深度强化学习基础 1:以狗狗学习握手为例
强化学习共同框架
在这个狗狗学习握手的场景中,强化学习的各个要素可以这样理解:
-
状态s(state): 狗狗所处的环境状况,比如主人伸出手掌的姿势、狗狗自身的姿势、周围的环境等。状态s描述了狗狗在特定时刻所感知到的环境信息。
-
动作a(action): 狗狗可以采取的行为,如抬起前爪、将爪子放在主人手上、坐下、站立等。这些是狗狗能够主动执行的所有可能行为。
-
奖励r(reward): 狗狗执行动作后获得的反馈。当狗狗正确抬爪握手时,获得骨头作为正向奖励;不握手则没有奖励;如果咬主人,则会受到负面惩罚。
-
策略π(policy): 狗狗在特定状态下选择动作的行为准则。比如,当主人伸出手时(状态s),狗狗应该抬起前爪放在主人手上(动作a)的概率很高。随着学习的进行,狗狗会优化这个策略,使得在正确的时机做出正确的动作。
-
状态值函数V(s): 表示狗狗处于状态s时,按照当前策略行动能够获得的长期期望奖励。例如,当主人伸手示意时(特定状态s),狗狗预期能获得的总奖励值。如果这个状态通常会引导到获得骨头的结果,那么这个状态的V值就会很高。
-
状态-动作值函数Q(s,a): 表示狗狗在状态s下执行动作a,然后按照当前策略行动所能获得的长期期望奖励。比如,当主人伸手(状态s)时,狗狗选择抬爪(动作a)的Q值会很高,因为这通常能获得骨头奖励;而选择咬人(另一个动作)的Q值会很低,因为会导致惩罚。
Agent(狗子)根据状态选择,并执行最优动作 - 拿最高奖励。
想象一下,我们开始训练一只名叫小黑的狗狗学习握手。
刚开始时,小黑对于什么行为会带来奖励一无所知,它处于初始状态s₀(主人伸出手)。
此时,小黑的策略π还很随机,它可能尝试各种动作a——坐下、转圈、抬爪等。
每种动作a都有其对应的状态-动作值Q(s₀,a),但由于小黑还没有学习经验,这些Q值初始都很低或相近。
当小黑随机尝试抬起前爪放在主人手上这个动作时,主人立即给予骨头奖励r。
通过这次经验,小黑更新了状态s₀的价值V(s₀),认识到这是一个有价值的状态。
同时,它也更新了在状态s₀下执行"抬爪"这个动作a的Q值Q(s₀,抬爪)。
随着训练的继续,小黑会不断调整其策略π,逐渐增加在状态s₀下选择"抬爪"动作的概率,因为这个动作的预期回报很高。
而如果小黑尝试了咬主人这个动作,会受到惩罚,导致这个动作的Q值大幅降低,使得小黑在未来的策略中减少选择这种行为的可能性。
经过多次训练后,小黑学会了最优策略π*:当主人伸手时(状态s),一定要抬爪放在主人手上(动作a),因为这个状态-动作组合有最高的Q值,能带来最大的期望奖励。
此时,小黑已经成功掌握了"握手"这个技能,实现了学习目标。
在整个过程中,小黑并不知道环境(主人的训练规则)是如何运作的,只能通过不断尝试不同动作,观察获得的奖励,进而优化自己的行为策略,这正是强化学习的核心思想。
主要的强化学习算法家族
- 基于值函数的方法
:如Q-learning和SARSA,它们专注于学习Q(s,a)值
- 基于策略的方法
:如策略梯度法,直接优化策略π
- 演员-评论家方法
:结合了以上两种方法的优点
- 基于模型的方法
:尝试学习环境的模型来辅助决策
Q-learning 算法:狗狗学习握手
小黑是一只正在学习握手的狗狗。Q-learning 算法的训练过程是这样的:
-
初始阶段:小黑对于主人伸手这个状态下应该做什么完全不知道。它有一个空白的"记忆表格"(Q表),记录每个状态下每个动作的价值。
-
探索与尝试:小黑开始随机尝试各种动作 - 有时抬爪,有时坐下,有时转圈。
-
更新Q值:当小黑尝试抬爪并获得骨头奖励时,它在Q表中记录:"主人伸手状态下,抬爪动作的Q值很高"。如果咬主人并受到惩罚,则记录这个动作的Q值很低。
-
贪心选择与探索平衡:随着训练进行,小黑大部分时间会选择Q值最高的动作(抬爪),但偶尔也会尝试其他动作,看看是否有更好的选择。
-
收敛到最优策略:最终,小黑的Q表会清晰地显示在主人伸手状态下,抬爪的Q值最高,它就会稳定地选择这个动作。
策略梯度法:狗狗学习握手
