MySQL学习笔记(四)——DML和DQL
目录
1. DML
1.1 添加数据
1.1.1 给指定字段添加数据
1.1.2 给全部字段添加数据
1.1.3 批量添加数据
1.2 修改数据
1.3 删除数据
2. DQL
2.1 基本语法
2.2 基础查询
2.2.1 查询多个字段
2.2.2 字段设置别名
2.2.3 去除重复记录
2.3 条件查询
2.4 聚合函数
2.5 分组查询
2.6 排序查询
2.7 分页查询
2.8 案例
2.9 执行顺序
3. DCL
3.1 管理用户
3.2 权限控制
1. DML
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
1.1 添加数据
1.1.1 给指定字段添加数据
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);- 给employee表所有的字段添加数据 ;
insert into employee(id,workno,name,gender,age,idcard,entrydate)
values(1,'1','Itcast','男',10,'123456789012345678','2000-01-01');- A. 方式一
- 在左侧的表名上双击,就可以查看这张表的数据。
- B. 方式二
- 可以直接一条查询数据的SQL语句, 语句如下:
-
select * from employee;
案例:
- 给employee表所有的字段添加数据
insert into employee(id,workno,name,gender,age,idcard,entrydate)
values(1,'1','Itcast','男',-1,'123456789012345678','2000-01-01');
1.1.2 给全部字段添加数据
INSERT INTO 表名 VALUES (值1, 值2, ...);- 插入数据到employee表,具体的SQL如下:
insert into employee values(2,'2','张无忌','男',18,'123456789012345670','2005-01-
01');1.1.3 批量添加数据
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值
1, 值2, ...) ;INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...) ;- 批量插入数据到employee表,具体的SQL如下:
insert into employee values(3,'3','韦一笑','男',38,'123456789012345670','2005-01-
01'),(4,'4','赵敏','女',18,'123456789012345670','2005-01-01');- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围内。
1.2 修改数据
UPDATE 表名 SET 字段名1 = 值1 , 字段名2 = 值2 , .... [ WHERE 条件 ] ;- A. 修改id为1的数据,将name修改为itheima
update employee set name = 'itheima' where id = 1;- B. 修改id为1的数据, 将name修改为小昭, gender修改为 女
update employee set name = '小昭' , gender = '女' where id = 1;- C. 将所有的员工入职日期修改为 2008-01-01
update employee set entrydate = '2008-01-01';- 修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
1.3 删除数据
DELETE FROM 表名 [ WHERE 条件 ] ;- A. 删除gender为女的员工
delete from employee where gender = '女';- B. 删除所有员工
delete from employee; - DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
- DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
- 当进行删除全部数据操作时,datagrip会提示我们,询问是否确认删除,我们直接点击执行即可。

