基于PyTorch 实现一个基于 Transformer 架构的字符级语言模型
这篇教程将带你一步步在 JupyterLab 中实现一个简单的语言模型。我们将从零开始,使用 PyTorch 实现一个基于 Transformer 架构的字符级语言模型。尽管在实际应用中,大多数人更倾向于使用 Hugging Face 的预训练模型,但本文的目的是让你了解语言模型的基本原理和实现步骤。接下来,我们会讲解数据预处理、模型构建、训练过程以及如何利用模型生成文本,每个环节都附有详细的代码和解释,力求让内容通俗易懂。
前言与背景
近年来,基于 Transformer 架构的语言模型(如 GPT 系列)在自然语言处理领域取得了巨大成功。Transformer 模型能够处理长距离依赖问题,在文本生成、机器翻译、对话系统等方面表现出色。然而,这些大规模模型通常需要海量数据和算力进行训练,对于初学者来说直接训练大模型并不现实。因此,本文将带领你通过一个简单的示例,使用字符级数据和小规模模型,体会构建语言模型的基本流程。
在本教程中,我们将使用 Python 和 PyTorch 实现整个流程。虽然我们的示例数据非常有限,但你可以在此基础上扩展数据集和模型复杂度,进一步深入学习语言模型的工作原理。
Transformer核心三要素
1. 自注意力机制:
-
输入向量经过三个不同的线性变换生成Q(查询)、K(键)、V(值)
-
计算查询与键的点积并缩放
-
通过softmax函数进行归一化
-
最后与值向量加权求和得到注意力输出

机器的重点记忆术:想象你在阅读小说时,大脑会自动关注"他举起剑"中的"剑"比"举起"更重要。Transformer的自注意力机制正是模拟这个过程,通过数学计算为每个词语分配注意力权重。在"今天天气真好"这句话中,模型会自动加强"天气"与"真好"的关联,理解这是对天气状况的积极评价。
代码示例中的nn.Transformer模块,内部就包含着复杂的注意力计算:这个公式如同精密的筛子,筛选出句子中最关键的语义信息。
Attention(Q,K,V)=softmax(QK^T/√d_k )V2. 位置编码:
-
根据位置索引分别用正弦/余弦函数生成编码
-
合成位置编码矩阵后与词嵌入相加
-
关键公式体现相对位置关系:PE(pos,2i)=sin(pos/10000^(2i/d))
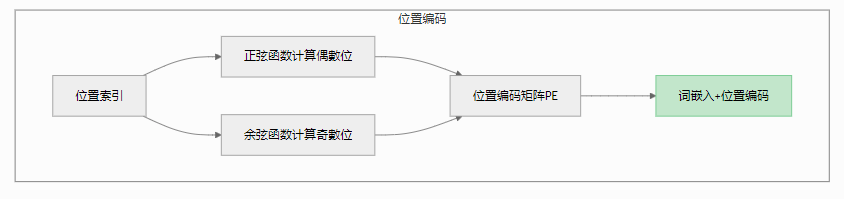
语言的时空定位仪:传统RNN像传送带处理词语,会混淆"狗咬人"与"人咬狗",会破坏词语顺序。Transformer采用正弦波位置编码,为每个位置生成独特的ID。如下面的代码所示,这种编码既能标记绝对位置,又能通过波形周期捕捉相对位置关系,完美保留"今天→天气→真好"的语序信息。
Transformer采用正弦波位置编码:
pe[:,0::2] = sin(position/10000^(2i/d_model))
pe[:,1::2] = cos(position/10000^(2i/d_model))这种设计让每个位置获得唯一坐标,既标记绝对位置,又通过波形周期捕捉相对距离,如同给每个词语佩戴GPS定位器。
3. 编码器-解码器架构:
-
编码器包含自注意力和前馈网络的多层堆叠
-
解码器先进行自注意力,再与编码输出进行交叉注意力
-
编码器输出作为K,V传递给解码器

