CNN注意力机制的进化史:深度解析10种注意力模块如何重塑卷积神经网络
🌟 引言:注意力为何改变CNN的命运?
就像人类视觉会优先聚焦于重要信息,深度学习模型也需要"学会看重点"。从2018年SENet首提通道注意力,到2024年SSCA探索空间-通道协同效应,注意力机制正成为CNN性能提升的核武器,这些注意力机制思想不仅不断改造提升着CNN,也影响到了Transformer架构中的注意力设计。本文带大家穿越6年技术迭代,揭秘那些改变视觉模型的注意力模块!
第一站:SENet(2018 CVPR)- 通道注意力的开山之作

核心思想:
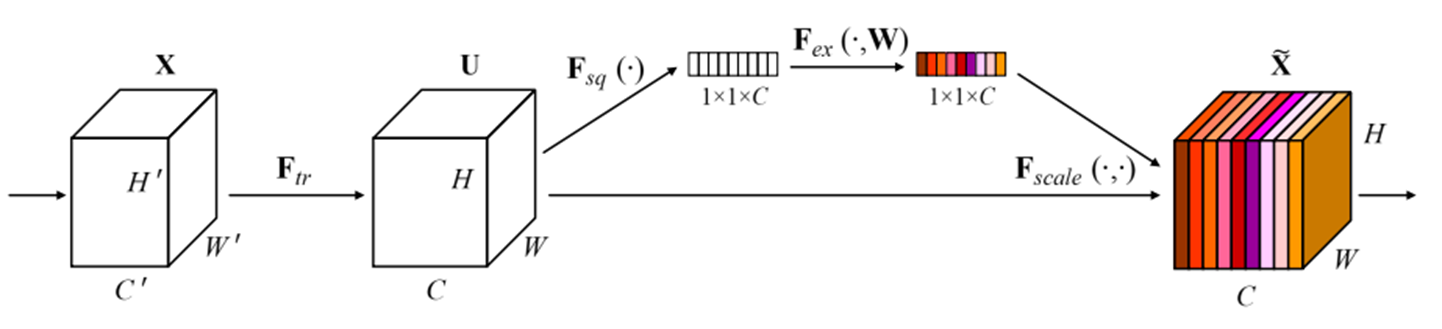
- Squeeze操作:用全局平均池化将H×W×C特征图压缩成1×1×C的通道描述符
- Excitation机制:通过全连接层+Sigmoid生成通道权重,实现特征的"有选择放大"
性能提升:在ResNet基础上Top-1准确率提升2.3%,参数仅增加0.5M
代码实现:
import torch
import torch.nn as nnclass SE(nn.Module):def __init__(self, channel, reduction= 16):super(SE, self).__init__()# part 1:(H, W, C) -> (1, 1, C)self.avg_pool = nn.AdaptiveAvgPool2d(1)# part 2, compute weight of each channelself.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid(), # nn.Softmax is OK here)def forward(self, x) :b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * yif __name__ == '__main__':# 创建随机输入张量,假设输入形状为(batch_size, channels, height, width)input_tensor = torch.randn(1, 64, 32, 32) # batch_size=1, channels=64, height=32, width=32# 创建SE块实例se_block = SE(channel=64)# 测试SE块output_se = se_block(input_tensor)print("Output shape of SE block:", output_se.shape)
第二站:CBAM(2018 ECCV)- 空间×通道的双重视角

创新点:
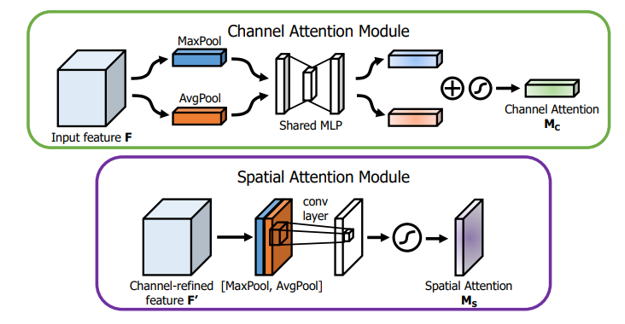
- 通道注意力:融合最大池化+平均池化,通过MLP学习通道间相关性。
- 空间注意力:在空间维度上进行注意力分配。它通过对输入特征图进行通道间的全局平均池化和全局最大池化,然后将这两个结果进行拼接,并通过一个7x7的卷积层来学习空间位置之间的相关性,最后使用sigmoid函数生成空间注意力权重。
亮点:在ResNet50上仅增加1.4%计算量,准确率提升3.1%
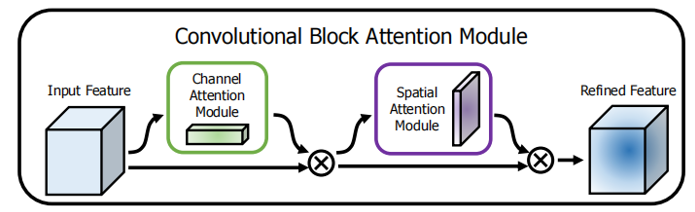
结构示意:输入 → 通道注意力 → 空间注意力 → 输出
代码实现:
import torch.nn as nn
import torchclass CBAM(nn.Module):def __init__(self,in_chans,reduction= 16,kernel_size= 7,min_channels= 8,):super(CBAM, self).__init__()# channel-wise attentionhidden_chans = max(in_chans // reduction, min_channels)self.mlp_chans = nn.Sequential(nn.Conv2d(in_chans, hidden_chans, kernel_size=1, bias=False),nn.ReLU(),nn.Conv2d(hidden_chans, in_chans, kernel_size=1, bias=False),)# space-wise attentionself.mlp_spaces = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=3, bias=False)self.gate = nn.Sigmoid()def forward(self, x: torch.Tensor) -> torch.Tensor:# (B, C, 1, 1)avg_x_s = x.mean((2, 3), keepdim=True)# (B, C, 1, 1)max_x_s = x.max(dim=2, keepdim=True)[0].max(dim=3, keepdim=True)[0]# (B, C, 1, 1)x = x * self.gate(self.mlp_chans(avg_x_s) + self.mlp_chans(max_x_s))# (B, 1, H, W)avg_x_c = x.mean(dim=1, keepdim=True)max_x_c = x.max(dim=1, keepdim=True)[0]x = x * self.gate(self.mlp_spaces(torch.cat((avg_x_c, max_x_c), dim=1)))return xif __name__ == '__main__':input_tensor = torch.randn(1, 64, 32, 32)ca_module = CBAM(in_chans=64)output_tensor = ca_module(input_tensor)print(output_tensor.shape)
第三站:DA(2019 CVPR)- 空间与通道的双重依赖