2. DQL
- SELECT
create table emp(id int comment '编号',workno varchar(10) comment '员工工号',name varchar(10) comment '姓名',gender char(1) comment '性别',age tinyint unsigned comment '年龄',idcard char(18) comment '身份证号码',workaddress varchar(50) comment '工作地址',entrydate date comment '入职时间'
) comment '员工表';insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (1, '00001', '柳岩666', '女', 20, '123456789012345678', '北京', '2000-01-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (2, '00002', '张无忌', '男', 18, '123456789012345670', '北京', '2005-09-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (3, '00003', '韦一笑', '男', 38, '123456789712345670', '上海', '2005-08-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (4, '00004', '赵敏', '女', 18, '123456757123845670', '北京', '2009-12-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (5, '00005', '小昭', '女', 16, '123456769012345678', '上海', '2007-07-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (6, '00006', '杨逍', '男', 28, '12345678931234567X', '北京', '2006-01-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (7, '00007', '范瑶', '男', 40, '123456789212345670', '北京', '2005-05-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (8, '00008', '黛绮丝', '女', 38, '123456157123645670', '天津', '2015-05-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (9, '00009', '范凉凉', '女', 45, '123156789012345678', '北京', '2010-04-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (10, '00010', '陈友谅', '男', 53, '123456789012345670', '上海', '2011-01-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (11, '00011', '张士诚', '男', 55, '123567897123465670', '江苏', '2015-05-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (12, '00012', '常遇春', '男', 32, '123446757152345670', '北京', '2004-02-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (13, '00013', '张三丰', '男', 88, '123656789012345678', '江苏', '2020-11-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (14, '00014', '灭绝', '女', 65, '123456719012345670', '西安', '2019-05-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (15, '00015', '胡青牛', '男', 70, '12345674971234567X', '西安', '2018-04-01');
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) values (16, '00016', '周芷若', '女', 18, null, '北京', '2012-06-01');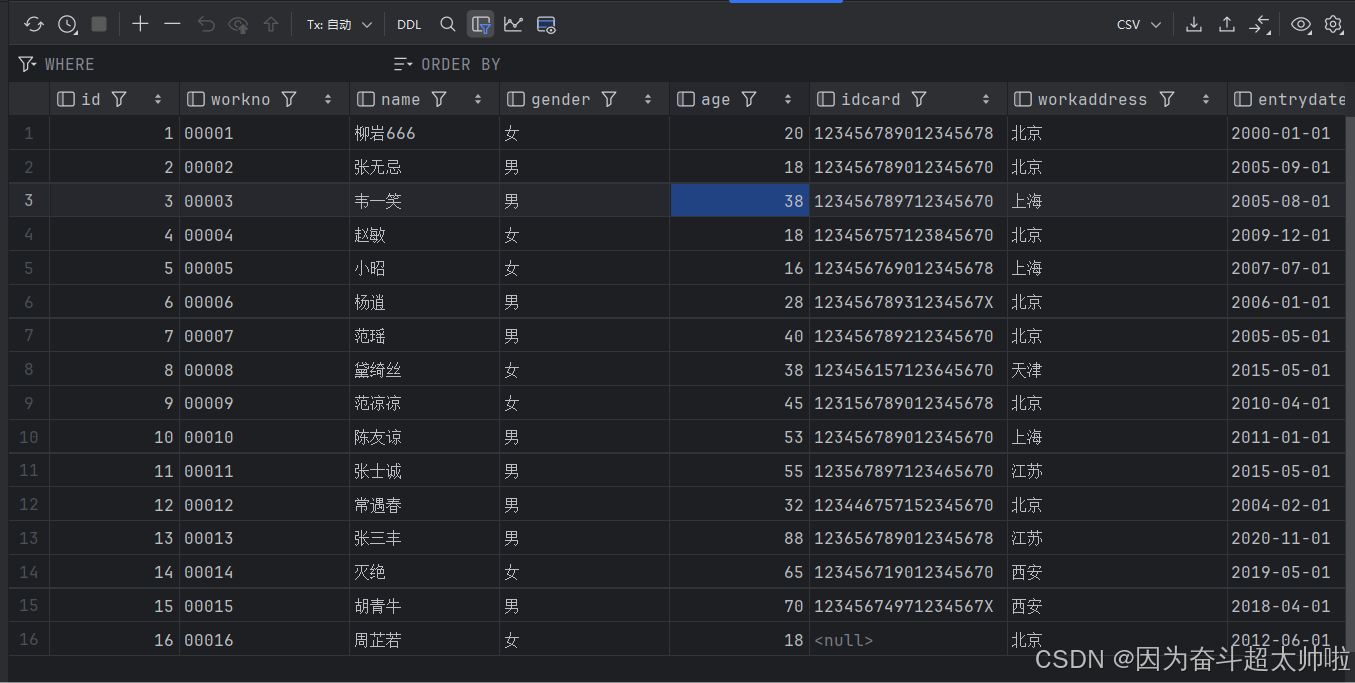
2.1 基本语法
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数- 基本查询(不带任何条件)
- 条件查询(WHERE)
- 聚合函数(count、max、min、avg、sum)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
2.2 基础查询
2.2.1 查询多个字段
SELECT 字段1, 字段2, 字段3 ... FROM 表名 ; SELECT * FROM 表名 ;- * 号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)。
2.2.2 字段设置别名
SELECT 字段1 [ AS 别名1 ] , 字段2 [ AS 别名2 ] ... FROM 表名; SELECT 字段1 [ 别名1 ] , 字段2 [ 别名2 ] ... FROM 表名;2.2.3 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;- A. 查询指定字段 name, workno, age并返回
select name,workno,age from emp;- B. 查询返回所有字
select id ,workno,name,gender,age,idcard,workaddress,entrydate from emp; select * from emp;- C. 查询所有员工的工作地址,起别名
select workaddress as '工作地址' from emp;-- as可以省略
select workaddress '工作地址' from emp;- D. 查询公司员工的上班地址有哪些(不要重复)
select distinct workaddress '工作地址' from emp;2.3 条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表 ; | 比较运算符 | 功能 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN ... AND ... | 在某个范围之内 ( 含最小、最大值 ) |
| IN(...) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| IS NULL | 是NULL |
| 逻辑运算符 | 功能 |
| AND 或 && | 并且 (多个条件同时成立) |
| OR 或 || | 或者 (多个条件任意一个成立) |
| NOT 或 ! | 非 , 不是 |
- A. 查询年龄等于 88 的员工
select * from emp where age = 88;- B. 查询年龄小于 20 的员工信息
select * from emp where age < 20;- C. 查询年龄小于等于 20 的员工信息
select * from emp where age <= 20;- D. 查询没有身份证号的员工信息
select * from emp where idcard is null; - E. 查询有身份证号的员工信息
