自动驾驶数据闭环中的MLOps实践:Kubernetes、Kubeflow与PyTorch的协同应用
目录
1. 引言
2. 系统架构与技术栈
2.1 Kubernetes:弹性可伸缩的计算资源池
2.2 Kubeflow:端到端的MLOps工作流
2.3 PyTorch分布式训练:高效的模型训练引擎
3. 增强型数据处理技术
3.1 联邦学习聚合
3.2 在线学习更新
3.3 角落案例挖掘
4. 复杂模型训练技术
4.1 多模态模型训练
4.2 PyTorchJob生成与分布式训练
5. 严格安全验证框架
5.1 形式化验证
5.2 对抗样本测试
5.3 边缘案例仿真
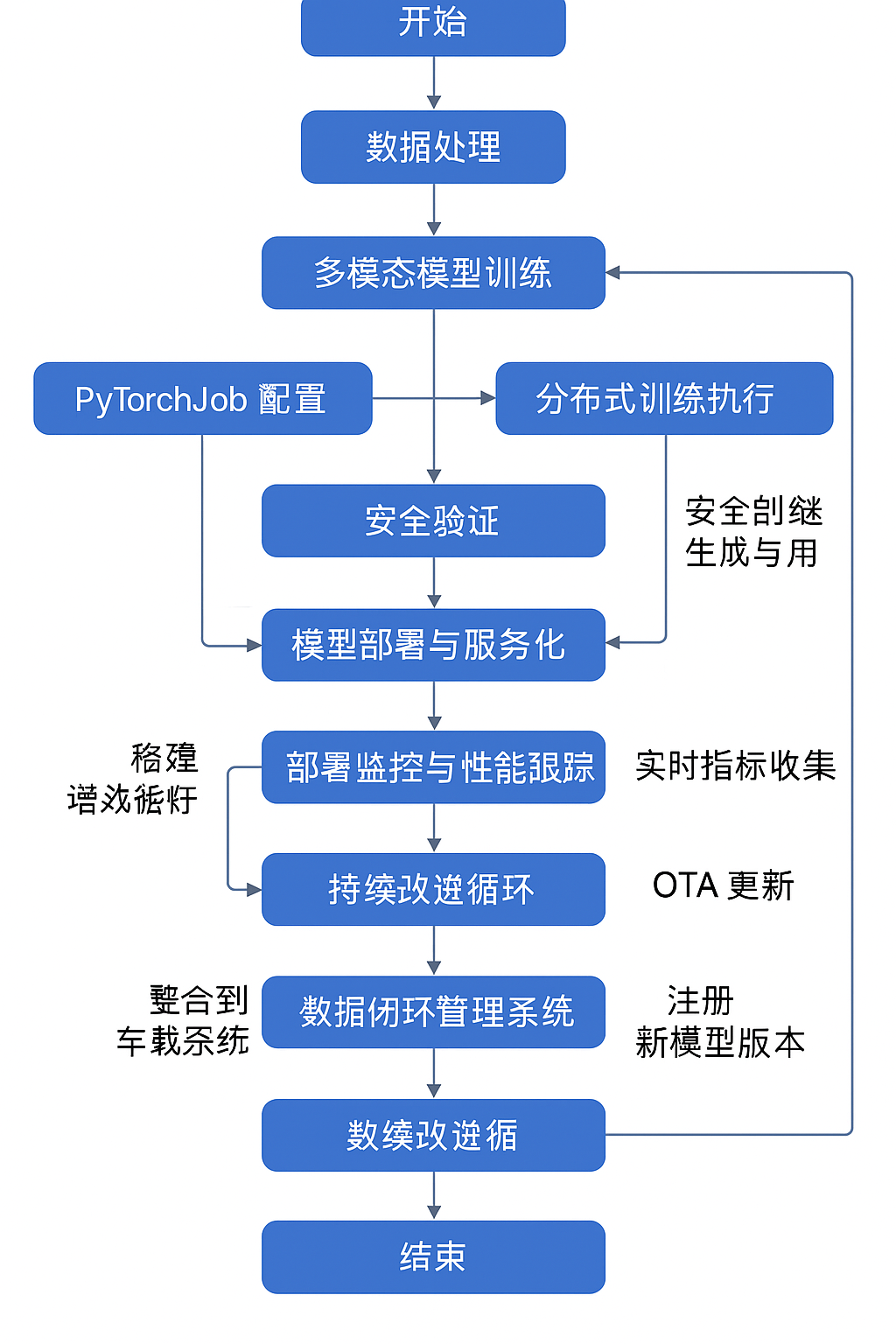
6. 整合数据闭环流水线
7. 模型部署与监控
7.1 模型部署与服务化
7.2 分布式训练执行
7.3 安全验证报告生成与使用
7.4 持续改进循环实现
8. 总结与展望
1. 引言
自动驾驶技术的快速发展面临海量多传感器数据、复杂模型训练和高安全性需求等挑战。构建高效、自动化、可扩展的MLOps平台成为实现算法持续优化和安全迭代的关键。本文深入探讨如何整合Kubernetes、Kubeflow和PyTorch分布式训练技术栈,打造支持自动驾驶数据闭环的强大基础设施。
2. 系统架构与技术栈
2.1 Kubernetes:弹性可伸缩的计算资源池
Kubernetes(K8s)作为容器编排平台,提供弹性的计算资源管理能力。它不仅调度CPU/GPU资源,还支持存储(如Ceph、PVC)和网络资源,能够运行分布式数据处理框架(如Apache Spark、Dask),实现大规模并行处理。
核心价值:
- 资源调度:通过resources.limits和requests精确分配GPU资源,支持NVIDIA MIG技术优化利用率
- 容错与扩展:自动重启失败Pod(restartPolicy: OnFailure),通过HPA动态伸缩
2.2 Kubeflow:端到端的MLOps工作流
Kubeflow基于Kubernetes,提供机器学习全生命周期管理,包括数据处理、训练、评估和部署。
核心组件:
- Kubeflow Pipelines:定义可重复、可版本化的工作流
- PyTorchJob:管理分布式训练任务
- KServe:实现模型部署与服务化
- MLMD:提供元数据管理,确保实验可追溯性
核心价值:
- 自动化:通过Pipeline编排复杂流程,减少人工干预
- 可扩展性:与K8s无缝集成,支持大规模任务
2.3 PyTorch分布式训练:高效的模型训练引擎
PyTorch通过其分布式数据并行(DDP)模块,支持多GPU、多节点训练,显著缩短训练时间。Kubeflow的PyTorchJob将其与K8s结合,通过声明式配置简化部署。
核心价值:
- 性能优化:利用torch.distributed实现高效的进程间通信
- 易用性:与Kubeflow集成后,开发者无需手动配置分布式环境
3. 增强型数据处理技术
3.1 联邦学习聚合
@func_to_container_op
def federated_learning_aggregation(model_path: str, edge_updates_path: str) -> str:"""联邦学习聚合:从边缘设备收集模型更新并聚合到主模型Args:model_path: 主模型路径edge_updates_path: 边缘设备模型更新路径Returns:更新后的模型路径"""import os# 模拟联邦学习聚合逻辑print(f"聚合来自边缘设备的模型更新: {edge_updates_path}")# 返回更新后的模型路径return os.path.join(os.path.dirname(model_path), "federated_updated_model.pt")联邦学习技术允许在数据源头(如车辆边缘设备)进行初步训练,仅将模型更新传回中心服务器,大幅减少数据传输量的同时保护数据隐私。
3.2 在线学习更新
@func_to_container_op
def online_learning_update(model_path: str, stream_data_path: str) -> str:"""在线学习更新:使用实时数据流增量更新模型Args:model_path: 当前模型路径stream_data_path: 实时数据流路径Returns:增量更新后的模型路径"""import os# 模拟在线学习更新逻辑print(f"使用实时数据流进行增量更新: {stream_data_path}")# 返回增量更新后的模型路径return os.path.join(os.path.dirname(model_path), "online_updated_model.pt")3.3 角落案例挖掘
@func_to_container_op
def mine_corner_cases(data_path: str, model_path: str) -> str:"""使用模型推理或嵌入聚类方法挖掘角落案例"""# 原有实现内容return data_path + "/corner_cases"智能角落案例挖掘通过模型推理(低置信度场景)或异常检测算法(如基于Embedding的聚类),精准识别高价值数据,避免在无效数据上浪费资源。
4. 复杂模型训练技术
4.1 多模态模型训练
@func_to_container_op
def multimodal_training(processed_data_path: str, model_config: str, base_model_path: str = "") -> str:"""多模态模型训练:支持图像、点云、雷达等多种传感器数据的联合训练Args:processed_data_path: 处理后的数据路径model_config: 模型配置(包含模态类型、网络架构等)base_model_path: 基础模型路径,用于持续训练Returns:训练后的多模态模型路径"""import os# 模拟多模态训练逻辑print(f"使用多模态数据进行训练: {processed_data_path}")print(f"模型配置: {model_config}")# 返回训练后的模型路径return "/mnt/models/multimodal_model.pt"多模态融合模型类实现:
class MultiModalFusionModel(nn.Module):"""多模态融合模型 - 支持图像、点云、雷达等多种输入"""def __init__(self, config):super(MultiModalFusionModel, self).__init__()# 解析配置self.modalities = config.get("modalities", ["camera", "lidar"])self.fusion_type = config.get("fusion_type", "late_fusion")self.num_classes = config.get("num_classes", 10)# 创建各模态的特征提取器self.encoders = nn.ModuleDict()# 针对不同模态设置不同的编码器if "camera" in self.modalities:# 图像编码器 (例如使用ResNet50)self.encoders["camera"] = self._create_image_encoder()if "lidar" in self.modalities:# 点云编码器 (例如使用PointNet++)self.encoders["lidar"] = self._create_lidar_encoder()if "radar" in self.modalities:# 雷达编码器 self.encoders["radar"] = self._create_radar_encoder()# 特征维度 (仅示例)feature_dim = 256# 不同的融合策略if self.fusion_type == "late_fusion":# 后期融合: 每个模态有各自的预测头,然后融合self.heads = nn.ModuleDict({modality: nn.Linear(feature_dim, self.num_classes)for modality in self.modalities})# 融合层 (简单加权平均)self.fusion_weights = nn.Parameter(torch.ones(len(self.modalities)) / len(self.modalities))elif self.fusion_type == "early_fusion":# 早期融合: 将特征连接后再预测total_dim = feature_dim * len(self.modalities)self.fusion_layer = nn.Sequential(nn.Linear(total_dim, feature_dim),nn.ReLU(),nn.Linear(feature_dim, self.num_classes))elif self.fusion_type == "deep_fusion":# 深度融合: 使用Transformer架构进行跨模态注意力融合encoder_layers = nn.TransformerEncoderLayer(d_model=feature_dim, nhead=8, dim_feedforward=2048)self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=6)self.fusion_layer = nn.Linear(feature_dim, self.num_classes)多模态融合支持三种融合策略:早期融合、后期融合和深度融合(基于Transformer的注意力机制),能够全面整合摄像头、激光雷达、雷达等多种传感器数据。
4.2 PyTorchJob生成与分布式训练
@func_to_container_op
def generate_pytorch_job_yaml(model_path: str, data_path: str, num_gpus: int = 8) -> str:"""生成大规模分布式训练的PyTorchJob YAML配置Args:model_path: 模型路径data_path: 数据路径num_gpus: GPU数量Returns:PyTorchJob YAML文件路径"""yaml_content = f"""
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:name: large-scale-trainingnamespace: kubeflow
spec:pytorchReplicaSpecs:Master:replicas: 1restartPolicy: OnFailuretemplate:spec:containers:- name: pytorchimage: your-registry/advanced-pytorch:v2.0command: ["python", "/opt/train.py"]env:- name: MODEL_PATHvalue: "{model_path}"- name: DATA_PATHvalue: "{data_path}"resources:limits:nvidia.com/gpu: 1Worker:replicas: {num_gpus - 1}restartPolicy: OnFailuretemplate:spec:containers:- name: pytorchimage: your-registry/advanced-pytorch:v2.0command: ["python", "/opt/train.py"]env:- name: MODEL_PATHvalue: "{model_path}"- name: DATA_PATHvalue: "{data_path}"resources:limits:nvidia.com/gpu: 1"""# 将YAML写入文件yaml_path = "/tmp/large_scale_training.yaml"with open(yaml_path, "w") as f:f.write(yaml_content)return yaml_path自动生成PyTorchJob YAML配置,简化了分布式训练部署流程,实现了KFP流水线与Kubeflow训练任务的无缝连接。PyTorchJob自动设置RANK、WORLD_SIZE等环境变量,屏蔽分布式配置复杂性,提升开发效率。
5. 严格安全验证框架
5.1 形式化验证
@func_to_container_op
def formal_verification(model_path: str) -> dict:"""形式化验证:使用形式化方法验证模型的关键安全属性Args:model_path: 模型路径Returns:验证结果,包含通过/失败状态和详细报告"""# 模拟形式化验证结果verification_results = {"status": "PASS","verified_properties": ["不会错误识别行人", "不会错误识别红灯", "保持安全距离"],"report_path": "/mnt/reports/formal_verification_report.pdf"}return verification_results形式化验证通过数学方法验证模型关键安全属性,如交通信号灯识别、行人检测和车道线检测等,确保模型在各种条件下都能正确运行。
5.2 对抗样本测试
@func_to_container_op
def adversarial_testing(model_path: str, num_attacks: int = 1000) -> dict:"""对抗样本测试:生成对抗样本并评估模型鲁棒性Args:model_path: 模型路径num_attacks: 对抗攻击数量Returns:测试结果,包含鲁棒性指标和失败案例"""# 模拟对抗测试结果adversarial_results = {"robustness_score": 0.92,"successful_attacks": 80,"total_attacks": num_attacks,"failure_cases_path": "/mnt/reports/adversarial_failures.json"}return adversarial_results对抗样本测试通过FGSM、PGD和Carlini-Wagner等方法生成特殊输入,评估模型对扰动的鲁棒性,识别和修复模型潜在的漏洞。
5.3 边缘案例仿真
@func_to_container_op
def edge_case_simulation(model_path: str, corner_cases_path: str) -> dict:"""边缘案例仿真:在挖掘的角落案例场景中进行更严格的仿真测试Args:model_path: 模型路径corner_cases_path: 角落案例数据路径Returns:仿真结果,包含性能指标和失败场景"""# 模拟边缘案例仿真结果edge_results = {"success_rate": 0.88,"failure_rate": 0.12,"critical_failures": 5,"detailed_report": "/mnt/reports/edge_case_simulation.json"}return edge_results仿真测试能够发现离线指标无法完全反映的潜在失效模式,尤其是在城市、高速公路、乡村道路和恶劣天气等多种环境下的极端场景表现。
6. 整合数据闭环流水线
@dsl.pipeline(name="Enhanced Autonomous Driving Pipeline",description="增强型自动驾驶数据闭环流水线:包含高效数据处理、复杂模型训练和严格安全验证"
)