听与说的完美配合:模型左侧的编码器像专注的倾听者,将输入语句转化为蕴含深意的"记忆晶体"。右侧的解码器则是睿智的回应者,边生成文字边参考记忆晶体。这种分工协作的设计,使得模型可以处理"听"与"说"两个不同维度的任务。这种分工在代码中体现为:
memory = transformer.encoder(src_emb) # 编码
output = transformer.decoder(tgt_emb, memory) # 解码七步构建对话机器人
第一步:构建语言密码本
char2idx = {'<sos>':0, '<eos>':1, '今':2, '天':3...} 如同为每个字符颁发身份证:
-
<sos>:对话开始符,相当于电话接通的"喂" -
<eos>:结束符,如同说"再见" -
<pad>:占位符,统一不同长度句子的处理
第二步:设计数据流水线
自定义Dataset类实现动态填充:确保每个批次的句子长度统一,如同将不同尺寸的包裹装入标准货箱。
def __getitem__(self, idx):src, tgt = self.pairs[idx]src_tensor = [0]+[字→编号] + [2]*(剩余长度)第三步:搭建神经网络
模型类包含四大核心组件:这相当于建造AI大脑的四个功能区域:感觉皮层、位置感知区、思维中枢、语言输出区。这个类定义了AI大脑的结构:先将文字转化为数学向量,添加位置印记,经过多层Transformer块处理,最终输出概率分布。
class MultiTurnTransformer(nn.Module):def __init__(self):self.embedding = nn.Embedding(...) # 词语数字化self.pos_encoder = PositionalEncoding() # 添加位置信息self.transformer = nn.Transformer(...) # 核心处理器 self.fc = nn.Linear(...) # 概率解码器第四步:训练策略优化
引入三大训练技巧:如同驾校教练的教学诀窍:控制学习速度、调整练习强度、增加训练变化。
torch.nn.utils.clip_grad_norm_(...) # 梯度裁剪
optim.Adam(..., betas=(0.9, 0.98)) # 优化器调参
temperature=0.7 # 温度采样第五步:智能回复生成
采用渐进式生成策略:训练过程如同教幼儿说话:反复展示"问题→答案"配对,通过反向传播算法自动调整神经网络参数。损失值下降曲线,直观展示模型的学习进度。
for _ in range(max_length):logits = model.fc(output[:, -1, :])next_token = topk_sampling(logits)这就像画家作画:先勾勒轮廓(首字),再逐步细化(后续词语),最后收笔(遇到<eos>)。
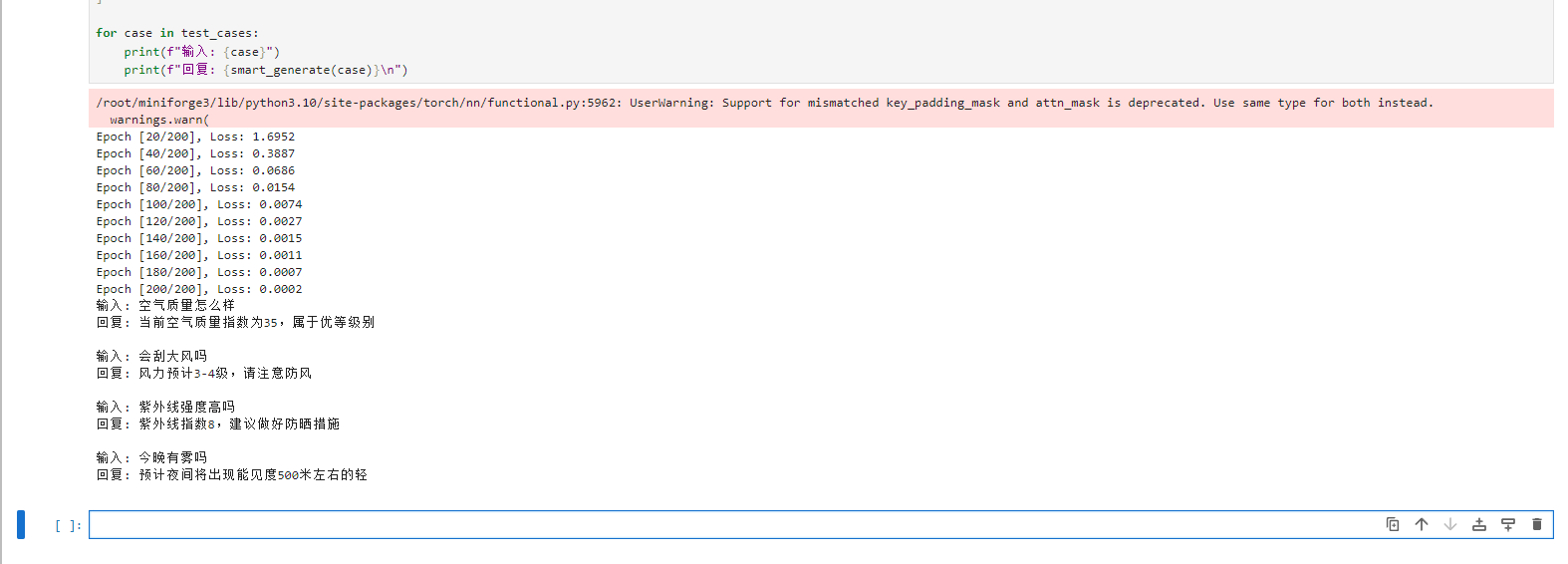
第六步:效果验证
测试案例显示模型已掌握天气对话:
输入: 紫外线强度高吗 → 回复: 指数8,建议防晒
输入: 今晚有雾吗 → 回复: 预计轻雾,能见度500米第七步:持续优化方向
-
数据层面:添加更多对话场景
-
模型层面:采用混合精度训练
-
部署层面:转换为TorchScript格式
技术突破的背后
1. 维度对齐的艺术
曾导致错误的四维张量问题,揭示了深度学习中的维度哲学:
-
输入序列:(batch_size, seq_len)
-
嵌入后:(batch_size, seq_len, d_model)
-
注意力权重:(batch_size, head, seq_len, seq_len)
这如同俄罗斯套娃,每一层维度都有其存在意义。
2. 掩码的辩证法
处理填充符号时,我们通过布尔掩码实现"选择性遗忘":
src_mask = (src == 2) # 标记填充位置这教会AI区分真实内容与占位符,如同人类区分重要信息与背景噪音。
3. 概率的创造力
温度参数调节生成多样性:
-
temperature=0.3:保守回答
-
temperature=1.2:创意回复
这恰似调节AI的"想象力旋钮",在准确性与创造性间寻找平衡。
从玩具模型到现实应用
当前实现虽能完成基础对话,但距离实用化仍有三大鸿沟:
-
数据饥渴:8组对话 vs ChatGPT的45TB语料
-
计算瓶颈:全连接注意力O(n²)复杂度
-
常识缺失:无法理解"郊游要带水"等常识
前沿解决方案包括:
-
稀疏注意力:局部聚焦代替全局计算
-
知识蒸馏:大模型能力迁移到小模型
-
多模态训练:结合视觉、语音等信息
对话式AI
当我们在JupyterLab中运行出第一个AI回复时,实际上正在参与重塑人机交互的未来。Transformer架构带来的不仅是技术革新,更是对人机关系的重新定义:
-
垂直领域深化:医疗、法律等专业对话助手
-
人格化演进:可定制的AI性格特征
-
多轮对话管理:实现上下文深度关联
正如深度学习先驱Yoshua Bengio所言:"语言理解是打开通用人工智能之门的钥匙。"当我们教会AI理解"天气真好"的深意时,也在为机器注入理解人类情感的种子。
代码之外的思考
每个技术细节的突破,都是人类认知边界的拓展。从torch.nn.Transformer到智能对话,这不仅关乎代码与算法,更映射着人类对创造智能生命的不懈追求。当你亲手运行出第一个AI回复时,请记住:那闪烁的光标,正书写着人机共生的新篇章。冲鸭~,年轻的我们。
完整代码如下
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import math
