LLMs基础学习(五)模型微调专题(中)
文章目录
- LLMs基础学习(五)模型微调专题(中)
- Adapter 类的微调
- 1 背景
- 2 技术原理
- 3 具体细节
- 4 Adapter 类其他方法的微调
- Prefix 类的微调
- 1 Prefix Tuning
- 2 Prompt Tuning
- 3 P - tuning
- 4 P - Tuning v2
- 5 总结
- LoRA 篇
- a. 什么是 LoRA?
- b. LoRA 的思路是什么?
- c. LoRA 的特点是什么?
- d. 一句话描述一下 LoRA
- 其他 LoRA 相关常见面试题
- a. LORA 应该作用于 Transformer 的哪个参数矩阵(Q、K、V)?
- b. 如何在已有 LoRA 模型上继续训练?
- c. LoRA 权重是否可以合入原模型?
- d. LoRA 微调方法为啥能加速训练?
- e. Rank 如何选取?
- f. LoRA 高效微调 如何避免过拟合?
- g. LoRA 矩阵初始化相关问题
LLMs基础学习(五)模型微调专题(中)
原视频链接
Adapter 类的微调
- 解释 Adapter 即适配器,Adapter Tuning 思想源自 2019 年发表的《Parameter-Efficient Transfer Learning for NLP》 ,当时主要基于 BERT 改进。
1 背景
- 指出预训练模型参数量增多,全量微调训练下游任务昂贵且耗时。
- 作者提出 Adapter Tuning,在预训练模型每层插入针对下游任务的参数(仅增加 3.6% 参数 ),微调时冻结模型主体,只训练特定任务参数,减少算力开销。
2 技术原理
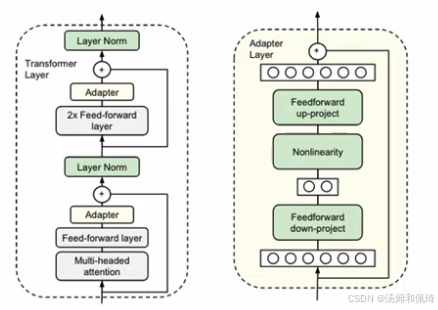
- 设计与嵌入:设计新的 Adapter 结构并嵌入 Transformer 结构。
- 插入位置:在每个 Transformer 层,于多头注意力投影后和第二个 feed - forward 层后,各增加一个 Adapter 结构。
- 训练方式:训练时固定预训练模型参数,仅微调新增的 Adapter 结构和 Layer Norm 层。
- 任务扩展:有新下游任务时,添加 Adapter 模块生成易扩展的下游模型,避免全量微调和灾难性遗忘。
- 配有两张图(Figure 2) ,左图展示在 Transformer 层两次插入适配器模块的位置;右图介绍适配器模块核心是参数少的瓶颈结构,含跳跃连接(skip - connection),微调时绿色部分(适配器模块、层归一化参数、最终分类层 )基于下游任务数据训练。
3 具体细节
- 模块构成:每个 Adapter 模块由两个前馈(Feed forward)子层组成。
- 降维:第一个前馈子层(down - project)将 Transformer 块输出从高维特征 d 投影到低维特征 m(m << d ) ,控制 m 限制 Adapter 模块参数量。
- 非线性变换:经非线性层(Nonlinearity ) 。
- 升维:第二个前馈子层(up - project)将 m 维特征还原为 d 维,作为 Adapter 模块输出。
- 跳跃连接:通过跳跃连接(skip - connection)将 Adapter 输入加到最终输出,使参数初始化接近 0 时也近似恒等映射,确保训练有效性。
- 实验表明,Adapter 方法少量参数训练效果媲美全量微调,引入 0.5% - 5% 模型参数可达全量微调模型 99% 性能。
4 Adapter 类其他方法的微调
- Adapter Fusion
- 将适配器训练分为知识提取和知识组合,解决灾难性遗忘、任务干扰和训练不稳定问题。
- 但增加模型参数量,降低推理性能。
- Adapter Drop
- 从较低 Transformer 层删除可变数量 Adapter 提升推理速度。
- 多任务推理时,动态减少计算开销,一定程度保持任务性能。
Prefix 类的微调
- Prefix 类微调包括 Prefix Tuning、Prompt Tuning、P - tuning、P - Tuning v2 等内容。
1 Prefix Tuning
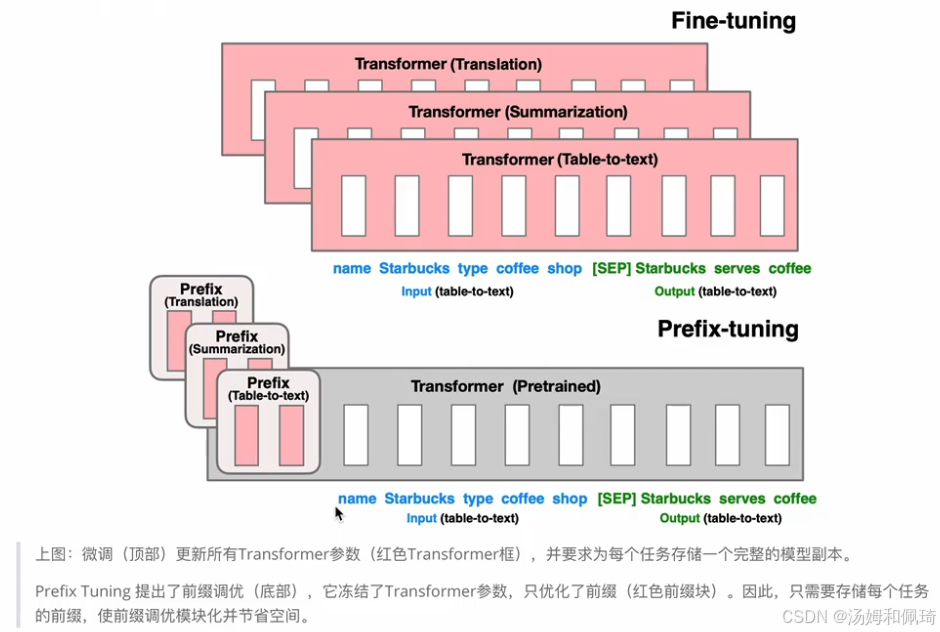
- 背景:在 Prefix Tuning 之前,相关工作主要是人工设计离散的模版或自动化搜索离散的模版。人工设计的模版对模型最终性能影响极为敏感,增加或减少一个词、变动词的位置,都会使模型性能产生较大变化。自动化搜索模版成本较高,且此前离散化 token 搜索出的结果往往并非最优。此外,传统微调范式利用预训练模型处理不同下游任务时,需为每个任务保存一份微调后的模型权重,不仅微调整个模型耗时久,还会占用大量存储空间。
- 技术原理:Prefix Tuning 源于论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》。该方法提出固定预训练语言模型,为语言模型添加可训练、任务特定的前缀。具体而言,在输入 token 之前构造一段与任务相关的 virtual tokens 作为 Prefix,训练时仅更新 Prefix 部分的参数,而预训练语言模型(PLM)中的其他部分参数保持固定。配有示意图,展示了在不同任务(如翻译、摘要生成、表格转文本 )中,Prefix - tuning 与传统 Fine - tuning 的差异。在 Prefix - tuning 中,Transformer(预训练)模型接收带有特定 Prefix(针对不同任务,如 Translation、Summarization、Table - to - text )的输入,而传统 Fine - tuning 则是针对不同任务分别训练独立的 Transformer 模型(如 Transformer (Translation)、Transformer (Summarization)、Transformer (Table - to - text) ) 。
2 Prompt Tuning
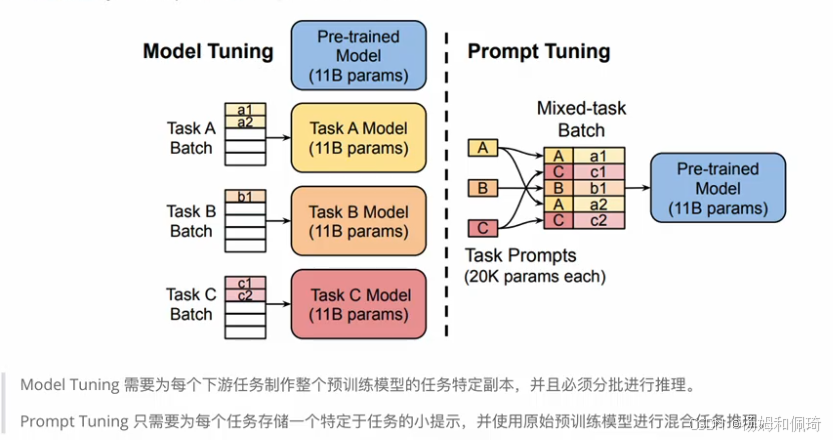
- 背景:大模型进行全量微调时,为每个任务训练一个模型,开销和部署成本都很高。离散的 prompts 方法不仅成本较高,而且效果欠佳。此外,之前的 Prefix Tuning 在更新参数时较为复杂。
- 技术原理:Prompt Tuning 源于论文《The Power of Scale for Parameter-Efficient Prompt Tuning》 ,该方法通过反向传播更新参数来学习 prompts,而不是采用人工设计 prompts 的方式。同时,冻结模型原始权重,仅训练 prompts 参数,训练完成后,用同一个模型即可进行多任务推理。可以将其看作是 Prefix Tuning 的简化版本,它为每个任务定义各自的 prompt,然后拼接到数据上作为输入,且仅在输入层加入 prompt tokens,不需要加入多层感知器(MLP,Multilayer Perceptron)进行调整以解决难训练的问题。配有示意图对比 Model Tuning 和 Prompt Tuning:Model Tuning 需要为每个下游任务制作整个预训练模型的任务特定副本,并且必须分批进行推理;而 Prompt Tuning 只需为每个任务存储一个特定于任务的小提示,并使用原始预训练模型进行混合任务推理。