核心思想:
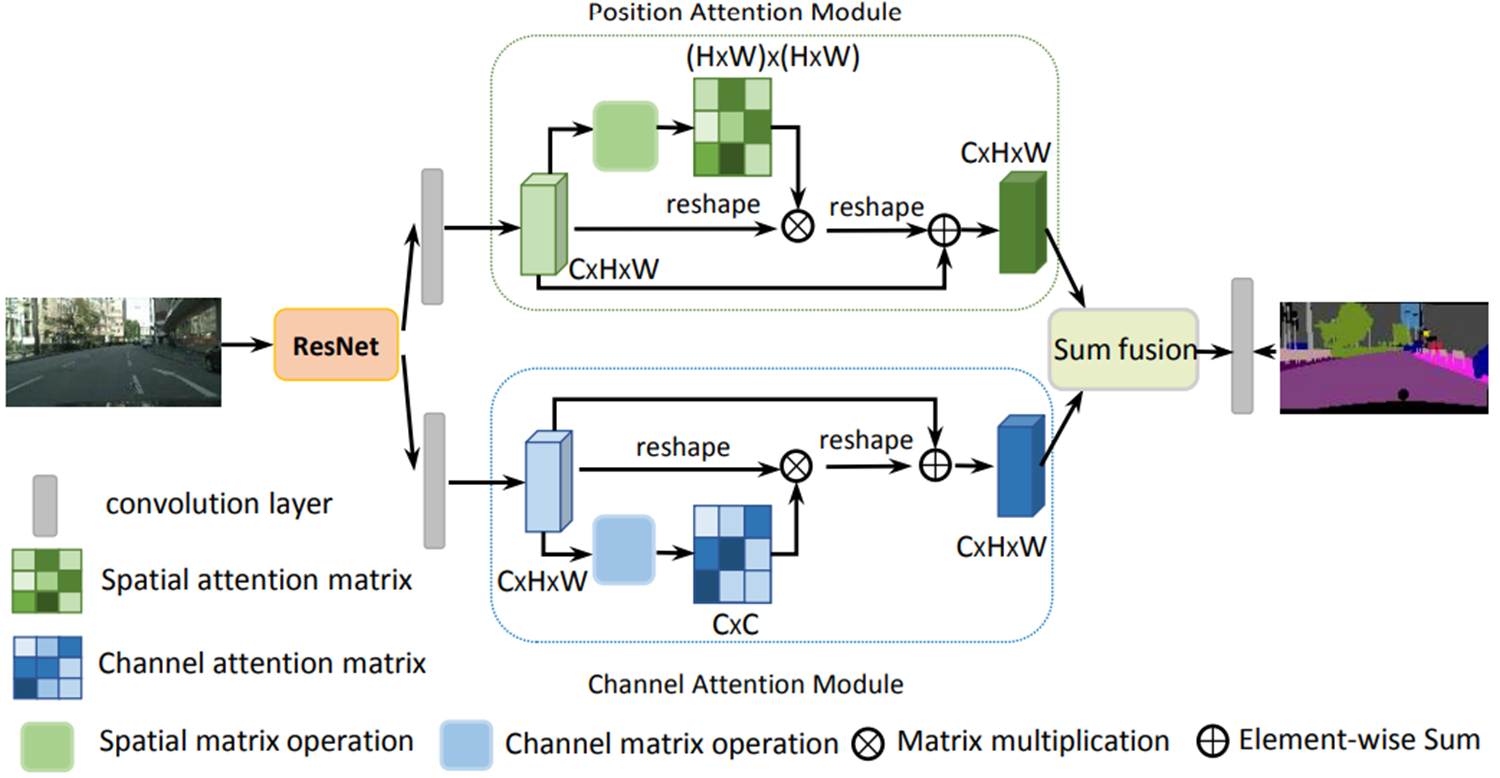
- 位置注意力模块:通过自注意力机制捕捉特征图中任意两个位置之间的空间依赖性
- 通道注意力模块:通过自注意力机制捕捉任意两个通道图之间的通道依赖性
- 融合策略:将两种注意力模块的输出进行融合,增强特征表示
结构示意:
-
在传统的扩张FCN之上附加了两种类型的注意力模块,分别模拟空间和通道维度中的语义相互依赖性
-
位置注意力模块通过自注意力机制捕捉特征图中任意两个位置之间的空间依赖
-
通道注意力模块使用类似的自注意力机制捕捉任意两个通道图之间的通道依赖性
-
最后,将这两个注意力模块的输出进行融合,以进一步增强特征表示
代码实现:
import torch
import torch.nn as nnclass PAM(nn.Module):"""position attention module with self-attention mechanism位置注意力模块,使用自注意力机制"""def __init__(self, in_chans: int):super(PAM, self).__init__()self.in_chans = in_chans# 定义三个卷积层:q、k、v,分别用于计算查询(Query)、键(Key)、值(Value)特征。self.q = nn.Conv2d(in_chans, in_chans // 8, kernel_size=1) # 查询卷积self.k = nn.Conv2d(in_chans, in_chans // 8, kernel_size=1) # 键卷积self.v = nn.Conv2d(in_chans, in_chans, kernel_size=1) # 值卷积# 定义一个可学习的缩放因子gammaself.gamma = nn.Parameter(torch.zeros(1))# Softmax操作用于计算注意力权重self.softmax = nn.Softmax(dim=-1)def forward(self, x: torch.Tensor):b, c, h, w = x.size() # 获取输入张量的尺寸,b为batch大小,c为通道数,h为高度,w为宽度# (B, HW, C) 计算查询q的形状,B是batch size,HW是特征图的空间展平后长度,C是通道数q = self.q(x).view(b, -1, h * w).permute(0, 2, 1) # 计算查询q,并将其展平成(B, HW, C)的形状,并做转置# (B, C, HW) 计算键k的形状,展平特征图为(B, C, HW)k = self.k(x).view(b, -1, h * w)# (B, C, HW) 计算值v的形状,展平特征图为(B, C, HW)v = self.v(x).view(b, -1, h * w)# (B, HW, HW) 计算注意力矩阵,q与k的乘积,再做softmax处理,得到注意力权重attn = self.softmax(torch.bmm(q, k)) # q和k的乘积,计算注意力分数并应用softmax# (B, C, HW) 计算输出结果,注意力矩阵与值v相乘,得到最终加权后的特征out = torch.bmm(v, attn.permute(0, 2, 1)) # 计算加权后的输出,注意力矩阵需要转置# 将输出的形状还原为原来的尺寸(B, C, H, W)out = out.view(b, c, h, w)# 使用gamma进行缩放,并将原始输入x与输出相加,形成残差连接out = self.gamma * out + xreturn outclass CAM(nn.Module):"""channel attention module with self-attention mechanism通道注意力模块,使用自注意力机制"""def __init__(self, in_chans: int):super(CAM, self).__init__()self.in_chans = in_chans# 定义一个可学习的缩放因子gammaself.gamma = nn.Parameter(torch.zeros(1))# Softmax操作用于计算注意力权重self.softmax = nn.Softmax(dim=-1)def forward(self, x: torch.Tensor) -> torch.Tensor:b, c, w, h = x.size() # 获取输入张量的尺寸,b为batch大小,c为通道数,w为宽度,h为高度# (B, C, HW) 将输入张量展平为(B, C, HW),HW表示宽度和高度的展平q = x.view(b, c, -1)# (B, HW, C) 转置得到(B, HW, C)形状,以便后续计算注意力k = x.view(b, c, -1).permute(0, 2, 1)# (B, C, HW) 直接用输入张量展平得到(B, C, HW)v = x.view(b, c, -1)# (B, C, C) 计算q和k的矩阵乘积,得到能量矩阵energy = torch.bmm(q, k)# 通过max操作处理能量矩阵,找到每个通道的最大能量,进行缩放energy_new = torch.max(energy, dim=-1, keepdim=True)[0].expand_as(energy) - energy# 计算注意力权重,使用softmax对缩放后的能量进行归一化attn = self.softmax(energy_new)# (B, C, HW) 使用注意力权重对v加权,得到加权后的输出out = torch.bmm(attn, v)# 将输出的形状还原为原来的尺寸(B, C, H, W)out = out.view(b, c, h, w)# 使用gamma进行缩放,并将原始输入x与输出相加,形成残差连接out = self.gamma * out + xreturn outclass DualAttention(nn.Module):def __init__(self, in_chans: int):super(DualAttention, self).__init__()self.in_chans = in_chansself.pam = PAM(in_chans)self.cam = CAM(in_chans)def forward(self, x: torch.Tensor) -> torch.Tensor:pam = self.pam(x)cam = self.cam(x)return pam + camif __name__ == '__main__':model = DualAttention(in_chans=64)x = torch.rand((3, 64, 40, 40))print(model(x).size())
第四站:SK(2019 CVPR)- 选择性核注意力

核心思想:
- 多核选择:通过不同大小的卷积核(如3×3、5×5)提取多尺度特征
- 自适应融合:根据输入特征动态选择最优卷积核大小,平衡计算复杂度和特征表达能力
结构示意:
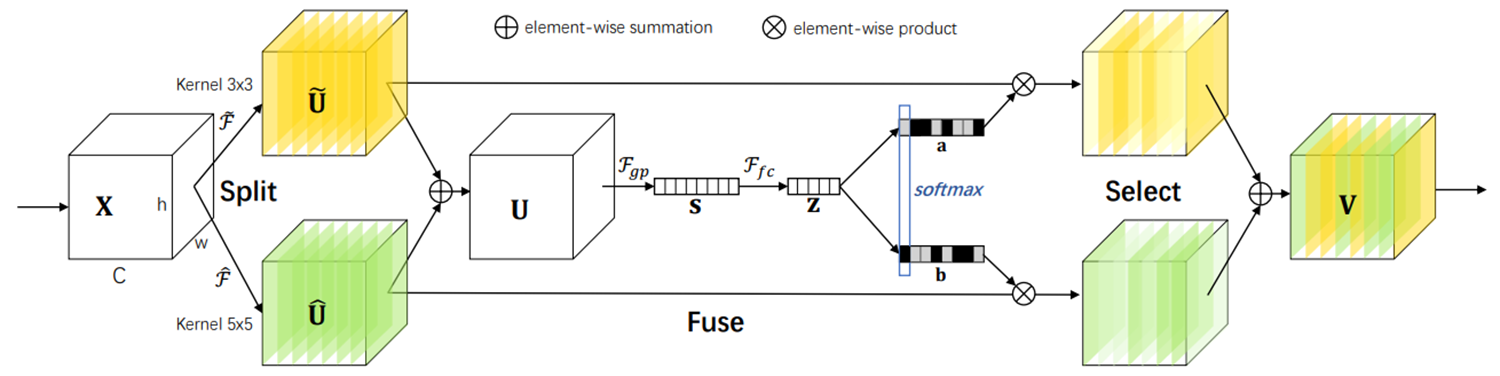
-
轻量级和高效性:ECA模块只涉及少量参数,同时带来明显的性能提升。它避免了传统注意力机制中的复杂降维和升维过程,通过局部跨通道交互策略,以一维卷积的方式高效实现。
-
局部跨通道交互:ECA模块通过一维卷积捕捉通道间的依赖关系,这种策略不需要降维,从而显著降低了模型复杂性。
-
自适应卷积核大小:ECA模块开发了一种方法来自适应选择一维卷积的核大小,以确定局部跨通道交互的覆盖范围。
性能表现:在ResNet50基础上Top-1准确率提升1.5%,计算量仅增加2.3%
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as Fdef auto_pad(k, d=1):"""自动计算卷积操作所需的填充量,确保输出尺寸符合要求。:param k: 卷积核的大小 (kernel size),通常为单一整数或者元组。:param d: 膨胀系数 (dilation),通常默认为1。膨胀系数影响卷积核的有效大小。:return: 填充量 (padding)"""# 如果卷积核大小是整数,转换为元组if isinstance(k, int):k = (k, k)# 如果膨胀系数大于1,卷积核的有效大小会增大effective_kernel_size = (k[0] - 1) * d + 1 # 计算膨胀后的卷积核大小# 假设我们希望使用“same”填充来保持输出尺寸和输入尺寸相同padding = (effective_kernel_size - 1) // 2 # 保证输出尺寸与输入尺寸一致return paddingclass ConvModule(nn.Module):def __init__(self,in_chans, hidden_chans, kernel_size,stride,groups=1,padding=0, dilation=0,norm_cfg='BN', act_cfg='ReLU'):super().__init__()self.conv = nn.Conv2d(in_chans,hidden_chans,kernel_size=kernel_size,stride=stride,groups=groups,padding=padding,dilation=dilation)if norm_cfg == 'BN':self.norm = nn.BatchNorm2d(hidden_chans)elif norm_cfg == 'GN':self.norm = nn.GroupNorm(32, hidden_chans)if act_cfg == 'ReLU':self.act = nn.ReLU(inplace=True)elif act_cfg == 'LeakyReLU':self.act = nn.LeakyReLU(inplace=True)elif act_cfg == 'HSwish':self.act = nn.Hardswish(inplace=True)def forward(self, x):x = self.conv(x)x = self.norm(x)x = self.act(x)return xclass SK(nn.Module):def __init__(self,in_chans,out_chans,num= 2,kernel_size= 3,stride= 1,groups= 1,reduction= 16,norm_cfg='BN',act_cfg='ReLU'):super(SK, self).__init__()self.num = numself.out_chans = out_chansself.kernel_size = kernel_sizeself.conv = nn.ModuleList()for i in range(num):self.conv.append(ConvModule(in_chans, out_chans, kernel_size, stride=stride, groups=groups, dilation=1 + i,padding=auto_pad(k=kernel_size, d=1 + i), norm_cfg=norm_cfg, act_cfg=act_cfg))# fc can be implemented by 1x1 convself.fc = nn.Sequential(# use relu act to improve nonlinear expression abilityConvModule(in_chans, out_chans // reduction, kernel_size=1,stride=stride, norm_cfg=norm_cfg, act_cfg=act_cfg),nn.Conv2d(out_chans // reduction, out_chans * self.num, kernel_size=1, bias=False))# compute channels weightself.softmax = nn.Softmax(dim=1)def forward(self, x: torch.Tensor) -> torch.Tensor:# use different convolutional kernel to convtemp_feature = [conv(x) for conv in self.conv]x = torch.stack(temp_feature, dim=1)# fuse different output and squeezeattn = x.sum(1).mean((2, 3), keepdim=True)# excitationattn = self.fc(attn)batch, c, h, w = attn.size()attn = attn.view(batch, self.num, self.out_chans, h, w)attn = self.softmax(attn)# selectx = x * attnx = torch.sum(x, dim=1)return xif __name__ == "__main__":model = SK(in_chans=64,out_chans=64)x = torch.rand((3, 64, 40, 40))print(model(x).size())
第五站:ECA-Net(2020 CVPR)- 用1D卷积颠覆传统注意力

