取到锁的线程都去调用zk.exists, 去监控各自自己前面的节点, 而没有去监听父节点//如果各自前面的节点发生删除事件的时候才回调自己, 并关注被删除的事件(所以会执行process回调)zk.exists("/" + children.get(i-1), this, this, "sdf");}}//上面zk.exists()的监听//监听的节点发生变化的Watcher事件监听@Overridepublic void process(WatchedEvent event) {//如果第一个获得锁的线程释放锁了, 那么其实只有第二个线程会收到回调事件//如果不是第一个哥们某一个挂了, 也能造成他后边的收到这个通知, 从而让他后边那个去watch挂掉这个哥们前边的, 保持顺序switch (event.getType()) {case None:break;case NodeCreated:break;case NodeDeleted:zk.getChildren("/", false, this ,"sdf");break;case NodeDataChanged:break;case NodeChildrenChanged:break;}}@Overridepublic void processResult(int rc, String path, Object ctx, Stat stat) {//TODO}
}三.分布式锁的测试类
public class TestLock {ZooKeeper zk;@Beforepublic void conn () {zk = ZKUtils.getZK();}@Afterpublic void close () {try {zk.close();} catch (InterruptedException e) {e.printStackTrace();}}@Testpublic void lock() {//10个线程都去抢锁for (int i = 0; i < 10; i++) {new Thread() {@Overridepublic void run() {WatchCallBack watchCallBack = new WatchCallBack();watchCallBack.setZk(zk);String threadName = Thread.currentThread().getName();watchCallBack.setThreadName(threadName);//每一个线程去抢锁watchCallBack.tryLock();//抢到锁之后才能干活System.out.println(threadName + " working...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}//干完活释放锁watchCallBack.unLock();}}.start();}while(true) {}}
}8.zk实现分布式队列和分布式屏障
(1)分布式队列的实现
步骤一:所有客户端都到"/queue"节点下创建一个临时顺序节点。
步骤二:通过调用getChildren()方法来获取"/queue"节点下的所有子节点。
步骤三:客户端确定自己的节点序号在所有子节点中的顺序。
步骤四:如果自己不是序号最小的子节点,那么就需要进入等待,同时调用exists()方法向比自己序号小的最后一个节点注册Watcher监听。
步骤五:如果客户端收到Watcher事件通知,重复步骤二。
(2)分布式屏障的实现
"/barrier"节点是一个已存在的默认节点,"/barrier"节点的值是数字n,表示Barrier值,比如10。
步骤一:首先,所有客户端都需要到"/barrier"节点下创建一个临时节点。
步骤二:然后,客户端通过getData()方法获取"/barrier"节点的数据内容,比如10。
步骤三:接着,客户端通过getChildren()方法获取"/barrier"节点下的所有子节点,同时注册对子节点列表变更的Watcher监听。
步骤四:如果客户端发现"/barrier"节点的子节点个数不足10个,那么就需要进入等待。
步骤五:如果客户端接收到了Watcher事件通知,那么就重复步骤三。
文章转载自:东阳马生架构
原文链接:zk基础—4.zk实现分布式功能 - 东阳马生架构 - 博客园
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:

zk基础—zk实现分布式功能
1.zk实现数据发布订阅 (1)发布订阅系统一般有推模式和拉模式 推模式:服务端主动将更新的数据发送给所有订阅的客户端。 拉模式:客户端主动发起请求来获取最新数据(定时轮询拉取)。 (2)zk采用了推拉相结合来实现发布订阅 首先客户端需要向服务端注册自己关…...

Tips:用proxy解决前后端分离项目中的跨域问题
在前后端分离项目中,"跨域问题"是浏览器基于同源策略(Same-Origin Policy)对跨域请求的安全限制。当你的前端(如运行在 http://localhost:3000 )和后端(如运行在 http://localhost:8080 &#…...

JMeterPlugins-Standard-1.4.0 插件详解:安装、功能与使用指南
JMeterPlugins-Standard-1.4.0 是 Apache JMeter(一款流行的开源负载和性能测试工具)的插件包,它扩展了 JMeter 的功能,提供了更多监听器(Listeners)、采样器(Samplers)和辅助组件&a…...