- 延伸面试题:探讨 prompt tuning 和 prefix tuning 在微调上的区别。指出二者都是自然语言处理任务中对预训练模型进行微调的方法,但在实现细节和应用场景上存在差异。具体区别包括:
- 参数更新位置:Prompt Tuning 通常只在输入层添加参数,而 Prefix Tuning 在每一层都添加了参数。
- 参数数量:Prefix Tuning 通常比 Prompt Tuning 有更多的可学习参数,因为它为模型的每一层都添加了前缀。
- 适用任务:Prompt Tuning 更适合于分类任务,而 Prefix Tuning 更适合于生成任务,因为它可以在不同层次上调整模型的行为。
- 训练效率:Prompt Tuning 通常有更高的训练效率。
3 P - tuning
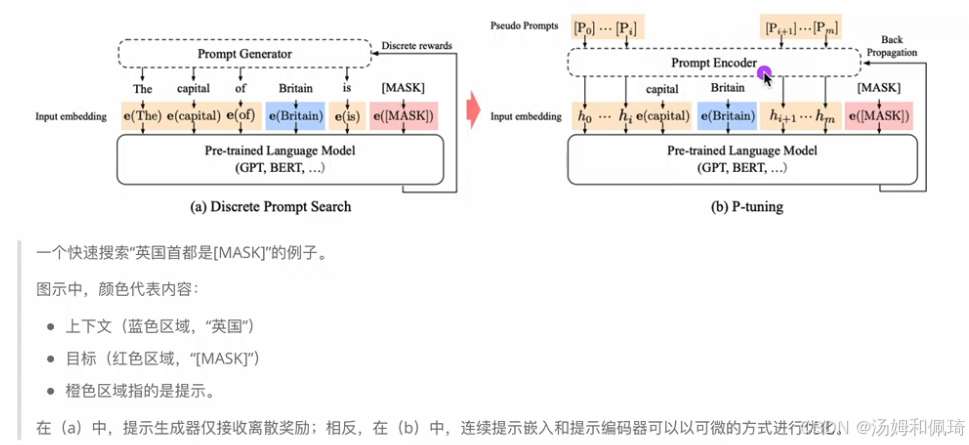
- 背景:提出 P - tuning 方法同样是为了解决之前提到的两个问题:一是大模型的 Prompt 构造方式严重影响下游任务的效果,例如 GPT - 3 采用人工构造的模版来进行上下文学习(in context learning),但人工设计的模版变化特别敏感,增减一个词或变动位置都会造成较大影响;二是近来的自动化搜索模版工作成本较高,且之前离散化的 token 搜索出来的结果可能不是最优的,导致性能不稳定。
- 技术原理:源于论文《GPT Understands, Too》 ,该方法设计了一种连续可微的 virtual token。具体是将 Prompt 转换为可以学习的 Embedding 层,并对 Prompt Embedding 进行一层处理。配有一个快速搜索 “英国首都是 [MASK]” 的例子图示,对比了 (a) Discrete Prompt Search 和 (b) P - tuning。在 (a) 中,提示生成器仅接收离散奖励;而在 (b) 中,连续提示嵌入和提示编码器可以以可微的方式进行优化。与 Prefix Tuning 相比,P - Tuning 加入了可微的 virtual token,但仅限于输入层,并非在每一层都添加;此外,virtual token 的位置不一定是前缀,插入的位置是可选的。
4 P - Tuning v2
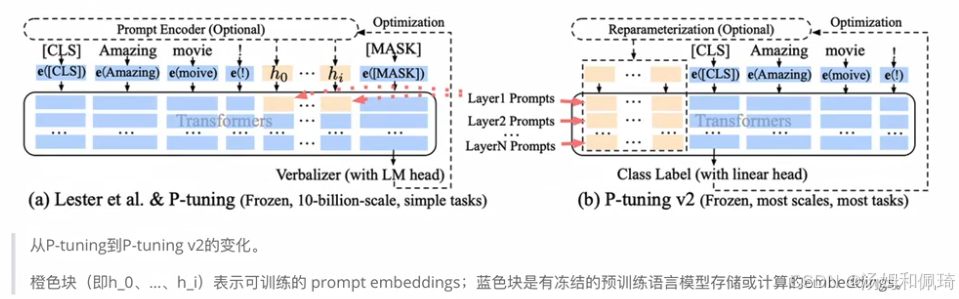
- 背景:指出之前的 Prompt Tuning 和 P - Tuning 等方法存在两个主要问题。
- 缺乏模型参数规模和任务通用性:从规模通用性看,Prompt Tuning 论文表明当模型参数规模超过 10B 时,提示优化可与全量微调媲美,但对于较小模型(100M - 1B ),提示优化和全量微调表现差异大,限制了提示优化适用性。从任务普遍性看,尽管 Prompt Tuning 和 P - tuning 在一些自然语言理解(NLU)基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
- 缺少深度提示优化:在 Prompt Tuning 和 P - tuning 中,连续提示只被插入 transformer 第一层的输入 embedding 序列中。在后续 transformer 层中,插入连续提示位置的 embedding 由之前的 transformer 层计算得出,这可能导致两个优化挑战:一是由于序列长度限制,可调参数数量有限;二是输入 embedding 对模型预测只有相对间接的影响。
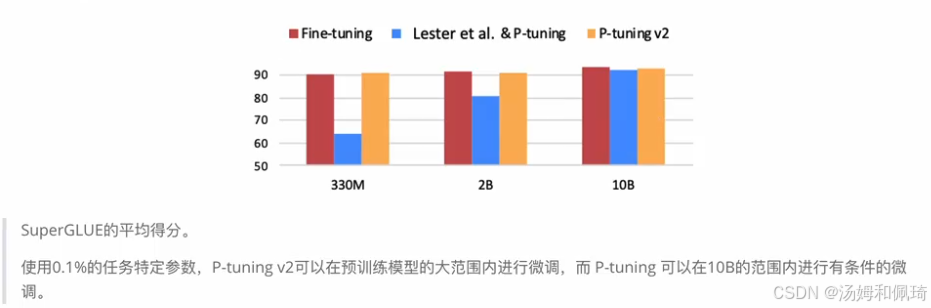
- 技术原理:源于论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》 ,P - Tuning v2 对 Prompt Tuning 和 P - Tuning 进行改进,作为跨规模和 NLU 任务的通用解决方案。该方法在每一层都加入了 Prompts tokens 作为输入,而非仅仅加在输入层,带来两方面好处:一是增加了更多可学习的参数(从 P - tuning 和 Prompt Tuning 的 0.01% 增加到 0.1% - 3% );二是加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。配有示意图展示从 P - tuning 到 P - tuning v2 的变化,其中橙色块(即(h_0)、… 、(h_j) )表示可训练的 prompt embeddings,蓝色块是有冻结的预训练语言模型存储或计算的 embeddings。还通过图表展示在不同模型规模(330M、2B、10B )下,Fine - tuning、Lester et al. & P - tuning、P - tuning v2 在 SuperGLUE 的平均得分对比,表明 P - Tuning v2 在不同规模模型和多种任务中表现优异,是一种在不同规模和任务中都可与微调相媲美的提示方法,尤其在序列标注等困难的序列任务上大幅超过 Prompt Tuning 和 P - Tuning。
5 总结
对 Prefix 类微调方法进行总结:
- Prefix Tuning:在每一个 Transformer 层都带上一些 virtual token 作为前缀,以适应不同的任务;通过优化多层 prefix,效果可与 fine - tuning 比肩。
- Prompt Tuning:该方法可看作是 Prefix Tuning 的简化版本,针对不同的任务,仅在输入层引入 virtual token 形式的软提示(soft prompt);主要优化单层 prefix,在大尺寸模型下效果与 fine - tuning 相当。
- P - Tuning:将 Prompt 转换为可以学习的 Embedding 层;相比 Prefix Tuning,仅在输入层加入可微的 virtual token,且 virtual token 的位置不一定是前缀,插入位置可选;通过优化单层 prefix,在大尺寸模型下与 fine - tuning 效果相当。
- P - Tuning v2:在每一个 Transformer 层都加入了 prompt token 作为输入,引入多任务学习,针对不同任务采用不同的提示长度;通过优化多层 prefix,在小尺寸和大尺寸模型中均能达到与 fine - tuning 相当的效果。
LoRA 篇
a. 什么是 LoRA?
- LoRA,英文全称为 Low - Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应 ,是微软的研究人员为了解决大语言模型微调问题而开发的一项技术。其核心是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
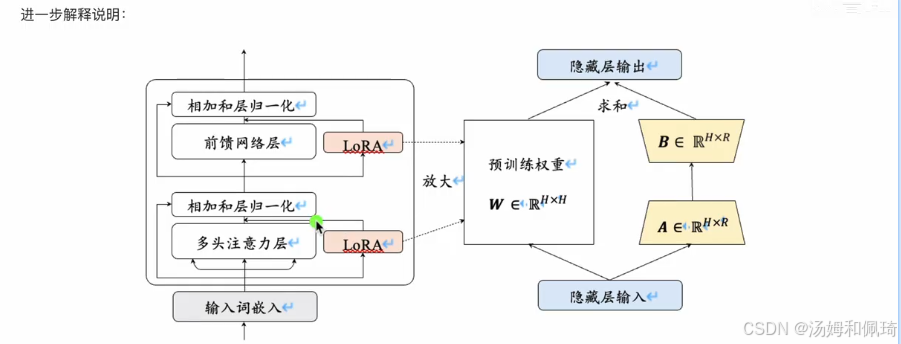