def enhanced_pipeline(date_range: str = "2025-03-01/2025-03-31",data_path: str = "/mnt/data",model_path: str = "/mnt/models/perception_v2.3.pt",edge_updates_path: str = "/mnt/edge_updates",stream_data_path: str = "/mnt/stream_data",num_gpus: int = 8,num_adversarial_attacks: int = 1000,num_simulation_scenarios: int = 1000
):# 1. 高效数据处理阶段download_task = download_raw_data(date_range, data_path).set_cpu_request('1').set_memory_request('2G')preprocess_task = preprocess_data(download_task.output).set_cpu_request('2').set_memory_request('4G')# 联邦学习聚合federated_task = federated_learning_aggregation(model_path, edge_updates_path).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')# 在线学习更新online_learning_task = online_learning_update(federated_task.output,stream_data_path).set_cpu_request('2').set_memory_request('4G').set_gpu_limit('1')# 角落案例挖掘mine_task = mine_corner_cases(preprocess_task.output, online_learning_task.output).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')# 2. 复杂模型训练阶段# 多模态模型训练multimodal_config = """{"modalities": ["camera", "lidar", "radar"],"fusion_type": "deep_fusion","architecture": "transformer"}"""multimodal_task = multimodal_training(preprocess_task.output,multimodal_config,online_learning_task.output).set_cpu_request('4').set_memory_request('16G').set_gpu_limit('2')# 生成大规模分布式训练配置pytorch_job_task = generate_pytorch_job_yaml(multimodal_task.output,preprocess_task.output,num_gpus).set_cpu_request('1').set_memory_request('2G')# 3. 严格安全验证阶段# 形式化验证formal_verification_task = formal_verification(multimodal_task.output).set_cpu_request('4').set_memory_request('8G')# 对抗样本测试adversarial_task = adversarial_testing(multimodal_task.output,num_adversarial_attacks).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')# 常规离线评估offline_eval_task = offline_evaluation(multimodal_task.output, preprocess_task.output).set_cpu_request('2').set_memory_request('4G')# 常规仿真评估simulation_task = simulation_evaluation(multimodal_task.output, num_simulation_scenarios).set_cpu_request('4').set_memory_request('8G')# 边缘案例仿真edge_simulation_task = edge_case_simulation(multimodal_task.output,mine_task.output).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')整合流水线将高效数据处理、复杂模型训练和严格安全验证整合为一体,形成完整闭环。每个组件根据计算需求自适应分配资源,实现全流程自动化执行。
7. 模型部署与监控
7.1 模型部署与服务化
# 将训练好的模型部署为推理服务
from kfp import dsl
from kfp.components import func_to_container_op@func_to_container_op
def deploy_model(model_path: str, service_name: str) -> str:"""将模型部署为KServe推理服务"""import yamlimport os# 生成KServe InferenceService YAMLservice_yaml = f"""apiVersion: "serving.kserve.io/v1beta1"kind: "InferenceService"metadata:name: "{service_name}"namespace: kubeflowspec:predictor:pytorch:storageUri: "pvc://model-pvc{model_path}"resources:limits:nvidia.com/gpu: 1"""# 将YAML写入文件并应用到集群yaml_path = f"/tmp/{service_name}.yaml"with open(yaml_path, "w") as f:f.write(service_yaml)# 模拟kubectl应用YAMLprint(f"应用KServe配置: {yaml_path}")# 返回服务访问点return f"https://{service_name}.kubeflow.example.com/v1/models/{service_name}"# 在流水线中调用
deploy_task = deploy_model(multimodal_task.output,f"perception-model-{workflow_id}"
).set_cpu_request('1').set_memory_request('2G')
- PyTorchJob YAML:用于大规模分布式训练,配置如何在多GPU环境中训练模型
- KServe InferenceService YAML:用于模型部署与服务化,配置如何提供模型推理服务
KServe支持Canary部署策略,实现模型的逐步放量和风险控制。监控系统收集模型在生产环境中的表现,并将低置信度预测等异常情况反馈到角落案例挖掘环节,形成完整数据闭环
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:name: "autonomous-driving-perception"namespace: kubeflow
spec:predictor:pytorch:storageUri: "pvc://model-pvc/models/perception_v2.4"resources:limits:nvidia.com/gpu: 17.2 分布式训练执行