JMeter 中,Token 和 Cookie 的区别及实际应用
在 JMeter 中,Token 和 Cookie 都是用于处理用户会话和身份验证的机制,但它们的 工作原理、存储方式 和 应用场景 有显著区别。以下是详细对比和实际应用指南: 1. 核心区别 特性Token (如 JWT、OAuth)Cookie存储位置通常存储在 HTTP 请求头(如 Authorization: Bearer <t…...

蓝桥杯真题——好数、R格式
目录 蓝桥杯2024年第十五届省赛真题-好数 【模拟题】 题目描述 输入格式 输出格式 样例输入 样例输出 提示 代码1:有两个案例过不了,超时 蓝桥杯2024年第十五届省赛真题-R 格式 【vector容器的使用】 题目描述 输入格式 输出格式 样例输入…...

JavaScript惰性加载优化实例
这是之前的一位朋友的酒桌之谈,他之前负责的一个电商项目,刚刚开发万,首页加载时间特别长,体验很差,所以就开始排查,发现是在首页一次性加载所有js导致的问题,这个问题在自己学习的时候并不明显…...

0_Pytorch中的张量操作
[引言]张量的概念 1.基本概念 张量是一个通用的多维数组,可以表示标量(0 维)、向量(1 维)、矩阵(2 维)以及更高维度的数据。张量是 PyTorch 中的核心数据结构,用于表示和操作数据。…...

Java面试43-常见的限流算法有哪些?
限流算法是一种系统保护策略,主要是避免在流量高峰导致系统被压垮,造成系统不可用的问题。 常见的限流算法有五种: 计数器限流,一般用在单一维度的访问频率限制上,比如短信验证码每隔60s只能发送一次,或者…...

牛客网:树的高度 ← 根节点为 0 号节点
【题目来源】 https://www.nowcoder.com/questionTerminal/4faa2d4849fa4627aa6d32a2e50b5b25 【题目描述】 现在有一棵合法的二叉树,树的节点都是用数字表示,现在给定这棵树上所有的父子关系,求这棵树的高度。 【输入格式】 输入的第一行表…...

Linux:进程程序替换execl
目录 引言 1.单进程版程序替换 2.程序替换原理 3.6种替换函数介绍 3.1 函数返回值 3.2 命名理解 3.3 环境变量参数 引言 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),我们所创建的所有的子进程,执行的代码&#x…...

⑩数据中心M-LAG 实战
一、配置指导自己去看今天操作的是M-LAG 基础实验 二、配置代码信息回顾 ### 1、配置 M-LAG 系统 MAC 地址<H3C>system-view[H3C]m-lag system-mac ?H-H-H MAC address2a7a-53ee-0100 Bridge MAC address[H3C]m-lag system-mac### 2、配置 M-LAG 系统编号…...

delphi idtcpserver 搭建tcp ,ssl协议服务端
如果想用indy idtcpserver实现tcp ssl,那么正是你需要的 首先生成证书: 2、windows生成pem证书 - 站着说话不腰疼 - 博客园 有证书后 idtcpserver 用的三个证书, IdServerIOHandlerSSLOpenSSL1.SSLOptions.CertFile = ca.crt IdServerIOHandlerSSLOpenSSL1.SSLOptions.…...

如何实现外观模式?
一、模式理解(用快递驿站比喻) 想象你网购了5件商品,分别来自不同快递公司。 外观模式就像小区门口的快递驿站,你不需要知道中通怎么分拣、顺丰怎么运输,只要到驿站报取件码就能拿到所有包裹。 在前端开发中…...

深入解析 Linux 文件系统权限:从基础到高级实践
引言 在 Linux 系统中,文件系统权限是保障数据安全和多用户协作的核心机制。想象这样一个场景: 你的服务器上有多个团队共享项目文件 财务数据必须严格保密,仅允许指定人员访问 开发团队需要共同编辑代码,但禁止随意删除他人文…...