革命性设计:
- 用1D卷积替代全连接层,降低98%参数量
- 自适应核大小选择算法,动态调整感受野
性能对比:
| 模块 | 参数量 | Top-1提升 |
|---|---|---|
| SENet | 1.5M | +2.3% |
| ECA-Net | 2.8k | +2.7% |
核心结构:
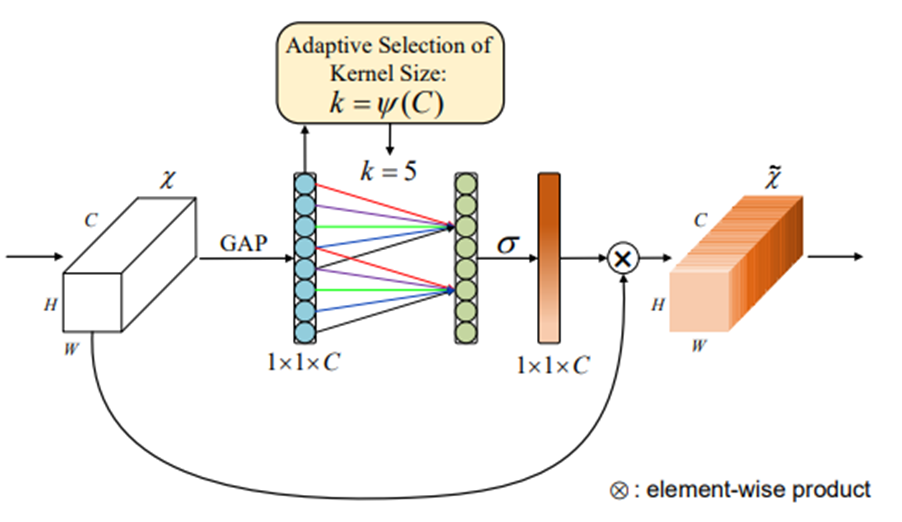
-
轻量级和高效性:ECA模块只涉及少量参数,同时带来明显的性能提升。它避免了传统注意力机制中的复杂降维和升维过程,通过局部跨通道交互策略,以一维卷积的方式高效实现。
-
局部跨通道交互:ECA模块通过一维卷积捕捉通道间的依赖关系,这种策略不需要降维,从而显著降低了模型复杂性。
-
自适应卷积核大小:ECA模块开发了一种方法来自适应选择一维卷积的核大小,以确定局部跨通道交互的覆盖范围。
第六站:CA(2021 CVPR)- 坐标注意力的巧妙设计

核心思想:
- 方向感知特征图:通过沿垂直和水平方向的全局平均池化,将特征图分解为两个独立的方向感知特征图
- 长距离依赖:在保留位置信息的同时,捕获特征图中不同位置的长距离依赖关系
- 高效融合:将两个方向感知特征图编码为注意力张量,实现空间和通道信息的高效融合
结构示意:
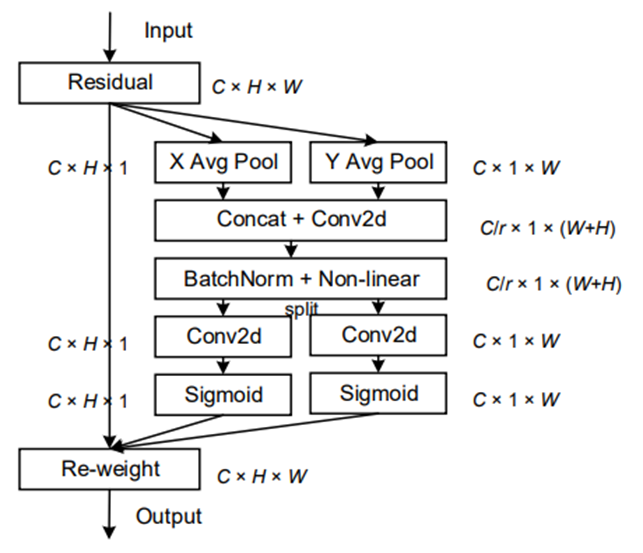
-
考虑了空间维度注意力和通道维度注意力,这有助于模型定位、识别和增强更有趣的对象。
-
CA利用两个2-D全局平均池化(GAP)操作分别沿着垂直和水平方向聚合输入特征到两个独立的方向感知特征图中。然后,分别将这两个特征图编码成一个注意力张量。
-
在这两个特征图(Cx1xW和CxHx1)中,一个使用GAP来模拟特征图在空间维度上的长距离依赖,同时在另一个空间维度保留位置信息。在这种情况下,两个特征图、空间信息和长距离依赖相互补充。
性能表现:在MobileNetV2上Top-1准确率提升5.1%,计算量仅增加1.2%
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ConvModule(nn.Module):def __init__(self,in_chans, hidden_chans, kernel_size=1, norm_cfg='BN', act_cfg='HSwish'):super().__init__()self.conv = nn.Conv2d(in_chans, hidden_chans, kernel_size=kernel_size)if norm_cfg == 'BN':self.norm = nn.BatchNorm2d(hidden_chans)elif norm_cfg == 'GN':self.norm = nn.GroupNorm(32, hidden_chans)if act_cfg == 'ReLU':self.act = nn.ReLU(inplace=True)elif act_cfg == 'LeakyReLU':self.act = nn.LeakyReLU(inplace=True)elif act_cfg == 'HSwish':self.act = nn.Hardswish(inplace=True)def forward(self, x):x = self.conv(x)x = self.norm(x)x = self.act(x)return xclass CoordinateAttention(nn.Module):"""坐标注意力模块,用于将位置信息嵌入到通道注意力中。"""def __init__(self,in_chans,reduction=32,norm_cfg='BN',act_cfg='HSwish'):super(CoordinateAttention, self).__init__()self.in_chans = in_chanshidden_chans = max(8, in_chans // reduction)self.conv = ConvModule(in_chans, hidden_chans, kernel_size=1, norm_cfg=norm_cfg, act_cfg=act_cfg)self.attn_h = nn.Conv2d(hidden_chans, in_chans, 1)self.attn_w = nn.Conv2d(hidden_chans, in_chans, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):b, c, h, w = x.size()# (b, c, h, 1)x_h = x.mean(3, keepdim=True)# (b, c, 1, w) -> (b, c, w, 1)x_w = x.mean(2, keepdim=True).permute(0, 1, 3, 2)# (b, c, h + w, 1)y = torch.cat((x_h, x_w), dim=2)y = self.conv(y)# split# x_h: (b, c, h, 1), x_w: (b, c, w, 1)x_h, x_w = torch.split(y, [h, w], dim=2)# (b, c, 1, w)x_w = x_w.permute(0, 1, 3, 2)# compute attentiona_h = self.sigmoid(self.attn_h(x_h))a_w = self.sigmoid(self.attn_w(x_w))return x * a_w * a_h# 示例用法
if __name__ == "__main__":# 创建一个输入特征图,假设批次大小为1,通道数为64,高度和宽度为32input_tensor = torch.randn(1, 64, 32, 32)# 创建CA模块实例,假设输入通道数为64,中间通道数为16ca_module = CoordinateAttention(in_chans=64, reduction=32)# 前向传播,获取带有坐标注意力的特征图output_tensor = ca_module(input_tensor)print(output_tensor.shape) # 输出形状应与输入特征图相同
第七站:SA(2021 ICASSP)- 洗牌注意力的创新

