【Linux】理解文件系统
目录
- 理解磁盘
- 物理结构
- 存储结构
- 磁盘的逻辑结构
- 逻辑抽象
- CHS && LBA地址的转化
- 文件系统
- 块概念
- 分区概念
- inode
- Ext2文件系统
- 宏观认识
- Boot Block
- Block Group
- 超级块(Super Block)
- 块组描述符表(Group Descriptor Table)
- 块位图(Block Bitmap)
- inode位图(Inode Bitmap)
- i节点表(Inode Table)
- 数据块(Data Block)
- 文件系统应答
- 创建文件
- 查找文件
- 修改文件
- 删除文件
- 目录与文件名
- 软硬链接
- 软链接数
- 硬链接
- 周边知识补充
- 路径解析
- 路径缓存
- struct dentry
- 进程与文件的关系
- 挂载分区
在上一篇 基础IO中,我们介绍了打开的文件是如何在内存中管理的;那么没有被打开的文件又是如何管理的呢?文件在存储介质上可以文分为磁盘文件和内存文件,内存文件前面所说的打开了的文件,下面我们来谈谈磁盘文件,也就是没有被打开的文件是如何在磁盘上管理的。
Linux下一切皆文件,对文件的管理是必不可少的;内存中的文件由操作系统直接管理,而磁盘上的文件也必须有一套文件系统进行管理。Linux中文件系统种类繁多,本文后续介绍的是Linux Ext2文件系统。
理解磁盘
物理结构
在介绍文件系统之前,我们应该了解一下磁盘的结构。
机械磁盘是计算机中唯⼀的⼀个机械设备,通常具有较高的存储容量,能够满足大量数据的存储需求,相比于固态硬盘,磁盘(也叫硬磁盘,硬盘)的制造成本较低,因此价格相对亲民,由于磁盘的读写方式需要物理接触,其读写速度相对固态硬盘较慢。

结构主要有:
- 盘片:磁盘的主体部分,通常由铝合金或玻璃制成,表面涂有磁性材料用于存储数据。盘片是平坦的圆形结构,固定在主轴上,由电动机带动高速旋转。
- 磁头:位于盘片上方和下方的读写装置,负责读取和写入数据。每张盘片的正反两面各有一个磁头,磁头通过悬臂支撑和定位。
- 悬臂:起到支撑和定位磁头的作用,确保磁头能够准确地移动到指定的磁道和扇区。
- 主轴和主马达:主轴用于固定盘片,主马达则提供动力使盘片高速旋转。
- 控制电路和接口:控制电路负责处理读写操作,接口则用于与计算机主板连接,传输数据。
其中,盘片可以有多片,一面盘片也可能有正反两个磁头进行IO。

存储结构
磁盘进行 I O IO IO时,由马达带动盘片高速旋转,磁头在悬臂的带动下准确地移动到指定的磁道和扇区进行数据的读写。

磁盘的逻辑结构可以体现在磁盘的划分。
磁盘的划分:
- 扇区(sector):盘片被分成许多扇形区域,是从磁盘读出和写⼊信息的最小单位,通常大小为 512 字节。
- 磁道(track):磁盘的每个盘面是由一组称之为磁道的同心圆构成。磁道是磁盘上用于存储数据的环形区域
- 柱面(cylinder):柱面指的是所有盘片表面上到主轴中心距离相等的磁道集合。它用于描述多个盘片驱动器的构造
- 磁头(head)数:每个盘片一般有上下两⾯,分别对应1个磁头,共2个磁头
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
- 圆盘(platter)数:就是盘片的数量
- 磁盘容量=磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
重点理解扇区,磁道,柱面三个概念。

注意:传动臂上的磁头是共进退的
在磁盘进行读写时,扇区是读写的单位,一般为 512 B y t e s 512Bytes 512Bytes,那么如何定位一个扇区进行数据读写呢?
答案是:CHS寻址法,观察上面对整个磁盘的逻辑划分,实际上已经对每一个基本单位——扇区做好划分了,这也是为什么要对磁盘进行划分的原因。
CHS寻址法:先确定磁头要访问哪⼀个柱面(磁道)(Cylinder),再确认具体是哪一个磁头(Header),最后定位在哪一个扇区(Sector)
CHS寻址:
对早期的磁盘⾮常有效,知道⽤哪个磁头,读取哪个柱⾯上的第⼏扇区就可以读到数据了。但是CHS模式⽀持的硬盘容量有限,因为系统⽤8bit来存储磁头地址,⽤10bit来存储柱⾯地址,⽤6bit来存储扇区地址,⽽⼀个扇区共有512Byte,这样使⽤CHS寻址⼀块硬盘最⼤容量为256 * 1024 * 63 * 512B = 8064 MB(1MB = 1048576B)(若按1MB=1000000B来算就是8.4GB)
二进制数据理解
都说计算机只认识二进制01序列,那么磁盘对应的01序列是什么呢?计算机确实只认识01序列,但这个01实际上代表的是两种状态;以计算机的视角看这两种状态,那么他就可以是01序列;而在磁盘的视角,这两种状态即可用是否带磁表示,即以N/S极表示;又或者在CPU的32位地址总线中,01以高低电平表示。
磁盘的逻辑结构
逻辑抽象
磁盘除了上面这种光盘的,还有一种软质的

磁带上⾯可以存储数据,我们可以把磁带“拉直”,形成线性结构。

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样每⼀个扇区,就有了⼀个线性地址(其实就是数组下标),这种地址叫做LBA(Logical Block Address)地址

- 注意:扇区规定下标从1开始
而实际过程中,传动臂上的磁头是共进退的。

柱面是⼀个逻辑上的概念,其实就是每一面上,相同半径的磁道逻辑上构成柱⾯。所以,磁盘物理上分了很多面,但是在我们看来,逻辑上,磁盘整体是由“柱面”卷起来的。
所以,磁盘的真实情况是:
磁道:
某⼀盘⾯的某⼀个磁道展开:

即:⼀维数组
柱面:
所有半径相同的同心圆磁道,即柱面展开:

柱面上的每个磁道,扇区个数是⼀样的,这不就是二维数组吗?
- 不考虑半径影响与磁道扇区个数的因素,统一认为每个磁道的扇区数相等。实际中,外层的磁道扇区数确实会多,但是也会有对应的转换算法,现在我们认为是每个磁道的扇区数是一致的即可。
整盘:
即将每个柱面都展开:

所以整个磁盘不就是多张⼆维的扇区数组表吗?(三维数组?)
如下图:
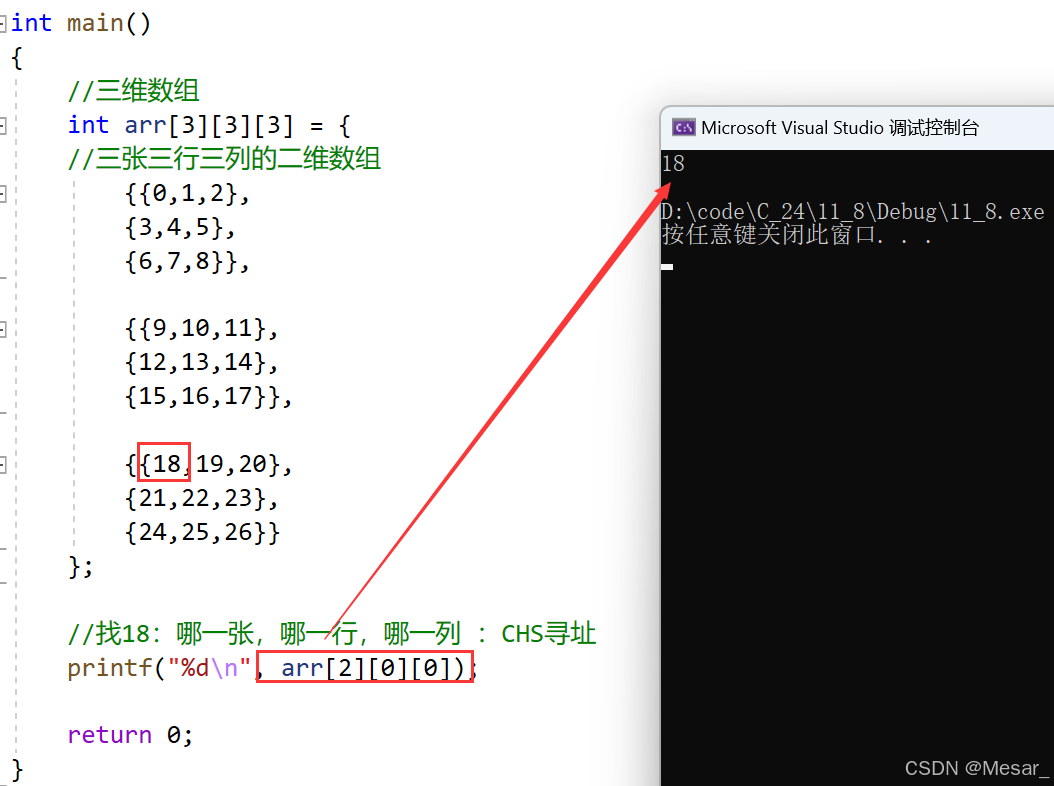
要在这张三维数组中找到一个数,如18;只需要知道在哪一张,第几行,第几列便可找到对应值了。
所以,寻址⼀个扇区:先找到哪⼀个柱面(Cylinder) ,再确定柱面内哪⼀个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了CHS。
而之前学过C/C++的数组,在我们看来,其实全部都是⼀维数组:

所以,每⼀个扇区都有⼀个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。
LBA地址的存在是为了解决传统CHS寻址方式的限制,提高存储设备的性能和效率,同时支持大容量存储和先进的存储管理技术。
但是磁盘使用的是CHS地址,而现在将磁盘逻辑抽象形成LBA地址,所以CHS地址必须与LBA进行转化。
CHS && LBA地址的转化
以下只是最简单的转换,每个磁道的扇区数认为是相同的
CHS转成LBA:
- LBA = 柱面号C *单个柱⾯的扇区总数 + 磁头号H *每磁道扇区数 + 扇区号S - 1
- 单个柱面的扇区总数 = 磁头数*每磁道扇区数
- 即:LBA = 柱面号C*(磁头数 * 每磁道扇区数) + 磁头号H * 每磁道扇区数 + 扇区号S - 1
- 扇区号通常是从1开始的,而在LBA中,地址是从0开始的
- 柱面和磁道都是从0开始编号的
- 总柱面,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS:
-
柱⾯号C = LBA // (磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
-
磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
-
扇区号S = (LBA % 每磁道扇区数) + 1
- 每个磁道的扇区数相同
-
“//”: 表示除取整


所以:从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。所以:从现在开始,磁盘就是⼀个元素为扇区的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS是使用磁盘,就可以用⼀个数字访问磁盘扇区了。
文件系统
完成了以上对磁盘物理结构介绍和逻辑抽象的工作,终于可以正式进入文件部分了。
块概念
其实硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样效率太低,而是⼀次性连续读取多个扇区,即⼀次性读取⼀个”块”(block)。硬盘的每个分区是被划分为⼀个个的”块”。⼀个”块”的大小是由格式化的时候确定的,并且不可以更改,最常见的是4KB,即连续八个扇区组成⼀个 ”块”。”块”是文件存取的最小单位。
一个扇区大小为 512 B y t e s 512Bytes 512Bytes, 4 K B = 4096 B y t e s 4KB=4096Bytes 4KB=4096Bytes,也顺便回忆一下有关字节的单位换算
1 B y t e = 8 b i t s 1 Byte = 8 bits 1Byte=8bits
1 K B = 1024 B y t e s 1 KB = 1024 Bytes 1KB=1024Bytes
1 M B = 1024 K B 1 MB = 1024 KB 1MB=1024KB
1 G B = 1024 M B 1 GB = 1024 MB 1GB=1024MB
1 T B = 1024 G B 1 TB = 1024 GB 1TB=1024GB
可以使用stat指令查看某一文件,可以看到OS确实是以“块”来读取的,扇区大小也为 512 B y t e s 512Bytes 512Bytes