同样是小黑学习握手,但策略梯度法不同:
-
直接学习策略:小黑不记录Q值表格,而是直接学习"看到主人伸手→抬爪"这样的策略映射。
-
概率分布:小黑的策略是一个概率分布 - "主人伸手时,80%概率抬爪,15%概率坐下,5%概率转圈"。
-
根据奖励调整概率:当抬爪获得骨头奖励后,小黑提高抬爪的概率;当其他动作没有奖励或受到惩罚时,降低这些动作的概率。
-
梯度上升:小黑按照"如果这个动作带来好结果,就增加它的概率"的原则来调整自己的行为倾向。
-
收敛到最优策略:最终,小黑会形成"主人伸手时,99%概率抬爪"的策略,完成训练目标。
演员-评论家算法:狗狗学习握手
小黑的大脑有两个部分工作:
-
评论家部分:评估状态的价值(V值),告诉小黑"主人伸手这个状态很有价值,可能会得到骨头"。
-
演员部分:决定具体动作,"既然主人伸手是有价值的状态,我应该选择抬爪这个动作"。
-
协同工作:评论家帮助小黑判断自己处于好的还是坏的状态,演员则负责在这些状态下选择合适的动作。
-
同步学习:小黑的评论家部分学习判断状态价值,演员部分学习在有价值的状态下选择最优动作。
-
共同进步:随着训练进行,评论家越来越准确地评估状态价值,演员越来越擅长选择好的动作,最终小黑稳定地在主人伸手时抬爪握手。
这些不同算法虽然侧重点和实现方式不同,但都在处理同样的核心概念 - 状态、动作、奖励、策略等,只是组织和学习这些概念的方式有所不同,就像不同的教学方法可以教会小黑同样的握手技能。
蒙特卡洛
蒙特卡洛方法的核心特点是通过完整经历(整个训练回合)来学习,而不是像其他方法那样逐步更新。
让我们看看这如何应用于训练小黑学习握手:
-
基于完整回合的学习:与Q-learning不同,蒙特卡洛方法要求小黑完成整个训练回合(或"情节"episode)后才会更新它的价值认知。
-
训练回合设计:一个完整回合可能是这样的:
-
开始:主人伸出手(初始状态)
-
小黑做出各种动作(抬爪、坐下等)
-
主人给予相应反馈(奖励或惩罚)
-
结束:主人收回手,训练回合结束
-
-
价值估计方式:蒙特卡洛方法直接通过多次训练回合的实际体验来估计各状态-动作组合的价值:
-
第一天训练:小黑在"主人伸手"状态下尝试"抬爪",最终获得骨头,记录这次体验
-
第二天训练:再次尝试"抬爪",再次获得骨头,记录下来
-
第三天训练:尝试"坐下",没有获得奖励,也记录下来
-
-
平均回报计算:小黑会计算每个状态-动作组合的平均回报:
-
"主人伸手+抬爪"组合在多次训练中平均获得+10的奖励
-
"主人伸手+坐下"组合平均获得0的奖励
-
-
探索与利用平衡:蒙特卡洛方法通常采用ε-贪心策略,即:
-
大部分时间(如90%)小黑选择当前认为最有价值的动作(抬爪)
-
少部分时间(如10%)随机尝试其他动作,确保充分探索所有可能性
-
-
策略改进:随着训练回合的增加,小黑逐渐形成更准确的状态-动作价值估计,并据此改进策略:
-
发现"主人伸手+抬爪"的平均回报最高
-
逐渐增加在"主人伸手"状态下选择"抬爪"的概率
-
-
没有自举(bootstrapping):与动态规划和时序差分方法不同,蒙特卡洛方法不依赖于估计值来更新估计值(不自举),而是完全基于实际经验。小黑不会基于对未来状态的预测来调整当前动作的价值,而是等待看到整个训练回合的实际结果。
实际训练过程可能是这样的:
小黑经历多个完整的训练回合,每个回合都从主人伸手开始,到主人收回手结束。
在每个回合中,小黑尝试不同的动作,并记录下这些动作最终带来的总奖励。
经过许多回合后,小黑会发现在主人伸手时选择抬爪动作,平均能获得最高的回报,于是它的策略会逐渐偏向于在主人伸手时选择抬爪这个动作。
这种方法的优点是概念简单直观,就像小黑凭借完整的训练经验来学习,而不是尝试预测中间步骤的价值。
缺点是需要等待整个回合结束才能学习,可能效率较低,特别是对于较长的训练回合。
时序差分
时序差分方法的核心特点是结合了蒙特卡洛方法的实际体验和动态规划的自举(bootstrapping)特性。
它不等待整个训练回合结束,而是在每一步之后就立即学习。应用于训练小黑学习握手:
-
逐步学习:时序差分方法的关键在于小黑不需要等待整个训练回合结束,而是每完成一个动作并观察到即时奖励和下一个状态后,就可以立即更新它的价值估计。
-
学习过程:训练可能是这样的:
-
主人伸出手(状态s)
-
小黑选择抬爪(动作a)
-
主人给予骨头奖励(奖励r)
-
主人继续维持伸手姿势(新状态s')
-
小黑立即更新它对"主人伸手+抬爪"这个组合的价值估计
-
-
TD误差:小黑会计算TD误差,即实际观察到的结果与预期的差异:
-
预期:小黑当前估计"主人伸手+抬爪"的价值是5分
-
实际观察:得到骨头(10分)和新状态(主人继续伸手)的价值
-
TD误差 = 实际观察 - 预期 = (10 + γ×新状态价值) - 5
-
-
价值更新公式:小黑使用TD误差来更新估计:
-
新估计 = 旧估计 + 学习率×TD误差
-
例如:新估计 = 5 + 0.1×(实际-5)
-
-
SARSA与Q-learning:时序差分家族有多种算法,主要区别在于如何选择和评估下一个动作:
- SARSA(在策略学习)
:小黑考虑它实际会选择的下一个动作来更新当前状态-动作价值
- Q-learning(离策略学习)
:小黑总是考虑下一状态中最优的动作来更新,不管它实际会选什么
- SARSA(在策略学习)
SARSA训练狗狗握手的具体过程:
-
主人伸手(状态s)
-
小黑选择抬爪(动作a),这个选择基于当前的策略(可能是ε-贪心)
-
小黑获得骨头奖励(奖励r)
-
主人继续伸手(新状态s')
-
小黑考虑下一个动作a'(比如继续保持爪子放在主人手上)
-
小黑更新Q值:Q(s,a) ← Q(s,a) + α[r + γQ(s',a') - Q(s,a)]
-
状态s变为s',动作a变为a',进入下一个时间步
Q-learning训练狗狗握手的具体过程:
-
主人伸手(状态s)
-
小黑选择抬爪(动作a)
-
小黑获得骨头奖励(奖励r)
-
主人继续伸手(新状态s')
-
小黑更新Q值:Q(s,a) ← Q(s,a) + α[r + γ max_a' Q(s',a') - Q(s,a)]
-
注意这里使用的是s'状态下最优动作的价值,而不是小黑实际会选的动作
-
-
状态变为s',选择新动作a'(可能基于ε-贪心策略),进入下一个时间步
时序差分方法的优势在于它结合了蒙特卡洛方法和动态规划的优点:既使用实际体验来学习(如蒙特卡洛),又不需要等待整个回合结束就能更新(如动态规划)。
对小黑来说,它可以在每次尝试握手后立即调整自己的策略,而不必等到一天的训练结束,大大提高了学习效率。
在实际应用中,时序差分方法通常比蒙特卡洛方法更受欢迎,因为它能够更快地学习和适应,特别是在环境变化较快或训练回合很长的情况下。
马尔科夫决策模型
假设我们正在训练小黑学习握手,从MDP的角度看这个过程:
1. 状态集合S: 所有可能的状态,如"主人站立伸手"、"主人蹲下伸手"、"主人没有伸手"等。
2. 动作集合A: 小黑可以采取的所有动作,如"抬右前爪"、"抬左前爪"、"坐下"、"站立"等。
3. 转移概率P(s'|s,a): 描述小黑在状态s下执行动作a后转移到新状态s'的概率。例如,小黑在"主人伸手"状态下执行"抬爪"动作后,可能95%的概率停留在"主人伸手"状态(因为主人等待握手完成),5%的概率转换到"主人没有伸手"状态(因为主人收回了手)。
4. 奖励函数R(s,a,s'): 定义小黑从状态s执行动作a并转移到状态s'时获得的奖励。例如:
- 从"主人伸手"→"抬爪"→"主人伸手" 奖励+10(得到骨头)
- 从"主人伸手"→"咬人"→"主人缩手" 奖励-20(受到惩罚)
- 从"主人伸手"→"坐下"→"主人伸手" 奖励0(无反应)
5. 折扣因子γ: 表示小黑对未来奖励的重视程度。例如γ=0.9意味着现在的骨头比未来的骨头重要,但未来的奖励仍然有很大影响。
6. 马尔科夫性质: MDP的关键假设是"无记忆性"—小黑下一个状态只取决于当前状态和动作,而不依赖于过去的历史。这意味着小黑不需要记住"十分钟前主人做了什么",只需要关注当前主人是否伸手。