生成的PyTorchJob配置会被提交到Kubernetes集群执行:
@func_to_container_op
def submit_pytorch_job(pytorch_job_yaml: str) -> str:"""提交PyTorchJob到Kubernetes集群执行分布式训练"""import subprocessimport timeimport json# 模拟kubectl应用PyTorchJobprint(f"应用PyTorchJob: {pytorch_job_yaml}")job_name = "large-scale-training"# 等待训练完成print(f"等待PyTorchJob {job_name} 完成...")# 实际实现应轮询检查作业状态# 返回训练结果return json.dumps({"job_name": job_name,"status": "Succeeded","training_time": "12h 34m","final_metrics": {"accuracy": 0.92,"loss": 0.08}})# 在流水线中调用
training_result = submit_pytorch_job(pytorch_job_task.output
).set_cpu_request('1').set_memory_request('2G')7.3 安全验证报告生成与使用
@func_to_container_op
def generate_safety_report(formal_results: dict, adversarial_results: dict,simulation_results: dict,edge_case_results: dict,model_info: str
) -> str:"""综合各项验证结果生成安全报告"""import jsonimport os# 解析模型信息model_info_dict = json.loads(model_info)# 计算整体安全分数formal_score = formal_results.get("verification_rate", 0) * 100adv_score = adversarial_results.get("robustness_score", 0) * 100sim_score = simulation_results.get("success_rate", 0) * 100edge_score = edge_case_results.get("success_rate", 0) * 100# 权重计算weights = [0.4, 0.2, 0.2, 0.2]total_score = sum([formal_score * weights[0], adv_score * weights[1],sim_score * weights[2],edge_score * weights[3]])# 生成报告report = {"model_version": model_info_dict.get("version", "unknown"),"safety_score": total_score,"status": "PASS" if total_score > 85 else "FAIL","verification_summary": {"formal_verification": formal_results,"adversarial_testing": adversarial_results,"simulation": simulation_results,"edge_cases": edge_case_results},"recommendations": _generate_recommendations(formal_results, adversarial_results, simulation_results, edge_case_results)}# 保存报告report_path = "/mnt/reports/safety_report.json"with open(report_path, "w") as f:json.dump(report, f, indent=2)return report_path# 在流水线中调用
safety_report = generate_safety_report(formal_verification_task.output,adversarial_task.output,simulation_task.output,edge_simulation_task.output,json.dumps({"version": "v2.4.0"})
).set_cpu_request('2').set_memory_request('4G')7.4 持续改进循环实现
建立反馈循环,自动更新训练数据:
@func_to_container_op
def update_training_dataset(corner_cases_path: str,failed_scenarios: dict,current_dataset_path: str
) -> str:"""将发现的问题案例整合到训练数据集中"""import osimport shutilimport json# 新数据集路径updated_dataset = f"{current_dataset_path}_enhanced"os.makedirs(updated_dataset, exist_ok=True)# 复制原始数据集print(f"复制基础数据集: {current_dataset_path} -> {updated_dataset}")# 添加角落案例print(f"整合角落案例: {corner_cases_path} -> {updated_dataset}/corner_cases")# 添加失败场景if isinstance(failed_scenarios, str):failed_scenarios = json.loads(failed_scenarios)critical_failures = failed_scenarios.get("critical_failures", [])print(f"整合{len(critical_failures)}个关键失败场景到数据集")# 记录数据集更新元数据metadata = {"base_dataset": current_dataset_path,"corner_cases_added": corner_cases_path,"critical_failures_added": len(critical_failures),"timestamp": time.strftime("%Y-%m-%d %H:%M:%S")}with open(f"{updated_dataset}/metadata.json", "w") as f:json.dump(metadata, f, indent=2)return updated_dataset# 在流水线中调用
updated_dataset = update_training_dataset(mine_task.output,edge_simulation_task.output,preprocess_task.output
).set_cpu_request('2').set_memory_request('4G')8. 总结与展望
通过整合Kubernetes、Kubeflow和PyTorch分布式训练技术栈,我们构建了一个高度自动化、可扩展、高效的自动驾驶数据闭环MLOps平台。系统引入了联邦学习和在线学习等高效数据处理技术,支持多模态模型和大规模分布式训练,并通过形式化验证和对抗样本测试等严格安全验证框架保障模型质量。
这一技术栈不仅缩短了模型迭代周期,还通过严格的评估和监控确保了安全性与可靠性,成为自动驾驶领域MLOps实践的典范,未来持续优化将推动技术迈向更高水平。
相关文章:

自动驾驶数据闭环中的MLOps实践:Kubernetes、Kubeflow与PyTorch的协同应用
目录 1. 引言 2. 系统架构与技术栈 2.1 Kubernetes:弹性可伸缩的计算资源池 2.2 Kubeflow:端到端的MLOps工作流 2.3 PyTorch分布式训练:高效的模型训练引擎 3. 增强型数据处理技术 3.1 联邦学习聚合 3.2 在线学习更新 3.3 角落案例挖…...

如何在Linux中更改主机名?修改主机最新方法
hostname是一个Linux操作系统的常用功能,允许识别服务器, 这可用于容易地确定两个服务器之间的差异。 除了服务器的个人识别,主机名与大多数网络进程一起使用,其他应用程序也可能依赖于此,本期将指导大家如何在Linux中…...

分盘,内网
分盘 查看创建分区 # 查看磁盘信息(确认目标磁盘,如/dev/sda) lsblkfdisk -l# 启动fdisk工具(需root权限) sudo fdisk /dev/sda# 步骤1:删除旧分区表(谨慎操作!) Comma…...

SQL122 删除索引
alter table examination_info drop index uniq_idx_exam_id; alter table examination_info drop index full_idx_tag; 描述 请删除examination_info表上的唯一索引uniq_idx_exam_id和全文索引full_idx_tag。 后台会通过 SHOW INDEX FROM examination_info 来对比输出结果。…...
)
【SQL】子查询详解(附例题)
子查询 子查询的表示形式为:(SELECT 语句),它是IN、EXISTS等运算符的运算数,它也出现于FROM子句和VALUES子句。包含子查询的查询叫做嵌套查询。嵌套查询分为相关嵌套查询和不想关嵌套查询 WHERE子句中的子查询 比较运算符 子查询的结果是…...

