机器学习——决策树
1.什么要学习决策树?
处处都是选择,并且到处都是岔路口。比如你发现某只股票几天时间内涨了很多,如果是你,你会买进吗?如果买进了,你就得承担后果,要么会大赚一笔,要么会血本无归。总之,用算法替代主观判断,避免情绪化投资决策。
2.什么是决策树?
决策树是一种常见的分类和回归模型。通俗来说,决策树其实就是一颗能替我们做决策的树,或者说是是一种树,一种依托于策略抉择而建立起来的树。(有点类似于编程语言中的if-else结构)

2.1基本概念
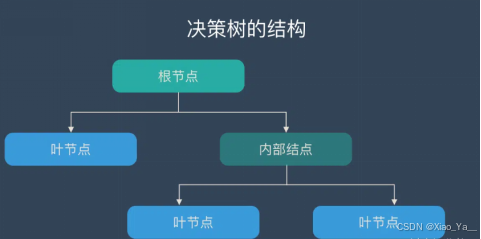
节点(Node):表示一个特征或属性。
根节点(Root Node):树的最顶层节点,表示整个数据集的初始分割。
内部节点(Internal Node)/子节点:除根节点和叶节点外的节点,用于进一步分割数据。
叶节点(Leaf Node):树的末端节点,表示分类或回归结果。
边(Edge):节点之间的连接,表示特征或属性的可能取值。
路径(Path):从根节点到叶节点的一条路径,表示一系列决策。
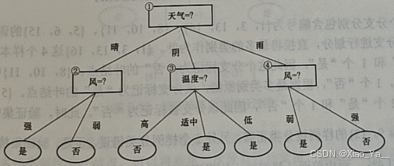
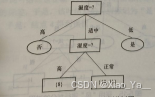
2.2图示例
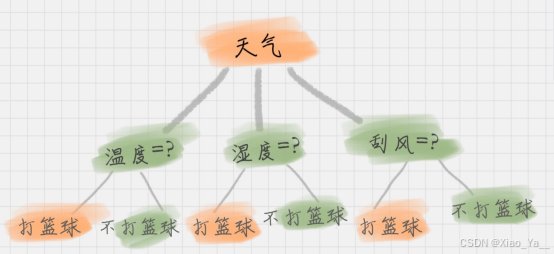
在这个推断的过程中,其实已经不知不觉中运用了一次,决策树的预测流程,也就是说这个脑回路就是一个决策树的模型。但模型确定好了,不管输入什么样的信息,都能预测出来到底是打篮球还是不打篮球,所以这才是理解决策树算法的关键!并不是理解如何根据输入来预测结果,关键在于如何构建出一个好的决策树模型,让我们的预测结果更加精准!
3.决策树的历史背景
决策树的概念可以追溯到20世纪60年代。最早的决策树算法之一是ID3(Iterative Dichotomiser 3),由Ross Quinlan在1986年提出。ID3通过信息增益(Information Gain)选择特征来构建决策树。随后,Quinlan提出了C4.5算法,它是ID3的改进版,处理了缺失值和连续属性问题。在20世纪90年代,Leo Breiman等人提出了CART(Classification and Regression Trees)算法,该算法不仅适用于分类任务,还适用于回归任务。此外,CART算法引入了基尼指数(Gini Index)作为分裂标准。
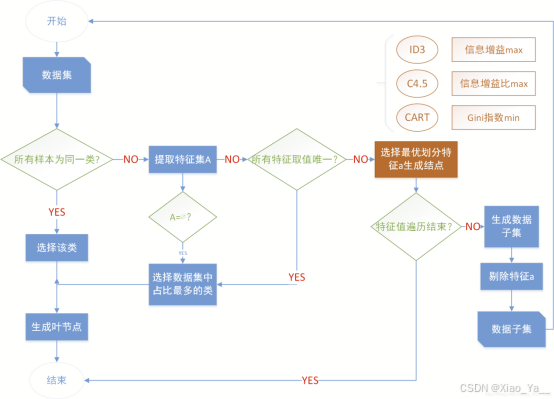
4.构建决策树
决策树算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。

4.1 选择最佳特征
一般来说,构建决策树时会遵循一个指标,有的是按信息增益来构建的,这种就叫ID3算法;有的是按信息增益比来构建的,这种叫C4.5算法;有的是按照基尼系数来构建的,这种叫CART算法。
4.1.1 ID3算法
整个ID3算法是围绕着信息增益来的,所以要弄清楚ID3算法的流程。首先需要弄清楚什么是信息增益?但是要搞清楚信息增益之前,还得弄明白一个概念—熵(entropy)。所以什么是熵?在信息论和概率统计中,为了表示某个随机变量的不确定性,就引出了一个概念叫熵。
这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度,而在信息学里面,熵是对不确定性的度量。香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
对于某个数据集D来说,假设数据集中有n类样本,其中第k样本的比例为pk,则该数据集的信息熵为:

数据集D的信息熵,反映了数据集D的混乱程度。Ent(D)越大,数据集中类别分布越混乱;Ent(D)越小,数据集D中类别越纯(比较极端的情况是:只有一个类别,此时Ent(D)为0)。
假设某个属性a把数据集D划分成了V个子集D1,D2,...,DV,那么划分后,每个子集的信息熵为Ent(D1),Ent(D2),...,Ent(DV)。将子集的熵加权求和,结果作为划分后子集的熵。权为每个子集中元素的比例,因此,引入属性a划分数据集后,新的熵为:

公式(1)为数据集初始的信息熵,公式(2)是引入属性a划分数据集后的信息熵,引入属性a前后,信息熵发生了改变。这种改变称为该属性带来的“信息增益”(information gain),记为:
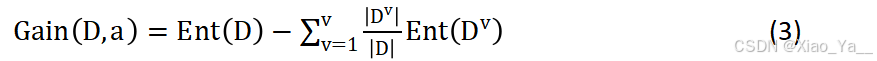
既然属性可以带来信息的改变,就可以用信息增益大的属性来划分数据。因此,需要分别计算每个属性的信息增益,选择信息增益最大的属性作为决策树的根节点,然后根据根节点的属性值划分数据集。对划分后的数据集继续计算其余属性的信息增益,再选择信息增益最大的作为子树的根节点,如此进行下去,直到某个子集“纯”了为止。
在理解了信息增益后,需要转变一下思路,把它套在机器学习上。
举个案例:
有11个样本的数据集D,其中标签属性中有7个输出为打篮球,4个为不打篮球。
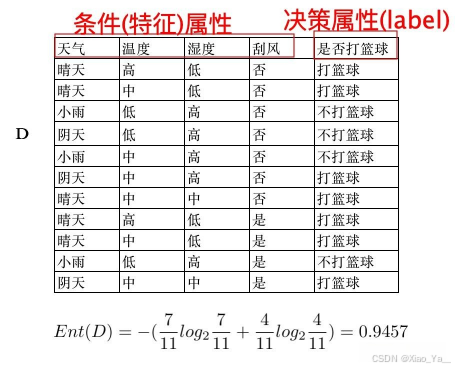
第一次划分:计算每个属性的信息增益,选择信息增益最大的节点作为根节点。
根据公式(1)计算出训练集初始的熵为:
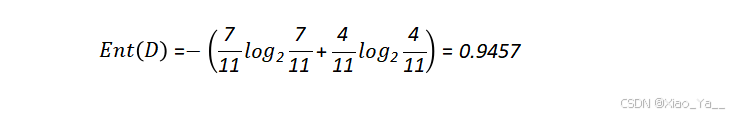
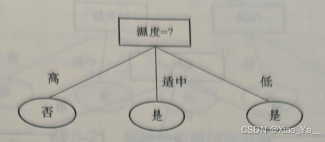
属性“天气”有3个取值(晴、阴、小雨),如果以天气作为属性进行划分:
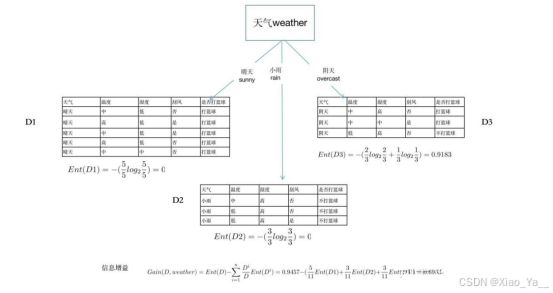
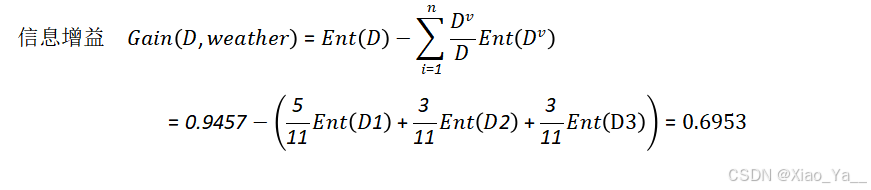
如果以温度作为属性划分:


湿度、刮风的计算细节就不再展示,同样的方法计算得出,当湿度作为属性进行划分,信息增益为0.6176;刮风作为属性进行划分,信息增益为0.0238。

计算结果显示,当天气作为属性时,信息增益最大。因为ID3算法就是寻找信息增益最大的属性作为节点,所以我们最终选取天气作为根节点。
天气已经确定为根节点,所以天气这个属性后面也不必再重复计算,以确保已经确定为节点的属性在任意路径最多只出现一次。
当天气等于晴天时,所有的结果都是打篮球,没有任何不确定性,所以不必再继续分下去,叶子节点就是打篮球;
当天气等于小雨时,所有的结果都是不打篮球,没有任何不确定性,所以也不必再继续分下去,叶子节点就是不打篮球;
当天气等于阴天时,结果有打篮球,也有不打篮球。所以我们必须再从温度、湿度、刮风等条件属性中,找到信息增益最大的属性作为节点,继续分裂下去。
计算方法和上面一样,分别求出当条件是温度、湿度、刮风时的信息增益。经过计算会发现选择属性温度时,信息增益最大,所以阴天这个分支,继续选择温度作为子节点。温度作为节点之后,再继续分裂,没有任何不确定性。当温度为中的时候,结果都是打篮球,低的时候,结果是不打篮球。所以整个决策树就构造完成了。
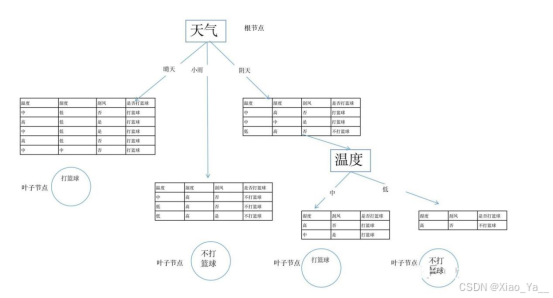
4.1.2 C4.5算法
采用信息增益作为选择最佳根节点的标准,会对取值数量较多的属性有偏好,为了避免这种偏好产生负面影响,著名的C4.5算法采用“增益率(比)”来作为确定最佳根节点的标准,其中,增益率的计算公式为:

其中,

IV(a)是属性a固有的属性。|D|表示数据集D中元素的数量。公式5本质上是熵。某个属性a的取值很多的时候,就会把数据集|D|划分成多个子集,那么这种划分就相当于比较混乱,IV(a)值就大,将其倒数作为系数去乘属性a的信息增益Gain(D,a),会压制信息增益对属性取值多的偏好。
例如,如上面所讲,对于天气属性取值有3个,将数据集划分为3部分,每部分数据的数量分别为5个、3个、3个。此时,天气属性的IV(天气)为:

从上面可以看出,属性的取值越多,其IV值越大,其IV值倒数越小,则按公式(4)计算出来的增益率被压制得越大。然而这样做又有了新的偏好,偏好属性取值数量少。C4.5算法在解决问题的时候,是将信息增益与增益率结合起来使用的,首先从候选属性中找到信息增益高于平均水平的属性,再选择增益率最高的属性作为根节点。

[天气]
/ | \
晴 / 阴 \ 雨
/ | \
打篮球 [温度] 不打篮球
/ \
中/ \低
/ \
打篮球 不打篮球
4.1.3 CART算法
除了信息增益、增益率可以作为构造决策树的标准外,还可以使用基尼指数来生成决策树。分类与回归树(classification and regression tree,CART)是一种基于基尼指数生成决策树的方法。
假设在分类问题中,数据集D有K个类,样本点属于第K类的概率为Pk,则数据集D的基尼值定义为:
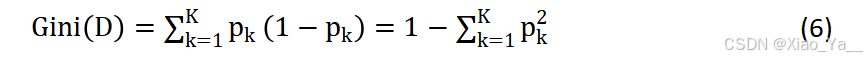
当数据集D中只有1个类别时,该类别出现的概率为1,Gini(D)=0,数据集是纯的,当数据集纯度越大,其基尼值越小。
引入某个属性a后,将数据集D划分为若干子集,属性a的基尼指数定义为:
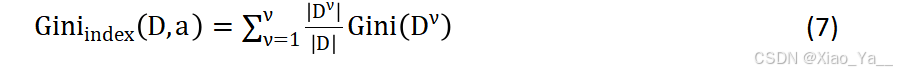
在构造决策树时,选择基尼指数最小的属性作为根节点。

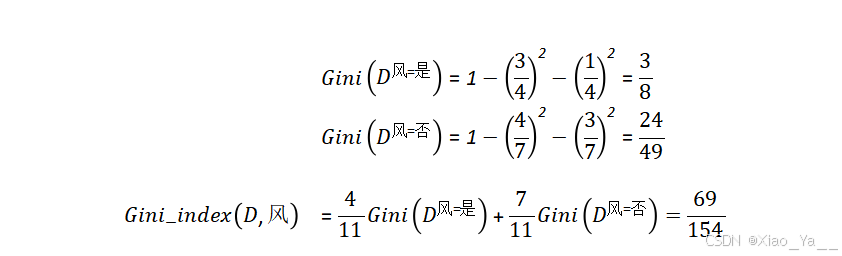
依次计算每个属性的基尼指数,并将基尼指数最小的属性作为决策树的根节点。其余过程与ID3决策树的构造过程类似。
[天气]
/ | \
晴 / 阴 \ 雨
/ | \
打篮球 [温度] 不打篮球
/ \
中/ \低
/ \
打篮球 不打篮球
5.决策树剪枝
无论是采用信息增益、增益率还是基尼指数构造决策树,构造出来一棵完全生长的决策树都会存在过拟合现象。为了降低过拟合的风险,需要对决策树进行剪枝处理(pruning)。决策树的剪枝有两种方法:预剪枝(pre-pruning)和后剪枝(post-pruning)。
预剪枝是指在决策树的生成过程中,在每一步划分时,确定了划分属性后,先要估计一下泛化能力。(泛化能力是指机器学习模型对未见过的数据(即训练数据之外的数据)的适应和预测能力。)若当前划分能带来泛化性能的提升,则划分,否则,停止划分,并将当前节点标记为叶节点。后剪枝则是先利用训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察泛化性能。做法就是将数据集分成训练集和验证集。训练集用于构造决策树,验证集用于泛化性能的评估。
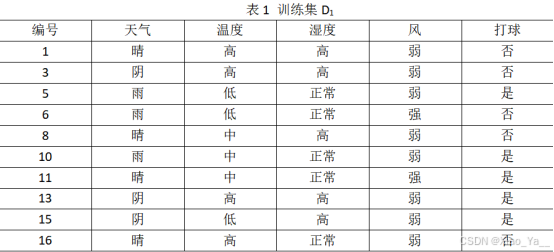
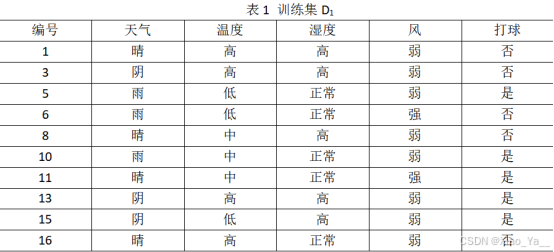
表1 训练集D1
| 编号 | 天气 | 温度 | 湿度 | 风 | 打球 |
| 1 | 晴 | 高 | 高 | 弱 | 否 |
| 3 | 阴 | 高 | 高 | 弱 | 否 |
| 5 | 雨 | 低 | 正常 | 弱 | 是 |
| 6 | 雨 | 低 | 正常 | 强 | 否 |
| 8 | 晴 | 中 | 高 | 弱 | 否 |
| 10 | 雨 | 中 | 正常 | 弱 | 是 |
| 11 | 晴 | 中 | 正常 | 强 | 是 |
| 13 | 阴 | 高 | 高 | 弱 | 是 |
| 15 | 阴 | 低 | 高 | 弱 | 是 |
| 16 | 晴 | 高 | 正常 | 弱 | 否 |
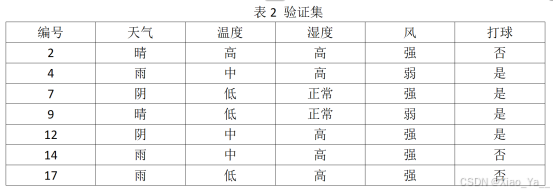
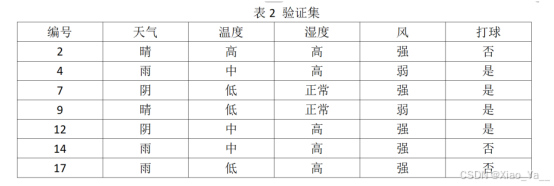
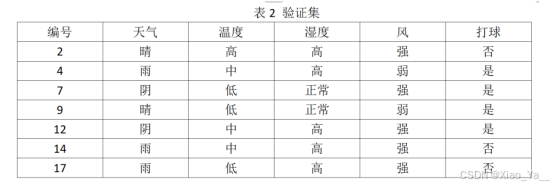
表2 验证集
| 编号 | 天气 | 温度 | 湿度 | 风 | 打球 |
| 2 | 晴 | 高 | 高 | 强 | 否 |
| 4 | 雨 | 中 | 高 | 弱 | 是 |
| 7 | 阴 | 低 | 正常 | 强 | 是 |
| 9 | 晴 | 低 | 正常 | 弱 | 是 |
| 12 | 阴 | 中 | 高 | 强 | 是 |
| 14 | 雨 | 中 | 高 | 强 | 否 |
| 17 | 雨 | 低 | 高 | 强 | 否 |
如果不进行剪枝处理:
根据训练集D1构造的未剪枝的决策树
5.1 预剪枝
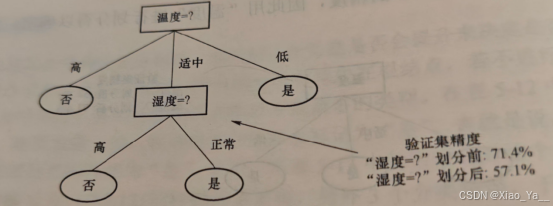
预剪枝过程是先确定的划分属性,再判断泛化性能是否会提升来决定是否进行划分。
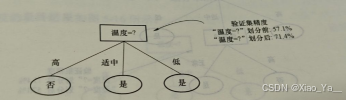
基于信息增益准则,在划分前,所有的样本都集中在根节点,若不进行划分,该节点将被标记为叶节点,其类别标记为训练样本数最多的类别。在训练集中,两类样本一样多,先随便选择一类。假设将这个叶节点标记为“是”,也就是说,不管什么样的数据,决策树都判断打球为“是”。验证集精度为57.1%,若要对数据集D1进行划分,选择信息增益最大的属性进行划分,计算各个属性的信息增益如下:

“天气”和“温度”属性的信息增益最大且相同,这里选择温度属性进行样例的划分,得到结果如图所示:

用温度属性生成的预剪枝决策树
预剪枝第1次划分过程
然后,决定是否对“温度=高”的分支进行划分。由于验证集中“温度=高”的样本只有编号为2的1个样例,而且已经分类正确,由于划分后不会增加验证集的精度,故不再进行划分。对“温度=适中”进行划分:

“湿度”的信息增益最大,故选择“湿度”进行划分。
预剪枝第2次划分
采用湿度进行第二次划分后,训练集被分割为2个分支,将样本类别出现最多的类别作为叶节点,可以得到第二次预剪枝决策树。
采用湿度进行划分后的决策树
用上面的决策树在验证集上分类,由于划分导致验证集精度降低,因此不用湿度进行划分。
接下来对“温度=低”进行划分:
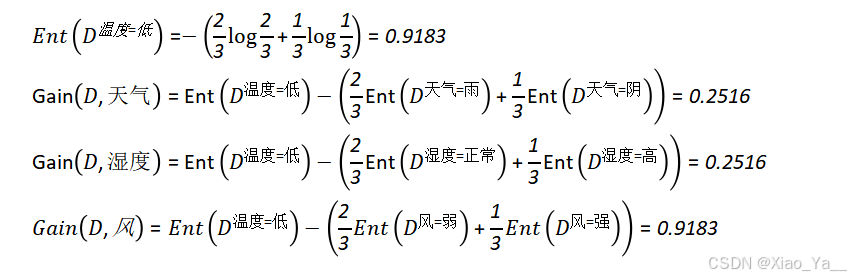
选择具有最大信息增益的风进行划分:
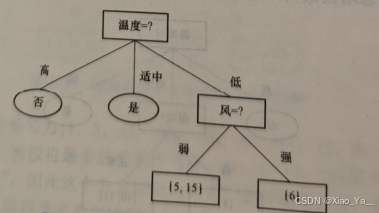
采用风进行划分的过程
用上面的决策树在验证集上分类,由于划分导致验证集精度降低,因此不用风进行划分。用风划分取消。预剪枝的最终结果:

预剪枝最终的决策树
5.2 后剪枝
后剪枝先从训练集生成一棵完整的决策树,根据表1中的训练集,构造的完全生成的决策树如下提,该决策树在验证集上的分类精度为71.4%。
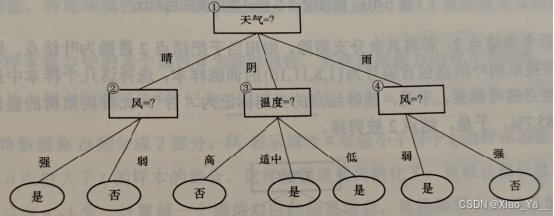
根据训练集构建的完全生长的决策树
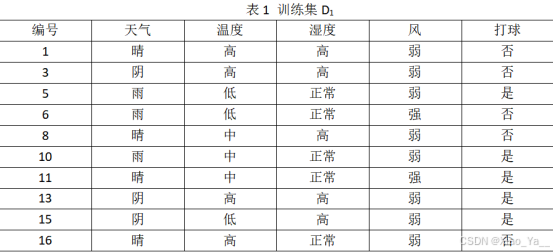
后剪枝首先考虑节点4,若将其余分支剪除,则相当于把节点4替换为叶节点,替换后的叶节点包含编号为{5,6,10}的训练样本,选择这几个样本中最多的类别作为叶节点的标签。此时决策树的验证集精度下降为42.9%,于是,节点4保留。如下图所示。
剪枝节点4验证集精度前后对比
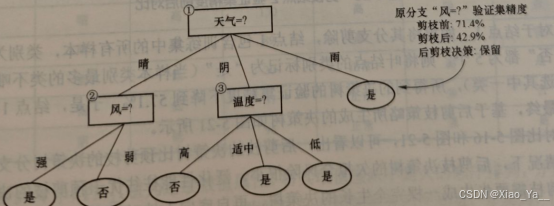
接下来考虑是否剪掉节点3,若将其余分支剪除,则相当于把节点3替换为叶节点,替换后的叶节点包含编号{3,13,15}的训练样本,该叶节点的类别标记为是。此时决策树的验证集精度仍为71.4%,没有得到改善。节点3得到保留。
剪枝节点3验证集精度前后对比
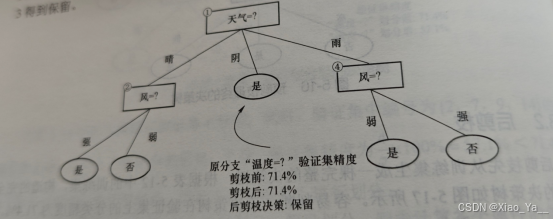
然后考虑节点2,替换后的叶节点包含编号为{1,8,11,16}的训练样本。

剪枝节点2验证集精度前后对比
对于节点1,如果将其分支剪除,节点1包含训练集中的所有样本,类别为是和否都为5个,则将叶节点的类别标记为是(当样本类别最多的类不唯一时,可任选其中一类),所得到的决策树的验证集精度下降到57.1%。节点1 保留。
最终,基于后剪枝策略所生成的决策树,如下图:
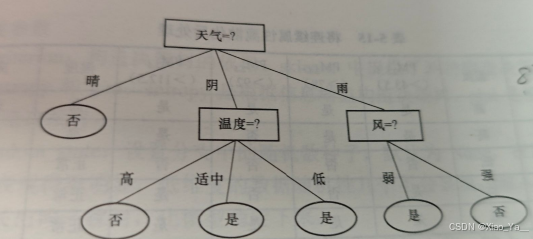
最终的后剪枝决策树
预剪枝最终的决策树
可以看出,后剪枝的决策树比预剪枝的决策树分支更多。一般,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝的决策树。但后剪枝需要先生成一棵完全生长的决策树,再自底向上地对树中所有的非叶子节点进行逐一判断,因此其训练过程中的时间开销比预剪枝决策树大很多。
6.决策树与集成学习
集成学习是将多个弱模型(如决策树)组合成一个强模型,以提高整体的预测性能。主要思想是:多个模型的“集体智慧”要优于单个模型的判断。(决策树是集成学习中最常用的基础模型。)
决策树比较容易过拟合,因此需要树的结构进行约束。利用剪枝等方法来砍掉冗余的分支,使得树结构尽量简单,以提高树模型在未训练数据上的预测表现(也就是泛化能力)。除此之外,集成学习(Ensemble Learning),横向地增加多个树,并利用多个树模型结果综合判断,也是个能提高模型性能常用方法。(集成学习通过多个决策树组合,弥补单棵树的不足。)
集成后的模型比单一决策树更强、更稳定、更精准。
相关文章:

机器学习——决策树
1.什么要学习决策树? 处处都是选择,并且到处都是岔路口。比如你发现某只股票几天时间内涨了很多,如果是你,你会买进吗?如果买进了,你就得承担后果,要么会大赚一笔,要么会血本无归。总之,用算法替代主观判断,避免情绪化投资决策。 …...

zk源码—2.通信协议和客户端原理二
大纲 1.ZooKeeper如何进行序列化 2.深入分析Jute的底层实现原理 3.ZooKeeper的网络通信协议详解 4.客户端的核心组件和初始化过程 5.客户端核心组件HostProvider 6.客户端核心组件ClientCnxn 7.客户端工作原理之会话创建过程 6.客户端核心组件ClientCnxn (1)客户端核心…...