select * from emp where idcard is not null;- F. 查询年龄不等于 88 的员工信息
select * from emp where age != 88;
select * from emp where age <> 88;- G. 查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息
select * from emp where age >= 15 && age <= 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age between 15 and 20;- H. 查询性别为 女 且年龄小于 25岁的员工信息
select * from emp where gender = '女' and age < 25;- I. 查询年龄等于18 或 20 或 40 的员工信息
select * from emp where age = 18 or age = 20 or age = 40;
select * from emp where age in(18,20,40);- J. 查询姓名为两个字的员工信息 _ %
- _匹配单个字符
- %匹配任意个字符
select * from emp where name like '__'; - K. 查询身份证号最后一位是X的员工信息
select * from emp where idcard like '%X';
select * from emp where idcard like '_________________X';2.4 聚合函数
| 函数 | 功能 |
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
SELECT 聚合函数(字段列表) FROM 表名 ;- NULL值是不参与所有聚合函数运算的。
- A. 统计该企业员工数量
select count(*) from emp; -- 统计的是总记录数
select count(idcard) from emp; -- 统计的是idcard字段不为null的记录数select count(1) from emp;- B. 统计该企业员工的平均年龄
select avg(age) from emp;- C. 统计该企业员工的最大年龄
select max(age) from emp;- D. 统计该企业员工的最小年龄
select min(age) from emp;- E. 统计西安地区员工的年龄之和
select sum(age) from emp where workaddress = '西安';2.5 分组查询
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后过滤条件 ];- 执行时机不同:
- where是分组之前进行过滤,不满足where条件,不参与分组;
- 而having是分组之后对结果进行过滤。
- 判断条件不同:
- where不能对聚合函数进行判断,而having可以。
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
- 执行顺序: where > 聚合函数 > having 。
- 支持多字段分组, 具体语法为 : group by columnA,columnB
- A. 根据性别分组 , 统计男性员工 和 女性员工的数量
select gender, count(*) from emp group by gender;- B. 根据性别分组 , 统计男性员工 和 女性员工的平均年龄
select gender, avg(age) from emp group by gender;- C. 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
select workaddress, count(*) as address_count from emp while age < 45 group by workaddress having address_count >= 3 ; - D. 统计各个工作地址上班的男性及女性员工的数量
select workaddress, gender, count(*) as '数量' from emp group by gender, workaddress;2.6 排序查询
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ; - ASC : 升序(默认值)
- DESC: 降序
注意事项:
- 如果是升序, 可以不指定排序方式ASC ;
- 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序 ;
- A. 根据年龄对公司的员工进行升序排序
select * from emp order by age asc;
select * from emp order by age;- B. 根据入职时间, 对员工进行降序排序
select * from emp order by entrydate desc; - C. 根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
select * from emp order by age asc , entrydate desc;2.7 分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数 ; - 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
- A. 查询第1页员工数据, 每页展示10条记录
select * from emp limit 0,10;
select * from emp limit 10;- B. 查询第2页员工数据, 每页展示10条记录 --------> (页码-1)*页展示记录数
- (2 - 1)* 10 = 10
select * from emp limit 10,10;2.8 案例
select * from emp where gender = '女' and age in(20,21,22,23);select * from emp while gender = '男' and ( age between 20 and 40 ) and name like '___';select gender, count(*) from emp where age < 60 group by gender; select name , age from emp where age <= 35 order by age asc , entrydate desc;select * from emp where gender = '男' and age between 20 and 40 order by age asc, entrydate asc limit 0, 5 ;- 前五个员工就是查询第一页的员工,每一页员工展示 5 条数据
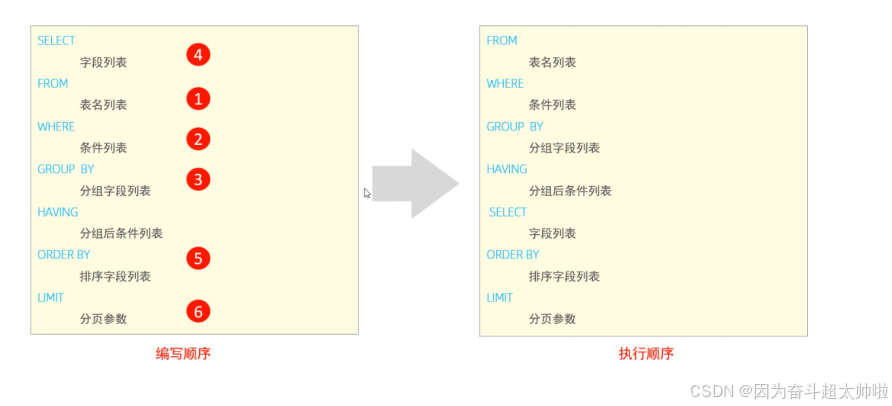
2.9 执行顺序
- 查询年龄大于15的员工姓名、年龄,并根据年龄进行升序排序。
select name , age from emp where age > 15 order by age asc;- 在查询时,我们给emp表起一个别名 e,然后在select 及 where中使用该别名。
select e.name , e.age from emp as e where e.age > 15 order by age asc;select e.name as ename , e.age as eage from emp as e where eage > 15 order by age asc; 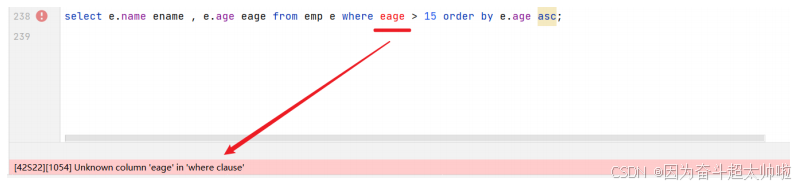
select e.name as ename , e.age as eage from emp as e where e.age > 15 order by eage asc;- from ... where ... group by ... having ... select ... order by ... limit ...
3. DCL