AI和传统命理的结合
deepseek的火热 也带来了AI命理学的爆火 1. 精准解析:AI加持,数据驱动 通过先进的人工智能算法,我们对海量的传统命理知识进行了深度学习和整合。无论是八字排盘、紫微斗数,还是风水布局、生肖运势,AI都能根据您的个…...

Java设计模式之抽象工厂模式:从入门到架构级实践
设计模式是构建高质量软件的基石,而抽象工厂模式作为创建型模式的代表,不仅解决了对象创建的问题,更在架构设计中扮演着关键角色。本文将从基础到高阶、从单机到分布式,全面剖析抽象工厂模式的应用场景与实战技巧。 一、从问题出发…...

摄像头模块对焦方式的类型
摄像头模块的对焦方式直接影响成像清晰度和使用场景适应性,不同技术各有其优缺点。以下是常见对焦方式及其原理、特点和应用场景的详细说明: 1. 固定对焦(Fixed Focus) 原理:镜头固定在特定距离(…...

九屏图分析法以手机为例
九屏图的两种视角 时间九屏图:关注系统的时间演化(过去、现在、未来),强调技术或产品的生命周期。空间九屏图:关注系统的层次结构(子系统、本系统、超系统࿰…...

【模板】前缀和
链接:【模板】前缀和 题目描述 给定一个长度为n的数组a1,a2,....ana_1, a_2,....a_na1,a2,....an. 接下来有q次查询, 每次查询有两个参数l, r. 对于每个询问, 请输出alal1....ara_la_{l1}....a_ralal1....ar 输入描述: 第一行包含两个整数n和q. 第…...

微信小程序多线程的使用
微信小程序的多线程主要通过 Worker 实现,用于处理复杂计算任务以避免阻塞主线程。以下是完整的使用指南和最佳实践: 一、Worker 核心机制 运行环境隔离 主线程与 Worker 线程内存不共享通信通过 postMessage 完成(数据拷贝而非共享ÿ…...

FPGA设计职位介绍|如何成为一名合格的数字前端设计工程师?
近年来FPGA行业持续升温,随着国产替代浪潮的加快推进,国家对可重构计算、边缘计算、自主可控等领域的扶持力度不断加大,FPGA作为灵活性高、可编程性强的重要芯片种类,在人工智能、通信、工业控制等应用中广受青睐。FPGA人才长期紧…...

Shell 基础
刷题: 思维导图: #include <stdio.h> // 手动定义32位有符号整数的范围 #define INT_MAX 2147483647 #define INT_MIN (-2147483647 - 1) int reverse(int x) { int rev 0; // 初始化反转后的数字为0 while (x ! 0) { // 当x不为0时ÿ…...

软件信息安全性测试如何进行?有哪些注意事项?
随着信息技术的高速发展,软件已经成为我们生活和工作中不可或缺的一部分。然而,随着软件产品的广泛普及,软件信息安全性问题也日益凸显,因此软件信息安全性测试必不可少。那么软件信息安全性测试应如何进行呢?在进行过程中又有哪…...

ragflow开启https访问:浏览器将自签证书添加到受信任的根证书颁发机构 ,当证书过期,还需要添加吗?
核心机制解析 信任链原理: 当您将自签名证书添加到"受信任的根证书颁发机构"后,系统会永久信任该证书的颁发者身份但证书本身的有效期和密钥匹配仍需验证证书更新的两种情况: 相同密钥续期:如果新证书使用相同的密钥对,浏览器通常会保持信任重新生成密钥:如果执…...

ragflow开启https访问:自签证书到期了,如何自动生成新证书
自动生成和更新自签名证书的方案 对于使用公网IP和自签名证书的RagFlow服务,要实现证书的自动生成和更新,可以采用以下方案: 方案一:使用脚本自动更新(推荐) 1. 创建自动更新脚本 在服务器上创建 ./docker/nginx/auto_renew_cert.sh 文件: #!/bin/bash# 证书路径 C…...

LLM面试题八
推荐算法工程师面试题 二分类的分类损失函数? 二分类的分类损失函数一般采用交叉熵(Cross Entropy)损失函数,即CE损失函数。二分类问题的CE损失函数可以写成:其中,y是真实标签,p是预测标签,取值为0或1。 …...

小行星轨道预测是怎么做的?从天文观测到 AI 模型的完整路径
目录 ☄️ 小行星轨道预测是怎么做的?从天文观测到 AI 模型的完整路径 🌌 一、什么是小行星轨道预测? 🔭 二、观测数据从哪里来? 🧮 三、经典动力学方法:数值积分 🤖 四、现代方…...
)
华为OD机试2025A卷 - 正整数到excel编号之间的转换(Java Python JS C++ C )
最新华为OD机试 真题目录:点击查看目录 华为OD面试真题精选:点击立即查看 题目描述 用过 excel 的都知道excel的列编号是这样的: a b c … z aa ab ac … az ba bb bc … yz za zb zc … zz aaa aab aac … 分别代表以下编号: 1 2 3 … 26 27 28 29 … 52 53 54 55…...
试题速浏、分类及浅析)
2024年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析
2024年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析 全国大学生数学建模竞赛(China Undergraduate Mathematical Contest in Modeling)是国家教委高教司和中国工业与应用数学学会共同主办的面向全国大学生的群众性科技活动,目的在于激…...

