10-MySQL-性能优化思路
1、优化思路
当我们发现了一个慢SQL的问题的时候,需要做性能优化,一般我们是为了提高SQL查询更快,一个查询的流程由下图的各环节组成,每个环节都会消耗时间,要减少消耗时候需要从各个环节都分析一遍。
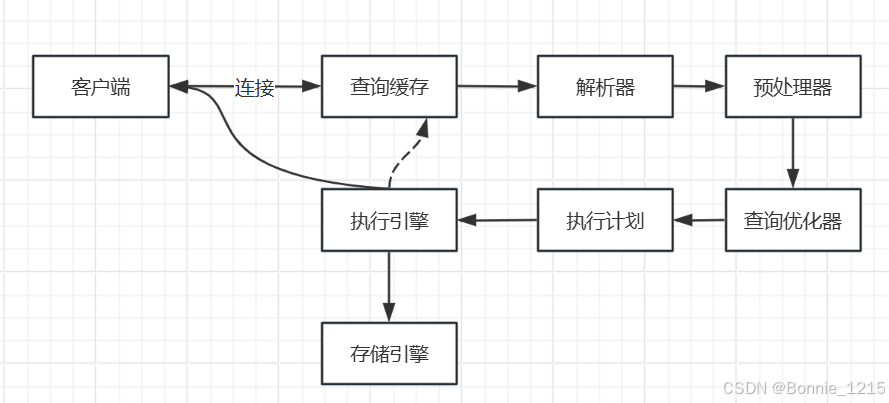
2 连接配置优化
第一个环节是客户端连接到服务端,这块可能会出现服务端连接数不够导致应用程序获取不到连接。
"MySQL error 1040 "Too many connections" 指的是你的数据库服务器达到了它的最大连接数限制。这通常发生在数据库服务器同时处理了太多的客户端连接请求时。
1、服务端:从服务端来说可以增加连接数,如果多个应用或者请求同时访问数据库,连接数不够的时候可以设置连接数更大些。
-- 修改最大连接数,当有多个应用连接的时候
SHOW VARIABLES LIKE 'max_connections';2、服务端:及时释放不活动的连接,交互式和非交互式的客户端默认超时时间都是28800秒,8小时,我们可以把值调小
-- 及时释放不活动的连接,注意不要释放连接池还在使用的连接
SHOW VARIABLES LIKE 'wait_timeout';3、客户端:减少从服务端获取的连接数,如果想要不上每一次执行SQL都创建一个新的连接,我们可以使用数据库连接池,实现连接的复用。比如dbcp、c3p0、阿里Druid、Hikari(springboot 2.x版本默认的连接池)
连接池也不是越大越好,只要维护好一定数量大小的连接池,其他客户端排队等待获取连接就可以了,有的时候连接池越大,效率反而越低。
Druid默认最大连接池大小是8,Hikari默认最大连接池大小是10。
一般建议连接池大小是机器核数乘以2+1,也就是说4核的机器,连接池维护9个连接就够了,这个公式从一定程度上来说对其他数据库也是适用的。
每一个连接,服务端都是需要创建一个线程来处理它的,连接数越多,服务端创建的线程数就会越多。创建连接会消耗时间消耗资源;而且在CPU同时执行执行超过核数的线程是通过分配时间片以及上下文切换方式实现的。CPU的核数是有限的,频繁的上下文切换会造成比较大的开销。
所以在修改数据库的配置的时候需要结合部署服务器的配置,比如服务器的CPU、内存、磁盘、网络。在不同硬件支撑下MySQL的配置也不尽相同。