探索
狗狗训练中的表现:
- 小黑尝试新的、未知的动作,如尝试抬左爪、右爪、坐下、转圈等
- 即使某些动作之前没有获得奖励,小黑依然会偶尔尝试它们
- 主人可能会鼓励狗狗尝试不同动作,增加它的行为多样性
目的:
- 发现可能带来更高奖励的新行为
- 防止狗狗只学会一种简单但不是最优的行为
- 探索环境中所有可能的状态-动作组合
利用(Exploitation)
狗狗训练中的表现:
- 小黑重复选择那些已知能带来骨头奖励的动作,如"主人伸手时抬右爪"
- 狗狗倾向于选择过去经验中证明有效的行为
- 狗狗依赖已有的知识来获取确定的奖励
目的:
- 最大化当前已知的回报
- 巩固和优化已学会的有效行为
- 在训练后期获得稳定表现
探索与利用的平衡
在狗狗训练中的具体例子:
1. ε-贪心策略: 小黑大部分时间(例如90%)选择Q值最高的动作(利用),但偶尔(10%)随机选择一个动作(探索)
- 例如:小黑90%的时间在主人伸手时抬爪,但偶尔也会尝试坐下或转圈
2. 退火探索: 训练初期小黑大量探索(尝试各种动作),随着训练进行逐渐减少探索增加利用
- 例如:刚开始训练时,小黑几乎随机尝试各种行为;训练后期,它主要选择已经学会的"握手"动作
3. 好奇心驱动: 小黑对不确定性高的状态-动作组合更感兴趣
- 例如:如果小黑不确定"主人蹲下伸手"这个新状态下应该做什么,会对这个状态产生"好奇心",主动探索
各算法的探索-利用策略
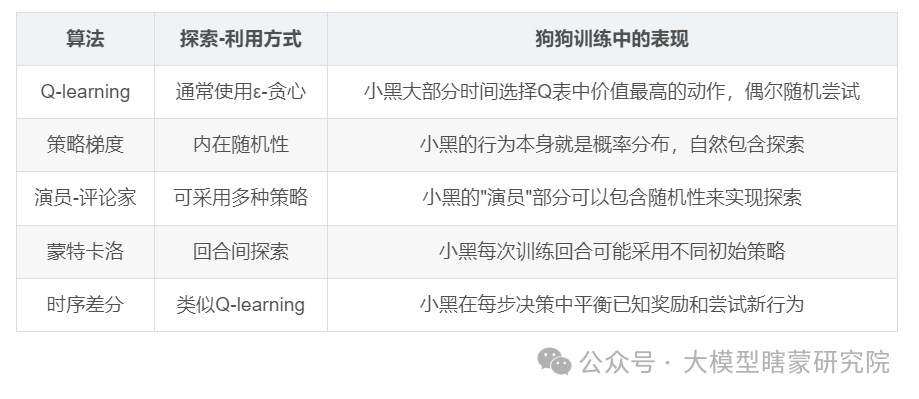
探索与利用的平衡是强化学习成功的关键——如果小黑只探索(总是尝试新动作),它可能永远学不会稳定的技能;
如果只利用(总是重复同一动作),它可能永远找不到最优行为。
好的训练需要在二者之间取得适当平衡,就像好的狗狗训练师会既鼓励狗狗尝试新行为,也强化已学会的正确行为。
相关文章:

深度强化学习基础 1:以狗狗学习握手为例
强化学习共同框架 在这个狗狗学习握手的场景中,强化学习的各个要素可以这样理解: 状态s(state): 狗狗所处的环境状况,比如主人伸出手掌的姿势、狗狗自身的姿势、周围的环境等。状态s描述了狗狗在特定时刻所感知到的环境信息。 动作a(action): 狗狗可以…...
)
【Kafka基础】topics命令行操作大全:高级命令解析(2)
1 强制删除主题 /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --delete \--zookeeper 192.168.10.33:2181 \--topic mytopic \--if-exists 参数说明: --zookeeper:直接连接Zookeeper删除(旧版本方式)--if-exists&…...

【redis】简介及在springboot中的使用
redis简介 基本概念 Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。 与MySQL数据库不…...

Windwos的DNS解析命令nslookup
nslookup 解析dns的命令 有两种使用方式,交互式&命令行方式。 交互式 C:\Users\Administrator>nslookup 默认服务器: UnKnown Address: fe80::52f7:edff:fe28:35de> www.baidu.com 服务器: UnKnown Address: fe80::52f7:edff:fe28:35de非权威应答:…...

Vue.js 实现下载模板和导入模板、数据比对功能核心实现。
在前端开发中,数据比对是一个常见需求,尤其在资产管理等场景中。本文将基于 Vue.js 和 Element UI,通过一个简化的代码示例,展示如何实现“新建比对”和“开始比对”功能的核心部分。 一、功能简介 我们将聚焦两个核心功能&…...

通过世界排名第一的免费开源ERP,构建富有弹性的智能供应链
概述 现行供应链模式的结构性弱点凸显了对整个行业进行重塑的必要性。正确策略和支持可以帮助您重塑供应链,降低成本,实现业务转型。开源智造(OSCG)所推出的Odoo免费开源ERP解决方案,将供应链转化为具有快速响应能力的…...

自动驾驶数据闭环中的MLOps实践:Kubernetes、Kubeflow与PyTorch的协同应用
目录 1. 引言 2. 系统架构与技术栈 2.1 Kubernetes:弹性可伸缩的计算资源池 2.2 Kubeflow:端到端的MLOps工作流 2.3 PyTorch分布式训练:高效的模型训练引擎 3. 增强型数据处理技术 3.1 联邦学习聚合 3.2 在线学习更新 3.3 角落案例挖…...

如何在Linux中更改主机名?修改主机最新方法
hostname是一个Linux操作系统的常用功能,允许识别服务器, 这可用于容易地确定两个服务器之间的差异。 除了服务器的个人识别,主机名与大多数网络进程一起使用,其他应用程序也可能依赖于此,本期将指导大家如何在Linux中…...

分盘,内网
分盘 查看创建分区 # 查看磁盘信息(确认目标磁盘,如/dev/sda) lsblkfdisk -l# 启动fdisk工具(需root权限) sudo fdisk /dev/sda# 步骤1:删除旧分区表(谨慎操作!) Comma…...

SQL122 删除索引
alter table examination_info drop index uniq_idx_exam_id; alter table examination_info drop index full_idx_tag; 描述 请删除examination_info表上的唯一索引uniq_idx_exam_id和全文索引full_idx_tag。 后台会通过 SHOW INDEX FROM examination_info 来对比输出结果。…...
)
【SQL】子查询详解(附例题)
子查询 子查询的表示形式为:(SELECT 语句),它是IN、EXISTS等运算符的运算数,它也出现于FROM子句和VALUES子句。包含子查询的查询叫做嵌套查询。嵌套查询分为相关嵌套查询和不想关嵌套查询 WHERE子句中的子查询 比较运算符 子查询的结果是…...

AI和传统命理的结合
deepseek的火热 也带来了AI命理学的爆火 1. 精准解析:AI加持,数据驱动 通过先进的人工智能算法,我们对海量的传统命理知识进行了深度学习和整合。无论是八字排盘、紫微斗数,还是风水布局、生肖运势,AI都能根据您的个…...

Java设计模式之抽象工厂模式:从入门到架构级实践
设计模式是构建高质量软件的基石,而抽象工厂模式作为创建型模式的代表,不仅解决了对象创建的问题,更在架构设计中扮演着关键角色。本文将从基础到高阶、从单机到分布式,全面剖析抽象工厂模式的应用场景与实战技巧。 一、从问题出发…...