import numpy as np# 超参数配置
d_model = 64
nhead = 4
num_layers = 2
dim_feedforward = 256
max_length = 20
batch_size = 2 # 小批量训练
learning_rate = 0.001
epochs = 200# 多轮对话数据集
dialogue_pairs = [("今天天气真好", "今天是阳光明媚的一天,可以出门郊游哦"),("明天有雨吗", "预计明天将有小到中雨,请带好雨具"),("周末气温如何", "周末气温在22-28摄氏度之间,适宜户外活动"),("空气质量怎么样", "当前空气质量指数为35,属于优等级别"),("会刮大风吗", "风力预计3-4级,请注意防风"),("紫外线强度高吗", "紫外线指数8,建议做好防晒措施"),("现在湿度多少", "当前相对湿度65%,体感舒适"),("今晚有雾吗", "预计夜间将出现能见度500米左右的轻雾")
]# 构建增强词汇表
all_chars = set()
for src, tgt in dialogue_pairs:all_chars.update(src)all_chars.update(tgt)chars = sorted(list(all_chars))
vocab_size = len(chars) + 3
char2idx = {'<sos>': 0, '<eos>': 1, '<pad>': 2}
char2idx.update({c: i + 3 for i, c in enumerate(chars)})
idx2char = {v: k for k, v in char2idx.items()}# 自定义数据集类
class DialogueDataset(Dataset):def __init__(self, pairs, max_len=max_length):self.pairs = pairsself.max_len = max_lendef __len__(self):return len(self.pairs)def __getitem__(self, idx):src, tgt = self.pairs[idx]# 统一处理逻辑def process_seq(text, is_target=False):indices = [char2idx['<sos>']]indices += [char2idx[c] for c in text][:self.max_len - 2]if is_target:indices.append(char2idx['<eos>'])padding = [char2idx['<pad>']] * (self.max_len - len(indices))return torch.LongTensor(indices + padding)src_tensor = process_seq(src)tgt_tensor = process_seq(tgt, is_target=True)return src_tensor, tgt_tensor# 创建数据加载器
dataset = DialogueDataset(dialogue_pairs)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 改进的位置编码
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:x.size(1), :]return x# 增强模型结构
class MultiTurnTransformer(nn.Module):def __init__(self):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model, padding_idx=char2idx['<pad>'])self.pos_encoder = PositionalEncoding(d_model)self.transformer = nn.Transformer(d_model=d_model,nhead=nhead,num_encoder_layers=num_layers,num_decoder_layers=num_layers,dim_feedforward=dim_feedforward,batch_first=True)self.fc = nn.Linear(d_model, vocab_size)self.init_weights()def init_weights(self):initrange = 0.1self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()self.fc.weight.data.uniform_(-initrange, initrange)def forward(self, src, tgt):# 创建布尔型填充掩码src_key_padding_mask = (src == char2idx['<pad>'])tgt_key_padding_mask = (tgt == char2idx['<pad>'])# 嵌入和位置编码src_emb = self.embedding(src) * math.sqrt(d_model)src_emb = self.pos_encoder(src_emb)tgt_emb = self.embedding(tgt) * math.sqrt(d_model)tgt_emb = self.pos_encoder(tgt_emb)# 生成注意力掩码(统一为布尔类型)seq_len = tgt.size(1)tgt_mask = nn.Transformer.generate_square_subsequent_mask(seq_len).to(src.device)# 修正后的Transformer处理output = self.transformer(src_emb, tgt_emb,tgt_mask=tgt_mask,src_key_padding_mask=src_key_padding_mask,tgt_key_padding_mask=tgt_key_padding_mask)return self.fc(output)# 初始化模型