核心思想:
- 通道重排:通过通道重排操作打乱通道顺序,增强模型对通道特征的表达能力
- 分组处理:将输入特征图的通道维度分成多个小组,分别计算通道注意力和空间注意力
- 信息交流:通过通道重排操作将不同子特征之间的信息进行交流
结构示意:
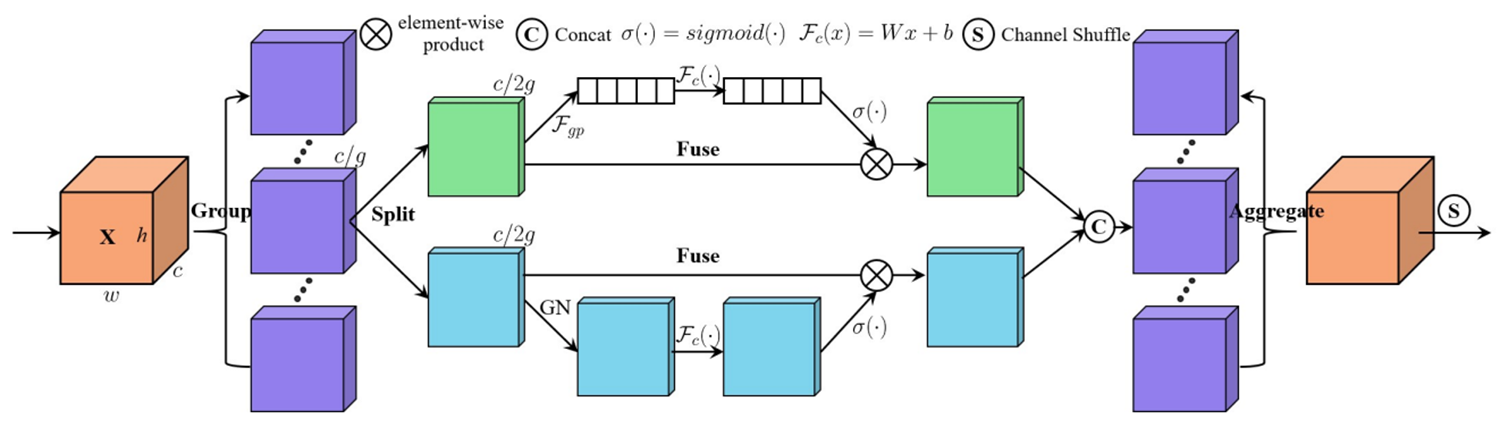
-
结合空间和通道注意力
-
通道重排技术:引入了通道重排,通过通道重排操作将通道顺序打乱,以增强模型对通道特征的表达能力。
-
SA先将输入特征图的通道维度分成多个小组,并进行分组处理。然后,对于每个子特征,使用全局平均池化和组归一化分别计算通道注意力和空间注意力。最后,使用通道重排操作将不同子特征之间的信息进行交流
性能表现:在轻量级模型中Top-1准确率提升3.8%,计算量仅增加1.5%
代码实现:
import torch
import torch.nn as nnclass SA(nn.Module):"""Shuffle Attention"""def __init__(self, in_chans: int, group_num: int = 64):super(SA, self).__init__() # 调用父类 (nn.Module) 的构造函数self.in_chans = in_chans # 输入的通道数self.group_num = group_num # 分组数,默认为64# channel weight and bias:定义通道的权重和偏置self.c_w = nn.Parameter(torch.zeros((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 通道的权重self.c_b = nn.Parameter(torch.ones((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 通道的偏置# spatial weight and bias:定义空间的权重和偏置self.s_w = nn.Parameter(torch.zeros((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 空间的权重self.s_b = nn.Parameter(torch.ones((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 空间的偏置self.gn = nn.GroupNorm(in_chans // (2 * group_num), in_chans // (2 * group_num)) # 定义 GroupNorm 层,用于归一化self.gate = nn.Sigmoid() # 定义 Sigmoid 激活函数,用于生成门控权重@staticmethoddef channel_shuffle(x: torch.Tensor, groups: int):b, c, h, w = x.shape # 获取输入张量的尺寸,b = batch size,c = 通道数,h = 高度,w = 宽度x = x.reshape(b, groups, -1, h, w) # 将输入张量按照 groups 分组,重塑形状x = x.permute(0, 2, 1, 3, 4) # 交换维度,使得通道分组在第二维# flatten:将分组后的张量展平x = x.reshape(b, -1, h, w) # 将分组后的张量恢复为原始的通道数维度return x # 返回重新排列后的张量def forward(self, x: torch.Tensor) -> torch.Tensor:b, c, h, w = x.size() # 获取输入 x 的尺寸,b = batch size,c = 通道数,h = 高度,w = 宽度# (B, C, H, W) -> (B * G, C // G, H, W):将输入张量按照分组数进行重塑x = x.reshape(b * self.group_num, -1, h, w) # 将输入按分组数分组并重新形状x_0, x_1 = x.chunk(2, dim=1) # 将张量 x 沿着通道维度 (dim=1) 切分成两个部分,分别命名为 x_0 和 x_1# (B * G, C // 2G, H, W) -> (B * G, C // 2G, 1, 1):计算通道权重xc = x_0.mean(dim=(2, 3), keepdim=True) # 对 x_0 在高宽维度 (dim=(2, 3)) 上取均值,得到每个通道的平均值xc = self.c_w * xc + self.c_b # 乘以通道权重并加上通道偏置xc = x_0 * self.gate(xc) # 使用 Sigmoid 激活函数进行门控操作,对 x_0 应用门控权重# (B * G, C // 2G, H, W) -> (B * G, C // 2G, 1, 1):计算空间权重xs = self.gn(x_1) # 对 x_1 进行 GroupNorm 归一化xs = self.s_w * xs + self.s_b # 乘以空间权重并加上空间偏置xs = x_1 * self.gate(xs) # 使用 Sigmoid 激活函数进行门控操作,对 x_1 应用门控权重out = torch.cat((xc, xs), dim=1) # 在通道维度上拼接 xc 和 xs,得到最终的输出out = out.reshape(b, -1, h, w) # 恢复为原始的形状 (B, C, H, W)out = self.channel_shuffle(out, 2) # 对输出张量进行通道洗牌,增加模型的表现力return out # 返回最终的输出张量if __name__ == '__main__':model = SA(in_chans=64,group_num=8)x = torch.rand((3, 64, 40, 40))print(model(x).size())
第八站 2023双子星之CPCA(Computers in Biology and Medicine 2023)