Python设计模式:构建模式
1. 什么是构建模式 构建模式(Builder Pattern)是一种创建型设计模式,它允许使用多个简单的对象一步步构建一个复杂的对象。构建模式通过将构建过程与表示分离,使得同样的构建过程可以创建不同的表示。换句话说,构建模…...
)
C++类间的 “接力棒“ 传递:继承(下)
文章目录 5. 继承与友元6.继承与静态成员7.菱形继承8.继承和组合希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力! 本篇接着补充继承方面的内容,同时本篇的菱形继承尤为重要 5. 继承与友元 class Student; class Person { public:fri…...
)
C++11QT复习 (十六)
文章目录 Day11 移动语义回顾一、移动语义基础概念二、自定义 String 类的移动语义实现输出运算符重载: 三、测试函数:验证移动与拷贝行为四、左值与右值的补充说明右值引用作为函数返回值 五、知识总结如何区分左值与右值? 六、附加说明&…...

Redis客户端命令到服务器底层对象机制的完整流程?什么是Redis对象机制?为什么要有Redis对象机制?
Redis客户端命令到服务器底层对象机制的完整流程 客户端 → RESP协议封装 → TCP传输 → 服务器事件循环 → 协议解析 → 命令表查找 → 对象机制 → 动态编码 → 数据结构操作 → 响应编码 → 网络回传 Redis客户端命令到服务器底层对象机制的完整流程可分为协议封装、命令解…...
)
鸿蒙NEXT开发节流、防抖工具类(ArkTs)
import { CacheUtil } from ./CacheUtil; import { DateUtil } from ./DateUtil;/*** 节流、防抖工具类(用于点击事件,防止按钮被重复点击)** author 鸿蒙布道师* since 2025/04/07*/ export class ClickUtil {private static throttleTimeou…...

Qt程序 Windows打包
目的 运行Qt的程序,遇上如下问题: 显然是少很多Qt库,那就把Qt库放到这里,Qt提供这一个命令windeployqt.exe. windeployqt windeployqt是Qt框架提供的一个工具,主要用于自动打包Windows平台上的Qt应用程序及其依赖项…...
:Databricks DLT 详解)
2025-04-07(DS复习):Databricks DLT 详解
Databricks Delta Live Tables (DLT) 详解 Delta Live Tables (DLT) 是 Databricks 提供的一个智能框架,用于构建可靠、可扩展的数据处理管道。它简化了ETL(提取、转换、加载)和ELT(提取、加载、转换)流程的开发和管理,特别适合在数据湖house架构中实现…...
——RTCP协议简介(中))
音视频入门基础:RTCP专题(3)——RTCP协议简介(中)
本文接着《音视频入门基础:RTCP专题(2)——RTCP协议简介(上)》,继续对RTCP协议进行简介。本文的一级标题从“九”开始。 九、Sender and Receiver Reports 本段内容对应《RFC 3550》的第6.4节。根据《RFC …...
生产者-消费者模式)
嵌入式工程师多线程编程(二)生产者-消费者模式
生产者-消费者模式详解:多线程编程的核心范式 生产者-消费者模式(Producer-Consumer Pattern)是多线程编程中最经典的设计模式之一,它通过解耦生产者和消费者的工作流程,实现了线程间的高效协作与资源管理。本文将深入剖析这一模式的原理、实…...

秒杀系统的性能优化
秒杀任务总体QPS预期是每秒几十万,对tomcat、redis、JVM参数进行优化。 tomcat线程数 4核8G的机器,一般就是开200-300个工作线程,这是个经验值。每秒一个线程处理3-5个请求,200多个线程的QPS可以达到1000左右。线程不能太多&…...

MySQL学习笔记集--索引
索引 索引是数据库中用于提高查询效率的一种数据结构。 它类似于书籍的目录,通过索引可以快速定位到表中的特定行,而无需扫描整个表。 索引的类型 主键索引(Primary Key Index) 自动创建,用于唯一标识表中的每一行。…...
与重绘(Repaint),写出高性能 CSS 动画)
深入理解重排(Reflow)与重绘(Repaint),写出高性能 CSS 动画
在前端开发中,CSS 动画是提升用户体验的重要手段,但很多开发者在使用动画时并不了解浏览器背后的渲染机制,导致动画卡顿甚至影响整体性能。本文将带你深入理解 CSS 中的两大核心概念 —— 重排(Reflow) 与 重绘&#x…...

Elasticsearch 从入门到实战:文档聚合操作及总结
四、文档操作:数据的增删改查 4.1 添加文档 文档(Document)是索引中的最小数据单元,使用 POST 或 PUT 添加: json POST /products/_doc/1 { "name": "华为Mate50 Pro", "price": 6…...

前缀和和差分笔记
前缀和和差分笔记 一维前缀和 示意图如下: 代码: **核心公式:sum[i]sum[i-1]a[i];(计算前缀和的)**#include<bits/stdc.h> using namespace std; const int N10000; #define ll long long int a[N],sum[N]; i…...

SSRF漏洞利用的小点总结和实战演练
含义理解: SSRF(Server-Side Request Forgery,服务器请求伪造)是一种由攻击者构造请求,由服务端发起请求的安全漏洞,一般情况下,SSRF攻击的目标是外网无法访问的内网系统。 攻击者通过篡改URL…...

IAR推动嵌入式开发:云就绪、可扩展的CI/CD和可持续自动化
全球领先的嵌入式系统开发软件解决方案供应商IAR正式发布全新云就绪平台,为嵌入式开发团队提供企业级的可扩展性、安全性和自动化能力。该平台于在德国纽伦堡举办的embedded world 2025展会上正式亮相,标志着将现代DevSecOps工作流集成到嵌入式软件开发中…...

瓦片数据合并方法
影像数据 假如有两份影像数据 1.全球底层影像0-5级别如下: 2.局部高清影像数据级别9-14如下: 合并方法 将9-14文件夹复制到全球底层0-5的目录下 如下: 然后合并xml文件 使得Tileset设置到最高级(包含所有级别)&…...