model = MultiTurnTransformer()
criterion = nn.CrossEntropyLoss(ignore_index=char2idx['<pad>'])
optimizer = optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.98), eps=1e-9)# 训练循环改进
for epoch in range(epochs):total_loss = 0for batch_idx, (src, tgt_full) in enumerate(dataloader):optimizer.zero_grad()# 准备输入输出tgt_input = tgt_full[:, :-1] # 输入序列:<sos> ... <last-1>tgt_output = tgt_full[:, 1:] # 目标序列:... <eos># 前向传播output = model(src, tgt_input)loss = criterion(output.reshape(-1, vocab_size), tgt_output.reshape(-1))# 反向传播loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)optimizer.step()total_loss += loss.item()avg_loss = total_loss / len(dataloader)if (epoch + 1) % 20 == 0:print(f'Epoch [{epoch + 1}/{epochs}], Loss: {avg_loss:.4f}')# 增强生成函数
# 修改生成函数中的输入预处理部分
def smart_generate(input_str, temperature=0.7, top_k=5):model.eval()with torch.no_grad():# 预处理输入(关键修正点)src_indices = [char2idx['<sos>']] + [char2idx[c] for c in input_str] + [char2idx['<eos>']]src = torch.LongTensor(src_indices).unsqueeze(0) # (1, seq_len)# 编码阶段src_emb = model.embedding(src) * math.sqrt(d_model)src_emb = model.pos_encoder(src_emb)memory = model.transformer.encoder(src_emb)# 解码初始化tgt = torch.LongTensor([[char2idx['<sos>']]]) # (1, 1)for _ in range(max_length):tgt_emb = model.embedding(tgt) * math.sqrt(d_model)tgt_emb = model.pos_encoder(tgt_emb)output = model.transformer.decoder(tgt_emb, memory)logits = model.fc(output[:, -1, :])# 采样策略logits = logits / temperaturetop_logits, top_indices = logits.topk(top_k, dim=-1)probs = torch.softmax(top_logits, dim=-1)next_token = top_indices[0, torch.multinomial(probs[0], 1)]if next_token == char2idx['<eos>']:breaktgt = torch.cat([tgt, next_token.unsqueeze(0)], dim=1)return ''.join([idx2char[idx.item()] for idx in tgt.squeeze()[1:]])# 测试多轮对话
test_cases = ["空气质量怎么样","会刮大风吗","紫外线强度高吗","今晚有雾吗"
]for case in test_cases:print(f"输入: {case}")print(f"回复: {smart_generate(case)}\n")相关文章:
基于PyTorch 实现一个基于 Transformer 架构的字符级语言模型
这篇教程将带你一步步在 JupyterLab 中实现一个简单的语言模型。我们将从零开始,使用 PyTorch 实现一个基于 Transformer 架构的字符级语言模型。尽管在实际应用中,大多数人更倾向于使用 Hugging Face 的预训练模型,但本文的目的是让你了解语…...