Vue3 实现进度条组件
样式如下,代码如下 <script setup> import { computed, defineEmits, defineProps, onMounted, ref, watch } from vue// 定义 props const props defineProps({// 初始百分比initialPercentage: {type: Number,default: 0,}, })// 定义 emits const emits…...

I²S协议概述与信号线说明
IIS协议概述 IS(Inter-IC Sound)协议,又称 IIS(Inter-IC Sound),是一种专门用于数字音频数据传输的串行总线标准,由飞利浦(Philips)公司提出。该协议通常用于微控制器…...

Redis 面经
1、说说什么是 Redis? Redis 是 Remote Dictionary Service 三个单词中加粗字母的组合,是一种基于键值对的 NoSQL 数据库。但比一般的键值对,比如 HashMap 强大的多,Redis 中的 value 支持 string、hash、 list、set、zset、Bitmaps、Hyper…...
)
设计模式 四、行为设计模式(1)
在设计模式的世界里,23种经典设计模式通常被分为三大类:创建型、结构型和行为型。创建型设计模式关注对象创建的问题,结构性设计模式关注于类或对象的组合和组装的问题,行为型设计模式则主要关注于类或对象之间的交互问题。 行为设…...

Python错误分析与调试
在Python编程的过程中,我们难免会遇到各种各样的错误,而有效地分析和调试这些错误,能让我们的代码快速恢复正常运行,今天就来和大家聊聊Python中错误分析与调试的相关内容。 错误分析 Python中的错误大致可以分为语法错误和逻…...

vue实现大转盘抽奖
用vue实现一个简单的大转盘抽奖案例 大转盘 一 转盘布局 <div class"lucky-wheel-content"><div class"lucky-wheel-prize" :style"wheelStyle" :class"isStart ? animated-icon : "transitionend"onWheelTransitionE…...
零基础入门系列第二篇:项目创建和初始化)
《从零搭建Vue3项目实战》(AI辅助搭建Vue3+ElemntPlus后台管理项目)零基础入门系列第二篇:项目创建和初始化
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 《从零搭建Vue3项目实战》(AI辅助…...

yum拒绝连接
YUM 拒绝连接的解决方案 当遇到 yum 无法连接的问题时,通常可以通过更换为更稳定的镜像源来解决问题。以下是具体的解决方法: 更换为阿里云源 如果当前的 yum 配置文件存在问题或网络不稳定,可以尝试将其替换为阿里云的镜像源。 备份原始配…...

信息学奥赛一本通 1861:【10NOIP提高组】关押罪犯 | 洛谷 P1525 [NOIP 2010 提高组] 关押罪犯
【题目链接】 ybt 1861:【10NOIP提高组】关押罪犯 洛谷 P1525 [NOIP 2010 提高组] 关押罪犯 【题目考点】 1. 图论:二分图 2. 二分答案 3. 种类并查集 【解题思路】 解法1:种类并查集 一个囚犯是一个顶点,一个囚犯对可以看…...

代码随想录算法训练营第十一天
LeetCode/卡码网题目: 144. 二叉树的前序遍历94. 二叉树的中序遍历145. 二叉树的后序遍历102. 二叉树的层序遍历107.二叉树的层次遍历II199. 二叉树的右视图637. 二叉树的层平均值429. N 叉树的层序遍历515. 在每个树行中找最大值116. 填充每个节点的下一个右侧节点指针117. 填…...

浅谈进程的就绪状态与挂起状态
就绪状态 进程获得除 CPU 之外的所需资源,一旦得到 CPU 就可以立即运行,不能运行的原因是还是因为 CPU 的资源太少,只能等待分配 CPU 资源。在系统中,处于就绪状态的进程可能有多个,通常是将它们组成一个进程就绪队列…...
)
37、web前端开发之Vue3保姆教程(一)
一、课程简介 本课程旨在帮助学员从零基础逐步掌握Web前端开发的核心技术,涵盖当前前端开发中的关键工具和框架。课程内容包括: Vue 3:主流前端框架,支持组件化开发和响应式数据管理,帮助学员高效构建现代Web应用。TypeScript:增强版JavaScript,提供静态类型支持,提高…...

cenos7升级gcc 9.3和Qt5.15版本教程
cenos7升级gcc 9.3和Qt5.15版本教程 文章目录 cenos7升级gcc 9.3和Qt5.15版本教程0、背景1、现状2、目标和思路3、升级前环境准备3.1 虚拟机联网配置3.2 镜像设置 4、升级gcc 9.35 升级Qt6 测试验证7 总结 0、背景 之前编码的环境一直是“拿来主义”,拷贝现成的虚拟…...
)
Scala总结(七)
集合(二) 数组 不可变数组与可变数组的转换 arr1.toBuffer //不可变数组转可变数组 arr2.toArray //可变数组转不可变数组 arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化arr1.toBuffer 返回结果才是一个可变数组ÿ…...

linux 使用 usermod 授权 普通用户 属组权限
之前写过这篇文章 linux 普通用户 使用 docker 只不过是使用 root 用户编辑 /etc/group用户所属组文件的方式 今天带来一种 usermod 命令行方式 以下3步,在root用户下操作 第一步,先创建一个普通用户测试使用 useradd miniuser第二步,授权到…...