分区概念
一块磁盘空间容量是巨大的,如果由操作系直接统一管理一块磁盘空间,管理成本是很高的,也没必要,一般不会有一个文件能直接要几乎一个盘的空间。所以将磁盘进行分区就很有必要了。就像我们国家的省区管理体制,国家将管理任务交给每一个省去做,这样就大大降低了管理成本,也提升了效率。这种思想称为分治思想。
可以通过 ll /dev/vda* -i 查看当前系统中的分区数及详细信息

- /dev/vda是一个虚拟磁盘设备,而 /dev/vda1是该虚拟磁盘上的第一个分区。
inode
首先需要明确一个概念:文件=属性+内容;如使用ll查看文件属性

ll读取存储在磁盘上的文件信息,然后显示出来。

这里也能看出另一个结论:在当前文件系统中(Ext)文件属性和内容是分开存放的。
文件属性和内容是分开存放,文件数据都储存在”块”中,那么很显然,我们还必须找到⼀个地方储存文件的元信息(属性信息),比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫inode,中文译名为”索引节点“
- 注意;文件名不属于文件属性,文件名并不在inode属性当中。
每⼀个文件都有对应的inode,里面包含了与该文件有关的⼀些信息。为了能解释清楚inode,我们需要是深入了解⼀下文件系统。inode的大小一般为 128 B y t e s 128Bytes 128Bytes
使用ll -i可查询inode编号

结论:
- Linux下文件的存储是属性和内容分离存储的
- Linux下,保存文件属性的集合叫做inode,一个文件只有唯一的inode
Ext2文件系统
文件系统种类很多,今天介绍的是Ext2文件系统

Ext2:这是为解决ext文件系统的缺陷而设计的可扩展的、高性能的文件系统,也被称为二级扩展文件系统。Ext2是1993年发布的,由Rey Card设计,是Linux文件系统类型中使用最多的格式,在速度和CPU利用率上表现突出,是GNU/Linux系统中标准的文件系统
要查看Linux系统中当前支持的文件系统类型,可以使用诸如df -T、mount等命令。这些命令将列出当前挂载的文件系统及其类型,以及系统启动时自动挂载的文件系统信息。
宏观认识
⽂件系统的目的就是组织和管理硬盘中的文件。在Linux 系统中,最常见的是 ext2 系列的文件系统。其早期版本为 ext2,后来又发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2 进行了增强,但是其核心设计并没有发生变化,我们仍是以较老的 ext2 作为演示对象。
ext2文件系统将整个分区划分成若干个同样大小的块组 (Block Group),如下图所示。只要能管理⼀个分区就能管理所有分区,也就能管理所有磁盘文件。
在一块磁盘中,可以有多个分区(分盘);partion为分区,每个区都可以有自己独立的文件系统,文件系统会把该分区以分治的思想继续划分为块组(Block Group)。只要把每个块组管理好了,这块分区就管理好了。接下来以块组(Block Group)为单位进行介绍文件系统。

介绍块组(Block Group)之前,先介绍Boot Block,也称Boot Sector;其不属于块组(Block Group),而是在分区的最开始的位置。
Boot Block
在Linux的ext2文件系统中,Boot Block只有一块。这块Boot Block位于文件系统的起始部分,通常占据分区的第一个块(或扇区),其大小为1KB。Boot Block中存储了引导加载程序(boot loader)和磁盘分区信息,这些信息在系统启动时至关重要。
值得注意的是,虽然整个分区可能包含多个块组(Block Group),但每个块组中并不包含额外的Boot Block。Boot Block是唯一的,并且位于文件系统的最前端,用于启动操作系统和识别磁盘分区。如果Boot损坏了,电脑很有可能就开不了机了,因为其包含了一些启动相关的信息。
下面正式开始对块组(Block Group)进行介绍。
Block Group
ext2文件系统会根据分区的大小划分为数个Block Group。如果说将国家(磁盘)划分为多个省(分区)分治,那么省又可以继续划分为市(块组)管理。

而每个Block Group都有着相同的结构组成:

注意BG的结构是固定好的。
超级块(Super Block)
存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck 和 inode的总量,未使⽤的block和inode的数量,⼀个block和inode的大小,最近⼀次挂载的时间,最近⼀次写入数据的时间,最近⼀次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
超级块在每个块组的开头都有⼀份拷贝(第⼀个块组必须有,后⾯的块组可以没有)。 为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常⼯作,就必须保证文件系统的super block信息在这种情况下也能正常访问。所以⼀个文件系统的super block会在多个block group中进行备份,这些super block区域的数据保持⼀致。
块组描述符表(Group Descriptor Table)
块组描述符表,描述块组属性信息。整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组 的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是DataBlocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷贝。
块位图(Block Bitmap)
Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。
inode位图(Inode Bitmap)
每个bit表⽰⼀个inode是否空闲可用
i节点表(Inode Table)
inode表的内容记录文件的属性以及该文件实际数据放置的区块。每个文件都有唯一的inode,每个inode大小均固定。文件系统能够建立的文件数量与inode的数量有关。
inode主要包括的数据有:文件的读写属性,文件的拥有者与用户组,文件的大小,文件的建立或状态改变时间(ctime),最近一次的读取时间(atime),最近修改的时间(mtime),定义文件特性的标识(flag),以及映射文件数据存放位置的方法等。
inode表可以理解为一个存放类型为inode的数组,但是其是在磁盘上的,所以不以数组相称,但可以这样理解。
inode编号是分区格式化后就确定的,SB,GDT格式化后就有inode的对应信息了,所以inode的数量是固定的。所以存在说inode编号用完了但是还有剩余数据块的情况。
注意:inode编号以分区为单位,整体划分,不可跨分区;这个也好理解,就像存在C盘的文件你不会去D盘。
数据块(Data Block)
数据块是真正存放文件内容的地方,也就是⼀个⼀个的Block,大小为 4 K B 4KB 4KB。根据不同的文件类型有以下几种情况:
- 对于普通文件,文件的数据存储在数据块中。
- 对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls -l命令看到的其它信息保存在该文件的inode中。
注意:Block号也是按照分区划分,不可跨分区,因为Block号与inode是配套使用的。
以上就是Block Group的所有组成,及其作用;了解这些之后,让我们看看对文件进行操作,文件系统是如何应答的。
文件系统应答
对文件进行增删查改,看看文件系统是如何应答的。
创建文件
申请创建一个文件的步骤如下:
- 通过遍历inode位图的方式,找到一个空闲的inode,与此同时将inode位图对应位置1表示已使用,并对GDT的相关信息更新。
- 在inode表当中找到对应的inode,并将文件的属性信息填充进inode结构中,此后将文件内容通过inode和Data Block映射写入数据块中。
- 添加文件名至当前目录文件的 Data block 中,同时将文件名和 inode 之中的属性链接起来。(稍后会介绍)
文件内容是如何通过inode映射到数据块中的?
当拿到一个inode号后,就可以在inode table找到对应的inode,在inode结构体中,有一个block数组,用来记录映射的块号,这样就能把数据写入数据块中了。