GZ036区块链卷一 EtherStore合约漏洞详解
题目 pragma solidity >0.8.3;contract EtherStore {mapping(address > uint) public balances;function deposit() public payable {balances[msg.sender] msg.value;emit Balance(balances[msg.sender]);}function withdraw() public {uint bal balances[msg.sender…...

医药流通行业批发公司IT运维转型:Prometheus+Grafana监控Spring Boot 3应用实践
一、引言:医药流通行业IT运维挑战与工具换代需求 在医药流通行业批发领域,业务的核心在于供应链的高效运转、订单处理的精准及时以及库存管理的动态平衡。随着互联网医疗的兴起和电商平台的渗透,传统医药批发企业正加速向数字化、智能化转型…...
(vscode))
编程助手fitten code使用说明(超详细)(vscode)
这两年 AI 发展迅猛,作为开发人员,我们总是追求更快、更高效的工作方式,AI 的出现可以说改变了很多人的编程方式。 AI 对我们来说就是一个可靠的编程助手,给我们提供了实时的建议和解决方,无论是快速修复错误、提升代…...

金融大模型
FinGPT 数据集:https://github.com/AI4Finance-Foundation/FinGPT/tree/master/fingpt/FinGPT-v3 FinGPT v3 系列是在新闻和微博情绪分析数据集上使用 LoRA 方法进行微调的LLM,在大多数金融情绪分析数据集上取得了最佳分数。 FinGPT v3.1 使用 chatgl…...

【Pandas】pandas DataFrame infer_objects
Pandas2.2 DataFrame Conversion 方法描述DataFrame.astype(dtype[, copy, errors])用于将 DataFrame 中的数据转换为指定的数据类型DataFrame.convert_dtypes([infer_objects, …])用于将 DataFrame 中的数据类型转换为更合适的类型DataFrame.infer_objects([copy])用于尝试…...

011_异常、泛型和集合框架
异常、泛型和集合框架 异常Java的异常体系异常的作用 自定义异常异常的处理方案异常的两种处理方式 泛型泛型类泛型接口泛型方法、通配符和上下限泛型支持的类型 集合框架集合体系结构Collection Collection集合Collection的遍历方式认识并发修改异常问题解决并发修改异常问题的…...

QTSql全解析:从连接到查询的数据库集成指南
概览 与数据库的有效集成是确保数据管理效率和应用性能的关键,Qt框架就提供了强大的QtSql模块,使得开发者能够轻松地进行数据库操作,包括连接、查询执行以及结果处理等 一、引入QtSql模块 首先,需要在项目中引入QtSql模块&…...
)
docker快捷打包脚本(ai版)
直接进入主题: 用这个脚本前提是你本地可以拉镜像仓库的镜像,并且在 本地有了,然后将所有的镜像tag写在一个文件中,和下面docker_tags.txt 对应,文件叫什么,脚本里对应改什么,给小白说的 #!/bi…...

分布式防护节点秒级切换:实战配置与自动化运维
摘要:针对DDoS攻击导致节点瘫痪的问题,本文基于群联AI云防护的智能调度系统,详解如何实现节点健康检查、秒级切换与自动化容灾,并提供Ansible部署脚本。 一、分布式节点的核心价值 资源分散:攻击者难以同时击溃所有节…...
)
TBE(TVM的扩展)
算子 张量 一个张量只有一种数据类型 在内存中只能线性存储,最终形成一个长的一维数组 晟腾AI的数据格式 AIPP是对我们常见的数据格式转化成AI core支持的数据格式 广播机制 TVM TBE的第一种开发方式:DSL TBE的第二种开发方式:TVM TBE的第…...

Jenkins配置的JDK,Maven和Git
1. 前置 在配置前,我们需要先把JDK,Maven和Git安装到Jenkins的服务器上。 (1)需要进入容器内部,执行命令:docker exec -u root -it 容器号/容器名称(2选1) bash -- 容器名称 dock…...

核心案例 | 湖南汽车工程职业大学无人机操控与编队技术实验室
核心案例 | 湖南汽车工程职业大学无人机操控与编队技术实验室 为满足当今无人机行业应用需求,推动无人机技术的教育与实践深度融合,北京卓翼智能科技有限公司旗下品牌飞思实验室与湖南汽车工程职业大学强强联手,共同建设无人机操控与编队技术…...