3.1 管理用户
select * from mysql.user;
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ;DROP USER '用户名'@'主机名' ; 注意事项:
- 在MySQL中需要通过用户名@主机名的方式,来唯一标识一个用户。
- 主机名可以使用 % 通配。
- 这类SQL开发人员操作的比较少,主要是DBA( Database Administrator 数据库管理员)使用。
- A. 创建用户itcast, 只能够在当前主机localhost访问, 密码123456;
create user 'itcast'@'localhost' identified by '123456'; - B. 创建用户heima, 可以在任意主机访问该数据库, 密码123456;
create user 'heima'@'%' identified by '123456';- C. 修改用户heima的访问密码为1234;
alter user 'heima'@'%' identified with mysql_native_password by '1234';- D. 删除 itcast@localhost 用户
drop user 'itcast'@'localhost';3.2 权限控制
| 权限 | 说明 |
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
SHOW GRANTS FOR '用户名'@'主机名' ; GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';- 多个权限之间,使用逗号分隔
- 授权时, 数据库名和表名可以使用 * 进行通配,代表所有。
- A. 查询 'heima'@'%' 用户的权限
show grants for 'heima'@'%'; - B. 授予 'heima'@'%' 用户itcast数据库所有表的所有操作权限
grant all on itcast.* to 'heima'@'%'; - C. 撤销 'heima'@'%' 用户的itcast数据库的所有权限
revoke all on itcast.* from 'heima'@'%';相关文章:
——DML和DQL)
MySQL学习笔记(四)——DML和DQL
目录 1. DML 1.1 添加数据 1.1.1 给指定字段添加数据 1.1.2 给全部字段添加数据 1.1.3 批量添加数据 1.2 修改数据 1.3 删除数据 2. DQL 2.1 基本语法 2.2 基础查询 2.2.1 查询多个字段 2.2.2 字段设置别名 2.2.3 去除重复记录 2.3 条件查询 2.4 聚合函数 2.5 …...