| 参数名称 | 案例值 | 描述 |
| key_buffer_size | 1024MB | 用于索引的缓冲区大小 |
| query_cache_size | 384MB | 查询缓存,不开启请设为0 |
| tmp_table_size | 1024MB | 临时表缓存大小 |
| innodb_buffer_pool_size | 4096MB | Innodb缓冲区大小 |
| innodb_log_buffer_size | 0MB | Innodb日志缓冲区大小 |
| sort_buffer_size | 4096KB | *连接数,每个线程排序的缓冲大小 |
| read_buffer_size | 4096KB | 连接数,读入缓冲区大小 |
| read_rnd_buffer_size | 2048KB | 连接数,随机读取缓冲区大小 |
| join_buffer_size | 8192KB | 连接数,关联表缓存大小 |
| thread_stack | 512KB | 连接数,每个线程的堆栈大小 |
| binlog_cache_size | 256KB | 连接数,二进制日志缓存大小(4096的倍数 |
| thread_cache_size | 256 | 线程池大小 |
| table_open_cache | 2048 | 表缓存(最大不要超过2048) |
| max_connections | 500 | 最大连接数 |
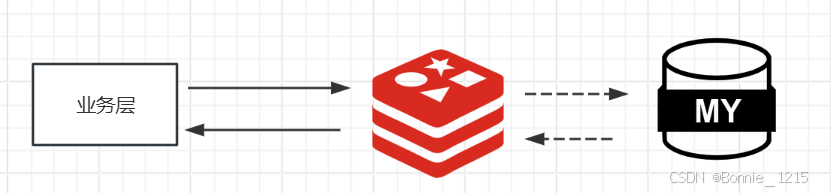
3 缓存-架构优化
3.1 缓存
在系统里面有一些很慢的查询,要么数据量大,要么关联的表多,要么计算逻辑非常复杂,这样的查询每次都会占用很长的连接时间。所以为了减轻数据库的压力,和提升查询效率,我们可以把数据放到内存缓存起来,比如使用redis;缓存适用于实时性不是特别高的业务,例如报表数据,一次查询2分钟,但是一天只需要查询一次。
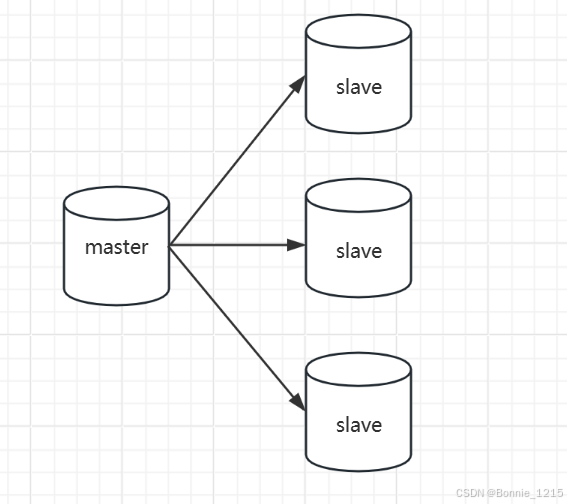
3.2 集群 主从复制
集群,冗余的处理方式,将请求发散到多个MySQL服务器中,减少单台服务器的压力;引入集群需要解决主从数据一致性的问题,一般使用的复制技术,将数据从主节点复制到从节点中。