- 配有一张示意图(Figure 1: Our reparametrization. We only train A and B. ) ,图中展示了预训练权重(Pretrained Weights, ( W ∈ R d × d (W \in \mathbb{R}^{d \times d} (W∈Rd×d) ) ,以及两个矩阵A( A = N ( 0 , σ 2 ) A = \mathcal{N}(0, \sigma^{2}) A=N(0,σ2),即 A A A服从均值为0,方差为 σ 2 \sigma^{2} σ2的正态分布 )和B((B = 0) ,初始化为零矩阵 ) 。输入 x x x经过预训练权重和这两个矩阵的运算得到隐藏层输出 h h h ,且仅训练 A A A和 B B B两个矩阵。
- 进一步解释说明中提到,在 Transformer 架构里,LoRA 应用于前馈网络层和多头注意力层。此前研究发现,模型在针对特定任务进行调整时,参数矩阵往往是过参数化(Over - parametrized)的,存在冗余。为解决这一问题,LoRA 提出在预测的参数矩阵上添加低秩分解矩阵来近似每层参数更新,进而减少下游所需训练的参数。
- 给定一个参数矩阵W ,其更新过程用以下公式表示: W = W 0 + Δ W W = W_0+\Delta W W=W0+ΔW ,其中 W 0 W_0 W0是原始参数矩阵, Δ W \Delta W ΔW是更新的梯度矩阵。原始矩阵 W 0 ∈ R H × H W_0 \in \mathbb{R}^{H \times H} W0∈RH×H ,通过低秩分解矩阵 A ∈ R H × R A \in \mathbb{R}^{H \times R} A∈RH×R和 B ∈ R R × H B \in \mathbb{R}^{R \times H} B∈RR×H来近似参数更新矩阵 Δ W = A ⋅ B T \Delta W = A \cdot B^T ΔW=A⋅BT ,这里 R ≪ H R \ll H R≪H ,R是减少后的秩。在微调期间,原始的矩阵参数 W 0 W_0 W0不会被更新,低秩分解矩阵A和B则是可训练参数,用于适配下游任务。在向前传播过程中,原始计算中间状态 h = W 0 ⋅ x h = W_0 \cdot x h=W0⋅x的公式修改为 h = W 0 ⋅ x + A ⋅ B T ⋅ x h = W_0 \cdot x + A \cdot B^T \cdot x h=W0⋅x+A⋅BT⋅x 。在训练完成后,将原始参数矩阵 W 0 W_0 W0和训练得到的权重A和B进行合并,即 W = W 0 + A ⋅ B T W = W_0 + A \cdot B^T W=W0+A⋅BT ,得到更新后的参数矩阵。因此,LoRA 微调得到的模型在解释时不会增加额外开销。
b. LoRA 的思路是什么?
- 旁路增加与低秩分解:在原模型的旁边增加一个额外的路径,这个额外路径被称为旁路,通过使用两个低秩矩阵分解来近似更新量。具体来说,首先将输入通过一个降维矩阵A ,然后通过一个升维矩阵B进行还原。这样的操作使得我们能够用更小的参数更新来捕捉必要的信息,从而减少计算开销。
- 训练策略:在微调过程中,原模型的参数保持不变,专注于训练降维和升维矩阵A和B 。这种方式避免了对所有模型参数进行训练,只更新额外的旁路,有效降低了计算复杂度和内存需求。
- 推理阶段整合:在推理时,将训练好的旁路矩阵BA与原模型参数进行相加,从而无需改变原有计算图,这种设计不会增加额外的实时计算开销。
- 初始化策略:降维矩阵A采用高斯分布(正态分布)来初始化,以赋予其随机特性;而升维矩阵B初始化为零矩阵,这样在开始训练时不会影响原有模型的输出,确保训练稳定性。
- 可插拔的任务切换:通过不同的A和B配置,可快速适应新的任务情境。当前任务可表示为 W 0 + B 1 A 1 W_0 + B_1A_1 W0+B1A1 ,只需移除或替换旁路中 LoRA 的部分(例如使用 B 2 A 2 B_2A_2 B2A2 )即可切换任务,实现快速的模型适应。
c. LoRA 的特点是什么?
- 将B、A加到W上可以消除推理延迟。
- 可以通过可插拔的形式切换到不同的任务。
- 设计得比较好,简单且效果好。
d. 一句话描述一下 LoRA
- LoRA 的实现思想很简单:就是冻结一个预训练模型的矩阵参数,并选择用A和B矩阵来替代,在下游任务时只更新A和B矩阵。
其他 LoRA 相关常见面试题
a. LORA 应该作用于 Transformer 的哪个参数矩阵(Q、K、V)?
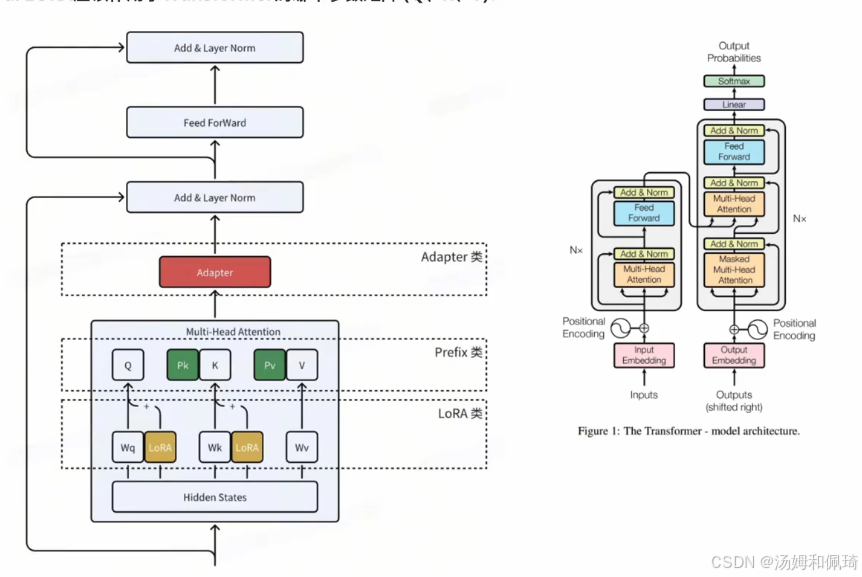
-
配有一张 Transformer 模型架构图,展示了 LoRA 类在 Transformer 架构中的作用位置。在多头注意力机制部分,涉及到用于生成查询向量的权重矩阵 W q W_q Wq、生成键向量的权重矩阵 W k W_k Wk、生成值向量的权重矩阵 W v W_v Wv ,此外还有用于将多头注意力的输出组合起来的输出投影权重矩阵 W o W_o Wo ,并将 LoRA 类与 Adapter 类、Prefix 类的位置进行了对比。
-
一张表格展示了在对 GPT - 3 的不同注意力权重应用 LoRA 后,在 WikiSQL 和 MultiNLI 数据集上的验证准确率。表格上方标注了可训练参数为 18M ,表格中不同权重类型( W q W_q Wq、 W k W_k Wk、 W v W_v Wv、 W o W_o Wo 以及它们的不同组合 )在不同秩(rank )下,在两个数据集上的验证准确率表现。例如, W q W_q Wq在秩为 8 时,WikiSQL 数据集上的准确率为 70.4% ,MultiNLI 数据集上的准确率为 91.0% 。研究发现,调整 W q W_q Wq和 W v W_v Wv一起提供了最佳的整体性能。需要注意的是,仅调整 Δ W q \Delta W_q ΔWq或 Δ W k \Delta W_k ΔWk会导致性能显著下降,而同时调整 W q W_q Wq和 W v W_v Wv则能得到不错的结果。这说明即使秩设为 4 , Δ W \Delta W ΔW中也能捕获足够的信息,因此比起只调整单一类型的大秩权重,调整更多种类的权重矩阵效果更好。
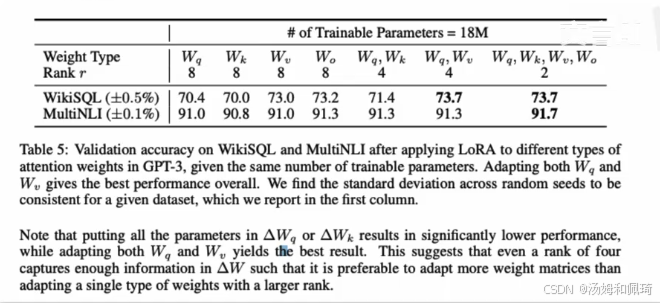
- 什么是 rank(秩)
- 在机器学习中,rank通常指矩阵的秩,它表示矩阵中线性独立行或列的数量。在 LoRA 方法中,rank用于限制可训练参数的数量,通过低秩表示来高效调整模型。
- 举例说明:假设你有一个大的权重矩阵W ,如果W的秩是 8 ,这意味着你能用 8 个线性独立的向量来表示这个矩阵,全部训练这样的矩阵会涉及许多参数;而如果使用秩为 4 的近似表示,你可以用 4 个向量来近似描述这个矩阵,这大大减少了需要训练的参数数量。通过降低秩,减少了参数空间的自由度,使得模型在训练时更加高效,而不会显著影响性能,这也是 LoRA 在权重矩阵上使用低秩表示的核心思想。表格中提到的rank为 8 或 4 时,表示的是对原始大的权重矩阵进行近似表示时所用的线性独立向量的数量,从而调整可训练参数数量。
- 对 WikiSQL 和 MultiNLI 两个数据集进行介绍:
- WikiSQL:这是一个用于自然语言处理(NLP)的数据集,专注于结构化查询语言(SQL)生成任务。具体来说,它提供了自然语言问题和相应 SQL 查询的对照,用于训练和评估能将自然语言转换为 SQL 查询的模型。
- MultiNLI(Multi - Genre Natural Language Inference):这是一个用于自然语言推理的广泛数据集,包含不同体裁的文本对。任务是判断一个给定前提和假设之间的关系,比如判断是蕴含、矛盾还是中立关系,用于评估模型在跨领域推理任务中的表现。