苹果签名的工具有哪些
嗯,用户问的是关于苹果企业签名的工具有哪些。首先,我需要确认用户的需求。苹果企业签名通常指的是使用苹果的企业开发者账号(Apple Developer Enterprise Program)来对应用进行签名,这样应用可以不通过App Store直接分…...

解决.net接口防暴力调用问题
在 .NET 中,为解决接口防暴力调用问题,可通过限制请求频率实现。下面给出几种不同实现方式。 基于内存的简单速率限制 此方法适用于单服务器环境,它借助内存字典来记录每个客户端的请求次数和时间。 MemoryRateLimitMiddleware.cs using …...

java设计模式-桥接模式
桥接模式(Bridge) 基本介绍 1、桥接模式(Bridge)是指:将实现与抽象放在两个不同的类层次中,是两个层次可以独立改变。 2、是一种结构设计模 3、Bridge模式给予类的最小单元设计原则,通过使用封装,聚合及继承等行为让不同的类承担不…...

cdw2: TypeScript
一、javascript的问题 二、初识typescript https://mp.weixin.qq.com/s/wnL1l-ERjTDykWM76l4Ajw 三、类型 二进制:ob开头,八进制:0o开头,十六进制:0x开头 开发中不这样写 这样写 匿名函数的参数最好不要…...

Linux驱动开发:SPI驱动开发原理
前言 本文章是根据韦东山老师的教学视频整理的学习笔记https://video.100ask.net/page/1712503 SPI 通信协议采用同步全双工传输机制,拓扑架构支持一主多从连接模式,这种模式在实际应用场景中颇为高效。其有效传输距离大致为 10m ,传输速率…...

Java 通过 JNI 调用 C++ 动态库的完整流程
介绍使用 JNI 调用 C 编写的动态链接库的全过程。 示例环境 项目说明JDK8C 编译器Visual Studio 2019Java 开发工具IntelliJ IDEA 2021.3操作系统Windows 10 Java 项目结构概览 编写 Java 类 在 org.jni.nativejni 包下创建类 HelloWorldJni.java: package org…...

oracle 11g密码长度和复杂度查看与设置
一 查看当前的密码复杂度设置 SELECT * FROM dba_profiles WHERE resource_name PASSWORD_VERIFY_FUNCTION; LIMIT表示分配给该 PROFILE 的密码验证函数名称。如果为 NULL,表示未设置密码验证函数。 #查看是否有相关密码验证函数 select object_name from dba…...

1021 Deepest Root
1021 Deepest Root 分数 25 全屏浏览 切换布局 作者 CHEN, Yue 单位 浙江大学 A graph which is connected and acyclic can be considered a tree. The height of the tree depends on the selected root. Now you are supposed to find the root that results in a highest…...

1. 三带一
所谓“三带一”牌型,即四张手牌中,有三张牌一样,另外一张不与其他牌相同,换种说法,四张手牌经过重新排列后,可以组成 AAABAAAB 型。 输入格式 第一行输入一个整数 TT ,代表斗地主的轮数。 接…...

pytorch计算图Computation_graph是什么
文章目录 一、AI系统中的计算图(宏观)二、动态计算图(微观)2.1 张量计算图2.2 计算图的定义2.3 节点类型2.4 计算图的动态性2.5 计算图的正向传播是立即执行的2.6 计算图在反向传播后立即销毁2.7 计算图中的Function2.8 计算图与反…...

HTML5元素
HTML5的<section>元素和<article>元素 <section>元素定义文档中的一部分,着重于对页面内容进行分块或者分段,通常可以分为引言、内容和联系人信息等几个部分。 <section><h1>WWF</h1><p>WWF 是世界自然基金…...