MySQL的主从复制实现:MySQL所有的更新语句会记录到Server的binlog中,有了这个binlog,从服务器不断获取服务器的binlog文件,然后解析里面的SQL语句中,在从服务器上面执行一遍,从而保证主从数据的一致性。
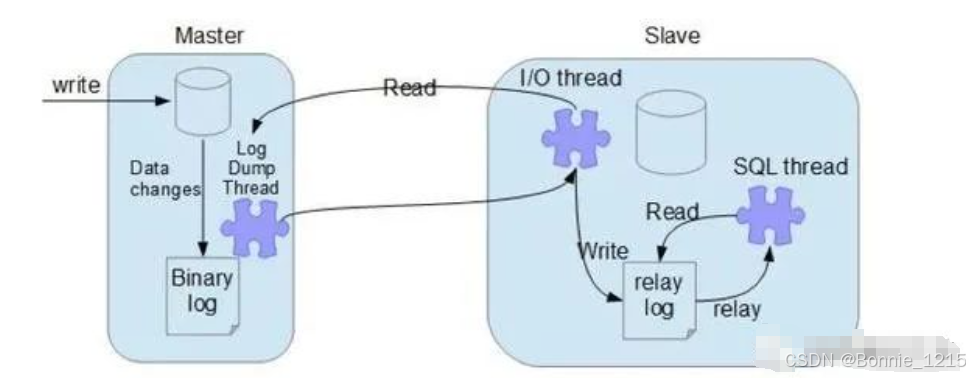
1)主节点 binary log dump 线程
当从节点连接主节点时,主节点会创建一个log dump 线程,用于发送binlog的内容。在读取binlog中的操作时,此线程会对主节点上的binlog加锁,当读取完成,在发送给从节点之前,锁会被释放。
(2)从节点I/O线程
当从节点上执行`start slave`命令之后,从节点会创建一个I/O线程用来连接主节点,请求主库中更新的binlog。I/O线程接收到主节点binlog dump 进程发来的更新之后,保存在本地relay-log(中继日志)中。
(3)从节点SQL线程
SQL线程负责读取relay log中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。
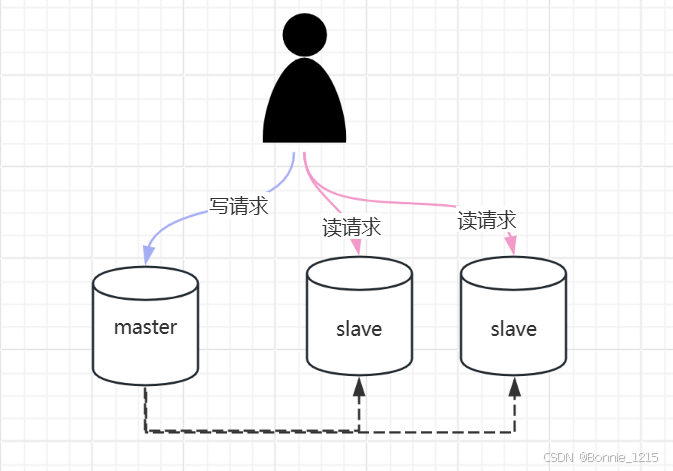 master节点只处理写请求,读请求分散到slave节点;这种方式虽然可以缓解单机的读写压力但是无法解决数据量很大的情况;因为主从结构中每个节点的数据都是相同的。
master节点只处理写请求,读请求分散到slave节点;这种方式虽然可以缓解单机的读写压力但是无法解决数据量很大的情况;因为主从结构中每个节点的数据都是相同的。
3.3 分库分表
分库分表总体上可以分为两大类,具体内容可以学习分库分表的课程。
垂直分表,减少并发压力;水平分表,解决存储瓶颈。
垂直分库的做法,把一个数据库按照业务拆分成不同的数据库。
水平分库分表:把单张表的数据按照一定的规则分布到多个数据库。
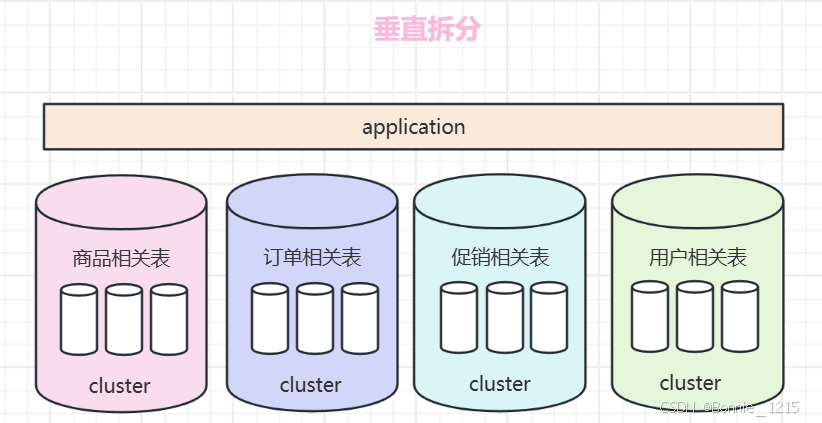
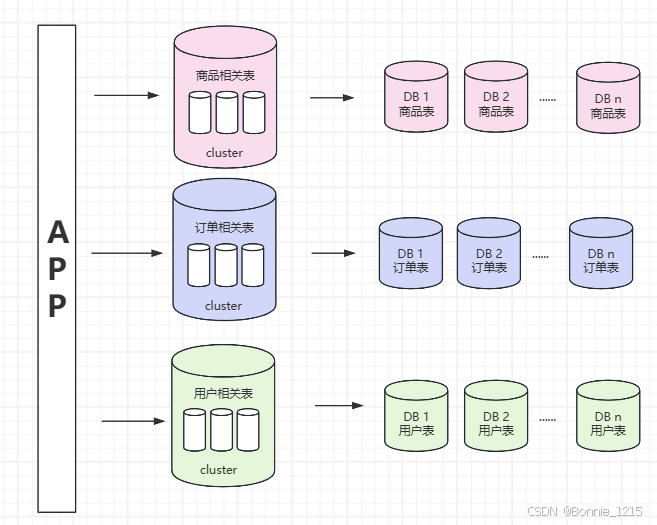
4 优化器 --SQL语句分析与优化
优化器的作用就是对我们的SQL语句进行优化分析,生成执行计划。在MySQL中有慢查询日志可以发现慢SQL。
4.1 慢查询日志
打开慢查询日志:SHOW VARIABLES LIKE 'slow_query%';