- 对表格结果分析
- 对表格中涉及的权重矩阵进行解释:
- 对表格中涉及的权重矩阵进行解释:
- W q W_q Wq:用于生成查询向量的权重矩阵。
- W k W_k Wk:用于生成键向量的权重矩阵。
- W v W_v Wv:用于生成值向量的权重矩阵。
- W o W_o Wo:用于将多头注意力的输出组合起来的输出投影权重矩阵。
- 对表格描述内容进行翻译:表 5 展示了在对 GPT - 3 的不同注意力权重应用 LoRA 后,在 WikiSQL 和 MultiNLI 数据集上的验证准确率,这里使用的是相同数量的可训练参数。调整 W q W_q Wq和 W v W_v Wv一起提供了最佳的整体性能。需要注意的是,仅调整 Δ W q \Delta W_q ΔWq或 Δ W k \Delta W_k ΔWk会导致性能显著下降,而同时调整 W q W_q Wq和 W v W_v Wv则能得到不错的结果。这说明即使秩设为 4 , Δ W \Delta W ΔW中也能捕获足够的信息,因此比起只调整单一类型的大秩权重,调整更多种类的权重矩阵效果更好。
- 从上表得出的结论:
- 将所有微调参数都放到 attention 的某一个参数矩阵的效果并不好,将可微调参数分配到 W q W_q Wq和 W v W_v Wv的效果更好。
- 即使是秩仅取 4 也能在 Δ W \Delta W ΔW中获得足够的信息。
- 因此在实际操作中,应当将可微调参数分配到多种类型权重矩阵中,而不应该用更大的秩单独微调某种类型的权重矩阵。
- 对表格中涉及的权重矩阵进行解释:
- 对表格中涉及的权重矩阵进行解释:
b. 如何在已有 LoRA 模型上继续训练?
主要探讨当已有的 LoRA 模型仅训练了一部分数据,而需要训练另一部分数据时的不同处理方式:
-
直接在现有的 LoRA 模型上继续训练
- 适用情况:当新的训练数据与之前用于训练 LoRA 模型的数据在特征、分布等方面较为相似,并且新任务与旧任务的性质、目标等也相近时适用。例如,之前用 LoRA 模型训练了一批新闻文本的情感分析任务,新数据依然是新闻文本的情感分析任务,且文本风格、主题等类似。
- 操作步骤:直接将新的数据用于继续训练现有的 LoRA 模型。在训练过程中,模型会基于已有的权重,结合新数据进一步更新权重,从而融合新的知识。
- 优点:这种方式能够保留模型在之前训练中所学到的知识,避免了重新训练带来的资源浪费,大大节省了训练时间和计算资源。比如在上述新闻文本情感分析任务中,模型之前学到的情感词特征等知识可以继续发挥作用。
- 注意事项:由于模型持续在新数据上训练,可能会出现过拟合的问题,尤其是当新数据存在一些特殊的噪声或偏差时。为避免过拟合,可以适当使用正则化技术,如 L1 或 L2 正则化。同时,如果新的数据分布与之前有明显差异,可能需要调整学习率或其他超参数,以确保模型能够更好地适应新数据。
-
将 LoRA 与基础模型合并后,再训练新的 LoRA
- 适用情况:当希望在模型中稳固之前学习到的知识,同时又要在一个与之前有一定关联但又不完全相同的新任务上进行进一步微调时适用。例如,之前用 LoRA 在基础模型上针对医疗文本的命名实体识别任务进行了训练,现在要进行医疗文本的关系抽取任务,这两个任务都与医疗文本相关,但具体目标不同。
- 操作步骤:首先,将现有的 LoRA 权重合并到基础模型中,得到一个融合了之前学习成果的新基础模型。然后,在这个新的基础模型上,使用新的数据训练新的 LoRA 层。
- 优点:通过将原来的知识固化到基础模型中,新的 LoRA 层可以专注于学习新任务的独特特征。这种方式有助于模块化地管理不同任务的适应,使得模型在不同任务上的学习和应用更加清晰和有条理。
- 缺点:由于将 LoRA 权重合并到基础模型以及再训练新的 LoRA 层,模型的整体大小可能会增加,从而占用更多的存储空间。
-
从头开始训练一个新的 LoRA 模型
- 适用情况:当新的任务与之前的任务在性质、领域等方面完全不同,或者担心之前学习到的知识会对新任务的学习产生干扰时适用。例如,之前使用 LoRA 模型进行图像描述生成任务,现在要进行金融市场趋势预测任务,这两个任务属于完全不同的领域。
- 操作步骤:直接使用基础模型,在新的数据上重新训练一个全新的 LoRA 模型,不依赖之前 LoRA 模型的权重。
- 优点:这种方式可以完全避免旧知识对新任务的干扰,使模型能够更加专注于新任务的特征学习。模型可以根据新任务的数据和目标,自由地学习和调整参数。
- 缺点:由于没有利用之前训练中获得的知识,可能需要更多的训练数据和时间来达到较好的性能。而且,如果存在一些公共的知识或特征可以在不同任务间共享,这种方式就会浪费这些潜在的资源。
-
总结:根据任务需求选择
- 任务相似时:建议直接在现有的 LoRA 模型上继续训练。这样可以保留并强化之前学习到的知识,使模型在新数据上能够基于已有经验更好地表现。在操作时,为了防止模型遗忘之前学习的内容,需要在新的训练过程中,适当混合之前的一些数据,让模型不断回顾和巩固旧知识。
- 任务不同但有相关性时:建议考虑合并 LoRA 与基础模型,然后训练新的 LoRA。因为基础模型可以固化之前的知识,而新的 LoRA 层能够专注于学习新任务的特征,这种方式有利于知识的模块化管理,提高模型在不同但相关任务上的适应性。
- 任务完全不同时:建议从头开始训练一个新的 LoRA 模型。这可以避免旧任务的知识对新任务学习的干扰,使模型能够更加纯粹地专注于新任务的特征提取和学习。
c. LoRA 权重是否可以合入原模型?
明确指出 LoRA 权重是可以合入原模型的。具体的操作方式是将训练好的低秩矩阵( B ∗ A B * A B∗A)与原模型的权重进行合并(相加),通过这种方式计算出新的权重,从而实现 LoRA 权重与原模型的融合。
d. LoRA 微调方法为啥能加速训练?
详细分析了 LoRA 微调方法能够加速训练的原因:
- 只更新了部分参数:LoRA 方法的核心在于只更新部分参数。例如在原论文中就选择只更新 Self Attention 的参数,在实际使用过程中,还可以根据具体需求灵活选择只更新部分层的参数。这种选择性更新参数的方式,大大减少了需要训练和调整的参数数量,从而降低了训练的复杂度和计算量。
- 减少了通信时间:由于 LoRA 更新的参数量大幅减少,在多卡训练的场景下,需要在不同计算卡之间传输的数据量也相应变少。数据传输量的降低直接减少了通信时间,使得训练过程中数据传输不再成为瓶颈,从而加速了整体训练速度。
- 采用了各种低精度加速技术:LoRA 微调采用了如 FP16、FP8 或者 INT8 量化等低精度加速技术。这些技术通过降低数据的精度表示,在一定程度上减少了计算量和内存占用,从而加快了计算速度,提升了训练效率。
不过,需要指出的是,这三方面加速训练的原因并非 LoRA 所独有的特性,事实上,几乎所有的参数高效微调方法都具备这些特点。但 LoRA 仍有其独特的优势:
- 低秩分解的直观性:LoRA 使用低秩分解的方式来更新和表示参数。这种方式在很多场景中能够很好地保持与全量微调相同的效果,同时其原理和操作非常直观,易于理解和实现。
- 预测阶段不增加推理成本:LoRA 的设计确保了在推理阶段不会增加额外的计算成本。因为微调的调整是通过低秩矩阵的形式添加的,并且在应用时已经被整合到模型参数中,不需要额外的运算,这有利于保持推理速度,使得模型在实际应用中能够高效运行。