【阻抗匹配】
自动匹配的实现: 检测反射信号:通过传感器(如定向耦合器)监测反射功率或驻波比(SWR),判断是否失配。控制单元:利用微控制器或专用芯片(如FPGA)分析检测数据&a…...

micro常用快捷键
micro常用快捷键 以下是 micro 编辑器 的常用快捷键整理,按功能分类清晰,方便快速查阅: 1. 基础操作 快捷键功能Ctrl S保存文件Ctrl Q退出编辑器Ctrl O打开文件Ctrl E打开命令栏(输入命令)Ctr…...

DNS域名解析服务
目录 DNS系统 DNS系统的作用 DNS系统的类型(服务器分类) 1. 递归解析器(Recursive Resolver) 2. 根域名服务器(Root Name Server) 3. 顶级域服务器(TLD Name Server)…...

Linux的目录结构
倒根树状结构 【注意】 / 表示根目录,相当于Windows的C盘 进入跟目录命令: cd / /bin:存放的系统命令或二进制文件,如:cd ls cp等 /sbin /usr/bin /dev:存放的设备节点文件 , 驱动文件 /…...

【Python】Python 100题 分类入门练习题 - 新手友好
Python 100题 分类入门练习题 - 新手友好篇 - 整合篇 一、数学问题题目1:组合数字题目2:利润计算题目3:完全平方数题目4:日期天数计算题目11:兔子繁殖问题题目18:数列求和题目19:完数判断题目21…...

Three.js 系列专题 7:性能优化与最佳实践
内容概述 随着 3D 场景复杂度的增加,性能优化变得至关重要。Three.js 项目可能因几何体数量、纹理大小或渲染设置而变慢。本专题将介绍减少 draw call、优化纹理和使用调试工具的最佳实践。 学习目标 学会减少 draw call 和几何体复杂度。掌握纹理压缩与内存管理。使用 Stat…...

特权FPGA之Johnson移位
完整代码: module johnson(clk,rst_n,led,sw1_n,sw2_n,sw3_n);input clk; //时钟信号,50MHz input rst_n; //复位信号,低电平有效 output[3:0] led; //LED控制,1--灭…...

聊聊 CSS
先补充一些概念 C/S(客户端/服务器):要下载到本地才能用 需要安装、偶尔更新、不跨平台 B/S(浏览器/服务器):在浏览器输入网址就可以使用 无需安装、无需更新、可跨平台 [!NOTE] B/S 架构优点如此之多&am…...

域名系统DNS
一 概述 域名系统DNS是互联网使用的命名系统,用来把便于人们使用的机器名称转换为IP地址,比如我们熟知的www.baidu.com,www.sina.com,这些域名的背后都对应着一个又一个的IP地址。由域名转换为IP的过程我们称为解析,解析的过程大…...

大模型ui设计SVG输出
你是一位资深 SVG 绘画设计师,现需根据以下产品需求创建SVG方案: 产品需求 约拍app 画板尺寸: 宽度:375px(基于提供的HTML移动设计)高度:812px(iPhone X/XS 尺寸) 配…...

利用securecrt的tftp服务器功能传递文件
日常经常能用到需要调测一些openwrt设备,要互相拷贝文件,没有开启ftp功能时,这时可以用到crt的tftp内置服务器功能,利用tftp功能传递文件。 配置方法: 打开设置→全局配置→终端→tftp配置设置c上内置tftp服务器时&a…...

基于STM32、HAL库的IP2736U快充协议芯片简介及驱动程序设计
一、简介: IP2736U是一款高性能的USB Type-C和Power Delivery(PD)控制器芯片,支持最新的USB PD 3.0规范。它具有以下特点: 支持USB Type-C和PD 3.0协议 内置MCU,可编程配置 支持多种供电角色(Source/Sink/DRP) 支持PPS可编程电源 支持多种快充协议(PD/QC/AFC/FCP/SCP等) I…...