核心贡献:
- 医学图像专用的通道先验机制
- 在脑肿瘤分割任务Dice系数提升6.8%
结构示意:
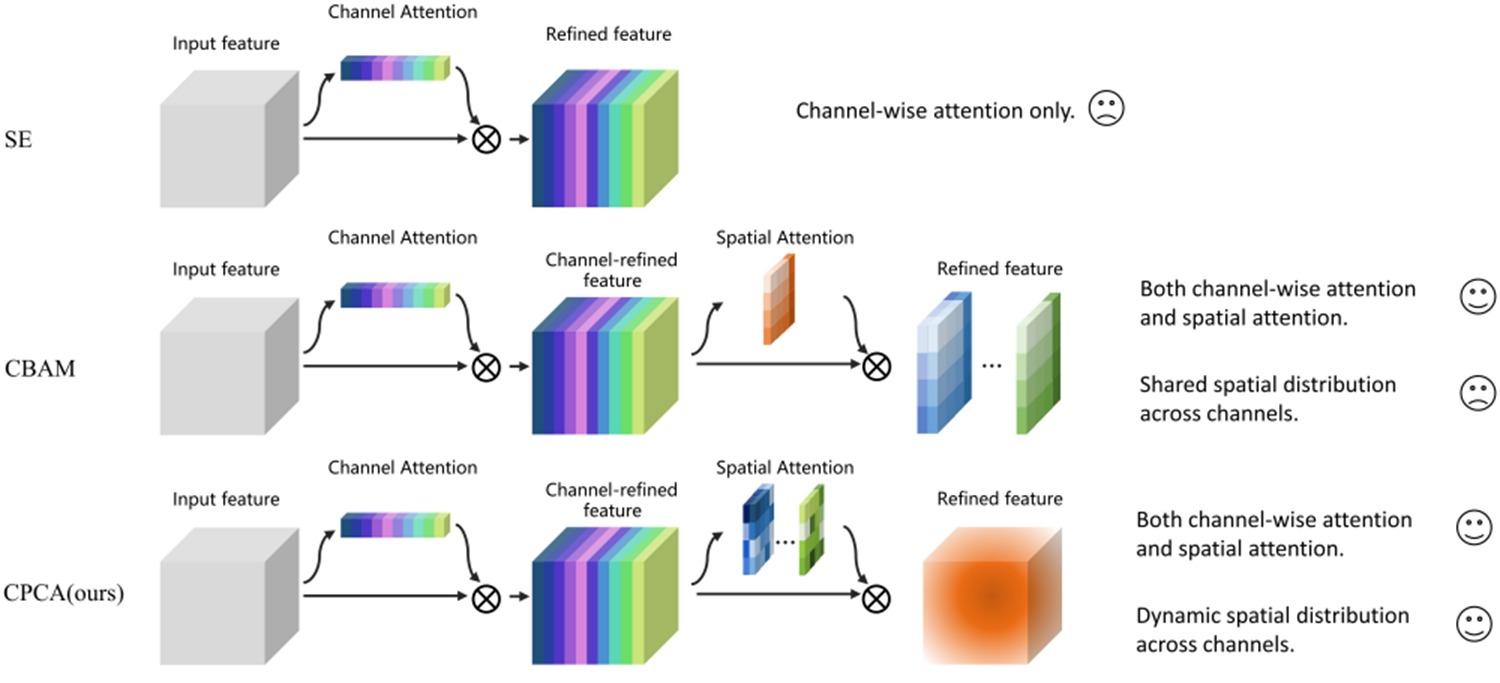
-
动态分配注意力权重:在通道和空间两个维度上动态分配注意力权重,CBAM只是在通道动态。
-
深度可分离卷积模块:采用不同尺度的条形卷积核来提取像素间的空间映射关系,降低计算复杂度的同时,确保了有效信息的提取。
-
通道先验:通过输入特征和通道注意力图的元素相乘来获得通道先验,然后将通道先验输入到深度卷积模块中以生成空间注意力图
代码实现:
import torch
import torch.nn as nnclass ChannelAttention(nn.Module):"""Channel attention module based on CPCAuse hidden_chans to reduce parameters instead of conventional convolution"""def __init__(self, in_chans: int, hidden_chans: int):super().__init__()self.fc1 = nn.Conv2d(in_chans, hidden_chans, kernel_size=1, stride=1, bias=True)self.fc2 = nn.Conv2d(hidden_chans, in_chans, kernel_size=1, stride=1, bias=True)self.act = nn.ReLU(inplace=True)self.in_chans = in_chansdef forward(self, x: torch.Tensor) -> torch.Tensor:"""x dim is (B, C, H, W)"""# (B, C, 1, 1)# 均值池化# 得到通道的全局描述,保留了通道的整体信息,但没有考虑局部的最强特征x1 = x.mean(dim=(2, 3), keepdim=True)x1 = self.fc2(self.act(self.fc1(x1)))x1 = torch.sigmoid(x1)# (B, C, 1, 1)# 最大池化# 保留了通道中的局部最强特征,能够突出图像中最显著的部分,而抑制较弱的特征x2 = x.max(dim=2, keepdim=True)[0].max(dim=3, keepdim=True)[0]x2 = self.fc2(self.act(self.fc1(x2)))x2 = torch.sigmoid(x2)x = x1 + x2x = x.view(-1, self.in_chans, 1, 1)return xclass CPCA(nn.Module):"""Channel Attention and Spatial Attention based on CPCA"""def __init__(self, in_chans, reduction= 16):super(CPCA, self).__init__()self.in_chans = in_chanshidden_chans = in_chans // reduction# 通道注意力(Channel Attention)self.ca = ChannelAttention(in_chans, hidden_chans)# 空间注意力(Spatial Attention)# 使用不同大小的卷积核来捕捉不同感受野的空间信息# 5x5深度可分离卷积self.dwc5_5 = nn.Conv2d(in_chans, in_chans, kernel_size=5, padding=2, groups=in_chans)# 1x7深度可分离卷积self.dwc1_7 = nn.Conv2d(in_chans, in_chans, kernel_size=(1, 7), padding=(0, 3), groups=in_chans)# 7x1深度可分离卷积self.dwc7_1 = nn.Conv2d(in_chans, in_chans, kernel_size=(7, 1), padding=(3, 0), groups=in_chans)# 1x11深度可分离卷积self.dwc1_11 = nn.Conv2d(in_chans, in_chans, kernel_size=(1, 11), padding=(0, 5), groups=in_chans)# 11x1深度可分离卷积self.dwc11_1 = nn.Conv2d(in_chans, in_chans, kernel_size=(11, 1), padding=(5, 0), groups=in_chans)# 1x21深度可分离卷积self.dwc1_21 = nn.Conv2d(in_chans, in_chans, kernel_size=(1, 21), padding=(0, 10), groups=in_chans)# 21x1深度可分离卷积self.dwc21_1 = nn.Conv2d(in_chans, in_chans, kernel_size=(21, 1), padding=(10, 0), groups=in_chans)# 用于建模不同感受野之间的特征连接self.conv = nn.Conv2d(in_chans, in_chans, kernel_size=1, padding=0)self.act = nn.GELU()def forward(self, x):x = self.conv(x) # 先用1x1卷积压缩通道x = self.act(x)channel_attn = self.ca(x) # 计算通道注意力x = channel_attn * x # 通道注意力加权输入特征# 计算空间注意力部分x_init = self.dwc5_5(x) # 先通过5x5卷积x1 = self.dwc1_7(x_init) # 1x7卷积x1 = self.dwc7_1(x1) # 7x1卷积x2 = self.dwc1_11(x_init) # 1x11卷积x2 = self.dwc11_1(x2) # 11x1卷积x3 = self.dwc1_21(x_init) # 1x21卷积x3 = self.dwc21_1(x3) # 21x1卷积# 合并不同卷积结果,形成空间注意力spatial_atn = x1 + x2 + x3 + x_init # 将不同感受野的特征求和spatial_atn = self.conv(spatial_atn) # 再通过1x1卷积进行处理y = x * spatial_atn # 将通道加权后的特征与空间注意力加权的特征相乘y = self.conv(y)return yif __name__ == '__main__':input_tensor = torch.randn(1, 64, 32, 32)attention_module = CPCA(in_chans=64)output_tensor = attention_module(input_tensor)print(output_tensor.shape)
第九站 :2023双子星之EMA**(ICASSP 2023)**

核心思想:
- 多尺度并行子网络捕获跨维度交互
- 在目标检测任务中mAP提升4.2%
结构示意:
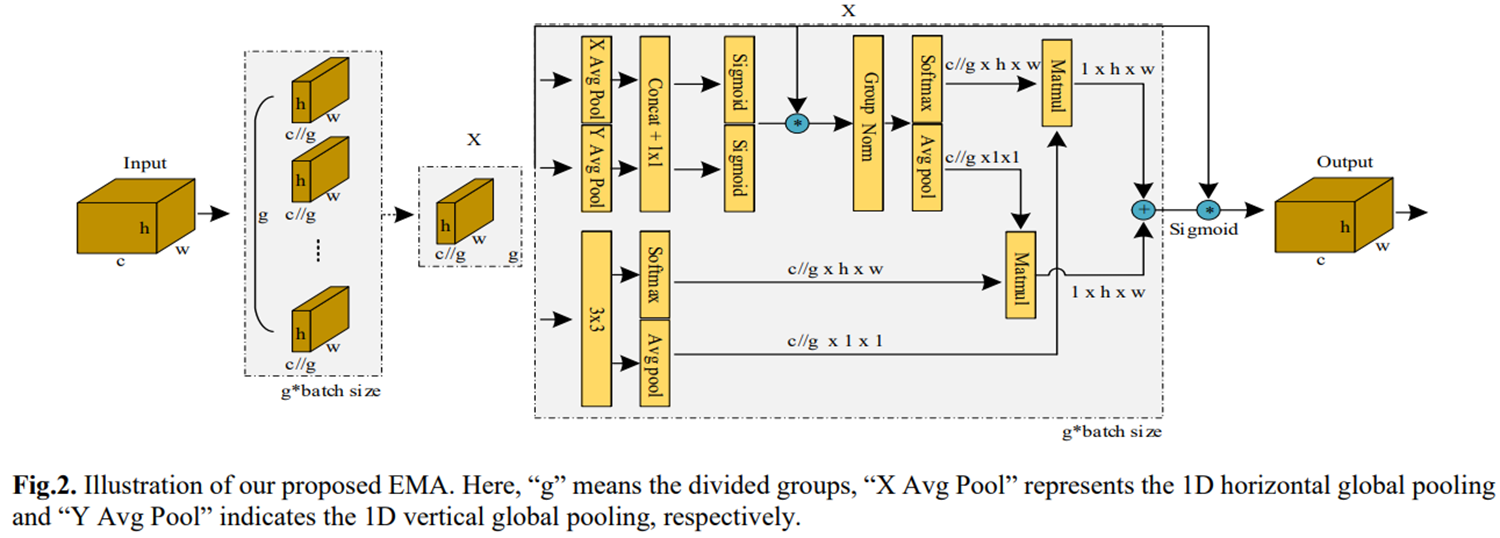
-
通道和空间注意力的结合
-
多尺度并行子网络:包括一个处理1x1卷积核和一个处理3x3卷积核的并行子网络。这种结构有助于有效捕获跨维度交互作用。
-
坐标注意力(CA)的再审视:EMA模块在坐标注意力(CA)的基础上进行了改进和优化。CA模块通过将位置信息嵌入通道注意力图中,实现了跨通道和空间信息的融合。EMA模块在此基础上进一步发展,通过并行子网络块有效捕获跨维度交互作用,建立不同维度之间的依赖关系
代码实现:
import torch
import torch.nn as nnclass EMA(nn.Module):"""EMA: Exponential Moving Average (指数移动平均)"""def __init__(self, channels, factor=32):super(EMA, self).__init__() # 调用父类 (nn.Module) 的构造函数self.groups = factor # 将 factor 赋值给 groups,决定分组数量assert channels // self.groups > 0 # 确保通道数可以被分组数整除,避免出错self.softmax = nn.Softmax(-1) # 定义 Softmax 激活函数,在最后一维进行归一化self.agp = nn.AdaptiveAvgPool2d((1, 1)) # 定义自适应平均池化层,将输入大小压缩为 1x1self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # 定义自适应池化层,按高度进行池化self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # 定义自适应池化层,按宽度进行池化self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 定义 GroupNorm 层self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1,padding=0) # 定义 1x1 卷积层self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1,padding=1) # 定义 3x3 卷积层def forward(self, x):b, c, h, w = x.size() # 获取输入 x 的尺寸,分别为 batch size (b), 通道数 (c), 高度 (h), 宽度 (w)group_x = x.reshape(b * self.groups, -1, h, w) # 将输入 x 重塑为 (b * groups, c//groups, h, w),用于分组处理x_h = self.pool_h(group_x) # 对每组的输入进行高度方向上的池化x_w = self.pool_w(group_x).permute(0, 1, 3, 2) # 对每组的输入进行宽度方向上的池化,并调整维度顺序hw = self.conv1x1(torch.cat([x_h, x_w], dim=2)) # 将池化后的结果在维度2 (高度和宽度) 上拼接,然后通过 1x1 卷积层x_h, x_w = torch.split(hw, [h, w], dim=2) # 将卷积后的结果分割为高度和宽度两个部分x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid()) # 对分组后的输入做加权操作并通过 GroupNormx2 = self.conv3x3(group_x) # 对分组后的输入做 3x3 卷积操作x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 对 x1 进行池化,Softmax 归一化x12 = x2.reshape(b * self.groups, c // self.groups, -1) # 将 x2 重塑为形状 (b*g, c//g, hw)x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 对 x2 进行池化,Softmax 归一化x22 = x1.reshape(b * self.groups, c // self.groups, -1) # 将 x1 重塑为形状 (b*g, c//g, hw)# 计算加权矩阵weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)# 将加权后的结果与输入相乘,并恢复为原始输入形状return (group_x * weights.sigmoid()).reshape(b, c, h, w)if __name__ == '__main__':model = EMA(channels=64)x = torch.rand((3, 64, 40, 40))print(model(x).size())
终章:SSCA(2024 arXiv)- 空间×通道的协同革命