RISC-V AIA学习---IPI 处理器间中断
对于有多个hart的机器,必须为每个 hart 提供一个由具体实现定义的内存地址。向这个地址写入数据,就能向该 hart 发送一个机器级软件中断(主代码为 3)。换句话说,机器级的 IPI 可以通过这种方式,以机器级软件…...

Automattic 裁员16%,Matt Mullenweg称此举旨在提升盈利能力并增强投资实力
2025年4月3日,Automattic——这家以 WordPress.com、Tumblr 和 WooCommerce 等产品闻名的公司,宣布裁减其全球员工队伍的16%。这一决定是在周三通过公司博客文章和 Slack 内部消息向员工透露的。根据裁员前 Automattic 官网显示的员工人数(1,…...

图解AUTOSAR_SWS_FlexRayInterface
AUTOSAR FlexRay Interface 模块分析 本文档基于AUTOSAR SWS FlexRayInterface规范,对FlexRay Interface模块进行详细分析。 1. FlexRay Interface 模块架构 1.1 模块架构概览 1.2 架构说明 FlexRay Interface模块是AUTOSAR中的ECU抽象层组件,为上层模块提供统一的抽象接…...

AI赋能ArcGIS Pro——水系网络AI智能提取 | GIS人工智能制图技术解析
我们之前做了做了几期的AIGIS的分享。我们今天要再次做一个分享。 AI赋能ArcGIS Pro——水系网络智能提取全解析 DeepSeek结合ArcGIS Pro制作一个批量建库的脚本工具(代码一字未改,直接运行) 看老外如何玩DeepSeek!15分钟快速创…...

STM32江科大----IIC
声明:本人跟随b站江科大学习,本文章是观看完视频后的一些个人总结和经验分享,也同时为了方便日后的复习,如果有错误请各位大佬指出,如果对你有帮助可以点个赞小小鼓励一下,本文章建议配合原视频使用❤️ 如…...
系统,提示词(Prompt)表现测试(数据说话))
RAG(检索增强生成)系统,提示词(Prompt)表现测试(数据说话)
在RAG(检索增强生成)系统中,评价提示词(Prompt)设计是否优秀,必须通过量化测试数据来验证,而非主观判断。以下是系统化的评估方法、测试指标和具体实现方案: 一、提示词优秀的核心标准 优秀的提示词应显著提升以下指标: 维度量化指标测试方法事实一致性Faithfulness …...

【leetcode hot 100 763】划分字母区间
解法一:用map记录<字母,字母出现的次数>,循环取出value-1,每次判断已经取出的字母(Set记录)是否还在后面存在(value>1),若存在继续循环,若不存在开启…...

PCB工艺:现代电子产品的核心制造技术
引言 PCB(Printed Circuit Board,印刷电路板)是电子设备的核心组成部分,几乎所有现代电子产品,从智能手机到航天设备,都依赖于PCB实现电路连接。PCB制造工艺的进步直接影响电子产品的性能、可靠性和成本。…...

【UE5 C++课程系列笔记】34——结构体与Json的相互转化
目录 准备工作 一、结构体转Json 二、Json转结构体 三、复杂结构体与Json的转换 主要通过借助FJsonObjectConverter类实现结构体和 JSON 之间的相互转换。 准备工作 首先新建一个结构体如下 添加两个方法分别用于将Struct转为Json、Json转为Struct 一、结构体转Json FStri…...
)
2025最新系统 Git 教程(二)
第2章 Git基础 2.1 Git 基础 - 获取 Git 仓库 如果你只想通过阅读一章来学习 Git,那么本章将是你的不二选择。 本章涵盖了你在使用 Git 完成各种工作时将会用到的各种基本命令。 在学习完本章之后,你应该能够配置并初始化一个仓库(reposito…...

力扣hot100_动态规划
动态规划 hot100_198. 打家劫舍 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。…...

玄机-第六章-哥斯拉4.0流量分析的测试报告
目录 一、测试环境 二、测试目的 三、操作过程 Flag1 Flag2 Flag3 Flag4 Flag5 Flag6 Flag7 Flag8 Flag9 Flag10 Flag11 Flag12 Flag13 pam_unix.so关键代码 四、结论 一、测试环境 靶场介绍:国内厂商设置的玄机靶场,以应急响应题目著…...

【Hadoop入门】Hadoop生态圈概述:核心组件与应用场景概述
1 Hadoop生态圈概述 Hadoop生态圈是以 HDFS(分布式存储) 和 YARN(资源调度) 为核心,围绕大数据存储、计算、管理、分析等需求发展出的一系列开源工具集合。 核心特点: 模块化:各组件专注解决特定…...

深度学习实战电力设备缺陷检测
本文采用YOLOv11作为核心算法框架,结合PyQt5构建用户界面,使用Python3进行开发。YOLOv11以其高效的实时检测能力,在多个目标检测任务中展现出卓越性能。本研究针对电力设备缺陷数据集进行训练和优化,该数据集包含丰富的电力设备缺…...
)
随机产生4位随机码(java)
Random类: 用于生成随机数 import java.util.Random; 导入必要的类 generateVerificationCode()方法: 这是一个静态方法,可以直接通过类名调用 返回一个6位数字的字符串,首位不为0 生成首位数字: random.nextInt…...
——RTCP协议简介(下))
音视频入门基础:RTCP专题(4)——RTCP协议简介(下)
本文接着《音视频入门基础:RTCP专题(3)——RTCP协议简介(中)》,继续对RTCP协议进行简介。本文的一级标题从“十四”开始。 十四、SDES: Source Description RTCP Packet 本段内容对应《RFC 3550》的第6.5节…...