大文件是如何存放的呢?
一个block数组中的个数为15,一个块 4 K B 4KB 4KB,全部用完也才 60 K B 60KB 60KB,所以,该block数组规定,只有前12个是直接映射到数据块,最后三个分别为一二三级索引。有了这些索引表,最多能构建TB级别的内容。

查找文件
已获取inode编号
- 遍历inode位图,若存在则直接访问该inode。
修改文件
- 查找该文件,访问inode
- 对属性或者内容进行修改
删除文件
- 查找该文件是否存在
- 若存在,直接把inode位图对应位置0,表示该文件已经删除,同时在inode的block数组中获取对应块号,将块位图中的对应块号置0,表示这些块可以被重新使用,允许被覆盖。
这也是为什么存放文件的时间要比删除文件的时间长的原因,Linux中根本就没有真正意义的删除,因为文件系统认为这是低效的行为,文件系统只认的inode,inode都没有,这个文件也就不可能找得到。所以,删除只需要将块位图和inode位图对应位置0即表示完成删除操作。
目录与文件名
介绍inode时我们就说文件名不属于文件属性不在inode当中。但作为用户,我们一直使用的是文件名,但文件名又不属于文件属性,不在inode当中。那我们是如何找到inode编号的呢?
Linux下一切皆文件,那么目录是文件吗?当然是啦!目录也是文件,磁盘上没有目录的概念,只有文件属性+文件内容的概念,所以目录也有自己的inode,那么目录的内容是什么呢?答案就是文件名与其inode的编号的映射。
所以,访问文件,必须打开当前目录,根据文件名,获得对应的inode号,然后进行文件访问,访问文件必须要知道当前工作目录,本质是必须能打开当前工作目录文件,查看目录文件的内容!
有了这个认知,再结合目录的rwx权限探讨为什么文件的操作受到目录权限的影响。
文件基本权限:
- 读(r):Read对文件而言,具有读取文件内容的权限;对目录来说,具有浏览该目录信息的权限。
- 写(w):Write对文件而言,具有修改文件内容的权限;对目录来说具有删除移动目录内文件的权限。
- 执行(x):execute对文件而言,具有执行文件的权限;对目录来说,具有进入目录的权限。
r:如果没有r权限,则无法浏览该目录信息

了解文件系统之后,我们就可以对这个现象做出解释了:
ll在查询该目录下所有文件的信息(属性),没有目录r权限,则无法读取目录信息,也就无法访问目录的inode,目录的内容就更加访问不了了。而目录的内容正是目录中所有文件名与其inode的编号的映射。,所以该目录下的文件信息就无法读取了。
w:如果没有w权限,则无法对文件进行增删的操作。

删除或创建一个文件的本质就是在块位图和inode位图将对应的块号和inode编号对应的位置为0,并把在对应目录再把文件名和inode映射清除即可。如果目录没有w权限,则无法修改目录内容,也就无法在该目录下进行文件的增删操作。
x:如果没有x权限,则无法进入文件

没有x执行权限的用户在尝试使用cd命令切换目录时,会收到权限拒绝的错误消息,这主要跟进程需要切换cwd( current working directory)有关。
总结:目录权限对目录内文件有约束的原因本质就是目录也是文件,也按照属性+内容的方式存储;而目录的内容就是该目录下文件名与其inode的映射关系,这也是为什么文件名不属于文件inode的原因。
软硬链接
使用ll查看文件属性时,属性我们都进行了介绍;但还有一个硬链接数没有介绍,如今了解了文件系统,便可进行介绍了。

软链接数
使用指令:ln -s 构建软链接,如:
ln -s log.txt slink_log
- 源文件在前,软链接在后。

可以看到,软链接的文件类型为l:软链接;且软链接与源文件都有自己独立的inode,表示是两个独立的文件,硬链接数为:1。
软链接就像Windows的快捷方式,可以链接一个藏得比较深的文件,这样就能直接通过软链接找到对应的文件了。
软链接的使用场景

如:在上级路径直接链接下一路径的文件,之后便可像操作该文件一样直接操作软链接

软链接的本质就是在自子的数据块中存储了源文件的路径,这样就能使用软链接找到源文件了。
软链接失效&取消软链接: 使用rm unlink都可以取消软链接。

- 删除软链接不影响源文件,因为他们是独立的两个文件,但是软链接必须依赖源文件。所以删除文件时不要再以为删除快捷方式就好了。
硬链接
我们已经知道,真正找到磁盘上文件的并不是文件名,而是inode。其实在linux中可以让多个文件名对应于同⼀个inode。这便是硬链接。
使用指令ln完成硬链接,如:ln log.txt log_cp。

可以看到log_cp和log.txt的链接状态完全相同,他们被称为指向文件的硬链接。内核记录了这个连接数,inode为787280的硬连接数为2。
我们在删除文件时干了两件事情:
- 在目录中将对应的记录删除
- 将硬连接数-1,如果为0,则将对应的磁盘释放。
以上述例子:log_cp和log.txt为同一个文件,可以理解为log_cp为log.txt的备份,只要硬链接数不为0,该文件则不会被删除。
硬链接的使用场景
硬链接的使用场景比较少,原因等会说;但是硬链接在Linux中经常使用:. 当前路径和..上级路径;
当我们使用mkdir -p dir/dir1/dir2 创建一串目录后,即便里面没有任何内容,用户也没有进行任何硬链接的操作,但是可以看到这个目录的硬链接数为3,这是为什么呢?