AWS SNS深度解析:构建高可用、可扩展的云原生消息通信解决方案
引言 在云原生架构中,高效的消息通信是系统解耦、实时响应的核心需求。AWS Simple Notification Service(SNS)作为一款全托管的发布/订阅(Pub/Sub)服务,为开发者提供了灵活、可靠的消息分发能力。本文将从…...
Spark部署核弹级避坑指南:从高并发集群调优到源码级安全加固(附万亿级日志分析实战+智能运维巡检系统))
大数据(5)Spark部署核弹级避坑指南:从高并发集群调优到源码级安全加固(附万亿级日志分析实战+智能运维巡检系统)
目录 背景一、Spark核心架构拆解1. 分布式计算五层模型 二、五步军工级部署阶段1:环境核弹级校验阶段2:集群拓扑构建阶段3:黄金配置模板阶段4:高可用启停阶段5:安全加固方案 三、万亿级日志分析实战1. 案例背景&#x…...

阿里云域名证书自动更新acme.sh
因为阿里云的免费证书只有三个月的有效期,每次更换都比较繁琐,所以找到了 acme.sh,还有一种 certbot 我没有去了解,就直接使用了 acme.sh 来更新证书,acme.sh 的主要特点就是: 支持多种 DNS 服务商自动化续…...

HCIP第二次作业
一、拓扑图 二、需求 1.按照图示的VLAN及IP地址需求,完成相关配置 2.要求SW1为VLAN 2/3的主根及主网关,SW2为vlan 20/30的主根及主网关,SW1和SW2互为备份 3.上层通过静态路由协议完成数据通信过程 4.AR1为企业出口路由器 5.要求全网可达…...

数据驱动可视化实战:图表狐精准生成图表的完整数据范式
一、数据输入黄金法则 图表狐 - AI图表生成工具,在线数据可视化要求数据描述必须包含三个核心要素: [主体对象] [量化指标] [维度划分] 错误示例 ❌: "展示各部门销售额对比" 正确示例 ✅: "2023年Q1-Q4各部门销售额&a…...

代码随想录算法训练营第五十二天|图论专题: 101. 孤岛的总面积、102. 沉没孤岛、103. 水流问题、104. 建造最大岛屿
101. 孤岛的总面积 本题要求找到不靠边的陆地面积,那么我们只要从周边找到陆地然后 通过 dfs或者bfs 将周边靠陆地且相邻的陆地都变成海洋,然后再去重新遍历地图 统计此时还剩下的陆地就可以了。 1、从左边和后边向中间遍历 2、从上边和下边向中间遍历…...
)
Sentinel核心源码分析(下)
文章目录 前言一、StatisticSlot的异常处理二、SentinelResourceAspect的异常处理三、entry.exit2.1、StatisticSlot的exit2.2、DegradeSlot的exit 总结 前言 在上篇中,主要记录了Sentinel与Spring Boot的整合,以及责任链的构建,执行的过程。…...

如何将内网的IP地址映射到外网?详细方法与步骤解析
01 为什么需要将内网IP映射到外网 在当今数字化时代,远程访问内网资源已成为许多企业和个人的刚需。将内网IP地址映射到外网的主要目的是允许外部网络访问内网中的特定服务,比如Web服务器、远程桌面、文件共享等应用场景。无论是企业需要远程办公访问内…...

八股补充说明
ConcurrentHashMap 默认使用16个段,主要是为了平衡并发性能和内存占用。16个段的选择来源于历史经验和实际测试,能够在多数应用中提供较好的性能。 注意:可达性分析法是对所有引用类型都进行分析 总结表: 引用类型与根对象的关系回…...
通过率未达100%)
数字三角形(dfs+动态规划)通过率未达100%
数字三角形 题目描述 上图给出了一个数字三角形。从三角形的顶部到底部有很多条不同的路径。对于每条路径,把路径上面的数加起来可以得到一个和,你的任务就是找到最大的和。 路径上的每一步只能从一个数走到下一层和它最近的左边的那个数或者右 边的那…...

版本控制工具——Git
目录 【版本控制系统】 【Git概述】 【Git下载】 【Git初始化本地仓库并推送】 【克隆目标仓库】 【Git团队开发的一种流程】 【Git客户端TortoiseGit】 【下载、克隆和分支之间的区别】 【下载GitHub中的子文件夹】 【不用魔法的访问方法】 【GitHub官方文档】 【版…...

计算机网络学习前言
前言 该部分说明计算机网络是什么?它有什么作用和功能?值不值得我们去学习?我们该如何学习?这几个部分去大概介绍计算机网络这门课程,往后会介绍计算机网络的具体知识点。 1.计算机网络是什么? 计算机网…...