单reactor实战
前言:reactor作为一种高性能的范式,值得我们学习 本次目标 实现一个基于的reactor 具备echo功能的服务器 核心组件 Reactor本身是靠一个事件驱动的框架,无疑引出一个类似于moduo的"EventLoop "以及boost.asio中的context而言,不断…...

【C#知识点详解】LinkedList<T>储存结构详解
今天来介绍一下LinkedList<T>的内部结构,说不多说直接开始。 内部数据 LinkedList是一个双向链表结构的容器,其内部为非连续的内存空间。LinkedList包含的主要成员示例如下: //起始LinkedListNode节点 internal LinkedListNode<T&g…...

智能穿梭车在快消行业的融合升级:效率革命与数据智能的双重赋能
快消品牌(FMCG)的核心挑战在于高频周转、海量SKU、短时效性,而智能穿梭车的技术进化(如AI调度、5G通信、柔性载具)与快消行业的业务需求(如全渠道订单履约、动态库存优化)深度结合,正…...
链表结构)
(二)链表结构
备注:根据coderwhy数据结构与算法课程进行笔记总结 1.数组缺点: 数组创建通常需要申请一段连续的内存空间,且大小固定,因此当前数组不能满足容量需求时,就需要扩容。在数组开头或中间位置插入数据成本很高࿰…...

oracle json笔记
文章目录 json_valuejson_value示例json_value on error如何使用 TODO json_queryjson_query示例 json_tablejson_table 示例 json_existsjson_exists示例json_exists报错 ORA-40458: 在谓词外部使用了 JSON_EXISTS json_objectjson_arrayjson_mergepatchjson_objectaggjson_ar…...

c编译和c++编译有什么区别?
文章目录 c编译和c编译有什么区别多态函数重载虚函数表 vtable 输入输出同步类型检查模板和特化链接 C 标准库 C 能编译 C 的代码吗? c编译和c编译有什么区别 多态 函数重载 C 支持多个同名函数(参数不同),这是编译期多态 编译…...

【Mysql】主从复制和读写分离
一、定义 1、什么是读写分离? 在主库master上负责处理事务性写入操作,在从库slave上负责处理查询操作,并通过主从复制将主库上的数据同步给从库。 2、为什么要读写分离? 从集中到分布,最基本的一个需求不是数据存储的…...

泛目录排名——深入理解与优化 SEO:提升网站可见性的关键策略
https://www.zhanqun.xin/ 在数字化时代,互联网上的信息呈爆炸式增长。对于企业和网站运营者而言,如何让自己的网站在海量的网络内容中脱颖而出,吸引目标受众的关注,成为了一项至关重要的挑战。搜索引擎优化(SEO&#…...

汇丰eee2
聚合和继承有什么样的优点和区别,什么时候决定用,现实开发中,选择哪一种去使用? 聚合的优点: 灵活性: 聚合是一种弱耦合关系,被聚合对象可以独立存在,可以灵活地替换或修改被聚合对…...
)
C#网络编程(Socket编程)
文章目录 0、写在前面的话1、Socket 介绍1.1 Socket是什么1.2 Socket在网络中的位置 2、C# 中的Socket参数2.1 超时控制参数2.2 缓冲区参数2.3 UDP专用参数 3、C# 中的Socket API3.1 Socket(构造函数)3.1.1 SocketType3.1.2 ProtocolType3.1.3 AddressFa…...

使用Python的Schedule库实现定时任务,并传递参数给任务函数
哈喽,大家好,我是木头左! 本文将详细介绍如何使用schedule库来创建定时任务,并展示如何向任务函数传递参数。 安装Schedule库 需要安装schedule库。你可以使用以下命令通过pip进行安装: pip install schedule基本用法 schedule库的基本用法非常简单。你可以通过调用sch…...

Unity Input 2023 Release-Notes
🌈Input 2023 Release-Notes 版本更新内容2023.2.17Input: Crash on InputDeviceIOCTL when closing Unity editor(UUM-10774)2023.2.16Input: Crash on InputDeviceIOCTL when closing Unity editor(UUM-10774)2023.2.15Input: Crash on InputDeviceIOCTL when clo…...

IP查询能够帮助企业进行数字化转型
企业如今正面临着用户行为碎片化、市场竞争白热化的挑战。那么企业要如何从海量网络数据中精准捕捉用户需求就十分重要了。而IP查询技术也正帮助越来越多的企业在精准营销、风险防控、合规运营等领域开辟新的增长空间。 https://www.ipdatacloud.com/?utm-sourceLMN&utm-…...