创建一个空目录后,实际上该目录中也会有两个隐藏目录.和..,即当前目录和上级目录,以dir为例:
当前目录.即是该目录的硬链接,而上级目录中test又会链接当前目录dir,这又是一个硬链接,而当前目录dir中的目录dir1中又会有指向上级目录的..的硬链接,这样一来,硬链接数就是3了。
但是:
用户不允许对目录进行硬链接,即便sudo提权;如在dir/dir1/dir2,对dir1进行硬链接,那么dir1的上级路径是dir还是这个硬链接呢?这样就会造成环路问题。所以,OS禁止用户对目录进行硬链接。


但是. ..不就是硬链接吗?那是因为这是OS自己链接的…。OS是谁啊,想干嘛干嘛,尔等就不要纠结了。
还有一个小知识点:
当前目录的硬链接数减去2即为该目录下所拥有目录的个数
周边知识补充
基于目录的内容是文件名(目录也是)与对应inode的映射,打开一个文件必须先打开目录访问其内容获取对应的inode,可是别忘了,目录也是文件。
路径解析
基于以上知识,提出以下的问题:
问题:打开当前工作录文件,查看当前⼯作⽬录⽂件的内容?当作目录不也是文件吗?我们访问当前工作目录不也是只知道当前工作目录的文件名吗?要访问它,不也得知道当前工作目录的inode吗?
是的,所以也要打开当前工作目录的上级目录,额…,上级目录不也是目录吗??不还是上面的问题吗?所以要获取一个文件的inode,就需要进行类似"递归"的操作,需要把路径中所有的目录全部解析,出口是根目录/。
而实际上,任何文件,都有路径,访问目标文件,比如:/home/mesar/L24/M11/Lesson3/file.c 都要从根目录开始,依次打开每一个目录,根据目录名,依次访问每个目录下指定的目录,直到访问到file.c。这个过程叫做Linux路径解析
所以,我们知道了:访问文件必须要有目录+文件名(即路径)原因;而根目录固定文件名,inode号,无需查找(OS知道),系统开机之后就必须知道。这也叫做:系统+用户共同构建Linux路径结构
路径缓存
打开一个文件需要知道其路径,而现在我们已经知道了要打开一个文件,必须先递归到根目录才能进行查找对应文件;而且即使连续两次都打开相同的文件,也必须进行两次相同的查找工作,这样效率未免也太低了。操作系统真的会按照路径解析的方式查找文件时每次都递归到根目录吗?原则上是,但是这样太慢,所以Linux会缓存历史路径结构,该路径由OS在内核中自己维护。
Linux中,在内核中维护树状路径结构的内核结构体叫做struct dentry

还记得一开始我们讲Linux的文件系统就是一颗多叉树吗?但是Linux磁盘中,存在真正的目录吗?不存在,只有文件。只保存文件属性+文件内容。这颗所谓的多叉树实际上就是struct dentry。

- 关注绿色的就好。
struct dentry
dentry是directory entry的缩写,用于表示文件系统中的目录项。它是Linux内核中的一个关键数据结构,主要用于快速定位文件系统中的文件或目录,并提供一种方法来缓存文件路径的各个部分
主要属性与结构:
- 文件名:
dentry结构体中包含了文件名信息,这是用于识别和定位文件或目录的基础。 - 指向inode的指针
struct inode *d_inode:inode是文件系统中用于存储文件属性信息的结构体,如权限、类型、大小、时间等dentry通过指向inode的指针,将用户空间的路径名与内核可以理解的文件或目录对象关联起来。 - 指向父dentry的指针
struct dentry *d_parent:这一属性有助于构建文件系统的目录树结构,使得Linux内核可以方便地遍历和查找文件。
dentry作为缓存,可以加速对文件系统的访问,减少对底层文件系统的调用。当文件被访问时,Linux内核会创建一个对应的dentry,并将其添加到dentry缓存中。这种缓存机制有助于提高文件系统的访问效率。
进程与文件的关系
在OS层面,打开文件的是进程,当通过open系统调用请求打开一个文件,这个调用(进程)最终会通过系统调用接口(SCI)进入内核空间,文件系统接收到请求,接着会查找与请求文件名对应的目录项(dentry)和索引节点(inode)在ext2文件系统中,这些信息存储在磁盘上,并在需要时被加载到内存中。一旦找到inode,内核会为这个打开的文件创建一个 struct file对象,并且会从当前进程的文件描述符表(file descriptor table)中分配一个空闲的文件描述符fd,最后,会将分配的文件描述符与 struct file 实例关联起来,并将这个关联信息存储在进程的文件描述符表中。

挂载分区
我们已经能够根据inode号在指定分区找文件了,也已经能根据目录文件内容,找指定的inode了,在指定的分区内,我们可以在权限范围内为所欲为了。可是:
问题:inode不是不能跨分区吗?Linux不是可以有多个分区吗?哪我怎么知道我在哪⼀个分区???
再来学习一个指令df -h,df(disk free)命令用于显示文件系统的磁盘空间使用情况。-h为可读模式,指令df -h可以用于查看可以使用的分区

Filesystem:显示文件系统的名称或设备名。例如,/dev/sda1可能是一个硬盘分区,而tmpfs是一种基于内存的文件系统。Size:显示文件系统的总大小。Used:显示已经使用的空间大小。Avail:显示还可以使用的空间大小。Use%:显示已用空间的百分比。Mounted on:显示文件系统挂载的挂载点,即文件系统中的哪个目录用于访问该文件系统
接下来进行一个小实验:
使用以下指令完成实验:
$ dd if=/dev/zero of=./disk.img bs=1M count=5 #制作⼀个⼤的磁盘块,就当做⼀个分区
$ mkfs.ext4 disk.img # 格式化写⼊⽂件系统
$ sudo mkdir /mnt/mydisk # 建⽴空⽬录
$ sudo mount -t ext4 ./disk.img /mnt/mydisk/ # 将分区挂载到指定的⽬录