技术亮点:
-
空间注意力(SMSA):
-
4路特征拆分+多核1D卷积(3/5/7/9)
-
Concat+GN+Sigmoid生成空间权重
-
-
通道注意力(PCSA):
-
渐进式特征池化+自注意力矩阵计算
-
在MobileNetV2上Top-1准确率提升5.1%
-
结构示意:
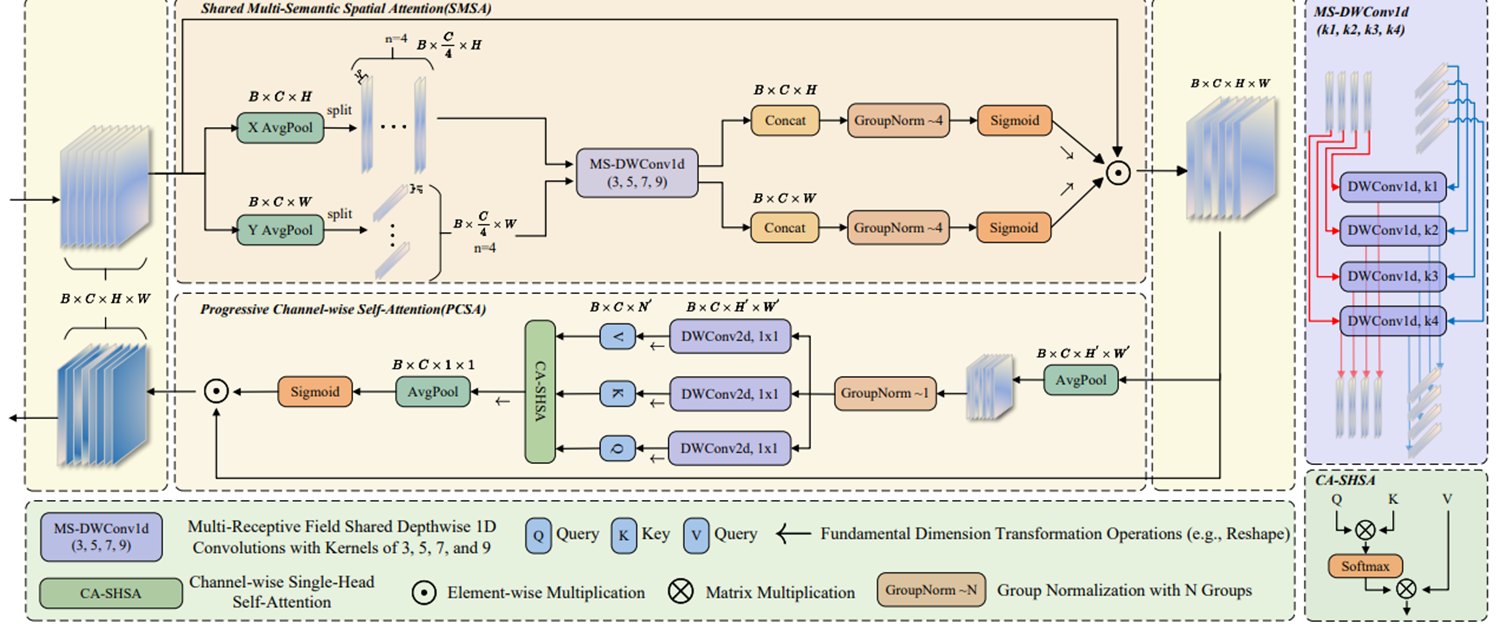
SMSA空间注意力实现原理
-
**平均池化:**分别沿高度和宽度方向
-
**特征拆分:**4等分
-
**特征提取:**四个深度共享1D卷积(卷积核大小分别为3,5,7,9)对各部分特征进行处理
-
空间注意力计算:Concat+GN+Sigmoid
PCSA 通道自注意力实现原理(渐进式)
-
下采样:可选平均池化、最大池化或重组合
-
特征归一化与变换:GN+1×1深度卷积生成查询(q)、键(k)和值(v)
-
注意力矩阵计算:
代码实现:
import typing as t
import torch
import torch.nn as nn
from einops import rearrangeclass SCSA(nn.Module):def __init__(self,dim: int,head_num: int,window_size: int = 7,group_kernel_sizes: t.List[int] = [3, 5, 7, 9],qkv_bias: bool = False,fuse_bn: bool = False,down_sample_mode: str = 'avg_pool',attn_drop_ratio: float = 0.,gate_layer: str = 'sigmoid',):super(SCSA, self).__init__() # 调用 nn.Module 的构造函数self.dim = dim # 特征维度self.head_num = head_num # 注意力头数self.head_dim = dim // head_num # 每个头的维度self.scaler = self.head_dim ** -0.5 # 缩放因子self.group_kernel_sizes = group_kernel_sizes # 分组卷积核大小self.window_size = window_size # 窗口大小self.qkv_bias = qkv_bias # 是否使用偏置self.fuse_bn = fuse_bn # 是否融合批归一化self.down_sample_mode = down_sample_mode # 下采样模式assert self.dim % 4 == 0, 'The dimension of input feature should be divisible by 4.' # 确保维度可被4整除self.group_chans = group_chans = self.dim // 4 # 分组通道数# 定义局部和全局深度卷积层self.local_dwc = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[0],padding=group_kernel_sizes[0] // 2, groups=group_chans)self.global_dwc_s = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[1],padding=group_kernel_sizes[1] // 2, groups=group_chans)self.global_dwc_m = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[2],padding=group_kernel_sizes[2] // 2, groups=group_chans)self.global_dwc_l = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[3],padding=group_kernel_sizes[3] // 2, groups=group_chans)# 注意力门控层self.sa_gate = nn.Softmax(dim=2) if gate_layer == 'softmax' else nn.Sigmoid()self.norm_h = nn.GroupNorm(4, dim) # 水平方向的归一化self.norm_w = nn.GroupNorm(4, dim) # 垂直方向的归一化self.conv_d = nn.Identity() # 直接连接self.norm = nn.GroupNorm(1, dim) # 通道归一化# 定义查询、键和值的卷积层self.q = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)self.k = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)self.v = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)self.attn_drop = nn.Dropout(attn_drop_ratio) # 注意力丢弃层self.ca_gate = nn.Softmax(dim=1) if gate_layer == 'softmax' else nn.Sigmoid() # 通道注意力门控# 根据窗口大小和下采样模式选择下采样函数if window_size == -1:self.down_func = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化else:if down_sample_mode == 'recombination':self.down_func = self.space_to_chans # 重组合下采样# 维度降低self.conv_d = nn.Conv2d(in_channels=dim * window_size ** 2, out_channels=dim, kernel_size=1, bias=False)elif down_sample_mode == 'avg_pool':self.down_func = nn.AvgPool2d(kernel_size=(window_size, window_size), stride=window_size) # 平均池化elif down_sample_mode == 'max_pool':self.down_func = nn.MaxPool2d(kernel_size=(window_size, window_size), stride=window_size) # 最大池化def forward(self, x: torch.Tensor) -> torch.Tensor:"""输入张量 x 的维度为 (B, C, H, W)"""# 计算空间注意力优先级b, c, h_, w_ = x.size() # 获取输入的形状# (B, C, H)x_h = x.mean(dim=3) # 沿着宽度维度求平均l_x_h, g_x_h_s, g_x_h_m, g_x_h_l = torch.split(x_h, self.group_chans, dim=1) # 拆分通道# (B, C, W)x_w = x.mean(dim=2) # 沿着高度维度求平均l_x_w, g_x_w_s, g_x_w_m, g_x_w_l = torch.split(x_w, self.group_chans, dim=1) # 拆分通道# 计算水平注意力x_h_attn = self.sa_gate(self.norm_h(torch.cat(( self.local_dwc(l_x_h),self.global_dwc_s(g_x_h_s),self.global_dwc_m(g_x_h_m),self.global_dwc_l(g_x_h_l),), dim=1)))x_h_attn = x_h_attn.view(b, c, h_, 1) # 调整形状# 计算垂直注意力x_w_attn = self.sa_gate(self.norm_w(torch.cat(( self.local_dwc(l_x_w),self.global_dwc_s(g_x_w_s),self.global_dwc_m(g_x_w_m),self.global_dwc_l(g_x_w_l)), dim=1)))x_w_attn = x_w_attn.view(b, c, 1, w_) # 调整形状# 计算最终的注意力加权x = x * x_h_attn * x_w_attn# 基于自注意力的通道注意力# 减少计算量y = self.down_func(x) # 下采样y = self.conv_d(y) # 维度转换_, _, h_, w_ = y.size() # 获取形状# 先归一化,然后重塑 -> (B, H, W, C) -> (B, C, H * W),并生成 q, k 和 vy = self.norm(y) # 归一化q = self.q(y) # 计算查询k = self.k(y) # 计算键v = self.v(y) # 计算值# (B, C, H, W) -> (B, head_num, head_dim, N)q = rearrange(q, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),head_dim=int(self.head_dim))k = rearrange(k, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),head_dim=int(self.head_dim))v = rearrange(v, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),head_dim=int(self.head_dim))# 计算注意力attn = q @ k.transpose(-2, -1) * self.scaler # 点积注意力计算attn = self.attn_drop(attn.softmax(dim=-1)) # 应用注意力丢弃# (B, head_num, head_dim, N)attn = attn @ v # 加权值# (B, C, H_, W_)attn = rearrange(attn, 'b head_num head_dim (h w) -> b (head_num head_dim) h w', h=int(h_), w=int(w_))# (B, C, 1, 1)attn = attn.mean((2, 3), keepdim=True) # 求平均attn = self.ca_gate(attn) # 应用通道注意力门控return attn * x # 返回加权后的输入if __name__ == "__main__":#参数: dim特征维度; head_num注意力头数; window_size = 7 窗口大小scsa = SCSA(dim=32, head_num=8, window_size=7)# 随机生成输入张量 (B, C, H, W)input_tensor = torch.rand(1, 32, 256, 256)# 打印输入张量的形状print(f"输入张量的形状: {input_tensor.shape}")# 前向传播output_tensor = scsa(input_tensor)# 打印输出张量的形状print(f"输出张量的形状: {output_tensor.shape}")
后续发展:注意力机制的三个趋势
- 高效性:向轻量化、无参数方向发展(如ECA、ELA)
- 多模态融合:探索视觉+语言的跨模态注意力
- 自适应机制:动态调整计算资源分配
结语
从SE到SSCA,注意力机制正从"单一增强"走向"协同进化"。下一个突破点会是动态可重构的注意力吗?让我们共同见证深度学习的新篇章!
相关文章:

CNN注意力机制的进化史:深度解析10种注意力模块如何重塑卷积神经网络
🌟 引言:注意力为何改变CNN的命运? 就像人类视觉会优先聚焦于重要信息,深度学习模型也需要"学会看重点"。从2018年SENet首提通道注意力,到2024年SSCA探索空间-通道协同效应,注意力机制正成为CNN…...

字符串与字符数组的对比
在 C 语言中,字符串 和 字符数组 密切相关,但又有重要区别。以下是它们的对比: 1. 基本定义 字符数组 (char array) 是一个固定大小的数组,元素类型是 char。可以存储字符序列,但不一定以 \0 结尾。例如:…...

mapbox进阶,模仿百度,实现不同楼栋室内楼层切换
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️fill-extrusion 三维填充(白膜)图层样…...
——图像金字塔(上采样、下采样))
OpenCv高阶(一)——图像金字塔(上采样、下采样)
目录 图像金字塔 一、上下采样原理 1、向下取样 2、向上采样 3、图像金字塔的作用 二、案例实现 1、高斯下采样 2、高斯金字塔中的上采样 3、对下采样的结果做上采样,图像变模糊,无法复原 4、拉普拉斯金字塔(图片复原) 图…...

如何避免“过度承诺”导致的验收失败
如何避免“过度承诺”导致的验收失败?关键在于: 评估可行性、设置合理目标、高频沟通反馈、阶段性验收、做好风险管理。其中设置合理目标至关重要,很多团队往往在项目初期为迎合客户或领导而报出“最理想方案”,忽略了资源、技术及…...

Python爬虫第7节-requests库的高级用法
目录 前言 一、文件上传 二、Cookies 三、会话维持 四、SSL证书验证 五、代理设置 六、超时设置 七、身份认证 八、Prepared Request 前言 上一节,我们认识了requests库的基本用法,像发起GET、POST请求,以及了解Response对象是什么。…...

mysql里面的TIMESTAMP类型对应java什么类型
在MySQL中,TIMESTAMP类型用来存储日期和时间值,显示为YYYY-MM-DD HH:MM:SS格式。在Java中,可以使用java.sql.Timestamp类来对应MySQL中的TIMESTAMP类型。 在Java的POJO(Plain Old Java Object)中,如果你想要…...

Java核心技术面试题
Java面试题分享 通过网盘分享的文件:面试题等2个文件 链接: https://pan.baidu.com/s/1Xw0PzkfAmL8uesYBvrW2-A?pwdpebt 提取码: pebt 一、Java基础篇 1. OOP面向对象 面向对象编程(OOP)是一种编程范式,它利用“类”和“对象”来…...
SpringBoot整合Kafka之生产者Producer)
【技海登峰】Kafka漫谈系列(十)SpringBoot整合Kafka之生产者Producer
【技海登峰】Kafka漫谈系列(十)SpringBoot整合Kafka之生产者Producer spring-kafka官方文档: https://docs.spring.io/spring-kafka/docs/2.8.10/reference/pdf/spring-kafka-reference.pdf KafkaTemplate API: https://docs.spring.io/spring-kafka/api/org/springframewo…...

【简单理解什么是简单工厂、工厂方法与抽象工厂模式】
一、简单工厂模式 1.简单工厂模式 通过一个工厂类集中管理对象的创建 ,通过参数决定具体创建哪个对象。 #适合对象类型较少且变化不频繁的场景,缺点是违反开闭原则(新增产品需修改工厂类) 开闭原则(对扩展开放对修改关闭) :当…...

C++之nullptr
文章目录 前言 一、NULL 1、代码 2、结果 二、nullptr 1、代码 2、结果 总结 前言 当我们谈论空指针时,很难避免谈及nullptr。nullptr是C++11引入的一个关键字,用来表示空指针。在C++中,空指针一直是一个容易引起混淆的问题,因为在早期版本的C++中,通常使用NULL来…...

Java List<JSONObject> 中的数据转换为 List<T>
从方法的功能推测,T 应该是一个具体的 Java Bean 类型,用于将 List<JSONObject> 中的数据转换为 List<T>。以下为你详细介绍如何传递泛型 T 以及如何实现该方法。 import com.alibaba.fastjson.JSONObject; import java.util.ArrayList; im…...

下【STL 之速通pair vector list stack queue set map 】
上一篇 【STL 之速通pair vector list stack queue set map 】 queue note priority_queue pq; 使用的还是很方便的 #include <iostream> #include <queue>using namespace std;int main() {// Queue 示例queue<int> q;q.push(10);q.push(20);q.push(30);…...

安装大数据分析利器Spark
大数据分析利器Spark:部署模式与实践全解析 在大数据领域,Spark是一个热门的开源框架,今天就带大家深入了解Spark及其常见部署模式。Spark是基于内存的快速、通用、可扩展的大数据分析计算引擎,诞生于伯克利大学。与Hadoop相比&a…...

遨游科普:三防平板是指哪三防?有哪些应用场景?
在工业4.0与数字化转型的浪潮中,平板电脑早已突破消费娱乐的边界,成为工业生产流程中不可或缺的智能终端。但是,传统消费级平板在复杂工业环境中的“脆弱性”——屏幕易碎、接口易进尘、机身惧水等问题——严重制约了其在专业领域的深度应用。…...

9. RabbitMQ 消息队列幂等性,优先级队列,惰性队列的详细说明
9. RabbitMQ 消息队列幂等性,优先级队列,惰性队列的详细说明 文章目录 9. RabbitMQ 消息队列幂等性,优先级队列,惰性队列的详细说明1. RabbitMQ 消息队列的 “ 幂等性 ” 的问题1.1 RabbitMQ 消息队列的“幂等性”的概念 2. Rabbi…...

k8s创建一个pod,查看状态和详细信息,进入pod,以及删除这个pod
在 Kubernetes(K8s)中,可以使用 kubectl 命令行工具来完成创建 Pod、查看状态和详细信息、进入 Pod 以及删除 Pod 的操作。以下是具体步骤: 创建一个 Pod: 假设你有一个简单的 nginx Pod 的 YAML 配置文件 nginx…...

从盲目清运到精准调度:一个AI芯片引发的智慧环卫升级
在深圳某科技园区的清晨,环卫工人老张发现一个奇怪现象:往常需要逐个检查的50个智能垃圾桶,今天系统自动标注了7个待清运点位。这背后是搭载全志T113-i处理器的智能垃圾桶系统在发挥作用,通过AI视觉识别将垃圾满溢检测准确率提升至…...

MQTT协议:IoT通信的轻量级选手
文章总结(帮你们节约时间) MQTT协议是一种轻量级的发布/订阅通信协议。MQTT通信包括连接建立、订阅、发布和断开等过程。MQTT基于TCP/IP,其通信过程涉及多种控制包和数据包。ESP32S3可以通过MQTT协议接收消息来控制IO9引脚上的LED。 想象一…...

Docker 入门指南:基础知识解析
1. 引言 1.1 为什么学习 Docker 1.1.1 Docker 的优势 环境一致:在不同环境中(开发、测试、生产)保持一致的运行环境。快速部署:容器启动速度快,适合微服务架构。资源隔离:容器之间相互隔离,避…...

【安当产品应用案例100集】043-安当物联网数据安全传输方案
一、需求背景 物联网(IoT)技术在当前世界各行业中的应用越来越广泛,数据安全和安全数据传输、鉴权成为了物联网解决方案不可或缺的一部分。如何通过有效的安全措施来保护物联网设备的数据传输和鉴权,确保数据在设备和服务器之间或…...
)
C#/.NET/.NET Core技术前沿周刊 | 第 33 期(2025年4.1-4.6)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。 欢迎投稿、推荐…...

Django视图详解
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 一、Django视图是什么? 视图(View) 是Django处理HTTP请求的核心组件。它接收一个HttpRequest对象,处理业务逻辑,并返回一个HttpResponse对象(…...