SQL学习笔记七
第九章用正则表达式进行搜索 9.1正则表达式介绍 正则表达式是用来匹配文本的特殊的串(字符集合)。如果你想从一个文本文件中提取电话号码,可以使用正则表达式。如果你需要查找名字中间有数字的所有文件,可以 使用一个正则表达式…...

MicroPython 开发ESP32应用教程 之 Timer、GPIO中断
随着我们课程的递进,大家会发现,我们之前课程中的例子,虽然功能都能实现,但总觉得体验感不够好,比如按键控制GRB灯珠的时候,很容易出现按键后,灯珠没有反应,还有蓝牙发送指令控制灯珠…...
)
【区块链安全 | 第三十七篇】合约审计之获取私有数据(一)
文章目录 私有数据访问私有数据实例存储槽Solidity 中的数据存储方式1. storage(持久化存储)定长数组变长数组 2. memory(临时内存)3. calldata 可见性关键字私有数据存储风险安全措施 私有数据 私有数据(Private Dat…...

20250408在荣品的PRO-RK3566开发板使用Rockchip原厂的buildroot系统时拿掉经常出现的list-iodomain.sh警告信息
rootrk3566-buildroot:/usr/bin# vi list-iodomain.sh rootrk3566-buildroot:/usr/bin# sync 【最后】 #chk_env #get_chip_id $1 #echo_msg "Get CHIP ID: $CHIP_ID" #get_iodomain_val 20250408在荣品的PRO-RK3566开发板使用Rockchip原厂的buildroot系统时拿掉经常…...

上下拉电阻详解
一、基本定义 上拉电阻:连接信号线与电源(VCC),确保信号在无驱动时保持高电平。 下拉电阻:连接信号线与地(GND),确保信号在无驱动时保持低电平。 二、核心作用 电平稳定 防止悬空引…...

特权FPGA之数码管
case语句的用法: 计数器不断的计数,每一个num对应数码管一种数据的输出。实例通俗易懂,一目了然。 timescale 1ns / 1ps// Company: // Engineer: // // Create Date: // Design Name: // Module Name: // Project Name: //…...

PyTorch 学习笔记
环境:python3.8 PyTorch2.4.1cpu PyCharm 参考链接: 快速入门 — PyTorch 教程 2.6.0cu124 文档 PyTorch 文档 — PyTorch 2.4 文档 快速入门 导入库 import torch from torch import nn from torch.utils.data import DataLoader from torchvision …...

MCP基础学习计划:从MCP入门到项目构建的全面指南
文章简介 ai生成的学计划有的连接是无效的,想着边学习边找输出文章,后续会继续链接更新 在人工智能和大语言模型(LLM)的快速发展下,掌握Model Context Protocol(MCP)成为提升AI应用能力的关键。…...
)
NO.77十六届蓝桥杯备战|数据结构-单调队列|质量检测(C++)
什么是单调队列? 单调队列,顾名思义,就是存储的元素要么单调递增要么单调递减的队列。注意,这⾥的队列和普通的队列不⼀样,是⼀个双端队列。单调队列解决的问题 ⼀般⽤于解决滑动窗⼝内最⼤值最⼩值问题,以…...

【有啥问啥】深入浅出讲解 Teacher Forcing 技术
深入浅出讲解 Teacher Forcing 技术 在序列生成任务(例如机器翻译、文本摘要、图像字幕生成等)中,循环神经网络(RNN)以及基于 Transformer 的模型通常采用自回归(autoregressive)的方式生成输出…...

redis数据迁移之通过redis-dump镜像
这里写目录标题 一、redis-dump 镜像打包1.1 安装windows docker1.2 idea项目创建1.3 idea镜像打包 二、redis数据迁移2.1 数据导出2.2 数据导入 一、redis-dump 镜像打包 没有找到可用的redis-dump镜像,需要自己打包一下,这里我是在idea直接打包的 1.…...

Redis哨兵模式下执行sentinel failover mymaster命令可能导致什么风险,如何避免
在 Redis 哨兵模式下执行 SENTINEL FAILOVER mymaster 命令会强制触发主节点切换(手动故障转移),虽然这是合法的管理操作,但可能带来以下风险及规避方法: 一、潜在风险 数据丢失风险 原因:主节点可能在故障…...