Nginx漏洞复现
vulhub起靶场 Nginx 文件名逻辑漏洞(CVE-2013-4547) 上传1.gif,内容为 <?php phpinfo();?> http://your-ip:8080/uploadfiles/1.gif[0x20][0x00].php访问文件位置,这里0x00要改包 先访问/uploadfiles/1.gif a.php&…...
插入排序 希尔排序)
数据结构|排序算法(二)插入排序 希尔排序
一、插入排序 1.算法思想 插入排序(Insertion Sort)是一种简单的排序算法,其基本思想是:将待排序的元素插入到已经有序的序列中,从而逐步构建有序序列。 具体过程如下: 把待排序的数组分为已排序和未排…...

OpenBMC:BmcWeb 处理http请求5 检查权限
OpenBMC:BmcWeb 处理http请求4 处理路由对象-CSDN博客 在通过url获取了路由对象后,如果该请求是有session的,那么下一步需要检查权限 1.validatePrivilege调用时传入了一个lambda(1)做为回调 validatePrivilege(req, asyncResp, rule,[req, asyncResp, &rule, params =…...
的详细步骤)
CentOS 系统磁盘扩容并挂载到根目录(/)的详细步骤
在使用 CentOS 系统时,经常会遇到需要扩展磁盘空间的情况。例如,当虚拟机的磁盘空间不足时,可以通过增加磁盘容量并将其挂载到根目录(/)来解决。以下是一个完整的操作流程,详细介绍了如何将新增的 10G 磁盘…...
)
Axure RP 9 for Mac 交互原型设计 安装教程@[TOC](文章目录)
Axure RP 9 for Mac 交互原型设计 安装教程TOC 一、介绍 Axure RP 9是一款功能强大的原型设计和协作工具。它不仅能够帮助用户快速创建出高质量的原型设计,还能促进团队成员之间的有效协作,从而极大地提高数字产品开发的效率和质量。拥有直观易用的界面…...
暴力娱乐篇19)
每日一题(小白)暴力娱乐篇19
样例: 6 1 1 4 5 1 4 输出: 56 66 52 44 54 64 分析题意可以得知,就是接收一串数字,将数字按照下标每次向右移动一位(末尾循环到第一位),每次移动玩计算一下下标和数字的乘积且累加。 ①接收…...

LeetCode 第53题:最大子数组和
题目描述: 给你一个整数数组nums,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。子数组是数组中的一个连续部分。 示例1: 输入:nums [-2,1,-3,4,-1,2,1,-5,4] 输出ÿ…...

顺序表:从数组到高效数据管理的进化之路
一、线性表:数据结构的 “基础骨架” 在数据结构的世界里,线性表是最基础的结构之一。它是由n个具有相同特性的数据元素组成的有限序列,就像一列整齐排列的士兵,每个元素都有唯一的前驱(除了第一个)和后继…...

TS知识补充第一篇 ✅
目录 1️⃣ any、unknow和never 2️⃣ 函数重载 3️⃣ typeof和keyof(配合构建字典类型的Demo,巨好用‼️) 4️⃣ TS的条件类型 5️⃣ TS的声明合并 一、any、unknow和never any any类型表示一个值可以是任何类型。通常在不确定变量的类型…...
模拟娱乐篇18)
每日一题(小白)模拟娱乐篇18
今天和大家一起玩个小游戏,给小朋友分糖果🍬 由题知就是小朋友每次给左手边的小朋友分一半糖果,一轮下来如果是奇数糖果老师就给他补一个直到所有小朋友拥有相同数量的糖果,问问老师发放了多少糖果。用程序进行模拟的大概思路就是…...

Linux系统学习Day2——在Linux系统中开发OpenCV
一、OpenCV简介 OpenCV(Open Source Computer Vision Library)是一个开源的跨平台计算机视觉和机器学习库,广泛应用于图像处理、视频分析、物体检测等领域。它提供了丰富的算法和高效的工具集,支持C、Python等多种语言,…...