SQL查询超过3秒记录到慢SQL中:SHOW VARIABLES LIKE '%long_query%';

参数修改的方式:
1、set动态修改(重启后失效)
-- 1开启,0关闭,重启后失效
SET @@global.slow_query_log=1;
-- 默认10秒,另开一个窗口才会查到最新值
SET @@global.slow_query_log=3;SHOW VARIABLES LIKE '%long_query%';
SHOW VARIABLES LIKE '%slow_query_log%';2 修改配置文件my.cnf
以下配置定义了慢查询日志的开关、时间、日志存放的路径
slow_query_log=ON
long_query_time=3
slow_query_log_file=/www/server/data/mysql-slow.log4.2 Explain执行计划(下期详细介绍)
EXPLAIN SELECT * FROM system_users;

4.3 SQL与索引优化
当我们遇到SQL语句比较复杂,有多个关联和子查询的时候,就要分析SQL语句有没有改写的方法。
比如说: select * from user_innodb limit 9000000,10; 问题就是偏移量比较大,按照B+树的存储方式,叶子页面是一个双向链表,会一个一个的向后查找,导致查询耗时很长。可以改成先过滤ID,再limit;比如 select * from user_innodb where id>9000000,10
5 存储引擎
5.1 存储引擎选择
根据不同的业务表选择不同的存储引擎,例如:查询插入操作的业务表,用MyISAM。临时数据用Memory,常规的并发大更新多的表用InnoDB。
5.2 分表或分区
交易历史表:可以在年底为下一个年度建立12个分区,每个与一个分区
渠道交易表:分成:当日表、当月表、历史表、历史表再做分区
5.3 字段定义
原则:使用可以正确存储数据的最小数据类型,为每一列选择合适的字段类型。
比如整数类型: tinyint smallint mediumint int integer bigint bit,不同的类型最大的存储范围是不一样的,占用的存储空间也是不一样的,比如性别,只有男、女这种枚举类型,可以使用tinyint字段存储。字符类型varchar char,变长情况下使用varchar更节省空间,但是对于varchar字段,需要一个字节来记录长度。比如联系地址。固定长度使用char,比如手机号码等等。
6 总结
在工作中如果遇到了数据库瓶颈需要优化的时候,可以从以下维度来优化:基于开发成本的原则可以从以下几点分析:
1)SQL与索引
2)存储引擎与表结构(Innodb、MyISAM,表拆分:垂直拆分、水平拆分)
3)数据库架构(主从架构提升并发读、按业务类型拆分库、多主多从水平拆分表数据,解决单张表存储容量过大的问题)
4)MySQL配置(缓冲池,bufferpool越大性能越好等)
5)硬件与操作系统(cpu 内存 网络带宽)
7 最佳实践
如果出现连接变慢、查询被阻塞,无法获取连接的情况
1、重启mysql
2、show processlist查看线程状态,连接数量、连接时间、状态
3、查看锁的状态
4、kill有问题的线程
对于具体的慢SQL
一、分析查询基本情况
涉及到的表结构、字段的索引情况、每张表的数据量、查询的业务含义。这样可能会发现有些SQL没有必要这么写或者表设计有问题(可以通过冗余字段提升性能)
二、找出慢的原因
可以通过Explain查看执行计划,分析SQL的执行情况,了解表访问顺序、访问类型、索引、扫描行数等信息。
如果总体的时间比较长,不确定哪一个因素影响最大,可以通过条件的增减、顺序的调整,找出引起查询慢的主要的原因,不断地尝试验证。定位出原因,比如没有走索引,或者在散列度很低的字段上增加了索引等情况。
创建索引或者联合索引
改写SQL,例如:
使用小表驱动大表
用join来代替子查询
not exist转换为left join is null
or 改成union
如果结果集允许重复的话,使用UNION ALL代替UNION
大偏移量的limit,先过滤再排序
表结构(冗余、拆分)、架构优化(缓存读写分类、分库分表)
业务层面的优化,必须条件是否必要
相关文章:

10-MySQL-性能优化思路
1、优化思路 当我们发现了一个慢SQL的问题的时候,需要做性能优化,一般我们是为了提高SQL查询更快,一个查询的流程由下图的各环节组成,每个环节都会消耗时间,要减少消耗时候需要从各个环节都分析一遍。 2 连接配置优化…...