e. Rank 如何选取?
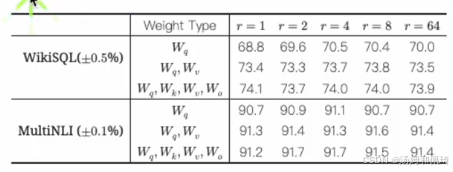
关于 LoRA 中 Rank 的取值,作者通过对比 1 - 64 不同的取值进行实验。实验结果表明,在效果上 Rank 在 4 - 8 之间表现最好,当 Rank 取值再高时,并没有带来效果的进一步提升。不过需要注意的是,论文中的实验是面向下游单一监督任务进行的。因此,在指令微调场景下,由于指令分布的广度等因素的影响,Rank 的选择还需要在 8 以上的取值进行进一步测试,以确定最适合的 Rank 值。同时,通过表格展示了不同权重类型( W q W_q Wq、 W q W v W_qW_v WqWv 、 W q W k W v W o W_qW_kW_vW_o WqWkWvWo )在不同 Rank 值( r = 1 r = 1 r=1、 r = 2 r = 2 r=2 、 r = 4 r = 4 r=4 、 r = 8 r = 8 r=8 、 r = 64 r = 64 r=64 )下,在 WikiSQL 和 MultiNLI 数据集上的实验结果,直观地反映了不同 Rank 取值对模型性能的影响。
f. LoRA 高效微调 如何避免过拟合?
过拟合是在使用 LoRA 进行微调时常见的问题,指的是模型在训练数据上表现良好,但在未见过的数据上表现不佳。这通常是因为模型过度学习了训练数据的细节和噪声,而未能抓住数据的普遍规律。针对这一问题,提出了以下避免过拟合的方法:
-
如何避免过拟合
- 减小 r(秩)值:在 LoRA 中,低秩矩阵的秩(即 r 值)决定了新增参数的数量。较大的 r 值意味着更多的参数,会使模型的容量增大,从而可能导致过拟合现象的发生。通过减小 r 值,可以减少模型需要学习的参数数量,进而降低模型的复杂度,使其不易过度拟合训练数据中的噪声。
- 增加数据集大小:更多的训练数据可以提供更全面的样本分布,使模型能够学习到更一般化的特征,而不是仅仅记住训练数据中的特殊情况。增加数据集大小可以让模型在更广泛的数据上进行训练,减少因数据不足导致的过拟合风险。
- 增加优化器的权重衰减率(weight decay):权重衰减是一种正则化方法,它通过在损失函数中添加权重的 L2 正则化项,来防止模型参数过大。增加权重衰减率可以限制模型参数的大小,避免参数过度增长导致过拟合,鼓励模型学习到更简单的参数配置。
- 增加 LoRA 层的 dropout 值:Dropout 是一种防止过拟合的技术,它通过在训练过程中随机忽略部分神经元,使模型不依赖于特定的神经元。在 LoRA 层增加 dropout,可以随机屏蔽部分 LoRA 层的参数,使模型更具鲁棒性,减少对特定参数的过度依赖,从而降低过拟合的风险。
-
总结
为了在使用 LoRA 进行高效微调时避免过拟合,可以从以下几个方面入手:
- 模型复杂度:通过减小 r 值,降低模型的复杂度,使其不易出现过拟合现象。
- 数据丰富度:增加训练数据的数量和多样性,提供更全面的学习素材,让模型能够学习到更通用的特征。
- 正则化技术:使用权重衰减和 dropout 等正则化方法,防止模型参数过大或对特定神经元产生过度依赖。这些方法可以单独使用,也可以结合使用,以达到最佳的防止过拟合的效果。
g. LoRA 矩阵初始化相关问题
前面已经了解到在 LoRA 矩阵初始化中:降维矩阵A采用高斯分布(正态分布)来初始化,以赋予其随机特性;升维矩阵B初始化为零矩阵,这样在开始训练时不会影响原有模型的输出,确保训练稳定性。权重更新公式为 W = W 0 + A ⋅ B T W = W_0 + A \cdot B^T W=W0+A⋅BT 。基于上述内容,进一步探讨以下问题:
-
为什么不将 A 和 B 都初始化为 0?
如果同时将A和B都初始化为零,那么权重更新 Δ W = A B T = 0 \Delta W = AB^T = 0 ΔW=ABT=0 这就意味着在训练开始时,模型的参数不会发生任何变化,会带来以下缺点:
- 可能出现梯度消失和对称性问题:所有神经元的初始状态和更新方向都相同,这会导致网络无法打破对称性。在这种情况下,神经元无法学习到多样化的特征,从而影响模型的表达能力,使其难以对复杂的数据模式进行有效建模。
- 训练困难:由于缺乏初始扰动,梯度更新可能会过于缓慢,导致训练过程的收敛速度变慢,甚至可能出现无法收敛的情况,使得模型难以达到理想的性能。
-
为什么不将 A 和 B 都使用高斯初始化?
如果同时将 A 和 B 都使用高斯随机初始化,此时初始的权重更新为 Δ W = A B T \Delta W = AB^T ΔW=ABT 。由于 A 和 B 都是随机初始化的,所以 Δ W \Delta W ΔW 也将是一个随机矩阵,并且这个随机矩阵可能具有较大的值。
- 初始扰动过大:过大的 Δ W \Delta W ΔW会在训练开始时对原有的预训练模型参数造成过大的扰动。这可能导致模型的输出偏离预期,进而使得训练不稳定。例如,预训练模型在之前学习到的合理参数分布,会因为这种过大的扰动而被打乱,无法基于之前的知识正常地进行新任务的学习,使得模型在训练初期难以朝着正确的方向调整参数。
- 收敛困难:过大的初始噪声(即由随机初始化带来的较大波动 )可能导致梯度爆炸问题。当梯度爆炸发生时,模型在参数更新过程中,梯度会变得过大,使得参数更新失去控制,难以找到正确的优化方向,从而严重影响训练效果,导致模型无法有效收敛到最优解,甚至可能使训练过程无法继续进行。
-
- 是否可以把 A 初始化为零矩阵,B 初始化为高斯分布(正态分布)?
在理论上,LoRA 的矩阵初始化方式是可以对调的。因为 LoRA 的核心思想是通过低秩分解来更新预训练权重矩阵 W 0 W_0 W0,最终训练的效果取决于模型对 Δ W = A B T \Delta W = AB^T ΔW=ABT 的学习能力,而不是特定的初始化方式。然而,对调初始化可能会产生以下影响:
- 优化过程:将B初始化为随机高斯分布,而A初始化为零,并不会改变预训练权重的初始状态。但在优化过程中,梯度对B和A的学习方向的影响可能会略有不同,这可能会影响模型的训练效率和最终性能。
- 数值稳定性:论文中推荐的初始化方式可能经过了大量的实验验证,确保了在实际应用中具有较好的数值稳定性。如果对调初始化,可能需要重新调试超参数(如学习率),以保证模型在训练过程中的数值稳定性,避免出现诸如梯度爆炸或消失等问题。
-
- 总结
通过将矩阵 A A A用高斯分布随机初始化,矩阵 B B B初始化为零,具有以下优点:
- 可以保持模型初始输出与预训练模型一致,避免初始扰动过大,使得模型在训练初期能够平稳地进行参数更新。
- 利用A的随机性打破对称性,为模型提供丰富的梯度信息,有助于神经元学习到多样化的特征,提升模型的表达能力。
- 在训练过程中,B从零开始逐步学习,能够有效控制权重更新的幅度,促进模型稳定收敛,提高训练的效率和效果。
相关文章:
模型微调专题(中))
LLMs基础学习(五)模型微调专题(中)
文章目录 LLMs基础学习(五)模型微调专题(中)Adapter 类的微调1 背景2 技术原理3 具体细节4 Adapter 类其他方法的微调 Prefix 类的微调1 Prefix Tuning2 Prompt Tuning3 P - tuning4 P - Tuning v25 总结 LoRA 篇a. 什么是 LoRA?…...