Redisson 实现分布式锁
在平常的开发工作中,我们经常会用到锁,那么锁有什么用呢?锁主要是控制对共享资源的访问顺序,防止多个线程并发操作导致数据不一致的问题。经常可能会听到乐观锁、悲观锁、分布式锁、行锁、表锁等等,那么我们今天总结下…...
数据结构进阶篇——搜索专题(广度优先搜索算法BFS和深度优先搜索算法DFS))
(适合中白)数据结构进阶篇——搜索专题(广度优先搜索算法BFS和深度优先搜索算法DFS)
深度优先搜索DFS&广度优先搜索BFS 深度优先搜索广度优先搜索 深度优先搜索 当碰到岔路口时,总是以深度作为前进的关键词,不碰到死胡同就不回头的这种搜索方式被称为深度优先搜索(Depth First Search) 深度优先搜索是一种枚举所有完整路径以遍历所有情…...

SGLang实战问题全解析:从分布式部署到性能调优的深度指南
引言:当高性能推理遇上复杂生产环境 在大型语言模型(LLM)的生产部署中,SGLang以其革命性的RadixAttention和结构化编程能力,正成为越来越多企业的首选推理引擎。然而,当我们将32B/70B级别的大模型部署到实际生产环境时࿰…...

Java大视界:解码航天遥测数据的银河密码——从GB到PB的技术革命
当长征火箭划破苍穹的瞬间,每秒产生的遥测数据足以填满一部4K电影。在这场与星辰对话的征程中,Java大数据生态正扮演着解码宇宙密码的"数字炼金师"。本文将带您穿越三个认知维度,揭示Java技术栈如何重构航天数据分析的底层逻辑。 …...
)》)
《C++探幽:STL(string类源码的简易实现(下))》
作者的个人gitee▶️ 作者的算法讲解主页 每日一言:“驿寄梅花,鱼传尺素,砌成此恨无重数。🌸🌸” 接《C探幽:STL(string类源码的简易实现(上))》🔴…...
)
求线性表的倒数第K项 (数组、头插法、尾插法)
给定一系列正整数,请设计一个尽可能高效的算法,查找倒数第K个位置上的数字。 输入格式: 输入首先给出一个正整数K,随后是若干非负整数,最后以一个负整数表示结尾(该负数不算在序列内,不要处理)…...

rustdesk自建服务器怎么填写客户端配置信息
目录 # id、api、中继都怎么填?rustdesk程序启动后服务不自动启动 # id、api、中继都怎么填? rustdesk程序启动后服务不自动启动 完全退出RudtDesk程序(右下角托盘区有的话,需要右键点退出) 创建windows服务ÿ…...

4月8日日记
今天抖音刷到一个视频 记了一下笔记 想做自媒体,直播,抖音是最大的平台,但是我的号之前因为跟人互喷被封号了 今天想把实名认证转移到新号上,试了一下竟然这次成功了,本以为能开直播了但是 还是因为之前的号有违规记…...

VScode添加python解释器
先安装python扩展 然后点ctrlshiftp搜索python:select,选择解析器(或者也可以直接点左下方的)...

Elasticsearch | ES索引模板、索引和索引别名的创建与管理
关注:CodingTechWork 引言 在使用 Elasticsearch (ES) 和 Kibana 构建数据存储和分析系统时,索引模板、索引和索引别名的管理是关键步骤。本文将详细介绍如何通过 RESTful API 和 Kibana Dev Tools 创建索引模板、索引以及索引别名,并提供具…...

用 Python 造轮子:打造轻量级 HTTP 调试工具
目录 一、为什么需要自建工具? 二、核心功能设计 三、技术选型 四、分步实现 第一步:搭建基础框架 第二步:实现请求转发逻辑 第三步:响应格式化处理 第四步:历史记录存储 五、进阶优化技巧 六、使用示例 七…...

java设计模式-原型模式
原型模式 1、原型模式(Prototype模式)是指:用原型实例指定创建对象的种类,并通过拷贝这些原型,创建新的对象 2、原型模式是一种创见性设计模式,允许一个对象再创建另一个可定制的对象,无需知道如何创建的细节。 3、工作…...

【Java设计模式】第9章 原型模式讲解
9. 原型模式 9.1 原型模式讲解 定义:通过拷贝原型实例创建新对象,无需调用构造函数。特点: 创建型模式无需了解创建细节适用场景: 类初始化消耗资源多对象创建过程繁琐(如属性赋值复杂)循环体中需创建大量对象优点: 性能优于直接new简化创建流程缺点: 必须实现clone()…...

Python 快速搭建一个小型的小行星轨道预测模型 Demo
目录 ✅ Demo 目标: 🧪 模型方案选择 方案 1:开普勒 LSTM 混合预测(推荐 💡) 方案 2:全 AI:LSTM 直接拟合轨迹 🚧 环境准备 🔧 示例代码结构ÿ…...