在Linux文件系统中,要对一个磁盘分区进行操作,必须通过文件来进行。而挂载(mount)就是把文件目录和分区连接起来的过程,它使得访问该目录就相当于访问对应的磁盘分区。
- 所要挂载的分区可以自己定
- 使用
umount进行分区卸载- 如卸载刚才挂载的分区:sudo umount /mnt/mydisk
/dev/loop0
/dev/loop0 在Linux系统中代表第⼀个循环设备(loop device)。循环设备,也被称为回环设备或者loopback设备,是⼀种伪设备(pseudo-device),它允许将⽂件作为块设备(block device)来使⽤。这种机制使得可以将⽂件(比如ISO镜像⽂件)挂载(mount)为⽂件系统,就像它们是物理硬盘分区或者外部存储设备⼀样。
分区写入文件系统,无法直接使用,需要和指定的目录关联,进行挂载才能使用,所以,可以根据访问目标文件的"路径前缀"准确判断我在哪⼀个分区。
相关文章:

【Linux】理解文件系统
目录 理解磁盘物理结构存储结构 磁盘的逻辑结构逻辑抽象CHS && LBA地址的转化 文件系统块概念分区概念inode Ext2文件系统宏观认识Boot BlockBlock Group超级块(Super Block)块组描述符表(Group Descriptor Table)块位图&…...
)
Python爬虫——城市数据分析与市场潜能计算(Pandas库)
使用Python进行城市市场潜能分析 简介 本教程将指导您如何使用Python和Pandas库来处理城市数据,包括GDP、面积和城市间距离。我们将计算每个城市的市场潜能,这有助于了解各城市的经济影响力。 步骤 1: 准备环境 确保您的环境中安装了Python和以下库&…...
——类和对象(上))
面向对象(二)——类和对象(上)
1 类的定义 做了关于对象的很多介绍,终于进入代码编写阶段。 本节中重点介绍类和对象的基本定义,属性和方法的基本使用方式。 【示例】类的定义方式 // 每一个源文件必须有且只有一个public class,并且类名和文件名保持一致! …...
)
嵌入式开发之ARM(一)
目录 1、认识RAM 1.2、ARM全球分布 1.3、ARM产品线 1.4、授权的厂商 1.5、ARM体系架构 1.6、ARM系统硬件组成和运行原理 2、搭建开发环境 3、ARM的工作模式及寄存器 3.1、ARM工作模式 3.2、ARM工作模式及寄存器框图 3.2.1、CPSR寄存器 1、认识RAM 成立于1990年11月,前…...
)
Ai编程cursor + sealos + devBox实现登录以及用户管理增删改查(十三)
一、什么是 Sealos? Sealos 是一款以 Kubernetes 为内核的云操作系统发行版。它以云原生的方式,抛弃了传统的云计算架构,转向以 Kubernetes 为云内核的新架构,使企业能够像使用个人电脑一样简单地使用云。 二、适用场景 业务运…...

手机镜头组如此突出,考虑恢复以前设计
现在手头看重照相。结果导致的问题就是,在背部要突出很高,以容纳镜头组件。这种设计真的好吗?并不见得。真实照片: VIVO X200系列镜头组照片-CSDN博客 考虑到现在镜头的情形,我建议恢复以前的设计,就是把镜…...

debian ubuntu armbian部署asp.net core 项目 开机自启动
我本地的环境是 rk3399机器,安装armbian系统。 1.安装.net core 组件 sudo apt-get update && \sudo apt-get install -y dotnet-sdk-8.0或者安装运行库,但无法生成编译项目 sudo apt-get update && \sudo apt-get install -y aspnet…...

Linux lsmod命令用于显示已经加载到内核中的模块的状态信息
1、lsmod命令 Linux lsmod命令用于显示已经加载到内核中的模块的状态信息。执行lsmod命令后会列出所有已载入系统的模块。Linux操作系统的核心具有模块化的特性,应此在编译核心时,务须把全部的功能都放入核心。您可以将这些功能编译成一个个单独的模块&…...

新增工作台模块,任务中心支持一键重跑,MeterSphere开源持续测试工具v3.5版本发布
2024年11月28日,MeterSphere开源持续测试工具正式发布v3.5版本。 在这一版本中,MeterSphere新增工作台模块,工作台可以统一汇总系统数据,提升测试数据的可视化程度并增强对数据的分析能力,为管理者提供测试工作的全局…...

歇一歇,写写段子
无聊的日子都在写段子1.0 中学的时候喜欢看意林之类的杂志, 里面的作者用乱七八糟的理由跑去旅游,然后说“阻碍你脚步的永远只有逃离的勇气和对生活的热爱”, 我觉得太对了,可惜 12306 付款方式里没有勇气和热爱,不…...

【数据库系列】Spring Boot如何配置Flyway的回调函数
Flyway 提供了回调机制,使您能够在特定的数据库迁移事件发生时执行自定义逻辑。通过实现 Flyway 的回调接口,可以在迁移前后执行操作,如记录日志、执行额外的 SQL 语句等。 1. 创建自定义回调类 要配置 Flyway 的回调函数,需要创…...

Ubuntu源码安装gitlab13.7集群多前端《二》
Ubuntu源码安装gitlab13.7《一》 gitaly需要调整的服务 redis socket->ipbind ....* # 0.0.0.0pg vim /etc/postgresql/14/main/pg_hba.confhost all all ..../32 md5gitaly vim /home/git/gitaly/config.tomlbin_dir "/home/gi…...

QT5.14 QML串口助手
基于 QML的 串口调试助手 这个代码有缺失,补了部分代码 ASCII HEX 工程共享, Qt版本 5.14.1 COM_QML 通过百度网盘分享的文件:COM_QML.zip 链接:https://pan.baidu.com/s/1MH2d6gIPDSoaX-syVWZsww?pwd5tge 提取码:…...

SQL Server 实战 - 多种连接
目录 背景 一、多种连接 1. 复合连接条件 2. 跨数据库连接 3. 隐连接 4. 自连接 5. 多表外连接 6. UNION ALL 二、一个对比例子 背景 本专栏文章以 SAP 实施顾问在实施项目中需要掌握的 sql 语句为偏向进行选题: 用例:SAP B1 的数据库工具&am…...