【区块链+ 人才服务】北京师范大学区块链底层链平台 | FISCO BCOS 应用案例
北京师范大学是教育部直属重点大学,2018 年 6 月,北京师范大学成立知识区块链研究中心,致力于区块链基础技术及其在教育领域的应用研究。 2020 年6 月18 日, 北京市人民政府办公厅发布《北京市区块链创新发展行 动计划(2020—202…...

java设计模式-模板方法模式
模板方法模式 编写制作豆浆的程序,说明如下 1)制作豆浆的流程选材添加配料浸泡放到豆浆机打碎 2)通过添加不同的配料,可以制作出不同口味的豆浆 3)选材、浸泡和放到豆浆机打碎这几个步骤对于制作每种口味的豆浆都是一样的 4)请使用模板方法模式完成 说明…...

同步通信、异步通信、并行传输和串行传输
同步通信、异步通信、并行传输和串行传输是通信与数据传输领域的关键概念,它们既相互关联又有本质区别。以下是详细解释和对比: 1. 核心概念分类 通信方式:描述数据传输的时序和协调规则。 同步通信(Synchronous Communi…...

JVM生产环境调优实战
案例三:JVM频繁Full GC优化 1. 项目背景(Situation) 在云中万维跨境支付的反洗钱系统中,我们负责对海量交易数据进行实时规则校验,以确保符合监管要求。系统日均处理交易量超过500万笔,峰值QPS达到3000&a…...

Python: sqlite3.OperationalError: no such table: ***解析
出现该错误说明数据库中没有成功创建 reviews 表。以下是完整的解决方案: 步骤 1:创建数据库表 在插入数据前,必须先执行建表语句。请通过以下任一方式创建表: 方式一:使用 SQLite 命令行 bash 复制 # 进入 SQLit…...
:鸿蒙初辟——从太极二进到混沌原初的编译天道)
JVM考古现场(十七):鸿蒙初辟——从太极二进到混沌原初的编译天道
"此刻正是奇点编译的第3.1415926秒!伏羲的算筹正在撕裂冯诺依曼架构的次元壁!诸君请看——这JVM堆内存中正在孕育盘古的元神!" 目录(终极扩展) 第一章:太极二进——内存模型的阴阳交缠 第二章&a…...
)
Python 字典和集合(字典推导)
本章内容的大纲如下: 常见的字典方法 如何处理查找不到的键 标准库中 dict 类型的变种set 和 frozenset 类型 散列表的工作原理 散列表带来的潜在影响(什么样的数据类型可作为键、不可预知的 顺序,等等) 字典推导 自 Python 2.7 …...

【AI】prompt engineering
prompt engineering ## prompt engineering ## prompt engineering ## prompt engineering 一、定义 Prompt 工程(Prompt Engineering)是指在使用语言模型(如 ChatGPT、文心一言等)等人工智能工具时,设计和优化输入提…...

小刚说C语言刷题——第18讲 循环之while和do-while语句
昨天我们讲了循环语句中的for语句,它主要用于循环次数已知的情况,但是对应循环次数未知的情况,我们又怎么办?这就要用到while和do-while语句了。 1.while语句 (1)语法格式 while(条件表达式) { 循环体; } (2)执行过程 当执…...

[Mysql]buffersize修改
1、找到my.cnf文件位置 ps -ef|grep mysqld 2、编辑my.cnf cd /etc/my.cnf.d vim my.cnf 一般修改为内存的50%~70% 3、重启服务 systemctl restart mysqld...

自定义数据结构的QVariant序列化 ASSERT failure in QVariant::save: “invalid type to save“
自定义数据结构放入QVariant,在序列化时抛出异常 ASSERT failure in QVariant::save: “invalid type to save” 自定义数据结构如struct MyData,除了要在结构体后面加 struct MyData { ... } Q_DECLARE_METATYPE(MyData)如果需要用到流的输入输出&…...

带约束的智能优化算法
带约束的智能优化算法 约束条件和优化问题(可改)粒子群算法麻雀搜索算法鲸鱼优化算法灰狼优化算法免疫优化算法人工蜂群算法沙猫群算法萤火虫算法资源 约束条件和优化问题(可改) 粒子群算法 麻雀搜索算法 鲸鱼优化算法 灰狼优化算法 免疫优化算法 人工蜂群算法 沙猫群算法 萤火…...

【硬核实战】从零打造智能五子棋AI:JavaScript实现与算法深度解析
🌟【硬核实战】从零打造智能五子棋AI:JavaScript实现与算法深度解析🌟 📜 前言:当传统棋艺遇上人工智能 五子棋作为中国传统棋类游戏,规则简单却变化无穷。本文将带你用纯前端技术实现一个具备AI对战功能…...

使用 kind 创建 K8s 集群并部署 StarRocks 的完整指南
使用 kind 创建 K8s 集群并部署 StarRocks 的完整指南 本文档详细介绍如何使用 kind 创建 Kubernetes 集群,并在其上使用 Helm 部署 StarRocks 集群(非高可用模式)。同时也包括如何访问 StarRocks 集群并导入数据。 目录 前提条件参考文档…...

华为OD全流程解析+备考攻略+经验分享
华为OD全流程解析,备考攻略 快捷目录 华为OD全流程解析,备考攻略一、什么是华为OD?二、什么是华为OD机试?三、华为OD面试流程四、华为OD薪资待遇及职级体系五、ABCDE卷类型及特点六、题型与考点七、机试备考策略八、薪资与转正九、…...

数据库中的数组: MySQL与StarRocks的数组操作解析
在现代数据处理中, 数组 (Array) 作为一种高效存储和操作结构化数据的方式, 被广泛应用于日志分析, 用户行为统计, 标签系统等场景. 然而, 不同数据库对数组的支持差异显著. 本文将以MySQL和StarRocks为例, 深入解析它们的数组操作能力, 并对比其适用场景. 文章目录 一 为什么需…...

Qt 交叉编译详细配置指南
一、Qt 交叉编译详细配置 1. 准备工作 1.1 安装交叉编译工具链 # 例如安装ARM工具链(Ubuntu/Debian) sudo apt-get install gcc-arm-linux-gnueabihf g++-arm-linux-gnueabihf# 或者64位ARM sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu 1.2 准备目标…...

【详细图文】在VScode中配置python开发环境
目录 一、下载安装VSCode 1、官网下载VSCode 2、安装VSCode 3、汉化vscode (1)已自动下载汉化版插件 (2)未自动下载汉化版插件 二、 下载安装Python 1、官网下载Python 2、安装Python (1)双击打开…...

strings.Fields 使用详解
目录 1. 官方包 2. 支持版本 3. 官方说明 4. 作用 5. 实现原理 6. 推荐使用场景和不推荐使用场景 推荐场景 不推荐场景 7. 使用场景示例 示例1:官方示例 示例2:解析服务器日志 示例3:清理用户输入 8. 性能比较 性能特点 对比表…...

PCI认证 密钥注入 ECC算法工具 NID_secp521r1 国密算法 openssl 全套证书生成,从证书提取公私钥数组 x,y等
步骤 1.全套证书已经生成。OK 2.找国芯要ECC加密解密签名验签代码。给的逻辑说明没有示例代码很难的上。 3.集成到工具 与SP联调。 1.用openssl全套证书生成及验证 注意:这里CA 签发 KLD 证书用的是SHA256。因为芯片只支持SHA256算法,不支持SHA512。改成统一。…...
概念)
微软 SC-900 认证-考核Azure 和 Microsoft 365中的安全、合规和身份管理(SCI)概念
微软 SC-900 认证介绍 SC-900 认证考试是微软推出的一项基础级别认证,全称为 Microsoft Certified: Security, Compliance, and Identity Fundamentals。该认证旨在验证考生对微软云服务(如 Azure 和 Microsoft 365)中的安全、合规和身份管理…...
完整指南)
Uniapp 集成极光推送(JPush)完整指南
文章目录 前言一、准备工作1. 注册极光开发者账号2. 创建应用3. Uniapp项目准备 二、集成极光推送插件方法一:使用UniPush(推荐)方法二:手动集成极光推送SDK 三、配置原生平台参数四、核心功能实现1. 获取RegistrationID2. 设置别…...

OpenCV图像平滑处理方法详解
文章目录 引言一、什么是图像平滑?二、常见的图像平滑方法1.先对图片加上噪声点2. 均值滤波(Averaging)3. 方框滤波(boxFilter)4. 中值滤波(Median Blur)5. 高斯滤波(Gaussian Blur&…...

Lua 中,`math.random` 的详细用法
在 Lua 中,math.random 是用于生成伪随机数的核心函数。以下是其详细用法、注意事项及常见问题的解决方案: Lua 中,math.random 的详细用法—目录 一、基础用法1. 生成随机浮点数(0 ≤ x < 1)2. 生成指定范围的随机…...
)
使用PX4,gazebo,mavros为旋翼添加下视的相机(仿真采集openrealm数据集-第一步)
目录 一.方法一(没成功) 1.运行PX4 2.运行mavros通讯 3.启动仿真世界和无人机 (1)单独测试相机 (2)make px4_sitl gazebo启动四旋翼iris无人机 二.方法二(成功) 1.通过 rosl…...

ATEngin开发记录_4_使用Premake5 自动化构建跨平台项目文件
该系列只做记录 不做教程 所以文章简洁直接 会列出碰到的问题和解决方案 只适合C萌新 文章目录 Permake5为什么使用 Premake? 项目实战总结一下:详细代码: Permake5 Premake5 是一个跨平台的构建配置工具,它允许开发者通过使用一个简单的脚…...
 和 hashCode())
equals() 和 hashCode()
作为 Java 开发者,我们经常会用到 equals() 和 hashCode() 这两个方法。 它们是 Object 类中定义的基础方法,看似简单,但如果理解不透彻,很容易在实际开发中踩坑。 本文将深入探讨这两个方法的作用、区别、以及如何正确地重写它们…...