PyCharm2024.3.5专业版解决Conda executable is not found问题
项目场景: pycharm使用anaconda 内的虚拟环境 pycharm 2024.3.5 专业版 C:\Users\Administrator>conda infoactive environment : transmute_recipe_generatoractive env location : D:\anaconda3\envs\transmute_recipe_generatorshell level : 1user config…...

滑动窗口思想 面试算法高频题
基本思想 滑动窗口思想其实就是快慢型的特例 计算机网络中滑动窗口协议(Sliding Window Protocol),该协议是TCP实现流量控制等的核心策略之一。事实上在与流量控制、熔断、限流、超时等场景下都会首先从滑动窗口的角度来思考问题࿰…...

Linux中特殊的变量
1.$# 含义:表示传入脚本或函数的参数数量。 用法:用于检查用户是否提供了足够的参数。 示例: #!/bin/bash echo "参数数量: $#"2.$? 含义:表示上一条命令的退出状态。如果命令成功执行,值为 0;…...

Linux文件系统与日志分析
目录 一.日志 1.1日志的定义 1.2日志的功能 1.3日志的分类 1.4日志的文件格式 1.5用户日志 1.6一些常见的日志 1.7日志消息的级别 二.系统日志管理 rsyslog 2.1rsyslog的定义 2.2rsyslog 配置文件 2.3rsyslog的实际应用----单独显示某一服务的日志 1.编辑rsyslog配…...

从传统物流到智能调度的全链路升级
一、TMS系统升级的核心目标与整体框架 (一)为什么要升级?传统物流管理的三大痛点 调度效率低下:过去依赖人工分单、手动匹配承运商,订单量大时容易出错,比如不同区域的订单混排导致运输路线绕路ÿ…...
问题)
UE5中如何修复后处理动画蓝图带来的自然状态下的metablriger身体绑定形变(如耸肩)问题
【[metablriger] UE5中如何修复后处理动画蓝图带来的自然状态下的metablriger身体绑定形变(如耸肩)问题】 UE5中如何修复后处理动画蓝图带来的自然状态下的metablriger身体绑定形变(如耸肩)问题...

STL_vector_01_基本用法
👋 Hi, I’m liubo👀 I’m interested in harmony🌱 I’m currently learning harmony💞️ I’m looking to collaborate on …📫 How to reach me …📇 sssssdsdsdsdsdsdasd🎃 dsdsdsdsdsddfsg…...

css2学习总结之尚品汇静态页面
css2总结之尚品汇 一、布局 在 PC 端网页中,一般都会有一个固定宽度且水平居中的盒子,来显示网页的主要内容,这是网页 的版心。 版心的宽度一般是 960 ~ 1200 像素之间。 版心可以是一个,也可以是多个。 二、布局相关名词 我…...

Lua 第5部分 表
表( Table )是 Lua 语言中最主要(事实上也是唯一的)和强大的数据结构。 使用表,Lua语言可以以一种简单、统一且高效的方式表示数组、集合、记录和其他很多数据结构。 Lua语言也使用表来表示包( package &am…...

01分数规划
https://ac.nowcoder.com/acm/contest/22353/1011 并不需要高级数据结构,对答案二分即可。 假定当前二分的答案为 x x x,则 ∑ v i ∑ w i ≥ x \frac{ \sum_{v_i} }{\sum_{w_i}} ≥ x ∑wi∑vi≥x 成立时 x x x 才可能是最后的答案。 化简式…...

无人机动力系统全维度解析:技术演进、选型策略与未来趋势
一、动力系统技术理念与设计逻辑 (一)核心技术指标 能量密度:决定续航能力的关键参数,单位为 Wh/kg。当前主流锂聚合物电池能量密度约 250-300Wh/kg,氢燃料电池可达 500-800Wh/kg,航空燃油则高达 12,000W…...
)
重新审视中国的GB标准(44495 – 44497)
此前,我们深入探讨了中国新推出的智能互联汽车(ICV)网络安全标准GB Standard 44495-2024。我们探讨了该标准对汽车制造商的影响、与UNECE R155和ISO/SAE 21434等全球标准的一致性,以及该标准对未来汽车网络安全的意义。 然而,GB 44495-2024并…...
之做一个简易的shell)
Linux进程控制(五)之做一个简易的shell
文章目录 做一个简易的shell预备知识代码实现运行结果 做一个简易的shell 重谈Shell shell是操作系统的一层外壳程序,帮我们用户执行指令, 获取到指令后,交给操作系统,操作系统执行完后,把执行结果通过shell交给用户…...

Apache Kafka全栈技术解析
目录 第一章 Kafka概述与核心价值 1.1 消息队列的演进与Kafka的诞生 1.2 Kafka的核心应用场景 1.3 Kafka生态全景图 第二章 Kafka核心概念与架构解析 2.1 核心概念深度剖析 2.2 Kafka架构设计精要 第三章 Kafka环境搭建与配置 3.1 单机部署实战 3.2 集群部署最佳实践 …...
)
结合 Flink/Spark 进行 AI 大数据处理(实时数据 + AI 推理的应用场景)
随着企业对实时智能决策的需求日益增强,将 Flink / Spark 等流批计算框架 与 大模型推理能力相结合,正在成为 AI 工业化落地的重要实践路径。本篇文章将深入介绍如何将 AI 模型集成到大数据流处理系统中,实现实时感知、智能判断与自动反馈。 1. 为什么需要“实时数据 + AI 推…...