Netty面试内容整理-Netty 工作原理
Netty 的工作原理主要基于异步、事件驱动的 I/O 模型,结合 Reactor 多线程模式和高效内存管理来实现高并发网络通信。以下是 Netty 的工作原理详细解析: Reactor 线程模型 Netty 基于 Reactor 模式 来处理并发连接和 I/O 操作,主要分为 单线程模型、多线程模型 和 主从多线程…...
—快速排序》)
数据结构基础之《(10)—快速排序》
一、快速排序基础 1、Partition过程 给定一个数组arr,和一个整数num。请把小于等于num的数放在数组的左边,大于num的数放在数组的右边。 要求额外空间复杂度O(1),时间复杂度O(N) 2、例子 区分小于等于num的数 (<区) [5 3 7 2 3 4 1] num…...

k8s 亲和性之Affinity
文章目录 1. Node Affinity(节点亲和性)节点亲和性类型配置示例常见场景: 2. Pod Affinity 和 Pod Anti-AffinityPod Affinity 配置示例Pod Anti-Affinity 配置示例常见场景: 3. 亲和性规则概述4. 亲和性和反亲和性的细节5. 亲和性…...

OpenNMT-py入门
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、安装二、快速开始1.准备数据2.训练模型3.翻译 总结 前言 OpenNMT-py是OpenNMT的Pytorch版本,它是一个 MIT的神经机器翻译框架。它被设计用于研…...
)
element-ui的下拉框报错:Cannot read properties of null (reading ‘disabled‘)
在使用element下拉框时,下拉框option必须点击输入框才关闭,点击其他地方报错:Cannot read properties of null (reading disabled) 造成报错原因:项目中使用了el-dropdown组件,但是在el-dropdown里面没有定义el-dropdo…...

【微服务】SpringBoot 对接飞书多维表格事件回调监听流程详解
目录 一、前言 二、前置准备 2.1 创建一个应用 2.2 准备一张测试使用的多维表 2.3 获取对接文档 2.4 工程中添加SDK 三、对接过程 3.1 配置Encrypt Key 和 Verification Token 3.2 配置订阅方式 3.3 添加事件 3.4 申请权限 3.5 编写订阅代码 3.6 订阅文档事件 3.7…...

docker常用命令
docker 常用命令 1、查看基本信息 docker info docker run --rm hello-world docker pull nginx docker run -p 8080:80 nginx docker image ls 查看详细信息 docker inspect nginx 查看当前正运行的容器 docker ps 后台运行容器 docker run -d -p 8080:80 nginx 给容器取个名字…...

如何调用百度文心一言API实现智能问答
诸神缄默不语-个人CSDN博文目录 百度需要先认证个人信息才能使用LLM API。 文章目录 1. 获得 API Key2. 撰写代码并实现提问和回答2.1 用openai包实现调用2.2 用openai包实现流式调用2.3 用openai包实现工具调用2.4 构建智能体2.5 文生图2.6 图生图 3. 用gradio建立大模型问答…...

数据类型扮演着至关重要的角色
在Java编程语言中,数据类型扮演着至关重要的角色,它们定义了变量能够存储的数据类型以及可以对这些数据执行的操作。Java的数据类型主要可以分为两大类:基本数据类型(也称为原始数据类型)和引用数据类型。 基本数据类…...

React 路由与组件通信:如何实现路由参数、查询参数、state和上下文的使用
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
《精讲》)
3.STM32通信接口之SPI通信---SPI实战(W25Q64存储模块介绍)《精讲》
上一节介绍了SPI的通信过程和方法,接下来就要进行STM32与外围模块通信了,这个模块是一块非易失型存储芯片,能够提供8MB的存储空间。接下来跟着Whappy脚步,进行探索新大陆吧!【免费】W25Q64(中英文数据手册)资源-CSDN文…...

yagmail邮件发送库:如何用Python实现自动化邮件营销?
🎥 作者简介: CSDN\阿里云\腾讯云\华为云开发社区优质创作者,专注分享大数据、Python、数据库、人工智能等领域的优质内容 🌸个人主页: 长风清留杨的博客 🍃形式准则: 无论成就大小,…...

vue elementui layout布局组件实现规则的弹性布局
背景:遇到在一个容器里,采用弹性盒布局的时候,如果元素个数改变,元素的排列会错乱。 解决方式 方式一:之前遇到的时候,是采用计算元素个数的方式,采用透明元素补齐的方式(比如一个有…...

Python虚拟环境管理工具:Pipenv
Python虚拟环境管理工具:Pipenv 前言1. Pipenv的功能和特点2. 安装Pipenv3. 基本使用3.1 创建项目并初始化 Pipenv3.2 使用虚拟环境3.3 安装开发依赖3.4 查看当前依赖3.5 锁定依赖3.6 升级依赖3.7 卸载依赖 4. Pipenv vs. Poetry5. 常见问题 总结 前言 Pipenv 是一个…...

Tomcat使用教程
下载地址:https://tomcat.apache.org/ 配置环境变量 变量名: CATALINA_HOME 变量值: D:\tools\apache-tomcat-9.0.97 Path: %CATALINA_HOME%\bin 启动Tomcat(打开命令提示符) startup.bat 解决乱码问题(打开conf\logging.properties) java.util.logging.Conso…...

Flink历史服务器-History Server
在以session模式提交作业后,我们可以在session集群里查看作业的详细信息,但是假如session集群重启后,则不能再查看到之前作业的信息;或者以yarn application或per-job或k8s application模式提交,都存在一个问题,就是在作业完成后(即Flink集群关闭),无法查看作业信息,…...

redis核心命令全局命令 + redis 常见的数据结构 + redis单线程模型
文章目录 一. 核心命令1. set2. get 二. 全局命令1. keys2. exists3. del4. expire5. ttl6. type 三. redis 常见的数据结构及内部编码四. redis单线程模型 一. 核心命令 1. set set key value key 和 value 都是string类型的 对于key value, 不需要加上引号, 就是表示字符串…...