摄像头模块对焦方式的类型
摄像头模块的对焦方式直接影响成像清晰度和使用场景适应性,不同技术各有其优缺点。以下是常见对焦方式及其原理、特点和应用场景的详细说明: 1. 固定对焦(Fixed Focus) 原理:镜头固定在特定距离(…...

九屏图分析法以手机为例
九屏图的两种视角 时间九屏图:关注系统的时间演化(过去、现在、未来),强调技术或产品的生命周期。空间九屏图:关注系统的层次结构(子系统、本系统、超系统࿰…...

【模板】前缀和
链接:【模板】前缀和 题目描述 给定一个长度为n的数组a1,a2,....ana_1, a_2,....a_na1,a2,....an. 接下来有q次查询, 每次查询有两个参数l, r. 对于每个询问, 请输出alal1....ara_la_{l1}....a_ralal1....ar 输入描述: 第一行包含两个整数n和q. 第…...

微信小程序多线程的使用
微信小程序的多线程主要通过 Worker 实现,用于处理复杂计算任务以避免阻塞主线程。以下是完整的使用指南和最佳实践: 一、Worker 核心机制 运行环境隔离 主线程与 Worker 线程内存不共享通信通过 postMessage 完成(数据拷贝而非共享ÿ…...

FPGA设计职位介绍|如何成为一名合格的数字前端设计工程师?
近年来FPGA行业持续升温,随着国产替代浪潮的加快推进,国家对可重构计算、边缘计算、自主可控等领域的扶持力度不断加大,FPGA作为灵活性高、可编程性强的重要芯片种类,在人工智能、通信、工业控制等应用中广受青睐。FPGA人才长期紧…...

Shell 基础
刷题: 思维导图: #include <stdio.h> // 手动定义32位有符号整数的范围 #define INT_MAX 2147483647 #define INT_MIN (-2147483647 - 1) int reverse(int x) { int rev 0; // 初始化反转后的数字为0 while (x ! 0) { // 当x不为0时ÿ…...

软件信息安全性测试如何进行?有哪些注意事项?
随着信息技术的高速发展,软件已经成为我们生活和工作中不可或缺的一部分。然而,随着软件产品的广泛普及,软件信息安全性问题也日益凸显,因此软件信息安全性测试必不可少。那么软件信息安全性测试应如何进行呢?在进行过程中又有哪…...

ragflow开启https访问:浏览器将自签证书添加到受信任的根证书颁发机构 ,当证书过期,还需要添加吗?
核心机制解析 信任链原理: 当您将自签名证书添加到"受信任的根证书颁发机构"后,系统会永久信任该证书的颁发者身份但证书本身的有效期和密钥匹配仍需验证证书更新的两种情况: 相同密钥续期:如果新证书使用相同的密钥对,浏览器通常会保持信任重新生成密钥:如果执…...

ragflow开启https访问:自签证书到期了,如何自动生成新证书
自动生成和更新自签名证书的方案 对于使用公网IP和自签名证书的RagFlow服务,要实现证书的自动生成和更新,可以采用以下方案: 方案一:使用脚本自动更新(推荐) 1. 创建自动更新脚本 在服务器上创建 ./docker/nginx/auto_renew_cert.sh 文件: #!/bin/bash# 证书路径 C…...

LLM面试题八
推荐算法工程师面试题 二分类的分类损失函数? 二分类的分类损失函数一般采用交叉熵(Cross Entropy)损失函数,即CE损失函数。二分类问题的CE损失函数可以写成:其中,y是真实标签,p是预测标签,取值为0或1。 …...

小行星轨道预测是怎么做的?从天文观测到 AI 模型的完整路径
目录 ☄️ 小行星轨道预测是怎么做的?从天文观测到 AI 模型的完整路径 🌌 一、什么是小行星轨道预测? 🔭 二、观测数据从哪里来? 🧮 三、经典动力学方法:数值积分 🤖 四、现代方…...
)
华为OD机试2025A卷 - 正整数到excel编号之间的转换(Java Python JS C++ C )
最新华为OD机试 真题目录:点击查看目录 华为OD面试真题精选:点击立即查看 题目描述 用过 excel 的都知道excel的列编号是这样的: a b c … z aa ab ac … az ba bb bc … yz za zb zc … zz aaa aab aac … 分别代表以下编号: 1 2 3 … 26 27 28 29 … 52 53 54 55…...
试题速浏、分类及浅析)
2024年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析
2024年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析 全国大学生数学建模竞赛(China Undergraduate Mathematical Contest in Modeling)是国家教委高教司和中国工业与应用数学学会共同主办的面向全国大学生的群众性科技活动,目的在于激…...