不同路由器网段之间的组建
实现PC1到PC7之间的通信 先将基础的ip都配置好 在AR6中将跳板配置好,ip route-static 192.168.5.0 24 64.1.1.2 在AR3中将跳板配置好,ip route-static 192.168.1.0 24 64.1.1.1 如此我们将可以实现通信了 还有第二种,实现PC1到…...

java设计模式-建造者模式
建造者模式(build) 建造者模式的四个角色 1、Product(产品角色): 一个具体的产品对象。 2、Builder(抽象建造者): 创建一个Product对象的各个部件指定的 接口或者抽象类。 3、ConcreteBuild(具体建造者):实现接口,构建和装配各个部…...

【泛函分析】
E.Kreyszig, Introductory functional analysis with applications, Wiley, 1989 1.1 Metric space 满足下面四个性质的映射称为度量:正定、0、对称性和三角不等式 推论:广义的三角不等式 度量可以看成一个映射,验证欧式距离&am…...

【NLP 面经 6】
当上帝赐予你荒野时,就意味着,他要你成为高飞的鹰 —— 25.4.3 一、机器翻译任务,Transformer结构模型改进 在自然语言处理的机器翻译任务中,你采用基于 Transformer 架构的模型。在翻译一些具有丰富文化内涵、习语或隐喻的句子时…...