Python爬虫第6节-requests库的基本用法
目录 前言 一、准备工作 二、实例引入 三、GET请求 3.1 基本示例 3.2 抓取网页 3.3 抓取二进制数据 3.4 添加headers 四、POST请求 五、响应 前言 前面我们学习了urllib的基础使用方法。不过,urllib在实际应用中存在一些不便之处。以网页验证和Cookies处理…...

当实体类中的属性名和表中的字段名不一样 ,怎么办
在不同的持久化框架中,当实体类中的属性名和表中的字段名不一致时,有不同的解决办法,下面为你详细介绍: 1. MyBatis MyBatis 是一个流行的持久层框架,有两种主要方式来处理属性名和字段名不一致的情况。 方式一&…...

我用deepseek制作了一份建设项目从立项到验收全流程手册《从蓝图到交付:建设项目全生命周期管理实战手册》
建设项目全流程详解(2025年更新版) 一、立项决策阶段 项目建议书编制 明确建设背景、必要性、初步规模及投资估算,形成《项目建议书》报审材料 12 可行性研究深化 完成市场供需分析、技术方案比选、环境影响评估、财务敏感性…...

力扣HOT100之链表:19. 删除链表的倒数第 N 个结点
这道题的思路比较简单,直接定义一个虚拟头节点,然后再定义快慢指针,快慢指针在初始状态下都指向虚拟头节点,然后让快指针先走n步,慢指针停在原地,然后快慢指针同步前进,当快指针fast指向最后一个…...

【Django】教程-11-ajax弹窗实现增删改查
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 【Django】教程-3-数据库相关介绍 【Django】教程-4-一个增删改查的Demo 【Django】教程-5-ModelForm增删改查规则校验【正则钩子函数】 【Django】教程-6-搜索框-条件查询前后端 【Django】教程…...

大厂算法面试 7 天冲刺:第7天-系统设计与模拟面试实战 —— 架构思维 + Java落地
🏗️ 第7天:系统设计与模拟面试实战 —— 架构思维 Java落地 📚 一、What:系统设计是什么? 系统设计是对一个复杂系统的高可用、高性能、高扩展性架构进行顶层思考和具体实现的过程。 🔧 涉及核心主题&a…...

面试题汇总06-场景题线上问题排查难点亮点
面试题汇总06-场景题&线上问题排查&难点亮点 【一】场景题【1】订单到期关闭如何实现【2】每天100w次登录请求,4C8G机器如何做JVM调优?(1)问题描述和分析(2)堆内存设置(3)垃圾收集器选择(4)各区大小设置(5)添加必要的日志【3】如果你的业务量突然提升100倍…...

AI训练存储架构革命:存储选型白皮书与万卡集群实战解析
一、引言 在人工智能技术持续高速发展的当下,AI 训练任务对存储系统的依赖愈发关键,而存储系统的选型也变得更为复杂。不同的 AI 训练场景,如机器学习与大模型训练,在模型特性、GPU 使用数量以及数据量带宽等方面的差异ÿ…...

数据结构实验3.1:顺序栈的基本操作与进制转换
文章目录 一,问题描述二,基本要求三,算法分析四,示例代码五,实验操作六,运行效果 一,问题描述 在数据处理中,常常会遇到需要对链接存储的线性表进行操作的情况。本次任务聚焦于将链…...

Docker与VNC的使用
https://hub.docker.com/r/dorowu/ubuntu-desktop-lxde-vnc 下载nvc 客户端 https://downloads.realvnc.com/download/file/viewer.files/VNC-Viewer-7.12.0-Windows.exe 服务端 docker pull dorowu/ubuntu-desktop-lxde-vnc#下载成功 docker pull dorowu/ubuntu-desktop-l…...

JGraphT 在 Spring Boot 中的应用实践
1. 引言 1.1 什么是 JGraphT JGraphT 是一个用于处理图数据结构和算法的 Java 库,提供了丰富的图类型和算法实现。 1.2 为什么使用 JGraphT 丰富的图类型:支持简单图、多重图、伪图等多种图类型。强大的算法库:提供最短路径、最小生成树、拓扑排序等多种算法。易于集成:…...

.net6 中实现邮件发送
一、开启邮箱服务 先要开启邮箱的 SMTP 服务,获取授权码,在实现代码发送邮件中充当邮箱密码用。 在邮箱的 设置 > 账号 > POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务中,把 SMTP 服务开启,获取授权码。 二、安装库 安装 …...