Vue3 实现进度条组件
样式如下,代码如下 <script setup> import { computed, defineEmits, defineProps, onMounted, ref, watch } from vue// 定义 props const props defineProps({// 初始百分比initialPercentage: {type: Number,default: 0,}, })// 定义 emits const emits…...

I²S协议概述与信号线说明
IIS协议概述 IS(Inter-IC Sound)协议,又称 IIS(Inter-IC Sound),是一种专门用于数字音频数据传输的串行总线标准,由飞利浦(Philips)公司提出。该协议通常用于微控制器…...

Redis 面经
1、说说什么是 Redis? Redis 是 Remote Dictionary Service 三个单词中加粗字母的组合,是一种基于键值对的 NoSQL 数据库。但比一般的键值对,比如 HashMap 强大的多,Redis 中的 value 支持 string、hash、 list、set、zset、Bitmaps、Hyper…...
)
设计模式 四、行为设计模式(1)
在设计模式的世界里,23种经典设计模式通常被分为三大类:创建型、结构型和行为型。创建型设计模式关注对象创建的问题,结构性设计模式关注于类或对象的组合和组装的问题,行为型设计模式则主要关注于类或对象之间的交互问题。 行为设…...

Python错误分析与调试
在Python编程的过程中,我们难免会遇到各种各样的错误,而有效地分析和调试这些错误,能让我们的代码快速恢复正常运行,今天就来和大家聊聊Python中错误分析与调试的相关内容。 错误分析 Python中的错误大致可以分为语法错误和逻…...

vue实现大转盘抽奖
用vue实现一个简单的大转盘抽奖案例 大转盘 一 转盘布局 <div class"lucky-wheel-content"><div class"lucky-wheel-prize" :style"wheelStyle" :class"isStart ? animated-icon : "transitionend"onWheelTransitionE…...
零基础入门系列第二篇:项目创建和初始化)
《从零搭建Vue3项目实战》(AI辅助搭建Vue3+ElemntPlus后台管理项目)零基础入门系列第二篇:项目创建和初始化
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 《从零搭建Vue3项目实战》(AI辅助…...

yum拒绝连接
YUM 拒绝连接的解决方案 当遇到 yum 无法连接的问题时,通常可以通过更换为更稳定的镜像源来解决问题。以下是具体的解决方法: 更换为阿里云源 如果当前的 yum 配置文件存在问题或网络不稳定,可以尝试将其替换为阿里云的镜像源。 备份原始配…...

信息学奥赛一本通 1861:【10NOIP提高组】关押罪犯 | 洛谷 P1525 [NOIP 2010 提高组] 关押罪犯
【题目链接】 ybt 1861:【10NOIP提高组】关押罪犯 洛谷 P1525 [NOIP 2010 提高组] 关押罪犯 【题目考点】 1. 图论:二分图 2. 二分答案 3. 种类并查集 【解题思路】 解法1:种类并查集 一个囚犯是一个顶点,一个囚犯对可以看…...

代码随想录算法训练营第十一天
LeetCode/卡码网题目: 144. 二叉树的前序遍历94. 二叉树的中序遍历145. 二叉树的后序遍历102. 二叉树的层序遍历107.二叉树的层次遍历II199. 二叉树的右视图637. 二叉树的层平均值429. N 叉树的层序遍历515. 在每个树行中找最大值116. 填充每个节点的下一个右侧节点指针117. 填…...

浅谈进程的就绪状态与挂起状态
就绪状态 进程获得除 CPU 之外的所需资源,一旦得到 CPU 就可以立即运行,不能运行的原因是还是因为 CPU 的资源太少,只能等待分配 CPU 资源。在系统中,处于就绪状态的进程可能有多个,通常是将它们组成一个进程就绪队列…...
)
37、web前端开发之Vue3保姆教程(一)
一、课程简介 本课程旨在帮助学员从零基础逐步掌握Web前端开发的核心技术,涵盖当前前端开发中的关键工具和框架。课程内容包括: Vue 3:主流前端框架,支持组件化开发和响应式数据管理,帮助学员高效构建现代Web应用。TypeScript:增强版JavaScript,提供静态类型支持,提高…...