Postman之参数化详解
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 小伙伴们,好久不见呀,今天呢笔者想和大家聊聊postman参数化,在接口测试中,部分参数每次发送请求是唯一的数值&a…...
)
【c++深入系列】:类和对象详解(下)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 你的人生剧本,不是父母的续集,不是子女的前传,更不是朋友的外传——你是自己故事的主角 ★★★ 本文前…...

浅谈「分词」:原理 + 方案对比 + 最佳实践
在文本搜索、自然语言处理、智能推荐等场景中,「分词」 是一个基础但至关重要的技术点。无论是用数据库做模糊查询,还是构建搜索引擎,分词都是提高效率和准确度的核心手段。 🔍 一、什么是分词? 分词(Tok…...

第十八:GC 垃圾回收
2.1 三色标记# 灰色:对象已被标记,但这个对象包含的子对象未标记黑色:对象已被标记,且这个对象包含的子对象也已标记,gcmarkBits对应的位为1(该对象不会在本次GC中被清理)白色:对象…...

【微机及接口技术】- 第七章 可编程定时/计数器
文章目录 第一节 定时/计数器的概述一、定时与计数二、定时方法 第二节 可编程定时/计数器8254一、8254-2的基本功能二、8254的内部结构和外部引脚三、8254 的工作方式1. 方式0:计数到零产生中断方式2. 方式1:硬件可重触发单稳方式3. 方式2:速…...

MES生产工单管理系统,Java+Vue,含源码与文档,实现生产工单全流程管理,提升制造执行效率与精准度
前言: MES生产工单管理系统是制造业数字化转型的核心工具,通过集成生产、数据、库存等模块,实现全流程数字化管理。以下是对各核心功能的详细解析: 一、生产管理 工单全生命周期管理 创建与派发:根据销售订单或生产计…...

【区块链安全 | 第三十五篇】溢出漏洞
文章目录 溢出上溢示例溢出漏洞溢出示例漏洞代码代码审计1. deposit 函数2. increaseLockTime 函数 攻击代码攻击过程总结修复建议审计思路 溢出 算术溢出(Arithmetic Overflow),简称溢出(Overflow),通常分…...

【自记录】ubuntu命令行下禁用指定声卡
设备上内置了一块声卡,出于某些原因我希望禁用他。 通过arecord -l可以查看到该设备 $ arecord -l **** List of CAPTURE Hardware Devices **** card 0: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio]Subdevices: 1/1Subdevice #0: subdevice…...
深度解析)
设计模式 Day 4:观察者模式(Observer Pattern)深度解析
在经历了前三天的对象创建型设计模式学习之后,今天我们开始进入行为型设计模式的探索之旅。行为型模式聚焦于对象之间的通信机制与协作方式,其中最经典且应用最广泛的就是——观察者模式(Observer Pattern)。本文将用8000字篇幅&a…...

`QTabWidget` 的标签页头设置样式,可以通过在 QSS 文件中定义 `QTabBar::tab` 的样式
要为 QTabWidget 的标签页头设置样式,可以通过在 QSS 文件中定义 QTabBar::tab 的样式来实现。以下是完整的代码示例和 QSS 文件内容,展示如何为标签页头设置背景颜色、文本颜色、悬停效果和选中效果。 ### **代码示例** cpp #include <QApplication…...

低代码开发革命:用 ZKmall开源商城可视化逻辑编排实现业务流程再造
ZKmall开源商城通过可视化逻辑编排引擎与低代码开发范式,重新定义了企业级电商业务流程的构建与优化方式。本文将从技术架构、核心能力、实践案例及行业价值等维度,解析其如何以"低代码流程引擎"组合拳实现业务流程再造的革命性突破。 一、低代…...