MySQL 触发器与存储过程:数据库的自动化工厂
在数据世界的工业区,有一座运转高效的自动化工厂,那里的机器人日夜不停地处理数据…这就是 MySQL 的触发器与存储过程系统,它让数据库从"手工作坊"变成了"现代化工厂"… 什么是 MySQL 触发器与存储过程?&…...

计科数据库第二次上机操作--实验二 表的简单查询
一、建数据库和表 1.启动数据库服务软件 Navicat 2.在 Navicat 中建立数据库 test 3. 在test数据库上建立teacher表: 二、基本查询 2.1 从teacher表中分别检索出教师的所有信息 SELECT * FROM teacher WHERE 教工号2000; SELECT * FROM t…...
】Sliding Window Maximum)
⭐算法OJ⭐滑动窗口最大值【双端队列(deque)】Sliding Window Maximum
文章目录 双端队列(deque)详解基本特性常用操作1. 构造和初始化2. 元素访问3. 修改操作4. 容量操作 性能特点时间复杂度:空间复杂度: 滑动窗口最大值题目描述方法思路解决代码 双端队列(deque)详解 双端队列(deque,全称double-ended queue)是…...

LeetCode刷题SQL笔记
系列博客目录 文章目录 系列博客目录1.distinct关键字 去除重复2.char_length()3.group by 与 count()连用4.date类型有个函数datediff()5.mod 函数6.join和left join的区别1. **JOIN(内连接,INNER JOIN)**示例: 2. **LEFT JOIN&a…...

Ubuntu中MATLAB启动图标设置
打开终端,键入 su root 输入root密码 键入:vi /usr/share/applications/Matlab.desktop 打开了一个空白文档,按键“i”,进入编辑模式,键入如下内容: [Desktop Entry] NameMatlabR2017b CommentMatlab R…...

Django分页教程及示例
推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 完整代码示例:结论Django的分页模块允许你将大量数据分割成更小的块(页面)。这对于以可管理的方式显示项目列表,如博客文章或产品…...

Ansible的使用
##### Ansible使用环境 - 控制节点 - 安装Ansible软件 - Python环境支持:Python>2.6 - 必要的模块:如PyYAML等 - 被控节点 - 启用SSH服务 - 允许控制节点登录,通常设置免密登录 - Python环境支持 http://www.ansible.com/ …...
)
JBDC Java数据库连接(1)
目录 JDBC概述 定义 JDBC API 实例 JDBC搭建 建立与数据库连接: 形式: 实例 获得Satement执行sql语句 Satement中的方法: 实例 实例 JDBC概述 定义 JDBC(Java DataBase Connectivity)java数据库连接是一种用于执行SQL…...

tomcat的负载均衡和会话保持
写你的想写的东西,写在tomcat的默认发布目录中 这里写了一个jsp的文件 访问成功 可以用nginx实现反向代理 tomcat负载均衡实现: 这里使用的算法是根据cookie值进行哈希,根据ip地址哈希会有问题.如果是同一台主机再怎么访问都是同一个ip。 t…...
)
蓝桥杯 web 新鲜的蔬菜(css3)
思路: 首先将.box容器设置为网格布局 display:grid;同时将网格分成3列3行 然后:通过子选择器或后代选择器选中相应的元素,再通过 grid-area 将其调整到相应的位置 答案: .box {display: grid;grid-template-columns: 1fr 1fr …...

【AI学习】初步了解TRL
TRL(Transformer Reinforcement Learning) 是由 Hugging Face 开发的一套基于强化学习(Reinforcement Learning, RL)的训练工具,专门用于优化和微调大规模语言模型(如 GPT、LLaMA 等)。它结合了…...

2025-04-07 NO.3 Quest3 MR 配置
文章目录 1 MR 介绍1.1 透视1.2 场景理解1.3 空间设置 2 配置 MR 环境2.1 场景配置2.2 MR 配置 3 运行测试 配置环境: Windows 11Unity 6000.0.42f1Meta SDK v74.0.2Quest3 1 MR 介绍 1.1 透视 透视(Passthrough)是将应用的背景从虚拟的…...

Kafka在Vue和Spring Boot中的使用实例
Kafka在Vue和Spring Boot中的使用实例 一、项目概述 本项目演示了如何在Vue前端和Spring Boot后端中集成Kafka,实现实时消息的发送和接收,以及数据的实时展示。 后端实现:springboot配置、kafka配置、消息模型和仓库、消息服务和消费者、we…...