地质科研智能革命:当大语言模型“扎根”地质现场、大语言模型本地化部署与AI智能体协同创新实践
在地质学迈向“深时数字地球”(Deep-time Digital Earth)的进程中,传统研究方法正面临海量异构数据(地质图件、遥感影像、地震波谱等)的解析挑战。大语言模型(LLM)与AI智能体的本地化部署技术&a…...
)
蓝桥王国(Dijkstra优先队列)
问题描述 小明是蓝桥王国的王子,今天是他登基之日。 在即将成为国王之前,老国王给他出了道题,他想要考验小明是否有能力管理国家。 题目的内容如下: 蓝桥王国一共有 N 个建筑和 M 条单向道路,每条道路都连接着两个…...

美团mtgsig1.1 分析 mtgsig
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 mtgsig有问题的请求3次左右…...

基于STM32、HAL库的CH224Q快充协议芯片简介及驱动程序设计
一、简介: CH224Q是一款USB Type-C快充协议芯片,支持多种快充协议,包括: USB PD 3.0 QC4 QC3.0/2.0 AFC FCP SCP APPLE 2.4A BC1.2 该芯片通过I2C接口与主控MCU通信,可以灵活配置输出电压和获取充电状态信息…...
—— 浅层路由和 Packaging)
SvelteKit 最新中文文档教程(18)—— 浅层路由和 Packaging
前言 Svelte,一个语法简洁、入门容易,面向未来的前端框架。 从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 6 年一直是开发者最感兴趣的前端框架 No.1: Svelte …...

蓝桥杯-数字诗意
问题描述 在诗人的眼中,数字是生活的韵律,也是诗意的表达。 小蓝,当代顶级诗人与数学家,被赋予了"数学诗人"的美誉。他擅长将冰冷的数字与抽象的诗意相融合,并用优雅的文字将数学之美展现于纸上。 某日&a…...

深入探索 Node.js 文件监听机制:从前端工程化到原理剖析
在现代化前端开发中,文件监听(File Watching)是实现高效开发体验的核心技术之一。从 webpack 的热模块替换到 Vite 的即时刷新,从 CSS 预处理到静态资源打包,背后都依赖于稳健的文件监听机制。本文将深入探讨基于 Node…...

2025 年河北交安安全员考试:巧用行业报告丰富知识储备
河北交通行业发展迅速,各类行业报告蕴含大量有价值信息。考生可从河北省交通运输行业发展报告、安全专项检查报告等资料入手。在行业发展报告中,了解本省交通建设规模、重点项目规划等内容,这些信息与交安安全员工作紧密相关。比如࿰…...

Java9新特性
新的Jshell Java9引入了交互式编程工具jshell,可用于快速测试和学习Java。 特性 该工具可用于快速测试代码片段,无需创建java文件。支持自动补全和历史命令支持保存和加载会话 不可变集合工厂方法 Java9新增了List.of()、Set.of()、Map.of()和Map.o…...
?)
CS内网渗透 - 如何通过冰蝎 Webshell 上线 Weblogic 服务器到 Cobalt Strike 并绕过杀软检测(360、火绒)?
目录 1. 冰蝎连接上 Weblogic 服务器如何上线到 Cobalt Strike 2. 服务器安装杀毒工具如何绕过杀软上线到 Cobalt Strike 2.1 杀软对 Webshell 命令执行的检测及绕过 2.2 杀软对 Cobalt Strike 上线木马的检测及绕过 2.3 杀软对这两方面的限制及综合绕过 3. 如何生成免杀…...

Linux开发过程中常用命令整理
docker ps -a查看所有(包括已经停止的) systemctl 功能:控制系统服务的启动关闭等 语法:systemctl start | stop | restart | disable | enable | status 服务名 start,启动stop,停止status,查看状态disable…...

触想工业一体机助力打造安全智能的数字化配电系统
一、项目开发背景 现代社会运行依赖稳定的电力供应,尤其在工业生产、城市基础设施、商业建筑等关键领域,即便是0.1秒的电力中断也可能导致严重后果。同时,随着全球用电负荷加剧及能源结构转型,对电力系统的运维效率、能源利用和数…...

从代码学习深度学习 - 序列到序列学习 GRU编解码器 PyTorch 版
文章目录 前言一、数据加载与预处理1.1 读取数据1.2 预处理数据1.3 词元化1.4 词频统计1.5 构建词汇表1.6 截断与填充1.7 转换为张量1.8 创建数据迭代器1.9 整合数据加载二、训练辅助工具2.1 时间记录器2.2 累加器2.3 准确率计算2.4 GPU 上的准确率评估2.5 GPU 设备选择2.6 梯度…...

华为AI-agent新作:使用自然语言生成工作流
论文标题 WorkTeam: Constructing Workflows from Natural Language with Multi-Agents 论文地址 https://arxiv.org/pdf/2503.22473 作者背景 华为,北京大学 动机 当下AI-agent产品百花齐放,尽管有ReAct、MCP等框架帮助大模型调用工具࿰…...
基于PyTorch 实现一个基于 Transformer 架构的字符级语言模型
这篇教程将带你一步步在 JupyterLab 中实现一个简单的语言模型。我们将从零开始,使用 PyTorch 实现一个基于 Transformer 架构的字符级语言模型。尽管在实际应用中,大多数人更倾向于使用 Hugging Face 的预训练模型,但本文的目的是让你了解语…...

苹果签名的工具有哪些
嗯,用户问的是关于苹果企业签名的工具有哪些。首先,我需要确认用户的需求。苹果企业签名通常指的是使用苹果的企业开发者账号(Apple Developer Enterprise Program)来对应用进行签名,这样应用可以不通过App Store直接分…...

解决.net接口防暴力调用问题
在 .NET 中,为解决接口防暴力调用问题,可通过限制请求频率实现。下面给出几种不同实现方式。 基于内存的简单速率限制 此方法适用于单服务器环境,它借助内存字典来记录每个客户端的请求次数和时间。 MemoryRateLimitMiddleware.cs using …...

java设计模式-桥接模式
桥接模式(Bridge) 基本介绍 1、桥接模式(Bridge)是指:将实现与抽象放在两个不同的类层次中,是两个层次可以独立改变。 2、是一种结构设计模 3、Bridge模式给予类的最小单元设计原则,通过使用封装,聚合及继承等行为让不同的类承担不…...

cdw2: TypeScript
一、javascript的问题 二、初识typescript https://mp.weixin.qq.com/s/wnL1l-ERjTDykWM76l4Ajw 三、类型 二进制:ob开头,八进制:0o开头,十六进制:0x开头 开发中不这样写 这样写 匿名函数的参数最好不要…...

Linux驱动开发:SPI驱动开发原理
前言 本文章是根据韦东山老师的教学视频整理的学习笔记https://video.100ask.net/page/1712503 SPI 通信协议采用同步全双工传输机制,拓扑架构支持一主多从连接模式,这种模式在实际应用场景中颇为高效。其有效传输距离大致为 10m ,传输速率…...

Java 通过 JNI 调用 C++ 动态库的完整流程
介绍使用 JNI 调用 C 编写的动态链接库的全过程。 示例环境 项目说明JDK8C 编译器Visual Studio 2019Java 开发工具IntelliJ IDEA 2021.3操作系统Windows 10 Java 项目结构概览 编写 Java 类 在 org.jni.nativejni 包下创建类 HelloWorldJni.java: package org…...

oracle 11g密码长度和复杂度查看与设置
一 查看当前的密码复杂度设置 SELECT * FROM dba_profiles WHERE resource_name PASSWORD_VERIFY_FUNCTION; LIMIT表示分配给该 PROFILE 的密码验证函数名称。如果为 NULL,表示未设置密码验证函数。 #查看是否有相关密码验证函数 select object_name from dba…...