CAN外设
目录 1. CAN外设结构 1.1 CAN外设发送流程 1.2 CAN外设接收流程 1.3 发送接受配置位 2. CAN外设过滤器 2.1 过滤器配置 2.2 测试模式 2.3 工作模式 2.4 过滤器对应中断 2.5 错误处理和离线恢复 1. CAN外设结构 以STM32F103为例。以下是它的内部结构框图。 其具体发…...
安卓开发中的状态列表图形(StateListDrawable)详解)
(七)安卓开发中的状态列表图形(StateListDrawable)详解
在安卓开发中,**状态列表图形(StateListDrawable)**是一种非常实用的资源,它允许开发者根据视图的不同状态(如按下、聚焦、选中等)来动态显示不同的图像或颜色。这种机制在创建交互式用户界面时尤为重要&am…...

2023年蓝桥杯第十四届CC++大学B组真题及代码
目录 1A:日期统计 解析代码_暴力_正解 2B:01串的熵 解析代码_暴力_正解 3C:冶炼金属 解析代码_暴力_正解 4D:飞机降落 解析代码_暴力dfs_正解 5E:接龙数列 解析代码_dp_正解 6F:岛屿个数 解析代…...

odo18实施——销售-仓库-采购-制造-制造外包-整个流程自动化单据功能的演示教程
安装模块 安装销售 、库存、采购、制造模块 2.开启外包功能 在进入制造应用点击 配置—>设置 勾选外包,点击保存 添加信息 一、添加客户信息 点击到销售应用 点击订单—>客户 点击新建 创建客户1,及其他客户相关信息,点…...

c++造轮子之REACTOR实战
本文实现的为单reactor 多线程(base) 非核心库 InetAddress 这个库简单而言 无疑是设置ip地址和端口 class InetAddress { public:struct sockaddr_in addr;socklen_t addr_len;InetAddress();InetAddress(const char* ip, uint16_t port);~InetAddress(); };具体而言: Ine…...

【Easylive】Elasticsearch搜索组件详解
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 一、Elasticsearch基础介绍 Elasticsearch(简称ES)是一个分布式、RESTful风格的搜索和分析引擎,基于Apache Lucene构建。在视频平台中,它主要用于: 全…...

基于AT89C51单片机的加减乘除液晶计算机设计
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/90574816?spm1001.2014.3001.5503 功能介绍: 可进行最高四位数的加减乘除运算,除法运算保留小数点后四位;4*4矩阵按键输入&…...

先进制造aps专题三十三 开源aps产品,frepple和dream对比分析
开源的两个aps产品,frepple和dream对比分析 frepple开源的基本不能用,第一它甘特图没开源,而且甘特图不允许你手工个修改,你想把它当成手工甘特图用也不行,第二,算法强制倒排,很少企业是倒排 …...

Vue3.2 项目打包成 Electron 桌面应用
本文将详细介绍如何将基于 Vue3.2 的项目打包成 Electron 桌面应用。通过结合 Electron 和 Vue CLI 工具链,可以轻松实现跨平台桌面应用的开发与发布。 1. 项目结构说明 项目主要分为以下几个部分: electron/main.js:Electron 主进程文件。…...

第16届蓝桥杯单片机模拟试题Ⅰ
试题 代码 sys.h #ifndef __SYS_H__ #define __SYS_H__#include <STC15F2K60S2.H> //onewire.c float getT(); //sys.c extern unsigned char UI; extern bit touch_mode; extern float jiaozhun; extern float canshu; extern float temper; void init74hc138(unsigned…...

ES:geoip_databases
如何查看 .geoip_databases 的内容 在Elasticsearch中,.geoip_databases 是一个特殊的索引,用于存储GeoIP数据库文件。这些文件通常用于地理信息的丰富(GeoIP enrichment)。以下是如何查看和管理这些数据库文件的方法:…...

企业级开发SpringBoost玩转Elasticsearch
案例 Spring Boot 提供了 spring-data-elasticsearch 模块,可以方便地集成 Elasticsearch。 下面我们将详细讲解如何在 Spring Boot 中使用 Elasticsearch 8,并提供示例代码。 1. 添加依赖: 首先,需要在 pom.xml 文件中添加 spring-data-e…...

边缘计算网关作用
一、数据采集与预处理 边缘计算网关作为物联网系统的“数据入口”,能够连接各种传感器和设备,实时采集数据。在数据传输到云端之前,它会对数据进行清洗、过滤和聚合,剔除重复、无效或冗余的信息,只将有价值的数据上传…...