层归一化详解及在 Stable Diffusion 中的应用分析
在深度学习中,归一化(Normalization)技术被广泛用于提升模型训练的稳定性和收敛速度。本文将详细介绍几种常见的归一化方式,并重点分析它们在 Stable Diffusion 模型中的实际使用场景。 一、常见的归一化技术 名称归一化维度应用…...

【C++DFS 马拉车】3327. 判断 DFS 字符串是否是回文串|2454
本文涉及知识点 CDFS 马拉车 LeetCode3327. 判断 DFS 字符串是否是回文串 给你一棵 n 个节点的树,树的根节点为 0 ,n 个节点的编号为 0 到 n - 1 。这棵树用一个长度为 n 的数组 parent 表示,其中 parent[i] 是节点 i 的父节点。由于节点 …...
)
前端开发vue项目(node-modules 可视化神器 Node Modules Inspector)
node-modules 可视化神器 Node Modules Inspector 简介功能特点使用场景实现原理 使用Node Modules Inspector提供 简介 Node Modules Inspector 是一个用于检查和分析 Node.js 项目中模块依赖关系的工具 功能特点 依赖分析:它能够深入剖析 Node.js项目中的模块依…...

25统计建模半自动化辅助排版模板及论文排版格式要求
1.除封面页外,不得在其他页出现学校、参赛队及指导教师的信息。 2.目录应由论文的篇、章、节、条、款以及附录题录等的序号、题名和页码组成。正文页码单独编列,其页码从正文第一页开始编写。 3.标题和正文:论文正文总标题(题目…...

武汉迅狐科技:AI赋能企业营销,打造智能获客新范式
在数字化营销竞争日益激烈的今天,武汉迅狐科技有限公司凭借其创新的AI技术和智能营销解决方案,正在帮助企业突破传统获客瓶颈,实现营销效率的指数级提升。作为一家专注于AI获客软件研发的高新技术企业,迅狐科技推出的矩阵系统、数…...

Tomcat:Java Web 应用开发的核心容器
在Java Web开发领域,Apache Tomcat凭借其开源特性、轻量级架构和强大的功能支持,成为开发者部署和运行Servlet、JSP应用的首选容器。作为Apache软件基金会旗下的Jakarta项目成果,Tomcat不仅实现了Java EE(现Jakarta EE)…...

Tomcat 安装与配置:超详细指南
目录 一、安装前的准备工作(一)配置 JAVA_HOME 环境变量 二、下载 Tomcat(一)Windows 系统(二)macOS/Linux 系统 三、安装 Tomcat(一)Windows 系统(二)Linux …...

科技快讯 | DeepSeek 公布模型新学习方式;Meta发布开源大模型Llama 4;谷歌推出 Android Auto 14.0 正式版
Meta发布开源大模型Llama 4,首次采用“混合专家架构“ 4月6日,Meta推出开源AI模型Llama 4,包括Scout和Maverick两个版本,具备多模态处理能力。Scout和Maverick参数量分别为170亿和4000亿,采用混合专家架构。Meta同时训…...

skynet.netpack四个核心函数详解
目录 1. netpack.filter(queue, msg, sz)2. netpack.pop(queue)3. netpack.tostring(msg, sz)4. netpack.clear(queue)完整使用场景示例总结 在 Skynet 中,netpack 模块提供了四个核心函数,用于处理网络数据包的接收、粘包解析和队列管理。以下是这四个函…...

Zephyr与Linux核心区别及适用领域分析
一、核心定位与目标场景 特性Zephyr RTOSLinux目标领域物联网终端、实时控制系统(资源受限设备)服务器、桌面系统、复杂嵌入式设备(如路由器)典型硬件MCU(ARM Cortex-M, RISC-V),内存<1MBMP…...
——优于select的epoll)
Linux网络编程(十五)——优于select的epoll
文章目录 15 优于select的epoll 15.1 epoll理解及应用 15.1.1 基于select的I/O复用技术速度慢的原因 15.1.2 select的优点 15.1.3 实现epoll时必要的函数和结构体 15.1.4 epoll_creat1 15.1.5 epoll_ctl 15.1.6 epoll_wait 15.1.7 基于epoll的回声服务器端 15.2 条件…...

PhotoShop学习07
1.为图像添加纹理 图层混合模式是混合 2 张图片的一种快捷方式,一般情况下为图片添加纹理外观可以用到混合模式。 这里有一副图片,我可以为其添加纹理,使之呈现出不同的效果。首先需要为当前图层添加一个纹理图片,可以使用置入嵌…...