1021 Deepest Root
1021 Deepest Root 分数 25 全屏浏览 切换布局 作者 CHEN, Yue 单位 浙江大学 A graph which is connected and acyclic can be considered a tree. The height of the tree depends on the selected root. Now you are supposed to find the root that results in a highest…...

1. 三带一
所谓“三带一”牌型,即四张手牌中,有三张牌一样,另外一张不与其他牌相同,换种说法,四张手牌经过重新排列后,可以组成 AAABAAAB 型。 输入格式 第一行输入一个整数 TT ,代表斗地主的轮数。 接…...

pytorch计算图Computation_graph是什么
文章目录 一、AI系统中的计算图(宏观)二、动态计算图(微观)2.1 张量计算图2.2 计算图的定义2.3 节点类型2.4 计算图的动态性2.5 计算图的正向传播是立即执行的2.6 计算图在反向传播后立即销毁2.7 计算图中的Function2.8 计算图与反…...

HTML5元素
HTML5的<section>元素和<article>元素 <section>元素定义文档中的一部分,着重于对页面内容进行分块或者分段,通常可以分为引言、内容和联系人信息等几个部分。 <section><h1>WWF</h1><p>WWF 是世界自然基金…...

单reactor实战
前言:reactor作为一种高性能的范式,值得我们学习 本次目标 实现一个基于的reactor 具备echo功能的服务器 核心组件 Reactor本身是靠一个事件驱动的框架,无疑引出一个类似于moduo的"EventLoop "以及boost.asio中的context而言,不断…...

【C#知识点详解】LinkedList<T>储存结构详解
今天来介绍一下LinkedList<T>的内部结构,说不多说直接开始。 内部数据 LinkedList是一个双向链表结构的容器,其内部为非连续的内存空间。LinkedList包含的主要成员示例如下: //起始LinkedListNode节点 internal LinkedListNode<T&g…...

智能穿梭车在快消行业的融合升级:效率革命与数据智能的双重赋能
快消品牌(FMCG)的核心挑战在于高频周转、海量SKU、短时效性,而智能穿梭车的技术进化(如AI调度、5G通信、柔性载具)与快消行业的业务需求(如全渠道订单履约、动态库存优化)深度结合,正…...
链表结构)
(二)链表结构
备注:根据coderwhy数据结构与算法课程进行笔记总结 1.数组缺点: 数组创建通常需要申请一段连续的内存空间,且大小固定,因此当前数组不能满足容量需求时,就需要扩容。在数组开头或中间位置插入数据成本很高࿰…...

oracle json笔记
文章目录 json_valuejson_value示例json_value on error如何使用 TODO json_queryjson_query示例 json_tablejson_table 示例 json_existsjson_exists示例json_exists报错 ORA-40458: 在谓词外部使用了 JSON_EXISTS json_objectjson_arrayjson_mergepatchjson_objectaggjson_ar…...

c编译和c++编译有什么区别?
文章目录 c编译和c编译有什么区别多态函数重载虚函数表 vtable 输入输出同步类型检查模板和特化链接 C 标准库 C 能编译 C 的代码吗? c编译和c编译有什么区别 多态 函数重载 C 支持多个同名函数(参数不同),这是编译期多态 编译…...

【Mysql】主从复制和读写分离
一、定义 1、什么是读写分离? 在主库master上负责处理事务性写入操作,在从库slave上负责处理查询操作,并通过主从复制将主库上的数据同步给从库。 2、为什么要读写分离? 从集中到分布,最基本的一个需求不是数据存储的…...

泛目录排名——深入理解与优化 SEO:提升网站可见性的关键策略
https://www.zhanqun.xin/ 在数字化时代,互联网上的信息呈爆炸式增长。对于企业和网站运营者而言,如何让自己的网站在海量的网络内容中脱颖而出,吸引目标受众的关注,成为了一项至关重要的挑战。搜索引擎优化(SEO&#…...

汇丰eee2
聚合和继承有什么样的优点和区别,什么时候决定用,现实开发中,选择哪一种去使用? 聚合的优点: 灵活性: 聚合是一种弱耦合关系,被聚合对象可以独立存在,可以灵活地替换或修改被聚合对…...
)
C#网络编程(Socket编程)
文章目录 0、写在前面的话1、Socket 介绍1.1 Socket是什么1.2 Socket在网络中的位置 2、C# 中的Socket参数2.1 超时控制参数2.2 缓冲区参数2.3 UDP专用参数 3、C# 中的Socket API3.1 Socket(构造函数)3.1.1 SocketType3.1.2 ProtocolType3.1.3 AddressFa…...

使用Python的Schedule库实现定时任务,并传递参数给任务函数
哈喽,大家好,我是木头左! 本文将详细介绍如何使用schedule库来创建定时任务,并展示如何向任务函数传递参数。 安装Schedule库 需要安装schedule库。你可以使用以下命令通过pip进行安装: pip install schedule基本用法 schedule库的基本用法非常简单。你可以通过调用sch…...

Unity Input 2023 Release-Notes
🌈Input 2023 Release-Notes 版本更新内容2023.2.17Input: Crash on InputDeviceIOCTL when closing Unity editor(UUM-10774)2023.2.16Input: Crash on InputDeviceIOCTL when closing Unity editor(UUM-10774)2023.2.15Input: Crash on InputDeviceIOCTL when clo…...

IP查询能够帮助企业进行数字化转型
企业如今正面临着用户行为碎片化、市场竞争白热化的挑战。那么企业要如何从海量网络数据中精准捕捉用户需求就十分重要了。而IP查询技术也正帮助越来越多的企业在精准营销、风险防控、合规运营等领域开辟新的增长空间。 https://www.ipdatacloud.com/?utm-sourceLMN&utm-…...

Nginx漏洞复现
vulhub起靶场 Nginx 文件名逻辑漏洞(CVE-2013-4547) 上传1.gif,内容为 <?php phpinfo();?> http://your-ip:8080/uploadfiles/1.gif[0x20][0x00].php访问文件位置,这里0x00要改包 先访问/uploadfiles/1.gif a.php&…...
插入排序 希尔排序)
数据结构|排序算法(二)插入排序 希尔排序
一、插入排序 1.算法思想 插入排序(Insertion Sort)是一种简单的排序算法,其基本思想是:将待排序的元素插入到已经有序的序列中,从而逐步构建有序序列。 具体过程如下: 把待排序的数组分为已排序和未排…...

OpenBMC:BmcWeb 处理http请求5 检查权限
OpenBMC:BmcWeb 处理http请求4 处理路由对象-CSDN博客 在通过url获取了路由对象后,如果该请求是有session的,那么下一步需要检查权限 1.validatePrivilege调用时传入了一个lambda(1)做为回调 validatePrivilege(req, asyncResp, rule,[req, asyncResp, &rule, params =…...
的详细步骤)
CentOS 系统磁盘扩容并挂载到根目录(/)的详细步骤
在使用 CentOS 系统时,经常会遇到需要扩展磁盘空间的情况。例如,当虚拟机的磁盘空间不足时,可以通过增加磁盘容量并将其挂载到根目录(/)来解决。以下是一个完整的操作流程,详细介绍了如何将新增的 10G 磁盘…...
)
Axure RP 9 for Mac 交互原型设计 安装教程@[TOC](文章目录)
Axure RP 9 for Mac 交互原型设计 安装教程TOC 一、介绍 Axure RP 9是一款功能强大的原型设计和协作工具。它不仅能够帮助用户快速创建出高质量的原型设计,还能促进团队成员之间的有效协作,从而极大地提高数字产品开发的效率和质量。拥有直观易用的界面…...
暴力娱乐篇19)
每日一题(小白)暴力娱乐篇19
样例: 6 1 1 4 5 1 4 输出: 56 66 52 44 54 64 分析题意可以得知,就是接收一串数字,将数字按照下标每次向右移动一位(末尾循环到第一位),每次移动玩计算一下下标和数字的乘积且累加。 ①接收…...