利用本地 Express Web 服务解决复杂的 Electron 通信链路的问题
背景 Web 服务对前端同学来说并不陌生,你们开发其他前端界面请求的后端接口就是 Web 服务,你们 npm run dev启动的也是一个本地的 Web 服务,前端的 js,html,css 都有从这个服务上拉取到的资源。 我们在开发 Electron…...
)
《自然-计算科学》诚邀您投稿计算社会科学研究(computational social science)
李升伟 编译 近年来,运用计算方法和工具来深化对社会科学长期议题理解的"计算社会科学"发展迅猛。这一增长主要得益于社交媒体数据、移动通信数据、数字化图书与历史档案、医疗记录等海量数据的涌现,这些资源不仅为验证现有社会科学理论提供了…...

【SPSS/EXCEl】主成分分析构建__综合评价指数
学习过程中实验操作的记录 1.数据准备和标准化: (1)区分正负相关性:判断每个因子是正向指标还是负向指标,计算每个的最大值和最小值 (2) 标准化: Min-Max标准化 Min-Max标准化(最大最小值法): 将数据映射到指定的区间ÿ…...

#node.js后端项目的部署相关了解
熟悉 Spring Boot 的 java -jar 启动方式,那咱们就用类比 实战方式,来彻底搞懂: 🚀 Node.js 后端项目的 部署 & 启动方式 ✅ 和 Spring Boot 的 java -jar xxx.jar 一样,Node.js 也可以一句命令启动,而…...
:DMP与PCP系统核心功能剖析)
程序化广告行业(69/89):DMP与PCP系统核心功能剖析
程序化广告行业(69/89):DMP与PCP系统核心功能剖析 在数字化营销浪潮中,程序化广告已成为企业精准触达目标受众的关键手段。作为行业探索者,我深知其中知识的繁杂与重要性。一直以来,都希望能和大家一同学习…...

基于Python的二手房数据挖掘与可视化深度分析
一、技术框架与数据概况 1.1 技术栈构成 import pandas as pd # 数据操作(v1.3.5) import numpy as np # 数值计算(v1.21.6) from pyecharts.charts import * # 交互式可视化(v1.9.1) from sklearn.preprocessing import StandardScaler # 数据标准化(可选扩展) …...

linux第三次作业
1、将你的虚拟机的网卡模式设置为nat模式,给虚拟机网卡配置三个主机位分别为100、200、168的ip地址 2、测试你的虚拟机是否能够ping通网关和dns,如果不能请修改网关和dns的地址 3、将如下内容写入/etc/hosts文件中(如果有多个ip地址则写多行&…...

C#编写HttpClient爬虫程序示例
要写一个使用C#和HttpClient的爬虫程序。首先,我需要了解HttpClient的基本用法。HttpClient是用来发送HTTP请求和接收响应的类,对吧?我记得在C#中使用它的时候需要注意一些事情,比如最好使用单例实例,而不是频繁创建和…...

关于Spring MVC在无注解情况下通过参数名匹配获取请求参数的详细说明,包含代码示例和总结表格
以下是关于Spring MVC在无注解情况下通过参数名匹配获取请求参数的详细说明,包含代码示例和总结表格: 1. 核心机制 Spring MVC通过参数名匹配实现无注解参数绑定: 条件:方法参数名需与请求参数(查询参数、表单参数&a…...

数智读书笔记系列027:《医疗健康大数据治理》构建智慧医疗的核心基石
一、图书介绍: 1.1 书籍基本信息 在当今数字化技术飞速发展的背景下,医疗行业正经历着前所未有的变革。信息化、智能化、数据驱动的趋势正在深入到医疗服务的各个环节,推动着医疗健康大数据成为医疗行业发展的核心资产。在这样的时代背景下,《医疗健康大数据治理》这本书应…...

Wayland介绍
Wayland 是一种现代化的显示服务器协议,旨在替代传统的 X Window System(X11),为 Linux 和类 Unix 系统提供更高效、安全的图形显示管理。以下是其核心要点: 1. 基本概念 显示服务器协议:Wayland 定义了客户…...

dockerTeskTop安装dify及使用deepseek
配置 在这之前,要把模型运行一起,我这里是 PS C:\Users\Administrator> ollama run deepseek-r1:8b 模型名称一定要写对 如果添加失败,参考 dify 1.0.1无法在ollama下新增LLM模型 - 何辉煌 - 博客园...