Java后端请求想接收多个对象入参的数据方法
在Java后端开发中,如果我们希望接收多个对象作为HTTP请求的入参,可以使用Spring Boot框架来简化这一过程。Spring Boot提供了强大的RESTful API支持,能够方便地处理各种HTTP请求。 1.示例:使用Spring Boot接收包含多个对象的HTTP…...
)
傅里叶变换FT——DFT——FFT(三者之间的关系)
FT 周期函数 f(t) 的傅里叶变换实质上是将函数信号分解为不同频率、不同幅值的正、余弦信号,如下图所示。换言之,无数个不同频率,不同幅值的正、余弦信号来不断逼近周期函数 f(t) 。 分解出的这些信号的频率都是基频 ω0 的整数倍࿰…...

华为HarmonyOS 让应用快速拥有账号能力 -- 2 获取用户头像昵称
场景介绍 如应用需要完善用户头像昵称信息,可使用Account Kit提供的头像昵称授权能力,用户允许应用获取头像昵称后,可快速完成个人信息填写。以下只针对Account kit提供的头像昵称授权能力进行介绍,若要获取头像还可通过场景化控…...

git命令-基本使用
#git安装后-指定名称和邮箱: $ git config --global user.name "Your Name" $ git config --global user.email "emailexample.com" #查看远程分支: git branch -a #查看本地分支: git branch #切换分支: git checkout…...

学习笔记050——SpringBoot学习1
文章目录 Spring Boot1、Spring Boot 配置文件2、Spring Boot 整合视图层3、Spring Boot 整合持久层 Spring Boot Spring Boot 可以快速构建基于 Spring 的 Java 应用,可以快速整合各种框架,不需要开发者进行配置,Spring Boot 会实现自动装配…...

【前端开发】微信裁剪图片上传
Cropper.js: 一款基于 JavaScript 的开源图片裁剪神器,支持图片裁剪、缩放、旋转 HTML页面引用: css:<link rel"stylesheet" type"text/css" href"css/cropper.css" /> js:<sc…...

【Golang】WaitGroup 实现原理
文章目录 前言一、介绍二、实现原理三、使用方式四、总结 前言 在并发编程中,协调多个 goroutine 的执行顺序和同步是一个常见的需求。Golang 提供了 sync.WaitGroup 来简化这一过程。WaitGroup 允许主 goroutine 等待一组 goroutine 完成工作。本文将详细介绍 syn…...

从被动响应到主动帮助,ProActive Agent开启人机交互新篇章
在人工智能领域,我们正见证着一场革命性的变革。传统的AI助手,如ChatGPT,需要明确的指令才能执行任务。但现在,清华大学联合面壁智能等团队提出了一种全新的主动式Agent交互范式——ProActive Agent,它能够主动观察环境…...

框架模块说明 #05 权限管理_03
背景 权限设计可以分为两个主要方面:操作权限和数据权限。前两篇文章已经详细介绍了操作权限的设计与实现,以及如何将其与菜单关联起来的具体方法。本篇将聚焦于数据权限,为您深入讲解相关的设计与实现方式。 全局开关 Value("${syst…...

autogen-agentchat 0.4.0.dev8版本的安装
1. 安装命令 pip install autogen-agentchat0.4.0.dev8 autogen-ext[openai]0.4.0.dev82. 版本检查 import autogen_agentchat print(autogen_agentchat.__version__)0.4.0.dev8import autogen_ext print(autogen_ext.__version__)0.4.0.dev83. 第一个案例 使用 autogen-age…...

JavaScript实现tab栏切换
JavaScript实现tab栏切换 代码功能概述 这段代码实现了一个简单的选项卡(Tab)切换功能。它通过操作 HTML 元素的类名(class)来控制哪些选项卡(Tab)和对应的内容板块显示,哪些隐藏。基本思路是先…...

yarn install遇到问题处理
1、Yarn在尝试安装一个依赖项时遇到了问题。具体来说,这个错误指出期望提升(hoist)的包的manifest文件丢失了,这通常是因为缓存中的数据损坏或不一致所致。 解决方法:有以下两种 1、清除Yarn缓存:运行 yarn…...

量化交易系统开发-实时行情自动化交易-8.9.通达信平台
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来会对于通达信平台介绍。 通达信…...

qt QAnimationDriver详解
1、概述 QAnimationDriver是Qt框架中提供的一个类,它主要用于自定义动画帧的时间控制和更新。通过继承和实现QAnimationDriver,开发者可以精确控制动画的时间步长和更新逻辑,从而实现丰富和灵活的动画效果。QAnimationDriver与QAbstractAnim…...

Nginx篇之实现nginx转发兼容HTTP和Websocket两种协议
Nginx实现同时兼容http协议和websocket协议 map $http_upgrade $eop_gateway {default "eop-gateway-http";websocket "eop-gateway-ws"; }# 控制 Connection header map $http_upgrade $connection_upgrade {default "keep-alive"; # HTTP …...

底部导航栏新增功能按键
场景需求: 在底部导航栏添加power案件,单击息屏,长按 关机 如下实现图 借此需求,需要掌握技能: 底部导航栏如何实现新增、修改、删除底部导航栏流程对底部导航栏部分样式如何修改。 比如放不下、顺序排列、坑点如…...

Mac安装MINIO服务器实现本地上传和下载服务
0.MINIO学习文档 Minio客户端mc使用 | Elibaron学习笔记 1.Mac安装MINIO 中文官方网址:MinIO下载和安装 | 用于创建高性能对象存储的代码和下载内容 (1) brew 安装 brew install minio/stable/minio (2)安装完成,执行brew i…...

SpringMVC:参数传递之日期类型参数传递
环境准备和参数传递请见:SpringMVC参数传递环境准备 日期类型比较特殊,因为对于日期的格式有N多中输入方式,比如: 2088-08-182088/08/1808/18/2088… 针对这么多日期格式,SpringMVC该如何接收,它能很好的处理日期类…...

【C语言基础】斐波那契数列
相信你是最棒哒!!! 文章目录 题目描述 正确代码: 总结 题目描述 菲波那契数列是指这样的数列: 数列的第一个和第二个数都为1,接下来每个数都等于前面2个数之和。 给出一个正整数k,要求菲波那契数列中第k个数…...