Redis持久化
Redis持久化 一.认识持久化1.简单介绍2.持久化策略 二.RDB1.快照2."定期"fork 3.RDB演示(1)手动执行save&bgsave触发一次生成快照(2)插入key,不手动执行bgsave(3)执行bgsave后,新旧文件的替换(4)通过配置自动生成rdb快照(5)rdb文件内容被故…...
 和 Tolerations(容忍度))
什么是 k8s 的 Taints(污点) 和 Tolerations(容忍度)
什么是 k8s 的 Taints(污点) 和 Tolerations(容忍度) 在 Kubernetes(K8s)中,Taints(污点)和 Tolerations(容忍度)用于影响 Pod 调度到节点的行为…...

是德科技KEYSIGHT校准件85039B
是德科技KEYSIGHT校准件85039B 是德科技KEYSIGHT校准件85039B 85039B Agilent | 85039B|校准件|网络分析仪校准件|3GHz|75欧|N型 品牌: 安捷伦 | Agilent | 惠普 | HP 主要技术指标 DC to 3GHz frequency range 主要描述 常用型号: 一、频谱分析仪或…...

以UE5第三方插件库为基础,编写自己的第三方库插件,并且能够在运行时复制.dll
首先,创建一个空白的C 项目,创建第三方插件库。如下图所示 编译自己的.Dll 和.lib 库,打开.sln 如下图 ExampleLibrary.h 的代码如下 #if defined _WIN32 || defined _WIN64 #define EXAMPLELIBRARY_IMPORT __declspec(dllimport) #elif d…...

StarRocks执行原理与SQL性能优化策略探索
https://zhuanlan.zhihu.com/p/15707561363 聚合优化实践 -- 通过count group by 优化 count distinct数据倾斜问题 除了前面所说的聚合度会对分组聚合造成比较大的影响外,我们还要考虑一个点,即数据倾斜问题。 背景: 如下为最初的用户计算uv的SQL SE…...

Java全栈面试宝典:JMM内存模型与Spring自动装配深度解析
目录 一、Java内存模型(JMM)核心原理 🔥 问题8:happens-before原则全景解析 JMM内存架构图 happens-before八大规则 线程安全验证案例 🔥 问题9:JMM解决可见性的三大武器 可见性保障机制 volatile双…...

拉普拉斯变换
【硬核】工科生都逃不掉的拉氏变换,居然又炫酷又实用|拉普拉斯变换原理、图解与应用,傅里叶变换进阶,控制理论必修课【喵星考拉】...

JavaScript之Json数据格式
介绍 JavaScript Object Notation, js对象标注法,是轻量级的数据交换格式完全独立于编程语言文本字符集必须用UTF-8格式,必须用“”任何支持的数据类型都可以用JSON表示JS内内置JSON解析JSON本质就是字符串 Json对象和JS对象互相转化 前端…...

Android WiFi协议之P2P介绍与实践
Android WiFi P2P WiFi P2P (Peer-to-Peer) 是 Android 提供的一种允许设备之间直接通过 WiFi 进行通信的技术,无需接入传统的 WiFi 网络或互联网。这种技术也被称为 WiFi Direct。 一、WiFi P2P 基本概念 1. 核心组件 P2P 设备:支持 WiFi P2P 的 And…...

android TabLayout中tabBackground和background的区别
在这段代码中,android:background"color/white" 和 app:tabBackground"android:color/transparent" 是两个不同的属性,它们的作用范围和用途完全不同。以下是它们的区别: 1. android:background 作用: 设置整…...

使用 `keytool` 生成 SSL 证书密钥库
使用 keytool 生成 SSL 证书密钥库:详细指南 在现代 Web 应用开发中,启用 HTTPS 是保护数据传输安全性和增强用户体验的重要步骤。对于基于 Java 的应用,如 Spring Boot 项目,keytool 是一个强大的工具,用于生成和管理…...

DC-DC电路和LDO电路
一、DC-DC电路 在电子电路中,将输入的直流电压转换为电路中所需要的直流电压的电路被称为DC-DC电源电路。 1、buck电路(降压电路) 功能:把12V输入电压转化为5V的输出电压。 上图中电池为12V供电,需要给负载输出5V电…...

智谛达科技引领AI人形机器人新时代
在这个科技日新月异的时代,人工智能(AI)如同一股不可阻挡的洪流,以前所未有的速度改变着我们的生活方式、工作模式乃至整个社会的运行逻辑。而在这场波澜壮阔的科技革命中,智谛达科技集团凭借其深厚的技术底蕴、前瞻性的战略眼光以及在AI人形机器人领域的深厚积累,正引领着整个…...

在ubuntu24上装ubuntu22
实验室上有一台只装了ubuntu24的电脑,但是项目要求在22上进行 搞两个ubuntu系统! 步骤一:制作22的启动盘 步骤二:进入bios安装界面 步骤三:选择try or install ubuntu 步骤四:选择try ubuntu 步骤五&…...

高精度算法
高精度加法 输入两个数,输出他们的和(高精度) 输入样例 111111111111111111111111111111 222222222222222222222222222222 输出样例 333333333333333333333333333333 #include <bits/stdc.h> using namespace std;string a,b; in…...