解释 Git 的基本概念和使用方式
Git 是一个分布式版本控制系统,用于跟踪文件的变化并协作开发项目。下面是 Git 的一些基本概念和使用方式: 仓库(Repository):Git 仓库是用来存储项目文件的地方,可以在本地计算机上创建一个本地仓库&#…...

【区块链安全 | 第三十三篇】备忘单
文章目录 备忘单操作符优先级备忘单ABI 编码和解码函数bytes 和 string 的成员Address 的成员区块与交易属性校验和断言数学和加密函数合约相关类型信息函数可见性说明符修饰符备忘单 操作符优先级备忘单 以下是操作符的优先级顺序,按评估顺序列出: 优先级描述操作符1后缀递…...

MyBatis的缓存、逆向工程、使用PageHelper、使用PageHelper
一、MyBatis的缓存 缓存:cache 缓存的作用:通过减少IO的方式,来提高程序的执行效率。 mybatis的缓存:将select语句的查询结果放到缓存(内存)当中,下一次还是这条select语句的话,直…...

GS+:地统计分析与空间插值工具
大家好,今天为大家介绍的软件是GS:一款用于地统计分析与空间数据处理的软件。与ArcGIS相比的话,它更适合专注于地质统计学分析的用户,尤其是需要对半方差函数进行深入分析和调整的场景下面。我们将从软件的主要功能、支持的系统、…...

C++类型转换详解
目录 一、内置 转 内置 二、内置 转 自定义 三、自定义 转 内置 四、自定义 转 自定义 五、类型转换规范化 1.static_case 2.reinterpret_cast 3.const_cast 4.dynamic_cast 六、RTTI 一、内置 转 内置 C兼容C语言,在内置类型之间转换规则和C语言一样的&am…...

scala-集合2
可变数组 定义变长数组 val arr01 ArrayBuffer[Any](3, 2, 5) (1)[Any]存放任意数据类型 (2)(3, 2, 5)初始化好的三个元素 (3)ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer 案例实操 Arra…...

Clang编译器优化选项
Clang 作为 C/C 编译器,提供了丰富的优化选项,以下是主要的优化相关选项分类和说明: 1. 优化级别(通用选项) 选项说明-O0默认级别,禁用所有优化,用于调试。-O1基础优化(代码大小和执…...

Java文件流操作 - 【Guava】IO工具
引言 Guava 使用术语 流来表示可关闭的,并且在底层资源中有位置状态的 I/O 数据流。字节流对应的工具类为 ByteSterams,字符流对应的工具类为 CharStreams。 Guava 中为了避免和流直接打交道,抽象出可读的 源 source 和可写的 汇 sink 两个概…...

C语言中单链表操作:查找节点与删除节点
一. 简介 前面学习了C语言中创建链表节点,向链表中插入节点等操作,文章如下: C语言中单向链表:创建节点与插入新节点-CSDN博客 本文继续学习c语言中对链表的其他操作,例如在链表中查找某个节点,删除链表…...

mapbox基础,加载栅格图片到地图
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️raster 栅格图层 api二、🍀使用本地载…...
调试 SELinux,如何管理 SELinux 的运行模式、安全策略、端口和上下文策略)
Linux红帽:RHCSA认证知识讲解(十 二)调试 SELinux,如何管理 SELinux 的运行模式、安全策略、端口和上下文策略
Linux红帽:RHCSA认证知识讲解(十 二)调试 SELinux,如何管理 SELinux 的运行模式、安全策略、端口和上下文策略 前言一、SELinux 简介二、SELinux 的运行模式2.1 查看和切换 SELinux 模式 三、SELinux 预设安全策略的开关控制四、管…...
模糊斜率熵Fuzzy Slope entropy+状态分类识别!2024年11月新作登上IEEE Trans顶刊
引言 2024年11月,研究者在测量领域国际顶级期刊《IEEE Transactions on Instrumentation and Measurement》(IF 5.6,JCR 1区,中科院二区)上发表科学研究成果,以“Optimized Fuzzy Slope Entropy: A Comple…...

【MATLAB】将数据保存在mat文件中 save/load/matfile
MAT文件为MATLAB格式的二进制文件 save()函数 save - 将工作区变量保存到文件中 save(filename) 将当前工作区中的所有变量保存在 MATLAB 格式的二进制文件(MAT 文件)filename 中。如果 filename 已存在,save 会覆盖该文件。 save(filena…...