cenos7升级gcc 9.3和Qt5.15版本教程
cenos7升级gcc 9.3和Qt5.15版本教程 文章目录 cenos7升级gcc 9.3和Qt5.15版本教程0、背景1、现状2、目标和思路3、升级前环境准备3.1 虚拟机联网配置3.2 镜像设置 4、升级gcc 9.35 升级Qt6 测试验证7 总结 0、背景 之前编码的环境一直是“拿来主义”,拷贝现成的虚拟…...
)
Scala总结(七)
集合(二) 数组 不可变数组与可变数组的转换 arr1.toBuffer //不可变数组转可变数组 arr2.toArray //可变数组转不可变数组 arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化arr1.toBuffer 返回结果才是一个可变数组ÿ…...

linux 使用 usermod 授权 普通用户 属组权限
之前写过这篇文章 linux 普通用户 使用 docker 只不过是使用 root 用户编辑 /etc/group用户所属组文件的方式 今天带来一种 usermod 命令行方式 以下3步,在root用户下操作 第一步,先创建一个普通用户测试使用 useradd miniuser第二步,授权到…...

Redis持久化
Redis持久化 一.认识持久化1.简单介绍2.持久化策略 二.RDB1.快照2."定期"fork 3.RDB演示(1)手动执行save&bgsave触发一次生成快照(2)插入key,不手动执行bgsave(3)执行bgsave后,新旧文件的替换(4)通过配置自动生成rdb快照(5)rdb文件内容被故…...
 和 Tolerations(容忍度))
什么是 k8s 的 Taints(污点) 和 Tolerations(容忍度)
什么是 k8s 的 Taints(污点) 和 Tolerations(容忍度) 在 Kubernetes(K8s)中,Taints(污点)和 Tolerations(容忍度)用于影响 Pod 调度到节点的行为…...

是德科技KEYSIGHT校准件85039B
是德科技KEYSIGHT校准件85039B 是德科技KEYSIGHT校准件85039B 85039B Agilent | 85039B|校准件|网络分析仪校准件|3GHz|75欧|N型 品牌: 安捷伦 | Agilent | 惠普 | HP 主要技术指标 DC to 3GHz frequency range 主要描述 常用型号: 一、频谱分析仪或…...

以UE5第三方插件库为基础,编写自己的第三方库插件,并且能够在运行时复制.dll
首先,创建一个空白的C 项目,创建第三方插件库。如下图所示 编译自己的.Dll 和.lib 库,打开.sln 如下图 ExampleLibrary.h 的代码如下 #if defined _WIN32 || defined _WIN64 #define EXAMPLELIBRARY_IMPORT __declspec(dllimport) #elif d…...

StarRocks执行原理与SQL性能优化策略探索
https://zhuanlan.zhihu.com/p/15707561363 聚合优化实践 -- 通过count group by 优化 count distinct数据倾斜问题 除了前面所说的聚合度会对分组聚合造成比较大的影响外,我们还要考虑一个点,即数据倾斜问题。 背景: 如下为最初的用户计算uv的SQL SE…...

Java全栈面试宝典:JMM内存模型与Spring自动装配深度解析
目录 一、Java内存模型(JMM)核心原理 🔥 问题8:happens-before原则全景解析 JMM内存架构图 happens-before八大规则 线程安全验证案例 🔥 问题9:JMM解决可见性的三大武器 可见性保障机制 volatile双…...

拉普拉斯变换
【硬核】工科生都逃不掉的拉氏变换,居然又炫酷又实用|拉普拉斯变换原理、图解与应用,傅里叶变换进阶,控制理论必修课【喵星考拉】...

JavaScript之Json数据格式
介绍 JavaScript Object Notation, js对象标注法,是轻量级的数据交换格式完全独立于编程语言文本字符集必须用UTF-8格式,必须用“”任何支持的数据类型都可以用JSON表示JS内内置JSON解析JSON本质就是字符串 Json对象和JS对象互相转化 前端…...

Android WiFi协议之P2P介绍与实践
Android WiFi P2P WiFi P2P (Peer-to-Peer) 是 Android 提供的一种允许设备之间直接通过 WiFi 进行通信的技术,无需接入传统的 WiFi 网络或互联网。这种技术也被称为 WiFi Direct。 一、WiFi P2P 基本概念 1. 核心组件 P2P 设备:支持 WiFi P2P 的 And…...